
WorldGen:从文本生成可漫游、可交互的三维场景
video:https://www.meta.com/blog/worldgen-3d-world-generation-reality-labs-generative-ai-research/
发表:CVPR-2026

图1.WorldGen生成的场景快照。每个场景由可独立编辑的对象组成,所有对象均为具备完整纹理的三维网格模型。依托显式几何结构,生成的场景原生支持碰撞检测与角色漫游,角色能够在场景内攀爬、跳跃并完成各类交互操作。产出的资源可直接部署至游戏引擎中。建议读者观看配套视频,以便更直观地感受生成场景的规模、结构与沉浸感。
摘要
本文提出了WorldGen方法,仅依靠单条文本提示词,即可生成完整、大型且支持漫游的三维场景。现有三维场景生成方法往往会在场景多样性、完整性与几何合理性之间产生取舍。本文突破了这一局限,所生成的大型场景会被拆解为一个个高质量的独立三维网格模型,能够兼容主流游戏引擎。
本方法首先借助语言驱动的程序化生成器,搭建场景基础空间结构与可漫游区域;随后通过图像生成器定义场景的主题、风格与细节内容。在此基础上,对规划完成的场景开展高质量、组合式三维重建:该环节先采用图像转三维模型算法完成整体重建,结合场景上下文与漫游需求,隐式确定所有场景物体的形态与位置;再将整体重建结果拆分为独立实体,并参考图像生成器的引导,对各个实体进行高分辨率重生成,补充精细细节。
本文针对核心设计方案开展消融实验,并与现有场景生成方法进行定性对比,验证了本方案能够弥补现有技术的不足。
1. 引言
为游戏及其他交互式应用制作三维内容需要耗费大量精力,同时对制作者的专业能力有着较高要求,完整游戏世界的三维建模工作更是如此。三维生成式人工智能有望大幅简化这类内容的创作流程,即便是非专业人员,也只需输入一段文本提示词,就能得到高质量、带有纹理的三维网格模型36, 38, 86, 88, 92。但现有模型大多仅能生成单个三维物体;想要设计出兼具完整性与实用性的完整游戏关卡(例如保证角色能够全程顺畅漫游、不会出现卡模问题),目前依旧存在诸多挑战,该问题也尚未得到有效解决。
本文提出了WorldGen这一全流程框架,仅通过单条文本提示词即可生成完整的三维场景(见图1)。针对当前自动化三维场景生成技术在画质、场景规模与功能性上存在的诸多难题,本文逐一进行了解决。
当前一大核心难题是,缺乏可用于训练场景生成模型的大规模三维场景数据集。受图像转三维模型相关研究启发,本文先利用图像生成器构思场景的结构与内容,再以生成的图像为引导完成三维场景重建。但这类模型无法保障最终场景具备实用功能,例如无法保证场景可正常漫游。为此,本文采用程序化生成器(PG) 输出的布局结果引导图像生成过程,程序化生成器能够便捷地施加各类结构约束。同时,我们借助大语言模型(LLM),让程序化生成器能够根据用户输入的提示词开展工作。
程序化生成器的生成能力虽存在局限性,但在本研究中,它能够确定场景的主体空间范围与可通行区域,并通过导航网格(navmesh)对上述区域进行表征。我们将这份粗略布局输入至图像生成器,由图像生成器塑造场景的细节、主题与视觉风格,以此保证场景的多样性。最终,图像生成结果与程序化生成器的输出共同构成一套场景规划方案。
本文第二项研究工作,是基于场景规划方案实现组合式、高分辨率的三维重建。一种常规思路是先对场景做目标分割,再逐个重建物体,但该方法缺失上下文关联推理能力,往往效果不佳:比如物体之间无法合理衔接,遮挡区域的问题尤为突出。对此,本文采用整体三维隐空间扩散模型38, 86, 88开展重建。将导航网格作为该模型的约束条件后,即便在引导图像中无法观测到的区域,也能保证场景结构连贯、支持正常漫游。
整体重建是结合上下文完成物体重建的一种简洁且高效的方式。但仅依靠整体重建,无法产出符合工程落地标准的三维场景,原因在于重建得到的几何模型分辨率不足。此外,若将整个场景合并为单一网格模型,也会给后续编辑、动画制作以及工程部署带来不便。为提升模型画质与模块化程度,本文结合组合式三维生成领域的前沿成果9,将重建后的整体场景拆解为独立物体。针对完整场景通常包含大量构件的特点,我们对原有模型进行改进,提升其处理效率。随后在保留场景整体结构的前提下,对每个独立构件进行优化,进一步提升视觉真实度。该优化流程分为两步:首先,利用图像生成器为每个物体生成高分辨率视图,补充丰富的视觉细节;其次,使用基于图像转三维模型微调得到的网格优化器57,结合低精度几何模型与生成图像中的视觉信息,重新生成每个物体的几何结构与纹理。
现有各类三维场景生成方法在设计前提、数据表达形式与输出结果上差异较大,因此本文结合消融实验与针对性对比实验对WorldGen开展综合评估。我们从定性与定量两个维度分析核心设计方案的合理性,并与当前主流的图像转三维模型方法进行对比,论证本方案的设计思路。同时,本文还将该方法与Marble76等现有场景生成系统进行定性对比。本文的主要创新点总结如下:
- 提出端到端框架WorldGen,该框架融合大语言模型驱动的程序化布局能力与高性能图像转三维先验知识,可根据文本生成具备实用功能、支持漫游的三维场景。
- 提出基于导航网格引导的整体重建策略,将结构约束引入三维隐空间扩散模型,即便在图像遮挡区域,也能保障场景整体结构连贯、可正常漫游。
- 提出一套组合式优化框架,可将整体网格拆解为独立物体并分别完成几何与纹理优化,最终生成高真实度、支持编辑且可直接应用于游戏的三维资源。
2. 相关工作
已有大量研究围绕三维场景生成问题展开,各类研究的设计前提与目标往往存在差异,因此相关方法大多仅能进行定性对比。基于视图的生成是其中一个主流研究方向。该方向的核心思路为:利用二维图像或视频生成器逐帧生成场景视图,同时完成场景三维结构重建。SynSin75是早期采用隐式几何表示的代表性工作;PixelSynth65、CompNVS39、Text2NeRF87以及Text2Room23等研究则实现了显式几何的重建。后续诸多工作从不同角度对上述思路进行了拓展1, 7, 8, 11, 12, 15, 16, 19, 20, 22, 24, 28, 29, 33--35, 37, 43, 44, 46, 49, 50, 54--56, 61, 66--68, 70, 71, 73, 74, 78, 80, 82, 83, 85, 89--91, 94, 96。但这类方法生成的三维场景具有逐次迭代、整体单一的特性,制约了最终效果与实际应用范围。
另一类研究聚焦于组合式场景生成:结合物理模拟得到的布局约束或是大语言模型的引导,将从数据库中检索得到41, 84或实时生成42, 52, 95的物体进行场景排布。还有部分方法会参照指定图像完成物体摆放13, 18, 21, 26, 31, 52,与本文思路较为接近。但这类方法普遍存在扩展性不足的问题,仅能完成少量物体的小型场景搭建。
程序化生成器依靠人工设计的流程与规则体系构建三维场景,计算机图形学领域已诞生大量此类生成工具。InfiniGen 与 InfiniGen Indoors43, 63等工具被用于制作计算机视觉数据集;SceneCraft25、SceneX93等工作则借助大语言模型智能体,将文本或图结构转化为可执行程序,进而完成场景构建。程序化生成技术的局限性在于,其依托代码、规则等形式化体系实现,实际生成效果的丰富度受限。本文利用程序化生成器搭建场景初始布局,再结合二维、三维生成模型丰富场景样式与细节。
当下三维生成技术的发展,很大程度得益于将三维隐空间模型拓展至场景生成任务。SceneFactor6可生成多房间室内场景;BlockFusion77与LT3SD51采用逐块拼接的方式拓展场景范围;NuiScene32将面向单体物体的VecSet模型86拓展至场景任务,可生成无边界户外场景,但输出结果不包含物体结构与纹理信息。这类基于隐空间的模型虽然能够生成完整的场景网格,但受限于三维场景训练数据的匮乏,生成内容多样性不足。本文依托文生图模型弥补了训练数据短缺的问题。
SynCity14结合预训练文生图与图生三维模型,以逐块拼接的形式构建场景。该工作与本文一样,利用图像生成器提升内容多样性,但其生成结果存在语义组合性差、拼接伪影明显、分辨率偏低等问题。还有部分研究尝试融合基于视图的方法与三维隐空间方法2, 3, 30, 40, 64, 72, 81,但难以实现大型完整场景的生成。此外,Genie58等交互式视频生成技术有望依托实时交互式视频生成器替代整套游戏开发流程,场景生成也被纳入其功能范畴。该方向虽具备巨大潜力,但目前距离落地应用仍较为遥远。而本文方法生成的三维资源,可适配当下主流硬件、开发工具与工作流程。
3. WorldGen 整体框架
本节依次介绍 WorldGen 的四大执行阶段:场景规划、场景重建、场景拆解与场景增强。
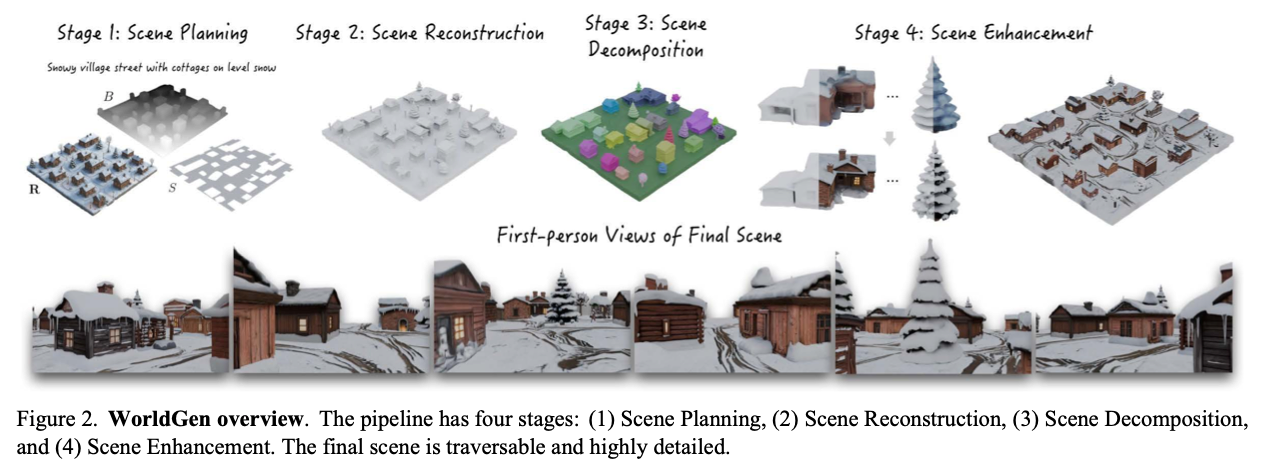
图2. WorldGen 整体流程。整套流水线包含四个阶段:(1) 场景规划、(2) 场景重建、(3) 场景拆解、(4) 场景增强。最终生成的场景可自由漫游且细节丰富。
3.1 场景规划
场景规划阶段的目标是将用户输入的提示词 y y y,转换为结构粗略但功能完备的场景规划方案 L = ( B , R , S ) L=(B, R, S) L=(B,R,S)。该方案由基础粗模布局 B B B、参考图像 R R R 和导航网格 S S S69 三部分组成,整体流程如图3所示。本阶段的核心作用是保证场景布局符合功能要求,具备可漫游特性。

图3. 三维布局生成流程。大语言模型解析输入提示词,将其转化为结构化参数(JSON 格式),以此驱动程序化生成器产出粗略三维基础粗模;随后将该粗模渲染为深度图,并以此为约束条件送入图像生成器,最终得到场景参考图像。
3.1.1 程序化基础粗模生成
本文采用文本驱动的程序化生成(PG)流程制作场景基础粗模,该方案参考了已有研究48, 62。整套程序化生成系统搭载语言交互模块:由大语言模型对文本提示词 y y y 进行解析,输出用于描述地形与布局参数的 JSON 配置文件,直接配置程序化生成流程,最终得到贴合用户创作意图的基础粗模布局 B B B。
具体而言,程序化生成流程分为三个步骤完成基础粗模的构建:地形生成、空间划分与分层资源布置。首先进行地形生成 ,搭建场景基底地貌,确定大范围几何特征,例如海拔、坡度、平坦区域等,为后续搭建建筑与规划通行路径提供基础。其次开展空间划分 ,将整片地形划分为不同功能区域,包括开阔场地、建筑群、过渡地带等。该步骤完成场景高层级的组织布局,在保障整体可漫游的同时,让场景的疏密程度与结构形态呈现差异化特征。最后执行资源布置,分多轮在各个区域内放置三维资源:优先摆放大型地标物体,确立场景主体结构与视觉焦点;再陆续添加小型物件与装饰元素,提升场景真实感与细节丰富度。这种多层级布置策略,能够生成结构统一且样式多样的场景,同时兼顾功能合理性与视觉丰富性。
3.1.2 导航网格与参考图像
上一环节得到的基础粗模布局 B B B,是由基础图元(地面平面与立方体)构成的三维网格,包含场景核心几何信息,同时也是可编辑的结构框架。我们基于该框架进一步提取导航网格 S S S、生成参考图像 R R R。
导航网格 S S S 直接借助 Recast 等经典算法53,从实体化的基础粗模布局 B B B 中提取得到。生成参考图像 R R R 时,先对基础粗模布局 B B B 做等轴测投影并渲染,得到深度图;再将该深度图作为约束条件,输入至基于深度的图像生成器中。本文将相机仰角设定为约 45 ∘ 45^\circ 45∘,以此在单张画面中最大化呈现场景全貌。除此之外,为弱化造型过于刻板的直线轮廓,我们对非地形区域的深度值施加小幅高斯扰动,扰动幅度与深度成正比,让最终生成图像中的建筑轮廓更自然,视觉表现也更加丰富。
3.2 场景重建
结合3.1节得到的场景规划方案 L = ( B , R , S ) L=(B, R, S) L=(B,R,S),本阶段将生成三维场景网格 M M M。该网格需要严格匹配整套规划方案:一方面要符合导航网格 S S S 定义的可通行区域,另一方面也要贴合参考图像 R R R 所呈现的整体构图与视觉风格。
3.2.1 基于导航网格约束的场景生成
基于导航网格的图生三维模型,需要使用由真实场景网格、对应参考图像、导航网格构成的三元组 ( M , R , S ) (M, R, S) (M,R,S) 进行训练。但目前业界暂无适配该任务的公开三维场景数据集。为此本文采用两阶段训练策略:首先在海量通用物体数据集上对图生三维模型开展预训练,让模型习得鲁棒的三维重建先验;随后在自主采集的场景三元组数据集上完成模型微调。本文的图生三维模型基于 VecSet 架构10, 86搭建,主干为三维隐空间扩散变换器,详细细节见补充材料。下文将介绍如何对该基础架构进行拓展,引入导航网格约束。
导航网格编码器与约束机制
本文借助交叉注意力机制,将导航网格信息融入三维扩散变换器。首先对导航网格 S S S 做序列化编码,编码器架构与 VecSet86 类似。第一步在导航网格 S S S 的表面均匀采样,得到稠密点云 P ∈ R M × 3 P \in \mathbb{R}^{M \times 3} P∈RM×3;再通过最远点采样算法对其下采样,得到稀疏点集 P ^ = FPS ( P ∣ K ) ∈ R K × 3 \hat{P} = \text{FPS}(P \mid K) \in \mathbb{R}^{K \times 3} P^=FPS(P∣K)∈RK×3。两组点集分别经由坐标位置编码器,将三维坐标转换为 D D D 维特征向量。随后稀疏点集通过交叉注意力层对稠密点集做特征聚合,让稀疏特征能够捕获导航网格精细的几何细节。最终得到的导航网格稀疏特征,会通过额外的交叉注意力层注入图生三维去噪扩散变换器的主干网络。
Q:为什么需要稠密点集和稀疏点集?
导航网格需要同时编码全局漫游布局和局部通行细节;
用稠密点集捕获所有局部精细几何(保障交互功能);
用 FPS 稀疏点集 表征全局结构,并压缩 Token 数量(控制算力、适配 Transformer);
通过交叉注意力将稠密点的细节蒸馏融合到稀疏特征中,实现 "信息无损压缩";
输出固定长度的稀疏特征,注入三维扩散变换器作为结构约束;
整套方案完全兼容 VecSet 基础架构,保证模型训练与泛化能力。
全局语义(稀疏点负责):场景整体通行区域划分、区域连通关系(宏观漫游逻辑);局部语义(稠密点负责):单块通行区的边界、宽度、坡度、台阶(微观交互逻辑)。
训练策略
模型训练基于预训练权重初始化,再使用自建数据集微调。本文对比了两种微调方案:仅更新新增交叉注意力层的权重、对整个变换器网络进行端到端全量微调。实验结果显示,第一种方案下,以倒角距离为评价标准,模型与导航网格的匹配度下降25%。这表明,想要生成与导航网格精准对齐的网格模型,必须对整个生成网络做联合适配;该任务涉及复杂的几何对齐与场景补全,仅依靠新增的约束层无法实现目标效果。
数据归一化
本文基于VecSet的图生三维模型在归一化空间中运算,所有网格都会被缩放至 − 1 , 1 3 -1, 1^3 −1,13 立方体范围内。训练阶段,我们根据对应场景网格的缩放系数对导航网格做等比例缩放,保证二者空间对齐;同时对导航网格与场景网格执行联合平移,使导航网格的地面平面中心落在坐标 ( 0 , 0 , 0 ) (0, 0, 0) (0,0,0) 处。该方式构建了稳定的空间参考,有效提升约束导航网格与生成场景网格的对齐效果。在推理阶段,由于不存在真实场景网格,我们依据程序化生成的基础粗模布局 B B B 计算缩放系数,并使用该系数完成导航网格的归一化与平移。
3.2.2 场景重建效果

图4.基于导航网格约束的场景生成。依次为:程序化生成布局及叠加的导航网格、参考图像、本文微调模型输出的三维场景和基线 图生三维模型输出结果、叠加导航网格的最终场景。
如图4所示,本文提出的导航网格约束模型生成的地形表面更加平滑规整,且能够严格贴合输入的通行约束,这是保障最终场景可顺畅漫游的核心。尽管部分地形细节可依靠纹理做视觉优化,但精准的几何基底是游戏交互功能落地的关键。此外,在建筑等结构化区域,本文模型的生成结果与参考图像匹配度更高,这一优势在复杂场景中表现得尤为突出。
为量化性能差异,本文在专门构建的场景评测基准上,将微调后的模型与基线图生三维模型、多款主流图生三维模型(记为模型A、模型B、模型C)进行对比。该基准包含50个程序化生成场景,每个场景的地形具备中等起伏高度,同时分布着10~30个密集物体。实验流程如下:分别从本文模型与基线模型的输出场景中提取导航网格;将所有几何模型归一化至 − 1 , 1 3 -1, 1^3 −1,13 立方体后,采用迭代最近点算法(ICP)将提取的导航网格与真实导航网格对齐;最后计算两组网格之间的倒角距离。实验结果如表1所示。本文模型的倒角距离相比各类基线模型降低了40%~50%,定量结果充分证明,本文模型与输入通行约束的空间对齐能力更强。更多详细实验内容见补充材料。
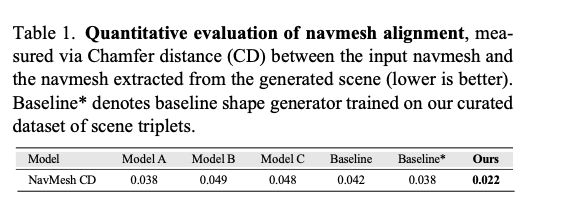
表1 导航网格对齐效果定量评估,指标为输入导航网格与生成场景提取导航网格之间的倒角距离(CD),数值越低代表效果越好。基线*表示在本文自建场景三元组数据集上训练得到的基础形状生成模型。

图5. 导航网格编辑效果。每一行依次展示对程序化生成布局及通行路径进行手动编辑后的结果。从左至右:原始布局与叠加导航网格、参考图像、叠加输入导航网格的生成三维场景、手动编辑后的导航网格、基于编辑后导航网格生成的最终三维场景。
本文进一步验证了当导航网格与参考图像存在小幅偏差时,模型的泛化能力。该测试场景具备很高的实际应用价值:由于将三维结构投影至单张视图存在固有歧义,想要通过编辑二维参考图像精准表达空间设计意图,往往流程繁琐甚至无法实现。而导航网格支持用户直接在三维空间中修改布局,操作简单且精度可控。本文设置了多组测试案例:在"丛林前哨站"场景中移除一处建筑,拓展可通行空间;在"吸血鬼城区"场景中降低建筑高度;在"泰加林营地"场景中小幅压低地形,塑造浅凹陷地貌以丰富地形层次。上述案例证明,本文的导航网格约束模型并非单纯复刻参考图像,而是能够理解空间布局与通行逻辑;即便布局约束与图像约束出现偏差,场景的结构与视觉风格依旧可以保持统一。
Q:为什么可以通过导航网格实现3d 场景编辑?
模型层面:双条件解耦,让导航网格独立管控三维结构,与参考图像负责的视觉风格互不干扰;
表征层面:原生三维网格规避 2D 投影歧义,支持直观的三维区域编辑;
训练层面:模型深度学习导航网格与 3D 几何的映射关系,具备空间逻辑推理能力;
流水线层面:结构骨架前置,上游编辑逐级传导至最终场景;
工程层面:编码器与归一化策略兼容各类编辑后的导航网格,保证运行稳定。
3.3 场景拆解
第二阶段输出的粗粒度整体纹理网格 M M M 将整个场景融合为单一几何模型,所有物体相互交织,难以对单个资源进行编辑与精细化优化。为解决该问题,本环节首先将网格 M M M 拆分为具备语义属性的独立物体与部件,后续再对拆分后的单个对象逐一做增强处理。
本文的拆解方案基于 AutoPartGen9 模型实现,该模型采用自回归方式逐一对网格部件进行拆分,生成单个部件时,会以整体场景网格以及此前已生成的所有部件作为前置条件。但原始 AutoPartGen 存在两处关键缺陷,无法直接应用于大规模场景拆解任务。其一,自回归的生成机制会导致推理速度缓慢,面对包含大量物体与部件的复杂场景时,计算开销极高;其二,该模型主要基于通用单体物体数据集训练,难以有效泛化到由多类物体构成、且各物体存在空间交互的完整场景。
导航网格管大框架:地形、道路、整片建筑、能不能漫游;
整体粘连网格 M是过渡产物:结构合格,但不分物体、细节粗糙、无法商用;
拆解 + 增强管单体资产:划分独立物体、打磨细节纹理、适配游戏引擎、支持局部精细化编辑。
3.3.1 面向场景的 AutoPartGen 加速优化
原始 AutoPartGen 会按照固定的字典序( z z z- x x x- y y y)生成部件,本文对此进行改进,依据部件连通度决定生成顺序。连通度定义为单个部件与其他部件发生空间碰撞的数量。我们按照连通度由高到低的顺序生成部件,优先提取起到结构支撑作用、与大量组件相连的核心支点部件。完成支点部件的拆分后,剩余几何结构可通过残差几何体的空间连通性分析快速完成拆解。例如在包含大量建筑与树木的户外场景中,地面通常拥有最高连通度;拆分出地面后,其余物体借助连通分量分析即可轻松完成拆解。
为适配该生成策略,本文对 AutoPartGen 进行功能扩展,支持将所有剩余几何结构作为一个特殊部件统一生成。我们引入二进制标记令牌,当该令牌被激活时,模型可在单次前向传播过程中输出全部剩余几何体。实际执行时采用五步调度方案:模型先依次生成四个核心支点部件,再输出剩余整体部件,最后对该剩余部件进一步开展连通分量分析,完成精细拆分。该优化方案大幅提升了复杂场景的拆解效率,整体处理时长从原本的十分钟缩短至约一分钟。

3.3.2 场景拆解数据集
对 AutoPartGen 进行场景级微调是保障拆解效果的关键,但目前业界没有现成的、附带部件标注的三维场景数据集。为此,本文自主构建了一套面向组合式三维场景的数据集。
首先,从内部海量三维资源库中筛选场景类数据。具体做法是利用视觉语言模型(VLM)对模型渲染图进行判别,筛选出具备多物体环境特征的资源,筛选标准包括:物体种类丰富、空间布局合理、包含完整地面结构等。
筛选出初始场景资源后,本文采用启发式规则,将原始几何模型处理为带有标准物体与部件划分的数据集。整套处理流程结合了连通性部件分割与地面感知推理,共分为四大步骤:
- 对网格顶点执行焊接处理后,提取拓扑连通分量,将其作为基础最小部件;
- 识别地面区域,并将路面标线等薄层附属结构合并至地面,形成独立部件;
- 对重复部件进行去重,同时迭代地将小型部件合并至空间距离最近的相邻部件,全程保证地面部件不被合并;
- 依据多项质量约束筛选最终数据,约束条件包含部件数量、部件尺寸失衡程度、地面识别置信度等。

3.3.3 拆解效果
本文从定性与定量两个维度,将所提方法与多款主流三维部件生成模型(主流部件生成模型A、模型B)进行对比测试。现有部件生成模型普遍无法有效泛化至复杂场景(见图6)。例如,主流部件生成模型A处理大型户外场景时,无法输出稳定的拆解结果;主流部件生成模型B会错误分割地形区域,有时会将建筑拆解为大量细碎组件,或是把地面与物体几何融合为单一部件。原始 AutoPartGen9 也存在部分大型物体拆解失败的问题,且推理耗时过长,难以落地于大规模场景。

图6. 场景拆解方法对比。相较于现有方法,本文方案的拆解结果噪声更少、轮廓更规整,同时推理速度更快。
本文还人工搭建了多样化合成评测数据集:在各类地形上摆放不同物体,将所有物体与地形做密封融合得到整体网格,并配套对应的真实部件标注。实验沿用已有研究9,45的评测规则:针对每一个真实标注部件,在模型预测结果中匹配最近邻部件,分别计算不同阈值下的倒角距离与F分数。实验结果如表2所示,本文模型在所有指标上均优于现有主流方法,同时保持了领先的推理速度。
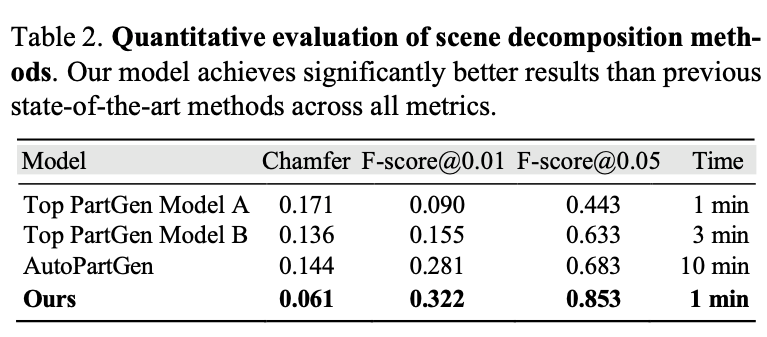
表2 场景拆解方法定量评估。本文模型在各项指标上均显著优于以往主流方法,且推理速度更具优势。
3.4 场景增强
本阶段为整个流水线的最后一步,主要工作是提升上一阶段拆分所得每个物体的几何精度,并为其生成最终纹理。该流程共分为三个步骤:首先针对单个物体生成高分辨率图像,弥补场景级参考图像在单物体分辨率与视角覆盖上的不足;其次借助网格优化模型,以生成图像为依据优化物体几何形态,同时保证优化后的物体仍与原始结构匹配,确保其在场景中正常拼接;最后结合优化后的几何模型与单物体高清图像,为每个物体生成高质量纹理。
3.4.1 单物体图像增强
本文首先采用 TRELLIS79 对整张粗粒度网格进行纹理初始化,为所有拆分后的物体赋予基础纹理。虽然 TRELLIS 生成的纹理分辨率低于多视角生成方法,但该算法原生基于三维空间运算,对物体自遮挡场景具备更强的鲁棒性。此阶段仅需让基础纹理体现物体的大致材质与风格,无需追求极致画质。由于原版 TRELLIS 主要针对单体物体训练,在完整场景上泛化效果欠佳,本文结合同时包含物体与场景数据的内部数据集,对该模型进行重新训练。
本环节的核心思路是:以物体的粗纹理渲染结果为条件,借助大语言-视觉模型(LLM-VLM) 优化物体外观。该环节的主要难点在于维持全场景的风格统一性------若对每个物体独立做增强处理,极易出现色彩、材质、艺术风格错乱的问题。为让图像生成器掌握全局场景信息,针对每一个目标物体,我们额外渲染一张场景俯视图,并使用橙色标注出当前待优化物体的位置,明确其在整体场景中的空间关系;同时将全局参考图像一同输入大语言-视觉模型。

图7. 单物体图像增强。将参考图像、标注目标物体的俯视图、物体粗纹理渲染图输入大语言-视觉模型,最终输出增强后的单物体图像。
生成增强图像的过程中,模型偶尔会产生不符合原始形态的畸变内容,因此本文增设校验环节:将增强后的图像与物体粗渲染图进行比对,若二者轮廓偏差过大,则舍弃该结果。重复图像增强流程,直至得到轮廓匹配、效果合格的输出(见图8)。

图8. 物体图像校验。校验机制会剔除与原始粗图轮廓不匹配的增强图像,左侧为不合格样例,右侧为最终合格结果。
3.4.2 单物体网格增强
本文采用网格优化模型57,以高保真单物体图像为引导,丰富模型的几何细节。该优化模型在基础图生三维架构之上进行拓展,额外引入粗粒度网格经过变分自编码器(VAE)得到的隐变量作为约束条件。更多技术细节可参见补充材料以及文献57。
3.4.3 单物体纹理增强
最后,结合优化完成的图像与几何模型,为每个物体生成高分辨率纹理。本文沿用成熟的纹理生成方案4, 27:对预训练文生图隐空间扩散模型进行微调,以目标视角的法向图与位置图为约束,生成具备三维一致性的物体多视角渲染图;再将多视角图像反向投影至UV贴图,得到物体最终纹理。相关技术细节详见补充材料。
4. 实验结果
整体效果展示
图1、图9以及补充材料中展示了大量由 WorldGen 端到端生成的场景样例。整体而言,该方法能够根据文本提示生成风格多样、细节丰富、真实感强的三维场景,角色可在场景内自由漫游,完全满足游戏引擎的使用要求。所有场景中的物体语义逻辑合理,纹理风格统一,配套的导航网格可支撑场景实时交互与探索。
整套流水线虽分为多个执行阶段,但借助多块GPU对子物体增强、纹理生成等模块并行运算,从输入文本提示词到产出完整带纹理、可漫游的三维场景,总耗时不足5分钟 。该特性能够极大降低人工操作成本,实现交互式三维场景的快速原型设计。

图9. WorldGen 生成效果展示。采用第一人称视角展示,相机在场景内随机采样,搭配通用空白天空盒。展示场景分别为:中世纪城镇广场、雪景村落、太空港口。
定性对比实验
现有各类场景生成系统在设计思路、场景表达形式、应用目标上差异较大,因此本文主要通过定性对比,区分不同方案生成场景的特性与适用场景。
首先将本文方法与各类图生三维生成器(包括多款商用主流方案)进行对比。这类模型对单个物体、小型简易场景的生成效果出色,但其设计定位为单次重建任务,并不适用于构造大型、组合式、支持自由漫游的交互式环境。这类方法产出的几何模型与纹理分辨率偏低,无法直接接入游戏引擎使用。

图10. 与两款主流商用图生三维系统对比。相较于单次生成方案,WorldGen 产出的场景细节丰富度优势显著。
其次,本文对比了 World Labs 推出的三维场景生成系统 Marble76。两种方法的输入形式与场景表征方式不同,为此本文尽可能统一实验条件开展对比:将本文生成的"中世纪村落"场景中心视角渲染图作为 Marble 的输入图像。实验结果表明,Marble 在输入视角附近能够呈现出极高的视觉保真度;但当相机逐渐远离初始视角后,场景的画质会出现明显衰减。
与之不同,WorldGen 从设计之初就面向大范围可漫游场景,采用显式几何结构:单场景覆盖范围约 50 × 50 50 \times 50 50×50 米,在整个可通行区域内,模型的几何形态与视觉风格始终保持一致,全面支持自由漫游与交互操作。

图11. Marble 生成效果展示。以单张输入视角图为基础,展示相机切换至不同视点后的场景效果。
局限性
当前方案仍存在一定不足:其一,本方法仅使用单张参考视图进行生成,目前仅能制作有边界的单层场景,暂不支持无边界场景以及多层立体场景的生成;其二,当前模型未实现资源实例复用,在物体分布密集的区域,会一定程度降低渲染效率。
未来工作将针对上述问题进行优化,例如引入增量生成技术、实现材质与几何资源的复用。更多相关探讨可参见补充材料。
5. 结论
本文提出了 WorldGen 端到端框架,结合程序化布局规划与导航网格引导的合成技术,实现了从文本到可漫游、可直接应用于游戏的三维场景的全流程生成。本工作验证了将程序化逻辑与生成式先验相结合的技术路线具备巨大潜力,有望进一步降低交互式三维内容的创作门槛。
思考
提出WorldGen端到端框架,其研究动机是现有文本驱动三维场景生成技术大多仅能制作单个物体或小规模场景,生成的大型场景普遍存在空间逻辑缺陷、无法支持角色漫游与交互的问题,高斯溅射、整体粘连网格等主流输出格式难以适配游戏引擎,也不支持单体精细化编辑,且单视图生成易出现投影歧义,难以兼顾场景多样性、几何完整性与实用功能;
该方法采用四阶段流水线完成场景生成,先依靠大语言模型驱动程序化生成器制作场景粗模,并提取导航网格与参考图像完成场景规划,再通过导航网格约束的三维隐扩散模型实现整体三维重建,接着优化AutoPartGen模型,按照部件连通度排序并搭配二进制令牌加速粘连网格拆解,最后利用大语言-视觉模型、网格优化与多视角纹理技术,逐个提升物体的几何精度与纹理质量;
其核心创新为融合大语言模型程序化布局与图像转三维先验,以导航网格作为硬约束保障场景可漫游且支持三维布局编辑,同时优化自回归拆解算法大幅提升大型场景拆解的效率与精度,还设计组合式细化框架完成整体网格拆分与单体画质优化;
在应用层面,该框架可在5分钟内基于单条文本生成风格统一、结构合规的大型三维场景,输出的标准显式纹理网格能直接接入主流游戏引擎,原生支持角色攀爬、跳跃、自由探索等交互操作,对比SynCity及各类图生三维基线模型,其生成结果的几何细节、纹理保真度与全局一致性更优,同时具备完整的单体增删改编辑能力,实现了从文本到可商用、可交互游戏级三维世界的快速生成。
该方法也存在明显局限性,它仅依托单张参考视图,只能生成有边界的单层场景,无法制作无边界大世界与多层立体结构,且未实现资产实例化与几何、材质复用,高密度场景渲染开销较大,全局生成架构也难以拓展至超大型开放世界。
补充材料
6. 视频
建议读者观看配套视频,以便更直观地感受 WorldGen 所生成场景的规模与复杂程度。具体而言,我们将生成的场景导入游戏引擎,并演示角色在各类环境中的漫游过程。受游戏引擎限制,我们对网格进行简化处理,将顶点总数控制在 40 万个以内,纹理则不做压缩。
https://www.meta.com/blog/worldgen-3d-world-generation-reality-labs-generative-ai-research/
7. 第一阶段:场景规划细节
7.1 程序化粗模生成
传统程序化生成(PG)方法依托人工设计的规则与流程,能够生成结构连贯、功能完备的虚拟环境,但这类方法可覆盖的场景类型十分有限,且无法通过自然语言提示词进行控制。本文借鉴近期文本驱动型程序化系统的相关研究48,62,为程序化生成系统增设语言交互接口。大语言模型对用户输入的提示词 y y y 进行解析,输出包含地形类型、物体密度、地势起伏程度、摆放规整度等参数的结构化 JSON 配置文件。这套参数用于配置模块化程序化生成流水线,最终生成贴合用户创作意图的场景粗模 B B B。
具体来说,本文的程序化生成流水线分为三步完成粗模构建:地形生成、空间划分与分层资产摆放。第一步为地形生成,构建场景基底地貌,定义大范围几何特征,包括海拔、坡度、平坦区域等,为后续搭建建筑与规划通行路径奠定基础。第二步是空间划分,将整片地形划分为不同功能区域,如开阔场地、建筑群、过渡地带等。该步骤完成场景的高层级布局规划,在保障整体可漫游性的同时,让场景在物体密度与空间结构上呈现差异化特征。最后一步为分层资产摆放,分多轮在各个区域内放置三维资源:优先摆放大型地标资产以确立场景主体结构与视觉焦点,再补充小型物体与装饰元素,提升场景真实感与细节丰富度。这种多层级摆放策略能够生成风格统一且形态多样的场景,同时兼顾布局合理性与视觉丰富性。
(1)地形生成
我们采用柏林噪声生成器60,或是基于解析后 JSON 参数配置的规则化高度图来合成地形。JSON 参数还会定义地形的各类属性,例如地形类型(平坦地形、陡坡地形)、表面粗糙度、海拔范围等,共同决定场景整体地貌形态与结构变化。
(2)空间划分
空间划分环节会将地形切分为多个独立区域,完成场景的整体结构规划,同时确定密集建筑群、开阔场地与过渡区域的分布位置。
对于规整类场景(如城市街区、网格布局村落),本文采用二元空间划分 17、均匀网格或k 维树 5,生成布局规整、呈正交分布的区域;对于自然风格或不规则地貌(如群岛、丛林),则使用沃罗诺伊图 、基于噪声的划分算法或随机游走算法59,生成边界自然、形态无规律的区域。
该环节完成环境的宏观布局设计,兼顾规整区域与开放空间,在保障场景可漫游性的同时提升视觉多样性。
(3)分层资产摆放
最后,我们以基础图元块作为各类场景元素的占位符,分三轮完成布局填充,以此体现场景的结构层级与空间语义。
① 首先放置核心地标资产(大型标志性建筑、主体楼宇);
② 其次参照地标资产的位置,排布树木、墙体、桥梁等中型元素;
③ 最后依据密度与集群分布参数,在剩余空间中填充小型装饰类资产。
流程末尾还会执行地形平滑处理,避免不同资产之间发生碰撞,进一步提升粗模几何的真实感与可交互性。在该阶段,我们仅通过三类划分方式实现空间体块的合理分布,并不会限定图元块对应的具体物体类型,而是交由后续图像生成器来定义其具体形态。
最终得到的粗模 B B B 是由地面平面、立方体等基础图元构成的三维网格,记录了场景的核心几何信息,同时也是可编辑的结构框架。后续我们将基于该框架提取导航网格 S S S、生成参考图像 R R R。
7.2 规划阶段效果
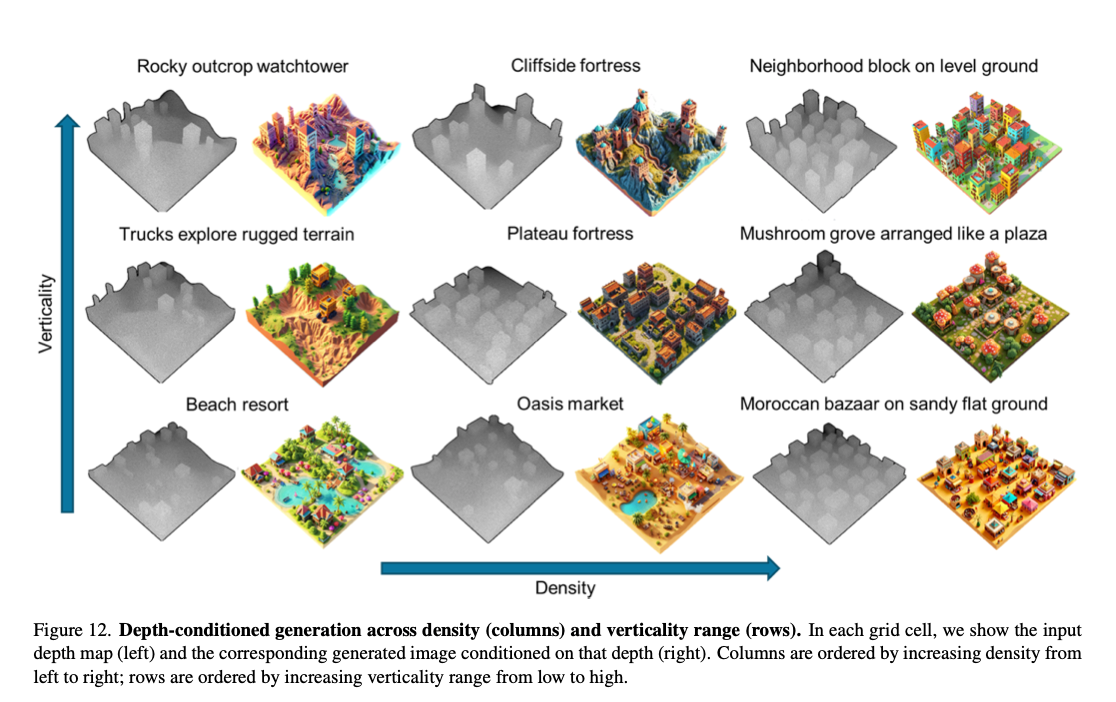
图12. 结合深度图的生成效果(按物体密度与地势起伏划分)。每个子图左侧为输入深度图,右侧为基于该深度图生成的对应图像。列方向从左至右物体密度逐步升高,行方向从上至下地势起伏程度逐步增大。
图12 展示了本文文本驱动布局模块生成的多组典型样例。不同样例对应不同的地形类型、地势起伏程度与物体密度,这三类也是决定场景结构与后续生成难度的核心要素。程序化生成的特性能够保证整片场景均具备可漫游性。
第一列对应低密度布局,包含多种地形类型,生成的空间开阔,角色通行难度低;第二列适当提升物体摆放密度,同时增加地势起伏变化,形成兼具开阔场地与密集活动区的丰富空间结构;第三列为高密度资产布局,对应结构复杂的场景环境。
8. 第二阶段:场景重建细节
8.1 图生三维基础模型
本文的形状生成器采用主流的 VecSet86 三维扩散模型表征方案,将完整场景或单个物体表示为一组无序隐向量集合。该扩散模型通过对向量集合执行去噪操作,结合输入图像的约束条件,重建出符号距离场(SDF)。
VecSet 隐式表征
VecSet 借助自编码器学习三维隐空间,实现三维物体的紧凑化表达。设某三维物体 x x x 由点云 P = ( p i , n i ) i = 1 M P={(p_{i}, n_{i})}{i=1}^{M} P=(pi,ni)i=1M 表示,其中点坐标 p i ∈ R 3 p{i} \in \mathbb{R}^{3} pi∈R3,法向量 n i ∈ S 2 n_{i} \in \mathbb{S}^{2} ni∈S2。编码器 E E E 将点云 P P P 映射为隐编码 z ∈ R K × D z \in \mathbb{R}^{K \times D} z∈RK×D,该编码由 K K K 个 D D D 维词元构成,即 z = E ( P ) z=E(P) z=E(P)。解码器 D D D 则负责重建物体的符号距离场:对于任意查询点 q ∈ R 3 q \in \mathbb{R}^{3} q∈R3,解码器输出该位置对应的符号距离场数值 D ( q ∣ z ) ∈ R D(q \mid z) \in \mathbb{R} D(q∣z)∈R。
编码器的执行流程如下:首先通过最远点采样(FPS) 对输入点云随机下采样,选取 K K K 个点构成子集 P ^ = FPS ( P ∣ K ) = { p ^ 1 , . . . , p ^ K } \hat{P}=\text{FPS}(P \mid K)=\{\hat{p}{1}, ..., \hat{p}{K}\} P^=FPS(P∣K)={p^1,...,p^K};随后采用正弦空间编码,将包含法向量的完整点云 P P P 特征映射至采样点集 P ^ \hat{P} P^,再经由交叉注意力层与多层标准 Transformer 网络处理,最终得到隐编码 z z z。
解码器的工作流程与编码器相反:以查询点 q q q 作为输入,计算对应符号距离场数值。最终得到的隐词元具备紧凑、排列无关的特性,是适用于扩散生成任务的三维表征形式。
图生三维隐扩散模型
本文的形状生成器训练一个以输入图像 I I I 为条件的扩散模型,用于生成三维物体隐编码。具体而言,模型对隐编码的条件分布 p ( z ∣ I ; Φ ) p(z \mid I ; \Phi) p(z∣I;Φ) 进行建模,并通过由 Transformer 结构 Φ \Phi Φ 构建的去噪扩散过程完成训练。
由隐编码 z z z 可定义对应的符号距离场,我们采用移动立方体算法 47,在 512 3 512^3 5123 分辨率的网格中提取出封闭三角网格。模型整体架构如图13(a)所示。
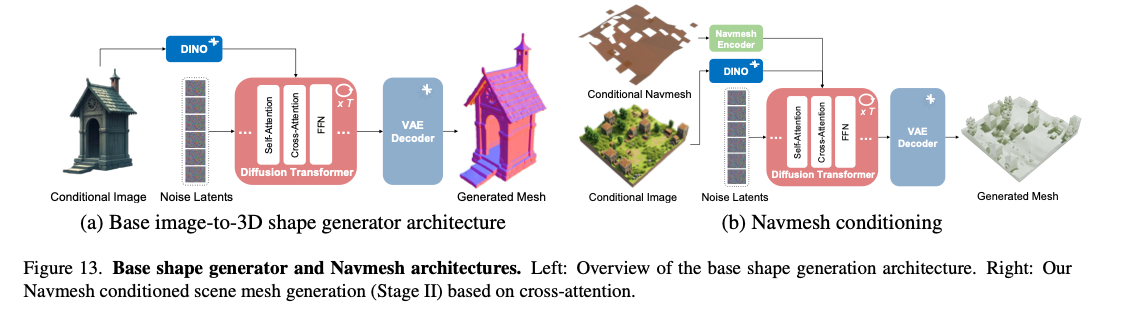
图13. 基础形状生成器与导航网格约束模块架构。左图:基础形状生成架构总览;右图:本文基于交叉注意力实现的导航网格约束型场景网格生成模块(第二阶段)。
模型训练
我们使用内部艺术家制作的三维资产数据集,完成 VecSet 自编码器与图生三维扩散模型的训练。
We train the VecSet autoencoder and the image-to-3D diffusion model in our shape generator using an internal dataset of artist-authored 3D assets.
8.2 导航网格约束
本文基于在自建场景三元组数据集上训练得到的基线图生三维模型开展消融实验。定量实验结果表明,本文方法与输入导航约束的空间对齐效果更优,验证了"结合自建场景三元组数据+导航网格约束"这一设计的有效性。
此外,我们在 256 个未参与训练的程序化生成三维场景上开展测试:本文模型输出三维网格的倒角距离为 0.036,而基线图生三维模型的倒角距离为 0.038。该结果证明,本文方案不仅能提升与导航网格的对齐精度,整体网格质量也更出色。
我们还在基于程序化方法构建的多类别场景评测基准上,将本文模型与基线图生三维模型进行对比,详细结果见表3。该评测基准包含三类不同场景:(1) 50 个地势起伏小的平坦地形场景,物体密度较高(单场景包含 10~30 个物体);(2) 40 个地势起伏大的山地复杂场景,物体分布稀疏(单场景平均 10 个物体);(3) 50 个地势起伏小且物体稀疏的场景(单场景物体数量少于 10 个)。定量实验证明,面对不同复杂程度的场景,本文方法的表现均优于基线模型。
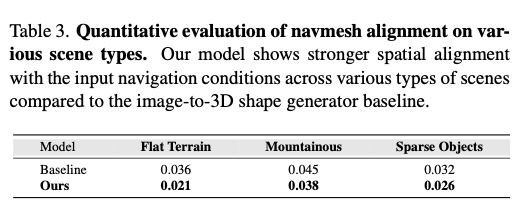
表3. 不同场景类型下导航网格对齐效果的定量评估。相较于基线图生三维形状生成模型,本文方法在各类场景中与输入导航约束的空间对齐效果均更优异。
9. 第四阶段:场景增强细节
9.1 结合大语言-视觉模型的单物体图像增强
为让大语言-视觉模型掌握完整的全局场景信息,我们基于整体场景网格 M M M 渲染俯视图,并使用红色高亮标注目标物体。将该俯视图与全局参考图像 R R R 一同输入大语言-视觉模型,模型会识别物体位置,并分析材质、色调等视觉属性。随后针对每个物体 x ^ i \hat{x}{i} x^i,渲染出其粗几何模型与低分辨率纹理对应的视图 I ^ i \hat{I}{i} I^i,作为图像增强环节的输入(见图7第三行)。
为验证本文图像增强策略的效果,我们开展消融实验,实验中不再使用俯视图,相关结果如图14所示。此时大语言-视觉模型仅依靠全局参考图像与单个物体的粗渲染图完成增强。由图14可见,仅输入全局参考图像时,模型很难生成风格统一、与原图高度契合的物体图像。这也说明,标注出目标物体的俯视图能够提供物体位置、语义以及周边环境等关键上下文信息,是保障图像增强效果的重要条件。

图14. 未使用俯视图时的单物体图像增强效果。若缺少整张场景的俯视图(该视图可为模型提供物体位置、周边环境等关键信息),大语言-视觉模型难以生成与整体场景风格统一、贴合参考图像的物体内容,最终输出图像会出现风格违和、与原图物体外观不符等问题。
9.2 单物体网格增强
本节对网格细化模型57进行简要介绍,其网络架构如图15所示。该模型将物体粗网格 x ^ i \hat{x}{i} x^i 与图像增强阶段输出的高分辨率图像作为输入,目标是生成高精细度物体网格 x i x{i} xi;生成过程会严格保留粗网格的整体姿态,同时补充丰富的几何细节。
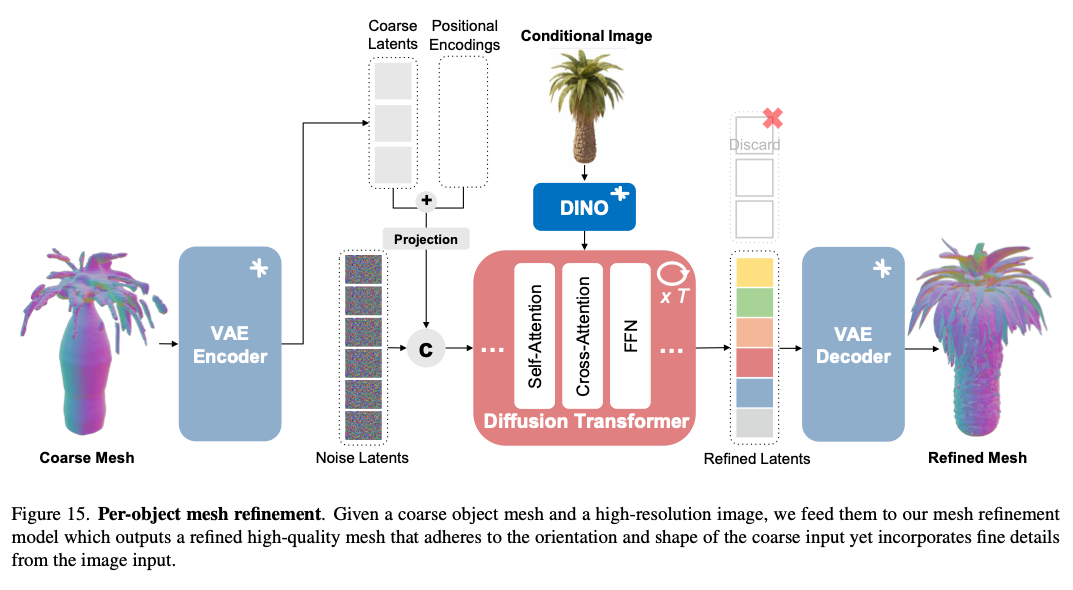
图15. 单物体网格细化流程。输入为物体粗网格与高分辨率图像,网格细化模型基于二者生成高精度网格,新网格在延续原始物体姿态与整体外形的基础上,融入图像中的精细几何特征。
9.3 单物体纹理增强
我们结合优化后的几何模型与增强图像,为每个物体生成高分辨率纹理。本文沿用成熟的纹理生成框架4,对预训练文生图隐扩散模型进行微调。模型以目标视角的法向图、位置图,以及经过光照分离处理的增强图像作为约束条件,生成具备三维一致性的多视角图像。最后将多视角图像反向投影至UV贴图,得到物体最终纹理。
光照分离处理:增强图像中包含完整光照、阴影、高光等渲染效果,会对纹理生成造成干扰。为此我们微调文生图隐扩散模型构建光照分离模块,将带光影的图像隐特征作为上下文输入,剥离画面中的光照信息。
多视角图像生成 :本文基于 Meta 3D TextureGen4 进行功能拓展,具体设计如下。第一,将条件图像的隐特征作为上下文输入,引导多视角图像的生成过程。第二,一共生成十张正交视角图像:包含8张沿物体周向均匀分布、间隔 45 ∘ 45^\circ 45∘ 的侧视图(仰角为 0 ∘ 0^\circ 0∘),以及顶视图、底视图各一张(见图16)。第三,采用序贯生成策略:先生成正视图,再依次生成侧视图,最后制作顶视图与底视图。实验证明,该策略能够有效提升跨视角一致性,减少几何畸变。

图16. 多视角纹理生成示意图。依次生成:(1)正视图、(2)以正视图为条件的侧视图、(3)顶视图、(4)结合所有已有视图生成的底视图。
解耦多视角注意力:本文将自注意力模块拆解为三类独立模块,分别为平面内注意力、参考注意力与多视角注意力,以此实现特征的结构化交互。
- 平面内注意力:每个视图独立对自身空间特征做注意力计算,保障单张图像内部的细节完整性与局部连贯性;
- 参考注意力:后续生成的所有视图通过交叉注意力与参考视图建立关联,确保所有视图的外观均和参考图像保持一致;
- 多视角注意力:各生成视图之间相互进行注意力交互,在贴合参考图的前提下,强化不同视角之间的三维全局一致性。
纹理后处理:完成十张多视角图像的生成后,将所有图像反向投影至物体UV空间,完成纹理贴图的初始化。该步骤可保证所有可视区域的纹理清晰、对齐准确。最后采用图像补全算法填充UV贴图中的微小空缺与视角盲区,得到完整、高质量的纹理,为后续场景组装做好准备。
10. 与SynCity对比
为进一步验证本文方法的综合能力,我们选取近期主流场景生成方法 SynCity14 开展定性对比,结果见图17。
本文与 SynCity 在场景结构设计、实用性、渲染表征形式上存在诸多差异。第一,SynCity 采用分块生成范式,并未考虑场景的可漫游性;而本文流水线从设计之初就面向可漫游场景,能够生成可供用户完整探索的大规模环境。
第二,分块机制会导致 SynCity 的生成结果出现区块边界伪影,也难以生成跨多个区块的大型物体。本文不存在该类限制,可生成跨大范围空间的场景元素,同时保证整体结构连贯。
第三,SynCity 以区块为基本生成单元,不会对物体进行显式拆分,因此难以开展细粒度的编辑与调整。本文则保留了独立物体结构,支持几何修改、外观替换、布局调整等灵活编辑操作。
第四,受分块生成方式影响,SynCity 无法严格约束全局一致性;本文流水线设置了多项机制保障全局风格与结构统一,生成场景的几何形态、空间布局、视觉观感整体协调。
第五,二者的渲染表征形式不同:SynCity 输出高斯溅射数据,目前无法直接适配主流实时渲染引擎;本文输出标准显式带纹理三维网格,可直接接入各类传统图形管线。
由于两类方法的设计前提与数据表征存在差异,无法使用完全一致的输入进行一对一对比。为保证对比的有效性,我们先使用 SynCity 生成场景并渲染全局效果图,再将该图像作为输入交由本文流水线完成重建。如图17所示,本文生成的场景几何细节更丰富,纹理保真度更高,整体结构也更为连贯。

图17. 与SynCity方法对比。左侧为本文WorldGen生成结果,右侧为SynCity生成结果。本文方法生成的场景具备更丰富的几何细节、更高的纹理质量,全局结构一致性也更优。
11. 风格一致性
我们进一步开展定量实验,验证本文方法在风格一致性上的表现。由于现有方法大多不具备显式独立物体表征,无法在物体维度开展对比,因此本文从场景整体维度进行评估:计算生成画面与输入文本提示词、参考图像之间的 CLIP 相似度,以此衡量风格统一程度。相似度数值越高,代表生成内容与预期风格匹配度越好。
实验选取中世纪村落场景的多帧画面进行测试,主要评估两项指标:(1) 图文匹配度;(2) 图图相似度。实验结果见表4。数据表明,本文方法在两项指标上均优于当前主流图文转三维模型(模型A、模型B)。
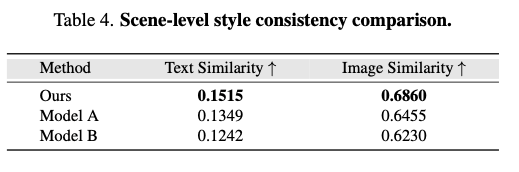
表4. 场景整体风格一致性对比。
上述结果证明,本文生成的场景与文本描述、参考图像的契合度更高,在无需物体级监督信息的前提下,实现了更优的全局风格一致性。
12. 局限性与未来工作
如正文所述,当前流水线仅依赖单张参考视图,因此仅能生成有边界、以单层结构为主的场景,无法实现无边界户外大世界、多层立体交互场景等复杂内容的生成。
同时,本文采用的全局规划与全局生成方案虽然能保证场景全局一致性,但在拓展至超大型环境时会成为性能瓶颈。想要实现无边界场景生成,需要改用滑动窗口、分块式等可拓展生成范式,在增量生成局部区域的同时维持全局特征统一。
对于超大型场景而言,性能瓶颈会从生成环节转移至数据表征环节。当前各类生成流水线均未充分探索几何与材质复用技术,而该技术对内存占用优化、实时渲染效率提升至关重要。本文目前未实现资产实例化(即重复结构的复用),在高密度场景中会产生大量冗余几何数据,进一步增加渲染开销。
未来研究将围绕以上问题展开多方向探索:
第一,引入增量生成、流式生成策略14,实现超大型场景的可拓展生成;
第二,设计专门的材质与几何复用机制,例如实例感知生成、资产库检索复用等方案,同时提升运行效率与视觉一致性;
第三,拓展流水线的适用范围,适配室内场景。室内场景存在空间约束更严苛、结构关系更复杂等难点。目前我们已开展初步实验,实现了楼梯、多层平台等室内复杂结构的生成,相关初步效果见图18。

图18. 多层平台生成样例。