LangChainv1:agent快速上手与中间件认识
这里需要提及一个点,在新版本v1中,agent已经从langgraph迁移到了langchain中。同时新版本的langchain已经摒弃了过往的链式编程思维,以后我们基本都是遵循图示思维去构建我们的应用。
一.快速上手
https://docs.langchain.com/oss/python/langchain/agents?search=create_agent
如果说之前学习的LangGraph是让我们能够精确到每个节点去控制应用的处理流程。那么agent就是一个已经为我们封装好的Graph图。基本的Agent的工作流程图如下:
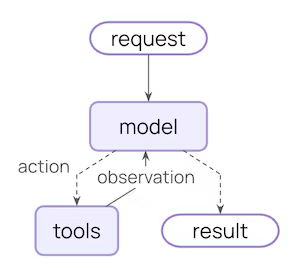
我们可以通过create_agent来创建一个agent,其中大部分参数之前我们也都学习过,因为它底层还是Langgraph那一套,所以主要参数的作用和LangGraph中的大差不差,有区别的地方再特殊说明。
可以去官方文档看下相关的参数,下面是一个最简单的例子:
python
from langchain.agents import create_agent
from langchain.agents.middleware import PIIMiddleware
from langchain_core.messages import HumanMessage
from langchain_openai import ChatOpenAI
from langchain_tavily import TavilySearch
from langchain.tools import tool
tavilySearchTool = TavilySearch(max_result=4)# max_results 返回的最大搜索结果
@tool
def searchLocation():
"""获取用户的位置信息"""
return "焦作"
agent = create_agent(
model=ChatOpenAI(model="gpt-4o-mini",base_url="https://api.kourichat.com/v1"),
tools=[tavilySearchTool,searchLocation],
)
response = agent.invoke(
{"messages" : [HumanMessage("可以告诉我我所处位置的今日天气如何吗?")]}
)
for msg in response["messages"]:
print(msg.type)我们可以看到最终的消息列表中的所有消息类型如下:
python
human
ai
tool
ai
tool
ai我们没有明显的告诉它位置,所以它会自己先去选择调用我们提供的工具去获取我们的位置,然后再调用网络搜索工具去查询信息。很好的展示了我们上面图所展示的循环。
二.中间件
2.1什么是中间件
基于快速上手部分我们所看的流程图,可以把整个模型的调用过程图示化如下:
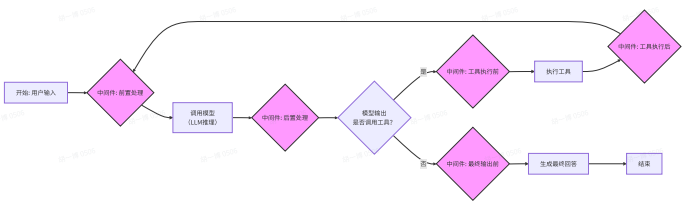
其中特殊颜色部分便是中间件可以发挥作用的部分,也就是说,基于agent给的基本流程,我们可以通过中间件来实现一些自定义的操作,比如过滤敏感词,验证用户信息或者监控token消耗数等等。
中间件的执行逻辑大致如下(图示的钩子类型是自定义中间件的内容,我们下面会都介绍的):
#mermaid-svg-QZDi4KGo0EgUim1c{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}@keyframes edge-animation-frame{from{stroke-dashoffset:0;}}@keyframes dash{to{stroke-dashoffset:0;}}#mermaid-svg-QZDi4KGo0EgUim1c .edge-animation-slow{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 50s linear infinite;stroke-linecap:round;}#mermaid-svg-QZDi4KGo0EgUim1c .edge-animation-fast{stroke-dasharray:9,5!important;stroke-dashoffset:900;animation:dash 20s linear infinite;stroke-linecap:round;}#mermaid-svg-QZDi4KGo0EgUim1c .error-icon{fill:#552222;}#mermaid-svg-QZDi4KGo0EgUim1c .error-text{fill:#552222;stroke:#552222;}#mermaid-svg-QZDi4KGo0EgUim1c .edge-thickness-normal{stroke-width:1px;}#mermaid-svg-QZDi4KGo0EgUim1c .edge-thickness-thick{stroke-width:3.5px;}#mermaid-svg-QZDi4KGo0EgUim1c .edge-pattern-solid{stroke-dasharray:0;}#mermaid-svg-QZDi4KGo0EgUim1c .edge-thickness-invisible{stroke-width:0;fill:none;}#mermaid-svg-QZDi4KGo0EgUim1c .edge-pattern-dashed{stroke-dasharray:3;}#mermaid-svg-QZDi4KGo0EgUim1c .edge-pattern-dotted{stroke-dasharray:2;}#mermaid-svg-QZDi4KGo0EgUim1c .marker{fill:#333333;stroke:#333333;}#mermaid-svg-QZDi4KGo0EgUim1c .marker.cross{stroke:#333333;}#mermaid-svg-QZDi4KGo0EgUim1c svg{font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;}#mermaid-svg-QZDi4KGo0EgUim1c p{margin:0;}#mermaid-svg-QZDi4KGo0EgUim1c .label{font-family:"trebuchet ms",verdana,arial,sans-serif;color:#333;}#mermaid-svg-QZDi4KGo0EgUim1c .cluster-label text{fill:#333;}#mermaid-svg-QZDi4KGo0EgUim1c .cluster-label span{color:#333;}#mermaid-svg-QZDi4KGo0EgUim1c .cluster-label span p{background-color:transparent;}#mermaid-svg-QZDi4KGo0EgUim1c .label text,#mermaid-svg-QZDi4KGo0EgUim1c span{fill:#333;color:#333;}#mermaid-svg-QZDi4KGo0EgUim1c .node rect,#mermaid-svg-QZDi4KGo0EgUim1c .node circle,#mermaid-svg-QZDi4KGo0EgUim1c .node ellipse,#mermaid-svg-QZDi4KGo0EgUim1c .node polygon,#mermaid-svg-QZDi4KGo0EgUim1c .node path{fill:#ECECFF;stroke:#9370DB;stroke-width:1px;}#mermaid-svg-QZDi4KGo0EgUim1c .rough-node .label text,#mermaid-svg-QZDi4KGo0EgUim1c .node .label text,#mermaid-svg-QZDi4KGo0EgUim1c .image-shape .label,#mermaid-svg-QZDi4KGo0EgUim1c .icon-shape .label{text-anchor:middle;}#mermaid-svg-QZDi4KGo0EgUim1c .node .katex path{fill:#000;stroke:#000;stroke-width:1px;}#mermaid-svg-QZDi4KGo0EgUim1c .rough-node .label,#mermaid-svg-QZDi4KGo0EgUim1c .node .label,#mermaid-svg-QZDi4KGo0EgUim1c .image-shape .label,#mermaid-svg-QZDi4KGo0EgUim1c .icon-shape .label{text-align:center;}#mermaid-svg-QZDi4KGo0EgUim1c .node.clickable{cursor:pointer;}#mermaid-svg-QZDi4KGo0EgUim1c .root .anchor path{fill:#333333!important;stroke-width:0;stroke:#333333;}#mermaid-svg-QZDi4KGo0EgUim1c .arrowheadPath{fill:#333333;}#mermaid-svg-QZDi4KGo0EgUim1c .edgePath .path{stroke:#333333;stroke-width:2.0px;}#mermaid-svg-QZDi4KGo0EgUim1c .flowchart-link{stroke:#333333;fill:none;}#mermaid-svg-QZDi4KGo0EgUim1c .edgeLabel{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-QZDi4KGo0EgUim1c .edgeLabel p{background-color:rgba(232,232,232, 0.8);}#mermaid-svg-QZDi4KGo0EgUim1c .edgeLabel rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-QZDi4KGo0EgUim1c .labelBkg{background-color:rgba(232, 232, 232, 0.5);}#mermaid-svg-QZDi4KGo0EgUim1c .cluster rect{fill:#ffffde;stroke:#aaaa33;stroke-width:1px;}#mermaid-svg-QZDi4KGo0EgUim1c .cluster text{fill:#333;}#mermaid-svg-QZDi4KGo0EgUim1c .cluster span{color:#333;}#mermaid-svg-QZDi4KGo0EgUim1c div.mermaidTooltip{position:absolute;text-align:center;max-width:200px;padding:2px;font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:12px;background:hsl(80, 100%, 96.2745098039%);border:1px solid #aaaa33;border-radius:2px;pointer-events:none;z-index:100;}#mermaid-svg-QZDi4KGo0EgUim1c .flowchartTitleText{text-anchor:middle;font-size:18px;fill:#333;}#mermaid-svg-QZDi4KGo0EgUim1c rect.text{fill:none;stroke-width:0;}#mermaid-svg-QZDi4KGo0EgUim1c .icon-shape,#mermaid-svg-QZDi4KGo0EgUim1c .image-shape{background-color:rgba(232,232,232, 0.8);text-align:center;}#mermaid-svg-QZDi4KGo0EgUim1c .icon-shape p,#mermaid-svg-QZDi4KGo0EgUim1c .image-shape p{background-color:rgba(232,232,232, 0.8);padding:2px;}#mermaid-svg-QZDi4KGo0EgUim1c .icon-shape rect,#mermaid-svg-QZDi4KGo0EgUim1c .image-shape rect{opacity:0.5;background-color:rgba(232,232,232, 0.8);fill:rgba(232,232,232, 0.8);}#mermaid-svg-QZDi4KGo0EgUim1c .label-icon{display:inline-block;height:1em;overflow:visible;vertical-align:-0.125em;}#mermaid-svg-QZDi4KGo0EgUim1c .node .label-icon path{fill:currentColor;stroke:revert;stroke-width:revert;}#mermaid-svg-QZDi4KGo0EgUim1c :root{--mermaid-font-family:"trebuchet ms",verdana,arial,sans-serif;} 钩子拦截点
智能体执行流程
开始执行
调用模型前
模型调用
模型响应后
工具执行
结束
⏪ before_model 钩子
(修改提示词/校验输入)
⏩ after_model 钩子
(检查输出/记录日志)
🔄 wrap_tool_call 钩子
(重试机制/权限控制)
怎么去定义一个中间件呢?先不急,我们先来用下官方已经给我们写好的一些中间件。
2.2预构建中间件
https://docs.langchain.com/oss/python/langchain/middleware/built-in#provider-agnostic-middleware
上面的文档中便是官方给我们已经写好的一些中间件,我们来挑两个比较简单的做个示例。
2.2.1SummarizationMiddleware
https://docs.langchain.com/oss/python/langchain/middleware/built-in#summarization
这个中间件旨在控制我们的上下文长度,也就是当我们的上下文超过规定最大值时,此中间件便会触发从而按照我们的设定总结部分上下文以达到压缩上下文的目的。
其API参考链接如下:
我们来看一个例子:
python
from langchain.agents import create_agent
from langchain.agents.middleware import PIIMiddleware, SummarizationMiddleware
from langchain_core.messages import HumanMessage
from langchain_openai import ChatOpenAI
from langchain_tavily import TavilySearch
from langchain.tools import tool
tavilySearchTool = TavilySearch(max_result=4)# max_results 返回的最大搜索结果
@tool
def searchLocation():
"""获取用户的位置信息"""
return "焦作"
middleware_list = [
SummarizationMiddleware(
model="gpt-4o-mini",
trigger=[("messages", 4)],#触发摘要生成的一个或多个阈值,可以设置多个阈值,达到任意其一则会触发总结
keep=("messages", 2),#裁剪时应确保哪些消息不应该被裁剪的保留策略,此处设置为最新两条消息进行保留
)
]
agent = create_agent(
model=ChatOpenAI(model="gpt-4o-mini",base_url="https://api.kourichat.com/v1"),
tools=[tavilySearchTool,searchLocation],
middleware=middleware_list
)
response = agent.invoke(
{"messages" : [HumanMessage("可以告诉我我所处位置的今日天气如何吗?")]}
)
for msg in response["messages"]:
print(msg.type)这里我们阈值设置低一些,能更好的见效,可以看到结果如下(原本应该是6条信息):
python
human
ai
tool
ai也就是当信息数达到4时,他帮我们对消息进行了总结,总结为一条humanMessage。更多用法可以看官方文档,很容易看懂的。
2.2.2PIIMiddleware
https://reference.langchain.com/python/langchain/agents/middleware/pii/PIIMiddleware
如果我们给ai发送的消息中包含我们自己的个人信息,为了防止对外泄漏我们的私人信息,我们可以在发起LLM调用时对消息进行拦截检查,如果发现私密信息,则对其进行部分遮盖或替换等。
我们来看一个简单的例子:
python
from langchain.agents import create_agent
from langchain.agents.middleware import PIIMiddleware
from langchain_core.messages import HumanMessage
from langchain_openai import ChatOpenAI
from langchain_tavily import TavilySearch
from langchain.tools import tool
tavilySearchTool = TavilySearch(max_result=4)# max_results 返回的最大搜索结果
@tool
def searchLocation():
"""获取用户的位置信息"""
return "焦作"
agent = create_agent(
model=ChatOpenAI(model="gpt-4o-mini",base_url="https://api.kourichat.com/v1"),
tools=[tavilySearchTool,searchLocation],
middleware=[
PIIMiddleware("email", strategy="mask", apply_to_input=True)
],
)
response = agent.invoke(
{"messages" : [HumanMessage("我的邮箱是114514.user@gmail.com,你知道我的邮箱是什么吗")]}
)
for msg in response["messages"]:
msg.pretty_print()可以看到我们的邮箱信息因为设置的是mask策略,所以对邮箱信息进行了部分遮蔽,导致ai无法知道我们的私密信息:
python
================================ Human Message =================================
我的邮箱是114514.user@****.com,你知道我的邮箱是什么吗
================================== Ai Message ==================================
抱歉,我无法查看或存储个人信息,包括您的邮箱地址。如果您有其他问题或者需要帮助,请告诉我!2.3自定义中间件
https://reference.langchain.com/python/langchain/middleware
2.3.1中间件风格(实际上是钩子)
现在,我们已经能理解中间件(Middleware) 是在 Agent 执行流程中特定节点插入逻辑的钩子(Hook) ,用于实现日志 、校验 、重试 、缓存 、状态跟踪等横切关注点。它不影响 Agent 核心逻辑,但可以拦截、修改请求/响应,甚至改变执行流向。
想要自定义中间件,需要先了解 LangChain 提供的两种风格的钩子,它们分别适用于不同场景。
节点风格
顺序执行,返回字典更新状态 。适合日志 、校验 、计数等线性逻辑。
| 钩子 | 触发时机 |
|---|---|
before_agent |
Agent 开始前(仅一次) |
before_model |
每次调用模型前 |
after_model |
每次模型响应后 |
after_agent |
Agent 结束后(仅一次) |
节点风格钩子调用顺序如下:
用户输入 --> before_agent --> before_model --> 模型调用 --> after_model --> after_agent --> 最终输出
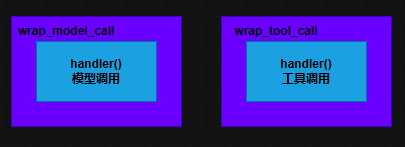
包装风格
完全控制被包裹的函数 ,可以决定是否调用 、调用几次 、修改参数/返回值 。适合重试 、缓存 、动态选择模型/工具。
| 钩子 | 包裹对象 |
|---|---|
wrap_model_call |
模型调用 |
wrap_tool_call |
工具调用 |
其实这种风格就是函数的嵌套调用,图示如下:
2.3.2创建自定义中间件
装饰器方式
如果我们自定义的中间件通常逻辑单一、职责明确 ,适合用装饰器式 快速实现。
我们直接来看一个例子:
python
from typing import Any, Callable
from langchain.agents import create_agent, AgentState
from langchain.agents.middleware import PIIMiddleware, before_agent, before_model, after_agent, after_model, \
wrap_model_call, ModelRequest, ModelResponse, wrap_tool_call
from langchain_core.messages import HumanMessage, ToolMessage
from langchain_openai import ChatOpenAI
from langchain_tavily import TavilySearch
from langchain.tools import tool
from langgraph.prebuilt.tool_node import ToolCallRequest
from langgraph.runtime import Runtime
from langgraph.types import Command
tavilySearchTool = TavilySearch(max_result=4)# max_results 返回的最大搜索结果
@before_agent
def log_before_agent(state : AgentState,runtime : Runtime) -> dict[str,Any] | None:
print("执行智能体之前调用")
return None
@before_model
def log_before_model(state : AgentState,runtime : Runtime) -> dict[str,Any] | None:
print("执行模型之前调用")
return None
@after_agent
def log_after_agent(state : AgentState,runtime : Runtime) -> dict[str,Any] | None:
print("执行智能体之后调用")
return None
@after_model
def log_after_model(state : AgentState,runtime : Runtime) -> dict[str,Any] | None:
print("执行模型之后调用")
return None
@wrap_model_call
def log_wrap_model_call(
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse]
) -> ModelResponse | None:
for i in range(0,3):
print(f"执行模型前的最新消息的内容为:{request.messages[-1].content}")
try:
response = handler(request)
print("[wrap_model_call]模型调用成功")
return response
except Exception as e:
if i == 2:
raise
print(f"模型调用失败,错误原因:{e},进行第{i + 1}/3次重试")
#走不到这里
return None
@wrap_tool_call
def log_wrap_tool_call(
request: ToolCallRequest,
handler: Callable[[ToolCallRequest], ToolMessage | Command]
) -> ToolMessage | Command | None:
for i in range(0,3):
print(f"目标执行工具的名称为:{request.tool_call.get("name")}。参数为:{request.tool_call.get("args")}")
try:
response = handler(request)
print("[wrap_tool_call]模型调用成功")
return response
except Exception as e:
if i == 2:
raise
print(f"工具调用失败,错误原因:{e},进行第{i + 1}/3次重试")
#走不到这里
return None
agent = create_agent(
model=ChatOpenAI(model="gpt-4o-mini",base_url="https://api.kourichat.com/v1"),
tools=[tavilySearchTool],
middleware=[
log_before_agent,log_before_model,log_after_agent,log_after_model,log_wrap_model_call,log_wrap_tool_call
],
)
result = agent.invoke(
{"messages" : [HumanMessage("可以为我简要介绍下上海今天的天气吗,不超过10个字")]}
)
for msg in result["messages"]:
msg.pretty_print()具体的回复内容就不看了,主要看它上面的模型执行流程:
python
执行智能体之前调用
执行模型之前调用
执行模型前的最新消息的内容为:可以为我简要介绍下上海今天的天气吗,不超过10个字
[wrap_model_call]模型调用成功
执行模型之后调用
目标执行工具的名称为:tavily_search。参数为:{'query': '上海 今天的天气', 'time_range': 'day', 'topic': 'general'}
[wrap_tool_call]模型调用成功
执行模型之前调用
执行模型前的最新消息的内容为:{"query": "上海 今天的天气", "follow_up_questions": null, "answer": null, "images": [],...}
[wrap_model_call]模型调用成功
执行模型之后调用
执行智能体之后调用每个钩子的执行流程正如我们上面所设想的那样。
类方式
上面的方式仅限于我们要定义的中间件简单的情况,如果比较复杂,还是建议以类方式进行自定义,所有自定义中间件需要继承自AgentMiddleware:
https://reference.langchain.com/python/langchain/agents/middleware/types/AgentMiddleware
你想要定义什么钩子,那么在类中的成员函数就需要和它的装饰器名称一致,我们来看一个例子:
python
from typing import Any, Callable
from langchain.agents import create_agent, AgentState
from langchain.agents.middleware import PIIMiddleware, before_agent, before_model, after_agent, after_model, \
wrap_model_call, ModelRequest, ModelResponse, wrap_tool_call, AgentMiddleware
from langchain_core.messages import HumanMessage, ToolMessage
from langchain_openai import ChatOpenAI
from langchain_tavily import TavilySearch
from langgraph.prebuilt.tool_node import ToolCallRequest
from langgraph.runtime import Runtime
from langgraph.types import Command
tavilySearchTool = TavilySearch(max_result=4)# max_results 返回的最大搜索结果
class MyMiddleware(AgentMiddleware):
def before_agent(self, state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
print("执行智能体之前调用")
return None
def before_model(self, state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
print("执行模型之前调用")
return None
def after_agent(self, state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
print("执行智能体之后调用")
return None
def after_model(self, state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
print("执行模型之后调用")
return None
def wrap_model_call(
self,
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse]
) -> ModelResponse | None:
for i in range(0, 3):
print(f"执行模型前的最新消息的内容为:{request.messages[-1].content}")
try:
response = handler(request)
print("[wrap_model_call]模型调用成功")
return response
except Exception as e:
if i == 2:
raise
print(f"模型调用失败,错误原因:{e},进行第{i + 1}/3次重试")
# 走不到这里
return None
def wrap_tool_call(
self,
request: ToolCallRequest,
handler: Callable[[ToolCallRequest], ToolMessage | Command]
) -> ToolMessage | Command | None:
for i in range(0, 3):
print(f"目标执行工具的名称为:{request.tool_call.get("name")}。参数为:{request.tool_call.get("args")}")
try:
response = handler(request)
print("[wrap_tool_call]模型调用成功")
return response
except Exception as e:
if i == 2:
raise
print(f"工具调用失败,错误原因:{e},进行第{i + 1}/3次重试")
# 走不到这里
return None
agent = create_agent(
model=ChatOpenAI(model="gpt-4o-mini",base_url="https://api.kourichat.com/v1"),
tools=[tavilySearchTool],
middleware=[
MyMiddleware()
],
)
result = agent.invoke(
{"messages" : [HumanMessage("可以为我简要介绍下上海今天的天气吗,不超过10个字")]}
)
for msg in result["messages"]:
msg.pretty_print()结果是和上面是一样的。
2.3.3自定义中间件执行顺序
如果我们同时使用多个不同的中间件,对于节点类型的执行顺序如下:
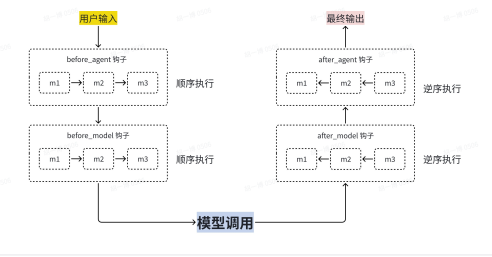
包装风格节点的执行顺序类似于函数嵌套:
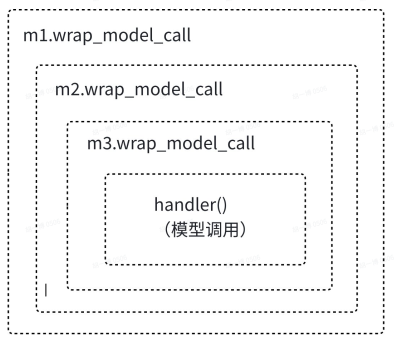
比如我们此时基于上面的类自定义方式去搞两个一模一样的自定义中间件,但是改下打印消息区分两个类,看下打印结果:
python
执行智能体之前调用
[1]执行智能体之前调用
执行模型之前调用
[1]执行模型之前调用
执行模型前的最新消息的内容为:可以为我简要介绍下上海今天的天气吗,不超过10个字
[1]执行模型前的最新消息的内容为:可以为我简要介绍下上海今天的天气吗,不超过10个字
[1][wrap_model_call]模型调用成功
[wrap_model_call]模型调用成功
[1]执行模型之后调用
执行模型之后调用
目标执行工具的名称为:tavily_search。参数为:{'query': '上海天气', 'start_date': '2024-01-20', 'end_date': '2024-01-20', 'topic': 'general'}
[1]目标执行工具的名称为:tavily_search。参数为:{'query': '上海天气', 'start_date': '2024-01-20', 'end_date': '2024-01-20', 'topic': 'general'}
[1][wrap_tool_call]模型调用成功
[wrap_tool_call]模型调用成功
执行模型之前调用
[1]执行模型之前调用
执行模型前的最新消息的内容为:{'error': ValueError('Error 400: start_date and end_date cannot be the same')}
[1]执行模型前的最新消息的内容为:{'error': ValueError('Error 400: start_date and end_date cannot be the same')}
[1][wrap_model_call]模型调用成功
[wrap_model_call]模型调用成功
[1]执行模型之后调用
执行模型之后调用
目标执行工具的名称为:tavily_search。参数为:{'query': '上海天气', 'start_date': '2024-01-20', 'end_date': '2024-01-21', 'topic': 'general'}
[1]目标执行工具的名称为:tavily_search。参数为:{'query': '上海天气', 'start_date': '2024-01-20', 'end_date': '2024-01-21', 'topic': 'general'}
[1][wrap_tool_call]模型调用成功
[wrap_tool_call]模型调用成功
执行模型之前调用
[1]执行模型之前调用
执行模型前的最新消息的内容为:{"query": "上海天气", "follow_up_questions": null, "answer": null, "images"...}
[1]执行模型前的最新消息的内容为:{"query": "上海天气", "follow_up_questions": null, "answer": null, "images": [],...}
[1][wrap_model_call]模型调用成功
[wrap_model_call]模型调用成功
[1]执行模型之后调用
执行模型之后调用
[1]执行智能体之后调用
执行智能体之后调用2.3.4自定义状态结构
因为agent是基于LangGraph构建的,所以它的自定义状态结构的方式与我们Graph那里很相似,不过这里我们需要让我们的自定义状态类继承自AgentState:
python
class TrackingState(AgentState):
model_call_count: NotRequired[int]
class UsageTrackingState(AgentState):
"""追踪令牌使用情况"""
last_model_call_tokens: NotRequired[int]多中间件组合时,状态更新支持通过字典或 Command 完成,并与 Graph 的 reducer 兼容:
- 对于非 reducer 字段 (如自定义键),外层中间件胜出(last-wins)
- 对于消息等 reducer 字段 ,所有更新累加
也就是说如果有多个中间件使用了不同的自定义状态,且这些状态中具有冲突字段,追加还好说,覆盖的话那就自然是冲突字段为后调用中间件所设置的值了。
如何对状态进行更新呢?
中间件可以修改 Agent 的状态(state),机制因钩子类型而异:
- 对于节点风格 :当想要进行简单状态更新(计数、标志等)时使用。可直接返回字典
- 对于包装风格 :当需要在模型调用或工具调用过程中基于请求/响应逻辑更新状态时(如记录使用量、触发摘要等)使用。通过
ExtendedModelResponse或Command更新状态- 在
wrap_model_call中返回ExtendedModelResponse,其中包含Command(update={...})来注入状态更新 - 在
wrap_tool_call中直接返回Command
- 在
我们来看下面一个例子:
python
from typing import Callable, Any, NotRequired
from langchain.agents import create_agent, AgentState
from langchain.agents.middleware import (
after_model, wrap_model_call, ModelRequest, ModelResponse,ExtendedModelResponse
)
from langchain.tools import tool
from langchain_openai import ChatOpenAI
from langgraph.runtime import Runtime
from langgraph.types import Command
@tool
def get_weather_for_location(city: str) -> str:
"""获取指定城市的天气信息。"""
return f"在{city}总是阳光明媚!"
class TrackingState(AgentState):
model_call_count: NotRequired[int]
class UsageTrackingState(AgentState):
"""追踪令牌使用情况"""
last_model_call_tokens: NotRequired[int]
@after_model(state_schema=TrackingState)
def add_counter(state: TrackingState, runtime: Runtime) -> dict[str, Any] | None:
return {"model_call_count": state.get("model_call_count", 0) + 1}
@wrap_model_call(state_schema=UsageTrackingState)
def track_usage(
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse],
) -> ExtendedModelResponse:
response = handler(request)
return ExtendedModelResponse(
model_response=response,
command=Command(update={
"last_model_call_tokens": response.result[-1].response_metadata["token_usage"]["completion_tokens"]
}),
)
# 定义 agent
agent = create_agent(
model=ChatOpenAI(model="gpt-4o-mini",base_url="https://api.kourichat.com/v1"),
tools=[get_weather_for_location],
system_prompt="你是一位乐于助人的助手。",
middleware=[add_counter, track_usage],
)
# 执行 agent
response = agent.invoke(
{"messages": [{"role": "user", "content": "北京的天气如何?"}]}
)
print(response.get("model_call_count")) # 2
print(response.get("last_model_call_tokens")) # 34当然上面是装饰器风格设置自定义状态类的方式,如果我们是类方式设置的话仅需要增加一个成员变量state_schema,然后设置它的值为我们的目标自定义类结构即可。
2.3.5提前退出
在节点样式钩子 (before_agent、before_model、after_model、after_agent)中,返回一个包含 jump_to 键的字典,即可将执行跳转到指定节点。
可用目标:
"end":直接结束 Agent(会触发after_agent钩子)"tools":跳到工具节点"model":跳到模型节点(会触发before_model钩子)
通过 @hook_config(can_jump_to=[...]) 装饰器声明允许的跳转目标(未声明的跳转会被忽略)。
比如我们看如下一个例子:
python
from typing import Any
from langchain.agents import create_agent, AgentState
from langchain.agents.middleware import (
hook_config, before_agent,
)
from langchain_core.messages import AIMessage
from langchain_openai import ChatOpenAI
from langgraph.runtime import Runtime
@before_agent
@hook_config(can_jump_to=["end"])
def check_for_blocked(state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
last = state["messages"][-1]
if "敏感词" in last.content:
return {
"messages": [AIMessage("无法回答该问题")], # 消息追加
"jump_to": "end"
}
return None
# 定义 agent
agent = create_agent(
model=ChatOpenAI(model="gpt-4o-mini",base_url="https://api.kourichat.com/v1"),
system_prompt="你是一位乐于助人的助手。",
middleware=[check_for_blocked],
)
# 执行 agent
response = agent.invoke(
{"messages": [{"role": "user", "content": "敏感词,北京的今日天气如何?"}]}
)
for msg in response["messages"]:
msg.pretty_print()结果如下:
python
================================ Human Message =================================
敏感词,北京的今日天气如何?
================================== Ai Message ==================================
无法回答该问题注意 :仅节点样式钩子 支持跳转,包装样式钩子 (wrap_model_call / wrap_tool_call)不支持。