一 主题框架
1.1 概念整理
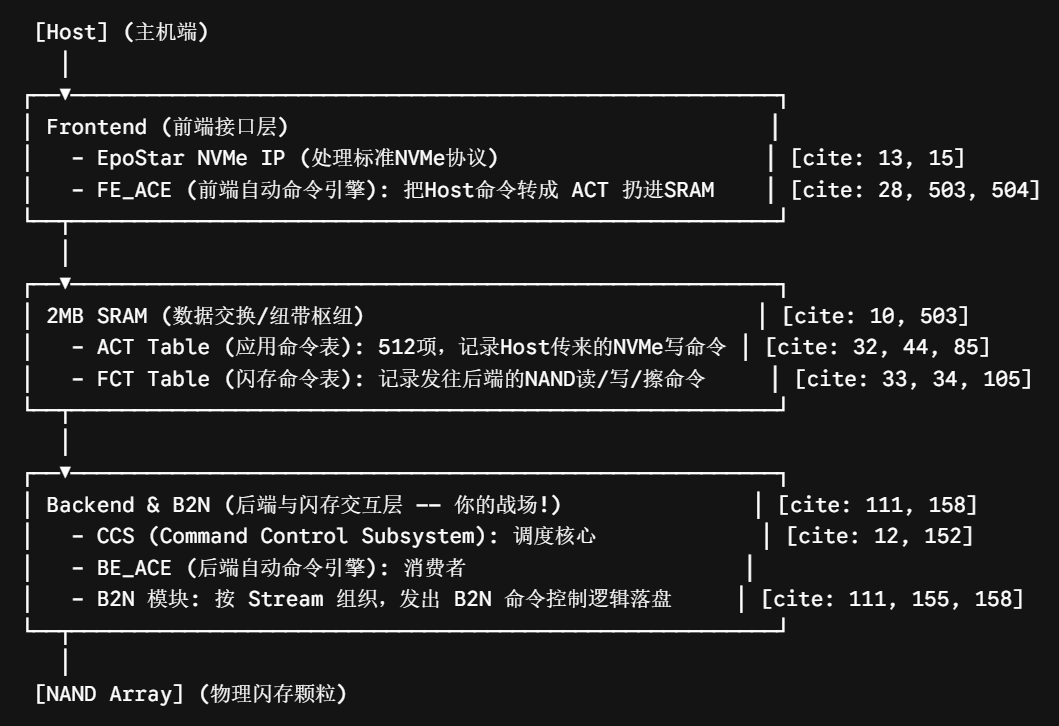
1 EpoStar NVMe IP
是一个第三方/外购的硬件模块,负责实现 NVMe 协议,让 SSD 能跟主机(比如服务器的 PCIe 接口)正常通信。你们固件不需要直接操作它,而是通过 ACE 引擎间接使用它的能力。
二 什么是B2N
2.1 定义
核心定义: B2N 是 Buffer To NAND 的缩写 。它是 FW 用来告诉 HW 某个特定数据流(Stream)如何按照指定顺序写到物理闪存中的"指挥官"。Buffer to NAND,告诉硬件"这一批数据按什么顺序、写到哪个闪存块"。它是后端写路径的调度器。
2.2 概念梳理
| 概念 | 一句话理解 | 文档位置 |
|---|---|---|
| Stream | 独立的写数据流,每个流有独立的B2N队列和RAID缓冲 | 4.1.4 |
| B2N命令 | 定义"这一笔写包含哪些页、按什么顺序编程" | 4.1.5 |
| W2P命令 | 真正搬运4KB数据到NAND的命令(B2N是调度,W2P是执行) | 4.4.1 |
| RAID缓冲共享 | 多个Stream共用有限的RAID奇偶校验缓冲,通过B2B命令切换 | 4.11 |
| FCT队列 | 后端命令的"收件箱",每个Stream独占一个B2N队列 | 4.4.2 |
与传统 SSD 的区别: ScaleFlux 的控制器支持硬件内联压缩 。因为数据压缩后的实际大小不确定,FW 无法直接决定数据写到哪个绝对物理地址(PBA) 。因此,B2N 命令现在更加强大:FW 只需要指定数据来自哪个 FCT 队列(后端队列),以及绑定相关的物理块信息,剩下的具体落盘、动态物理地址分配由硬件自动完成 。
十 整理 For Interview
如果你能在面试中讲清楚"一个带压缩的 4K 非对齐写,从 NVMe CQ 到最终落 NAND,经过哪些缓冲、异常时怎么回滚、PF 时怎么保证不丢数据",这绝对能打动下一家做企业级存储、SSD 主控、或计算存储的公司。
十一 Stream什么含义
这个Stream具体是什么含义啊?是逻辑的概念,还是物理的概念,为何会一共有16个Stream,为何会最多支持16个stream,Stream的数量多少,与后端NAND的配置信息有关吗
在 Myrtle 架构中,Stream(数据流)是一个"软硬件协同的半物理、半逻辑"的概念,但它最终是由底层的物理硬件资源(硬件通路)深度绑定的。
为了帮你彻底搞懂它,我们把你的问题拆解成四个核心疑问来逐一剖析:
1. Stream 具体是什么含义?是逻辑概念还是物理概念?
它是一个由硬件资源硬性支撑的逻辑隔离通道。
- 从逻辑上看: 它代表一类具有相同生命周期或特性的数据流。比如主机写入的"热数据"和固件搬运的"垃圾回收(GC)数据",如果在物理上混在一起写进同一个闪存块(Block),会导致严重的写放大(Write Amplification)。Stream 的存在就是为了在逻辑上把它们分流。
- 从物理上看: 它是一组固定的硬件寄存器、消息队列(Message Queue)和硬件 Buffer 资源的组合。
- 文档中提到,每一个 Stream 都有自己独立的 B2N 消息队列。
- 当 FW(固件)向硬件下发一个 B2N 命令时,必须带上
STREAM_ID。硬件(CCS/BE_ACE)看到这个 ID,就会自动调用专门为该 Stream 分配的物理硬件上下文和压缩/降噪硬件引擎。
所以,它就像是高速公路上的专用车道。车道本身是物理划分出来的(有固定的硬件资源),但跑什么车(热数据流、GC流、掉电保护流)是由固件在逻辑上定义的。
2. 为什么一共有 16 个 Stream?(它是怎么分配的)
文档里定义 16 个 Stream,是为了精细化管理 SSD 内部各种不同来源和去向的数据。这 16 个流在系统里的分工非常明确:
- Host 业务流(8 个 Hot Streams): 分配给前端 Host,用来支持 NVMe 协议中的 Multi-Stream 特性。不同应用或不同文件的写请求可以绑定不同的 Stream,让它们在物理闪存上隔离开。
- 垃圾回收流(1 个 GC Stream): 专门用于垃圾回收时搬运有效数据。
- 磨损均衡流(1 个 Wear Leveling Stream): 专门用于数据搬移以平衡擦写寿命。
- 掉电保护流(1 个 PF Stream): 文档第 6 章重点提及。当发生异常掉电时,系统需要紧急把内存里的残余数据冲刷到 SLC 预留块中。这个过程不能和普通的业务流混用,必须走专用的物理硬件通道,也就是 PF Stream。
- 其他系统流(如元数据、日志等): 占用剩下的几个 Stream。
3. 为什么最多支持 16 个 Stream?(为什么不能是 32 个或 64 个?)
控制芯片设计最多支持 16 个,这完全是由芯片设计时的硬件成本和架构限制(Silicon Cost)决定的。支持更多的 Stream,硬件上需要付出巨大的代价:
- 硬件上下文与寄存器数量: 控制器内部的 CCS(命令控制子系统)和 BE_ACE 需要为每一个 Stream 维护一套独立的硬件状态机和配置寄存器。Stream 数量翻倍,这部分硬件电路面积(SRAM 和寄存器阵列)也要跟着翻倍。
- 2MB SRAM 的容量限制: 文档提到 FW 和 HW 交互的核心是那块 2MB 的 SRAM。所有的 FCT 表项、消息队列(SQ/CQ)都在这里。如果 Stream 数量太多,每个 Stream 专属的硬件消息队列就会严重瓜分这块宝贵的 SRAM 空间。
- 硬件压缩引擎的并发能力: ScaleFlux 的核心卖点是内联压缩。芯片内部的硬件压缩模块在同一时间能处理的并发数据流(Stream Context)是有限的。16 个是平衡了性能、功耗和芯片面积(Die Size)之后的黄金数字。
4. Stream 的数量多少,与后端 NAND 的配置信息有关吗?
没有直接的因果关系,但它们在架构设计上是高度协同的。
- 无直接关系(从芯片设计角度): Stream 的最大数量(16个)在芯片卷片(Tape-out)硬件电路做好那一刻就固定了。无论你后端挂的是三星、东芝还是长江存储(YMTC)的 NAND,无论你配置了多少个 Channel(通道)或 Die,硬件 Stream 的上限就是 16 个。它不会因为你多贴了几颗闪存颗粒就变成 32 个。
- 有深度协同(从数据流向角度): * 每一个 Stream 内部的数据,最终是要打散并并发写入后端所有 Channel 和 Die 上的。
- 文档中提到,B2N(Buffer to NAND)模块的核心任务,就是把某个 Stream 里的数据,映射并均匀地分发到后端的物理 Super Block(超级块)中。
- 你的工作切入点: 在写 B2N 固件代码时,你需要确保当一个 Stream 启动写入时,它申请到的后端物理资源(比如 FCT 资源池里的 Entry)能够最优地匹配当前 NAND 的通道配置,从而把后端的带宽全部跑满。
总结一张记忆卡片:
| 问题 | 核心结论 | 形象比喻 |
|---|---|---|
| Stream 是什么? | 软硬件协同的隔离通道(绑定了 B2N 队列等硬件资源) | 高速公路上的专用车道 |
| 为什么是 16 个? | 8个给Host,其余给GC、磨损均衡、掉电保护(PF)等内部机制 | 乘用车道、货车道、消防应急专用道(PF) |
| 为什么最多 16 个? | 芯片硬件电路限制(寄存器、SRAM空间、压缩引擎能力的物理上限) | 桥梁宽度有限,最多只能拓宽出 16 条车道 |
| 与 NAND 配置有关吗? | 无关。 芯片设计时已固定,但固件调度时需要让流均匀落盘 | 车道数量固定,但车流最终要均匀分流到后端的各个目的地(NAND) |
有了这个大局观,你再去读文档 4.1.4 的 Stream 分配表和第 6 章的掉电冲刷流程,就会发现条理清晰得多!