CrewAI 是当前最流行的开源多智能体协作框架之一,它让开发者能够像组建一支真实团队一样,编排多个 AI Agent 分工协作、自动完成复杂任务。在本教程中,我们将从基础概念讲起,逐步深入到高级特性,并配合多个实战案例,帮助你全面掌握 CrewAI 的使用方法。
什么是 CrewAI
CrewAI 是一个基于 Python 的开源框架,专门用于编排和协调多个自主 AI Agent(智能体)进行协作。它的核心设计理念是"让 AI 像一个团队一样工作"------每个 Agent 都有自己的角色(Role)、目标(Goal)和背景故事(Backstory),通过分工合作来完成单个 Agent 难以胜任的复杂任务。
CrewAI 由 João Moura 于 2023 年创建,在 GitHub 上已获得超过 30000 颗星。它的底层基于 LangChain 构建,但通过高度抽象的 API 设计,将多智能体编排的复杂度大幅降低。开发者只需要定义几个 Agent、几个 Task、一个 Crew,然后调用 kickoff() 就能启动一整套协作流程,这种"声明式"的编程风格是 CrewAI 最受欢迎的特性之一。
CrewAI 与其他框架的对比

在多智能体领域,CrewAI 并非唯一选择。下面将它与几个主流框架做一对比,帮助你理解 CrewAI 的定位:
CrewAI vs AutoGen(微软):AutoGen 更偏向"对话式"的多智能体协作,Agent 之间通过对话来回交流,灵活度极高但配置复杂度也高。CrewAI 则采用"任务驱动"的方式,通过明确的角色分工和流程编排来组织协作,入门门槛更低,更适合"流水线"式的应用场景。如果你的需求是让几个专家讨论出一个方案,AutoGen 可能更合适;如果你的需求是让一组角色按流程完成一系列任务,CrewAI 是更好的选择。
CrewAI vs LangGraph:LangGraph 是 LangChain 团队推出的图编排框架,可以构建非常复杂的 Agent 工作流(包括循环、条件分支、状态机等)。它的灵活度最高,但学习曲线也最陡峭,需要理解图论和状态管理的概念。CrewAI 牺牲了一部分灵活度来换取极佳的开发体验------大多数场景下,CrewAI 的 Process 和 Flow 就能覆盖你的需求。
CrewAI vs MetaGPT:MetaGPT 侧重于模拟软件开发公司的组织结构,预设了产品经理、架构师、工程师等角色,非常适合自动化软件开发场景。CrewAI 则更加通用,你可以用它构建任何领域的 Agent 团队。
简而言之,CrewAI 的定位是"低门槛、高产出"的多智能体框架。它在易用性和功能性之间取得了很好的平衡,是当前入门多智能体系统的首选框架。
典型应用场景
CrewAI 的适用范围非常广泛,以下是一些已被验证的典型案例:
内容创作流水线:研究员搜集素材 → 撰稿人撰写初稿 → 编辑审核修改 → SEO 专家优化发布。这是 CrewAI 最经典的使用场景,也是本教程将要实现的案例。
自动化研究报告:数据分析师提取数据 → 行业研究员分析趋势 → 报告撰写人生成报告 → 质量审核员验证结论。适合金融分析、市场调研等需要定期生成报告的领域。
智能客服系统:意图识别 Agent 分类问题 → FAQ Agent 回答常见问题 → 技术支持 Agent 处理技术难题 → 满意度分析师评估服务质量。结合 Flow 工作流可以实现智能路由。
代码审查团队:代码审查员检查代码质量 → 安全专家排查漏洞 → 性能分析师评估性能 → 文档撰写员生成审查报告。
自动化测试流水线:测试设计师生成测试用例 → 测试执行者运行测试 → 缺陷分析师分析失败原因 → 修复建议者提供修复方案。
与传统的单 Agent 方案相比,CrewAI 的优势在于:
-
角色化分工:每个 Agent 有明确的职责,就像团队中的不同岗位------研究员、写手、审核员各司其职。这种"专人专事"的设计让每个 Agent 的输出更加专业和可控。
-
灵活的协作流程:支持顺序执行、层级管理、共识决策等多种流程模式,适配不同的业务场景。你可以根据任务特性选择最合适的执行策略。
-
工具生态丰富:内置搜索引擎、文件读写、网页抓取、数据库查询等工具,也支持自定义工具扩展。Agent 不再只是"纸上谈兵",而是能够主动获取信息和执行操作。
-
记忆系统:Agent 可以记住之前的交互信息,在多轮对话和长期任务中保持上下文一致性。这对于需要"记住"项目背景和历史决策的场景至关重要。
-
Flow 工作流:支持将多个 Crew 串联成复杂的事件驱动工作流,实现更高层次的编排。这让你可以构建真正的"企业级"多智能体系统。
环境准备与安装
前置条件
在开始之前,请确保你的环境满足以下要求:
-
Python 版本:Python 3.10 或更高版本(推荐使用 3.11+)
-
操作系统:macOS、Linux 或 Windows 均可
-
网络环境:需要能够访问 LLM 服务的 API(如 OpenAI、Azure OpenAI、本地 Ollama 等)
-
磁盘空间:CrewAI 本身很小,但如果使用本地模型(如 Ollama),需要预留模型文件的空间
建议使用虚拟环境来隔离项目依赖:
bash
# 创建虚拟环境
python -m venv crewai-env
# 激活虚拟环境
# macOS / Linux:
source crewai-env/bin/activate
# Windows:
crewai-env\Scripts\activate安装 CrewAI
核心安装命令:
bash
pip install crewai如需使用 CrewAI 提供的内置工具集(如搜索引擎、文件工具等),需安装扩展包:
bash
pip install 'crewai[tools]'CrewAI 底层使用 LiteLLM 作为模型适配层,因此你可以方便地切换不同的 LLM 提供商。如果需要使用特定的 LLM,可能还需安装对应的 SDK:
bash
pip install litellm # 多模型适配层(crewai 会自动安装)
pip install openai # OpenAI API
pip install langchain-ollama # 本地 Ollama 模型
pip install anthropic # Anthropic Claude API
pip install google-generativeai # Google Gemini API安装完成后,可以验证版本:
bash
python -c "import crewai; print(crewai.__version__)"使用 CLI 创建项目
CrewAI 提供了便捷的命令行工具来快速初始化项目。这是官方推荐的起步方式:
bash
# 创建一个新项目
crewai create crew my_ai_team
# 进入项目目录
cd my_ai_team这会自动生成一个结构完整的项目骨架:
bash
my_ai_team/
├── pyproject.toml # 项目配置和依赖
├── README.md # 项目说明
├── .env # 环境变量(放 API 密钥)
├── src/
│ └── my_ai_team/
│ ├── config/
│ │ ├── agents.yaml # Agent 配置文件
│ │ └── tasks.yaml # Task 配置文件
│ ├── tools/
│ │ └── custom_tool.py # 自定义工具模板
│ ├── crew.py # Crew 定义和组装
│ └── main.py # 入口文件这个结构遵循"配置与代码分离"的最佳实践。Agent 和 Task 的定义放在 YAML 文件中,方便非技术人员也能修改 Agent 的行为;Crew 的组装逻辑放在 Python 代码中。
常用 CLI 命令:
bash
# 运行 Crew
crewai run
# 训练 Agent(通过多次迭代来提升输出质量)
crewai train -n 5 # 训练5轮
# 查看帮助
crewai --helpcrewai train 是一个非常有用的功能------它会让 Crew 反复执行任务,并将每一轮的反馈积累起来,逐步提升输出质量。这类似于对 Agent 进行"在职培训"。
配置 API 密钥
CrewAI 默认使用 OpenAI 的 GPT-4 系列模型。在项目根目录创建 .env 文件来配置密钥:
env
# .env 文件
OPENAI_API_KEY=sk-your-openai-api-key-here
# 如果使用 Serper 搜索引擎工具
SERPER_API_KEY=your-serper-api-key-here如果你使用其他 LLM 提供商,例如 Azure OpenAI:
env
AZURE_API_KEY=your-azure-key
AZURE_API_BASE=https://your-resource.openai.azure.com/
AZURE_API_VERSION=2024-02-15-preview如果使用 Anthropic Claude:
env
ANTHROPIC_API_KEY=your-anthropic-key如果使用 Google Gemini:
env
GEMINI_API_KEY=your-gemini-key如果想使用本地模型(通过 Ollama),需要先安装并启动 Ollama:
bash
# 安装 Ollama(macOS/Linux)
curl -fsSL https://ollama.com/install.sh | sh
# 拉取模型
ollama pull llama3.1
# 在 .env 中配置
OLLAMA_API_BASE=http://localhost:11434在代码中加载环境变量:
python
from dotenv import load_dotenv
load_dotenv()为不同 Agent 配置不同模型
一个常见的优化策略是为不同角色的 Agent 使用不同的模型------用便宜快速的模型处理简单任务,用强大的模型处理复杂任务:
python
from crewai import Agent
# 研究员用最强模型(需要深度理解和分析)
researcher = Agent(
role="研究员",
goal="深度分析技术趋势",
backstory="...",
llm="gpt-4o", # 最强但最贵
)
# 写手用中等模型(需要创造力但分析要求较低)
writer = Agent(
role="写手",
goal="撰写技术文章",
backstory="...",
llm="gpt-4o-mini", # 性价比高
)
# 编辑用 Claude(擅长文字润色和修改)
editor = Agent(
role="编辑",
goal="优化文章质量",
backstory="...",
llm="claude-3-5-sonnet-20241022", # 使用 Claude
)这种"混合模型"策略可以在保证质量的同时有效控制成本。
核心概念总览
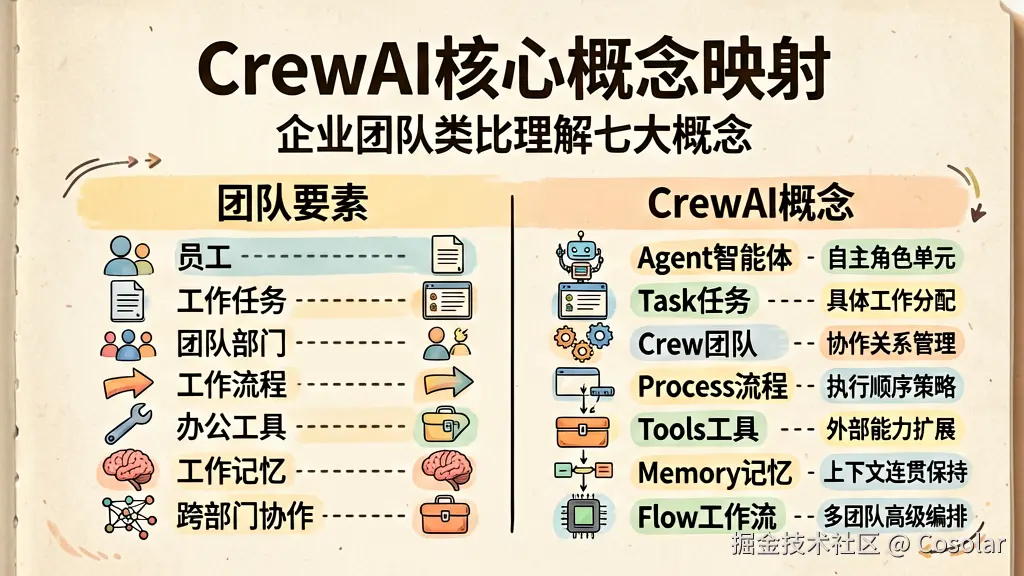
CrewAI 的架构可以类比为一个真实的企业团队。下面是几个核心概念的对照关系:
| 真实团队要素 | CrewAI 概念 | 说明 |
|---|---|---|
| 员工 | Agent(智能体) | 拥有特定角色和技能的自主单元 |
| 工作任务 | Task(任务) | 分配给 Agent 的具体工作 |
| 团队/部门 | Crew(团队) | Agent 和 Task 的集合,管理协作关系 |
| 工作流程 | Process(流程) | 定义任务的执行顺序和策略 |
| 办公工具 | Tools(工具) | Agent 完成任务时使用的外部能力 |
| 工作记忆 | Memory(记忆) | Agent 的记忆系统,保持上下文连贯 |
| 跨部门协作 | Flow(工作流) | 编排多个 Crew 的高级工作流 |
这些概念构成了 CrewAI 的核心骨架,接下来我们将逐一深入讲解。
执行生命周期
理解 CrewAI 的执行生命周期有助于你更好地调试和优化你的系统。当你调用 crew.kickoff() 时,底层发生了以下过程:
第一步:规划阶段(可选) 。如果启用了 planning=True,Crew 会先进行一次整体规划,分析任务之间的依赖关系,制定执行策略。这个阶段的输出会被记录并影响后续的执行顺序。
第二步:任务分配。根据 Process 类型,系统将任务分配给对应的 Agent。在 Sequential 模式下按顺序分配;在 Hierarchical 模式下由 Manager Agent 动态分配。
第三步:Agent 执行 。每个 Agent 接收到任务后,会经历一个"思考-行动-观察"的循环(类似 ReAct 模式):Agent 先思考如何完成任务,然后决定使用哪些工具,获取工具返回的结果,再根据结果继续思考或输出最终答案。这个循环会持续进行,直到 Agent 认为任务完成或达到 max_iter 上限。
第四步:上下文传递 。当一个任务完成后,其输出会被传递给下一个任务(通过 context 参数)。在 Sequential 模式下,前一个任务的输出自动成为下一个任务的上下文。
第五步:质量验证 。如果 Task 配置了 guardrail,系统会调用验证函数检查输出质量。验证不通过则重新执行任务(最多 max_retries 次)。
第六步:结果汇总。所有任务完成后,最后一个任务的输出作为整个 Crew 的最终结果返回,同时记录 Token 使用统计等元数据。
Agent(智能体)
Agent 是 CrewAI 中最基本的执行单元。每个 Agent 都扮演一个特定角色,拥有明确的目标和行为背景。你可以把 Agent 理解为团队中的一名"员工"------他知道自己是谁、要做什么、为什么要做。
Agent 核心参数
创建 Agent 时,可以配置以下关键参数:
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
role |
str | 必填 | Agent 的角色名称,定义其在团队中的职能 |
goal |
str | 必填 | Agent 的目标,指导其决策方向 |
backstory |
str | 必填 | Agent 的背景故事,提供行为动机和个性 |
llm |
str/LLM | "gpt-4o-mini" |
使用的语言模型 |
tools |
list | [] |
Agent 可使用的工具列表 |
allow_delegation |
bool | False |
是否允许将任务委托给其他 Agent |
verbose |
bool | False |
是否输出详细的执行日志 |
max_iter |
int | 20 |
最大迭代次数,防止无限循环 |
memory |
bool/Memory | False |
是否启用记忆功能 |
respect_context_window |
bool | True |
超出上下文窗口时是否自动摘要 |
reasoning |
bool | False |
是否启用执行前推理规划 |
max_rpm |
int | None |
每分钟最大请求数限制 |
inject_date |
bool | False |
是否自动注入当前日期 |
通过代码创建 Agent
下面是一个创建研究员 Agent 的完整示例:
python
from crewai import Agent
from crewai_tools import SerperDevTool
# 创建一个高级研究员 Agent
researcher = Agent(
role="高级数据研究员",
goal="发现和总结人工智能领域的最新突破和技术趋势",
backstory="""你是一位在人工智能领域拥有15年研究经验的资深研究员。
你擅长从海量信息中提取关键洞见,并对技术趋势有敏锐的判断力。
你的研究成果经常被发表在顶级学术期刊上。""",
tools=[SerperDevTool()], # 使用 Serper 搜索引擎
llm="gpt-4o", # 使用 GPT-4o 模型
verbose=True, # 输出详细日志
allow_delegation=False, # 不允许委托任务
max_iter=15, # 最大迭代15次
memory=True, # 启用记忆
)你也可以创建多个不同角色的 Agent 组成团队:
python
# 创建写手 Agent
writer = Agent(
role="资深技术撰稿人",
goal="将复杂的技术概念转化为清晰、易懂的文章内容",
backstory="""你是一位经验丰富的技术写手,擅长用通俗的语言
解释复杂概念。你的文章在技术社区中广受欢迎,帮助了无数
初学者理解前沿技术。""",
verbose=True,
allow_delegation=False,
)
# 创建编辑 Agent
editor = Agent(
role="内容质量总监",
goal="确保所有输出内容的准确性、连贯性和高质量",
backstory="""你是一位严谨的编辑,对文字质量有着近乎苛刻的要求。
你曾在多家知名媒体担任主编,有丰富的内容审核和质量把控经验。""",
verbose=True,
allow_delegation=True, # 允许委托任务给其他 Agent
)通过 YAML 配置 Agent
CrewAI 支持通过 YAML 文件定义 Agent,这在项目较大时更易于维护。使用 CLI 创建项目后,会在 src/{project}/config/agents.yaml 中自动生成配置模板:
yaml
# agents.yaml
researcher:
role: "高级数据研究员"
goal: "发现和总结{topic}领域的最新突破"
backstory: >
你是一位在{topic}领域拥有丰富经验的研究员,
擅长从海量信息中提取关键洞见。
verbose: true
allow_delegation: false
tools:
- SerperDevTool
writer:
role: "资深技术撰稿人"
goal: "将技术研究成果转化为高质量的科普文章"
backstory: >
你是一位技术写手,擅长用通俗语言解释复杂概念。
verbose: trueYAML 中的 {topic} 等占位符会在运行时被实际值替换。在代码中通过 Agent.from_config() 加载:
python
from crewai import Agent
researcher = Agent.from_config(
config_path="config/agents.yaml",
agent_name="researcher",
topic="人工智能"
)Agent 高级特性
推理模式(Reasoning):启用后 Agent 会在执行前先进行规划思考,适合复杂决策场景。开启推理模式后,Agent 会在每次执行工具之前先"想一想":我需要做什么?最佳的执行路径是什么?哪些信息是我还缺的?这种类似 Chain-of-Thought 的机制可以显著提升复杂任务的完成质量,但也会增加 Token 消耗。
python
planner = Agent(
role="项目策划师",
goal="制定最优的项目执行方案",
backstory="你是一位资深项目经理。",
reasoning=True, # 启用推理
)日期感知:让 Agent 知道当前日期,适合涉及时效性信息的任务。启用后,系统会在 Agent 的系统提示词中自动注入当前日期,让 Agent 能够做出时效性判断。
python
news_agent = Agent(
role="新闻分析师",
goal="分析最新的行业新闻",
backstory="你关注全球新闻动态。",
inject_date=True, # 自动注入当前日期
)委托机制(Delegation) :当 allow_delegation=True 时,Agent 可以将自己无法完成或不擅长完成的任务"委托"给 Crew 中的其他 Agent。这在层级流程中特别有用------管理者 Agent 可以分析任务特点,然后将子任务分配给最合适的团队成员。
委托的工作方式如下:当一个 Agent 决定委托任务时,它会分析 Crew 中其他 Agent 的角色和能力描述,选择最合适的 Agent 来接收任务。接收任务的 Agent 完成后,结果会返回给委托者,委托者再将结果整合到自己的输出中。
python
# 管理者 Agent------可以委托任务给其他人
manager = Agent(
role="项目管理者",
goal="协调团队完成所有任务",
backstory="你是一位经验丰富的技术项目经理。",
allow_delegation=True, # 允许委托
max_iter=25, # 管理者可能需要更多迭代
)
# 专家 Agent------专注执行被委托的任务
expert = Agent(
role="数据分析专家",
goal="提供精准的数据分析结果",
backstory="你是数据科学领域的资深专家。",
allow_delegation=False, # 专家不需要委托
)步骤回调(step_callback):你可以为 Agent 注册一个回调函数,在 Agent 每执行一步(每次思考/工具调用)时都会被调用。这对于实时监控 Agent 行为、自定义日志记录非常有用。
python
def on_step(step):
"""在 Agent 每一步执行时调用"""
print(f"[步骤回调] 思考: {step.thought}")
if step.tool:
print(f"[步骤回调] 使用工具: {step.tool.name}")
print("---")
researcher = Agent(
role="研究员",
goal="研究技术趋势",
backstory="你是一位资深研究员。",
step_callback=on_step,
)上下文窗口管理 :当 Agent 处理的对话内容过长、接近 LLM 的上下文窗口限制时,CrewAI 会自动进行上下文摘要(如果 respect_context_window=True)。这意味着 Agent 不会因为上下文过长而崩溃,而是会智能地将之前的对话内容压缩为摘要,继续工作。
python
researcher = Agent(
role="研究员",
goal="...",
backstory="...",
respect_context_window=True, # 默认开启
# 你也可以设置摘要的触发阈值
max_context_length=8000, # 超过8000 token 时触发摘要
)独立使用 Agent:Agent 也可以不通过 Crew,直接独立执行任务。这在调试阶段或只需要单个 Agent 完成简单任务时非常方便:
python
result = researcher.kickoff("分析一下2025年大模型领域的最新进展")
print(result)
# 也可以传入多个输入
for topic in ["大语言模型", "多模态模型", "AI Agent"]:
result = researcher.kickoff(f"分析{topic}的最新进展")
print(f"--- {topic} ---")
print(result.raw)Task(任务)
Task 是分配给 Agent 的具体工作任务。一个 Task 清楚地描述了需要做什么、期望的输出是什么,以及可以使用哪些工具。
Task 核心参数
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
description |
str | 必填 | 任务的详细描述,说明需要做什么 |
expected_output |
str | 必填 | 期望的输出格式和内容 |
agent |
Agent | None |
负责执行此任务的 Agent |
context |
list | [] |
上下文任务列表,提供前置信息 |
tools |
list | [] |
该任务可使用的工具(覆盖 Agent 级别的工具) |
output_file |
str | None |
将输出保存到指定文件路径 |
markdown |
bool | False |
是否将输出格式化为 Markdown |
guardrail |
function | None |
输出验证函数,确保质量 |
max_retries |
int | 2 |
Guardrail 验证失败时的最大重试次数 |
async_execution |
bool | False |
是否异步执行 |
创建 Task 示例
python
from crewai import Task
# 研究任务
research_task = Task(
description="""针对"{topic}"主题进行深入研究,收集最新的
技术进展、关键数据点和行业趋势。重点关注:
1. 最近6个月内的重大突破
2. 主要参与公司和研究机构
3. 潜在的应用场景和市场影响""",
expected_output="""一份结构化的研究报告,包含:
- 至少5个关键技术进展及其详细描述
- 相关数据和统计信息
- 来源链接和参考资料""",
agent=researcher,
tools=[SerperDevTool()],
output_file="research_report.md", # 自动保存到文件
)
# 写作任务 ------ 依赖研究任务的输出作为上下文
writing_task = Task(
description="""基于研究团队提供的报告,撰写一篇面向技术爱好者的
深度文章。要求:
- 开篇要有吸引力的引言
- 正文结构清晰,逻辑连贯
- 适当使用数据和案例支撑观点
- 结尾有独到的总结和展望""",
expected_output="一篇1500-2000字的高质量技术文章",
agent=writer,
context=[research_task], # 以研究任务的输出作为上下文
markdown=True,
)
# 编辑审核任务
editing_task = Task(
description="""审核文章的以下方面:
- 事实准确性:核实所有技术细节和数据
- 逻辑连贯性:确保论述流畅自然
- 语言质量:修正语法和用词错误
- 可读性:优化段落结构和过渡句""",
expected_output="审核通过的最终版文章,附带修改说明",
agent=editor,
context=[writing_task],
)Task 输出格式
CrewAI 支持多种输出格式,你可以通过 output_json 和 output_pydantic 参数来指定:
python
from pydantic import BaseModel
# 定义 Pydantic 模型来约束输出格式
class ArticleOutput(BaseModel):
title: str
summary: str
content: str
word_count: int
tags: list[str]
# 使用 Pydantic 模型约束输出
writing_task = Task(
description="撰写一篇技术文章",
expected_output="结构化的文章数据",
output_pydantic=ArticleOutput,
agent=writer,
)
# 执行后获取结构化输出
result = crew.kickoff()
print(result.pydantic.title) # 访问标题
print(result.pydantic.tags) # 访问标签列表也可以使用 JSON 格式输出:
python
task = Task(
description="分析市场数据",
expected_output="JSON 格式的分析结果",
output_json={"market_size": "", "growth_rate": "", "key_players": []},
agent=analyst,
)Guardrail(护栏)机制
Guardrail 是 CrewAI 的质量保障机制,允许你在 Task 输出传递给下一个 Task 之前进行验证。如果验证失败,Agent 会带着错误信息重新执行任务。
Guardrail 函数需要返回一个元组 (is_valid: bool, result_or_error: str)。当 is_valid 为 False 时,result_or_error 会被作为错误反馈传回给 Agent,告诉它哪里出了问题、需要如何改进。Agent 会根据这个反馈重新执行任务,直到通过验证或达到 max_retries 上限。
python
def quality_check(output: str) -> tuple[bool, str]:
"""验证文章质量。
返回 (是否通过, 错误信息) 的元组。"""
if len(output) < 500:
return False, "文章长度不足500字,请扩充内容。"
if "参考" not in output and "来源" not in output:
return False, "缺少参考来源,请补充引用信息。"
return True, output
research_task = Task(
description="深入研究AI技术趋势",
expected_output="详细的技术报告",
agent=researcher,
guardrail=quality_check,
max_retries=3, # 最多重试3次
)你也可以使用基于 LLM 的 Guardrail,让另一个 AI 来审查输出质量:
python
def llm_guardrail(output: str) -> tuple[bool, str]:
"""使用 LLM 评估输出质量"""
from crewai import Agent
judge = Agent(
role="质量评审员",
goal="评估内容是否达到发布标准",
backstory="你是一位严格的内容评审专家。",
llm="gpt-4o-mini", # 用小模型节省成本
)
result = judge.kickoff(f"请评估以下内容的质量,如果合格返回'PASS',否则指出问题:\n{output}")
if "PASS" in result.raw:
return True, output
return False, result.raw # 将评审意见作为错误反馈Task 上下文传递详解
context 参数是 Task 之间信息传递的桥梁。理解它的工作机制对于构建复杂的多 Agent 流水线至关重要。
当你设置 context=[task_a, task_b] 时,task_a 和 task_b 的完整输出会被拼接到当前任务的描述中,作为 Agent 的输入参考。这意味着当前任务的 Agent 可以"看到"之前任务的结果。
python
# 研究任务------无 context,是第一个任务
research_task = Task(
description="研究{topic}",
expected_output="研究报告",
agent=researcher,
)
# 写作任务------以研究任务的输出为 context
writing_task = Task(
description="基于研究报告撰写文章",
expected_output="技术文章",
agent=writer,
context=[research_task], # 写作时能看到研究报告的完整内容
)
# 审核任务------同时参考研究和写作两个任务的输出
review_task = Task(
description="审核文章的准确性",
expected_output="审核报告",
agent=reviewer,
context=[research_task, writing_task], # 同时看到研究原始数据和文章
)需要注意的是,context 传递的是任务的最终输出文本。如果上下文过长且 Agent 启用了 respect_context_window=True,CrewAI 会自动对上下文进行摘要压缩。
异步执行与回调
对于耗时的任务,你可以启用异步执行,让多个任务并行运行:
python
# 并行执行的研究任务
research_task_a = Task(
description="研究量子计算最新进展",
expected_output="量子计算研究报告",
agent=researcher_a,
async_execution=True, # 异步执行
)
research_task_b = Task(
description="研究脑机接口最新进展",
expected_output="脑机接口研究报告",
agent=researcher_b,
async_execution=True, # 异步执行
)
# 汇总任务------等待上面两个任务完成后再执行
summary_task = Task(
description="汇总两份研究报告,生成综合分析报告",
expected_output="综合分析报告",
agent=summarizer,
context=[research_task_a, research_task_b],
)Task 也支持 callback 参数,在任务完成时触发回调:
python
def on_task_complete(output):
"""任务完成时的回调函数"""
print(f"任务已完成,输出长度: {len(output)} 字符")
# 可以在这里做一些后处理,比如保存到数据库、发送通知等
research_task = Task(
description="研究AI技术趋势",
expected_output="研究报告",
agent=researcher,
callback=on_task_complete,
)人类介入(Human Input)
CrewAI 支持在任务执行过程中请求人类输入,让真人参与关键决策环节。当 human_input=True 时,Agent 在完成任务后会将输出呈现给人类审阅,人类可以提供反馈或修改意见,Agent 会根据反馈调整输出。
python
critical_task = Task(
description="制定产品定价策略",
expected_output="定价策略方案",
agent=strategist,
human_input=True, # 请求人类审核
)这个功能在涉及重要决策、合规审核或需要人类判断的场景中非常实用。
Crew(团队)
Crew 是 Agent 和 Task 的容器,负责管理它们之间的协作关系和执行流程。你可以把 Crew 理解为一个"项目组"------它决定了谁来做哪些事、按什么顺序来做。
Crew 核心参数
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
agents |
list | 必填 | 团队中的 Agent 列表 |
tasks |
list | 必填 | 要执行的任务列表 |
process |
Process | sequential |
执行流程类型 |
memory |
bool | False |
是否启用团队记忆 |
cache |
bool | True |
是否启用工具调用缓存 |
planning |
bool | False |
是否启用执行前规划 |
manager_llm |
str/LLM | None |
层级流程中管理者的 LLM |
manager_agent |
Agent | None |
自定义管理者 Agent |
verbose |
bool/int | False |
日志详细程度 |
max_rpm |
int | None |
每分钟最大请求数 |
share_crew |
bool | False |
是否分享 Crew 信息用于改进 |
创建 Crew
python
from crewai import Crew, Process
# 创建内容创作团队
content_crew = Crew(
agents=[researcher, writer, editor],
tasks=[research_task, writing_task, editing_task],
process=Process.sequential, # 顺序执行
memory=True, # 启用记忆
cache=True, # 启用缓存
verbose=True,
)
# 启动执行
result = content_crew.kickoff(
inputs={"topic": "2025年大语言模型发展趋势"}
)
print(result.raw) # 原始文本输出
print(result.token_usage) # Token 使用统计kickoff() 是 Crew 的主执行方法,你也可以传入一个 inputs 字典来动态替换 Task 描述中的占位符。
Crew 输出对象
kickoff() 返回的是一个 CrewOutput 对象,它包含了丰富的执行信息:
python
result = crew.kickoff()
# 主要属性
print(result.raw) # 最后一个任务的原始文本输出
print(result.pydantic) # Pydantic 格式输出(如果配置了 output_pydantic)
print(result.json_dict) # JSON 字典格式输出(如果配置了 output_json)
print(result.token_usage) # Token 使用统计
print(result.tasks_output) # 所有任务的输出列表
# 遍历每个任务的输出
for task_output in result.tasks_output:
print(f"任务: {task_output.description[:50]}...")
print(f"Agent: {task_output.agent}")
print(f"输出: {task_output.raw[:200]}...")
print("---")批量执行 kickoff_for_each
当你需要对多组输入分别执行同一个 Crew 时,kickoff_for_each() 是一个非常高效的方法。它会自动为每组输入创建一次独立的执行:
python
# 对多个主题分别执行研究
topics = [
{"topic": "大语言模型"},
{"topic": "计算机视觉"},
{"topic": "强化学习"},
]
results = crew.kickoff_for_each(inputs=topics)
for i, result in enumerate(results):
print(f"\n{'='*50}")
print(f"主题 {i+1}: {topics[i]['topic']}")
print(f"输出: {result.raw[:500]}...")训练 Crew
CrewAI 的 train() 方法可以让 Crew 通过多次迭代来逐步提升输出质量。每次训练轮次,Crew 都会执行任务、收集反馈,并将经验积累到记忆中:
python
# 训练5轮
crew.train(
n_iterations=5,
inputs={"topic": "AI 安全"},
)
# 训练后再执行正式任务,质量会明显提升
result = crew.kickoff(inputs={"topic": "AI 安全"})训练的核心原理是利用记忆系统------每轮执行的反馈会被存储到记忆中,后续轮次可以访问这些经验,从而避免重复犯错。
Crew 级别回调
与 Agent 的 step_callback 类似,Crew 也支持两个级别的回调:
python
def on_step(step):
"""每个 Agent 的每一步都会触发"""
pass
def on_task_complete(task_output):
"""每个任务完成时触发"""
print(f"任务完成: {task_output.description[:50]}")
print(f"输出: {task_output.raw[:100]}...")
crew = Crew(
agents=[researcher, writer, editor],
tasks=[research_task, writing_task, editing_task],
step_callback=on_step, # 步骤级回调
task_callback=on_task_complete, # 任务级回调
)检查点(Checkpoint)机制
对于长时间运行的 Crew,你可以配置检查点来保存中间状态。如果执行过程中出错,可以从检查点恢复而不需要从头开始:
python
crew = Crew(
agents=[researcher, writer, editor],
tasks=[research_task, writing_task, editing_task],
checkpoint={
"enabled": True,
"save_path": "./checkpoints/my_crew",
},
)Process(执行流程)
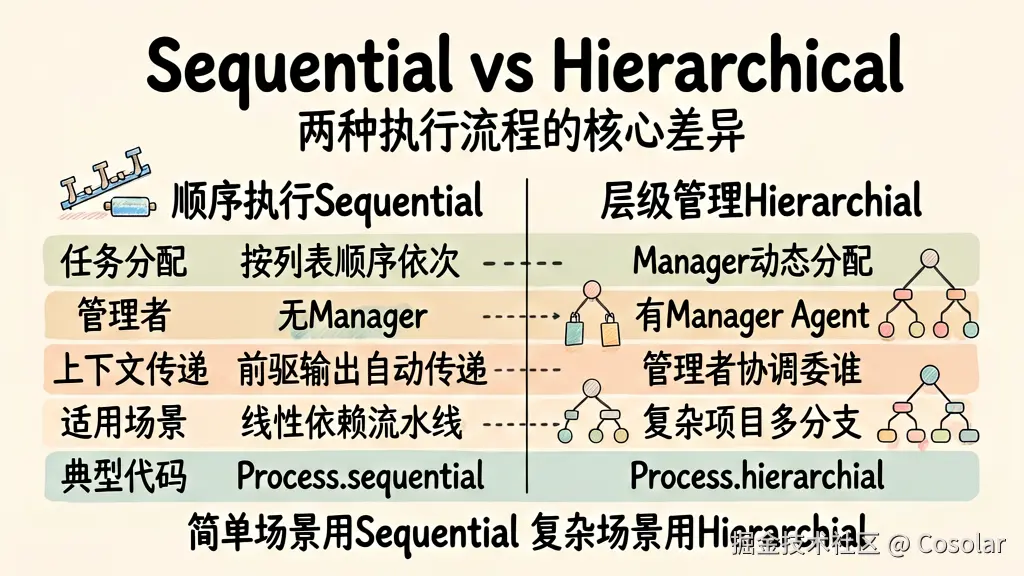
Process 定义了 Crew 中任务的执行策略。CrewAI 提供了三种流程类型,适用于不同复杂度的场景。
Sequential 顺序流程
最简单的模式------任务按照列表中的顺序依次执行,前一个任务的输出自动作为下一个任务的上下文。就像一条流水线,每个工位完成自己的部分后交给下一个。
python
crew = Crew(
agents=[researcher, writer, editor],
tasks=[research_task, writing_task, editing_task],
process=Process.sequential,
)执行流程为:research_task → writing_task → editing_task
在顺序流程中,你不需要显式设置 context 参数------系统会自动将前一个任务的输出作为下一个任务的上下文。但如果你在 Task 中设置了 context 指向其他任务,那么以显式指定的 context 为准。
执行细节:假设我们有三个任务 A、B、C。系统首先执行 A,等待 A 完成后,将 A 的输出注入 B 的上下文中,然后执行 B。B 完成后再将 B 的输出注入 C 的上下文中,最后执行 C。整个流程是严格线性的。
适用场景:任务之间有明确的前后依赖关系,比如"先调研,再写稿,最后审核"。大多数"流水线"式的场景都适合用 Sequential 模式。
注意事项 :Sequential 模式下任务不能并行执行,总耗时是所有任务耗时的总和。如果需要并行,考虑使用 Task 的 async_execution 参数。
Hierarchical 层级流程
在这个模式中,Crew 会自动创建一个"管理者" Agent(或你可以自定义),由它来决定任务的分配和执行顺序。管理者会根据每个 Agent 的角色和能力来分派任务,类似于企业中的经理安排工作。
管理者 Agent 的工作方式是:它首先分析所有待执行的任务,然后根据每个 Agent 的 role、goal、backstory 来判断谁最适合执行哪个任务。管理者还可以将一个大任务拆分成多个子任务,分配给不同的 Agent 协作完成。
python
# 方式一:让系统自动创建管理者
crew = Crew(
agents=[researcher, writer, editor, designer],
tasks=[research_task, writing_task, editing_task, design_task],
process=Process.hierarchical,
manager_llm="gpt-4o", # 管理者使用的 LLM(建议用强模型)
)
# 方式二:使用自定义管理者 Agent(推荐)
project_manager = Agent(
role="项目经理",
goal="高效协调团队完成所有任务",
backstory="""你是一位经验丰富的技术项目经理,擅长根据团队成员的
特长来分配工作,确保项目按时高质量交付。""",
allow_delegation=True,
llm="gpt-4o",
)
crew = Crew(
agents=[researcher, writer, editor, designer],
tasks=[research_task, writing_task, editing_task, design_task],
process=Process.hierarchical,
manager_agent=project_manager, # 使用自定义管理者
)执行细节:管理者 Agent 会首先"阅读"所有任务的描述和每个 Agent 的能力描述。然后它制定一个执行计划,决定哪个任务分配给哪个 Agent、以什么顺序执行。在执行过程中,管理者会监控每个任务的进展,必要时重新分配任务或提供指导。
适用场景:团队成员较多(4个以上 Agent)、任务分配需要根据实际情况动态决定的复杂场景。当任务之间的依赖关系不是简单的线性关系,而是需要"有人统筹"时,Hierarchical 是更好的选择。
注意事项:管理者 Agent 会消耗额外的 Token(因为它需要理解所有任务和 Agent 的信息),建议为管理者使用较强的模型(如 GPT-4o),同时控制团队成员数量在合理范围内。
Consensual 共识流程
这是 CrewAI 新增的流程类型,多个 Agent 通过协商讨论来共同完成任务的决策。每个 Agent 对任务提出自己的观点,最终达成共识。
这个模式模拟了"专家委员会"的决策过程。当面对一个需要多领域视角的复杂问题时,不同领域的专家会从各自的角度分析问题,然后综合各方意见得出最终结论。
python
# 创建不同领域的专家
risk_analyst = Agent(
role="风险分析师",
goal="评估项目的潜在风险",
backstory="你擅长识别和量化各类商业风险。",
)
market_analyst = Agent(
role="市场分析师",
goal="分析市场前景和竞争态势",
backstory="你对市场趋势有敏锐的洞察力。",
)
tech_analyst = Agent(
role="技术评估师",
goal="评估技术可行性和实现难度",
backstory="你是资深技术架构师,擅长技术可行性评估。",
)
investment_task = Task(
description="评估是否应该投资'XYZ'AI创业项目",
expected_output="综合分析报告,包含风险评估、市场分析和可行性结论",
)
crew = Crew(
agents=[risk_analyst, market_analyst, tech_analyst],
tasks=[investment_task],
process=Process.consensual,
)适用场景:需要多领域专家共同决策的场景,比如投资分析、产品设计、技术选型等。当一个问题没有唯一的正确答案,需要从多个角度综合考虑时,Consensual 模式特别有价值。
如何选择流程类型
以下是一个简单的决策参考:
如果你的任务是"流水线"式的------前一步的输出是后一步的输入------选择 Sequential。这是最常见的场景,也是默认模式。
如果你的任务涉及多个 Agent、需要有人统筹分配、任务之间有复杂的依赖关系------选择 Hierarchical。适合团队规模较大的场景。
如果你的任务需要多领域视角的综合判断、追求"集体智慧"------选择 Consensual。适合决策类任务。
Tools(工具)
工具是 Agent 执行任务时的"武器"------搜索引擎、文件读写、数据分析等能力都通过工具来实现。没有工具的 Agent 只能依赖自身的知识储备,而配备工具的 Agent 则可以主动获取信息和执行操作。
内置工具
安装 crewai[tools] 后可以使用多种内置工具:
python
from crewai_tools import (
SerperDevTool, # 搜索引擎(需 Serper API Key)
WebsiteSearchTool, # 网页内容搜索
FileReadTool, # 文件读取
DirectoryReadTool, # 目录浏览
CSVSearchTool, # CSV 文件搜索
JSONSearchTool, # JSON 文件搜索
PDFSearchTool, # PDF 文档搜索
DOCXSearchTool, # Word 文档搜索
TXTSearchTool, # 纯文本搜索
CodeDocsSearchTool, # 代码文档搜索
GithubSearchTool, # GitHub 搜索
)
# 使用搜索引擎工具
search_tool = SerperDevTool()
researcher = Agent(
role="研究员",
goal="搜索最新信息",
backstory="你是一位信息搜索专家。",
tools=[search_tool],
)自定义工具
你可以继承 BaseTool 类来创建自定义工具,让 Agent 拥有特定领域的能力:
python
from crewai.tools import BaseTool
from typing import Type
from pydantic import BaseModel, Field
class WeatherInput(BaseModel):
"""天气查询工具的输入参数模型"""
city: str = Field(description="要查询天气的城市名称")
class WeatherTool(BaseTool):
name: str = "天气查询工具"
description: str = "查询指定城市的实时天气信息"
args_schema: Type[BaseModel] = WeatherInput
def _run(self, city: str) -> str:
# 实际调用天气 API
import requests
api_key = "your-weather-api-key"
url = f"https://api.weatherapi.com/v1/current.json?key={api_key}&q={city}"
response = requests.get(url)
data = response.json()
temp = data["current"]["temp_c"]
condition = data["current"]["condition"]["text"]
return f"{city}当前天气:{condition},温度 {temp}°C"
# 在 Agent 中使用
weather_agent = Agent(
role="天气播报员",
goal="为用户提供准确的天气信息",
backstory="你是一位专业的气象播报员。",
tools=[WeatherTool()],
)@tool 装饰器
对于简单的工具函数,可以使用 @tool 装饰器快速创建:
python
from crewai.tools import tool
@tool("计算器")
def calculator(expression: str) -> str:
"""计算数学表达式。
Args:
expression: 要计算的数学表达式字符串,如 '2 + 3 * 4'
"""
try:
result = eval(expression)
return f"计算结果:{expression} = {result}"
except Exception as e:
return f"计算错误:{str(e)}"
# 使用
math_agent = Agent(
role="数学助手",
goal="帮助用户进行数学计算",
backstory="你是一位数学计算专家。",
tools=[calculator],
)工具还支持异步执行和缓存机制来提升性能:
python
@tool("异步数据查询")
async def async_query(database: str, query: str) -> str:
"""异步查询数据库数据。"""
# 模拟异步操作
import asyncio
await asyncio.sleep(1)
return f"查询结果:{database} - {query}"工具缓存与错误处理
CrewAI 内置了工具调用缓存机制。当同一个工具被相同参数多次调用时,系统会直接返回缓存结果而不会重新执行,这可以显著减少 API 调用次数和成本。
python
# Crew 级别启用缓存(默认开启)
crew = Crew(
agents=[researcher],
tasks=[research_task],
cache=True, # 默认 True
)
# 也可以在工具级别禁用缓存
from crewai_tools import SerperDevTool
# 每次搜索都获取最新结果
search_tool = SerperDevTool(cache=False)对于自定义工具,你可以通过添加错误处理逻辑来提升健壮性。Agent 在遇到工具错误时不会崩溃,而是会看到错误信息并尝试调整策略:
python
class DatabaseTool(BaseTool):
name: str = "数据库查询工具"
description: str = "查询公司数据库中的信息"
def _run(self, query: str) -> str:
try:
# 模拟数据库查询
import requests
response = requests.get(
f"https://api.example.com/search?q={query}",
timeout=10,
)
response.raise_for_status()
return response.json()["results"]
except requests.Timeout:
return "查询超时,请稍后重试或缩小查询范围。"
except requests.ConnectionError:
return "无法连接到数据库,请检查网络。"
except Exception as e:
return f"查询出错:{str(e)}。请尝试使用不同的查询条件。"注意上面工具返回的不是抛出异常,而是返回一个包含错误信息的字符串。这样做的好处是 Agent 能"读"到错误信息并据此调整策略(比如换一种搜索关键词),而不是直接终止执行。
工具组合使用
一个 Agent 可以同时配备多个工具。Agent 会根据任务需要智能选择使用哪个工具------它会根据每个工具的 name 和 description 来判断哪个工具最适合当前步骤。
python
from crewai_tools import SerperDevTool, WebsiteSearchTool, FileReadTool
researcher = Agent(
role="全栈研究员",
goal="全方位收集和分析信息",
backstory="你是一位能力全面的研究员。",
tools=[
SerperDevTool(), # 搜索最新信息
WebsiteSearchTool(), # 深入分析特定网页
FileReadTool(), # 读取本地文件
],
)你也可以在 Task 级别指定工具,覆盖 Agent 级别的工具配置。这在需要限制 Agent 在特定任务中只能使用某些工具时很有用:
python
# Agent 有很多工具
researcher = Agent(
role="研究员",
goal="...",
backstory="...",
tools=[SerperDevTool(), WebsiteSearchTool(), FileReadTool()],
)
# 但这个任务只允许使用搜索工具
restricted_task = Task(
description="只使用搜索引擎查找公开信息",
expected_output="搜索结果列表",
agent=researcher,
tools=[SerperDevTool()], # 限制只用搜索工具
)Memory(记忆系统)
记忆系统让 Agent 能够"记住"之前的交互信息。这对于多轮对话、长期项目和需要保持一致性的任务尤为重要。
统一记忆模型
CrewAI 最新版本使用了统一的 Memory 类,替代了之前分散的短期记忆、长期记忆、实体记忆和外部记忆类型,提供了一个简洁而强大的 API:
python
from crewai import Memory
# 创建记忆实例
memory = Memory()
# 存储信息
memory.remember("项目选择了 PostgreSQL 作为数据库")
memory.remember("客户偏好简洁的 UI 设计风格")
# 检索相关信息
matches = memory.recall("项目使用什么数据库?")
print(matches) # 返回相关的记忆条目配置记忆
在 Crew 级别启用记忆(最简单的使用方式):
python
crew = Crew(
agents=[researcher, writer],
tasks=[research_task, writing_task],
memory=True, # 一行开启记忆
)高级配置------自定义记忆的权重、嵌入模型等:
python
from crewai import Memory, Crew
memory = Memory(
embedder={
"provider": "openai",
"config": {
"model": "text-embedding-3-small",
}
},
llm="gpt-4o",
# 调整检索权重
recency_weight=0.3, # 时间新鲜度权重
semantic_weight=0.5, # 语义相似度权重
importance_weight=0.2, # 重要性权重
)
crew = Crew(
agents=[researcher, writer],
tasks=[research_task, writing_task],
memory=memory,
)记忆作用域
你可以为不同的 Agent 分配不同的记忆作用域,实现记忆隔离或共享:
python
# 为研究员创建独立记忆空间
researcher_memory = Memory()
researcher = Agent(
role="研究员",
goal="深入研究技术趋势",
backstory="你是一位资深研究员。",
memory=researcher_memory.scope("/agent/researcher"),
)
# 为写手创建独立记忆空间
writer_memory = Memory()
writer = Agent(
role="写手",
goal="撰写技术文章",
backstory="你是一位技术撰稿人。",
memory=writer_memory.scope("/agent/writer"),
)不同的作用域路径意味着记忆互不干扰,而相同路径的 Agent 可以共享记忆。
记忆的实际应用场景
为了更好地理解记忆系统的价值,下面列出几个典型的应用场景:
长期项目管理:当你需要 Crew 在多天内持续为一个项目工作时,记忆可以让 Agent "记住"之前做出的决策、收集的信息和已完成的工作,避免每次执行都从零开始。
python
# 第一天的工作
crew = Crew(agents=[...], tasks=[...], memory=True)
day1_result = crew.kickoff(inputs={"task": "分析项目需求"})
# 第二天的工作------Agent 会"记住"第一天的分析结果
crew = Crew(agents=[...], tasks=[...], memory=True)
day2_result = crew.kickoff(inputs={"task": "基于需求分析制定开发计划"})
# Agent 知道之前的需求分析结论,不会重复分析风格一致性:在内容创作场景中,记忆可以帮助 Agent 保持写作风格和术语使用的一致性。写手 Agent 会"记住"之前文章中使用的风格和术语,在新文章中保持一致。
避免重复搜索:结合工具缓存,记忆可以让研究员 Agent 避免重复搜索相同的信息。如果之前已经搜索过某个话题,Agent 可以直接从记忆中获取结果。
记忆容量管理 :记忆系统会自动管理存储容量。当记忆条目过多时,系统会根据 recency_weight(时间新鲜度)、semantic_weight(语义相关度)和 importance_weight(重要性)这三个权重来决定哪些记忆保留、哪些被压缩或丢弃。你可以根据业务需要调整这些权重。
Flow(工作流编排)
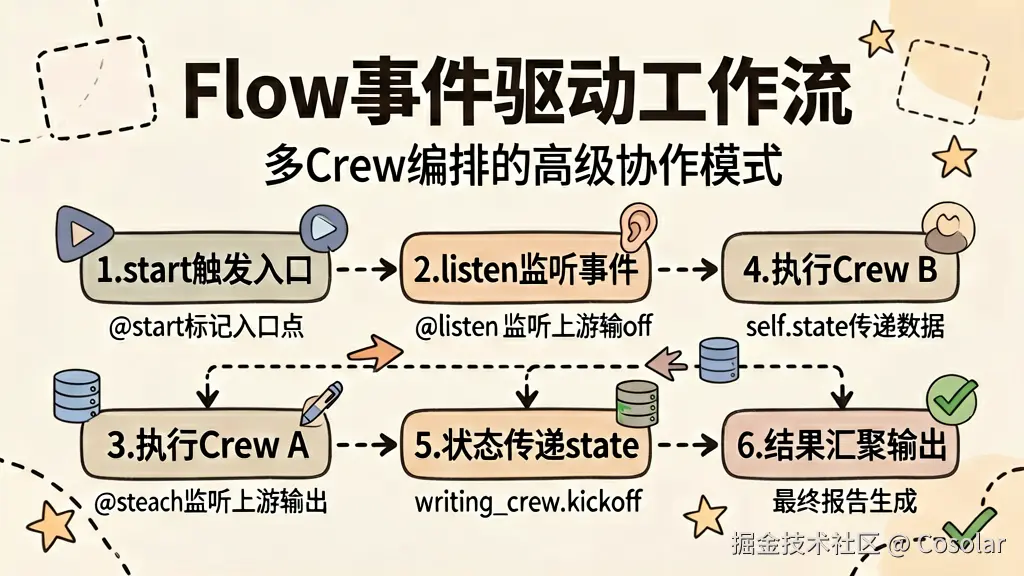
Flow 是 CrewAI 的高级编排能力,允许你将多个 Crew 组织成结构化的事件驱动工作流。如果说 Crew 是一个团队,那么 Flow 就是多个团队之间的协调机制。
Flow 基本概念
Flow 采用事件驱动的设计模式,通过 @start 标记入口点,@listen 监听上游事件来触发下游步骤。状态数据通过 self.state 在各步骤之间传递。
python
from crewai.flow.flow import Flow, listen, start
class ContentFlow(Flow):
"""内容创作工作流"""
@start()
def research(self):
"""第一步:启动研究"""
research_crew = create_research_crew()
result = research_crew.kickoff(inputs={"topic": "AI趋势"})
self.state.research_result = result.raw
return result.raw
@listen(research)
def write_article(self, research_output):
"""第二步:基于研究结果写文章"""
writing_crew = create_writing_crew()
result = writing_crew.kickoff(
inputs={"research_data": research_output}
)
self.state.article = result.raw
return result.raw
@listen(write_article)
def publish(self, article):
"""第三步:发布文章"""
print(f"文章已准备发布,长度:{len(article)} 字")
self.state.published = True
# 启动 Flow
flow = ContentFlow()
flow.kickoff()
# 访问状态
print(flow.state.published) # True@start 与 @listen 装饰器
@start() 标记 Flow 的入口方法。一个 Flow 可以有多个 @start() 方法,它们会并行执行。@listen() 指定该方法监听哪个上游步骤的输出:
python
class ParallelFlow(Flow):
@start()
def step_a(self):
"""并行执行的第一步 A"""
return "A 的结果"
@start()
def step_b(self):
"""并行执行的第一步 B"""
return "B 的结果"
@listen(step_a)
def process_a(self, result):
"""处理 A 的结果"""
self.state.a_done = True
@listen(step_b)
def process_b(self, result):
"""处理 B 的结果"""
self.state.b_done = True
@listen(process_a, process_b)
def final_step(self):
"""当 A 和 B 都完成后执行"""
print("所有步骤完成!")路由与状态管理
使用 @router() 可以根据条件将流程路由到不同的分支:
python
from crewai.flow.flow import Flow, listen, start, router
class SmartFlow(Flow):
@start()
def analyze(self):
"""分析输入内容"""
self.state.complexity = "high" # 模拟分析结果
return self.state.complexity
@router(analyze)
def route_by_complexity(self):
"""根据复杂度路由到不同处理分支"""
if self.state.complexity == "high":
return "complex_path"
return "simple_path"
@listen("complex_path")
def handle_complex(self):
"""处理复杂任务------使用完整 Crew"""
full_crew = create_full_crew()
result = full_crew.kickoff()
self.state.result = result.raw
@listen("simple_path")
def handle_simple(self):
"""处理简单任务------使用轻量 Agent"""
simple_agent = create_simple_agent()
result = simple_agent.kickoff("处理简单任务")
self.state.result = result.rawFlow 错误处理
在真实的生产环境中,Flow 的某些步骤可能会失败(API 超时、LLM 返回异常等)。你可以在 Flow 中添加错误处理逻辑来增强健壮性:
python
class RobustFlow(Flow):
@start()
def fetch_data(self):
"""获取数据"""
try:
crew = create_data_crew()
result = crew.kickoff()
self.state.data = result.raw
self.state.fetch_success = True
return result.raw
except Exception as e:
self.state.fetch_success = False
self.state.error = str(e)
return None
@listen(fetch_data)
def process_data(self, data):
"""处理数据------包含降级逻辑"""
if not self.state.fetch_success:
self.state.result = f"数据获取失败:{self.state.error}。使用缓存数据。"
return
# 正常处理逻辑
analysis_crew = create_analysis_crew()
result = analysis_crew.kickoff(
inputs={"data": data}
)
self.state.result = result.rawFlow 状态持久化
Flow 的 self.state 默认是内存中的,Flow 执行结束后就丢失了。如果你需要在多次运行之间保留状态,可以自定义状态的序列化/反序列化逻辑:
python
import json
from pathlib import Path
from crewai.flow.flow import Flow, listen, start
class PersistentFlow(Flow):
def __init__(self):
super().__init__()
self._state_file = Path("flow_state.json")
# 恢复之前的状态
if self._state_file.exists():
saved = json.loads(self._state_file.read_text())
for key, value in saved.items():
setattr(self.state, key, value)
def save_state(self):
"""将当前状态保存到文件"""
state_dict = {
key: getattr(self.state, key)
for key in dir(self.state)
if not key.startswith('_')
}
self._state_file.write_text(json.dumps(state_dict, ensure_ascii=False, indent=2))
@start()
def step_one(self):
self.state.step_one_done = True
self.state.data = "一些重要数据"
self.save_state()
return self.state.data
@listen(step_one)
def step_two(self, data):
self.state.result = f"处理完成: {data}"
self.save_state()Flow 的实战模式
在实际项目中,Flow 经常被用来实现以下几种模式:
扇出-扇入模式(Fan-out/Fan-in):一个步骤的输出被分发到多个并行步骤处理,然后所有并行步骤的结果汇聚到一个汇总步骤。这在需要"分头调研,然后汇总"的场景中非常常见。
python
class FanOutFlow(Flow):
@start()
def generate_queries(self):
"""生成多个查询方向"""
return ["技术趋势", "市场分析", "竞争格局"]
@listen(generate_queries)
def research_tech(self, queries):
"""研究方向一"""
# ...
self.state.tech_result = "技术趋势分析结果"
@listen(generate_queries)
def research_market(self, queries):
"""研究方向二"""
# ...
self.state.market_result = "市场分析结果"
@listen(research_tech, research_market)
def synthesize(self):
"""汇总所有研究方向的结果"""
self.state.final_report = f"技术: {self.state.tech_result}\n市场: {self.state.market_result}"管道模式(Pipeline):每个步骤对数据进行增量处理,像流水线一样逐步精炼。
python
class PipelineFlow(Flow):
@start()
def raw_input(self):
self.state.data = "原始用户反馈数据"
return self.state.data
@listen(raw_input)
def clean(self, data):
"""数据清洗"""
self.state.cleaned = f"清洗后的: {data}"
return self.state.cleaned
@listen(clean)
def analyze(self, cleaned):
"""数据分析"""
self.state.analysis = f"分析结果: {cleaned}"
return self.state.analysis
@listen(analyze)
def report(self, analysis):
"""生成报告"""
self.state.report = f"最终报告: {analysis}"
return self.state.report实战案例:构建一个自动化内容创作团队
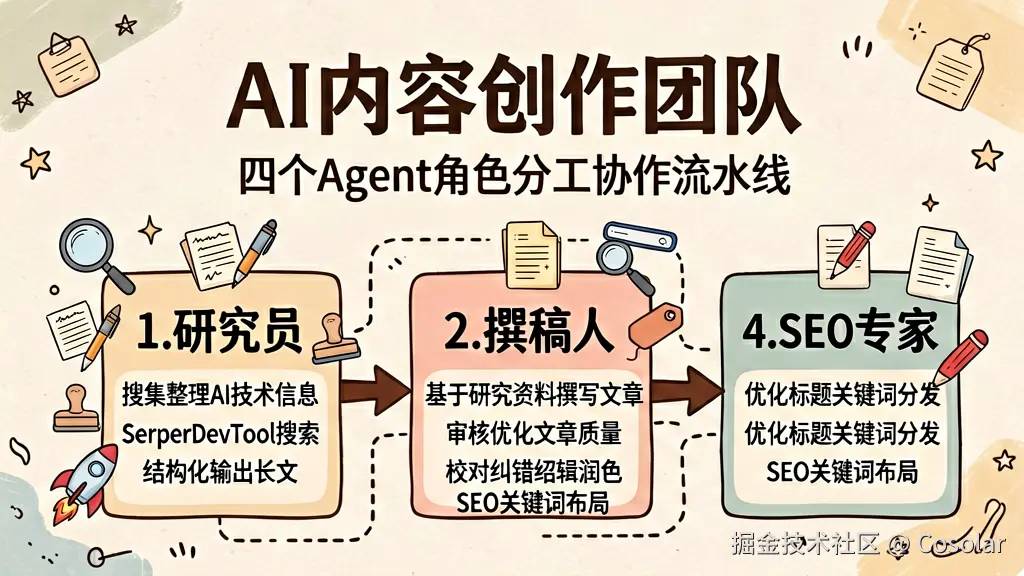
下面我们通过一个完整的案例,将前面学到的所有概念串联起来,构建一个自动化的内容创作团队。
需求分析
我们的目标是构建一个"AI 技术文章创作团队",包含以下角色:
-
研究员:搜索和整理最新的 AI 技术信息
-
撰稿人:基于研究资料撰写文章
-
编辑:审核并优化文章质量
-
SEO 专家:优化文章标题和关键词
定义 Agent
python
from crewai import Agent
from crewai_tools import SerperDevTool, WebsiteSearchTool
# 研究员
researcher = Agent(
role="AI 技术研究员",
goal="深入研究{topic}的最新进展和技术细节",
backstory="""你是 AI 领域的资深研究员,拥有敏锐的技术洞察力。
你擅长从学术论文、技术博客和行业报告中提取关键信息。""",
tools=[SerperDevTool(), WebsiteSearchTool()],
verbose=True,
max_iter=15,
)
# 撰稿人
writer = Agent(
role="技术文章撰稿人",
goal="将技术研究成果转化为引人入胜的文章",
backstory="""你是一位才华横溢的技术写手,能够将复杂的
技术概念转化为普通读者也能理解的内容。你的文章既有
深度又有温度。""",
verbose=True,
)
# 编辑
editor = Agent(
role="内容质量编辑",
goal="确保文章质量达到发布标准",
backstory="""你是一位经验丰富的内容编辑,对文章质量
有着极高的标准。你关注每一个细节,从事实准确性到
语言流畅度。""",
verbose=True,
allow_delegation=True,
)
# SEO 专家
seo_expert = Agent(
role="SEO 优化专家",
goal="优化文章的搜索引擎可见性和吸引力",
backstory="""你是 SEO 领域的专家,精通搜索引擎算法和
用户搜索行为。你知道什么样的标题和关键词能吸引
更多读者。""",
verbose=True,
)定义 Task
python
from crewai import Task
# 研究任务
research_task = Task(
description="""对"{topic}"进行全面深入的研究。
搜集以下信息:
- 最近6个月的关键技术进展(至少5项)
- 主要的参与公司/机构及其贡献
- 技术原理的简明解释
- 实际应用案例
- 行业专家的观点和预测
确保所有信息都有可靠来源。""",
expected_output="""结构化的研究报告,包含:
1. 技术进展摘要(每项100-200字)
2. 关键数据和统计信息
3. 来源列表(含URL)
报告总长度1500-2500字。""",
agent=researcher,
output_file="outputs/research_report.md",
)
# 写作任务
writing_task = Task(
description="""基于研究报告撰写一篇面向技术爱好者的深度文章。
要求:
- 标题要吸引人
- 开篇用案例或数据引出话题
- 正文分3-5个小节,逻辑清晰
- 适当使用类比帮助理解
- 结尾有独到见解和未来展望""",
expected_output="一篇2000-3000字的完整技术文章,Markdown 格式",
agent=writer,
context=[research_task],
output_file="outputs/draft_article.md",
markdown=True,
)
# 编辑审核任务
editing_task = Task(
description="""全面审核文章质量,检查:
1. 事实准确性------核实所有技术细节
2. 逻辑连贯性------论述是否流畅
3. 语言质量------语法、用词、句式
4. 结构合理性------章节划分和过渡
5. 可读性------是否适合目标读者
输出审核通过后的最终版本。""",
expected_output="最终版文章和简要审核报告",
agent=editor,
context=[writing_task],
output_file="outputs/final_article.md",
)
# SEO 优化任务
seo_task = Task(
description="""为文章进行 SEO 优化:
1. 生成5个备选标题(兼顾搜索量和吸引力)
2. 提取8-10个关键词
3. 撰写150字以内的摘要
4. 生成 meta description""",
expected_output="""JSON 格式输出:
{
"titles": ["标题1", "标题2", ...],
"keywords": ["关键词1", "关键词2", ...],
"summary": "文章摘要",
"meta_description": "meta 描述"
}""",
agent=seo_expert,
context=[editing_task],
output_json={
"titles": [],
"keywords": [],
"summary": "",
"meta_description": "",
},
output_file="outputs/seo_data.json",
)组装 Crew 并执行
python
from crewai import Crew, Process
from dotenv import load_dotenv
load_dotenv()
# 组装团队
content_crew = Crew(
agents=[researcher, writer, editor, seo_expert],
tasks=[research_task, writing_task, editing_task, seo_task],
process=Process.sequential,
memory=True,
cache=True,
verbose=True,
planning=True, # 启用执行前规划
)
# 启动执行
result = content_crew.kickoff(
inputs={"topic": "2025年多模态大模型的技术进展与应用前景"}
)
# 查看结果
print("=" * 50)
print("执行完成!")
print(f"最终输出:\n{result.raw}")
print(f"\nToken 使用统计:{result.token_usage}")运行结果与解析
执行后,你会看到以下输出文件:
-
outputs/research_report.md------ 研究员的调研报告 -
outputs/draft_article.md------ 撰稿人的初稿 -
outputs/final_article.md------ 编辑审核后的终稿 -
outputs/seo_data.json------ SEO 优化数据
开启 verbose=True 后,控制台会详细展示每个 Agent 的思考过程、工具调用和决策逻辑,这对于调试和优化你的 Crew 非常有价值。
实战案例:使用 Flow 构建智能客服系统
这个案例展示如何用 Flow 将多个 Crew 串联成一个智能客服工作流:
python
from crewai import Agent, Task, Crew, Process
from crewai.flow.flow import Flow, listen, start, router
# ---- Agent 定义 ----
intent_agent = Agent(
role="意图识别专家",
goal="准确识别用户的咨询意图",
backstory="你是NLP专家,擅长理解用户真实需求。",
)
faq_agent = Agent(
role="FAQ 客服",
goal="快速准确地回答常见问题",
backstory="你是资深客服,熟悉所有产品FAQ。",
)
tech_agent = Agent(
role="技术支持工程师",
goal="解决用户的技术问题",
backstory="你是技术专家,擅长排查和解决复杂技术问题。",
allow_delegation=True,
)
satisfaction_agent = Agent(
role="客户满意度分析师",
goal="评估本次服务的质量并生成改进建议",
backstory="你专注于客户服务体验优化。",
)
# ---- Task 定义 ----
intent_task = Task(
description="分析用户消息'{user_message}',识别意图类型:faq/technical/complaint",
expected_output="意图类型字符串:faq、technical 或 complaint",
agent=intent_agent,
)
faq_task = Task(
description="回答用户问题:{user_message}",
expected_output="清晰、友好的回答",
agent=faq_agent,
)
tech_task = Task(
description="诊断并解决用户技术问题:{user_message}",
expected_output="问题诊断和解决方案",
agent=tech_agent,
)
satisfaction_task = Task(
description="评估本次客服交互质量",
expected_output="满意度评分和改进建议",
agent=satisfaction_agent,
)
# ---- Crew 定义 ----
intent_crew = Crew(agents=[intent_agent], tasks=[intent_task])
faq_crew = Crew(agents=[faq_agent], tasks=[faq_task])
tech_crew = Crew(agents=[tech_agent], tasks=[tech_task])
review_crew = Crew(agents=[satisfaction_agent], tasks=[satisfaction_task])
# ---- Flow 定义 ----
class CustomerServiceFlow(Flow):
"""智能客服工作流"""
@start()
def identify_intent(self):
"""识别用户意图"""
result = intent_crew.kickoff(
inputs={"user_message": self.state.user_message}
)
self.state.intent = result.raw.strip().lower()
self.state.response = ""
return self.state.intent
@router(identify_intent)
def route_by_intent(self):
"""根据意图路由到不同的处理 Crew"""
if "faq" in self.state.intent:
return "handle_faq"
elif "technical" in self.state.intent:
return "handle_technical"
else:
return "handle_complaint"
@listen("handle_faq")
def handle_faq(self):
"""处理常见问题"""
result = faq_crew.kickoff(
inputs={"user_message": self.state.user_message}
)
self.state.response = result.raw
@listen("handle_technical")
def handle_technical(self):
"""处理技术问题"""
result = tech_crew.kickoff(
inputs={"user_message": self.state.user_message}
)
self.state.response = result.raw
@listen("handle_complaint")
def handle_complaint(self):
"""处理投诉(也走技术支持路径)"""
result = tech_crew.kickoff(
inputs={"user_message": self.state.user_message}
)
self.state.response = result.raw
@listen(handle_faq, handle_technical, handle_complaint)
def review_service(self):
"""服务评价"""
result = review_crew.kickoff()
self.state.review = result.raw
return {
"response": self.state.response,
"review": self.state.review,
}
# ---- 运行 ----
flow = CustomerServiceFlow()
flow.state.user_message = "我购买的会员为什么无法使用高级功能?"
result = flow.kickoff()
print(f"客服回复:{result['response']}")
print(f"服务评估:{result['review']}")实战案例:构建数据分析流水线
这个案例展示如何用 CrewAI 构建一个完整的数据分析团队,从数据收集到最终报告生成。这个案例特别适合需要定期生成数据驱动报告的团队。
python
from crewai import Agent, Task, Crew, Process
from crewai_tools import FileReadTool, CSVSearchTool
# ---- Agent 定义 ----
data_collector = Agent(
role="数据采集工程师",
goal="从多个数据源收集和整理原始数据",
backstory="""你是一位数据工程专家,擅长从各种来源收集和清洗数据。
你对数据质量有严格的标准,确保收集的数据准确、完整、一致。""",
tools=[FileReadTool(), CSVSearchTool()],
verbose=True,
max_iter=10,
)
data_analyst = Agent(
role="数据分析师",
goal="从数据中发现有意义的模式和趋势",
backstory="""你是一位资深数据分析师,拥有统计学和数据科学的
深厚功底。你擅长使用统计方法和可视化来揭示数据背后的故事。""",
verbose=True,
reasoning=True, # 启用推理,让分析更有深度
)
insight_generator = Agent(
role="商业洞察专家",
goal="将数据分析结果转化为可执行的商业建议",
backstory="""你同时拥有数据分析和商业战略两方面的经验。你能够将
技术层面的数据发现翻译成业务人员能理解的洞察和行动建议。""",
verbose=True,
)
report_writer = Agent(
role="报告撰写人",
goal="生成结构清晰、结论明确的数据分析报告",
backstory="""你是专业的商业报告撰写人,擅长制作面向管理层的
数据报告。你的报告以清晰、简洁、可操作性强著称。""",
verbose=True,
)
# ---- Task 定义 ----
collection_task = Task(
description="""收集并整理{data_source}中的数据。
要求:
1. 检查数据的完整性和一致性
2. 标注数据质量问题
3. 提取关键指标和维度
4. 生成数据概览摘要""",
expected_output="""数据概览报告,包含:
- 数据量、时间范围、主要字段
- 数据质量评估
- 关键指标的初步统计""",
agent=data_collector,
)
analysis_task = Task(
description="""对收集到的数据进行深入分析:
1. 识别数据中的关键趋势和异常
2. 计算核心指标的变化率和同比/环比
3. 发现数据之间的相关性
4. 标注需要重点关注的发现""",
expected_output="详细的分析结果,包含具体数据和统计指标",
agent=data_analyst,
context=[collection_task],
)
insight_task = Task(
description="""基于数据分析结果,提炼商业洞察:
1. 将每个数据发现转化为商业含义
2. 提出具体的行动建议(至少3条)
3. 评估每条建议的预期影响和实施难度
4. 标注风险和注意事项""",
expected_output="商业洞察报告,包含行动建议矩阵",
agent=insight_generator,
context=[analysis_task],
)
report_task = Task(
description="""整合所有分析结果,生成面向管理层的最终报告:
1. 执行摘要(200字以内)
2. 核心发现(不超过5条)
3. 行动建议及优先级
4. 附录:详细数据和分析
风格要求:简洁、专业、面向决策。""",
expected_output="一份完整的数据分析报告,Markdown 格式",
agent=report_writer,
context=[insight_task, analysis_task],
output_file="outputs/data_analysis_report.md",
markdown=True,
)
# ---- 组装并执行 ----
analysis_crew = Crew(
agents=[data_collector, data_analyst, insight_generator, report_writer],
tasks=[collection_task, analysis_task, insight_task, report_task],
process=Process.sequential,
memory=True,
verbose=True,
)
result = analysis_crew.kickoff(
inputs={"data_source": "2025年Q1销售数据"}
)
print(f"分析完成!报告已保存到 outputs/data_analysis_report.md")
print(f"总 Token 消耗: {result.token_usage}")这个案例展示了 CrewAI 在数据处理领域的典型应用。注意 insight_generator 这个角色------它的作用不是做更多分析,而是充当"翻译",将技术语言转化为商业语言。这种角色设计在实际项目中非常有价值,因为它解决了"分析师的报告业务人员看不懂"这个常见痛点。
最佳实践与常见问题
最佳实践
1. 角色设计要具体且有区分度
避免创建功能重叠的 Agent。每个 Agent 的 role、goal、backstory 应该清晰描述其独特价值。好的 backstory 应该包含:该 Agent 的专业领域、工作经验年限、性格特点和工作方式。
python
# 好的设计------角色明确,backstory 丰富
analyst = Agent(
role="数据分析师",
goal="从数据中发现趋势和模式",
backstory="""你是一位拥有10年经验的数据分析师,曾在麦肯锡和
高盛担任分析顾问。你的分析风格是数据驱动、严谨客观,
你总是用数据说话,不轻易下结论。""",
)
strategist = Agent(
role="市场策略师",
goal="基于分析结果制定行动方案",
backstory="""你是一位富有创造力的市场策略师,擅长将数据洞察
转化为切实可行的营销方案。你注重 ROI,善于在有限预算内
实现最大效果。""",
)
# 不好的设计------角色模糊,backstory 空洞
agent1 = Agent(role="助手A", goal="帮助完成任务", backstory="你是一个助手。")
agent2 = Agent(role="助手B", goal="协助完成任务", backstory="你也是助手。")2. Task 描述要具体,预期输出要明确
模糊的任务描述会导致 Agent 行为不可预测。越具体越好,越明确越好。好的 Task 应该包含:做什么、怎么做、做到什么程度、以什么格式输出。
python
# 好的 Task------具体、明确、可衡量
task = Task(
description="搜索2025年Q1中国AI行业融资数据,列出前10大融资事件",
expected_output="包含公司名称、融资金额、轮次、投资方的表格",
)
# 不好的 Task------模糊、不可衡量
task = Task(
description="研究AI行业",
expected_output="一份报告",
)3. 合理使用记忆和缓存
对于需要保持一致性的长期任务启用 memory,对于工具调用频繁的场景启用 cache:
python
crew = Crew(
agents=[...],
tasks=[...],
memory=True, # 长期项目建议开启
cache=True, # 减少重复 API 调用
)但也要注意:如果你的任务每次都需要全新信息(比如实时新闻),可以关闭缓存。如果任务之间不需要共享上下文,可以不启用记忆以节省 Token。
4. 设置合理的 max_iter
过高的迭代次数可能浪费 Token,过低可能导致任务未完成。一般建议:简单任务设置 5-10 次,中等复杂度设置 10-15 次,复杂分析类任务设置 15-25 次。
python
# 简单任务------不需要太多迭代
simple_agent = Agent(role="格式化助手", ..., max_iter=5)
# 复杂任务------需要多步搜索和分析
complex_agent = Agent(role="深度研究员", ..., max_iter=20)5. 善用 Guardrail 保证质量
对于关键输出环节,添加验证逻辑确保质量达标。Guardrail 是 CrewAI 中性价比最高的质量保障机制:
python
def validate_code(output):
if "error" in output.lower():
return False, "代码包含错误,请修复后重新提交。"
return True, output6. 渐进式构建和调试
不要一上来就构建一个包含 10 个 Agent 的庞大 Crew。推荐的开发流程是:
首先,从 2 个 Agent、2 个 Task 的最小可行 Crew 开始。然后,开启 verbose=True 观察每个 Agent 的思考和行为过程。根据观察结果,逐步调整 Agent 的 backstory 和 Task 的 description。确认基础 Crew 工作正常后,再逐步添加更多 Agent 和 Task。
7. 使用 YAML 配置管理大型项目
当你的 Crew 包含超过 3 个 Agent 时,强烈建议将 Agent 和 Task 的定义放在 YAML 文件中,而不是硬编码在 Python 代码里。这样做的好处是:配置更清晰、易于版本控制、非技术人员也能修改 Agent 行为。
8. 成本控制策略
在实际项目中,API 调用成本是需要重点关注的。以下是几个有效的成本控制策略:为简单任务使用便宜模型(如 gpt-4o-mini);启用缓存减少重复调用;缩短 backstory 和 description 到必要长度;使用 max_iter 控制迭代上限;用 max_rpm 防止意外的高频调用。
常见问题排查
问题 1:Agent 执行时间过长或陷入循环
原因通常是 max_iter 设置过高,或任务描述不够明确,导致 Agent 不知道何时"停下来"。解决方法:降低 max_iter,优化 Task 描述使其更具体,在 expected_output 中明确说明"什么时候算完成"。
问题 2:Token 消耗过大
这可能是由多个因素导致的。启用 cache=True 缓存工具调用结果;使用更小、更便宜的模型处理简单任务(llm="gpt-4o-mini");缩短 backstory 和 description 的长度;降低 max_iter 上限;如果是 Hierarchical 流程,注意管理者 Agent 的 Token 消耗(它会消耗大量 Token 来理解全局)。
问题 3:Agent 输出质量不稳定
同一个 Crew 执行两次,输出质量可能差异较大。这是 LLM 的固有特性,但可以通过以下方式缓解:启用 reasoning=True 让 Agent 在执行前进行规划;使用 Guardrail 机制确保输出质量有底线;在 Task 描述中提供具体的输出格式示例;启用 memory=True 让 Agent 从历史经验中学习。
问题 4:多 Agent 之间信息传递不畅
表现为后续 Task 的 Agent 没有"看到"前序 Task 的输出,或误解了输出的含义。确保 Task 之间的 context 参数正确设置;启用 memory=True 让 Agent 可以访问历史信息;在 Task 描述中明确说明"请基于前序任务提供的研究报告来撰写文章"这样的指引。
问题 5:API 速率限制错误
当多个 Agent 同时发起 API 请求时,容易触发速率限制。设置 max_rpm 参数控制请求频率:
python
crew = Crew(
agents=[...],
tasks=[...],
max_rpm=10, # 每分钟最多10个请求
)问题 6:导入错误 "No module named 'crewai'"
确保你已激活正确的虚拟环境,并且在该环境中安装了 crewai。如果使用 crewai[tools],确保安装时使用了正确的引号(在 Zsh/Bash 中 [ 和 ] 是特殊字符)。
问题 7:Flow 中步骤执行顺序不符合预期
Flow 的执行顺序由 @listen 装饰器决定,而不是方法在代码中的位置。确保每个 @listen() 都正确指向了它的上游步骤。如果多个步骤监听同一个源,它们会并行执行。
总结
CrewAI 是目前最易上手的多智能体协作框架之一。通过本教程,我们系统地学习了以下内容:
核心概念:Agent(智能体)是执行单元,通过 role/goal/backstory 定义其身份和行为;Task(任务)是工作内容,通过 description/expected_output 明确目标;Crew(团队)是协作容器,负责将 Agent 和 Task 组织在一起;Process(流程)是执行策略,决定了任务如何被分配和执行;Tools(工具)是能力扩展,让 Agent 能够与外部世界交互;Memory(记忆)是信息保持,让 Agent 能够在多次执行间保持连贯性。
流程模式:Sequential 适合有明确先后顺序的任务链,是最常用也最简单的模式;Hierarchical 适合需要动态分配的复杂场景,由管理者 Agent 统筹全局;Consensual 适合多专家协商决策,追求"集体智慧"。
高级编排 :Flow 允许将多个 Crew 组织成事件驱动的工作流,通过 @start 标记入口、@listen 触发下游、@router 条件路由,实现灵活的流程控制。支持并行执行、错误处理和状态持久化。
工具系统 :内置丰富的工具(搜索、文件、网页等),支持继承 BaseTool 创建自定义工具,也支持 @tool 装饰器快速定义简单工具。工具支持缓存、异步执行和错误处理。
实战技巧:角色设计要具体且有区分度、任务描述要明确且可衡量、善用记忆和缓存来保持连贯性并降低成本、设置合理的迭代次数防止无限循环、使用 Guardrail 保证输出质量底线、采用渐进式构建方式从小 Crew 开始逐步扩展。
成本控制:为不同角色选择不同级别的模型、启用缓存减少重复 API 调用、合理设置 max_iter 和 max_rpm 参数、精简 backstory 和 description 的长度。
CrewAI 的学习曲线相对平缓,但其能力上限很高。从简单的双 Agent 协作到复杂的多 Crew 工作流编排,它都能胜任。建议你从一个小项目开始------比如用两个 Agent 完成一个简单的"研究 + 写作"任务------然后逐步增加复杂度,在实践中深入理解各个组件的配合方式。
推荐学习路径
入门阶段:理解 Agent/Task/Crew 三个核心概念,能够搭建一个 Sequential 流程的双 Agent Crew。
进阶阶段:掌握 Tools 的自定义开发、Memory 的配置和使用、Guardrail 质量保障机制。尝试为不同 Agent 配置不同的 LLM 模型。
高级阶段:学会使用 Flow 编排多个 Crew、使用 Hierarchical 和 Consensual 流程模式、实现生产级的错误处理和监控。
生产阶段:关注成本控制、性能优化、可观测性(日志、指标),将 CrewAI 集成到你的 CI/CD 流水线中。
参考资源
如需进一步了解,可参考以下资源: