导读
想象你正闭着眼睛拧一个灯泡。你不需要看到螺纹是否对齐------指尖传来的细微阻力变化、旋转时的咔嗒振动、接触面积的微妙扩大,这些触觉信号足以引导你完成整个过程。然而对于机器人来说,这种人类习以为常的能力却是一道难以逾越的鸿沟。
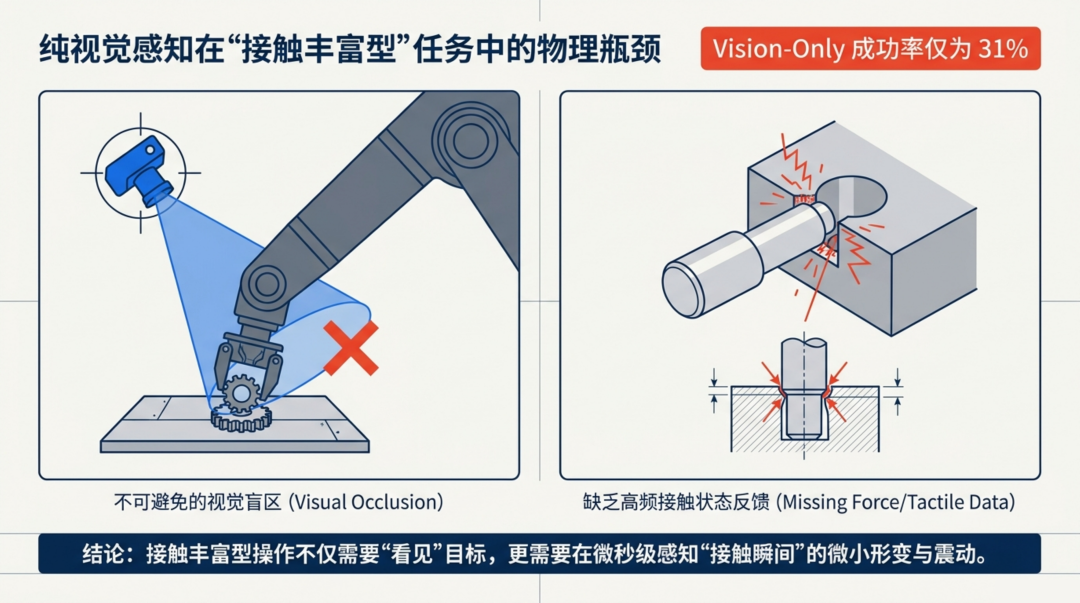
当前大多数机器人操作系统严重依赖视觉。但在齿轮组装、钥匙插锁这类"接触丰富型"任务中,目标物体一旦被夹爪遮挡,摄像头就成了摆设。即便加入触觉传感器,单一类型的触觉反馈也只能捕捉物理交互的一个侧面------要么看得清表面形变却跟不上瞬态冲击,要么感知得到高频振动却缺乏空间上下文。
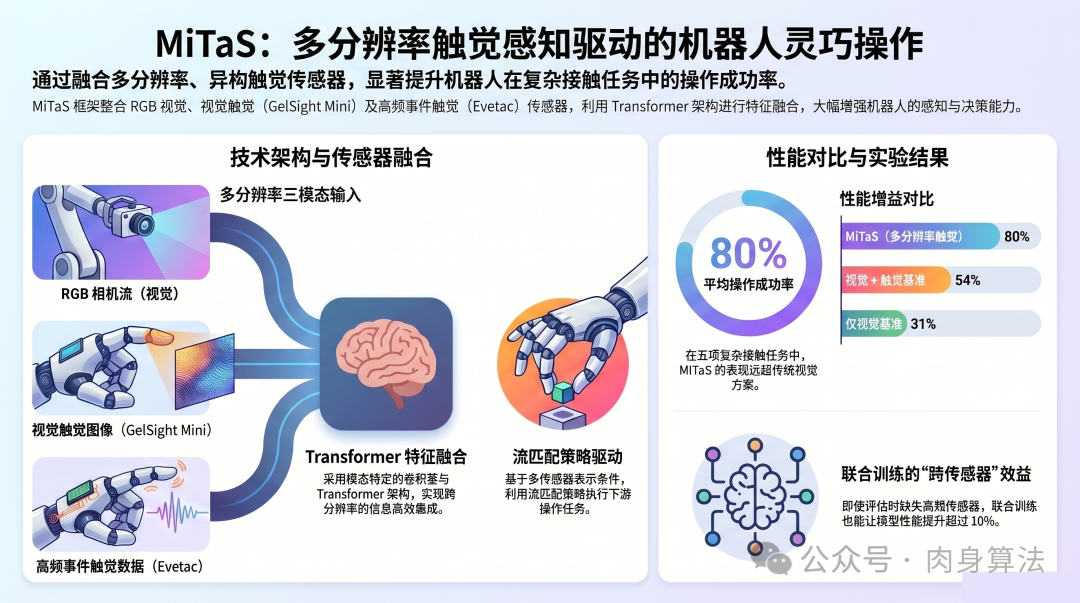
来自达姆施塔特工业大学的 Rickmer Krohn 等人给出了一个直击要害的答案:MiTaS(Multi-Resolution Tactile Sensing)。这一框架首次将低频视觉触觉传感器(GelSight Mini)与高频事件触觉传感器(Evetac)同时集成到模仿学习系统中,配合 Transformer 融合与流匹配策略,在五项高难度接触操作任务中实现了 80% 的平均成功率------相比纯视觉方案(31%)提升了近 2.6 倍。
背景与动机
机器人操作领域正经历一场从"看得见"到"摸得着"的范式转变。RGB 摄像头提供的宏观视觉信息固然重要,但在接触密集型场景下,两个根本性问题暴露无遗:
第一,视觉遮挡不可避免。 当机器人夹持物体时,目标区域几乎完全被手指和工具遮挡。钥匙是否对准锁芯?齿轮的齿牙是否啮合?这些关键信息在摄像头画面中无从获取。
第二,接触动力学发生在毫秒尺度。 插入时的瞬间卡滞、滑动前的微小振动、螺纹啮合的力矩突变------这些事件的持续时间可能不到 0.01 秒,远超传统帧率相机的捕捉能力。
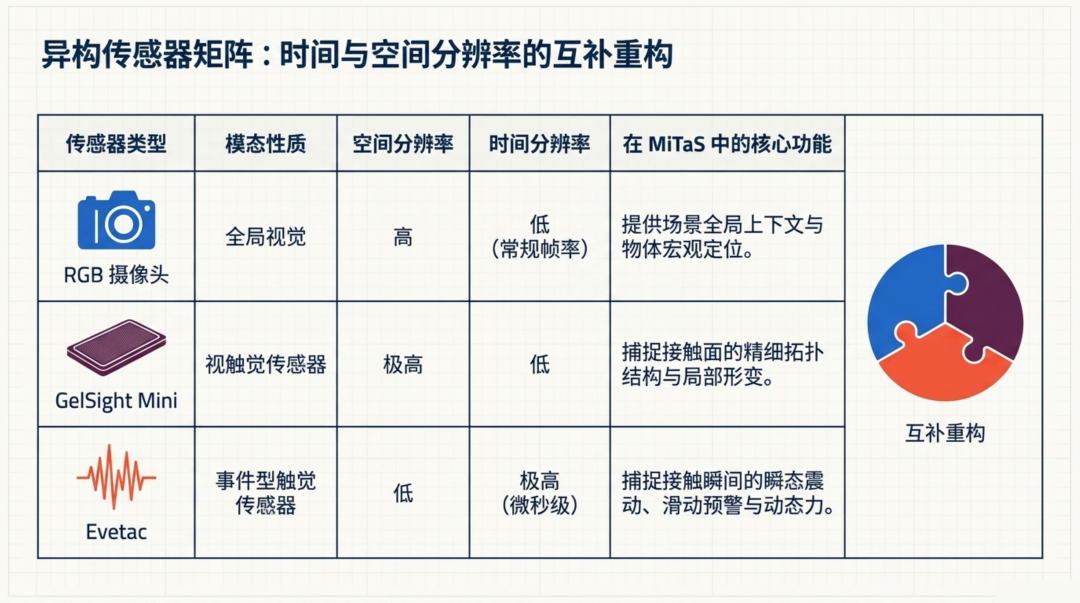
现有的视觉触觉传感器(如 GelSight 系列)通过捕捉弹性体表面的变形图像,提供了精细的空间接触信息------它能"看清"指尖下的表面纹理和局部几何。但它本质上仍是帧率相机,受限于 25 Hz 的采样频率,对快速冲击和高频振动力不从心。
另一方面,近年涌现的事件触觉传感器(如 Evetac)以 200 Hz 甚至更高的频率异步记录像素级亮度变化,天然适合捕捉瞬态接触事件。但它的空间分辨率相对有限,且数据形态(事件流)与传统图像截然不同。
关键洞察在于:这两类传感器不是竞争关系,而是互补关系。 一个擅长"看清"接触面的细节,另一个擅长"听到"接触瞬间的振动。MiTaS 的核心贡献,就是设计了一套能够同时消化这两种截然不同数据流的统一架构。
核心方法
模态专用卷积主干:让每种传感器说同一种语言
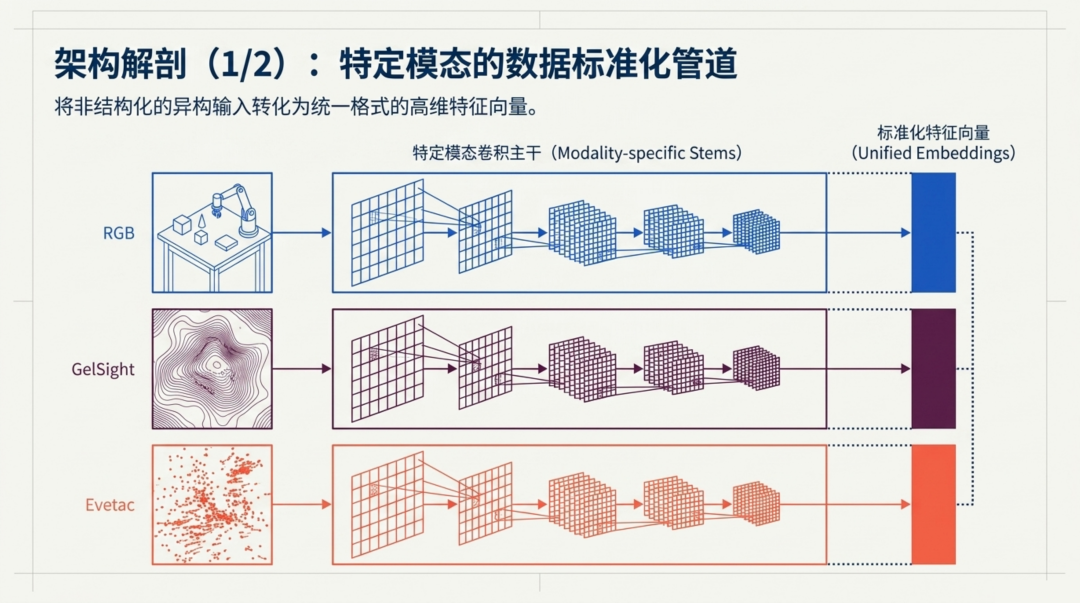
MiTaS 面临的第一个难题是:三种传感器的数据长得完全不一样。RGB 相机输出二维彩色图像,GelSight Mini 输出触觉变形图像,Evetac 则输出随时间累积的事件帧序列。直接拼接显然行不通。
解决方案是为每种模态设计专用的卷积主干(Convolutional Stem),各自将原始数据转化为统一格式的高维特征向量:
-
视觉主干:输入两帧 128x128 的 RGB 图像沿通道堆叠,经过四层步长为 2 的 2D 卷积,输出 16x16 的 token 网格,每个 token 维度 D=256。
-
GelSight 主干:结构与视觉主干镜像对称,处理 120x160 分辨率的触觉图像,产生 12x16 的 token 网格。
-
Evetac 主干 :这是最精巧的部分------采用四层 3D 卷积处理 16 帧时间堆叠数据(16x120x160),前三层在时间和空间维度同时以步长 2 下采样,最后一层用 (2x4x5) 的卷积核将时间维度完全塌陷,最终生成与 GelSight 匹配的 12x16 token 网格。
这种设计的妙处在于:每个模态的编码器保留了该传感器特有的数据结构(特别是 Evetac 的时空 3D 结构),而输出端却统一为相同维度的 token 序列。每个 token 还会加上学习到的位置编码和模态嵌入,告诉下游模块"我来自哪个传感器的哪个空间位置"。
Transformer 融合与流匹配策略:从感知到决策
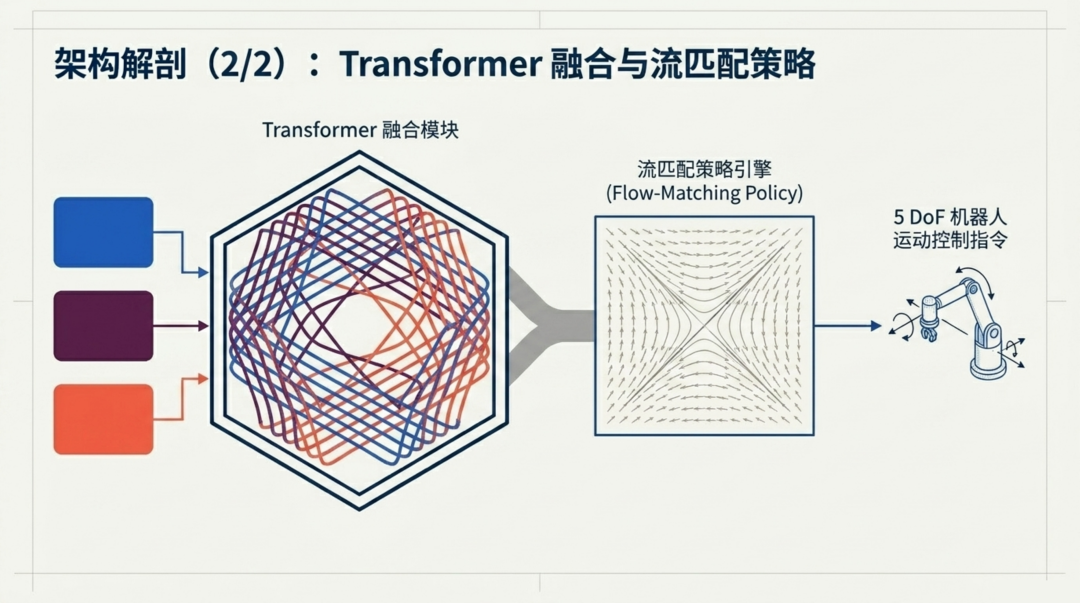
三条编码通道汇聚后,所有 token 被拼接成一个长序列,送入 Transformer 编码器。这里没有人工设定"视觉优先"或"触觉优先"的规则------多头自注意力机制让模型自己学习在什么时候关注哪个传感器。
融合后的特征序列作为条件,驱动一个**条件流匹配策略(Conditional Flow Matching Policy)**来生成机器人的运动指令。具体而言:
-
策略头是一个包含 10 个 DiT(Diffusion Transformer)块的网络
-
训练时,从噪声到目标动作的直线路径上采样中间状态,学习回归速度场
-
推理时,从随机噪声出发,通过 10 步欧拉积分沿学习到的速度场"流动"到最终动作
-
动作空间为 4 维增量指令:三轴平移加偏航角旋转 (dx, dy, dz, d-yaw)
一个值得注意的细节是:策略的观测空间中完全不包含机器人本体感知状态。所有运动决策必须仅从视觉和触觉信号中推断------这意味着模型被迫学习从感官输入中提取深层物理理解,而非走"看关节角度就知道该怎么动"的捷径。动作预测窗口为 16 步,但每次只执行前 1-3 步就重新规划,兼顾了时间连贯性和响应速度。
协同训练:硬件受限时的"知识蒸馏"
MiTaS 还提出了一个极具实用价值的协同训练方案。现实部署中,Evetac 这样的高频事件传感器可能因成本或可靠性原因无法搭载。协同训练的思路是:训练时用三种传感器,部署时只用两种。
具体做法是在每个训练批次中,50% 的样本包含 Evetac 数据,50% 不包含。这迫使网络在两种情况下都要输出正确的动作,间接地让高频触觉信息"蒸馏"到视觉和 GelSight 的特征表示中。结果表明,协同训练在齿轮组装上提升 10%、板面擦拭上提升 15%、灯泡连接上提升 25%。
实验与结果
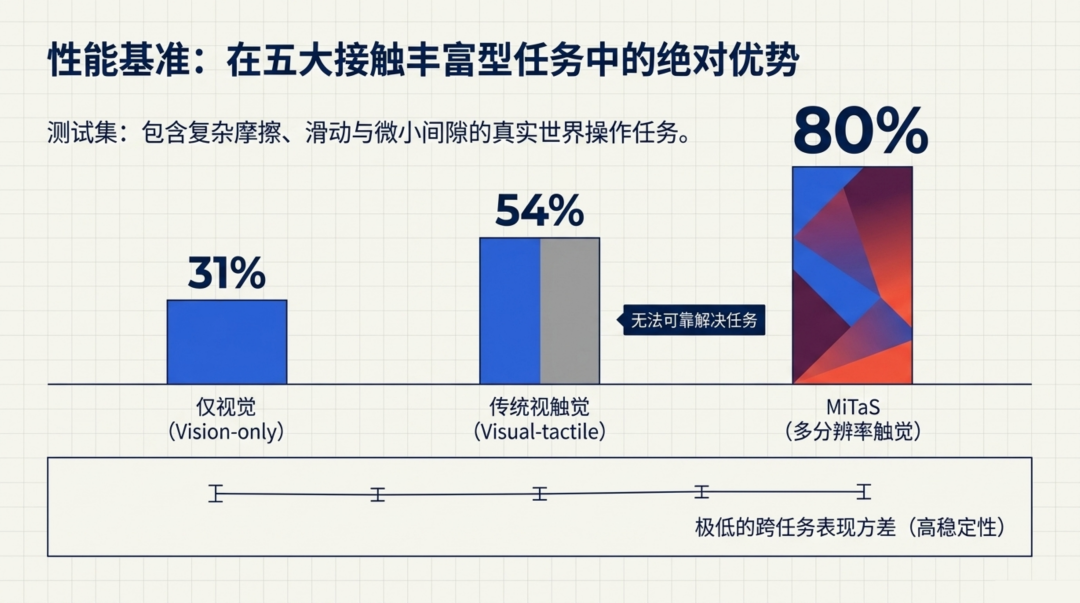
研究在五项精心设计的接触丰富型操作任务上进行了系统评估,每个任务仅用 30 份遥操作演示进行训练:
| 任务 | MiTaS (V+G+E) | Sparsh-X (V+G+E) | ViT (仅视觉) |
|---|---|---|---|
| 齿轮组装 | 90% | 50% | 40% |
| 板面擦拭 | 90% | 85% | 60% |
| 灯具安装 | 80% | 70% | 55% |
| 钥匙插锁 | 75% | 10% | 0% |
| 灯泡连接 | 65% | 55% | 0% |
| 平均 | 80% | 54% | 31% |
几组数据尤其值得关注:
钥匙插锁任务是分水岭。纯视觉方案在这里完全失败(0%),因为钥匙一旦接近锁芯就完全被遮挡。Sparsh-X 虽然能将钥匙部分插入,却总是卡在锁道中间无法完成(10%)。MiTaS 靠多分辨率触觉反馈------GelSight 提供在手定位,Evetac 感知微小角度偏差导致的壁面摩擦------达到了 75%。
灯泡连接任务同样如此。GU10 灯泡的两个插脚需要精确对准插槽,纯视觉无法区分"悬停在插座上方"和"已经插入"这两个视觉上几乎相同的状态,但 Evetac 的接触脉冲信号可以清晰地标记出插入的瞬间。
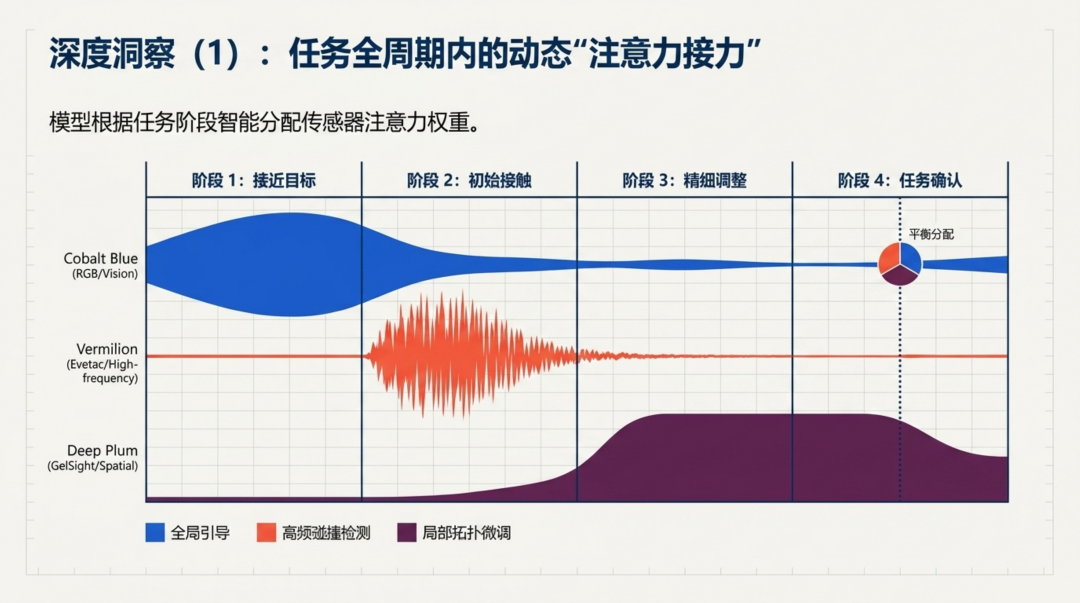
注意力分析揭示了模型如何智能地调度三种感官通道:
-
接近阶段:视觉(蓝色)占据主导,提供目标位置和全局导航
-
初始接触阶段:Evetac(橙色)的注意力骤然升高,捕捉接触冲击的瞬态信号
-
精细调整阶段:GelSight(紫色)逐渐主导,提供局部形变信息指导对位和旋入
-
任务确认阶段:三者趋于均衡,协同验证任务是否完成
这种动态注意力分配不是人工编码的,而是端到端训练自发涌现的。它从机制层面验证了多分辨率触觉融合的必要性------不同传感器在任务的不同阶段扮演不可替代的角色。
讨论与思考
<img src="images/slide-09.png" alt="协同训练的"幽灵感知效应":训练期使用的 Evetac 即使在部署时缺失,仍能提升基础模型性能" title="协同训练的"幽灵感知效应":训练期使用的 Evetac 即使在部署时缺失,仍能提升基础模型性能">
MiTaS 真正的创新不在于"加了更多传感器",而在于"如何让异构传感器协同增效"。
从架构层面看,模态专用 CNN 主干加 Transformer 全注意力融合的设计范式具有高度通用性。它不假设传感器之间存在固定的主次关系,而是让数据驱动的注意力机制自适应地分配权重。这与人类感知系统的工作方式高度吻合------我们并非时刻等权地处理视觉、听觉和触觉,而是根据当前情境动态切换"主导感官通道"。
协同训练方案揭示了一个更深层的现象:高频触觉信息在训练过程中并非仅仅增加了一个输入维度,而是重塑了整个特征空间的几何结构。即便在推理时移除 Evetac,经过协同训练的 GelSight 特征仍然隐含地编码了高频动力学信息。这种"幽灵感知"效应暗示,多模态训练可能是一种被低估的特征增强手段。
当然,MiTaS 也有明显的局限。当前的 4 自由度动作空间和 15 Hz 的重规划频率限制了其在更复杂场景中的应用。实验只验证了一对特定的触觉传感器组合(GelSight + Evetac),能否无缝替换为其他触觉技术尚不明确。此外,每个任务 30 份演示的数据规模虽然在当前基准下足够,但面向通用操作策略的扩展路径仍待探索。
从更宏观的视角来看,MiTaS 的成功传递了一个清晰的信号:在接触丰富型操作领域,传感器的多样性比单一传感器的精度更重要。 与其追求一个"万能传感器",不如设计能够整合多种互补感知模态的智能融合架构。这一思路与具身智能领域近年来从"大模型驱动"转向"感知-行动闭环"的趋势高度契合。
总结
-
MiTaS 首次在模仿学习中融合视觉、低频视觉触觉和高频事件触觉三种模态,通过模态专用 CNN 主干和 Transformer 注意力融合实现异构传感器的协同。
-
80% 的平均成功率显著超越所有基线,特别是在钥匙插锁(75% vs 0%)和灯泡连接(65% vs 0%)等高遮挡任务中展现出触觉的不可替代性。
-
注意力分析揭示了模型自发学习的"感官切换"策略------接近时靠视觉、接触时靠事件触觉、精细操作时靠空间触觉。
-
协同训练方案具有重要的工程实用价值:训练时使用全套传感器,部署时可去掉昂贵的高频传感器,仍能获得显著性能提升。
-
当前局限在于动作空间受限、传感器泛化性未验证、以及控制频率的天花板,但框架本身具备向更复杂场景扩展的潜力。
本文基于 Multi-Resolution Tactile Imitation Learning for Contact-Rich Robotic Manipulation1 解读。
引用链接
1Multi-Resolution Tactile Imitation Learning for Contact-Rich Robotic Manipulation: https://arxiv.org/abs/2606.06281