赛力斯(SERES)作为华为深度赋能的高端智能电动汽车品牌,旗下AITO问界系列凭借华为HarmonyOS智能座舱、HUAWEI ADS高阶智能驾驶及DriveONE电驱平台,构建了M5、M7、M9等覆盖中型到大型SUV的产品矩阵。在渠道策略上,赛力斯采用"授权用户中心+鸿蒙智行授权用户中心"的双轨模式,依托华为终端渠道势能与传统汽车经销商网络,快速构建全国线下触点。
目前,品牌已在全国31个省市区布局 413家门店,覆盖一线城市核心商圈及二三线城市主要汽车贸易园区,重点门店更配备"星夜服务"(18:00-21:00延时营业),形成"白天销售体验+夜间维保服务"的全时段服务闭环。这些用户中心不仅是交付终端,更是鸿蒙生态体验入口------用户可亲身体验鸿蒙座舱与华为手机、手表等设备的无缝流转,以及"一键遥控泊车"、"城市NCA"等创新智驾功能。
本文采用程序化方式解析赛力斯官方门店页面(https://auto.seres.cn/map)的服务端渲染(SSR)HTML。与传统API需多轮分页请求不同,该页面将所有门店数据预渲染在HTML中,仅需一次HTTP GET请求即可获取完整数据集。使用Python的requests库发起请求,设置User-Agent模拟浏览器,超时30秒。通过正则表达式<li\^\>*class="store-list"\^\>*>(.*?)</li>匹配每个门店区块,分别提取:<h2>中的门店名称、营业时间::\s*(.*?)</p>中的常规时段、星夜服务::\s*(.*?)</p>中的夜间时段、门店电话::\s*(.*?)</p>中的电话、门店地址::\s*(.*?)</p>中的地址,以及<span>中的服务标签。
页面未直接提供省份和城市字段,需从地址字符串反推。建立省份别名映射(如"北京"→"北京市")和城市-省份映射(如"苏州"→"江苏省"),对"肃省"等错写进行替换修复。优先从地址开头15字符匹配省份,若失败则从门店名称提取城市关键词;直辖市直接赋值。最终输出CSV(UTF-8 BOM编码)包含name、province、city、addr、phone、hours、night、tags共8个字段。共采集413条有效记录,少数未匹配的会在控制台输出以便人工校对。数据可用于门店密度统计、城市层级渗透分析、星夜服务覆盖率评估及渠道空白区域识别。
赛力斯门店查询地址:赛力斯汽车官方门店地图
打开开发者工具(F12 → Network → 刷新页面),找到第一个请求,你会发现一个map/的 HTML 响应体------这便是关键:赛力斯的门店页面采用了 Vue.js 服务端渲染(SSR),所有门店数据在服务器端就已完成渲染,以 413 个 <li class="store-list"> 标签的形式直接嵌入 HTML 源码中;
首先,我们找到网点数据的存储位置,然后看3个关键部分标头、负载、 预览;
标头:通常包括URL的连接,也就是目标资源的位置;
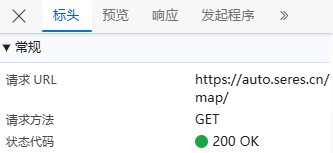
**负载:**对于GET请求:负载通常包含了传递的参数,有些网页负载可能为空,或者没有负载,因为所有参数都通过URL传递,这里就没有负载;
**预览:**指的是对响应内容的快速查看或摘要显示,可以帮助用户快速了解返回的数据结构或内容片段,我们可以看到数据直接就在HTML页面里;

门店 HTML 结构解析
接下来,我们开始解析 HTML 结构,获取具体数据,在 HTML 中,每家门店是一个独立的 <li class="store-list"> 块,结构如下:
python
<li class="store-list">
<h2>AITO授权用户中心•北京姚家园</h2>
<div class="type-list"><span>星夜服务</span></div>
<p>营业时间:08:30-17:30</p>
<p>星夜服务:18:00-21:00</p>
<p>门店电话:010-51332233</p>
<p>门店地址:北京市朝阳区朝阳北路63号</p>
</li>提取规则:
| HTML 标签/内容 | 匹配方式 | 对应字段 |
|---|---|---|
<h2>...</h2> |
正则提取标签内容 | 门店名称 |
营业时间:... |
正则 营业时间[::](.*?)</p> |
营业时间 |
星夜服务:... |
正则 星夜服务[::](.*?)</p> |
星夜服务时间 |
门店电话:... |
正则 门店电话[::](.*?)</p> |
联系电话 |
门店地址:... |
正则 门店地址[::](.*?)</p> |
门店地址 |
<span>星夜服务</span> |
正则提取 span 内容 | 服务标签 |
注意: 页面并未直接提供省份和城市字段,需要从"门店地址"字符串中通过省市区关键词匹配反推。此外,地址中存在少量非标准写法(如"苏州吴中经济开发区"缺少"市"字、"肃省天水市"实为"甘肃省天水市"),需要在解析逻辑中做容错处理。
方法思路
整体流程分为三步,且仅需一次 HTTP 请求:
- 获取页面 HTML:用 requests.get() 直接拉取 赛力斯汽车 的完整 HTML 响应;
- 正则提取门店块:匹配所有 <li class="store-list"> 标签,逐块解析字段;
- 地址反推省市区:从"门店地址"字符串中匹配省份和城市关键词,映射为标准行政区划名称。
**第一步:**利用requests库发送HTTP请求获取所有门店信息,并根据标签进行保存,另存为csv;
完整代码#运行环境 Python 3.11
python
import csv
import os
import re
import requests
resp = requests.get('https://auto.seres.cn/map',
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'},
timeout=30)
resp.encoding = 'utf-8'
html = resp.text
pattern = r'<li[^>]*class="store-list"[^>]*>(.*?)</li>'
blocks = re.findall(pattern, html, re.DOTALL)
PROVINCE_ALIASES = {
'北京市': ['北京'], '天津市': ['天津'], '河北省': ['河北'], '山西省': ['山西'],
'内蒙古自治区': ['内蒙古'], '辽宁省': ['辽宁'], '吉林省': ['吉林'],
'黑龙江省': ['黑龙江'], '上海市': ['上海'], '江苏省': ['江苏'],
'浙江省': ['浙江'], '安徽省': ['安徽'], '福建省': ['福建'],
'江西省': ['江西'], '山东省': ['山东'], '河南省': ['河南'],
'湖北省': ['湖北'], '湖南省': ['湖南'], '广东省': ['广东'],
'广西壮族自治区': ['广西'], '海南省': ['海南'], '重庆市': ['重庆'],
'四川省': ['四川'], '贵州省': ['贵州'], '云南省': ['云南'],
'西藏自治区': ['西藏'], '陕西省': ['陕西'], '甘肃省': ['甘肃'],
'青海省': ['青海'], '宁夏回族自治区': ['宁夏'],
'新疆维吾尔自治区': ['新疆'],
}
# City to province mapping
CITY_PROVINCE = {
'东莞市': '广东省', '中山市': '广东省', '佛山市': '广东省', '珠海市': '广东省',
'深圳市': '广东省', '广州市': '广东省', '惠州市': '广东省', '汕头市': '广东省',
'厦门市': '福建省', '福州市': '福建省', '泉州市': '福建省',
'南宁市': '广西壮族自治区', '桂林市': '广西壮族自治区', '柳州市': '广西壮族自治区',
'杭州市': '浙江省', '宁波市': '浙江省', '温州市': '浙江省', '嘉兴市': '浙江省',
'苏州市': '江苏省', '南京市': '江苏省', '无锡市': '江苏省', '常州市': '江苏省',
'扬州市': '江苏省', '徐州市': '江苏省', '南通市': '江苏省', '盐城市': '江苏省',
'武汉市': '湖北省', '宜昌市': '湖北省', '襄阳市': '湖北省',
'成都市': '四川省', '绵阳市': '四川省', '德阳市': '四川省',
'长沙市': '湖南省', '株洲市': '湖南省', '湘潭市': '湖南省',
'济南市': '山东省', '青岛市': '山东省', '烟台市': '山东省', '淄博市': '山东省',
'潍坊市': '山东省', '临沂市': '山东省', '济宁市': '山东省',
'郑州市': '河南省', '洛阳市': '河南省', '开封市': '河南省', '新乡市': '河南省',
'西安市': '陕西省', '咸阳市': '陕西省', '宝鸡市': '陕西省',
'昆明市': '云南省', '曲靖市': '云南省', '大理市': '云南省',
'贵阳市': '贵州省', '遵义市': '贵州省',
'合肥市': '安徽省', '芜湖市': '安徽省', '蚌埠市': '安徽省',
'南昌市': '江西省', '九江市': '江西省',
'沈阳市': '辽宁省', '大连市': '辽宁省',
'长春市': '吉林省', '吉林市': '吉林省',
'哈尔滨市': '黑龙江省', '大庆市': '黑龙江省',
'太原市': '山西省', '大同市': '山西省',
'兰州市': '甘肃省',
'西宁市': '青海省',
'银川市': '宁夏回族自治区',
'乌鲁木齐市': '新疆维吾尔自治区',
'呼和浩特市': '内蒙古自治区', '包头市': '内蒙古自治区',
'拉萨市': '西藏自治区',
'海口市': '海南省', '三亚市': '海南省',
'石家庄市': '河北省', '唐山市': '河北省', '保定市': '河北省', '邯郸市': '河北省',
# Other cities
'六盘水市': '贵州省', '都匀市': '贵州省', '黔南布依族苗族自治州': '贵州省',
'安阳市': '河南省', '许昌市': '河南省', '南阳市': '河南省', '平顶山市': '河南省',
'随州市': '湖北省', '黄石市': '湖北省', '荆州市': '湖北省',
'岳阳市': '湖南省', '益阳市': '湖南省',
'赣州市': '江西省',
'常熟市': '江苏省', '昆山市': '江苏省',
'温岭市': '浙江省', '乐清市': '浙江省', '长兴县': '浙江省',
'宜宾市': '四川省', '泸州市': '四川省', '攀枝花市': '四川省',
'克拉玛依市': '新疆维吾尔自治区', '库尔勒市': '新疆维吾尔自治区',
# More cities
'泰州市': '江苏省', '宿迁市': '江苏省', '肇庆市': '广东省', '六安市': '安徽省',
'信阳市': '河南省', '邵阳市': '湖南省', '商丘市': '河南省', '娄底市': '湖南省',
'威海市': '山东省', '滨州市': '山东省', '自贡市': '四川省', '承德市': '河北省',
'驻马店市': '河南省', '舟山市': '浙江省', '周口市': '河南省', '通化市': '吉林省',
'秦皇岛市': '河北省', '运城市': '山西省', '临汾市': '山西省', '茂名市': '广东省',
'渭南市': '陕西省', '绍兴市': '浙江省', '台州市': '浙江省', '金华市': '浙江省',
'湖州市': '浙江省', '衢州市': '浙江省', '丽水市': '浙江省',
'德州市': '山东省', '聊城市': '山东省', '菏泽市': '山东省', '日照市': '山东省',
'镇江市': '江苏省', '连云港市': '江苏省', '淮安市': '江苏省',
'十堰市': '湖北省', '孝感市': '湖北省', '荆门市': '湖北省', '鄂州市': '湖北省',
'郴州市': '湖南省', '永州市': '湖南省', '怀化市': '湖南省',
'河源市': '广东省', '清远市': '广东省', '韶关市': '广东省', '梅州市': '广东省',
'揭阳市': '广东省', '潮州市': '广东省', '湛江市': '广东省', '云浮市': '广东省',
'漳州市': '福建省', '宁德市': '福建省', '莆田市': '福建省', '龙岩市': '福建省',
'保定市': '河北省', '张家口市': '河北省', '沧州市': '河北省', '廊坊市': '河北省',
'衡水市': '河北省', '邢台市': '河北省',
'晋城市': '山西省', '长治市': '山西省', '朔州市': '山西省', '晋中市': '山西省',
'锦州市': '辽宁省', '鞍山市': '辽宁省', '抚顺市': '辽宁省', '营口市': '辽宁省',
'盘锦市': '辽宁省', '朝阳市': '辽宁省', '丹东市': '辽宁省',
'四平市': '吉林省', '延边朝鲜族自治州': '吉林省',
'鹤岗市': '黑龙江省', '牡丹江市': '黑龙江省', '绥化市': '黑龙江省',
'漯河市': '河南省', '濮阳市': '河南省', '三门峡市': '河南省',
'宜春市': '江西省', '景德镇市': '江西省', '上饶市': '江西省',
'德阳市': '四川省', '南充市': '四川省', '遂宁市': '四川省', '乐山市': '四川省',
'眉山市': '四川省', '广安市': '四川省', '达州市': '四川省',
'毕节市': '贵州省', '安顺市': '贵州省', '黔东南苗族侗族自治州': '贵州省',
'玉溪市': '云南省', '红河哈尼族彝族自治州': '云南省',
'汉中市': '陕西省', '延安市': '陕西省', '榆林市': '陕西省',
'白银市': '甘肃省', '天水市': '甘肃省', '酒泉市': '甘肃省',
'海东市': '青海省', '海西蒙古族藏族自治州': '青海省',
'喀什地区': '新疆维吾尔自治区', '巴音郭楞蒙古自治州': '新疆维吾尔自治区',
}
def extract_province_city(addr, name_hint=''):
if not addr:
return '', ''
# Fix common typos
addr = addr.replace('肃省', '甘肃省')
province = ''
city = ''
# 1. Try province alias
for full, aliases in PROVINCE_ALIASES.items():
for a in aliases:
idx = addr.find(a)
if idx >= 0 and idx < 15:
province = full
break
if province:
break
# 2. Try city-to-province mapping (with and without 市 suffix)
if not province:
for city_name, prov in CITY_PROVINCE.items():
if addr.startswith(city_name):
province = prov
city = city_name
break
# Try without 市/州/区 suffix
base = re.sub(r'[市州县区盟]$', '', city_name)
if len(base) >= 2 and (addr.startswith(base) or base in addr[:10]):
province = prov
city = city_name
break
# 3. Try from store name (e.g., "AITO授权用户中心•北京姚家园")
if not province and name_hint:
for full, aliases in PROVINCE_ALIASES.items():
for a in aliases:
if a in name_hint:
province = full
break
if province:
break
# 4. Extract city from address (only if province is known)
if province and not city:
rest = addr
for a in PROVINCE_ALIASES.get(province, []):
idx = rest.find(a)
if idx >= 0:
rest = rest[idx + len(a):]
break
pattern_city = r'([\u4e00-\u9fff]{2,4}(?:市|地区|州|盟|县))'
pattern_auto_region = r'([\u4e00-\u9fff]{4,8}(?:自治州|自治县))'
m = re.match(pattern_city, rest)
if not m:
m = re.match(pattern_auto_region, rest)
if m:
city = m.group(1)
elif province in ['北京市', '天津市', '上海市', '重庆市']:
city = province
if province in ['北京市', '天津市', '上海市', '重庆市']:
city = province
return province, city
stores = []
for block in blocks:
s = {}
nm = re.search(r'<h2[^>]*>(.*?)</h2>', block)
store_name = ''
if nm:
store_name = re.sub(r'<[^>]+>', '', nm.group(1)).strip()
s['name'] = store_name
tag_spans = re.findall(r'<span[^>]*>(.*?)</span>', block)
tags = [t.strip() for t in tag_spans if t.strip() and len(t.strip()) < 20 and t.strip()]
s['tags'] = '|'.join(tags)
for label, key in [('营业时间', 'hours'), ('星夜服务', 'night'), ('门店电话', 'phone'), ('门店地址', 'addr')]:
m = re.search(rf'{label}[::]\s*(.*?)</p>', block)
s[key] = re.sub(r'<[^>]+>', '', m.group(1)).strip() if m else ''
province, city = extract_province_city(s.get('addr', ''), store_name)
s['province'] = province
s['city'] = city
stores.append(s)
# Save CSV directly in current directory
csv_path = 'SERES_store_data.csv'
with open(csv_path, 'w', newline='', encoding='utf-8-sig') as f:
writer = csv.DictWriter(f, fieldnames=['name', 'province', 'city', 'addr', 'phone', 'hours', 'night', 'tags'])
writer.writeheader()
writer.writerows(stores)
empty = [s for s in stores if not s['province']]
prov_count = {}
for s in stores:
p = s.get('province', '?')
prov_count[p] = prov_count.get(p, 0) + 1
# Print summary in Chinese
total = len(stores)
unmatched = len(empty)
print(f"成功提取 {total} 家门店信息,其中 {unmatched} 家未能识别省份。")
if unmatched > 0:
print("以下门店未匹配到省份(可检查地址或补充映射):")
for s in empty:
print(f" {s['name'][:60]} | {s['addr'][:80]}")数据会以csv表格的形式,保存在运行脚本的目录下,表格名:SERES_store_data.csv;
数据字段说明:
| 字段 | 示例 | 说明 |
|---|---|---|
name |
AITO授权用户中心•北京姚家园 | 门店全称 |
province |
北京市 | 省级行政区(标准名称) |
city |
北京市 | 地级市/区 |
addr |
北京市朝阳区朝阳北路63号 | 详细地址 |
phone |
010-51332233 | 联系电话 |
hours |
08:30-17:30 | 常规营业时间 |
night |
18:00-21:00 | 星夜服务时间(空=不支持) |
tags |
星夜服务 | 服务标签 |
第二步: 坐标系转换,由于赛力斯门店数据使用的是高德坐标系(GCJ-02),为了在ArcGIS上准确展示而不发生偏移,我们需要将门店的坐标从GCJ-02转换为WGS-84坐标系。我们可以利用coord-convert库中的gcj2wgs(lng, lat)函数,也可以用免费这个网站:批量转换工具:地理编码 (高德) 地址转经纬度 - 批量工具网;
对CSV文件中的门店坐标列进行转换,完成坐标转换后,再将数据导入ArcGIS进行可视化;
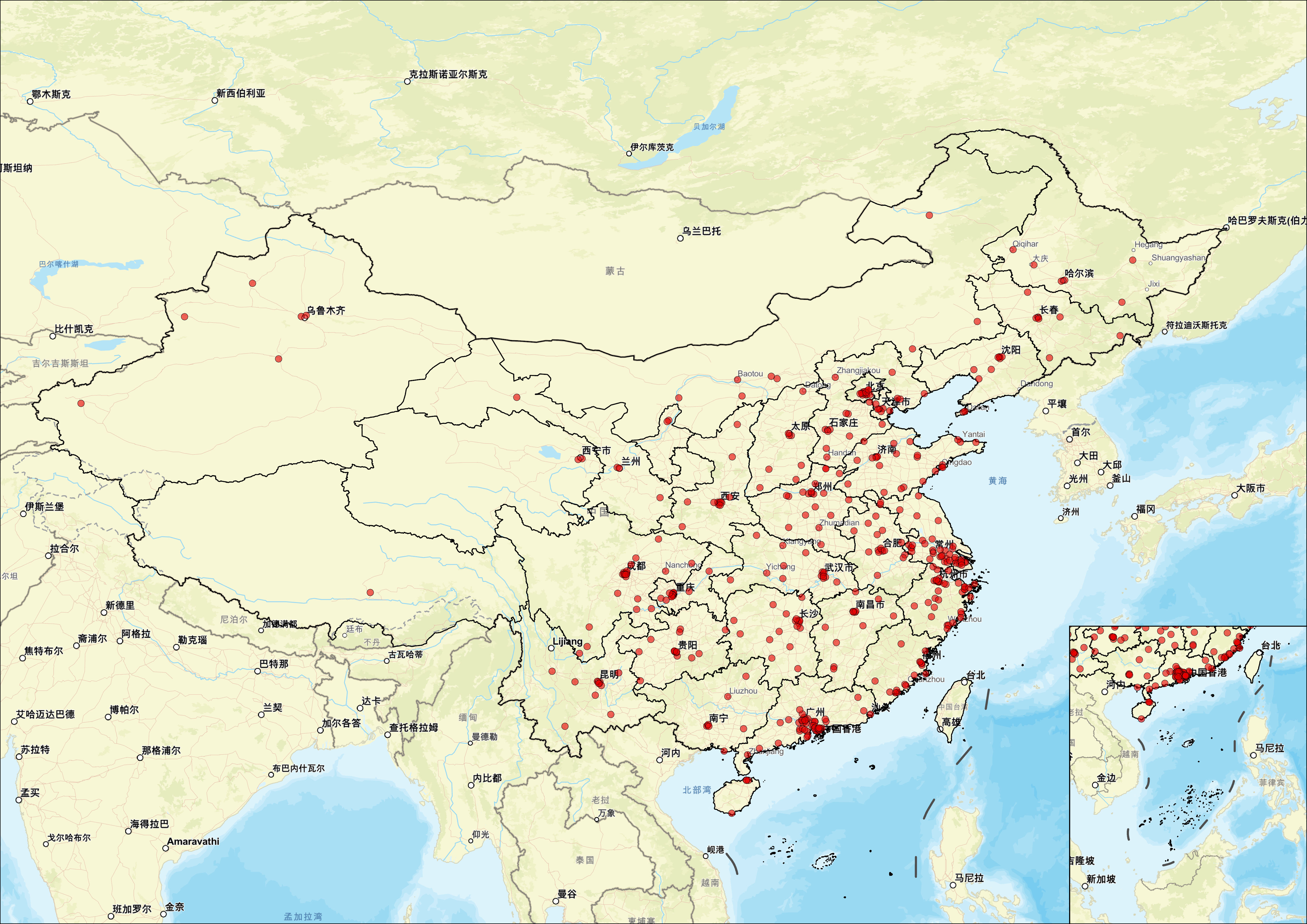
接下来,我们基于采集到的413家门店数据,我们从空间分布、城市层级渗透、战略缺口三个维度进行分析。
第一段:空间分布特征
赛力斯门店呈现显著的"东部密集、西部稀疏、沿海优先"格局。TOP 5 省份------广东省(45家)、浙江省(34家)、江苏省(26家)、山东省(22家)、四川省(18家)------合计占比超过35%,与智己汽车的"东密西疏"分布高度相似。但赛力斯的差异化在于:中西部省份(贵州14家、云南11家、新疆6家)的渗透率明显高于同期的智己,这与华为终端渠道在三四线城市的既有网络深度密切相关------AITO门店多依托于华为授权体验店的选址逻辑,天然具备更广的触达半径。
第二段:城市层级渗透情况
从城市能级看:一线城市(北上广深)门店约40+家,以"鸿蒙智行授权用户中心"旗舰店为主,兼具销售、交付、售后全功能;新一线及省会城市(如杭州、成都、武汉、长沙)单城普遍3-5家;普通地级市(如遵义、都匀、邵阳、信阳)已出现1-2家门店覆盖,部分县级市(诸暨、乐清、温岭)亦有布局。值得注意的是,新疆克拉玛依、库尔勒,青海西宁,宁夏银川等西北边远城市均已设立门店------赛力斯的渠道下沉速度和广度在当前新能源品牌中处于领先梯队。
第三段:星夜服务覆盖分析
413家门店中,超半数支持"星夜服务"(延时营业至21:00),这一比例显著高于行业平均水平。星夜服务门店的地域分布与整体门店分布基本一致,但在一线城市和新一线城市的核心商圈门店中覆盖率更高------说明品牌将延时服务作为差异化竞争手段,重点服务于高净值用户的晚间看车、试驾和维保需求。不过,部分中西部门店的星夜服务标注存在信息缺失,可能是数据录入问题而非实际不提供,建议在数据分析时加以区分。
第四段:战略缺口与机会
当前明显空白和薄弱区域包括:
- 东北地区:吉林(6家)、辽宁(10家)、黑龙江(7家),三省合计23家,不足广东一省数量,且集中在沈阳、大连、长春、哈尔滨四城,地级市几乎空白;
- 西北内陆:宁夏仅1家、青海2家、甘肃3家、西藏1家------这些省份的新能源渗透率本身较低,但充电基建正在快速改善,是潜在的下沉机会;
- 港澳台地区:页面显示"香港特别行政区"、"澳门特别行政区"、"台湾省"选项但当前无实际门店数据,国际化拓展尚未启动。
文章仅用于分享个人学习成果与个人存档之用,分享知识,如有侵权,请联系作者进行删除。所有信息均基于作者的个人理解和经验,不代表任何官方立场或权威解读。