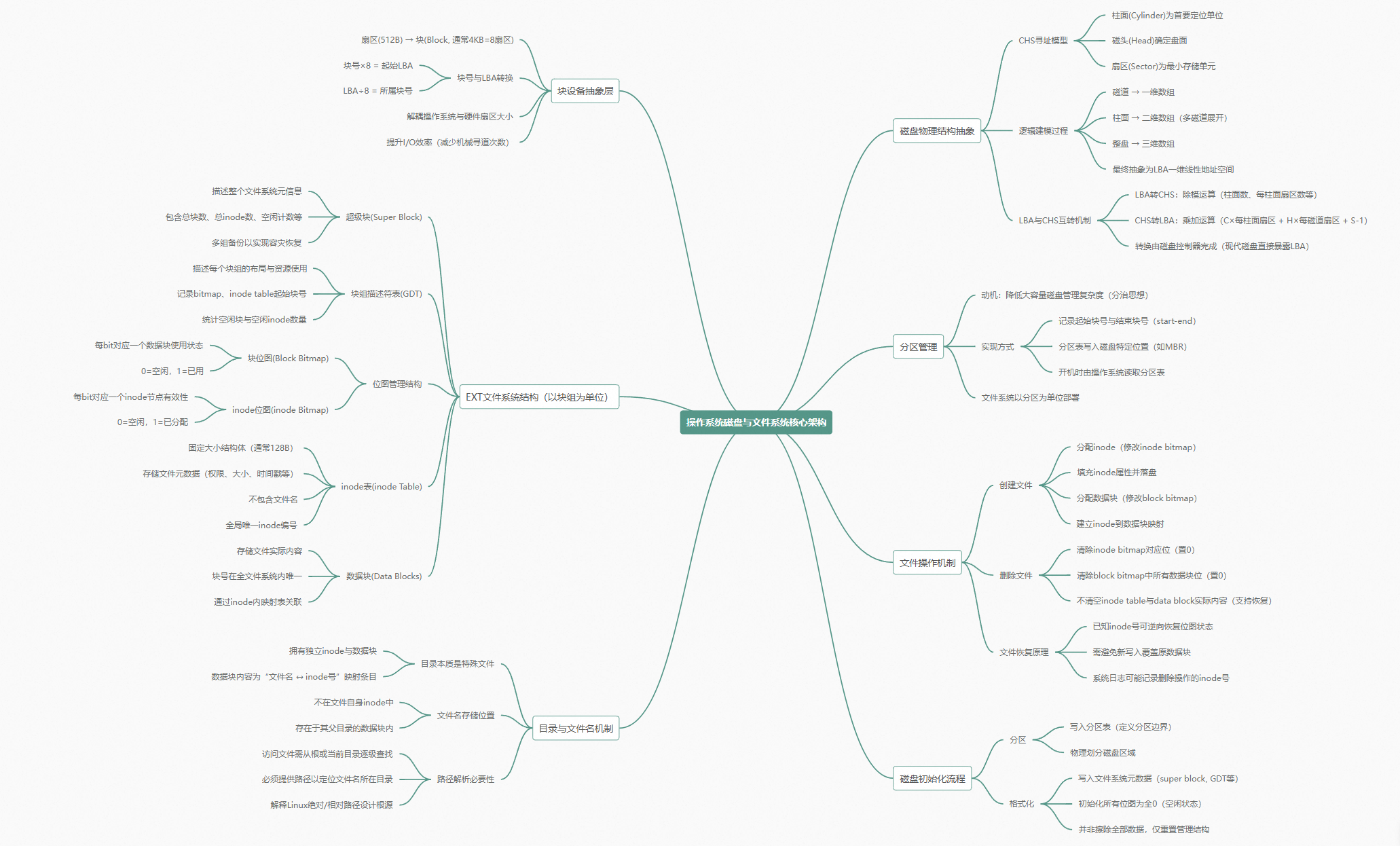
你的磁盘根本不是一个盘子
先做一个实验。打开你的 Linux 终端,敲:
bash
mkdir testdir
touch testdir/file.txt
ls -li testdir/你会看到两行输出,每行开头都有一个数字。比如 8182、8183。这个数字叫 inode 号。记下来,后面会反复用到。
现在把 file.txt 删掉:
bash
rm testdir/file.txt然后------假设你知道这个文件原来的 inode 号------你其实可以把它恢复回来。不是从回收站恢复,是真的让那个文件重新出现。只要你知道它的 inode 号,而且你的数据块还没被覆盖。
这不是魔法。这是位图。
往下看,我告诉你到底发生了什么。
磁头、柱面和那个该死的 CHS
先得聊磁盘的物理结构。这块如果你以前学过,可能学得不太对------我也搞错过。
磁盘有三组概念:磁头 、磁道 、扇区。你拿来定位任意一个扇区,需要三个参数:哪个磁头(哪一面)、哪个磁道、哪个扇区。
但这里有一个关键细节容易漏掉:所有磁头是共进退的 。你是三片六面的盘,六个磁头一起动,一起停。它们同时指向同一组磁道------只不过在不同的盘面上。这一组相同半径的磁道,合起来叫一个柱面。
所以磁盘寻址的真实顺序是:先找柱面,再找磁头,最后找扇区。记作 CHS------Cylinder、Head、Sector。不是 HCS,不是 SCH。就是 CHS。
这还带来了一个有意思的设计:如果你写一个 24MB 的文件,磁盘可以把数据分散写到同一柱面的不同盘面上------一个磁道 4MB,六面同时写。因为磁头共进退,换柱面要物理摆臂,不换柱面只切换磁头是电子切换,快得多。先写满一个柱面再换下一个,比你跨柱面跳来跳去效率高一个量级。
费曼式追问:换个问法,不用 CHS 这三个字母,还能说清楚吗?能。你要找一个扇区,先问"在第几个同心圆上",再问"在哪一层盘面上",最后问"在这个圆的第几个切片上"。就是三维坐标,就这么回事。
把一个柱面剪开
现在做一件物理上不可能、逻辑上极管用的事:把磁盘上某一个柱面"剪"下来,"摊"平。
一个柱面由多个磁道(每个盘面一个)构成。每个磁道上有固定数量的扇区。把每个磁道展开,它就是一条线------一个一维数组,数组元素是扇区。
把整个柱面展开呢?每个盘面贡献一个一维数组,叠在一起------一个柱面就是一个二维数组。
磁盘有多少柱面?比如 7 个。把 0 号柱面、1 号柱面、2 号柱面......依次卷在一起------整块磁盘就是一个三维数组。
一维构成二维,二维构成三维。磁盘 = 三维数组。这就是逻辑建模。小时候吃过的果丹皮知道吧?一圈一圈卷起来的------每一个柱面就是一圈果丹皮,卷在一起就是整块盘。
用数组下标定位,你只需要三个数字------柱面号、磁头号、扇区号------就能定位任意一个扇区。CHS 就是三维数组的下标。
不妨用 C 数组来过一遍。int a[5] 是一维数组,5 个元素。int b[2][5] 是二维数组,2 行 5 列,但它在内存里也是连续放的------就是把两个 a[5] 拼在一起。int c[4][2][5] 就是三维,4 个 b[2][5] 拼在一起。三维数组在内存里就是一维的。
现在回到磁盘上去。对应关系是这样的:
int a[5] → 一个磁道(磁道上的扇区)
int b[2][5] → 一个柱面(多盘面的同半径磁道)
int c[4][2][5] → 整块磁盘(多个柱面卷在一起)这个类比有点粗糙,但够用。如果非要追问"不同半径的磁道扇区数怎么可能一样",答案是:在逻辑上我们假定一样。实际磁盘内部有 ZBR(区域位记录)技术,外层磁道扇区更多。但操作系统不需要知道------这是磁盘控制器内部做的屏蔽。这个类比在这里开始失效,但不影响我们理解的核心。
LBA:把三维数组压成一维
三维数组在内存里怎么存的?是连续的。不管你定义的是 int a[3][2][5] 还是什么,最终在物理内存里都是一条线。一维数组。
所以磁盘也可以这么看。不用再考虑柱面、磁头、扇区,直接把所有扇区从 0 开始编号:扇区 0、扇区 1、扇区 2......扇区 N。这个编号就叫 LBA------Logical Block Address,逻辑块地址。
谁做的这个抽象? 操作系统。
操作系统在开机时识别磁盘,获取几个参数就够:
- 磁盘总容量
- 扇区大小(通常是 512 字节)
- 柱面数
- 盘面数(磁头数)
- 每个磁道的扇区数
有了这些,操作系统就能动态算出一共有多少个扇区。扇区总数知道了,LBA 地址空间自然就有了------就像你知道内存大小是 4GB,32 位地址空间自然就覆盖了全部物理内存一样。
不需要在操作系统里把每个扇区都"定义"出来。 只需要知道总数。0 到 N-1 的地址空间就全有了。
LBA 和 CHS 是怎么互相换算的
LBA → CHS:三维数组下标 → 一维数组下标,除法和取模。
假设一个柱面有 16 个扇区(2 个磁头 × 每个磁道 8 个扇区),LBA 地址是 9。
柱面号 = 9 ÷ 16 = 0 → C = 0
剩余 = 9 % 16 = 9
磁头号 = 9 ÷ 8 = 1 → H = 1
扇区号 = 9 % 8 = 1(+1=2) → S = 2换个更大的例子,LBA 是 19:
柱面号 = 19 ÷ 16 = 1 → C = 1 (跳过了 0 号柱面所有的 16 个扇区)
剩余 = 19 % 16 = 3
磁头号 = 3 ÷ 8 = 0 → H = 0
扇区号 = 3 % 8 = 3(+1=4) → S = 4CHS → LBA:反过来,三维下标转一维。LBA 由三部分组成:
- 前面 N 个完整柱面的扇区:柱面号 × 单个柱面扇区数
- 当前柱面内前面 N 个完整磁道的扇区:磁头号 × 每个磁道扇区数
- 当前磁道内的位置:扇区号 - 1(因为扇区号从 1 开始,LBA 从 0 开始)
三者相加,就是 LBA。
用 C 数组的视角再过一遍。 拿 int c[4][2][5] 来说,你想找第 11 号元素(从 0 开始数,012345678910,11 是第 12 个)在三维里的位置:
每个 b[2][5] 有 2×5 = 10 个元素
11 ÷ 10 = 1 → 在第 1 号二维数组里(也就是柱面号 = 1)
11 % 10 = 1 → 在这个二维数组里排第 1 号(从 0 开始)
现在问题缩小为:在 b[2][5] 里找第 1 号元素
每个 a[5] 有 5 个元素
1 ÷ 5 = 0 → 在第 0 号一维数组里(也就是磁头号 = 0)
1 % 5 = 1 → 在这个一维数组的第 1 号位置(扇区号,但扇区从 1 开始,所以是 1+1=2)结论:一维下标 11 → 三维坐标 (1, 0, 2)。对应到磁盘就是 LBA=11 → CHS=(1, 0, 2)。就是除模运算。换个方向,CHS→LBA 就是做乘法再加。就这么点事。
这个换算工作谁来做? 当代磁盘自己做的。老式磁盘只认 CHS,需要操作系统算。现在的磁盘直接给操作系统暴露 LBA------磁盘内部的控制器芯片自己把 LBA 转成 CHS 去驱动物理磁头。
诚实标注 :磁盘内部有芯片、有寄存器。有数据寄存器、地址寄存器、读写控制寄存器。你往磁盘的特定寄存器写数据,磁盘控制器就根据这些数据去操作物理硬件。这和你们学的"总线"对上号了------数据总线、地址总线、控制总线。有些物理地址直接编制给外设了,访问外设寄存器跟访问内存几乎一样(统一编址)。所以总结一下,操作系统要往磁盘写数据,需要给磁盘三样东西:LBA 地址 (写到哪)、数据的地址 (数据在哪,可能用 DMA 直接搬运)、读写控制位(读还是写)。磁盘拿到这三样,自己就把活干了。这里我其实应该画张表才能说清楚,等哪天单开一篇。
块:为什么不直接拿扇区干活
好,现在磁盘对操作系统来说就是一个大的一维数组,每个元素是一个 512 字节的扇区。直接用不就行了?
两个问题。
第一,耦合。 操作系统这次按 512 字节读,下次硬件升级成 1024 了呢?操作系统得跟着改。
第二,而且更要命,效率。 磁盘是机械设备。一次读 512 字节,数据量太小。操作系统跑起来要频繁访问磁盘------读文件、写文件、换页------单次 IO 太小,整机效率会完蛋。
所以操作系统在文件系统层面引入了一个新单位:块(block) 。最常用的大小是 4KB。
一个扇区 512 字节,一个块 4KB------一个块 = 8 个连续的扇区。不是在物理盘面上连续,是在 LBA 地址上连续。8 个 LBA 地址挨着。
现在你往上再抽象一层:整个磁盘不再是一维扇区数组了,而是一维的块数组 。块 0、块 1、块 2......块 N。这就是为什么磁盘被叫做块设备。
总字节数 ÷ 512 = 扇区总数
扇区总数 ÷ 8 = 块总数块号和 LBA 的换算
比上面那个还简单:
块号 × 8 = 该块第一个扇区的 LBA 地址
块号 × 8 + 0~7 = 该块 8 个扇区各自的 LBA 地址
LBA ÷ 8(整数除法)= 该扇区所属的块号比如 LBA 是 3,3 ÷ 8 = 0,在块 0。LBA 是 9,9 ÷ 8 = 1,在块 1。LBA 是 10,10 ÷ 8 = 1,还在块 1。
块号转 8 个 LBA 再转 8 组 CHS,一次给磁盘下发 8 个地址------磁盘一次读写 4KB。这就是 IO 的基本单位。另外,块号乘以 8 等价于左移 3 位,所以硬件层面算得飞快。
题外话:操作系统怎么管理磁盘请求队列
你在系统里跑着几十个进程,每个都可能读写磁盘。A 进程想读块 0 和块 2,B 进程想读块 1 和块 3。这些请求怎么管?
先描述再组织。 每一个访问磁盘的请求在内核里被封装成一个 struct request,里面装着:目标块号、读还是写、发起者是谁。所有 request 用链表串成队列,挂在磁盘的描述结构体 struct disk 里面。
有意思的是,操作系统可以对请求做合并优化------A 想要块 0 和块 2,B 想要块 1 和块 3,如果它们可以拼成连续的 0、1、2、3,那就合并成一个大请求一次发下去。磁头不用跳来跳去。底层还有电梯调度算法、超时策略等各种花样。做存储或驱动开发的同学会深入接触到,这里只点到为止。
分区:800GB 太大了,切成小块管
你一块磁盘 800GB。怎么管?全放一起管,跨度太大,磁头来回摆,盘片转来转去,管理成本爆炸。
所以我们要分区。
800GB 切成 200GB + 200GB + 400GB。现在你只需要管好一个 200GB 的分区,然后把管理方式复制到另外两个分区。
分区怎么表达?极其简单:起始块号 + 结束块号 。就两个数字。和虚拟地址空间的 start/end 一个思路,只不过地址空间是临时的(进程退出就没了),分区是持久的(关机还在)。这些分区信息存在磁盘特定位置的一张分区表里,操作系统启动时读出来。
磁盘上还有一个特殊的区域叫 MBR(主引导记录),它是一个数据块,里面塞了两样东西:一段引导代码(boot code),负责把操作系统加载到内存;一张分区表,记录了磁盘上所有分区各自从哪开始到哪结束。操作系统开机时读 MBR,既加载了自己,也知道了磁盘的分区情况。
另外,文件系统是以分区为单位的。 一个分区写入一种文件系统,不同分区可以写不同的文件系统------C 盘用 ext4,D 盘用 NTFS,完全没问题(当然在 Linux 下通常都是 ext 系列)。不能跨分区做文件系统操作。
块组:200GB 还是太大,再切
分区 200GB 还是不好管。所以继续切:把一个分区分成若干个块组(block group)。
200GB 切 20 个组,每个组管 10GB。把 10GB 管好了,ctrl-c、ctrl-v 到 20 个组,整个分区就管好了。一个分区管好了,ctrl-c、ctrl-v 到所有分区,整块盘就管好了。
这叫分治。 把大问题肢解成小问题。
管理国家和管磁盘哪个容易?磁盘。因为国家每个地区文化、语言、产业都不一样,你管好西藏不代表管好浙江。但磁盘------管它是哪个组、哪个分区------统统都是 512 字节的扇区,统统都是 LBA 地址,统统都是 4KB 的块。磁盘天然适合分治。
好了,现在我们把视角缩到一个块组。只要搞清楚一个块组里有什么,整个文件系统你就搞清楚了。
一个块组长什么样
一个块组内部由以下几部分构成:
┌──────────────┐ ← 这一小坨是管理数据,占地很小
│ Superblock │
│ GDT │
│ Block Bitmap │
│ Inode Bitmap │
│ Inode Table │
├──────────────┤
│ │
│ Data Blocks │ ← 这一大坨才是真正放文件内容的地方
│ │
│ │
└──────────────┘上面那些管理字段,图上是比例失调的------实际它们加起来可能只占这个组的 1%~2%,剩下的全是 data blocks。因为磁盘主要就是用来存数据的,不是你管理自己用的工商局。
这些字段------Superblock、GDT、两个 Bitmap------统称为管理数据(metadata)。它们是文件系统向磁盘里写的"自己用"的数据,格式固定、位置固定,专门用来管普通文件的。跟普通用户的文件内容不混在一起。就像你要管一个省,你得先派一套领导班子过去------这些管理数据就是"领导班子"。
下面一个一个说。
Superblock:整个文件系统的身份证
Superblock 描述的是整个文件系统的信息。整个分区有多少个块,多少 inode,块多大,inode 多大,有多少个块组,每个块组有多少块、多少 inode,最近一次挂载时间......
用代码来说,对应内核里的 struct ext2_super_block。它里面的字段包括:
- 整个文件系统有多少 inode
- 整个文件系统有多少 block
- 空闲 block 数、空闲 inode 数
- 第一个数据块的块号
- 每个组里有多少 block、多少 inode
- 挂载时间、写入时间
- inode 结构体大小(128 字节)
- 第一个未被使用的 inode 号
问题:Superblock 是管整个分区的,那它怎么出现在"某一个组里面"了?它不应该像 MBR 一样放在分区最开头,然后才跟着组 0、组 1、组 2 吗?
答案:容灾。Superblock 是整个分区最重要的数据结构------它坏了,整个分区的数据基本就完了。所以 ext 系列文件系统会在若干个块组里(通常是 2~3 个)备份 Superblock。图上把它画在组里面,就是在暗示"它有备份"。当某个 Superblock 因为磁盘震动或什么原因损坏时,可以从备份里恢复。这就是为什么 Windows 有时候弹"文件系统损坏,是否修复",你点"是"等一会儿就好了------有时候就是 Superblock 的数据恢复了,有时候恢复不了就得丢数据。
GDT:一个块组的导航图
GDT(Group Descriptor Table) ,块组描述符表。它管理一个组的使用情况。
你分了多少个块组,就有多少个块组描述符------每个块组一个。GDT 本身也是一个结构体,在内存里填好,二进制写到磁盘上。每个描述符记录这个组里:
- Block Bitmap 从哪个块开始(起始块号)
- Inode Bitmap 从哪个块开始
- Inode Table 从哪个块开始
- 空闲 block 数、空闲 inode 数
- 该组里目录占用了多少个 inode
- 后面还有一些填充位
因为各个区域是连续存放的,知道起始块号,下一个区域的起始块号自然就能推出来。剩下的全是 data blocks 的地盘。
Block Bitmap 和 Data Blocks:内容层
Data Blocks 是整个组里面占比最大的区域。它们就是一堆 4KB 的块,存文件的内容。
每一个块在这个文件系统里有一个唯一的块号------不是组内从 0 开始编号,是跨组的全局唯一。
问题来了:这么多块,我怎么知道哪些被用了、哪些还空着?
用位图。 Block Bitmap 是一组连续的内存,每一个比特位对应一个数据块。比特位为 1 → 该块已被占用。比特位为 0 → 该块空闲。
算一下:一个块组 10GB,忽略管理数据的开销,大概有 10GB ÷ 4KB ≈ 2,621,440 个数据块。一个 Bitmap 块是 4KB = 4096 字节 = 32768 个比特位。所以需要 2,621,440 ÷ 32,768 ≈ 80 个 Bitmap 块来表示所有数据块的使用情况。
所以 Block Bitmap 不是单个 4KB 块,它可能是一小组连续的 4KB 块,共同构成一张大位图。
申请数据块怎么做? 在 Bitmap 里找第一个值为 0 的比特位,改成 1,这个比特位对应的数据块就是你的了。
但是------这个位图在磁盘上啊,你不能直接在磁盘上改。操作系统会把对应的 Bitmap 块以 4KB 为单位加载到内存里,在内存里修改,然后再刷新写回磁盘。读取和刷新的单位都是 4KB。
Inode Table 和 Inode Bitmap:属性层
Linux 系统里,文件和目录的区别在存储层面几乎不存在。它们都由两部分组成:属性 + 内容。
属性用 inode 来表达。inode 是一个结构体------struct ext2_inode,大小固定,在 ext2 里是 128 字节。里面存什么?
mode --- 文件类型和权限
uid, gid --- 拥有者、所属组
size --- 文件大小
atime --- 最后访问时间
ctime --- 创建时间
mtime --- 最后修改时间
blocks --- 文件占了多少个块
block[15] --- 数据块映射表(后面详聊)
... 其他字段注意到没有?没有文件名字段。 文件名不在 inode 里。这是故意的,后面会讲为什么。
所有文件(包括目录)的属性类别都一样------都有 mode、uid、size、时间戳这些东西。区别只在于值不同:你的文件 size=4096,我的 size=512。就像每个人都有身高属性,你一米八,我一米七------结构一样,值不同。
一个文件一个 inode。一个分组里可能有上万个文件,所以 Inode Table 就是所有 inode 结构体排在一起的一块区域。如果分组里有 10000 个文件,需要 10000 × 128 ÷ 4096 ≈ 312 个块来放 Inode Table。
有意思的是,4KB 一块,一个 inode 128 字节,一块能装 32 个 inode(4096 ÷ 128 = 32)。所以操作系统读取 Inode Table 时不是一次只读一个 inode,而是一次读一个 4KB 块------顺带就把相邻的 31 个 inode 也读出来了。要修改属性也是在内存里改,然后整块刷回磁盘。
同样,你怎么知道 Inode Table 里哪些 inode 已经被占用了、哪些还空着?
Inode Bitmap。 和 Block Bitmap 一样一样的东西。比特位的位置映射到 Inode Table 里具体的 inode,比特位为 1 表示该 inode 有效,为 0 表示空闲。
你现在知道
ls -l到底在干什么了吗?它就是在读文件的 inode 属性------mode(权限位)、uid(拥有者)、size、时间戳------然后格式化输出给你看。ls -li多了一个-i,顺便把 inode 号也打印出来了。
一个零字节文件占不占磁盘空间?
占。必须占。
你新建一个大小为 0 的普通文件------比如 touch empty.txt------它不占 data blocks,但必须占据 Inode Table 里的一个 inode(128 字节)。属性总要存的吧?mode、uid、时间戳,这些东西放哪?
这也是为什么"文件大小"和"磁盘占用"是两个不同概念。0 字节文件的文件大小是 0,磁盘占用至少是一个 inode 的大小(再加上目录里的映射条目)。
inode 用完但数据块没用完,存在吗?
存在。反过来也存在------数据块用完了但 inode 还有剩。
因为划分块组时,每个组有多少 inode、多少 block 是预先固定好的(写死在 Superblock 里)。如果你的分区里全是几十 GB 的大文件,每条记录只占一个 inode 但要耗巨量数据块,数据块可能先耗光,你的 inode 还多着呢。反过来,全是几字节的小文件,每个都要消耗一个 inode,inode 先用完。面试题就这意思。
ext 系列文件系统,ext2 是基础,ext3 和 ext4 向后兼容 ext2,只不过加了日志(journaling)、数据冗余、安全等新特性。ext2 是核心骨架,搞懂了它,ext3/ext4 只是往里加模块。Linux 里应用最广的文件系统就是 ext 家族,没有之一,所以拿它来讲。
拿着 inode 号,怎么找到文件
好,假设我知道一个文件的 inode 号------比如 2014。怎么在整个分区里找到它?
先得知道它在哪个块组里。每个块组里 inode 的个数是固定的(这个数字写在 Superblock 里)。假设每个组 1000 个 inode:
2014 ÷ 1000 = 2 → 在第 2 号块组(从 0 开始)
2014 % 1000 = 14 → 在该组的第 14 号 inode进到 2 号组之后:
- 查 Inode Bitmap 的第 14 个比特位------如果是 1,这个文件合法存在
- 在 Inode Table 里定位到第 14 个 inode,读出所有属性
- 在 inode 内部有一张数据块映射表(block15),告诉你文件内容存在哪些 data block 里
- 根据映射表找到数据块,读出内容
每一个 inode 有自己唯一的 inode 号,全文件系统唯一。 这句话等于说:你手里只要有 inode 号,不需要文件名,就能找到文件。
等一下------15 个块怎么够? inode 里面的映射表 block[15] 只有 15 个位置,每个指向一个 4KB 的块,15 × 4KB = 60KB。文件超过 60KB 怎么办?
15 个位置是这样分的:前 12 个直接指向数据块(direct blocks),第 13 个指向一个"间接块"(indirect block)------这个块本身不存文件内容,存的是更多数据块的块号列表(一个 4KB 块能装 1024 个 4 字节的块号)。第 14 个是二级间接,第 15 个是三级间接。一层一层扩展开,能支持几百 GB 的大文件。这只是简单提一下,间接块的具体机制下篇展开,现在你只需要知道"inode 里确实有字段把内容和属性连起来了"就够了。
增、删、改、恢复------全在位图上动刀子
新建一个文件
- 确定你在哪个块组里(跟负载均衡策略有关,简单情况就是找空闲 inode 最多的组)
- 查 Inode Bitmap,找第一个为 0 的比特位,在内存里改成 1
- 在内存里 构建一个
struct ext2_inode,填入文件的 mode、uid、大小(初始 0)、当前时间戳等属性 - 如果有内容要写,查 Block Bitmap 在内存里申请数据块,在 inode 的映射表里记下块号,把内容写进数据块
- 把 inode、数据块、两个位图的修改全部刷新到磁盘
查找/修改一个文件
查 inode 号 → 确认块组 → 查 Inode Bitmap 确认合法 → 读 Inode Table 获取属性 → 根据映射表读 data blocks。
改属性就在内存里改 inode 结构体,刷新回 Inode Table。改内容就改 data blocks,可能还要调整 Block Bitmap 和映射表。
删除一个文件
这就是整个故事最精彩的部分。
删一个文件,你不需要清空 inode,不需要清空 data blocks。你只需要做两件事:
- 在 Inode Bitmap 里,把该文件对应的比特位从 1 改成 0
- 根据 inode 的映射表,找到该文件占用的所有数据块,在 Block Bitmap 里把对应的比特位从 1 改成 0
没了。就两步。清位图就完事了。
这就是为什么你往电脑里拷一部 4GB 电影要花 30 秒,但删除它------包括清空回收站------只要 2 秒。写入文件要真实地往磁盘灌 4GB 数据,删除文件只需要翻两个位图里的几个比特位。盖房子要打地基砌砖,拆房子只需要在墙上贴个"危房待拆"的标签,下一个住户(下一个写操作)来了直接覆盖盖新的。
命名 ≠ 理解:你口口声声说"删文件",但你实际上根本没删任何东西。数据块里的内容还在原地,一寸没动。你只是把管理标记改了------告诉文件系统"这块地可以再卖了"。换个问法:如果你被人追杀,你删掉一个文件就跑,追你的人拿个磁盘恢复工具两分钟就能恢复出来。你到底删了什么?你什么都没删。
恢复一个被删除的文件
既然删除只是翻了位图,那恢复就是把位图翻回来:
- 知道文件的 inode 号(系统日志里有记录你删了什么文件)
- 根据 inode 号找到所在块组
- 在 Inode Bitmap 里把对应比特位从 0 改回 1
- 读 inode,拿到映射表,找到之前占用的数据块
- 在 Block Bitmap 里把这些块的比特位从 0 改回 1
前提:数据块还没被覆盖。如果你删完文件后又写入了新文件,新文件可能复用了这些刚"释放"的 inode 或数据块,一旦覆盖就回不来了。
误删文件后的最佳做法 :什么都别做。不要创建文件,不要写入数据,不要安装软件。立刻停手。然后换一台机器,找恢复工具(Linux 下有 fsck、extundelete 之类),研究清楚了再去那台机器上操作。在公司里如果误删了重要数据,直接汇报给组长,别自己瞎折腾------越折腾越可能把数据块覆盖掉。
等等------文件名存在哪?
你早就该问了。我说了半天 inode 里有 mode、uid、size、时间戳、块映射表......文件名呢?
文件名不在 inode 里。
为什么?猜几个理由:
- 文件名是字符串,可长可短,而 inode 结构体大小是固定的 128 字节------放不定长的东西不方便
- 更深层的原因马上揭晓
目录也是文件
ls -li 执行一下。
8181 drwxr-xr-x 2 user user 4096 Jun 9 10:00 testdir/
8182 -rw-r--r-- 1 user user 0 Jun 9 10:00 file.txt看到没?目录也有 inode 号。 8181 就是 testdir 这个目录的 inode 号。
目录在磁盘上的存储方式和普通文件一模一样------都是由 inode + data blocks 构成。普通文件的内容是你写的代码、图片的二进制数据;目录的内容是什么?
目录的 data blocks 里存的是文件名和 inode 号的映射关系。
换句话说,目录的数据块里面,是一条一条的记录,每条记录长这样:
[inode号] [文件名长度] [文件类型] [文件名]
8182 8 普通文件 file.txt
8183 3 目录 subdir所以当你敲 cat testdir/file.txt 的时候,操作系统干的事情是:
- 打开
testdir这个目录文件,读它的 data blocks - 在 data blocks 里搜索 "file.txt" 这个文件名
- 找到对应的 inode 号------8182
- 根据 8182 找到 inode,拿到属性
- 根据 inode 里的映射表,找到数据块
- 把数据块的内容读出来,显示到屏幕上
同样,echo "hello" >> file.txt 就是:找到 inode → 查 Block Bitmap 申请新数据块 → 把 "hello" 写进数据块 → 更新 inode 的 size 和映射表 → 全部刷新到磁盘。ls -l file.txt 根本不碰 data blocks,只读 inode 里的属性------mode、uid、size、时间戳------格式化打印。
文件名的归属问题解决了 :文件名不保存在文件自己的 inode 里,而是保存在它所在的目录文件的 data blocks 里。
这就解释了为什么:
- 在当前目录下新建文件,你必须对该目录有写权限------因为你要往这个目录文件的 data blocks 里写入一条新的映射记录
- 要读取目录下文件的属性,你必须对目录有读权限------因为你要先读目录的 data blocks 才能拿到 inode 号
- 要删除一个文件,你必须对目录有写权限------因为你要从目录的 data blocks 里删掉那条映射记录
为什么必须有路径
要访问一个文件,你必须先打开它所在的目录 。可目录本身也是一个文件------要打开目录 /home/user/testdir/,你得先打开 /home/user/;要打开 /home/user/,你得先打开 /home/;要打开 /home/,你得先打开 /。
这就是路径解析。一连串的"读目录 → 找 inode → 读目录 → 找 inode",直到找到目标文件。
Linux 系统里访问文件必须有路径------因为不提供路径,操作系统就不知道去哪一级目录里找那条"文件名→inode 号"的映射。这就是为什么操作系统要拼命帮你记录当前工作目录(cwd),就是为了让相对路径能工作。
问题一环扣一环:
- 根目录
/的上级目录是谁? - 路径解析要一层一层找,性能怎么办?
- 软链接和硬链接到底区别在哪?
这些下篇再说。
格式化到底干了什么
一块磁盘要正常用,得分两个阶段。
第一阶段:分区。 本质就是向磁盘特定位置(MBR 的分区表区域)写入"起始块号 + 结束块号"这样的条目。Windows 上你看到 C 盘 D 盘 E 盘,大部分情况是同一块物理盘分了三个区。
第二阶段:格式化。 本质是向你刚分好的那个分区里写入文件系统管理数据。右键点 C 盘 → 格式化 → 确认------
不是在把整个磁盘一格一格清零。没必要,也太慢。
格式化的本质是写入文件系统管理数据:
- 写入 Superblock(文件系统全局参数)
- 写入 GDT(每个块组的描述符)
- 把 Block Bitmap 全部清零------告诉系统"这些数据块谁都可以用"
- 把 Inode Bitmap 全部清零------告诉系统"这些 inode 没人占"
清零位图 = 所有文件"消失"。数据块里的内容还在原地(除非被覆盖),只是管理信息说"这片地没人了"。这就是为什么格式化后的数据有时也能恢复------只要管理信息还没被全新覆盖,老数据就还在。
货物崇拜检测:你是不是觉得格式化 = "清空磁盘"?你按那个按钮,进度条跑完了,你看到的是"空盘"。但磁盘扇区上的 0 和 1 纹丝未动。你只是把管理数据的标签全部撕掉了。去掉所有外在形式------右键、格式化、进度条------核心目的达成了吗?你只是想让这块盘"重新干净"。清掉位图就够了,不摸数据------这是聪明,不是偷懒。
所以到底发生了什么?就五件事
- 磁盘在逻辑上是一个三维数组------柱面 × 磁头 × 扇区,每个扇区有一个 LBA 地址作为一维下标。LBA 和 CHS 通过除模运算互相转化
- 块是文件系统操作的基本单位------8 个连续扇区组成一个 4KB 的块,磁盘从"扇区设备"抽象成"块设备"
- 块组是分治的结果------一个组里包含 Superblock、GDT、Block Bitmap(管数据块)、Inode Bitmap(管属性)、Inode Table(存文件属性)、Data Blocks(存文件内容)
- 删除文件只清位图------这就是为什么删除快、恢复有可能。格式化也是清位图,只不过清得更多
- 目录是特殊的文件------它的 data blocks 里面不存内容,存的是"文件名 → inode 号"的映射。所以文件名不在 inode 里,在目录里
就这么回事。
记住:你的磁盘上从来没有"文件"这个东西。只有 inode、位图、数据块。操作系统帮你把这三样东西摆到一起,让你觉得你手里握着一个"文件"。文件是个幻觉。一个很有用的幻觉。