01 前言
- 开发痛点:做全球化数据采集、SEO监测、竞品分析的小伙伴应该深有体会。项目如果需要同时接入Google、Bing、Yandex等多个搜索引擎,传统开发模式简直折磨人------不同引擎要单独找服务商、单独写对接代码、单独适配差异化返回格式,不仅开发周期长,后续迭代维护还要同时维护多套逻辑,冗余工作量直接翻倍。
- 优解方案:今天给大家安利Dataify统一搜索SERP API。直白点说:单一接口+统一账号+一套通用代码,直接打通四大主流搜索引擎,彻底告别重复造轮子,把开发效率拉满。
Dataify - AI![]() https://www.dataify.com/?utm_source=yanyj&utm_term=01
https://www.dataify.com/?utm_source=yanyj&utm_term=01
02 核心能力
- 核心亮点:平台直接封装Google、Bing、Yandex、DuckDuckGo四大搜索引擎底层能力,标准化REST接口开箱即用。我们开发者不用纠结采集策略、反爬对抗、网页源码解析这些底层琐事,专注业务逻辑就行。
- 引擎全覆盖&适配场景:
- Google搜索:实时捕获平台数据,洞察定价、监控竞品、精准收集用户评论。
- Bing搜索:微软必应搜索结果 - 替代搜索引擎数据。
- Yandex搜索:轻松获取本地化、精准且实时的结构化数据,服务范围涵盖自然搜索、广告、图片与地图等。
- DuckDuckGo搜索:规模、稳定可靠地获取精准实时数据,满足市场监测与 SEO 等需求。
03 接入前置准备
整套接入流程超级简单,没有复杂资质审核,总共三步,新手也能一键上手:
- 步骤1:注册Dataify账号:全程傻瓜式操作,无需实名认证,一分钟就能完成注册,零门槛入门。
- 步骤2:获取专属API密钥:账号登录后,API Key直接展示在页面右上角,无需额外申请,复制保存即可,这是后续调用接口的核心凭证。
- 步骤3:配置开发环境:仅Python开发环境即可,整个项目只依赖requests库,打开终端输入一行安装命令,直接搞定环境配置。
04 快速接入
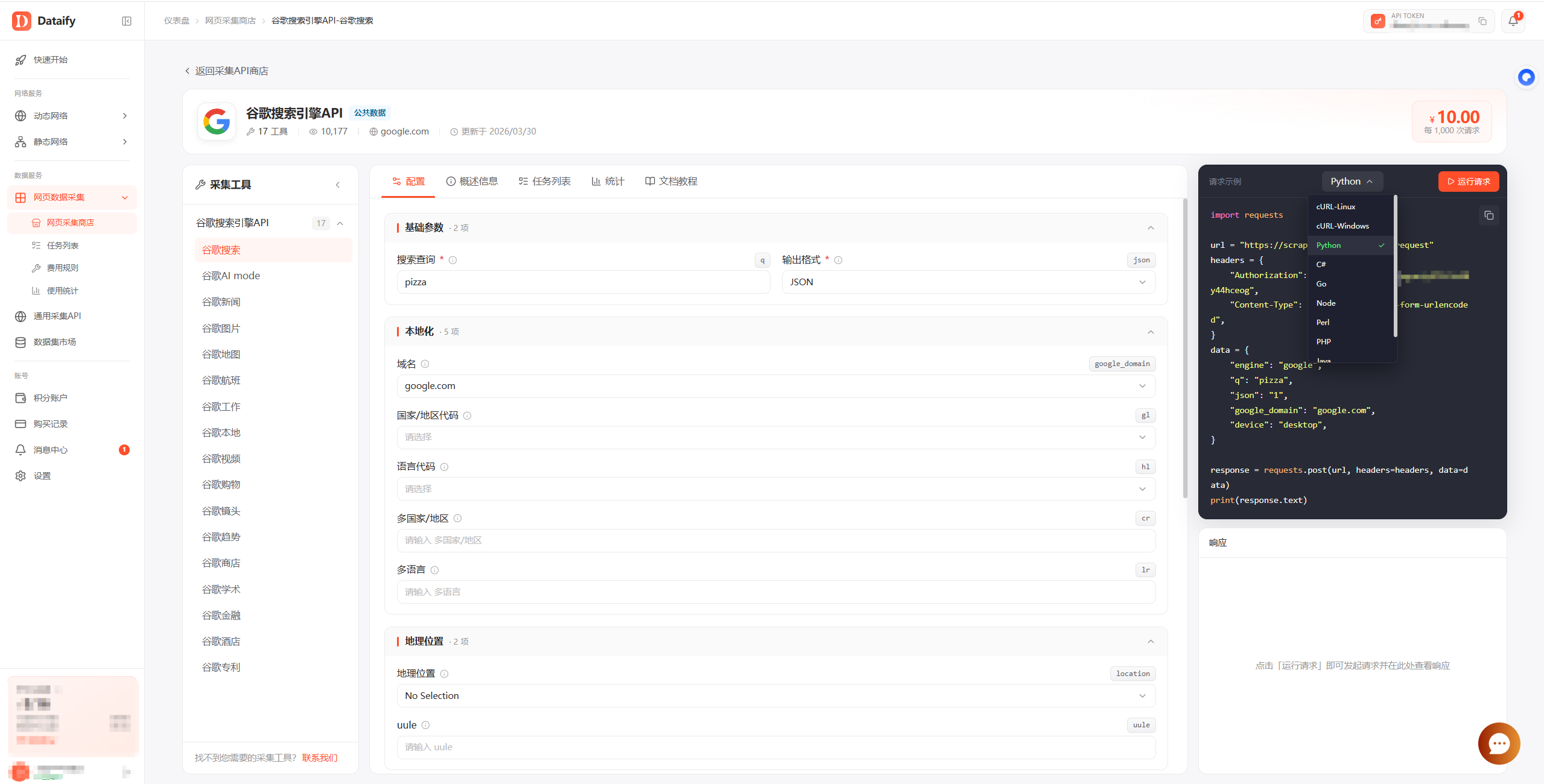
官方控制台已经内置全引擎现成代码模板,不用自己从零编写。大家直接进入官方商店,选中需要调用的搜索引擎API,切换至对应编程语言版本,一键复制到本地,或者直接在线试运行,快速验证接口可用性。
05 返回数据
- 四种标准化返回格式 :支持
JSON/JSON+HTML/HTML/Light JSON四种输出模式。比较好的一点:四大搜索引擎返回结构一样,不用针对不同引擎写多套解析脚本,一套代码通吃全部数据源。 - 通用字段封装:平台已封装标题、摘要、链接、发布时间、来源站点等通用核心字段,抹平各引擎字段命名差异,降低数据解析难度。
- 通用解析脚本:文档内附带适配全引擎的结果解析代码,直接复用就能批量提取有效数据,省去自主解析数据的冗余步骤。
06 单/多引擎调用方案
6.1 单引擎调用
适合只需要单一搜索引擎数据的场景,代码精简、逻辑直白、延迟更低。我在代码模板里加了详细功能注释,直接复制修改关键词、地域参数就能直接跑,修改13行为你的api token复用即可。
6.1.1 谷歌搜索引擎API
python
"""
Google 搜索 - 独立调用示例
用法:改 keyword,直接跑,结果保存为 JSON 文件
"""
import requests
import json
import os
from datetime import datetime
# ── 配置 ──────────────────────────────────────────────
URL = "https://scraperapi.dataify.com/request"
TOKEN = "Bearer 改为你的api token"
headers = {
"Authorization": TOKEN,
"Content-Type": "application/x-www-form-urlencoded",
}
# ── 改这里 ────────────────────────────────────────────
KEYWORD = "SEO优化工具" # ← 改关键词
# ─────────────────────────────────────────────────────────
data = {
# ── 必填 ──
"engine": "google",
"q": KEYWORD,
"json": "1", # 1=JSON 2=JSON+HTML 3=HTML 4=Light JSON
# ── 本地化(按需取消注释)──
# "gl": "us", # 国家:us/cn/jp/uk/de/fr
# "hl": "en", # 语言:en/zh-cn/zh-tw/ja/ko/de/fr
# "cr": "countryUS", # 限定国家,多个用 I 连接
# "lr": "lang_en", # 限定语言,多个用 | 连接
# ── 分页 ──
# "start": "0", # 0=第1页 10=第2页 20=第3页
# ────
# "safe": "active", # 安全搜索:active=开 off=关
# "nfpr": "0", # 排除自动更正:1=排除 0=保留
# "filter": "1", # 相似结果过滤:1=启用 0=关闭
# "tbs": "", # 搜索(日期/文件类型等)
# ── 平台 ──
"device": "desktop", # desktop / tablet / mobile
# "render_js": "false", # JS 渲染:true=开(慢) false=关
# "no_cache": "false", # 不用缓存:true=每次重抓
}
# ── 发送请求 ──────────────────────────────────────────
resp = requests.post(URL, headers=headers, data=data, timeout=30)
result = resp.json() if resp.status_code == 200 else {"error": resp.text}
# ── 保存 JSON 到文件夹 ───────────────────────────────
folder = "result_google"
os.makedirs(folder, exist_ok=True)
filepath = os.path.join(folder, f"result_{datetime.now().strftime('%Y%m%d_%H%M%S')}.json")
with open(filepath, "w", encoding="utf-8") as f:
json.dump(result, f, ensure_ascii=False, indent=2)
print(f"✅ 结果已保存:{filepath}")使用后 会自动生成文件夹和时间戳json文件 方便使用
6.1.2 Bing搜索引擎API
python
"""
Bing 搜索 - 独立调用示例
用法:改 keyword,直接跑,结果保存为 JSON 文件
"""
import requests
import json
import os
from datetime import datetime
# ── 配置 ────────────────────────────────────────────
URL = "https://scraperapi.dataify.com/request"
TOKEN = "Bearer 改为你的api token"
headers = {
"Authorization": TOKEN,
"Content-Type": "application/x-www-form-urlencoded",
}
# ── 改这里 ──────────────────────────────────────────
KEYWORD = "SEO" # ← 改关键词
# ────────────────────────────────────────────────────────
data = {
# ── 必填 ──
"engine": "bing_news",
"q": KEYWORD,
"json": "1", # 1=JSON 2=JSON+HTML 3=HTML 4=Light JSON
# ── 本地化(按需取消注释)──
# "mkt": "en-US", # 市场/语言:zh-CN/en-US/en-GB/ja-JP/ko-KR
# "cc": "US", # 国家:CN/US/JP/GB/DE/FR/KR
# ── 分页 ──
# "first": "1", # 起始偏移
# "count": "10", # 每页条数(建议值)
# ── ──
# "safeSearch": "Moderate", # Off / Moderate(默认) / Strict
# "qft": "", # 新闻过滤/排序
# ── 平台 ──
# "no_cache": "false",
}
# ── 发送请求 ──────────────────────────────────────
resp = requests.post(URL, headers=headers, data=data, timeout=30)
result = resp.json() if resp.status_code == 200 else {"error": resp.text}
# Dataify API 有时将整个 JSON 对象包在一个字符串里返回,需二次解析
if isinstance(result, str):
result = json.loads(result)
print(json.dumps(result, ensure_ascii=False, indent=2))
# ── 保存 JSON 到文件夹 ───────────────────────────
folder = "result_bing"
os.makedirs(folder, exist_ok=True)
filepath = os.path.join(folder, "result_" + datetime.now().strftime("%Y%m%d_%H%M%S") + ".json")
with open(filepath, "w", encoding="utf-8") as f:
json.dump(result, f, ensure_ascii=False, indent=2)
print("✅ 结果已保存:" + filepath)这里有个要注意的点 避免json二次转义 不然会出现\
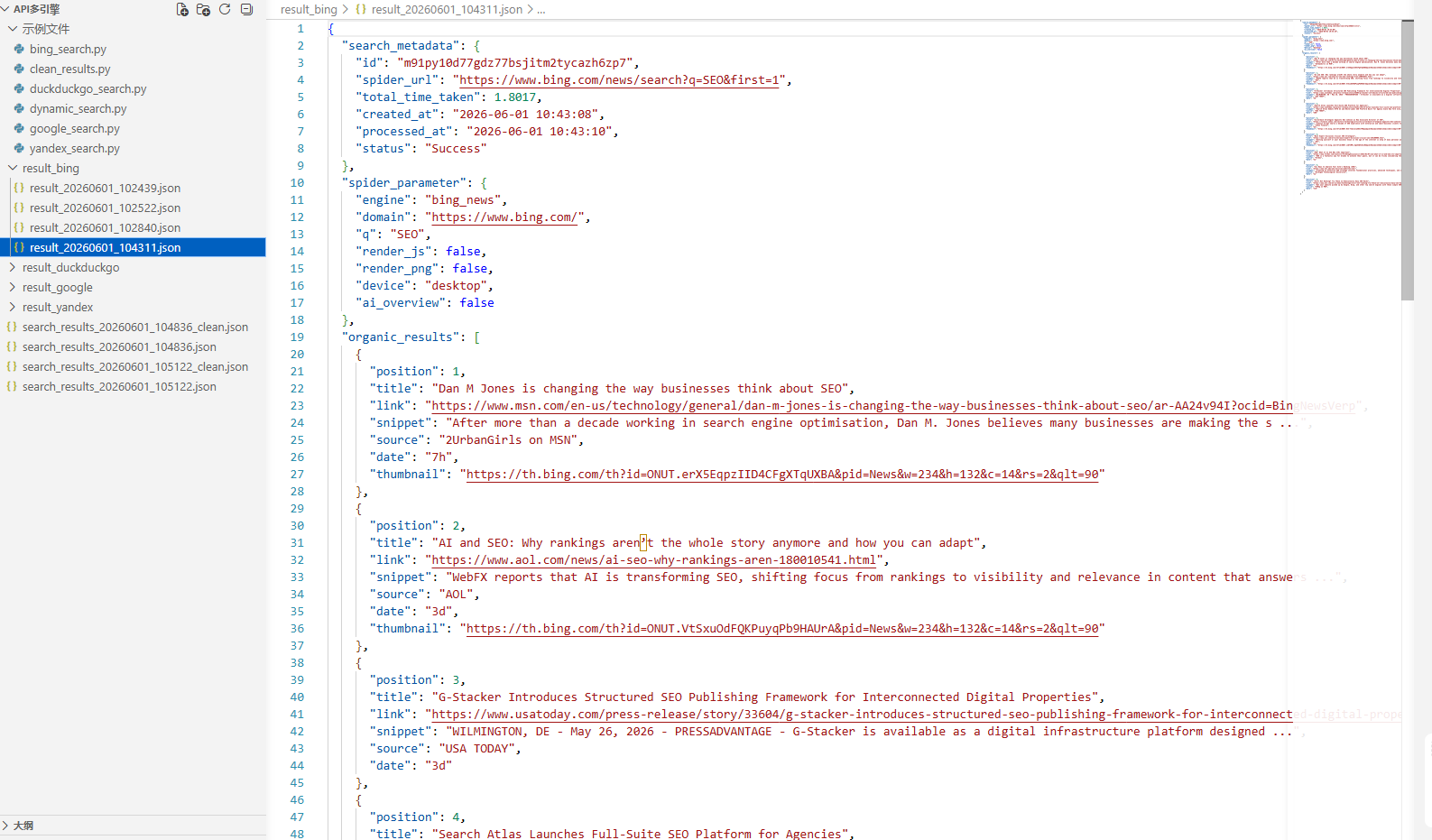
6.1.3 Yandex搜索引擎API
python
"""
Yandex 搜索 - 独立调用示例
用法:改 keyword,直接跑,结果保存为 JSON 文件
"""
import requests
import json
import os
from datetime import datetime
# ── 配置 ─────────────────────────────────────────
URL = "https://scraperapi.dataify.com/request"
TOKEN = "Bearer 改为你的api token"
headers = {"Authorization": TOKEN, "Content-Type": "application/x-www-form-urlencoded"}
# ── 改这里 ───────────────────────────────────────
KEYWORD = "SEO优化工具" # ← 改关键词
# ────────────────────────────────────────────────────
data = {
# ── 必填 ──
"engine": "yandex",
"text": KEYWORD, # Yandex 用 text(不是 q)
"json": "1", # 1=JSON 2=JSON+HTML 3=HTML 4=Light
# ── 本地化(按需取消注释)──
"yandex_domain": "yandex.com", # yandex.com / yandex.ru / ya.ru 等
"lang": "en", # en/ru/zh-cn/zh-tw/ja/ko/de/fr/es
# "lr": "", # 地区 ID(数字)
# ── 分页 ──
"p": "0", # 0=第1页 1=第2页
# ── ──
"family_mode": "1", # 0=关 1=中等(默认) 2=严格
"fix_typo": "TRUE", # TRUE=自动纠错 FALSE=关闭
"groups_on_page": "20", # 每页群组数:10/20/30/50
# ── 平台 ──
# "no_cache": "false",
}
# ── 发送请求 ──────────────────────────────────────
resp = requests.post(URL, headers=headers, data=data, timeout=30)
result = resp.json() if resp.status_code == 200 else {"error": resp.text}
if isinstance(result, str):
result = json.loads(result)
print(result)
# ── 保存 JSON 到文件夹 ─────────────────────────
folder = "result_yandex"
os.makedirs(folder, exist_ok=True)
filepath = os.path.join(folder, "result_" + datetime.now().strftime("%Y%m%d_%H%M%S") + ".json")
with open(filepath, "w", encoding="utf-8") as f:
json.dump(result, f, ensure_ascii=False, indent=2)
print("✅ 结果已保存:" + filepath)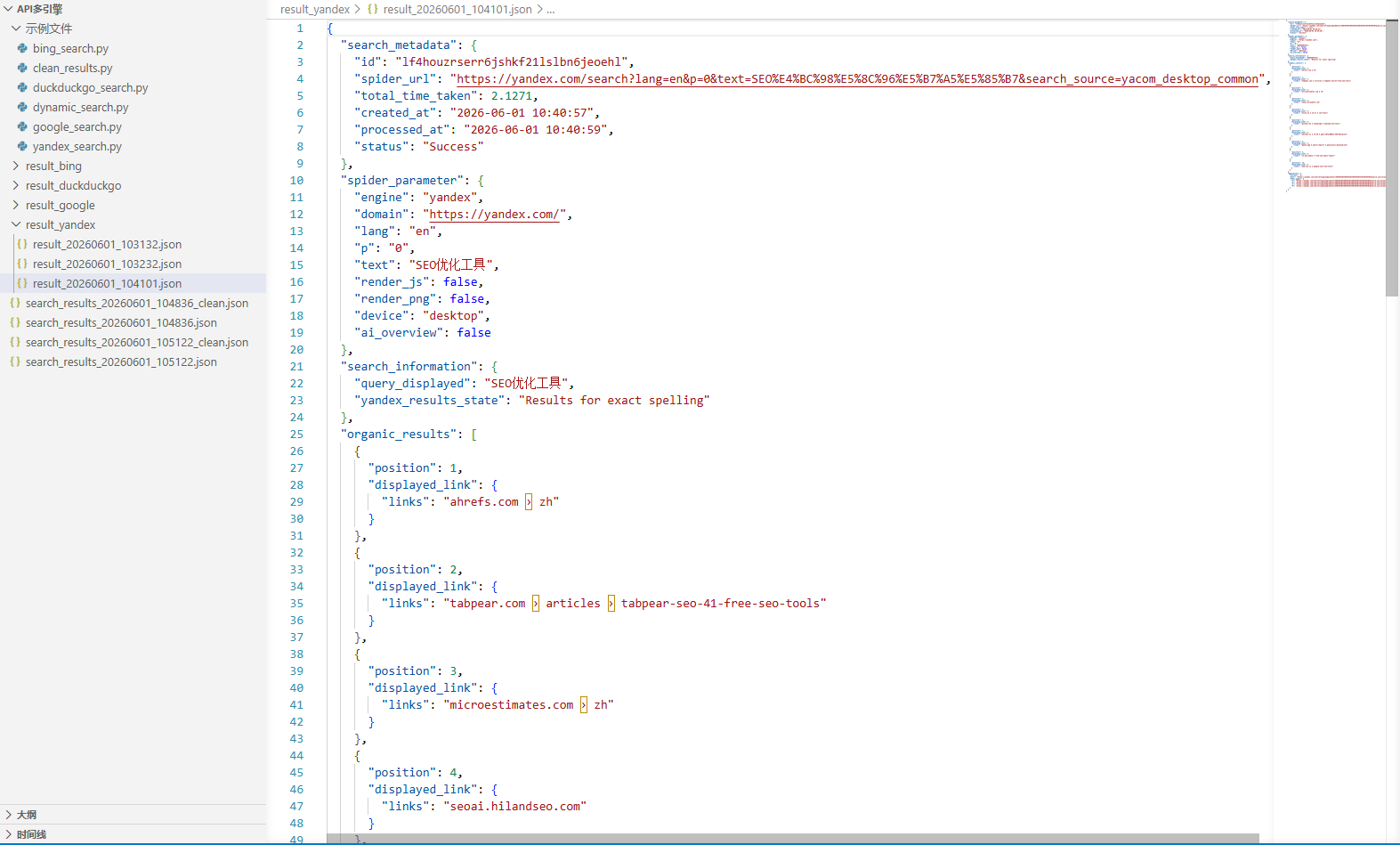
6.1.4 DuckDuckGo搜索引擎API
python
"""
DuckDuckGo 搜索 - 独立调用示例
用法:改 keyword,直接跑,结果保存为 JSON 文件
"""
import requests
import json
import os
from datetime import datetime
# ── 配置 ──────────────────────────────────────
URL = "https://scraperapi.dataify.com/request"
TOKEN = "Bearer 改为你的api token"
headers = {"Authorization": TOKEN, "Content-Type": "application/x-www-form-urlencoded"}
# ── 改这里 ─────────────────────────────────
KEYWORD = "SEO优化工具" # ← 改关键词
# ──────────────────────────────────────────────
data = {
# ── 必填 ──
"engine": "duckduckgo",
"q": KEYWORD,
"json": "1", # 1=JSON 2=JSON+HTML 3=HTML 4=Light
# ── 本地化(按需取消注释)──
# "kl": "us-en", # 地区:us-en / uk-en / fr-fr / de-de / zh-cn
# ── ──
"search_assist": "FALSE", # TRUE=开AI辅助 FALSE=关(和 m 不能同时用)
"safe": "-1", # 1=严格 -1=中等(默认) -2=关闭
# "df": "w", # 日期过滤:d=一天 w=一周 m=一月 y=一年
# ── 分页 ──
"start": "0", # 0=第1页(≤35条) 35=第2页(≤50条)
"m": "50", # 结果数(1-50,和 search_assist 不能同时用)
# ── 平台 ──
# "no_cache": "false",
}
# ── 发送请求 ──────────────────────────────────
resp = requests.post(URL, headers=headers, data=data, timeout=30)
result = resp.json() if resp.status_code == 200 else {"error": resp.text}
# Dataify API 有时将整个 JSON 对象包在一个字符串里返回,需二次解析
if isinstance(result, str):
result = json.loads(result)
# ── 保存 JSON 到文件夹 ─────────────────────
folder = "result_duckduckgo"
os.makedirs(folder, exist_ok=True)
filepath = os.path.join(folder, "result_" + datetime.now().strftime("%Y%m%d_%H%M%S") + ".json")
with open(filepath, "w", encoding="utf-8") as f:
json.dump(result, f, ensure_ascii=False, indent=2)
print("✅ 结果已保存:" + filepath)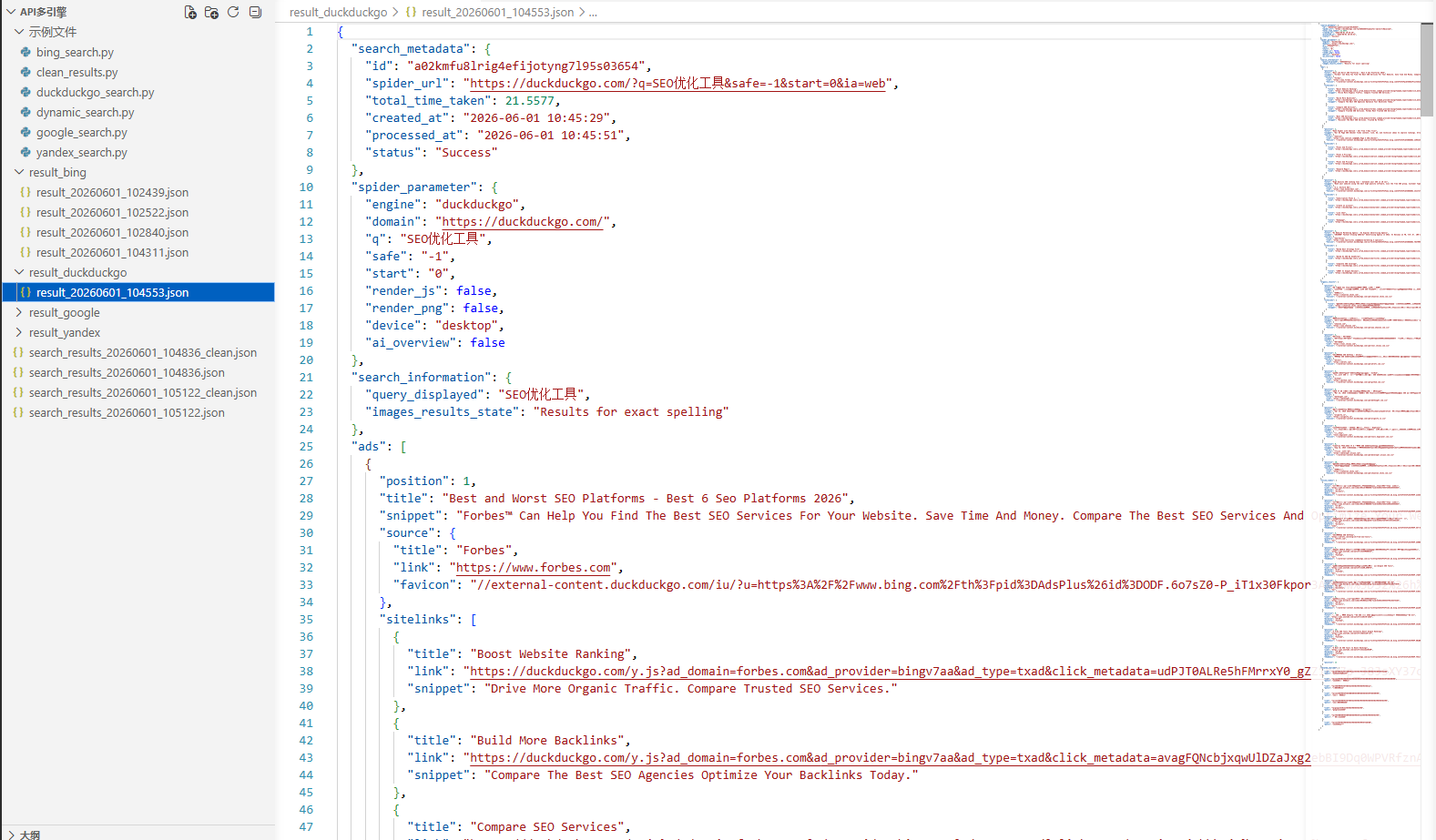
6.2 多引擎混合调用
适合全球化调研、多维度数据对比、批量采集场景。通过循环遍历逻辑,批量调用四大引擎,内置参数自适应逻辑,自动适配各引擎专属请求参数,附带完整可直接运行的全套源码,记得33行修改为你的api token。
python
"""
动态搜索引擎 API 批量调用工具
========================================
功能:支持多引擎选择、关键词数组遍历、JSON 结果保存
执行逻辑:
- 先选关键词 → 再选引擎 → 确认后执行
- 循环次数 = 所选关键词的数量
- 每个关键词依次被选中的引擎搜索
- 例如:5 个关键词 × 4 个引擎 = 20 次请求
- 每次请求同时写入「原始版」和「精简版」两个 JSON 文件
注意:精简版会自动去除 base64 图片等大量无用字段,
让结果文件更小、更易读。
"""
# ──────────────────────────────────────────────────────
# 标准库 & 第三方库导入
# ──────────────────────────────────────────────────────
import requests # HTTP 请求库(需 pip install requests)
import time # 用于请求间隔等待
import json # JSON 序列化 / 反序列化
import os # 文件路径判断
from datetime import datetime # 时间戳生成
# ══════════════════════════════════════════════════════
# 全局配置区(修改这里来定制你的搜索任务)
# ══════════════════════════════════════════════════════
# API 接入点和鉴权 Token
API_URL = "https://scraperapi.dataify.com/request"
AUTH_TOKEN = "Bearer 换成你的api token"
# ── 搜索引擎字典 ──────────────────────────────────────
# 格式:{ 用户输入编号: { "name": 显示名称, "engine": API 参数值 } }
ENGINES = {
"1": {"name": "Google", "engine": "google"},
"2": {"name": "Bing", "engine": "bing_news"},
"3": {"name": "Yandex", "engine": "yandex"},
"4": {"name": "DuckDuckGo","engine": "duckduckgo"},
}
# ── 关键词配置 ──────────────────────────────────────
# 支持两种写法:
# 字符串: KEYWORDS = "Python" → 只搜这一个词
# 列表: KEYWORDS = ["科技", "AI", ...] → 让用户选择范围,逐个搜索
# ──────────────────────────────────────────────────
KEYWORDS = [
"科技",
"引擎",
]
# ── 各引擎的默认请求参数 ─────────────────────────────
# ══════════════════════════════════════════════════════
# DEFAULT_PARAMS ------ 各引擎完整参数字典
#
# 设计原则:
# ✅ 激活行(无 # 前缀)= 实际生效的参数
# 💤 注释行(# "key": ...)= 备用开关,取消注释即可启用
#
# 参数来源:google_search.py / bing_search.py /
# yandex_search.py / duckduckgo_search.py
# ══════════════════════════════════════════════════════
DEFAULT_PARAMS = {
# ──────────────────────────────────────────────────
# Google 引擎参数
# ──────────────────────────────────────────────────
"google": {
# ---------- 【基础参数】 ----------
"json": "1", # 输出格式:1=JSON, 2=JSON+HTML, 3=HTML, 4=Light JSON
# ---------- 【本地化参数】 ----------
"google_domain": "google.com", # Google 域名
# 常用域名:google.com / google.co.jp / google.de / google.fr
# google.co.uk / google.com.cn / google.com.au
# "gl": "us", # 国家/地区代码(us/cn/jp/uk/de/fr)
# "hl": "en", # 语言代码(en/zh-cn/zh-tw/ja/ko/de/fr)
# "cr": "countryUS", # 多国家限制,格式:country{大写代码},用 I 分隔
# "lr": "lang_en", # 多语言限制,格式:lang_{代码},用 | 分隔
# ---------- 【地理位置参数】 ----------
# "location": "United States", # 搜索发起地理位置(不能与 uule/lat/lon 同时用)
# "uule": "", # Google 编码的精确位置(不能与 location/lat/lon 同时用)
# ---------- 【分页参数】 ----------
# "start": "0", # 起始偏移量:0=第一页, 10=第二页, 20=第三页
# ---------- 【过滤器】 ----------
# "tbs": "", # 搜索(专利/日期范围/文件类型等)
# "safe": "active", # 安全搜索:active=开启, off=关闭
# "nfpr": "0", # 排除自动更正结果:1=排除, 0=包含(默认)
# "filter": "1", # 类似/省略结果过滤:1=启用(默认), 0=不使用
# ---------- 【Dataify 平台参数】 ----------
"device": "desktop", # 设备类型:desktop / tablet / mobile
# "render_js": "false", # JS渲染:true=开启(耗时增加), false=关闭(默认)
# "no_cache": "false", # 不使用缓存:true=每次重新抓取, false=使用缓存(默认)
# "ai_overview": "false", # Google AI Overview:true=开启, false=关闭(默认)
},
# ──────────────────────────────────────────────────
# Bing News 引擎参数
# ──────────────────────────────────────────────────
"bing_news": {
# ---------- 【基础参数】 ----------
"json": "1", # 输出格式:1=JSON, 2=JSON+HTML, 3=HTML, 4=Light JSON
# engine 会在 build_request_data 中自动注入,此处无需写
# ---------- 【地理位置参数】 ----------
# "mkt": "en-US", # 市场/语言代码(zh-CN / zh-HK / en-US / en-GB / ja-JP / ko-KR)
# "cc": "US", # 国家/地区代码(US / CN / JP / GB / DE / FR / KR / RU / BR)
# ---------- 【分页参数】 ----------
# "first": "1", # 起始偏移量:1=第一条, 10=从第十条开始
# "count": "10", # 每页结果数(建议值,实际返回数可能不同)
# ---------- 【参数】 ----------
# "qft": "", # 新闻排序/过滤(参考 Bing API 文档)
# "safeSearch": "Moderate", # 安全搜索:Off / Moderate(默认)/ Strict
# ---------- 【Dataify 平台参数】 ----------
# "no_cache": "false", # 不使用缓存:true=每次重新抓取, false=使用缓存(默认)
},
# ──────────────────────────────────────────────────
# Yandex 引擎参数
# ──────────────────────────────────────────────────
"yandex": {
# ---------- 【基础参数】 ----------
"json": "1", # 输出格式:1=JSON, 2=JSON+HTML, 3=HTML, 4=Light JSON
# 注意:Yandex 关键词参数名为 "text",由 build_request_data 自动注入
# ---------- 【本地化参数】 ----------
"yandex_domain": "yandex.com", # Yandex 域名
# 可选:yandex.com / yandex.ru / ya.ru / yandex.by / yandex.kz
# yandex.uz / yandex.com.tr / yandex.az / yandex.com.ge
# yandex.com.am / yandex.co.il / yandex.md / yandex.tm
# yandex.tj / yandex.eu
"lang": "en", # 语言:en / ru / zh-cn / zh-tw / ja / ko / de / fr / es
# "lr": "", # 地区 ID(数字,参考 Yandex 地区 ID 列表)
# ---------- 【分页参数】 ----------
"p": "0", # 页码(从 0 开始):0=第一页, 1=第二页
# ---------- 【参数】 ----------
"family_mode": "1", # 家庭模式:0=关闭, 1=中等(默认), 2=严格
"fix_typo": "TRUE", # 自动纠错:TRUE=启用(默认), FALSE=不使用
"groups_on_page": "20", # 每页群组数(默认 20,可设 10/30/50)
# ---------- 【Dataify 平台参数】 ----------
# "no_cache": "false", # 不使用缓存:true=每次重新抓取, false=使用缓存(默认)
},
# ──────────────────────────────────────────────────
# DuckDuckGo 引擎参数
# ──────────────────────────────────────────────────
"duckduckgo": {
# ---------- 【基础参数】 ----------
"json": "1", # 输出格式:1=JSON, 2=JSON+HTML, 3=HTML, 4=Light JSON
# ---------- 【本地化参数】 ----------
# "kl": "us-en", # 地区代码(us-en / uk-en / fr-fr / de-de / zh-cn)
# ---------- 【参数】 ----------
"search_assist": "FALSE", # AI 搜索辅助:true=启用, FALSE=不使用(默认)
# 注意:search_assist 与 m 参数不能同时使用!
# ---------- 【过滤器】 ----------
"safe": "-1", # 安全搜索:1=严格, -1=中等(默认), -2=关闭
# "df": "w", # 日期过滤:d=过去一天, w=一周, m=一月, y=一年
# # 自定义范围:开始日期..结束日期(如 "2024-01-01..2024-06-30")
# ---------- 【分页参数】 ----------
"start": "0", # 起始偏移量:0=第一页(≤35条), 35=第二页(≤50条)
"m": "50", # 结果数(1-50)
# 注意:m 与 search_assist 不能同时使用!
# 不带偏移量时返回 35 条,带偏移量时50 条
# ---------- 【Dataify 平台参数】 ----------
# "no_cache": "false", # 不使用缓存:true=每次重新抓取, false=使用缓存(默认)
},
}
# ── 精简 JSON 时需要「整个字段」剔除的 key 列表 ─────
# 这些字段要么是 base64 大图、要么是无实际意义的元信息
CLEAN_REMOVE_KEYS = {
# 图片相关(base64 数据极大)
"image", "original", "source_logo", "favicon", "icon",
# 无用的 Google 元数据字段
"about_page_link", "about_this_result", "redirect_link",
# 分页链接(通常不需要批量保存)
"pages",
}
# ══════════════════════════════════════════════════════
# 工具函数
# ══════════════════════════════════════════════════════
def print_banner():
"""打印程序欢迎横幅"""
print("=" * 60)
print(" 搜索引擎 API 批量调用工具")
print("=" * 60)
# ── 精简 JSON 相关 ────────────────────────────────────
def clean_value(value):
"""
递归清理一个 JSON 值:
- 如果是 dict,删除 CLEAN_REMOVE_KEYS 中指定的键,
并对其余值继续递归清理
- 如果是 list,对每个元素递归清理
- 其他类型直接返回
"""
if isinstance(value, dict):
cleaned = {}
for k, v in value.items():
if k in CLEAN_REMOVE_KEYS:
continue # 跳过需要删除的字段
cleaned[k] = clean_value(v)
return cleaned
elif isinstance(value, list):
return [clean_value(item) for item in value]
else:
return value # 字符串、数字、布尔等直接返回
def make_clean_record(raw_record):
"""
将一条「原始 result_record」生成对应的「精简版记录」。
原始 result 可能是:
1. dict(正常 JSON 响应)
2. str(某些引擎返回的 JSON 字符串,需先 parse)
3. 其他(报错信息等)
精简逻辑:
- 先尝试将 str 类型的 result 解析为 dict
- 再对整个 result 执行 clean_value 递归剔除
"""
# 深拷贝一份,避免修改原始数据
import copy
record = copy.deepcopy(raw_record)
raw_result = record.get("result")
# 如果 result 是字符串(Bing / DuckDuckGo 有时会这样),先 parse 一次
if isinstance(raw_result, str):
try:
raw_result = json.loads(raw_result)
except (json.JSONDecodeError, TypeError):
pass # parse 失败就保留原始字符串
# 递归清理
record["result"] = clean_value(raw_result)
return record
# ── 关键词选择 ────────────────────────────────────────
def select_keyword_range(keywords):
"""
【步骤 1】让用户选择要搜索的关键词范围。
支持三种输入方式:
1. 单个数字:如 "3" → 只搜第 3 个关键词
2. 范围格式:如 "3,7" → 搜第 3 到第 7 个(共 5 个)
3. all → 搜全部关键词
返回:选中的关键词列表(list of str)
"""
# ── 单字符串模式:直接返回,不需要选择 ──────────
if isinstance(keywords, str):
print(f"\n✓ 关键词: {keywords}(单字符串模式)")
return [keywords]
# ── 列表模式 ──────────────────────────────────────
n = len(keywords)
print("\n【步骤 1】选择关键词")
print("-" * 60)
print(f"可用关键词(共 {n} 个):")
for i, kw in enumerate(keywords):
print(f" {i + 1:>2}. {kw}")
print("-" * 60)
print("输入说明:")
print(" 单个数字 示例: 3 → 只用第 3 个")
print(" 范围(逗号) 示例: 3,7 → 第 3 到第 7 个(共 5 个)")
print(" all 回车 → 使用全部关键词")
print("-" * 60)
user_input = input("请选择关键词范围(直接回车 = all): ").strip()
# 回车或输入 all → 全选
if user_input == "" or user_input.lower() == "all":
print(f"✓ 已选全部 {n} 个关键词")
return list(keywords)
# 范围格式:x,y
if "," in user_input:
parts = user_input.split(",", 1) # 拆一次逗号
try:
start = int(parts[0].strip())
end = int(parts[1].strip())
# 验证合法性
if not (1 <= start <= end <= n):
print(f"⚠ 范围 {start},{end} 超出 1~{n},已改为全选")
return list(keywords)
selected = keywords[start - 1 : end] # 转换为 0 索引
print(f"✓ 已选第 {start} 到第 {end} 个(共 {len(selected)} 个)")
return selected
except ValueError:
print("⚠ 格式有误,已改为全选")
return list(keywords)
# 单个数字
try:
idx = int(user_input)
if 1 <= idx <= n:
print(f"✓ 已选第 {idx} 个: {keywords[idx - 1]}")
return [keywords[idx - 1]]
else:
print(f"⚠ 超出范围(1~{n}),已改为全选")
return list(keywords)
except ValueError:
print("⚠ 无法识别,已改为全选")
return list(keywords)
# ── 引擎选择 ──────────────────────────────────────────
def select_engines():
"""
【步骤 2】让用户选择要使用的搜索引擎。
支持两种输入方式:
1. 数字组合:如 "12" 或 "1 2" → 选 Google + Bing
2. 0 或 all 或直接回车 → 全选
设计重点:允许用户用空格/逗号/粘连数字等多种格式输入,
统一提取其中的有效数字字符。
"""
print("\n【步骤 2】选择搜索引擎")
print("-" * 60)
for key, val in ENGINES.items():
print(f" {key}. {val['name']} ({val['engine']})")
print("-" * 60)
print("输入说明:")
print(" 单个: 1 → 只用 Google")
print(" 多个: 12 或 1 2 或 1,2 → Google + Bing")
print(" 全选: 0 / all / 直接回车")
print("-" * 60)
user_input = input("请选择引擎: ").strip()
# 全选触发条件
if user_input in ("", "0", "all"):
selected = list(ENGINES.keys())
print(f"✓ 已选全部引擎: {[ENGINES[k]['name'] for k in selected]}")
return selected
# 提取所有出现过的合法数字(去重、保序)
seen = set()
selected = []
for ch in user_input:
if ch in ENGINES and ch not in seen:
seen.add(ch)
selected.append(ch)
if not selected:
# 没有识别到任何有效引擎 → 全选作为 fallback
selected = list(ENGINES.keys())
print(f"⚠ 未识别到有效引擎,已改为全选")
else:
print(f"✓ 已选引擎: {[ENGINES[k]['name'] for k in selected]}")
return selected
# ── 请求构建与发送 ────────────────────────────────────
def build_request_data(engine_type, keyword):
"""
构建发往 API 的 POST 表单数据。
- 以该引擎的 DEFAULT_PARAMS 为基础
- 追加 engine 类型字段
- 追加关键词(Yandex 使用 "text" 参数,其余用 "q")
返回:dict,将被 requests 以 form-urlencoded 格式发送
"""
data = DEFAULT_PARAMS.get(engine_type, {}).copy()
data["engine"] = engine_type
# Yandex API 的关键词参数名与其他引擎不同
if engine_type == "yandex":
data["text"] = keyword
else:
data["q"] = keyword
return data
def send_request(data, attempt_num, total_attempts):
"""
发送一次 API 请求并返回解析后的 JSON 结果。
参数:
data - 请求表单数据(dict)
attempt_num - 当前是第几次请求(用于打印进度)
total_attempts - 总请求次数
返回:
成功 → dict(解析后的 JSON)
失败 → dict 包含 "error" 键
异常处理:超时、网络错误、非 JSON 响应会被捕获
"""
headers = {
"Authorization": AUTH_TOKEN,
"Content-Type": "application/x-www-form-urlencoded",
}
try:
print(f"\n 📤 发送请求 [{attempt_num}/{total_attempts}]...")
response = requests.post(
API_URL,
headers=headers,
data=data,
timeout=30 # 30 秒超时
)
if response.status_code == 200:
print(f" ✅ 请求成功 (HTTP 200)")
try:
result = response.json()
# Dataify API 有时将整个 JSON 对象包在一个字符串里返回
# resp.json() 得到 str 而非 dict,print 看着正常
# 但 json.dump(str) 会触发二次编码,导致保存文件里出现反斜杠
if isinstance(result, str):
result = json.loads(result)
return result
except json.JSONDecodeError:
# 极少数情况:API 返回了非 JSON 文本
print(f" ⚠ 响应内容不是 JSON 格式,已保存原始文本")
return {"raw_text": response.text}
else:
print(f" ❌ 请求失败 (HTTP {response.status_code})")
return {"error": f"HTTP {response.status_code}", "text": response.text}
except requests.exceptions.Timeout:
print(f" ⏰ 请求超时(超过 30 秒)")
return {"error": "Timeout"}
except requests.exceptions.RequestException as e:
print(f" ❌ 网络异常: {str(e)}")
return {"error": str(e)}
# ── JSON 文件保存 ─────────────────────────────────────
def append_to_json_file(record, filename):
"""
将一条记录追加到指定 JSON 文件(数组格式)。
文件结构:JSON 数组 [ {...}, {...}, ... ]
如果文件不存在,先创建空数组文件,再追加。
返回:True(成功)/ False(失败)
"""
try:
# 文件不存在时初始化为空数组
if not os.path.exists(filename):
with open(filename, "w", encoding="utf-8") as f:
json.dump([], f, ensure_ascii=False, indent=2)
# 读取已有内容
with open(filename, "r", encoding="utf-8") as f:
try:
data = json.load(f)
except json.JSONDecodeError:
data = [] # 文件损坏时重置
# 追加新记录并写回
data.append(record)
with open(filename, "w", encoding="utf-8") as f:
json.dump(data, f, ensure_ascii=False, indent=2)
return True
except Exception as e:
print(f" ⚠ 文件写入失败 [{filename}]: {str(e)}")
return False
# ══════════════════════════════════════════════════════
# 主程序入口
# ══════════════════════════════════════════════════════
def main():
"""
主函数:协调整个搜索任务的执行流程
流程:
1. 打印欢迎横幅
2. 用户选择关键词范围
3. 用户选择搜索引擎
4. 显示执行计划,等待确认
5. 逐条发送请求:每条结果追加写入「原始版」和「精简版」两个文件
6. 打印汇总信息
"""
print_banner()
# ── 步骤 1:选择关键词 ────────────────────────────
selected_keywords = select_keyword_range(KEYWORDS)
# ── 步骤 2:选择引擎 ──────────────────────────────
selected_engines = select_engines()
# ── 计划摘要 ──────────────────────────────────────
total_requests = len(selected_engines) * len(selected_keywords)
print(f"\n{'=' * 60}")
print(f"📊 执行计划")
print(f" 关键词: {len(selected_keywords)} 个")
for i, kw in enumerate(selected_keywords):
print(f" [{i+1}] {kw}")
print(f" 引擎: {[ENGINES[k]['name'] for k in selected_engines]}")
print(f" 总请求: {total_requests} = {len(selected_keywords)} 关键词 × {len(selected_engines)} 引擎")
print(f"{'=' * 60}")
# ── 确认开始 ──────────────────────────────────────
confirm = input("\n是否开始执行?(y/n,回车默认 y): ").strip().lower()
if confirm == "n":
print("已取消")
return
# ── 生成带时间戳的文件名 ──────────────────────────
# 原始文件:保存完整 API 响应(含 base64 图片等)
# 精简文件:自动剔除 base64 图片及噪音字段,体积更小
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
raw_file = f"search_results_{timestamp}.json"
clean_file = f"search_results_{timestamp}_clean.json"
print(f"\n💾 原始文件: {raw_file}")
print(f"💾 精简文件: {clean_file}")
# ── 开始执行请求循环 ──────────────────────────────
print(f"\n{'=' * 60}")
print("🚀 开始执行...")
print(f"{'=' * 60}")
request_counter = 0
# 外层循环:按关键词逐个搜索
for kw_idx, keyword in enumerate(selected_keywords):
print(f"\n{'#' * 60}")
print(f"# 关键词 [{kw_idx + 1}/{len(selected_keywords)}]: {keyword}")
print(f"{'#' * 60}")
# 内层循环:每个关键词依次被所有引擎搜索
for eng_idx, engine_key in enumerate(selected_engines):
request_counter += 1
engine_info = ENGINES[engine_key]
engine_name = engine_info["name"]
engine_type = engine_info["engine"]
print(f"\n[{request_counter}/{total_requests}] "
f"引擎 {eng_idx + 1}/{len(selected_engines)}: {engine_name}")
# 构建请求参数并发送
data = build_request_data(engine_type, keyword)
result = send_request(data, request_counter, total_requests)
# ── 组装「原始记录」 ──────────────────────
# 保存了所有字段,包括 base64 图片
raw_record = {
"request_index": request_counter, # 请求序号
"keyword": keyword, # 搜索关键词
"engine": engine_name, # 引擎名称
"engine_type": engine_type, # 引擎 API 类型
"timestamp": datetime.now().isoformat(),
"result": result # 完整 API 响应
}
# ── 组装「精简记录」 ──────────────────────
# 剔除所有 base64 图片字段及噪音元数据
clean_record = make_clean_record(raw_record)
# 追加写入两个 JSON 文件
if append_to_json_file(raw_record, raw_file):
print(f" 💾 原始版已保存")
if append_to_json_file(clean_record, clean_file):
print(f" ✨ 精简版已保存")
# 请求间隔(最后一条不需要等待)
# if request_counter < total_requests:
# print(f" ⏳ 等待 1 秒...")
# time.sleep(1)
# ── 执行完成汇总 ──────────────────────────────────
print(f"\n{'=' * 60}")
print(f"✅ 执行完成!")
print(f" 共发送: {request_counter} 个请求")
print(f" 原始文件: {raw_file}")
print(f" 精简文件: {clean_file} ← 推荐查看这个,体积更小")
print(f"{'=' * 60}")
# ── 程序入口守卫 ──────────────────────────────────────
# 只有直接运行本文件时才执行 main()
# 被 import 引入时不会自动执行
if __name__ == "__main__":
main()这里我做了自定义搜索和引擎选择 json也分为了原版和精简版
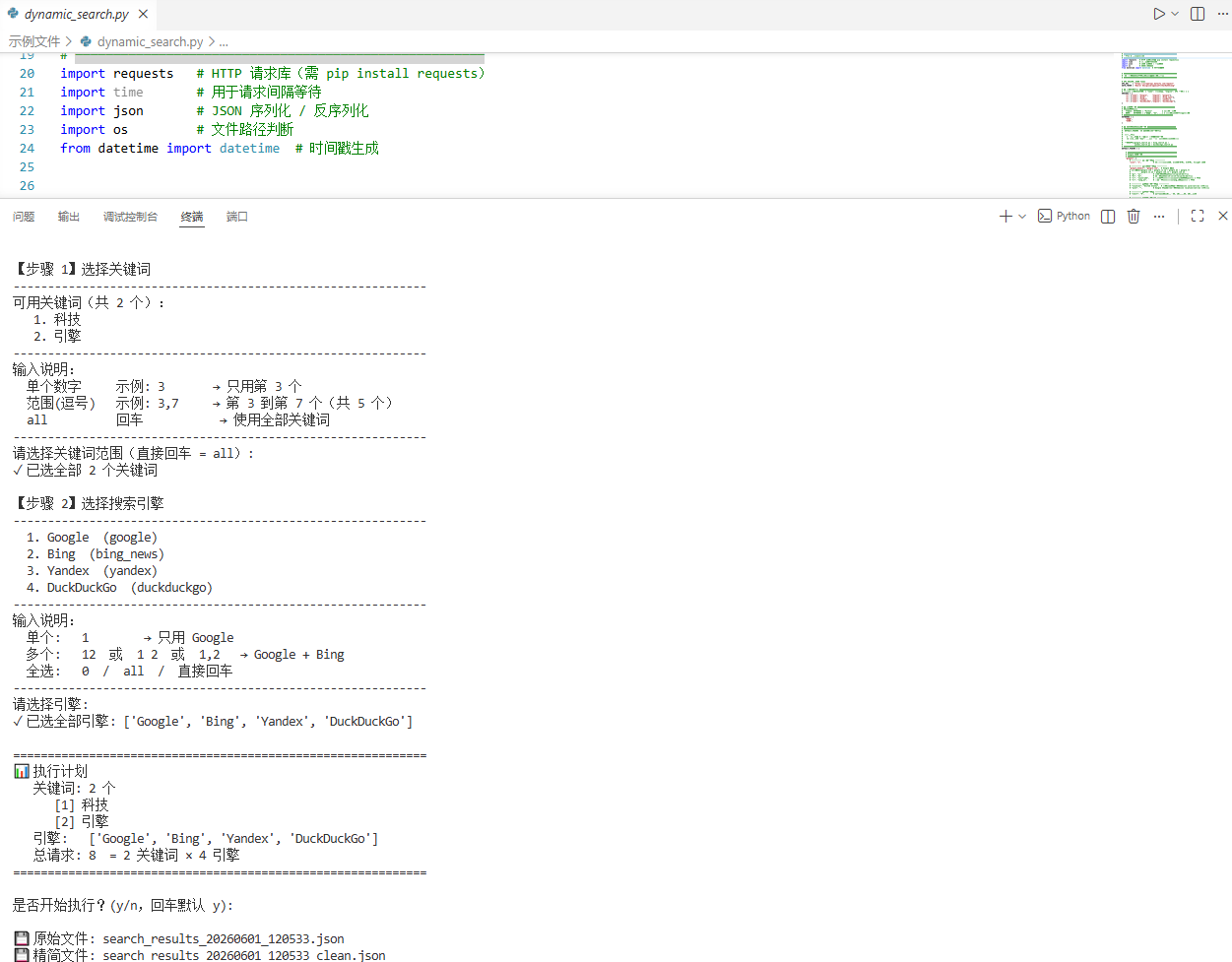
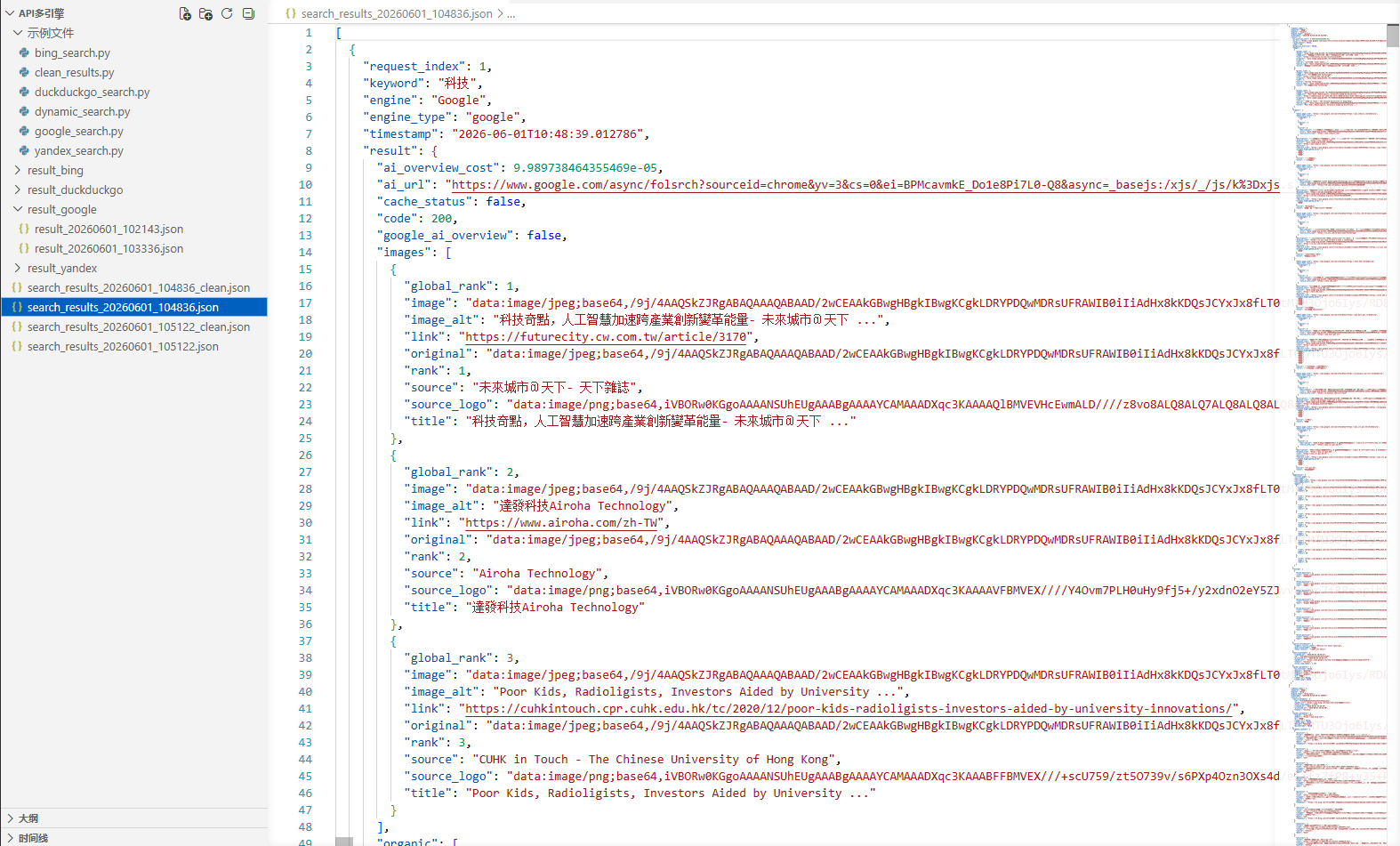
原始文件:保存完整 API 响应(含 base64 图片等):
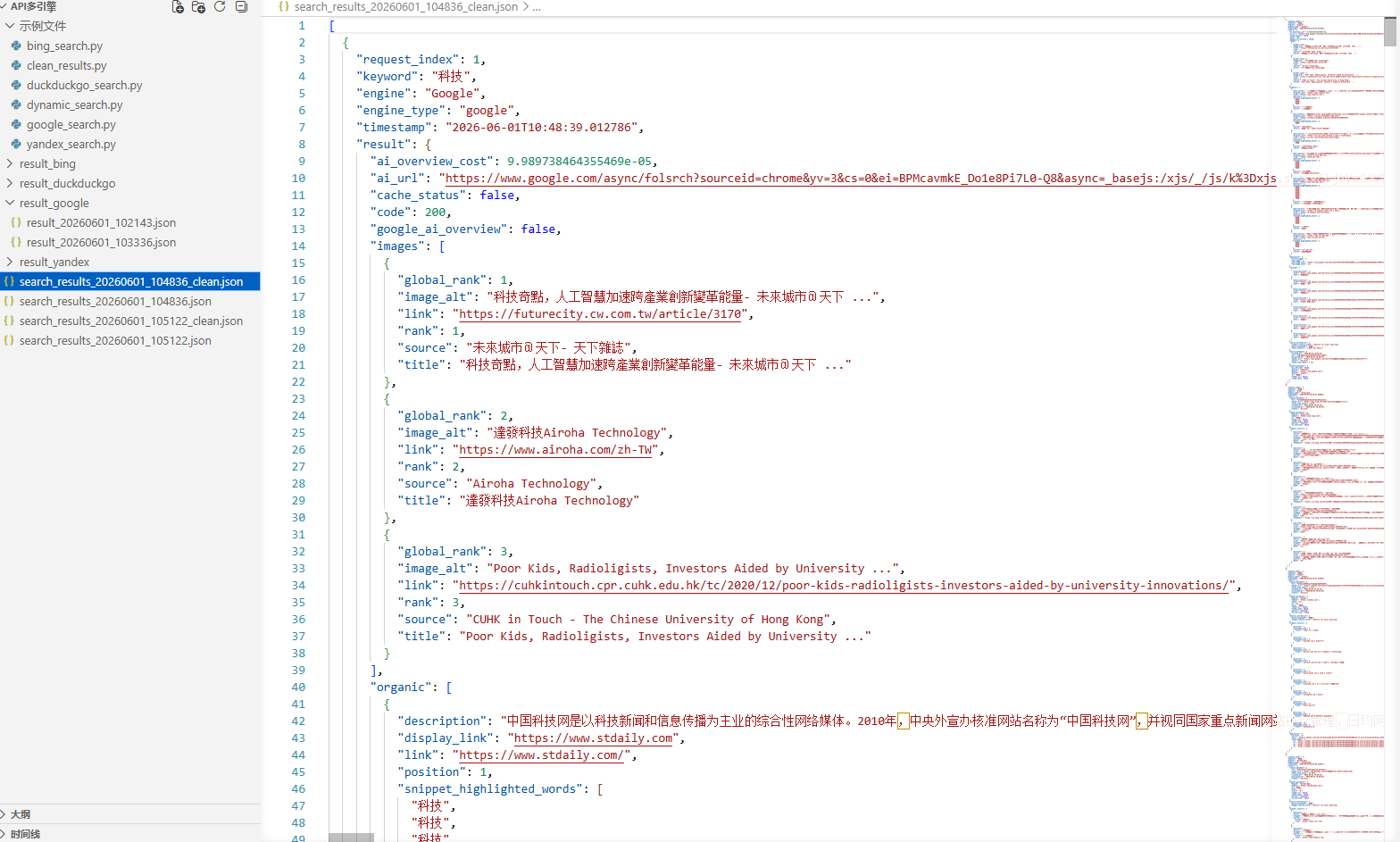
精简文件:自动剔除 base64 图片及噪音字段,体积更小:
07 高阶玩法
默认参数能满足基础搜索需求,但想要适配精细化业务场景,必须学会自定义筛选参数。我帮大家梳理了比较实用的本地化、时间过滤两类高阶参数,四大引擎全部兼容,取消代码内注释即可直接启用。
7.1 语言&地域过滤
同一个关键词,不同地区、不同语言环境下,搜索结果天差地别。举个简单例子:检索"SEO优化工具",美版结果清一色海外工具,中文版则以国内站长工具为主。实现该效果的核心就是地域、语言参数。
常用配置速查:
|------------|-----------------------|--------------|---------------|----------------|
| 你想要的效果 | Google | Bing | Yandex | DuckDuckGo |
| 搜中文内容 | gl: "cn", hl: "zh-cn" | mkt: "zh-CN" | lang: "zh-cn" | kl: "zh-cn" |
| 搜英文内容 | gl: "us", hl: "en" | mkt: "en-US" | lang: "en" | kl: "us-en" |
| 搜日文内容 | gl: "jp", hl: "ja" | mkt: "ja-JP" | lang: "ja" | kl: "jp-jp" |
避坑重点 :各引擎参数命名不统一,千万别记混!Google用 gl(地区)/hl(语言),Bing用 mkt市场参数,Yandex用 lang语言参数,DuckDuckGo用 kl地域参数。我已经在代码模板里按引擎分类整理好,无需死记硬背。
7.2 时间范围过滤
做行业热点追踪、短期舆情监控时,我们往往只需要近期更新的内容,时间过滤参数就能解决冗余数据问题。
简单科普:DuckDuckGo依靠 df 参数限定时间范围,Google通过 tbs 参数实现过滤,支持按天/周/月/自定义时间段筛选。
|------------------------|---------|
| 值 | 含义 |
| d | 过去一天 |
| w | 过去一周 |
| m | 过去一月 |
| y | 过去一年 |
| 2024-01-01..2024-06-30 | 自定义日期范围 |
7.3 功能验证
- ✅ 语言过滤:配置
hl: "zh-cn"后,Google优先返回中文标题与摘要内容 - ✅ 地区过滤:配置
mkt: "zh-CN"后,Bing优先展示中国地区本地化内容 - ✅ 时间过滤:配置
df: "w"后,DuckDuckGo仅展示一周内更新的搜索结果 - ✅ 安全搜索:四大引擎均内置独立安全风险参数,可自主调节
08 适配人群
- 中小型开发团队:不想投入人力维护多套采集程序、对抗反爬机制,低成本快速接入成熟搜索能力。
- 数据运营/SEO从业者:需要多引擎横向对比数据,支撑市场调研、关键词布局、竞品分析工作。
- 全球化业务团队:业务覆盖多国地区,需要适配不同国家本地化搜索引擎,统一管理数据源。
09 后续接入指引
- 官方文档地址:简介 - Dataify 官方完整文档链接,包含冷门参数、限额说明、计费规则等详细内容,可供深度查阅。
- 简单接入:注册账号→复制API Key→复用本文配套代码,5分钟即可完成接口请求调试。