半监督学习:让未标记数据也发光的机器学习范式
在机器学习的世界里,标注数据就像黄金一样珍贵------标注一张医疗CT影像需要放射科专家数小时,标注一段语音需要逐字转录,标注一张图片的语义分割需要逐像素勾勒。但与此同时,互联网上每天产生的未标记数据却像潮水般涌来:海量的未分类图片、未转录的语音、未标注的文本。如果只能用少量标注数据训练模型,就像拿着金碗讨饭吃;而半监督学习(Semi-Supervised Learning),就是教我们如何把这些"免费"的未标记数据变成提升模型性能的宝藏。
13.1 未标记样本:被忽略的宝藏
13.1.1 什么是半监督学习
传统的监督学习需要全部样本都有标记 ,无监督学习则完全不使用标记 ,而半监督学习介于两者之间:它同时利用少量有标记样本 和大量未标记样本进行学习。
打个通俗的比方:监督学习就像老师拿着标准答案教你做题;无监督学习就像给你一堆题,让你自己按题型分类;半监督学习则是老师只给你几道题的答案,让你通过这几道题,自己搞懂剩下的一整本习题集。
13.1.2 两个核心假设
半监督学习能成立,依赖于两个基本假设,这也是所有半监督算法的"立身之本":
- 聚类假设:物以类聚,同一簇的样本属于同一个类别。如果未标记样本和某个有标记样本聚在一起,那它大概率和这个有标记样本是同一类。
- 流形假设:近朱者赤,相近的样本有相似的输出。数据分布在一个低维流形上,相邻样本的标记应该平滑过渡。
13.1.3 直推学习 vs 归纳学习
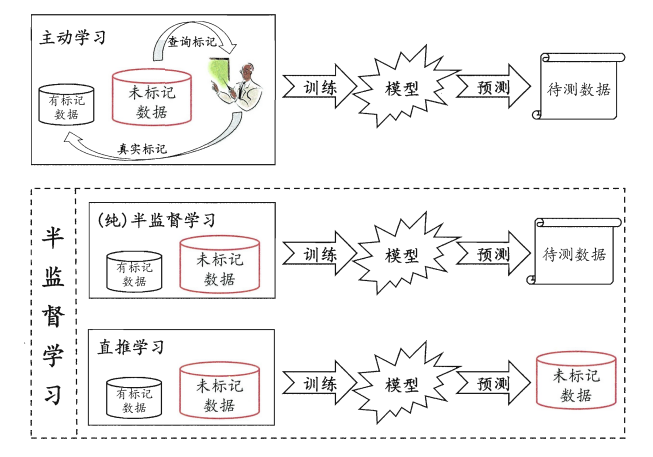
半监督学习分为两大流派:
- 直推学习(Transductive Learning):只关心给定的未标记样本的标记,不要求模型能泛化到新的未见样本。相当于"开卷考试",考试范围就是这些未标记样本。
- 归纳学习(Inductive Learning):目标是学到一个能泛化到所有未见样本的通用模型。相当于"闭卷考试",学会了知识点,不管出什么新题都能做。
13.2 生成式方法:假设数据来自同一个"工厂"
生成式方法是最早的半监督学习方法,它的核心思想非常朴素:所有样本(不管有没有标记)都来自同一个生成模型,未标记样本的标记只是这个模型的隐变量,我们可以用EM算法来求解这个模型的参数。
13.2.1 基本原理
假设数据由kkk个混合成分生成,每个混合成分对应一个类别。对于高斯混合模型(GMM)来说,数据的生成过程是:
- 先以概率αi\alpha_iαi选择第iii个混合成分
- 再根据第iii个成分的高斯分布N(μi,Σi)N(\mu_i,\Sigma_i)N(μi,Σi)生成一个样本
那么,包含lll个有标记样本和uuu个未标记样本的数据集的对数似然函数为:
LL(Θ)=∑i=1llnp(xi,yi∣Θ)+∑i=l+1l+ulnp(xi∣Θ) LL(\Theta) = \sum_{i=1}^{l} \ln p(x_i,y_i|\Theta) + \sum_{i=l+1}^{l+u} \ln p(x_i|\Theta) LL(Θ)=i=1∑llnp(xi,yi∣Θ)+i=l+1∑l+ulnp(xi∣Θ)
其中:
- Θ={αi,μi,Σi}i=1k\Theta = \{\alpha_i,\mu_i,\Sigma_i\}_{i=1}^kΘ={αi,μi,Σi}i=1k是模型的所有参数
- αi\alpha_iαi是第iii个混合成分的混合系数,满足∑i=1kαi=1\sum_{i=1}^k \alpha_i=1∑i=1kαi=1
- μi\mu_iμi和Σi\Sigma_iΣi分别是第iii个高斯分布的均值和协方差矩阵
- p(xi,yi∣Θ)=αyip(xi∣yi,Θ)p(x_i,y_i|\Theta) = \alpha_{y_i} p(x_i|y_i,\Theta)p(xi,yi∣Θ)=αyip(xi∣yi,Θ)是有标记样本的联合概率
- p(xi∣Θ)=∑j=1kαjp(xi∣j,Θ)p(x_i|\Theta) = \sum_{j=1}^k \alpha_j p(x_i|j,\Theta)p(xi∣Θ)=∑j=1kαjp(xi∣j,Θ)是未标记样本的边缘概率
13.2.2 EM算法求解
由于未标记样本的标记是隐变量,我们用EM算法迭代求解:
- E步 :根据当前模型参数,计算每个未标记样本属于各个类别的后验概率γij=p(yi=j∣xi,Θ)\gamma_{ij} = p(y_i=j|x_i,\Theta)γij=p(yi=j∣xi,Θ)
- M步 :利用所有样本(有标记样本的真实标记+未标记样本的后验概率)更新模型参数Θ\ThetaΘ
重复E步和M步,直到对数似然函数收敛。
13.2.3 优缺点分析
- 优点:原理简单,容易实现,当模型假设和真实数据分布一致时效果很好
- 缺点:模型假设太强,如果假设的生成模型和真实数据不符,未标记数据反而会降低模型性能(这就是"免费的午餐不是白吃的")
13.3 半监督SVM:在低密度区域划界
半监督支持向量机(Semi-Supervised SVM,简称S3VM)最著名的实现是TSVM(Transductive SVM),它的核心思想是:最优划分超平面不仅要分开有标记样本,还要穿过数据分布的低密度区域。
13.3.1 目标函数
TSVM的目标函数在标准SVM的基础上,增加了对未标记样本的约束:
minw,b,y^,ξ12∥w∥2+Cl∑i=1lξi+Cu∑i=l+1l+uξi \min_{w,b,\hat{y},\xi} \frac{1}{2}\|w\|^2 + C_l\sum_{i=1}^{l}\xi_i + C_u\sum_{i=l+1}^{l+u}\xi_i w,b,y^,ξmin21∥w∥2+Cli=1∑lξi+Cui=l+1∑l+uξi
约束条件:
{yi(wTxi+b)≥1−ξi,i=1,2,...,ly^i(wTxi+b)≥1−ξi,i=l+1,...,l+uξi≥0,i=1,2,...,l+u \begin{cases} y_i(w^T x_i + b) \geq 1 - \xi_i, & i=1,2,...,l \\ \hat{y}_i(w^T x_i + b) \geq 1 - \xi_i, & i=l+1,...,l+u \\ \xi_i \geq 0, & i=1,2,...,l+u \end{cases} ⎩ ⎨ ⎧yi(wTxi+b)≥1−ξi,y^i(wTxi+b)≥1−ξi,ξi≥0,i=1,2,...,li=l+1,...,l+ui=1,2,...,l+u
其中:
- www是超平面的法向量,决定超平面的方向
- bbb是超平面的截距,决定超平面到原点的距离
- y^i∈{−1,+1}\hat{y}_i \in \{-1,+1\}y^i∈{−1,+1}是未标记样本xix_ixi的伪标记
- ξi\xi_iξi是松弛变量,允许样本不满足间隔约束,对应软间隔
- ClC_lCl是有标记样本的惩罚系数,控制有标记样本的分类误差权重
- CuC_uCu是未标记样本的惩罚系数,通常Cu≪ClC_u \ll C_lCu≪Cl,因为未标记样本的伪标记不可靠
13.3.2 求解过程
TSVM的目标函数是非凸的,求解比较复杂,基本思路是:
- 先用有标记样本训练一个标准SVM
- 用这个SVM给所有未标记样本赋伪标记y^i\hat{y}_iy^i
- 求解当前伪标记下的TSVM目标函数,得到新的超平面
- 交换两个未标记样本的伪标记,如果能降低目标函数值,就保留交换
- 重复步骤3-4,直到没有可以交换的伪标记
13.3.3 核心代码示例
python
import numpy as np
from sklearn.svm import SVC
from sklearn.datasets import make_moons
from sklearn.metrics import accuracy_score
# 生成月牙形数据集,100个有标记,900个未标记
X, y = make_moons(n_samples=1000, noise=0.1, random_state=42)
y_true = y.copy()
y[100:] = -1 # 未标记样本标记为-1
# 步骤1:用有标记样本训练初始SVM
svm = SVC(kernel='linear', C=1.0)
svm.fit(X[y != -1], y[y != -1])
y_pred_initial = svm.predict(X)
print(f"仅用有标记样本的准确率: {accuracy_score(y_true, y_pred_initial):.4f}")
# 步骤2:给未标记样本赋伪标记
y_hat = svm.predict(X)
y_hat[y != -1] = y[y != -1] # 保留有标记样本的真实标记
# 步骤3:简单的TSVM迭代(简化版)
C_l = 1.0
C_u = 0.1
for _ in range(10):
# 用当前所有标记(真实+伪标记)训练SVM
svm_tsvm = SVC(kernel='linear', C=C_l)
svm_tsvm.fit(X, y_hat)
# 计算每个样本的间隔
margins = svm_tsvm.decision_function(X)
# 寻找可以交换的未标记样本对
improved = False
for i in range(100, 1000):
for j in range(i+1, 1000):
if y_hat[i] != y_hat[j]:
# 交换伪标记
y_hat[i], y_hat[j] = y_hat[j], y_hat[i]
# 计算新的目标函数值(简化版)
new_margins = svm_tsvm.decision_function(X)
new_loss = 0.5 * np.linalg.norm(svm_tsvm.coef_)**2
new_loss += C_l * np.sum(np.maximum(0, 1 - y_hat[:100] * new_margins[:100]))
new_loss += C_u * np.sum(np.maximum(0, 1 - y_hat[100:] * new_margins[100:]))
# 如果损失降低,保留交换
if new_loss < 0.5 * np.linalg.norm(svm_tsvm.coef_)**2 + C_l * np.sum(np.maximum(0, 1 - y_hat[:100] * margins[:100])) + C_u * np.sum(np.maximum(0, 1 - y_hat[100:] * margins[100:])):
improved = True
else:
# 否则换回来
y_hat[i], y_hat[j] = y_hat[j], y_hat[i]
if not improved:
break
y_pred_tsvm = svm_tsvm.predict(X)
print(f"TSVM的准确率: {accuracy_score(y_true, y_pred_tsvm):.4f}")13.4 图半监督学习:让标记像传染病一样传播
图半监督学习的核心思想是:把样本构造成一个图,结点代表样本,边代表样本之间的相似度,然后让有标记样本的标记沿着边向未标记样本传播。这就像传染病扩散,和感染者接触越密切的人,越容易被感染。
13.4.1 图的构建
首先需要把数据集构造成一个无向加权图G=(V,E)G=(V,E)G=(V,E),其中:
- 顶点集V={x1,x2,...,xl+u}V = \{x_1,x_2,...,x_{l+u}\}V={x1,x2,...,xl+u},每个顶点对应一个样本
- 边集EEE中的边(i,j)(i,j)(i,j)的权重wijw_{ij}wij表示样本xix_ixi和xjx_jxj的相似度
常用的构图方法有两种:
- k近邻图:每个样本和它最近的k个样本相连
- ϵ\epsilonϵ近邻图 :每个样本和距离小于ϵ\epsilonϵ的所有样本相连
边的权重通常用高斯核计算:
wij=exp(−∥xi−xj∥22σ2) w_{ij} = \exp\left(-\frac{\|x_i - x_j\|^2}{2\sigma^2}\right) wij=exp(−2σ2∥xi−xj∥2)
其中σ\sigmaσ是高斯核的带宽,控制相似度的衰减速度。
13.4.2 标记传播算法
标记传播(Label Propagation)是最常用的图半监督算法,它的迭代公式为:
Yt+1=D−1WYt Y_{t+1} = D^{-1} W Y_t Yt+1=D−1WYt
其中:
- Yt∈R(l+u)×cY_t \in \mathbb{R}^{(l+u) \times c}Yt∈R(l+u)×c是第ttt轮的标记矩阵,ccc是类别数,Yti,jY_ti,jYti,j表示样本xix_ixi属于第jjj类的概率
- W∈R(l+u)×(l+u)W \in \mathbb{R}^{(l+u) \times (l+u)}W∈R(l+u)×(l+u)是相似度矩阵,Wi,j=wijWi,j = w_{ij}Wi,j=wij
- DDD是度矩阵,是一个对角矩阵,Di,i=∑j=1l+uwijDi,i = \sum_{j=1}^{l+u} w_{ij}Di,i=∑j=1l+uwij
迭代过程中,有标记样本的标记保持不变,直到标记矩阵收敛。
13.4.3 实验结果分析
我们在西瓜数据集4.0上进行标记传播实验,结果如图1所示:
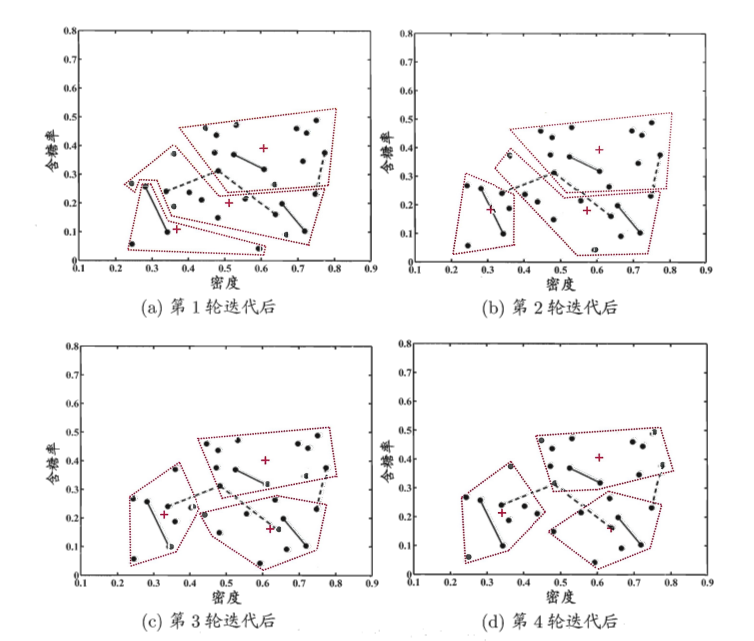
图1 西瓜数据集4.0上的标记传播结果
从图中可以看到:
- 第1轮迭代后,标记只传播到了和有标记样本直接相连的样本
- 第2轮迭代后,标记开始向更远的样本扩散
- 第3轮迭代后,大部分样本都获得了稳定的标记
- 第4轮迭代后,标记完全收敛,得到最终的分类结果
13.5 基于分歧的方法:三个臭皮匠顶个诸葛亮
基于分歧的方法(Disagreement-based Methods)的核心思想是:利用多个学习器之间的分歧来利用未标记数据。如果两个学习器对某个未标记样本的预测结果一致,说明这个样本的标记比较可靠,可以作为伪标记加入训练集;如果预测结果不一致,说明这个样本还有学习价值,需要进一步探索。
13.5.1 协同训练:双视图的互相学习
协同训练(Co-training)是基于分歧方法的鼻祖,它要求数据有两个充分且条件独立的视图。
- 充分:每个视图都包含足够的信息来训练出一个好的分类器
- 条件独立:在给定类别标记的条件下,两个视图相互独立
算法步骤:
- 从有标记样本中分别在两个视图上训练两个分类器h1h_1h1和h2h_2h2
- 每个分类器从缓冲池的未标记样本中,挑选自己最有把握的ppp个正例和nnn个反例,赋予伪标记
- 把这些伪标记样本加入对方的训练集,重新训练两个分类器
- 重复步骤2-3,直到两个分类器都不再变化或达到最大迭代次数
13.5.2 有趣的案例:电影分类的协同训练
假设我们要做电影分类,把电影分为"动作片"和"爱情片"。我们有两个视图:
- 视图1:电影的画面特征(比如每秒的镜头切换次数、爆炸场景的占比)
- 视图2:电影的声音特征(比如背景音乐的节奏、对话的占比)
首先用少量有标记电影分别训练两个分类器:
- 画面分类器认为"镜头切换快、爆炸多"的是动作片
- 声音分类器认为"背景音乐节奏快、对话少"的是动作片
然后,画面分类器把自己最有把握的10部未标记电影标记为动作片,送给声音分类器;声音分类器也把自己最有把握的10部未标记电影标记为爱情片,送给画面分类器。两个分类器用对方提供的伪标记样本更新自己,不断迭代,最终两个分类器的性能都会得到提升。
13.5.3 单视图的扩展
现实中很多数据没有天然的两个视图,于是研究者提出了很多单视图的变体:
- 用不同的学习算法(比如SVM和决策树)作为两个学习器
- 用不同的数据采样(比如Bagging采样不同的子集)作为两个学习器
- 用不同的参数设置(比如不同的神经网络层数)作为两个学习器
本质上,只要能产生两个有显著分歧且性能尚可的学习器,就能用基于分歧的方法。
13.6 半监督聚类:给聚类加一点"导航"
聚类是无监督学习任务,但现实中我们往往能获得一些额外的监督信息,比如"这两个样本必须在同一个簇"或者"这两个样本不能在同一个簇"。半监督聚类就是利用这些监督信息来获得更好的聚类结果。
13.6.1 两种监督信息
半监督聚类的监督信息主要有两种:
- 必连约束(Must-link) :样本xix_ixi和xjx_jxj必须属于同一个簇
- 勿连约束(Cannot-link) :样本xix_ixi和xjx_jxj必须不属于同一个簇
13.6.2 约束k均值算法
约束k均值(Constrained k-means)算法是k均值算法的扩展,它在聚类过程中必须满足所有的必连和勿连约束。算法流程如图2所示:

图2 约束k均值算法流程
13.6.3 实验结果分析
我们在西瓜数据集4.0上进行约束k均值实验,设置以下约束:
- 必连约束:(x4,x25),(x12,x20),(x14,x17)(x_4,x_25),(x_{12},x_{20}),(x_{14},x_{17})(x4,x25),(x12,x20),(x14,x17)
- 勿连约束:(x2,x21),(x13,x23),(x19,x23)(x_2,x_{21}),(x_{13},x_{23}),(x_{19},x_{23})(x2,x21),(x13,x23),(x19,x23)
最终的聚类结果为:
C1={x3,x5,x7,x9,x13,x14,x16,x17,x21}C2={x6,x8,x10,x11,x12,x15,x18,x19,x20}C3={x1,x2,x4,x22,x23,x24,x25,x26,x27,x28,x29,x30} \begin{align*} C_1 &= \{x_3,x_5,x_7,x_9,x_{13},x_{14},x_{16},x_{17},x_{21}\} \\ C_2 &= \{x_6,x_8,x_{10},x_{11},x_{12},x_{15},x_{18},x_{19},x_{20}\} \\ C_3 &= \{x_1,x_2,x_4,x_{22},x_{23},x_{24},x_{25},x_{26},x_{27},x_{28},x_{29},x_{30}\} \end{align*} C1C2C3={x3,x5,x7,x9,x13,x14,x16,x17,x21}={x6,x8,x10,x11,x12,x15,x18,x19,x20}={x1,x2,x4,x22,x23,x24,x25,x26,x27,x28,x29,x30}
可以看到,所有的必连和勿连约束都得到了满足,聚类结果比无监督的k均值更符合我们的先验知识。
13.6.4 约束种子k均值算法
另一种监督信息是少量有标记样本,约束种子k均值(Constrained Seed k-means)算法用这些有标记样本作为"种子"来初始化簇中心,并且在迭代过程中不改变种子样本的簇隶属。算法流程如图3所示:

图3 约束种子k均值算法流程
13.7 总结与展望
半监督学习为我们解决"标注数据稀缺"的问题提供了强大的工具,从最早的生成式方法,到后来的半监督SVM、图半监督学习、基于分歧的方法,再到现在深度学习中的伪标签、对比学习,半监督学习的思想一直在不断发展。
当然,半监督学习也不是万能的:如果数据不满足聚类假设或流形假设,未标记数据反而会帮倒忙;如果模型假设太强,也会导致性能下降。但随着大数据时代的到来,未标记数据越来越多,半监督学习必将在更多的领域发挥重要作用。