代码地址:https://gitee.com/CodeMao01/spring-ai-learn
一、快速开始
注意:先自行下个ollma,然后拉个本地大模型,我用的qwen2:7b
1.1、基础配置
xml配置:
xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.5.14</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.example</groupId>
<artifactId>spring-ai-learn</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>spring-ai-learn</name>
<description>spring-ai-learn</description>
<url/>
<licenses>
<license/>
</licenses>
<developers>
<developer/>
</developers>
<scm>
<connection/>
<developerConnection/>
<tag/>
<url/>
</scm>
<properties>
<java.version>17</java.version>
<spring-ai.version>1.1.0</spring-ai.version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>${spring-ai.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--响应式编程 流式输出-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-ollama</artifactId>
</dependency>
<!--API文档增强工具-->
<dependency>
<groupId>com.github.xiaoymin</groupId>
<artifactId>knife4j-openapi3-jakarta-spring-boot-starter</artifactId>
<version>4.5.0</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.42</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>yaml配置:
yaml
spring:
application:
name: spring-ai-learn
ai:
ollama:
base-url: http://localhost:11434
chat:
model: qwen2:7b
server:
port: 80801.2、简单调用(流式 + 非流式)
java
package com.example.springailearn.controller;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.http.MediaType;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
@RestController
public class ChatClientController {
private final ChatClient chatClient;
public ChatClientController(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder.build();
}
@GetMapping("/chat")
public String chat(String message) {
return chatClient.prompt(message).call().content();
}
@GetMapping(value = "/prompt", produces = MediaType.TEXT_HTML_VALUE + ";charset = utf-8")
public Flux<String> prompt(String message) {
return chatClient.prompt(message).stream().content();
}
}url: localhost:8080/doc.html
二、chatClient
2.1、三种创建方式
- ChatClient.Builder
- create
- build
java
package com.example.springailearn.controller;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.http.MediaType;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
@RestController
public class ChatClientController {
private final ChatClient chatClient;
private final ChatModel chatModel;
public ChatClientController(ChatClient.Builder chatClientBuilder, ChatModel chatModel) {
// 第一种:通过自动注入builder
// this.chatClient = chatClientBuilder.build();
// 第二种:create
this.chatModel = chatModel;
// this.chatClient = ChatClient.create(chatModel);
// 第三种: build
this.chatClient = ChatClient.builder(chatModel).build();
}
@GetMapping("/chat")
public String chat(String message) {
return chatClient.prompt(message).call().content();
}
@GetMapping(value = "/prompt", produces = MediaType.TEXT_HTML_VALUE + ";charset = utf-8")
public Flux<String> prompt(String message) {
return chatClient.prompt(message).stream().content();
}
}ChatModel是通过<font style="background-color:rgba(0, 0, 0, 0.06);">OllamaChatAutoConfiguration</font>自动注入的,可以通过配置文件关掉
ChatClient.Builder是通过<font style="background-color:#D8DAD9;">ChatClientAutoConfiguration</font>注入,可以通过配置文件关掉,关掉则需要手动配置ChatClient
yaml
spring:
ai:
chat:
client:
enabled: false
java
package com.example.springailearn.config;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class AiConfig {
@Bean
public ChatClient chatClient(ChatModel chatModel) {
return ChatClient.builder(chatModel).build();
}
}
java
package com.example.springailearn.controller;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.http.MediaType;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
@RestController
public class ChatClientController {
@Autowired
private ChatClient chatClient;
// private final ChatClient chatClient;
// private final ChatModel chatModel;
//
//
// public ChatClientController(ChatClient.Builder chatClientBuilder, ChatModel chatModel) {
// // 第一种:通过自动注入builder
//// this.chatClient = chatClientBuilder.build();
// // 第二种:create
// this.chatModel = chatModel;
//// this.chatClient = ChatClient.create(chatModel);
// // 第三种: build
// this.chatClient = ChatClient.builder(chatModel).build();
//
// }
@GetMapping("/chat")
public String chat(String message) {
return chatClient.prompt(message).call().content();
}
@GetMapping(value = "/prompt", produces = MediaType.TEXT_HTML_VALUE + ";charset = utf-8")
public Flux<String> prompt(String message) {
return chatClient.prompt(message).stream().content();
}
}2.2、默认系统提示词和用户提示词
| 维度 | defaultSystem | defaultUser |
|---|---|---|
| 作用范围 | 全局生效,影响所有用户交互的底层逻辑 | 会话级生效,仅影响当前用户输入的上下文 |
| 功能目标 | 定义AI模型的"角色身份"和"行为规范" | 定义用户的"初始输入"或"会话上下文 |
| 代码配置位置 | 通常在 @Configuration类中全局配置 |
可在全局配置或每次调用时动态传入 |
| 典型场景 | 设置AI为"专业法律顾问"或"幽默段子手" | 设置用户初始查询为"推荐旅游目的地"或"会话ID" |
默认系统提示词
- 可以使用
defaultSystem(String)方法,传入一个字符串作为默认系统提示词。 - 可以使用
defaultSystem(Resource)方法,传入一个Resource对象作为默认系统提示词。Resource对象可以是一个文件、一个URL、一个InputStream等。 - 可以使用
defaultSystem(Consumer<ChatClientRequestSpec>)方法,传入一个Consumer对象作为默认系统提示词。Consumer对象可以接受一个ChatClientRequestSpec对象作为参数,并设置ChatClient的相关参数。
默认用户提示词
系统提示词和用户提示词的区别是:系统提示词是模型在开始对话时使用的提示词,用户提示词是模型接收到的用户输入。
设置默认用户提示词的方式和系统提示词结构一样,可以使用 defaultUser() 方法。
- 可以使用
defaultUser(String)方法,传入一个字符串作为默认用户提示词。 - 可以使用
defaultUser(Resource)方法,传入一个Resource对象作为默认用户提示词。Resource对象可以是一个文件、一个URL、一个InputStream等。 - 可以使用
defaultUser(Consumer<ChatClientRequestSpec>)方法,传入一个Consumer对象作为默认用户提示词。Consumer对象可以接受一个ChatClientRequestSpec对象作为参数,并设置ChatClient的相关参数。回答问题要在50个字以内。ChatClient.builder()
java
package com.example.springailearn.config;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.Resource;
@Configuration
public class AiConfig {
@Value("classpath:system.txt")
private Resource resource;
@Value("classpath:user.txt")
private Resource userResource;
@Bean
public ChatClient chatClient(ChatModel chatModel) {
return ChatClient.builder(chatModel)
// .defaultSystem("你的名字是杉菜")
// .defaultSystem(resource)
// .defaultSystem(system -> system.text("你的名字是:{name}").param("name", "老菜花"))
// .defaultUser("每次回答要加:大哥")
// .defaultUser(user -> user.text("每次回答要加:大哥"))
.defaultUser(userResource)
.build();
}
}解决流式输出乱码:
yaml
server:
port: 8080
servlet:
encoding:
charset: UTF-8
force: true
enabled: true2.3、Response
2.3.1、chatResponse
模型调用成功后,ChatClient会返回一个响应对象,该对象封装了模型的输出结果。
响应对象结构如下:
java
ChatResponse chatResponse = chatClient.prompt()
.user("Tell me a joke")
.call()
.chatResponse();ChatResponse是对大模型model的输出结果进行封装的类,json结构如下所示:
上面三个key对应的是ChatResponse的三个get方法,result数据来自于results中的第一条数据。metadata主要封装的是元数据信息,包含如下信息:
我们来看一下rateLimit中的数据,内容如下:
RateLimit 是一个抽象数据类型,用于封装来自AI提供商API的速率限制元数据,包括API密钥的配额信息和当前余额状态。
请求相关限制
- getRequestsLimit(): 获取请求速率限制的上限值,表示在限流重置前允许的最大请求数
- getRequestsRemaining(): 获取剩余可使用的请求数量,表示在达到限流前还能发送多少请求
- getRequestsReset(): 获取请求限流重置的时间间隔,表示距离限流重置还需要多长时间
令牌相关限制
- getTokensLimit(): 获取令牌速率限制的上限值,表示在限流重置前允许的最大令牌数
- getTokensRemaining(): 获取剩余可使用的令牌数量,表示在达到限流前还有多少令牌可用
- getTokensReset(): 获取令牌限流重置的时间间隔,表示距离令牌限流重置还需要多长时间
requestReset和tokensReset返回类型为Duration,ISO 8601 Duration 格式说明如下:
前缀标识:
- P:表示Period(周期)的开始
- T:表示Time(时间)部分的开始,用于区分日期和时间部分
各部分含义:
- S:秒(Seconds)
- M:分钟(Minutes)或月份(Months),在时间部分(T之后)表示分钟
- H:小时(Hours)
- D:天数(Days)
示例解析:
- PT20.345S → 20.345秒
- PT15M → 15分钟(15×60=900秒)
- PT10H → 10小时(10×3600=36000秒)
- P2D → 2天(2×86400=172800秒)
- P2DT3H4M → 2天3小时4分钟
- PT-6H3M → -6小时+3分钟
- -PT6H3M → -6小时-3分钟
- -PT-6H+3M → +6小时-3分钟
Usage 接口详解
Prompt Tokens 相关
- getPromptTokens(): 获取AI请求中提示词(prompt)部分消耗的令牌数量
返回类型为 Integer
这部分tokens代表用户输入内容的token消耗
Completion Tokens 相关
- getCompletionTokens(): 获取AI响应中生成内容(completion)部分消耗的令牌数量
返回类型为 Integer
这部分tokens代表模型输出内容的token消耗
Total Tokens 计算
- getTotalTokens(): 返回整个AI请求过程中消耗的总令牌数
默认实现方法,自动计算prompt和completion的tokens总和
内部逻辑会处理null值情况,确保计算安全
公式:totalTokens = promptTokens + completionTokens
原始使用数据
- getNativeUsage(): 返回底层模型API响应中的原始使用数据对象
返回类型为 Object,具体类型由API响应决定
保留了最原始的用量统计信息
在来看一下模型调用结果中Results中的数据结构:
result中包含metadata和output,metadata的信息如图所示,output其实就是AI Message,这个我们会在后面的课程进行介绍。finishReason上面显示的"stop",表示停止。
2.3.2、chatClientResponse = chatResponse + context
2.3.3、entity
- 非流式entity
- 流式entity
当对模型进行流式处理时,你不可以使用 entity() 方法将模型的输出映射到Java对象。但是我们也需要获取模型的输出结果,映射出一个Java对象。可以获取到流中的所有数据,再使用Convertor对流进行转换。
plain
package com.example.springailearn.controller;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.model.ChatResponse;
import org.springframework.ai.converter.BeanOutputConverter;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.core.ParameterizedTypeReference;
import org.springframework.http.MediaType;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
import java.util.List;
import java.util.stream.Collectors;
@RestController
public class ChatClientController {
@Autowired
private ChatClient chatClient;
// private final ChatClient chatClient;
// private final ChatModel chatModel;
//
//
// public ChatClientController(ChatClient.Builder chatClientBuilder, ChatModel chatModel) {
// // 第一种:通过自动注入builder
//// this.chatClient = chatClientBuilder.build();
// // 第二种:create
// this.chatModel = chatModel;
//// this.chatClient = ChatClient.create(chatModel);
// // 第三种: build
// this.chatClient = ChatClient.builder(chatModel).build();
//
// }
@GetMapping("/chat")
public ChatResponse chat(String message) {
return chatClient.prompt(message).call().chatResponse();
}
@GetMapping(value = "/prompt", produces = MediaType.TEXT_HTML_VALUE)
public Flux<String> prompt(String message) {
return chatClient.prompt(message).stream().content();
}
record ActorFilms(String actor, List<String> movies) {}
@GetMapping("/entity")
public ActorFilms entity(String message) {
return chatClient.prompt(message).call().entity(ActorFilms.class);
}
@GetMapping("/entityList")
public List<ActorFilms> entityList(String message) {
return chatClient.prompt(message).call().entity(new ParameterizedTypeReference<List<ActorFilms>>(){});
}
@GetMapping("/entityStream")
public List<ActorFilms> entityStream(String message) {
var converter = new BeanOutputConverter<>(new ParameterizedTypeReference<List<ActorFilms>>(){});
Flux<String> flux = this.chatClient.prompt().user(u -> u.text("{format}").param("format", converter.getFormat()))
.stream().content();
String collect = flux.collectList().block().stream().collect(Collectors.joining());
return converter.convert(collect);
}
}三、advisor
3.1、基本介绍
Advisor 的核心功能是通过拦截器链的方式,在 AI 模型处理请求的前后执行特定操作。其工作流程分为非流式和流式两种场景:
- 非流式处理:通过 CallAdvisor 及其链 CallAdvisorChain 管理。
- 流式处理:通过 StreamAdvisor 及其链 StreamAdvisorChain 管理,支持对流式数据(如实时生成的文本)进行拦截和增强。
BaseAdvisor接口继承了CallAdvisor和StreamAdvisor,提供before和after方法处理流式和非流式请求,请求先经过所有 BaseAdvisor 的 before 方法处理,然后由模型执行,最后依次调用 after 方法处理响应。
每个 Advisor 实现 org.springframework.ai.chat.client.advisor.api.Advisor 接口,该接口继承自 Ordered,允许通过 getOrder() 方法定义执行顺序(数值越小优先级越高)。
3.2、内置 Advisor 示例
Spring AI 提供了多个内置 Advisor,覆盖常见应用场景:
MessageChatMemoryAdvisor :将用户问题和模型回答添加到上下文历史中,实现短期记忆功能。需确保所用模型支持历史记录管理。
PromptChatMemoryAdvisor :与上述类似,但将上下文历史封装到 SystemPrompt 中,兼容不支持 messages 参数的模型。
QuestionAnswerAdvisor :集成 RAG(检索增强生成)功能,通过调用知识库检索相关信息,丰富提示词。
SafeGuardAdvisor :进行敏感词校验,若用户输入触发敏感词规则,会拦截请求并终止后续处理,保障内容安全。
SimpleLoggerAdvisor :用于打印请求和响应的日志,便于调试。
VectorStoreChatMemoryAdvisor:从矢量存储器中获取内存并将其添加到提示词的系统文本中。该Advisor对于高效搜索和检索大型数据集中的相关信息非常有用。
SimpleLoggerAdvisor是内置的一个Advisor,用于打印请求和响应的日志,便于调试。开启 SimpleLoggerAdvisor 可以通过以下方式:
java
package com.example.springailearn.config;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.SimpleLoggerAdvisor;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.Resource;
@Configuration
public class AiConfig {
@Value("classpath:system.txt")
private Resource resource;
@Value("classpath:user.txt")
private Resource userResource;
@Bean
public ChatClient chatClient(ChatModel chatModel) {
// chatClient ==> chatMode ==> api
return ChatClient.builder(chatModel)
// .defaultSystem("你的名字是杉菜")
// .defaultSystem(resource)
// .defaultSystem(system -> system.text("你的名字是:{name}").param("name", "老菜花"))
// .defaultUser("每次回答要加:大哥")
// .defaultUser(user -> user.text("每次回答要加:大哥"))
// .defaultUser(userResource)
.defaultAdvisors(simpleLoggerAdvisor())
// .defaultAdvisors(new SimpleLoggerAdvisor())
.build();
}
@Bean
public SimpleLoggerAdvisor simpleLoggerAdvisor() {
return new SimpleLoggerAdvisor();
}
}同时需要在配置文件中设置日志打印级别:
yaml
logging:
level:
org.springframework.ai.chat.client.advisor: DEBUG我们再来分析一下SimpleLoggerAdvisor 的实现:
java
public class SimpleLoggerAdvisor implements CallAdvisor, StreamAdvisor {
private static final Logger logger = LoggerFactory.getLogger(SimpleLoggerAdvisor.class);
@Override
public String getName() {
return this.getClass().getSimpleName();
}
@Override
public int getOrder() {
return 0;
}
@Override
public ChatClientResponse adviseCall(ChatClientRequest chatClientRequest, CallAdvisorChain callAdvisorChain) {
logRequest(chatClientRequest);
ChatClientResponse chatClientResponse = callAdvisorChain.nextCall(chatClientRequest);
logResponse(chatClientResponse);
return chatClientResponse;
}
@Override
public Flux<ChatClientResponse> adviseStream(ChatClientRequest chatClientRequest,
StreamAdvisorChain streamAdvisorChain) {
logRequest(chatClientRequest);
Flux<ChatClientResponse> chatClientResponses = streamAdvisorChain.nextStream(chatClientRequest);
return new ChatClientMessageAggregator().aggregateChatClientResponse(chatClientResponses, this::logResponse);
}
private void logRequest(ChatClientRequest request) {
logger.debug("request: {}", request);
}
private void logResponse(ChatClientResponse chatClientResponse) {
logger.debug("response: {}", chatClientResponse);
}
}- 为Advisor提供独特的名称。
- 你可以通过设置顺序值来控制执行顺序。较低的数值先执行。
- 这是一个将Flux响应聚合为单一ChatClientResponse的实用类。 这对于日志记录或其他处理方式非常有用,这些处理可以观察整个响应,而非流中单个项目。 注意,你不能更改响应,因为它是只读作。MessageAggregatorMessageAggregator
safeGuardAdvisor:进行敏感词校验,若用户输入触发敏感词规则,会拦截请求并终止后续处理,保障内容安全。
java
package com.example.springailearn.config;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.SafeGuardAdvisor;
import org.springframework.ai.chat.client.advisor.SimpleLoggerAdvisor;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.Resource;
import java.util.List;
@Configuration
public class AiConfig {
@Value("classpath:system.txt")
private Resource resource;
@Value("classpath:user.txt")
private Resource userResource;
@Bean
public ChatClient chatClient(ChatModel chatModel) {
// chatClient ==> chatMode ==> api
return ChatClient.builder(chatModel)
// .defaultSystem("你的名字是杉菜")
// .defaultSystem(resource)
// .defaultSystem(system -> system.text("你的名字是:{name}").param("name", "老菜花"))
// .defaultUser("每次回答要加:大哥")
// .defaultUser(user -> user.text("每次回答要加:大哥"))
// .defaultUser(userResource)
.defaultAdvisors(simpleLoggerAdvisor(), safeGuardAdvisor())
// .defaultAdvisors(new SimpleLoggerAdvisor())
.build();
}
@Bean
public SimpleLoggerAdvisor simpleLoggerAdvisor() {
return new SimpleLoggerAdvisor();
}
@Bean
public SafeGuardAdvisor safeGuardAdvisor() {
// return new SafeGuardAdvisor(List.of("你是谁?"));
return SafeGuardAdvisor.builder()
.sensitiveWords(List.of("你是谁?"))
.failureResponse("不能说敏感词").build();
}
}源码分析:就是判断下用户提示词是否在敏感词列表中,有则自定义个ChatResponse
java
/*
* Copyright 2023-2025 the original author or authors.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* https://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.springframework.ai.chat.client.advisor;
import java.util.List;
import java.util.Map;
import reactor.core.publisher.Flux;
import org.springframework.ai.chat.client.ChatClientRequest;
import org.springframework.ai.chat.client.ChatClientResponse;
import org.springframework.ai.chat.client.advisor.api.CallAdvisor;
import org.springframework.ai.chat.client.advisor.api.CallAdvisorChain;
import org.springframework.ai.chat.client.advisor.api.StreamAdvisor;
import org.springframework.ai.chat.client.advisor.api.StreamAdvisorChain;
import org.springframework.ai.chat.messages.AssistantMessage;
import org.springframework.ai.chat.model.ChatResponse;
import org.springframework.ai.chat.model.Generation;
import org.springframework.util.Assert;
import org.springframework.util.CollectionUtils;
/**
* An advisor that blocks the call to the model provider if the user input contains any of
* the sensitive words.
*
* @author Christian Tzolov
* @author Ilayaperumal Gopinathan
* @author Thomas Vitale
* @since 1.0.0
*/
public class SafeGuardAdvisor implements CallAdvisor, StreamAdvisor {
private static final String DEFAULT_FAILURE_RESPONSE = "I'm unable to respond to that due to sensitive content. Could we rephrase or discuss something else?";
private static final int DEFAULT_ORDER = 0;
private final String failureResponse;
private final List<String> sensitiveWords;
private final int order;
public SafeGuardAdvisor(List<String> sensitiveWords) {
this(sensitiveWords, DEFAULT_FAILURE_RESPONSE, DEFAULT_ORDER);
}
public SafeGuardAdvisor(List<String> sensitiveWords, String failureResponse, int order) {
Assert.notNull(sensitiveWords, "Sensitive words must not be null!");
Assert.notNull(failureResponse, "Failure response must not be null!");
this.sensitiveWords = sensitiveWords;
this.failureResponse = failureResponse;
this.order = order;
}
public static Builder builder() {
return new Builder();
}
public String getName() {
return this.getClass().getSimpleName();
}
@Override
public ChatClientResponse adviseCall(ChatClientRequest chatClientRequest, CallAdvisorChain callAdvisorChain) {
if (!CollectionUtils.isEmpty(this.sensitiveWords)
&& this.sensitiveWords.stream().anyMatch(w -> chatClientRequest.prompt().getContents().contains(w))) {
return createFailureResponse(chatClientRequest);
}
return callAdvisorChain.nextCall(chatClientRequest);
}
@Override
public Flux<ChatClientResponse> adviseStream(ChatClientRequest chatClientRequest,
StreamAdvisorChain streamAdvisorChain) {
if (!CollectionUtils.isEmpty(this.sensitiveWords)
&& this.sensitiveWords.stream().anyMatch(w -> chatClientRequest.prompt().getContents().contains(w))) {
return Flux.just(createFailureResponse(chatClientRequest));
}
return streamAdvisorChain.nextStream(chatClientRequest);
}
private ChatClientResponse createFailureResponse(ChatClientRequest chatClientRequest) {
return ChatClientResponse.builder()
.chatResponse(ChatResponse.builder()
.generations(List.of(new Generation(new AssistantMessage(this.failureResponse))))
.build())
.context(Map.copyOf(chatClientRequest.context()))
.build();
}
@Override
public int getOrder() {
return this.order;
}
public static final class Builder {
private List<String> sensitiveWords;
private String failureResponse = DEFAULT_FAILURE_RESPONSE;
private int order = DEFAULT_ORDER;
private Builder() {
}
public Builder sensitiveWords(List<String> sensitiveWords) {
this.sensitiveWords = sensitiveWords;
return this;
}
public Builder failureResponse(String failureResponse) {
this.failureResponse = failureResponse;
return this;
}
public Builder order(int order) {
this.order = order;
return this;
}
public SafeGuardAdvisor build() {
return new SafeGuardAdvisor(this.sensitiveWords, this.failureResponse, this.order);
}
}
}3.3、自定义advisor
自定义 Advisor
开发者可通过实现 CallAdvisor 或 StreamAdvisor 接口创建自定义 Advisor。例如,基于 BaseAdvisor 抽象类可简化实现,只需重写 before 和 after 方法。 自定义 Advisor 的典型用途包括:
数据转换 :在发送给模型前格式化输入数据,或在返回客户端前优化响应结构。
重复任务封装:将常见模式(如日志记录、权限检查)封装为可重用组件,提升开发效率。
Re-Reading (Re2) Advisor
《重读提升大型语言模型中的推理能力》一文介绍了一种称为重读(Re-Reading,简称Re2)的技术,它提升了大型语言模型的推理能力。 Re2的技巧需要像这样增强输入提示:
plain
{Input_Query}
Read the question again: {Input_Query}实现一个将Re2技术应用于用户输入查询的顾问,可以如下作:
java
package com.example.springailearn.advisor;
import org.springframework.ai.chat.client.ChatClientRequest;
import org.springframework.ai.chat.client.ChatClientResponse;
import org.springframework.ai.chat.client.advisor.api.AdvisorChain;
import org.springframework.ai.chat.client.advisor.api.BaseAdvisor;
import org.springframework.ai.chat.prompt.PromptTemplate;
import java.util.Map;
public class ReReadingAdvisor implements BaseAdvisor {
private static final String DEFAULT_RE2_ADVISE_TEMPLATE = """
{re2_input_query}
Read the question again: {re2_input_query}
""";
private final String re2AdviseTemplate;
public ReReadingAdvisor() {
this(DEFAULT_RE2_ADVISE_TEMPLATE);
}
public ReReadingAdvisor(String re2AdviseTemplate) {
this.re2AdviseTemplate = re2AdviseTemplate;
}
@Override
public ChatClientRequest before(ChatClientRequest chatClientRequest, AdvisorChain advisorChain) {
String render = PromptTemplate.builder()
.template(this.re2AdviseTemplate)
.variables(Map.of("re2_input_query", chatClientRequest.prompt().getUserMessage().getText()))
.build().render();
return chatClientRequest.mutate().prompt(chatClientRequest.prompt().augmentUserMessage(render)).build();
}
@Override
public ChatClientResponse after(ChatClientResponse chatClientResponse, AdvisorChain advisorChain) {
return chatClientResponse;
}
@Override
public int getOrder() {
return 0;
}
}
java
package com.example.springailearn.config;
import com.example.springailearn.advisor.ReReadingAdvisor;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.SafeGuardAdvisor;
import org.springframework.ai.chat.client.advisor.SimpleLoggerAdvisor;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.Resource;
import java.util.List;
@Configuration
public class AiConfig {
@Value("classpath:system.txt")
private Resource resource;
@Value("classpath:user.txt")
private Resource userResource;
@Bean
public ChatClient chatClient(ChatModel chatModel) {
// chatClient ==> chatMode ==> api
return ChatClient.builder(chatModel)
// .defaultSystem("你的名字是杉菜")
// .defaultSystem(resource)
// .defaultSystem(system -> system.text("你的名字是:{name}").param("name", "老菜花"))
// .defaultUser("每次回答要加:大哥")
// .defaultUser(user -> user.text("每次回答要加:大哥"))
// .defaultUser(userResource)
.defaultAdvisors(simpleLoggerAdvisor(), safeGuardAdvisor(), new ReReadingAdvisor())
// .defaultAdvisors(new SimpleLoggerAdvisor())
.build();
}
@Bean
public SimpleLoggerAdvisor simpleLoggerAdvisor() {
return new SimpleLoggerAdvisor();
}
@Bean
public SafeGuardAdvisor safeGuardAdvisor() {
// return new SafeGuardAdvisor(List.of("你是谁?"));
return SafeGuardAdvisor.builder()
.sensitiveWords(List.of("你是谁?"))
.failureResponse("不能说敏感词").build();
}
}注意事项与最佳实践
执行顺序:多个 Advisor 的顺序由 getOrder() 决定,相同优先级时顺序不确定,需显式设置顺序以避免依赖问题。
四、Prompt
4.1、简单介绍及使用
在Spring AI框架中,Prompt是与大语言模型交互的核心机制,它通过结构化的输入指导模型生成期望的输出。Prompt本质上是一系列Message对象的集合,这些对象定义了对话的角色(如用户、系统或助手)和内容,从而构建完整的交互上下文。
Prompt的基本构成与核心组件
以下是Prompt类的简短版本,为了简洁起见省略了构造函数和实用方法:
java
public class Prompt implements ModelRequest<List<Message>> {
private final List<Message> messages;
private ChatOptions chatOptions;
}Prompt由多个Message组成,每个Message具有特定的MessageType(如USER、SYSTEM或ASSISTANT),并包含文本内容和元数据。 在Spring AI中,Prompt类封装了这些Message列表及请求选项(如温度、最大Token数)。例如,通过ChatClient的call方法传入Prompt,即可触发模型推理并获取响应。 这种设计允许开发者灵活组织对话历史、系统指令和用户输入,形成完整的交互链路。
MessageType
每个消息都被分配了特定的角色。 这些角色负责对信息进行分类,明确提示中每个部分的上下文和目的,供AI模型使用。 这种结构化的方法增强了与AI沟通的细腻度和有效性,因为提示的每个部分在互动中都扮演着独特且明确的角色。
主要职责包括:
- 系统角色(SYSTEM):指导AI的行为和响应风格,设定AI如何解释和响应输入的参数或规则。这就像在发起对话前先给AI提供指令。
- 用户角色(USER):代表用户的输入------他们对AI的问题、命令或陈述。这一角色至关重要,因为它构成了人工智能应对的基础。
- 助理角色(ASSISTANT):AI对用户输入的回应。 这不仅仅是一个回答或反应,更对于保持对话的流畅性至关重要。 通过追踪AI之前的回复(其"助理角色"消息),系统确保互动连贯且符合上下文。 助手消息也可能包含功能工具调用请求信息。 它就像AI中的一个特殊功能,用于执行特定功能,比如计算、获取数据或其他不仅仅是说话的任务。
- 工具/功能角色(TOOL):工具/功能角色专注于返回工具的更多信息。
java
public enum MessageType {
USER("user"),
ASSISTANT("assistant"),
SYSTEM("system"),
TOOL("tool");
}
java
@GetMapping("/prompt")
public String prompt(String message) {
Prompt prompt = Prompt.builder()
.messages(UserMessage.builder().text(message).build())
.chatOptions(OllamaChatOptions.builder().disableThinking().build())
.build();
// return chatClient.prompt(prompt).call().content();
return chatClient.prompt().user(message).options(OllamaChatOptions.builder().disableThinking().build()).call().content();
}4.2、PromptTemplate
PromptTemplate是Spring AI提供的高级工具,用于处理提示词的动态生成和插值。它基于StringTemplate引擎,支持将静态模板与动态参数结合。 例如,可以通过资源文件注入提示模板内容,避免硬编码在Java代码中,提升可维护性。
4.2.1、PromptTemplate及变体
PromptTemplate基本使用:
java
// 基本使用
PromptTemplate promptTemplate = PromptTemplate.builder()
.template("{format}")
.variables(Map.of("format", "hello"))
.build();
String render = promptTemplate.render();
System.out.println(render);此外,PromptTemplate支持多种变体(了解即可):
- SystemPromptTemplate用于设置全局上下文或角色行为
- AssistantPromptTemplate处理助手消息
- 而FunctionPromptTemplate则专门用于函数调用场景。
这种模板化方式简化了复杂Prompt的构建,尤其适用于需要重复使用或参数化调整的场景。
java
public static void main(String[] args) {
// // 基本使用
// PromptTemplate promptTemplate = PromptTemplate.builder()
// .template("{format}")
// .variables(Map.of("format", "hello"))
// .build();
//
// String render = promptTemplate.render();
// System.out.println(render);
SystemPromptTemplate systemPromptTemplate = SystemPromptTemplate.builder()
.template("{format}")
.variables(Map.of("format", "hello"))
.build();
String render = systemPromptTemplate.render();
System.out.println(render);
}4.2.2、render渲染方式
- 返回String
- 返回Prompt
- 返回Message
java
// 渲染方式
PromptTemplate promptTemplate = PromptTemplate.builder()
.template("{format}")
.build();
// 第一种
String render = promptTemplate.render(Map.of("format", "hello"));
System.out.println(render);
// 第二种
Prompt prompt = promptTemplate.create(Map.of("format", "hello"));
System.out.println(prompt.getContents());
// 第三种
Message message = promptTemplate.createMessage(Map.of("format", "hello"));
System.out.println(message.getText());4.2.3、自定义渲染
- StTemplateRenderer:自定义分隔符
java
PromptTemplate promptTemplate = PromptTemplate.builder()
.template("<format>")
.renderer(StTemplateRenderer.builder()
.startDelimiterToken('<').endDelimiterToken('>')
// 没渲染不报错
.validationMode(ValidationMode.NONE)
.build())
.build();
System.out.println(promptTemplate.render(Map.of("format", "hello")));- NoOpTemplateRenderer:无动态插入变量
java
PromptTemplate promptTemplate = PromptTemplate.builder()
.template("<format>")
.renderer(new NoOpTemplateRenderer())
.build();
System.out.println(promptTemplate.render(Map.of("format", "hello")));- 炫技
java
PromptTemplate promptTemplate = PromptTemplate.builder()
.template("{format; separator=\", \"}")
.renderer(StTemplateRenderer.builder().validationMode(ValidationMode.NONE).build())
.build();
String render = promptTemplate.render(Map.of("format", List.of("hello", "world")));
System.out.println(render);五、结构化数据
LLM产生结构化输出的能力对于依赖可靠解析输出值的下游应用程序很重要。开发人员希望快速将AI模型的结果转换为数据类型,如JSON、XML或Java类,这些数据类型可以传递给其他应用程序函数和方法。
Spring AI <font style="background-color:rgba(0, 0, 0, 0.06);">Structured Output Converters</font>有助于将LLM输出转换为结构化格式。
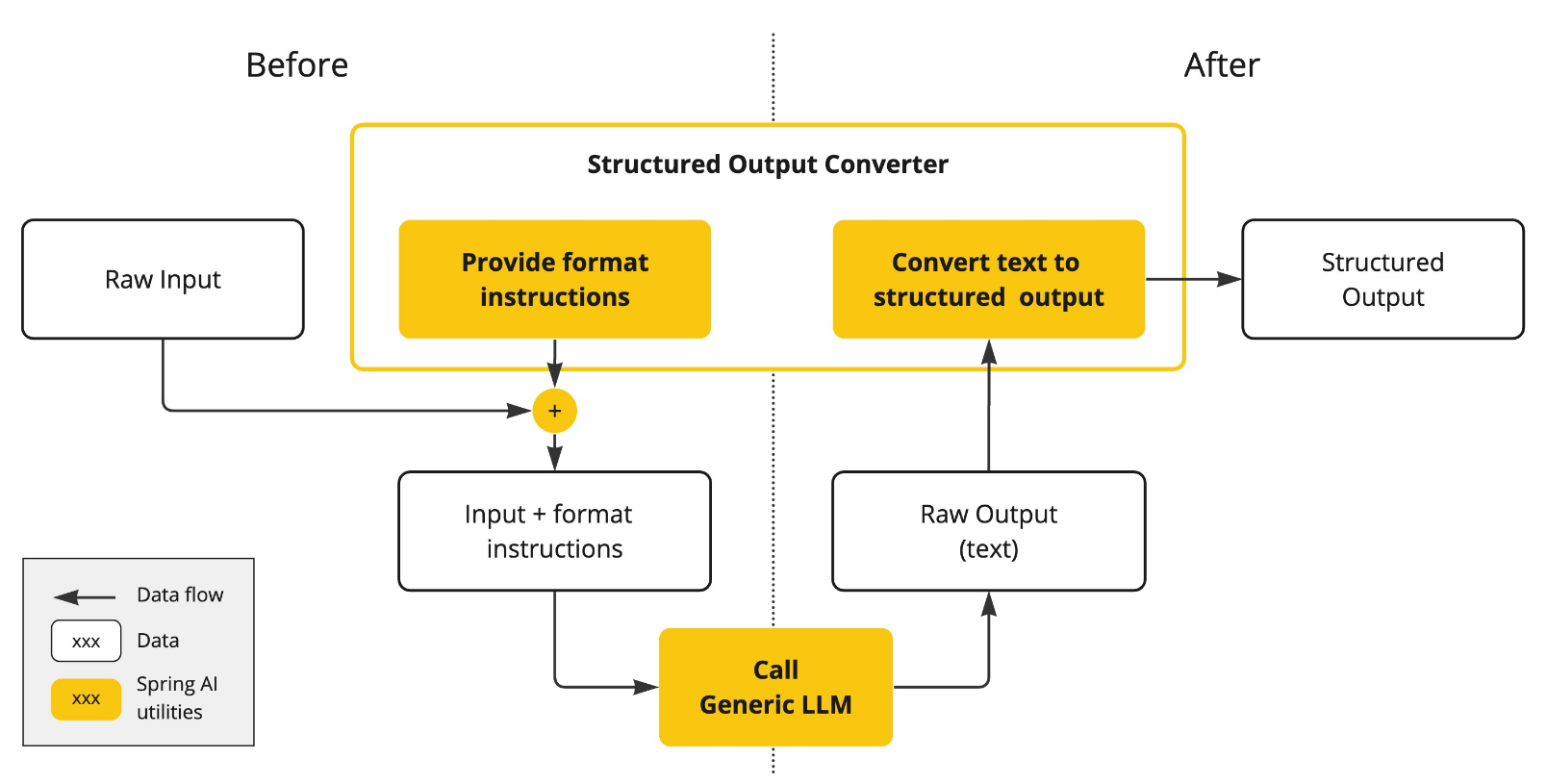
原理:在LLM调用之前,转换器将格式指令附加到提示,为模型提供生成所需输出结构的明确指导。这些指令充当蓝图,塑造模型的响应以符合指定的格式。在LLM调用之后,转换器获取模型的输出文本并将其转换为结构化类型的实例。此转换过程涉及解析原始文本输出并将其映射到相应的结构化数据表示,例如JSON、XML或特定领域的数据结构。
目前,Spring AI提供 BeanOutputConverter、MapOutputConverter和 ListOutputConverter实现:
BeanOutputConverter<T>-使用指定的Java类(例如Bean)或ParameterizedTypeReference进行配置,此转换器采用FormatProvider实现,指示AI模型生成符合从指定Java类派生的DRAFT_2020_12、JSON Schema的JSON响应。随后,它利用ObjectMapper将JSON输出反序列化为目标类的Java对象实例。MapOutputConverter-使用FormatProvider实现扩展AbstractMessageOutputConverter的功能,该实现指导AI模型生成符合RFC8259的JSON响应。此外,它还包含一个转换器实现,该实现利用提供的MessageConverter将JSON有效负载转换为java.util.Map<String, Object>实例。ListOutputConverter-扩展AbstractConversionServiceOutputConverter并包含为逗号分隔列表输出量身定制的FormatProvider实现。转换器实现使用提供的ConversionService将模型文本输出转换为java.util.List。
5.1、BeanOutputConverter
目的:转换成Bean
java
record ActorFilms(@JsonPropertyDescription("演员") String actor,
@JsonPropertyDescription("电影") List<String> movies) {}
@GetMapping("/entity")
public ActorFilms entity(String message) {
return chatClient.prompt(message).call().entity(ActorFilms.class);
}
@GetMapping("/entityList")
public List<ActorFilms> entityList(String message) {
return chatClient.prompt(message).call().entity(new ParameterizedTypeReference<List<ActorFilms>>(){});
}
@GetMapping("/entityStream")
public List<ActorFilms> entityStream(String message) {
var converter = new BeanOutputConverter<>(new ParameterizedTypeReference<List<ActorFilms>>(){});
Flux<String> flux = this.chatClient.prompt().user(u -> u.text("{format}").param("format", converter.getFormat()))
.stream().content();
String collect = flux.collectList().block().stream().collect(Collectors.joining());
return converter.convert(collect);
}5.2、MapOutputConverter
目的:转换成Map
java
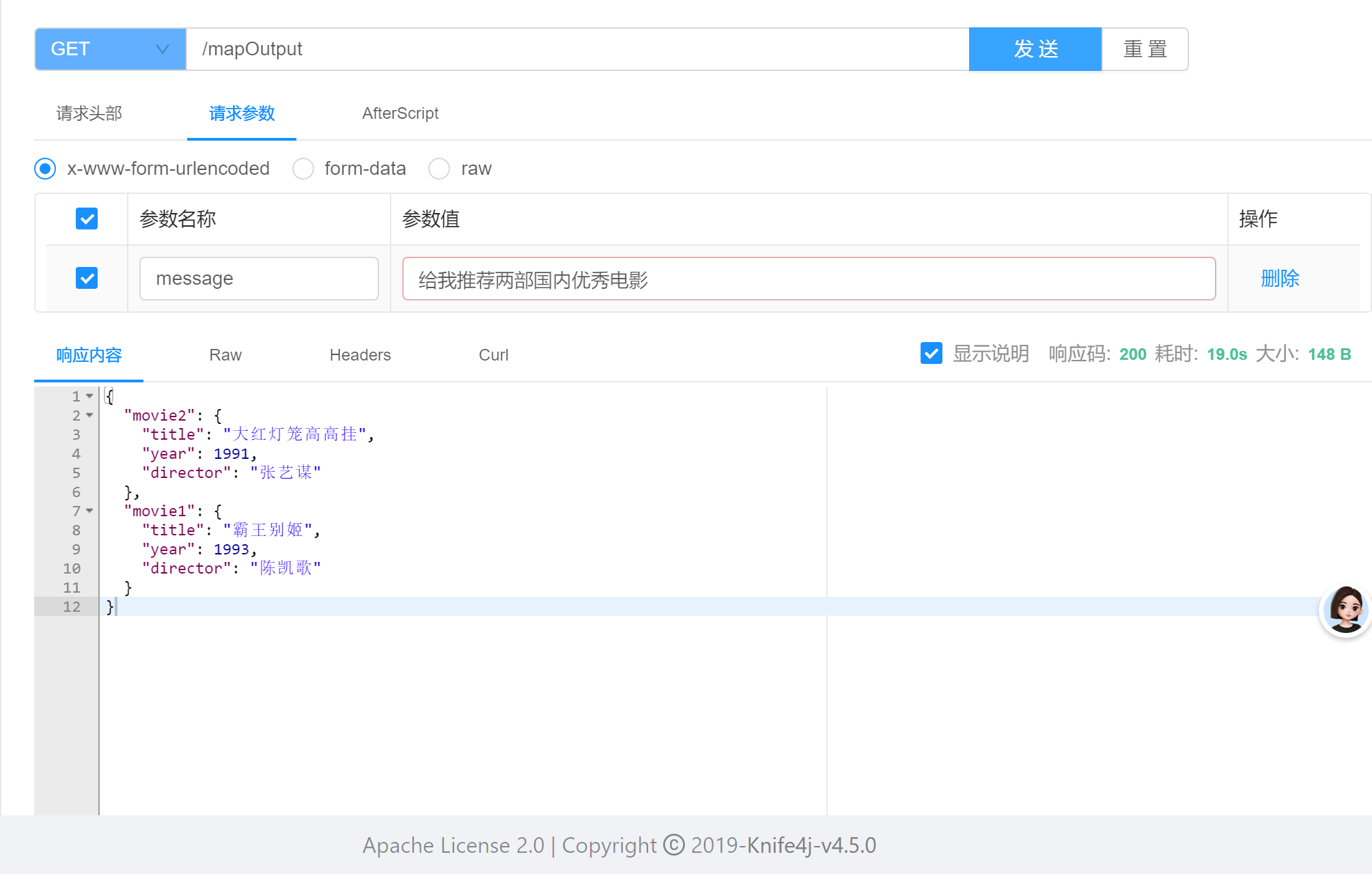
@GetMapping("/mapOutput")
public Map<String, Object> mapOutput(String message) {
return chatClient.prompt().user(message).call().entity(new MapOutputConverter());
}
5.3、ListOutputConverter
目的:转换成List
java
@GetMapping("/ListOutput")
public List<String> ListOutput(String message) {
return chatClient.prompt().user(message).call().entity(new ListOutputConverter());
}5.4、本机结构化输出
注意:spring ai版本必须是1.1.2及以上,及模型必须支持(下面有列出的模型)
许多现代AI模型现在为结构化输出提供原生支持,与基于提示的格式相比,它提供了更可靠的结果。Spring AI通过本机结构化输出功能支持这一点。
当使用本机结构化输出时,BeanOutputConverter生成的JSON模式直接发送到模型的结构化输出API,无需在提示符中使用格式指令。这种方法提供:
- 更高的可靠性:模型保证输出符合模式
- 更简洁的提示:无需附加格式说明
- 更好的性能:模型可以在内部优化结构化输出
使用本机结构化输出
要启用本机结构化输出,请使用 AdvisorParams.ENABLE_NATIVE_STRUCTURED_OUTPUT参数:
java
ActorsFilms actorsFilms = ChatClient.create(chatModel).prompt()
.advisors(AdvisorParams.ENABLE_NATIVE_STRUCTURED_OUTPUT)
.user("Generate the filmography for a random actor.")
.call()
.entity(ActorsFilms.class);您也可以使用 ChatClient.Builder上的 defaultAdvisors()进行全局设置:
java
@Bean
ChatClient chatClient(ChatClient.Builder builder) {
return builder
.defaultAdvisors(AdvisorParams.ENABLE_NATIVE_STRUCTURED_OUTPUT)
.build();
}原生结构化输出支持的模型
以下模型目前支持原生结构化输出:
- OpenAI : GPT-4o and later models with JSON Schema support
- Anthropic : Claude 3.5 Sonnet and later models
- Vertex AI Gemini : Gemini 1.5 Pro and later models
某些AI模型(例如OpenAI)在顶层不支持本机对象数组。在这种情况下,您可以使用Spring AI默认结构化输出转换(无需本机结构化输出Advisor)
六、多模态输入
不仅仅文字,还有图片视频等等
java
@GetMapping("/multimodelity")
public Object multimodeality(String message) {
var imageResource = new ClassPathResource("test.png");
var userMessage = UserMessage.builder()
.text(message)
// .media(new Media(MimeTypeUtils.IMAGE_PNG, imageResource))
.media(Media.builder().mimeType(MimeTypeUtils.IMAGE_PNG).data(imageResource).build())
.build();
return chatClient.prompt().messages(userMessage)
.options(OllamaChatOptions.builder().model("qwen3-vl:2b").build())
.call().content();
}七、ChatModel
简介:各个大模型都有自己的ChatModel,用来和大模型进行直接交互,相对比较底层,上层是Spring AI封装的ChatClient
7.1、基本使用
java
@GetMapping("/chat/model")
public String chatModel(String message) {
// return chatModel.call(message);
ChatResponse chatResponse = chatModel.call(Prompt.builder()
.content(message)
.chatOptions(OllamaChatOptions.builder().enableThinking().build())
.build());
System.out.println(chatResponse.getResult().getMetadata().get("thinking").toString());
return chatResponse.getResult().getOutput().getText();
}7.2、OllamaChatModel
7.2.1、自动拉取模型
Spring AI Ollama可以在您的Ollama实例中不可用时自动拉取模型。此功能对于开发和测试以及将应用程序部署到新环境特别有用。
拉模型有三种策略:
always(在PullModelStrategy.ALWAYS中定义):始终提取模型,即使它已经可用。用于确保您使用的是模型的最新版本。when_missing(在PullModelStrategy.WHEN_MISSING):仅在模型尚不可用时才拉取它。这可能会导致使用旧版本的模型。never(在PullModelStrategy.NEVER中定义):从不自动拉取模型。
由于下载模型时的潜在延迟,不建议在生产环境中自动拉取。相反,请考虑提前评估和预下载必要的模型。
通过配置属性和默认选项定义的所有模型都可以在启动时自动拉取。您可以使用配置属性配置拉取策略、超时和最大重试次数:
yaml
spring:
ai:
ollama:
init:
pull-model-strategy: always
timeout: 60s
max-retries: 1在Ollama中所有指定的模型都可用之前,应用程序不会完成其初始化。根据模型大小和Internet连接速度,这可能会显着减慢应用程序的启动时间。
您可以在启动时初始化其他模型,这对于在运行时动态使用的模型很有用:
yaml
spring:
ai:
ollama:
init:
pull-model-strategy: always
chat:
additional-models:
- llama3.2
- qwen2.5如果您只想将拉动策略应用于特定类型的模型,您可以从初始化任务中排除聊天模型:
yaml
spring:
ai:
ollama:
init:
pull-model-strategy: always
chat:
include: false此配置将对除聊天模型之外的所有模型应用拉动策略。
7.2.2、思维方式(推理)
Ollama支持推理模型的思维模式,这些模型可以在提供最终答案之前发出其内部推理过程。此功能适用于Qwen3、DeepSeek-v3.1、DeepSeek R1和GPT-OSS等模型。
默认行为(Ollama 0.12+) :具有思考能力的模型(如
qwen3:*-thinking、deepseek-r1、deepseek-v3.1) 默认情况下自动启用思考 ,当思考选项未显式设置时。标准模型(如qwen2.5:*、llama3.2)默认情况下不启用思考。要显式控制此行为,请使用.enableThinking()或.disableThinking()。
大多数型号(Qwen3、DeepSeek-v3.1、DeepSeek R1)支持简单的布尔启用/禁用:
java
ChatResponse response = chatModel.call(
new Prompt(
"How many letter 'r' are in the word 'strawberry'?",
OllamaChatOptions.builder()
.model("qwen3:0.6b")
.enableThinking()
.build()
));
// Access the thinking process
String thinking = response.getResult().getMetadata().get("thinking");
String answer = response.getResult().getOutput().getText();您还可以禁用显式思维:
plain
ChatResponse response = chatModel.call(
new Prompt(
"What is 2+2?",
OllamaChatOptions.builder()
.model("qwen3:0.6b")
.disableThinking()
.build()
));思考内容可在响应元数据中找到:
java
ChatResponse response = chatModel.call(
new Prompt(
"Calculate 17 × 23",
OllamaChatOptions.builder()
.model("deepseek-r1")
.enableThinking()
.build()
));
// Get the reasoning process
String thinking = response.getResult().getMetadata().get("thinking");
System.out.println("Reasoning: " + thinking);
// Output: "17 × 20 = 340, 17 × 3 = 51, 340 + 51 = 391"
// Get the final answer
String answer = response.getResult().getOutput().getText();
System.out.println("Answer: " + answer);
// Output: "The answer is 391"思维模式也适用于流式响应:
java
Flux<ChatResponse> stream = chatModel.stream(
new Prompt(
"Explain quantum entanglement",
OllamaChatOptions.builder()
.model("qwen3")
.enableThinking()
.build()
));
stream.subscribe(response -> {
String thinking = response.getResult().getMetadata().get("thinking");
String content = response.getResult().getOutput().getContent();
if (thinking != null && !thinking.isEmpty()) {
System.out.println("[Thinking] " + thinking);
}
if (content != null && !content.isEmpty()) {
System.out.println("[Response] " + content);
}
});7.2.3、自定义OllamaChatModel
java
@GetMapping("/chat/ollama")
public String chatOllama(String message) {
OllamaApi ollamaApi = OllamaApi.builder().build();
OllamaChatModel ollamaChatModel = OllamaChatModel.builder()
.ollamaApi(ollamaApi)
.defaultOptions(OllamaChatOptions.builder().model("qwen2:7b").build())
.build();
return ollamaChatModel.call(message);
}八、ChatMemory
大型语言模型(LLM)是无状态的,这意味着它们不保留有关先前交互的信息。当您想在多个交互中维护上下文或状态时,这可能是一个限制。为了解决这个问题,Spring AI提供了聊天记忆功能,允许您在与LLM的多个交互中存储和检索信息。
通过 ChatMemory抽象,您可以实现各种类型的内存以支持不同的用例。消息的底层存储由 ChatMemoryRepository处理,其唯一职责是存储和检索 消息。由 ChatMemory实现来决定保留哪些消息以及何时删除它们。策略可能包括保留最后N条消息、将消息保留一段时间或将消息保持在某个令牌限制内。
在选择记忆类型之前,必须了解聊天记忆和聊天历史之间的区别。
- 聊天记忆。大型语言模型保留并用于在整个对话中保持上下文感知的信息。
- 聊天历史。整个对话历史记录,包括用户和模型之间交换的所有消息。
ChatMemory ChatMemory抽象旨在管理 聊天内存 。它允许您存储和检索与当前对话上下文相关的消息。但是,它不是最适合存储 聊天历史记录 。如果您需要维护所有交换消息的完整记录,您应该考虑使用不同的方法,例如依靠Spring Data高效存储和检索完整的聊天历史记录。
Spring AI会自动配置一个可以直接在应用程序中使用的 ChatMemory。默认情况下,它使用内存存储库来存储消息(InMemoryChatMemoryRepository),并使用 MessageWindowChatMemory实现来管理对话历史记录。如果已经配置了不同的存储库(例如Cassandra、JDBC或Neo4j),Spring AI将改用它。
MessageWindowChatMemory将消息窗口维护到指定的最大大小。当消息数量超过最大值时,旧消息将被删除,同时保留系统消息。默认窗口大小为20条消息。
java
MessageWindowChatMemory memory = MessageWindowChatMemory.builder()
.maxMessages(10)
.build();这是Spring AI用于自动配置 ChatMemory的默认消息类型。
Spring AI为存储聊天内存提供了 ChatMemoryRepository的抽象。本节介绍Spring AI提供的内置存储库以及如何使用它们,但如果需要,您也可以实现自己的存储库。
8.1、内存存储库
InMemoryChatMemoryRepository在内存中存储消息,使用 ConcurrentHashMap。
默认情况下,如果尚未配置其他存储库,Spring AI会自动配置一个 InMemoryChatMemoryRepository类型的 ChatMemoryRepositorybean,您可以直接在应用程序中使用它。
java
@Autowired
ChatMemoryRepository chatMemoryRepository;如果您更愿意手动创建 InMemoryChatMemoryRepository,可以执行如下操作:
java
ChatMemoryRepository repository = new InMemoryChatMemoryRepository();
java
@Bean
public ChatClient chatClient(ChatModel chatModel, ChatMemory chatMemory) {
// chatClient ==> chatMode ==> api
return ChatClient.builder(chatModel)
// .defaultSystem("你的名字是杉菜")
// .defaultSystem(resource)
// .defaultSystem(system -> system.text("你的名字是:{name}").param("name", "老菜花"))
// .defaultUser("每次回答要加:大哥")
// .defaultUser(user -> user.text("每次回答要加:大哥"))
// .defaultUser(userResource)
.defaultAdvisors(simpleLoggerAdvisor(),
safeGuardAdvisor(),
new ReReadingAdvisor(),
MessageChatMemoryAdvisor.builder(chatMemory).build())
// .defaultAdvisors(new SimpleLoggerAdvisor())
.build();
}
java
@GetMapping("/chat/memory")
public String chatMemory(String message) {
return chatClient.prompt(message)
.options(OllamaChatOptions.builder().disableThinking().build()).call().content();
}8.2、JdbcChatMemroy
8.2.1、基本使用
JdbcChatMemoryRepository是使用JDBC将消息存储在关系数据库中的内置实现,它支持开箱即用的多个数据库,适用于需要持久存储聊天内存的应用程序。
xml
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-chat-memory-repository-jdbc</artifactId>
</dependency>
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
</dependency>我们使用mysql作为存储数据库,需要在application.yml中配置:
yaml
spring:
datasource:
url: jdbc:mysql://localhost:3306/spring-ai-learn?useSSL=false&serverTimezone=Asia/Shanghai&characterEncoding=utf-8&allowPublicKeyRetrieval=true
username: root
password: root
ai:
chat:
client:
enabled: false
memory:
repository:
jdbc:
initialize-schema: always自动配置将在启动时使用特定于供应商的数据库SQL脚本自动创建 SPRING_AI_CHAT_MEMORY表。默认情况下,模式初始化仅适用于嵌入式数据库(H2、HSQL、Derby等)。
**您可以使用 ****spring.ai.chat.memory.repository.jdbc.initialize-schema**属性控制模式初始化:
properties
spring.ai.chat.memory.repository.jdbc.initialize-schema=embedded # Only for embedded DBs (default)
spring.ai.chat.memory.repository.jdbc.initialize-schema=always # Always initialize
spring.ai.chat.memory.repository.jdbc.initialize-schema=never # Never initialize (useful with Flyway/Liquibase)要覆盖模式脚本位置,请使用:
properties
spring.ai.chat.memory.repository.jdbc.schema=classpath:/custom/path/schema-mysql.sql
java
@Bean
public ChatClient chatClient(
// @Qualifier("dashScopeChatModel")
ChatModel chatModel, ChatMemory chatMemory) {
// chatClient ==> chatMode ==> api
return ChatClient.builder(chatModel)
// .defaultSystem("你的名字是杉菜")
// .defaultSystem(resource)
// .defaultSystem(system -> system.text("你的名字是:{name}").param("name", "老菜花"))
// .defaultUser("每次回答要加:大哥")
// .defaultUser(user -> user.text("每次回答要加:大哥"))
// .defaultUser(userResource)
.defaultAdvisors(simpleLoggerAdvisor(),
safeGuardAdvisor(),
new ReReadingAdvisor()
,MessageChatMemoryAdvisor.builder(chatMemory).build()
)
// .defaultAdvisors(new SimpleLoggerAdvisor())
.build();
}8.2.2、支持的数据库和方言抽象
Spring AI通过方言抽象支持多个关系数据库。开箱即用支持以下数据库:
- PostgreSQL
- MySQL/MariaDB
- SQL服务器
- HSQLDB
- Oracle数据库
使用 JdbcChatMemoryRepositoryDialect.from(DataSource)时,可以从JDBC URL自动检测正确的方言。您可以通过实现 JdbcChatMemoryRepositoryDialect接口来扩展对其他数据库的支持。
使用ChatClient API时,您可以提供 ChatMemory实现来维护跨多个交互的对话上下文。
Spring AI提供了一些内置顾问,您可以根据需要使用它们来配置 ChatClient的内存行为。
目前,执行工具调用时与大语言模型交换的中间消息不存储在内存中,这是当前实现的限制,将在未来版本中解决。如果需要存储这些消息,请参阅用户控制工具执行的说明。
MessageChatMemoryAdvisor.此顾问使用提供的ChatMemory实现管理对话内存。在每次交互中,它从内存中检索对话历史,并将其作为消息集合包含在提示中。PromptChatMemoryAdvisor.此顾问使用提供的ChatMemory实现管理对话内存。在每次交互中,它从内存中检索对话历史并将其作为纯文本附加到系统提示符中。VectorStoreChatMemoryAdvisor.此顾问使用提供的VectorStore实现管理对话内存。在每次交互中,它从向量存储中检索对话历史,并将其作为纯文本附加到系统消息中。
九、Tool Calling
工具调用(也称为函数调用)是AI应用程序中的一种常见模式,允许模型与一组API或工具交互,从而增强其功能。
工具主要用于:
- 信息检索。此类工具可用于从外部来源检索信息,例如数据库、Web服务、文件系统或Web搜索引擎。目标是增强模型的知识,使其能够回答否则无法回答的问题。因此,它们可用于检索增强生成(RAG)场景。例如,工具可用于检索给定位置的当前天气、检索最新新闻文章或查询数据库以获取特定记录。
- 采取行动。此类工具可用于在软件系统中采取行动,例如发送电子邮件、在数据库中创建新记录、提交表单或触发工作流。目标是自动化原本需要人工干预或显式编程的任务。例如,工具可用于为与聊天机器人交互的客户预订航班、在网页上填写表单或在代码生成场景中实现基于自动化测试(TDD)的Java类。
尽管我们通常将工具调用称为模型能力,但实际上由客户端应用程序提供工具调用逻辑。模型只能请求工具调用并提供输入参数,而应用程序负责从输入参数执行工具调用并返回结果。模型永远无法访问作为工具提供的任何API,这是一个关键的安全考虑因素。
Spring AI提供了方便的API来定义工具、解析来自模型的工具调用请求以及执行工具调用。
9.1、快速入门-Tool注解
让我们看看如何在Spring AI中开始使用工具调用。我们将实现两个简单的工具:一个用于信息检索,一个用于采取行动。
信息检索工具:将用于获取用户时区的当前日期和时间。
动作工具:将用于设置指定时间的警报。
java
public class DateTimeTools {
private static final String DATE_TIME_FORMAT = "yyyy-MM-dd HH:mm:ss";
@Tool(description = "获取当前时间")
public static String getCurrentTime() {
return LocalDateTime.now().format(DateTimeFormatter.ofPattern(DATE_TIME_FORMAT));
}
@Tool(description = "设置闹钟")
public void setAlarm(@ToolParam(description = "时间, 参数格式:" + DATE_TIME_FORMAT) String time) {
System.out.println("设置闹钟: " + time);
}
}
plain
@GetMapping("/tool/call")
public String toolCall(String message) {
return chatClient.prompt(message)
.tools(new DateTimeTools())
.options(OllamaChatOptions.builder().disableThinking().build())
.call().content();
}9.2、Function tool callback
java
public record CityRequest(@JsonPropertyDescription("城市") @JsonProperty("city") String city) {
}
java
public class WeatherTools implements Function<CityRequest, String> {
@Override
public String apply(CityRequest cityRequest) {
return "当前城市:" + cityRequest.city() + "天气:晴转多云";
}
}
java
@GetMapping("/tool/call")
public String toolCall(String message) {
ToolCallback functionToolCallBack = FunctionToolCallback.builder("getWeatherByCity", new WeatherTools())
.description("获取当前城市的天气")
.inputType(CityRequest.class)
.build();
return chatClient.prompt(message)
// .system(system -> system.text("当前时间:{now}").param("now", DateTimeTools.getCurrentTime()))
// .tools(new DateTimeTools())
.toolCallbacks(functionToolCallBack)
.options(OllamaChatOptions.builder().disableThinking().build())
.call().content();
}9.3、Bean方式
java
@Configuration(proxyBeanMethods = false)
public class ToolConfig {
@Bean
@Description("根据城市获取天气")
public Function<CityRequest, String> getWeatherByCity() {
return new WeatherTools();
}
}
java
@GetMapping("/tool/call")
public String toolCall(String message) {
// ToolCallback functionToolCallBack = FunctionToolCallback.builder("getWeatherByCity", new WeatherTools())
// .description("获取当前城市的天气")
// .inputType(CityRequest.class)
// .build();
return chatClient.prompt(message)
// .system(system -> system.text("当前时间:{now}").param("now", DateTimeTools.getCurrentTime()))
// .tools(new DateTimeTools())
// .toolCallbacks(functionToolCallBack)
.toolNames("getWeatherByCity")
.options(OllamaChatOptions.builder().disableThinking().build())
.call().content();
}9.4、ChatModel方式
java
@GetMapping("/tool/call/model")
public String toolCallModel(String message) {
ToolCallingChatOptions options = ToolCallingChatOptions.builder()
.toolNames("getWeatherByCity")
.build();
Prompt prompt = Prompt.builder()
.chatOptions(options)
.messages(UserMessage.builder().text(message).build())
.build();
return chatModel.call(prompt).getResult().getOutput().getText();
}十、Model Context Protocol (MCP)
模型上下文协议(MCP)是一个标准化的协议,使AI模型能够以结构化的方式与外部工具和资源进行交互。将其视为您的AI模型与现实世界之间的桥梁-允许它们通过一致的接口访问数据库、API、文件系统和其他外部服务。它支持多种传输机制,以提供跨不同环境的灵活性。
Spring AI通过专用的引导启动器和MCP Java注解为MCP提供全面支持,使构建复杂的AI驱动应用程序比以往任何时候都更容易,这些应用程序可以无缝连接到外部系统。这意味着Spring开发人员可以参与MCP生态系统的两个方面------构建使用MCP服务器的AI应用程序和创建向更广泛的AI社区公开基于Spring的服务的MCP服务器。
10.1、快速入门
10.1.1、mcp-server
- xml
xml
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-mcp-server-webmvc</artifactId>
</dependency>- java
java
@Service
public class WeatherTools {
@McpTool(description = "通过城市获取天气")
public String getWeatherByCity(@McpToolParam(description = "城市") String city) {
return "当前城市:" + city + "天气:晴转多云";
}
}10.1.2、mcp-client
- pom
xml
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-mcp-client</artifactId>
</dependency>- yaml
java
spring:
ai:
mcp:
client:
sse:
connections:
weather-server:
url: http://localhost:8081- java
java
@Autowired
private ToolCallbackProvider toolCallbackProvider;
@GetMapping("/mcp")
public String mcp(String message) {
return chatClient.prompt(message)
.toolCallbacks(toolCallbackProvider)
.options(OllamaChatOptions.builder().disableThinking().build())
.call().content();
}10.2、切换Streamable协议
传统 MCP 的 SSE 方案是双端点架构,SSE 长连接只能服务端单向下发数据,客户端上行请求只能走独立 POST 接口,两条连接依靠会话 ID 绑定,部署时必须会话粘滞,难以水平扩容,也无法适配 Serverless 云服务。 而 Streamable HTTP 采用单一端点,收发通信统一入口,既能普通短请求应答,也能按需升级 SSE 流式输出,支持无状态集群部署,兼容性和扩展性远优于老式 SSE
- mcp-server
xml
spring:
ai:
mcp:
server:
protocol: STREAMABLE- mcp-client
java
spring:
ai:
mcp:
client:
streamable-http:
connections:
weather-server:
url: http://localhost:808110.3、操作文件
- 文件目录配置 放到resoure下面,名称是:mcp-servers.json
java
{
"mcpServers": {
"filesystem": {
"command": "D:\\soft\\nodejs\\npx.cmd",
"args": [
"-y",
"@modelcontextprotocol/server-filesystem",
"D:\\Desktop\\pic"
]
}
}
}- yaml
xml
spring:
ai:
mcp:
client:
streamable-http:
connections:
weather-server:
url: http://localhost:8081
stdio:
servers-configuration: classpath:mcp-servers.json- java
java
@GetMapping("/mcp")
public String mcp(String message) {
return chatClient.prompt(message)
.system("如果涉及到文件操作,则目录是: D:\\Desktop\\pic")
.toolCallbacks(toolCallbackProvider)
.options(OllamaChatOptions.builder().disableThinking().build())
.call().content();
}十一、RAG
检索增强生成(RAG)是一种有助于克服大型语言模型的局限性的技术,这些模型在长格式内容、事实准确性和上下文感知方面遇到困难。
Spring AI通过提供模块化架构来支持RAG,允许您自己构建自定义RAG流或使用 AdvisorAPI使用开箱即用的RAG流。
简单的说:就是在大模型回答问题的时候,外链了个属于自己的数据库
向量数据库对比:
| 向量数据库 | 数据承载上限 | 高可用集群能力 | 核心优势 | 明显短板 | 最佳适用场景 |
|---|---|---|---|---|---|
| Milvus | 百亿级向量 | 完整分片、副本、冷热分层、多租户 | 国内生态第一,海量数据稳,企业级运维齐全 | 单机轻量部署偏重,小工具资源浪费 | 政企大 RAG、百万~百亿知识库、高并发客服平台、私有化多租户系统 |
| Weaviate | 千万级向量 | 仅小规模集群,大规模性能衰减 | 上手零难度,自带 GraphQL、多模态、简易 UI,向量 + 元数据一体 | 超大集群性能不如 Milvus,内置 text2vec 推理耗内存 | 中小企业知识库、内部工具、图文多模态 RAG、快速验证业务、十万 - 千万向量 |
| Qdrant | 千万级向量 | 基础副本容错,集群成熟度一般 | 内存占用极低、单机吞吐速度极强、磁盘索引优化好 | 国内技术支持少,政企落地案例少 | 海外 SaaS 项目、追求单机极致检索速度的服务 |
| PGVector | 百万级封顶 | 复用 Postgres 原有高可用 | 存量 PG 业务无需新增中间件,SQL 统一操作业务 + 向量 | 数据量一大性能暴跌,并发承载力弱 | 已有 Postgres 技术栈、十万级小型文档库、低成本增量改造 RAG |
| FAISS | 无上限(需自研封装) | 无原生集群,全部自主开发 | 检索算法精度、速度学术界标杆 | 无持久化、无接口、无权限,封装开发成本极高 | 大厂自研底层基座、算法实验、定制化超大规模架构 |
| Chroma | 十万级以内 | 无高可用、宕机易丢数据 | 一行代码启动,零配置,适配 LangChain | 完全不能上生产,并发、容错、扩容全缺失 | 仅本地代码调试、Demo 演示、个人笔记本测试 |
| Pinecone | 云端弹性无限扩容 | 厂商全权托管高可用 | 零运维开箱即用,海外快速上线 | 数据必须出境,按量计费,敏感业务不可用 | 海外无隐私 C 端产品、不想运维集群的海外创业项目 |
向量转换大模型对比:
| 模型名称 | 参数量 | 最低硬件要求 | C-MTEB 中文精度 | 商用授权 | 推理速度 | 最大上下文长度 | 核心定位 |
|---|---|---|---|---|---|---|---|
| BGE-M3:567m | 0.567B | 8G 内存 CPU 可直接运行 | 第一梯队高分 | MIT 完全免费商用 | 快 | 8192(长短文本通用) | 通用场景行业万金油(你当前在用) |
| bge-large-zh-v1.5 | 1.3B | 6G + 显存独立 GPU | 中文精度天花板 | MIT 完全免费商用 | 慢 | 8192 | 高严谨垂直专业场景高精度需求 |
| gte-large-zh | 1.5B | 6G + 显存 GPU | 略低于 bge-large | Apache2.0 免费商用 | 较慢 | 8192 | 中英多语言混合知识库 |
| all-MiniLM-L6-v2 | 0.066B | 2G 内存任意电脑 | 中文精度明显降级 | MIT 免费商用 | 极速 | 仅 256 短文本 | 仅限测试、简易内部小工具,禁止正式 RAG |
| e5-base-v2 | 0.34B | 4G 内存 CPU | 英文顶尖、中文拉胯 | MIT 免费商用 | 中速 | 短文本 | 纯英文海外跨境业务 |
11.1、环境配置
- weaviate向量数据下载(可以只做存储和检索)
shell
docker run -d -p 8080:8080 -p 50051:50051 --name weaviate semitechnologies/weaviate:1.32.3- 向量数据库可视化工具下载
- pom
xml
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-advisors-vector-store</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-weaviate</artifactId>
</dependency>- yaml配置
- 连接weaviate向量数据库
- 通过向量模型转换成向量存储到向量数据库当中,然后也可以用weaviate内置 text2vec模块进行向量化,一般用向量大模型进行向量化来减少向量数据库的压力,当然模型越好检索能力越强
yaml
spring:
ai:
ollama:
embedding:
options:
model: bge-m3:567m
vectorstore:
weaviate:
url: http://localhost:8080
scheme: http
initialize-schema: true
collection-name: spring-ai-learn- 基础的数据检索和写入
java
@RestController
public class VectorWriteController {
private final WeaviateVectorStore vectorStore;
public VectorWriteController(WeaviateVectorStore vectorStore) {
this.vectorStore = vectorStore;
}
@GetMapping("/write/single")
public String writeSingle(String message) {
Document document = new Document(message, Map.of("eat", "吃"));
vectorStore.add(List.of(document));
return "success";
}
@GetMapping("/search")
public List<Document> search(String query) {
return vectorStore.similaritySearch(query);
}
}11.2、向量检索与写入-通用写法
java
@Autowired
private VectorStore vectorStore;
@GetMapping("/vector")
public String vector(String message) {
// return vectorStore.similaritySearch(message).stream().map(Document::getText).collect(Collectors.joining("\n"));
return vectorStore.similaritySearch(SearchRequest.builder()
.query(message)
.similarityThreshold(0.8)
.topK(2)
.build()).stream()
.map(Document::getText).collect(Collectors.joining("\n"));
}
@GetMapping("/vector/write")
public String vectorWrite(String message) {
Document document = new Document(message, Map.of("eat", "吃"));
vectorStore.add(List.of(document));
return "success";
}11.3、QuestionAnswerAdvisor
LLM+向量数据库的结合使用:
java
@GetMapping("/rag")
public String rag(String message) {
return chatClient.prompt(message)
.advisors(QuestionAnswerAdvisor.builder(vectorStore).build())
.call().content();
}