影刀RPA实操指南:小红书笔记批量采集------从搜索到翻页到存表格的完整流程
小红书是内容电商的核心阵地,商品种草、用户评价、竞品分析都绕不开它。
但小红书的采集有一个特点:笔记流是滚动加载的,不是传统分页。而且单页卡片多,XPath结构有嵌套。
这篇给一个从零到落地的完整流程,拿来改一改关键词就能直接用。
一、开始前需要准备的
- 影刀客户端登录状态:确保影刀内置浏览器已经登录了小红书网页版
- Python图标:左下角确认已点亮(流程里会用到一小段Python做数据清洗)
- 目标搜索词:定好搜什么,比如"防晒霜推荐"
二、完整流程拆解
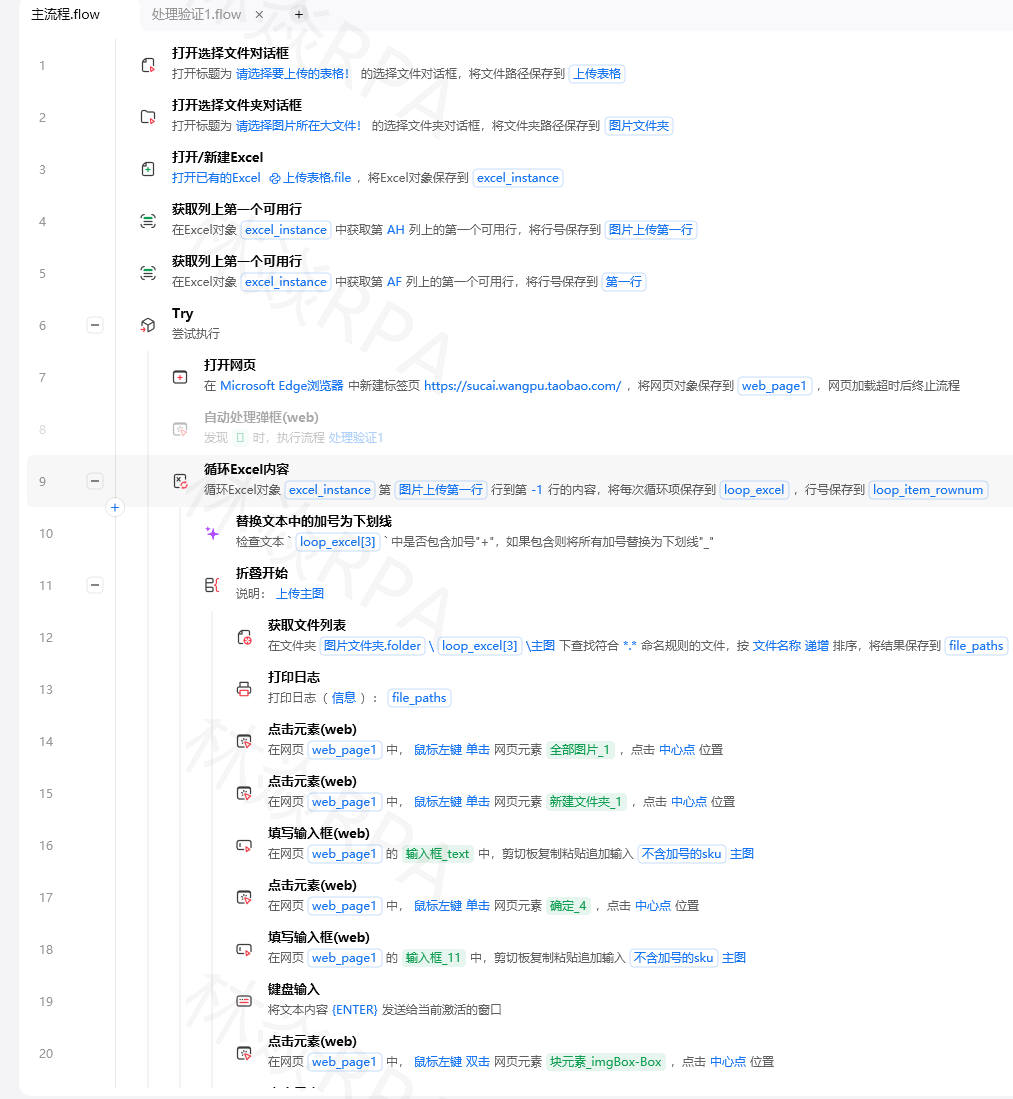
整个流程分成5步:
- 打开小红书搜索页 → 输入关键词 → 搜索
- 滚动加载笔记流(滚动加载法翻页)
- 获取相似元素列表 → 遍历提取每条笔记的标题、作者、点赞、链接
- Pandas清洗数据(去重、格式化)
拼多多店群自动化报活动上架!
- 导出Excel + 可选飞书通知
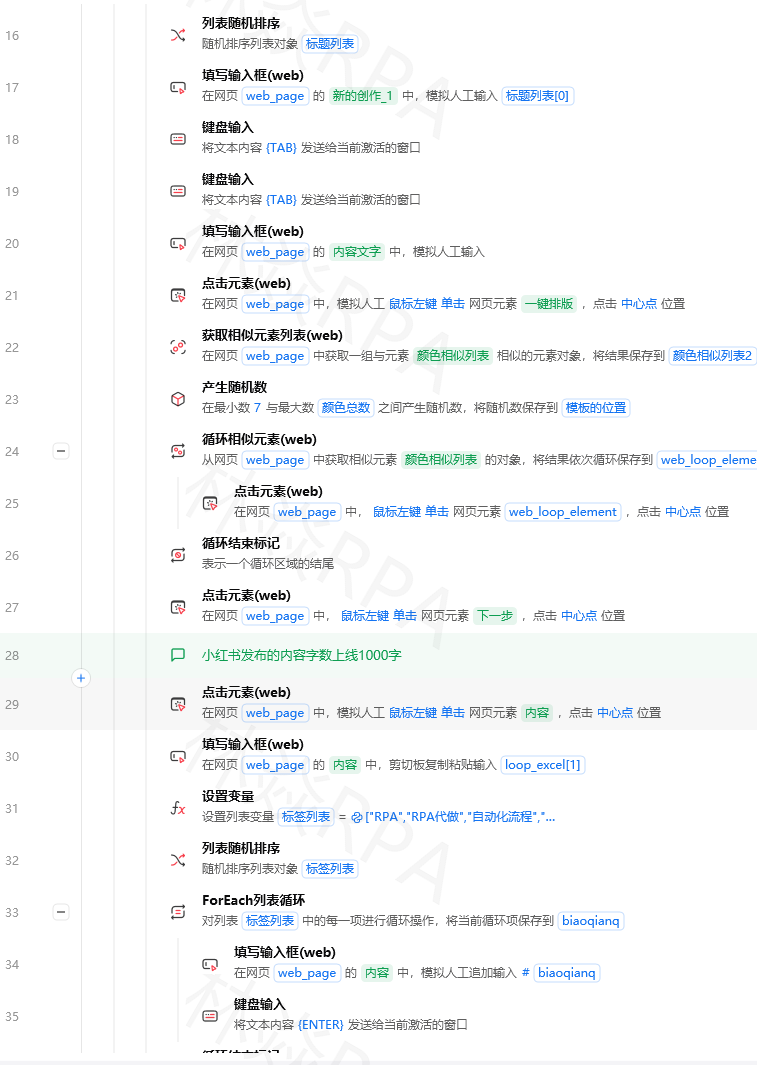
三、代码实现
python
# ===== 步骤1:打开页面 + 搜索 =====
打开网页("https://www.xiaohongshu.com/explore")
等待元素出现("首页标识", 5秒)
# 点击搜索框
点击元素("搜索输入框")
输入文本("搜索输入框", "防晒霜推荐")
点击元素("搜索按钮")
等待元素出现("搜索结果列表", 5秒)
# ===== 步骤2:滚动加载笔记流 =====
新建Excel -> 笔记数据表
写入行数据(笔记数据表, ["序号", "笔记标题", "作者", "点赞数", "笔记链接"])
滚动次数 = 30
序号 = 0
固定次数循环(滚动次数, 当前滚动):
# 每次滚动前记录已有数量
获取相似元素列表("笔记卡片列表") -> 旧列表
旧数量 = 列表长度(旧列表)
# 滚动到底部
页面滚动到底部()
等待元素出现("新笔记加载中的标识", 2秒)
固定等待(2秒)
# 检查是否有新内容
获取相似元素列表("笔记卡片列表") -> 新列表
新数量 = 列表长度(新列表)
如果 新数量 == 旧数量:
输出日志("无新内容,停止滚动在第" + str(当前滚动) + "次")
跳出循环
# ===== 步骤3:遍历采集所有笔记 =====
获取相似元素列表("全部笔记卡片列表") -> 全部卡片
遍历列表(全部卡片, 当前卡片):
序号 = 序号 + 1
# 笔记标题 --- 用相对XPath从卡片容器里取
# 捕获元素:当前卡片内 //div[@class='title']
获取元素文本(当前卡片, ".//div[contains(@class,'title')]") -> 笔记标题
# 作者名 --- 用参照物定位(通过作者头像后面的span)
# 捕获元素:当前卡片内 //a[@class='author-wrapper']//span
获取元素文本(当前卡片, ".//a[contains(@class,'author')]//span[contains(@class,'name')]") -> 作者名
# 点赞数 --- 如果有具体数值span
# 捕获元素:当前卡片内 //span[contains(@class,'like-count')]
获取元素文本(当前卡片, ".//span[contains(@class,'like') or contains(@class,'count')]") -> 点赞数
# 笔记链接 --- 从卡片内的a标签取href属性
获取元素属性(当前卡片, ".//a[@class='cover']", "href") -> 笔记链接
# 写入表格
写入行数据(笔记数据表, [序号, 笔记标题, 作者名, 点赞数, 笔记链接])
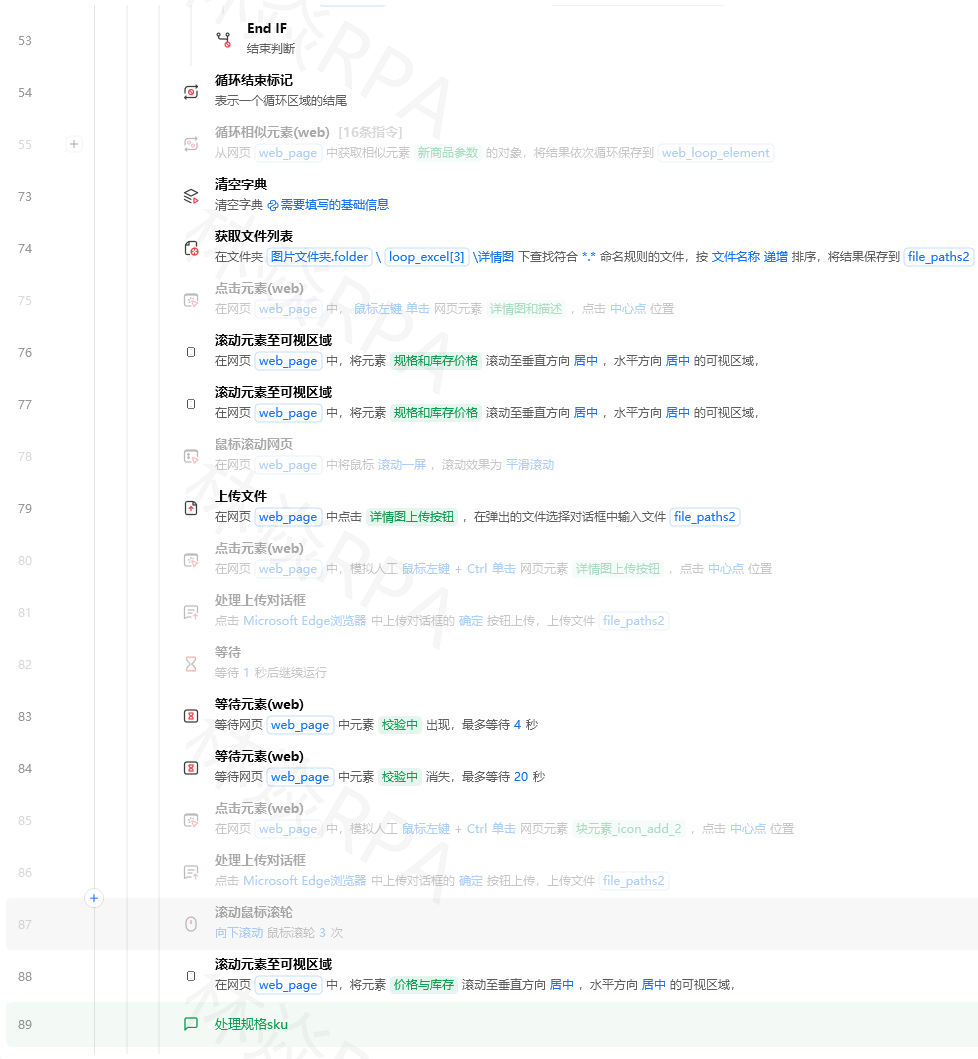
# ===== 步骤4:Python清洗(可选) =====
# 如果你不需要Pandas清洗,跳过这一步直接导出
导出表格(笔记数据表, "D:\小红书_防晒霜_原始.xlsx")四、滚动加载的终止条件怎么设
有两个方案:

方案A:固定滚动N次(简单可靠)
设一个足够大的值(比如30次),配合"无新内容就跳出"的逻辑,不会真的滚30次。
python
滚动次数 = 30 # 最大值
固定次数循环(滚动次数, 当前滚动):
记录滚动前数量
滚动到底部
等待(2秒)
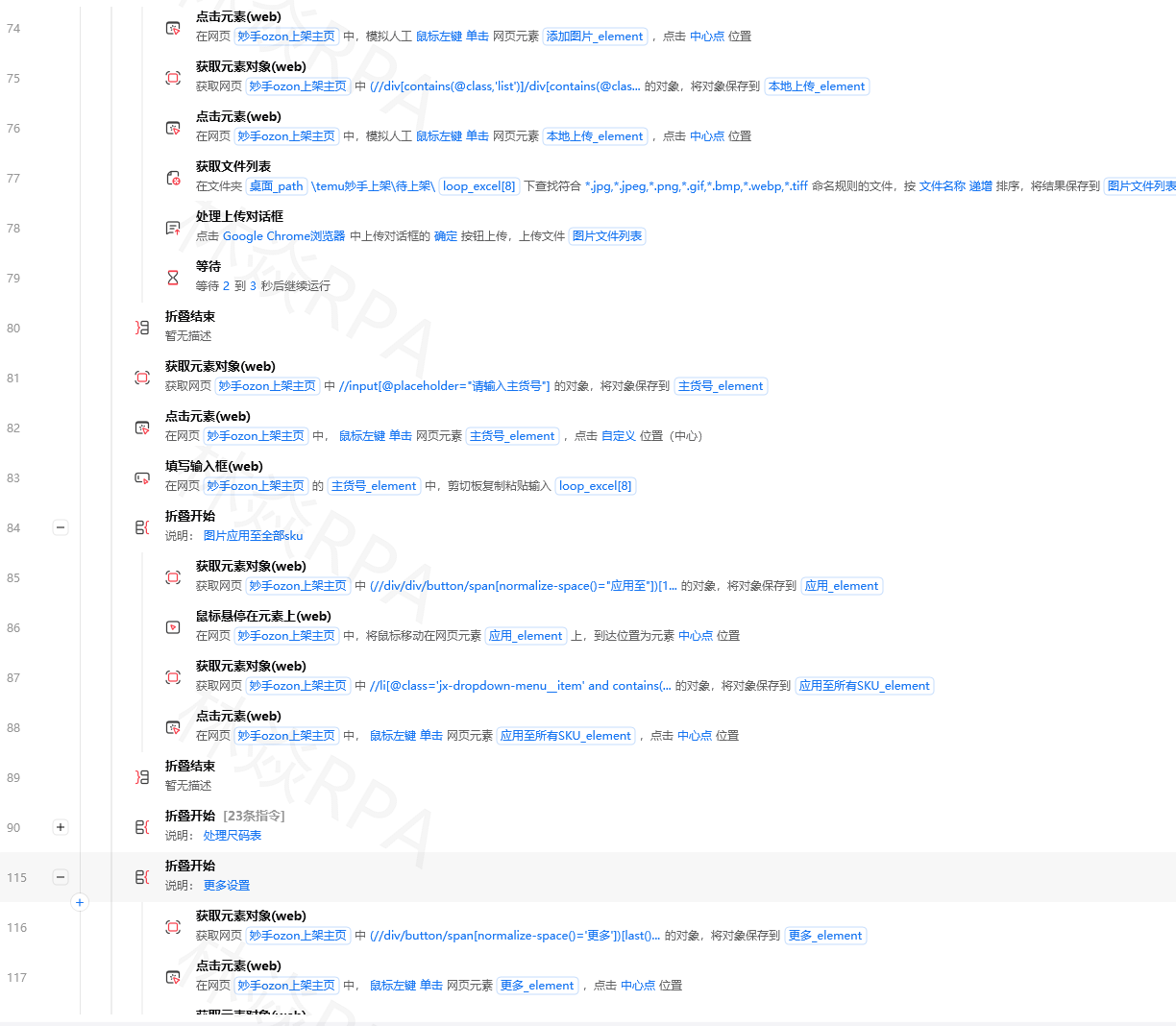
如果 当前数量 == 旧数量:
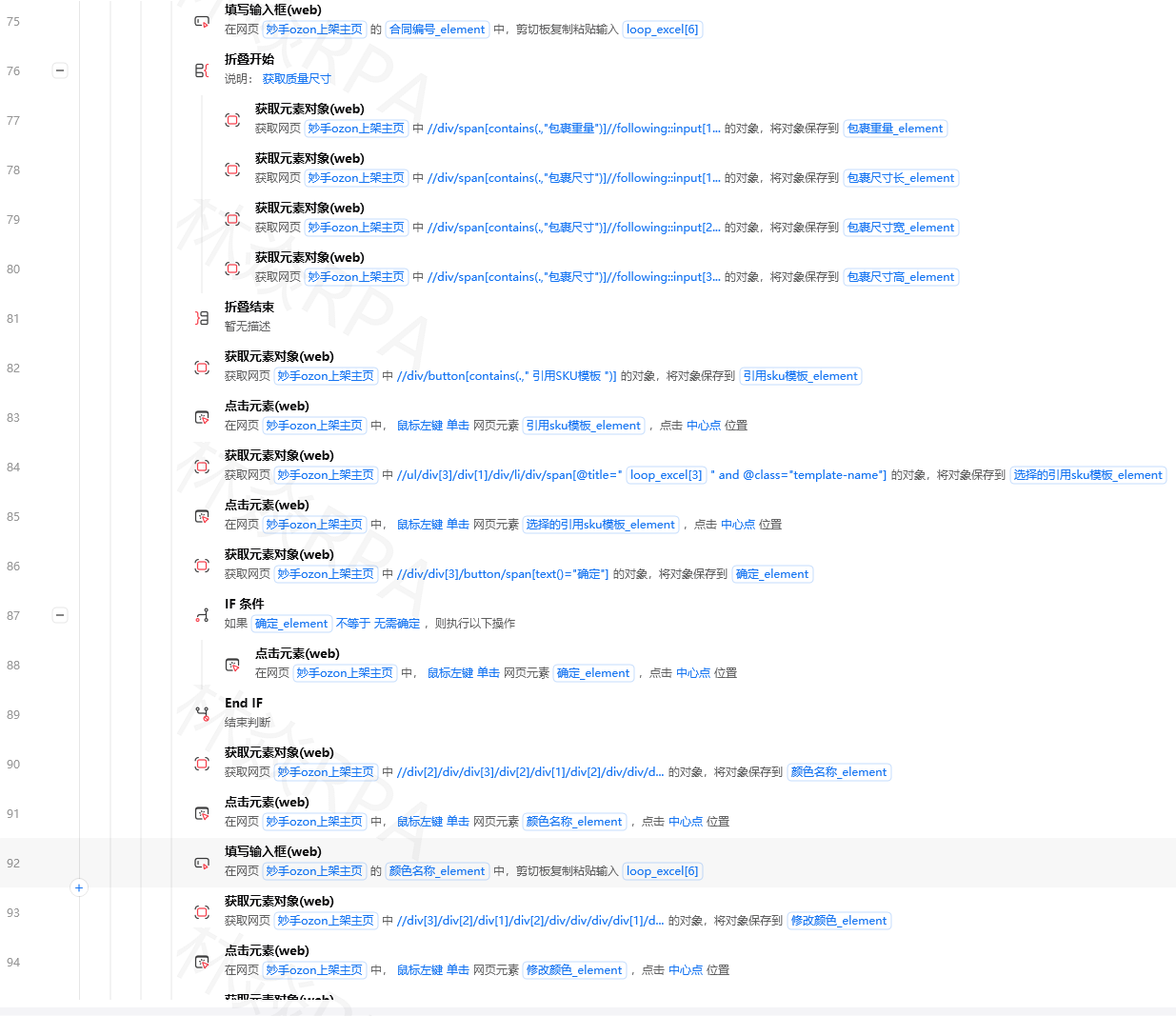
跳出循环方案B:滚动到页面底部的"已无更多内容"提示
python
条件循环(True):
滚动到底部
等待(2秒)
判断元素是否存在("已无更多内容提示")

如果 结果为真:
跳出循环问题:有些小版本更新后这个提示的class可能会变。方案A更稳。
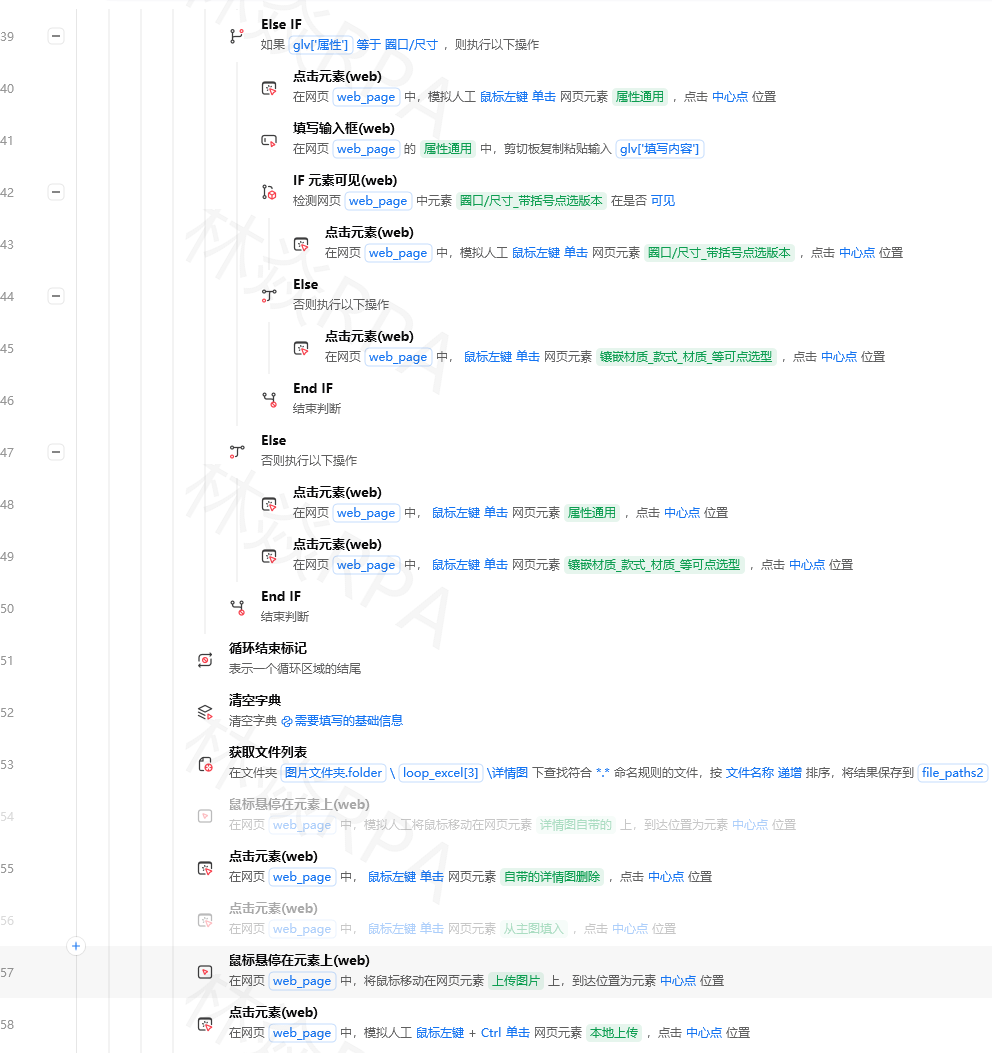
五、小红书特有坑
坑1:登录态
小红书网页版对未登录用户的限制比较严。搜索几次后就会弹登录弹窗。
解决:先在影刀内置浏览器里手动登录一次小红书,勾选"记住我"。
坑2:笔记卡片class不稳定
小红书的CSS类名有时是哈希值,比如 class="fe3d2a",每次改版都可能变。
解决:避免依赖完整class名,用部分匹配。
TEMU店群矩阵自动化运营核价报活动
python
# ❌ 完整的哈希class
//div[@class='fe3d2a b8c91e']
# ✅ 用contains部分匹配更稳定的特征

//div[contains(@class,'note-item')]
//section[@data-v-xxx] # data属性更稳坑3:图片懒加载导致元素位置偏移
滚动加载过程中,图片从上到下逐步渲染,dom树会不断重排。如果采集速度太快,可能取到错位的元素。
解决:每次滚动后多等1~2秒。
六、最终导出后的数据长什么样
| 序号 | 笔记标题 | 作者 | 点赞数 | 笔记链接 |
|---|---|---|---|---|
| 1 | 今年防晒霜测评,这几款真的好用 | 美妆达人小A | 2.3万 | https://www.xiaohongshu.com/... |
 |
| 2 | 学生党防晒霜推荐50元以下 | 学生党看过来 | 1.5万 | https://www.xiaohongshu.com/... |
七、扩展:采集某个博主的所有笔记
上面的流程是搜索采集 。如果你需要采集某个博主的全部笔记:
python
# 思路:进入博主主页→滚动加载→采集
打开网页("https://www.xiaohongshu.com/user/profile/用户ID")
等待元素出现("笔记列表容器", 5秒)
# 后面的滚动加载和采集逻辑同上进入博主主页的方法:在小红书网页版搜博主名字→点进主页→地址栏复制URL里的用户ID。
作者:林焱
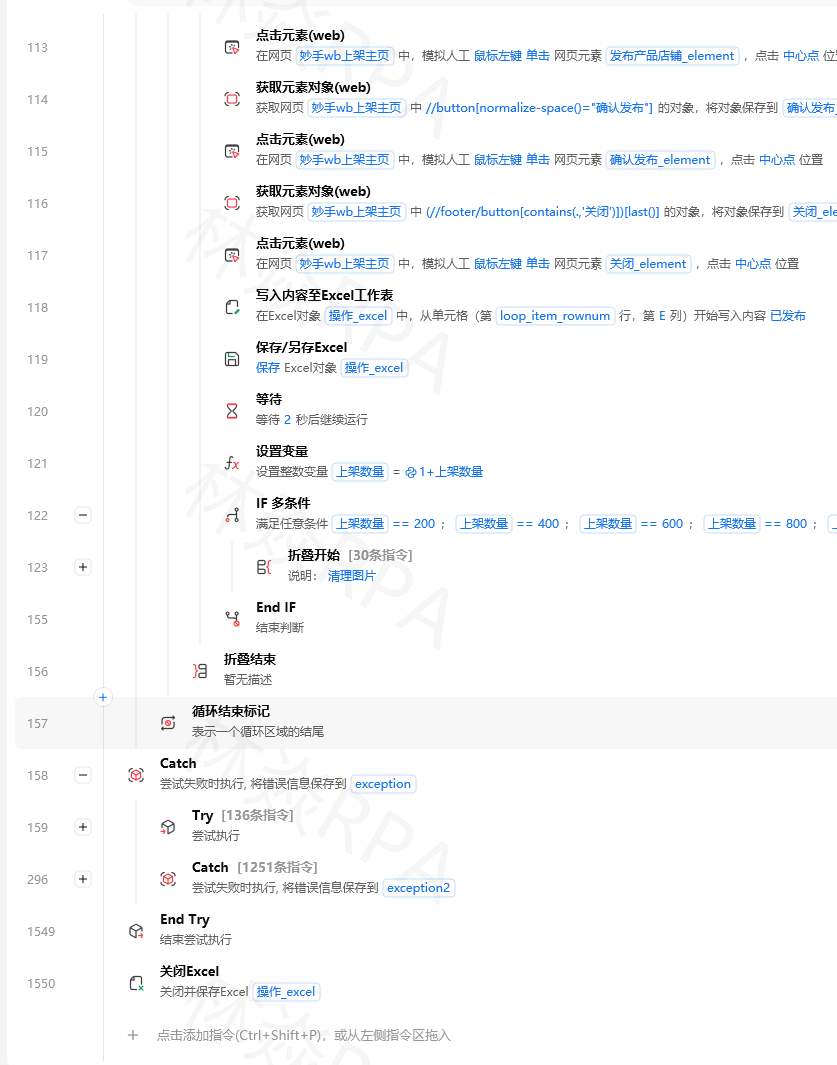
本文为《影刀RPA学习手册》系列文章之一,内容源于实操经验的整理与分享。