图5展示了经预处理后的示例场景,其对应占据网格的维度为 1059 × 478 × 1059 1059 \times 478 \times 1059 1059×478×1059。为适配模型训练,沿 x y xy xy平面与 z z z轴方向,将整体场景划分为尺寸为 ( 50 , h v o x , 50 ) (50, h_{vox}, 50) (50,hvox,50) 的小型分块,其中 y y y轴为高度轴。分块采样规则为 occ i − 25 : i + 25 , : , k − 25 : k + 25 \text{occ}i-25: i+25,:, k-25: k+25 occi−25:i+25,:,k−25:k+25, i i i、 k k k 分别代表场景在 x x x轴、 z z z轴方向的采样坐标。单个分块的体素高度 h v o x ≤ 478 h_{vox} \le 478 hvox≤478,由该分块内位置最高的被占据体素决定。
训练阶段,在分块的占据网格内采样坐标点 r v o x = ( x v o x , y v o x , z v o x ) r_{vox}=(x_{vox}, y_{vox}, z_{vox}) rvox=(xvox,yvox,zvox),坐标满足 0 ≤ x v o x , z v o x ≤ 50 0 \le x_{vox}, z_{vox} \le 50 0≤xvox,zvox≤50 且 0 ≤ y v o x ≤ h v o x 0 \le y_{vox} \le h_{vox} 0≤yvox≤hvox,同时提取每个坐标对应的真实占据值 o ˉ \bar{o} oˉ。随后对采样坐标执行归一化操作:
r = 2 ⋅ ( r v o x / d ) − 1 r=2 \cdot (r_{vox} / d)-1 r=2⋅(rvox/d)−1
式中 d = ( d x , d y , d z ) d=(d_{x}, d_{y}, d_{z}) d=(dx,dy,dz) 为各坐标轴对应的归一化尺度。
分块的真实高度计算公式为:
h ~ = 2 ⋅ ( h v o x / 50 ) − 1 \tilde{h}=2 \cdot (h_{vox} / 50)-1 h~=2⋅(hvox/50)−1
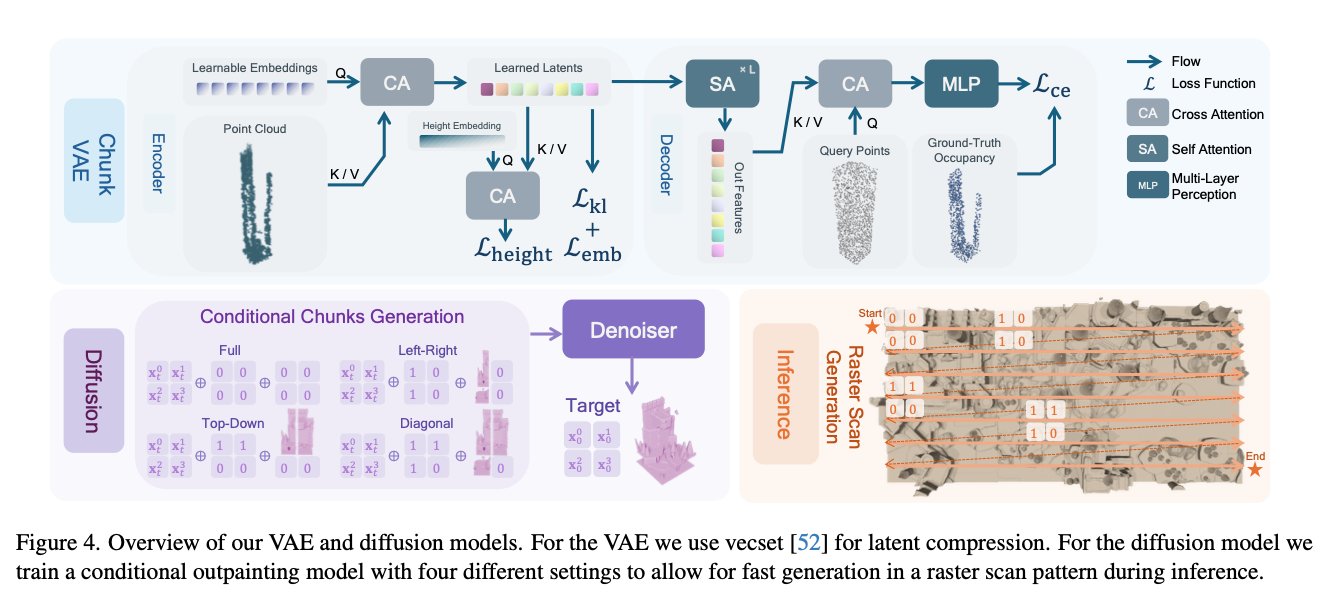
编码器 ε \varepsilon ε 负责将高度各不相同的场景分块集合 P P P,压缩为维度统一的向量集。对于任意分块 P i P_i Pi,首先从中均匀采样固定数量的点云 p ∈ R N p × 3 p \in \mathbb{R}^{N_p \times 3} p∈RNp×3,点云总数记为 N p N_p Np。本文参考3DShape2Vecset52的架构,使用交叉注意力(CA)层对点云特征进行聚合,依托一组可学习的固定特征大幅缩减特征令牌数量,得到紧凑的特征表示。
随后通过全连接(FC)层预测隐特征的均值与方差,并运用重参数化技巧21生成场景分块的嵌入特征,最终输出 z p = E ( p ) ∈ R V × c z^p=E(p) \in \mathbb{R}^{V \times c} zp=E(p)∈RV×c。其中 V V V 为向量数量, c c c 为特征通道数。
实验发现,该基础结构容易出现变分自编码器典型的后验坍缩42问题。为此本文设计了一种新型正则化方案:从同一个场景分块 P i P_i Pi 中额外采样一组点云 q ∈ R N p × 3 q \in \mathbb{R}^{N_p \times 3} q∈RNp×3,约束两组点云对应的嵌入特征保持一致,对应的损失函数为:
L e m b = ( z p − z q ) 2 L_{emb}=(z^p-z^q)^2 Lemb=(zp−zq)2
具体实现方式为:学习高度嵌入特征 e h ∈ R 1 × c e_h \in \mathbb{R}^{1 \times c} eh∈R1×c,将其与隐特征执行交叉注意力运算,再通过全连接层得到预测高度 h ¨ = FC ( CA ( z p , e h ) ) \ddot{h}=\text{FC}(\text{CA}(z^p, e_h)) h¨=FC(CA(zp,eh))。高度损失函数定义为:
L h e i g h t = ( h ^ − h ~ ) 2 L_{height}=(\hat{h}-\tilde{h})^2 Lheight=(h^−h~)2
其中 h ^ \hat{h} h^ 为模型预测高度, h ~ \tilde{h} h~ 为分块真实高度。
3.2.2 解码器
解码器将嵌入特征依次经过 L L L 层自注意力(SA)层处理,得到输出特征 f o u t = SA ( L ) ∘ ⋯ ∘ SA ( 1 ) ( z p ) f_{out} = \text{SA}^{(L)} \circ \dots \circ \text{SA}^{(1)}(z^p) fout=SA(L)∘⋯∘SA(1)(zp)。随后将输出特征输入三平面分支或向量集分支,解码得到空间占据信息。
三平面分支
对于三平面分支,先将 f o u t f_{out} fout 重塑为三平面结构,再参照LRM16的方式通过反卷积完成上采样,最终得到特征网格 T ∈ R 3 × h t r i × w t r i × c t r i T \in \mathbb{R}^{3 \times h_{tri} \times w_{tri} \times c_{tri}} T∈R3×htri×wtri×ctri。
按照3.1节规则对查询点 r t r i r_{tri} rtri 做归一化,此时归一化尺度设置为 d = ( 50 , 50 ⋅ S , 50 ) d=(50, 50 \cdot S, 50) d=(50,50⋅S,50),尺度因子 S S S 用于进一步压缩 y y y轴方向的坐标。为保证坐标取值落在 − 1 , 1 -1, 1−1,1 区间内、满足三平面采样要求,本文对坐标进行截断处理。本文定义三平面左边界与下边界为 − 1 -1 −1,右边界与上边界为 1 1 1。
通过双线性插值从三平面中提取特征并完成特征拼接,再经由全连接层预测查询点的占据值 o ^ r \hat{o}_r o^r。
向量集分支
向量集分支中,查询点 r v e c r_{vec} rvec 的归一化尺度统一设为 d = ( 50 , 50 , 50 ) d=(50,50,50) d=(50,50,50)。依托交叉注意力机制完成占据值预测,计算方式如下:
o ^ r = FC ( CA ( f o u t , PE ( r v e c ) ) ) \hat{o}r=\text{FC}(\text{CA}(f{out}, \text{PE}(r_{vec}))) o^r=FC(CA(fout,PE(rvec)))
其中 PE \text{PE} PE 代表查询点的傅里叶位置编码。
损失函数
本文采用二元交叉熵损失 L c e = BCE ( o ^ r , o ~ r ) L_{ce}=\text{BCE}(\hat{o}_r, \tilde{o}_r) Lce=BCE(o^r,o~r) 监督占据值预测, o ~ r \tilde{o}r o~r 为真实占据值;同时引入KL散度损失 L k l L{kl} Lkl 约束嵌入特征的分布,相关细节可参考Zhang等人的工作52。
模型总损失函数为:
L = λ k l L k l + λ e m b L e m b + λ c e L c e + λ h e i g h t L h e i g h t L=\lambda_{kl} L_{kl}+\lambda_{emb} L_{emb}+\lambda_{ce} L_{ce}+\lambda_{height} L_{height} L=λklLkl+λembLemb+λceLce+λheightLheight
本文采用DDPM15构建扩散概率模型。训练阶段,从场景中采样一组呈 2 × 2 2 \times 2 2×2 网格排布的相邻分块隐特征 { z 0 , z 1 , z 2 , z 3 } \{z^0, z^1, z^2, z^3\} {z0,z1,z2,z3},该组特征由变分自编码器编码得到,分块排布顺序见图4。
每一轮训练中,首先随机选取时间步 t ∈ 1 , T t \in 1, T t∈1,T,并采样高斯噪声 ϵ ∼ N ( 0 , I ) \epsilon \sim \mathcal{N}(0, I) ϵ∼N(0,I),将噪声叠加到嵌入特征组上,得到含噪隐特征 X t = { x t 0 , x t 1 , x t 2 , x t 3 } ∈ R 4 × V × c X_t=\{x_t^0, x_t^1, x_t^2, x_t^3\} \in \mathbb{R}^{4 \times V \times c} Xt={xt0,xt1,xt2,xt3}∈R4×V×c。其中 x t i ∈ R V × c x_t^i \in \mathbb{R}^{V \times c} xti∈RV×c 代表第 i i i 个分块在时间步 t t t 下的含噪隐特征。
扩散模型将含噪隐特征 x t x_t xt 作为输入,同时接收二值掩码与对应条件嵌入特征。掩码用于标记已生成的分块,条件嵌入特征则为外补绘制提供上下文信息。本文共设计四种约束配置,每种配置对应专属掩码 M M M 与条件嵌入特征 Z c o n d Z_{cond} Zcond,如图4所示。
E X , C , ϵ ∼ N ( 0 , I ) , t ∥ ϵ − ϵ θ ( ( X t ⊕ C ) , t ) ∥ 2 2 \mathbb{E}_{X, C, \epsilon \sim \mathcal{N}(0, I), t}\big\\\|\\epsilon-\\epsilon_\\theta\\left(\\left(X_t \\oplus C\\right), t\\right)\\\|_2\^2\\big EX,C,ϵ∼N(0,I),t∥ϵ−ϵθ((Xt⊕C),t)∥22
单场景实验采用图5中的预处理场景开展训练。实验不再单独采样小型分块,而是选取尺寸为 ( 100 , h v o x , 100 ) (100, h_{vox}, 100) (100,hvox,100) 的四分块 进行采样,该四分块由 2 × 2 2 \times 2 2×2 排布、尺寸为 ( 50 , h v o x , 50 ) (50, h_{vox}, 50) (50,hvox,50) 的小型分块构成。采样规则为 occ i − 50 : i + 50 , : , k − 50 : k + 50 \text{occ}i-50: i+50,:, k-50: k+50 occi−50:i+50,:,k−50:k+50,沿场景的 x x x 轴与 z z z 轴完成采样。实验总计采样10万个四分块,其中9.5万个作为训练集,5000个作为验证集。这些四分块彼此存在重叠,但因采样坐标不同,内容并不重复。
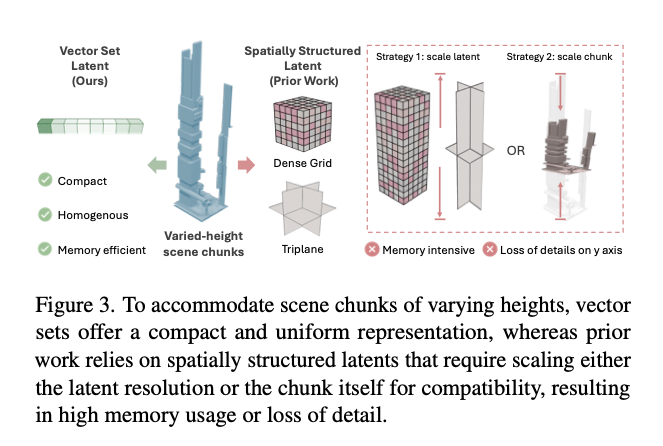
本文排除了稠密网格类方法31,33:稠密网格的显存占用会随分辨率呈三次方增长,而三平面仅为二次方增长;在本任务中,部分场景分块的高度可达其 x 、 z x、z x、z 轴维度的8.5倍,会进一步加剧稠密网格的显存消耗。与此同时,LT3SD33要求自编码器与扩散模型均执行多尺度训练,会显著增加整体训练耗时。
变分自编码器配置
三平面基线模型:设置隐特征数量 V = 3 × 4 2 V=3 \times 4^2 V=3×42,调整归一化尺度因子 S S S 与反卷积层数(反卷积层数决定模型输出分辨率),相关配置见表1。
向量集模型:设置向量数量 V = 16 V=16 V=16,该配置在保留几何保真度的同时,能够支撑扩散模型高效训练。
两类特征表示统一设置特征通道数 c = 64 c=64 c=64,单分块采样点云数量 N p = 4096 N_p=4096 Np=4096;三平面分支的输出通道数 c t r i = 40 c_{tri}=40 ctri=40。解码器共包含 L = 24 L=24 L=24 层自注意力层。所有变分自编码器模型均训练160轮,每次迭代会为每个分块采样4096个查询点,用于占据值的监督学习。
扩散模型配置
所有扩散模型均采用25层类UNet Transformer29作为去噪主干网络。三平面扩散模型基于变分自编码器输出的隐特征训练,三平面输出分辨率设为 h t r i = w t r i = 64 h_{tri}=w_{tri}=64 htri=wtri=64,尺度因子 S = 6 S=6 S=6。所有扩散模型统一训练320轮,批次大小设置为192。由于扩散模型会一次性生成 2 × 2 2 \times 2 2×2 网格内的4个分块,Transformer的输入令牌长度为 4 × V 4 \times V 4×V。
表3 不同变分自编码器主干网络的重建结果定量对比。 h ^ \hat{h} h^ 代表采用模型预测高度计算占据值, h ~ \tilde{h} h~ 代表采用真实高度计算占据值。
表3为各类模型的重建量化结果,可以看出向量集模型的重建效果优于所有三平面配置。实验分别使用**预测高度 h ^ \hat{h} h^与 真实高度 h ~ \tilde{h} h~**重构网格并计算倒角距离、F分数,两组结果数值高度接近,这也验证了本文高度预测模块具备较高的精度。
对于三平面模型而言,其性能受限于变分自编码器的输出分辨率:当输出分辨率从 3 × 32 2 3 \times 32^2 3×322 提升至 3 × 64 2 3 \times 64^2 3×642 时,模型重建效果逐步提升。但针对高层建筑场景,若建筑高度超出尺度因子 S = 6 S=6 S=6 的适配范围,三平面采样阶段的坐标截断操作会导致高层建筑结构无法完整重建。若将尺度因子 S S S 调整至8.5(匹配数据集内最高分块的高度), y y y 轴方向会被过度压缩,造成精度大幅下降,模型整体性能明显退化。
图6为规模 21 × 21 21 \times 21 21×21 的场景可视化结果。三平面模型无法还原精细的建筑细节,还易产生噪声伪影,这也是其FPD、KPD指标偏高的核心原因,问题根源在于 y y y 轴方向查询点的压缩处理。结合表2可知,向量集模型的训练速度约为三平面模型的2.5倍,显存占用仅为后者的一半。这是因为向量集对应的令牌总数更少,令牌数量仅为三平面模型的三分之一。