来源总览: 《DM8 系统管理员手册》22.6"执行计划"、附录 4"执行计划操作符"、
MONITOR监控参数和动态性能视图;本地《DM8_DIsql 使用手册》3.3.19AUTOTRACE;《DM8_SQL 语言使用手册》附录 3ET。达梦社区资料:《达梦数据库 SQL 优化入门 ------ 执行计划详解》《dm 的 SQL 监控》《执行计划和达梦优化的基础篇》。
1. 本次学习主线
理解 SQL 从"写出来"到"真正跑起来"的过程。SQL 是声明式语言,用户只写"我要什么数据",没有直接写"先扫哪个表、用哪个索引、怎么连接、在哪里排序"。这些执行动作由数据库优化器和执行器完成。
一条 SQL 大致会经过这条链路:
text
SQL 文本
-> 语法/语义分析
-> 查询优化器生成候选计划
-> 根据统计信息和代价模型选择计划
-> 执行器按计划中的操作符逐个执行
-> 返回结果或完成 DML这里面有几个关键词:
- 统计信息:优化器判断"表有多少行、某列选择性怎么样、索引值分布如何"的依据。
- 执行计划:优化器选出来的执行路线,告诉执行器按什么顺序访问表、索引、排序、聚合、连接。
- 操作符:执行计划中的每一个具体动作,比如扫描、过滤、投影、排序、哈希连接、索引定位。
- 实际执行统计:SQL 真正执行后,每个操作符到底执行了多少次、花了多久、用了多少内存或临时空间。
所以这几个东西对 SQL 执行的意义是:
| 内容 | 对 SQL 执行的影响 |
|---|---|
| 表结构和索引 | 决定优化器有哪些访问路径可选 |
| 统计信息 | 决定优化器估算行数和代价是否靠谱 |
| 执行计划 | 决定 SQL 实际按照哪条路线访问数据 |
| 操作符 | 决定每一步到底是在扫描、定位、过滤、连接还是排序 |
AUTOTRACE / ET |
用真实执行数据验证计划估算是否靠谱 |
如果统计信息不准,优化器可能误判某个条件会返回很少数据,结果选了嵌套循环;实际返回很多行时,就可能变慢。如果缺少合适索引,计划里可能只能做扫描;如果排序或哈希数据量很大,还可能消耗内存或落临时空间。
来源: 《DM8 系统管理员手册》22.6 说明执行计划是优化器为 SQL 设计并交给执行器执行的方式;达梦社区《达梦数据库 SQL 优化入门 ------ 执行计划详解》也强调执行计划由 SQL、表结构、索引与统计信息共同影响,并将 SQL 拆成多个操作符节点。
本次工具链按下面方式理解:
| 层次 | 工具 | 主要回答的问题 |
|---|---|---|
| 预计怎么执行 | EXPLAIN、EXPLAIN FOR |
优化器准备走什么访问路径、连接方式和排序聚合方式 |
| 实际怎么执行 | SET AUTOTRACE TRACE/TRACEONLY |
SQL 真正执行后,实际计划和统计信息是什么 |
| 时间花在哪里 | ET(exec_id) |
哪个操作符耗时最高,进入次数、内存、临时空间是否异常 |
执行计划、AUTOTRACE、ET 要放在一起理解。EXPLAIN 适合先看形状,AUTOTRACE 适合确认实际执行,ET 适合定位耗时节点。
2. 执行计划基础
来源: 《DM8 系统管理员手册》22.6"执行计划";达梦社区《达梦数据库执行计划查看方式》《达梦数据库 SQL 优化入门 ------ 执行计划详解》。
执行计划可以理解为 SQL 的"施工图"。SQL 写的是目标,比如:
sql
SELECT A.C1 + 1, B.D2
FROM T1 A, T2 B
WHERE A.C1 = B.D1;这条 SQL 只说了:我要把 T1 和 T2 按 A.C1 = B.D1 连起来,再返回 A.C1 + 1 和 B.D2。但是它没有说:
- 先读
T1还是先读T2? - 是全表扫描,还是走索引?
- 连接用嵌套循环、哈希连接,还是归并连接?
- 表达式
A.C1 + 1在哪一步算? - 结果怎么返回给客户端?
这些问题就是执行计划要回答的。
2.1 用 EXPLAIN 看预估计划
在 DIsql 中可以直接使用:
sql
EXPLAIN SELECT A.C1 + 1, B.D2
FROM T1 A, T2 B
WHERE A.C1 = B.D1;也可以用 EXPLAIN FOR 以表格方式查看:
sql
EXPLAIN FOR
SELECT A.C1 + 1, B.D2
FROM T1 A, T2 B
WHERE A.C1 = B.D1;手册中的典型输出类似:
text
1 #NSET2: [1, 12, 56]
2 #PRJT2: [1, 12, 56]; exp_num(2), is_atom(FALSE)
3 #NEST LOOP INDEX JOIN2: [1, 12, 56]
4 #CSCN2: [1, 4, 52]; INDEX33555510(T2 as B); btr_scan(1); need_slct(0)
5 #SSEK2: [1, 3, 4]; scan_type(ASC), IDX_T1_C1(T1 as A), scan_range[B.D1,B.D1], is_global(0)这不是从第 1 行到第 5 行顺序执行。它是一棵树,应该从缩进最深的底层节点往上看。可以按下面这样翻译成人话:
| 行号 | 操作符 | 它在做什么 |
|---|---|---|
| 4 | CSCN2 |
扫描 T2,把 T2 的行作为连接的左侧输入 |
| 5 | SSEK2 |
用 B.D1 的值到 T1 的二级索引 IDX_T1_C1 上定位匹配行 |
| 3 | NEST LOOP INDEX JOIN2 |
做索引嵌套连接:左边每来一行,就去右边索引探测一次 |
| 2 | PRJT2 |
计算并返回 select 列表里的表达式,比如 A.C1 + 1 |
| 1 | NSET2 |
收集最终结果并返回给客户端 |
读执行计划时先记住两个方向:
- 执行计划是一棵树。控制流从上往下传递,数据流从下往上传递。
#操作符: [cost, rows, bytes]中的三个数字可以理解为估算代价、估算行数和估算行宽。它们不是实际耗时,实际耗时要通过AUTOTRACE、ET或监控视图确认。
这里最重要的是 rows。如果优化器估算某一步只有几行,但实际有几十万行,那么后面选择的连接方式、排序方式就可能不合适。
2.2 用 EXPLAIN FOR 看表格计划
EXPLAIN FOR 会把计划拆成表格字段,更适合看表名、索引名、扫描范围、过滤条件和连接条件。
sql
EXPLAIN FOR
SELECT A.C1 + 1, B.D2
FROM T1 A, T2 B
WHERE A.C1 = B.D1;常看这些列:
| 字段 | 含义 | 重点 |
|---|---|---|
LEVEL_ID |
操作符在计划树中的层级 | 层级越深,越接近数据访问入口 |
OPERATION |
操作符名称 | 判断扫描、索引定位、连接、排序、聚合 |
TAB_NAME |
表名 | 确认当前节点访问哪张表 |
IDX_NAME |
索引名 | 判断是否用了预期索引 |
SCAN_TYPE |
扫描类型 | 看正向、范围、等值等访问方式 |
SCAN_RANGE |
扫描范围 | 判断索引查找范围是否收敛 |
ROW_NUMS |
估算结果行数 | 和实际行数差距大时,要怀疑统计信息 |
FILTER |
过滤条件 | 看谓词是否下推到合适节点 |
JOIN_COND |
连接条件 | 看连接条件是否被正确识别 |
2.3 入门读计划的顺序
实际看计划时不要一上来就背操作符,可以按这个顺序:
- 先看底层访问路径:是全表扫描、聚集索引扫描、二级索引扫描还是索引定位。
- 再看中间处理:过滤、投影、排序、聚合、连接。
- 最后看顶层输出:结果集收集、DML 操作或插入更新删除。
- 对比估算和实际:
EXPLAIN看估算,AUTOTRACE和ET看真实执行。
一个实用判断是:如果计划中底层大面积是扫描,SQL 又只想取很少数据,就要检查索引和过滤条件;如果连接节点耗时高,要看连接顺序和两侧行数;如果排序或哈希节点耗时高,要看内存、临时空间和返回行数。
3. 常见操作符分类
来源: 《DM8 系统管理员手册》附录 4"执行计划操作符";达梦社区《达梦数据库学习15:执行计划》《执行计划和达梦优化的基础篇》。
附录 4 的操作符很多,学习和复现实验不适合全部平铺。下面只整理本次实验和日常 SQL 调优最常见的一批。
| 类型 | 常见操作符 | 理解口径 |
|---|---|---|
| 结果输出 | NSET2 |
查询计划的顶层结果集收集节点 |
| 表达式计算 | PRJT2 |
投影运算,计算 select 列表中的表达式 |
| 条件过滤 | SLCT2 |
选择运算,处理 WHERE 条件过滤 |
| 聚集索引访问 | CSCN2、CSEK2 |
聚集索引扫描、聚集索引定位 |
| 二级索引访问 | SSCN、SSEK2 |
二级索引扫描、二级索引定位 |
| 回表定位 | BLKUP2 |
通过二级索引记录定位聚集索引记录 |
| 排序 | SORT3 |
ORDER BY、去重、部分归并场景中的排序 |
| 聚合 | AAGR2、FAGR2、HAGR2、SAGR2 |
简单聚集、快速聚集、HASH 分组、流式分组 |
| 连接 | HASH2 INNER JOIN、NEST LOOP INDEX JOIN2 |
哈希内连接、索引嵌套连接 |
| 临时结果 | NTTS2、HEAP TABLE SCAN |
临时表或临时结果集扫描 |
| DML | INSERT、UPDATE、DELETE |
增删改操作的顶层或关键节点 |
| 并行/分布式 | LOCAL GATHER、MPP GATHER、MPP DISTRIBUTE |
本地并行或 MPP 场景的数据收集、重分发 |
几个容易混淆的点:
-
EXPLAIN里的代价是估算值,不要直接当成毫秒数。 -
CSCN2、SSCN这类扫描,是沿着表或索引顺序扫一段甚至全部数据。即使SSCN名字里有索引,也不等于我们平常说的"高效走索引"。 -
SSEK2、CSEK2这类定位,是通过键值范围更直接地找到目标数据,通常更适合返回少量数据的查询。 -
BLKUP2表示通过二级索引找到记录后,还要回到聚集索引或表记录取完整列。回表次数多时,随机访问成本可能明显增加。
4. 模拟复现设计
来源: 《DM8 系统管理员手册》22.6 示例建表、索引和连接计划;达梦社区《达梦数据库 SQL 优化入门 ------ 执行计划详解》中的"建测试表 -> 看 EXPLAIN -> 用 AUTOTRACE/ET 对比实际执行"思路。
4.1 初始化测试表
sql
DROP TABLE IF EXISTS T1;
DROP TABLE IF EXISTS T2;
CREATE TABLE T1(
C1 INT,
C2 VARCHAR(20),
C3 INT
);
CREATE TABLE T2(
D1 INT,
D2 VARCHAR(20),
D3 INT
);
INSERT INTO T1 VALUES(1, 'A', 10);
INSERT INTO T1 VALUES(2, 'B', 20);
INSERT INTO T1 VALUES(3, 'C', 30);
INSERT INTO T1 VALUES(4, 'D', 40);
INSERT INTO T1 VALUES(5, 'E', 50);
INSERT INTO T2 VALUES(1, 'A', 100);
INSERT INTO T2 VALUES(2, 'B', 200);
INSERT INTO T2 VALUES(5, 'C', 500);
INSERT INTO T2 VALUES(6, 'D', 600);
CREATE INDEX IDX_T1_C1 ON T1(C1);
CREATE INDEX IDX_T2_D1 ON T2(D1);4.1.1 为什么测试前要关注统计信息
如果统计信息缺失或过期,优化器可能会误判。例如表实际有 100 万行,但统计信息显示很少;或者某列实际重复值很多,但优化器估算选择性很高。这样就可能选错访问路径或连接方式。
所以如果同样的 SQL 在不同环境中执行计划差异很大,测试环境中,可以先收集统计信息,让优化器有相对准确的估算依据:
sql
SP_TAB_STAT_INIT(USER, 'T1');
SP_TAB_STAT_INIT(USER, 'T2');这一步的意义不是"让 SQL 一定变快",而是让优化器更接近真实数据分布,减少因为估算错误导致的计划差异。
4.2 复现扫描、过滤、投影
sql
EXPLAIN
SELECT C1 + 1 AS C1_NEW, C2
FROM T1
WHERE C3 >= 20;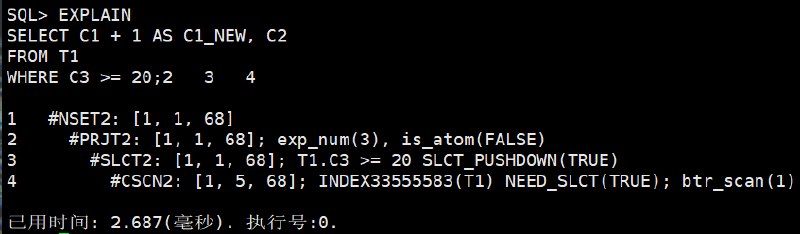
text
1 #NSET2: [1, 1, 68]
2 #PRJT2: [1, 1, 68]; exp_num(3), is_atom(FALSE)
3 #SLCT2: [1, 1, 68]; T1.C3 >= 20 SLCT_PUSHDOWN(TRUE)
4 #CSCN2: [1, 5, 68]; INDEX33555583(T1) NEED_SLCT(TRUE); btr_scan(1)这张图展示的是"扫描 + 过滤 + 投影"的完整过程。
从最底层看,CSCN2 访问 T1,估算会扫描 5 行,每行约 68 字节。这里使用的是表的聚集索引扫描,不是二级索引定位,因为 WHERE C3 >= 20 这个条件没有对应的 C3 索引。
上面的 SLCT2 执行过滤条件 T1.C3 >= 20。这里有两个标记值得注意:
SLCT_PUSHDOWN(TRUE):过滤条件可以下推,不是等所有数据都返回到最上层再过滤。NEED_SLCT(TRUE):扫描节点需要配合执行过滤条件。
PRJT2 的 exp_num(3) 表示投影层要处理 3 个表达式或输出项。这里不只是简单返回列,还包括 C1 + 1 AS C1_NEW 这种表达式计算。
最终 NSET2 收集结果返回客户端。整个计划可以读成:先扫 T1,边扫边判断 C3 >= 20,满足条件后计算输出列,再返回结果。
关注点:
PRJT2:计算C1 + 1和输出列。SLCT2:处理C3 >= 20过滤条件。CSCN2:扫描表的聚集索引。
如果 WHERE 条件列没有合适索引,通常会看到扫描后再过滤。此时不要只看表小不小,要理解访问路径是否能利用索引。
4.3 复现二级索引定位
sql
EXPLAIN
SELECT C1, C2
FROM T1
WHERE C1 = 3;
text
1 #NSET2: [1, 1, 64]
2 #PRJT2: [1, 1, 64]; exp_num(3), is_atom(FALSE)
3 #BLKUP2: [1, 1, 64]; IDX_T1_C1(T1)
4 #SSEK2: [1, 1, 64]; scan_type(ASC), IDX_T1_C1(T1), scan_range[3,3], is_global(0)这张图的重点是 SSEK2 + BLKUP2。
SSEK2 使用二级索引 IDX_T1_C1,扫描范围是 scan_range[3,3]。这说明优化器没有扫描整张表,而是根据条件 C1 = 3 到索引里做等值定位。[3,3] 可以理解为起点和终点都是 3,所以范围非常窄。
但是 SQL 查询的是 C1, C2。索引 IDX_T1_C1 只包含 C1,不包含 C2,所以光查索引还不够,必须回到表记录里把 C2 取出来。这就是 BLKUP2 的作用,也就是回表。
所以这条计划不是"只走索引就结束",而是:
text
先用 IDX_T1_C1 定位 C1=3 的索引记录
-> 再通过 BLKUP2 回表取 C2
-> PRJT2 整理输出列
-> NSET2 返回结果关注点:
- 如果使用
IDX_T1_C1,可能出现SSEK2。 - 如果查询列不能只靠二级索引满足,可能出现回表相关节点。
scan_range[3,3]一类信息表示索引定位范围。
4.4 复现排序
sql
EXPLAIN
SELECT C1, C2, C3
FROM T1
ORDER BY C3 DESC;
text
1 #NSET2: [1, 5, 68]
2 #PRJT2: [1, 5, 68]; exp_num(4), is_atom(FALSE)
3 #SORT3: [1, 5, 68]; key_num(1), partition_key_num(0), is_distinct(FALSE), top_flag(0), is_adaptive(0)
4 #CSCN2: [1, 5, 68]; INDEX33555583(T1); btr_scan(1)这张图展示的是排序为什么会出现在计划里。
底层 CSCN2 先把 T1 的 5 行数据扫出来。因为当前只有 C1 上的索引,没有 C3 上的索引,而 SQL 要求 ORDER BY C3 DESC,数据库不能直接按已有索引顺序返回,所以中间必须加一个 SORT3 排序节点。
SORT3 中几个参数可以这样看:
key_num(1):排序键只有 1 个,就是C3。is_distinct(FALSE):这次排序不是为了去重。top_flag(0):不是TOP N排序。is_adaptive(0):没有触发自适应排序优化。
所以执行路径是:
text
CSCN2 扫出 T1 数据
-> SORT3 按 C3 DESC 排序
-> PRJT2 输出 C1、C2、C3
-> NSET2 返回如果以后数据量很大,SORT3 就要重点关注。排序可能消耗内存,内存不足还可能用临时空间,这时要结合 AUTOTRACE 里的 sorts(memory)、sorts(disk),以及 ET 里的 MEM_USED(KB)、DISK_USED(KB) 判断。
关注点:
SORT3表示排序节点。- 如果排序列已有合适索引,优化器可能通过索引顺序减少或去掉排序。
4.5 复现聚合
无分组聚合:
sql
EXPLAIN
SELECT COUNT(*)
FROM T1;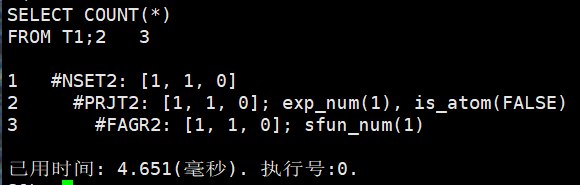
text
1 #NSET2: [1, 1, 0]
2 #PRJT2: [1, 1, 0]; exp_num(1), is_atom(FALSE)
3 #FAGR2: [1, 1, 0]; sfun_num(1)这张图和前面几张不一样,底层没有出现 CSCN2。原因是 SQL 是:
sql
SELECT COUNT(*) FROM T1;它只需要知道表里有多少行,不需要返回具体列,也不需要逐行计算表达式。优化器选择了 FAGR2 快速聚集。sfun_num(1) 表示这里有 1 个集函数,也就是 COUNT(*)。
可以把它理解为:这类简单 COUNT(*) 场景,数据库可能利用已有元信息或更快的聚集路径完成统计,不一定要像普通查询那样把行一条条向上返回。最终 PRJT2 只输出一个计数结果,NSET2 返回给客户端。
注意:不是所有 COUNT 都一定是 FAGR2。一旦加了过滤条件、分组、复杂表达式,计划就可能变成扫描、过滤再聚合。
带分组聚合:
sql
EXPLAIN
SELECT C3, COUNT(*)
FROM T1
GROUP BY C3;
text
1 #NSET2: [1, 1, 4]
2 #PRJT2: [1, 1, 4]; exp_num(2), is_atom(FALSE)
3 #HAGR2: [1, 1, 4]; grp_num(1), sfun_num(1), distinct_flag[0]; slave_empty(0) keys(T1.C3)
4 #CSCN2: [1, 5, 4]; INDEX33555583(T1); btr_scan(1)这张图说明 GROUP BY 为什么比单纯 COUNT(*) 多了一层扫描。
SQL 是按 C3 分组统计:
sql
SELECT C3, COUNT(*)
FROM T1
GROUP BY C3;数据库必须先知道每一行的 C3 是什么,所以底层需要 CSCN2 扫描 T1。扫出来后,HAGR2 按 keys(T1.C3) 做 HASH 分组。
几个参数的含义:
grp_num(1):分组列 1 个,即C3。sfun_num(1):聚合函数 1 个,即COUNT(*)。keys(T1.C3):哈希分组使用的分组键。
这和上一张 FAGR2 的差异很关键:COUNT(*) 没有分组,可以快速聚集;GROUP BY C3 必须读取 C3 并按值归组,所以出现 CSCN2 + HAGR2。
4.6 复现连接
sql
EXPLAIN
SELECT A.C1, A.C2, B.D2
FROM T1 A
JOIN T2 B
ON A.C1 = B.D1;
text
1 #NSET2: [1, 16, 104]
2 #PRJT2: [1, 16, 104]; exp_num(3), is_atom(FALSE)
3 #NEST LOOP INDEX JOIN2: [1, 16, 104]
4 #CSCN2: [1, 4, 52]; INDEX33555584(T2 as B); btr_scan(1)
5 #BLKUP2: [1, 4, 4]; IDX_T1_C1(A)
6 #SSEK2: [1, 4, 4]; scan_type(ASC), IDX_T1_C1(T1 as A), scan_range[B.D1,B.D1], is_global(0)这张图是索引嵌套连接的典型结构。
先看左右孩子:
- 左孩子是
CSCN2,扫描T2 as B,估算 4 行。 - 右孩子是
SSEK2 + BLKUP2,使用T1的索引IDX_T1_C1。
NEST LOOP INDEX JOIN2 的执行逻辑是:
text
从 T2 取一行 B
-> 拿 B.D1 的值
-> 到 T1 的 IDX_T1_C1 索引上找 C1 = B.D1 的记录
-> 找到后回表取需要的列
-> 继续取 T2 下一行截图里的 scan_range[B.D1,B.D1] 很重要,它说明右侧索引查找的范围不是固定常量,而是由左侧当前行的 B.D1 动态传入。左侧 T2 每返回一行,右侧就按这个值探测一次索引。
4.7 复现 DML 操作符
sql
EXPLAIN
INSERT INTO T1 VALUES(10, 'X', 100);
EXPLAIN
UPDATE T1
SET C3 = C3 + 1
WHERE C1 = 1;
EXPLAIN
DELETE FROM T1
WHERE C1 = 10;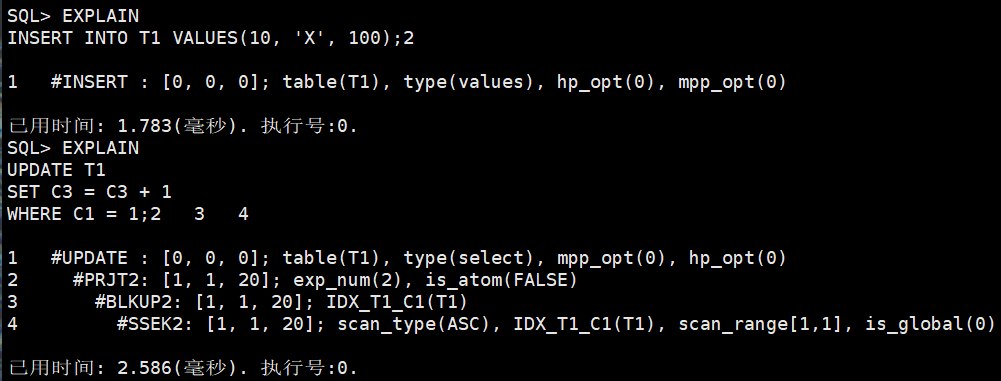
text
EXPLAIN INSERT INTO T1 VALUES(10, 'X', 100);
1 #INSERT: [0, 0, 0]; table(T1), type(values), hp_opt(0), mpp_opt(0)INSERT 语句这里非常直接,只有一个顶层 INSERT 操作符。table(T1) 表示目标表是 T1,type(values) 表示插入来源是 VALUES 形式,不是 INSERT SELECT。因为它不需要先查询其他表,也不需要过滤或连接,所以没有 CSCN2、SSEK2 这类访问节点。
同一张图下面还有 UPDATE:
text
1 #UPDATE: [0, 0, 0]; table(T1), type(select), mpp_opt(0), hp_opt(0)
2 #PRJT2: [1, 1, 20]; exp_num(2), is_atom(FALSE)
3 #BLKUP2: [1, 1, 20]; IDX_T1_C1(T1)
4 #SSEK2: [1, 1, 20]; scan_type(ASC), IDX_T1_C1(T1), scan_range[1,1], is_global(0)UPDATE 虽然最终是修改数据,但它也要先找到要修改的行。WHERE C1 = 1 可以使用 IDX_T1_C1,所以底层先 SSEK2 定位 C1=1,然后 BLKUP2 回表找到实际记录,再由 PRJT2 计算更新所需表达式,最后交给 UPDATE 节点修改。
这里的 type(select) 可以理解为:更新目标行来自一个查询结果。很多 DML 本质上都是"先查出目标行,再执行修改/删除"。
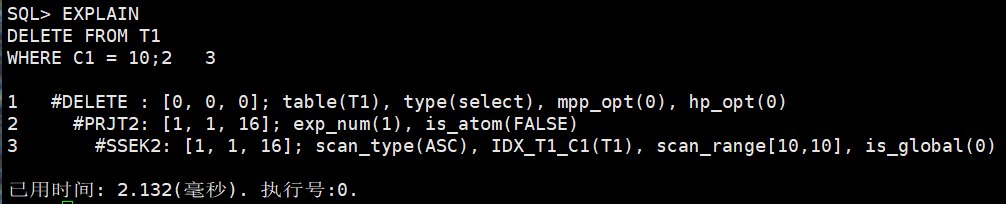
text
1 #DELETE: [0, 0, 0]; table(T1), type(select), mpp_opt(0), hp_opt(0)
2 #PRJT2: [1, 1, 16]; exp_num(1), is_atom(FALSE)
3 #SSEK2: [1, 1, 16]; scan_type(ASC), IDX_T1_C1(T1), scan_range[10,10], is_global(0)DELETE FROM T1 WHERE C1 = 10 也是先定位目标行,再执行删除。这里直接用 SSEK2 通过 IDX_T1_C1 找 C1=10 的记录。
和 UPDATE 截图相比,这里没有出现 BLKUP2。可以理解为这次删除所需的信息较少,计划中直接通过索引定位到删除目标。实际环境中是否需要回表,要看表结构、索引、删除实现和优化器选择,不能机械认为所有 DELETE 都一定只有 SSEK2。
这两张 DML 图要记住一个结论:INSERT 可以只有插入节点;UPDATE、DELETE 通常要先走一个查询路径找到目标行。慢 DML 很多时候不是"改"慢,而是"找要改的行"慢。
关注点:
- DML 计划也有访问路径,不只是一个
INSERT/UPDATE/DELETE节点。 UPDATE、DELETE如果能利用索引定位,影响范围更清楚。- 真实执行 DML 前要确认事务边界,实验环境可以在事务中观察后回滚。
清理测试对象:
sql
DROP TABLE IF EXISTS T1;
DROP TABLE IF EXISTS T2;5. TRACE / AUTOTRACE 使用
来源: 《DM8_DIsql 使用手册》3.3.19
AUTOTRACE;达梦社区《达梦数据库执行计划查看方式》《达梦数据库 SQL 优化入门 ------ 执行计划详解》。
5.1 EXPLAIN 和 AUTOTRACE 的区别
EXPLAIN 只生成执行计划,不真正执行 SQL。它适合快速判断优化器预计选择的访问路径,但对于复杂 SQL、计划缓存、运行时变化,可能和实际执行存在差异。
AUTOTRACE TRACE 会执行 SQL,并打印实际执行计划和部分统计信息。TRACEONLY 也会执行 SQL,但查询语句不打印结果集,适合避免大结果集刷屏。
可以这样理解:
| 工具 | 是否真正执行 SQL | 适合用途 |
|---|---|---|
EXPLAIN |
不执行 | 快速看优化器预估计划 |
EXPLAIN FOR |
不执行 | 用表格字段看计划细节 |
AUTOTRACE TRACE |
执行 | 看实际计划、结果和统计信息 |
AUTOTRACE TRACEONLY |
执行 | 看实际计划和统计信息,但不打印查询结果 |
所以排查慢 SQL 时,EXPLAIN 只能算第一眼判断。真正要确认"这条 SQL 跑起来到底怎么样",还要看 AUTOTRACE 或 ET。
5.2 开启监控参数
AUTOTRACE TRACE/TRACEONLY 要有实际意义,需要打开相关监控参数:
sql
SP_SET_PARA_VALUE(1, 'ENABLE_MONITOR', 1);
SP_SET_PARA_VALUE(1, 'MONITOR_SQL_EXEC', 1);
SP_SET_PARA_VALUE(1, 'ENABLE_MONITOR_DMSQL', 1);查看当前参数:
sql
SELECT PARA_NAME, PARA_VALUE
FROM V$DM_INI
WHERE PARA_NAME IN (
'ENABLE_MONITOR',
'MONITOR_SQL_EXEC',
'ENABLE_MONITOR_DMSQL',
'DMSQL_ET_CNT'
);说明:
ENABLE_MONITOR是总开关。MONITOR_SQL_EXEC影响执行计划节点、操作符执行历史等信息。ENABLE_MONITOR_DMSQL影响动态 SQL 执行时间监控。DMSQL_ET_CNT控制V$DMSQL_EXEC_TIME容量。
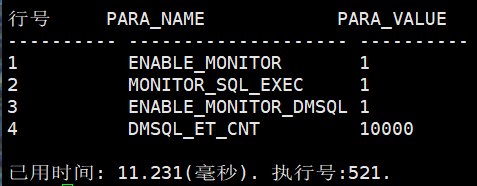
text
ENABLE_MONITOR 1
MONITOR_SQL_EXEC 1
ENABLE_MONITOR_DMSQL 1
DMSQL_ET_CNT 10000这张图说明当前会话或实例已经具备查看实际执行监控信息的条件。
ENABLE_MONITOR=1:总监控开关打开。MONITOR_SQL_EXEC=1:会记录 SQL 执行节点信息,这和ET、V$SQL_NODE_HISTORY关系很大。ENABLE_MONITOR_DMSQL=1:动态 SQL 执行时间监控打开,AUTOTRACE TRACE/TRACEONLY展示执行过程统计时需要它配合。DMSQL_ET_CNT=10000:V$DMSQL_EXEC_TIME最多保留 10000 条记录。
这一步不是调优 SQL 本身,而是打开"观察工具"。如果这些参数没开,后面即使执行 AUTOTRACE 或 ET,也可能看不到有效的实际执行信息。
5.3 使用 AUTOTRACE
sql
SET AUTOTRACE TRACEONLY;
SELECT A.C1, A.C2, B.D2
FROM T1 A
JOIN T2 B
ON A.C1 = B.D1
WHERE A.C1 >= 2
ORDER BY A.C1;
SET AUTOTRACE OFF;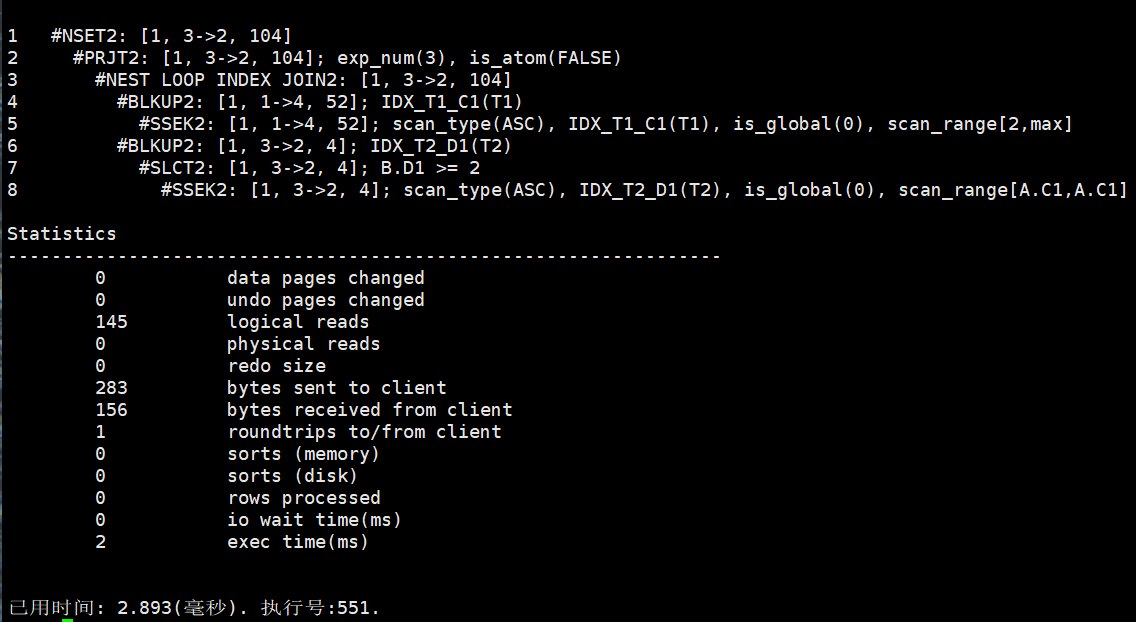
text
1 #NSET2: [1, 3->2, 104]
2 #PRJT2: [1, 3->2, 104]; exp_num(3), is_atom(FALSE)
3 #NEST LOOP INDEX JOIN2: [1, 3->2, 104]
4 #BLKUP2: [1, 1->4, 52]; IDX_T1_C1(T1)
5 #SSEK2: [1, 1->4, 52]; scan_type(ASC), IDX_T1_C1(T1), is_global(0), scan_range[2,max]
6 #BLKUP2: [1, 3->2, 4]; IDX_T2_D1(T2)
7 #SLCT2: [1, 3->2, 4]; B.D1 >= 2
8 #SSEK2: [1, 3->2, 4]; scan_type(ASC), IDX_T2_D1(T2), is_global(0), scan_range[A.C1,A.C1]这张是 AUTOTRACE TRACEONLY 的结果,和普通 EXPLAIN 最大区别是:它执行了 SQL,所以计划里出现了类似 3->2、1->4 这样的信息。可以把它理解为估算值和实际执行反馈的对比,用来观察优化器估算和真实返回是否接近。
这条 SQL 的条件是:
sql
WHERE A.C1 >= 2
ORDER BY A.C1;计划没有出现 SORT3,这是一个关键现象。原因是底层先通过 IDX_T1_C1 按 scan_range[2,max] 顺序定位 T1 中 C1 >= 2 的数据,输出顺序已经能满足 ORDER BY A.C1,所以不需要额外排序。这个和前面 ORDER BY C3 DESC 出现 SORT3 正好形成对比:C3 没有合适索引,需要排序;C1 有索引,可以利用索引顺序。
连接部分可以这样读:
text
先通过 IDX_T1_C1 找 A.C1 >= 2 的 T1 行
-> 对每个 A.C1,到 T2 的 IDX_T2_D1 上查 D1 = A.C1
-> SLCT2 再确认 B.D1 >= 2
-> PRJT2 输出 A.C1、A.C2、B.D2下面的 Statistics 是真实执行统计:
logical reads = 145:逻辑读 145 次,说明主要从缓冲区访问数据页。physical reads = 0:没有物理读,说明这次没有从磁盘读入页面,数据大概率已经在内存中。sorts(memory) = 0、sorts(disk) = 0:没有发生内存排序或磁盘排序,也印证了计划里没有SORT3。rows processed = 0:这里不要理解成"SQL 没有查到数据"。因为当前使用的是TRACEONLY,它执行查询但不打印查询结果集,所以统计项里可能不会按普通查询结果行数展示。io wait time(ms) = 0:没有明显 I/O 等待。exec time(ms) = 2:服务端执行耗时约 2 毫秒。
截图最后还有"已用时间 2.893 毫秒,执行号 551"。这里的执行号可以拿去做 ET(551),进一步看每个操作符的耗时分布。
解读顺序:
- 先看实际执行计划中有没有预期操作符。
- 再看统计信息中的执行时间、发送接收字节、数据页变化等指标。
- 如果执行结果和
EXPLAIN不一致,优先考虑统计信息变化、计划缓存、参数和实际绑定值影响。
6. ET 使用与解读
来源: 《DM8_SQL 语言使用手册》附录 3
ET;《DM8 系统管理员手册》V$SQL_NODE_HISTORY;达梦社区《具体操作 | 我们已经知道有一个语句慢了,怎么处理?(行业黑话:看下 ET 和执行计划)》《dm 的 SQL 监控》《达梦数据库 SQL 优化入门 ------ 执行计划详解》。
ET(id) 用于统计指定执行 ID 的所有操作符执行时间。它需要 ENABLE_MONITOR=1 和 MONITOR_SQL_EXEC=1。
6.1 基本使用流程
先执行 SQL,记录 DIsql 输出中的执行号:
sql
SELECT COUNT(*)
FROM SYSOBJECTS
WHERE NAME = 'SYSDBA';假设输出中看到:
text
已用时间: 14.641(毫秒). 执行号:26.再执行:
sql
ET(26);6.2 ET 输出字段怎么读
| 字段 | 含义 | 解读重点 |
|---|---|---|
OP |
操作符名称 | 对应执行计划里的节点类型 |
TIME(US) |
操作符耗时,单位微秒 | 看真实耗时,不等同于 EXPLAIN 代价 |
PERCENT |
当前节点耗时占比 | 优先分析占比最高的节点 |
RANK |
耗时排名 | 快速定位前几名热点操作符 |
SEQ |
操作符在计划中的序号 | 和 EXPLAIN 输出行号对应 |
N_ENTER |
节点进入次数 | 判断嵌套循环、索引探测是否执行过多 |
MEM_USED(KB) |
操作符使用内存 | 关注排序、HASH、临时结果 |
DISK_USED(KB) |
预期或使用磁盘空间 | 判断是否可能落临时空间 |

text
OP TIME(US) PERCENT RANK SEQ N_ENTER
PRJT2 1 0.97% 4 2 4
AAGR2 6 5.83% 3 3 4
SSEK2 40 38.83% 2 4 2
NSET2 56 54.37% 1 1 3这张图不是执行计划,而是某个执行号对应的操作符耗时统计。它的价值是告诉我们"真实时间花在哪里"。
这次结果里耗时排名是:
NSET2:56 微秒,占 54.37%。SSEK2:40 微秒,占 38.83%。AAGR2:6 微秒,占 5.83%。PRJT2:1 微秒,占 0.97%。
几个点要分开理解:
SEQ对应执行计划中的行号。比如NSET2的SEQ=1,说明它是计划第 1 行。N_ENTER表示进入该节点的次数,不是返回行数。PRJT2、AAGR2的N_ENTER=4,说明执行过程中这些节点被进入了 4 次。SSEK2占比 38.83%,说明这条 SQL 的实际成本里,索引定位是比较主要的一部分。NSET2占比最高,但这次总耗时只有微秒级,测试表很小,不代表NSET2是性能问题。小数据实验里,客户端返回、节点调度、计时粒度都会让顶层节点占比显得偏高。MEM_USED(KB)、DISK_USED(KB)都是 0,说明这次没有明显排序、HASH 或临时空间压力。
读 ET 时不要只看第一名,要结合总耗时看。比如这次最大也只有 56 微秒,说明它适合理解执行过程,不适合作为慢 SQL 结论。如果生产 SQL 中某个 SORT3、HASH2 INNER JOIN、SSEK2 持续占几百毫秒甚至几秒,才需要进一步分析索引、连接顺序、统计信息或临时空间。
6.3 ET 的判断口径
ET 最有价值的地方是把计划树和真实执行成本连起来。执行计划告诉你每一步是什么操作,ET 告诉你每一步实际花了多少时间:
- 如果
SORT3占比高,优先看排序列是否有合适索引、返回行数是否过大、是否可以减少排序范围。 - 如果
HASH2 INNER JOIN占比高,关注连接两侧行数、连接列统计信息、哈希表内存。 - 如果
NEST LOOP INDEX JOIN2的N_ENTER很高,说明右侧索引探测次数多,要看驱动表行数是否过大。 - 如果
CSCN2或SSCN占比高,说明扫描本身就是主要成本,要看过滤条件、索引、统计信息和返回行数。 - 如果
MEM_USED(KB)、DISK_USED(KB)较高,优先排查排序、哈希、临时结果相关 SQL。
我的理解是:EXPLAIN 告诉我"计划长什么样",ET 告诉我"时间花在哪里"。调优时不能只凭操作符名字下结论,要结合耗时占比、进入次数和行数估算一起看。
7. 总结
今天这部分学习可以归纳成一句话:先会看计划树,再会找真实耗时,最后再追问优化器为什么这样选。
实际排查时建议按下面顺序走:
- 用
EXPLAIN快速看 SQL 的访问路径和计划形状。 - 用
AUTOTRACE TRACEONLY执行一次,确认实际计划和统计信息。 - 记录执行号,用
ET(exec_id)找最耗时的操作符。 - 如果问题集中在排序、哈希、扫描、索引连接,再结合统计信息、索引、SQL 写法继续分析。
这套方法比单独背操作符更有用。操作符名称只是入口,真正要培养的是把 SQL 文本、执行计划和监控数据串起来判断的能力。
拓展参考资料
- DM8系统管理员手册.md` 22.6"执行计划"、附录 4"执行计划操作符"。
- DM8_DIsql使用手册.md
3.3.19AUTOTRACE`。 - DM8_SQL语言使用手册.md
附录 3ET`。 - 达梦社区:达梦数据库 SQL 优化入门 ------ 执行计划详解。
- 达梦社区:dm 的 SQL 监控。
- 达梦社区:具体操作 | 我们已经知道有一个语句慢了,怎么处理?(行业黑话:看下 ET 和执行计划)。
- 达梦社区:执行计划和达梦优化的基础篇 | 和优化器做朋友。
- 达梦社区:达梦数据库执行计划查看方式。