作者:Chang Zhu,Kui Xiong,Yutao Xiang,Zhongyi Wen,Wei Zhang,Huaizong Shao
DOI:10.1109/TSP.2026.3665693
文章目录
-
- 摘要
- [I. 引言](#I. 引言)
- [II. 预备知识](#II. 预备知识)
-
- [A. 相关工作](#A. 相关工作)
-
- [1. 低秩张量补全](#1. 低秩张量补全)
- [2. 互相关熵(**correntropy**)](#2. 互相关熵(correntropy))
- [3. 问题陈述](#3. 问题陈述)
- [B. 信号模型](#B. 信号模型)
- [C. 问题建模](#C. 问题建模)
- [III. 所提出算法](#III. 所提出算法)
-
- [A. CCHQ 优化](#A. CCHQ 优化)
- [B. MCCC-CGSR 算法](#B. MCCC-CGSR 算法)
- [C. 自适应核宽度与停止准则](#C. 自适应核宽度与停止准则)
- [D. 收敛性分析](#D. 收敛性分析)
- [E. 复杂度分析](#E. 复杂度分析)
摘要
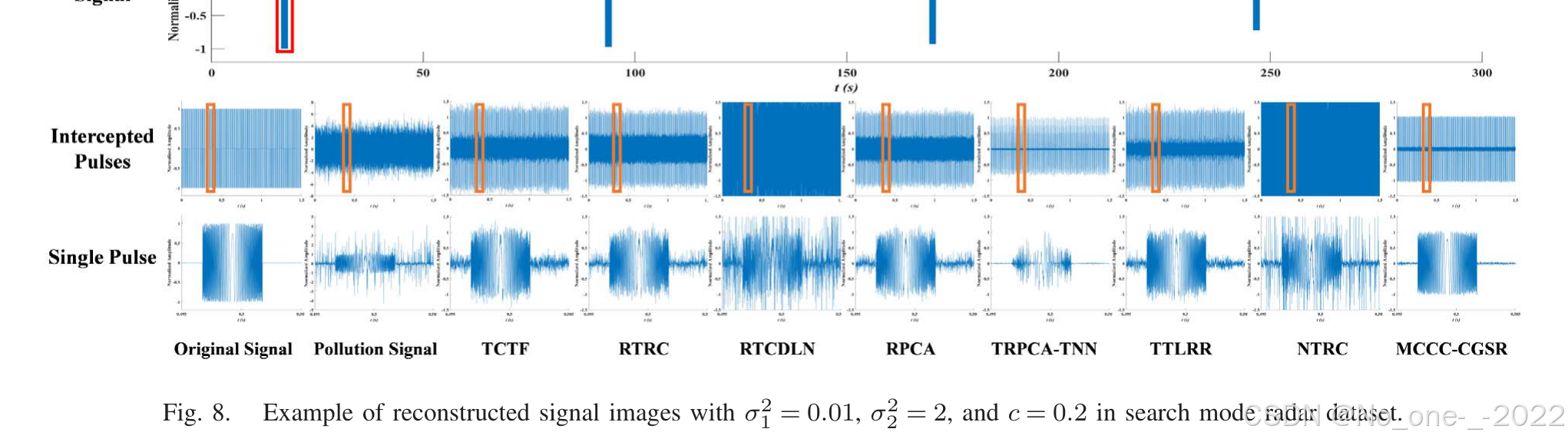
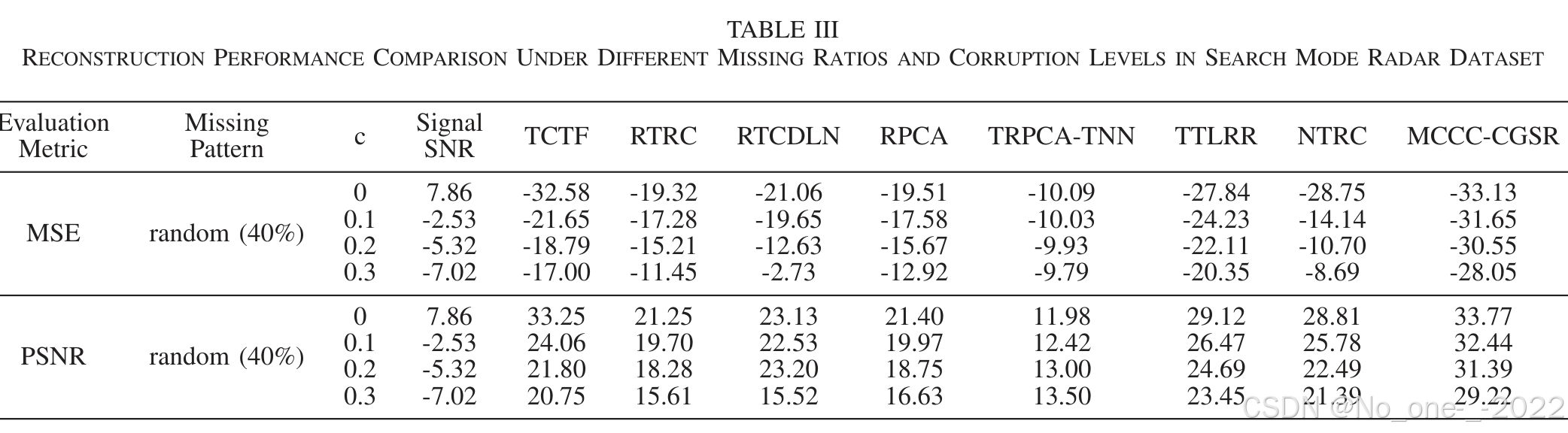
多功能相控阵雷达(Multi-Function Phased Array Radar, MFPAR)的感知是现代电子侦察系统的基础。然而,当前对 MFPAR 进行感知与估计的方法主要依赖脉冲描述字(Pulse Descriptor Word, PDW)的直接测量,在复杂电磁环境与零星干扰环境下容易出现鲁棒性不足和适应性不灵活的问题。传统压缩感知和基于矩阵的信号重构方法难以处理 MFPAR 信号的高维性与脉冲噪声;现有张量补全方法通常也缺乏对电子侦察中固有的复值数据和复杂电磁环境的支持。为此,本文提出一种面向电子侦察的鲁棒重构框架,将复互相关熵(complex correntropy)与复共轭梯度(Complex Conjugate Gradient, CCG)优化引入复值张量补全。该方法显著增强了对脉冲离群点的鲁棒性,并为信号分选、参数估计和雷达识别等下游任务提供了基础。具体而言,本文在最大复互相关熵准则下建立鲁棒信号重构目标函数;随后在所得鲁棒优化框架中采用半二次(Half-Quadratic, HQ)优化结合 CCG 算法,得到最大复互相关熵准则共轭梯度信号重构(Maximum Complex Correntropy Criterion with Conjugate Gradient Signal Reconstruction, MCCC-CGSR)算法。大量数值仿真表明,MCCC-CGSR 在重构精度和计算效率方面优于若干先进对比方法。
关键词: 鲁棒信号重构,复互相关熵(complex correntropy),复共轭梯度,半二次优化,张量补全。
I. 引言
电磁频谱与信号感知对于电子侦察系统中的雷达信号感知和分析具有重要意义,已成为突出的研究热点 1-3。高质量截获信号是决定 PDW 测量精度以及雷达感知准确性的关键数据来源。随着 MFPAR 和电子反反制技术的发展,截获信号越来越容易受到严重干扰、复杂电磁环境中的离群点以及信息缺失的影响,这会显著降低信号分选、识别与感知性能 4。此外,由于 MFPAR 运行方式灵活且自适应,截获信号通常呈现高维和结构复杂的特点,这给高效信号处理与分析带来了挑战 5。因此,有必要为不确定脉冲干扰(impulsive interference)下的电子侦察系统设计鲁棒信号重构方法。
注:
- Impulsive interference(脉冲干扰). 在本文语境中,它指随机、短时出现且幅值很高的异常干扰样本;后文信号模型把它和低方差高斯噪声一起描述为"混合噪声",即少数样本会突然偏离正常背景噪声水平。
- 为什么需要鲁棒重构. 普通 ℓ 2 \ell_2 ℓ2 或 Frobenius 范数会平方放大这类大误差,使少数脉冲离群点主导优化目标;因此本文用复互相关熵降低大误差样本权重,避免重构结果被突发干扰拖偏。
信号重构已经成为电磁信号处理中的活跃研究方向,并广泛应用于频谱感知 6、合成孔径雷达(Synthetic Aperture Radar, SAR)图像恢复 7 和干扰抑制 8。压缩感知(Compressive Sensing, CS)理论能够通过非线性迭代优化,从低维测量中重构信号 9;相关研究已用于认知无线电频谱恢复 10、雷达频谱重构 11、目标参数估计 12 和雷达成像 13。在雷达信号处理中,矩阵补全常用于 SAR 图像重构 14、波达方向(Direction of Arrival, DOA)估计 15 以及多输入多输出(Multiple-Input Multiple-Output, MIMO)雷达系统设计 16。也有研究将 CS 与矩阵补全结合 17,以更有效地完成频谱感知和信号恢复。
然而,上述方法大多基于 CS 或矩阵补全,处理的数据结构通常维度较低,并且常常忽略噪声和离群点的存在,因此限制了它们在复杂电磁环境以及高维、多域信号处理场景中的适用性。张量是矩阵在高维空间中的自然推广,适合处理大规模、多通道数据。近年来,张量补全与张量分解技术在矩阵方法基础上快速发展 18。张量补全旨在利用低秩结构恢复部分观测张量中的缺失元素,已有方法包括基于 CANDECOMP/PARAFAC 分解的交替最小化 19, 20、基于 Tucker 分解的黎曼流形优化 21, 22,以及基于张量奇异值分解(tensor Singular Value Decomposition, t-SVD)的凸松弛 23, 24 和交替最小化算法 25, 26。不过,相比图像修复和音频信号重构,张量补全在雷达信号重构和频谱感知中的应用仍较有限,现有工作多集中于雷达成像 27, 28 和 DOA 估计 29, 30。
在实际电磁环境中,截获信号还会受到周围辐射源产生的多种噪声与干扰污染。多数现有算法使用二阶统计量构造代价模型,这类模型在高斯噪声下有效,但在包含高斯分量和脉冲离群点的混合噪声下性能会明显下降。因此,已有一些鲁棒张量补全方法用于减轻离群点影响 31-40,例如鲁棒张量环补全在 MIMO 雷达定位 36 和目标估计 37 中处理受污染观测数据;截断 Frobenius 范数方法(capped Frobenius norm method)通过自适应截断大误差抑制离群点,同时保持正常元素的最小二乘最优性 38。另一类增强离群点鲁棒性的有效方法基于字典学习和低秩表示(dictionary learning and low-rank representation),并在图像和视频重构任务中取得了良好效果 39, 40。此外,深度张量补全方法也被用于图像修复和高动态范围成像 41-43,其中 CNet 41 仅利用不完整张量观测即可有效重构图像,并保持可解释性。
但这些张量补全方法主要面向图像和视频等实值数据,通常聚焦高斯噪声抑制,而没有充分考虑 MFPAR 发射信号的特性以及复杂电磁环境对截获信号的影响。在实际电子侦察系统中,截获雷达信号通常以同相/正交(In-phase and Quadrature, IQ)数据流表示,可建模为复值张量;电磁环境则往往由高斯噪声与脉冲离群点混合构成。由此可见,需要开发专门面向复值信号的鲁棒张量补全方法,以在困难条件下重构截获雷达信号。
本文考虑侦察机在存在零星自主干扰的情况下截获 MFPAR 信号的场景,并提出一种鲁棒复值电磁信号重构方法。主要贡献如下。
- 提出一种基于张量补全和复互相关熵的鲁棒雷达信号重构框架。接收机对来自 MFPAR 的截获信号进行下变频和采样,形成三阶张量;复互相关熵用于替代传统 Frobenius 范数作为代价度量,从而降低离群点影响,并将重构任务转化为张量补全优化问题。
- 利用 HQ 优化方法推导一种加权信号重构方法,用于求解非凸鲁棒重构问题。该方法构造指数函数的共轭函数以获得目标函数上界,再通过交替优化将问题转化为加权张量补全形式,并证明所得问题的收敛性。
- 提出 MCCC-CGSR 算法,用于求解鲁棒电磁信号重构问题。理论分析和数值仿真表明,该算法能够在混合噪声与脉冲干扰下实现更优重构性能和更低计算代价。
II. 预备知识
A. 相关工作
1. 低秩张量补全
张量补全的目标是从观测信号张量 M Ω \boldsymbol{\mathcal{M}}\Omega MΩ 中恢复原始信号张量 M ∈ C n 1 × n 2 × n 3 \boldsymbol{\mathcal{M}}\in\mathbb{C}^{n_1\times n_2\times n_3} M∈Cn1×n2×n3,其中 Ω \Omega Ω 为非零元素索引集。若 ( i , j , k ) ∈ Ω (i,j,k)\in\Omega (i,j,k)∈Ω,则 ( M Ω ) i j k = M i j k (\boldsymbol{\mathcal{M}}\Omega){ijk}=\boldsymbol{\mathcal{M}}{ijk} (MΩ)ijk=Mijk;否则观测缺少有效数据分量。定义指示张量 P \boldsymbol{\mathcal{P}} P:
P i j k = { 1 , i f ( i , j , k ) ∈ Ω , 0 , o t h e r w i s e . (1) \boldsymbol{\mathcal{P}}_{ijk}= \left\{ \begin{array}{ll} 1, & \mathrm{if}\ (i,j,k)\in\Omega,\\ 0, & \mathrm{otherwise}. \end{array} \right. \tag{1} Pijk={1,0,if (i,j,k)∈Ω,otherwise.(1)
利用低秩结构,低 tubal 秩张量补全 47 可表示为
min C rank t ( C ) , s . t . P ∘ ( C − M ) = 0 , (2) \min_{\boldsymbol{\mathcal{C}}}\ \operatorname{rank}_t(\boldsymbol{\mathcal{C}}), \quad \mathrm{s.t.}\quad \boldsymbol{\mathcal{P}}\circ(\boldsymbol{\mathcal{C}}-\boldsymbol{\mathcal{M}})=0, \tag{2} Cmin rankt(C),s.t.P∘(C−M)=0,(2)
其中 C \boldsymbol{\mathcal{C}} C 为重构张量, rank t ( C ) \operatorname{rank}_t(\boldsymbol{\mathcal{C}}) rankt(C) 为 tubal 秩, ∘ \circ ∘ 为 Hadamard 积。式 (2) 是 NP-hard 问题,因此已有研究通过张量核范数进行凸松弛 23, 24。
受矩阵补全中幂分解(power factorization method)思想启发,也可将目标张量分解为两个小张量的 t-product 25, 26:
min X , Y ∥ P ∘ ( M − X ∗ Y ) ∥ F 2 . (3) \min_{\boldsymbol{\mathcal{X}},\boldsymbol{\mathcal{Y}}} \left\|\boldsymbol{\mathcal{P}}\circ(\boldsymbol{\mathcal{M}}- \boldsymbol{\mathcal{X}}*\boldsymbol{\mathcal{Y}})\right\|_F^2. \tag{3} X,Ymin∥P∘(M−X∗Y)∥F2.(3)
上述算法通常基于 ℓ 2 \ell_2 ℓ2 范数代价函数,适合高斯噪声,但对离群点鲁棒性不足。常见做法是采用 ℓ p \ell_p ℓp 范数( 0 < p < 2 0<p<2 0<p<2)作为代价函数 35-37:
min C ∥ C ∥ L , s . t . ∥ P ∘ ( C − M ) ∥ p p ≤ δ , (4) \min_{\boldsymbol{\mathcal{C}}}\ \left\|\boldsymbol{\mathcal{C}}\right\|_{\mathbb{L}}, \quad \mathrm{s.t.}\quad \left\|\boldsymbol{\mathcal{P}}\circ(\boldsymbol{\mathcal{C}}-\boldsymbol{\mathcal{M}})\right\|_p^p\le \delta, \tag{4} Cmin ∥C∥L,s.t.∥P∘(C−M)∥pp≤δ,(4)
其中 δ > 0 \delta>0 δ>0 控制拟合误差, ∥ ⋅ ∥ L \|\cdot\|_{\mathbb{L}} ∥⋅∥L 表示对数范数, ∥ ⋅ ∥ p \|\cdot\|_p ∥⋅∥p 表示 ℓ p \ell_p ℓp 范数。
注:
- Logarithmic norm(对数范数). 在这里, ∥ C ∥ L \|\boldsymbol{\mathcal{C}}\|{\mathbb{L}} ∥C∥L 通常不是严格数学意义上的范数,而是一种用于近似低秩约束的非凸正则项。直观上,它对奇异值施加对数惩罚,例如矩阵情形常写成 ∥ X ∥ L = ∑ i log ( σ i ( X ) + ϵ ) \|X\|{\mathbb{L}}=\sum_i\log(\sigma_i(X)+\epsilon) ∥X∥L=∑ilog(σi(X)+ϵ),其中 σ i ( X ) \sigma_i(X) σi(X) 是奇异值, ϵ > 0 \epsilon>0 ϵ>0 用于避免 log ( 0 ) \log(0) log(0)。
- 为什么能鼓励低秩. 直接最小化 rank ( X ) \operatorname{rank}(X) rank(X) 很难;核范数 ∑ i σ i ( X ) \sum_i\sigma_i(X) ∑iσi(X) 是常见凸替代,但会较强地惩罚大的奇异值。对数惩罚增长更慢,更接近"数非零奇异值"的低秩目标。因此,式 (4) 可以理解为:在观测误差不超过 δ \delta δ 的条件下,寻找一个对数范数尽可能小、也就是尽可能低秩的重构张量 C \boldsymbol{\mathcal{C}} C。
2. 互相关熵(correntropy)
互相关熵(correntropy )是两个随机变量之间的局部非线性相似度。给定随机变量 X X X 与 Y Y Y,互相关熵 44 定义为
V ( X , Y ) = E κ σ ( X − Y ) = ∫ κ σ ( x , y ) d F X Y ( x , y ) , (5) V(X,Y)=\mathbb{E}\\kappa_\\sigma(X-Y) =\int \kappa_\sigma(x,y)\,dF_{XY}(x,y), \tag{5} V(X,Y)=Eκσ(X−Y)=∫κσ(x,y)dFXY(x,y),(5)
其中 E ⋅ \mathbb{E}\\cdot E⋅ 为期望, κ σ ( ⋅ ) \kappa_\sigma(\cdot) κσ(⋅) 是核宽度为 σ \sigma σ 的平移不变 Mercer 核, F X Y F_{XY} FXY 是联合分布函数。在各种核函数中,高斯核因其平滑性和局部性(smoothness and locality)而被广泛采用,定义为
κ σ ( x , y ) = exp ( − ( x − y ) 2 2 σ 2 ) . (6) \kappa_\sigma(x,y)=\exp\left(-\frac{(x-y)^2}{2\sigma^2}\right). \tag{6} κσ(x,y)=exp(−2σ2(x−y)2).(6)
注:
- Smoothness(平滑性). 指高斯核函数随误差 x − y x-y x−y 连续、平滑地变化,且可微性好;因此把它放进损失函数后,梯度更新通常更稳定,也更适合后文的优化推导。
- Locality(局部性). 指当 x x x 和 y y y 很接近时核值接近 1,而误差 ∣ x − y ∣ |x-y| ∣x−y∣ 变大时核值会指数衰减。放到本文语境中,这意味着大误差或脉冲离群点在互相关熵代价中的权重会被压低,从而提升鲁棒性。
给定有限样本 { x i , y i } i = 1 N \{x_i,y_i\}_{i=1}^N {xi,yi}i=1N,互相关熵可经验近似为
V ^ σ ( X , Y ) = 1 N ∑ i = 1 N κ σ ( x i − y i ) = 1 N ∑ i = 1 N exp ( − e i 2 2 σ 2 ) , (7) \widehat{V}\sigma(X,Y)=\frac{1}{N}\sum{i=1}^N\kappa_\sigma(x_i-y_i) =\frac{1}{N}\sum_{i=1}^N\exp\left(-\frac{e_i^2}{2\sigma^2}\right), \tag{7} V σ(X,Y)=N1i=1∑Nκσ(xi−yi)=N1i=1∑Nexp(−2σ2ei2),(7)
其中 e i = x i − y i e_i=x_i-y_i ei=xi−yi。互相关熵能够捕捉高阶统计量,因此可有效缓解离群点影响 44。
3. 问题陈述
现有鲁棒张量补全和互相关熵建模方法多面向实值图像/视频数据,并常假设高斯噪声或极稀疏离群点。它们直接用于脉冲干扰下复值截获雷达数据的信号级重构时仍存在局限。因此,本文重点开发面向侦察系统的鲁棒复值信号级重构框架,以处理复杂电磁环境中的 IQ 数据流,并为信号分选、参数估计和雷达识别等后续任务提供可靠输入。
B. 信号模型
本文考虑图 1 所示的侦察场景。假设在给定相干处理间隔(Coherent Processing Interval, CPI)内,MFPAR 在每个波束上发射 N N N 个脉冲,脉冲之间由固定脉冲重复间隔(Pulse Repetition Interval, PRI)分隔。第 m m m 个脉冲为 s m ( t ) = s ( t − m T p ) s_m(t)=s(t-mT_p) sm(t)=s(t−mTp),其中 T p T_p Tp 为 PRI, s ( t ) s(t) s(t) 是连续时间线性调频(Linear Frequency-Modulated, LFM)波形:
s ( t ) = { exp ( j π μ t 2 ) , 0 ≤ t ≤ t p , 0 , o t h e r w i s e , (8) s(t)= \left\{ \begin{array}{ll} \exp(j\pi\mu t^2), & 0\le t\le t_p,\\ 0, & \mathrm{otherwise}, \end{array} \right. \tag{8} s(t)={exp(jπμt2),0,0≤t≤tp,otherwise,(8)
其中 μ = B / t p \mu=B/t_p μ=B/tp 为调频率, B B B 为扫频带宽, t p t_p tp 为脉宽。中心频率 f c f_c fc 下,一个 CPI 内第 m m m 个发射通带脉冲为
x m ( t ) = s m ( t ) exp ( j 2 π f c t ) . (9) x_m(t)=s_m(t)\exp(j2\pi f_c t). \tag{9} xm(t)=sm(t)exp(j2πfct).(9)
若侦察机位于距离 R 0 R_0 R0 处并以恒定速度 v v v 运动,则截获信号为
r m ( t ) = α x m ( t − τ m ) + n m ( t ) , (10) r_m(t)=\alpha x_m(t-\tau_m)+n_m(t), \tag{10} rm(t)=αxm(t−τm)+nm(t),(10)
其中 α \alpha α 为信号衰减因子, τ m \tau_m τm 为第 m m m 个脉冲时延:
τ m = R 0 − v m T p c . (11) \tau_m=\frac{R_0-vmT_p}{c}. \tag{11} τm=cR0−vmTp.(11)
n m ( t ) n_m(t) nm(t) 表示由低方差零均值高斯噪声和随机高幅值离群点组成的混合噪声。
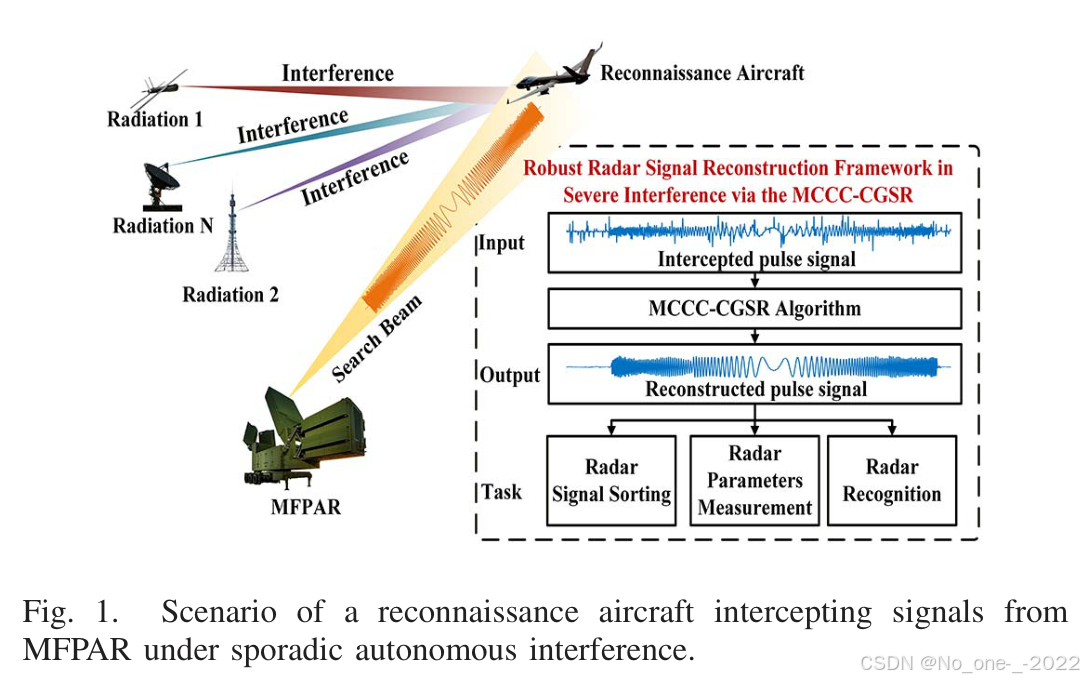
图 1. 零星自主干扰下侦察机截获 MFPAR 信号的场景。
接收机下变频后,第 m m m 个脉冲的基带信号为
z m ( t ) = α s m ( t − τ m ) exp ( − j 2 π f c τ m ) + N m ( t ) , (12) z_m(t)=\alpha s_m(t-\tau_m)\exp(-j2\pi f_c\tau_m)+N_m(t), \tag{12} zm(t)=αsm(t−τm)exp(−j2πfcτm)+Nm(t),(12)
其中 N m ( t ) N_m(t) Nm(t) 为基带混合噪声。根据 MFPAR 帧周期和雷达数据采集方案,构造三阶复值张量 M ∈ C n 1 × n 2 × n 3 \boldsymbol{\mathcal{M}}\in\mathbb{C}^{n_1\times n_2\times n_3} M∈Cn1×n2×n3 表示截获信号; n 1 n_1 n1、 n 2 n_2 n2、 n 3 n_3 n3 分别对应 CPI 近似数量、每个脉冲采样数以及 MFPAR 波束照射次数。张量元素定义为
M i j k = z k , j i , (13) \boldsymbol{\mathcal{M}}{ijk}=z{k,j}i, \tag{13} Mijk=zk,ji,(13)
其中 z k , j i z_{k,j}i zk,ji 表示第 k k k 次波束照射下第 j j j 个脉冲对应基带截获信号 z j ( t ) z_j(t) zj(t) 的第 i i i 个采样。
注:
- 张量维度的理解. 式 (13) 的下标关系表明, i i i 更像脉冲内采样索引, j j j 更像脉冲索引, k k k 更像波束照射索引。因此,前文"每个波束发射 N N N 个脉冲"可理解为对应张量中的脉冲维度;论文将该维度一般记作 n 2 n_2 n2,而不是直接写成 N N N。
- 原文表述的含混处. 原文对 n 1 , n 2 n_1,n_2 n1,n2 的文字说明略显含混。结合 M i j k = z k , j i \boldsymbol{\mathcal{M}}{ijk}=z{k,j}i Mijk=zk,ji,更稳妥的读法是以式 (13) 的索引定义为准: i i i 对应采样点, j j j 对应脉冲, k k k 对应波束照射。
C. 问题建模
记观测基带信号张量为 M Ω ∈ C n 1 × n 2 × n 3 \boldsymbol{\mathcal{M}}\Omega\in\mathbb{C}^{n_1\times n_2\times n_3} MΩ∈Cn1×n2×n3,重构任务是从 M Ω \boldsymbol{\mathcal{M}}\Omega MΩ 中恢复原始信号张量 M \boldsymbol{\mathcal{M}} M。由于复杂电磁环境和低截获概率技术(low-probability-of-intercept techniques, LPI techniques)会造成数据缺失,引入式 (1) 的指示张量 P \boldsymbol{\mathcal{P}} P。MFPAR 发射信号包含冗余且高度相似的信息,使截获信号张量具有低 tubal 秩结构,因此低 tubal 秩信号重构可表示为式 (3)。
注:
- LPI techniques(低截获概率技术). 指雷达通过降低发射功率、频率捷变/跳频/扩频、快速改变波形、窄波束定向发射、间歇发射或不规则脉冲模式等策略,使侦察接收机更难发现、截获或完整捕获其信号。
- 与张量缺失的关系. 在本文语境中,LPI 技术解释了为什么侦察系统得到的是部分观测张量 M Ω \boldsymbol{\mathcal{M}}\Omega MΩ:MFPAR 可能有意让信号不容易被完整截获,导致雷达 IQ 数据出现缺失,因此需要从 M Ω \boldsymbol{\mathcal{M}}\Omega MΩ 恢复完整信号张量 M \boldsymbol{\mathcal{M}} M。
由于截获信号在接收端表示为复数 IQ 数据流,本文将互相关熵从实数域扩展到复数域。令 X = a + j b X=a+jb X=a+jb、 Y = c + j d Y=c+jd Y=c+jd 为复随机变量,则复互相关熵定义为
V σ C ( X , Y ) = E κ σ C ( X − Y ) = 1 N ∑ i = 1 N exp ( − e i e i ∗ 2 σ 2 ) , (14) V_\sigma^C(X,Y)=\mathbb{E}\\kappa_\\sigma\^C(X-Y) =\frac{1}{N}\sum_{i=1}^N \exp\left(-\frac{e_i e_i^*}{2\sigma^2}\right), \tag{14} VσC(X,Y)=EκσC(X−Y)=N1i=1∑Nexp(−2σ2eiei∗),(14)
其中 ( ⋅ ) ∗ (\cdot)^* (⋅)∗ 表示(refers to)复共轭, κ σ C ( ⋅ ) \kappa_\sigma^C(\cdot) κσC(⋅) 为复高斯核函数。最大复互相关熵准则(maximum complex correntropy criterion,MCCC)定义为
J M C C C = E κ σ C ( X − Y ) . (15) J_{\mathrm{MCCC}}=\mathbb{E}\\kappa_\\sigma\^C(X-Y). \tag{15} JMCCC=EκσC(X−Y).(15)
注:
- 为什么这样定义 MCCC. 式 (15) 实际上是把式 (14) 的复互相关熵直接作为优化准则: κ σ C ( X − Y ) = exp ( − ∣ X − Y ∣ 2 / ( 2 σ 2 ) ) \kappa_\sigma^C(X-Y)=\exp(-|X-Y|^2/(2\sigma^2)) κσC(X−Y)=exp(−∣X−Y∣2/(2σ2)) 表示复残差 X − Y X-Y X−Y 的有界局部相似度。残差越小,核值越接近 1;残差越大,核值越接近 0。因此,对该核值取期望,就是衡量 X X X 与 Y Y Y 在随机样本意义下的平均相似度。
- 为什么要最大化它. 传统最小二乘等价于惩罚 ∣ X − Y ∣ 2 |X-Y|^2 ∣X−Y∣2,少数大误差会被平方放大,从而容易主导优化结果;MCCC 则最大化平均核相似度 E κ σ C ( X − Y ) \mathbb{E}\\kappa_\\sigma\^C(X-Y) EκσC(X−Y),大误差或脉冲离群点的贡献会被指数衰减压低。因此,它更适合本文含噪声、离群点和复值 IQ 数据的雷达信号重构问题。
于是,含离群点与噪声的复杂电磁环境下,MFPAR 截获信号重构问题为
max X , Y J ( X , Y ) = ∑ i = 1 n 1 ∑ j = 1 n 2 ∑ k = 1 n 3 P i j k exp ( − E i j k E i j k ∗ 2 σ 2 ) , (16) \max_{\boldsymbol{\mathcal{X}},\boldsymbol{\mathcal{Y}}} J(\boldsymbol{\mathcal{X}},\boldsymbol{\mathcal{Y}}) =\sum_{i=1}^{n_1}\sum_{j=1}^{n_2}\sum_{k=1}^{n_3} \boldsymbol{\mathcal{P}}{ijk}\exp\left(-\frac{\boldsymbol{\mathcal{E}}{ijk}\boldsymbol{\mathcal{E}}_{ijk}^*}{2\sigma^2}\right), \tag{16} X,YmaxJ(X,Y)=i=1∑n1j=1∑n2k=1∑n3Pijkexp(−2σ2EijkEijk∗),(16)
其中 E i j k = M i j k − ( X ∗ Y ) i j k \boldsymbol{\mathcal{E}}{ijk}=\boldsymbol{\mathcal{M}}{ijk}-(\boldsymbol{\mathcal{X}}*\boldsymbol{\mathcal{Y}})_{ijk} Eijk=Mijk−(X∗Y)ijk。由于该目标函数是复值非解析函数,标准微积分不能直接应用,需要使用 Wirtinger 微积分计算梯度和 Hessian。
命题 1: 式 (16) 的复值优化问题是非凸的。 Proof: 见附录 A:命题 1 证明。 \boxed{\textbf{命题 1:}\ \text{式 (16) 的复值优化问题是非凸的。}\quad \textbf{Proof:}\ \text{见附录 A:命题 1 证明。}} 命题 1: 式 (16) 的复值优化问题是非凸的。Proof: 见附录 A:命题 1 证明。
III. 所提出算法
本节首先基于 HQ 优化提出复互相关熵半二次(Complex Correntropy Half-Quadratic, CCHQ)方法,再结合 CCG 得到 MCCC-CGSR 算法,并给出自适应核宽度策略、停止准则、收敛性和复杂度分析。
A. CCHQ 优化
由于 CC-Loss 函数 (16) 的复 Hessian 矩阵为负定,其凸性无法得到保证。因此,CC-Loss 不能直接用于凸优化问题。半二次优化(half-quadratic optimization, HQ optimization)方法 52 适用于处理非凸问题,它通过引入辅助变量,将原目标函数转换为 HQ 形式。因此,本文采用 HQ 优化技术,将 CC-Loss 函数转换为加权张量补全问题,并据此提出复互相关熵半二次(complex correntropy half-quadratic, CCHQ)方法。
由于 CC-Loss 函数符合指数函数形式,首先引入标准指数函数 f ( x ) = exp ( x ) f(x)=\exp(x) f(x)=exp(x),其中 x ∈ C x\in\mathbb{C} x∈C。根据共轭函数理论 51,有如下命题。
命题 2: 存在指数函数 f ( x ) = exp ( − x ) 的共轭函数 ϕ ( t ) = − t ln ( − t ) + t , t < 0. Proof: 见附录 B。 \boxed{ \begin{aligned} &\textbf{命题 2:}\ \text{存在指数函数 } f(x)=\exp(-x) \text{ 的共轭函数}\\ &\phi(t)=-t\ln(-t)+t,\quad t<0.\\ &\textbf{Proof:}\ \text{见附录 B。} \end{aligned} } 命题 2: 存在指数函数 f(x)=exp(−x) 的共轭函数ϕ(t)=−tln(−t)+t,t<0.Proof: 见附录 B。
该共轭函数满足
exp ( − x ) = sup t < 0 ( t x − ϕ ( t ) ) , (17) \exp(-x)=\sup_{t<0}\left(tx-\phi(t)\right), \tag{17} exp(−x)=t<0sup(tx−ϕ(t)),(17)
其中,该函数的上界在 t = − exp ( − x ) t=-\exp(-x) t=−exp(−x) 处取得。基于命题 2,将 x x x 替换为 E i j k E i j k ∗ / ( 2 σ 2 ) \boldsymbol{\mathcal{E}}{ijk}\boldsymbol{\mathcal{E}}{ijk}^*/(2\sigma^2) EijkEijk∗/(2σ2),其中 E i j k = M i j k − ( X ∗ Y ) i j k \boldsymbol{\mathcal{E}}{ijk}=\boldsymbol{\mathcal{M}}{ijk}-(\boldsymbol{\mathcal{X}}*\boldsymbol{\mathcal{Y}})_{ijk} Eijk=Mijk−(X∗Y)ijk,则指数项可表示为
exp ( − E i j k E i j k ∗ 2 σ 2 ) = sup t < 0 ( t E i j k E i j k ∗ 2 σ 2 − ϕ ( t ) ) , (18) \exp\left(-\frac{\boldsymbol{\mathcal{E}}{ijk}\boldsymbol{\mathcal{E}}{ijk}^*}{2\sigma^2}\right) =\sup_{t<0}\left(t\frac{\boldsymbol{\mathcal{E}}{ijk}\boldsymbol{\mathcal{E}}{ijk}^*}{2\sigma^2}-\phi(t)\right), \tag{18} exp(−2σ2EijkEijk∗)=t<0sup(t2σ2EijkEijk∗−ϕ(t)),(18)
其中 ϕ ( t ) = − t ln ( − t ) + t \phi(t)=-t\ln(-t)+t ϕ(t)=−tln(−t)+t 表示共轭函数。利用上述松弛形式和 CC-Loss 函数 (16),CC-Loss 可重写为
J ( X , Y , R ) = max R i j k < 0 ∑ i , j , k P i j k R i j k 2 σ 2 ∣ M i j k − ( X ∗ Y ) i j k ∣ 2 − P i j k ϕ ( R i j k ) . (19) J(\boldsymbol{\mathcal{X}},\boldsymbol{\mathcal{Y}},\boldsymbol{\mathcal{R}}) =\max_{\boldsymbol{\mathcal{R}}{ijk}<0} \sum{i,j,k} \boldsymbol{\mathcal{P}}{ijk}\frac{\boldsymbol{\mathcal{R}}{ijk}}{2\sigma^2} \left|\boldsymbol{\mathcal{M}}{ijk}-(\boldsymbol{\mathcal{X}}*\boldsymbol{\mathcal{Y}}){ijk}\right|^2-\boldsymbol{\mathcal{P}}{ijk}\phi(\boldsymbol{\mathcal{R}}{ijk}). \tag{19} J(X,Y,R)=Rijk<0maxi,j,k∑Pijk2σ2Rijk∣Mijk−(X∗Y)ijk∣2−Pijkϕ(Rijk).(19)
其中 ∣ ⋅ ∣ |\cdot| ∣⋅∣ 表示复数域中的模运算。由 (19) 可见,下式是仅关于 R i j k \boldsymbol{\mathcal{R}}_{ijk} Rijk 的函数:
P i j k R i j k 2 σ 2 ∣ M i j k − ( X ∗ Y ) i j k ∣ 2 − P i j k ϕ ( R i j k ) . (20) \boldsymbol{\mathcal{P}}{ijk}\frac{\boldsymbol{\mathcal{R}}{ijk}}{2\sigma^2} \left|\boldsymbol{\mathcal{M}}{ijk}-(\boldsymbol{\mathcal{X}}*\boldsymbol{\mathcal{Y}}){ijk}\right|^2-\boldsymbol{\mathcal{P}}{ijk}\phi(\boldsymbol{\mathcal{R}}{ijk}). \tag{20} Pijk2σ2Rijk∣Mijk−(X∗Y)ijk∣2−Pijkϕ(Rijk).(20)
因此,固定 X \boldsymbol{\mathcal{X}} X 和 Y \boldsymbol{\mathcal{Y}} Y 时,式 (19) 的解可以由式 (18) 得到。一旦 R \boldsymbol{\mathcal{R}} R 的取值被指定,信号重构问题 (16) 就退化为加权张量补全问题,可表示为
min X , Y ∑ i , j , k − P i j k R i j k 2 σ 2 ∣ M i j k − ( X ∗ Y ) i j k ∣ 2 , (21) \min_{\boldsymbol{\mathcal{X}},\boldsymbol{\mathcal{Y}}} \sum_{i,j,k}-\boldsymbol{\mathcal{P}}{ijk}\frac{\boldsymbol{\mathcal{R}}{ijk}}{2\sigma^2} \left|\boldsymbol{\mathcal{M}}{ijk}-(\boldsymbol{\mathcal{X}}*\boldsymbol{\mathcal{Y}}){ijk}\right|^2, \tag{21} X,Ymini,j,k∑−Pijk2σ2Rijk∣Mijk−(X∗Y)ijk∣2,(21)
其中
R i j k = − exp ( − P i j k ∣ M i j k − ( X ∗ Y ) i j k ∣ 2 2 σ 2 ) . (22) \boldsymbol{\mathcal{R}}{ijk} =-\exp\left(-\frac{\boldsymbol{\mathcal{P}}{ijk}\left|\boldsymbol{\mathcal{M}}{ijk}-(\boldsymbol{\mathcal{X}}*\boldsymbol{\mathcal{Y}}){ijk}\right|^2}{2\sigma^2}\right). \tag{22} Rijk=−exp(−2σ2Pijk∣Mijk−(X∗Y)ijk∣2).(22)
注:
- 为什么式 (22) 的指数里会出现 P i j k \boldsymbol{\mathcal{P}}_{ijk} Pijk。 如果严格从式 (18) 对 exp ( − ∣ E i j k ∣ 2 / ( 2 σ 2 ) ) \exp\!\left(-|\boldsymbol{\mathcal{E}}{ijk}|^2/(2\sigma^2)\right) exp(−∣Eijk∣2/(2σ2)) 做半二次变换,辅助变量应为 − exp ( − ∣ E i j k ∣ 2 / ( 2 σ 2 ) ) -\exp\!\left(-|\boldsymbol{\mathcal{E}}{ijk}|^2/(2\sigma^2)\right) −exp(−∣Eijk∣2/(2σ2)),看起来不会自然出现 P i j k \boldsymbol{\mathcal{P}}{ijk} Pijk。这里可以理解为作者先利用二值掩码性质 P i j k ∈ { 0 , 1 } \boldsymbol{\mathcal{P}}{ijk}\in\{0,1\} Pijk∈{0,1} 和 P i j k 2 = P i j k \boldsymbol{\mathcal{P}}{ijk}^2=\boldsymbol{\mathcal{P}}{ijk} Pijk2=Pijk,把单项
P i j k exp ( − s i j k ) \boldsymbol{\mathcal{P}}{ijk}\exp(-s{ijk}) Pijkexp(−sijk) 等价写成 P i j k exp ( − P i j k s i j k ) \boldsymbol{\mathcal{P}}{ijk}\exp(-\boldsymbol{\mathcal{P}}{ijk}s_{ijk}) Pijkexp(−Pijksijk),其中 s i j k = ∣ E i j k ∣ 2 / ( 2 σ 2 ) s_{ijk}=|\boldsymbol{\mathcal{E}}{ijk}|^2/(2\sigma^2) sijk=∣Eijk∣2/(2σ2),再对 x = P i j k s i j k x=\boldsymbol{\mathcal{P}}{ijk}s_{ijk} x=Pijksijk 使用半二次公式。- 对算法结果的影响. 当 P i j k = 1 \boldsymbol{\mathcal{P}}{ijk}=1 Pijk=1 时,式 (22) 恢复为标准更新 − exp ( − ∣ E i j k ∣ 2 / ( 2 σ 2 ) ) -\exp(-|\boldsymbol{\mathcal{E}}{ijk}|^2/(2\sigma^2)) −exp(−∣Eijk∣2/(2σ2));当 P i j k = 0 \boldsymbol{\mathcal{P}}{ijk}=0 Pijk=0 时,式 (22) 给出 R i j k = − 1 \boldsymbol{\mathcal{R}}{ijk}=-1 Rijk=−1。由于后续目标和梯度中仍有 P ∘ ( ⋅ ) \boldsymbol{\mathcal{P}}\circ(\cdot) P∘(⋅),缺失条目的残差贡献会被掩码置零,因此这个默认值不会影响观测条目的优化。
- 推导严谨性. 因此,这里更像是一个紧凑写法:算法上基本没有实质问题,但从式 (18) 到式 (22) 少写了" P i j k exp ( − s i j k ) = P i j k exp ( − P i j k s i j k ) \boldsymbol{\mathcal{P}}{ijk}\exp(-s{ijk})=\boldsymbol{\mathcal{P}}{ijk}\exp(-\boldsymbol{\mathcal{P}}{ijk}s_{ijk}) Pijkexp(−sijk)=Pijkexp(−Pijksijk)"这一步说明。该解释依赖 P i j k \boldsymbol{\mathcal{P}}{ijk} Pijk 是二值观测指示变量;如果 P i j k \boldsymbol{\mathcal{P}}{ijk} Pijk 是一般连续权重,则把它放入指数项就不再与原目标等价。
至此,本文将该方法命名为 CCHQ 方法。此外,这些权重由 MCCC 推导而来。由于 MCCC 的特性,误差较大的信号重构样本对优化的贡献很小,从而可以有效抑制大离群点的影响。因此,可以有效地采用标准优化算法来求解问题 (21)。
B. MCCC-CGSR 算法
应用 CCHQ 方法之后,可以得到用于鲁棒信号重构的目标函数。在给出优化方法之前,为了表述清楚并便于推导 MCCC-CGSR 算法,式 (21) 可以改写为
min X , Y J ( X , Y ) = min X , Y ∥ Q ∘ P ∘ ( M − X ∗ Y ) ∥ F 2 , (23) \min_{\boldsymbol{\mathcal{X}},\boldsymbol{\mathcal{Y}}} J(\boldsymbol{\mathcal{X}},\boldsymbol{\mathcal{Y}}) =\min_{\boldsymbol{\mathcal{X}},\boldsymbol{\mathcal{Y}}} \left\|\boldsymbol{\mathcal{Q}}\circ\boldsymbol{\mathcal{P}}\circ(\boldsymbol{\mathcal{M}}-\boldsymbol{\mathcal{X}}*\boldsymbol{\mathcal{Y}})\right\|_F^2, \tag{23} X,YminJ(X,Y)=X,Ymin∥Q∘P∘(M−X∗Y)∥F2,(23)
其中
Q i j k = − 1 2 σ 2 R i j k . (24) \boldsymbol{\mathcal{Q}}{ijk} =\sqrt{-\frac{1}{2\sigma^2}\boldsymbol{\mathcal{R}}{ijk}}. \tag{24} Qijk=−2σ21Rijk .(24)
然而,尽管式 (23) 总体上仍是非凸函数,但值得注意的是,当 X \boldsymbol{\mathcal{X}} X 或 Y \boldsymbol{\mathcal{Y}} Y 中任意一个固定时,式 (23) 关于另一个张量是凸函数。为方便起见,先将式 (23) 乘以 1 / 2 1/2 1/2,从而将优化问题重写为
min X , Y 1 2 ∥ Q ∘ P ∘ ( M − X ∗ Y ) ∥ F 2 . (25) \min_{\boldsymbol{\mathcal{X}},\boldsymbol{\mathcal{Y}}} \frac{1}{2}\left\|\boldsymbol{\mathcal{Q}}\circ\boldsymbol{\mathcal{P}}\circ(\boldsymbol{\mathcal{M}}-\boldsymbol{\mathcal{X}}*\boldsymbol{\mathcal{Y}})\right\|_F^2. \tag{25} X,Ymin21∥Q∘P∘(M−X∗Y)∥F2.(25)
然而,由于 t-product 结构本身较为复杂,在优化过程中直接化简较困难,并且通常会带来更高的计算代价。因此,引入一个与 t-product 有关的引理,以便简化该优化问题。
引理 1 48: 设 A ∈ C n 1 × n 2 × n 3 和 B ∈ C n 2 × n 4 × n 5 为任意两个张量, 令 F = A ∗ B ,则有以下性质: 1 ) ∥ A ∥ F 2 = 1 n 3 ∥ A ‾ ∥ F 2 ; 2 ) F = A ∗ B ⇔ F ‾ = A ‾ B ‾ . \boxed{ \begin{aligned} &\textbf{引理 1 48:}\ \text{设 } \boldsymbol{\mathcal{A}}\in\mathbb{C}^{n_1\times n_2\times n_3} \text{ 和 } \boldsymbol{\mathcal{B}}\in\mathbb{C}^{n_2\times n_4\times n_5}\text{ 为任意两个张量,}\\ &\text{令 } \boldsymbol{\mathcal{F}}=\boldsymbol{\mathcal{A}}*\boldsymbol{\mathcal{B}}\text{,则有以下性质:}\\ &1)\ \|\boldsymbol{\mathcal{A}}\|_F^2=\frac{1}{n_3}\|\overline{\mathbf{A}}\|_F^2;\\ &2)\ \boldsymbol{\mathcal{F}}=\boldsymbol{\mathcal{A}}*\boldsymbol{\mathcal{B}} \Leftrightarrow \overline{\mathbf{F}}=\overline{\mathbf{A}}\overline{\mathbf{B}}. \end{aligned} } 引理 1 48: 设 A∈Cn1×n2×n3 和 B∈Cn2×n4×n5 为任意两个张量,令 F=A∗B,则有以下性质:1) ∥A∥F2=n31∥A∥F2;2) F=A∗B⇔F=AB.
其中 A ‾ = bdiag ( A ‾ ) \overline{\mathbf{A}}=\operatorname{bdiag}(\overline{\boldsymbol{\mathcal{A}}}) A=bdiag(A), bdiag ( ⋅ ) \operatorname{bdiag}(\cdot) bdiag(⋅) 表示将张量 A \boldsymbol{\mathcal{A}} A 映射为块对角矩阵(block diagonal matrix) A ‾ \overline{\mathbf{A}} A 的算子,其定义为
A ‾ = bdiag ( A ‾ ) = A ‾ : : 1 A ‾ : : 2 ⋱ A ‾ : : n 3 . \overline{\mathbf{A}}=\operatorname{bdiag}(\overline{\boldsymbol{\mathcal{A}}})= \begin{bmatrix} \overline{\boldsymbol{\mathcal{A}}}{::1} & & &\\ & \overline{\boldsymbol{\mathcal{A}}}{::2} & &\\ & & \ddots &\\ & & & \overline{\boldsymbol{\mathcal{A}}}_{::n_3} \end{bmatrix}. A=bdiag(A)= A::1A::2⋱A::n3 .
注:
- bdiag \operatorname{bdiag} bdiag 定义本身. 这里更严谨的理解是:先对原始张量 A \boldsymbol{\mathcal{A}} A 沿第三维做 FFT,得到频域张量 A ‾ \overline{\boldsymbol{\mathcal{A}}} A;再把 A ‾ : : 1 , ... , A ‾ : : n 3 \overline{\boldsymbol{\mathcal{A}}}{::1},\ldots,\overline{\boldsymbol{\mathcal{A}}}{::n_3} A::1,...,A::n3 这些 frontal slices 排成块对角矩阵 A ‾ \overline{\mathbf{A}} A。因此, A ‾ \overline{\boldsymbol{\mathcal{A}}} A 仍是三阶张量,而 A ‾ \overline{\mathbf{A}} A 是二维块对角矩阵;二者不应混为同一个对象。
- frontal slice 与对角块不能混写. 以 X ‾ = fft ( X , , 3 ) \overline{\boldsymbol{\mathcal{X}}}=\operatorname{fft}(\boldsymbol{\mathcal{X}},\[\],3) X=fft(X,\[\],3) 为例, X ‾ : : k \overline{\boldsymbol{\mathcal{X}}}{::k} X::k 表示 Fourier 域三阶张量的第 k k k 个 frontal slice;而 X ‾ b d = bdiag ( X ‾ ) \overline{\mathbf{X}}{bd}=\operatorname{bdiag}(\overline{\boldsymbol{\mathcal{X}}}) Xbd=bdiag(X) 已经是二维块对角矩阵,其第 k k k 个对角块应写作 X ‾ b d k k \\overline{\\mathbf{X}}_{bd}{kk} Xbdkk。二者数值上对应,即 X ‾ b d k k = X ‾ : : k \\overline{\\mathbf{X}}_{bd}{kk}=\overline{\boldsymbol{\mathcal{X}}}{::k} Xbdkk=X::k,但不能把块对角矩阵再写成 X ‾ b d , : : k \overline{\mathbf{X}}{bd,::k} Xbd,::k 这样的三阶张量切片符号。
- 论文符号不严谨处. 原文说 bdiag ( ⋅ ) \operatorname{bdiag}(\cdot) bdiag(⋅) 将张量 A \boldsymbol{\mathcal{A}} A 映射为 A ‾ \overline{\mathbf{A}} A,但公式实际使用的是 bdiag ( A ‾ ) \operatorname{bdiag}(\overline{\boldsymbol{\mathcal{A}}}) bdiag(A)。也就是说, bdiag \operatorname{bdiag} bdiag 排列的是 Fourier 域张量的切片,而不是直接排列原始时域张量 A \boldsymbol{\mathcal{A}} A 的切片。
- 第三维可能有笔误. 标准 t-product 要求 A \boldsymbol{\mathcal{A}} A 和 B \boldsymbol{\mathcal{B}} B 的第三维相同,才能在 Fourier 域逐片相乘。若 A ∈ C n 1 × n 2 × n 3 \boldsymbol{\mathcal{A}}\in\mathbb{C}^{n_1\times n_2\times n_3} A∈Cn1×n2×n3,通常应有 B ∈ C n 2 × n 4 × n 3 \boldsymbol{\mathcal{B}}\in\mathbb{C}^{n_2\times n_4\times n_3} B∈Cn2×n4×n3;原文写成 n 5 n_5 n5 时,除非默认 n 5 = n 3 n_5=n_3 n5=n3,否则 A ‾ B ‾ \overline{\mathbf{A}}\overline{\mathbf{B}} AB 的块矩阵维度无法匹配。
- 式 (25) 到式 (26) 的跳步. 引理可以解释 t-product 部分在 Fourier 域变成逐 slice 矩阵乘法,即 X ‾ : : k Y ‾ : : k \overline{\boldsymbol{\mathcal{X}}}{::k}\overline{\boldsymbol{\mathcal{Y}}}{::k} X::kY::k;但 Q ∘ P ∘ ( ⋅ ) \boldsymbol{\mathcal{Q}}\circ\boldsymbol{\mathcal{P}}\circ(\cdot) Q∘P∘(⋅) 中的 Hadamard 乘积经 FFT 后一般不会自然变成 Q ‾ : : k ∘ P ‾ : : k ∘ ( ⋅ ) \overline{\boldsymbol{\mathcal{Q}}}{::k}\circ\overline{\boldsymbol{\mathcal{P}}}{::k}\circ(\cdot) Q::k∘P::k∘(⋅)。论文在这里直接给出式 (26),可理解为采用了 Fourier 域权重写法或省略了额外说明。
基于引理 1,问题 (25) 等价于
min X ‾ , Y ‾ 1 2 n 3 ∑ k = 1 n 3 ∥ Q ‾ : : k ∘ P ‾ : : k ∘ ( M ‾ : : k − X ‾ : : k Y ‾ : : k ) ∥ F 2 , (26) \min_{\overline{\boldsymbol{\mathcal{X}}},\overline{\boldsymbol{\mathcal{Y}}}} \frac{1}{2n_3}\sum_{k=1}^{n_3} \left\|\overline{\boldsymbol{\mathcal{Q}}}{::k}\circ\overline{\boldsymbol{\mathcal{P}}}{::k}\circ \left(\overline{\boldsymbol{\mathcal{M}}}{::k}-\overline{\boldsymbol{\mathcal{X}}}{::k}\overline{\boldsymbol{\mathcal{Y}}}_{::k}\right)\right\|_F^2, \tag{26} X,Ymin2n31k=1∑n3 Q::k∘P::k∘(M::k−X::kY::k) F2,(26)
其中 Q ‾ : : k \overline{\boldsymbol{\mathcal{Q}}}{::k} Q::k 表示张量 Q \boldsymbol{\mathcal{Q}} Q 沿第三维做 Fourier 变换后得到的第 k k k 个 frontal slice;式 (26) 中的 P ‾ : : k \overline{\boldsymbol{\mathcal{P}}}{::k} P::k、 M ‾ : : k \overline{\boldsymbol{\mathcal{M}}}{::k} M::k、 X ‾ : : k \overline{\boldsymbol{\mathcal{X}}}{::k} X::k 和 Y ‾ : : k \overline{\boldsymbol{\mathcal{Y}}}_{::k} Y::k 也按同一约定理解。考虑到 X ‾ \overline{\boldsymbol{\mathcal{X}}} X 和 Y ‾ \overline{\boldsymbol{\mathcal{Y}}} Y 的各个 slice 彼此独立,该问题可以写为
min X ‾ : : k , Y ‾ : : k J k ( X ‾ : : k , Y ‾ : : k ) = 1 2 ∥ Q ‾ : : k ∘ P ‾ : : k ∘ ( M ‾ : : k − X ‾ : : k Y ‾ : : k ) ∥ F 2 . (27) \min_{\overline{\boldsymbol{\mathcal{X}}}{::k},\overline{\boldsymbol{\mathcal{Y}}}{::k}} J_k(\overline{\boldsymbol{\mathcal{X}}}{::k},\overline{\boldsymbol{\mathcal{Y}}}{::k}) =\frac{1}{2}\left\|\overline{\boldsymbol{\mathcal{Q}}}{::k}\circ\overline{\boldsymbol{\mathcal{P}}}{::k}\circ \left(\overline{\boldsymbol{\mathcal{M}}}{::k}-\overline{\boldsymbol{\mathcal{X}}}{::k}\overline{\boldsymbol{\mathcal{Y}}}_{::k}\right)\right\|_F^2. \tag{27} X::k,Y::kminJk(X::k,Y::k)=21 Q::k∘P::k∘(M::k−X::kY::k) F2.(27)
注:
- 式 (27) 的自变量. 原文左侧写作 J ( X ‾ , Y ‾ ) J(\overline{\boldsymbol{\mathcal{X}}},\overline{\boldsymbol{\mathcal{Y}}}) J(X,Y),但右侧只含第 k k k 个 frontal slice。结合前一句"各个 slice 彼此独立",更一致的理解是式 (27) 表示第 k k k 个 Fourier slice 上的子问题,因此这里记为 J k ( X ‾ : : k , Y ‾ : : k ) J_k(\overline{\boldsymbol{\mathcal{X}}}{::k},\overline{\boldsymbol{\mathcal{Y}}}{::k}) Jk(X::k,Y::k)。
为了进一步研究式 (27),下面给出最大复互相关熵定二次函数优化命题。
命题 3: 当 X 或 Y 固定时, 最大复互相关熵加权信号重构问题 (27) 是定二次函数优化问题。 Proof: 见附录 C。 \boxed{ \begin{aligned} &\textbf{命题 3:}\ \text{当 } \boldsymbol{\mathcal{X}} \text{ 或 } \boldsymbol{\mathcal{Y}} \text{ 固定时,}\\ &\text{最大复互相关熵加权信号重构问题 (27) 是定二次函数优化问题。}\\ &\textbf{Proof:}\ \text{见附录 C。} \end{aligned} } 命题 3: 当 X 或 Y 固定时,最大复互相关熵加权信号重构问题 (27) 是定二次函数优化问题。Proof: 见附录 C。
注:
- "definite quadratic function optimization problem". 这里可理解为"正定二次函数优化问题":虽然式 (27) 同时关于 X ‾ : : k \overline{\boldsymbol{\mathcal{X}}}{::k} X::k 和 Y ‾ : : k \overline{\boldsymbol{\mathcal{Y}}}{::k} Y::k 含有乘积项、整体并非凸问题,但当固定其中一个因子时,另一个因子的子问题会变成二次型最小化问题。附录 C 中通过向量化得到 1 2 x H D x + Re { b H x } \frac{1}{2}\mathbf{x}^H\mathbf{D}\mathbf{x}+\operatorname{Re}\{\mathbf{b}^H\mathbf{x}\} 21xHDx+Re{bHx},并说明 D > 0 \mathbf{D}>0 D>0,因此该子问题是正定二次问题,具有唯一全局最优解。这也是后文可以采用交替优化和 CG 方法分别更新 X \boldsymbol{\mathcal{X}} X、 Y \boldsymbol{\mathcal{Y}} Y 的原因。
因此,通过应用 CCHQ 方法,最大复互相关熵准则问题在固定 X \boldsymbol{\mathcal{X}} X 或 Y \boldsymbol{\mathcal{Y}} Y 时被转化为一个良定义的二次优化问题,可以使用 Newton 方法或共轭梯度(Conjugate Gradient, CG)方法等凸优化技术高效求解。本文构造 X \boldsymbol{\mathcal{X}} X 与 Y \boldsymbol{\mathcal{Y}} Y 之间的交替优化策略,并且由于复数域中的 CG 方法具有性能优良、计算复杂度适中和收敛速度快等特点,本文采用该方法进行求解。
首先,固定 Y \boldsymbol{\mathcal{Y}} Y 并更新 X \boldsymbol{\mathcal{X}} X。根据 Wirtinger calculus 50,令 F ‾ : : k = Q ‾ : : k ∘ P ‾ : : k \overline{\boldsymbol{\mathcal{F}}}{::k}=\overline{\boldsymbol{\mathcal{Q}}}{::k}\circ\overline{\boldsymbol{\mathcal{P}}}_{::k} F::k=Q::k∘P::k,则第 t t t 次迭代中 J ( X ‾ , Y ‾ ) J(\overline{\boldsymbol{\mathcal{X}}},\overline{\boldsymbol{\mathcal{Y}}}) J(X,Y) 关于 X ‾ \overline{\boldsymbol{\mathcal{X}}} X 的偏导数为
g X ‾ , t = ∂ J ∂ X ‾ ∗ = ( A : : k , t ∘ ( F ‾ : : k , t ) ∗ ) ( Y ‾ : : k , t ) H , (28) g_{\overline{\boldsymbol{\mathcal{X}}},t} =\frac{\partial J}{\partial \overline{\boldsymbol{\mathcal{X}}}^*} =\left(\boldsymbol{\mathcal{A}}{::k,t}\circ(\overline{\boldsymbol{\mathcal{F}}}{::k,t})^*\right) (\overline{\boldsymbol{\mathcal{Y}}}_{::k,t})^H, \tag{28} gX,t=∂X∗∂J=(A::k,t∘(F::k,t)∗)(Y::k,t)H,(28)
其中
A : : k , t = F ‾ : : k , t ∘ ( M ‾ : : k , t − X ‾ : : k , t Y ‾ : : k , t ) . (29) \boldsymbol{\mathcal{A}}{::k,t} =\overline{\boldsymbol{\mathcal{F}}}{::k,t}\circ \left(\overline{\boldsymbol{\mathcal{M}}}{::k,t}- \overline{\boldsymbol{\mathcal{X}}}{::k,t}\overline{\boldsymbol{\mathcal{Y}}}_{::k,t}\right). \tag{29} A::k,t=F::k,t∘(M::k,t−X::k,tY::k,t).(29)
注:
为什么式 (28) 中会出现 A : : k , t ∘ ( F ‾ : : k , t ) ∗ \boldsymbol{\mathcal{A}}{::k,t}\circ(\overline{\boldsymbol{\mathcal{F}}}{::k,t})^* A::k,t∘(F::k,t)∗. 这可以从 Frobenius 内积下 Hadamard 加权算子的伴随关系理解。对任意同尺寸矩阵 A , F , Z \mathbf A,\mathbf F,\mathbf Z A,F,Z,要用到下面这个恒等式:
Tr A H ( F ∘ Z ) = Tr ( A ∘ F ∗ ) H Z . \operatorname{Tr}\!\left\\mathbf A\^H(\\mathbf F\\circ\\mathbf Z)\\right=\operatorname{Tr}\!\left(\\mathbf A\\circ\\mathbf F\^\*)\^H\\mathbf Z\\right. TrAH(F∘Z)=Tr(A∘F∗)HZ.
用向量化和对角矩阵可以直接证明。记 vec ( A ) = a \operatorname{vec}(\mathbf A)=\mathbf a vec(A)=a、 vec ( F ) = f \operatorname{vec}(\mathbf F)=\mathbf f vec(F)=f、 vec ( Z ) = z \operatorname{vec}(\mathbf Z)=\mathbf z vec(Z)=z,这里 vec ( ⋅ ) \operatorname{vec}(\cdot) vec(⋅) 表示按列堆叠成向量。令 D f = diag ( f ) \mathbf D_{\mathbf f}=\operatorname{diag}(\mathbf f) Df=diag(f),则 Hadamard 乘积向量化后为:
vec ( F ∘ Z ) = diag ( f ) z = D f z . \operatorname{vec}(\mathbf F\circ\mathbf Z)=\operatorname{diag}(\mathbf f)\mathbf z=\mathbf D_{\mathbf f}\mathbf z. vec(F∘Z)=diag(f)z=Dfz.
Frobenius 内积与向量化满足:
Tr ( A H B ) = vec ( A ) H vec ( B ) . \operatorname{Tr}(\mathbf A^H\mathbf B)=\operatorname{vec}(\mathbf A)^H\operatorname{vec}(\mathbf B). Tr(AHB)=vec(A)Hvec(B).
因此左边可以写成:
Tr A H ( F ∘ Z ) = a H vec ( F ∘ Z ) = a H D f z . \operatorname{Tr}\!\left\\mathbf A\^H(\\mathbf F\\circ\\mathbf Z)\\right=\mathbf a^H\operatorname{vec}(\mathbf F\circ\mathbf Z)=\mathbf a^H\mathbf D_{\mathbf f}\mathbf z. TrAH(F∘Z)=aHvec(F∘Z)=aHDfz.
接下来把 D f \mathbf D_{\mathbf f} Df 从内积右边"移到"左边。由于 a H D f = ( D f H a ) H \mathbf a^H\mathbf D_{\mathbf f}=(\mathbf D_{\mathbf f}^H\mathbf a)^H aHDf=(DfHa)H,所以有:
a H D f z = ( D f H a ) H z . \mathbf a^H\mathbf D_{\mathbf f}\mathbf z=(\mathbf D_{\mathbf f}^H\mathbf a)^H\mathbf z. aHDfz=(DfHa)Hz.
又因为 D f H = diag ( f ) H = diag ( f ∗ ) \mathbf D_{\mathbf f}^H=\operatorname{diag}(\mathbf f)^H=\operatorname{diag}(\mathbf f^*) DfH=diag(f)H=diag(f∗),所以:
D f H a = diag ( f ∗ ) vec ( A ) = vec ( A ∘ F ∗ ) . \mathbf D_{\mathbf f}^H\mathbf a=\operatorname{diag}(\mathbf f^*)\operatorname{vec}(\mathbf A)=\operatorname{vec}(\mathbf A\circ\mathbf F^*). DfHa=diag(f∗)vec(A)=vec(A∘F∗).
于是:
( D f H a ) H z = vec ( A ∘ F ∗ ) H vec ( Z ) = Tr ( A ∘ F ∗ ) H Z . (\mathbf D_{\mathbf f}^H\mathbf a)^H\mathbf z=\operatorname{vec}(\mathbf A\circ\mathbf F^*)^H\operatorname{vec}(\mathbf Z)=\operatorname{Tr}\!\left(\\mathbf A\\circ\\mathbf F\^\*)\^H\\mathbf Z\\right. (DfHa)Hz=vec(A∘F∗)Hvec(Z)=Tr(A∘F∗)HZ.
因此得到:
Tr A H ( F ∘ Z ) = Tr ( A ∘ F ∗ ) H Z . \operatorname{Tr}\!\left\\mathbf A\^H(\\mathbf F\\circ\\mathbf Z)\\right=\operatorname{Tr}\!\left(\\mathbf A\\circ\\mathbf F\^\*)\^H\\mathbf Z\\right. TrAH(F∘Z)=Tr(A∘F∗)HZ.
这个证明的本质是: F ∘ ( ⋅ ) \mathbf F\circ(\cdot) F∘(⋅) 不是普通矩阵乘法,而是一个对矩阵每个元素分别加权的线性算子。向量化以后,这个线性算子就变成对角矩阵 D f \mathbf D_{\mathbf f} Df。把它从 Frobenius 内积的第二个位置移到第一个位置时,按照复内积的规则必须取 Hermitian,所以 D f \mathbf D_{\mathbf f} Df 变成 D f H \mathbf D_{\mathbf f}^H DfH,对应到矩阵形式就是 F \mathbf F F 变成 F ∗ \mathbf F^* F∗。
算子伴随写法. 更抽象地说,可以定义 Hadamard 加权算子 L F ( Z ) = F ∘ Z \mathcal L_{\mathbf F}(\mathbf Z)=\mathbf F\circ\mathbf Z LF(Z)=F∘Z。在 Frobenius 内积 ⟨ U , V ⟩ F = Tr ( U H V ) \langle \mathbf U,\mathbf V\rangle_F=\operatorname{Tr}(\mathbf U^H\mathbf V) ⟨U,V⟩F=Tr(UHV) 下,伴随算子 L F ∗ \mathcal L_{\mathbf F}^* LF∗ 由下面关系定义:
⟨ A , L F ( Z ) ⟩ F = ⟨ L F ∗ ( A ) , Z ⟩ F . \langle \mathbf A,\mathcal L_{\mathbf F}(\mathbf Z)\rangle_F=\langle \mathcal L_{\mathbf F}^*(\mathbf A),\mathbf Z\rangle_F. ⟨A,LF(Z)⟩F=⟨LF∗(A),Z⟩F.
根据上面的向量化推导, L F ∗ ( A ) = A ∘ F ∗ \mathcal L_{\mathbf F}^*(\mathbf A)=\mathbf A\circ\mathbf F^* LF∗(A)=A∘F∗,因此:
⟨ A , F ∘ Z ⟩ F = ⟨ A ∘ F ∗ , Z ⟩ F . \langle \mathbf A,\mathbf F\circ\mathbf Z\rangle_F=\langle \mathbf A\circ\mathbf F^*,\mathbf Z\rangle_F. ⟨A,F∘Z⟩F=⟨A∘F∗,Z⟩F.
写成迹形式正是:
Tr A H ( F ∘ Z ) = Tr ( A ∘ F ∗ ) H Z . \operatorname{Tr}\!\left\\mathbf A\^H(\\mathbf F\\circ\\mathbf Z)\\right=\operatorname{Tr}\!\left(\\mathbf A\\circ\\mathbf F\^\*)\^H\\mathbf Z\\right. TrAH(F∘Z)=Tr(A∘F∗)HZ.
直观理解. F ∘ ( ⋅ ) \mathbf F\circ(\cdot) F∘(⋅) 是逐元素加权线性算子,它在 Frobenius 内积下的伴随算子是 F ∗ ∘ ( ⋅ ) \mathbf F^*\circ(\cdot) F∗∘(⋅)。因此,在求导时如果要把 F \mathbf F F 从内积右边的扰动项转到左边的残差项上,权重必须变成 F ∗ \mathbf F^* F∗。这就是式 (28) 中 ( F ‾ : : k , t ) ∗ (\overline{\boldsymbol{\mathcal{F}}}_{::k,t})^* (F::k,t)∗ 的来源。
从目标函数微分看式 (28). 只看第 k k k 个 Fourier slice,并暂时省略 : : k , t ::k,t ::k,t 下标。令 X = X ‾ : : k , t \mathbf X=\overline{\boldsymbol{\mathcal X}}{::k,t} X=X::k,t、 Y = Y ‾ : : k , t \mathbf Y=\overline{\boldsymbol{\mathcal Y}}{::k,t} Y=Y::k,t、 M = M ‾ : : k , t \mathbf M=\overline{\boldsymbol{\mathcal M}}{::k,t} M=M::k,t、 F = F ‾ : : k , t \mathbf F=\overline{\boldsymbol{\mathcal F}}{::k,t} F=F::k,t。固定 Y \mathbf Y Y 后,目标函数为:
J ( X ) = 1 2 ∥ F ∘ ( M − X Y ) ∥ F 2 . J(\mathbf X)=\frac12\left\|\mathbf F\circ(\mathbf M-\mathbf X\mathbf Y)\right\|_F^2. J(X)=21∥F∘(M−XY)∥F2.
定义残差 E = M − X Y \mathbf E=\mathbf M-\mathbf X\mathbf Y E=M−XY,加权残差 A = F ∘ E \mathbf A=\mathbf F\circ\mathbf E A=F∘E,于是:
J ( X ) = 1 2 ∥ A ∥ F 2 = 1 2 Tr ( A H A ) . J(\mathbf X)=\frac12\|\mathbf A\|_F^2=\frac12\operatorname{Tr}(\mathbf A^H\mathbf A). J(X)=21∥A∥F2=21Tr(AHA).
对目标函数求微分。因为 J J J 是实值函数,所以:
d J = Re { Tr ( A H d A ) } . dJ=\operatorname{Re}\left\{\operatorname{Tr}(\mathbf A^H d\mathbf A)\right\}. dJ=Re{Tr(AHdA)}.
又因为 F , M , Y \mathbf F,\mathbf M,\mathbf Y F,M,Y 固定,只有 X \mathbf X X 变化,所以:
d A = F ∘ d ( M − X Y ) = − F ∘ ( d X Y ) . d\mathbf A=\mathbf F\circ d(\mathbf M-\mathbf X\mathbf Y)=-\mathbf F\circ(d\mathbf X\mathbf Y). dA=F∘d(M−XY)=−F∘(dXY).
代回并使用上面的伴随关系,取 Z = d X Y \mathbf Z=d\mathbf X\mathbf Y Z=dXY,可得:
d J = − Re { Tr ( A ∘ F ∗ ) H d X Y } . dJ=-\operatorname{Re}\left\{\operatorname{Tr}\left(\\mathbf A\\circ\\mathbf F\^\*)\^H d\\mathbf X\\mathbf Y\\right\right\}. dJ=−Re{Tr(A∘F∗)HdXY}.
再用迹的循环性质把 Y \mathbf Y Y 移到右边,也就是你指出的这一步:
Tr ( A ∘ F ∗ ) H d X Y = Tr ( ( A ∘ F ∗ ) Y H ) H d X . \operatorname{Tr}\left(\\mathbf A\\circ\\mathbf F\^\*)\^H d\\mathbf X\\mathbf Y\\right=\operatorname{Tr}\left\\left((\\mathbf A\\circ\\mathbf F\^\*)\\mathbf Y\^H\\right)\^H d\\mathbf X\\right. Tr(A∘F∗)HdXY=Tr((A∘F∗)YH)HdX.
因而:
d J = − Re { Tr ( ( A ∘ F ∗ ) Y H ) H d X } . dJ=-\operatorname{Re}\left\{\operatorname{Tr}\left\\left((\\mathbf A\\circ\\mathbf F\^\*)\\mathbf Y\^H\\right)\^H d\\mathbf X\\right\right\}. dJ=−Re{Tr((A∘F∗)YH)HdX}.
按照 d J = Re { Tr ( ∇ X J ) H d X } dJ=\operatorname{Re}\{\operatorname{Tr}(\\nabla_{\\mathbf X}J)\^H d\\mathbf X\} dJ=Re{Tr(∇XJ)HdX} 的常见定义,严格梯度为:
∇ X J = − ( A ∘ F ∗ ) Y H . \nabla_{\mathbf X}J=-(\mathbf A\circ\mathbf F^*)\mathbf Y^H. ∇XJ=−(A∘F∗)YH.
因此式 (28) 中的 ( A : : k , t ∘ ( F ‾ : : k , t ) ∗ ) ( Y ‾ : : k , t ) H (\boldsymbol{\mathcal A}{::k,t}\circ(\overline{\boldsymbol{\mathcal F}}{::k,t})^*)(\overline{\boldsymbol{\mathcal Y}}{::k,t})^H (A::k,t∘(F::k,t)∗)(Y::k,t)H 可以看作由微分推导自然出现的核心梯度项。由于残差采用 M − X Y \mathbf M-\mathbf X\mathbf Y M−XY,它相当于严格梯度的负号版本,即 g X ‾ , t = − ∇ X J g{\overline{\boldsymbol{\mathcal X}},t}=-\nabla_{\mathbf X}J gX,t=−∇XJ;后续共轭方向中使用 − g X ‾ , t -g_{\overline{\boldsymbol{\mathcal X}},t} −gX,t,需要结合论文的符号约定一起理解。
且 ( ⋅ ) H (\cdot)^H (⋅)H 表示矩阵的共轭转置。类似于标准 CG 方法,共轭方向可以定义为
d X ‾ , t = { − g X ‾ , t , t = 0 , − g X ‾ , t + β X ‾ , t d X ‾ , t − 1 , t > 0 , (30) d_{\overline{\boldsymbol{\mathcal{X}}},t}= \left\{ \begin{array}{ll} -g_{\overline{\boldsymbol{\mathcal{X}}},t}, & t=0,\\ -g_{\overline{\boldsymbol{\mathcal{X}}},t}+\beta_{\overline{\boldsymbol{\mathcal{X}}},t}d_{\overline{\boldsymbol{\mathcal{X}}},t-1}, & t>0, \end{array} \right. \tag{30} dX,t={−gX,t,−gX,t+βX,tdX,t−1,t=0,t>0,(30)
并且基于 Polak-Ribière(PR)方法 53, β X ‾ , t \beta_{\overline{\boldsymbol{\mathcal{X}}},t} βX,t 可以计算为
β X ‾ , t = ( g X ‾ , t + 1 ) H ( g X ‾ , t + 1 − g X ‾ , t ) ( g X ‾ , t + 1 ) H g X ‾ , t . (31) \beta_{\overline{\boldsymbol{\mathcal{X}}},t} =\frac{(g_{\overline{\boldsymbol{\mathcal{X}}},t+1})^H (g_{\overline{\boldsymbol{\mathcal{X}}},t+1}-g_{\overline{\boldsymbol{\mathcal{X}}},t})} {(g_{\overline{\boldsymbol{\mathcal{X}}},t+1})^H g_{\overline{\boldsymbol{\mathcal{X}}},t}}. \tag{31} βX,t=(gX,t+1)HgX,t(gX,t+1)H(gX,t+1−gX,t).(31)
注意,由于本文考虑的是复值信号,该公式不同于原始 PR 方法中的公式。确定共轭方向和参数 β X ‾ , t \beta_{\overline{\boldsymbol{\mathcal{X}}},t} βX,t 后,最优一维步长 α X ‾ , t \alpha_{\overline{\boldsymbol{\mathcal{X}}},t} αX,t 可以通过求解以下最小化问题得到:
α X ‾ , t = arg min α X ‾ , t J ( X ‾ : : k , t + α X ‾ , t d X ‾ , t ) (32) \alpha_{\overline{\boldsymbol{\mathcal{X}}},t} =\arg\min_{\alpha_{\overline{\boldsymbol{\mathcal{X}}},t}} J\left(\overline{\boldsymbol{\mathcal{X}}}{::k,t}+ \alpha{\overline{\boldsymbol{\mathcal{X}}},t}d_{\overline{\boldsymbol{\mathcal{X}}},t}\right) \tag{32} αX,t=argαX,tminJ(X::k,t+αX,tdX,t)(32)
利用 Frobenius 范数的性质,式 (32) 可以等价地改写为迹函数形式,这通常更便于基于梯度的优化。令 B : : k , t = F ‾ : : k , t ∘ ( d X ‾ , t Y ‾ : : k , t ) \boldsymbol{\mathcal{B}}{::k,t}=\overline{\boldsymbol{\mathcal{F}}}{::k,t}\circ(d_{\overline{\boldsymbol{\mathcal{X}}},t}\overline{\boldsymbol{\mathcal{Y}}}_{::k,t}) B::k,t=F::k,t∘(dX,tY::k,t),则式 (32) 可表示为
arg min α X ‾ , t Tr ( ( A : : k , t − α X ‾ , t B : : k , t ) H ( A : : k , t − α X ‾ , t B : : k , t ) ) = Re { Tr ( ( A : : k , t ) H B : : k , t ) } Tr ( ( B : : k , t ) H B : : k , t ) = α X ‾ , t , (33) \arg\min_{\alpha_{\overline{\boldsymbol{\mathcal{X}}},t}} \operatorname{Tr}\left( \left(\boldsymbol{\mathcal{A}}{::k,t}-\alpha{\overline{\boldsymbol{\mathcal{X}}},t}\boldsymbol{\mathcal{B}}{::k,t}\right)^H \left(\boldsymbol{\mathcal{A}}{::k,t}-\alpha_{\overline{\boldsymbol{\mathcal{X}}},t}\boldsymbol{\mathcal{B}}{::k,t}\right) \right) =\frac{\operatorname{Re}\{\operatorname{Tr}((\boldsymbol{\mathcal{A}}{::k,t})^H\boldsymbol{\mathcal{B}}{::k,t})\}} {\operatorname{Tr}((\boldsymbol{\mathcal{B}}{::k,t})^H\boldsymbol{\mathcal{B}}{::k,t})} =\alpha{\overline{\boldsymbol{\mathcal{X}}},t}, \tag{33} argαX,tminTr((A::k,t−αX,tB::k,t)H(A::k,t−αX,tB::k,t))=Tr((B::k,t)HB::k,t)Re{Tr((A::k,t)HB::k,t)}=αX,t,(33)
其中 Re { ⋅ } \operatorname{Re}\{\cdot\} Re{⋅} 表示取实部算子, Tr ( ⋅ ) \operatorname{Tr}(\cdot) Tr(⋅) 表示迹算子。因此,傅里叶域中张量 X \boldsymbol{\mathcal{X}} X 的每个 slice X ‾ : : k , t + 1 \overline{\boldsymbol{\mathcal{X}}}_{::k,t+1} X::k,t+1 可更新为
X ‾ : : k , t + 1 = X ‾ : : k , t + α X ‾ , t d X ‾ , t . (34) \overline{\boldsymbol{\mathcal{X}}}{::k,t+1} =\overline{\boldsymbol{\mathcal{X}}}{::k,t}+\alpha_{\overline{\boldsymbol{\mathcal{X}}},t}d_{\overline{\boldsymbol{\mathcal{X}}},t}. \tag{34} X::k,t+1=X::k,t+αX,tdX,t.(34)
类似地,在更新 X ‾ \overline{\boldsymbol{\mathcal{X}}} X 并固定它之后,第 t t t 次迭代中 J ( X ‾ , Y ‾ ) J(\overline{\boldsymbol{\mathcal{X}}},\overline{\boldsymbol{\mathcal{Y}}}) J(X,Y) 关于 Y ‾ \overline{\boldsymbol{\mathcal{Y}}} Y 的偏导数为
g Y ‾ , t = ( X ‾ : : k , t + 1 ) H ( C : : k , t ∘ ( F ‾ : : k , t ) ∗ ) , (35) g_{\overline{\boldsymbol{\mathcal{Y}}},t} =(\overline{\boldsymbol{\mathcal{X}}}{::k,t+1})^H \left(\boldsymbol{\mathcal{C}}{::k,t}\circ(\overline{\boldsymbol{\mathcal{F}}}_{::k,t})^*\right), \tag{35} gY,t=(X::k,t+1)H(C::k,t∘(F::k,t)∗),(35)
其中 C : : k , t = F ‾ : : k , t ∘ ( M ‾ : : k , t − X ‾ : : k , t + 1 Y ‾ : : k , t ) \boldsymbol{\mathcal{C}}{::k,t}=\overline{\boldsymbol{\mathcal{F}}}{::k,t}\circ(\overline{\boldsymbol{\mathcal{M}}}{::k,t}-\overline{\boldsymbol{\mathcal{X}}}{::k,t+1}\overline{\boldsymbol{\mathcal{Y}}}_{::k,t}) C::k,t=F::k,t∘(M::k,t−X::k,t+1Y::k,t)。相应的共轭方向可定义为
d Y ‾ , t = { − g Y ‾ , t , t = 0 , − g Y ‾ , t + β Y ‾ , t d Y ‾ , t − 1 , t > 0 , (36) d_{\overline{\boldsymbol{\mathcal{Y}}},t}= \left\{ \begin{array}{ll} -g_{\overline{\boldsymbol{\mathcal{Y}}},t}, & t=0,\\ -g_{\overline{\boldsymbol{\mathcal{Y}}},t}+\beta_{\overline{\boldsymbol{\mathcal{Y}}},t}d_{\overline{\boldsymbol{\mathcal{Y}}},t-1}, & t>0, \end{array} \right. \tag{36} dY,t={−gY,t,−gY,t+βY,tdY,t−1,t=0,t>0,(36)
令 D : : k , t = F ‾ : : k , t ∘ ( X ‾ : : k , t + 1 d Y ‾ , t ) \boldsymbol{\mathcal{D}}{::k,t}=\overline{\boldsymbol{\mathcal{F}}}{::k,t}\circ(\overline{\boldsymbol{\mathcal{X}}}{::k,t+1}d{\overline{\boldsymbol{\mathcal{Y}}},t}) D::k,t=F::k,t∘(X::k,t+1dY,t)。对应的 β Y ‾ , t \beta_{\overline{\boldsymbol{\mathcal{Y}}},t} βY,t 和步长 α Y ‾ , t \alpha_{\overline{\boldsymbol{\mathcal{Y}}},t} αY,t 可计算为
β Y ‾ , t = ( g Y ‾ , t + 1 ) H ( g Y ‾ , t + 1 − g Y ‾ , t ) ( g Y ‾ , t + 1 ) H g Y ‾ , t , (37) \beta_{\overline{\boldsymbol{\mathcal{Y}}},t} =\frac{(g_{\overline{\boldsymbol{\mathcal{Y}}},t+1})^H (g_{\overline{\boldsymbol{\mathcal{Y}}},t+1}-g_{\overline{\boldsymbol{\mathcal{Y}}},t})} {(g_{\overline{\boldsymbol{\mathcal{Y}}},t+1})^H g_{\overline{\boldsymbol{\mathcal{Y}}},t}}, \tag{37} βY,t=(gY,t+1)HgY,t(gY,t+1)H(gY,t+1−gY,t),(37)
α Y ‾ , t = Re { Tr ( ( C : : k , t ) H D : : k , t ) } Tr ( ( D : : k , t ) H D : : k , t ) , (38) \alpha_{\overline{\boldsymbol{\mathcal{Y}}},t} =\frac{\operatorname{Re}\{\operatorname{Tr}((\boldsymbol{\mathcal{C}}{::k,t})^H\boldsymbol{\mathcal{D}}{::k,t})\}} {\operatorname{Tr}((\boldsymbol{\mathcal{D}}{::k,t})^H\boldsymbol{\mathcal{D}}{::k,t})}, \tag{38} αY,t=Tr((D::k,t)HD::k,t)Re{Tr((C::k,t)HD::k,t)},(38)
最后,傅里叶域中张量 Y \boldsymbol{\mathcal{Y}} Y 的每个 slice Y ‾ : : k , t + 1 \overline{\boldsymbol{\mathcal{Y}}}_{::k,t+1} Y::k,t+1 可更新为
Y ‾ : : k , t + 1 = Y ‾ : : k , t + α Y ‾ , t d Y ‾ , t . (39) \overline{\boldsymbol{\mathcal{Y}}}{::k,t+1} =\overline{\boldsymbol{\mathcal{Y}}}{::k,t}+\alpha_{\overline{\boldsymbol{\mathcal{Y}}},t}d_{\overline{\boldsymbol{\mathcal{Y}}},t}. \tag{39} Y::k,t+1=Y::k,t+αY,tdY,t.(39)
至此,通过采用交替更新策略, X \boldsymbol{\mathcal{X}} X 和 Y \boldsymbol{\mathcal{Y}} Y 可分别利用式 (34) 和式 (39) 迭代更新,直至收敛。
C. 自适应核宽度与停止准则
为提升收敛速度,第 t t t 次迭代后的核宽度设为
σ t + 1 = max ( η max ( u ( 0.25 ) , t , u ( 0.75 ) , t ) , σ min ) , (40) \sigma_{t+1}=\max\left(\eta\max\left(u_{(0.25),t},u_{(0.75),t}\right),\sigma_{\min}\right), \tag{40} σt+1=max(ηmax(u(0.25),t,u(0.75),t),σmin),(40)
其中 u t = real ( M − X t ∗ Y t ) + imag ( M − X t ∗ Y t ) u_t=\operatorname{real}(\boldsymbol{\mathcal{M}}-\boldsymbol{\mathcal{X}}_t*\boldsymbol{\mathcal{Y}}_t)+\operatorname{imag}(\boldsymbol{\mathcal{M}}-\boldsymbol{\mathcal{X}}_t*\boldsymbol{\mathcal{Y}}t) ut=real(M−Xt∗Yt)+imag(M−Xt∗Yt), u ( q ) u{(q)} u(q) 为第 q q q 分位数。
第 t t t 次迭代后的残差为
ε t = Q t ∘ P ∘ ( M − X t ∗ Y t ) . (41) \varepsilon_t=\boldsymbol{\mathcal{Q}}_t\circ\boldsymbol{\mathcal{P}}\circ(\boldsymbol{\mathcal{M}}-\boldsymbol{\mathcal{X}}_t*\boldsymbol{\mathcal{Y}}_t). \tag{41} εt=Qt∘P∘(M−Xt∗Yt).(41)
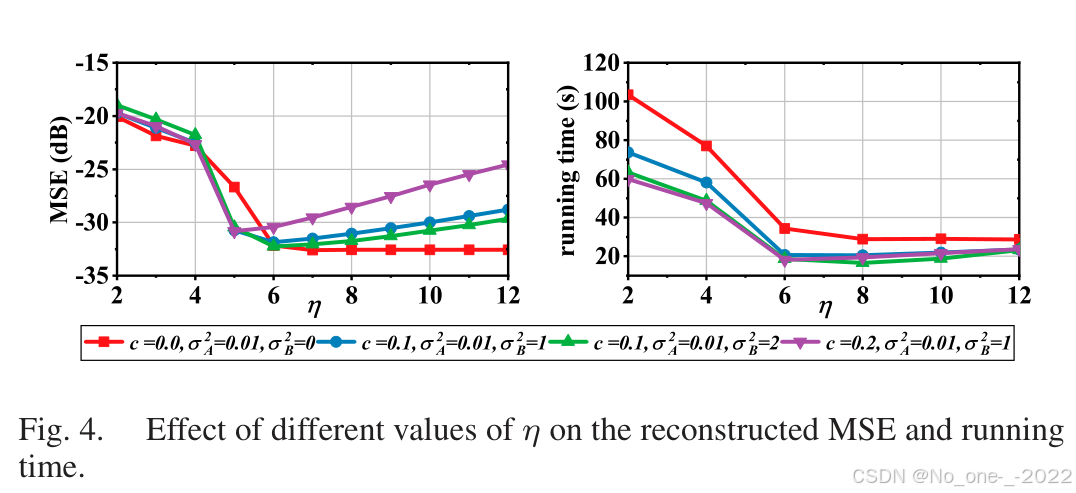
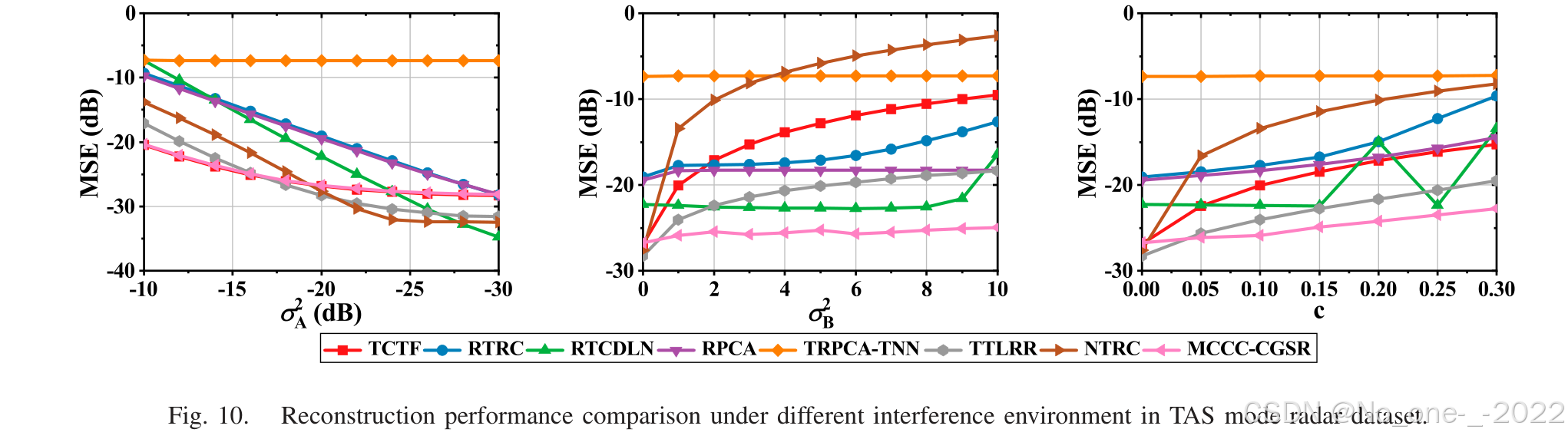
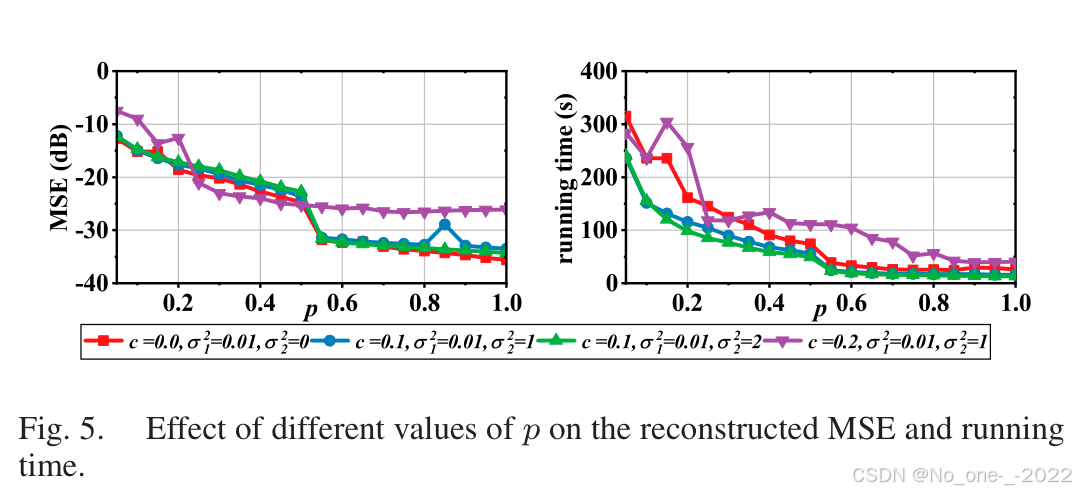
当 ∥ ε t + 1 ∥ F 2 − ∥ ε t ∥ F 2 \|\varepsilon_{t+1}\|_F^2-\|\varepsilon_t\|_F^2 ∥εt+1∥F2−∥εt∥F2 小于阈值 e e e 时终止。实验中采用 e < 10 − 5 e<10^{-5} e<10−5。核宽度参数 η \eta η 决定离群点抑制强度:较大 η \eta η 对应更宽核宽度,离群点抑制更强;较小 η \eta η 抑制更弱。

Algorithm 1. 复杂电磁环境下截获信号重构的 MCCC-CGSR 算法。
D. 收敛性分析
令 E i j k , t = M i j k − ( X i j k , t ∗ Y i j k , t ) \boldsymbol{\mathcal{E}}{ijk,t}=\boldsymbol{\mathcal{M}}{ijk}-(\boldsymbol{\mathcal{X}}{ijk,t}*\boldsymbol{\mathcal{Y}}{ijk,t}) Eijk,t=Mijk−(Xijk,t∗Yijk,t),并定义
H 1 ( X t , Y t ) = ∑ i , j , k P i j k exp ( − ∣ E i j k , t ∣ 2 2 σ 2 ) , H_1(\boldsymbol{\mathcal{X}}t,\boldsymbol{\mathcal{Y}}t) =\sum{i,j,k}\boldsymbol{\mathcal{P}}{ijk} \exp\left(-\frac{|\boldsymbol{\mathcal{E}}_{ijk,t}|^2}{2\sigma^2}\right), H1(Xt,Yt)=i,j,k∑Pijkexp(−2σ2∣Eijk,t∣2),
H 2 ( X t , Y t , R t ) = ∑ i , j , k P i j k ( R i j k , t 2 σ 2 ∣ E i j k , t ∣ 2 − ϕ ( R i j k , t ) ) , H_2(\boldsymbol{\mathcal{X}}t,\boldsymbol{\mathcal{Y}}t,\boldsymbol{\mathcal{R}}t) =\sum{i,j,k}\boldsymbol{\mathcal{P}}{ijk} \left(\frac{\boldsymbol{\mathcal{R}}{ijk,t}}{2\sigma^2}|\boldsymbol{\mathcal{E}}{ijk,t}|^2-\phi(\boldsymbol{\mathcal{R}}{ijk,t})\right), H2(Xt,Yt,Rt)=i,j,k∑Pijk(2σ2Rijk,t∣Eijk,t∣2−ϕ(Rijk,t)),
H 3 ( X t , Y t , R t ) = ∑ i , j , k − P i j k R i j k 2 σ t 2 ∣ E i j k , t ∣ 2 . H_3(\boldsymbol{\mathcal{X}}t,\boldsymbol{\mathcal{Y}}t,\boldsymbol{\mathcal{R}}t) =\sum{i,j,k}-\boldsymbol{\mathcal{P}}{ijk}\frac{\boldsymbol{\mathcal{R}}{ijk}}{2\sigma_t^2}|\boldsymbol{\mathcal{E}}_{ijk,t}|^2. H3(Xt,Yt,Rt)=i,j,k∑−Pijk2σt2Rijk∣Eijk,t∣2.
定理 1: Algorithm 1 生成的 H 3 ( X t , Y t , R t ) 随变量更新非增,且有下界。因此目标函数值收敛。 Proof: 见附录 D:定理 1 证明。 \boxed{ \begin{aligned} &\textbf{定理 1:}\ \text{Algorithm 1 生成的 } H_3(\boldsymbol{\mathcal{X}}_t,\boldsymbol{\mathcal{Y}}_t,\boldsymbol{\mathcal{R}}_t)\text{ 随变量更新非增,且有下界。因此目标函数值收敛。} \\ &\textbf{Proof:}\ \text{见附录 D:定理 1 证明。} \end{aligned} } 定理 1: Algorithm 1 生成的 H3(Xt,Yt,Rt) 随变量更新非增,且有下界。因此目标函数值收敛。Proof: 见附录 D:定理 1 证明。
定理 2: 对任意有限初始目标函数值,Algorithm 1 生成的序列 { ( X t , Y t , R t ) } 有界; 存在子序列收敛到聚点;该聚点是 H 3 的临界点;整个序列是 Cauchy 序列。 Proof: 见附录 E:定理 2 证明。 \boxed{ \begin{aligned} &\textbf{定理 2:}\ \text{对任意有限初始目标函数值,Algorithm 1 生成的序列 } \displaystyle \{(\boldsymbol{\mathcal{X}}_t,\boldsymbol{\mathcal{Y}}_t,\boldsymbol{\mathcal{R}}_t)\}\ \text{有界;} \\ &\text{存在子序列收敛到聚点;该聚点是 } H_3 \text{ 的临界点;整个序列是 Cauchy 序列。} \\ &\textbf{Proof:}\ \text{见附录 E:定理 2 证明。} \end{aligned} } 定理 2: 对任意有限初始目标函数值,Algorithm 1 生成的序列 {(Xt,Yt,Rt)} 有界;存在子序列收敛到聚点;该聚点是 H3 的临界点;整个序列是 Cauchy 序列。Proof: 见附录 E:定理 2 证明。
E. 复杂度分析
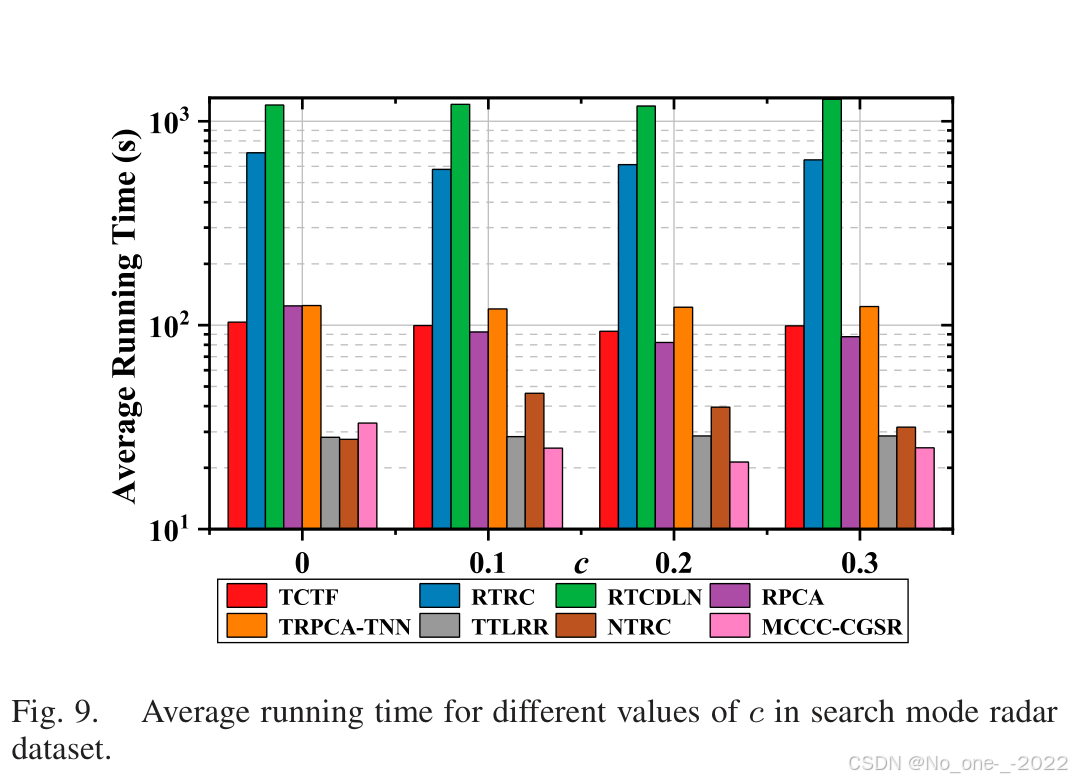
每次迭代中,选择核宽度 σ i \sigma_i σi 后,计算 X ∗ Y \boldsymbol{\mathcal{X}}*\boldsymbol{\mathcal{Y}} X∗Y 和 u ( q ) u(q) u(q) 的复杂度分别为 O ( r n 1 n 2 n 3 log n 3 + r n 1 n 2 n 3 ) O(rn_1n_2n_3\log n_3+rn_1n_2n_3) O(rn1n2n3logn3+rn1n2n3) 与 O ( n 1 n 2 n 3 ) O(n_1n_2n_3) O(n1n2n3)。计算 R \boldsymbol{\mathcal{R}} R 复用中间结果,复杂度为 O ( n 1 n 2 n 3 ) O(n_1n_2n_3) O(n1n2n3)。梯度 g X ‾ g_{\overline{\boldsymbol{\mathcal{X}}}} gX 与 g Y ‾ g_{\overline{\boldsymbol{\mathcal{Y}}}} gY 需要 FFT 运算,复杂度均为 O ( r n 1 n 2 n 3 log n 3 + r n 1 n 2 n 3 ) O(rn_1n_2n_3\log n_3+rn_1n_2n_3) O(rn1n2n3logn3+rn1n2n3)。因此,MCCC-CGSR 每次迭代总体复杂度为 O ( r n 1 n 2 n 3 log n 3 + r n 1 n 2 n 3 ) O(rn_1n_2n_3\log n_3+rn_1n_2n_3) O(rn1n2n3logn3+rn1n2n3)。