Linux 集群技术
一、Linux 集群的本质
1.1 什么是 Linux 集群?
集群(Cluster)是将多台独立的 Linux 服务器(节点)通过网络互联,在软件层面实现协同工作,对外呈现为一个 "逻辑整体" 的技术体系。其核心目标是解决两大核心痛点:
- 单点故障(高可用):单一服务器宕机导致业务中断,集群通过 "多节点冗余" 实现故障自动切换;
- 性能瓶颈(可扩展):单服务器 CPU、内存、IO 资源有限,集群通过 "负载分担" 将任务分发至多节点,提升整体处理能力。
相较于 Windows 集群,Linux 集群的核心优势在于:开源组件生态丰富(如 Pacemaker、LVS、Kubernetes)、无 license 授权成本、内核级可定制(如内核参数优化、容器化适配),因此成为互联网、金融、科研等领域的主流选择。
1.2 集群的核心特性
无论何种类型的 Linux 集群,均具备三大核心特性:
- 透明性:用户 / 应用无需感知节点数量,通过统一入口(如 VIP、域名)访问集群,操作体验与单服务器无差异;
- 高可用(HA):通过 "心跳检测" 与 "资源切换",节点故障时任务自动迁移至健康节点,业务中断时间通常控制在秒级;
- 可扩展性:支持 "横向扩容"(新增节点)与 "纵向升级"(提升单节点配置),且横向扩容无需中断业务运行。
二、Linux 集群的分类
根据业务场景与核心诉求的差异,Linux 集群可分为四大核心类型,不同类型对应差异化的技术栈与应用场景,需结合业务目标选择适配架构。
2.1 高可用集群(HA Cluster)
核心目标
解决单点故障问题,保障关键业务(如数据库、核心 API 服务)的连续运行,可用性指标通常要求达到 99.99%(每年停机时间不超过 52.56 分钟)。
技术原理
- 心跳检测:节点间通过专用网络(如 Corosync 的 UDP 多播)实时发送 "心跳包",检测对方健康状态;若心跳中断超过阈值(如 3 秒),则判定节点故障;
- 资源代理(RA):集群通过 "资源代理" 管理业务组件(如 IP、数据库服务、文件系统),故障时自动将资源从故障节点迁移至健康节点;
- 脑裂防护:通过 "quorum 机制"(投票仲裁)避免多节点同时争抢资源(如 3 节点集群需 2 票以上才允许资源切换),常见实现如 Stonith(Shoot The Other Node In The Head,强制关闭故障节点)。
Linux 典型实现
- Pacemaker + Corosync:开源 HA 集群的事实标准,支持复杂资源依赖(如 "先启动数据库,再启动 API 服务"),兼容物理机与虚拟机部署模式;
- Keepalived:基于 VRRP 协议的轻量级 HA 方案,主打 VIP(虚拟 IP)切换,适合 Web 服务、负载均衡器的高可用场景,配置简洁但功能相对单一。
应用场景
- 金融核心系统(如银行转账、证券交易服务);
- 数据库主从切换(如 MySQL 主从集群的自动 failover)。
2.2 负载均衡集群(LB Cluster)
核心目标
将客户端请求均匀分发至多节点,避免单节点过载,同时实现 "故障屏蔽"(故障节点自动剔除),提升业务整体吞吐量。
技术原理
- 调度层:接收客户端请求,通过 "调度算法" 分配到后端节点,分为 "四层负载"(基于 TCP/UDP 端口,如 LVS)与 "七层负载"(基于 HTTP/HTTPS 内容,如 Nginx);
- 后端节点池:处理实际业务的 Linux 服务器,需保持配置一致性(如 Web 服务的静态文件同步);
- 健康检查:定期检测后端节点状态(如 TCP 端口探测、HTTP 返回码检测),故障节点自动移出集群,恢复后重新加入。
Linux 典型实现
| 类型 | 代表工具 | 调度算法 | 优势 | 适用场景 |
|---|---|---|---|---|
| 四层负载 | LVS(Linux Virtual Server) | RR(轮询)、WLC(加权最小连接)、SH(源地址哈希) | 内核级转发,性能极高(单机支持百万并发) | 高并发 TCP 服务(如数据库、游戏服) |
| 七层负载 | Nginx | 加权轮询、IP 哈希、URL 哈希 | 支持 HTTP 缓存、SSL 卸载、URL 路由 | Web 服务、API 网关 |
| 分布式负载 | HAProxy + Keepalived | 动态加权、leastconn(最小连接) | 支持 TCP/HTTP 混合负载,健康检查丰富 | 复杂业务场景(如微服务架构) |
应用场景
- 电商秒杀(如双 11 的 Web 流量分发);
- 视频网站的 CDN 边缘节点负载调度。
2.3 计算型集群(HPC Cluster)
核心目标
将大规模计算任务拆解为子任务,分发至多节点并行计算,提升整体算力,适用于科学计算、数据分析等 CPU/GPU 密集型场景。
技术原理
- 任务调度层:接收计算任务并拆解分配,常见工具如 Slurm、Torque;
- 节点通信层:通过高速网络(如 InfiniBand)实现节点间数据交互,避免网络成为算力瓶颈;
- 并行计算框架:基于 MPI(Message Passing Interface)或 Spark 等框架,实现任务并行执行(如 MPI 实现多节点 CPU 协同,Spark 实现分布式内存计算)。
Linux 典型实现
- Slurm + MPI:科研领域主流方案,支持 GPU/CPU 资源调度,可管理数千节点的集群;
- Hadoop YARN + Spark:大数据领域计算集群,基于 Linux 节点构建,支持 PB 级数据的分布式分析。
应用场景
- 气象预测(如全球气候模型计算);
- 人工智能训练(如基于 GPU 集群的深度学习模型训练)。
2.4 存储型集群(Storage Cluster)
核心目标
将多节点的本地存储资源整合为 "统一存储池",提供高容量、高 IOPS(每秒输入输出)、高可靠的存储服务,解决单一存储设备的容量与可靠性瓶颈。
技术原理
- 分布式文件系统:将文件拆分为块(Block)存储到多节点,通过元数据服务器(MDS)管理文件位置,如 GlusterFS、CephFS;
- 块存储集群:将存储资源虚拟化为块设备(类似硬盘),提供给客户端使用,如 Ceph RBD;
- 对象存储集群:以 "对象"(Key-Value)形式存储数据,支持海量小文件存储,如 Ceph S3、MinIO。
Linux 典型实现
- Ceph:开源存储集群的 "全能选手",支持文件、块、对象三种存储模式,通过 CRUSH 算法实现数据分布式存储与冗余(如 3 副本存储,允许 1 节点故障);
- GlusterFS:基于 POSIX 标准的分布式文件系统,配置简单,适合中小企业的存储整合需求。
应用场景
- 云平台存储(如 OpenStack 搭配 Ceph 提供虚拟机存储);
- 视频监控存储(如 PB 级监控录像的集中存储)。
三、Linux 集群的核心技术
3.1 集群通信
节点间的可靠通信是集群运行的基础,Linux 集群主要通过两类技术实现:
- 心跳通信:用于检测节点健康状态,常见协议如 Corosync 的 UDP 多播(适合小规模集群)、VRRP(适合 HA 集群的 VIP 切换);
- 数据通信:用于节点间业务数据交互,如 MPI 的 RDMA(远程直接内存访问,绕过内核直接访问内存,降低延迟)、Ceph 的 RADOS 协议(对象存储底层通信协议)。
关键问题与解决方案:
- 网络分区(脑裂):通过 quorum 机制(如 3 节点需 2 票仲裁)或冗余网络(双网卡绑定)避免;
- 通信延迟:采用高速网络(如 100Gbps 以太网、InfiniBand),并优化内核参数(如调整 TCP 缓冲区大小)。
3.2 资源调度
资源调度决定集群如何分配 CPU、内存、存储等资源,核心目标是 "高利用率" 与 "业务优先":
- 静态调度:提前分配资源(如为数据库节点预留固定 CPU),适合资源需求稳定的场景;
- 动态调度:根据业务负载实时调整资源(如 Kubernetes 的 HPA 自动扩缩容),适合流量波动大的场景。
Linux 典型调度工具:
- Pacemaker:HA 集群的资源调度,支持资源依赖与约束(如 "资源 A 必须在节点 1 运行");
- Kubernetes Scheduler:容器集群的调度,基于节点亲和性、资源请求等规则分配 Pod;
- Slurm:HPC 集群的调度,支持 GPU/CPU 资源的精细化分配(如为某任务分配 2 个 GPU)。
3.3 一致性算法
分布式集群中,多节点需保持数据一致(如 HA 集群的资源状态、K8s 的 etcd 数据),常见一致性算法包括:
- Raft:简化版 Paxos 算法,通过 "leader 选举 + 日志复制" 实现一致性,如 etcd、Consul 采用;
- Paxos:经典一致性算法,通过多轮投票确保故障节点下数据仍一致,但实现复杂度高;
- Gossip:去中心化的一致性协议,适合大规模集群(如 Cassandra),通过节点间 "流言传播" 同步数据。
Linux 集群中的应用:
- etcd(K8s 核心数据库):基于 Raft 算法,保障集群配置数据的一致性;
- Corosync:HA 集群通信层,通过 Gossip 协议同步节点状态。
四、Linux 集群的运维与监控
4.1 集群监控:实时掌握状态
核心监控指标
- 节点层面:CPU 利用率、内存使用率、磁盘 IO、网络流量;
- 服务层面:LVS 连接数、K8s Pod 状态、Ceph 存储使用率;
- 业务层面:请求延迟、错误率、吞吐量。
Linux 监控工具栈
- Prometheus + Grafana:Prometheus 通过 node_exporter 采集节点资源指标,Grafana 提供可视化仪表盘(含 Linux 集群现成模板);
- ELK Stack:Elasticsearch 存储日志、Logstash 收集日志、Kibana 分析日志,定位集群故障(如节点宕机日志排查);
- Zabbix:传统监控工具,支持 Linux 集群节点与服务监控,提供邮件 / 短信告警。
4.2 集群备份与恢复
- 配置备份 :定期备份 HA 集群的 Pacemaker 配置、K8s 的 etcd 数据(如执行
etcdctl snapshot save命令); - 数据备份:存储集群(如 Ceph)开启数据冗余(3 副本),同时定期备份核心业务数据(如数据库全量 / 增量备份);
- 灾难恢复:跨区域部署集群(如主集群在上海,备集群在北京),通过异步复制实现数据同步,极端故障时切换至备集群。
4.3 常见故障排查
- 节点故障:查看 Corosync 日志(/var/log/cluster/corosync.log)分析心跳中断原因,检查网络或节点硬件;
- 负载不均 :LVS 集群通过
ipvsadm -Ln --stats查看各节点连接数,调整调度算法(如改为 WLC); - 存储延迟 :Ceph 集群通过
ceph -s查看健康状态,检查 OSD(对象存储守护进程)是否故障,优化 CRUSH 规则。
五、Linux 集群的未来趋势
5.1 云原生集群的普及
Kubernetes 已成为云原生集群标准,未来 Linux 集群将深度融合云原生技术:
- 边缘集群:在 5G 基站、物联网设备等边缘节点部署轻量级 K8s(如 K3s),实现边缘计算与云端协同;
- Serverless 集群:基于 Knative 等框架,用户无需管理节点,直接部署 "无服务器" 应用,集群自动分配资源。
5.2 AI 与集群的融合
- AI 驱动的调度:通过机器学习预测业务负载,动态调整集群资源(如预测电商流量峰值,提前扩容);
- GPU/TPU 集群:针对 AI 训练场景,优化 Linux 集群的 GPU 资源调度(如 NVIDIA 的 K8s Device Plugin),提升训练效率。
5.3 安全与隐私增强
- 零信任架构:Linux 集群通过 SPIFFE/SPIRE 实现节点与服务身份认证,通过 Istio 实现服务间加密通信;
- 隐私计算集群:基于 Linux 节点构建联邦学习集群,实现多机构数据 "可用不可见",保护数据隐私。
六、总结
从中小企业的 LVS 负载均衡集群,到互联网大厂的 K8s 云原生集群,再到科研机构的 HPC 计算集群,Linux 始终是集群技术的核心载体。掌握 Linux 集群,不仅是理解 "多节点协同" 的技术逻辑,更是掌握应对大规模业务、高并发、高可靠需求的核心能力。
随着云原生、AI、边缘计算的发展,Linux 集群正从 "资源聚合工具" 进化为 "智能业务平台"------ 它不再仅是算力 / 存储的整合,更是业务创新的核心支撑。对于技术从业者而言,深入理解 Linux 集群的原理与实践,将成为应对数字化转型挑战的关键竞争力。
高可用与负载均衡
一、HA 集群核心价值与适用场景
规划部署 HA 集群时,核心问题是:将服务纳入 HA 集群后,可用性是否能实质性提升?
答案取决于服务自身特性与客户端配置逻辑:
- 无需 HA 集群的场景:自带故障转移 / 负载均衡能力的服务(如 DNS、LDAP),这类服务本身支持多节点(主从 / 多主)数据冗余,且客户端可配置多服务器地址,HA 集群无法额外提升可用性。
- HA 集群收益显著的场景:无原生 Failover/LB 能力的服务(如 Openstack 中的 RabbitMQ、Galera),纳入 HA 集群可大幅降低单点故障风险。
注意:HA 集群并非万能
- 应用程序自身 BUG 导致的崩溃,会在集群节点间扩散,HA 仅能切换节点但无法解决 BUG 本身;
- HA 集群不保障端到端冗余,若网络架构存在单点故障(如网关、交换机),即使集群正常,客户端仍无法访问服务。
二、Keepalived 高可用技术深度解析
2.1 Keepalived 核心定位
Keepalived 是基于 C 语言开发的路由管理工具,核心目标是为 Linux 系统及基础设施提供负载均衡 与高可用性能力:
- 初始设计目标:为 LVS(Linux Virtual Server)监控集群节点状态,自动剔除故障节点;
- 核心扩展能力:集成 VRRP 协议,解决静态路由单点故障问题,实现 HA 集群的核心能力。
2.2 VRRP 协议原理(虚拟路由冗余协议)
2.2.1 协议诞生背景
传统静态路由 / 默认网关模式下,路由器是网络通信的单点瓶颈,一旦故障会导致主机间通信中断。VRRP 协议通过虚拟路由冗余机制,实现路由器故障时的透明切换。
2.2.2 核心工作机制
VRRP 将多台物理路由器虚拟为一个虚拟路由器,对外提供统一的虚拟 IP(VIP),核心角色与流程如下:
| 角色 | 核心职责 |
|---|---|
| 主路由器(Master) | 由选举算法产生,持有 VIP,处理 ARP 请求、ICMP 转发等网络功能,持续发送 VRRP 心跳报文 |
| 备份路由器(BACKUP) | 仅接收 Master 的心跳报文,监控其状态;Master 故障时重新选举新 Master |
- 唯一标识:每个虚拟路由器对应唯一 VRID(1-255),VRID+VIP 组构成虚拟路由器;
- 报文传输:通过 IP 多播发送 VRRP 报文,仅 Master 主动发送,BACKUP 被动监听;
- 切换逻辑:Master 故障时,BACKUP 无法接收心跳,触发选举,优先级最高的 BACKUP 升级为 Master,切换过程对用户完全透明。
2.2.3 Keepalived 的多层检测能力
Keepalived 基于 TCP/IP 三层(网络层)、四层(传输层)、七层(应用层)实现节点状态检测:
| 层级 | 检测协议 / 方式 | 核心逻辑 |
|---|---|---|
| 网络层 | ICMP(类似 Ping) | 向集群节点发送 ICMP 数据包,无响应则判定节点故障,剔除出集群 |
| 传输层 | TCP/UDP 端口扫描 | 检测核心端口(如 WEB 的 80、SSH 的 22)是否有数据响应,无响应则判定端口异常 |
| 应用层 | 自定义脚本 / 程序 | 按用户配置检测应用服务状态(如进程存活、业务接口可用),异常则剔除节点 |
2.3 Keepalived 脑裂问题(Split-Brain)
2.3.1 脑裂定义
Keepalived 集群中,主从节点因通信中断,各自判定对方故障,同时争抢 VIP 等资源,导致集群状态混乱的现象。
2.3.2 脑裂产生原因
- 网络故障:主从节点心跳线路(专用网线 / 交换机)断连、延迟过高;
- 防火墙拦截:VRRP 协议默认 UDP 112 端口被防火墙屏蔽;
- 资源耗尽:节点 CPU / 内存耗尽,无法响应心跳请求;
- 配置错误:vrrp_instance 的 state、priority、authentication 等参数不一致。
2.3.3 脑裂核心危害
- 双节点同时持有 VIP,客户端请求分发混乱(部分成功、部分失败);
- 数据库 / 存储类服务易引发数据不一致(双写冲突);
- 集群丧失高可用能力,甚至因资源竞争导致服务崩溃。
2.3.4 脑裂预防与解决方案
方案 1:增加心跳检测线路
配置多网卡检测,避免单线路故障导致心跳中断:
bash
vrrp_instance VI_1 {
state MASTER
interface eth0 # 主网卡
virtual_router_id 51
priority 100
advert_int 1
# 同时检测备用网卡(如eth1)
track_interface {
eth0
eth1
}
}方案 2:启用 VRRP 认证
防止非法节点干扰,确保心跳信息可靠:
bash
vrrp_instance VI_1 {
# ... 其他配置
authentication {
auth_type PASS # 认证类型(PASS或AH)
auth_pass 123456 # 密码(所有节点必须一致)
}
}方案 3:配置防火墙允许 VRRP 通信
bash
# CentOS系统示例:开放VRRP协议
firewall-cmd --add-protocol=vrrp --permanent
firewall-cmd --reload方案 4:部署第三方检测 / 隔离脚本
通过 notify 脚本检测脑裂并强制隔离异常节点:
ini
vrrp_instance VI_1 {
# 其他核心配置...
# 节点切换为Master/BACKUP时触发脚本
notify_master "/etc/keepalived/check_split_brain.sh master"
notify_backup "/etc/keepalived/check_split_brain.sh backup"
}脚本逻辑:通过 ping / 端口检测确认对端状态,若判定脑裂,执行 kill/reboot 等操作隔离异常节点
方案 5:降低脑裂影响范围
- 业务层防护:数据库采用主从复制 + 读写分离,避免双写冲突;存储使用分布式锁(如 Redis)控制资源独占;
- 监控告警:通过 Zabbix/Prometheus 监控 VRRP 状态,发现双主节点时立即告警。
2.4 Keepalived 实战配置(Web 服务高可用)
2.4.1 实验网络拓扑
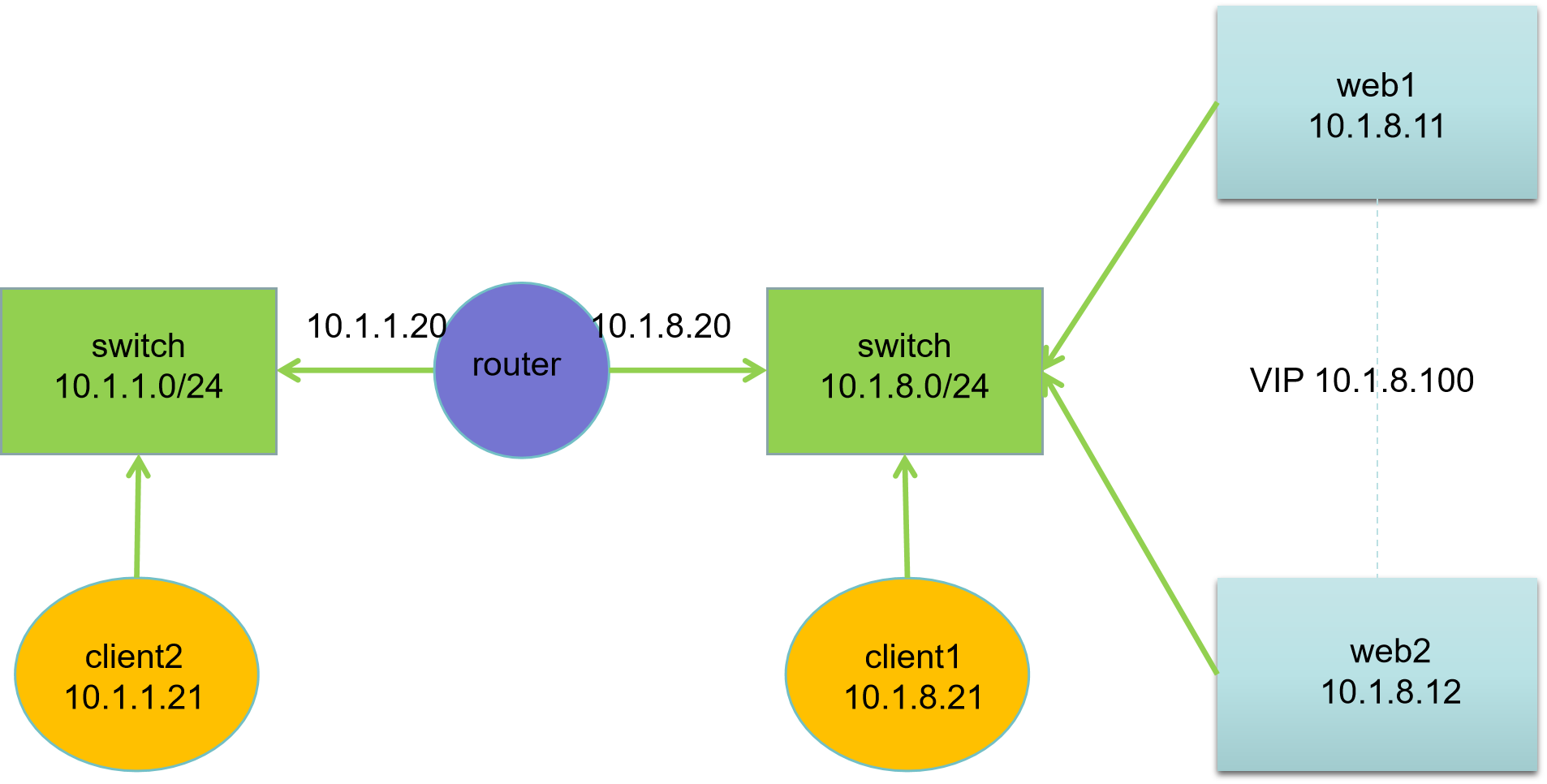
| 主机名 | IP地址 | 服务器角色 |
|---|---|---|
| client2.liu.cloud | 10.1.1.21 | 客户端 |
| client1.liu.cloud | 10.1.8.21 | 客户端 |
| router.liu.cloud | 10.1.1.20, 10.1.8.20 | 路由器 |
| web1.liu.cloud | 10.1.8.11 | Web 服务器 |
| web2.liu.cloud | 10.1.8.12 | Web 服务器 |
网络基础说明:
- 所有主机网卡:ens33(NAT 模式)、ens36(HostOnly 模式);
- 网关配置:10.1.1.0/24 网段网关为 10.1.1.20,10.1.8.0/24 网段网关为 10.1.8.20。
2.4.2 部署 Web 服务(Nginx)
bash
# ====== web1节点操作 ======
# 安装Nginx
[root@web1 ~ 13:44:47]# yum install -y nginx
# 自定义首页内容(标识节点)
[root@web1 ~ 13:48:14]# echo Welcome to $(hostname) > /usr/share/nginx/html/index.html
# 开机自启并启动Nginx
[root@web1 ~ 13:48:43]# systemctl enable nginx.service --now
# ====== web2节点操作 ======
[root@web2 ~ 13:44:49]# yum install -y nginx
[root@web2 ~ 13:48:24]# echo Welcome to $(hostname) > /usr/share/nginx/html/index.html
[root@web2 ~ 13:48:47]# systemctl enable nginx.service --now
# ====== 验证Web服务 ======
[root@client ~ 13:44:24]# curl 10.1.8.11 # 访问web1
Welcome to web1.liu.cloud
[root@client ~ 13:49:46]# curl 10.1.8.12 # 访问web2
Welcome to web2.liu.cloud2.4.3 配置 Keepalived(主从模式)
步骤 1:配置备节点(web2)
bash
# 安装Keepalived
[root@web2 ~ 13:49:19]# yum install -y keepalived
# 备份原始配置文件
[root@web2 ~ 13:50:15]# cp /etc/keepalived/keepalived.conf {,.ori}
# 编辑核心配置文件
[root@web2 ~ 13:50:50]# vim /etc/keepalived/keepalived.conf
bash
! Configuration File for keepalived
# 全局配置段
global_defs {
router_id web2 # 路由器唯一标识,集群内节点不可重复
}
# VRRP实例配置段(对应Nginx服务高可用)
vrrp_instance nginx {
state BACKUP # 节点角色:备节点
interface ens33 # VIP绑定的网卡接口
virtual_router_id 51 # 虚拟路由器ID,集群内所有节点需一致(1-255)
priority 100 # 优先级:数值越高优先级越高(备节点优先级低于主节点)
advert_int 1 # VRRP心跳通告间隔,单位:秒
# 心跳认证配置(防止非法节点接入)
authentication {
auth_type PASS # 认证类型:PASS(密码认证)
auth_pass 1111 # 认证密码,集群内所有节点需一致
}
# 虚拟IP(VIP)配置:对外提供服务的统一地址
virtual_ipaddress {
10.1.8.10/24
}
}启动并验证:
bash
# 开机自启Keepalived
[root@web2 ~ 14:19:06]# systemctl enable keepalived
# 查看IP(确认VIP是否临时绑定)
[root@web2 ~ 14:19:21]# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
ens33 UP 10.1.8.12/24 10.1.8.10/24 fe80::c53b:5:fec9:7bbe/64 fe80::89e1:4d89:b3a7:116c/64 fe80::7855:7e61:6f34:5333/64 步骤 2:配置主节点(web1)
bash
# 安装Keepalived
[root@web1 ~ 13:53:05]# yum install -y keepalived.x86_64
# 备份原始配置文件
[root@web1 ~ 14:20:34]# cp /etc/keepalived/keepalived.conf {,.ori}
# 编辑核心配置文件
[root@web1 ~ 14:20:55]# vim /etc/keepalived/keepalived.conf
bash
! Configuration File for keepalived
global_defs {
router_id web1
}
vrrp_instance nginx {
state MASTER
interface ens33
virtual_router_id 51
priority 200
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.1.8.10/24
}
}启动并验证:
bash
# 开机自启并启动Keepalived
[root@web1 ~ 14:22:12]# systemctl enable keepalived.service --now
# 查看VIP绑定状态(主节点接管VIP)
[root@web1 ~ 14:22:43]# nmcli device show ens33 |grep IP4.ADDRESS
IP4.ADDRESS[1]: 10.1.8.11/24
IP4.ADDRESS[2]: 10.1.8.10/24
# 备节点VIP释放验证
[root@web2 ~ 14:31:39]# nmcli device show ens33 |grep IP4.ADDRESS
IP4.ADDRESS[1]: 10.1.8.12/242.4.4 高可用切换验证
bash
# 1. 正常状态:访问VIP,请求路由到主节点web1
[root@client ~ 13:53:05]# curl 10.1.8.10
Welcome to web1.liu.cloud
# 2. 模拟主节点故障:停止web1的Keepalived服务
[root@web1 ~ 14:23:08]# systemctl stop keepalived.service
# 再次访问VIP,自动切换到备节点web2
[root@client ~ 14:23:57]# curl 10.1.8.10
Welcome to web2.liu.cloud
# 3. 主节点恢复:重启web1的Keepalived服务
[root@web1 ~ 14:24:17]# systemctl enable keepalived.service --now
# 访问VIP,切回主节点web1
[root@client ~ 14:24:22]# curl 10.1.8.10
Welcome to web1.liu.cloud2.5 Keepalived 配置文件全解析
配置文件路径:/etc/keepalived/keepalived.conf
核心分为三大段:GLOBAL(全局配置)、VRRPD(VRRP 协议配置)、LVS(LVS 服务管理)
完整示例:
bash
! Configuration File for keepalived
# 全局配置
global_defs {
# 邮件接收者清单
notification_email {
acassen@firewall.loc
failover@firewall.loc
sysadmin@firewall.loc
}
# 邮件发送者
notification_email_from Alexandre.Cassen@firewall.loc
# 邮件发送服务器
smtp_server 192.168.200.1
# 连接邮件服务器超时时间
smtp_connect_timeout 30
# 标识本机名称,集群中主机身份标识名称不能重复
router_id LVS_DEVEL
# 检查一个VRRP通告中的所有地址是很耗时的。设置这个标志意味着,如果这个通告和之前接收到的通告来自同一个主路由器,则不会执行检查。
vrrp_skip_check_adv_addr
# 严格遵守VRRP协议。
vrrp_strict
# 接口发送免费ARP消息的延迟毫秒数
vrrp_garp_interval 0
# 接口发送未经请求的NA消息的延迟毫秒数
vrrp_gna_interval 0
}
# VRRP协议配置
# VI_1是虚拟实例名称,可自定义
vrrp_instance VI_1 {
# 指定当前节点角色,可以值MASTER和BACKUP,角色由priority决定,这里的值不重要。
state MASTER
# VIP使用的接口
interface eth0
#从0到255的任意唯一数字,用于区分VRRPD的多个实例,同一个高可用集群使用相同的id
virtual_router_id 51
# 用于选举为MASTER,高于其他节点50,将成为MASTER
priority 100
# VRRP通告之间间隔,1s
advert_int 1
# VRRP通告认证凭据
authentication {
auth_type PASS
auth_pass 1111
}
# 提供的VIP列表,还可以通过<IPADDR>/<MASK>指定多个地址
virtual_ipaddress {
192.168.200.16
192.168.200.17
192.168.200.18
}
}
# LVS服务管理配置
# 虚拟服务器是 192.168.200.100 443
virtual_server 192.168.200.100 443 {
# delay timer for service polling
delay_loop 6
# LVS scheduler,支持lb_algo rr|wrr|lc|wlc|lblc|sh|dh
lb_algo rr
# LVS forwarding method,支持NAT|DR|TUN
lb_kind NAT
# LVS persistence timeout in seconds, default 6 minutes
persistence_timeout 50
# L4 protocol,支持TCP|UDP|SCTP
protocol TCP
# one entry for each realserver
real_server 192.168.201.100 443 {
# relative weight to use, default: 1
weight 1
}
}详细信息参考keepalived.conf (5)
2.6 Keepalived 日志配置
bash
# 以下步骤在 web1 和 web2 节点完成
vim /etc/sysconfig/keepalived
# 把 KEEPALIVED_OPTIONS="-D"
# 修改为:KEEPALIVED_OPTIONS="-D -d -S 0"
# 重启 keepalived,查看日志
systemctl restart keepalived.service
vim /etc/rsyslog.d/keepalived.conf
local0.* /var/log/keepalived.log
# 重启日志服务
systemctl restart rsyslog
# 监控日志
tail -f /var/log/keepalived.log2.7 Keepalived 心跳源 IP 配置
可通过mcast_src_ip指定 VRRP 心跳报文的源 IP,提升网络隔离性:
bash
! Configuration File for keepalived
global_defs {
router_id Cluster1
}
vrrp_instance Nginx {
state MASTER
interface ens36
mcast_src_ip 20.0.0.11
virtual_router_id 51
priority 110
advert_int 1
authentication {
auth_type PASS
auth_pass 1111
}
virtual_ipaddress {
10.1.1.10/24
}
}三、Nginx 负载均衡技术实战
3.1 Nginx 核心定位与版本选型
Nginx 是高性能反向代理服务器,兼具负载均衡能力:
- 部署位置:位于 Web 服务器前端,缓存响应、转发请求,隐藏后端真实节点;
- 核心价值:提升响应速度、分摊后端节点压力、隐藏后端架构。
主流 Nginx 版本对比:
| 版本类型 | 核心特点 | 适用场景 |
|---|---|---|
| 官方版 | 基础功能完善,定期更新安全补丁,轻量稳定 | 通用场景、中小规模业务 |
| Nginx Plus | 商业版本,含会话保持、动态 DNS、高级监控等企业级功能,提供官方技术支持 | 企业级核心业务、高要求场景 |
| OpenResty | 集成 LuaJIT,支持 Lua 扩展开发,可定制化能力极强 | 高定制化、动态业务逻辑场景 |
| Tengine | 阿里开源分支,优化大型网站性能,支持动态模块加载 | 大型互联网应用、高并发场景 |
3.2 Nginx 负载均衡实验配置
3.2.1 实验网络拓扑
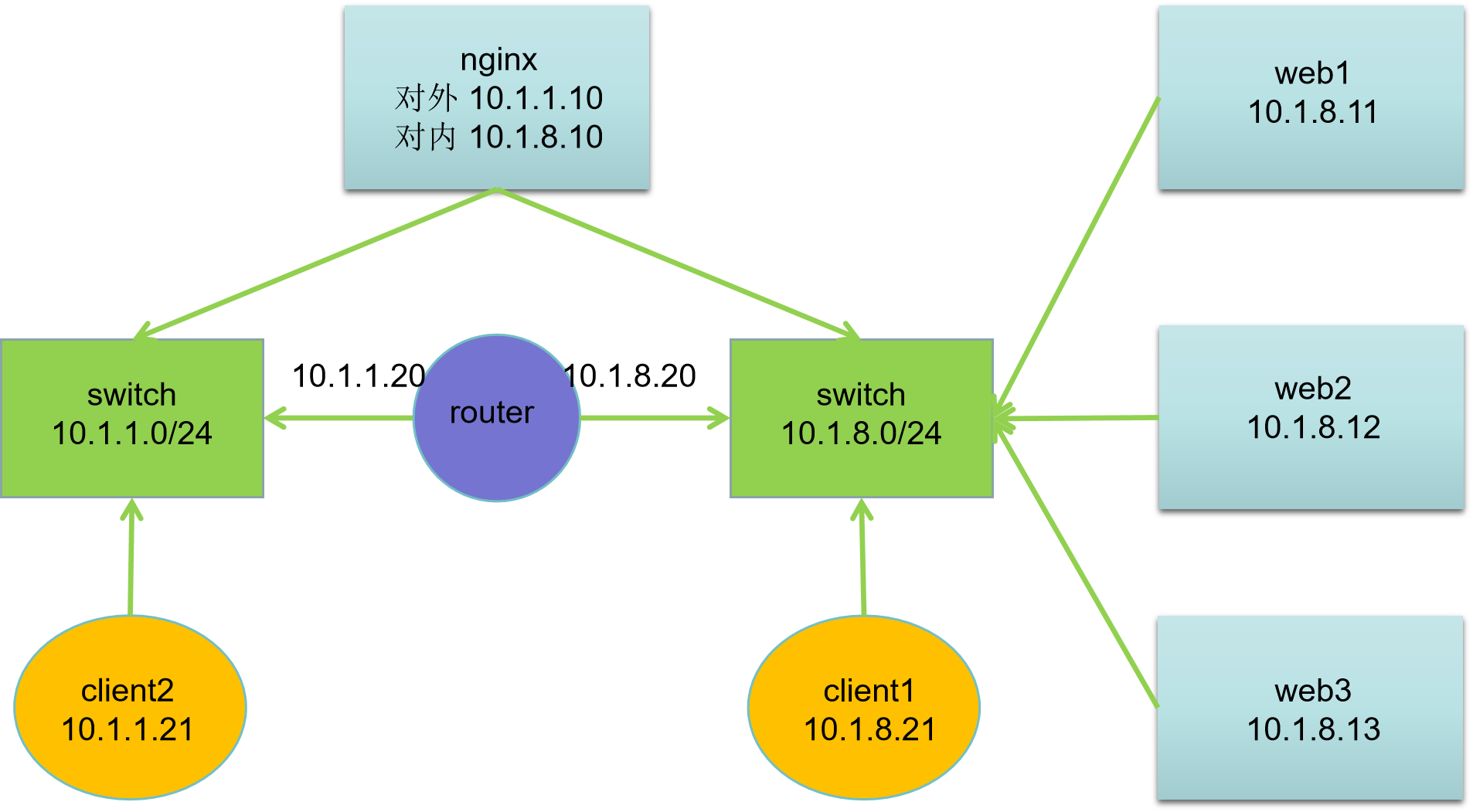
| 主机名 | IP地址 | 服务器角色 |
|---|---|---|
| client2.liu.cloud | 10.1.1.21 | 客户端 |
| client1.liu.cloud | 10.1.8.21 | 客户端 |
| router.liu.cloud | 10.1.1.20, 10.1.8.20 | 路由器 |
| nginx.liu.cloud | 10.1.1.10, 10.1.8.10 | 代理服务器 |
| web1.liu.cloud | 10.1.8.11 | Web 服务器 |
| web2.liu.cloud | 10.1.8.12 | Web 服务器 |
| web3.liu.cloud | 10.1.8.13 | Web 服务器 |
网络基础说明:
- 所有主机网卡:ens33(NAT 模式)、ens36(HostOnly 模式);
- 网关配置:10.1.1.0/24 网段网关为 10.1.1.20,10.1.8.0/24 网段网关为 10.1.8.20。
3.2.2 基础环境配置
步骤 1:主机名 / IP / 网关统一配置
bash
# ====== nginx节点操作:配置hosts文件 ======
[root@nginx ~ 15:56:55]# ssh-keygen -t rsa -N '' -f ~/.ssh/id_rsa # 生成免密登录密钥
[root@nginx ~ 15:58:57]# vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
10.1.8.11 web1.liu.cloud web1
10.1.8.12 web2.liu.cloud web2
10.1.8.13 web3.liu.cloud web3
10.1.8.20 router.liu.cloud router
10.1.1.20 router.liu.cloud router
10.1.8.10 nginx.liu.cloud nginx
10.1.1.10 nginx.liu.cloud nginx
10.1.8.21 client1.liu.cloud client1
10.1.1.21 client2.liu.cloud client2
# ====== 批量推送公钥(免密登录) ======
[root@nginx ~ 16:02:43]# for host in web1 web2 web3 nginx router client1 client2;do sshpass -p123 ssh-copy-id root@$host;done
# ====== 验证各节点IP配置 ======
[root@nginx ~ 16:07:10]# for host in 10.1.8.{10..13} 10.1.8.{20,21} 10.1.1.21; do ssh root@$host 'echo -en $(hostname):;ip -br a | egrep -o "10.1.[18].[0-9]+" | tr "\n" " ";echo'; done
nginx.liu.cloud:10.1.8.10 10.1.1.10
web1.liu.cloud:10.1.8.11
web2.liu.cloud:10.1.8.12
web3.liu.cloud:10.1.8.13
router.liu.cloud:10.1.8.20 10.1.1.20
client1.liu.cloud:10.1.8.21
client2.liu.cloud:10.1.1.21
# ====== 客户端网关配置示例(client2) ======
[root@client2 ~ 15:57:17]# nmcli connection modify ens33 ipv4.gateway 10.1.1.20
[root@client2 ~ 16:18:06]# nmcli connection up ens33
# ====== 验证各节点网关 ======
[root@nginx ~ 16:15:01]# for host in 10.1.8.{10..13} 10.1.8.{20,21} 10.1.1.21; do ssh root@$host ip route | awk 'NR==1 {print $3}'; done
10.1.8.2
10.1.8.2
10.1.8.2
10.1.8.2
10.1.8.2
10.1.8.2
10.1.1.20步骤 2:路由器节点开启转发与地址伪装
bash
# ====== router节点操作 ======
[root@router ~ 16:22:26]# echo "net.ipv4.ip_forward=1">> /etc/sysctl.conf # 开启IP转发
[root@router ~ 16:23:49]# sysctl -p # 生效配置
net.ipv4.ip_forward = 1
# 开启防火墙并配置地址伪装(NAT)
[root@router ~ 16:24:40]# systemctl enable firewalld.service --now
[root@router ~ 16:24:58]# firewall-cmd --add-masquerade # 临时生效
success
[root@router ~ 16:25:09]# firewall-cmd --add-masquerade --permanent # 永久生效
success步骤 3:部署后端 Web 服务
bash
# ====== 批量安装Nginx ======
[root@web1 ~ 15:48:08]# yum install -y nginx
[root@web2 ~ 15:48:14]# yum install -y nginx
[root@web3 ~ 15:48:21]# yum install -y nginx
# ====== 验证各节点网络连通性 ======
[root@nginx ~ 16:25:22]# for host in 10.1.8.{10..13} 10.1.8.{20,21} 10.1.1.21; do ssh root@$host 'hostname;if ping -c2 1.1.1.1 &>/dev/null;then echo ok;else echo no ok;fi'; done
nginx.liu.cloud
ok
web1.liu.cloud
ok
web2.liu.cloud
ok
web3.liu.cloud
ok