用 OCR、PDF 转文本和摘要接口构建 RAG 文档入库 Agent
摘要:RAG 系统的效果很大程度取决于文档入库质量。本文用图片 OCR、PDF 转文本和 PDF 摘要接口演示一个文档入库 Agent:先把文件内容变成可检索文本,再生成摘要和索引元数据。
关键词:RAG 文档入库、OCR API、PDF 转文本 API、PDF 摘要 API、知识库 Agent
问题背景
企业知识库里常见的资料并不都是纯文本,很多是扫描件、PDF 报告、合同截图或演示材料。如果直接把文件丢给模型,成本高、失败难定位,也不方便做增量更新。
更稳定的做法是把文档处理拆开:识别文本、生成摘要、切分段落、写入向量库。Agent 负责判断文件类型和调度工具,底层内容转换由接口完成。
Agent 工作流
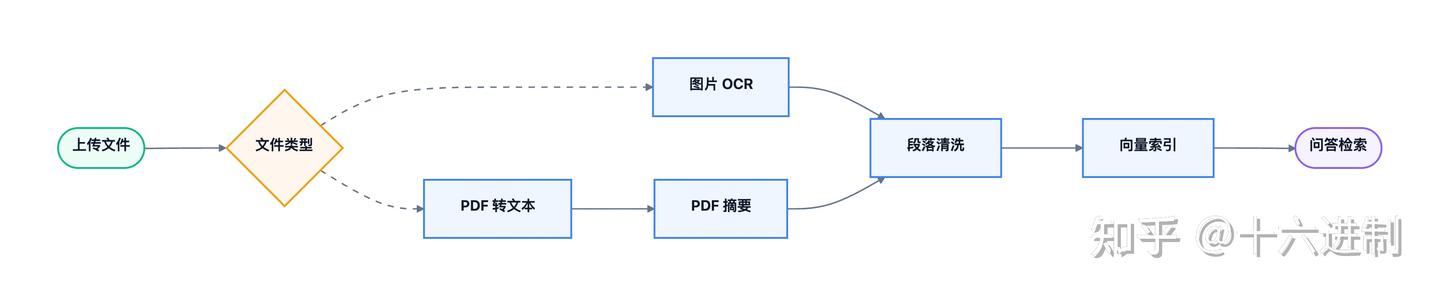
接口编排
| 步骤 | 接口 | 请求方式 | 用途 |
|---|---|---|---|
| 图片识别 | 通用图片文件流 OCR 到文本 | POST | 处理图片、扫描件、截图中的文字 |
| PDF 文本抽取 | 通用 PDF 文件流 OCR 到文本 | POST | 把 PDF 转成可检索文本 |
| PDF 摘要 | PDF 全文多语言 AI 摘要 | POST | 生成文档摘要,作为检索元数据 |
调用示例
上传 PDF 并抽取文本:
bash
curl -X POST "https://api.gugudata.com/imagerecognition/pdf2text?appkey=YOUR_APPKEY" \
-F "file=@./report.pdf"对同一份 PDF 生成摘要:
bash
curl -X POST "https://api.gugudata.com/ai/summarize?appkey=YOUR_APPKEY&lang=zh-cn&streaming=false" \
-F "file=@./report.pdf"Python 侧可以把转换结果交给入库任务:
python
import requests
APPKEY = "YOUR_APPKEY"
def pdf_to_text(path: str) -> str:
"""Convert a PDF file to text before indexing."""
with open(path, "rb") as file_obj:
response = requests.post(
"https://api.gugudata.com/imagerecognition/pdf2text",
params={"appkey": APPKEY},
files={"file": file_obj},
timeout=120,
)
response.raise_for_status()
payload = response.json()
return payload["Data"]入库设计
文档入库时建议保存这些字段:
| 字段 | 说明 |
|---|---|
| document_id | 自己系统里的文档 ID |
| source_file | 原始文件名或业务来源 |
| extracted_text | OCR 或 PDF 转文本结果 |
| summary | 摘要接口返回的文档摘要 |
| chunk_id | 分段后的文本块 ID |
| extracted_at | 转换时间,便于刷新和审计 |
错误处理
图片或 PDF 转换失败时,Agent 不应该直接生成答案。它应该把文档标记为"转换失败",保留失败原因,并允许人工重新上传或换用更清晰的文件。对于大文件,可以先做文件大小和格式检查,再调用接口,减少无效请求。
工程注意点
- OCR 结果要保留原始页码或文件来源,方便定位答案出处。
- 分段时不要只按固定字数切分,要尽量保留标题、段落和表格上下文。
- 入库前去掉明显页眉、页脚和重复水印,减少检索噪声。
- 对敏感文档先做权限控制,再开放给问答系统。
标准架构拆解
文档 RAG 入库通常分为"文件处理"和"检索构建"两条线:
| 模块 | 责任 |
|---|---|
| 文件接收 | 接收 PDF、图片或扫描件,并记录来源 |
| 内容转换 | OCR、PDF 转文本、PDF 摘要 |
| 文本规范化 | 清理页眉页脚、合并断行、保留页码 |
| 分块索引 | 按标题、页码和语义边界切分文本 |
| 检索服务 | 向量检索、关键词检索和答案引用 |
Agent 不应该直接跳到问答。只有当文档完成转换、分块、索引和权限标记后,才适合作为问答数据源。否则答案很难解释,也难以追踪来源。
数据流与接口边界
推荐的数据流是:
- 文件上传后生成
document_id。 - 根据文件类型选择 OCR 或 PDF 转文本。
- 对 PDF 同步生成摘要,作为文档级元数据。
- 清洗文本并保留页码、段落和来源文件。
- 生成 chunk,并写入向量库或全文索引。
- 查询时返回答案、引用片段和页码。
OCR 接口和 PDF 转文本接口的输出属于"原始识别文本",不建议直接作为最终答案。摘要接口输出属于"文档级概览",适合放在文档列表、搜索结果卡片或问答上下文开头。
可靠性与观测
文档入库要关注以下指标:
| 指标 | 用途 |
|---|---|
| conversion_success_rate | 文件转换成功率 |
| extracted_text_length | 判断空白页或低质量扫描件 |
| chunk_count | 判断分块是否异常 |
| indexing_latency_ms | 入库耗时 |
| answer_citation_rate | 问答是否能返回引用来源 |
失败状态要明确记录在文档级别。常见状态包括"等待转换""转换失败""等待索引""索引完成""权限未配置"。这样前端和运营都能知道文档处于哪一步。
落地清单
- 文件入库前先计算哈希,避免重复上传。
- 每个 chunk 保存
document_id、页码、标题路径和原文片段。 - 摘要只作为辅助元数据,不替代原文检索。
- 权限控制要在检索前生效,不是在生成答案后再过滤。
- 对扫描质量差的文档建立人工复核入口。
可扩展方向
这个 Agent 可以继续接入 PII 去除接口,在入库前处理个人信息;也可以接入关键词提取接口,为每份文档生成标签,提高搜索和推荐质量。