
【作者主页】Francek Chen
【专栏介绍】⌈ ⌈ ⌈大数据技术原理与应用 ⌋ ⌋ ⌋专栏系统介绍大数据的相关知识,分为大数据基础篇、大数据存储与管理篇、大数据处理与分析篇、大数据应用篇。内容包含大数据概述、大数据处理架构Hadoop、分布式文件系统HDFS、分布式数据库HBase、NoSQL数据库、云数据库、MapReduce、Hadoop再探讨、数据仓库Hive、Spark、流计算、Flink、图计算、数据可视化,以及大数据在互联网领域、生物医学领域的应用和大数据的其他应用。
【GitCode】专栏资源保存在我的GitCode仓库:https://gitcode.com/Morse_Chen/BigData_principle_application。
文章目录
MapReduce 可以很好地应用于各种计算问题,下面以关系代数运算、分组与聚合运算、矩阵-向量乘法、矩阵乘法为例,介绍如何采用 MapReduce 计算模型来实现各种运算。
一、MapReduce 在关系代数运算中的应用
针对数据的很多运算,都可以很容易地采用数据库查询语言来表达,即使这些查询本身并不在数据库管理系统中执行。关系数据库中的关系(Relation)可以看成由一系列属性组成的表,关系中的行称为元组(Tuple),属性的集合称为关系的模式。下面介绍基于 MapReduce 模型的关系上的标准运算,包括选择、投影、并、交、差以及自然连接。
(一)关系的选择运算
对于关系的选择运算,只需要 Map 过程就能实现,对于关系 R R R 中的每个元组 t t t,检测其是否满足条件的所需元组,如果满足条件,则输出键值对 < t t t, t t t>。也就是说,键和值都是 t t t。这时的 Reduce 函数就只是一个恒等式,对输入不作任何变换就直接输出。
(二)关系的投影运算
假设对关系 R R R 投影后的属性集为 S S S。在 Map 函数中,对于 R R R 中的每个元组 t t t,剔除 t t t 中不属于 S S S 的字段得到元组 t ′ t' t′,输出键值对 < t ′ t' t′, t ′ t' t′>。对于 Map 任务产生的每个键 t ′ t' t′,可能存在一个或多个键值对 < t ′ t' t′, t ′ t' t′>,因此需要通过 Reduce 函数来剔除冗余,把属性值完全相同的元组合并起来得到 < t ′ t' t′,< t ′ t' t′, t ′ t' t′, t ′ t' t′,...>>,剔除冗余后只输出一个 < t ′ t' t′, t ′ t' t′>。
(三)关系的并、交、差运算
对两个关系求并集时,Map 任务将两个关系的元组转换成键值对 < t t t, t t t>,Reduce 任务则是一个剔除冗余数据的过程(合并到一个文件中)。
对两个关系求交集时,使用与并集相同的 Map 过程。在 Reduce 过程中,如果键 t t t 有两个相同值与它关联,则输出一个元组 < t t t, t t t>,如果与键关联的只有一个值,则输出空值(NULL)。
对两个关系求差时,Map 过程产生的键值对不仅要记录元组的信息,还要记录该元组来自哪个关系( R R R 或 S S S)。Reduce 过程中将键值相同的 t t t 合并后,与键 t t t 相关联的值如果只有 R R R(说明该元组只属于 R R R,不属于 S S S),就输出元组,其他情况均输出空值。
(四)关系的自然连接运算
在 MapReduce 环境下执行两个关系的连接操作的方法如下:假设关系 R ( A , B ) R(A,B) R(A,B) 和 S ( B , C ) S(B,C) S(B,C) 都存储在一个文件中,为了连接这些关系,必须把来自每个关系的各个元组都和一个键关联,这个键就是属性 B B B 的值。可以使用 Map 过程把来自 R R R 的每个元组 < a a a, b b b> 转换成一个键值对 < b b b,< R R R, a a a>>,其中的键就是 b b b,值就是 < R R R, a a a>。注意,这里把关系 R R R 包含到值中,这样做使得我们可以在 Reduce 阶段,只把那些来自 R R R 的元组和来自 S S S 的元组进行匹配。类似地,可以使用 Map 过程把来自 S S S 的每个元组 < b b b, c c c> 转换成一个键值对 < b b b,< S S S, c c c>>,键是 b b b,值是 < S S S, c c c>。Reduce 进程的任务就是,把来自关系 R R R 和 S S S 的具有共同属性 B B B 值的元组进行合并。这样,所有具有特定 B B B 值的元组必须被发送到同一个 Reduce 进程。假设使用 k k k 个 Reduce 进程,这里选择一个 Hash 函数 h h h,它可以把属性 B B B 的值映射到 k k k 个 Hash 桶,每个哈希值对应一个 Reduce 进程,每个 Map 进程将键是 b b b 的键值对都发送到与 Hash 值 h ( b ) h(b) h(b) 对应的 Reduce 进程,Reduce 进程将连接后的元组 < a a a, b b b, c c c> 写到一个单独的输出文件中。
图1以某工厂接到的订单与仓库货存为例,演示了关系的自然连接运算的 MapReduce 过程。
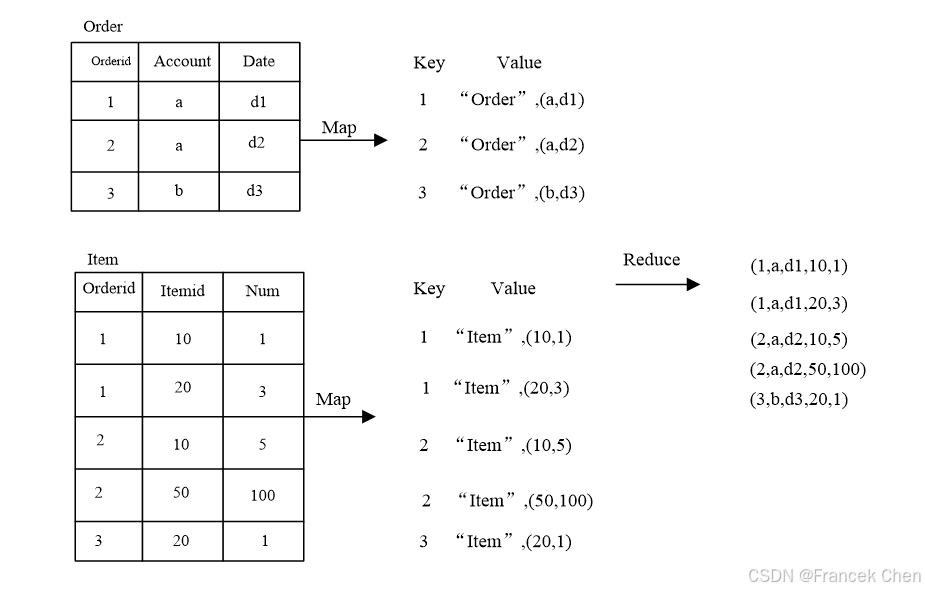
图1 基于MapReduce关系的自然连接运算实例
二、分组与聚合运算
词频计算就是典型的分组聚合运算。在 Map 过程中,选择关系的某一字段(也可以是某些属性构成的属性表)的值作为键,其他字段的值作为与键相关联的值。将该键值对输入 Reduce 过程后,对相同键相关联的值施加某种聚合运算,如 SUM(求和)、COUNT(计数)、AVG(求平均值)、MIN(求最小值)和 MAX(求最大值)等,输出则为<键,聚合运算结果>。
三、矩阵-向量乘法
假定一个 n n n 维向量 V V V,其第 j j j 个元素记为 v j v_j vj,假定一个 n × n n×n n×n 的矩阵 M M M,其第 i i i 行第 j j j 列元素记为 m i j m_{ij} mij,则矩阵 M M M 和向量 V V V 的乘积是一个 n n n 维向量 X X X,其第 i i i 个元素 x i = ∑ j = 1 n m i j v j x_i = \sum\limits_{j=1}^n m_{ij} v_j xi=j=1∑nmijvj。
矩阵 M M M 和向量 V V V 各自会在分布式文件系统(如 HDFS)中存成一个文件。假定我们可以获得矩阵元素的行列下标,如从矩阵元素在文件中的位置来获得,或者从元素显式存储的三元组 < i i i, j j j, m i j m_{ij} mij>中获得。计算矩阵-向量乘法的 Map 和 Reduce 函数可以按照如下方式设计。
(1)Map 函数。每个 Map 任务将整个向量 V V V 和矩阵 M M M 的一个文件块作为输入。对每个矩阵元素 m i j m_{ij} mij,Map 任务会产生键值对 < i i i, m i j m_{ij} mij v j v_j vj>。因此,计算 x i x_i xi 的所有 n n n 个求和项 m i j v j m_{ij}v_j mijvj 的键都相同,即都是 i i i。
(2)Reduce 函数。Reduce 任务将所有与给定键 i i i 关联的值相加即可得到 < i i i, x i x_i xi>。
如果 n n n 的值过大,使向量 V V V 无法完全放入内存,那么,在计算过程中需要多次将向量的一部分导入内存,这会导致大量的磁盘访问。一种替代方案是,将矩阵分割成多个宽度相等的垂直条,同时将向量分割成同样数目的水平条,每个水平条的高度等于矩阵垂直条的宽度。图2是矩阵 M M M 和向量 V V V 的分割示意,其中矩阵和向量都分割成 5 个条。
矩阵第 i i i 个垂直条只和第 i i i 个水平条相乘。因此,可以将矩阵的每个条存成一个文件,同样,将向量的每个条存成一个文件。矩阵某个条的一个文件块及对应的完整向量条输送到每个 Map 任务。然后,Map 任务和 Reduce 任务可以按照上述过程来运行。
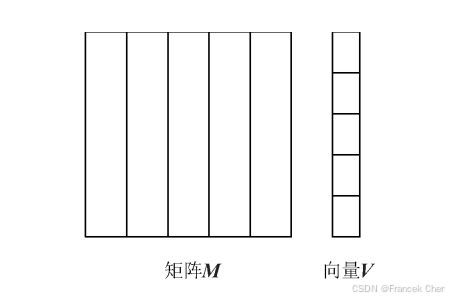
图2 矩阵M和向量V的分割示意
四、矩阵乘法
矩阵 M M M 第 i i i 行第 j j j 列的元素记为 m i j m_{ij} mij,矩阵 N N N 第 j j j 行第 k k k 列的元素记为 n j k n_{jk} njk,矩阵 P = M × N P=M×N P=M×N,其第 i i i 行第 k k k 列元素为 p i k = ∑ j m i j n j k p_{ik} = \sum\limits_{j} m_{ij}n_{jk} pik=j∑mijnjk。
我们可以把矩阵看成一个带有 3 个属性的关系:行下标、列下标和值。因此,矩阵 M M M 可以看成关系 M M M,记为 M ( I , J , V ) M(I,J,V) M(I,J,V),元组为 < i i i, j j j, m i j m_{ij} mij>,矩阵 N N N 可以看作关系 N N N,记为 N ( J , K , W ) N(J,K,W) N(J,K,W),元组为 < j j j, k k k, n j k n_{jk} njk>。
矩阵乘法可以看作一个自然连接运算再加上分组聚合运算。关系 M M M 和 N N N 根据公共属性 J J J 将每个元组连接得到元组 < i i i, j j j, k k k, v v v, w w w>,这个五字段元组代表了两个矩阵的元素对 < m i j m_{ij} mij, n j k n_{jk} njk>,对矩阵元素进行求积运算后可以得到四字段元组 < i i i, j j j, k k k, v × w v×w v×w>,然后进行分组聚合运算。其中, I I I、 K K K 是分组属性, V × W V×W V×W 的积是聚合结果。综上所述,矩阵乘法可以通过两个 MapReduce 运算的串联来实现,整个过程如下。
1. 自然连接阶段
Map 函数:对每个矩阵元素 m i j m_{ij} mij 产生一个键值对 < j j j,< M M M, i i i, m i j m_{ij} mij>>,对每个矩阵元素 n j k n_{jk} njk 产生一个键值对 < j j j,< N N N, k k k, n j k n_{jk} njk>>。
Reduce 函数:对每个相同键 j j j,输出所有满足形式 < j j j,< i i i, k k k, m i j n j k m_{ij}n_{jk} mijnjk>>的元组。
2. 分组聚合阶段
Map 函数:对自然连接阶段产生的键值对 < j j j,<< i 1 i_1 i1, k 1 k_1 k1, v 1 v_1 v1>,< i 2 i_2 i2, k 2 k_2 k2, v 2 v_2 v2>,...,< i p i_p ip, k p k_p kp, v p v_p vp>>>(其中,每个 v q v_q vq 是对应的 m q j m_{qj} mqj 和 n j q n_{jq} njq 的乘积), Map 任务会产生 p p p 个键值对 <<< i 1 i_1 i1, k 1 k_1 k1>, v 1 v_1 v1>,<< i 2 i_2 i2, k 2 k_2 k2>, v 2 v_2 v2>,...,<< i p i_p ip, k p k_p kp>, v p v_p vp>>。
Reduce 函数:对每个键 < i i i, k k k>,计算与此键关联的所有值的和,结果记为 << i i i, k k k>, v v v>。其中, v v v 就是矩阵 P P P 的第 i i i 行、第 k k k 列的值。
小结
MapReduce 通过分治思想高效处理大规模数据。在关系代数中,选择、投影利用 Map 直接过滤或裁剪字段,投影需 Reduce 去重;并、交、差通过 Map 标记元组来源,Reduce 按关联值数量决定输出。自然连接以连接属性为键,将不同关系的元组分发至同一 Reduce 进行匹配。分组与聚合以分组字段为键,Reduce 执行 SUM、COUNT 等操作。矩阵-向量乘法以矩阵行号为键,将每个元素与对应向量分量乘积汇集求和,向量过大时可分块处理。矩阵乘法则通过两个阶段实现:先以列号/行号为键做自然连接,再以行、列号为键做分组求和。这些实例展示了 MapReduce 的通用性与扩展性。
欢迎 点赞👍 | 收藏⭐ | 评论✍ | 关注🤗
