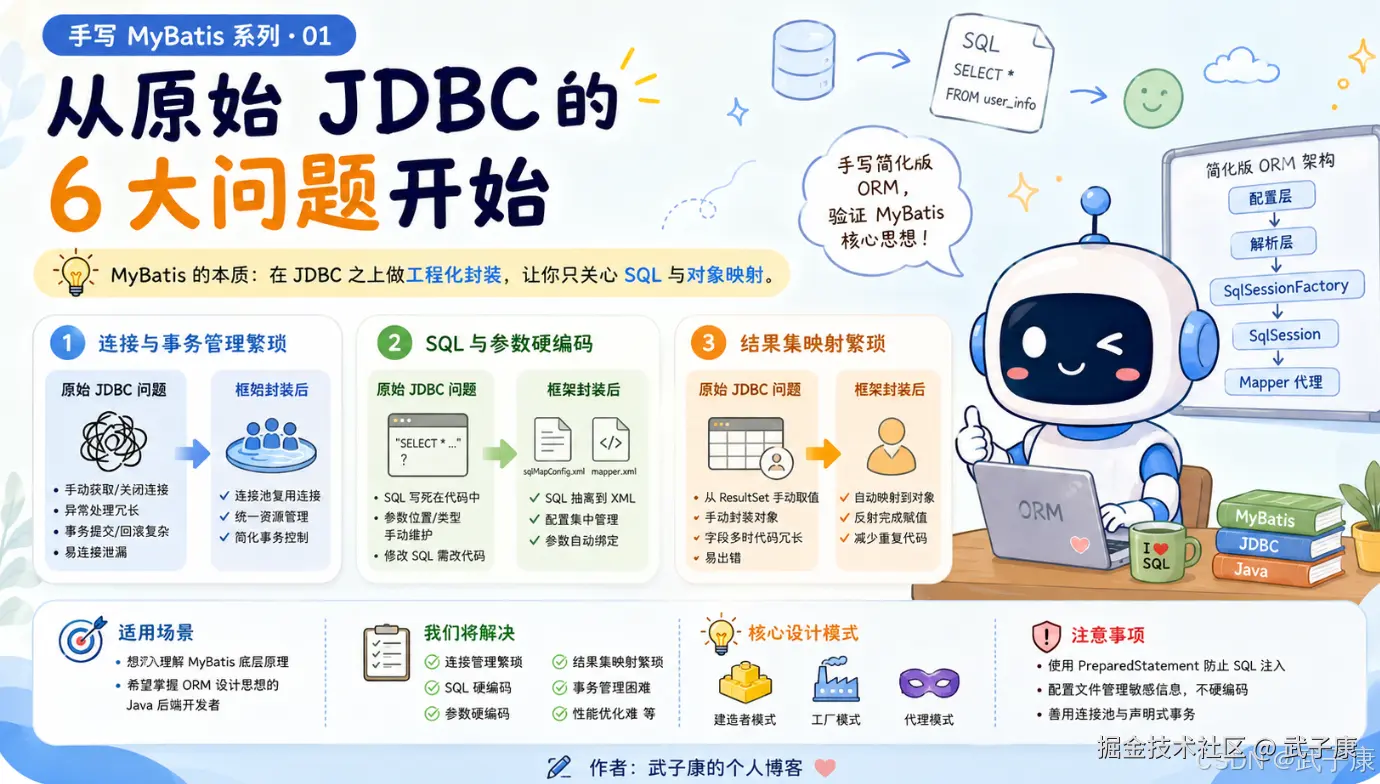
TL;DR
- 场景:面向准备深入理解 MyBatis 底层原理的 Java 后端开发者,以最原始的 JDBC 查询代码为起点,系统梳理连接管理、SQL 硬编码、参数硬编码、结果集映射、事务管理、缓存与连接池等 6 大工程痛点,并给出简化版 ORM 框架的整体设计骨架(配置层 → 解析层 → SqlSessionFactory → SqlSession → Mapper 代理)。
- 结论:MyBatis 的本质不是替代 SQL,而是在 JDBC 之上做一层工程化封装,把手工管理连接、参数占位、结果集解析、事务控制这些重复、易错、低价值的模板代码收敛到框架内部,让开发者只关心 SQL 与对象映射;这一系列文章会按"抽配置 → 封执行器 → 封 SqlSession → 动态代理 Mapper"的顺序,从零手写一个简化版 ORM 来验证这套思路。
- 产出:可运行的原始 JDBC 查询示例 + 一份完整的问题清单(代码冗余 / 缺乏灵活性 / 结果集映射繁琐 / 事务管理困难 / 性能优化难 / 安全性 / 开发效率低 / 调试维护难 / 缺乏高级特性)+ 简化版 ORM 框架的整体架构图(使用端 sqlMapConfig.xml + mapper.xml,框架端 Configuration + MappedStatement + SqlSessionFactoryBuilder + SqlSessionFactory + SqlSession + 代理 Mapper)+ 涉及的三大设计模式说明(建造者、工厂、代理)。
作者:武子康的个人博客
手写 MyBatis(1):从原始 JDBC 暴露的 6 大问题开始
这一篇是手写 MyBatis 系列的第一篇。
在正式开始实现 ORM 框架之前,我们先从最原始的 JDBC 写法入手,看一下直接使用 JDBC 操作数据库会遇到哪些问题。后续文章会在这些问题的基础上,逐步抽取配置、封装执行器、封装 SqlSession、实现 Mapper 代理,最终完成一个简化版的 MyBatis 框架。
新建项目
首先新建一个 Maven 项目,这里不展开 Maven 项目的创建过程。
项目中需要引入 MySQL 驱动依赖。这里使用的是 mysql-connector-java,你也可以根据自己的 MySQL 版本选择合适的驱动版本。
xml
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.29</version>
</dependency>注意:如果是公开发布的博客,代码中的数据库地址、用户名、密码不要使用真实信息,建议统一改成示例值,避免泄露环境信息。
创建数据
为了方便测试,我们先准备一张用户表。
需要你提前创建好数据库,然后执行下面的建表语句:
sql
CREATE TABLE `user_info` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`username` varchar(255) DEFAULT NULL,
`password` varchar(255) DEFAULT NULL,
`age` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8 COLLATE=utf8_general_ci;为了后续查询方便,可以插入一条测试数据:
sql
INSERT INTO `user_info` (`username`, `password`, `age`)
VALUES ('wzk', '123456', 18);这张表结构非常简单,只有 id、username、password、age 四个字段。后面我们会使用 JDBC 查询这张表中的数据,并观察原始 JDBC 写法中存在的问题。
编写代码
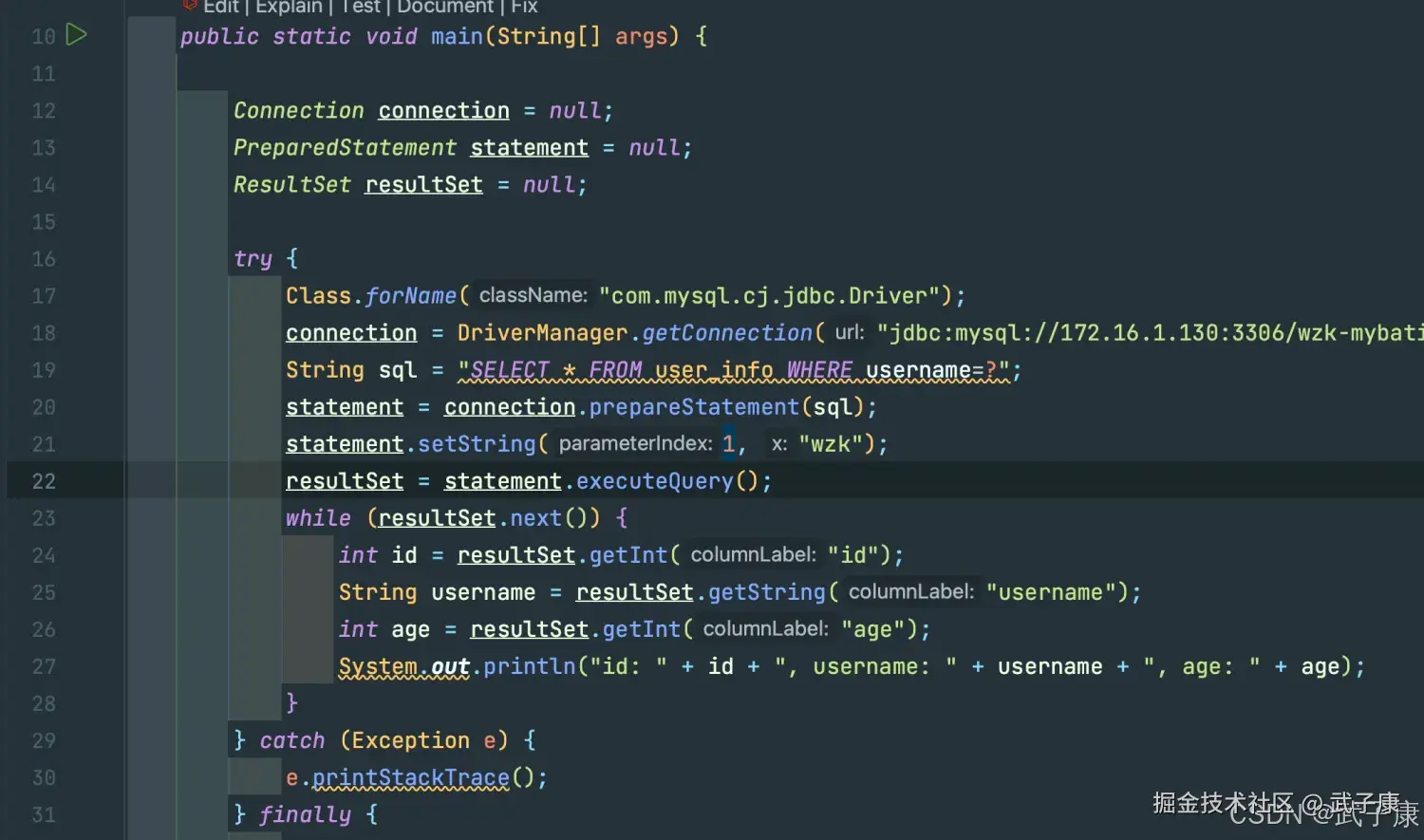
下面是一个最常见的 JDBC 查询示例。
它的流程大致如下:
- 加载数据库驱动;
- 获取数据库连接;
- 编写 SQL;
- 创建
PreparedStatement; - 设置 SQL 参数;
- 执行查询;
- 遍历
ResultSet; - 手动关闭资源。
java
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
public class MyBatisTest {
public static void main(String[] args) {
Connection connection = null;
PreparedStatement statement = null;
ResultSet resultSet = null;
try {
// 1. 加载数据库驱动
Class.forName("com.mysql.cj.jdbc.Driver");
// 2. 获取数据库连接
connection = DriverManager.getConnection(
"jdbc:mysql://127.0.0.1:3306/wzk-mybatis?characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai",
"root",
"root"
);
// 3. 编写 SQL
String sql = "SELECT * FROM user_info WHERE username = ?";
// 4. 创建 PreparedStatement
statement = connection.prepareStatement(sql);
// 5. 设置参数
statement.setString(1, "wzk");
// 6. 执行查询
resultSet = statement.executeQuery();
// 7. 解析结果集
while (resultSet.next()) {
int id = resultSet.getInt("id");
String username = resultSet.getString("username");
int age = resultSet.getInt("age");
System.out.println("id: " + id + ", username: " + username + ", age: " + age);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
// 8. 释放资源
if (resultSet != null) {
try {
resultSet.close();
} catch (Exception e) {
e.printStackTrace();
}
}
if (statement != null) {
try {
statement.close();
} catch (Exception e) {
e.printStackTrace();
}
}
if (connection != null) {
try {
connection.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
}对应的截图如下所示:
测试运行
运行之后,控制台输出如下:
shell
id: 1, username: wzk, age: 18
Process finished with exit code 0对应截图如下所示:
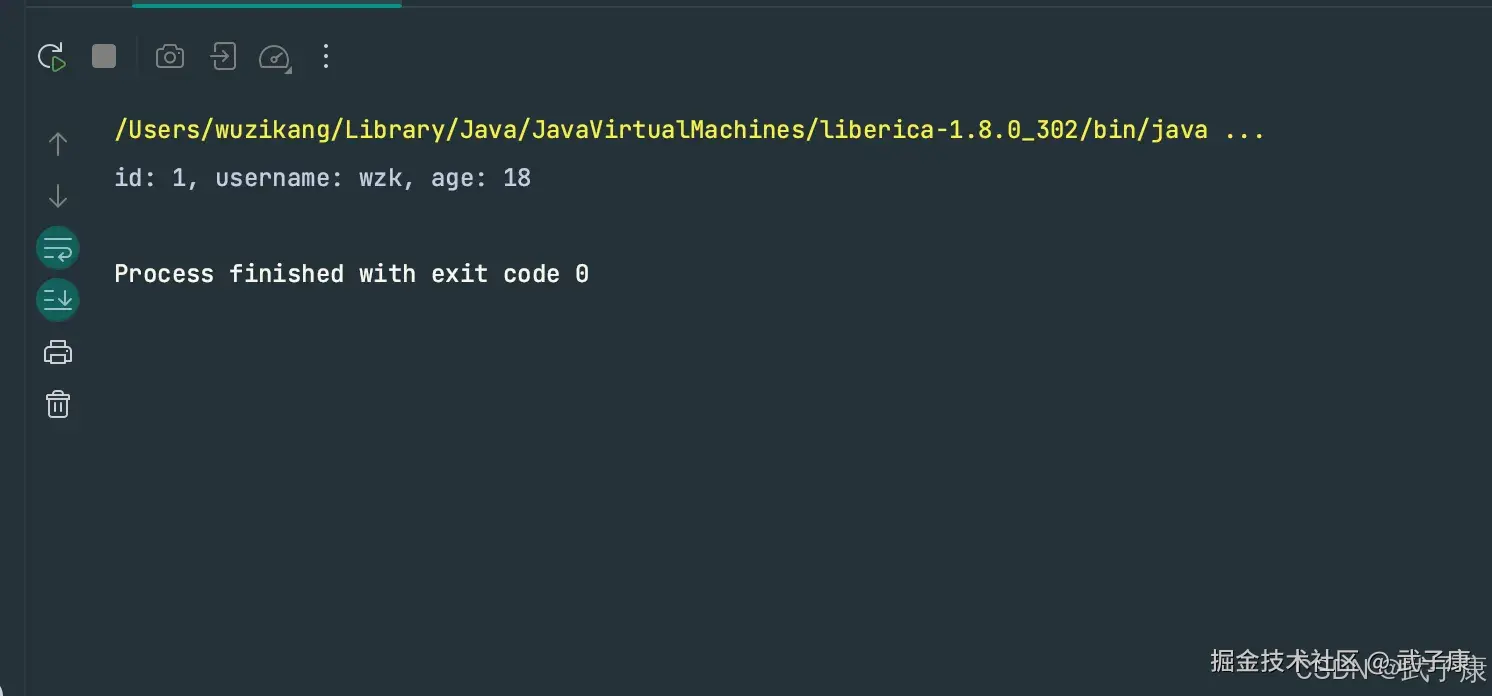
从结果来看,代码可以正常查询数据库,也能把 user_info 表中的数据打印出来。
但是问题也很明显:虽然只是查询一条数据,我们已经写了大量和业务无关的代码。
真正有业务意义的代码其实只有两部分:
java
String sql = "SELECT * FROM user_info WHERE username = ?";
statement.setString(1, "wzk");以及结果集解析部分:
java
int id = resultSet.getInt("id");
String username = resultSet.getString("username");
int age = resultSet.getInt("age");其他大部分代码都在处理连接、异常、资源释放、参数设置、结果集遍历等重复性工作。
这正是 ORM 框架需要解决的问题。
问题总结
使用传统 Java JDBC 进行数据库开发,虽然可以直接完成数据库操作,但是存在很多明显问题。
上面的原始 JDBC 开发主要有以下几个痛点:
- 数据库连接的创建和释放需要手动处理,频繁创建连接会造成资源浪费,影响系统性能。
- SQL 语句直接写死在 Java 代码中,后续修改 SQL、调整查询条件、变更字段都会比较麻烦。
- 参数设置和结果集解析都是硬编码,SQL 一旦变化,Java 代码也需要跟着修改。
- 查询结果没有自动封装成对象,需要开发者手动从
ResultSet中取值,再手动赋值。 - 异常处理和资源释放代码过多,真正的业务逻辑反而被淹没。
下面展开分析这些问题。
代码复杂性和冗余性
手动管理连接
每次操作数据库,都需要手动获取连接、关闭连接,并且还要处理异常。
java
Connection connection = DriverManager.getConnection(...);如果忘记关闭连接,或者异常情况下资源没有正确释放,就可能造成连接泄漏。项目规模较小时问题不明显,一旦并发量上来,连接泄漏就可能导致数据库连接被耗尽。
重复代码过多
每次执行 SQL 时,基本都要重复编写下面这些步骤:
- 创建数据库连接;
- 创建
PreparedStatement; - 设置 SQL 参数;
- 执行 SQL;
- 遍历
ResultSet; - 关闭
ResultSet; - 关闭
PreparedStatement; - 关闭
Connection。
这些代码和具体业务关系不大,但每一个数据库操作都要写一遍,代码会越来越臃肿。
异常处理冗长
JDBC 中大量 API 都可能抛出异常,所以代码中会出现大量 try-catch-finally。
这会导致一个问题:明明只是执行一个简单查询,却要写很多异常处理和资源释放代码,可读性比较差。
缺乏灵活性
SQL 硬编码
SQL 语句直接写在 Java 代码中:
java
String sql = "SELECT * FROM user_info WHERE username = ?";这种方式的问题是 SQL 和 Java 代码耦合在一起。
如果后续要修改查询字段、调整查询条件、增加排序、增加分页,都需要改 Java 代码。对于大型项目来说,SQL 分散在各个类中,也不方便统一维护和排查问题。
更好的方式是将 SQL 从 Java 代码中抽离出去,例如放到 XML 文件中统一管理。这也是 MyBatis 的核心设计之一。
参数设置硬编码
当前代码中参数是这样设置的:
java
statement.setString(1, "wzk");这里的问题是参数位置和参数类型都需要手动维护。
如果 SQL 中参数数量变多,例如:
sql
SELECT * FROM user_info WHERE username = ? AND age = ?那么 Java 代码也要跟着修改:
java
statement.setString(1, "wzk");
statement.setInt(2, 18);参数越多,维护成本越高,也越容易出错。
结果集映射繁琐
JDBC 查询出来的是 ResultSet,它不是 Java 对象。
我们需要手动从结果集中取出字段:
java
int id = resultSet.getInt("id");
String username = resultSet.getString("username");
int age = resultSet.getInt("age");如果希望把查询结果封装成一个 UserInfo 对象,还需要继续写:
java
UserInfo userInfo = new UserInfo();
userInfo.setId(id);
userInfo.setUsername(username);
userInfo.setAge(age);这类代码非常机械,重复性很高。
如果表字段很多,或者查询结果很多,这部分代码会变得非常冗长。字段名一旦写错,也只能在运行时暴露问题。
ORM 框架的一个核心价值,就是自动完成数据库字段和 Java 对象属性之间的映射。
事务管理困难
JDBC 本身支持事务,但事务也需要手动控制。
例如:
java
connection.setAutoCommit(false);
try {
// 执行多个 SQL
connection.commit();
} catch (Exception e) {
connection.rollback();
}这种写法的问题是:
- 每次涉及事务都要手动提交和回滚;
- 事务代码容易和业务代码混在一起;
- 一旦异常处理不严谨,可能导致数据不一致;
- 多个方法之间共享同一个连接时,管理成本会进一步提高。
在真实项目中,我们通常会把事务交给 Spring 来统一管理,而不是在业务代码中手动写 commit 和 rollback。
性能优化难度大
缺少连接池
直接使用 DriverManager.getConnection() 获取连接,每次都会创建新的数据库连接。
数据库连接的创建成本比较高。如果每次请求都创建和销毁连接,性能会受到明显影响。
实际项目中一般都会使用连接池,例如:
- HikariCP
- Druid
- C3P0
连接池可以提前创建一批数据库连接,应用程序需要时直接复用,用完之后归还给连接池,而不是每次都重新创建。
缺少缓存机制
JDBC 本身不提供一级缓存、二级缓存等机制。
每次查询都会访问数据库。如果某些数据频繁查询、变化不大,就需要开发者自己额外引入缓存方案。
MyBatis 中虽然不是强缓存框架,但它提供了一级缓存和二级缓存的设计,可以在一定程度上减少重复查询。
安全性问题
JDBC 本身不是不安全,关键取决于开发者如何使用。
如果使用 PreparedStatement,可以避免大部分 SQL 注入问题:
java
String sql = "SELECT * FROM user_info WHERE username = ?";
statement = connection.prepareStatement(sql);
statement.setString(1, username);但如果直接拼接 SQL,就会有 SQL 注入风险:
java
String sql = "SELECT * FROM user_info WHERE username = '" + username + "'";所以在任何情况下,都不建议直接拼接用户输入。
此外,数据库地址、用户名、密码也不应该直接暴露在公开代码中。实际项目中一般会放到配置文件、环境变量或配置中心中统一管理。
开发效率低
传统 JDBC 需要开发者处理大量底层细节,例如:
- 驱动加载;
- 连接获取;
- 参数设置;
- SQL 执行;
- 结果集解析;
- 异常处理;
- 资源释放。
这些工作不是没有价值,而是不应该在每一个业务方法中重复编写。
当项目规模变大后,直接使用 JDBC 会导致代码难以复用、难以维护,也不利于分层设计。
调试和维护困难
由于 SQL 分散在 Java 代码中,出现问题时不容易统一排查。
例如:
- 某个字段名写错;
- SQL 条件拼错;
- 参数位置设置错误;
- 结果集字段类型转换错误;
- 连接没有释放;
- 查询性能较差。
这些问题都可能隐藏在大量重复代码中。
如果能够把 SQL、参数、结果映射、执行流程统一管理,维护成本会低很多。
缺乏高级特性支持
JDBC 是底层 API,它提供的是基础能力,不会主动帮我们解决更高层的问题。
例如:
- SQL 与 Java 代码解耦;
- 自动参数映射;
- 自动结果集映射;
- Mapper 接口代理;
- 动态 SQL;
- 统一事务管理;
- 查询缓存;
- 插件扩展;
- 日志打印。
这些能力都需要在 JDBC 之上继续封装。
MyBatis 的本质,就是在 JDBC 之上做了一层封装,让开发者可以更专注于 SQL 和对象映射,而不是反复处理 JDBC 的模板代码。
解决方案
为了解决上述问题,现代 Java 开发中通常会使用更高层的封装方案。
常见方案包括:
- Spring JDBC Template:对 JDBC 进行模板化封装,减少重复代码。
- MyBatis:半自动 ORM 框架,保留 SQL 控制权,同时提供参数映射、结果映射、Mapper 代理等能力。
- Hibernate / JPA:更完整的 ORM 框架,强调对象和表之间的自动映射。
- 连接池技术:例如 HikariCP、Druid,用于提升连接复用能力。
- Spring 事务管理:通过声明式事务简化事务提交和回滚。
这一系列文章的目标不是直接使用 MyBatis,而是通过手写一个简化版 ORM 框架,理解 MyBatis 的核心原理。
我们要解决的核心问题包括:
- 使用数据库连接池管理连接;
- 将 SQL 语句从 Java 代码中抽取到 XML 中;
- 解析 XML 配置文件;
- 保存数据库连接信息和 SQL 映射信息;
- 使用反射完成参数绑定;
- 使用反射完成结果集到实体对象的映射;
- 封装 SqlSession,统一对外提供查询方法;
- 使用代理模式生成 Mapper 接口实现类。
自定义框架
接下来,我们先设计一个简化版框架的大致结构。
这部分先只做整体说明,后续文章会逐步补全每个模块的具体实现。
使用端
从使用者角度看,我们希望框架最终能够像 MyBatis 一样,通过配置文件管理数据库连接和 SQL。
核心配置主要包括两个文件:
sqlMapConfig.xml:存放数据库连接信息,并引入 mapper.xml;mapper.xml:存放具体 SQL 语句的配置信息。
resources 目录整体结构如下:
其中,sqlMapConfig.xml 可以理解为全局配置文件,主要负责描述数据库连接信息,以及加载哪些 Mapper 配置文件。
mapper.xml 则负责描述具体的 SQL,例如:
- SQL 的唯一标识;
- SQL 语句内容;
- 入参类型;
- 返回值类型;
- 查询类型。
这样做的好处是:Java 代码不再直接关心 SQL 的具体内容,SQL 可以统一放到 XML 中维护。
框架端
框架端要做的事情,就是读取这些配置文件,然后把配置文件中的内容转换成 Java 对象,最后基于这些对象执行 JDBC 操作。
整体流程可以简单理解为:
- 读取
sqlMapConfig.xml; - 解析数据库连接信息;
- 解析 mapper.xml 路径;
- 继续读取并解析 mapper.xml;
- 将每一条 SQL 封装成
MappedStatement; - 将全局配置信息封装成
Configuration; - 创建
SqlSessionFactory; - 通过
SqlSessionFactory创建SqlSession; - 通过
SqlSession执行查询; - 将查询结果映射成 Java 对象。
读取配置
配置文件读取完成后,本质上是一个输入流。
我们需要创建一些 Java Bean 来保存解析后的配置内容,方便后续使用。
核心对象主要有两个:
ConfigurationMappedStatement
Configuration 用于保存全局配置,主要包括:
- 数据库连接信息;
- 数据源对象;
Map<String, MappedStatement>。
其中,Map<String, MappedStatement> 用来保存所有 SQL 映射信息。
为了保证每一条 SQL 的唯一性,可以使用下面的格式作为 key:
text
namespace + "." + id例如:
text
com.wzk.mapper.UserMapper.findByUsernameMappedStatement 用于保存一条 SQL 的详细信息,主要包括:
- SQL 语句;
- SQL 类型;
- 入参 Java 类型;
- 返回值 Java 类型;
- statementId。
这样,后续只要根据 statementId 找到对应的 MappedStatement,就可以知道要执行哪条 SQL、参数类型是什么、返回值类型是什么。
解析配置
接下来需要创建 SqlSessionFactoryBuilder 类。
它主要负责解析 XML 配置文件,并创建 SqlSessionFactory。
它要做的事情包括:
- 使用 dom4j 解析
sqlMapConfig.xml; - 获取数据库连接信息;
- 获取 mapper.xml 的路径;
- 继续解析 mapper.xml;
- 将解析结果封装到
Configuration和MappedStatement中; - 创建
SqlSessionFactory的实现类。
这里的设计和 MyBatis 中的 SqlSessionFactoryBuilder 思路类似。
SqlSessionFactoryBuilder 不负责执行 SQL,它只负责构建框架运行所需要的核心配置对象。
SqlSessionFactory
SqlSessionFactory 是一个工厂接口,它的核心方法是:
java
SqlSession openSession();它的作用是创建 SqlSession。
可以理解为:配置解析完成后,我们会得到一个 SqlSessionFactory,后续所有数据库操作都通过它来创建 SqlSession。
简化版接口可以设计成这样:
java
public interface SqlSessionFactory {
SqlSession openSession();
}对应的实现类可以叫:
java
DefaultSqlSessionFactory它内部持有 Configuration 对象,每次调用 openSession() 时,都会创建一个新的 SqlSession 实例,并把 Configuration 传递进去。
sqlSession接口及实现类
SqlSession 是框架对外暴露的核心操作接口。
它主要用于封装 CRUD 方法,例如:
selectList:查询多条数据;selectOne:查询单条数据;- 后续还可以扩展
insert、update、delete。
简化版接口可以设计成这样:
java
public interface SqlSession {
<E> List<E> selectList(String statementId, Object... params);
<T> T selectOne(String statementId, Object... params);
}具体实现类可以叫:
java
DefaultSqlSession它内部主要完成以下工作:
- 根据
statementId找到对应的MappedStatement; - 获取 SQL 语句;
- 获取数据库连接;
- 使用
PreparedStatement设置参数; - 执行 SQL;
- 遍历
ResultSet; - 使用反射创建返回值对象;
- 将数据库字段值设置到 Java 对象属性中;
- 返回查询结果。
这样,JDBC 中大量重复的模板代码就可以被封装到 SqlSession 内部。
使用者只需要调用:
java
UserInfo user = sqlSession.selectOne(
"com.wzk.mapper.UserMapper.findByUsername",
"wzk"
);不再需要手动编写连接管理、参数设置、结果集解析等重复逻辑。
设计模式
在这个简化版 ORM 框架中,会涉及几个典型设计模式。
建造者模式
SqlSessionFactoryBuilder 用于读取配置文件,并一步步构建出 SqlSessionFactory。
它屏蔽了复杂的构建过程,让使用者只需要关心最终结果。
工厂模式
SqlSessionFactory 用于创建 SqlSession。
使用者不需要关心 SqlSession 的具体实现类,只需要通过工厂方法获取接口对象。
代理模式
后续实现 Mapper 接口时,会用到代理模式。
我们希望最终可以这样使用:
java
UserMapper userMapper = sqlSession.getMapper(UserMapper.class);
UserInfo userInfo = userMapper.findByUsername("wzk");这里的 UserMapper 是一个接口,并没有手写实现类。
框架会在运行时通过动态代理生成接口的代理对象。当调用 findByUsername 方法时,代理对象会根据接口全限定名和方法名拼接出 statementId,然后找到对应 SQL 并执行。
这也是 MyBatis Mapper 接口能够工作的核心原理。
小结
这一篇主要通过原始 JDBC 查询示例,引出了传统 JDBC 开发中的几个核心问题:
- 连接管理繁琐;
- SQL 硬编码;
- 参数设置重复;
- 结果集映射繁琐;
- 事务管理复杂;
- 代码冗余;
- 可维护性差。
MyBatis 的价值不是替代 SQL,而是把 JDBC 中重复、机械、易错的部分封装起来,让开发者可以更专注于 SQL 本身和业务逻辑。
后续文章会基于这一篇的问题,开始逐步实现简化版 MyBatis 框架,包括配置解析、SqlSession 封装、结果集映射、Mapper 动态代理等内容。