Ai-Agent学习历程------ 情感语音机器人实践 🤖
- 前言
- 难点分析
- 整体实现思路和步骤
-
-
-
- [1. 媒体传输与接驳 (Transport)](#1. 媒体传输与接驳 (Transport))
- [2. 静音检测与断句 (VAD & STT)](#2. 静音检测与断句 (VAD & STT))
- [3. 智能体大脑决策 (LLM)](#3. 智能体大脑决策 (LLM))
- [4. 专属声音合成 (TTS)](#4. 专属声音合成 (TTS))
- [5. 音频回传播放 (Playback)](#5. 音频回传播放 (Playback))
- 注意点:电脑至少需要16G的内存,32G运行起来才会流畅
-
-
- 一、媒体传输与接驳 (Transport)
-
- [1.1 部署准备与环境要求](#1.1 部署准备与环境要求)
-
- [(1) 基础运行环境准备](#(1) 基础运行环境准备)
-
- [1. 操作系统选择与配置](#1. 操作系统选择与配置)
- [2. Docker 引擎安装验证](#2. Docker 引擎安装验证)
- [(2) 网络与端口规划](#(2) 网络与端口规划)
-
- [1. WebRTC 安全域限制说明(重要)](#1. WebRTC 安全域限制说明(重要))
- [2. 端口分配与防火墙开放规则](#2. 端口分配与防火墙开放规则)
- [1.2 LiveKit Server 的本地 Docker 部署](#1.2 LiveKit Server 的本地 Docker 部署)
- [1.3 生成连接 Token 与开发工具安装](#1.3 生成连接 Token 与开发工具安装)
-
- [(1) 生成测试 Token](#(1) 生成测试 Token)
- [1.4 WebRTC 网页客户端联调验证](#1.4 WebRTC 网页客户端联调验证)
-
- [(1) 准备连接地址与 Token](#(1) 准备连接地址与 Token)
- [(2) 在浏览器中调试连接](#(2) 在浏览器中调试连接)
- [1.5 基础 Python Agent 骨架搭建](#1.5 基础 Python Agent 骨架搭建)
-
- (1)项目整体包结构
- (2)配置和依赖文件
-
- [1. 依赖文件](#1. 依赖文件)
- [2. 骨架文件](#2. 骨架文件)
- (3)运行流程
- 接下来先进行原理解析,之后统一进行每一阶段的代码解析
- 二、静音检测与断句 (VAD & STT)
-
- [2.1 实时音频帧捕获与数据流处理](#2.1 实时音频帧捕获与数据流处理)
-
- [(1) LiveKit 音频帧结构与底层格式](#(1) LiveKit 音频帧结构与底层格式)
-
- [1. PCM 编码的物理本质](#1. PCM 编码的物理本质)
- [2. LiveKit 默认音频参数分析](#2. LiveKit 默认音频参数分析)
- [3. `AudioStream` 与 `AudioFrameEvent`](#3.
AudioStream与AudioFrameEvent)
- [(2) 为什么必须进行重采样(Resampling)与单声道化](#(2) 为什么必须进行重采样(Resampling)与单声道化)
-
- [1. 采样率不匹配的灾难性后果](#1. 采样率不匹配的灾难性后果)
- [2. 声道合并(Stereo to Mono)的必要性](#2. 声道合并(Stereo to Mono)的必要性)
- [(3) 工业级实现方案与数据切块(Chunking)机制](#(3) 工业级实现方案与数据切块(Chunking)机制)
-
- [1. 异步音频流捕获逻辑](#1. 异步音频流捕获逻辑)
- [2. 32ms 级别的时间片对齐(Chunking)](#2. 32ms 级别的时间片对齐(Chunking))
- [2.2 Silero VAD 本地集成与状态机设计](#2.2 Silero VAD 本地集成与状态机设计)
-
- [(1) Silero VAD 模型加载与运行原理](#(1) Silero VAD 模型加载与运行原理)
-
- [1. 为什么弃用传统能量 VAD,选择深度学习 VAD?](#1. 为什么弃用传统能量 VAD,选择深度学习 VAD?)
- [2. 流式推理机制(Streaming Inference)](#2. 流式推理机制(Streaming Inference))
- [(2) 实时静音/非静音状态机设计 (SOS 与 EOS 机制)](#(2) 实时静音/非静音状态机设计 (SOS 与 EOS 机制))
-
- [1. 双状态转换逻辑(原理)](#1. 双状态转换逻辑(原理))
- [2. 【本项目路径】LiveKit `VADStream` 已封装状态机](#2. 【本项目路径】LiveKit
VADStream已封装状态机)
- [(3) 关键参数调优与工业级边缘优化](#(3) 关键参数调优与工业级边缘优化)
-
- [1. 核心参数推荐值](#1. 核心参数推荐值)
- [2. 音频前垫与后垫 (Speech Padding)](#2. 音频前垫与后垫 (Speech Padding))
- [2.3 Faster-Whisper 本地部署与加速推理](#2.3 Faster-Whisper 本地部署与加速推理)
-
- [(1) Faster-Whisper 与 CTranslate2 优化原理](#(1) Faster-Whisper 与 CTranslate2 优化原理)
-
- [1. 为什么不直接使用 OpenAI 原版 Whisper?](#1. 为什么不直接使用 OpenAI 原版 Whisper?)
- [2. 为什么在 2026 年首选 `large-v3-turbo` 模型?](#2. 为什么在 2026 年首选
large-v3-turbo模型?)
- [(2) Windows 本地 GPU 推理环境与依赖配置](#(2) Windows 本地 GPU 推理环境与依赖配置)
-
- [1. 显存开销与精度选择](#1. 显存开销与精度选择)
- [2. 首次运行与模型缓存](#2. 首次运行与模型缓存)
- [(3) 核心参数调优与延迟极限压缩](#(3) 核心参数调优与延迟极限压缩)
-
- [1. 核心调优参数一览](#1. 核心调优参数一览)
- [2. 【本项目路径】STT 输入格式与管线衔接](#2. 【本项目路径】STT 输入格式与管线衔接)
- [(4) 阶段 2 手动验收预期(Meet 联调)](#(4) 阶段 2 手动验收预期(Meet 联调))
- [2.4 代码实战](#2.4 代码实战)
-
- (1)增加依赖和环境变量
- [(2)修改 config 配置文件,增加VAD和STT的配置](#(2)修改 config 配置文件,增加VAD和STT的配置)
- (3)核心main文件以及其他(方便点直接将我的源码进行展示)
- [三、 智能体大脑决策 (LLM)](#三、 智能体大脑决策 (LLM))
-
- [3.1 DeepSeek API 流式调用与极速响应配置](#3.1 DeepSeek API 流式调用与极速响应配置)
-
- [(1) 为什么首选 deepseek-v4-flash 及其架构特点](#(1) 为什么首选 deepseek-v4-flash 及其架构特点)
-
- [1. 废弃平滑过渡与别名映射](#1. 废弃平滑过渡与别名映射)
- [2. 混合专家模型 (MoE) 架构](#2. 混合专家模型 (MoE) 架构)
- [(2) 关键优化:显式关闭思考模式(Thinking Mode)以斩断首字延迟(TTFT)](#(2) 关键优化:显式关闭思考模式(Thinking Mode)以斩断首字延迟(TTFT))
-
- [1. 思考模式对语音交互的"致命伤"](#1. 思考模式对语音交互的“致命伤”)
- [2. 如何显式关闭思考模式](#2. 如何显式关闭思考模式)
- [(3) 异步流式输出(Streaming)的技术核心与非阻塞消费](#(3) 异步流式输出(Streaming)的技术核心与非阻塞消费)
-
- [1. 为什么"流式输出"是绝对红线?](#1. 为什么“流式输出”是绝对红线?)
- [2. 异步消费队列(Async Queue)的设计方式](#2. 异步消费队列(Async Queue)的设计方式)
- [3.2 陪伴型 System Prompt 与语音化特征设计](#3.2 陪伴型 System Prompt 与语音化特征设计)
-
- [(1) 情感陪伴人设(Persona)构建与同理心机制](#(1) 情感陪伴人设(Persona)构建与同理心机制)
-
- [1. 倾听与验证(Validation)优先](#1. 倾听与验证(Validation)优先)
- [2. 口语语气词与反馈(Backchanneling)](#2. 口语语气词与反馈(Backchanneling))
- [(2) "听觉优先(Voice-First)"的输出限制与净化](#(2) “听觉优先(Voice-First)”的输出限制与净化)
-
- [1. 绝对禁用的 Markdown 语法](#1. 绝对禁用的 Markdown 语法)
- [2. 字数与轮次控制(Turn-taking)](#2. 字数与轮次控制(Turn-taking))
- [3. 彻底过滤 Emoji 与图形符号](#3. 彻底过滤 Emoji 与图形符号)
- [(3) 针对 deepseek-v4-flash 的结构化提示词编写策略](#(3) 针对 deepseek-v4-flash 的结构化提示词编写策略)
-
- [结构化 Prompt 模块推荐:](#结构化 Prompt 模块推荐:)
- [3.3 实时会话历史与上下文记忆管理](#3.3 实时会话历史与上下文记忆管理)
-
- [(1) 为什么会话历史对 DeepSeek Context Caching 极为敏感](#(1) 为什么会话历史对 DeepSeek Context Caching 极为敏感)
-
- [1. DeepSeek 的自动缓存机制](#1. DeepSeek 的自动缓存机制)
- [2. "滑动窗口"引发的缓存雪崩(Cache Miss)](#2. “滑动窗口”引发的缓存雪崩(Cache Miss))
- [(2) 块级压缩(Batch Compaction)策略:防止缓存雪崩](#(2) 块级压缩(Batch Compaction)策略:防止缓存雪崩)
-
- [1. 块级压缩的运作机制](#1. 块级压缩的运作机制)
- [(3) 动态记忆抽离与持久化(UserProfile Injection)方案](#(3) 动态记忆抽离与持久化(UserProfile Injection)方案)
-
- [1. 结构化记忆提取(Background Worker)](#1. 结构化记忆提取(Background Worker))
- [2. 原文存储](#2. 原文存储)
- [3. 动态 System Prompt 注入](#3. 动态 System Prompt 注入)
- [3.4 文本流前置正则化与句子级切片](#3.4 文本流前置正则化与句子级切片)
-
- [(1) 文本正则化(Text Normalization)的核心逻辑](#(1) 文本正则化(Text Normalization)的核心逻辑)
-
- [1. 数字口语化转化](#1. 数字口语化转化)
- [2. 特殊符号与单位清洗](#2. 特殊符号与单位清洗)
- [(2) 标点符号拦截器与流式句子级切片(Sentence Slicing)算法](#(2) 标点符号拦截器与流式句子级切片(Sentence Slicing)算法)
-
- [1. 划分断句优先级](#1. 划分断句优先级)
- [(3) 并行流水线(Pipeline)架构设计](#(3) 并行流水线(Pipeline)架构设计)
-
- [💡 该流水线的极致性能优势:](#💡 该流水线的极致性能优势:)
- [四、云端语音合成 (TTS) 学习地图 --- MiniMax API 路线](#四、云端语音合成 (TTS) 学习地图 — MiniMax API 路线)
-
- [4.1 核心目标与技术选型方案](#4.1 核心目标与技术选型方案)
-
- [(1) 阶段数据流与整体目标](#(1) 阶段数据流与整体目标)
-
- [1. 现状回顾与数据流设计](#1. 现状回顾与数据流设计)
- [2. 阶段核心目标](#2. 阶段核心目标)
- [(2) 云端 API 与本地推理的选型对比](#(2) 云端 API 与本地推理的选型对比)
- [4.2 开放平台接入与系统配置](#4.2 开放平台接入与系统配置)
-
- [(1) 账号、鉴权与高可用策略](#(1) 账号、鉴权与高可用策略)
-
- [1. 鉴权机制与接口地址](#1. 鉴权机制与接口地址)
- [2. 常见异常状态码与防护设计](#2. 常见异常状态码与防护设计)
- [(2) 系统环境变量与功能开关设计](#(2) 系统环境变量与功能开关设计)
-
- [1. 核心环境变量清单](#1. 核心环境变量清单)
- [2. 弱断句配置逻辑](#2. 弱断句配置逻辑)
- [(3) 网络与接口连通性验证](#(3) 网络与接口连通性验证)
-
- [1. 独立探活机制](#1. 独立探活机制)
- [2. 解耦联调思想](#2. 解耦联调思想)
- [4.3 MiniMax T2A HTTP 协议与客户端封装](#4.3 MiniMax T2A HTTP 协议与客户端封装)
-
- [(1) 请求体结构与响应协议](#(1) 请求体结构与响应协议)
-
- [1. 协议定义与核心字段](#1. 协议定义与核心字段)
- [2. 响应格式与 Hex 解码](#2. 响应格式与 Hex 解码)
- [3. 基础响应拦截](#3. 基础响应拦截)
- [(2) 推理策略选择:非流式 vs 句级流式](#(2) 推理策略选择:非流式 vs 句级流式)
-
- [1. 适用场景差异分析](#1. 适用场景差异分析)
- [2. 生产环境策略实践](#2. 生产环境策略实践)
- [(3) 异常处理与可观测性监控](#(3) 异常处理与可观测性监控)
-
- [1. 可观测性指标追踪](#1. 可观测性指标追踪)
- [2. 超时与重试策略](#2. 超时与重试策略)
- [(4) 语音情感与表达参数控制(可选)](#(4) 语音情感与表达参数控制(可选))
-
- [1. 情绪与语气控制](#1. 情绪与语气控制)
- [4.4 音频前置切片与异步队列流水线](#4.4 音频前置切片与异步队列流水线)
-
- [(1) 复用前置清洗与断句管线](#(1) 复用前置清洗与断句管线)
-
- [1. 强弱断句判定逻辑](#1. 强弱断句判定逻辑)
- [2. 文本正则化对齐](#2. 文本正则化对齐)
- [(2) 异步任务队列设计](#(2) 异步任务队列设计)
-
- [1. 串行播放与并行合成的平衡](#1. 串行播放与并行合成的平衡)
- [2. 队列接口职责定义](#2. 队列接口职责定义)
- [3. 生产者-消费者非阻塞关系](#3. 生产者-消费者非阻塞关系)
- [4.5 信号处理、重采样与 LiveKit 出站发布](#4.5 信号处理、重采样与 LiveKit 出站发布)
-
- [(1) 音频格式选择:PCM vs MP3](#(1) 音频格式选择:PCM vs MP3)
-
- [1. 编解码延迟考量](#1. 编解码延迟考量)
- [(2) 信号处理与采样率上采样(Upsampling)](#(2) 信号处理与采样率上采样(Upsampling))
-
- [1. 32kHz 到 48kHz 的数学转换](#1. 32kHz 到 48kHz 的数学转换)
- [(3) LiveKit 动态音轨发布流程](#(3) LiveKit 动态音轨发布流程)
-
- [1. 创建音频源与本地音轨](#1. 创建音频源与本地音轨)
- [2. 20ms 时间片对齐与推送](#2. 20ms 时间片对齐与推送)
- [(4) 浏览器端订阅逻辑](#(4) 浏览器端订阅逻辑)
-
- [1. WebRTC 原生订阅机制](#1. WebRTC 原生订阅机制)
- [4.6 端到端延迟预算与物理资源隔离](#4.6 端到端延迟预算与物理资源隔离)
-
- [(1) 延迟预算分配](#(1) 延迟预算分配)
- [(2) 流水线时间线重叠示意](#(2) 流水线时间线重叠示意)
- [(3) 物理资源隔离方案](#(3) 物理资源隔离方案)
- [4.7 物理打断控制与并发状态机](#4.7 物理打断控制与并发状态机)
-
- [(1) Barge-in 触发机制](#(1) Barge-in 触发机制)
- [(2) 核心打断操作步骤](#(2) 核心打断操作步骤)
- [(3) 并发状态机转移图](#(3) 并发状态机转移图)
- [4.8 全链路测试、验收与调参运维](#4.8 全链路测试、验收与调参运维)
-
- [(1) 单元测试覆盖要点](#(1) 单元测试覆盖要点)
- [(2) 全链路集成测试与日志验证](#(2) 全链路集成测试与日志验证)
-
- [1. 调试环境准备](#1. 调试环境准备)
- [2. 全链路日志链分析](#2. 全链路日志链分析)
- [3. 打断行为验证](#3. 打断行为验证)
- [(3) 常见瓶颈与运维调参指南](#(3) 常见瓶颈与运维调参指南)
- [4.8 本地部署与云端 API 方案对比](#4.8 本地部署与云端 API 方案对比)
-
- [(1) 实操对比清单](#(1) 实操对比清单)
- 总结
前言
在经历了两大Agent学习阶段之后,分别是:(这两章建议大家看一下,非常全面。)
Ai-Agent学习历程------ 阶段2------LangChain Core(基本调用、tools、简单上下文等)
Ai-Agent学习历程------ 阶段3------RAG 与记忆机制
决定做一个情感语音机器人的实践,一方面是巩固已经学习的知识点,一方面则是增加自己的动手能力。
当然,也确实想做这么一个,之前看抖音是用微信语音电话实现的,不过这种方案目前风险较大,所以采用了其它方式,并且会做出适当的改进。
代码下载位置在最下方,但这是本地部署的,如果不看博客很难起来,因为涉及一些配置,比较麻烦
难点分析
做这个项目的最大难点就是根本不知道怎么实现,虽然我们对大模型的调用熟悉了,怎么接入语音?怎么实现对话?怎么克隆音色等等,首先我们搞懂下面这张图,也就是数据是怎么流通的。
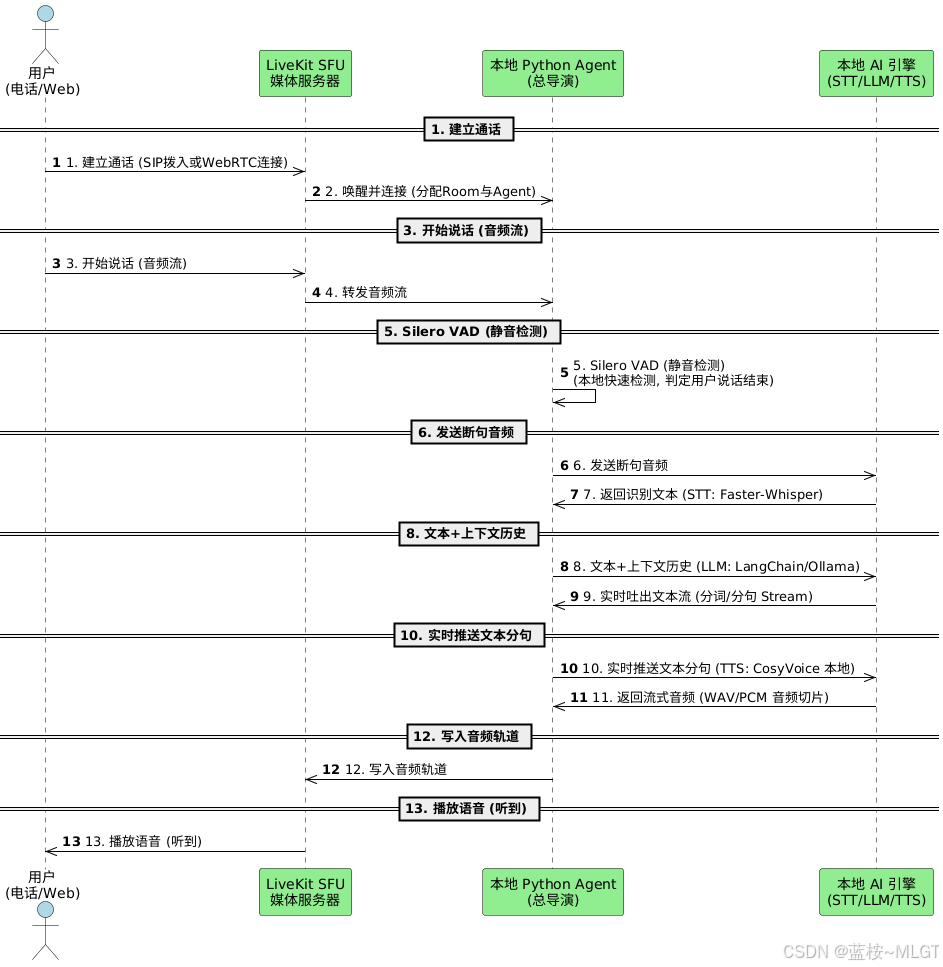
上述图有一个错误点,不使用本地大模型,还是接入性价比高的DeepSeek。
可以看到哪些东西是我们不熟悉的:
- LiveKit Serve
- Silero VAD
- Faster-Whisper
- CosyVoice
- LiveKit Python Agent SDK
不要害怕,至少对怎么实现已经有了一个简单的框架,现在我们就来一步步进行攻克。
整体实现思路和步骤
1. 媒体传输与接驳 (Transport)
- 职责:实现音频流的低延迟采集与双向双工传输。
- 本地方案 :LiveKit Server (Docker 部署)。 建议:前期在本地通过 WebRTC 网页客户端调试,跑通后再通过 SIP 模块接入真实的电话线路。
2. 静音检测与断句 (VAD & STT)
- 职责:识别用户何时开始/结束说话,并将音频切片转化为文本。
- 本地方案 :
- VAD :Silero VAD (轻量化,跑在 CPU 上,用于检测说话结束)。
- STT :Faster-Whisper (Whisper 本地加速推理版,建议使用 Large-v3-Turbo 模型)。
3. 智能体大脑决策 (LLM)
- 职责:理解意图,结合上下文与历史记忆,流式(Stream)输出回答文本。
- 方案:接入Deepseek
4. 专属声音合成 (TTS)
- 职责:流式接收 LLM 文本,用克隆的专属音色合成音频片段(Audio Chunks)。
- 本地方案 :CosyVoice (适合高质量中文音色克隆) 或 Kokoro-TTS (极轻量化方案)。
5. 音频回传播放 (Playback)
- 职责:将生成的音频分包写入 LiveKit 音频轨道,传回电话或客户端。
- 本地方案 :LiveKit Python Agent SDK (自动处理音频重采样与帧推送)。
注意点:电脑至少需要16G的内存,32G运行起来才会流畅
一、媒体传输与接驳 (Transport)
1.1 部署准备与环境要求
(1) 基础运行环境准备
- 操作系统推荐(Linux/Ubuntu 22.04 LTS 或 macOS,Windows 用户建议使用 WSL2)。
- 安装 Docker 与 Docker Compose。
1. 操作系统选择与配置
为了保障容器化部署的兼容性,建议首选 Linux 操作系统。(我的本机是window)
- Linux (推荐):Ubuntu 22.04 LTS 或更高版本。原生支持 Docker 的主机网络模式(Host Network),这对 WebRTC 这种需要映射大量 UDP 端口的服务极为友好。
- macOS :支持开发调试,但由于 Docker 在 macOS 上的虚拟化机制,无法使用
host网络模式,需要手动限制并映射 UDP 端口。 - Windows:必须安装 WSL2 (Windows Subsystem for Linux 2),这是docker的基础环境,不过安装好docker之后这个自动会提示安装的。
这就是对应的wsl版本,这一步可以跳过,直接进入docker安装。
2. Docker 引擎安装验证
LiveKit 服务将完全运行在 Docker 容器中。请确保已安装 Docker Engine 和 Docker Compose(建议 Docker 版本 >= 20.10,Docker Compose 版本 >= 2.0)。
可以通过以下命令验证本地 Docker 环境:
bash
# 检查 Docker 引擎是否正常运行
docker --version
# 检查 Docker Compose 是否安装
docker compose version(2) 网络与端口规划
1. WebRTC 安全域限制说明(重要)
现代浏览器(如 Chrome、Safari、Edge)的安全策略对 WebRTC 音视频采集有严格限制:
- 本地调试 (localhost / 127.0.0.1):浏览器允许使用非加密的 HTTP 和 WS 协议调用麦克风、摄像头。
- 跨设备调试 (如手机与电脑连入同一局域网测试) :浏览器强制要求 必须使用安全的 HTTPS 和 WSS 协议。若直接使用局域网 IP(如
http://192.168.1.100:7880)访问,浏览器会直接禁用麦克风权限。 - 当前阶段策略 :只在本地通过网页调试,网页端和服务端运行在同一台电脑 上,通过
http://localhost进行连接,从而规避配置 SSL 证书的复杂性。
2. 端口分配与防火墙开放规则
LiveKit Server 运行时需要使用以下端口。之后我们一步一步放行
| 端口号 / 范围 | 协议 | 作用 | 宿主机网络模式 (Linux) | 桥接网络模式 (macOS/Windows) |
|---|---|---|---|---|
| 7880 | TCP | API 接口与 WebSocket 信令通道 | 自动绑定 | 必须映射 |
| 7881 | TCP | TURN-over-TCP 媒体传输备份通道 | 自动绑定 | 可选映射 |
| 50000 - 60000 | UDP | WebRTC 媒体流传输通道(音频数据包) | 自动绑定 | 需要限制范围后映射 |
⚠️ 注意(针对 macOS / Windows 开发环境) :
在 macOS 或 Windows 上运行 Docker 时,如果将 10000 个 UDP 端口(50000-60000)一次性映射给 Docker 容器,会导致 Docker Desktop 消耗海量内存甚至直接卡死。
解决方法 :在接下来的 1.2 步骤中,我们将在配置文件中将 UDP 端口范围缩小至50000-50010,只映射这 10 个 UDP 端口用于本地单人开发调试。
1.2 LiveKit Server 的本地 Docker 部署
针对 Windows 系统的 Docker Desktop 环境,由于其虚拟机网络的特殊性,我们无法使用 Linux 上的 host(主机)网络模式。我们需要采用"桥接端口映射(Bridge Port Mapping)"的方式,并严格限制 WebRTC 媒体传输的 UDP 端口范围,防止系统资源过载。
(1)LiveKit 配置文件准备 (livekit.yaml)
在本地目录下新建一个名为 livekit.yaml 的文件,写入以下内容:
yaml
# livekit.yaml
# 基础服务端口配置
port: 7880
# WebRTC 传输配置
rtc:
# TCP 备用传输端口(当 UDP 受限时使用)
tcp_port: 7881
# 限制 UDP 端口范围(针对 Windows Docker 优化,仅预留 11 个端口用于本地单人调试)
port_range_start: 50000
port_range_end: 50010
# 本地调试关闭外部 IP 自动探测
use_external_ip: false
# 身份验证密钥配对(后续 Python Agent 和前端连接时必须使用相同的 Key)
keys:
devkey: "secret"
# 基础日志配置
logging:
level: info配置项关键说明:
port_range_start与port_range_end:我们将默认的一万个端口范围限制在50000-50010。这对于本地单人联调完全足够,同时可以避免 Windows 下 Docker 代理进程占用过高的 CPU 和内存。keys:设置了用户名devkey,密码为secret的凭证。这是本地联调的临时凭证。
(2)使用 Docker Compose 启动服务
在同一目录下新建一个名为 docker-compose.yml 的文件,写入以下内容:
yaml
# docker-compose.yml
version: '3.8'
services:
livekit:
image: livekit/livekit-server:latest
container_name: livekit-server
restart: unless-stopped
# 显式映射暴露的端口到宿主机 Windows
ports:
- "7880:7880/tcp" # WebSocket 信令和 API 接口
- "7881:7881/tcp" # WebRTC TCP 传输备用端口
- "50000-50010:50000-50010/udp" # WebRTC 媒体流 (UDP 范围)
volumes:
# 将宿主机当前的配置文件挂载到容器内
- ./livekit.yaml:/etc/livekit.yaml:ro
# 启动命令:指定使用挂载的配置文件启动
command: ["--config", "/etc/livekit.yaml"](注意:在 Windows 环境下挂载路径使用相对路径 ./livekit.yaml 即可)
启动与验证步骤:
-
启动容器
打开 Windows PowerShell,切换到包含这两个文件的
livekit-dev目录下,运行以下命令启动服务:powershelldocker compose up -d(参数
-d表示在后台运行。如果是第一次运行,Docker 将自动从官方仓库下载livekit/livekit-server镜像。) -
验证运行状态
运行以下命令查看容器状态,确保
State为Up且端口映射正确:powershelldocker compose ps -
查看服务运行日志
运行以下命令检查 LiveKit 服务初始化过程中是否有报错:
powershelldocker compose logs livekit
在docker中就可以看到了
1.3 生成连接 Token 与开发工具安装
(1) 生成测试 Token
先安装lk工具
cmd
winget install LiveKit.LiveKitCLI
注意: 新开一个cmd,重新加载环境变量。
直接在 Windows 命令行(CMD 或 PowerShell)中运行以下命令:
cmd
lk token create --api-key devkey --api-secret secret --join --room room1 --identity user1 --valid-for 240h关键参数解析:
--api-key devkey和--api-secret secret:必须与在livekit.yaml中配置的keys严格一致。--join:授予此 Token 加入房间的权限。--room room1:指定该 Token 只能加入名为room1的房间(如果该房间在服务器中不存在,LiveKit 会在客户端连接时自动创建它)。--identity user1:指定该用户的唯一标识符(Identity)为user1。--valid-for 240h:设置此 Token 的有效期为 240小时(默认较短,为了本地调试方便,建议设长一些,但不要太长了,有可能报错)。
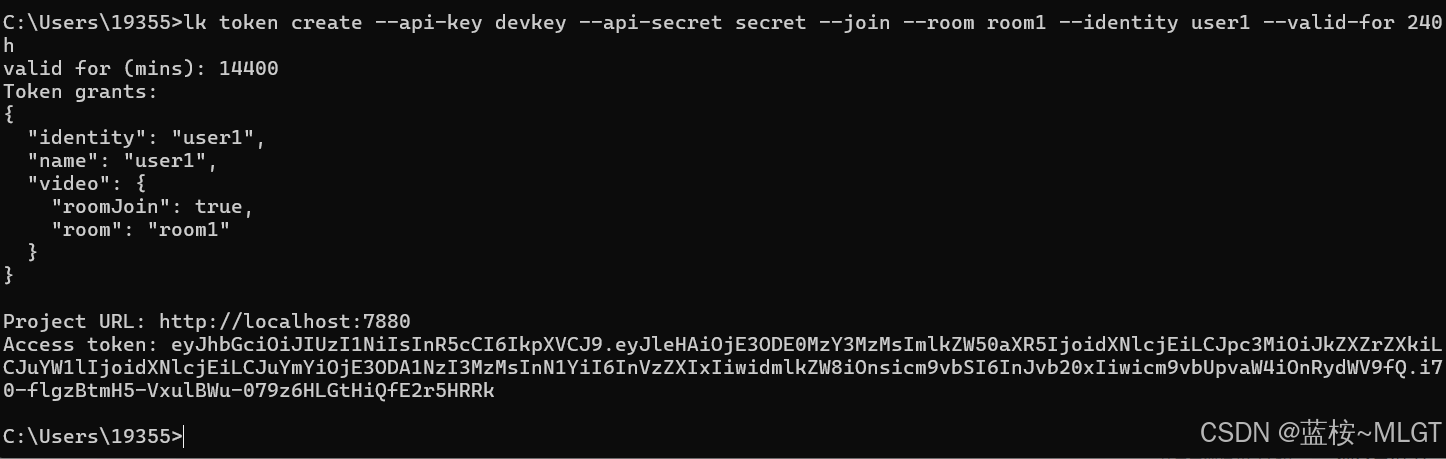
将其保存下来之后使用(这是我本地的,自己需要生成)
python
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJleHAiOjE3ODE0MzY3MzMsImlkZW50aXR5IjoidXNlcjEiLCJpc3MiOiJkZXZrZXkiLCJuYW1lIjoidXNiLCJuYmYiOjE3ODA1NzI3MzMsInN1YiI6InVzZXIxIiwidmlkZW8iOnsicm9vbSI6InJvb20xIiwicm9vbUpvaW4iOnRydWV9fQ.i70-flgzBtmH5-VxulBWu-079z6HLGtHiQfE2r5HRRk1.4 WebRTC 网页客户端联调验证
(1) 准备连接地址与 Token
为了成功连接,我们需要以下两个核心信息:
- LiveKit Server 地址 :因为是在 Windows 本机调试,连接地址为:
ws://localhost:7880 - 临时 Token :即在 1.3 中通过命令行(或 Python 脚本)生成的以
eyJ...开头的超长 JWT 字符串。
(2) 在浏览器中调试连接
LiveKit 官方客户端提供了一种极简的"快速连接"方式。可以通过拼接 URL 直接在浏览器中拉起连接:
-
拼接快速连接链接 :
将下方的
<TOKEN>替换为在 1.3 中生成的真实 Token:texthttps://meet.livekit.io/custom?liveKitUrl=ws://localhost:7880&token=<TOKEN> -
在浏览器中打开该链接 :
建议使用 Chrome 、Edge 或 Safari 浏览器打开该网址。
-
授予媒体权限 :
页面加载后,浏览器会弹窗申请麦克风和摄像头权限。点击"允许"(若拒绝,WebRTC 媒体流将无法初始化)。
-
成功连接状态 :
如果连接成功,将直接进入一个音视频会议房间,并在屏幕上看到自己的摄像头画面,听到麦克风采集的声音。
后台可以看到日志
1.5 基础 Python Agent 骨架搭建
注意点:
接下来基本上代码占据主体,核心都将在代码中体现,需要着重看代码
在博客最后会给出完整项目或者git地址
(1)项目整体包结构
(2)配置和依赖文件
1. 依赖文件
requirements-dev.txt:开发依赖文件
txt
# 这里分为两个requirements是一个工程化思维,本地的测试依赖和运行时依赖分开,正式环境只需要执行标准的requirements即可
-r requirements.txt
pytest>=8.0.0,<9.0.0
pytest-asyncio>=0.24.0,<1.0.0
PyJWT>=2.8.0,<3.0.0requirements.txt:核心依赖文件
txt
livekit>=1.0.0,<2.0.0
livekit-api>=1.0.0,<2.0.0
python-dotenv>=1.0.0,<2.0.0pytest.ini:测试脚本
python
[pytest]
asyncio_mode = auto
asyncio_default_fixture_loop_scope = function
pythonpath = src.env:环境配置文件
python
# LiveKit 服务 WebSocket 地址(本机 Docker 联调用 ws://localhost:7880)
LIVEKIT_URL=ws://localhost:7880
# API 密钥名,须与 livekit-dev/livekit.yaml 中 keys 的键名一致
LIVEKIT_API_KEY=devkey
# API 密钥值,须与 livekit.yaml 中对应 secret 一致
LIVEKIT_API_SECRET=secret
# Agent 加入的房间名,须与浏览器 Meet 使用的 room 相同(如 room1)
LIVEKIT_ROOM=room1
# Agent 在房间内的唯一标识,勿与网页端 user1 重复
LIVEKIT_AGENT_IDENTITY=companion-bot
# 每收到多少帧音频打印一次汇总日志(首帧仍会单独打印)
AUDIO_LOG_EVERY_N_FRAMES=50
# 日志级别:DEBUG / INFO / WARNING / ERROR
LOG_LEVEL=INFO2. 骨架文件
token.py:动态生成Agent端Token
python
from __future__ import annotations
from livekit import api
from voice_agent.config import Settings
# 该方法是用了给Agent动态生成Token的,和之前在网页上生成的Token不是一个性质
# 这是是程序的密钥,而之前是user1的进门密钥,作用不同
def build_agent_token(settings: Settings) -> str:
return (
api.AccessToken(settings.api_key, settings.api_secret)
.with_identity(settings.agent_identity)
.with_name("Companion Bot")
.with_grants(
api.VideoGrants(
room_join=True,
room=settings.room,
can_publish=True,
can_subscribe=True,
)
)
.to_jwt()
)config.py:配置加载文件
python
from __future__ import annotations
import os
from dataclasses import dataclass
from dotenv import load_dotenv
_REQUIRED = (
"LIVEKIT_URL",
"LIVEKIT_API_KEY",
"LIVEKIT_API_SECRET",
"LIVEKIT_ROOM",
"LIVEKIT_AGENT_IDENTITY",
)
class ConfigError(ValueError):
"""Raised when required LiveKit configuration is missing or invalid."""
@dataclass(frozen=True)
class Settings:
url: str
api_key: str
api_secret: str
room: str
agent_identity: str
audio_log_every_n_frames: int = 50
log_level: str = "INFO"
def _require(name: str) -> str:
value = os.getenv(name)
if not value or not value.strip():
raise ConfigError(f"Missing required environment variable: {name}")
return value.strip()
# 加载设置,*表示调用时必须使用关键字传参,不能使用占位符
def load_settings(*, env_file: str | None = None) -> Settings:
load_dotenv(env_file)
# 列表推导式
missing = [name for name in _REQUIRED if not os.getenv(name, "").strip()]
if missing:
raise ConfigError(
f"Missing required environment variables: {', '.join(missing)}"
)
every_n = int(os.getenv("AUDIO_LOG_EVERY_N_FRAMES", "50"))
if every_n < 1:
raise ConfigError("AUDIO_LOG_EVERY_N_FRAMES must be >= 1")
return Settings(
url=_require("LIVEKIT_URL"),
api_key=_require("LIVEKIT_API_KEY"),
api_secret=_require("LIVEKIT_API_SECRET"),
room=_require("LIVEKIT_ROOM"),
agent_identity=_require("LIVEKIT_AGENT_IDENTITY"),
audio_log_every_n_frames=every_n,
log_level=os.getenv("LOG_LEVEL", "INFO").strip().upper() or "INFO",
)audio_probe.py:音频探针
python
"""
音频探针(1.5 联调阶段)。
职责:从 LiveKit AudioStream 逐帧读取远端 PCM,统计帧数与字节数并打日志,
用于验证「浏览器麦克风 → LiveKit → Python Agent」链路是否打通。
后续可在此演进为 VAD 缓冲区等,本节不做语音识别。
"""
from __future__ import annotations
import logging
from typing import AsyncIterator, Protocol
logger = logging.getLogger(__name__)
# --- 类型约定(Protocol):描述「一帧音频」至少要有哪些字段,便于单元测试用 FakeFrame 模拟 ---
class AudioFrameLike(Protocol):
@property
def sample_rate(self) -> int: ...
@property
def num_channels(self) -> int: ...
@property
def samples_per_channel(self) -> int: ...
# LiveKit 的 AudioStream 每次迭代给出的是 AudioFrameEvent,真正的 PCM 在 .frame 里
class AudioFrameEventLike(Protocol):
frame: AudioFrameLike
def unwrap_audio_frame(item: AudioFrameLike | AudioFrameEventLike) -> AudioFrameLike:
"""统一取出 AudioFrame:有 .frame 则解包事件,否则认为已是裸帧。"""
if hasattr(item, "frame"):
return item.frame # type: ignore[union-attr]
return item
def frame_byte_size(frame: AudioFrameLike) -> int:
"""估算本帧 PCM 字节数:每采样 2 字节(int16)× 每声道采样数 × 声道数。"""
return frame.samples_per_channel * frame.num_channels * 2
async def consume_audio_stream(
stream: AsyncIterator[AudioFrameLike],
*,
participant_identity: str,
track_sid: str,
log_every: int,
) -> None:
"""
异步消费一整条远端音频流,直到对方挂断或轨结束。
由 events.py 在 track_subscribed 后以 asyncio.create_task 在后台运行。
"""
frame_count = 0
byte_count = 0
sample_rate: int | None = None
# async for:从 AudioStream 持续取帧(阻塞式等待下一帧,不占用线程)
async for item in stream:
frame = unwrap_audio_frame(item)
frame_count += 1
byte_count += frame_byte_size(frame)
sample_rate = frame.sample_rate
# 首帧单独打日志,便于确认「已经收到声音」
if frame_count == 1:
logger.info(
"first audio frame from %s track=%s sr=%d ch=%d",
participant_identity,
track_sid,
frame.sample_rate,
frame.num_channels,
)
# 每 log_every 帧汇总一次(频率由 .env 中 AUDIO_LOG_EVERY_N_FRAMES 控制)
if frame_count % log_every == 0:
logger.info(
"audio from %s: frames=%d bytes=%d sr=%s",
participant_identity,
frame_count,
byte_count,
sample_rate,
)events.py:事件回调
python
from __future__ import annotations
import asyncio
import logging
from typing import Callable
from livekit import rtc
from voice_agent.audio_probe import consume_audio_stream
from voice_agent.config import Settings
logger = logging.getLogger(__name__)
# Callable[[asyncio.Task[None]], None],不要误当做一个数组
# # └──── 参数 ────┘ └返回┘
def register_room_handlers(
room: rtc.Room,
settings: Settings,
*,
local_identity: str,
on_audio_task: Callable[[asyncio.Task[None]], None] | None = None,
) -> None:
"""为 Room 注册事件回调:参与者进出、音轨发布/订阅,并在收到远端音频时启动消费任务。"""
# 记录所有正在运行的音频消费协程,便于后续扩展(如退出时统一 cancel)
audio_tasks: set[asyncio.Task[None]] = set()
def _track_task(task: asyncio.Task[None]) -> None:
"""把新创建的音频任务纳入集合;任务结束后自动从集合移除。"""
audio_tasks.add(task)
# 任务结束后自动从集合移除,audio_tasks.discard等价于lambda t: audio_tasks.discard(t)
task.add_done_callback(audio_tasks.discard)
if on_audio_task:
on_audio_task(task)
# --- 1. 参与者进入房间(例如浏览器端的 user1 加入 room1)---
@room.on("participant_connected")
def on_participant_connected(participant: rtc.RemoteParticipant) -> None:
logger.info(
"participant_connected identity=%s room=%s",
participant.identity,
settings.room,
)
# --- 2. 参与者离开房间 ---
@room.on("participant_disconnected")
def on_participant_disconnected(participant: rtc.RemoteParticipant) -> None:
logger.info(
"participant_disconnected identity=%s room=%s",
participant.identity,
settings.room,
)
# --- 3. 远端发布音轨(对方打开麦克风/摄像头时触发,仅打日志便于联调)---
@room.on("track_published")
def on_track_published(
publication: rtc.RemoteTrackPublication,
participant: rtc.RemoteParticipant,
) -> None:
logger.info(
"track_published identity=%s kind=%s sid=%s",
participant.identity,
publication.kind,
publication.sid,
)
# --- 4. 本端成功订阅远端音轨(真正开始收 RTP 音频的时机)---
@room.on("track_subscribed")
def on_track_subscribed(
track: rtc.Track,
publication: rtc.RemoteTrackPublication,
participant: rtc.RemoteParticipant,
) -> None:
logger.info(
"track_subscribed identity=%s kind=%s sid=%s",
participant.identity,
track.kind,
track.sid,
)
# 4.1 只处理音频轨,忽略视频等
if track.kind != rtc.TrackKind.KIND_AUDIO:
return
# 4.2 忽略本 Agent 自己的轨,只统计远端(如 user1)发来的声音
if participant.identity == local_identity:
return
# 4.3 将 LiveKit 音轨包装为异步音频流,逐帧读取 PCM 数据
audio_stream = rtc.AudioStream(track)
# 4.4 在后台协程中消费音频流(统计帧数/字节,见 audio_probe.py)
task = asyncio.create_task(
consume_audio_stream(
audio_stream,
participant_identity=participant.identity,
track_sid=track.sid,
log_every=settings.audio_log_every_n_frames,
),
name=f"audio-{participant.identity}-{track.sid}",
)
_track_task(task)main.py:Agent入口文件
python
"""
Agent 程序入口(1.5 Transport 层)。
流程:加载 .env → 生成 JWT → 连接 LiveKit 房间 → 注册事件回调 → 保持运行直至 Ctrl+C → 断开连接。
启动:$env:PYTHONPATH="src"; python -m voice_agent
"""
from __future__ import annotations
import asyncio
import logging
import sys
from livekit import rtc
from voice_agent.config import ConfigError, Settings, load_settings
from voice_agent.events import register_room_handlers
from voice_agent.token import build_agent_token
logger = logging.getLogger(__name__)
def _configure_logging(level: str) -> None:
"""按 LOG_LEVEL 配置根日志格式(各模块 logger 继承此配置)。"""
logging.basicConfig(
level=getattr(logging, level, logging.INFO),
format="%(asctime)s %(levelname)s [%(name)s] %(message)s",
)
async def run_agent(settings: Settings) -> None:
"""连接房间并阻塞等待,直到进程结束或事件循环被取消。"""
# 1. 用 API Key/Secret 签发 Agent 专用 Token(identity=companion-bot)
token = build_agent_token(settings)
room = rtc.Room()
# 2. 注册参与者/音轨事件;收到远端音频时在后台 consume_audio_stream
register_room_handlers(
room,
settings,
local_identity=settings.agent_identity,
)
# 3. WebSocket 入房(url 来自 .env,如 ws://localhost:7880)
logger.info(
"connecting url=%s room=%s identity=%s",
settings.url,
settings.room,
settings.agent_identity,
)
await room.connect(settings.url, token)
logger.info(
"connected room=%s local_identity=%s",
room.name,
room.local_participant.identity,
)
# 4. 永久等待:Future 永不完成,直到 Ctrl+C 导致 asyncio.run 取消所有任务
try:
await asyncio.Future()
except asyncio.CancelledError:
pass
finally:
# 5. 退出时断开房间,释放 WebRTC 连接
logger.info("disconnecting")
await room.disconnect()
def main() -> None:
"""同步入口:供 `python -m voice_agent` 或 __main__ 调用。"""
# 读取 .env 并校验必填项;失败则打印错误并以退出码 1 结束
try:
settings = load_settings()
except ConfigError as exc:
print(f"Configuration error: {exc}", file=sys.stderr)
sys.exit(1)
_configure_logging(settings.log_level)
# asyncio.run 创建事件循环,执行 run_agent;Ctrl+C 触发 KeyboardInterrupt
try:
asyncio.run(run_agent(settings))
except KeyboardInterrupt:
logger.info("stopped by user")
# 直接运行本文件时走 main;被 import 时不会自动连房间
if __name__ == "__main__":
main()main.py:入口
python
from voice_agent.main import main
if __name__ == "__main__":
main()init.py:初始化
python
"""情感语音机器人 --- LiveKit Transport 层骨架(1.5)。"""
__version__ = "0.1.0"(3)运行流程
第一步: 安装依赖
python
pip install -r requirements-dev.txt第二步: 执行测试
python
pytest运行结果:
python
=============================================================================== test session starts ===============================================================================
platform win32 -- Python 3.13.12, pytest-8.4.2, pluggy-1.5.0
rootdir: C:\pythonProjects\PythonProject\agent_skeleton
configfile: pytest.ini
plugins: anyio-4.10.0, langsmith-0.8.6, asyncio-0.26.0
asyncio: mode=Mode.AUTO, asyncio_default_fixture_loop_scope=function, asyncio_default_test_loop_scope=function
collected 7 items
tests\test_audio_probe.py ... [ 42%]
tests\test_config.py ... [ 85%]
tests\test_token.py . [100%]
================================================================================ 7 passed in 0.30s ================================================================================第三步: 启动Python项目,浏览器打开之前的路径进入房间,此时后台应该是:
你在浏览器能看到两个用户,一个是你自己user1 ,一个是Agent代表的用户companion-bot
到这一步我们基本就调试通了,可以进行下一步
接下来先进行原理解析,之后统一进行每一阶段的代码解析
二、静音检测与断句 (VAD & STT)
工程说明(与本项目一致)
下文先讲通用原理;实际代码采用
livekit-plugins-silero的VADStream做断句,Faster-Whisper(CUDA) 做转写,不手写 Silero ONNX 环形缓冲与状态机。
2.1 实时音频帧捕获与数据流处理
在 WebRTC 音频流与 AI 模型(VAD / STT)之间,存在着一道天然的「数据格式鸿沟」。要实现稳定、低延迟的语音交互,我们首先需要理解音频帧在内存中的物理结构,以及为什么要对它进行重采样。
(1) LiveKit 音频帧结构与底层格式
1. PCM 编码的物理本质
用户麦克风采集并流经 LiveKit 的音频,在 Opus 解码后是以 PCM (Pulse Code Modulation,脉冲编码调制) 格式存在于内存中的。
- PCM 是无损、未压缩的原始音频。它在计算机中表现为一个连续的数组,数组中的每个数值(Sample,采样点)代表该时刻声音振幅的强弱。
- LiveKit Python SDK 将这些原始字节封装在
rtc.AudioFrame对象中。开发者可通过frame.data(int16 的 memoryview)访问采样数据;底层原始字节也可由 frame 内部 buffer 取得。
这里我们要有一个直觉:对于图片、视频、音频等特殊格式的数据,在底层往往都是在操作 bytes / 采样数组。
2. LiveKit 默认音频参数分析
WebRTC 协议为了保证高保真的人声和极佳的抗丢包性能,其底层的 Opus 编解码器默认采用以下参数进行音频采集和传输:
- 采样率 (Sample Rate) :通常为 48,000 Hz (48kHz) 或 44,100 Hz (44.1kHz)。这意味着每秒钟要对声音振幅进行 48,000 次采样。
- 声道数 (Channels) :通常为 单声道 (Mono) 或 双声道 (Stereo / 2 Channels)。
- 位深 (Bit Depth) / 采样格式 :通常为 16-bit 有符号整数 (S16LE) 。在内存中,每个采样点占 2 字节(Bytes),取值范围在
-32768到32767之间。
3. AudioStream 与 AudioFrameEvent
LiveKit 的 rtc.AudioStream(track) 是异步迭代器,但每次迭代得到的往往是 AudioFrameEvent,真正的 PCM 在 event.frame 里。阶段 1 联调与阶段 2 管线都需要先解包再处理,否则拿不到有效采样数据。
(2) 为什么必须进行重采样(Resampling)与单声道化
1. 采样率不匹配的灾难性后果
后续我们要对接的 Silero VAD 和 Faster-Whisper ,其背后的深度学习模型在训练时,输入音频的标准采样率全部都是 16,000 Hz (16kHz)。
如果直接把 LiveKit 的 48kHz 音频数据送入 16kHz 的模型,而不进行重采样,会导致以下严重后果:
- 「慢动作怪兽音」效应:16kHz 的模型每秒只会按 16,000 个采样点理解时间轴。若误把 48,000 个采样点当作「1 秒」,相当于把语速放慢约 3 倍、音调降低数个八度,模型几乎无法识别正常人类语言。
- 维度不匹配(Shape Mismatch) :VAD 模型对输入窗长有严格限制(例如 Silero 在 16kHz 下以 512 采样 ≈ 32ms 为推理窗口)。
因此,我们必须通过重采样算法(如多相滤波等),将 48kHz 的音频等比下采样(Downsample)到 16kHz。
【本项目路径】 :在送入 VAD 前,使用 rtc.AudioResampler 将 LiveKit 帧转为 16kHz 单声道 int16 (Mono16kConverter)。
说明 :livekit-plugins-silero 的 VADStream 内部也支持对非 16kHz 输入做重采样;本项目选择在 push 前显式转为 16kHz,逻辑更清晰,且与 Whisper 输入采样率一致。
2. 声道合并(Stereo to Mono)的必要性
STT 模型在识别语义时不需要空间定位信息,双声道音频只会成倍增加计算负担(数据量翻倍)。
- 处理方法 :若收到双声道(Stereo)音频,将左右声道做数学平均
(Left + Right) / 2合并为单声道(Mono),可立即减少约 50% 的后续推理开销。
(3) 工业级实现方案与数据切块(Chunking)机制
1. 异步音频流捕获逻辑
- LiveKit Python SDK 提供异步迭代器
rtc.AudioStream(track)。 - 代码应启动专门的异步任务(Coroutine),不断
async for item in audio_stream捞取音频帧(解包为frame)。 - 该过程必须 非阻塞:若在循环内执行耗时计算(如 Whisper 推理),会阻塞事件循环,导致 WebRTC 缓冲区积压、丢包和卡顿。
【本项目路径】:
- 音频读取:
async for+push_frame(轻量)。 - Whisper 推理:放入
asyncio.to_thread(或线程池),并用锁保证同一时刻只有一个转写任务,避免阻塞 LiveKit。
2. 32ms 级别的时间片对齐(Chunking)
AI 模型无法一次处理无限长流,它们以固定时间窗观测音频:
- Silero VAD 在 16kHz 下,常见推理窗为 512 采样 ≈ 32ms (亦常见 256 采样 ≈ 16ms,视模型/配置而定)。
- 1 个 16-bit 采样 = 2 字节;512 采样 = 1024 字节 PCM。
【自研路径】:若自行对接 Silero ONNX,通常需实现环形缓冲区(Ring Buffer):重采样为 16kHz mono 后,累计满 512 采样(1024 字节)再送入 VAD。
【本项目路径】 :无需手写该 Ring Buffer 。livekit-plugins-silero 的 VADStream 在内部完成分窗、缓冲与状态机;应用层只需在重采样后 vad_stream.push_frame(frame) ,在 END_OF_SPEECH 时从 event.frames 取整段 utterance 送 STT。
2.2 Silero VAD 本地集成与状态机设计
在实时语音对话系统中,VAD(Voice Activity Detection,语音活动检测 / 端点检测) 是智能体的大脑前哨:控制何时开始积累一段用户语音、何时判定「一句话说完」并触发 STT。
(1) Silero VAD 模型加载与运行原理
1. 为什么弃用传统能量 VAD,选择深度学习 VAD?
- 传统 VAD(如 WebRTC VAD):基于短时能量、过零率等物理特征。安静环境尚可,但键盘声、拍桌、重呼吸等易误触发。
- Silero VAD(深度学习):在海量多语言、多噪声语料上训练,对「是否为人声」更鲁棒,强噪声下仍较稳定。
- 计算开销 :提供 ONNX 等轻量格式;单次 32ms 窗推理在 CPU 上通常约 0.5~1.5ms,适合实时链路。
【本项目路径】 :VAD 使用 livekit-plugins-silero ,推理 force_cpu=True (CPU 跑 VAD);Whisper 使用 CUDA ,形成常见的 「VAD@CPU + STT@GPU」 异构部署。
2. 流式推理机制(Streaming Inference)
在 16kHz 下,Silero 以固定长度窗(如 512 采样 / 32ms)滑动推理:
- 模型内部输入 :归一化 float32 ,数值约 -1.0, 1.0。
- 模型输出 :0.0~1.0 的
speech_prob,表示当前窗内为人声的概率。
【本项目路径】 :应用层向 VADStream 推送 rtc.AudioFrame(int16 PCM) 即可;int16 → float32 归一化在插件内部完成,无需在业务代码里先转 Tensor。
(2) 实时静音/非静音状态机设计 (SOS 与 EOS 机制)
speech_prob 每约 32ms 更新一次。若简单使用 if speech_prob > 0.5,在爆破音、换气、短暂停顿时会产生 状态抖动 ,必须引入 状态机 与 连续帧判定。
1. 双状态转换逻辑(原理)
核心状态:SILENT(静音/空闲) 与 SPEAKING(正在说话)。
-
SOS(Start of Speech,开始说话)
- 机制 :在
SILENT下,连续 M 个窗speech_prob高于阈值 → 判定开始说话 →SPEAKING。 - 动作 :开始积累本句音频;若智能体正在播放 TTS,应 Barge-in 打断 (阶段 3 TTS 实现后再做,本节仅述原理)。
- 机制 :在
-
EOS(End of Speech,结束说话 / 断句)
- 机制 :在
SPEAKING下,连续 N 个窗speech_prob低于阈值(等价于持续静音超过一定时长)→ 判定说完 →SILENT。 - 动作 :锁定本句音频,整段送 Faster-Whisper;然后清空句缓冲,等待下一句。
- 机制 :在
2. 【本项目路径】LiveKit VADStream 已封装状态机
手写 SILENT/SPEAKING 与 M/N 计数可加深理解;本项目不手写,而使用插件事件:
| 事件 | 含义 |
|---|---|
VADEventType.START_OF_SPEECH |
对应 SOS |
VADEventType.END_OF_SPEECH |
对应 EOS;event.frames 即整句 PCM(含前垫) |
对应配置项(.env / silero.VAD.load(...))与原理参数关系:
| 插件参数 | 典型配置 | 对应原理 |
|---|---|---|
activation_threshold |
0.5 |
人声概率阈值 threshold |
min_speech_duration |
默认 0.05s;工业上可酌情调大(如 ~0.15s) |
SOS 最短人声持续时间,过滤咳嗽/短噪 |
min_silence_duration |
0.55~0.8s (本项目默认 0.55s) |
EOS 允许的句中停顿;直接影响应答延迟 |
prefix_padding_duration |
默认 0.5s | 前垫,减轻句首吞字 |
(3) 关键参数调优与工业级边缘优化
1. 核心参数推荐值
| 参数名 | 典型推荐值 | 物理意义 |
|---|---|---|
threshold / activation_threshold |
0.45~0.50 |
判定为人声的概率阈值。越小越灵敏,越易受噪声影响。 |
min_speech_duration |
插件默认 50ms ;工业推荐约 150ms | 短于该时长不触发 SOS,可滤短促噪声。 |
min_silence_duration |
550~800ms(约 17~25 个 32ms 窗) | 句末静音超过该值触发 EOS。决定断句与应答延迟的关键参数。 |
2. 音频前垫与后垫 (Speech Padding)
VAD 判定 SOS 存在延迟(需连续若干窗确认),句首辅音/「喂、你」等可能已在延迟窗口内过去,直接截断会导致 吞字。
- 前垫(Prepend) :保留并拼接触发 SOS 之前 的一小段历史音频。
【本项目路径】 :由插件prefix_padding_duration完成;END_OF_SPEECH的event.frames已含前垫,无需自维护 300ms 滑动历史缓冲。 - 后垫(Append) :句末略保留尾音,避免词尾被切掉。Silero / LiveKit 插件在 EOS 逻辑中一并处理;自研时可手动追加约 200ms 【自研路径】。
2.3 Faster-Whisper 本地部署与加速推理
当 VAD 判定 EOS 并输出整段 utterance 后,系统进入 STT(语音转文字) 。情感陪伴场景下,希望在用户说完后 尽快 得到文本(GPU + 小模型 + 低 beam 时常见 数百 ms 级 ;CPU 或 beam_size=5 往往更慢)。
(1) Faster-Whisper 与 CTranslate2 优化原理
1. 为什么不直接使用 OpenAI 原版 Whisper?
- 原版 Whisper:基于 PyTorch,准确率高,但实时场景下推理与显存占用偏大。
- Faster-Whisper :使用 C++ CTranslate2 引擎,在相同模型规模下通常比原版 快数倍,显存占用更低。
2. 为什么在 2026 年首选 large-v3-turbo 模型?
- 原版
large-v3解码层较深,生成速度相对慢。 large-v3-turbo精简了解码层(如 8 层),在保持较高中文能力的同时,转写速度通常可提升 数倍 ;配合本地 GPU ,适合实时对话。显存紧张时可先用small/base验证链路,再换回 turbo。
(2) Windows 本地 GPU 推理环境与依赖配置
在 Windows 下使用 Faster-Whisper 的 GPU 加速,关键是 NVIDIA 驱动 与 CTranslate2 的 CUDA 构建 可用。
注意 :Faster-Whisper 不依赖 PyTorch 做推理 (核心是 ctranslate2 )。验收时除驱动外,应确认
faster-whisper/ctranslate2能使用 CUDA ;仅检测torch.cuda.is_available()并不足够。
1. 显存开销与精度选择
large-v3-turbo 权重约 1.6GB 量级,推理时显存与 compute_type 相关:
float16(推荐,本项目默认) :约 2.5~3.0GB 显存;RTX 30/40 等显卡上通常速度较好。int8_float16(混合量化) :权重更省(约 1.8GB 级),适合 8GB 以下 显卡调试。
2. 首次运行与模型缓存
首次运行会从 Hugging Face 等源 下载 Whisper 权重 (体积大,需稳定网络与磁盘空间)。Silero ONNX 亦可能在首次加载时下载。联调阶段可配置 UTTERANCE_DEBUG_DIR,将 VAD 断句 WAV 落盘,便于核对断句是否准确。
(3) 核心参数调优与延迟极限压缩
WhisperModel.transcribe() 默认参数偏 离线准确率 。实时语音应关闭多余路径,并避免与上游 VAD 重复断句。
1. 核心调优参数一览
-
language="zh"(锁定中文)- 不指定时,模型可能先做语种检测,增加 约 150~300ms 量级开销。
- 中文情感机器人建议显式
zh(本项目.env:WHISPER_LANGUAGE=zh)。
-
beam_size=1(贪婪解码,低延迟推荐)beam_size=5会保留更多候选路径,质量略好但 计算量显著增加。- 实时交互推荐
1;本项目默认5便于初期验证准确率,上线可调为1。
-
temperature=0(确定性)- 减少随机采样与复读幻觉;Faster-Whisper 默认即偏确定性,建议保持
0。
- 减少随机采样与复读幻觉;Faster-Whisper 默认即偏确定性,建议保持
-
vad_filter=False(必须,与 Silero 配合时)- Faster-Whisper 内置 VAD 用于切长音频。
- 上游已用 Silero 断句时,必须关闭 ,否则可能 重复切分、丢字或延迟增加。
- 【本项目路径】 :
transcribe(..., vad_filter=False)。
-
initial_prompt(可选)- 引导简体中文与口语风格,例如:
"这是一段简体中文情感陪伴对话,语气亲切。" - 可改善儿化音、语气词识别;本项目尚未接入,可作为后续优化。
- 引导简体中文与口语风格,例如:
2. 【本项目路径】STT 输入格式与管线衔接
- VAD
END_OF_SPEECH→event.frames(16kHz mono int16 列表)。 - 合并为 float32 数组,数值 ÷ 32768.0 ,范围约 -1, 1。
asyncio.to_thread调用transcribe,避免阻塞 LiveKit 事件循环。- 过短 utterance(如 < 0.1s)可丢弃,避免噪声触发无意义 STT。
(4) 阶段 2 手动验收预期(Meet 联调)
livekit-dev已启动;.env已配置 VAD / STT。$env:PYTHONPATH="src"; python -m voice_agent- Meet 进房说话,句末停顿 >
VAD_MIN_SILENCE_DURATION(默认 0.55s)。 - 控制台预期:
speech started from user1speech ended from user1 duration=...transcript from user1: "..."
- 若仅有 VAD 无文本:检查 CUDA / 显存 /
WHISPER_LANGUAGE/ utterance 是否过短 ;若断句不准:调VAD_MIN_SILENCE_DURATION或VAD_ACTIVATION_THRESHOLD,并用UTTERANCE_DEBUG_DIR试听 WAV。
2.4 代码实战
(1)增加依赖和环境变量
env
python
# LiveKit 服务 WebSocket 地址(本机 Docker 联调用 ws://localhost:7880)
LIVEKIT_URL=ws://localhost:7880
# API 密钥名,须与 livekit-dev/livekit.yaml 中 keys 的键名一致
LIVEKIT_API_KEY=devkey
# API 密钥值,须与 livekit.yaml 中对应 secret 一致
LIVEKIT_API_SECRET=secret
# Agent 加入的房间名,须与浏览器 Meet 使用的 room 相同(如 room1)
LIVEKIT_ROOM=room1
# Agent 在房间内的唯一标识,勿与网页端 user1 重复
LIVEKIT_AGENT_IDENTITY=companion-bot
# 每收到多少帧音频打印一次汇总日志(首帧仍会单独打印)
AUDIO_LOG_EVERY_N_FRAMES=50
# 日志级别:DEBUG / INFO / WARNING / ERROR
LOG_LEVEL=INFO
# --- VAD(Silero)---
# 推理采样率,仅支持 8000 或 16000
VAD_SAMPLE_RATE=16000
# 句末静音持续多久判定一句话结束(秒)
VAD_MIN_SILENCE_DURATION=0.55
# 语音激活概率阈值(0~1)
VAD_ACTIVATION_THRESHOLD=0.5
# --- STT(Faster-Whisper + CUDA)---
WHISPER_MODEL=large-v3-turbo
#WHISPER_MODEL=small
WHISPER_DEVICE=cuda
# CUDA 推荐 float16;CPU 可用 int8
WHISPER_COMPUTE_TYPE=float16
# 留空或 auto 表示自动检测语言
WHISPER_LANGUAGE=zh
WHISPER_BEAM_SIZE=5
# 可选:保存断句 WAV 便于试听(留空则不保存)
UTTERANCE_DEBUG_DIR=
# Windows CUDA:Purfview cuBLAS/cuDNN 解压目录(含 cublas64_12.dll)
# PyCharm 未重启导致 PATH 不生效时,Agent 仍可通过此项加载 DLL
CUDA_DLL_DIR=C:\env\cuda12_libsrequirements
text
livekit>=1.0.0,<2.0.0
livekit-api>=1.0.0,<2.0.0
python-dotenv>=1.0.0,<2.0.0
livekit-agents>=1.5.0,<2.0.0
livekit-plugins-silero>=1.5.0,<2.0.0
faster-whisper>=1.0.0,<2.0.0
numpy>=1.26.0,<3.0.0这里有一个注意点,因为我是直接使用GPU进行语音转写的,没有使用轻量级的CPU,因为最终还是得转到GPU,如果机器有限可以使用CPU形式。
测试过程比较麻烦,可能会遇到各种的环境问题,毕竟在window中兼容不是那么好
之后下载一个GPU依赖,用来进行语音转写:
- 下载地址:https://github.com/Purfview/whisper-standalone-win/releases/download/libs/cuBLAS.and.cuDNN_CUDA12_win_v2.7z
- 之后解压缩到一个位置,会看到下面的情况(记住这个位置,要配置环境变量)
- 配置环境变量,到用户即可
(2)修改 config 配置文件,增加VAD和STT的配置
python
from __future__ import annotations
import os
from dataclasses import dataclass
from dotenv import load_dotenv
_REQUIRED = (
"LIVEKIT_URL",
"LIVEKIT_API_KEY",
"LIVEKIT_API_SECRET",
"LIVEKIT_ROOM",
"LIVEKIT_AGENT_IDENTITY",
)
_VAD_SAMPLE_RATES = frozenset({8000, 16000})
class ConfigError(ValueError):
"""Raised when required LiveKit configuration is missing or invalid."""
@dataclass(frozen=True)
class Settings:
# --- LiveKit 连接(阶段 1 Transport)---
url: str # WebSocket 地址,如 ws://localhost:7880
api_key: str # API 密钥名,与 livekit.yaml 中 keys 键名一致
api_secret: str # API 密钥值,用于签发 Agent JWT
room: str # Agent 加入的房间名,须与 Meet 端相同
agent_identity: str # Agent 在房间内的 identity,勿与网页 user1 重复
# --- 通用 ---
log_level: str = "INFO" # 日志级别:DEBUG / INFO / WARNING / ERROR
# --- Silero VAD(阶段 2 断句)---
vad_sample_rate: int = 16000 # VAD 推理采样率,仅支持 8000 或 16000
vad_min_silence_duration: float = 0.55 # 句末静音持续多久判定 EOS(秒)
vad_activation_threshold: float = 0.5 # 人声概率阈值,越高越不易误触发
# --- Faster-Whisper STT(阶段 2 转写)---
whisper_model: str = "large-v3-turbo" # Whisper 模型名
whisper_device: str = "cuda" # 推理设备:cuda 或 cpu
whisper_compute_type: str = "float16" # 量化/精度:CUDA 常用 float16,CPU 可用 int8
whisper_language: str | None = "zh" # 识别语言;None 表示自动检测
whisper_beam_size: int = 5 # 束搜索宽度;1 更快,5 更准确(调试默认)
# --- 调试 ---
utterance_debug_dir: str | None = None # 非空时将 VAD 断句 WAV 保存到该目录
def _require(name: str) -> str:
value = os.getenv(name)
if not value or not value.strip():
raise ConfigError(f"Missing required environment variable: {name}")
return value.strip()
def _optional_language(raw: str) -> str | None:
value = raw.strip()
if not value or value.lower() == "auto":
return None
return value
def load_settings(*, env_file: str | None = None) -> Settings:
load_dotenv(env_file)
missing = [name for name in _REQUIRED if not os.getenv(name, "").strip()]
if missing:
raise ConfigError(
f"Missing required environment variables: {', '.join(missing)}"
)
vad_sample_rate = int(os.getenv("VAD_SAMPLE_RATE", "16000"))
if vad_sample_rate not in _VAD_SAMPLE_RATES:
raise ConfigError("VAD_SAMPLE_RATE must be 8000 or 16000")
vad_min_silence = float(os.getenv("VAD_MIN_SILENCE_DURATION", "0.55"))
if vad_min_silence <= 0:
raise ConfigError("VAD_MIN_SILENCE_DURATION must be > 0")
vad_threshold = float(os.getenv("VAD_ACTIVATION_THRESHOLD", "0.5"))
if not 0.0 < vad_threshold < 1.0:
raise ConfigError("VAD_ACTIVATION_THRESHOLD must be between 0 and 1")
whisper_beam_size = int(os.getenv("WHISPER_BEAM_SIZE", "5"))
if whisper_beam_size < 1:
raise ConfigError("WHISPER_BEAM_SIZE must be >= 1")
debug_dir = os.getenv("UTTERANCE_DEBUG_DIR", "").strip() or None
return Settings(
url=_require("LIVEKIT_URL"),
api_key=_require("LIVEKIT_API_KEY"),
api_secret=_require("LIVEKIT_API_SECRET"),
room=_require("LIVEKIT_ROOM"),
agent_identity=_require("LIVEKIT_AGENT_IDENTITY"),
log_level=os.getenv("LOG_LEVEL", "INFO").strip().upper() or "INFO",
vad_sample_rate=vad_sample_rate,
vad_min_silence_duration=vad_min_silence,
vad_activation_threshold=vad_threshold,
whisper_model=os.getenv("WHISPER_MODEL", "large-v3-turbo").strip(),
whisper_device=os.getenv("WHISPER_DEVICE", "cuda").strip(),
whisper_compute_type=os.getenv("WHISPER_COMPUTE_TYPE", "float16").strip(),
whisper_language=_optional_language(os.getenv("WHISPER_LANGUAGE", "zh")),
whisper_beam_size=whisper_beam_size,
utterance_debug_dir=debug_dir,
)(3)核心main文件以及其他(方便点直接将我的源码进行展示)
直接下载即可 第二阶段资源
这个是需要VIP下载的,之后我会上传完整代码到gitee或者GitHub,有兴趣的可以看看。
大致的运行效果如下:
python
2026-06-06 14:50:02,600 INFO [voice_agent.audio_consumer] [VAD] SOS 开始说话:identity=user1
2026-06-06 14:50:05,450 INFO [voice_agent.audio_consumer] [VAD] EOS 断句完成:identity=user1 duration=2.34s
2026-06-06 14:50:05,450 INFO [voice_agent.pipeline.stt] [STT] 开始转写:3.41s 音频,language=zh beam_size=5
2026-06-06 14:50:05,453 INFO [faster_whisper] Processing audio with duration 00:03.412
2026-06-06 14:50:06,350 INFO [voice_agent.audio_consumer] [VAD] SOS 开始说话:identity=user1
2026-06-06 14:50:06,467 INFO [voice_agent.audio_consumer] [STT] 转写结果 identity=user1: "现在开始测试一下说后打断"
2026-06-06 14:50:08,724 INFO [voice_agent.audio_consumer] [VAD] EOS 断句完成:identity=user1 duration=1.86s
2026-06-06 14:50:08,724 INFO [voice_agent.pipeline.stt] [STT] 开始转写:2.93s 音频,language=zh beam_size=5
2026-06-06 14:50:08,732 INFO [faster_whisper] Processing audio with duration 00:02.932
2026-06-06 14:50:08,940 INFO [voice_agent.audio_consumer] [VAD] SOS 开始说话:identity=user1
2026-06-06 14:50:09,275 INFO [voice_agent.audio_consumer] [STT] 转写结果 identity=user1: "Tadana Tadana Tadana"
2026-06-06 14:50:10,961 INFO [voice_agent.audio_consumer] [VAD] EOS 断句完成:identity=user1 duration=1.50s
2026-06-06 14:50:10,961 INFO [voice_agent.pipeline.stt] [STT] 开始转写:2.58s 音频,language=zh beam_size=5
2026-06-06 14:50:10,963 INFO [faster_whisper] Processing audio with duration 00:02.580
2026-06-06 14:50:11,261 INFO [voice_agent.audio_consumer] [STT] 转写结果 identity=user1: "欸欸欸 唱了唱了"
2026-06-06 14:50:17,341 INFO [voice_agent.main] [Transport] 断开连接
2026-06-06 14:50:17,344 INFO [voice_agent.audio_consumer] [管线] 音轨结束,收尾:identity=user1 共收到 1794 帧
2026-06-06 14:50:17,347 INFO [voice_agent.audio_consumer] [管线] 消费任务结束:identity=user1 track_sid=TR_AMHYLhrgjFz5JN
2026-06-06 14:50:17,354 INFO [livekit] livekit::room:1646:livekit::room - disconnected from room with reason: ClientInitiated下一阶段预告(阶段 3) :LLM 理解 + 记忆;TTS 回传与 Barge-in 打断。当前阶段 2 仅完成 「听到 → 断句 → 转文字」,尚未生成回复语音。
在第二阶段成功将用户的语音转化为文字(STT)后,系统便进入了第三阶段:智能体大脑决策 (LLM)。
三、 智能体大脑决策 (LLM)
3.1 DeepSeek API 流式调用与极速响应配置
(1) 为什么首选 deepseek-v4-flash 及其架构特点
1. 废弃平滑过渡与别名映射
根据官方公告,旧版的 deepseek-chat 会被完全映射为 deepseek-v4-flash 的非思考模式(Non-thinking Mode)。直接接入新一代 V4 架构,能享受到更强的长上下文控制能力和更佳的口语表达。
2. 混合专家模型 (MoE) 架构
deepseek-v4-flash 拥有 284B 的总参数,但在推理时仅激活其中的 13B 参数。
- 超高吞吐率 :由于激活参数量小,配合 V4 全新的 Multi-Head Latent Attention 升级架构,它在公网 API 的输出速度能达到惊人的 100 ~ 150 TPS(每秒生成的 Token 数)。
- 极佳的性价比:百万输入 Token 仅需 0.14 美元左右,百万输出 Token 仅需 0.28 美元。这极大降低了陪伴机器人长时间在线、多轮长对话交互的运行成本。
(2) 关键优化:显式关闭思考模式(Thinking Mode)以斩断首字延迟(TTFT)
1. 思考模式对语音交互的"致命伤"
DeepSeek V4 系列原生支持"思考链(Chain of Thought)",并且在默认配置下,API 里的思考模式是自动开启的。
- 流程瓶颈 :当开启思考时,API 必须先输出一大段被
<think>...</think>包裹的推理思考内容,然后再输出最终答案(content)。 - 延迟灾难:在文本交互中,思考能提高准确率;但在语音通话中,哪怕模型只思考 1 秒钟,首字延迟(TTFT - Time to First Token)也会飙升至 1 秒以上,导致聊天体验极具"对讲机"式的迟钝感。
2. 如何显式关闭思考模式
为了达成类似真人对话的秒级响应,我们必须强制模型进入 即时模式(Instant Mode / Non-thinking Mode) 。
在使用标准的 OpenAI-compatible 客户端库时,需要配置请求中的 extra_body 参数:
python
# Cursor 编写核心:在请求参数中显式加入该配置
extra_body={"thinking": {"type": "disabled"}}- 实现效果 :显式关闭
thinking后,DeepSeek 接口将彻底斩断推理开销,不返回任何reasoning_content。首字响应延迟(TTFT)将被极限压制到 100ms ~ 150ms 以内。
(3) 异步流式输出(Streaming)的技术核心与非阻塞消费
1. 为什么"流式输出"是绝对红线?
在不使用流式输出(即 stream=False)时,API 需要等待 DeepSeek 把整句话(比如 30 个字)全部写完后,再一次性打包通过网络返回。在 100 TPS 的高速度下,生成 30 个字也需要 300ms,加上网络 RTT 延迟,用户会有明显的卡顿感。
开启 stream=True 后,大模型每生成一个字符碎片(Delta),服务器便会通过 Server-Sent Events (SSE) 协议立即推送给我们的本地程序。
2. 异步消费队列(Async Queue)的设计方式
在 Python 端,接收 LLM 的流式输出和将其传递给 TTS 进行合成,必须采用完全解耦、并发运行的架构。
- 生产者(Producer)逻辑 :
编写一个异步生成器函数。它负责向 DeepSeek 发起连接并设置stream=True。随后,使用async for chunk in response循环不断读取新字符。每读取到一个字符,就立刻将其放入一个 Pythonasyncio.Queue(异步队列)中。 - 消费者(Consumer)逻辑 :
另一个并行的异步任务会作为一个消费者,实时从该asyncio.Queue中await queue.get()取出文字。这个消费者不需要等待大模型吐完所有的字,它只需看到队列里积累了足够组成一句话的字数(配合接下来的 3.4 标点断句算法),就立刻将该句"零延迟"抛给第四阶段的合成器(TTS)。
通过这种双任务队列架构,大模型的文字生成时间被巧妙地"隐藏"在了语音合成的并行流水线中。
3.2 陪伴型 System Prompt 与语音化特征设计
将传统的文本大模型塑造成一个自然、温润的情感陪伴智能体,关键在于提示词工程(Prompt Engineering)。传统的"全能助手"式回复习惯输出结构清晰、信息量巨大的长篇大论,这在语音交互中会带来极差的听觉疲劳感。
本节我们将解析如何构建一个"听觉优先(Voice-First)"的 System Prompt,以及如何约束模型的输出行为。
(1) 情感陪伴人设(Persona)构建与同理心机制
1. 倾听与验证(Validation)优先
传统助手在面对用户诉苦(如"我今天搞砸了面试")时,往往会立刻列出"面试失败的 5 个建议"。这种逻辑在陪伴场景中是极其生硬的。
- 同理心循环(Empathy Loop) :在 Prompt 中,必须强制模型在回复的前半句首先进行情绪同步和安慰(例如:"抱抱你,面试不顺利确实很让人沮丧......")。只有在完成了情绪安抚后,才能以朋友的角度委婉给出建议。
2. 口语语气词与反馈(Backchanneling)
真人说话时,会夹杂大量的语气词和动态反馈,这能极大地消解机器人的冰冷感。
- 语气词注入:在人设中,引导模型自然地使用诸如"唔......"、"诶?"、"哈~"、"嘛......"、"呢/呀/啦"等口语化词汇。
- 段落节奏感:引导模型模仿人说话时的停顿感,避免使用"然而"、"因此"、"综上所述"等过于书面和考究的学术连接词,改用"不过"、"所以说"、"那......"等日常口语转折。
(2) "听觉优先(Voice-First)"的输出限制与净化
大模型默认非常喜欢输出精美的格式,我们必须通过极高权重的规则对其进行"净化"。
1. 绝对禁用的 Markdown 语法
语音合成模型(TTS)在读取 Markdown 格式时会产生严重的语调错误,甚至直接将特殊字符读出来。
- 规则设定 :必须在 Prompt 中严厉禁止输出
*斜体*、**加粗**、### 标题、- 无序列表、1. 有序列表、[超链接]、代码块以及各种括号。所有的输出必须是纯净无污染的连续自然文本。
2. 字数与轮次控制(Turn-taking)
如果机器人一口气连续说 100 字以上(播放时长超过 20 秒),用户会很快失去注意力,交互会退化成"听广播"。
- 单次回答字数限制 :在 Prompt 中,限制单次回复的长度在 50 到 80 字以内(通常不超过 3 句话)。
- 互动引导(Interactivity):鼓励模型在每轮对话的结尾,以一个温柔、自然的开放式问题反问用户(例如:"那你今晚打算吃点什么来奖励自己呀?"),以此引导用户继续表达,形成良性的多轮互动。
3. 彻底过滤 Emoji 与图形符号
虽然 😊、🐱 等 Emoji 在屏幕上很可爱,但很多高质量的 TTS 模型在遇到它们时,会出现声音突然断裂、吞音,或者直接生硬地念出其中文译名(如"笑脸")。
- 规避策略 :在 System Prompt 底部设立最高优先级禁令:
"在任何情况下都绝对不要在回复中夹带任何表情符号(Emoji)或图形符号。"
(3) 针对 deepseek-v4-flash 的结构化提示词编写策略
deepseek-v4-flash 模型得益于其 MoE 架构的微调机制,对 XML 标签结构 有着极佳的解析能力。构建 Prompt 时,建议使用标准的 XML 结构来拆分规则,这比一整篇大白话的提示词具有更强的约束力和更低的角色偏离率。
结构化 Prompt 模块推荐:
<identity>标签:定义智能体的名字、性格(温和、耐心、带有一点幽默感)以及与用户的关系(贴心的挚友)。<empathy_guidelines>标签:规定情绪反馈的权重。例如:"当用户表达负面情绪时,优先安抚,不主动说教。"<voice_constraints>标签 :专门放入"Voice-First"的硬性红线规则(如:字数、Markdown 禁用、Emoji 禁用、数字汉字化)。通过将规则打包,deepseek-v4-flash在长对话中能始终保持极其稳定的语音格式输出。
3.3 实时会话历史与上下文记忆管理
大语言模型(LLM)本身是无状态的(Stateless) 。为了让陪伴智能体拥有"记忆",我们必须在每次发起 API 请求时,将所有的历史对话上下文(即包含 user 和 assistant 的消息数组)作为一个整体打包发送给 DeepSeek。
(1) 为什么会话历史对 DeepSeek Context Caching 极为敏感
1. DeepSeek 的自动缓存机制
deepseek-v4-flash 默认开启了基于硬盘的自动上下文缓存(Context Caching on Disk)。
- 缓存命中规则 :DeepSeek 从第 0 个 Token(即最开头的 System Prompt)开始向后进行严格的字节级前缀匹配(Byte-identical Prefix Matching)。如果当前请求的前缀与前一轮请求的前缀完全一致,重合的部分就会直接命中缓存(收费暴降 90%,且首字延迟压制到最低)。
2. "滑动窗口"引发的缓存雪崩(Cache Miss)
传统的上下文管理通常采用"逐轮滑窗(Sliding Window)":即每新增一轮对话,就从列表头部丢弃最老的一轮对话,以维持固定的消息数量。
- 雪崩原理 :一旦您删除了最开头的第 1 轮对话,整个消息列表的开头(第 0 字节)就发生了改变 。这会导致 DeepSeek 的前缀匹配机制完全失效,引发整轮 Prompt 的 Cache Miss。
- 后果:原本 100ms 的延迟可能会因为需要重新计算全部 KV Cache 而飙升到 600ms 以上,且每一轮都需要支付昂贵的"缓存未命中"输入费用。
(2) 块级压缩(Batch Compaction)策略:防止缓存雪崩
为了解决上述冲突,在 Cursor 中编写内存管理器时,不能采用逐轮滑窗,而应采用块级压缩策略:
1. 块级压缩的运作机制
- 常态下:只追加,不删除 。
在对话进行时,允许消息列表持续自然增长(例如 1 轮、2 轮、3 轮......直到 15 轮)。因为每次都是在尾部追加新对话,其最开头的前缀是 100% 稳定的,能实现 100% 的缓存命中率(Cache Hit)。 - 临界点:一次性大块裁剪(Compaction) 。
只有当检测到历史对话的总 Token 数超过了设定阈值(例如达到 8,000 Tokens)时,才触发一次单次大块裁剪。一次性将最老的前 10 轮对话全部切除,仅保留最近的 5 轮。 - 性能对比 :
- 逐轮滑窗 :从第 10 轮开始,以后每一轮对话都会发生 Cache Miss。
- 块级压缩 :只有在触发裁剪的那唯一一轮会产生一次 Cache Miss,之后随着新的追加,立刻重新恢复 100% 的 Cache Hit。这能将 90% 以上的会话控制在超低延迟状态。
(3) 动态记忆抽离与持久化(UserProfile Injection)方案
既然我们会在临界点进行大块裁剪,那些被切除的历史对话(比如用户在第 2 轮提到的"我今天心情不好是因为跟妈妈吵架了")就会永久丢失。
为了让智能体保持长久、深刻的情感羁绊记忆,我们需要在内存管理之外设计一套动态记忆提取与注入机制。
1. 结构化记忆提取(Background Worker)
设计一个并行的轻量级后台任务。每当一轮对话结束触发 EOS 时,异步触发一个极简的逻辑:
- 如果用户话语中包含关键个人信息(名字、宠物、喜好、重大生活事件、当日心情),将其提取为键值对(例如:
{ "user_mood": "sad", "reason": "fight with mother" })。 - 将该键值对保存到本地的一个轻量级 JSON 文件或 SQLite 数据库中(以 LiveKit 传入的用户 Identity 或 RoomID 作为 Key)。
2. 原文存储
接入向量数据库,将原文通过向量存储在数据库中,每次对话之前如果需要则检索向量库,可以加入多个轻量级模型判断是否需要注入历史信息,比如用户提问昨天我干了什么等等。
3. 动态 System Prompt 注入
在下一轮向 DeepSeek 发起请求前,内存管理器从本地读取该用户的结构化记忆,并将其格式化为 XML 标签,动态插入到 System Prompt 的最尾部。
-
注入示例:
xml<system_prompt> ... (固定不变的基础人设) </system_prompt> <user_profile_memory> 用户姓名: 小明 近期重大事件: 今天和妈妈吵架了,心情低落。 喜欢的动物: 猫咪 </user_profile_memory> -
对缓存的友好性:由于用户的个人画像和近期记忆在短时间内是高度稳定的(不会每轮都变),将其置于 System Prompt 头部(或紧随其后)依然能被 DeepSeek 极好地缓存。
-
实现效果 :即使真实的对话历史已经被大块裁剪,智能体依然能通过读取
<user_profile_memory>保持长期记忆(例如在第 20 轮突然主动关心:"小明,你和妈妈和好了吗?"),给用户带来极高的人性化陪伴体验。
3.4 文本流前置正则化与句子级切片
如果对大模型流式吐出的文本直接进行语音合成,会遇到两个破坏性的痛点:
- 发音灾难 :TTS 模型遇到数字(如
2026)、百分号(如80%)或外语缩写时,往往会出现生硬的单字拼读或直接跳过,严重损害听觉体验。 - 延迟与语调的矛盾:如果等大模型全部生成完再合成,延迟会高达数秒;如果一个字一个字送给 TTS 合成,TTS 会因为没有上下文而失去抑扬顿挫的语气,听起来像没有感情的机器人。
为了完美隐藏 LLM 的生成时间并保持自然的语音语调,我们必须在本地实现文本流前置正则化 与标点符号级动态切片。
(1) 文本正则化(Text Normalization)的核心逻辑
文本正则化的目的是将所有的非口语书面符号,在送入 TTS 之前,于内存中实时转化为纯中文拼音可读的口语字。
1. 数字口语化转化
- 年份转化 :例如
2026应该转化为二零二六年,而不是两千零二十六。 - 数值与基数转化 :例如
123应该转化为一百二十三。 - 百分比与小数 :例如
12.5%应该转化为百分之十二点五。
2. 特殊符号与单位清洗
- 将
$转化为美元,¥转化为元。 - 剔除所有不可读的字符(如
*、_、#、[、]等 Markdown 标记符号),防止 TTS 发生爆音或异常停顿。 - 剔除残留的表情符号(Emoji)。
(2) 标点符号拦截器与流式句子级切片(Sentence Slicing)算法
这是控制系统首字延迟(TTFT)的核心算法。其核心思想是:让 TTS 每次合成的单位,既能形成完整的语调起伏,又不至于让用户等待太久。
1. 划分断句优先级
我们在缓冲区(Buffer)积攒字符时,根据不同的标点符号设定不同的切片行为:
- 强断句符号 :句号(
。)、问号(?)、感叹号(!)以及换行符。- 策略 :无论当前缓冲区攒了多少个字,只要一出现这些符号,必须立刻强制切片并把这句话弹出送往 TTS。因为这些符号代表了一句完整话的终结,TTS 能够完美还原句尾的降调或升调。
- 弱断句符号 :逗号(
,)、分号(;)、冒号(:)。- 策略 :为了防止句子过短导致发音像挤牙膏,我们需要设置一个
min_sentence_len(最小切片字数,通常设为 8 ~ 12 个字)。 - 只有当缓冲区积攒的字数超过 10 个字,且最新收到的字符是逗号时,才触发切片。如果少于 10 个字,则继续在缓冲区积攒,等待后面的字符。
- 策略 :为了防止句子过短导致发音像挤牙膏,我们需要设置一个
(3) 并行流水线(Pipeline)架构设计
利用 Python 的 asyncio 协程搭建一个三级异步流水线(Pipeline) 。三级任务通过两个 asyncio.Queue(异步队列)进行无缝数据传递:
text
[ DeepSeek V4-Flash API ] (流式生成)
|
| (1. 逐个吐出字符 Delta)
v
=================== [ Task 1: LLM_STREAM_TASK ] ===================
* 职责:持续读取 API 的流式输出,将字符实时 Push 到 char_queue
===================================================================
|
| (char_queue)
v
=================== [ Task 2: TEXT_PROCESS_TASK ] =================
* 职责:从 char_queue 消费字符
* 维护句缓冲区 buffer
* 运行文本正则化正则匹配(如数字转中文)
* 判断标点符号阈值进行 Sentence Slicing 切片
* 将切好的整句(如"抱抱你,今天过得开心吗?")Push 到 sentence_queue
===================================================================
|
| (sentence_queue)
v
=================== [ Task 3: TTS_SYNTHESIS_TASK ] ================
* 职责:从 sentence_queue 消费完整句子,并按顺序立即送往
第四阶段的本地 CosyVoice 引擎进行流式音频合成。
===================================================================💡 该流水线的极致性能优势:
通过此架构,当 DeepSeek 刚刚吐出第 1 句话的句号时,Task 2 立刻切片送给 Task 3 合成 。
此时,用户已经在听第 1 句话的声音了 ,而大模型其实还在后台默默生成第 2 句和第 3 句话。这种并行流水线能将整个大模型的网络生成延迟100% 隐藏起来,让您的情感机器人拥有近乎真人的交互响应体验。
四、云端语音合成 (TTS) 学习地图 --- MiniMax API 路线
4.1 核心目标与技术选型方案
(1) 阶段数据流与整体目标
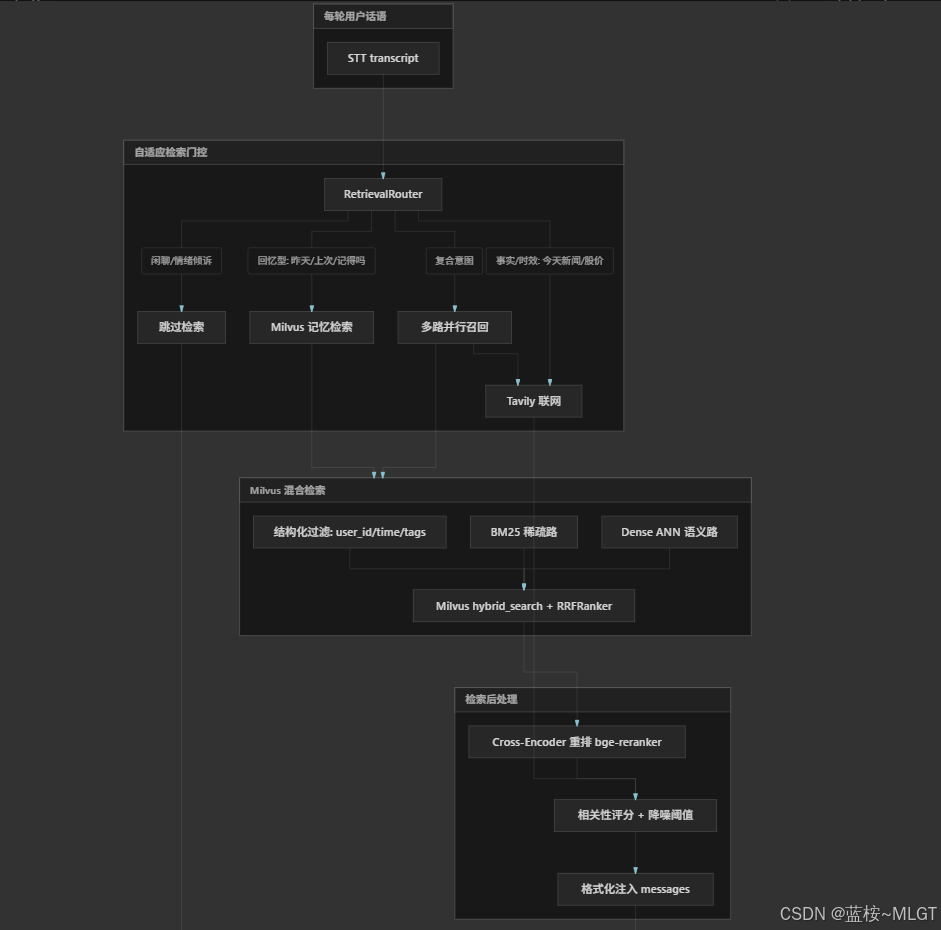
1. 现状回顾与数据流设计
当前已打通"听觉与思考"链路:浏览器麦克风输入 → LiveKit 音频接收 → 静音检测(VAD) → 语音识别(STT) → 检索增强(RAG) → 语言模型(LLM)流式回复并完成句子切片。
第四阶段的建设目标是在不增加本地显卡计算负担的前提下,补齐"说出去"这一环,实现从文本流到浏览器端播放的闭环。
#mermaid-svg-XFaRC23Xp66q9Yw8{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}@keyframes edge-animation-frame{from{stroke-dashoffset:0;}}@keyframes dash{to{stroke-dashoffset:0;}}#mermaid-svg-XFaRC23Xp66q9Yw8 .edge-animation-slow{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 50s linear infinite;stroke-linecap:round;}#mermaid-svg-XFaRC23Xp66q9Yw8 .edge-animation-fast{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 20s linear infinite;stroke-linecap:round;}#mermaid-svg-XFaRC23Xp66q9Yw8 .error-icon{fill:#552222;}#mermaid-svg-XFaRC23Xp66q9Yw8 .error-text{fill:#552222;stroke:#552222;}#mermaid-svg-XFaRC23Xp66q9Yw8 .edge-thickness-normal{stroke-width:1px;}#mermaid-svg-XFaRC23Xp66q9Yw8 .edge-thickness-thick{stroke-width:3.5px;}#mermaid-svg-XFaRC23Xp66q9Yw8 .edge-pattern-solid{stroke-dasharray:0;}#mermaid-svg-XFaRC23Xp66q9Yw8 .edge-thickness-invisible{stroke-width:0;fill:none;}#mermaid-svg-XFaRC23Xp66q9Yw8 .edge-pattern-dashed{stroke-dasharray:3;}#mermaid-svg-XFaRC23Xp66q9Yw8 .edge-pattern-dotted{stroke-dasharray:2;}#mermaid-svg-XFaRC23Xp66q9Yw8 .marker{fill:#333333;stroke:#333333;}#mermaid-svg-XFaRC23Xp66q9Yw8 .marker.cross{stroke:#333333;}#mermaid-svg-XFaRC23Xp66q9Yw8 svg{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;}#mermaid-svg-XFaRC23Xp66q9Yw8 p{margin:0;}#mermaid-svg-XFaRC23Xp66q9Yw8 .label{font-family:"trebuchet ms",verdana,arial,sans-serif;color:#333;}#mermaid-svg-XFaRC23Xp66q9Yw8 .cluster-label text{fill:#333;}#mermaid-svg-XFaRC23Xp66q9Yw8 .cluster-label span{color:#333;}#mermaid-svg-XFaRC23Xp66q9Yw8 .cluster-label span p{background-color:transparent;}#mermaid-svg-XFaRC23Xp66q9Yw8 .label text,#mermaid-svg-XFaRC23Xp66q9Yw8 span{fill:#333;color:#333;}#mermaid-svg-XFaRC23Xp66q9Yw8 .node rect,#mermaid-svg-XFaRC23Xp66q9Yw8 .node circle,#mermaid-svg-XFaRC23Xp66q9Yw8 .node ellipse,#mermaid-svg-XFaRC23Xp66q9Yw8 .node polygon,#mermaid-svg-XFaRC23Xp66q9Yw8 .node path{fill:#ECECFF;stroke:#9370DB;stroke-width:1px;}#mermaid-svg-XFaRC23Xp66q9Yw8 .rough-node .label text,#mermaid-svg-XFaRC23Xp66q9Yw8 .node .label text,#mermaid-svg-XFaRC23Xp66q9Yw8 .image-shape .label,#mermaid-svg-XFaRC23Xp66q9Yw8 .icon-shape .label{text-anchor:middle;}#mermaid-svg-XFaRC23Xp66q9Yw8 .node .katex path{fill:#000;stroke:#000;stroke-width:1px;}#mermaid-svg-XFaRC23Xp66q9Yw8 .rough-node .label,#mermaid-svg-XFaRC23Xp66q9Yw8 .node .label,#mermaid-svg-XFaRC23Xp66q9Yw8 .image-shape .label,#mermaid-svg-XFaRC23Xp66q9Yw8 .icon-shape .label{text-align:center;}#mermaid-svg-XFaRC23Xp66q9Yw8 .node.clickable{cursor:pointer;}#mermaid-svg-XFaRC23Xp66q9Yw8 .root .anchor path{fill:#333333!important;stroke-width:0;stroke:#333333;}#mermaid-svg-XFaRC23Xp66q9Yw8 .arrowheadPath{fill:#333333;}#mermaid-svg-XFaRC23Xp66q9Yw8 .edgePath .path{stroke:#333333;stroke-width:2.0px;}#mermaid-svg-XFaRC23Xp66q9Yw8 .flowchart-link{stroke:#333333;fill:none;}#mermaid-svg-XFaRC23Xp66q9Yw8 .edgeLabel{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-XFaRC23Xp66q9Yw8 .edgeLabel p{background-color:rgba(232,232,232, 0.8);}#mermaid-svg-XFaRC23Xp66q9Yw8 .edgeLabel rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-XFaRC23Xp66q9Yw8 .labelBkg{background-color:rgba(232, 232, 232, 0.5);}#mermaid-svg-XFaRC23Xp66q9Yw8 .cluster rect{fill:#ffffde;stroke:#aaaa33;stroke-width:1px;}#mermaid-svg-XFaRC23Xp66q9Yw8 .cluster text{fill:#333;}#mermaid-svg-XFaRC23Xp66q9Yw8 .cluster span{color:#333;}#mermaid-svg-XFaRC23Xp66q9Yw8 div.mermaidTooltip{position:absolute;text-align:center;max-width:200px;padding:2px;font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:12px;background:hsl(80, 100%, 96.2745098039%);border:1px solid #aaaa33;border-radius:2px;pointer-events:none;z-index:100;}#mermaid-svg-XFaRC23Xp66q9Yw8 .flowchartTitleText{text-anchor:middle;font-size:18px;fill:#333;}#mermaid-svg-XFaRC23Xp66q9Yw8 rect.text{fill:none;stroke-width:0;}#mermaid-svg-XFaRC23Xp66q9Yw8 .icon-shape,#mermaid-svg-XFaRC23Xp66q9Yw8 .image-shape{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-XFaRC23Xp66q9Yw8 .icon-shape p,#mermaid-svg-XFaRC23Xp66q9Yw8 .image-shape p{background-color:rgba(232,232,232, 0.8);padding:2px;}#mermaid-svg-XFaRC23Xp66q9Yw8 .icon-shape .label rect,#mermaid-svg-XFaRC23Xp66q9Yw8 .image-shape .label rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-XFaRC23Xp66q9Yw8 .label-icon{display:inline-block;height:1em;overflow:visible;vertical-align:-0.125em;}#mermaid-svg-XFaRC23Xp66q9Yw8 .node .label-icon path{fill:currentColor;stroke:revert;stroke-width:revert;}#mermaid-svg-XFaRC23Xp66q9Yw8 :root{--mermaid-font-family:"trebuchet ms",verdana,arial,sans-serif;} 本阶段:流式合成与播放通路
已实现:输入与决策链路
物理打断
浏览器麦克风
LiveKit 接收音轨
VAD 语音检测
STT 文本转译
编排调度中心
知识库/向量库检索
LLM 流式回复
句子切片与正则化
日志输出/无音频
云端 MiniMax T2A
Hex PCM 数据解码
重采样至 48kHz
LiveKit 发布音轨
浏览器端接收播放
VAD 开始说话信号
代码执行流程,可根据图片进行对应
#mermaid-svg-iSETHRLhVmZ2TGgo{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}@keyframes edge-animation-frame{from{stroke-dashoffset:0;}}@keyframes dash{to{stroke-dashoffset:0;}}#mermaid-svg-iSETHRLhVmZ2TGgo .edge-animation-slow{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 50s linear infinite;stroke-linecap:round;}#mermaid-svg-iSETHRLhVmZ2TGgo .edge-animation-fast{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 20s linear infinite;stroke-linecap:round;}#mermaid-svg-iSETHRLhVmZ2TGgo .error-icon{fill:#552222;}#mermaid-svg-iSETHRLhVmZ2TGgo .error-text{fill:#552222;stroke:#552222;}#mermaid-svg-iSETHRLhVmZ2TGgo .edge-thickness-normal{stroke-width:1px;}#mermaid-svg-iSETHRLhVmZ2TGgo .edge-thickness-thick{stroke-width:3.5px;}#mermaid-svg-iSETHRLhVmZ2TGgo .edge-pattern-solid{stroke-dasharray:0;}#mermaid-svg-iSETHRLhVmZ2TGgo .edge-thickness-invisible{stroke-width:0;fill:none;}#mermaid-svg-iSETHRLhVmZ2TGgo .edge-pattern-dashed{stroke-dasharray:3;}#mermaid-svg-iSETHRLhVmZ2TGgo .edge-pattern-dotted{stroke-dasharray:2;}#mermaid-svg-iSETHRLhVmZ2TGgo .marker{fill:#333333;stroke:#333333;}#mermaid-svg-iSETHRLhVmZ2TGgo .marker.cross{stroke:#333333;}#mermaid-svg-iSETHRLhVmZ2TGgo svg{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;}#mermaid-svg-iSETHRLhVmZ2TGgo p{margin:0;}#mermaid-svg-iSETHRLhVmZ2TGgo .label{font-family:"trebuchet ms",verdana,arial,sans-serif;color:#333;}#mermaid-svg-iSETHRLhVmZ2TGgo .cluster-label text{fill:#333;}#mermaid-svg-iSETHRLhVmZ2TGgo .cluster-label span{color:#333;}#mermaid-svg-iSETHRLhVmZ2TGgo .cluster-label span p{background-color:transparent;}#mermaid-svg-iSETHRLhVmZ2TGgo .label text,#mermaid-svg-iSETHRLhVmZ2TGgo span{fill:#333;color:#333;}#mermaid-svg-iSETHRLhVmZ2TGgo .node rect,#mermaid-svg-iSETHRLhVmZ2TGgo .node circle,#mermaid-svg-iSETHRLhVmZ2TGgo .node ellipse,#mermaid-svg-iSETHRLhVmZ2TGgo .node polygon,#mermaid-svg-iSETHRLhVmZ2TGgo .node path{fill:#ECECFF;stroke:#9370DB;stroke-width:1px;}#mermaid-svg-iSETHRLhVmZ2TGgo .rough-node .label text,#mermaid-svg-iSETHRLhVmZ2TGgo .node .label text,#mermaid-svg-iSETHRLhVmZ2TGgo .image-shape .label,#mermaid-svg-iSETHRLhVmZ2TGgo .icon-shape .label{text-anchor:middle;}#mermaid-svg-iSETHRLhVmZ2TGgo .node .katex path{fill:#000;stroke:#000;stroke-width:1px;}#mermaid-svg-iSETHRLhVmZ2TGgo .rough-node .label,#mermaid-svg-iSETHRLhVmZ2TGgo .node .label,#mermaid-svg-iSETHRLhVmZ2TGgo .image-shape .label,#mermaid-svg-iSETHRLhVmZ2TGgo .icon-shape .label{text-align:center;}#mermaid-svg-iSETHRLhVmZ2TGgo .node.clickable{cursor:pointer;}#mermaid-svg-iSETHRLhVmZ2TGgo .root .anchor path{fill:#333333!important;stroke-width:0;stroke:#333333;}#mermaid-svg-iSETHRLhVmZ2TGgo .arrowheadPath{fill:#333333;}#mermaid-svg-iSETHRLhVmZ2TGgo .edgePath .path{stroke:#333333;stroke-width:2.0px;}#mermaid-svg-iSETHRLhVmZ2TGgo .flowchart-link{stroke:#333333;fill:none;}#mermaid-svg-iSETHRLhVmZ2TGgo .edgeLabel{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-iSETHRLhVmZ2TGgo .edgeLabel p{background-color:rgba(232,232,232, 0.8);}#mermaid-svg-iSETHRLhVmZ2TGgo .edgeLabel rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-iSETHRLhVmZ2TGgo .labelBkg{background-color:rgba(232, 232, 232, 0.5);}#mermaid-svg-iSETHRLhVmZ2TGgo .cluster rect{fill:#ffffde;stroke:#aaaa33;stroke-width:1px;}#mermaid-svg-iSETHRLhVmZ2TGgo .cluster text{fill:#333;}#mermaid-svg-iSETHRLhVmZ2TGgo .cluster span{color:#333;}#mermaid-svg-iSETHRLhVmZ2TGgo div.mermaidTooltip{position:absolute;text-align:center;max-width:200px;padding:2px;font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:12px;background:hsl(80, 100%, 96.2745098039%);border:1px solid #aaaa33;border-radius:2px;pointer-events:none;z-index:100;}#mermaid-svg-iSETHRLhVmZ2TGgo .flowchartTitleText{text-anchor:middle;font-size:18px;fill:#333;}#mermaid-svg-iSETHRLhVmZ2TGgo rect.text{fill:none;stroke-width:0;}#mermaid-svg-iSETHRLhVmZ2TGgo .icon-shape,#mermaid-svg-iSETHRLhVmZ2TGgo .image-shape{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-iSETHRLhVmZ2TGgo .icon-shape p,#mermaid-svg-iSETHRLhVmZ2TGgo .image-shape p{background-color:rgba(232,232,232, 0.8);padding:2px;}#mermaid-svg-iSETHRLhVmZ2TGgo .icon-shape .label rect,#mermaid-svg-iSETHRLhVmZ2TGgo .image-shape .label rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-iSETHRLhVmZ2TGgo .label-icon{display:inline-block;height:1em;overflow:visible;vertical-align:-0.125em;}#mermaid-svg-iSETHRLhVmZ2TGgo .node .label-icon path{fill:currentColor;stroke:revert;stroke-width:revert;}#mermaid-svg-iSETHRLhVmZ2TGgo :root{--mermaid-font-family:"trebuchet ms",verdana,arial,sans-serif;} 出站 audio_publisher
TTS 后台 tts_queue worker
单轮对话 orchestrator
启动阶段 main.py
是
否
is_tts_active
AudioSource + LocalAudioTrack
PcmPublisher + MinimaxT2AClient
TTSQueue.start worker
DialogOrchestrator 注入 tts_queue
room.connect + publish_track
on_user_utterance
interrupt 清上轮
检索 + 拼 messages
LLM stream 生产者
句切片消费者
enqueue(sent)
deque 取句
有 prefetch?
play_pcm 缓存
synthesize_stream HTTP
feed_pcm 边收边播
finish_stream 冲刷
下一句
32k PCM 重采样 48k
20ms 切帧
capture_frame
Meet 浏览器播放
2. 阶段核心目标
- 流式合成:接收大模型流式切片产生的文本,通过云端接口完成高拟真度声音合成并解码。
- 物理重采样:将合成出的原始音频,上采样对齐至 LiveKit 期望的采样率,并按照音频时间戳打包推送。
- 低延迟通道:浏览器通过 WebRTC 直接订阅智能体发布的本地音轨,无需额外的传输链路。
- 主动打断(Barge-in):在用户开始说话(VAD 触发开始)时,瞬间中断云端请求并冲刷本地播放缓冲。
(2) 云端 API 与本地推理的选型对比
在资源调配上,使用云端 API 与在本地部署深度学习 TTS(如 CosyVoice 等)有明显的策略差异:
| 评估维度 | 本地轻量化模型 / 专属克隆 | 云端开放平台 API |
|---|---|---|
| 本地 GPU 占用 | 频繁与语音识别(STT)模块争抢显存 | 零本地推理资源占用,显卡由 STT 独占 |
| 部署与运维成本 | 需下载数 GB 权重,依赖复杂的音频编译链 | 仅需网络通信组件,版本随云端自动更新 |
| 延迟控制 | 在本地半精度(FP16)加速下可控制在极低范围 | 采用句级流式(Stream)交互,首包响应稳定 |
| 拟真度与表达 | 需要准备较多微调数据集以训练语气起伏 | 预置丰富的系统音色,支持情绪与语气词标签 |
| 计算开销 | 消耗本地功耗与 CPU 算力 | 按照合成的字符数量计量收费 |
4.2 开放平台接入与系统配置
(1) 账号、鉴权与高可用策略
1. 鉴权机制与接口地址
- 使用 HTTP Bearer 鉴权,请求头中需携带
Authorization: Bearer <API_KEY>。 - 平台通常提供不同地域的接口节点,可在主节点出现网络抖动时自动切换至备用节点(如北京等高可用节点)。
2. 常见异常状态码与防护设计
在代码中需要对云端响应进行健壮性捕获,常见的业务状态码包括:
| 状态码 | 业务状态含义 | 容错与防护处理建议 |
|---|---|---|
0 |
成功 | 解析返回数据包,提取音频流 |
1001 |
服务端超时 | 检查单句文本是否过长,并执行重试机制 |
1002 / 1039 |
限流 / TPM 限额 | 引入指数退避重试,限制预取(Prefetch)并发数 |
1004 |
鉴权失败 | 检查配置文件中的密钥有效性 |
1042 |
文本包含过多非法字符 | 优化前置正则化模块,过滤乱码及数学符号 |
2013 |
请求参数异常 | 检查模型版本名称与音色标识符是否匹配 |
(2) 系统环境变量与功能开关设计
1. 核心环境变量清单
在系统的配置模块中,需引入以下参数控制合成行为:
- 密钥配置:控制云端鉴权的 API Key。
- 模型标识:例如选择低延迟的极速版模型,或高音质的旗舰版模型。
- 音色定制:指定系统预设音色或通过克隆生成的专属音色 ID。
- 采样配置:包括云端合成的采样率(如 32kHz 或 16kHz)和本地发布重采样的目标频率(如 48kHz)。
- 表达参数:语速、音量、预设情绪(如冷静、愉快等)。
2. 弱断句配置逻辑
现有的"句子切片器"中已配置弱断句累积字数(例如 10 个字),这个字数阈值是决定切分给云端合成器的最小文本粒度。
(3) 网络与接口连通性验证
1. 独立探活机制
在将合成器模块并入主业务循环前,推荐编写独立的探活脚本进行单点测试:
- 模拟读取配置文件中的鉴权信息。
- 使用非流式模式(
stream=false),对固定测试文本(例如"你好,我是小暖。")发起合成请求。 - 将返回的十六进制字符解码为原始 PCM 字节,手动添加 WAV 音频头并保存至本地,进行人工回放试听。
2. 解耦联调思想
通过独立脚本验证,能够提前将"云端网络与音色配置问题"与"本地 LiveKit 轨发布问题"进行解耦,大幅降低后期的调试难度。
4.3 MiniMax T2A HTTP 协议与客户端封装
(1) 请求体结构与响应协议
1. 协议定义与核心字段
向端点发起 POST 请求,请求体使用标准 JSON 格式。以下为核心控制参数:
model:模型版本号。text:当前切出的文本片段(长度通常有上限约束,超出推荐使用流式)。stream:是否开启流式响应。在实时会话中推荐设为true。voice_setting:配置音色 ID、语速、音量和音调。audio_setting:指定合成的采样率(推荐使用较高质量的 32000Hz)、声道数(通常为 1,单声道)和编码格式(PCM)。
2. 响应格式与 Hex 解码
- 非流式:一次性返回一个 JSON 数据包,其中音频数据通常经过 Hex(十六进制字符串)或 Base64 编码,并附带本次请求的总字符消耗和音频物理时长。
- 流式 :接口通过 SSE(Server-Sent Events)持续推回数据块。通过解析每个分片中
data.status的状态值判断流是否结束(1代表传输中,2代表最后一片,并附带最终的统计信息)。 - 二进制解码:获取到 Hex 格式的字符串后,在本地使用二进制工具将其转换为 PCM 有符号 16 位单声道音频。
3. 基础响应拦截
解析音频字段前,必须先校验基础返回结构中的 base_resp.status_code 是否为 0。如果返回非零值,应立即抛出业务异常,中止后续无意义的二进制解析。
(2) 推理策略选择:非流式 vs 句级流式
1. 适用场景差异分析
- 非流式:适用于系统初始化探活、极短的引导提示语合成。缺点是必须要整句话合成完毕后才能下载,难以保障连贯的交互体验。
- 流式(Stream):采用"边合成边推回"的方式。结合文本切片器,可以极大地压缩首个音频包的到达时间。
2. 生产环境策略实践
对话控制中心采用一句一请求、句内流式的平衡设计:
- 当 LLM 产生文本流时,切片器只要切出一句完整的句子(通常小于 50 个字),便立刻向云端发起一次 T2A 请求。
- 每一个 T2A 请求开启
stream=true,边接收返回的二进制音频切片,边送入本地音频发布轨道。无需等待整个 LLM 回复完全结束。
(3) 异常处理与可观测性监控
1. 可观测性指标追踪
系统需要对每一次合成链路进行精细化度量,包括日志记录接口返回的 trace_id(排查云端抖动的唯一凭证)、本次消耗的字符数、合成出的音频物理时长,以及 TTFA(Time To First Audio) 延迟指标。
2. 超时与重试策略
- 建立连接超时与数据流式读取超时判定(例如,10s 内无新数据块推回则主动切断)。
- 针对网络抖动引起的暂时性错误,引入有限次数(如最多 2 次)的退避重试,若持续失败则跳过当前句的合成,保证控制主进程不会卡死。
(4) 语音情感与表达参数控制(可选)
1. 情绪与语气控制
- 音色情绪:支持传入具体的情绪标签。在情感陪伴场景下,可以选择让模型根据文本上下文自动匹配语调。
- 语气标签:部分高级模型支持在文本中插入呼吸声或笑声等特殊控制符,但需要在 LLM 人设 Prompt 中严格约束其输出频率,避免出现不自然的声音表现。
- 停顿标记:可以在句子拼接处手动插入时间占位符(如停顿符号),使长句间的转换更贴近真人呼吸节奏。
4.4 音频前置切片与异步队列流水线
(1) 复用前置清洗与断句管线
1. 强弱断句判定逻辑
大模型的流式输出先通过文本切片器进行缓冲:
- 遇到强断句符号(如。!?或换行符)立即执行切句。
- 遇到弱断句符号(如,;:),若缓冲区字符数达到设定的最少字数,也执行切分。
2. 文本正则化对齐
切出的句子必须经过正则化处理,将阿拉伯数字、百分号等符号转换为拼音读法,并剔除所有 Markdown 格式和 Emoji 表情,防止云端合成器在读取这些字符时产生吞音或断音。
(2) 异步任务队列设计
1. 串行播放与并行合成的平衡
为了实现无缝的对话流,系统需要协调"LLM 生成、TTS 合成、设备播放"三个维度的时序关系:
LiveKit 音轨源 云端合成接口 异步任务队列 句子切片器 LLM 流式生成器 LiveKit 音轨源 云端合成接口 异步任务队列 句子切片器 LLM 流式生成器 #mermaid-svg-9SMjsKuQdI4EAX8B{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}@keyframes edge-animation-frame{from{stroke-dashoffset:0;}}@keyframes dash{to{stroke-dashoffset:0;}}#mermaid-svg-9SMjsKuQdI4EAX8B .edge-animation-slow{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 50s linear infinite;stroke-linecap:round;}#mermaid-svg-9SMjsKuQdI4EAX8B .edge-animation-fast{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 20s linear infinite;stroke-linecap:round;}#mermaid-svg-9SMjsKuQdI4EAX8B .error-icon{fill:#552222;}#mermaid-svg-9SMjsKuQdI4EAX8B .error-text{fill:#552222;stroke:#552222;}#mermaid-svg-9SMjsKuQdI4EAX8B .edge-thickness-normal{stroke-width:1px;}#mermaid-svg-9SMjsKuQdI4EAX8B .edge-thickness-thick{stroke-width:3.5px;}#mermaid-svg-9SMjsKuQdI4EAX8B .edge-pattern-solid{stroke-dasharray:0;}#mermaid-svg-9SMjsKuQdI4EAX8B .edge-thickness-invisible{stroke-width:0;fill:none;}#mermaid-svg-9SMjsKuQdI4EAX8B .edge-pattern-dashed{stroke-dasharray:3;}#mermaid-svg-9SMjsKuQdI4EAX8B .edge-pattern-dotted{stroke-dasharray:2;}#mermaid-svg-9SMjsKuQdI4EAX8B .marker{fill:#333333;stroke:#333333;}#mermaid-svg-9SMjsKuQdI4EAX8B .marker.cross{stroke:#333333;}#mermaid-svg-9SMjsKuQdI4EAX8B svg{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;}#mermaid-svg-9SMjsKuQdI4EAX8B p{margin:0;}#mermaid-svg-9SMjsKuQdI4EAX8B .actor{stroke:hsl(259.6261682243, 59.7765363128%, 87.9019607843%);fill:#ECECFF;}#mermaid-svg-9SMjsKuQdI4EAX8B text.actor>tspan{fill:black;stroke:none;}#mermaid-svg-9SMjsKuQdI4EAX8B .actor-line{stroke:hsl(259.6261682243, 59.7765363128%, 87.9019607843%);}#mermaid-svg-9SMjsKuQdI4EAX8B .innerArc{stroke-width:1.5;stroke-dasharray:none;}#mermaid-svg-9SMjsKuQdI4EAX8B .messageLine0{stroke-width:1.5;stroke-dasharray:none;stroke:#333;}#mermaid-svg-9SMjsKuQdI4EAX8B .messageLine1{stroke-width:1.5;stroke-dasharray:2,2;stroke:#333;}#mermaid-svg-9SMjsKuQdI4EAX8B #arrowhead path{fill:#333;stroke:#333;}#mermaid-svg-9SMjsKuQdI4EAX8B .sequenceNumber{fill:white;}#mermaid-svg-9SMjsKuQdI4EAX8B #sequencenumber{fill:#333;}#mermaid-svg-9SMjsKuQdI4EAX8B #crosshead path{fill:#333;stroke:#333;}#mermaid-svg-9SMjsKuQdI4EAX8B .messageText{fill:#333;stroke:none;}#mermaid-svg-9SMjsKuQdI4EAX8B .labelBox{stroke:hsl(259.6261682243, 59.7765363128%, 87.9019607843%);fill:#ECECFF;}#mermaid-svg-9SMjsKuQdI4EAX8B .labelText,#mermaid-svg-9SMjsKuQdI4EAX8B .labelText>tspan{fill:black;stroke:none;}#mermaid-svg-9SMjsKuQdI4EAX8B .loopText,#mermaid-svg-9SMjsKuQdI4EAX8B .loopText>tspan{fill:black;stroke:none;}#mermaid-svg-9SMjsKuQdI4EAX8B .loopLine{stroke-width:2px;stroke-dasharray:2,2;stroke:hsl(259.6261682243, 59.7765363128%, 87.9019607843%);fill:hsl(259.6261682243, 59.7765363128%, 87.9019607843%);}#mermaid-svg-9SMjsKuQdI4EAX8B .note{stroke:#aaaa33;fill:#fff5ad;}#mermaid-svg-9SMjsKuQdI4EAX8B .noteText,#mermaid-svg-9SMjsKuQdI4EAX8B .noteText>tspan{fill:black;stroke:none;}#mermaid-svg-9SMjsKuQdI4EAX8B .activation0{fill:#f4f4f4;stroke:#666;}#mermaid-svg-9SMjsKuQdI4EAX8B .activation1{fill:#f4f4f4;stroke:#666;}#mermaid-svg-9SMjsKuQdI4EAX8B .activation2{fill:#f4f4f4;stroke:#666;}#mermaid-svg-9SMjsKuQdI4EAX8B .actorPopupMenu{position:absolute;}#mermaid-svg-9SMjsKuQdI4EAX8B .actorPopupMenuPanel{position:absolute;fill:#ECECFF;box-shadow:0px 8px 16px 0px rgba(0,0,0,0.2);filter:drop-shadow(3px 5px 2px rgb(0 0 0 / 0.4));}#mermaid-svg-9SMjsKuQdI4EAX8B .actor-man line{stroke:hsl(259.6261682243, 59.7765363128%, 87.9019607843%);fill:#ECECFF;}#mermaid-svg-9SMjsKuQdI4EAX8B .actor-man circle,#mermaid-svg-9SMjsKuQdI4EAX8B line{stroke:hsl(259.6261682243, 59.7765363128%, 87.9019607843%);fill:#ECECFF;stroke-width:2px;}#mermaid-svg-9SMjsKuQdI4EAX8B :root{--mermaid-font-family:"trebuchet ms",verdana,arial,sans-serif;} 逐字推送 放入完整句 (enqueue) 异步并发合成 (prefetch) 返回音频切片 (Hex) 顺次播放音频 (capture_frame)
- 播放串行:句子之间的音频播放必须严格首尾相接,不能发生声音重叠。
- 合成并行(预取) :在播放第 N N N 句音频的同时,后台应当已经开始向云端请求合成第 N + 1 N+1 N+1 句音频。这种 Pipeline 预取机制可以极大地消除长对话中的句间卡顿。
2. 队列接口职责定义
异步任务队列应具备以下控制接口:
enqueue:将清洗后的文本和会话身份标识放入队列。cancel:当用户发生打断时,清空当前队列中等待播放和合成的所有任务。is_speaking:供状态机查询,判断当前智能体是否正处于发声状态。
3. 生产者-消费者非阻塞关系
利用异步队列实现 LLM 与 TTS 模块的解耦。大模型流式消费者作为生产者,一旦产生句子即刻放入队列;TTS 消费线程独立运转,从而实现生成与合成的完全异步并行。
4.5 信号处理、重采样与 LiveKit 出站发布
(1) 音频格式选择:PCM vs MP3
1. 编解码延迟考量
- PCM(推荐):云端直接输出原始的脉冲编码调制数据。获取到数据后,只需进行简单的 Hex 转换即可得到 16 位整型音频数组,无需额外的解码依赖,延迟极低。
- MP3:虽然传输体积较小,但本地必须加载额外的解码库,会引入不必要的编解码 CPU 开销和系统复杂性。
(2) 信号处理与采样率上采样(Upsampling)
1. 32kHz 到 48kHz 的数学转换
- 云端合成模型的最高采样率通常为 32kHz 或 24kHz,而 WebRTC (LiveKit) 出站的标准音频流要求统一采用 48kHz、单声道、16-bit signed integer (PCM) 格式。
- 系统需要在本地实现一个音频重采样器(利用插值与滤波算法),将合成出的 32kHz 音频流转换为 48kHz。这与输入端(将 48kHz 下采样至 16kHz 供给 VAD/STT)是一个互逆的信号处理过程。
(3) LiveKit 动态音轨发布流程
1. 创建音频源与本地音轨
在客户端建立连接并进入房间后,本地必须注册并发布属于智能体自身的音频轨道:
- 创建一个 48,000Hz 采样率、单声道的本地音频源(
AudioSource)。 - 基于此音频源,创建对应的本地音频轨道(
LocalAudioTrack)。 - 将该轨道发布到 LiveKit 房间中,供其他房间参与者(浏览器端)订阅。
2. 20ms 时间片对齐与推送
WebRTC 传输音频必须对齐到固定的物理时间窗口(通常为 20毫秒 的帧长)。
- 计算原理 :对于 48kHz 单声道 16-bit 的音频:
单帧采样点 = 48000 × 0.02 = 960 个 \text{单帧采样点} = 48000 \times 0.02 = 960\text{ 个} 单帧采样点=48000×0.02=960 个
单帧字节数 = 960 × ( 16 / 8 ) × 1 声道 = 1920 字节 \text{单帧字节数} = 960 \times (16 / 8) \times 1\text{声道} = 1920\text{ 字节} 单帧字节数=960×(16/8)×1声道=1920 字节 - 实现逻辑 :从重采样缓冲区中以 1920 字节为固定步长,切分出一个个
AudioFrame帧,并通过capture_frame异步推入本地音频源。必须严格控制推送速率与音频播放物理时长一致,避免发生爆音或播放器欠载。
(4) 浏览器端订阅逻辑
1. WebRTC 原生订阅机制
智能体发布音轨后,浏览器端的 LiveKit 客户端会自动捕获这一新音轨的加入事件,并在底层建立 WebRTC 订阅通路进行音频播放。这一过程完全依赖媒体通道完成,不需要本地再额外编写 WebSocket 传输音频。
4.6 端到端延迟预算与物理资源隔离
(1) 延迟预算分配
系统的体感延迟(用户说完到听到声音的时间差)主要由三部分组成:
总体感延迟 ≈ LLM 首字延迟 (TTFT) + 首句切出耗时 + TTS 首包合成延迟 (TTFA) \text{总体感延迟} \approx \text{LLM 首字延迟 (TTFT)} + \text{首句切出耗时} + \text{TTS 首包合成延迟 (TTFA)} 总体感延迟≈LLM 首字延迟 (TTFT)+首句切出耗时+TTS 首包合成延迟 (TTFA)
为了将体感延迟压制在 3 秒以内的黄金交互带,各环节的设计指标如下:
| 阶段 | 延迟来源 | 本阶段核心优化手段 |
|---|---|---|
| LLM 首字响应 (TTFT) | 大模型网络 RTT 与首字推理时间 | 启用流式(stream=True)输出,并结合 DeepSeek 前缀缓存控制 1.2.4, 1.2.5 |
| 首句切出耗时 | 等待大模型生成第一个标点符号的时间 | 动态调小弱断句的累积字数阈值(如设为 6~8 个字),减少前置等待 |
| TTS 首包到达 (TTFA) | 云端网络往返与音频流首包合成时间 | 采用极速版轻量模型 + stream=true 句级流式推送 + TCP 长连接预保持 |
(2) 流水线时间线重叠示意
通过异步并行管线,大模型后续字符的生成、合成开销,可以完全隐藏在当前句子的播放时间窗口内:
#mermaid-svg-LwYqbFsB0iF7qbqU{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}@keyframes edge-animation-frame{from{stroke-dashoffset:0;}}@keyframes dash{to{stroke-dashoffset:0;}}#mermaid-svg-LwYqbFsB0iF7qbqU .edge-animation-slow{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 50s linear infinite;stroke-linecap:round;}#mermaid-svg-LwYqbFsB0iF7qbqU .edge-animation-fast{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 20s linear infinite;stroke-linecap:round;}#mermaid-svg-LwYqbFsB0iF7qbqU .error-icon{fill:#552222;}#mermaid-svg-LwYqbFsB0iF7qbqU .error-text{fill:#552222;stroke:#552222;}#mermaid-svg-LwYqbFsB0iF7qbqU .edge-thickness-normal{stroke-width:1px;}#mermaid-svg-LwYqbFsB0iF7qbqU .edge-thickness-thick{stroke-width:3.5px;}#mermaid-svg-LwYqbFsB0iF7qbqU .edge-pattern-solid{stroke-dasharray:0;}#mermaid-svg-LwYqbFsB0iF7qbqU .edge-thickness-invisible{stroke-width:0;fill:none;}#mermaid-svg-LwYqbFsB0iF7qbqU .edge-pattern-dashed{stroke-dasharray:3;}#mermaid-svg-LwYqbFsB0iF7qbqU .edge-pattern-dotted{stroke-dasharray:2;}#mermaid-svg-LwYqbFsB0iF7qbqU .marker{fill:#333333;stroke:#333333;}#mermaid-svg-LwYqbFsB0iF7qbqU .marker.cross{stroke:#333333;}#mermaid-svg-LwYqbFsB0iF7qbqU svg{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;}#mermaid-svg-LwYqbFsB0iF7qbqU p{margin:0;}#mermaid-svg-LwYqbFsB0iF7qbqU .mermaid-main-font{font-family:"trebuchet ms",verdana,arial,sans-serif;}#mermaid-svg-LwYqbFsB0iF7qbqU .exclude-range{fill:#eeeeee;}#mermaid-svg-LwYqbFsB0iF7qbqU .section{stroke:none;opacity:0.2;}#mermaid-svg-LwYqbFsB0iF7qbqU .section0{fill:rgba(102, 102, 255, 0.49);}#mermaid-svg-LwYqbFsB0iF7qbqU .section2{fill:#fff400;}#mermaid-svg-LwYqbFsB0iF7qbqU .section1,#mermaid-svg-LwYqbFsB0iF7qbqU .section3{fill:white;opacity:0.2;}#mermaid-svg-LwYqbFsB0iF7qbqU .sectionTitle0{fill:#333;}#mermaid-svg-LwYqbFsB0iF7qbqU .sectionTitle1{fill:#333;}#mermaid-svg-LwYqbFsB0iF7qbqU .sectionTitle2{fill:#333;}#mermaid-svg-LwYqbFsB0iF7qbqU .sectionTitle3{fill:#333;}#mermaid-svg-LwYqbFsB0iF7qbqU .sectionTitle{text-anchor:start;font-family:"trebuchet ms",verdana,arial,sans-serif;}#mermaid-svg-LwYqbFsB0iF7qbqU .grid .tick{stroke:lightgrey;opacity:0.8;shape-rendering:crispEdges;}#mermaid-svg-LwYqbFsB0iF7qbqU .grid .tick text{font-family:"trebuchet ms",verdana,arial,sans-serif;fill:#333;}#mermaid-svg-LwYqbFsB0iF7qbqU .grid path{stroke-width:0;}#mermaid-svg-LwYqbFsB0iF7qbqU .today{fill:none;stroke:red;stroke-width:2px;}#mermaid-svg-LwYqbFsB0iF7qbqU .task{stroke-width:2;}#mermaid-svg-LwYqbFsB0iF7qbqU .taskText{text-anchor:middle;font-family:"trebuchet ms",verdana,arial,sans-serif;}#mermaid-svg-LwYqbFsB0iF7qbqU .taskTextOutsideRight{fill:black;text-anchor:start;font-family:"trebuchet ms",verdana,arial,sans-serif;}#mermaid-svg-LwYqbFsB0iF7qbqU .taskTextOutsideLeft{fill:black;text-anchor:end;}#mermaid-svg-LwYqbFsB0iF7qbqU .task.clickable{cursor:pointer;}#mermaid-svg-LwYqbFsB0iF7qbqU .taskText.clickable{cursor:pointer;fill:#003163!important;font-weight:bold;}#mermaid-svg-LwYqbFsB0iF7qbqU .taskTextOutsideLeft.clickable{cursor:pointer;fill:#003163!important;font-weight:bold;}#mermaid-svg-LwYqbFsB0iF7qbqU .taskTextOutsideRight.clickable{cursor:pointer;fill:#003163!important;font-weight:bold;}#mermaid-svg-LwYqbFsB0iF7qbqU .taskText0,#mermaid-svg-LwYqbFsB0iF7qbqU .taskText1,#mermaid-svg-LwYqbFsB0iF7qbqU .taskText2,#mermaid-svg-LwYqbFsB0iF7qbqU .taskText3{fill:white;}#mermaid-svg-LwYqbFsB0iF7qbqU .task0,#mermaid-svg-LwYqbFsB0iF7qbqU .task1,#mermaid-svg-LwYqbFsB0iF7qbqU .task2,#mermaid-svg-LwYqbFsB0iF7qbqU .task3{fill:#8a90dd;stroke:#534fbc;}#mermaid-svg-LwYqbFsB0iF7qbqU .taskTextOutside0,#mermaid-svg-LwYqbFsB0iF7qbqU .taskTextOutside2{fill:black;}#mermaid-svg-LwYqbFsB0iF7qbqU .taskTextOutside1,#mermaid-svg-LwYqbFsB0iF7qbqU .taskTextOutside3{fill:black;}#mermaid-svg-LwYqbFsB0iF7qbqU .active0,#mermaid-svg-LwYqbFsB0iF7qbqU .active1,#mermaid-svg-LwYqbFsB0iF7qbqU .active2,#mermaid-svg-LwYqbFsB0iF7qbqU .active3{fill:#bfc7ff;stroke:#534fbc;}#mermaid-svg-LwYqbFsB0iF7qbqU .activeText0,#mermaid-svg-LwYqbFsB0iF7qbqU .activeText1,#mermaid-svg-LwYqbFsB0iF7qbqU .activeText2,#mermaid-svg-LwYqbFsB0iF7qbqU .activeText3{fill:black!important;}#mermaid-svg-LwYqbFsB0iF7qbqU .done0,#mermaid-svg-LwYqbFsB0iF7qbqU .done1,#mermaid-svg-LwYqbFsB0iF7qbqU .done2,#mermaid-svg-LwYqbFsB0iF7qbqU .done3{stroke:grey;fill:lightgrey;stroke-width:2;}#mermaid-svg-LwYqbFsB0iF7qbqU .doneText0,#mermaid-svg-LwYqbFsB0iF7qbqU .doneText1,#mermaid-svg-LwYqbFsB0iF7qbqU .doneText2,#mermaid-svg-LwYqbFsB0iF7qbqU .doneText3{fill:black!important;}#mermaid-svg-LwYqbFsB0iF7qbqU .doneText0.taskTextOutsideLeft,#mermaid-svg-LwYqbFsB0iF7qbqU .doneText0.taskTextOutsideRight,#mermaid-svg-LwYqbFsB0iF7qbqU .doneText1.taskTextOutsideLeft,#mermaid-svg-LwYqbFsB0iF7qbqU .doneText1.taskTextOutsideRight,#mermaid-svg-LwYqbFsB0iF7qbqU .doneText2.taskTextOutsideLeft,#mermaid-svg-LwYqbFsB0iF7qbqU .doneText2.taskTextOutsideRight,#mermaid-svg-LwYqbFsB0iF7qbqU .doneText3.taskTextOutsideLeft,#mermaid-svg-LwYqbFsB0iF7qbqU .doneText3.taskTextOutsideRight{fill:black!important;}#mermaid-svg-LwYqbFsB0iF7qbqU .crit0,#mermaid-svg-LwYqbFsB0iF7qbqU .crit1,#mermaid-svg-LwYqbFsB0iF7qbqU .crit2,#mermaid-svg-LwYqbFsB0iF7qbqU .crit3{stroke:#ff8888;fill:red;stroke-width:2;}#mermaid-svg-LwYqbFsB0iF7qbqU .activeCrit0,#mermaid-svg-LwYqbFsB0iF7qbqU .activeCrit1,#mermaid-svg-LwYqbFsB0iF7qbqU .activeCrit2,#mermaid-svg-LwYqbFsB0iF7qbqU .activeCrit3{stroke:#ff8888;fill:#bfc7ff;stroke-width:2;}#mermaid-svg-LwYqbFsB0iF7qbqU .doneCrit0,#mermaid-svg-LwYqbFsB0iF7qbqU .doneCrit1,#mermaid-svg-LwYqbFsB0iF7qbqU .doneCrit2,#mermaid-svg-LwYqbFsB0iF7qbqU .doneCrit3{stroke:#ff8888;fill:lightgrey;stroke-width:2;cursor:pointer;shape-rendering:crispEdges;}#mermaid-svg-LwYqbFsB0iF7qbqU .milestone{transform:rotate(45deg) scale(0.8,0.8);}#mermaid-svg-LwYqbFsB0iF7qbqU .milestoneText{font-style:italic;}#mermaid-svg-LwYqbFsB0iF7qbqU .doneCritText0,#mermaid-svg-LwYqbFsB0iF7qbqU .doneCritText1,#mermaid-svg-LwYqbFsB0iF7qbqU .doneCritText2,#mermaid-svg-LwYqbFsB0iF7qbqU .doneCritText3{fill:black!important;}#mermaid-svg-LwYqbFsB0iF7qbqU .doneCritText0.taskTextOutsideLeft,#mermaid-svg-LwYqbFsB0iF7qbqU .doneCritText0.taskTextOutsideRight,#mermaid-svg-LwYqbFsB0iF7qbqU .doneCritText1.taskTextOutsideLeft,#mermaid-svg-LwYqbFsB0iF7qbqU .doneCritText1.taskTextOutsideRight,#mermaid-svg-LwYqbFsB0iF7qbqU .doneCritText2.taskTextOutsideLeft,#mermaid-svg-LwYqbFsB0iF7qbqU .doneCritText2.taskTextOutsideRight,#mermaid-svg-LwYqbFsB0iF7qbqU .doneCritText3.taskTextOutsideLeft,#mermaid-svg-LwYqbFsB0iF7qbqU .doneCritText3.taskTextOutsideRight{fill:black!important;}#mermaid-svg-LwYqbFsB0iF7qbqU .vert{stroke:navy;}#mermaid-svg-LwYqbFsB0iF7qbqU .vertText{font-size:15px;text-anchor:middle;fill:navy!important;}#mermaid-svg-LwYqbFsB0iF7qbqU .activeCritText0,#mermaid-svg-LwYqbFsB0iF7qbqU .activeCritText1,#mermaid-svg-LwYqbFsB0iF7qbqU .activeCritText2,#mermaid-svg-LwYqbFsB0iF7qbqU .activeCritText3{fill:black!important;}#mermaid-svg-LwYqbFsB0iF7qbqU .titleText{text-anchor:middle;font-size:18px;fill:#333;font-family:"trebuchet ms",verdana,arial,sans-serif;}#mermaid-svg-LwYqbFsB0iF7qbqU :root{--mermaid-font-family:"trebuchet ms",verdana,arial,sans-serif;} 0 0 1 1 2 2 3 3 4 4 5 流式生成句 1、句 2、句 3 合成句 1 合成句 2 播放句 1 合成句 3 播放句 2 播放句 3 LLM 回复生成 TTS 云端合成 本地音轨播放 单轮对话音频流水线并行时序
(3) 物理资源隔离方案
通过采用云端 API 模式,本地机器可以实现极其合理的物理设备负载划分:
| 模块组件 | 运算载体 | 资源占用特征与说明 |
|---|---|---|
| 语音识别 (STT) | 本地显卡 GPU (CUDA) | Faster-Whisper 推理独占显存与 CUDA 核心 |
| 向量嵌入 (Embedding) | 本地 CPU | 运行轻量化模型进行特征向量提取,避免与显卡抢占显存 |
| 静音检测 (VAD) | 本地 CPU | Silero VAD 单线程运行,开销较低 |
| 语音合成 (TTS) | 云端服务器 | 通过 HTTP 请求完成,本地几乎不占用 GPU 与显存 |
4.7 物理打断控制与并发状态机
(1) Barge-in 触发机制
在情感陪伴机器人中,自然交流的前提是允许随时打断 。
当用户在智能体说话过程中突然开口时,本地的 VAD 模块会瞬间触发 START_OF_SPEECH(SOS) 信号。控制中心一旦接收到该信号,必须立刻终止当前的播报流程。
(2) 核心打断操作步骤
- 音频轨冲刷(Flush) :立刻停止向 LiveKit
AudioSource推送新的音频帧,必要时推送极短的静音包,冲刷掉底层播放器的音频缓冲,实现"瞬间闭嘴"的效果。 - 连接终止(Abort):发送终止信号,强行中断正在进行中的云端 TTS 异步 HTTP 流。
- LLM 截断:取消当前的大模型流式生成任务(Cancel Generator Task),向字符管道写入哨兵结束符号。
- 会话归档:根据产品策略,丢弃当前轮次中生成但未被完整播报出来的文本,避免其污染上下文历史。
(3) 并发状态机转移图
系统运转时,处于一个高频切换的状态机中:
#mermaid-svg-nfOFPMTORfSbVm7I{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}@keyframes edge-animation-frame{from{stroke-dashoffset:0;}}@keyframes dash{to{stroke-dashoffset:0;}}#mermaid-svg-nfOFPMTORfSbVm7I .edge-animation-slow{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 50s linear infinite;stroke-linecap:round;}#mermaid-svg-nfOFPMTORfSbVm7I .edge-animation-fast{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 20s linear infinite;stroke-linecap:round;}#mermaid-svg-nfOFPMTORfSbVm7I .error-icon{fill:#552222;}#mermaid-svg-nfOFPMTORfSbVm7I .error-text{fill:#552222;stroke:#552222;}#mermaid-svg-nfOFPMTORfSbVm7I .edge-thickness-normal{stroke-width:1px;}#mermaid-svg-nfOFPMTORfSbVm7I .edge-thickness-thick{stroke-width:3.5px;}#mermaid-svg-nfOFPMTORfSbVm7I .edge-pattern-solid{stroke-dasharray:0;}#mermaid-svg-nfOFPMTORfSbVm7I .edge-thickness-invisible{stroke-width:0;fill:none;}#mermaid-svg-nfOFPMTORfSbVm7I .edge-pattern-dashed{stroke-dasharray:3;}#mermaid-svg-nfOFPMTORfSbVm7I .edge-pattern-dotted{stroke-dasharray:2;}#mermaid-svg-nfOFPMTORfSbVm7I .marker{fill:#333333;stroke:#333333;}#mermaid-svg-nfOFPMTORfSbVm7I .marker.cross{stroke:#333333;}#mermaid-svg-nfOFPMTORfSbVm7I svg{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;}#mermaid-svg-nfOFPMTORfSbVm7I p{margin:0;}#mermaid-svg-nfOFPMTORfSbVm7I defs #statediagram-barbEnd{fill:#333333;stroke:#333333;}#mermaid-svg-nfOFPMTORfSbVm7I g.stateGroup text{fill:#9370DB;stroke:none;font-size:10px;}#mermaid-svg-nfOFPMTORfSbVm7I g.stateGroup text{fill:#333;stroke:none;font-size:10px;}#mermaid-svg-nfOFPMTORfSbVm7I g.stateGroup .state-title{font-weight:bolder;fill:#131300;}#mermaid-svg-nfOFPMTORfSbVm7I g.stateGroup rect{fill:#ECECFF;stroke:#9370DB;}#mermaid-svg-nfOFPMTORfSbVm7I g.stateGroup line{stroke:#333333;stroke-width:1;}#mermaid-svg-nfOFPMTORfSbVm7I .transition{stroke:#333333;stroke-width:1;fill:none;}#mermaid-svg-nfOFPMTORfSbVm7I .stateGroup .composit{fill:white;border-bottom:1px;}#mermaid-svg-nfOFPMTORfSbVm7I .stateGroup .alt-composit{fill:#e0e0e0;border-bottom:1px;}#mermaid-svg-nfOFPMTORfSbVm7I .state-note{stroke:#aaaa33;fill:#fff5ad;}#mermaid-svg-nfOFPMTORfSbVm7I .state-note text{fill:black;stroke:none;font-size:10px;}#mermaid-svg-nfOFPMTORfSbVm7I .stateLabel .box{stroke:none;stroke-width:0;fill:#ECECFF;opacity:0.5;}#mermaid-svg-nfOFPMTORfSbVm7I .edgeLabel .label rect{fill:#ECECFF;opacity:0.5;}#mermaid-svg-nfOFPMTORfSbVm7I .edgeLabel{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-nfOFPMTORfSbVm7I .edgeLabel p{background-color:rgba(232,232,232, 0.8);}#mermaid-svg-nfOFPMTORfSbVm7I .edgeLabel rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-nfOFPMTORfSbVm7I .edgeLabel .label text{fill:#333;}#mermaid-svg-nfOFPMTORfSbVm7I .label div .edgeLabel{color:#333;}#mermaid-svg-nfOFPMTORfSbVm7I .stateLabel text{fill:#131300;font-size:10px;font-weight:bold;}#mermaid-svg-nfOFPMTORfSbVm7I .node circle.state-start{fill:#333333;stroke:#333333;}#mermaid-svg-nfOFPMTORfSbVm7I .node .fork-join{fill:#333333;stroke:#333333;}#mermaid-svg-nfOFPMTORfSbVm7I .node circle.state-end{fill:#9370DB;stroke:white;stroke-width:1.5;}#mermaid-svg-nfOFPMTORfSbVm7I .end-state-inner{fill:white;stroke-width:1.5;}#mermaid-svg-nfOFPMTORfSbVm7I .node rect{fill:#ECECFF;stroke:#9370DB;stroke-width:1px;}#mermaid-svg-nfOFPMTORfSbVm7I .node polygon{fill:#ECECFF;stroke:#9370DB;stroke-width:1px;}#mermaid-svg-nfOFPMTORfSbVm7I #statediagram-barbEnd{fill:#333333;}#mermaid-svg-nfOFPMTORfSbVm7I .statediagram-cluster rect{fill:#ECECFF;stroke:#9370DB;stroke-width:1px;}#mermaid-svg-nfOFPMTORfSbVm7I .cluster-label,#mermaid-svg-nfOFPMTORfSbVm7I .nodeLabel{color:#131300;}#mermaid-svg-nfOFPMTORfSbVm7I .statediagram-cluster rect.outer{rx:5px;ry:5px;}#mermaid-svg-nfOFPMTORfSbVm7I .statediagram-state .divider{stroke:#9370DB;}#mermaid-svg-nfOFPMTORfSbVm7I .statediagram-state .title-state{rx:5px;ry:5px;}#mermaid-svg-nfOFPMTORfSbVm7I .statediagram-cluster.statediagram-cluster .inner{fill:white;}#mermaid-svg-nfOFPMTORfSbVm7I .statediagram-cluster.statediagram-cluster-alt .inner{fill:#f0f0f0;}#mermaid-svg-nfOFPMTORfSbVm7I .statediagram-cluster .inner{rx:0;ry:0;}#mermaid-svg-nfOFPMTORfSbVm7I .statediagram-state rect.basic{rx:5px;ry:5px;}#mermaid-svg-nfOFPMTORfSbVm7I .statediagram-state rect.divider{stroke-dasharray:10,10;fill:#f0f0f0;}#mermaid-svg-nfOFPMTORfSbVm7I .note-edge{stroke-dasharray:5;}#mermaid-svg-nfOFPMTORfSbVm7I .statediagram-note rect{fill:#fff5ad;stroke:#aaaa33;stroke-width:1px;rx:0;ry:0;}#mermaid-svg-nfOFPMTORfSbVm7I .statediagram-note rect{fill:#fff5ad;stroke:#aaaa33;stroke-width:1px;rx:0;ry:0;}#mermaid-svg-nfOFPMTORfSbVm7I .statediagram-note text{fill:black;}#mermaid-svg-nfOFPMTORfSbVm7I .statediagram-note .nodeLabel{color:black;}#mermaid-svg-nfOFPMTORfSbVm7I .statediagram .edgeLabel{color:red;}#mermaid-svg-nfOFPMTORfSbVm7I #dependencyStart,#mermaid-svg-nfOFPMTORfSbVm7I #dependencyEnd{fill:#333333;stroke:#333333;stroke-width:1;}#mermaid-svg-nfOFPMTORfSbVm7I .statediagramTitleText{text-anchor:middle;font-size:18px;fill:#333;}#mermaid-svg-nfOFPMTORfSbVm7I :root{--mermaid-font-family:"trebuchet ms",verdana,arial,sans-serif;} 1.空闲状态
音频顺次播放完毕
2.聆听状态
检测到 VAD_SOS
用户插话触发 Barge_in_SOS
用户在 AI 思考时强行插话
3.思考状态
VAD_EOS 且 STT 转译完毕
4.播报状态
TTS 收到首帧并开始推送
状态机各个核心周期的特性如下:
| 状态名称 | 核心行为定义 | 用户在此阶段的行为 |
|---|---|---|
| 1.空闲状态 (Idle) | 智能体保持静默,等待用户输入 | 用户可以随时开口说话 |
| 2.聆听状态 (Listening) | 智能体音轨关闭,VAD 与 STT 正在捕获用户声音 | 用户说话中,智能体处于输入状态 |
| 3.思考状态 (Thinking) | STT 转译完毕,LLM 正在生成,TTS 正在合成首句 | 支持用户在此阶段插话(直接打断,返回聆听状态) |
| 4.播报状态 (Speaking) | 本地正在向 LiveKit 推送音频时间帧,用户听到声音 | 支持用户在此阶段插话(强制打断,音频截断复位) |
4.8 全链路测试、验收与调参运维
(1) 单元测试覆盖要点
- 接口客户端测试 :利用 Mock 工具模拟云端 API 的流式响应数据,验证二进制 Hex 解码逻辑以及当遇到
base_resp异常错误码时的异常抛出。 - 异步队列测试 :验证句子的有序写入、
cancel()的中断响应性能、预取(Prefetch)逻辑的正常运作,以及is_speaking状态标识的准确性。 - 联合闭环测试:Mock 音频合成端,断言当文本切片器切出句子时,会话队列是否能在第一时间调用合成器。
(2) 全链路集成测试与日志验证
1. 调试环境准备
启动本地 LiveKit 服务及向量数据库,激活本地 Python 虚拟环境。
2. 全链路日志链分析
通过启动全功能智能体,通过网页端进房通话,通过观察控制台日志流是否形成一个完整的闭环逻辑:
text
12:00:01 [VAD] SOS 检测到用户开始说话
12:00:03 [VAD] EOS 检测到用户说话结束
12:00:04 [STT] 识别到用户文本:"你今天过得怎么样?"
12:00:04 [检索] 触发知识库检索路由,成功调取上下文背景
12:00:05 [LLM] 大模型吐出第一句切片文本:"我今天过得很开心呀,你呢?"
12:00:05 [TTS] 发起 T2A 合成请求,API 追踪 ID: tx_992104...
12:00:05 [TTS] 接收到首包音频数据,首包延迟 TTFA: 180ms
12:00:08 [TTS] 当前句子音频推送完成,持续播放时长: 3100ms3. 打断行为验证
在智能体回复正在播放时,用户对着麦克风发出声音。控制台应立即出现 [VAD] SOS 日志,同时耳机里智能体的声音应在 50ms 内瞬间切断,代表打断机制完全生效。
(3) 常见瓶颈与运维调参指南
在系统联合调试和日常运维中,可以通过以下表格定位并优化体验瓶颈:
| 体验不良现象 | 瓶颈排查方向 | 推荐调优手段 |
|---|---|---|
| AI 说话断断续续,句与句之间有明显的空白停顿 | 弱断句阈值设置不合理,导致句子切得太碎,合成器频繁建立连接。 | 适当增大 MIN_SENTENCE_LEN(如设为 12~15 字);确保预取(Prefetch)机制正常启动。 |
| 说完话后,AI 响应非常慢,体感等待超过 5 秒 | 首句切出等待过长;或者云端 API 首字返回慢。 | 减小 MIN_SENTENCE_LEN 限制;更换为极速版模型;检查 stream=true 是否被误关闭。 |
| AI 说话的声音机械、音色刺耳或没有起伏 | 选用的模型版本偏向离线长文本,或者音色 ID 搭配不当。 | 切换高音质版的模型;精选更具表现力的预设音色 ID。 |
| 播放出的声音语速像播音员,不像日常聊天 | 默认语速参数偏慢。 | 调整语速参数(在 0.9 ~ 1.1 之间微调,找到最自然的聊天步调)。 |
| 频繁遇到 1002/1039 API 限流报错 | 触发了云端接口的并发或 TPM 阈值上限。 | 降低 prefetch 预取任务的最高并发限制;申请提高接口配额。 |
| API 字符消耗计费过高,成本失控 | 大模型生成的单次回复字数过长。 | 在 LLM 的人设 System Prompt 中强行加入单次回复不超过 60 字的物理限制。 |
| 终端日志显示播放完毕,但浏览器里没有任何声音 | LiveKit 音轨没有被正常发布;或者采样率发生偏差。 | 确认 publish_track 成功执行;检查重采样目标是否精确为 48,000Hz;检查浏览器端播放器是否静音。 |
4.8 本地部署与云端 API 方案对比
(1) 实操对比清单
若将前期制定的本地 CosyVoice 部署方案 与当前落地的 MiniMax API 方案 进行过程映射,可以清晰地看出架构精简的程度:
| CosyVoice 本地部署物理步骤 | MiniMax API 云端集成步骤(本仓库) |
|---|---|
| (1) 物理显卡与 Python PyTorch 深度对齐 | 仅需本地安装轻量级 HTTP 通信库,配置 API 鉴权密钥。 |
| (2) 部署 Matcha-TTS/sox/pnnx 等复杂底层依赖 | 完全免去本地底层依赖,不干扰现有运行环境。 |
| (3) 下载数 GB 的权重文件并执行 FP16 显存初始化 | 在代码请求参数中指定云端模型名称即可。 |
| (4) 本地流式推理并运行自回归与流匹配模型 | 建立异步长连接,直接通过 SSE 接收返回的数据流分片。 |
| (5) 运行声码器,将梅尔频谱图还原为 24kHz PCM 字节 | 直接从返回的 JSON 结构中解码十六进制数据获得 PCM。 |
| (6) 本地重采样、切块并发布音频帧至 LiveKit | 步骤相同:将 PCM 上采样至 48kHz,按 20ms 时间帧推送至 LiveKit 音轨。 |
总结
经过不断调试,最终的效果已经实现了流程的交流,但是还有些许不足,毕竟语音这一块儿还是比较复杂,适合自己玩玩。
如果过程中有问题请勿喷,纯个人分享
代码可下载,代码地址:情感陪伴语音机器人