💞目的:本系列是个人整理为了
AI Infra面试的,整理期间苛求每个知识点,平衡理解简易度与深入程度。🥰来源:材料主要源于
web资料进行的,每个知识点参考热门博客和国产AI助手,其中也可能含有一些的个人思考。🤭结语:如果有帮到你的地方,就点个赞和关注一下呗,谢谢🎈🎄🌷
🌈系列文章:【AI Infra面试】基础学习汇总篇
文章目录
-
- 概述
- GPU架构代际演进
-
- [Fermi 架构(2010)](#Fermi 架构(2010))
- [Pascal 架构(2016)](#Pascal 架构(2016))
- [Ampere 架构(2020)](#Ampere 架构(2020))
- [Hopper 架构(2022)](#Hopper 架构(2022))
- 架构演进对比表
- GPU的执行
-
- 三层模型关系总览
-
- [1. 三个模型分别回答什么问题](#1. 三个模型分别回答什么问题)
- [2. 三层模型的映射关系](#2. 三层模型的映射关系)
- [3. Warp:连接逻辑与物理的关键桥梁](#3. Warp:连接逻辑与物理的关键桥梁)
- [1. 执行模型](#1. 执行模型)
-
- SIMT(单指令多线程)
-
- [SIMD vs SIMT 对比表(面试必背)](#SIMD vs SIMT 对比表(面试必背))
- Kernel(核函数)
- [GPU 逻辑执行流程](#GPU 逻辑执行流程)
- [2. 线程层次模型](#2. 线程层次模型)
-
- [Grid → Block → Thread 层级](#Grid → Block → Thread 层级)
- 线程索引计算(面试高频)
- 存储层次
-
- [Shared Memory 与 L1 Cache 的关系(面试高频)](#Shared Memory 与 L1 Cache 的关系(面试高频))
- [Bank Conflict(面试高频)](#Bank Conflict(面试高频))
- [3. 物理映射模型](#3. 物理映射模型)
-
- [GPU 硬件层级架构:GPC → TPC → SM](#GPU 硬件层级架构:GPC → TPC → SM)
- [CUDA Core vs Tensor Core](#CUDA Core vs Tensor Core)
- [SM 内部结构](#SM 内部结构)
- Warp(线程束)
-
- 概述
- [Warp 的组成](#Warp 的组成)
- [Warp 上下文](#Warp 上下文)
- [Warp 调度](#Warp 调度)
- [分支发散(Warp Divergence)](#分支发散(Warp Divergence))
- 延迟隐藏
- Occupancy(占用率)(面试高频)
- [内存合并访问 Coalesced Access(面试高频)](#内存合并访问 Coalesced Access(面试高频))
- 多卡互联与通信
-
- 为什么需要多卡互联
- [NVLink / NVSwitch](#NVLink / NVSwitch)
- [NCCL(NVIDIA Collective Communication Library)](#NCCL(NVIDIA Collective Communication Library))
- 其他
- 参考博客
常见问题:https://jishuzhan.net/article/2034210310282870785
概述
基本知识
- GPU vs CPU:为什么GPU为什么更适合AI计算
- 设计目标
CPU 是低延迟导向(Latency-Oriented):适合处理复杂的串行任务,晶体管大量用于分支预测、乱序执行、大缓存GPU 是高吞吐量导向(Throughput-Oriented):适合处理大规模的并行计算任务,晶体管绝大部分用于ALU(算术逻辑单元)
- 核心架构(Core)
CPU「少而强」:采用少量高性能大核心(通常几核~几十核),每个核心配备超大缓存、复杂控制单元、分支预测 / 乱序执行硬件GPU「多而简」:采用成百上千个轻量化小核心(流处理器 SP) 的众核架构,控制单元极简、缓存很小
- 执行模型
- CPU采用
多指令多数据模型(MIMD):每个核心可以独立执行不同的指令和数据,适合多分支、强依赖、不规则的复杂串行计算 - GPU采用
单指令多线程模型(SIMT):一条指令可以同时驱动大量线程执行相同操作,适合规则、无分支、高度重复的并行计算
- CPU采用
- 存储架构
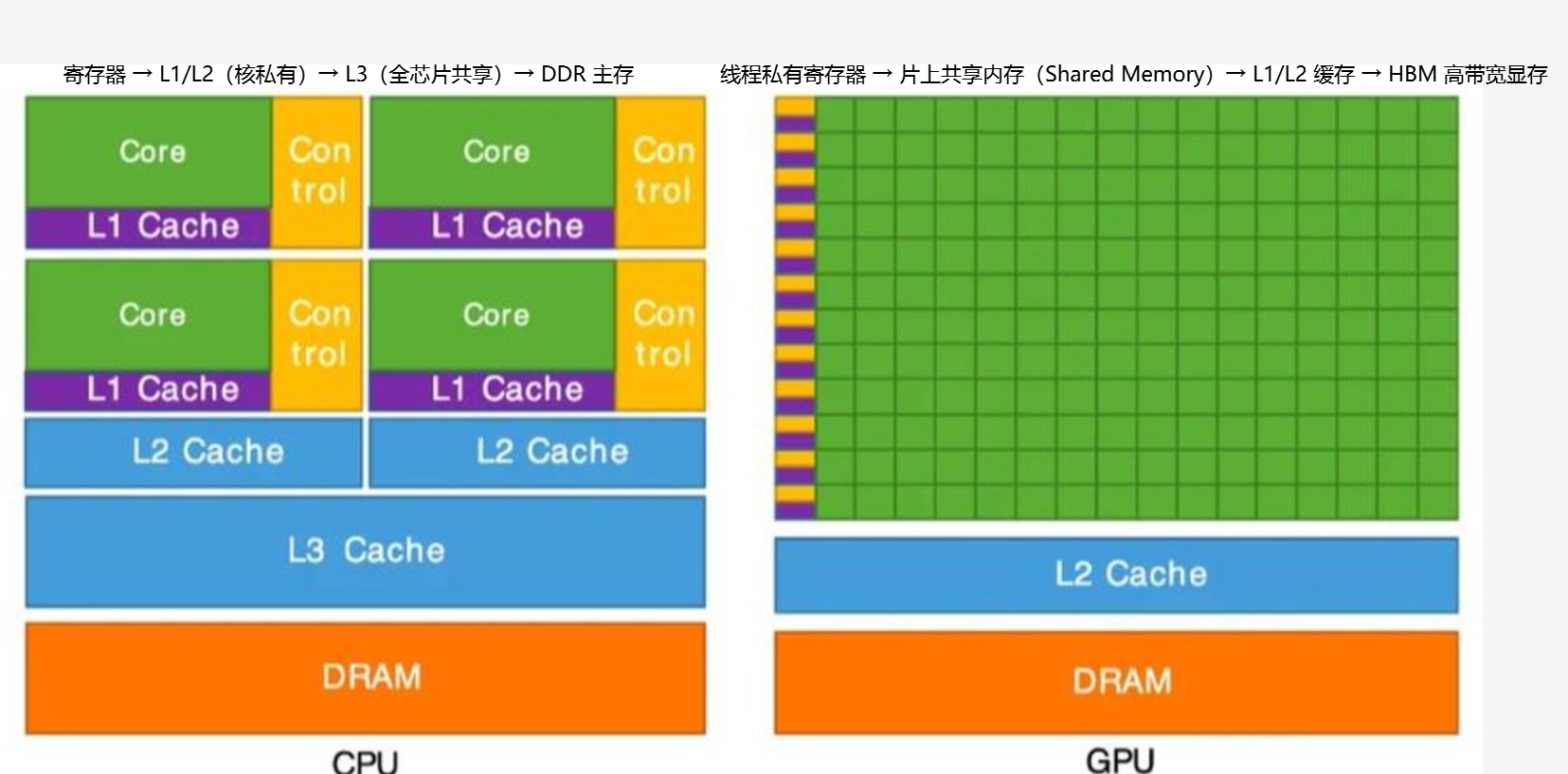
- CPU:采用强一致性的MESI协议,通过多级大缓存,减少内存访问延迟。寄存器 → L1/L2(核私有)→ L3(全芯片共享)→ DDR 主存
- GPU:采用弱一致性的显示同步,通过Shared Memory 进行线程间的高效数据复用。线程私有寄存器 → 片上共享内存(Shared Memory)→ L1/L2 缓存 → HBM 高带宽显存
- 设计目标
- SIMD和SIMT的区别
- 数据寻址方式
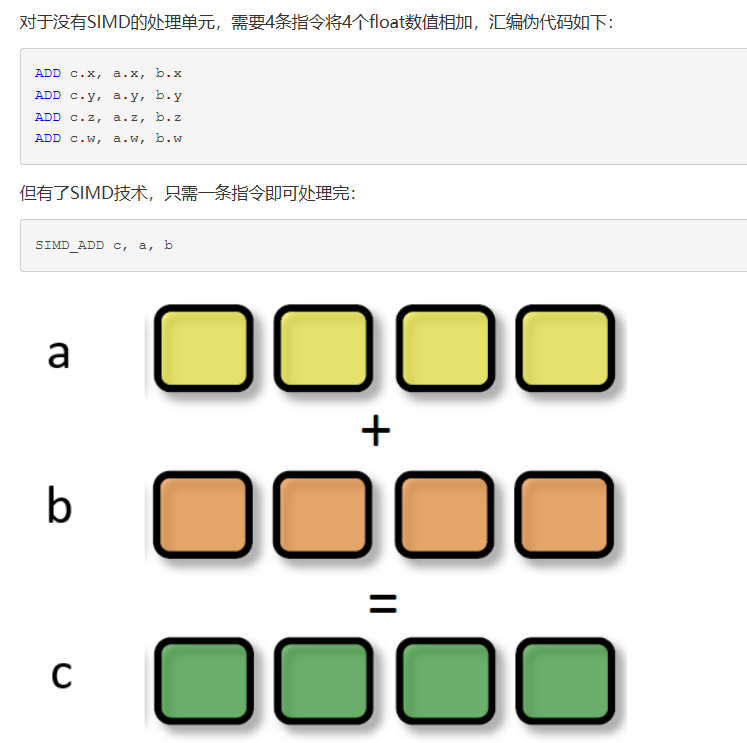
- SIMD:SIMD 指令的操作数是向量寄存器,CPU 会一次性从内存地址 ptr 读取连续 16 字节加载到向量寄存器中,若分散无法一次加载会导致效率降低
- SIMT:每个线程都有独立的程序计数器 (PC) 和寄存器,即同一个 Warp 里的 32 个线程可以访问内存中完全不连续的地址
- 分支处理能力
- SIMD寄存器中同时装着多个数据共享同一个地址指针,对于分支结构只能让所有数据都走一遍分支计算,最后用位掩码选择对应每个数据原来对应的分支结果
- SIMT中一个Warp的32个线程共享同一个指令调度器,对于分支结构通过调度器在不同周期对线程分时调度,轮流屏蔽实现分支路径的执行
- 数据寻址方式
- GPU的执行
- 执行模型:GPU 以 SIMT 方式执行海量轻量级线程
- 单指令多线程:同一条指令被广播给一组线程(Warp/Wavefront),每个线程用自己的寄存器状态独立执行,处理不同的数据。
- 分支发散(Divergence):当同 Warp 内线程走不同分支路径时,GPU 需串行化执行各分支路径,屏蔽未走该路径的线程,导致性能下降。
- 零开销调度:Warp 调度器通过快速切换就绪 Warp 来隐藏内存延迟;当某 Warp 等待数据时,立刻调度另一个 Warp 执行。
- 延迟隐藏:依靠大量并发线程(高 Occupancy)而非高速缓存来掩盖访存延迟。
- 线程组织模型:线程按 Thread-Block-Grid 逻辑组织
- Thread:最基本的执行单元,拥有独立的寄存器和程序计数器(PC)
- Block:一组能够通过 Shared Memory 交换数据且通过
__syncthreads()互相等待的线程集合,是资源分配和线程协作的最小单位 - 索引方式:线程通过内置变量 threadIdx、blockIdx、blockDim、gridDim 计算出全局唯一的线程ID,从而映射到不同数据
- 物理映射模型:通过 Warp→SM→Core 的层次映射到物理硬件上
- 执行模型:GPU 以 SIMT 方式执行海量轻量级线程
GPU架构代际演进
本节将介绍 NVIDIA GPU 架构从 Fermi 到 Hopper 的演进历程,帮助读者理解不同架构的核心特性及其对 AI 训练/推理的影响。(面试高频)
Fermi 架构(2010)
- 代表显卡:GTX 480、Tesla C2050
- 核心特性
- 首次引入 L1/L2 缓存分层架构,告别早期 GPU 无缓存时代
- 每个 SM 配备 64KB 可配置 Shared Memory / L1 Cache
- 支持 ECC 显存纠错,首次面向数据中心部署
- 引入 GigaThread 引擎,实现硬件级线程调度
- AI 场景意义
- Fermi 是现代 GPU 计算架构的起点,CUDA 生态在此代真正成熟
- 首次让 GPU 从纯图形渲染转向通用并行计算(GPGPU)
- 为后续架构的 AI 加速奠定了缓存层次和线程调度基础
Pascal 架构(2016)
- 代表显卡:GTX 1080、Titan X、Tesla P100
- 核心特性
- GP100 首次引入 NVLink(第一代),GPU 间直连带宽高达 160 GB/s,远超 PCIe 3.0 的 32 GB/s
- 首次原生支持 FP16 半精度计算,深度学习训练吞吐量翻倍
- 显存压缩技术(Delta Color Compression)提升有效带宽
- 16nm FinFET 工艺,能效比大幅提升
- AI 场景意义
- NVLink 的诞生解决了多卡训练中的通信瓶颈,为大规模分布式训练奠定基础
- FP16 支持让 Pascal 成为第一代真正适合深度学习训练的 GPU
- P100 是数据中心 AI 计算的标志性产品
Ampere 架构(2020)
- 代表显卡:RTX 3090、A100、A30
- 核心特性
- 第三代 Tensor Core:支持结构化稀疏性加速(2:4 结构化稀疏性,理论吞吐翻倍)
- 多实例 GPU(MIG):单张 A100 可虚拟分割为最多 7 个独立实例,提升资源利用率
- 第三代 NVLink + NVSwitch:A100 搭载 12 条 NVLink 3.0,多卡全互联带宽达 600 GB/s
- HBM2e 显存,容量可达 80GB,带宽超 2 TB/s
- 支持 TF32 精度:FP32 的数值范围 + FP16 的吞吐速度,无需改代码即可加速 AI 训练
- AI 场景意义
- A100 是 2020-2023 年数据中心 AI 训练的绝对主力,支撑了 GPT-3 等大规模模型训练
- MIG 让云厂商可以细粒度出租 GPU 算力,是 AI Infra 面试中的高频话题
- TF32 和结构化稀疏性代表了"软件透明加速"的设计哲学
Hopper 架构(2022)
- 代表显卡:H100、H200
- 核心特性
- 第四代 Tensor Core :原生支持 FP8(E4M3/E5M2),吞吐量较 FP16 再翻倍
- Transformer Engine:硬件自动在 FP8/FP16/FP32 间动态切换精度,专为 Transformer 架构优化
- 第四代 NVLink + NVSwitch:单链路带宽 900 GB/s,支持 256 卡集群全互联
- DPX 指令集:硬件加速动态规划算法,拓展 AI 应用场景
- HBM3 显存,容量可达 80GB~141GB
- AI 场景意义
- H100 是当前大模型训练(LLaMA、GPT-4 级别)的标配算力,FP8 + Transformer Engine 让万亿参数模型训练成为可能
- FP8 的两种格式:E4M3(4 位指数 3 位尾数,精度高,适合前向传播)和 E5M2(5 位指数 2 位尾数,动态范围大,适合梯度计算)
- 256 卡 NVSwitch 全互联拓扑是 DGX H100 超级计算机的核心设计
架构演进对比表
| 架构 | 年代 | 代表显卡 | 核心创新 | AI 面试考点 |
|---|---|---|---|---|
| Fermi | 2010 | GTX 480 | L1/L2 缓存、64KB Shared Memory | 现代 GPU 计算架构起点 |
| Pascal | 2016 | P100 | 首代 NVLink、FP16 支持 | NVLink 诞生、多卡 P2P 通信基础 |
| Ampere | 2020 | A100 | MIG、第三代 Tensor Core、TF32 | 数据中心主力、MIG 资源隔离、稀疏性加速 |
| Hopper | 2022 | H100 | FP8、Transformer Engine、NVLink4 | 大模型训练标配、FP8 量化训练、256 卡全互联 |
GPU的执行
GPU的整个执行链路可以分为三层理解:上层是"怎么算"的执行模型,中间是"数据怎么组织"的线程层次模型,底层是"硬件怎么映射"的物理映射模型。
三层模型关系总览
理解 GPU 执行,本质上是从三个视角看同一件事:程序员定义"算什么",运行时决定"怎么组织",硬件负责"怎么跑"。三者相互映射,形成完整的执行闭环。(面试高频)
1. 三个模型分别回答什么问题
-
执行模型(编程视角)
- 回答:怎么算
- 程序员编写 Kernel 函数,定义每个线程要执行的计算逻辑
- SIMT 机制决定了同一条指令如何被大量线程复用,实现并行加速
- 核心概念:Kernel、SIMT、Warp Divergence、零开销调度
-
线程层次模型(组织视角)
- 回答:数据怎么组织
- 程序员通过
<<<gridDim, blockDim>>>将数据切片映射到 Thread - Thread → Block → Grid 形成逻辑组织空间,每个线程通过索引公式定位自己的数据
- 核心概念:Thread、Block、Grid、线程索引、Shared Memory、同步屏障
-
物理映射模型(硬件视角)
- 回答:硬件怎么映射
- GigaThread 引擎将 Grid 中的 Block 分发到各个 SM
- SM 内部将 Thread 按 32 个一组分成 Warp,由 Warp Scheduler 调度到执行单元
- 最终落到 CUDA Core / Tensor Core 上执行具体运算
- 核心概念:SM、Warp、CUDA Core、Tensor Core、寄存器文件
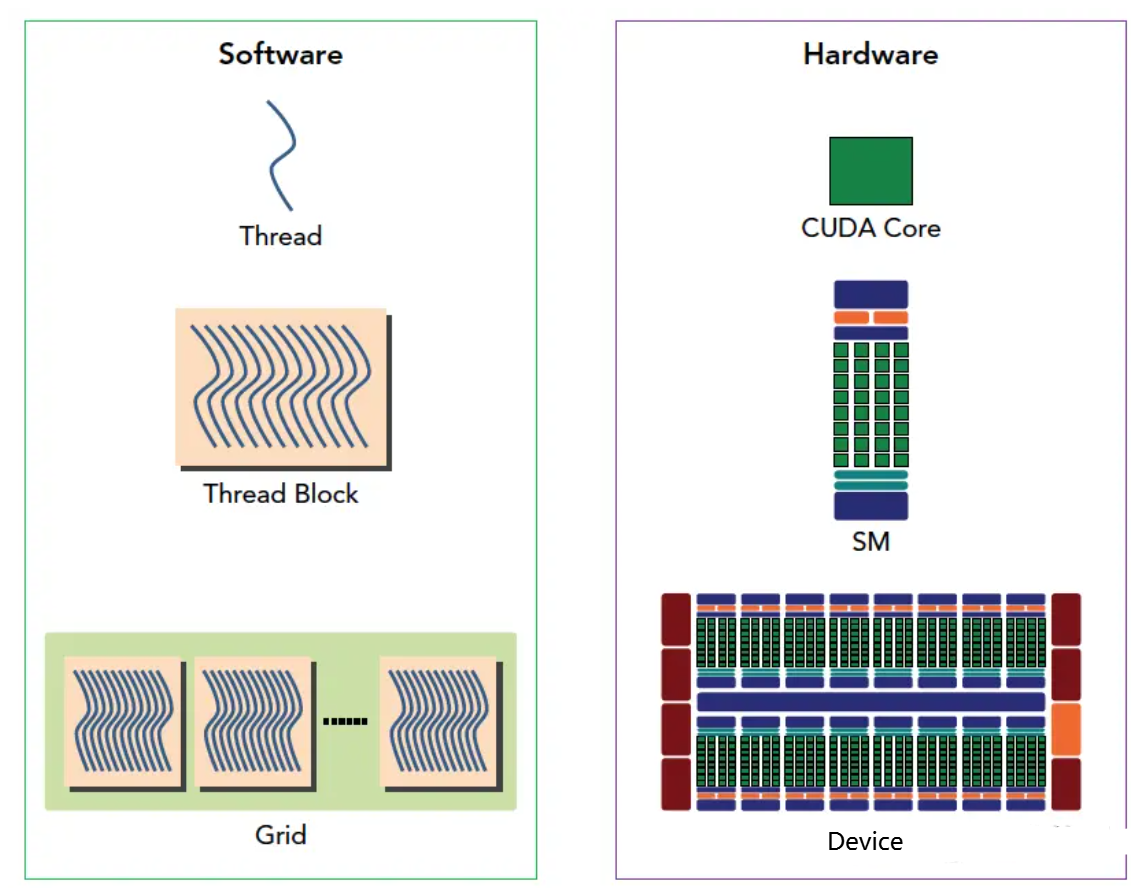
2. 三层模型的映射关系
软件层(程序员定义)
Kernel(Grid of Blocks)
│
▼
┌─────────────────────────────────────┐
│ CUDA Runtime / GigaThread Engine │ ← 运行时调度
│ Block → 分发到空闲 SM │
└─────────────────────────────────────┘
│
▼
硬件层(物理执行)
SM(流式多处理器)
│
├── 寄存器文件(Register File)
├── Shared Memory / L1 Cache
└── Warp Scheduler
│
▼
Warp(32 Threads)
│
▼
CUDA Core / Tensor Core3. Warp:连接逻辑与物理的关键桥梁
Warp 是三层模型中最关键的"粘合剂":
- 对程序员而言:Warp 是透明的,程序员只定义 Thread 和 Block
- 对硬件而言:Warp 是基本调度单元,SM 以 Warp 为单位分配资源和调度执行
- 对性能而言:Warp 的行为(如 Divergence、Coalesced Access、Bank Conflict)直接决定程序效率
面试要点:回答"GPU 执行流程"类问题时,建议按三层模型递进阐述:先说明逻辑层的线程组织,再说运行时的分发调度,最后讲硬件层的 Warp 执行。这种回答方式体现了对 GPU 全栈执行链路的理解深度。
1. 执行模型
SIMT(单指令多线程)
- SIMT 的核心思想
- 一条指令同时驱动多个线程执行相同操作,每个线程处理不同的数据
- 与 SIMD 的核心区别:SIMT 中每个线程有独立 PC 和寄存器,可以访问不连续的内存地址;SIMD 操作向量寄存器,要求数据连续对齐
- 执行特点
- 同一个 Warp 的 32 个线程在同一时钟周期执行同一条指令
- 每个线程拥有独立的程序计数器和寄存器,可处理不同的数据地址
- 分支发散时,硬件分时调度,轮流屏蔽
SIMD vs SIMT 对比表(面试必背)
| 对比维度 | SIMD | SIMT |
|---|---|---|
| 数据寻址 | 操作向量寄存器,要求数据在内存中连续对齐 | 每个线程有独立寄存器,可访问完全不连续的地址 |
| 分支处理 | 所有数据走全部分支,用位掩码选择结果 | Warp 内线程分时调度,轮流屏蔽未走分支的线程 |
| 编程模型 | 显式向量指令(如 AVX-512 _mm512_add_ps) |
隐式并行,程序员写标量代码,硬件自动广播到 Warp |
| 延迟隐藏 | 依赖 CPU 缓存和乱序执行 | 依赖大量并发 Warp 的零开销切换 |
| 适用场景 | CPU 上的向量化计算 | GPU 上的大规模数据并行 |
面试要点:SIMD 和 SIMT 的本质区别是"向量寄存器 vs 独立线程上下文"。SIMD 的并行是指令级别的显式向量操作;SIMT 的并行是线程级别的隐式广播,每个线程有独立的 PC 和寄存器,更灵活但硬件控制开销更大。
Kernel(核函数)
- 定义:在 C/C++ 中通过
__global__修饰的函数,必须发送到 GPU 上执行 - 原理:CPU 调用 Kernel 时并不执行其逻辑,而是 Launch 到 GPU 中由多个线程同时计算
- 线程配置语法
kernel<<<gridDim, blockDim>>>(args);gridDim:定义 Grid 中包含多少个 Block(可以是 1D/2D/3D)blockDim:定义每个 Block 中包含多少个 Thread(可以是 1D/2D/3D)- 示例:
matmul<<<dim3(16, 16), dim3(16, 16)>>>(d_A, d_B, d_C);表示 16×16 的 Block 网格,每个 Block 有 16×16 个 Thread
- 特点
- 返回类型:必须是 void(GPU 执行异步,CPU 不等待返回值)
- 关键字:必须使用
__global__修饰符
- blockDim 建议取 32 的整数倍 (如 128、256)
- 因为 Warp 由 32 个 Thread 组成,若 blockDim 不是 32 的倍数,最后一个 Warp 会出现 Inactive Thread,浪费 SM 资源
- 常见面试数值:128(寄存器压力大时)、256(通用场景)、512(Shared Memory 充足时)
GPU 逻辑执行流程
从 CPU 发射 Kernel 到 GPU 执行完成的全过程:
- Kernel 启动:CPU 调用 Kernel 函数,CUDA 驱动将 Kernel 加载到 GPU 并生成对应的 Grid,发送到 Giga Thread Engine
- Giga 调度
- 资源检查:GigaThread 引擎扫描所有 SM 资源状态
- Block 分发:将 Grid 中的 Block 分配到空闲 SM。这里的 Block 分发正是将线程层次模型中的逻辑 Block 映射到物理映射模型中的 SM
- 分发遵循规则:
- 同一 Block 的所有 Thread 必须在同一 SM 执行,一个 SM 支持多个 Block 并发驻留
- 每个 Block 分到的寄存器、共享内存是独占的,直到 Block 全部执行完成才回收
- 若 SM 资源不足,Block 进入等待队列
- Block 初始化:SM 为 Block 分配寄存器、共享内存,创建线程索引与执行上下文
- Warp 形成与调度(SM 内部)
- Warp 分组:SM 将 Block 中的 Thread 按 32 个一组自动分组为 Warp(硬件强制)
- 若 Block 线程数非 32 倍数,剩余 Thread 组成的 Warp 中会有 Inactive Thread(仍占资源)
- Warp 是连接线程层次模型(Thread/Block)与物理映射模型(SM 调度)的关键桥梁
- Warp 调度器监控所有活跃 Warp 状态,每个时钟周期选择 1-2 个就绪 Warp 发射指令
- 采用零开销线程切换隐藏内存延迟
- Thread 执行(SIMT 模式)
- Warp Scheduler 将指令分发到 SM 的执行单元(CUDA Core、Tensor Core 等)
- 同一 Warp 所有 Thread 执行相同指令,每个 Thread 有独立寄存器处理不同数据
- 分支处理:若出现条件分支,Warp 必须执行所有分支路径,仅激活满足条件的 Thread
- 线程同步:Block 内 Thread 可通过
__syncthreads()屏障同步
- 资源释放与结果返回
- Block 完成 → SM 释放寄存器与共享内存
- Grid 完成 → GPU 通知 CPU
- CPU 将结果从显存拷贝回主存
上图展示了从 CPU 启动 Kernel 到 GPU 完成计算并返回结果的完整执行链路,涵盖了 GigaThread 分发、SM 内部 Warp 调度、SIMT 执行和资源回收四个关键阶段。
2. 线程层次模型
Grid → Block → Thread 层级
GPU 的线程组织是三层逻辑层次,程序员通过 <<<gridDim, blockDim>>> 语法在代码中直接定义:
-
Grid(网格)
- 定义:一个 Kernel Launch 对应的所有线程的集合
- 作用:为每个线程提供全局唯一的坐标索引(blockIdx + gridDim),以便找到对应的数据切片
- 特点
- 无全局同步:Grid 内的 Block 之间无法相互等待。跨 Block 通信只能通过结束当前 Kernel、写回显存、启动新 Kernel 来实现
- 乱序并发:Block 无序、独立地投喂给空闲 SM,不能假定 Block 0 比 Block 100 先执行完
-
Block(线程块)
- 定义:Grid 被划分为若干个 Block,是资源分配和线程协作的最小单位。一组能够通过 Shared Memory 交换数据且通过
__syncthreads()互相等待的线程集合 - 作用:Block 内部线程可以高效协作,Block 之间完全独立
- 特点
- 三维可配置:Block 可以配置为 1D/2D/3D(
blockDim.x,blockDim.y,blockDim.z) - 容量限制:每个 Block 最多包含 1024 个 Thread(不同架构略有差异,如早期架构限制为 512 或 1024)
- 共享内存:同一 Block 内所有 Thread 可访问同一块高速 Shared Memory
- 同步机制:通过
__syncthreads()进行屏障同步 - SM 绑定:Block 一旦分配到某个 SM,整个生命周期内不会迁移
- 线程数建议:通常取 32 的整数倍,常见值为 128、256、512
- 三维可配置:Block 可以配置为 1D/2D/3D(
- 定义:Grid 被划分为若干个 Block,是资源分配和线程协作的最小单位。一组能够通过 Shared Memory 交换数据且通过
-
Thread(线程)
- 定义:CUDA 并行程序的最基本单元
- 特点
- 每个 Thread 的局部变量映射到 SM 的寄存器文件
- Thread 的算术运算由 SM 中的 CUDA Core 完成
- 每个 Thread 拥有独立的程序计数器(PC)和寄存器状态
线程索引计算(面试高频)
线程索引是连接逻辑线程层次与数据切片的桥梁。Grid 和 Block 可以配置为 1D/2D/3D,但硬件中线性排列,必须通过公式计算全局唯一 ID。(面试高频)
-
一维索引(最常用)
cudaint idx = threadIdx.x + blockIdx.x * blockDim.x;threadIdx.x:当前 Thread 在 Block 内的局部索引(0 ~ blockDim.x-1)blockIdx.x:当前 Block 在 Grid 内的索引(0 ~ gridDim.x-1)blockDim.x:每个 Block 包含的 Thread 数量- 全局 ID 范围:
0 ~ gridDim.x * blockDim.x - 1
-
二维索引(矩阵运算场景)
cudaint row = blockIdx.y * blockDim.y + threadIdx.y; int col = blockIdx.x * blockDim.x + threadIdx.x;- 适用于矩阵乘法、卷积等二维数据并行场景
row和col分别对应矩阵的行和列坐标
-
三维索引(体数据/3D 卷积)
cudaint x = blockIdx.x * blockDim.x + threadIdx.x; int y = blockIdx.y * blockDim.y + threadIdx.y; int z = blockIdx.z * blockDim.z + threadIdx.z;- 适用于 3D 图像处理、科学计算中的体数据(Volume Data)
-
面试要点
- 为什么需要这样计算?------因为 Grid/Block 可以配置为多维,但底层硬件和执行都是线性的,必须通过公式将多维坐标展平为全局唯一 ID
- 常见问题:如果
gridDim=2, blockDim=256,Thread 的全局 ID 范围是多少?------0 到 511 - 注意边界检查:Kernel 中通常需要
if (idx < N) return;防止越界访问
存储层次
从快到慢、从私有到共享的层级排序(面试必背):
| 层级 | 位置 | 速度 | 容量 | 访问范围 | 生命周期 | 管理方式 |
|---|---|---|---|---|---|---|
| Register | SM 内部 | 最快(1 周期) | 有限(KB 级) | 单个 Thread | Thread | 编译器自动分配 |
| Shared Memory | SM 内部 | 快(~20 周期) | 48KB-164KB/SM | 同 Block 内 | Block | 显式管理(程序员控制) |
| L1 Cache | SM 内部 | 较快 | 与 Shared Memory 共享物理存储 | 同 SM 内 | 自动管理 | 透明缓存(硬件自动管理) |
| L2 Cache | 芯片级 | 中等(100~200 周期) | 几 MB | 全 GPU | 自动管理 | 硬件自动管理 |
| Global Memory | 显存(HBM/GDDR) | 慢(~400 周期) | 几 GB~几十 GB | 全 Grid | 应用程序 | 显式管理 |
| Constant Memory | 显存(只读缓存) | 快(缓存命中时) | 64KB | 全 Grid | 应用程序 | 只读,缓存优化 |
| Texture Memory | 显存(只读缓存) | 快(空间局部性) | 大 | 全 Grid | 应用程序 | 只读,针对 2D 空间局部性优化 |
Shared Memory 与 L1 Cache 的关系(面试高频)
Shared Memory 和 L1 Cache 在物理上是同一块片上高速存储器,这是 GPU 存储架构中最重要的设计之一。(面试高频)
-
物理同构
- 在 NVIDIA GPU 中,Shared Memory 和 L1 Cache 共享同一块 SRAM 资源
- 可以通过编译配置或运行时 API 调整两者的划分比例
- 例如:64KB 总容量可配置为 48KB Shared + 16KB L1,或 16KB Shared + 48KB L1(具体数值随架构变化)
-
本质区别
- Shared Memory:显式管理,程序员直接读写指定地址,没有 Tag 查找开销,延迟最低
- L1 Cache:透明缓存,硬件自动管理缓存行(Cache Line)的加载和替换,需要 Tag 比较和查找
- 面试常考:Shared Memory 为什么比 L1 更快?------因为避免了 Cache Tag 比较和查找开销,直接由程序员指定地址,无需硬件猜测数据是否在缓存中
-
使用策略
- 数据复用明确、访问模式规律 → 用 Shared Memory 手动管理,性能最优
- 数据访问不规则、难以预测 → 依赖 L1 Cache 自动缓存,降低编程复杂度
Bank Conflict(面试高频)
Bank Conflict 是 Shared Memory 性能优化的核心考点,理解它对于写出高性能 CUDA 程序至关重要。(面试高频)
-
Bank 机制
- Shared Memory 被划分为 32 个 Bank(对应一个 Warp 的 32 个 Thread)
- 每个 Bank 可以独立访问,理想情况下一个 Warp 的 32 个 Thread 同时访问 32 个不同 Bank,完全并行
-
Bank Conflict 定义
- 当一个 Warp 中的多个 Thread 同时访问同一个 Bank 的不同地址时,发生 Bank Conflict
- 硬件需要串行化这些访问,导致性能下降
- 冲突越严重(越多 Thread 落在同一 Bank),串行次数越多,性能越差
-
无 Conflict 的特殊情况
- Broadcast :Warp 内所有 Thread 访问同一个地址时,硬件通过广播机制一次性送达所有 Thread,不产生 Conflict
- 32 个 Thread 访问 32 个不同 Bank:完全并行,最优情况
-
避免方法
- 设计数据布局时,确保相邻 Thread 访问的地址落在不同 Bank
- 常见技巧:填充(Padding)------在数据结构中添加额外字段,使访问步长跳过 Bank 边界
- 例如:对于
float数组(4 字节),若 Thread i 访问array[i],Bank = i % 32,无 Conflict;若访问array[i * 2],则 Thread 0 和 Thread 16 都落在 Bank 0,产生 2-way Conflict
-
面试要点
- Shared Memory 为什么快?------因为 Bank 并行访问,延迟低(~20 周期)
- 什么情况下会变慢?------Bank Conflict 时串行化,最坏情况退化为 32 次串行访问
- 如何检测 Bank Conflict?------Nsight Compute 等性能分析工具可以报告 Shared Memory 的 Bank Conflict 次数
速度对比概览:
- 寄存器:SM 内部,线程私有,速度 1~10ns,每个 SM 几 MB
- 共享内存:SM 内部,线程块共享,速度 10~20ns,每个 SM 几十 MB,可手动管理,是 CUDA 优化重点
- L1 缓存:SM 内部,透明缓存,速度 20~40ns
- L2 缓存:GPU 全局,所有 SM 共享,速度 100~200ns,容量数 GB
- 全局显存:GPU 板载,速度 500~1000ns,容量数十 GB,是访存瓶颈所在
- CPU 内存:主机端,速度约 10000ns,容量上百 GB,通过 PCIe 与 GPU 传输数据
3. 物理映射模型
GPU 硬件层级架构:GPC → TPC → SM
GPU Chip
├── GPC (图形处理簇) × N
│ ├── 光栅引擎
│ └── TPC (纹理处理簇) × M
│ ├── SM (流式多处理器)
│ ├── SM
│ ├── 纹理单元
│ └── PolyMorph Engine
│ └── CUDA Core / Tensor Core / RT Core- GPC(图形处理簇)
- GPU 中的最高逻辑层级,控制和管理内部资源,实现独立调度和计算
- 多个 GPC 间并行工作,共同构成 GPU 总算力
- TPC(纹理处理簇)
- GPC 与 SM 之间的任务分发与数据调度枢纽
- 负责将工作负载分配到内部的 SM 执行单元
- 组成:固定数量的 SM(现代架构通常是 2 个)、纹理单元、PolyMorph Engine
- SM(流式多处理器)
- GPU 最底层的实际计算执行单元
- 通过调度线程束、调用 CUDA Core 与 Tensor Core,完成矩阵乘、卷积等密集计算
- 依托本地缓存(Shared Memory / L1)实现高速数据读写
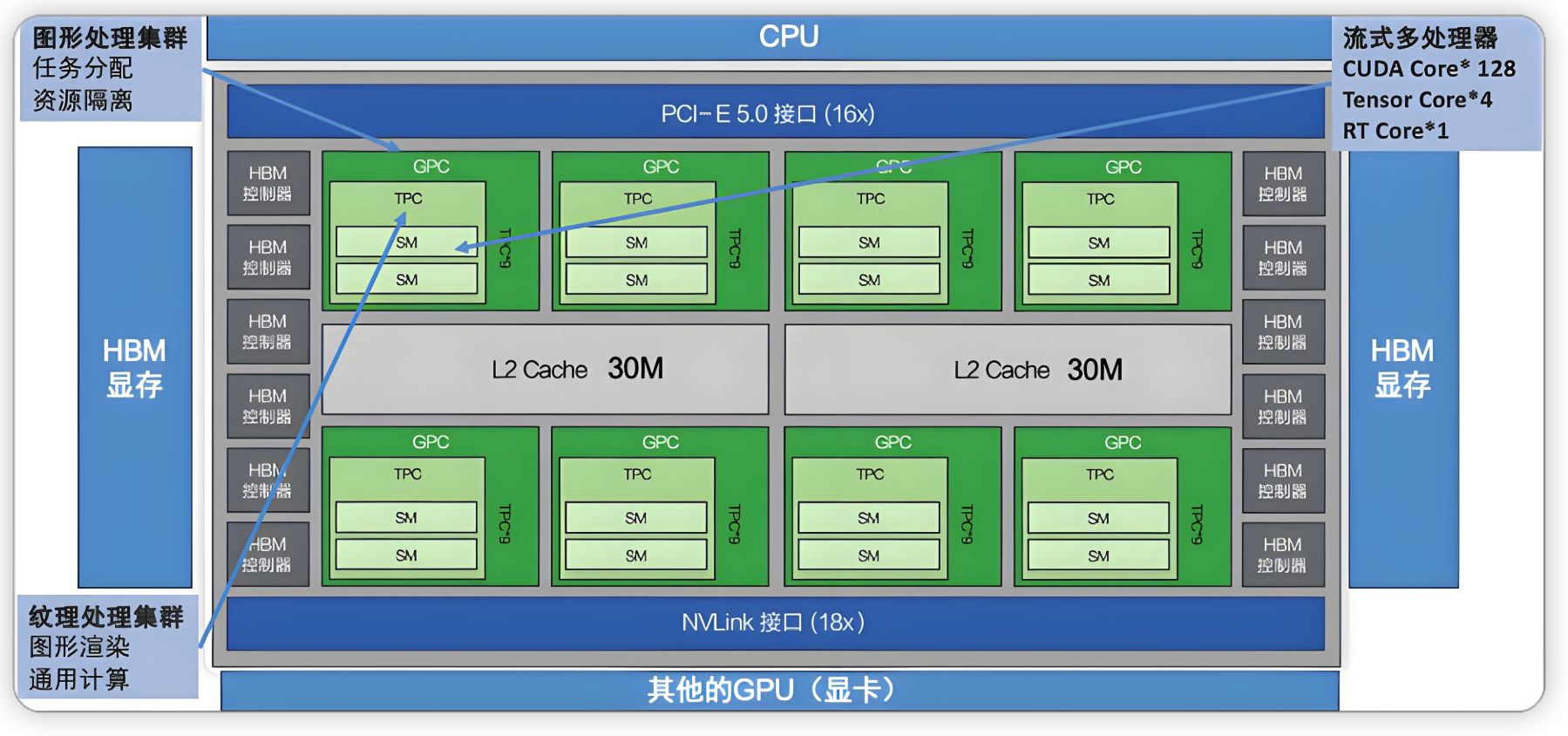
上图展示了 NVIDIA GPU 的物理层级架构:从 GPU Chip 到 GPC、TPC,再到 SM 的层次分解,以及 SM 内部的执行单元组成。
CUDA Core vs Tensor Core
| 维度 | CUDA Core | Tensor Core |
|---|---|---|
| 设计目标 | 通用并行计算单元 | 专用张量计算加速单元 |
| 适用场景 | 标量和向量运算 | 矩阵乘累加 D = A×B + C |
| 精度 | FP32/FP64/INT32 全精度 | FP16/TF32/INT8/FP8 混合低精度 |
| 速度 | 多指令周期模拟低精度 | FP16 吞吐量可达 CUDA Core 的 16-32 倍 |
| 约束 | 通用性强 | 要求数据严格内存对齐(8/16 倍数) |
面试要点:Tensor Core 的本质是"矩阵计算专用电路",将原本需要数百条 CUDA Core 指令完成的矩阵乘累加(GEMM)压缩为单条指令周期。这是 GPU AI 加速的核心硬件基础,也是量化训练(FP8/FP16)能够大幅提升吞吐的根本原因。
SM 内部结构
SM 是 GPU 的基本计算单元,主要组成:
- 标量核心(CUDA Core):包含 FP32、FP64、INT32 计算单元
- 张量核心(Tensor Core):Hopper 架构下每 SM 配备 4 个第四代 Tensor Core,支持 FP8/FP16/FP32/BF16
- 光线追踪核心(RT Core):仅在图像相关计算阶段激活
- 寄存器文件(Register File):线程私有数据存储
- 共享内存 / L1 缓存:可配置划分,Block 内数据共享
- Warp Scheduler :负责 Warp 的发射与调度
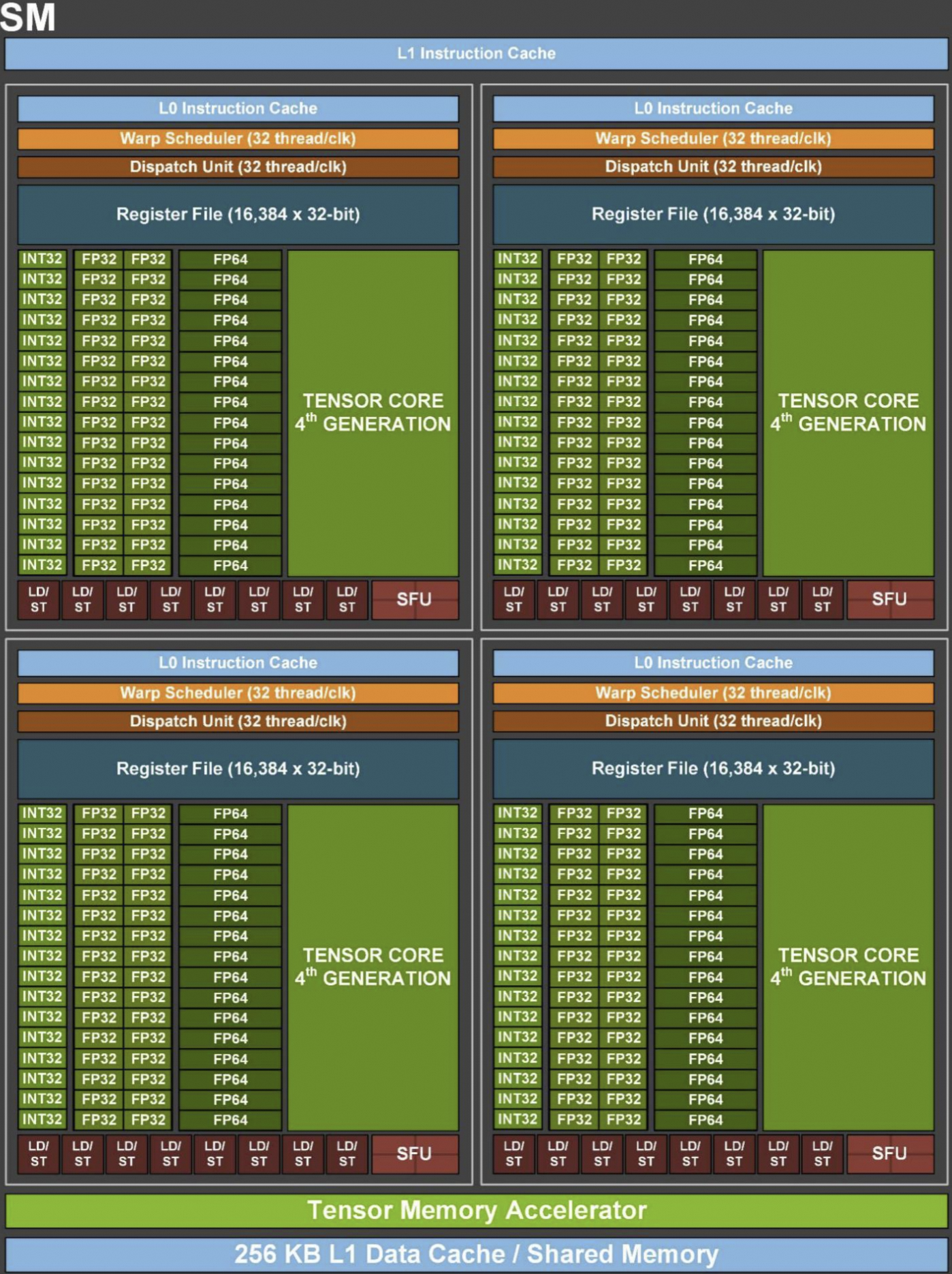
上图展示了 SM 内部的详细结构,包括 CUDA Core、Tensor Core、寄存器文件、Shared Memory / L1 Cache、Warp Scheduler 等关键组件,以及它们之间的数据通路。
Warp(线程束)
概述
- 定义:NVIDIA GPU 中的基本执行单元,1 个 Warp = 32 个 Thread
- 定位:Warp 是硬件调度单元,对程序员透明,由 SM 自动将 Thread 分组形成
- 与线程层次的关系:Block 是逻辑概念(程序员定义),Warp 是物理概念(硬件强制)
Warp 的组成
一个 Warp 包含 32 个并行 Thread,这些 Thread 执行于 SIMT 模式:
- 所有 Thread 执行同一条指令
- 每个 Thread 使用各自的 Data 执行该指令
- 若 Block 线程数不是 32 的倍数,硬件会补齐完整 Warp,多余 Thread 为 Inactive 状态,但仍消耗 SM 资源
- Block 大小(blockDim)通常建议设为 32 的整数倍(如 128、256)以避免资源浪费
Warp 上下文
每个 Warp 在 SM 中维护独立的执行上下文:
- 程序计数器(PC):记录当前执行指令地址
- 寄存器(Register):每个 Thread 的私有变量映射到寄存器文件
- 共享内存(Shared Memory):所属 Block 分配的共享内存区域
Warp 调度
SM 中的 Warp Scheduler 负责:
- 监控所有活跃 Warp 状态(就绪/等待内存/等待同步)
- 每个时钟周期选择 1-2 个就绪 Warp 发射指令(取决于 SM 架构)
- Warp 状态分为三类:
- Selected Warp:当前被选中执行的 Warp
- Eligible Warp:已就绪、等待被调度的 Warp
- Stalled Warp:因访存或同步等待而停滞的 Warp
- Warp 适合执行需满足两个条件:
- 32 个 CUDA Core 有空闲
- 所有当前指令的参数已准备就绪
分支发散(Warp Divergence)
- 同一 Warp 内的 Thread 执行 if-else 走了不同分支时,硬件会分时调度,轮流屏蔽
- 若所有 Thread 走相同分支,则同步执行
- 分支越多,并行效率越低,最坏情况退化为串行
延迟隐藏
- 指令延迟(Latency):指令从开始到执行完成消耗的时钟周期
- 指令发射(Issue):将指令发送到执行单元
- 核心思想:通过零开销线程切换,将指令延迟隐藏于调度其他 Warp 的过程中
- 目标:每个 Cycle 都有 Eligible Warp 被调度,使计算资源充分利用
Occupancy(占用率)(面试高频)
Occupancy 是衡量 SM 资源利用率的核心指标,也是 CUDA 性能优化的首要考虑因素。(面试高频)
-
定义
- Occupancy = 每个 SM 上实际驻留的 Warp 数量 / 该 SM 支持的最大 Warp 数量
- 比值越高,表示 SM 的并行度越高,越容易找到 Ready Warp 掩盖延迟
-
影响因素
- 每个 Thread 使用的寄存器数量:寄存器需求越大,SM 能同时驻留的 Warp 越少
- 每个 Block 使用的 Shared Memory 数量:Shared Memory 占用越大,能并发的 Block 越少
- 每个 Block 的 Thread 数量:Block 太大可能超出 SM 的 Thread 容量限制
- 硬件限制:每个 SM 最大 Block 数、最大 Warp 数、最大 Thread 数(架构相关)
-
Occupancy 与延迟隐藏的关系
- 高 Occupancy 是延迟隐藏的前提:Warp 越多,越容易在某 Warp Stall 时找到其他 Ready Warp 继续执行
- 但 Occupancy 不是唯一指标:即使 Occupancy 不是 100%,只要计算密集度足够高,性能也可能很好
-
为什么不是越高越好?(面试高频)
- 过度追求 Occupancy 可能导致每个 Thread 的寄存器配额被压缩
- 当寄存器需求超出 SM 寄存器文件容量时,会发生寄存器溢出(Register Spilling)
- 溢出的寄存器数据被存放到 Local Memory(本质上是 Global Memory),导致访存延迟剧增
- 实际优化中需要在 Occupancy 和寄存器压力之间找到平衡点
-
面试要点
- 如何提高 Occupancy?------减小寄存器使用量(如限制局部变量)、合理配置 Shared Memory、选择合适 blockDim
- Occupancy 和性能一定成正比吗?------不一定,计算密集型 Kernel 对 Occupancy 敏感度低于访存密集型 Kernel
内存合并访问 Coalesced Access(面试高频)
Coalesced Access 是 CUDA 全局内存性能优化的第一原则,直接影响 Kernel 的访存效率。(面试高频)
-
定义
- 当一个 Warp 中的 32 个线程访问全局内存时,如果这些访问地址在物理上是连续的,硬件可以将多次访问合并为一次或少数几次事务(Transaction),大幅减少访存次数
- 理想情况下,32 个 Thread 访问 128 字节连续地址(假设 float,每个 4 字节),可合并为 1-2 个缓存行事务
-
理想情况 vs 最坏情况
- 理想情况 :Thread i 访问地址
base + i × 4,地址完全连续,合并为最少事务数 - 最坏情况:32 个线程访问完全分散的地址,需要 32 次独立事务,性能骤降
- 中间情况:部分连续,事务数介于理想和最坏之间
- 理想情况 :Thread i 访问地址
-
优化建议
- 确保内存访问模式具有 Stride-1 连续性:相邻线程访问相邻地址
- 数据布局采用 SoA(Structure of Arrays)而非 AoS(Array of Structures),确保同一线程对同类型字段的访问是连续的
- 使用
__align__或cudaMallocPitch确保内存对齐
-
面试要点
- 问"如何优化 CUDA 全局内存访问?"必答 Coalesced Access
- 矩阵转置为什么性能差?------因为读是连续的(Coalesced),但写是不连续的(Strided),需要利用 Shared Memory 做中转优化
- Global Memory 访问延迟约 400 周期,Coalesced 是减少事务数的核心手段
多卡互联与通信
随着大模型参数规模从十亿增长到万亿级别,单卡显存已无法满足需求,多卡分布式训练成为常态。理解多卡互联技术(NVLink/NVSwitch)和通信库(NCCL)是 AI Infra 面试中的核心考点。(面试高频)
为什么需要多卡互联
-
显存瓶颈
- GPT-3 175B 参数模型,FP16 训练需要约 350GB 显存存储参数,远超单卡 80GB(H100)容量
- 即使使用 ZeRO 等显存优化技术,也需要多张 GPU 共同承载模型状态
-
算力需求
- 大模型训练需要海量计算,单卡算力(如 H100 的 989 TFLOPS FP8)仍不足以在合理时间内完成训练
- 数据并行(Data Parallelism)需要将数据分片到多卡,卡间需要同步梯度
-
通信瓶颈
- 传统 PCIe 带宽低(PCIe 4.0 x16 约 32 GB/s)、延迟高,且需要经过 CPU 芯片组,成为多卡训练的主要瓶颈
- 每次 AllReduce 操作需要传输的梯度数据量巨大,低效互联会严重拖慢训练速度
NVLink / NVSwitch
-
NVLink:GPU 直连高速通道
- 设计目标:绕过 PCIe 瓶颈,实现 GPU 与 GPU 之间的直接高速通信
- 带宽演进 :
- NVLink 1.0(Pascal):20 GB/s 每链路,4 链路共 80 GB/s
- NVLink 2.0(Volta):25 GB/s 每链路,6 链路共 150 GB/s
- NVLink 3.0(Ampere):50 GB/s 每链路,12 链路共 600 GB/s
- NVLink 4.0(Hopper):100 GB/s 每链路,18 链路共 900 GB/s
- 特点:低延迟、高带宽、无需经过 CPU,支持 P2P(Peer-to-Peer)显存访问
-
NVSwitch:全互联拓扑交换机
- 设计目标:在 8 卡/16 卡/256 卡集群中实现任意两卡之间的直接通信
- 工作机制:NVSwitch 是一个独立的交换芯片,每个 GPU 通过 NVLink 连接到 NVSwitch,形成全互联(Full Mesh)拓扑
- 典型配置 :
- DGX A100:6 个 NVSwitch,8 卡 A100 全互联,任意两卡带宽 600 GB/s
- DGX H100:4 个 NVSwitch,8 卡 H100 全互联,任意两卡带宽 900 GB/s
- DGX GH200:256 卡 Grace Hopper 超级芯片,通过 NVSwitch 全互联
- 面试要点:NVSwitch 让多卡通信不再受拓扑限制,AllReduce 等集合通信可以高效并行
-
PCIe vs NVLink 对比
| 维度 | PCIe 4.0 x16 | NVLink 4.0 |
|---|---|---|
| 带宽 | ~32 GB/s | ~900 GB/s(H100) |
| 延迟 | 高(需经过 CPU) | 低(GPU 直连) |
| 拓扑 | 树形(经过 Root Complex) | 全互联(通过 NVSwitch) |
| P2P 访问 | 支持但性能受限 | 原生高效支持 |
| 适用场景 | 单卡/双卡工作站 | 多卡服务器/集群 |
NCCL(NVIDIA Collective Communication Library)
-
定义与作用
- NCCL 是 NVIDIA 提供的开源集合通信库,封装了多卡间集合通信原语
- 与 MPI 类似,但专为 GPU 和 NVLink 优化,是分布式深度学习框架的底层通信支柱
- PyTorch 的
DistributedDataParallel、TensorFlow 的MirroredStrategy底层均调用 NCCL
-
核心通信原语
- Broadcast:一个节点发送数据到所有节点
- Reduce:所有节点的数据归约(如求和)到一个节点
- AllReduce:所有节点的数据归约后,结果分发到所有节点(数据并行训练中最常用,用于同步梯度)
- AllGather:所有节点收集所有数据,每个节点获得完整数据
- ReduceScatter:数据先归约再分发给各节点
-
AllReduce 算法(面试高频)
- Ring 算法 :节点组成逻辑环,数据分块沿环传递,每步每个节点只与相邻节点通信
- 优点:实现简单,通信量均衡
- 缺点:延迟随节点数线性增长,不适合大规模集群
- Tree 算法(NCCL 2.4+) :节点组成二叉树,数据在树中向上归约、向下广播
- 优点:延迟为 O(log N),适合大规模集群
- 缺点:根节点带宽压力大
- NVLink 全互联优化:在 DGX 等 NVSwitch 全互联拓扑中,NCCL 可以利用多链路并行传输,突破单链路带宽限制
- Ring 算法 :节点组成逻辑环,数据分块沿环传递,每步每个节点只与相邻节点通信
-
通信与计算重叠
- 现代分布式训练框架利用 CUDA Stream 和 NCCL 的异步通信,实现"计算下一层的同时通信上一层梯度"
- 这种重叠(Overlap)可以隐藏通信延迟,提升 GPU 利用率
- 面试常考:如何减少分布式训练的通信开销?------梯度压缩、通信与计算重叠、使用更高带宽的 NVLink
-
面试要点
- NCCL 与 MPI 的区别?------NCCL 专为 GPU 设计,优化了 GPU Direct RDMA 和 NVLink P2P
- 数据并行训练中为什么 AllReduce 是瓶颈?------因为每轮迭代都需要同步所有卡的梯度,参数量越大通信量越大
- 如何优化多卡通信?------使用 NVLink 而非 PCIe、启用通信与计算重叠、梯度量化/压缩、使用更大的 batch size 减少通信频率
其他
按精度量化
量化是 AI 推理加速的核心手段,底层依赖 Tensor Core 对低精度的原生支持(参见物理映射模型中 Tensor Core 章节)。选择合适的量化策略需要在精度损失和吞吐提升之间找到平衡。(面试高频)
-
W8A8 (INT8)
- 定义:量化后权重/激活为 8 位整数,采用对称/非对称量化
- 场景:经典模型推理加速,2 倍压缩比,大多数推理卡可用
- 特点:INT8 计算在 Turing/Ampere/Hopper 的 Tensor Core 中均有原生支持
-
W8A8_FP8
- 定义:FP8(8 位浮点),NVIDIA H100 等原生支持,分 E4M3(4 位指数 3 位尾数,精度高)和 E5M2(5 位指数 2 位尾数,范围大)
- 场景:大模型推理/训练,压缩比与 INT8 同但动态范围更优,吞吐提升约 1.6×
- E4M3 vs E5M2 的分配策略:前向传播通常使用 E4M3(需要更高精度),反向传播(梯度)通常使用 E5M2(需要更大动态范围)
- Hopper 的 Transformer Engine 可以在前向/反向过程中自动选择最优 FP8 格式
-
INT4 / NF4
- 定义:4 位极致压缩,4 倍压缩比
- NF4(NormalFloat4)假设数据服从正态分布,非均匀量化,信息损失更小,通常用于 QLoRA 的权重存储
- 注意:INT4 计算需要解量化到更高精度执行,通常只用于存储压缩,不直接用于计算加速