🌈个人主页: 秦jh__https://blog.csdn.net/qinjh_?spm=1010.2135.3001.5343
🔥 系列专栏: https://blog.csdn.net/qinjh_/category_13137010.html

目录
[案例二:使用示例数据增强 LangChain 信息提取能力](#案例二:使用示例数据增强 LangChain 信息提取能力)
[示例选择器(Example selectors)](#示例选择器(Example selectors))
[按长度选择示例 (Length)](#按长度选择示例 (Length))
[通过 ngram 重叠选择示例(Ngram)](#通过 ngram 重叠选择示例(Ngram))
前言
💬 hello! 各位铁子们大家好哇。
今日更新了LangChain相关内容
🎉 欢迎大家关注🔍点赞👍收藏⭐️留言📝
少样本提示(few-shotting)
概念
少样本提示是一种通过向 LLM 提供少量具体示例或样本,来教会它如何执行某项特定任务的技术。提 高模型性能的最有效方法之一是给出一个【模型示例】指导大模型你想做什么、怎么做。下面用一个 例子解释少样本提示的作用。
- 参考之前学习的内容,我们可以将其想象为"零样本提示":直接给模型一道考题,不给任何例 子。模型会凭借已有的知识直接回答。例如我们输入 "What is 2 🦜 9?" ,答案可能是:
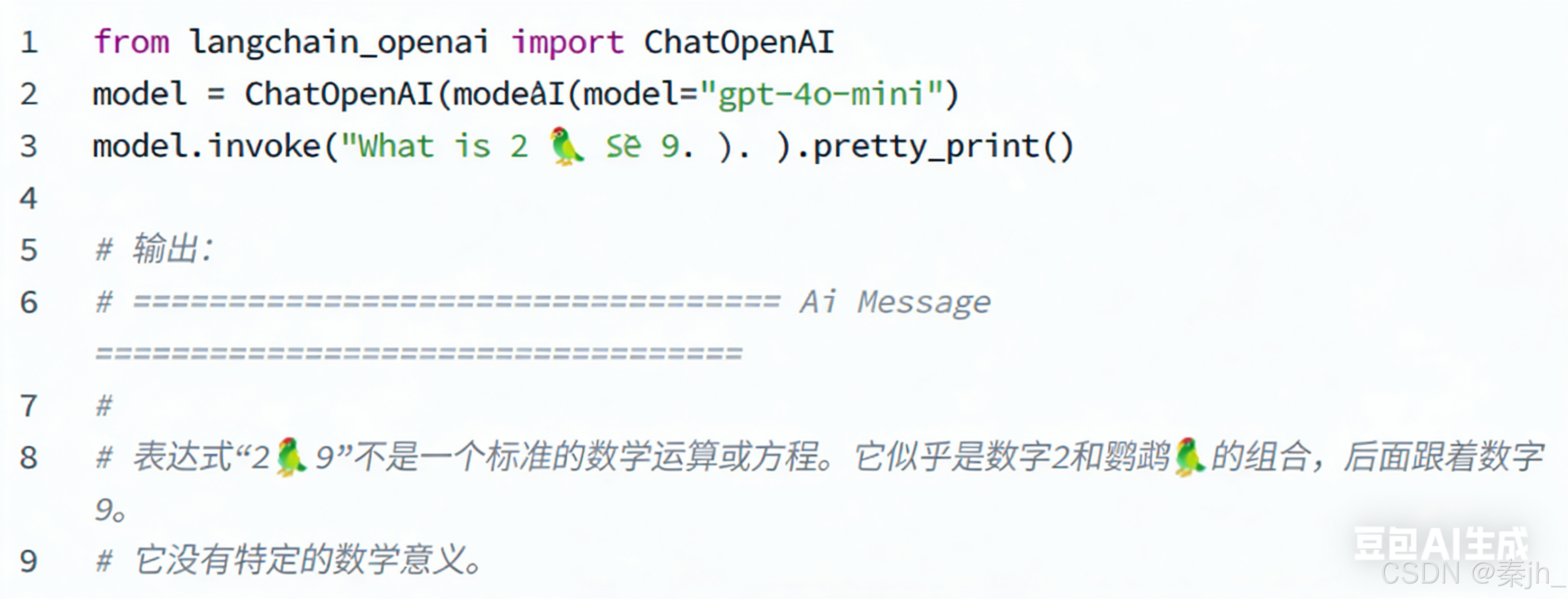
- 少样本提示则是在给出考题前,先给它看几道类似的、附有正确答案的例题。添加示例输入和预期 输出的技术给到模型提示,让模型通过例题来理解任务应该怎么做。例如以下样例,模型通过样例 后可以发现 🦜 与 ➕ 含义相似,便可以按照此规则得出 What is 2 🦜 9? 的结果是 11 :
python
examples = [
{"input": "2 🦜 2", "output": "4"},
{"input": "2 🦜 3", "output": "5"},
]这能解决什么问题?LLM 虽然知识渊博,但有时我们需要它以非常特定的格式、风格或逻辑来回答问 题。提供正确的示例可以减少模型"胡说八道"或犯低级错误的概率,将其输出约束在你提供的范例 范围内。举个例子更能理解:
- 强制要求模型以特定的格式(如JSON、XML、特定的列表样式)输出结果。样例可以当作格式样 板。
- 有些任务很难用文字指令清晰描述(例如:"请用莎士比亚的风格写作")。提供几个例子比写长 篇大论的指令更有效。
- 对于需要多步推理的复杂任务,示例可以展示出思考链,引导模型遵循类似的推理路径。
实现少样本提示
实现少样本提示的第一步也是最重要的一步是提出一个好的示例数据集。好的示例应该在运行时相 关、清晰、信息丰富,并提供模型尚不知道的信息。
如何让大模型看懂这份示例呢?之前我们说过聊天模型读的是聊天消息。因此,接下来我们需要将示 例集实例化成聊天模型可以读懂的聊天消息。对于 LangChain 就需要创建一个
FewShotChatMessagePromptTemplate 对象来实例化示例集。 FewShotChatMessagePromptTemplate 是一个提示词模板,专门用来将示例集实例化为聊天消 息,用法如下所示:
python
from langchain_core.prompts import ChatPromptTemplate,FewShotChatMessagePromptTemplate
examples = [
{"input": "2 🦜 2", "output": "4"},
{"input": "2 🦜 3", "output": "5"},
]
example_prompt = ChatPromptTemplate(
[
("human", "{input}"),
("ai", "{output}"),
]
)
few_shot_prompt = FewShotChatMessagePromptTemplate(
example_prompt=example_prompt, # ChatPromptTemplate,用于格式化单个示例
examples=examples, # 样本示例
)
print(few_shot_prompt.invoke({}).to_messages())可以得到示例集转化的聊天消息列表,结果如下:
python
[
HumanMessage(content='2 🦜 2', additional_kwargs={}, response_metadata=
{}),
AIMessage(content='4', additional_kwargs={}, response_metadata={}),
HumanMessage(content='2 🦜 3', additional_kwargs={}, response_metadata=
{}),
AIMessage(content='5', additional_kwargs={}, response_metadata={})
]先来看看 class langchain_core.prompts.few_shot.FewShotChatMessagePromptTemplate ,它也实 现了标准的 Runnable 接口。
类初始化参数说明:
- examples :样本示例。
- example_prompt :ChatPromptTemplate,用于格式化单个示例
类方法说明:
- .invoke() 方法:此方法与其他 Runnable 实例的 .invoke() 方法类似。输入一个字典给 它,返回完整的提示内容 PromptValue :
- PromptValue 的 to_string() 方法可以将提示值作为【字符串】返回。
- PromptValue 的 to_messages() 方法可以将提示作为【消息列表】返回。
最后,得到示例集消息列表后,就可以带上一起发起请求:
python
final_prompt = ChatPromptTemplate(
[
("system", "你是一个神奇的数学奇才。"),
few_shot_prompt,
("human", "{input}"),
]
)
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-4o-mini")
chain = final_prompt | model
chain.invoke({"input": "What is 2 🦜 9?"}).pretty_print()结果如下:
python
================================== Ai Message ==================================
11使用案例
案例一:推理引导
我们希望输入: 《教父》和《星球大战》的导演来自同一个国家吗?
让聊天模型可以先分析再得出结论,而不是直接得出结论。分析过程需要展示出来,示例如下:
python
model = ChatOpenAI(model="gpt-4o-mini")
# 文本提示词模板
example_prompt = PromptTemplate.from_template("Question: {question}\n{answer}")
# 创建示例集
examples = [
{
"question": "李白和杜甫,谁更长寿?",
"answer": """
是否需要后续问题:是的。
后续问题:李白享年多少岁?
中间答案:李白享年61岁。
后续问题:杜甫享年多少岁?
中间答案:杜甫享年58岁。
所以最终答案是:李白
"""
},
{
"question": "腾讯的创始人什么时候出生?",
"answer": """
是否需要后续问题:是的。
后续问题:腾讯的创始人是谁?
中间答案:腾讯由马化腾创立。
后续问题:马化腾什么时候出生?
中间答案:马化腾出生于1971年10月29日。
所以最终答案是:1971年10月29日
""",
},
{
"question": "孙中山的外祖父是谁?",
"answer": """
是否需要后续问题:是的。
后续问题:孙中山的母亲是谁?
中间答案:孙中山的母亲是杨太夫人。
后续问题:杨太夫人的父亲是谁?
中间答案:杨太夫人的父亲是杨胜辉。
所以最终答案是:杨胜辉
""",
},
{
"question": "电影《红高粱》和《霸王别姬》的导演来自同一个国家吗?",
"answer": """
是否需要后续问题:是的。
后续问题:《红高粱》的导演是谁?
中间答案:《红高粱》的导演是张艺谋。
后续问题:张艺来自哪里?
中间答案:中国。
后续问题:《霸王别姬》的导演是谁?
中间答案:《霸王别姬》的导演是陈凯歌。
后续问题:陈凯歌来自哪里?
中间答案:中国。
所以最终答案是:是
""",
},
]
print(example_prompt.invoke(examples[0]).to_string())结果如下:
python
Question: 李白和杜甫,谁更长寿?
是否需要后续问题:是的。
后续问题:李白享年多少岁?
中间答案:李白享年61岁。
后续问题:杜甫享年多少岁?
中间答案:杜甫享年58岁。
所以最终答案是:李白接下来我们需要格式化完整的样本提示。此时可以创建一个 FewShotPromptTemplate 对象来初 始化少样本提示模板。其接收少量示例和少量示例的格式化程序。如下所示:
python
from langchain_core.prompts import FewShotPromptTemplate
prompt = FewShotPromptTemplate(
examples=examples,
example_prompt=example_prompt, # PromptTemplate,用于格式化单个示例
suffix="Question: {input}", # 放在示例之后的提示模板字符串。
input_variables=["input"], # 变量的名称列表,这些变量的值需要作为提示词的输入。
)
print(
prompt.invoke({"input": "《教父》和《星球大战》的导演来自同一个国家吗?"}).to_string()
)结果如下
python
Question: 李白和杜甫,谁更长寿?
是否需要后续问题:是的。
后续问题:李白享年多少岁?
中间答案:李白享年61岁。
后续问题:杜甫享年多少岁?
中间答案:杜甫享年58岁。
所以最终答案是:李白
Question: 腾讯的创始人什么时候出生?
是否需要后续问题:是的。
后续问题:腾讯的创始人是谁?
中间答案:腾讯由马化腾创立。
后续问题:马化腾什么时候出生?
中间答案:马化腾出生于1971年10月29日。
所以最终答案是:1971年10月29日
Question: 孙中山的外祖父是谁?
是否需要后续问题:是的。
后续问题:孙中山的母亲是谁?
中间答案:孙中山的母亲是杨太夫人。
后续问题:杨太夫人的父亲是谁?
中间答案:杨太夫人的父亲是杨胜辉。
所以最终答案是:杨胜辉
Question: 电影《红高粱》和《霸王别姬》的导演来自同一个国家吗?
是否需要后续问题:是的。
后续问题:《红高粱》的导演是谁?
中间答案:《红高粱》的导演是张艺谋。
后续问题:张艺来自哪里?
中间答案:中国。
后续问题:《霸王别姬》的导演是谁?
中间答案:《霸王别姬》的导演是陈凯歌。
后续问题:陈凯歌来自哪里?
中间答案:中国。
所以最终答案是:是
Question: 《教父》和《星球大战》的导演来自同一个国家吗?通过为模型提供这样的示例,我们可以引导模型做出更好的响应。
来看下 class langchain_core.prompts.few_shot.FewShotPromptTemplate ,它也实 现了标准的 Runnable 接口。
类初始化参数说明:
- examples :样本示例。
- example_prompt :PromptTemplate,用于格式化单个示例
- prefix :放在示例前面的提示模板字符串。
- suffix :放在示例之后的提示模板字符串。
- input_variables :变量的名称列表,这些变量的值需要作为提示词的输入。
类方法说明:
- .invoke() 方法:此方法与其他 Runnable 实例的 .invoke() 方法类似。输入一个字典给提 示符模板,返回完整的提示内容 PromptValue :
- PromptValue 的 to_string() 方法可以将提示值作为【字符串】返回。
- PromptValue 的 to_messages() 方法可以将提示作为【消息列表】返回。
接下来让我们调用聊天模型看看结果,完整代码如下:
python
from langchain_core.prompts import FewShotChatMessagePromptTemplate, FewShotPromptTemplate, PromptTemplate
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-4o-mini")
# 文本提示词模板
example_prompt = PromptTemplate.from_template("Question: {question}\n{answer}")
# 创建示例集
examples = [
{
"question": "李白和杜甫,谁更长寿?",
"answer": """
是否需要后续问题:是的。
后续问题:李白享年多少岁?
中间答案:李白享年61岁。
后续问题:杜甫享年多少岁?
中间答案:杜甫享年58岁。
所以最终答案是:李白
"""
},
{
"question": "腾讯的创始人什么时候出生?",
"answer": """
是否需要后续问题:是的。
后续问题:腾讯的创始人是谁?
中间答案:腾讯由马化腾创立。
后续问题:马化腾什么时候出生?
中间答案:马化腾出生于1971年10月29日。
所以最终答案是:1971年10月29日
""",
},
{
"question": "孙中山的外祖父是谁?",
"answer": """
是否需要后续问题:是的。
后续问题:孙中山的母亲是谁?
中间答案:孙中山的母亲是杨太夫人。
后续问题:杨太夫人的父亲是谁?
中间答案:杨太夫人的父亲是杨胜辉。
所以最终答案是:杨胜辉
""",
},
{
"question": "电影《红高粱》和《霸王别姬》的导演来自同一个国家吗?",
"answer": """
是否需要后续问题:是的。
后续问题:《红高粱》的导演是谁?
中间答案:《红高粱》的导演是张艺谋。
后续问题:张艺来自哪里?
中间答案:中国。
后续问题:《霸王别姬》的导演是谁?
中间答案:《霸王别姬》的导演是陈凯歌。
后续问题:陈凯歌来自哪里?
中间答案:中国。
所以最终答案是:是
""",
},
]
# 消息通过提示词模板构建出来
# FewShotPromptTemplate 针对文本、消息
few_shot_prompt = FewShotPromptTemplate(
examples=examples,
example_prompt=example_prompt, # PromptTemplate,用于格式化单个示例
suffix="Question: {input}", # suffix表示放在示例之后的模板字符串
input_variables=["input"], # 输入变量列表
)
chain = few_shot_prompt | model
chain.invoke({"input": "《教父》和《星球大战》的导演是否来自一个国家?"}).pretty_print()结果如下:
python
================================== Ai Message ==================================
是否需要后续问题:是的。
后续问题:《教父》的导演是谁?
中间答案:《教父》的导演是弗朗西斯·福特·科波拉。
后续问题:弗朗西斯·福特·科波拉来自哪里?
中间答案:弗朗西斯·福特·科波拉来自美国。
后续问题:《星球大战》的导演是谁?
中间答案:《星球大战》的导演是乔治·卢卡斯。
后续问题:乔治·卢卡斯来自哪里?
中间答案:乔治·卢卡斯也来自美国。
所以最终答案是:是案例二:使用示例数据增强 LangChain 信息提取能力
实现一个基于 LangChain 的结构化信息提取系统, 专门从文本中提取人物相关信息。
例如我们希望,对于输入以下文本:
"篮球场上,身高两米的中锋王伟默契地将球传给一米七的后卫挚友李明,完成一记绝杀。这对老友 用十年配合弥补了身高的差距。"
代码会提取出结构化数据,如下所示:
python
people=[
Person(name="王伟", height_in_meters="2", skin_color=None, hair_color=None),
Person(name="李明", height_in_meters="1.7", skin_color=None,hair_color=None)
]实现如下:
第一步:定义结构化返回对象。

第二步:定义两个关键示例,每个示例中包含【文本】和【希望输出】:
- 无人物场景:文本中没有人名,期望返回空列表
- 部分信息场景:只有名字,其他字段缺失

第三步:定义提示词模板。

第四步:构造请求的消息列表。处理逻辑:
- 遍历每个示例对:文本、期望输出
- 根据 是否有人员信息 生成自然语言响应: "检测到人" or "未检测到人"
- 使用 tool_example_to_messages 转换格式,将每个示例转换为模型可理解的消息格式

tool_example_to_messages 方法说明:
- 此功能处于测试阶段。它正在积极开发中,因此 API 可能会发生变化。
- 此方法是一个工具方法,它可以将单个示例转换为聊天模型可以识别的消息列表。
- 参数说明:
- input :输入字符串
- tool_calls :listBaseModel,表示为 Pydantic BaseModel 的工具调用列表
- ai_response :可选的。如果提供,将是最终 AIMessage 的内容。
- 返回值:listBaseMessage 消息列表
测试一下:
python
# 实例化提示词
formatted_prompt = prompt_template.invoke({
"example_messages": example_messages,
"new_message": "篮球场上,身高两米的中锋王伟默契地将球传给一米七的后卫挚友李明,完成
一记绝杀。"
"这对老友用十年配合弥补了身高的差距。"
})
# 打印
for message in formatted_prompt.to_messages():
message.pretty_print()结果如下:
python
================================ System Message================================
你是一个提取信息的专家,只从文本中提取相关信息。如果您不知道要提取的属性的值,属性值返回
null
================================ Human Message=================================
海洋是广阔而蓝色的。它有两万多英尺深。
================================== Ai Message==================================
Tool Calls:
Data (f81f0c81-108d-4c06-88dc-9e5f5289749e)
Call ID: f81f0c81-108d-4c06-88dc-9e5f5289749e
Args:
people: []
================================= Tool Message=================================
You have correctly called this tool.
================================== Ai Message==================================
未检测到人
================================ Human Message=================================
小强从中国远行到美国。
================================== Ai Message==================================
Tool Calls:
Data (ace46c82-07e0-455c-aaef-c13da7328e45)
Call ID: ace46c82-07e0-455c-aaef-c13da7328e45
Args:
people: [{'name': '小强', 'hair_color': None, 'skin_color': None,
'height_in_meters': None}]
================================= Tool Message=================================
You have correctly called this tool.
================================== Ai Message==================================
检测到人
================================ Human Message=================================
篮球场上,身高两米的中锋王伟默契地将球传给一米七的后卫挚友李明,完成一记绝杀。这对老友用十
年配合弥补了身高的差距。消息已经被我们构造成功!可以看到,一个示例经过转换构建出了4条消息: HumanMessage 、 AiMessage(tool) 、 ToolMessage 、 AiMessage 。
第五步:初始化模型并绑定结构化输出模式,最后构件链,并调用。
python
from langchain_openai import ChatOpenAI
# 定义结构化输出模型,自动解析为 Pydantic 对象
model = ChatOpenAI(model="gpt-4o-mini")
structured_model = model.with_structured_output(schema=Data)
chain = prompt_template | structured_model
result = chain.invoke({
"example_messages": example_messages,
"new_message": "篮球场上,身高两米的中锋王伟默契地将球传给一米七的后卫挚友李明,完成
一记绝杀。"
"这对老友用十年配合弥补了身高的差距。"
})
print("\n")
print(result)结果如下:
python
people=[
Person(name='王伟', hair_color=None, skin_color=None,height_in_meters='2.0'),
Person(name='李明', hair_color=None, skin_color=None,height_in_meters='1.7')
]完整代码:



总结:该案例展示了 LangChain 在结构化信息提取中的核心能力:通过Pydantic定义输出模式、少样 本学习引导模型行为、提示词模板动态组装上下文,以及链式调用简化流程。最终实现从非结构化文 本中精准提取结构化数据。
示例选择器(Example selectors)
概念
一旦我们有了示例数据集,就需要考虑提示中应该有多少个示例。关键的权衡是,更多的示例通常会 提高性能,但更大的提示会增加成本和延迟。超过某个阈值,太多示例可能会开始混淆模型。
找到正确数量的示例在很大程度上取决于模型、任务、示例的质量以及成本和延迟限制。有趣的是, 模型越好,它需要精准的示例就越少。但其实,最佳的方法是使用不同数量的示例进行一些实验。
若此时我们有【大量】的示例数据集。对于大模型来说,就没必要全部使用与参考。我们需要有一种 方法可以根据给定的输入,从数据集中选择示例。
在 LangChain 中,示例选择器就可以帮我们从一组【示例的集合】中根据具体策略选择正确的【示例 子集】构建少样本提示。
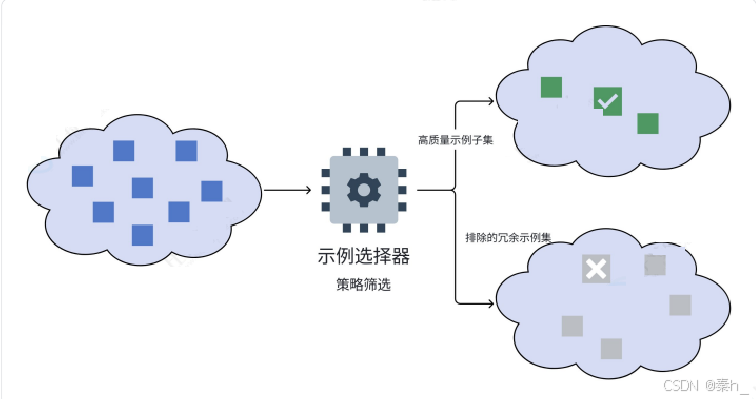
选择策略有:
- Length :根据特定【长度】内可以容纳的数量选择示例。
- Similarity :使用输入和示例之间的【语义相似性】来决定选择哪些示例。选择策略有:
- MMR :使用输入和示例之间的【最大边际相关性】来决定要选择哪些示例。
- Ngram :使用输入和示例之间的【ngram 重叠】来决定要选择哪些示例。
这些其实都是自然语言处理(NLP)里的相似性衡量问题。
按长度选择示例 (Length)
当我们担心构造提示时,将超过上下文窗口长度,根据特定长度内可以容纳的数量选择示例。对于较 长的输入,它将选择更少的示例来包含;而对于较短的输入,它将选择更多示例。
实现按长度选择示例的示例选择器是:
class langchain_core.example_selectors.length_based.LengthBasedExampleSelecto r 类,其参数如下:
- example_prompt :PromptTemplate,用于格式化示例的提示模板。
- examples :模板所需的示例列表。
- max_length :提示的最大长度,超过该长度将剪切示例。
- get_text_length :测量提示长度的方法。默认为字数统计
内置方法:
- add_example(example: dictstr, str) :将新示例添加到列表中。
输入:一个字典,其中键作为输入变量,值作为其值。
- select_examples(input_variables: dictstr, str) → listdict :根据输 入长度选择要使用的示例。
输入:一个字典,其中键作为输入变量,值作为其值。
输出:要包含在提示中的示例列表。
演示一下如何使用长度示例选择器:
- 给一个示例集,输入和输出互为反义词
- 定义 PromptTemplate 字符串模板,包含输入和输出两个"占位符"
- 定义 LengthBasedExampleSelector 长度示例选择器,设置初始示例集与最大长度
- 定义一个 FewShotPromptTemplate 模板对象,用于实例化示例,将示例转化为聊天消息
- 打印消息结果
python
# 反义词示例集合
examples = [
{"input": "happy", "output": "sad"},
{"input": "tall", "output": "short"},
{"input": "energetic", "output": "lethargic"},
{"input": "sunny", "output": "gloomy"},
{"input": "windy", "output": "calm"},
]
# 示例模板(文本)
example_prompt = PromptTemplate.from_template("Input: {input}\nOutput: {output}")
# 示例选择器(长度)
example_selector = LengthBasedExampleSelector(
examples=examples,
example_prompt=example_prompt,
max_length=25, # 格式化示例的最大长度
# 用于获取字符串长度的函数,用于确定包含哪些示例。
# 如果没有指定,它是作为默认值提供的。
# 该函数返回一个整数,表示字符串中由换行符或空格分隔的"单词"数量
# get_text_length: Callable[[str], int] = lambda x: len(re.split("\n| ", x))
)
# 少样本模板
# 转换 Message
few_shot_prompt = FewShotPromptTemplate(
example_selector=example_selector, # 示例选择器
example_prompt=example_prompt,
prefix="给出每个输入的反义词:",
suffix="Input: {adjective}\nOutput: ",
input_variables=["adjective"],
)
print(
few_shot_prompt.invoke({"adjective": "worried"}).to_messages()[0].content
)按语义相似性选择示例(Similarity)
概念
什么是语义相似?它是衡量文本在【含义上】的接近程度。例如下述两段文本:
text1 = "我喜欢猫" text2 = "我讨厌狗"
这两段文本表面相似度低,但语义上都是表达对动物的态度。 再例如:
text1 = "苹果很甜" text2 = "苹果市值创新高"
"苹果"可以指水果或公司,语义相似可以解决一词多义问题,因此这两段文本语义上不相似。
LangChain 能根据输入和示例之间的语义相似性来决定选择哪些示例,它通过查找与输入具有最大余 弦相似性的嵌入示例来实现这一点。
实现
实现按语义相似性选择示例的示例选择器是: class langchain_core.example_selectors.semantic_similarity.SemanticSimilarity ExampleSelector 类,
内置方法:
from_examples() :根据示例集生成语义相似示例选择器
- 输入:
- examples :示例列表
- embeddings :初始化的嵌入 API 接口,如 OpenAIEmbeddings()
- vectorstore_cls :向量存储数据库接口类。
- k :最终要选择的示例的数量。默认值为 4。
- 输出:语义相似性示例选择器
add_example(example: dictstr, str) :将新示例添加到列表中。
- 输入:一个字典,其中键作为输入变量,值作为其值。
select_examples(input_variables: dictstr, str) → listdict :根据输 入选择要使用的示例。
- 输入:一个字典,其中键作为输入变量,值作为其值。
- 输出:要包含在提示中的示例列表。
演示一下如何使用语义相似示例选择器:
python
# 反义词示例集合
examples = [
{"input": "happy", "output": "sad"},
{"input": "tall", "output": "short"},
{"input": "energetic", "output": "lethargic"},
{"input": "sunny", "output": "gloomy"},
{"input": "windy", "output": "calm"},
]
# 示例模板(文本)
example_prompt = PromptTemplate.from_template("Input: {input}\nOutput: {output}")
# 示例选择器(语义相似性)
example_selector = SemanticSimilarityExampleSelector.from_examples(
examples, # 示例集
OpenAIEmbeddings(model="text-embedding-3-large"), # 使用嵌入模型的能力度量语义
Chroma, # 存储向量:向量数据库
k=2, # 生成示例的数量
)
# 少样本模板
# 转换 Message
few_shot_prompt = FewShotPromptTemplate(
example_selector=example_selector, # 示例选择器
example_prompt=example_prompt,
prefix="给出每个输入的反义词:",
suffix="Input: {adjective}\nOutput: ",
input_variables=["adjective"],
)
print(
few_shot_prompt.invoke({"adjective": "worried"}).to_messages()[0].content
)按最大边际相关性选择示例(MMR)
概念
什么是最大边际相关性?它是一种重新排序算法,它使用语义相似性作为基础工具,从一个候选集中 挑选出一组既能代表查询主题又彼此多样化的结果。
听起来好像和语义相似性类似,用一个例子看下两者的区别:
- 【语义相似性】就像面试官衡量每个应聘者与职位要求的匹配度。他会给每个应聘者打一个分数。
- 【最大边际相关性】就像团队经理(MMR算法)要组建一个团队。目标是选出一组"精华"结果, 而不是一个单一结果:
- 每个成员都要满足基本职位要求(满足相关性)。
- 但经理不希望团队里全是只会一种技能的程序员。他需要前端、后端、算法、测试等不同专长 的人,以确保团队能力全面、减少冗余(新颖性/多样性)。
- 经理的策略是:先招一个最匹配的技术大牛(第一步),然后接下来招的人,既要技术达标, 又要和已招的人技能互补(迭代过程)。
了解下使用最大边际相关性的场景,更能让我们理解其概念:
- 语义相似性使用场景:搜索引擎的基础排序、重复检测、聚类、语义搜索。
- MMR 使用场景:
- 推荐系统:推荐与用户兴趣相关但又不同类型的物品,避免"信息茧房"。
- 文档摘要:从长文档中选择能代表主旨又包含不同信息的句子,避免摘要内容重复。
- RAG (检索增强生成):在从知识库检索完一堆相关文档后,使用 MMR 进行去重和多样化筛选, 再交给LLM生成答案,能有效提升答案质量和减少幻觉。
实现
了解了相关概念后,LangChain 提供了按最大边际相关性选择示例的能力,该示例选择器是: class langchain_core.example_selectors.semantic_similarity.MaxMarginalRelevan ceExampleSelector 类,内置方法:
from_examples() :根据示例集生成 MMR 示例选择器
- 输入:
- examples :示例列表
- embeddings :初始化的嵌入 API 接口,如 OpenAIEmbeddings()
- vectorstore_cls :向量存储数据库接口类。
- k :最终要选择的示例的数量。默认值为 4。
- 输出:MMR 示例选择器
add_example(example: dictstr, str) :将新示例添加到列表中。
- 输入:一个字典,其中键作为输入变量,值作为其值。
select_examples(input_variables: dictstr, str) → listdict :根据输 入选择要使用的示例。
- 输入:一个字典,其中键作为输入变量,值作为其值。
- 输出:要包含在提示中的示例列表。
演示一下如何使用 MMR 示例选择器:
python
# 反义词示例集合
examples = [
{"input": "happy", "output": "sad"},
{"input": "tall", "output": "short"},
{"input": "energetic", "output": "lethargic"},
{"input": "sunny", "output": "gloomy"},
{"input": "windy", "output": "calm"},
]
# 示例模板(文本)
example_prompt = PromptTemplate.from_template("Input: {input}\nOutput: {output}")
# 示例选择器(MMR)
example_selector = MaxMarginalRelevanceExampleSelector.from_examples(
examples, # 示例集
OpenAIEmbeddings(model="text-embedding-3-large"), # 使用嵌入模型的能力度量语义
Chroma, # 存储向量:向量数据库
k=5, # 生成示例的数量
)
# 少样本模板
# 转换 Message
few_shot_prompt = FewShotPromptTemplate(
example_selector=example_selector, # 示例选择器
example_prompt=example_prompt,
prefix="给出每个输入的反义词:",
suffix="Input: {adjective}\nOutput: ",
input_variables=["adjective"],
)
print(
few_shot_prompt.invoke({"adjective": "worried"}).to_messages()[0].content
)通过 ngram 重叠选择示例(Ngram)
概念
什么是【ngram】?ngram 指一个文本序列中连续的 n 个词(word) 或字符(character)。
什么是【ngram 重叠】?通过计算它们之间共同拥有的 ngram 数量来一种衡量两段文本相似度的方 法。
例如下述两段文本:
text1 = "苹果手机很好用" (分词后: 苹果 手机 很 好用 )
text2 = "这款手机很好用" (分词后: 这款 手机 很 好用 )
这两段文本单词重复度很高,连续三个词的相同的情况也存在,因此 ngram 重叠高。
再看个例子:
text1 = 苹果手机很好用" (分词后: 苹果 手机 很 好用 )
text2 = "iPhone 非常不错" (分词后: iPhone 非常 不错 )
这两段文本在含义上非常相似,但它们的 ngram 重叠度为 0。
因此,传统 ngram 重叠是一种表面形式的匹配。它只关心词是否完全一样,但对于同义词却无法处 理。
什么是【语义 ngram 重叠】?不再比较词本身,而是比较词背后的语义向量(Embedding)。也就 是说,它不是看两个词 苹果 和 iPhone 的字面是否相同,而是计算它们在语义空间中的向量是 否相似。如果相似度超过某个阈值,就认为它们"重叠"了。还是看这个例子:
text1 = 苹果手机很好用" (分词后: 苹果 手机 很 好用 )
text2 = "iPhone 非常不错" (分词后: iPhone 非常 不错 )
- 计算 苹果 和 iPhone 的向量相似度 → 得分 0.95 (很高,视为重叠)
- 计算 手机 和 iPhone 的向量相似度 → 得分 0.88 (很高,但可能不会同时计分,取决于算法设 计,避免重复计算)
- 计算 很 和 非常 的向量相似度 → 得分 0.90 (很高,视为重叠)
- 计算 好用 和 不错 的向量相似度 → 得分 0.82 (很高,视为重叠)
- 最终,语义上的 unigram 重叠度可能为 3 或 4(非常相似!)。
那么语义 ngram 重叠的使用场景是什么?语义 ngram 重叠常用于需要更精准语义评估的场景,例如 剽窃检测 , 能够发现那些改换了词汇但保留了核心思想的"智能"剽窃。
实现
LangChain 实现按语义 ngram 重叠选择示例的示例选择器是: class langchain_community.example_selectors.ngram_overlap.NGramOverlapExample Selector 类,其参数如下:
- example_prompt :PromptTemplate,用于格式化示例的提示模板。
- examples :模板所需的示例列表。
- threshold :算法停止的阈值。默认设置为 -1.0。
- 对于负阈值:按 重叠分数 对示例进行排序,但不排除任何示例。
- 对于等于 0.0 的阈值:按 重叠分数 进行排序,并排除与输入没有 ngram 重叠的示例。
- 对于大于 1.0 的阈值:排除所有示例,并返回一个空列表。
内置方法:
- add_example(example: dictstr, str) :将新示例添加到列表中。
- 输入:一个字典,其中键作为输入变量,值作为其值。
- select_examples(input_variables: dictstr, str) → listdict :返回 根据输入得到的重叠分数排序的降序示例列表。
- 输入:一个字典,其中键作为输入变量,值作为其值。
- 输出:要包含在提示中的示例列表。
演示一下如何使用语义相似示例选择器;
python
# 示例模板(文本)
example_prompt = PromptTemplate.from_template("Input: {input}\nOutput: {output}")
examples = [
{"input": "See Spot run.", "output": "看见Spot跑。"},
{"input": "My dog barks.", "output": "我的狗叫。"},
{"input": "Spot can run.", "output": "Spot可以跑。"},
]
# 示例选择器(NGram)
example_selector = NGramOverlapExampleSelector(
examples=examples,
example_prompt=example_prompt,
threshold=1.0, # 阈值.
# 负值代表不相干的示例也被筛选出来
# 0.0,输出结果是只与输入重叠的示例
# 大于等于1.0,排除所有示例,返回空列表
)
few_shot_prompt = FewShotPromptTemplate(
example_selector=example_selector, # 示例选择器
example_prompt=example_prompt,
prefix="给出每个输入的中文翻译:",
suffix="Input: {sentence}\nOutput: ",
input_variables=["sentence"],
)
print(
few_shot_prompt.invoke({"sentence": "Spot can run fast."}).to_messages()[0].content
)