👉 欢迎阅读这篇文章 👇
目录
- 1、数据结构的基本概念
-
- 1.1基本概念
- 1.2数据结构的三要素
- [1.3 数据类型和抽象数据类型](#1.3 数据类型和抽象数据类型)
- 1.4总结
- 2、算法的基本概念
- 3、算法的时间复杂度
-
- [3.1 分析算法的时间效率](#3.1 分析算法的时间效率)
- 3.2时间复杂度的渐进表示法
- 3.3时间复杂度经典样例分析
-
- [3.3.1 O ( N ) O(N) O(N)级](#3.3.1 O ( N ) O(N) O(N)级)
- [3.3.2 O ( N 2 ) O(N^2) O(N2)级](#3.3.2 O ( N 2 ) O(N^2) O(N2)级)
- [3.3.3 O ( N 3 ) O(N^3) O(N3)级](#3.3.3 O ( N 3 ) O(N^3) O(N3)级)
- [3.3.4 O ( l o g N ) O(logN) O(logN) 级](#3.3.4 O ( l o g N ) O(logN) O(logN) 级)
- [3.3.5 O ( 1 ) O(1) O(1) 级](#3.3.5 O ( 1 ) O(1) O(1) 级)
- 3.4递归算法时间复杂度
- 4、算法的空间复杂度
-
- 4.1空间复杂度经典样例分析
-
- [4.1.1 O ( 1 ) O(1) O(1) 级](#4.1.1 O ( 1 ) O(1) O(1) 级)
- 4.1.2轮转数组
-
- [4.1.2.1旋转数组时间复杂度为 O ( N 2 ) O(N^2) O(N2) ,空间复杂度为 O ( 1 ) O(1) O(1)的解题思路](#4.1.2.1旋转数组时间复杂度为 O ( N 2 ) O(N^2) O(N2) ,空间复杂度为 O ( 1 ) O(1) O(1)的解题思路)
- [4.1.2.2旋转数组时间复杂度为 O ( N ) O(N) O(N) ,空间复杂度为 O ( N ) O(N) O(N) 的解题思路](#4.1.2.2旋转数组时间复杂度为 O ( N ) O(N) O(N) ,空间复杂度为 O ( N ) O(N) O(N) 的解题思路)
- [4.1.2.3旋转数组时间复杂度为 O ( N ) O(N) O(N) ,空间复杂度为 O ( 1 ) O(1) O(1) 的解题思路](#4.1.2.3旋转数组时间复杂度为 O ( N ) O(N) O(N) ,空间复杂度为 O ( 1 ) O(1) O(1) 的解题思路)
- 4.1.3递归算法空间复杂度
1、数据结构的基本概念
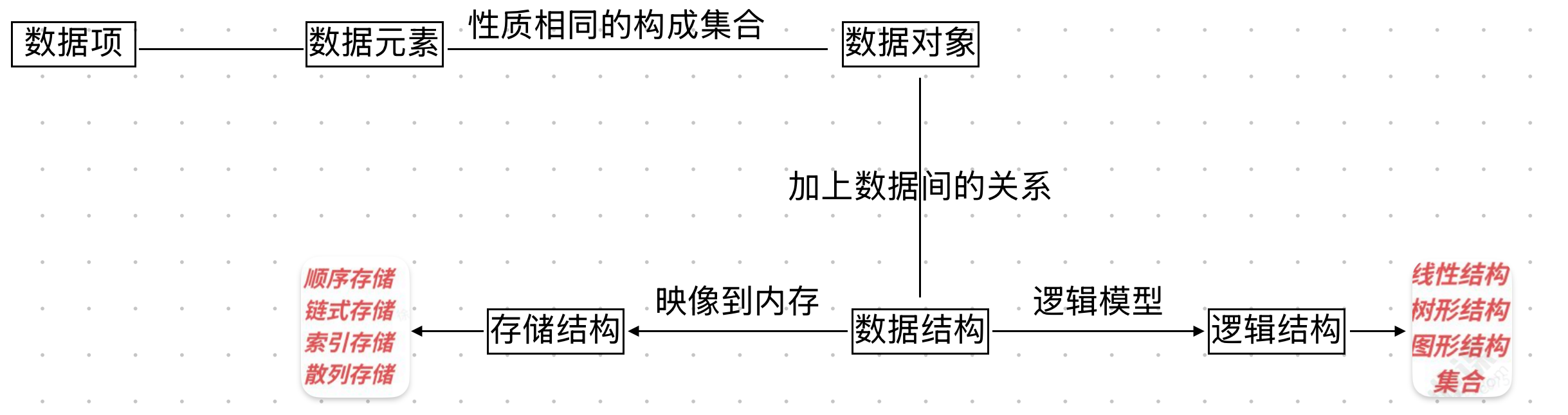
1.1基本概念
- 数据 :数据是对客观事物的符号表示,是所有能被输入到计算机中并被程序处理的符号的总称。可以是数字、字符、字符串、图像、声⾳等。如:
202、"wang"、"男"这些独立的数字或者字符串都是数据。 - 数据元素 :是数据的基本单位,在计算机程序中通常作为⼀个整体进⾏考虑和处理。⼀个元素可以由若⼲个数据项 构成,数据项 是数据不可分割的最⼩单位。如:
{学号:101, 姓名:"张三",成绩:95, 性别:"男"}是⼀名学⽣的完整信息就是⼀个数据元素 ,其中:成绩:95就是一个数据项。 - 数据对象:具有相同性质的数据元素的集合,是数据的子集。如:全班学⽣的花名册就是⼀个数据对象。
- 数据对象 (集合) ⊇ 数据元素 (个体) ⊇ 数据项(属性),所有这些都是数据的表现形式
下面用结构体来举例描述
c
struct stu
{
char name[20];
int age;
float score;
};
int main()
{
struct stu s[]={{"zhangsan",18,90.0f},{"lisi",20,89.5f},{"wangwu",19,87.5f}};
//结构体变量的每个成员s[i].name/s[i].age/s[i].score------数据项
//结构体变量s[i]------数据元素
//结构体数组s------数据对象
return 0;
}1.2数据结构的三要素
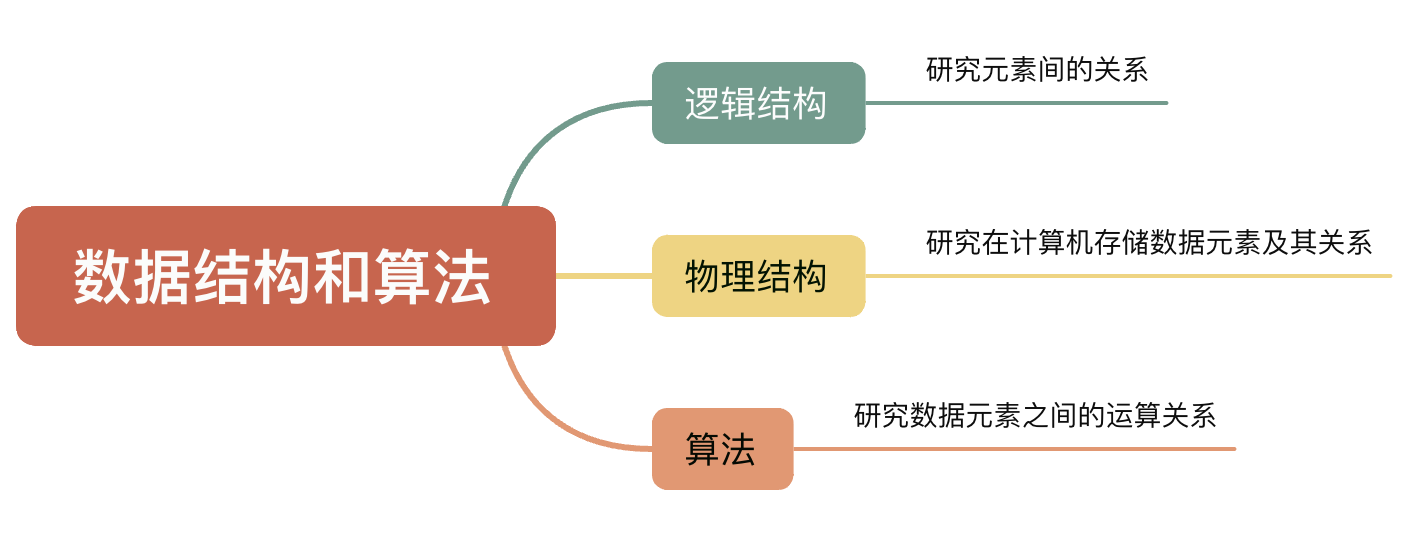
数据结构: 数据元素之间不是孤立存在的,他们之间存在着某种关系,数据元素互相之间的关系称为结构,数据结构是带结构的数据元素的集合。
数据结构的三要素:
- 逻辑结构 :描述数据元素之间的逻辑关系。逻辑结构可以分为:线性结构、树形结构、图形结构(⽹状结构)、集合;也可以直接分为线性结构和⾮线性结构(树形、图形、集合)。
-
- 线性结构:数据元素之间存在⼀对⼀的关系,除了第⼀个元素,所有元素都有唯⼀前驱,除了最后⼀个元素,所有元素都有唯⼀后继。⾮线性结构可能有多个直接前驱和直接后继。
-
- 树形结构:数据元素之间存在⼀对多的关系
-
- 图形结构:数据元素之间存在多对多的关系
-
- 集合中的数据元素属于⼀个集合,除此之外别⽆其他关系
- 物理结构(存储结构): 数据元素及其关系在计算机存储结构中表示,物理结构主要有四种:顺序存储、链式存储、索引存储、散列存储。
-
- 顺序存储:把逻辑上相邻的数据元素存放在一段连续物理存储单元中,数据之间的逻辑关系可以由物理存储关系体现。
-
- 链式存储:逻辑上相邻的数据元素存储在任意的⼀组物理存储单元中,数据元素之间的逻辑关系⽤指针来表示。
-
- 索引存储:存储元素信息的同时,还建⽴了索引表,索引表中的每项称为索引项,索引项的⼀般形式为(关键字,地址)。
-
- 散列存储:根据数据元素中的关键字计算出该数据元素的存储地址。
- 数据运算和实现: 对数据元素可以施加的操作,以及这些操作在相应的存储结构上的实现。
1.3 数据类型和抽象数据类型
- 数据类型是⼀个值的集合和定义在这个值集上的⼀组操作的总称,数据类型⼀般可分为:原⼦类型和结构类型。
-
- 原⼦类型:原⼦类型的值是不可以再分解的。如C语⾔的
int、double、char等基本数据类型
- 原⼦类型:原⼦类型的值是不可以再分解的。如C语⾔的
-
- 结构类型:结构类型的值是由若⼲成分按某种结构组成,是可以分解的。如C语⾔中定义的⼀个结构体类型。
- 抽象数据类型:抽象数据类型(Abstract Data Type, ADT) 是⼀种数学模型加上在该模型上定义的⼀组操作的集合,它定义了数据对象、数据关系以及对数据的操作,但隐藏了具体实现细节。
1.4总结
2、算法的基本概念
2.1算法和数据结构
算法(Algorithm)是解决特定问题的求解步骤的⼀种描述,是⼀系列解决问题指令的有限序列。它描述了如何通过⼀系列操作将输⼊转换为期望的输出。算法代表着⽤系统的⽅法描述解决问题的策略机制,精⼼设计的算法可以带来更⾼的运⾏效率。
前⾯我们提到数据元素不是孤⽴存在的,它们之间存在着某种关系,数据元素互相之间的关系称为结构,也就是说数据结构是相互之间存在⼀种或者多种特定关系的数据元素的集合。精⼼选择的数据结构可以带来更⾼的运⾏或者存储效率。
算法 + 数据结构 = 程序(Algorithms + Data Structures = Programs),这意味着的程序的好和快是直接由程序所采⽤的数据结构和算法决定的。提出这⼀公式的瑞⼠计算机科学家尼克劳斯·沃斯(Niklaus Wirth)是1984年图灵奖得主,Pascal之⽗。
数据结构和算法的是紧密耦合、相辅相成的,数据结构通过算法实现操作,算法根据数据结构设计实现细节。同⼀个问题,采⽤不同的数据结构,其算法可能完全不同,效率可能也有很⼤差别。⽐如我们要排序⼀组数据,数据分别存储在数组中和链表中,就要选择适合的排序算法,实现细节和效率都是有很⼤的差别的。
2.2算法的特性
- 有穷性:算法必须在有限步骤内结束,不能⽆限循环或永远不终⽌。
- 确定性:算法的每⼀步骤必须有确切、⽆歧义⽆⼆义性的定义。对于相同的输⼊必须得到相同的输出。
- 可⾏性:算法是可执⾏的,算法中描述的操作都是通过已经实现的基本运算执⾏有限次来实现。
- 输⼊:算法有零个或多个输⼊,这些输⼊取⾃特定的对象集合。
- 输出:算法有⼀个或多个输出。输出是算法处理输⼊后得到的结果,与输⼊有特定关系。
2.3算法设计的要求
- 正确性:算法能正确的解决求解的问题。
- 可读性:算法的思路是便于理解的,可读性强的。
- 健壮性:当输⼊数据⾮法时,算法也能适当的做出进⾏处理,⽽不会产⽣莫名其妙的结果。
- ⾼效率与低存储要求:⾼效率就是执⾏时间尽可能低,低存储就是执⾏过程中使⽤更少的存储空间。
3、算法的时间复杂度
3.1 分析算法的时间效率
要解决一个问题可以有不同的算法去解决,如何判断哪个算法更好?一个好的算法首先要满足的是正确性,其次就是可读性、健壮性,这三点都满足的前提下就要通过评估算法效率 的优劣来选择,算法效率 分为时间效率 和空间效率。
时间效率 是算法运行的时候消耗的时间,空间效率 是算法实现过程额外耗费的空间。
分析时间效率有两种方法,第一种是实现算法后进行统计(事后统计),第二种是是事前估算。
第一种方法需要先实现算法,并且严重依赖环境,如编程语言、CPU、编译器等,容易掩盖算法本身的优劣。
我们重点关注事前估算,总结事前估算的公式,算法的运行时间为 ∑ i = 1 , j = 1 M , K C i ∗ N i \sum\limits_{i=1,j=1}^{M,K}C_i*N_i i=1,j=1∑M,KCi∗Ni C i C_i Ci是每条代码语句消耗的时间, N i N_i Ni是每条语句执行的次数。
例
我们给出了⼀个简单的summation累加算法,根据上⾯的事前估算公式可以得到算法运行时间 f ( N ) = C 1 ∗ 1 + C 2 ∗ 1 + C 3 ∗ ( N + 1 ) + C 4 ∗ N + C 5 ∗ N + C 6 ∗ 1 f(N)=C1*1+C2*1+C3*(N+1)+C4*N+C5*N+C6*1 f(N)=C1∗1+C2∗1+C3∗(N+1)+C4∗N+C5∗N+C6∗1
c
int Summation(int N) { //消耗时间 //执行次数
int ret = 0; //C1 1
int i = 1; //C2 1
while (i <= N) { //C3 N+1
ret += i; //C4 N
i++; //C5 N
}
return ret; //C6 1
}上方的事前估算公式中,每条代码语句消耗的时间 C i C_i Ci本质上与算法是无关的,它跟实现的编程语⾔、编译器、CPU等环境因素相关,这⾥是进⾏事前估算,既然是估算我们可以简单的假设每条语句消耗的时间是⼀样的,即 C i = 1 C_i=1 Ci=1,这样事前估算就可以简化为所有代码语句的执⾏次数之和,这样我们就可以脱离软硬件等环境因素来分析算法的时间效率了。如Summation函数的时间效率就可以⽤函数 f ( N ) = 1 + 1 + ( N + 1 ) + N + N + 1 = 3 ∗ N + 4 f(N)=1+1+(N+1)+N+N+1=3*N+4 f(N)=1+1+(N+1)+N+N+1=3∗N+4来表示。
3.2时间复杂度的渐进表示法
- 假设算法a的执行次数函数 f a ( N ) = 100 ∗ N f_a(N) = 100 ∗ N fa(N)=100∗N,算法b的执行次数函数是 f b ( N ) = N 2 f_b (N) = N^2 fb(N)=N2,那么哪个算法更好一些呢?
-
- 当N=50时,算法a执行5000次,算法b执行2500次,b更快。
-
- 当N=1000时:算法a执⾏100000次,算法b执⾏1000000次,算法a更快。
- 当N比较小的时候b更快,但是随着N不断增⼤,算法a总是更快的。所以在进行事前估算的时候需要关注的是算法执行次数随着规模变化的执行速度 ,也就是算法执行次数的量级
有时候两个算法的执行函数比较复杂,所以我们通过分析时间复杂度来确定量级,进而得知他们随着规模变化的增长速度。
我们用渐进表示法来表示时间复杂度
渐进表示法关心的是当数据规模 n 无限变大时,算法运行时间的增长趋势。
最常用的:大 O 表示法 𝑂 ( 𝑓 ( 𝑛 ) ) 𝑂(𝑓(𝑛)) O(f(n))
- 算法运行时间的上界(最坏情况),表示算法最多执行多少步。给算法的效率画一个上限,保证不会比这个更慢。
- 我们平时说的时间复杂度,默认就是大 O 表示法。
计算时间复杂度时,只看最高阶项,忽略所有无关项
- 忽略常数项
𝑂 ( 𝑛 + 100 ) = 𝑂 ( 𝑛 ) 𝑂(𝑛+100) = 𝑂(𝑛) O(n+100)=O(n) - 忽略低阶项
𝑂 ( 𝑛 2 + 3 𝑛 ) = 𝑂 ( 𝑛 2 ) 𝑂(𝑛²+3𝑛) = 𝑂(𝑛²) O(n2+3n)=O(n2) - 忽略系数
𝑂 ( 2 𝑛 ) = 𝑂 ( 𝑛 ) , 𝑂 ( 5 𝑛 2 ) = 𝑂 ( 𝑛 2 ) 𝑂(2𝑛) = 𝑂(𝑛),𝑂(5𝑛²) = 𝑂(𝑛²) O(2n)=O(n),O(5n2)=O(n2) - 只保留增长最快的项
𝑂 ( 𝑛 3 + 𝑛 2 + 𝑛 ) = 𝑂 ( 𝑛 3 ) 𝑂(𝑛³+𝑛²+𝑛) = 𝑂(𝑛³) O(n3+n2+n)=O(n3) - 若没有跟N相关的项,只有常数项,则时间复杂度为 O ( 1 ) O(1) O(1)
计算时间复杂度本质是估算算法属于哪个数量级,那么我们实际中不需要先求出它的执⾏次数 𝑓 ( 𝑛 ) 𝑓(𝑛) f(n),再去求 𝑂 ( 𝑓 ( 𝑛 ) ) 𝑂(𝑓(𝑛)) O(f(n))
- 我们只需要关注循环语句,因为普通语句的执⾏次数都算是常数项,可以忽略。
- 循环语句中我们只计算内部的⼀个基本语句执⾏次数即可,其他其他语法叠加计算出的也是这个项的系数,系数也是可以忽略的。如
for(int i = 0; i < n; ++i){++x;},我们直接计算++x的执⾏次数为N即可,i<n和++i也⼀起计算的话影响的也是系数,系数最后还是被忽略掉了。 - 多个循环语句,⼀般优先看嵌套层数最多的循环,找出最⾼阶项,⼀般⼀层循环就是 N N N,两层就是 N 2 N^2 N2,三层循环是 N 3 N^3 N3,但是实际中需要都算⼀下,因为有时⼀层循环不⼀定是 N N N,两层嵌套循环也可能不是 N 2 N^2 N2等等,所以还是要计算具体的算法逻辑。
常见的时间复杂度量级
O ( 1 ) < O ( l o g N ) < O ( N ) < O ( N ∗ l o g N ) < O ( N 2 ) < O ( N 3 ) < O ( 2 N ) < O ( N ! ) O(1)<O(logN)<O(N)<O(N*logN)<O(N^2)<O(N^3)<O(2^N)<O(N!) O(1)<O(logN)<O(N)<O(N∗logN)<O(N2)<O(N3)<O(2N)<O(N!)
注意:
由于对数存在换底公式 f ( N ) = l o g a N = l o g b N l o g b a f(N)=log_aN=\frac{log_bN}{log_ba} f(N)=logaN=logbalogbN, l o g b a log_ba logba是一个常数,所以 O ( l o g a N ) = O ( l o g b ) N O(loga_N) = O(logb)N O(logaN)=O(logb)N,也就意味着时间复杂度的渐进表⽰法中,所有的对数都是同⼀量级的。所以对数级的算法我们⼀般⽤ O ( l o g N ) O(logN) O(logN)表示。
3.3时间复杂度经典样例分析
3.3.1 O ( N ) O(N) O(N)级
根据时间复杂度计算规则,Summation算法的时间复杂度 O ( N ) O(N) O(N)
c
int Summation(int N) {
int ret = 0;
int i = 1;
while (i <= N) {
ret += i;
i++;
}
return ret;
}3.3.2 O ( N 2 ) O(N^2) O(N2)级
冒泡排序的数据⽐较和交换次数是⼀个1⾄N的等差数列, f ( N ) = N ∗ ( N + 1 ) 2 f(N)=\frac{N*(N+1)}{2} f(N)=2N∗(N+1),我们只保留最⾼阶项,BubbleSort算法的时间复杂度 O ( N 2 ) O(N^2) O(N2)。
c
void BubbleSort(int* a, int n) {
assert(a);
for (size_t end = n; end > 0; --end) {
for (size_t i = 1; i < end; ++i) {
if (a[i-1] > a[i]) {
Swap(&a[i-1], &a[i]);
}
}
}
}3.3.3 O ( N 3 ) O(N^3) O(N3)级
MatrixMultiply是⼀个矩阵相乘并打印结果的算法,我们只保留最⾼阶项,那么矩阵相乘部分的执⾏次数阶数明显⾼于打印结果部分的执⾏次数,所以我们只关注矩阵相乘部分,MatrixMultiply算法的时间复杂度 O ( N 3 ) O(N^3) O(N3)
c
#define N 3
void MatrixMultiply(int A[][N], int B[][N], int C[][N]) {
// 矩阵相乘
for (int i = 0; i < N; i++) {
for (int j = 0; j < N; j++) {
C[i][j] = 0;
for (int k = 0; k < N; k++) {
C[i][j] += A[i][k] * B[k][j];
}
}
}
// 打印结果
for (int i = 0; i < N; i++) {
for (int j = 0; j < N; j++) {
printf("%d ", C[i][j]);
}
printf("\n");
}
}3.3.4 O ( l o g N ) O(logN) O(logN) 级
Count算法是⼀个循环打印程序,不同于普通循环 ++i ,它每循环⼀次 i*=2 ,假设循环了x次,循环结束的条件是 2 x > = N 2^x>=N 2x>=N, x > = l o g 2 N x>=log_2N x>=log2N,执行次数是 l o g 2 N log_2N log2N次。Count算法的时间复杂度 O ( l o g 2 N ) O(log_2N) O(log2N)
c
#include <stdio.h>
void Count(int n) {
for (int i = 1; i < n; i *= 2) {
printf("%d\n", i);
}
}
int main() {
Count(100);
return 0;
}3.3.5 O ( 1 ) O(1) O(1) 级
Print100算法是⼀个循环打印程序,它的循环最多循环100次打印前100个数,Print100算法时间复杂度是 O ( 1 ) O(1) O(1)。
c
void Print100(int* a, int n) {
for (int i = 0; i < n && i < 100; i++) {
printf("%d ", a[i]);
}
printf("\n");
}3.4递归算法时间复杂度
递归算法的时间复杂度为 O ( ∑ i = 1 M f i ( N ) ) O(\sum\limits_{i=1}^{M}f_i(N)) O(i=1∑Mfi(N))M为递归的次数, f i ( N ) ) f_i(N)) fi(N))为每次递归的执行次数,递归算法的时间复杂度等于M次递归的执⾏次数的累加和。
Fac算法每次递归的执⾏次数是 O ( 1 ) O(1) O(1),递归N+1次,所以时间复杂度为 O ( N ) O(N) O(N)。
c
long long Fac(size_t N){
if(0 == N)
return 1;
return Fac(N-1)*N;
}4、算法的空间复杂度
和时间复杂度类似,我们使⽤的⽅法是事前估算,Func函数占⽤的空间⼤⼩为 f ( N ) = C 1 ∗ 1 + C 2 ∗ 1 + C 3 ∗ N f(N)=C1*1+C2*1+C3*N f(N)=C1∗1+C2∗1+C3∗N,每个变量消耗的空间本质跟算法是⽆关的,它跟实现的
编程语⾔、编译器等环境因素相关,那么我们这⾥是进⾏事前估算,既然是估算我们可以简单的假设每个变量的⼤⼩都是⼀样的 ,则 f ( N ) = 1 + 1 + N f(N) = 1 + 1 + N f(N)=1+1+N
c
double Func(int N) { // 空间⼤⼩(字节) 变量个数
double ret = 0; // C1 1
int i = 1; // C2 1
char tmp[N]; // C3 N
while (i <= N) {
ret += i;
i++;
}
return ret;
}- 跟时间复杂度度分析类似,我们关注的是随着问题规模N趋于很⼤时,空间占⽤的增⻓量级,所以也使⽤渐进表⽰,找到最⾼阶项,忽略常数和系数等。则
Func函数的空间复杂度为 O ( f ( N ) ) = O ( N ) O(f(N)) = O(N) O(f(N))=O(N)。 - 空间复杂度是算法因设计思路所需的额外开辟的空间 ,我们事前估算的是空间随问题规模(通常⽤N表⽰)增⻓的变化趋势。算法输⼊数据本⾝占⽤的空间不计⼊空间复杂度分析 ,因为那是算法的输⼊数据占据的空间,我们关⼼的是算法为了实现其功能⽽额外开辟的空间。
- 常⻅的空间复杂度量级: O ( 1 ) < O ( l o g N ) < O ( N ) < O ( N 2 ) O(1) < O(logN) < O(N) < O(N^2) O(1)<O(logN)<O(N)<O(N2)
- 若算法在执⾏过程中额外需要常数级别的额外空间 O ( 1 ) O(1) O(1) ,⼀般称这样的算法为原地算法。
4.1空间复杂度经典样例分析
4.1.1 O ( 1 ) O(1) O(1) 级
Summation算法申请了2个变量,所以空间复杂度 O ( 1 ) O(1) O(1)
c
int Summation(int N) {
int ret = 0;
int i = 1;
while (i <= N) {
ret += i;
i++;
}
return ret;
}4.1.2轮转数组
给定一个整数数组 nums,将数组中的元素向右轮转 k 个位置,其中 k 是非负数。
4.1.2.1旋转数组时间复杂度为 O ( N 2 ) O(N^2) O(N2) ,空间复杂度为 O ( 1 ) O(1) O(1)的解题思路
c
void rotate(int* nums, int numsSize, int k) {
while(k--)
{
int temp = nums[numsSize-1];
int i = 0;
for(i = numsSize;i>=2;i--)
{
nums[i-1]=nums[i-2];
}
nums[0]=temp;
}
}每次将数组中数据右轮转⼀位,轮转k次的思路,则时间复杂度为 O ( N 2 ) O(N^2) O(N2) ,空间复杂度为 O ( 1 ) O(1) O(1),
4.1.2.2旋转数组时间复杂度为 O ( N ) O(N) O(N) ,空间复杂度为 O ( N ) O(N) O(N) 的解题思路
c
void rotate(int* nums, int numsSize, int k) {
k%=numsSize;
int*arr=(int*)malloc(k*sizeof(int));
memmove(arr,nums+numsSize-k,k*sizeof(int));
memmove(nums+k,nums,(numsSize-k)*sizeof(int));
memmove(nums,arr,k*sizeof(int));
}采⽤空间换时间,开辟⼀个额外的跟nums⼀样⼤的临时数组arr,将nums的后k个数据挪动到arr的前k个位置,再将nums前n-k个拷贝到arr的后n-k个位置,再将arr的全部内容拷贝到nums里。
时间复杂度为 O ( N ) O(N) O(N) ,空间复杂度为 O ( N ) O(N) O(N)
4.1.2.3旋转数组时间复杂度为 O ( N ) O(N) O(N) ,空间复杂度为 O ( 1 ) O(1) O(1) 的解题思路
c
void reverse(int*arr,int x)
{
int left = 0;
int right = x-1;
while(left<right)
{
int temp = 0;
temp = arr[left];
arr[left]=arr[right];
arr[right]=temp;
left++;
right--;
}
}
void rotate(int* nums, int numsSize, int k) {
k%=numsSize;
reverse(nums,numsSize-k);
reverse(nums+numsSize-k,k);
reverse(nums,numsSize);
}采用三部翻转的方法,先将前n-k个数据逆序,再将后k个数据逆序,最终将所有数据逆序,就能得到结果。
时间复杂度为 O ( N ) O(N) O(N) ,空间复杂度为 O ( 1 ) O(1) O(1)
4.1.3递归算法空间复杂度
递归算法的空间复杂度为 S ( N ) = O ( ∑ i = 1 M f i ( N ) ) S(N)=O(\sum\limits_{i=1}^Mf_i(N)) S(N)=O(i=1∑Mfi(N)), M M M为递归的深度 , f i ( N ) f_i(N) fi(N)为每次递归算法的额外空间消耗。Fac阶乘使用递归实现,递归深度为 O ( N ) O(N) O(N),每次递归额外空间消耗为常数,空间复杂度为 O ( N ) O(N) O(N)。
c
// 计算递归求阶乘Fac算法的空间复杂度?
long long Fac(size_t N){
if (N <= 0)
return 1;
return Fac(N - 1) * N;
}