文章目录
- 前言
- [一、GPU vs CPU:为什么GPU适合并行计算?](#一、GPU vs CPU:为什么GPU适合并行计算?)
- 二、GPU的整体架构:从芯片到核心
-
- [2.1 GPU的层级结构](#2.1 GPU的层级结构)
- [2.2 A100/H100芯片架构图](#2.2 A100/H100芯片架构图)
- 三、SM内部架构详解
-
- [3.1 SM(流式多处理器)内部结构](#3.1 SM(流式多处理器)内部结构)
- [3.2 一个SM的详细数据(以A100为例)](#3.2 一个SM的详细数据(以A100为例))
- 四、Warp:最小的执行单元
-
- [4.1 Warp的内部结构](#4.1 Warp的内部结构)
- [4.2 Warp的执行过程](#4.2 Warp的执行过程)
- [五、计算核心的进化:CUDA Core → Tensor Core](#五、计算核心的进化:CUDA Core → Tensor Core)
-
- [5.1 CUDA Core vs Tensor Core 对比图](#5.1 CUDA Core vs Tensor Core 对比图)
- [5.2 各代Tensor Core演进](#5.2 各代Tensor Core演进)
- 六、内存层次结构
-
- [6.1 GPU内存层次图](#6.1 GPU内存层次图)
- 七、从硬件到软件的映射
-
- [7.1 CUDA线程层次与硬件映射](#7.1 CUDA线程层次与硬件映射)
- [7.2 硬件资源限制示意图](#7.2 硬件资源限制示意图)
- 八、NVIDIA核心性能参数全景图
-
- [💡 编程调优的关键洞察](#💡 编程调优的关键洞察)
- 九、动手实践
-
- [9.1 查询你的GPU信息](#9.1 查询你的GPU信息)
- [9.2 编译运行](#9.2 编译运行)
- 十、本节总结
-
- [10.1 核心要点回顾](#10.1 核心要点回顾)
- [10.2 下节预告](#10.2 下节预告)
- 十一、参考资料
- 十二、面试真题(2024-2026)
-
- Q1:解释GPU的SIMT模型和CPU的SIMD有什么区别?
- Q2:什么是Warp?Warp的大小为什么是32?
- Q3:什么是Occupancy?如何计算和优化?
- [Q4:Tensor Core和CUDA Core有什么区别?分别在什么场景使用?](#Q4:Tensor Core和CUDA Core有什么区别?分别在什么场景使用?)
- Q5:SM上同时能跑多少个线程?受什么限制?
- Q5:SM上同时能跑多少个线程?受什么限制?
前言
不懂硬件,写不出高性能CUDA代码
很多初学者学CUDA,上来就写核函数,结果发现:同样的算法,别人比我快10倍,还不知道为什么。
原因很简单:你不了解GPU这个"合作伙伴"的脾气秉性。
就像你要用好一个人,得知道他是急性子还是慢性子、擅长数学还是语文。GPU也一样------它的架构设计,直接决定了什么样的代码跑得快,什么样的代码跑得慢。
今天,我们就从硬件层面,彻底搞懂现代GPU的工作原理。
一、GPU vs CPU:为什么GPU适合并行计算?
先看一张经典的对比图:
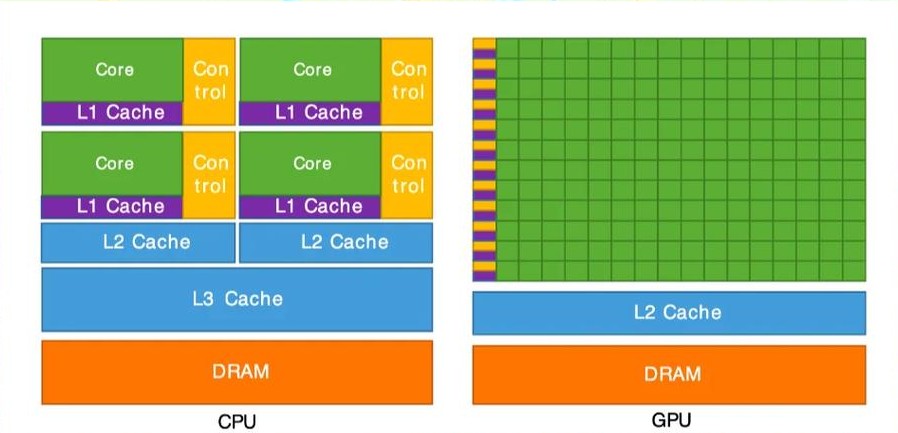
| CPU | GPU |
|---|---|
| 少数强大核心 | 数千个简单核心 |
| 复杂控制单元 | 简单控制单元 |
| 大容量缓存 | 小容量缓存 |
| 适合串行任务 | 适合并行任务 |
一句话总结:
- CPU是博士:一个顶十个,擅长处理复杂问题
- GPU是小学生:单个能力弱,但一万人一起上,干活比博士快
这就是所谓的延迟优化 vs 吞吐优化。
二、GPU的整体架构:从芯片到核心
2.1 GPU的层级结构
现代GPU是一个复杂的多层结构:
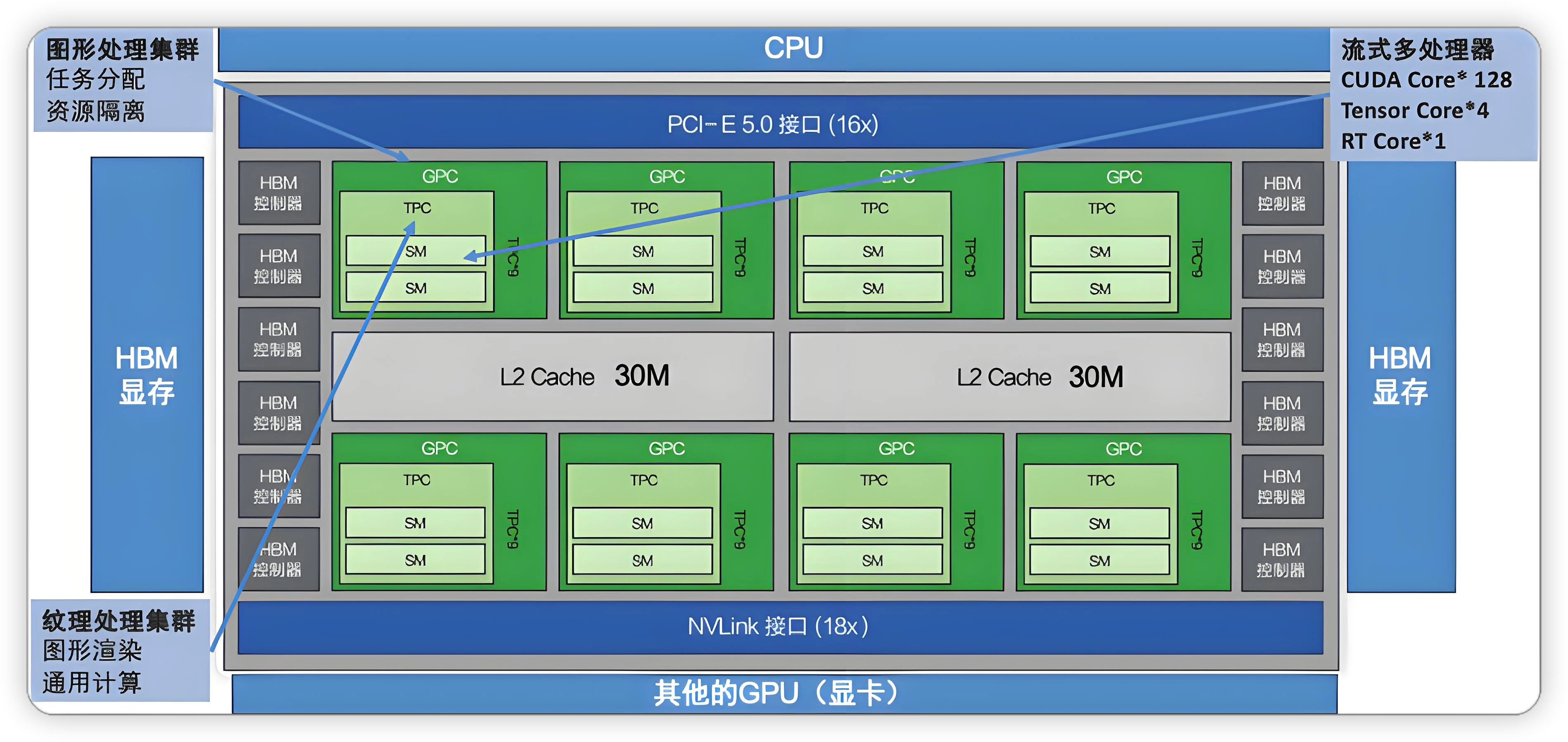
层级说明:
- GPC(图形处理簇):GPU的最高层级划分,每个GPC包含多个TPC
- TPC(纹理处理簇):每个TPC包含1-2个SM
- SM(流式多处理器):最核心的计算单元,我们编程直接打交道的对象
2.2 A100/H100芯片架构图
以NVIDIA A100(Ampere架构)为例:

A100关键数据:
- 108个SM
- 40MB L2缓存
- 40/80GB HBM2显存
- 1.6TB/s显存带宽
三、SM内部架构详解
3.1 SM(流式多处理器)内部结构
SM是GPU最核心的计算单元,我们直接看它的内部构造:
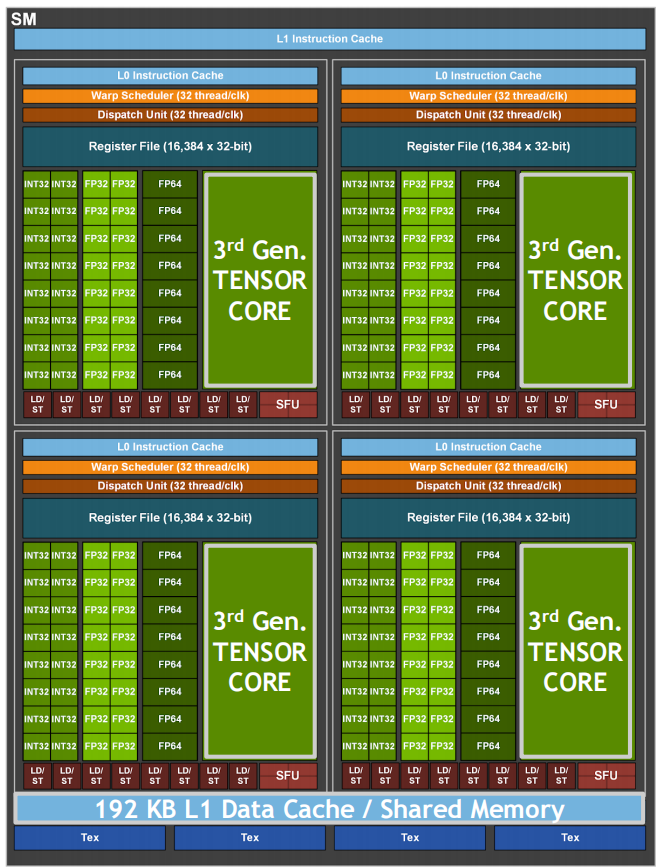
3.2 一个SM的详细数据(以A100为例)
| 组件 | 数量 | 说明 |
|---|---|---|
| Warp调度器 | 4个 | 每个时钟周期可调度2条指令 |
| CUDA Core (FP32) | 64个 | 单精度浮点运算 |
| CUDA Core (INT32) | 64个 | 整数运算 |
| FP64 Core | 32个 | 双精度浮点运算(部分型号减半) |
| Tensor Core | 4个 | 第四代Tensor Core |
| 寄存器文件 | 256KB | 65536个32位寄存器 |
| 共享内存/L1 | 164KB | 可配置为共享内存或L1缓存 |
| 最大线程数 | 2048个 | 同时驻留的线程数 |
| 最大Warp数 | 64个 | 同时驻留的warp数 |
| 最大线程块数 | 32个 | 同时驻留的block数 |
四、Warp:最小的执行单元
4.1 Warp的内部结构
┌──────────────────────────────────────────────────────────────────┐
│ 一个Warp(32个线程) │
│ │
│ 线程ID: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 │
│ ┌───┐┌───┐┌───┐┌───┐┌───┐┌───┐┌───┐┌───┐┌───┐┌───┐┌───┐┌───┐┌───┐┌───┐
│ │T0 ││T1 ││T2 ││T3 ││T4 ││T5 ││T6 ││T7 ││T8 ││T9 ││T10││T11││T12││T13│
│ └───┘└───┘└───┘└───┘└───┘└───┘└───┘└───┘└───┘└───┘└───┘└───┘└───┘└───┘
│ │
│ 线程ID:14 15 16 17 18 19 20 21 22 23 24 25 26 27 │
│ ┌───┐┌───┐┌───┐┌───┐┌───┐┌───┐┌───┐┌───┐┌───┐┌───┐┌───┐┌───┐┌───┐┌───┐
│ │T14││T15││T16││T17││T18││T19││T20││T21││T22││T23││T24││T25││T26││T27│
│ └───┘└───┘└───┘└───┘└───┘└───┘└───┘└───┘└───┘└───┘└───┘└───┘└───┘└───┘
│ │
│ 线程ID:28 29 30 31 │
│ ┌───┐┌───┐┌───┐┌───┐ │
│ │T28││T29││T30││T31│ │
│ └───┘└───┘└───┘└───┘ │
│ │
│ 所有线程执行同一条指令: │
│ ┌──────────────────────────────────────────────────────────┐ │
│ │ instruction: a = b + c │ │
│ └──────────────────────────────────────────────────────────┘ │
│ │
│ 但每个线程操作不同的数据: │
│ ┌──────────────────────────────────────────────────────────┐ │
│ │ T0: a0 = b0 + c0 │ │
│ │ T1: a1 = b1 + c1 │ │
│ │ ... │ │
│ │ T31: a31 = b31 + c31 │ │
│ └──────────────────────────────────────────────────────────┘ │
└──────────────────────────────────────────────────────────────────┘4.2 Warp的执行过程
时间轴 →
┌──────────────────────────────────────────────────────────────────┐
│ │
│ Warp调度器每次选择一个Warp执行一条指令: │
│ │
│ ┌────────────┐ │
│ │ Warp 0 │ ──→ 指令1 (a=b+c) │
│ └────────────┘ │
│ ↓ │
│ ┌────────────┐ │
│ │ Warp 1 │ ──→ 指令1 (a=b+c) │
│ └────────────┘ │
│ ↓ │
│ ┌────────────┐ │
│ │ Warp 2 │ ──→ 指令1 (a=b+c) │
│ └────────────┘ │
│ ↓ │
│ ┌────────────┐ │
│ │ Warp 0 │ ──→ 指令2 (d=a*e) ← 第一个Warp回来了 │
│ └────────────┘ │
│ │
│ 如果Warp 0在等待数据(比如访存): │
│ ┌────────────┐ │
│ │ Warp 0 │ ──→ 访存指令 (load) │
│ └────────────┘ │
│ ↓ (等待数据) │
│ ┌────────────┐ │
│ │ Warp 3 │ ──→ 执行计算 (不用等) ← 零开销切换 │
│ └────────────┘ │
│ ↓ │
│ ┌────────────┐ │
│ │ Warp 4 │ ──→ 执行计算 │
│ └────────────┘ │
│ ↓ │
│ ┌────────────┐ │
│ │ Warp 0 │ ──→ 数据回来了,继续执行下一指令 │
│ └────────────┘ │
│ │
└──────────────────────────────────────────────────────────────────┘五、计算核心的进化:CUDA Core → Tensor Core
5.1 CUDA Core vs Tensor Core 对比图
┌──────────────────────────────────────────────────────────────────┐
│ CUDA Core (标量单元) │
│ │
│ 一次做一个运算: │
│ ┌──────────────────────────────────────────────────────────┐ │
│ │ a = b * c + d │ │
│ │ │ │
│ │ b ──┐ │ │
│ │ ├─→ [MUL] ──→ [ADD] ──→ a │ │
│ │ c ──┘ ↑ │ │
│ │ │ │ │
│ │ d ─────────────┘ │ │
│ └──────────────────────────────────────────────────────────┘ │
│ │
│ Tensor Core (矩阵单元) │
│ │
│ 一次做一个4×4矩阵乘加: │
│ ┌──────────────────────────────────────────────────────────┐ │
│ │ D = A × B + C │ │
│ │ │ │
│ │ ┌─────────┐ │ │
│ │ │ A (4x4) │ │ │
│ │ └─────────┘ │ │
│ │ × │ │
│ │ ┌─────────┐ │ │
│ │ │ B (4x4) │ │ │
│ │ └─────────┘ │ │
│ │ = │ │
│ │ ┌─────────┐ ┌─────────┐ │ │
│ │ │ A×B │ + │ C (4x4) │ = D (4x4) │ │
│ │ │ (4x4) │ └─────────┘ │ │
│ │ └─────────┘ │ │
│ └──────────────────────────────────────────────────────────┘ │
│ │
│ 一次Tensor Core运算 = 64次CUDA Core运算 │
└──────────────────────────────────────────────────────────────────┘5.2 各代Tensor Core演进
┌──────────────────────────────────────────────────────────────────┐
│ Tensor Core 代际演进 │
├──────────────────────────────────────────────────────────────────┤
│ │
│ Volta (V100, 2017) ──────────────────┐ │
│ ┌──────────────────────────────────┐│ │
│ │ 支持:FP16输入,FP32累加 ││ │
│ │ 性能:125 TFLOPS (FP16) ││ │
│ └──────────────────────────────────┘│ │
│ ↓ │ │
│ Turing (T4, 2018) ─────────────────┐│ │
│ ┌──────────────────────────────────┐││ │
│ │ 新增:INT8、INT4量化支持 │││ │
│ │ 性能:65 TFLOPS (FP16) │↓│ │
│ │ 130 TOPS (INT8) │ │ │
│ └──────────────────────────────────┘ │ │
│ ↓ │ │
│ Ampere (A100, 2020) ───────────────┐│ │
│ ┌──────────────────────────────────┐││ │
│ │ 新增:BF16、TF32、结构化稀疏 │││ │
│ │ 性能:312 TFLOPS (FP16) │↓│ │
│ │ 624 TOPS (稀疏) │ │ │
│ └──────────────────────────────────┘ │ │
│ ↓ │ │
│ Hopper (H100, 2022) ───────────────┐│ │
│ ┌──────────────────────────────────┐││ │
│ │ 新增:FP8、Transformer引擎 │││ │
│ │ 性能:1979 TFLOPS (FP8) │↓│ │
│ │ 3958 TOPS (稀疏) │ │ │
│ └──────────────────────────────────┘ │ │
│ ↓ │ │
│ Blackwell (B200, 2024) ────────────┘ │
│ ┌──────────────────────────────────┐ │
│ │ 新增:FP4、第二代Transformer引擎 │ │
│ │ 性能:4500 TFLOPS (FP8) │ │
│ │ 9000 TOPS (稀疏) │ │
│ └──────────────────────────────────┘ │
│ │
└──────────────────────────────────────────────────────────────────┘六、内存层次结构
6.1 GPU内存层次图
速度 (周期) 容量 (每SM)
↓ ↓
寄存器 ┌─────────┐ ┌─────────┐
<1周期 │ │ 最快 │ ~20KB │ 最小
└─────────┘ └─────────┘
↓ ↓
共享内存/L1 ┌─────────┐ ┌─────────┐
~30周期 │ │ │164KB │
└─────────┘ └─────────┘
↓ ↓
只读常量缓存 ┌─────────┐ ┌─────────┐
~30周期 │ │ │ ~50KB │
└─────────┘ └─────────┘
↓ ↓
纹理缓存 ┌─────────┐ ┌─────────┐
~100周期 │ │ │ ~50KB │
└─────────┘ └─────────┘
↓ ↓
L2缓存 ┌─────────┐ ┌─────────┐
~200周期 │ │ │ 40MB │ (全局)
└─────────┘ │ (A100) │
↓ ↓
全局内存 ┌─────────┐ ┌─────────┐
~400周期 │ │ 最慢 │40-80GB │ 最大
└─────────┘ └─────────┘
速度差异:寄存器 : 共享内存 : 全局内存 ≈ 1 : 30 : 400七、从硬件到软件的映射
7.1 CUDA线程层次与硬件映射
┌──────────────────────────────────────────────────────────────────┐
│ CUDA软件概念 → GPU硬件映射 │
├──────────────────────────────────────────────────────────────────┤
│ │
│ 软件概念层: │
│ ┌──────────────────────────────────────────────────────────┐ │
│ │ Grid (网格) │ │
│ │ ┌──────┐ ┌──────┐ ┌──────┐ ┌──────┐ │ │
│ │ │Block0│ │Block1│ │Block2│ │Block3│ ...... │ │
│ │ └──────┘ └──────┘ └──────┘ └──────┘ │ │
│ └──────────────────────────────────────────────────────────┘ │
│ ↓ │
│ ↓ (由GigaThread引擎分发) │
│ ↓ │
│ 硬件层: │
│ ┌──────────────────────────────────────────────────────────┐ │
│ │ GPU芯片 │ │
│ │ ┌────────┐ ┌────────┐ ┌────────┐ ┌────────┐ │ │
│ │ │ SM0 │ │ SM1 │ │ SM2 │ │ SM3 │ ...... │ │
│ │ └────────┘ └────────┘ └────────┘ └────────┘ │ │
│ └──────────────────────────────────────────────────────────┘ │
│ ↓ │
│ ↓ (Block分配到SM) │
│ ↓ │
│ ┌──────────────────────────────────────────────────────────┐ │
│ │ SM内部 │ │
│ │ ┌────────────────────────────────────────────────────┐ │ │
│ │ │ Block分配到SM后,切分成Warp执行: │ │ │
│ │ │ │ │ │
│ │ │ Warp 0: 线程 0-31 ──→ 调度到CUDA Core执行 │ │ │
│ │ │ Warp 1: 线程32-63 ──→ 调度到CUDA Core执行 │ │ │
│ │ │ Warp 2: 线程64-95 ──→ 调度到CUDA Core执行 │ │ │
│ │ │ Warp 3: 线程96-127 ──→ 调度到CUDA Core执行 │ │ │
│ │ │ ... │ │ │
│ │ └────────────────────────────────────────────────────┘ │ │
│ └──────────────────────────────────────────────────────────┘ │
└──────────────────────────────────────────────────────────────────┘7.2 硬件资源限制示意图
┌──────────────────────────────────────────────────────────────────┐
│ SM资源限制示意图 │
├──────────────────────────────────────────────────────────────────┤
│ │
│ 一个SM最多能同时容纳: │
│ ┌──────────────────────────────────────────────────────────┐ │
│ │ 2048个线程 = 64个Warp × 32线程 │ │
│ └──────────────────────────────────────────────────────────┘ │
│ ↓ │
│ 但实际受限于: │
│ │
│ ┌──────────────────────────────────────────────────────────┐ │
│ │ 寄存器限制 │ │
│ │ ┌────────────────────────────────────────────────────┐ │ │
│ │ │ 寄存器总数: 65536 │ │ │
│ │ │ 每个线程用32寄存器 → 2048线程 ✅ │ │ │
│ │ │ 每个线程用64寄存器 → 1024线程 ❌ │ │ │
│ │ │ 每个线程用128寄存器 → 512线程 ❌ │ │ │
│ │ └────────────────────────────────────────────────────┘ │ │
│ └──────────────────────────────────────────────────────────┘ │
│ │
│ ┌──────────────────────────────────────────────────────────┐ │
│ │ 共享内存限制 │ │
│ │ ┌────────────────────────────────────────────────────┐ │ │
│ │ │ 共享内存总数: 164KB │ │ │
│ │ │ 每个Block用16KB → 10个Block (164÷16≈10) ❌ │ │ │
│ │ │ 每个Block用32KB → 5个Block (164÷32≈5) ❌ │ │ │
│ │ │ 每个Block用48KB → 3个Block (164÷48≈3) ❌ │ │ │
│ │ └────────────────────────────────────────────────────┘ │ │
│ └──────────────────────────────────────────────────────────┘ │
│ │
│ ┌──────────────────────────────────────────────────────────┐ │
│ │ 线程块限制 │ │
│ │ ┌────────────────────────────────────────────────────┐ │ │
│ │ │ 最大Block数: 32 │ │ │
│ │ │ 即使寄存器/共享内存够用,也不能超过32个Block ❌ │ │ │
│ │ └────────────────────────────────────────────────────┘ │ │
│ └──────────────────────────────────────────────────────────┘ │
│ │
│ 实际活跃Warp数 = min(理论最大, 寄存器限制, 共享内存限制, Block限制) │
│ Occupancy = 实际活跃Warp数 / 64 │
└──────────────────────────────────────────────────────────────────┘八、NVIDIA核心性能参数全景图
下面的表格汇总了从Volta到Blackwell架构的关键型号在编程和模型选型时最关注的硬指标:
| 型号 | 架构 | FP16 算力 (TFLOPS) | BF16 算力 (TFLOPS) | FP8 算力 (TFLOPS) | INT8 算力 (TOPS) | FP64 算力 (TFLOPS) | 显存带宽 | 显存容量 | 关键互联技术 |
|---|---|---|---|---|---|---|---|---|---|
| V100 | Volta | 125 | 不原生支持 | 不原生支持 | 不原生支持 | 7.8 | 900 GB/s | 32GB HBM2 | NVLink 2.0 |
| A100 | Ampere | 312 | 312 | 不原生支持 | 624 | 19.5 | 2.0 TB/s (HBM2e) | 80GB HBM2e | NVLink 3.0 (600 GB/s) |
| A800 (中国特供版) | Ampere | 312 | 312 | 不原生支持 | 624 | 19.5 | 2.0 TB/s (HBM2e) | 80GB HBM2e | NVLink 带宽受限 (400 GB/s) |
| H100 | Hopper | 1,979 | 1,979 | 3,958 | 3,958 | 67 | 3.35 TB/s (HBM3) | 80GB HBM3 | NVLink 4.0 (900 GB/s) |
| H800 (中国特供版) | Hopper | 1,979 | 1,979 | 3,958 | 3,958 | 67 | 3.35 TB/s (HBM3) | 80GB HBM3 | NVLink 带宽受限 (400 GB/s) |
| H200 | Hopper | ~1,979 | ~1,979 | ~3,958 | ~3,958 | 67 | 4.8 TB/s (HBM3e) | 141GB HBM3e | NVLink 4.0 (900 GB/s) |
| L40S | Ada Lovelace | 733 | 733 | 1,466 | 1,466 | 91.6 (FP32) | 864 GB/s (GDDR6) | 48GB GDDR6 | 不支持NVLink |
| B100 | Blackwell | 待发布 | 待发布 | ~7,900 (预估) | 待发布 | 待发布 | ~4.8 TB/s (HBM3e) | 192GB HBM3e | NVLink 5.0 (1.8 TB/s) |
| RTX 5090 | Blackwell | 83 (FP32) | 83 | 支持 | 支持 | 1.3 (典型值) | ~1 TB/s (GDDR7) | 32GB GDDR7 | 不支持 |
| RTX PRO 4500 | Blackwell | 支持 | 支持 | 支持 (含FP4) | 支持 | 1.4 (典型值) | 896 GB/s (GDDR7 with ECC) | 32GB GDDR7 with ECC | 不支持 |
| H100 NVL (94G) | Hopper | 1,979 | 1,979 | 3,958 | 3,958 | 67 | 3.9 TB/s (HBM3) | 94GB HBM3 (单卡) | NVLink 4.0 |
💡 编程调优的关键洞察
这些参数对于编程实践意味着什么?
-
精度选择直接决定性能上限:
- 对于大模型训练 ,H100及后续架构对FP8的原生支持是关键。它能在保持模型精度的同时,大幅提升计算吞吐量并降低显存占用,是降低万亿参数模型训练成本的核心技术 。
- BF16 在A100及之后架构上成为主流,因其动态范围与FP32相同,简化了混合精度训练的难度 。
- 如果你的工作负载涉及科学计算(如分子动力学、气候模拟) ,FP64性能是刚需。H100的FP64性能是A100的3倍以上,而V100至今仍在这一领域有应用 。
-
内存带宽与容量:大模型的"命门":
- H200的4.8TB/s带宽和141GB容量 是一个分水岭。它意味着像Llama 3 70B这样的模型可以单卡部署,无需复杂的模型并行策略,从而显著降低推理延迟并简化工程实现 。对于编程而言,这意味着可以尝试更长的序列长度和更大的batch size。
- H100 NVL (94G) 的双卡配置,为参数量超过80B的模型提供了一种高带宽、大容量的解决方案,尤其适合推理场景 。
-
互联技术决定多卡扩展效率:
- 在进行多卡分布式训练 时,NVLink带宽至关重要。H100的900GB/s NVLink 能保证梯度同步等通信操作几乎不成为瓶颈,实现近线性的加速比。
- 特别留意中国特供版A800/H800,其NVLink带宽被显著限制 。如果你的训练任务对卡间通信极为敏感(如使用GSPMD等并行策略),这个差异会对编程和性能优化策略产生重要影响。
-
架构特性:针对性优化
- Transformer Engine (H100+):编程时可以利用其自动在FP8和FP16间切换的能力,简化了低精度训练的代码复杂度 。
- L40S:它拥有RT核心,在AI推理的同时具备强大的3D图形渲染能力 。如果你的应用是AI+图形学(如数字人、Omniverse),这是编程时需要重点利用的异构计算特性。
- RTX PRO 4500 :作为工作站显卡,它支持ECC显存纠错,这对需要长时间运行、数据零差错的专业计算和科学工作流至关重要 。
九、动手实践
9.1 查询你的GPU信息
运行以下代码,查看你的GPU硬件参数:
cpp
#include <cuda_runtime.h>
#include <stdio.h>
int main() {
int deviceCount;
cudaGetDeviceCount(&deviceCount);
for (int i = 0; i < deviceCount; i++) {
cudaDeviceProp prop;
cudaGetDeviceProperties(&prop, i);
printf("GPU %d: %s\n", i, prop.name);
printf(" 计算能力: %d.%d\n", prop.major, prop.minor);
printf(" SM数量: %d\n", prop.multiProcessorCount);
printf(" 每个SM最大线程数: %d\n", prop.maxThreadsPerMultiProcessor);
printf(" 每个SM最大Warp数: %d\n", prop.maxThreadsPerMultiProcessor / 32);
printf(" 最大线程块大小: %d\n", prop.maxThreadsPerBlock);
printf(" 寄存器数量/SM: %d\n", prop.regsPerMultiprocessor);
printf(" 共享内存大小/SM: %.2f KB\n", prop.sharedMemPerMultiprocessor / 1024.0);
printf(" 全局内存大小: %.2f GB\n", prop.totalGlobalMem / (1024.0*1024*1024));
printf(" L2缓存大小: %d KB\n", prop.l2CacheSize / 1024);
printf("----------------------------------------\n");
}
return 0;
}9.2 编译运行
bash
nvcc device_query.cu -o device_query
./device_query十、本节总结
10.1 核心要点回顾
-
GPU是吞吐优先的设计:几千个简单核心,通过大量线程隐藏延迟
-
SM是核心计算单元:每个SM有自己的CUDA Core、Tensor Core、寄存器、共享内存
-
Warp是执行最小单位:32个线程一起执行同一条指令
-
零开销调度:通过切换Warp隐藏访存延迟
-
Tensor Core是AI加速核心:一次完成64次乘加运算
-
Occupancy决定性能:受寄存器、共享内存限制
10.2 下节预告
下一节我们将深入GPU内存体系,搞懂:
- 全局内存为什么慢?
- 共享内存怎么用才能快?
- 寄存器溢出会怎样?
- 如何通过内存优化让性能翻倍?
十一、参考资料
- NVIDIA ADAADA Architectute Nvidia:
- NVIDIA Hopper Architectute Nvidia:
- NVIDIA Ampere GPU Architecture:
- NVIDIA GPU Turing
- NVIDIA V100 数据中心GPU (官网)
- NVIDIA A100 GPU 为现代数据中心提供强大动能 (官网)
- NVIDIA A100 GPUs Power the Modern Data Center (官网英文)
- NVIDIA H100 Tensor Core GPU (官网英文)
- NVIDIA H200 GPU (官网英文)
- NVIDIA Enterprise Reference Architecture: Appendix B (NVIDIA官方文档)
- NVIDIA Enterprise Reference Architecture: Appendix A (NVIDIA官方文档)
- NVIDIA GeForce RTX 5090 显卡 (官网)
十二、面试真题(2024-2026)
Q1:解释GPU的SIMT模型和CPU的SIMD有什么区别?
考察点:对两种并行模型的理解
参考答案:
- SIMD(单指令多数据):一条指令同时操作多个数据,所有单元步调一致(如CPU的AVX指令)。数据必须连续存储,处理分支困难。
- SIMT(单指令多线程):多个线程执行同一条指令,但每个线程可以访问不同地址、可以有独立分支(虽然分支会序列化)。
- SIMT更灵活,适合图形学和AI等不规则并行任务,这也是GPU适合AI的原因。
Q2:什么是Warp?Warp的大小为什么是32?
考察点:对硬件细节的了解
参考答案:
- Warp是GPU调度的最小单位,32个线程组成一个warp。
- 32是设计权衡的结果:太小则调度开销占比大,太大则分支开销大、资源浪费。
- 从Tesla架构开始就定为32,一直延续至今,保证了软件生态的兼容性。
Q3:什么是Occupancy?如何计算和优化?
考察点:性能优化基础
参考答案:
- Occupancy = 活跃warp数 / 最大支持warp数(通常64)。
- 计算方法:受限于寄存器、共享内存、线程块大小。
- 优化方法:
- 减少每个线程使用的寄存器(
-maxrregcount编译选项) - 减少每个Block使用的共享内存
- 调整Block大小(128-256通常较好)
- 使用
__launch_bounds__提示编译器
- 减少每个线程使用的寄存器(
Q4:Tensor Core和CUDA Core有什么区别?分别在什么场景使用?
考察点:对现代GPU架构的理解
参考答案:
- CUDA Core:通用标量单元,适合控制流复杂、非规则计算。
- Tensor Core:专用矩阵乘加单元,一次完成4×4矩阵乘加(64次运算)。
- 使用场景:
- CUDA Core:自定义算子、元素级操作、复杂逻辑
- Tensor Core:矩阵乘法、卷积、AI训练/推理
- 开发中:一般用cuBLAS、cuDNN自动调用Tensor Core,手写需用
wmma命名空间API。
Q5:SM上同时能跑多少个线程?受什么限制?
考察点:对硬件资源约束的理解
参考答案 :
以A100为例,理论上限2048线程(64 warp × 32线程)。
实际受三重限制:
- 寄存器限制:65536寄存器 ÷ 每线程寄存器数
- 共享内存限制:164KB ÷ 每Block共享内存 × 每Block线程数
- 线程块限制 :最多32个Block同时驻留
最终取三者最小值。
思考题 :
如果你的核函数每个线程用64个寄存器,每个Block有256个线程,每个Block用32KB共享内存。在A100上,一个SM最多能同时跑多少个线程?
提示:A100每个SM有65536个寄存器、164KB共享内存、最多64个warp、最多32个Block。
计算。
- Tensor Core:专用矩阵乘加单元,一次完成4×4矩阵乘加(64次运算)。
- 使用场景:
- CUDA Core:自定义算子、元素级操作、复杂逻辑
- Tensor Core:矩阵乘法、卷积、AI训练/推理
- 开发中:一般用cuBLAS、cuDNN自动调用Tensor Core,手写需用
wmma命名空间API。
Q5:SM上同时能跑多少个线程?受什么限制?
考察点:对硬件资源约束的理解
参考答案 :
以A100为例,理论上限2048线程(64 warp × 32线程)。
实际受三重限制:
- 寄存器限制:65536寄存器 ÷ 每线程寄存器数
- 共享内存限制:164KB ÷ 每Block共享内存 × 每Block线程数
- 线程块限制 :最多32个Block同时驻留
最终取三者最小值。
思考题 :
如果你的核函数每个线程用64个寄存器,每个Block有256个线程,每个Block用32KB共享内存。在A100上,一个SM最多能同时跑多少个线程?
提示:A100每个SM有65536个寄存器、164KB共享内存、最多64个warp、最多32个Block。
欢迎在评论区留下你的答案!