目录
[二、LocateAnything 整体框架架构](#二、LocateAnything 整体框架架构)
[三、核心创新 1:并行框解码(PBD)深度解析](#三、核心创新 1:并行框解码(PBD)深度解析)
[四、核心创新 2:LocateAnything-Data 大规模数据集](#四、核心创新 2:LocateAnything-Data 大规模数据集)
论文《LocateAnything: Fast and High-Quality Vision-Language Grounding with Parallel Box Decoding》超详细解读
版本信息:v1 提交于 2026 年 5 月 26 日,v2 修订版发布于 2026 年 5 月 27 日;DOI:10.48550/arXiv.2605.27365
所属领域:计算机视觉与模式识别 (cs.CV)、人工智能 (cs.AI)、机器学习 (cs.LG)、机器人学 (cs.RO)
作者团队:由 NVIDIA 联合香港理工大学、普林斯顿大学、南京大学等多所高校与企业研究者共同完成,核心作者包含 Shihao Wang、Shilong Liu、Zhiding Yu 等,是视觉语言模型(VLM)领域顶尖联合团队。
开源状态 :已开源轻量化版本 LocateAnything-3B(30 亿参数),支持主流部署框架,可覆盖多类视觉定位落地场景。
https://huggingface.co/nvidia/LocateAnything-3B

一、核心任务定义与行业背景
1. 核心任务界定
本文聚焦统一视觉几何定位任务,一套框架同时支持六大细分场景,覆盖当下工业界主流视觉定位需求:
- 视觉语言定位(Vision-Language Grounding):输入图像 + 自然语言指令,在图中定位文本描述的目标(如 "找出图中的红色水杯");
- 开放词汇目标检测:无固定类别限制,识别图像内所有目标并输出边界框;
- GUI 界面定位:智能体自动识别软件界面按钮、输入框等交互元素;
- 文档解析定位:定位文档内表格、文字、图片等版式元素;
- OCR 文本定位:精准框选图像中的文本区域;
- 图像 / 视频指点定位:基于视觉指向信号完成目标框选。
这类任务是机器人具身智能、自动驾驶、智能办公、视频安防、移动端 AI 交互的核心底层能力 ,对推理速度 和定位精度(尤其是高 IoU 精细定位) 均有严苛要求。
2. 现有主流技术路线与通用痛点
当前绝大多数视觉语言模型(如 Qwen-VL、LLaVA、Ferret 等)均采用坐标 Token 串行自回归解码方案,也是本文重点批判的技术范式。
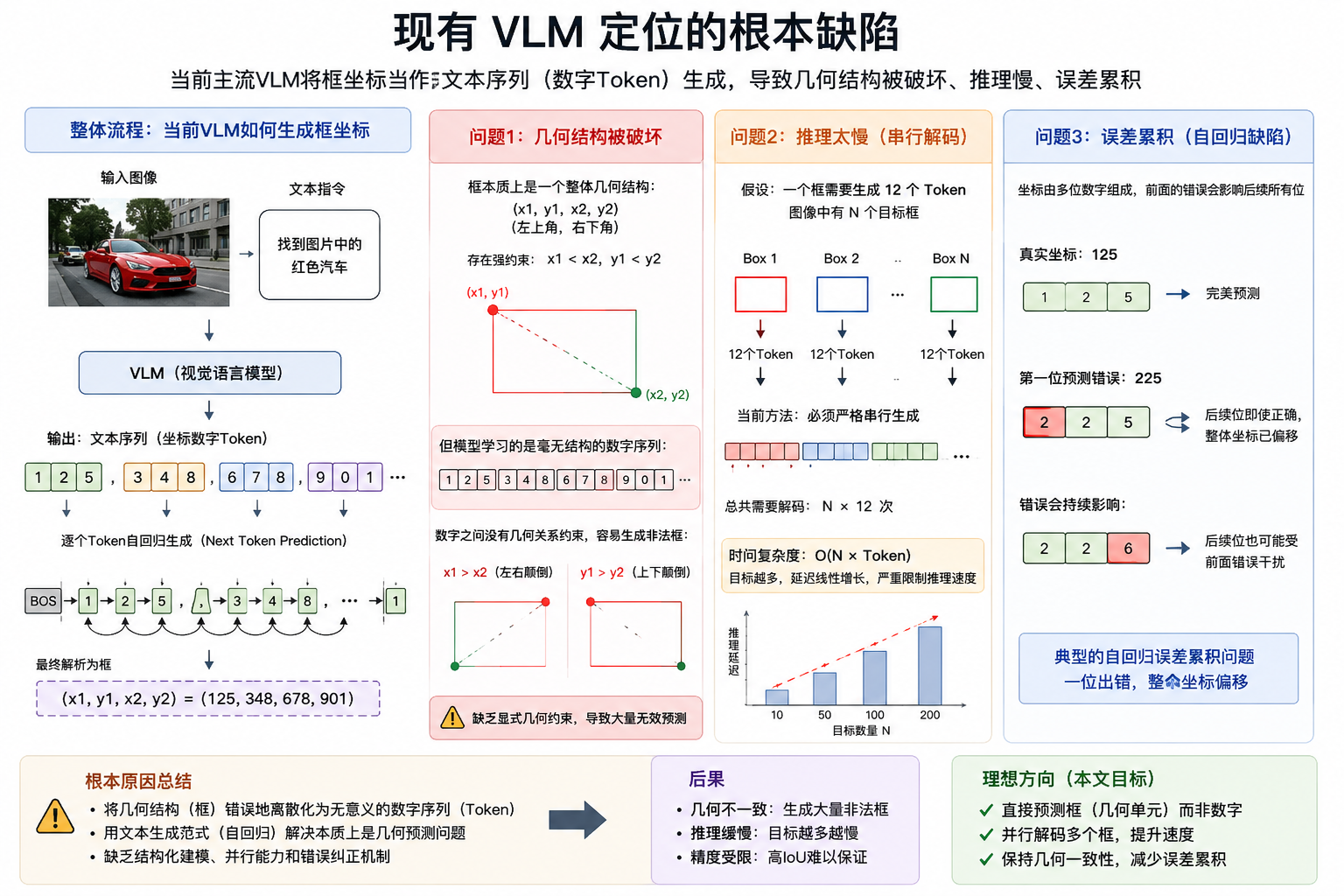
(1)传统范式工作原理
模型将表征目标的二维边界框(x ₁,y ₁,x ₂,y ₂) 拆解为多个独立一维坐标 Token,按照固定时序逐一生成:<bbox_start> → x₁ → y₁ → x₂ → y₂ → <bbox_end>。每一个 Token 的生成严格依赖前序所有 Token,属于典型的串行自回归逻辑。
行业内现有方案分为两类,但缺陷高度一致:
- 原生 Token 方案:复用大语言模型词表生成坐标,改造成本低,但解码速度慢、易出现幻觉;
- 新增专用 Token 方案:引入额外视觉定位 Token,精度略有提升,但仍无法摆脱串行时序依赖,且需要大规模重训。
(2)两大根本性瓶颈(论文核心切入点)
1.几何结构失配,高 IoU 定位精度差
边界框的四个坐标是强耦合几何单元 (天然满足x₂>x₁、y₂>y₁的空间约束),但逐 Token 独立学习、解码会割裂坐标间的关联。模型难以隐式学习几何规则,极易生成畸形框、坐标错位、非法边界框,在高 IoU(交并比)精细定位场景(如机器人抓取、医疗影像)误差尤为突出。
2.串行生成导致推理吞吐量瓶颈
自回归解码的时间复杂度为 O(K*N)(K为单目标框的 Token 数量,N为图像内目标总数)。目标越多,解码步数线性膨胀,推理时延急剧升高。该问题直接限制模型在实时机器人、海量视频流、端侧设备等低时延场景的落地。
简单类比:传统串行解码如同逐字念电话号码 ,必须按顺序逐个输出数字;而本文方案则是一次性输出完整号码,从底层重构解码逻辑。
二、LocateAnything 整体框架架构
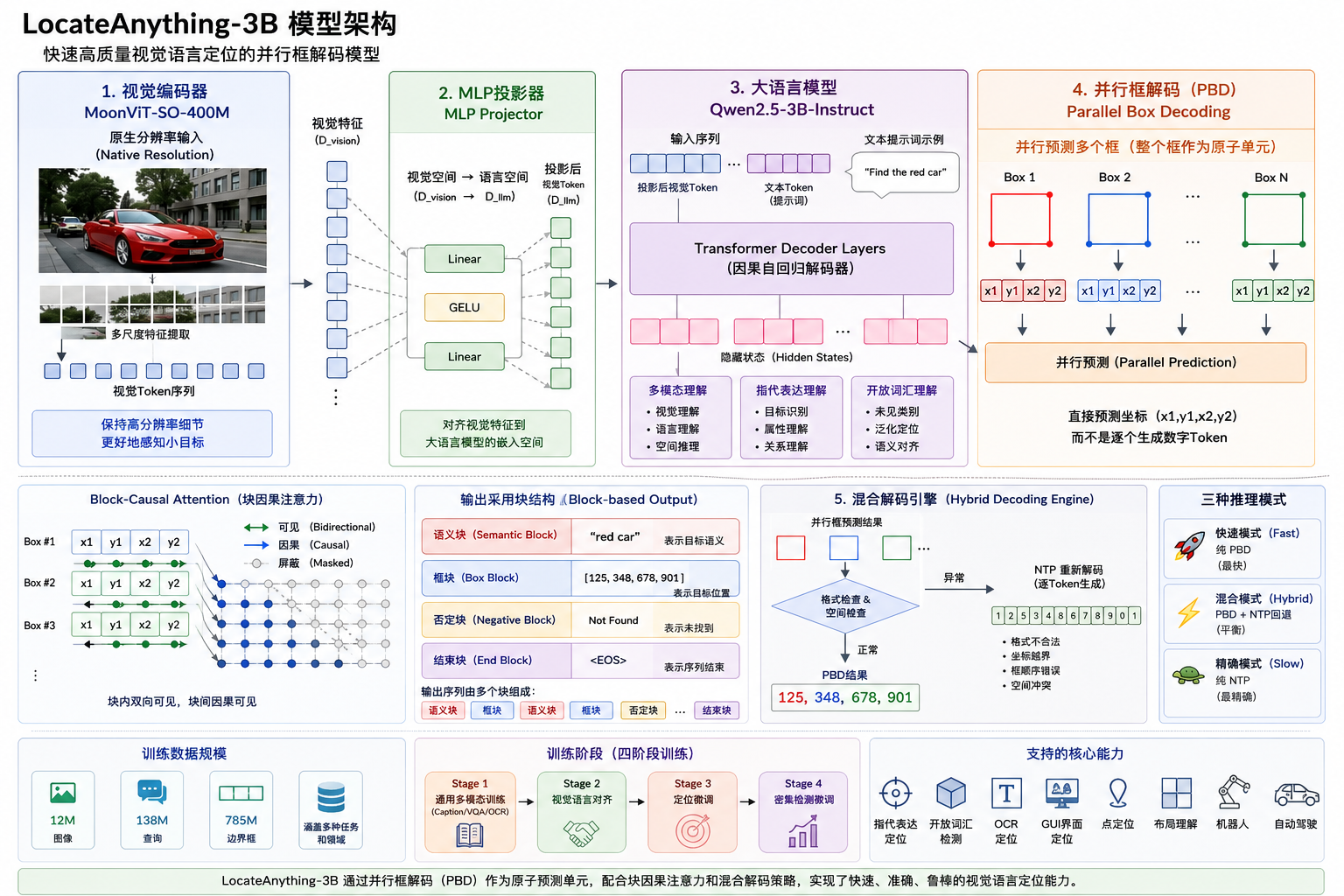
LocateAnything 是一套生成式统一视觉定位与检测框架,基于现有主流 VLM 架构轻量化改造,核心仅替换解码层为并行框解码(PBD),兼容现有视觉编码器、跨模态融合模块,迁移成本极低。整体流水线分为 5 个模块,全链路支持上述六大定位任务:
- 多模态输入分支
- 视觉语言定位 / GUI / 文档任务:输入图像 + 自然语言 Prompt;
- 纯目标检测 / OCR 任务:仅输入图像,搭配内置任务指令。
- 视觉编码器
沿用成熟图像特征提取主干,输出图像全局与局部视觉特征,保证视觉表征能力的延续性。
3.跨模态融合层
融合视觉特征与文本特征(纯检测任务可跳过文本分支),生成统一多模态特征,送入解码模块。
4.核心解码层:Parallel Box Decoding(PBD,并行框解码)
框架核心创新模块,替代传统串行 Token 解码器,将边界框、关键点等几何元素作为原子单元单步解码。
5.后处理校验层
对 PBD 输出的坐标做简单规则校验(过滤x₂<x₁等非法框),最终输出目标边界框、对应文本 / 类别标签,完成全流程推理。
架构核心优势:一套框架兼容多类视觉定位任务,无需为不同场景设计独立分支,工程部署效率高。
三、核心创新 1:并行框解码(PBD)深度解析
Parallel Box Decoding(PBD)是论文最核心的技术贡献,也是突破传统范式的关键。该方案借鉴多 Token 预测(MTP) 思想,并针对视觉几何任务做定制化改造,是业内首次将块级并行解码系统性落地于 VLM 视觉定位任务。
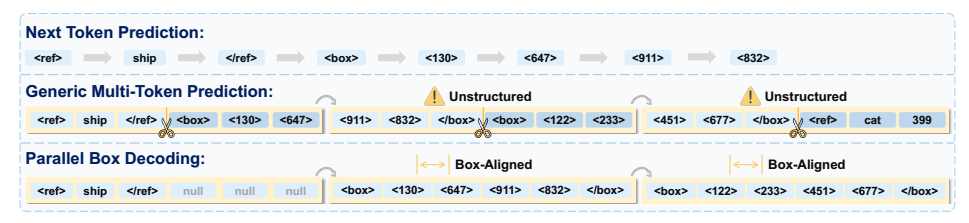
1. 核心设计理念
摒弃 "拆分坐标 + 逐 Token 串行生成" 的思路,定义视觉几何原子单元 :将完整 2D 边界框、图像关键点视为不可拆分的基础解码单元。模型在单次前向传播中直接预测整个几何单元的所有坐标,无时序依赖、无需分步解码。
2. 工作机制与时间复杂度优化
- 单框解码逻辑:一个边界框(4 个坐标)被封装为一个固定长度的原子 Token 块,模型一步输出(x₁,y₁,x₂,y₂)全部坐标,解码步数从 4 步压缩为 1 步;
- 多目标并行逻辑:当图像内存在多个目标框时,所有几何原子单元可并行解码,互不等待;
- 复杂度变化:解码时间复杂度从传统串行的 O(K*N) 降至 O(N),极端批量场景下可接近 O(1),吞吐量实现质的飞跃。
3. 两大核心价值
- 保全几何一致性,提升高 IoU 精度
由于模型直接学习完整边界框的特征,天然建模四个坐标的空间约束关系,从根源减少畸形框、坐标偏移问题。实验证明,该设计对高 IoU(IoU>0.8、IoU>0.9)精细定位的提升效果最为显著。
2.释放并行算力,彻底解决推理时延瓶颈
消除自回归的时序依赖,硬件算力可被充分利用。在批量图像处理、密集目标检测场景下,解码吞吐量远高于传统串行方案,完美适配实时交互场景。
4. 三种自适应推理模式(落地关键设计)
为兼顾极致速度 与极限精度,团队针对不同业务场景设计三类解码模式,可动态切换:
- Fast Mode(快速模式)
纯 PBD 并行解码,优先保障吞吐量与低时延。适配机器人实时抓取、GUI 自动化、实时监控等强实时场景。
2.Slow Mode(高精度模式)
保留部分串行校验逻辑,牺牲少量速度换取极致定位精度。适配离线图像标注、医疗影像定位、工业质检等对时延无要求、但精度要求极高的场景。
3.Hybrid Mode(混合模式,默认模式)
智能自适应切换:常规场景使用 PBD 并行解码;当检测到格式异常、空间歧义、目标遮挡严重时,自动切回传统串行解码兜底。平衡速度与鲁棒性,是通用场景最优选择。
5. 解码范式横向对比
| 解码范式 | 生成逻辑 | 几何一致性 | 推理速度 | 适用场景 |
|---|---|---|---|---|
| 传统逐 Token 串行解码 | 逐个生成坐标 Token,强时序依赖 | 差,易出现畸形框 | 慢,目标越多越卡顿 | 离线高精度评测(老旧方案) |
| 通用多 Token 预测 (MTP) | 单步预测多个文本 Token | 无几何约束,不适配视觉框 | 较快 | 纯文本生成任务 |
| 本文 PBD 并行框解码 | 完整边界框 / 关键点作为原子单元单步输出 | 优,天然匹配几何约束 | 极快,支持多目标并行 | 全场景视觉定位、检测 |
四、核心创新 2:LocateAnything-Data 大规模数据集
仅靠解码范式优化无法充分挖掘模型性能上限,团队配套搭建可扩展数据引擎,并构建了业内规模领先的视觉定位数据集 LocateAnything-Data,与 PBD 形成互补增益。
1. 数据集核心参数
- 总训练样本:超 1.38 亿条;
- 独立原图数量:1200 万张;
- 标注边界框总量:7.85 亿个;
- 覆盖任务:六大类视觉定位子任务(视觉语言定位、目标检测、GUI 定位、文档解析、OCR、指点定位)。
2. 可扩展数据引擎作用
自研流水线支持海量数据爬取、清洗、去重、标注对齐、格式统一,解决了亿级数据集构建过程中的效率、噪声、格式不统一三大工程难题,保障数据集质量与迭代能力。
3. 数据多样性设计(精度提升核心支撑)
传统视觉定位数据集普遍存在场景单一、小目标 / 遮挡目标样本不足、图文配对匮乏等问题。该数据集从 5 个维度强化多样性:
- 场景多样性:覆盖自然场景、室内家居、工业车间、交通路况、办公文档、软件界面等全行业场景;
- 目标多样性:包含常规大目标、极小目标、遮挡目标、低分辨率模糊目标、细粒度相似目标;
- 模态配对多样性:海量图文配对样本,强化图像特征与自然语言的关联能力;
- 标注多样性:统一边界框标注规范,同时兼容检测、定位两类任务的标注逻辑;
- 成像多样性:包含不同光照、角度、画质的图像,提升模型复杂工况下的鲁棒性。
4. 数据集与 PBD 的协同关系
论文通过消融实验证实二者具备强互补性:
- 仅使用 PBD + 传统小规模数据集:推理速度大幅提升,但高精度定位能力受数据限制,上限较低;
- 仅使用串行解码 + LocateAnything-Data 大数据集:精度小幅提升,但串行解码的速度瓶颈无法解决;
- PBD + LocateAnything-Data 组合:同时实现速度暴涨 与高 IoU 精度跃升,达到最优综合性能。
五、实验评测与核心量化结果
团队在COCO、LVIS、DocLayNet、ScreenSpot-Pro等 7 个业内主流基准数据集上完成全维度评测,同时对比数十款主流 VLM 与专用定位模型,核心结果如下:
1. 核心评测指标
- 速度指标:解码吞吐量(samples/second,单位时间处理样本数)、单样本推理时延;
- 精度指标:高 IoU 定位准确率、LVIS mean F1、mAP(目标检测通用指标)、GUI / 文档任务专项精度。
2. 关键量化结论
- 推理速度突破
相比主流基线模型 Qwen3-VL,解码吞吐量最高提升 11.5 倍;综合场景下平均吞吐提升 2.5 倍以上。3B 轻量化模型即可实现远超 30B 大模型的推理速度,端侧落地优势显著。
- 定位精度全面领先
- LVIS 数据集 mean F1 指标相比基线提升3.8%;
- 所有基准数据集上,高 IoU 定位质量实现碾压式提升,畸形框、坐标错误大幅减少;
- 轻量化 3B 版本在 GUI 定位任务中,性能超越 Qwen3-VL-30B、专用模型 GUI-Owl-32B 等百亿级大模型,实现 "小模型打大模型"。
- 速度 - 精度权衡被打破
传统视觉定位模型普遍存在 "提速必降精度、提精度必降速度" 的矛盾。LocateAnything 首次在通用视觉定位领域推进了速度 - 精度前沿(speed-accuracy frontier),做到 "速度、精度双提升"。
2.多任务泛化能力优异
在文档解析、OCR、视频定位等细分任务上均取得 SOTA(当前最优)结果,证明框架具备极强的通用泛化能力,并非针对单一数据集过拟合。
3. 消融实验核心结论
- PBD 并行解码是速度提升的核心因素,同时直接改善框的几何合理性;
- 1.38 亿规模的 LocateAnything-Data 是高精度、强泛化能力的核心支撑;
- 两大模块缺一不可,组合使用才能发挥最大价值,验证了论文 "并行解码 + 大规模数据" 的核心思路。
六、论文五大核心贡献
结合学术创新、技术落地、工程价值三个维度,可将本文贡献分为五类:
1. 范式创新(学术层面)
打破生成式 VLM 领域 "坐标 Token 串行自回归解码" 的主流范式,首次将几何原子单元并行解码系统性应用于视觉定位与检测任务。证明 "贴合视觉任务几何特性的解码逻辑",远优于通用文本式逐 Token 解码,为领域提供全新建模思路。
2. 技术模块创新(算法层面)
设计通用型PBD 并行框解码模块,轻量化、即插即用,可无缝嵌入绝大多数现有生成式视觉语言模型,改造成本低、复用性强;同时原生支持边界框、关键点两类几何元素,具备向其他视觉几何任务拓展的潜力。
3. 统一框架创新(工程层面)
搭建 LocateAnything 统一生成式框架,一套架构兼容 6 大类视觉定位子任务,简化多场景部署流程,降低工业界落地成本。
4. 数据集贡献(资源层面)
发布超 1.38 亿样本的 LocateAnything-Data 数据集,并开源可扩展数据引擎方案。海量多样化数据补齐了高精度视觉定位的数据短板,为后续同领域研究提供高质量公共资源。
5. 落地工程创新(产业层面)
设计 Fast/Slow/Hybrid 三类自适应推理模式,兼顾实时场景与高精度场景需求;开源 3B 轻量化模型,让高性能视觉定位能力可下沉至端侧设备、小型机器人,推动技术从实验室走向产业落地。
七、主流方案横向对比
| 技术方案 | 代表模型 | 优势 | 核心缺陷 | 本文 LocateAnything 优势 |
|---|---|---|---|---|
| 传统 CNN/Transformer 检测器(非生成式) | YOLO、Faster R-CNN | 推理速度快、检测精度稳定 | 无法原生融合自然语言,不支持视觉语言定位任务 | 保留多模态能力,速度持平甚至超越传统检测器 |
| 串行 Token 解码生成式 VLM | Qwen-VL、LLaVA | 统一架构、多模态能力强 | 速度慢、高 IoU 定位精度差 | PBD 解码提速 10 倍以上,同时优化精细定位精度 |
| 专用视觉定位大模型 | GUI-Owl、RefCOCO 专项模型 | 细分任务精度高 | 通用性差、模型体积庞大、推理时延高 | 3B 小模型性能超越百亿级专用模型,全场景通用 |
八、细分应用场景(产业落地方向)
依托 "高速 + 高精度 + 多任务通用" 三大特性,LocateAnything 可覆盖全行业视觉定位需求,核心落地场景如下:
- 机器人具身智能(核心场景)
- 场景:服务机器人语音指令抓取、工业机器人工件定位、机器人导航避障;
- 需求匹配:Fast 模式低时延满足实时交互,PBD 高 IoU 精度保障抓取、作业的准确性。
- 智能 GUI 自动化与办公文档解析
- 场景:AI 智能体操作软件、自动化办公、PDF / 纸质文档版式解析;
- 需求匹配:兼容 GUI 定位、文档解析双任务,混合模式平衡速度与歧义处理能力。
- 自动驾驶与车载感知
- 场景:车外行人、车辆、路障精细化定位,车内交互界面识别;
- 需求匹配:高 IoU 精度保障行车安全,低时延适配车载实时感知系统。
- 智能安防与视频大数据分析
- 场景:海量监控视频目标检索、异常行为目标定位;
- 需求匹配:高并行解码吞吐,可批量处理视频流,亿级数据集保障复杂场景泛化性。
- 移动端与嵌入式端 AI
- 场景:手机智能识图、图文搜图、AR 交互、嵌入式视觉设备;
- 需求匹配:3B 轻量化模型算力消耗低,适配端侧有限硬件资源。
- 医疗影像辅助诊断(拓展场景)
- 场景:CT、X 光片病灶区域定位(结合文本病灶描述);
- 需求匹配:Slow 模式极致高 IoU 精度,满足医疗影像精细标注需求。
九、工作局限性与现存问题
基于论文原文及公开评测信息,该工作仍存在部分待优化点,也是后续研究的切入点:
- 复杂几何任务拓展不足
目前 PBD 仅验证了边界框、关键点两类简单几何单元,尚未针对语义分割、实例分割、3D 视觉框等复杂几何结构做适配,向分割、3D 视觉领域拓展的有效性仍需验证。
2.极端工况鲁棒性待补充
公开实验未重点测试极小黑目标、完全遮挡、全模糊图像、极端光照等极限场景,模型在恶劣工况下的稳定性有待进一步验证。
3.数据集细节未完全公开
仅披露数据集规模与任务覆盖范围,未公开数据来源、类别分布、偏见检测结果,后续研究者使用时需自行校验数据公平性与噪声情况。
4.混合模式歧义处理仍有优化空间
当图像内目标高度重叠、语义模糊时,混合模式切换串行解码的频率升高,小幅损失整体吞吐量。
十、未来研究拓展方向
结合本文核心思路与行业痛点,后续研究可从技术拓展、模型优化、数据迭代、落地优化四大方向推进:
1. 技术模块拓展(短期)
- 将 PBD 并行解码拓展至语义分割、人体姿态估计、实例分割等视觉几何任务;
- 基于 PBD 设计 3D 边界框并行解码方案,拓展至 3D 视觉定位、3D 目标检测。
2. 模型轻量化与架构优化(工程向)
- 针对微型嵌入式设备做模型蒸馏、量化、剪枝,进一步降低端侧算力消耗;
- 设计动态块解码策略,根据目标复杂度自适应调整并行块大小,进一步优化速度 - 精度平衡。
3. 数据集迭代与优化(数据向)
- 对 LocateAnything-Data 做去偏、去噪处理,构建医疗、自动驾驶等细分领域专用子集;
- 结合弱监督、自监督技术,降低亿级数据集的人工标注成本。
4. 多模态与视频场景升级(中长期)
- 结合大语言模型(LLM)实现 "逻辑推理 + 视觉定位" 端到端联动,支持复杂多轮指令定位;
- 将 PBD 拓展至视频领域,实现帧间目标跟踪 + 定位的时空联合并行解码。
5. 落地部署优化
针对云端集群、边缘设备做算子优化、推理引擎适配,结合动态批处理技术,进一步放大 PBD 的并行吞吐优势。
十一、全文总结
1. 核心逻辑复盘
传统视觉语言定位模型:二维边界框拆分→一维坐标 Token→串行逐步解码 → 几何割裂 + 推理卡顿;
本文 LocateAnything:边界框 / 关键点作为几何原子单元→PBD 单步并行解码 (保全几何一致性 + 提速)+ 1.38 亿大规模数据集(提升泛化与精度)→ 打破速度 - 精度权衡,实现双维度突破。
2. 论文核心价值总结
- 算法层面:用 PBD 并行框解码重构了 VLM 视觉定位的解码范式,从底层解决串行解码的两大历史痛点;
- 数据层面:构建亿级多任务数据集,拉高了高精度视觉定位的训练数据门槛;
- 产业层面:轻量化模型 + 多自适应推理模式,让高速、高精度视觉定位技术全面走向端侧、机器人、安防等落地场景;
- 领域引领:为后续视觉几何任务、多模态大模型解码设计提供了全新思路,推动视觉语言定位领域进入 "并行解码" 新阶段。
整体而言,LocateAnything 是一篇理论创新扎实、工程落地完善、产业价值突出的标杆性工作,也是 2026 年视觉语言模型领域针对视觉定位任务的代表性成果。
十二、代码实测
测试代码,
#locate.py
import re
import torch
from PIL import Image
from transformers import AutoModel, AutoTokenizer, AutoProcessor
from PIL import Image, ImageDraw, ImageFont
class LocateAnythingWorker:
"""Stateful worker that loads the model once and serves perception queries."""
def __init__(self, model_path: str, device: str = "cuda", dtype=torch.bfloat16):
self.device = device
self.dtype = dtype
self.tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
self.processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
self.model = AutoModel.from_pretrained(
model_path,
torch_dtype=dtype,
trust_remote_code=True,
).to(device).eval()
@torch.no_grad()
def predict(
self,
image: Image.Image,
question: str,
generation_mode: str = "hybrid", # "fast" (MTP) | "slow" (NTP/AR) | "hybrid"
max_new_tokens: int = 2048,
temperature: float = 0.7,
verbose: bool = True,
) -> dict:
messages = [
{"role": "user", "content": [
{"type": "image", "image": image},
{"type": "text", "text": question},
]}
]
text = self.processor.py_apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
images, videos = self.processor.process_vision_info(messages)
inputs = self.processor(
text=[text], images=images, videos=videos, return_tensors="pt"
).to(self.device)
pixel_values = inputs["pixel_values"].to(self.dtype)
input_ids = inputs["input_ids"]
image_grid_hws = inputs.get("image_grid_hws", None)
response = self.model.generate(
pixel_values=pixel_values,
input_ids=input_ids,
attention_mask=inputs["attention_mask"],
image_grid_hws=image_grid_hws,
tokenizer=self.tokenizer,
max_new_tokens=max_new_tokens,
use_cache=True,
generation_mode=generation_mode,
temperature=temperature,
do_sample=True,
top_p=0.9,
repetition_penalty=1.1,
verbose=verbose,
)
result = {"answer": response[0] if isinstance(response, tuple) else response}
if isinstance(response, tuple) and len(response) >= 3:
result["history"] = response[1]
result["stats"] = response[2]
return result
# ---- Convenience methods for each task ----
def detect(self, image: Image.Image, categories: list[str], **kwargs) -> dict:
"""Object detection / document layout analysis."""
cats = "</c>".join(categories)
prompt = f"Locate all the instances that matches the following description: {cats}."
return self.predict(image, prompt, **kwargs)
def ground_single(self, image: Image.Image, phrase: str, **kwargs) -> dict:
"""Phrase grounding --- single instance."""
prompt = f"Locate a single instance that matches the following description: {phrase}."
return self.predict(image, prompt, **kwargs)
def ground_multi(self, image: Image.Image, phrase: str, **kwargs) -> dict:
"""Phrase grounding --- multiple instances."""
prompt = f"Locate all the instances that match the following description: {phrase}."
return self.predict(image, prompt, **kwargs)
def ground_text(self, image: Image.Image, phrase: str, **kwargs) -> dict:
"""Text grounding."""
prompt = f"Please locate the text referred as {phrase}."
return self.predict(image, prompt, **kwargs)
def detect_text(self, image: Image.Image, **kwargs) -> dict:
"""Scene text detection."""
prompt = "Detect all the text in box format."
return self.predict(image, prompt, **kwargs)
def ground_gui(self, image: Image.Image, phrase: str, output_type: str = "box", **kwargs) -> dict:
"""GUI grounding (box or point)."""
if output_type == "point":
prompt = f"Point to: {phrase}."
else:
prompt = f"Locate the region that matches the following description: {phrase}."
return self.predict(image, prompt, **kwargs)
def point(self, image: Image.Image, phrase: str, **kwargs) -> dict:
"""Pointing."""
prompt = f"Point to: {phrase}."
return self.predict(image, prompt, **kwargs)
# ---- Utility: parse model output ----
@staticmethod
def parse_boxes(answer: str, image_width: int, image_height: int) -> list[dict]:
"""Parse model output into pixel-coordinate bounding boxes.
Coordinates in model output are normalized integers in [0, 1000].
"""
boxes = []
for m in re.finditer(r"<box><(\d+)><(\d+)><(\d+)><(\d+)></box>", answer):
x1, y1, x2, y2 = [int(g) for g in m.groups()]
boxes.append({
"x1": x1 / 1000 * image_width,
"y1": y1 / 1000 * image_height,
"x2": x2 / 1000 * image_width,
"y2": y2 / 1000 * image_height,
})
return boxes
@staticmethod
def parse_points(answer: str, image_width: int, image_height: int) -> list[dict]:
"""Parse model output into pixel-coordinate points."""
points = []
for m in re.finditer(r"<box><(\d+)><(\d+)></box>", answer):
x, y = int(m.group(1)), int(m.group(2))
points.append({
"x": x / 1000 * image_width,
"y": y / 1000 * image_height,
})
return points
# ---- NEW: visualize detection result on image ----
@staticmethod
def visualize(image: Image.Image, answer: str, output_path: str = "detection_output.jpg"):
"""Parse detection answer and draw boxes/labels on the image, then save.
Output format in terminal:
Detection: <ref>person</ref><box><0><512><98><807></box>...
"""
img = image.copy()
draw = ImageDraw.Draw(img)
w, h = img.size
# Color palette for different categories
colors = [
(255, 0, 0), # red
(0, 255, 0), # green
(0, 0, 255), # blue
(255, 255, 0), # yellow
(255, 0, 255), # magenta
(0, 255, 255), # cyan
(255, 128, 0), # orange
(128, 0, 255), # purple
]
# Try to load a decent font; fallback to default if unavailable
try:
font = ImageFont.truetype("/usr/share/fonts/truetype/dejavu/DejaVuSans.ttf", 20)
except Exception:
try:
font = ImageFont.truetype("DejaVuSans.ttf", 20)
except Exception:
font = ImageFont.load_default()
ref_re = re.compile(r'<ref>(.*?)</ref>')
box_re = re.compile(r'<box>(.*?)</box>')
coord_re = re.compile(r'<(\d+)>')
refs = list(ref_re.finditer(answer))
color_idx = 0
for i, ref_m in enumerate(refs):
label = ref_m.group(1)
start = ref_m.end()
end = refs[i + 1].start() if i + 1 < len(refs) else len(answer)
segment = answer[start:end]
color = colors[color_idx % len(colors)]
color_idx += 1
for box_m in box_re.finditer(segment):
content = box_m.group(1).strip()
if content == "None" or not content:
continue
nums = coord_re.findall(content)
if len(nums) != 4:
continue
x1, y1, x2, y2 = [int(n) for n in nums]
px1 = x1 / 1000 * w
py1 = y1 / 1000 * h
px2 = x2 / 1000 * w
py2 = y2 / 1000 * h
# Draw bounding box
draw.rectangle([px1, py1, px2, py2], outline=color, width=3)
# Draw label background
text = label
bbox = draw.textbbox((0, 0), text, font=font)
tw, th = bbox[2] - bbox[0], bbox[3] - bbox[1]
ty1 = max(0, py1 - th - 4)
ty2 = py1
draw.rectangle([px1, ty1, px1 + tw + 4, ty2], fill=color)
draw.text((px1 + 2, ty1), text, fill=(255, 255, 255), font=font)
img.save(output_path)
print(f"Image saved to: {output_path}")
print("Detection:", answer)
return output_path
if __name__=="__main__":
worker = LocateAnythingWorker("./LocateAnything-3B")
img = Image.open("bus.jpg").convert("RGB")
# Object Detection
result = worker.detect(img, ["person", "car", "bicycle", "bus", "window", "glasses", "hand", "shoes"])
print("Detection:", result["answer"])
# >>> 新增:可视化并保存 <<<
worker.visualize(img, result["answer"], output_path="bus_detection.jpg")
# Phrase Grounding (multiple)
result = worker.ground_multi(img, "people wearing red shirts")
print("Grounding:", result["answer"])
# Scene Text Detection
result = worker.detect_text(img)
print("Text Detection:", result["answer"])
# Pointing
result = worker.point(img, "the traffic light")
print("Pointing:", result["answer"])
# GUI Grounding (point)
result = worker.ground_gui(img, "the search button", output_type="point")
print("GUI Point:", result["answer"])
# Parse structured output into pixel coordinates
w, h = img.size
boxes = LocateAnythingWorker.parse_boxes(result["answer"], w, h)
points = LocateAnythingWorker.parse_points(result["answer"], w, h)
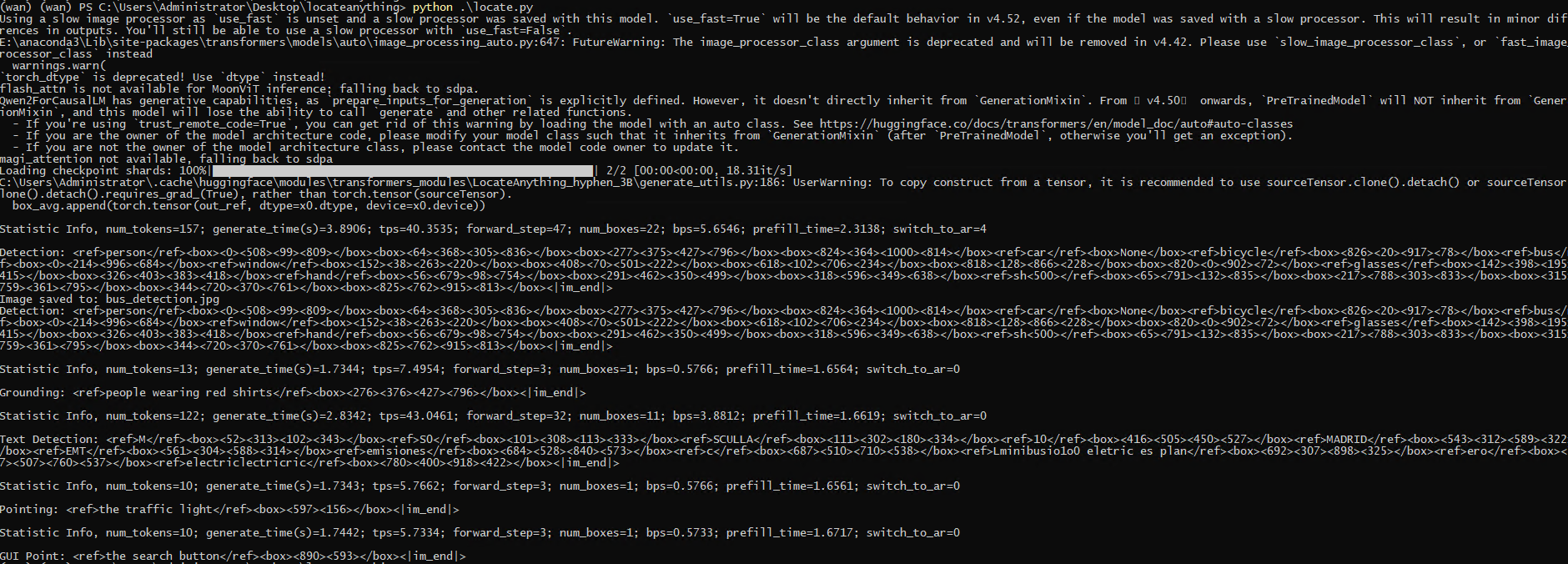
个人感觉主流的目标检测大类都可以识别,效果也非常好,对于细分领域的小众类别无法识别。比如识别煤矿的球磨机、钩子等就识别不出。