text-to-image (T2I)generation图像生成领域中表现最好的是商业闭源proprietary方案,如Nano Banana Pro 和Seedream 4.0,在开源方案中,如Qwen-Image, Hunyuan-Image-3.0 ,FLUX.2,参数也要20B~80B,而z-image只需要6B参数,显存VRAM也只需要16GB。效果可以达到照片级生成和双语渲染photorealistic generation and bilingual text rendering。效果逼近商业级生成模型的同时,模型代码和权重都是开源的。
z-image挑战了"scale-at-all-costs" 不惜代价追求scale的规则,通过对整个模型生命周期进行系统性优化------从精心策划的数据基础设施到精简的训练流程------仅用 31.4万 H800 GPU 小时(约合 63 万美元)就完成了完整的训练工作流。

数据
数据上Efficient Data Infrastructure,meta记录了图像长宽,感知哈希值perceptual hash (pHash),这样可以快速去除比例奇怪的,重复的数据。还会计算压缩比,信息熵bytes-per-pixel (BPP) ,视觉缺陷偏色、模糊、可见的水印以及过度的噪点等。还会进行审美打分,AI痕迹检测,语义检测等,还有CN-CLIP检测的图文相关性。
除了图像本身,就像冰山一样,图像之外还有很多的背景知识需要学习。比如识别到埃菲尔铁塔,就要知道相关的历史信息,位置信息。所以还需要构建World Knowledge Topological Graph,它基于维基百科,把抽象的,冷门知识(PageRank 分低的)删除,增加热点相关的。
同时使用了OCR和世界知识:
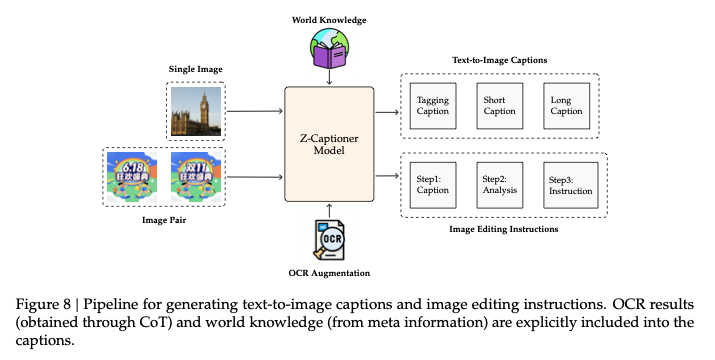
OCR的过程不进行翻译,只保留原始信息;World Knowledge是图像之外的相关信息,如照片中埃菲尔铁塔的位置,历史等,来自于meta information。
设计了五种不同类型的图像描述,包括长描述、中描述、短描述 ,以及标签(Tags) 和模拟用户提示词(Simulated User Prompts)。通过结合元信息(meta information)来进行图像描述,从而将世界知识融入到所有这五种描述类型中。这一做法显著减轻了幻觉问题,尤其是在我们的描述生成器识别并命名特定实体(如公众人物、著名地标或已知事件)时。
结构
结构上Efficient Architecture,受LLM中decoder-only的影响,提出了Scalable Single-Stream Multi-Modal Diffusion Transformer(S3-DiT)。
对文本,使用Qwen3-4B作为the text encoder,对图像,使用Flux VAE,编辑器则使用**SigLIP 2。**与Single-Stream相对应的是dual-stream,把text和imgae分别单独处理。Single-Stream的含义是将text和图像的各种形式统一为单个序列,然后送入Transformer backbone,这样可以使得参数效率最大化,训练和推理都更高效。
虽然文本和图像都是长序列,但是图像和文本分别有空间信息和时间信息,所以需要使用3D RoPE 赋予它们不同的位置信息:
- 图像 Token(空间维度) :图像被切分成很多小块(Token),它们在 宽(W)和高(H) 这两个空间维度上展开。RoPE 会告诉模型:"这个 Token 在图片的左上角,那个在右下角"。
- 文本 Token(时间维度) :文本是一个接一个排列的,因此沿着 时间(T)维度 递增。RoPE 会告诉模型:"这是句子的第1个词,那是第2个词"。
- 对于编辑,reference image tokens and target image tokens 在spatial 上是对齐的,temporal 上错位一个时间单位,并且使用time-conditioning values来区分。
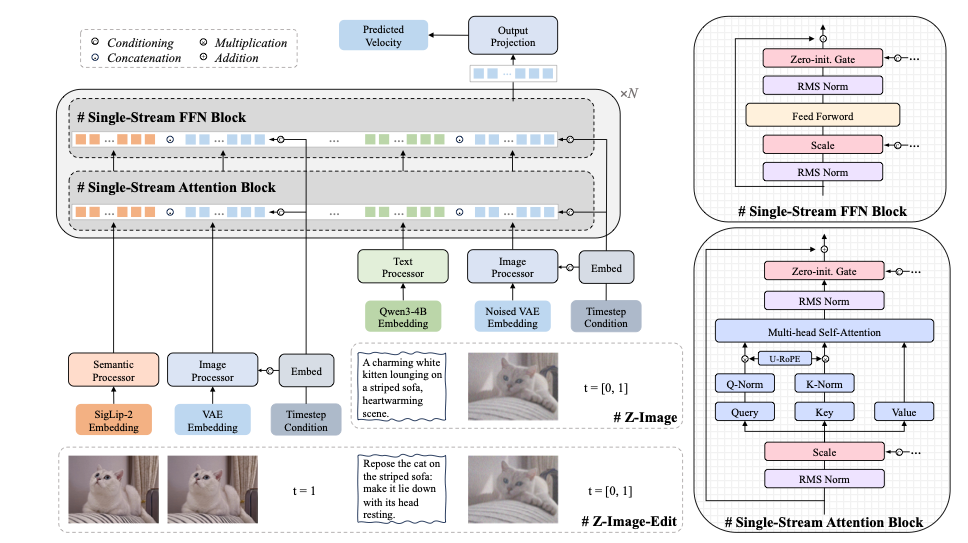
从图中可以看出来,不同模态的特征先经过modality-specific processors,然后concate之后分别送入了attention block和FFN block,这就是典型的transformer架构。modality-specific processors本身也是由two transformer blocks构成,让不同模态的 Token 在进入统一网络前,先完成"模态内对齐",避免直接把差异巨大的文本和图像 Token 扔进同一个网络导致训练不稳定。
为了进一步提升稳定性,使用了QK-Norm(Query-Key 归一化)和Sandwich-Norm(三明治归一化)。Attention 的 logits 是 Q 和 K 的点积,如果 Q/K 的幅值过大,点积结果会非常大,经过 Softmax 后会变成极端的 one-hot 分布,导致梯度消失或爆炸。深层 Transformer 中,信号经过层层传递后容易出现幅值漂移(越来越大或越来越小)。Sandwich-Norm 在每一层的入口和出口都"掐住"信号幅值,防止信号在深层网络中失控。QK-Norm 将 Q/K 的幅值约束在合理范围内,使 Attention 分布更平滑,训练更稳定。Sandwich-Norm在每个 Attention 和 FFN 模块的输入和输出两端都做归一化,像三明治一样把模块"夹"在中间:
Input → [Norm] → Attention/FFN → [Norm] → Output(QK-Norm、Sandwich-Norm)统一使用 RMSNorm 实现。RMSNorm 相比 LayerNorm 去掉了均值中心化,只保留方差归一化,计算更轻量,在大模型中已被广泛验证有效。
条件向量(如时间步嵌入)被投影为两组参数:scale(缩放) 和 gate(门控)
x_normalized → scale * x_normalized + gate * F(x_normalized)策略
Efficient Training Strategy
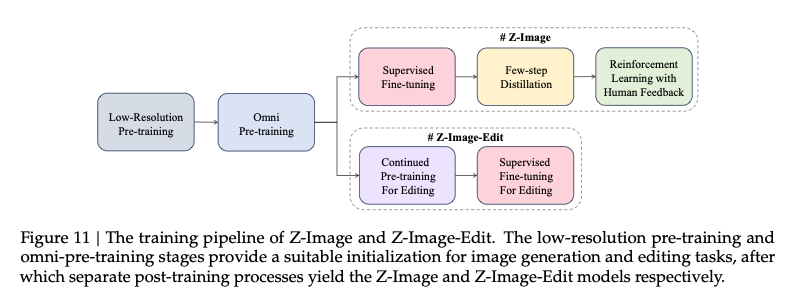
- 第一步(打基础) Low-resolution Pre-training:先用256低分辨率的小图让模型快速入门,获取基础的视觉与语义对齐以及图像合成的核心知识,所以这一步的关键是cross-modal alignment and knowledge injection
统扩散模型(如 DDPM、Stable Diffusion)的训练目标是:给一张加了噪声的图,让模型预测噪声本身,然后从图中减去噪声来逐步"去噪"。而 Flow Matching 的思路完全不同:它把生成过程看作一条从噪声到清晰图像的连续路径(轨迹),模型的任务是学习这条路径上每一点的运动方向和速度。路径更简洁:线性插值路径比传统扩散的多步噪声添加过程更直接,理论上可以用更少的推理步数。训练更稳定:目标是一个确定性的、方差较小的量,相比预测随机噪声更容易学习。
和SD3一样,使用logit-normal noise sampler ,取代在0,1 区间均匀采样,因为不同t的任务难度不同,Logit-Normal 采样器让时间步 tt 的采样分布呈"钟形。除了时间t,同样噪声下,分辨率也会影响SNR,所以高分辨率图像 → 使用更大的 t(更多噪声),降低 SNR
- 第二步(练全能)Omni-pre-training:不分开训练画画和修图,而是把所有技能(不同尺寸、生成、编辑)揉在一起练,省去了重复烧显卡的环节。
在打好文生图基础之后,通过"分辨率多样化 + 任务多样化 + 字幕多样化"的三重扩展,让模型在预训练阶段就具备尽可能全面的能力,为后续的精细微调和下游任务打下坚实基础。
任意分辨率训练(Arbitrary-Resolution Training),不再固定分辨率和ratio,否则会带来信息丢失。
文生图与图生图联合训练(Joint Text-to-Image and Image-to-Image Training)
多层次双语字幕训练(Multi-level and Bilingual Caption Training),双语字幕通过Z-Captioner 得到
- 第三步(配外挂)PE-aware Supervised Fine-tuning:在微调时,专门配合prompt enhancer (PE)进行联合训练,让模型完美适配这个"外挂大脑",而且不需要额外花钱去训练大语言模型,性价比极高。
监督微调(SFT)阶段 的核心思想------分布收窄(Distribution Narrowing),将生成分布收窄到一个聚焦的、高保真的子流形(focused, high-fidelity sub-manifold)上。这个阶段使用的文本和图像都更加高质量,
**SFT的同时还需要保证模型没有忘记那些稀有的长尾数据,方法是动态重采样(Tagged Resampling):BM25 检索算法得到每个样本的稀有度,**稀有概念(如罕见实体、特定艺术风格)被采样的概率提高。
没有选择复杂的推理时路由(inference routing,即根据输入动态选择不同模型),而是采用了一个极其简洁的方案------在参数空间中对多个 SFT 变体做线性插值:从同一个预训练 backbone 出发,分别 fine-tune 出多个 SFT 变体。
每个变体在训练时略微偏向不同的能力维度(如一个偏向指令跟随,一个偏向美学渲染)。
训练完成后,将这些变体的权重按系数做线性加权平均,得到最终模型。
- 第四步,少步蒸馏Few-Step Distillation(FSD)
目标非常明确:让模型从"画得好"变成"画得又快又好"。SFT之后的模型仍然需要50步才能有一个好的效果,再加上使用Classifier-Free Guidance (CFG) ,每一步又要重复两次,分别带着prompt和不带着prompt,所以一共要100步,100个Number of Function Evaluations (NFEs)。
蒸馏的目的就是减少步数,比如学术界当时非常热门的 DMD(Distribution Matching Distillation,分布匹配蒸馏)。但是DMD会导致细节丢失和偏色 loss of high-frequency details and noticeable color shifts。
所以使用了Decoupled DMD and DMDR。Decoupled DMD是把DMD最重要的两个模块进行解耦,CFG-Augmentation(CA,CFG 增强),高效地构建学生模型的少步生成能力;Distribution Matching(DM,分布匹配)主要充当强正则化器,确保训练过程的稳定性,并消除生成过程中出现的伪影/瑕疵(artifacts)。 既然两者职责不同,就应该用不同的噪声调度策略 来分别优化它们。并且DM的正则化能力正好可以解决Reinforcement Learning可能面临的**"奖励黑客"(reward hacking),这就有了**DMDR。

- 第五步,终极对齐(RLHF)(基于人类反馈的强化学习)
为了兼顾客观标准和主观审美,作者设计了一个循序渐进的优化流程:
| 阶段 | 方法 | 核心目标 |
|---|---|---|
| 第一阶段 | DPO (Direct Preference Optimization) | 离线对齐:这是一个离线(Offline)阶段,不需要实时与环境交互。它的目的是让模型高效地建立起对客观标准的稳健遵循能力(比如基本的构图、无明显的逻辑错误等)。 |
| 第二阶段 | GRPO (Group Relative Policy Optimization) | 在线微调:在 DPO 打好底子后,利用奖励模型提供的细粒度信号,对模型进行更深度的优化,主要针对主观质量(比如画面是否足够惊艳、光影是否自然等)。 |
主要体现在三个方面(如图14所示):
照片真实感(Photorealism)
审美质量(Aesthetic quality)
指令遵循能力(Instruction following)

工程优化
工程上的优化:
- DP+FSDP2
VAE 和 Text Encoder训练 时是冻结的,使用标准数据并行(DP),每个 GPU 持有一份完整的模型副本,DiT 主干:FSDP2 分片策略,将模型的参数、梯度、优化器状态全部分片(shard)到多个 GPU 上,每个 GPU 只持有其中一部分。
2.梯度检查点(Gradient Checkpointing)
不保存所有中间激活值,只保存部分关键节点的激活值,反向传播时从最近的关键节点重新计算(recompute)中间结果。
3.torch.compile 加速。
将模型的计算图进行融合优化(kernel fusion)、算子重排等编译优化。
- 加速计算:减少 GPU kernel 启动开销,提升算子执行效率。
- 优化内存:通过算子融合减少中间张量的分配和释放,降低内存碎片。
- Dynamic Batch Sizing
因为图片分辨率不同,生成的 Token 序列长度就不同。如果硬把它们塞进同一个 Batch,短序列的图片就得疯狂"注水"(Padding)来对齐最长的图片,这既浪费显存又拖慢速度。为此,Z-Image 设计了一套**"智能分班 + 动态排课"**的策略。根据每张训练样本元数据(metadata)里记录的高和宽,直接算出它大概会生成多长的 Token 序列。采样器(Sampler)会把序列长度相近的样本分到同一个 Batch 里。长序列用小 Batch,短序列用大batch
实战
先从推理开始。有两种推理方式,一种是使用原生的pytorch,一种是使用Diffusers库GitHub - Tongyi-MAI/Z-Image · GitHub
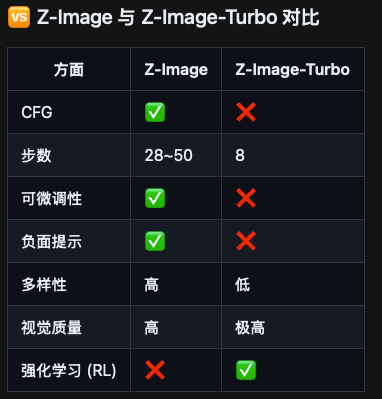
inference.py中的ensure_model_weights会自动判断有没有模型文件,没有的话会自动下载。国内建议从造相-Z-Image提前手动下载:modelscope download --model Tongyi-MAI/Z-Image模型也分为标准版和加速版,Z-Image-Turbo 以速度为核心,而 Z-Image 则是一个完整容量、未经蒸馏的 Transformer 模型,旨在为需要最高级别创作自由度的创作者、研究人员和开发者提供坚实基础。
得到的结果:
|----------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| | |
|  | prompt = "两名年轻亚裔女性紧密站在一起,背景为朴素的灰色纹理墙面,可能是室内地毯地面。左侧女性留着长卷发,身穿藏青色毛衣,左袖有奶油色褶皱装饰,内搭白色立领衬衫,下身白色裤子,佩戴小巧金色耳钉,双臂交叉于背后。右侧女性留直肩长发,身穿奶油色卫衣,胸前印有\"Tun the tables\"字样,下方为\"New ideas\",搭配白色裤子;佩戴银色小环耳环,双臂交叉于胸前。两人均面带微笑直视镜头。照片,自然光照明,柔和阴影,以藏青、奶油白为主的中性色调,休闲时尚摄影,中等景深,面部和上半身对焦清晰,姿态放松,表情友好,室内环境,地毯地面,纯色背景。" |
| prompt = "两名年轻亚裔女性紧密站在一起,背景为朴素的灰色纹理墙面,可能是室内地毯地面。左侧女性留着长卷发,身穿藏青色毛衣,左袖有奶油色褶皱装饰,内搭白色立领衬衫,下身白色裤子,佩戴小巧金色耳钉,双臂交叉于背后。右侧女性留直肩长发,身穿奶油色卫衣,胸前印有\"Tun the tables\"字样,下方为\"New ideas\",搭配白色裤子;佩戴银色小环耳环,双臂交叉于胸前。两人均面带微笑直视镜头。照片,自然光照明,柔和阴影,以藏青、奶油白为主的中性色调,休闲时尚摄影,中等景深,面部和上半身对焦清晰,姿态放松,表情友好,室内环境,地毯地面,纯色背景。" |
reference: