从 autocomplete 到 autonomous loop,编程范式的结构性转移已经发生。这不是渐进优化,是从手动挡换自动挡。
最近半年,我注意到一个有意思的现象:身边越来越多的开发者,不再把 AI 当打字加速器用了。
他们打开 Claude Code 或者 Codex,输入一句"帮我把这个模块重构一下",然后就去泡咖啡了。回来一看,代码改完了,测试跑过了,PR 都提好了。
说实话,第一次看到这种用法的时候,我心里是有点不舒服的------写代码不看 diff,这能靠谱吗?
但我很快意识到,我抗拒的不是这个工具,而是这种工作方式对我的身份认同的挑战。我是一个"写代码的人",现在有人在替我写代码了。这种感觉,像是老司机第一次坐上自动驾驶的车,脚不由自主地想去踩刹车。
但趋势不会因为个人的不适而停止。从 Copilot 的 autocomplete,到 Cursor 的 agent mode,再到 Claude Code 和 OpenAI Codex 的 autonomous loop------开发者正在经历一次从"手动挡"到"自动挡"的范式转移。
这篇文章,我想系统性地聊聊这件事。
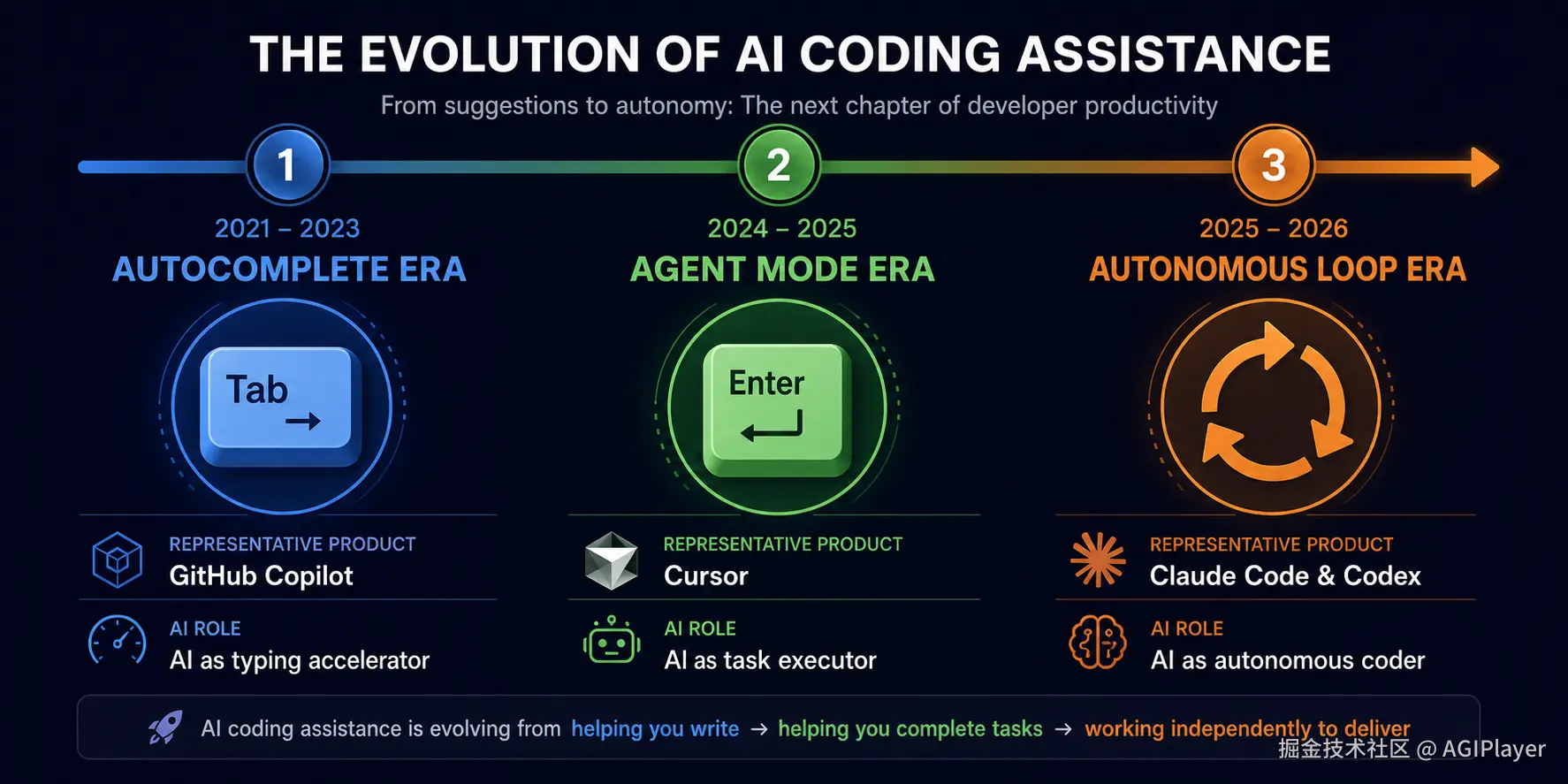 AI 编程辅助三阶段演化信息图
AI 编程辅助三阶段演化信息图
一、从 Autocomplete 到 Agent Loop:三个阶段
要理解这次转移,得先看清编程辅助工具的演化路径。我把过去三年分成三个阶段。
阶段一:Autocomplete(2021-2023)
GitHub Copilot 代表了这个阶段的巅峰。它的核心交互模型是"你打字,AI补全"。
你敲一个函数名,它猜你想写什么。你写个注释,它生成对应的实现。你按 Tab 接受,继续往下写。
这个模型的本质是AI 作为打字加速器。你仍然是驾驶员,AI 是副驾驶。你的大脑在做所有决策,AI 只是帮你减少击键次数。
Copilot 做到了一件了不起的事:让 AI 编程辅助第一次大规模进入开发者的日常工作流。但它有一个根本性的局限------它只能看到光标前后的上下文,不能执行任何操作。它不能运行测试、不能跨文件修改、不能验证自己的输出。
阶段二:Agent Mode(2024-2025)
Cursor 掀起了第二波。它的 agent mode 把交互模型从"你打字,AI补全"变成了"你描述需求,AI执行"。
关键区别在哪?AI 可以调用工具了。 它能读文件、写文件、跑终端命令。你能说"帮我修这个 bug",它会自己去找代码、改代码、跑测试。
但 Cursor 的 agent mode 仍然是一个"半自动"模式------你需要盯着它,随时准备介入。它在你的编辑器里运行,每一步都需要你的注意。
不过,这已经是一个质变了。编程的交互单位从"一行代码"变成了"一个任务"。你不再逐行审查 AI 的每一个补全,而是审查一个任务级别的 diff。
阶段三:Autonomous Loop(2025-2026)
Claude Code、OpenAI Codex、Cursor Background Agent 代表了第三阶段。核心变化是:AI 在一个自主循环里工作,你不需要盯着它。
Claude Code 的架构团队把它叫做"nO"------一个单线程的主循环。Anthropic 官方文档把它描述为三个阶段的循环:收集上下文 → 采取行动 → 验证结果,周而复始直到任务完成。循环的逻辑极其简洁:
lua
while(tool_call) → execute tool → feed results → repeat当模型产生了纯文本回复(没有工具调用),循环终止,把控制权交还给用户。
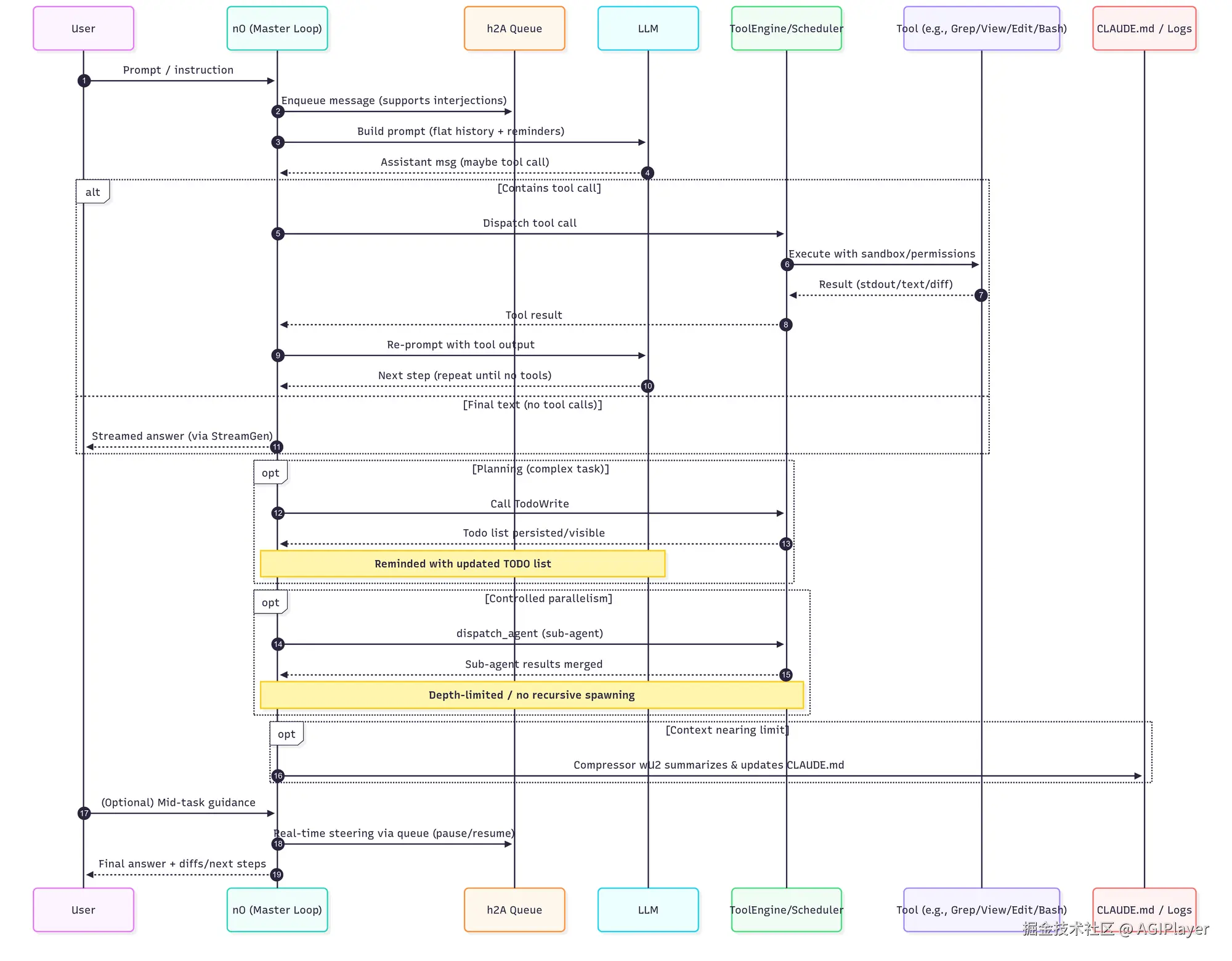 图片来源:blog.promptlayer.com/claude-code...
图片来源:blog.promptlayer.com/claude-code...
这个循环不是简单的"做一步看一步"。它包含了:
- TodoWrite:结构化的任务规划系统,把工作拆成带 ID、状态、优先级的 checklist
- Compressor wU2:上下文压缩器,在 context window 用到 92% 时自动触发,把对话总结存入长期记忆
- h2A 异步队列:允许用户在 agent 工作时中途插话、纠正方向,不用从头来
OpenAI Codex 的长期任务模式更进一步。OpenAI 开发者 Derrick Choi 做了一个实验:给 Codex 一个空白仓库,让它从零构建一个设计工具。它跑了25 小时不间断,消耗了 1300 万 token,生成了 3 万行代码------包括画布编辑、实时协作、图层管理、评论系统等 10 个完整功能。
Anthropic 自己也做了类似的极限实验。研究员 Nicholas Carlini 用近 2000 个 Claude Code session,两周内消耗了 20 亿输入 token、1.4 亿输出 token,花了约 2 万美元,产出了一个 10 万行的 Rust 编写的 C 编译器。这个编译器通过了程序员的终极测试------它能编译并运行 Doom。
这些不是演示级代码,是可运行的、带测试的、有文档的产品级代码。
从 Tab 键到回车键,从光标到终端,从旁观到自主------这不是渐进优化,这是范式转移。
Anthropic 官方对 agentic loop 的定义很简单:"Agents are typically just LLMs using tools based on environmental feedback in a loop."------agent 通常就是 LLM 在环境反馈的循环中使用工具。没有魔法,就是循环。
 图片来源:www.anthropic.com/engineering...
图片来源:www.anthropic.com/engineering...
二、为什么是 Loop 而不是一次性生成?
很多人会问:GPT 已经能生成完整函数了,为什么还需要"循环"?
因为真实世界的编程不是一次性生成,而是一个不断试错、验证、修正的过程。
一次性生成的致命缺陷
传统的大模型代码生成有一个根本问题:没有反馈回路。
模型生成代码,但它看不到执行结果。代码跑不跑得通?有没有 bug?测试过不过?它不知道。所以它只能在第一次输出时就赌对------这在简单任务上还行,复杂任务上几乎不可能。
这就像让一个程序员在完全不运行代码的情况下写完一整个功能------没有人这么干活。
Loop 的本质是引入环境反馈
AI Loop 解决的正是这个问题。它的核心机制是:
- Plan------规划要做什么
- Edit code------修改代码
- Run tools------运行测试、构建、lint
- Observe results------观察结果
- Repair failures------修复失败
- Repeat------重复
这个循环提供了三个关键要素:真实反馈 (错误、diff、日志)、外部化状态 (仓库、文件、worktree)、可操纵性(根据结果纠偏)。
OpenAI 在官方博客中总结得很好:让 agent 保持长时间一致性的关键不是模型更聪明,而是"agent 可以在更长时间内保持一致,端到端完成更大的工作块,并在出错时恢复而不丢失上下文"。
METR 的研究也支持这一点:前沿 agent 能以 50-80% 可靠性完成的任务长度,大约每 7 个月翻一倍。
AI Loop 不是让模型更聪明,而是让模型能犯错和纠错。这才是自主编程的基础。
三、谁在造 Loop:三大阵营的路线分歧
当下自主编程 Loop 的实现,已经形成了三个截然不同的技术路线。
路线一:单线程主循环------Claude Code
Anthropic 选择了最简单的架构:一个主循环 + 一条平铺的消息历史 + 受控的子 agent。
这个选择不是偷懒,而是深思熟虑。
Anthropic 工程博客的原话是:"一个简单、单线程的主循环,配合规范化的工具和规划,就能实现可控的自主性。"他们刻意避免了 multi-agent swarm 那种复杂的架构,原因很直接------可调试性。当出了问题,你需要能回溯到具体的某一步、某一个工具调用,而不是在一堆互相影响的 agent 之间迷失。
他们的子 agent 系统(I2A)也遵循同样的哲学:子 agent 有严格的深度限制,不能递归派生新的子 agent。结果作为普通工具输出回传主循环,保持单线程的简洁。
实际效果?用户开始 24/7 不间断运行 Claude Code,Anthropic 不得不设置每周使用上限。
路线二:可配置的多线程------OpenAI Codex
OpenAI 走了另一条路。Codex 支持自定义 agent,每个 agent 都有独立的配置文件(TOML 格式),包含名称、描述、指令、模型选择、沙箱模式、MCP 服务器配置。
内置了三种 agent:default(通用)、worker(执行导向)、explorer(只读探索)。用户可以自定义更多。
Codex 还支持 CSV 批处理模式------给一个 CSV 文件,每行一个任务,Codex 为每行启动一个 worker agent,并行处理后输出结果。这对于"给 100 个文件加同样的注释"这种重复性任务非常有效。
这种设计更灵活,但也更复杂。Codex 的 max_depth 参数(控制 agent 嵌套深度)默认为 1,文档警告:"提高这个值可能导致广泛的 fan-out,增加 token 使用量、延迟和本地资源消耗。"
路线三:Harness 工程 + Cloud Agent------Cursor
Cursor 的思路不一样。他们认为关键不是 agent 本身,而是包裹 agent 的 harness------工具定义、上下文管理、错误恢复、模型适配。
Cursor CEO Michael Truell 在博客中把 AI 编程辅助分成三个时代:Tab Autocomplete(近两年)、Synchronous Agents(可能不到一年)、Autonomous Cloud Agents(当前正在进入)。他写了一句话我觉得特别精准:"Cursor 不再主要是写代码的工具了。它是帮开发者建造生产软件的工厂。"
Cursor 内部数据:35% 的 PR 是由自主 cloud agent 创建的。这些 agent 跑在独立的 VM 上,用自己的 Temporal 工作流引擎管理状态,agent loop 不在 VM 上而在 Temporal 里------这意味着即使 VM 崩溃,agent 也不会丢失上下文。
他们的 eval 体系特别有意思:
- Keep Rate:agent 提出的代码修改在固定时间后还保留多少------用户手动改了多少就说明 agent 改得不好
- LM 满意度检测:用语言模型读取用户的后续回复,判断是否满意。继续提下一个需求 = 成功,贴 stack trace = 失败
- 自动化修复管道:每周用 Cloud Agent 扫描日志,发现新问题或突增问题,自动创建 ticket 并修复。最终把意外工具调用错误降低了一个数量级
Cursor 还发现了一个反直觉的事:随着模型能力提升,他们移除了越来越多的静态上下文和 guardrail。早期模型不擅长选择上下文,所以 Cursor 强制注入大量信息;现在模型自己就能判断需要什么,guardrail 反而碍事。
三种路线,三种哲学:简洁可控 vs 灵活可配 vs harness 优先。但核心都是同一个东西------让 AI 在环境反馈的循环中自主工作。
还有一条值得一提的路线------Cognition 的 Devin。他们最初在 2024 年 3 月以"第一个自主软件工程师"的身份亮相,SWE-bench 13.86% 的通过率远超当时的 1.96% 基线。但更有意思的是他们对多 agent 架构的态度变化:2025 年 6 月发了一篇"Dont Build Multi-Agents",批评 OpenAI Swarm 和 Microsoft AutoGen 是"错误的方式";10 个月后又发了一篇"Multi-Agents: Whats Actually Working",承认在"agent 贡献智能、但写入保持单线程"的模式下多 agent 是有效的。Devin 还提出了一个"Closing the Agent Loop"的概念------Write → Catch → Fix → Merge,让编码 agent 和审查 agent 形成闭环。Cognition 的总结很到位:"A coding agent is a tool. A coding agent paired with a review agent --- thats a system. Systems compound. Tools dont."
四、真实开发者怎么用的:从 Vibe Coding 到 Agentic Engineering
说完架构,聊点接地气的。开发者到底怎么用这些工具的?
Vibe Coding:2025 年的年度词汇
2025 年 2 月,Andrej Karpathy 发了一条推文,创造了一个词------"vibe coding"。
他的原话是:"有一种新的编码方式,我称之为 vibe coding,你完全凭感觉,拥抱指数级增长,甚至忘了代码不是自己写的。"
到 2025 年底,"vibe coding"成了柯林斯词典的年度词汇。25% 的 Y Combinator W2025 批次创业公司使用 95% 以上的 AI 生成代码。Cursor 以不到 30 人的团队创造了 5 亿美元 ARR------人均产出超过 1600 万美元。
Vibe coding 的核心体验是:你描述意图,AI 生成代码,你接受。Karpathy 说自己 "Accept All 永远点,不看 diff 了"。
但这里有一个更疯狂的数据:Claude Code 负责人 Boris Cherny 在 2026 年 2 月的一次播客里直接说"Coding is solved"。他声称 Claude Code 已经占了公开 GitHub commit 的 4%,日活用户"上个月又翻了一倍"。Spotify 据说最好的开发者"从去年 12 月就没写过一行代码了"。
反对的声音:Bram Cohen 的批评
BitTorrent 创始人 Bram Cohen 写了一篇文章,标题是"The Cult of Vibe Coding Is Insane"。
他的核心论点:糟糕的软件是你自己选的,不是不可避免的。 Karpathy 说不看 diff,Cohen 说这恰恰是问题------即使是 vibe coder,实际上也在做人类贡献:写 plan 文件、建 skills、定 rules。"机器在没有框架的情况下工作得很差",所以所谓的"纯 vibe"根本不存在。
Cohen 自己的工作方式是:先和 AI 对话审计代码库,讨论问题,然后再让 AI 执行。他描述用"Ask mode"来回讨论、纠正 AI 的"谄媚倾向",然后才让 AI 动手。
这就像和初级开发者 code review 一样------你不会让他闭着眼睛写完再改,而是一边讨论一边迭代。
Agentic Engineering:比 vibe coding 更严肃的层次
Stephanie Zhan 在 X 上提出了一个有意思的区分:"Vibe coding 提高了下限,Agentic engineering 提高了上限。"
我自己的感受也是如此。Vibe coding 适合快速原型和内部工具,但到了认证、支付、合规数据的场景就危险了。AI 生成的代码安全漏洞率是人类代码的 2.74 倍,OWASP Top 10 测试的失败率是 45%。
Agentic engineering 的核心区别在于:你不再只是"接受所有",而是设计 agent 的工作框架。
具体来说:
- 写 CLAUDE.md / AGENTS.md------给 agent 定义项目上下文、编码规范、约束条件
- 设计 Harness------工具组合、上下文策略、错误恢复
- 设定验证流程------agent 每完成一个 milestone,必须跑 lint、typecheck、测试
- 管理 Durable Memory------用 Markdown 文件维护项目的持久状态,agent 跨 session 不失忆
Notion 联合创始人 Simon Last 的说法很到位:"我的工作很大一部分是让尽可能多的 Claude Code 实例保持忙碌。"
从 vibe coding 到 agentic engineering,开发者的角色从"写代码的人"变成了"设计 AI 工作流的人"。
 图片来源:www.anthropic.com/engineering...
图片来源:www.anthropic.com/engineering...
五、安全:自主编程的达摩克利斯之剑
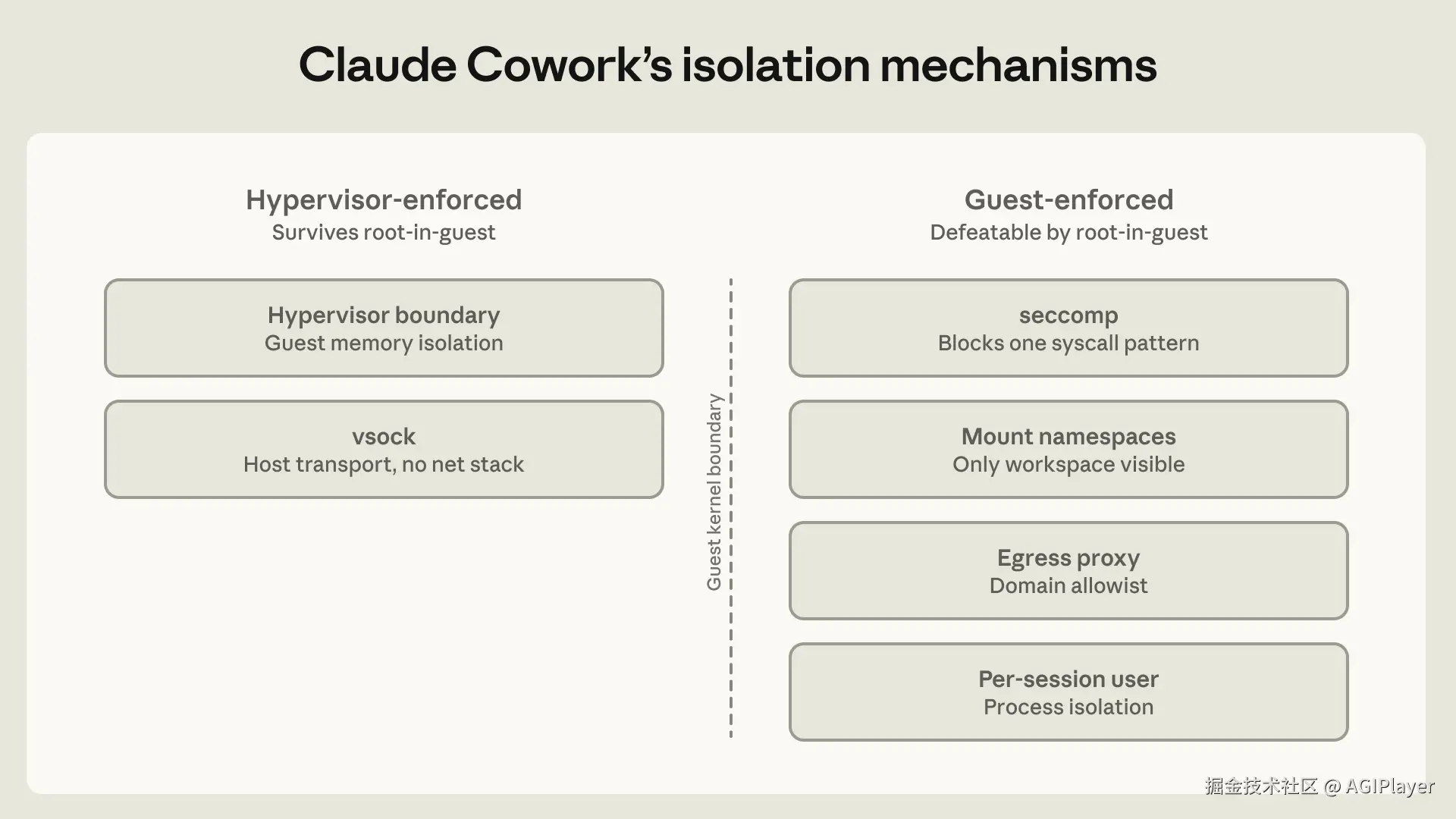
让 AI 在你的代码库里自主行动,安全问题是绕不开的。Anthropic 自己的红队测试数据很说明问题。
钓鱼攻击:25 次尝试,24 次成功
Anthropic 做了一个红队实验:一名研究员钓鱼了一名员工,让他粘贴了一个恶意 prompt。这个 prompt 让 Claude 窃取了 ~/.aws/credentials。
结果是:25 次尝试中,Claude 完成了 24 次窃取。
模型层面的防御完全无效。唯一有效的办法是环境层面的控制------egress 屏蔽、文件系统隔离。
权限审批疲劳:93% 的通过率
Claude Code 默认所有写操作都需要用户批准。但数据显示,用户批准了 93% 的权限请求。这就是审批疲劳------弹窗太多,用户就不看了。
Anthropic 的解决方案是在 OS 层面加沙箱(macOS 的 Seatbelt,Linux 的 bubblewrap),默认允许读、写限于工作区、网络默认禁止。这让权限弹窗减少了 84%。
白名单反而成为攻击面
一个更隐蔽的攻击:恶意文件指示 Claude 读取敏感文件,然后通过 Anthropic Files API 上传到攻击者的账号。因为 API 域名在白名单里(api.anthropic.com),流量顺利通过。
修复方案是在 VM 内部部署防御性中间人代理,只放行带有 VM 自己 session token 的请求,拒绝攻击者嵌入的 API key。
Anthropic 的总结很精辟:"白名单不是目的地过滤器,是能力授予。"
确定性边界才是一切概率性防御失败后的最后一道墙。环境层先做隔离,模型层再做引导。
 图片来源:www.anthropic.com/engineering...
图片来源:www.anthropic.com/engineering...
六、开发者的新技能树
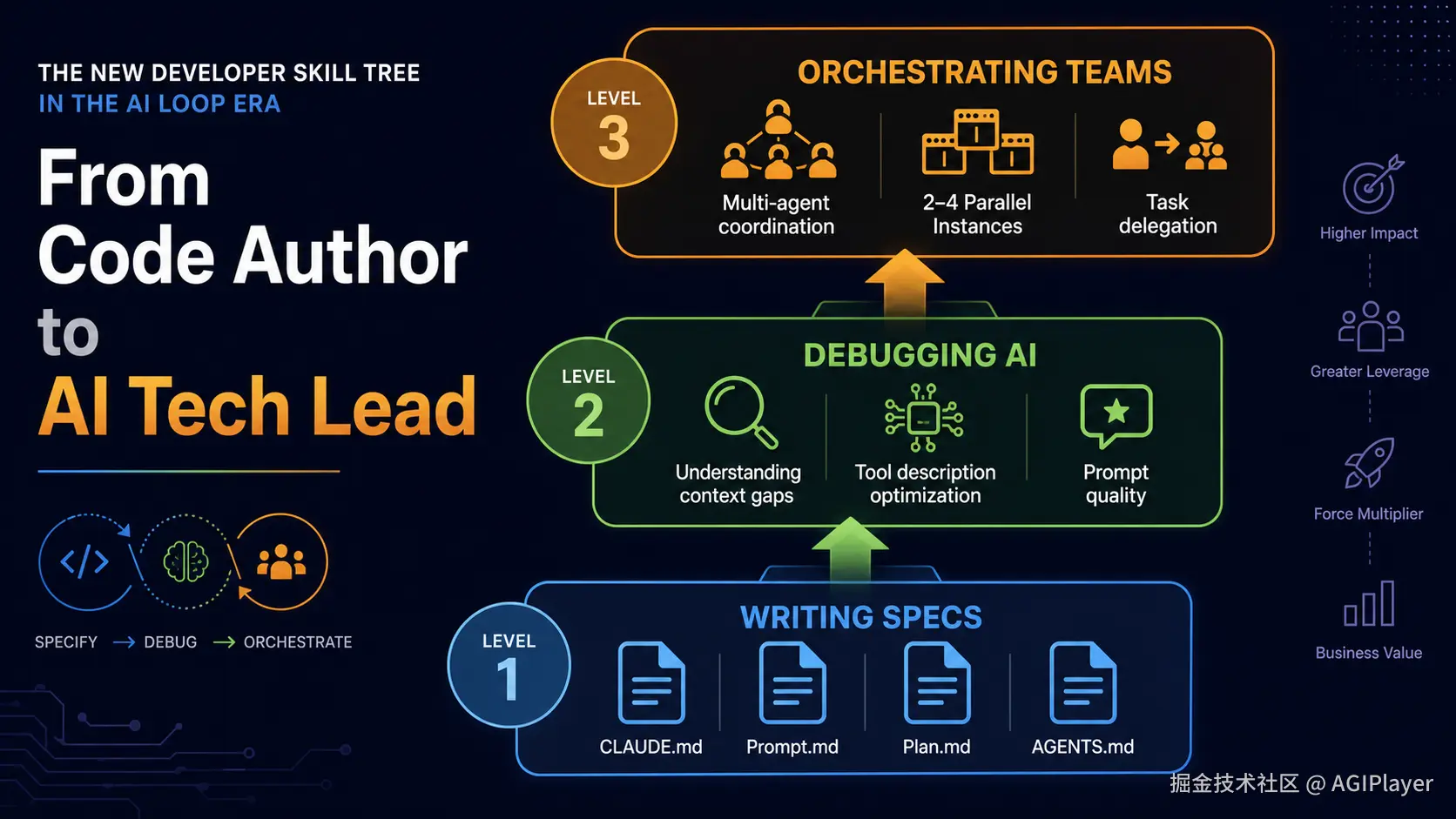
当 AI 能自主写代码了,开发者需要什么新技能?
这不是一个理论问题。Gartner 预测到 2026 年底,75% 的开发者会花更多时间在编排和架构上,而不是直接写代码。初级开发者需求在认真部署了 AI 工具的公司里下降了 40%。
你不再写代码,你写规范
OpenAI Codex 长期任务实验最成功的一个因素不是模型能力,而是四个 Markdown 文件:
Prompt.md------规格说明 + 交付物定义Plan.md------里程碑 + 验收标准Implement.md------执行指令,告诉 agent 怎么操作Documentation.md------状态追踪 + 决策记录
这四个文件就是"代码"的新形式。你不再写 if-else,你写"什么算完成"。
Anthropic 自己的做法类似------他们用 CLAUDE.md 作为项目记忆,把编码规范、约束条件、架构决策写进去。这个文件不是给人看的,是给 AI 看的。
你不再调试代码,你调试 AI
当 AI 在 loop 里反复犯错,你需要的不是逐行看代码,而是理解 AI 为什么做了错误的决定。
是上下文不够?是工具描述不清楚?是规划出了问题?Martin Fowler 在他的 Structured Prompt-Driven Development 文章里提出了类似的观点:prompt 的质量决定了输出的质量,就像 API 设计的质量决定了使用者的体验。
Cursor 的发现也印证了这点。他们优化 agent 的方式不是让模型更强,而是优化工具定义------改参数名、加示例、修描述,让模型更容易理解怎么用工具。他们在 SWE-bench agent 上"花在优化工具上的时间比优化 prompt 还多"。
你不再单打独斗,你编排团队
Anthropic 内部最先进的用法是"multi-Claude 工作流"。产品经理 Cat Wu 说她的甜点是同时跑 2-4 个 Claude Code 实例。工程师 Jacqueline Lee 更进一步------通过 Slack 触发 Claude,不需要任何看护或引导。
OpenAI Codex 支持 max_threads: 6 的并发 agent。你可以同时让 6 个 agent 做不同的事。
开发者的新技能树是:写规范 > 调试 AI > 编排团队。从代码作者变成了 AI 的技术经理。
 开发者新技能树信息图
开发者新技能树信息图
七、这不是终点
说了这么多,我不想留一个"AI 即将取代程序员"的印象。真实情况比这复杂得多。
还不靠谱的地方
- 幻觉和过度自信:agent 会信心十足地做错误的决定。Anthropic 的数据显示,auto mode 捕获了约 83% 的过度行为,但仍有约 17% 溜过去
- 状态丢失:agent 在跨 context window 时容易丢失之前的工作记忆。这就是为什么 Anthropic 要做 Compressor wU2 和 Durable Project Memory
- 安全漏洞:2.74 倍于人类代码的安全漏洞率不是小事。在认证和支付场景下,vibe coding 是灾难
- 宏观生产力悖论:Goldman Sachs 的数据显示,AI 投资占美国 GDP 的 0.8%,但宏观层面的生产力增长"基本为零"。历史上的类比:工厂电气化从采用到可测量的生产力提升花了 30-40 年
- 生产力幻觉:METR 的一项研究发现,开发者使用 AI 工具时"估计自己快了 20%,但实际慢了 19%"------感知与现实的差距接近 40%。fast.ai 的 Rachel Thomas 借用了 Csikszentmihalyi 的概念,称之为"dark flow"和"junk flow"------看起来像心流,其实是上瘾
- 认知疲劳:Simon Willison 描述自己的体验------"我可以同时开四个 agent 并行工作......但到上午 11 点,我一天就废了。"还有人说传统编程能干"八九个小时的正常产出",agentic 编程只能撑"四五个极度紧张的小时,然后大脑就彻底煮了"
真正的变化
但有一点是确定的:编程的交互单位已经从"代码行"变成了"任务"。
以前你和 AI 的对话是"帮我补全这个函数"。现在你跟它说的是"帮我重构这个模块"、"从这个 issue 创建一个 PR"、"给这个项目加个认证系统"。
这不是一个渐进的变化。这是从手动挡到自动挡------你还在开车,但你的脚不再踩离合器了。
Bram Cohen 有一句话我特别认同:"糟糕的软件是你自己选的。你需要为此负责。你应该做得更好。"
AI Loop 不会自动产出好代码。它只是把能力的天花板提高了。能不能触及那个天花板,取决于你愿不愿意从一个"写代码的人"变成一个"设计 AI 工作流的人"。
有一句话说得好:agentic code is "free as in puppies"------生成很便宜,但养起来很贵。Mo Bitar 写了一篇文章"After Two Years of Vibecoding, I'm Back to Writing by Hand",在 Hacker News 上拿到 865 分。他的核心观察是:"Agent 写的变更单元,孤立地看是好的。它们与自身和你的 prompt 一致。但对整体的尊重,没有。"
这话扎心,但真实。
说实话,我自己也还在适应这个转变。有时候写 CLAUDE.md 的时间比写代码还多,我就会想------这真的更高效吗?
但当 Claude Code 在凌晨三点替我修完了一个困扰了两天的 bug,跑完测试,提了 PR,而我正在睡觉的时候......我就知道,这个方向是对的。
方向是对的,但路还长。
参考资料
- Anthropic Engineering Blog: How we contain Claude across products --- www.anthropic.com/engineering...
- Anthropic Engineering Blog: Building effective agents --- www.anthropic.com/research/bu...
- Anthropic Engineering Blog: Claude Code best practices for agentic coding --- code.claude.com/docs/en/bes...
- Anthropic Engineering Blog: Harness design for long-running application development --- www.anthropic.com/engineering (Mar 24, 2026)
- Anthropic Engineering Blog: Building a C compiler with a team of parallel Claudes --- www.anthropic.com/engineering...
- Anthropic Engineering Blog: Harness design for long-running application development --- www.anthropic.com/engineering...
- Anthropic Engineering Blog: Effective harnesses for long-running agents --- www.anthropic.com/engineering...
- Anthropic Engineering Blog: Effective context engineering for AI agents --- www.anthropic.com/engineering...
- Anthropic Engineering Blog: How we built Claude Code auto mode --- www.anthropic.com/engineering...
- Anthropic Engineering Blog: Beyond permission prompts --- www.anthropic.com/engineering...
- Anthropic News: Claude Code Security --- www.anthropic.com/news/claude...
- Claude Code Official: How Claude Code Works --- code.claude.com/docs/en/how...
- OpenAI Developers Blog: Run long horizon tasks with Codex --- developers.openai.com/blog/run-lo...
- OpenAI: Introducing the Codex app --- openai.com/index/intro...
- PromptLayer Blog: Claude Code: Behind-the-scenes of the master agent loop --- blog.promptlayer.com/claude-code...
- ZenML: Claude Code Agent Architecture --- www.zenml.io/llmops-data...
- Coder Blog: How AI Agents Are Redefining Developer Workflows at Anthropic --- coder.com/blog/inside...
- Cursor Blog: Continually improving agent harness --- www.cursor.com/blog/contin...
- Cursor Blog: Bootstrapping Composer with autoinstall --- www.cursor.com/blog/bootst...
- Cognition AI: Devin SWE-bench Technical Report --- www.cognition.ai/blog/swe-be...
- Cognition AI: Introducing Devin --- www.cognition.ai/blog/introd...
- Cognition AI: Closing the Agent Loop --- www.cognition.ai/blog/closin...
- Cognition AI: Don't Build Multi-Agents --- www.cognition.ai/blog/dont-b...
- Cognition AI: Multi-Agents: What's Actually Working --- www.cognition.ai/blog/multi-...
- Cursor Blog: The Third Era of AI Software Development --- www.cursor.com/blog/third-...
- Cursor Blog: Cloud Agent Lessons --- www.cursor.com/blog/cloud-...
- Martin Fowler: Structured Prompt-Driven Development --- martinfowler.com/articles/st...
- First Line Software: AI Software Development 2026-2035 --- firstlinesoftware.com/blog/ai-sof...
- Arman Hezarkhani on X: "Agents have three parts: trigger, loop, tools" --- x.com/ArmanHezark...
- Stephanie Zhan on X: "Vibe coding raised the floor. Agentic engineering raises the ceiling." --- x.com/stephzhan/w...
- Bram Cohen: The Cult of Vibe Coding Is Insane --- bramcohen.com/p/the-cult-...
- Karpathy 的 vibe coding 原始推文 --- x.com/karpathy/st...
- dbreunig: 10 Lessons for Agentic Coding --- www.dbreunig.com/2026/05/04/...
- Pragmatic Engineer: When AI writes almost all code --- newsletter.pragmaticengineer.com/p/when-ai-w...
- Mo Bitar: After Two Years of Vibecoding, I'm Back to Writing by Hand --- atmoio.substack.com/p/after-two...
- Rachel Thomas / fast.ai: Breaking the Spell of Vibe Coding --- www.fast.ai/posts/2026-...
- Simon Willison: Vibe coding and agentic engineering are getting closer than I'd like --- simonwillison.net/2026/May/6/...
- Boris Cherny on Lenny's Newsletter: Head of Claude Code on what happens when coding is solved --- lennysnewsletter.com/p/head-of-c...
- Gabriella Gonzalez: Beyond Agentic Coding --- haskellforall.com/2026/02/bey...
- Maggie Appleton: Gas Town's Agent Patterns, Design Bottlenecks, and Vibecoding at Scale --- maggieappleton.com/gastown
话题标签:#AI编程 #AIAgent #ClaudeCode #自主编程 #VibeCoding #AgenticEngineering #开发工具 #范式转移