前言
这两年做 AI 应用,很多团队最先搭起来的是模型调用链路,最后最容易失控的却是数据层。
一开始,大家通常只把 PostgreSQL 或 MySQL 当成"普通业务库":用户表、订单表、会话表、消息表,该怎么建还怎么建。等产品开始要求"记住用户说过什么""能从历史对话里找回相似上下文""支持长期记忆"和"支持知识增强"时,问题就来了。
如果关系型数据放在 MySQL,语义检索放在独立向量库,那么你很快会遇到几类典型成本:一是双写 ,写一条消息时既要写业务库又要写向量库;二是一致性 ,消息改了但 embedding 没重算,检索结果就会失真;三是拼装查询,先召回向量结果,再回业务库查详情,最后还要手动合并上下文。
这也是为什么越来越多 AI 应用会把 PostgreSQL 作为核心数据库。原因不只是它"稳定""成熟",而是它借助 pgvector 之后,能把关系数据、对话数据、向量数据和语义检索能力放进同一套体系里。
本期我们不讲空泛概念,而是围绕一个完整目标来拆解:如何用 PostgreSQL + pgvector 存储用户、会话、消息,并用 Node.js / TypeORM 跑通 CRUD 与语义检索。读完后,大家会得到三个结果:
- 知道为什么 AI 应用更适合把长期记忆落在 PostgreSQL。
- 能亲手搭出一个最小可运行示例,完成消息写入与相似度搜索。
- 明白从原生
pg到 TypeORM 的分层方式,知道什么时候该直接写 SQL,什么时候该交给 ORM。
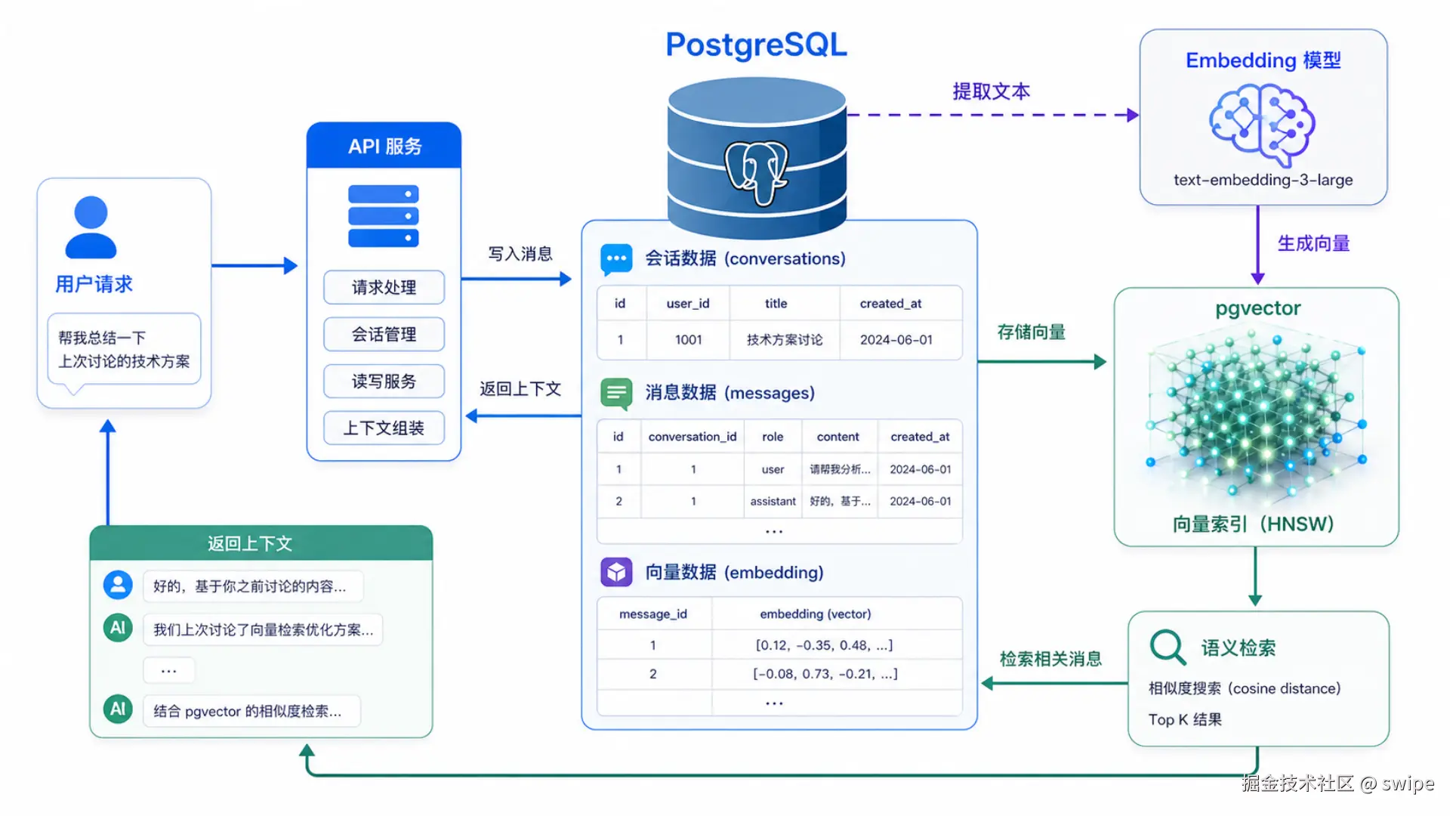
图 1:用户请求、Embedding 模型、PostgreSQL、pgvector 与语义检索之间的整体协作关系。
一、长期记忆层:为 AI 应用的数据架构做减法
1.1 为什么需要长期记忆层?
很多人第一次做 AI 聊天、Agent 或 RAG 系统时,会先把"对话记录"和"语义检索"拆成两套能力看待。前者是传统数据库的事情,后者是向量数据库的事情。这个拆法在概念上没错,但在工程实现上并不轻。
先看一个典型场景。用户发来一条消息,系统需要完成下面几步:
- 把消息文本存到消息表。
- 调用 Embedding 模型生成向量。
- 把向量写到向量索引系统。
- 下次检索时先做语义召回。
- 根据召回结果回查消息详情。
- 再把这些上下文拼成模型输入。
如果这几步分散在两套存储里,问题就会变成"流程可跑",但"系统变重"。你需要考虑消息更新后向量是否同步刷新,消息删除后向量是否同步删除,检索命中后如何按用户、按会话、按时间做二次过滤。
长期记忆层的价值,本质上不是把文本变成向量,而是把'结构化业务关系'和'语义理解能力'放到一个可维护的数据闭环里。
对于 AI 应用来说,这一层至少要解决 4 件事:
- 能表达用户、会话、消息之间的关系。
- 能保存消息原文和对应 embedding。
- 能按业务条件过滤,再按语义相似度排序。
- 能被上层服务稳定接入,而不是到处散落脚本逻辑。
1.2 长期记忆层适用场景
下面这几类场景,特别适合用 PostgreSQL + pgvector 一体化实现:
-
多轮对话产品 用户、会话、消息天然是关系型结构,同时消息又需要做历史召回。把这两部分放进一套表结构,最省维护成本。
-
Agent 的任务记忆 Agent 在执行任务时,既要记录步骤、状态、工具输出,也要根据语义找回相似任务轨迹。关系字段和向量字段会同时发挥作用。
-
企业内部知识问答 文档切片、来源元数据、组织权限、更新时间这些是强结构化信息;相似度搜索是语义能力。统一落在 PostgreSQL,更方便按权限、部门、时间做联合过滤。
-
带业务约束的 RAG 很多 RAG 不是"全库搜一遍",而是"只搜当前租户、当前项目、当前会话相关数据"。这正是关系查询和向量查询要协同的场景。
-
中小规模 AI 产品的第一版架构 如果业务还在验证期,先引入独立向量库往往会让系统复杂度提前膨胀。PostgreSQL 一体化方案更适合快速落地。
1.3 长期记忆层核心原理
可以把 PostgreSQL 在这里理解成一栋"同一地址的仓库楼"。
- 一楼放业务关系:用户、会话、消息、时间、状态。
- 二楼放语义索引:每条消息对应的 embedding。
- 电梯就是 SQL:你可以在一次查询里同时使用结构过滤和向量排序。
它的核心流程可以拆成这样:
-
输入是什么 输入通常是一条消息文本,外加它所属的
userId、conversationId、role等结构化信息。 -
触发条件是什么 当消息创建、更新,或者用户发起语义搜索时,会触发 embedding 生成或向量检索。
-
中间处理了什么 系统先把文本转成向量,再把这个向量写入 PostgreSQL 的
vector字段;检索时再把查询文本转成向量,通过pgvector的距离运算符完成排序。 -
输出结果是什么 输出不是"只有向量命中 ID",而是可以直接返回消息内容、角色、时间、相似度分数等完整结果。
-
对整体系统产生什么影响 关系查询和语义查询不再分裂成两条链路。上层 API 可以围绕一个统一数据模型开发,维护成本明显下降。
一个非常关键的点是:向量检索在 AI 系统里不是替代关系模型,而是补充关系模型。
用户是谁、消息属于哪个会话、哪些数据能被当前请求访问,这些都还是关系型数据库最擅长的事情。pgvector 的意义,是让 PostgreSQL 在保留这些能力的同时,再多出语义检索这一条腿。
二、快速上手:构建第一个可运行示例
这一节我们直接搭一个最小示例,目标很明确:
- 用 Docker 启动一个带
pgvector的 PostgreSQL。 - 创建
users、conversations、messages三张表。 - 用 Node.js 写入消息。
- 对部分消息生成 embedding。
- 在指定会话内做一次语义检索。
2.1 环境准备
本示例使用的技术栈如下:
- PostgreSQL 16
pgvector- Node.js
pg@langchain/openaidotenv
先安装依赖:
bash
pnpm add pg @langchain/openai dotenv然后准备一个 .env:
env
DATABASE_URL=postgresql://user:123456@localhost:5432/hello_pg
OPENAI_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
OPENAI_API_KEY=sk-xxxx
EMBEDDING_MODEL=text-embedding-v3这里的关键点有两个:
DATABASE_URL用来连接 PostgreSQL。OPENAI_BASE_URL、OPENAI_API_KEY、EMBEDDING_MODEL用来生成文本 embedding。
2.2 启动数据库
先看 docker-compose.yml:
yaml
services:
postgres:
image: pgvector/pgvector:pg16
container_name: pg_vector_db
restart: always
environment:
POSTGRES_USER: user
POSTGRES_PASSWORD: 123456
POSTGRES_DB: hello_pg
ports:
- "5432:5432"
volumes:
- ./volumes/postgres:/var/lib/postgresql/data
- ./init-scripts:/docker-entrypoint-initdb.d
healthcheck:
test: ["CMD-SHELL", "pg_isready -U user -d hello_pg"]
interval: 5s
timeout: 5s
retries: 5
pgadmin:
image: dpage/pgadmin4:latest
container_name: pgadmin
environment:
PGADMIN_DEFAULT_EMAIL: admin@admin.com
PGADMIN_DEFAULT_PASSWORD: admin
ports:
- "8088:80"
depends_on:
- postgres执行:
bash
docker compose up -d这个配置的整体作用很简单:postgres 服务负责数据库本体,pgadmin 用于图形化查看表结构和数据。把 SQL 脚本挂到 /docker-entrypoint-initdb.d 后,容器第一次启动时就会自动执行建表脚本。
2.3 创建表结构
建表 SQL 如下:
sql
CREATE EXTENSION IF NOT EXISTS vector;
CREATE TABLE IF NOT EXISTS users (
id SERIAL PRIMARY KEY,
name TEXT NOT NULL,
created_at TIMESTAMPTZ DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE IF NOT EXISTS conversations (
id SERIAL PRIMARY KEY,
user_id INTEGER NOT NULL,
title TEXT,
created_at TIMESTAMPTZ DEFAULT CURRENT_TIMESTAMP,
CONSTRAINT fk_conversations_user
FOREIGN KEY (user_id) REFERENCES users(id)
ON DELETE CASCADE
);
CREATE TABLE IF NOT EXISTS messages (
id SERIAL PRIMARY KEY,
conversation_id INTEGER NOT NULL,
role TEXT NOT NULL CHECK (role IN ('user', 'assistant', 'system')),
content TEXT NOT NULL,
embedding vector(1024),
created_at TIMESTAMPTZ DEFAULT CURRENT_TIMESTAMP,
CONSTRAINT fk_messages_conversation
FOREIGN KEY (conversation_id) REFERENCES conversations(id)
ON DELETE CASCADE
);
CREATE INDEX IF NOT EXISTS idx_messages_embedding
ON messages USING hnsw (embedding vector_cosine_ops);这段 SQL 的核心作用是把三件事一次讲清:
users -> conversations -> messages是标准关系模型。embedding vector(1024)让每条消息都可以携带语义向量。hnsw索引让相似度检索不至于每次全表扫描。
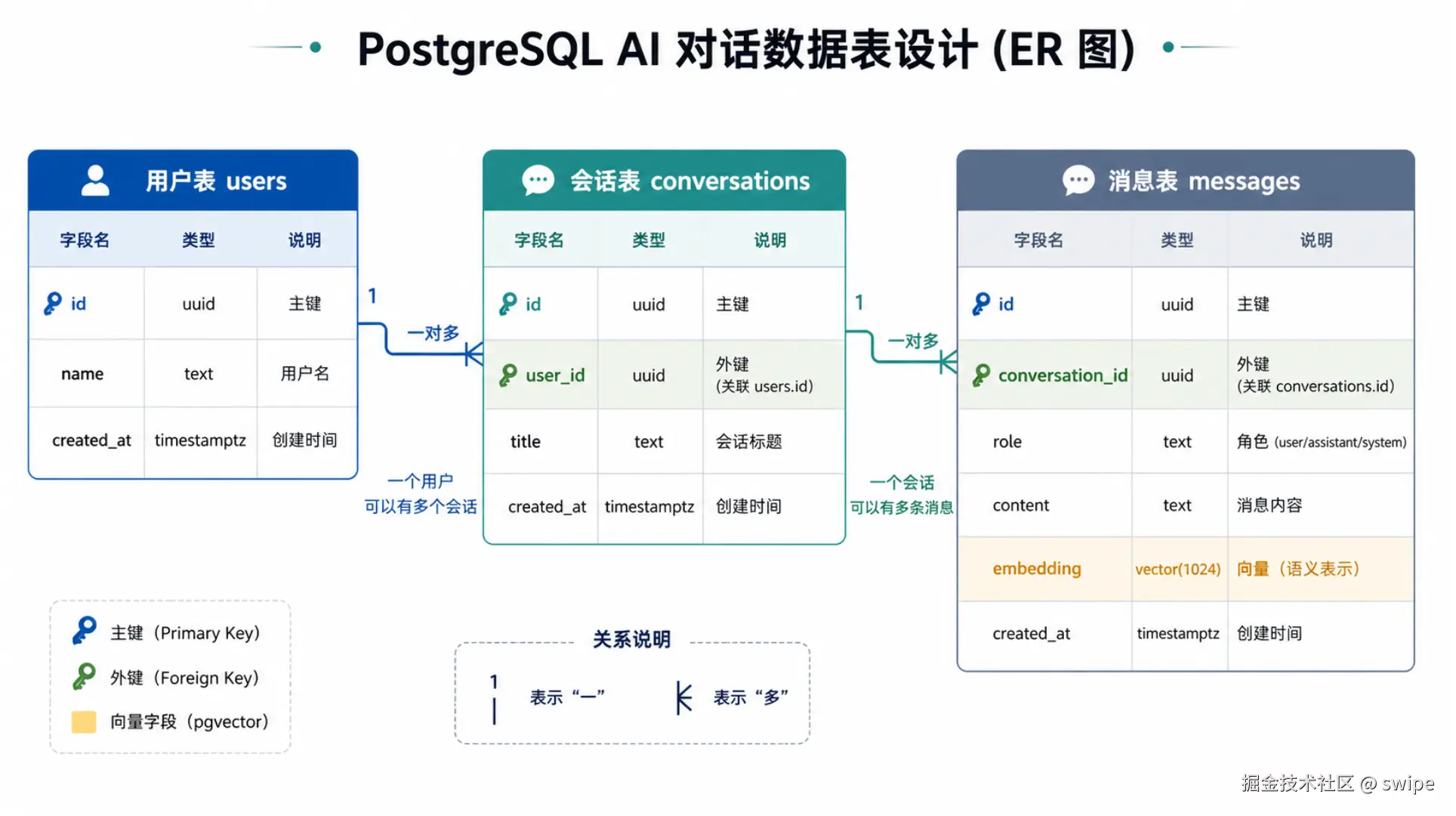
图 2:users、conversations、messages 三张核心表的主外键关系,以及 embedding 向量字段所在位置。
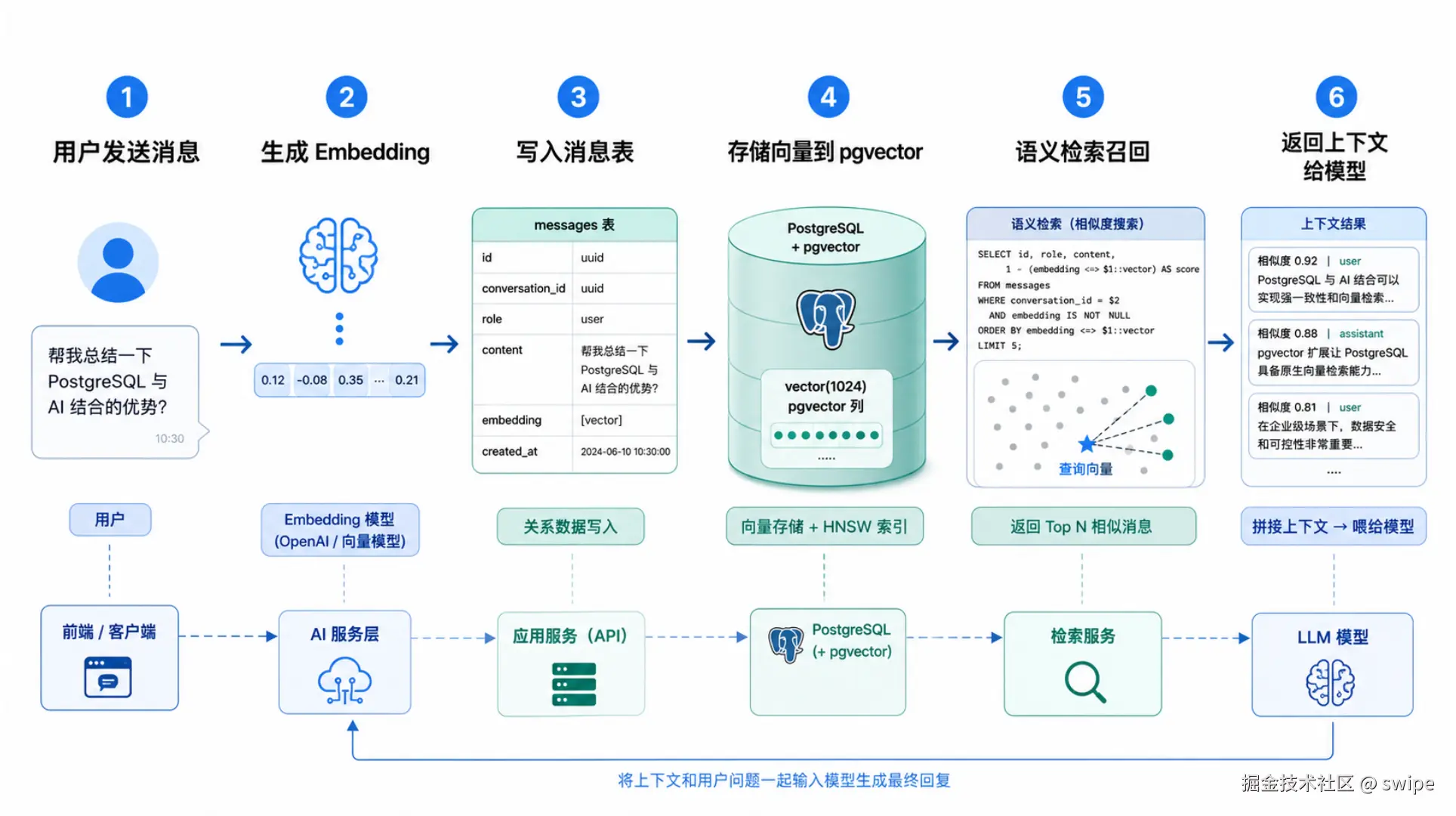
图 3:一条消息从写入、向量化、入库,到后续语义检索与返回上下文的完整链路。
为什么这样配置?因为 AI 对话数据天生同时具备两种属性:
一方面,它是结构化业务数据;另一方面,它又是适合做相似度匹配的语义数据。把这两种属性放在同一张 messages 表中,后面的检索和回查才会足够顺。
2.4 连接数据库并封装查询
先准备一个最小数据库连接层:
js
import dotenv from "dotenv";
import pg from "pg";
dotenv.config({ override: true });
const { Pool } = pg;
const pool = new Pool({
connectionString: process.env.DATABASE_URL,
});
export async function query(text, params) {
return pool.query(text, params);
}
export { pool };这段代码的作用不是"为了封装而封装",而是解决两个工程问题:
- 用连接池复用数据库连接,避免每次查询都重新建连接。
- 强制走参数化查询,避免把变量直接拼进 SQL。
2.5 写入消息并生成 embedding
下面是最关键的一段:写消息时,可选地为它生成 embedding。
js
import dotenv from "dotenv";
import { OpenAIEmbeddings } from "@langchain/openai";
import { query } from "./db.mjs";
dotenv.config({ override: true });
const VALID_ROLES = ["user", "assistant", "system"];
let embeddings;
function getEmbeddings() {
if (!embeddings) {
embeddings = new OpenAIEmbeddings({
model: process.env.EMBEDDING_MODEL || "text-embedding-v3",
apiKey: process.env.OPENAI_API_KEY,
configuration: {
baseURL: process.env.OPENAI_BASE_URL,
},
});
}
return embeddings;
}
export async function createMessage(conversationId, role, content, withEmbedding = false) {
if (!VALID_ROLES.includes(role)) {
throw new Error("非法 role");
}
if (withEmbedding) {
const vector = await getEmbeddings().embedQuery(content);
const { rows } = await query(
`INSERT INTO messages (conversation_id, role, content, embedding)
VALUES ($1, $2, $3, $4::vector)
RETURNING id, conversation_id, role, content, created_at`,
[conversationId, role, content, JSON.stringify(vector)]
);
return rows[0];
}
const { rows } = await query(
`INSERT INTO messages (conversation_id, role, content)
VALUES ($1, $2, $3)
RETURNING *`,
[conversationId, role, content]
);
return rows[0];
}这段代码有 4 个重点:
OpenAIEmbeddings负责把文本转成向量。withEmbedding决定当前写入是否参与语义检索。$4::vector明确告诉 PostgreSQL:这个参数要按vector类型写入。- 返回结果里不强制带上 embedding,本质上是为了减少无意义的大字段传输。
2.6 语义检索:只在当前会话里找相似消息
有了消息和向量,接下来就能做语义检索:
js
export async function searchSimilarMessages(conversationId, searchText, limit = 5) {
const vector = await getEmbeddings().embedQuery(searchText);
const { rows } = await query(
`SELECT id, conversation_id, role, content, created_at,
1 - (embedding <=> $1::vector) AS similarity
FROM messages
WHERE conversation_id = $2 AND embedding IS NOT NULL
ORDER BY embedding <=> $1::vector
LIMIT $3`,
[JSON.stringify(vector), conversationId, limit]
);
return rows;
}这里的核心 API 是 embedding <=> $1::vector。
- 它表示按余弦距离比较两段向量。
- 距离越小,代表语义越相近。
1 - distance则是为了得到更直观的相似度分数。
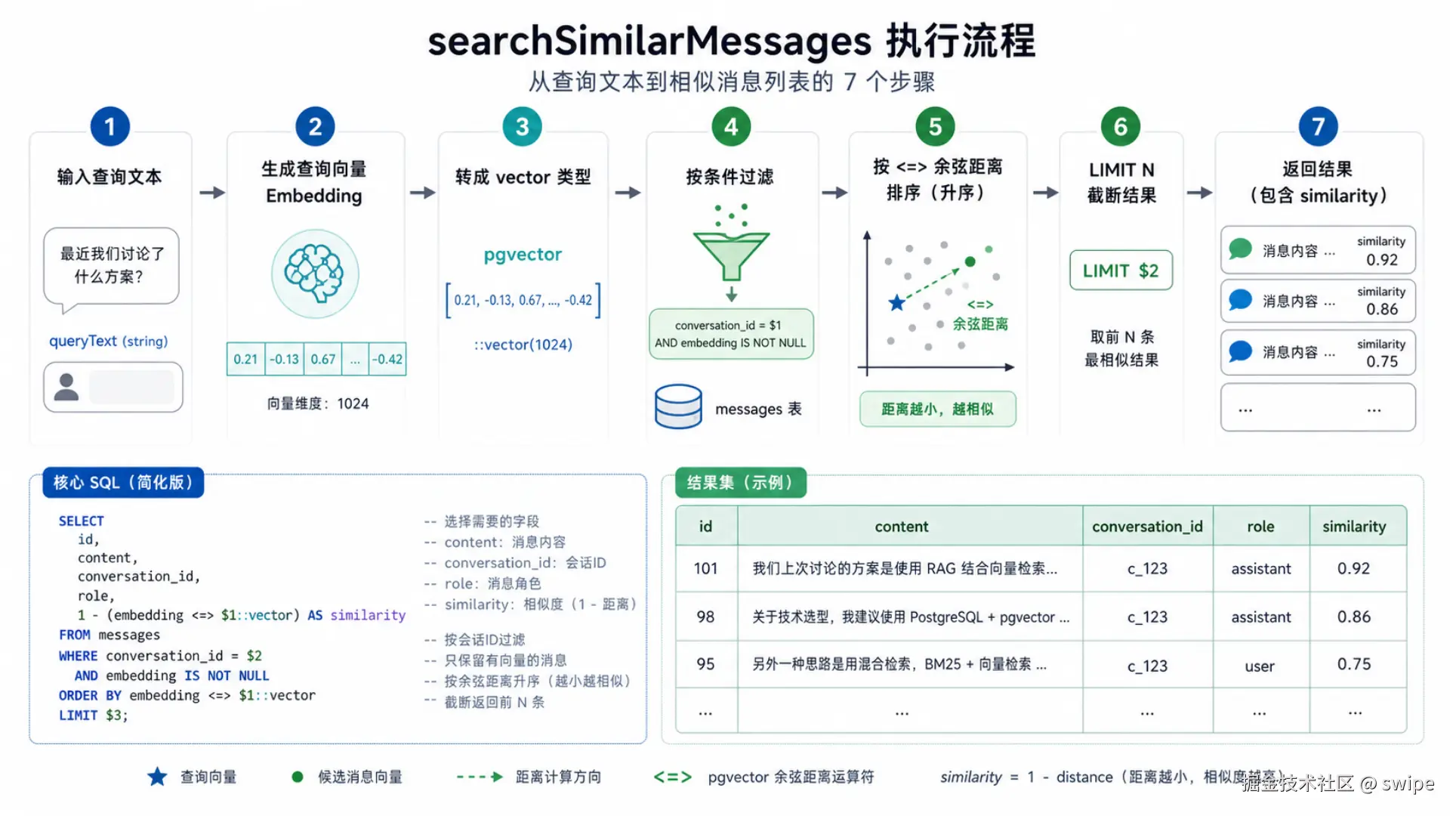
图 4:searchSimilarMessages 从查询文本向量化,到过滤、排序、截断,再返回相似度结果的执行路径。
为什么示例里只在当前会话内搜索?因为真实业务里,长期记忆几乎都带范围约束。你要的往往不是"全库最像的一段话",而是"当前用户、当前会话、当前任务上下文里最相关的一段话"。
2.7 一个串行演示脚本
把这些流程串起来,大概会是这样:
js
const user = await createUser("张三");
const conversation = await createConversation(user.id, "第一次对话");
await createMessage(conversation.id, "user", "你好,请介绍一下 PostgreSQL");
await createMessage(conversation.id, "assistant", "PostgreSQL 是一个功能强大的开源关系型数据库。");
await createMessage(conversation.id, "user", "PostgreSQL 支持哪些数据类型?", true);
await createMessage(conversation.id, "assistant", "PostgreSQL 支持整数、文本、JSON、数组,以及 pgvector 提供的向量类型。", true);
await createMessage(conversation.id, "user", "怎么做相似度搜索?", true);
await createMessage(conversation.id, "assistant", "可以使用 pgvector 的 cosine 距离运算符配合 hnsw 索引。", true);
const results = await searchSimilarMessages(conversation.id, "向量相似度怎么查", 3);
console.log(results);运行结果会发生什么?
- 前两条消息只做普通写入。
- 后四条消息会额外生成 embedding。
- 当搜索"向量相似度怎么查"时,系统会优先召回和
pgvector、cosine、相似度搜索相关的消息。
这就是一个最小可运行的长期记忆层雏形。它已经具备了用户、会话、消息、embedding 和语义检索这几块核心能力。
三、核心配置与关键流程详解
跑通示例只是第一步。真正进入项目后,大家更关心的是:哪些配置和流程最关键,哪些地方最容易踩坑。
这一节我们重点拆 5 个点。
3.1 vector(1024):它是什么,控制什么行为?
它是什么:
messages.embedding 字段的类型定义,表示这个字段保存的是 1024 维向量。
它控制什么行为:
它决定 PostgreSQL 如何存储 embedding,也决定后续相似度计算的合法输入格式。
常见配置方式:
vector(1024):适合text-embedding-v3这类 1024 维模型。- 其他维度:前提是必须和你的 embedding 模型输出一致。
推荐使用场景:
只要一条文本后续要参与语义检索,就应该有对应的向量字段。
容易踩坑的地方:
向量维度必须和模型输出完全一致。 如果模型输出 1536 维,你却把字段建成 vector(1024),写入时就会直接失败。
3.2 hnsw 索引:为什么它重要?
它是什么:
pgvector 为向量检索提供的近似最近邻索引方式之一。
它控制什么行为:
它影响的是检索性能,尤其是消息量上来之后,搜索是否还能维持可用延迟。
常见配置方式:
sql
CREATE INDEX IF NOT EXISTS idx_messages_embedding
ON messages USING hnsw (embedding vector_cosine_ops);推荐使用场景:
消息量达到一定规模,并且语义搜索是高频路径时,应该尽早加上。
容易踩坑的地方:
- 小数据量时你可能感受不到索引收益,但一旦数据增多,没有索引的检索代价会迅速上升。
- 度量方式要和你的检索目标匹配。文本语义检索里,
vector_cosine_ops是更常见的选择。
3.3 withEmbedding:为什么建议把它做成显式开关?
它是什么:
应用层写消息时的一个控制参数,用来决定当前写入是否生成向量。
它控制什么行为:
它控制的是成本与能力之间的平衡。
常见配置方式:
- 普通消息:只写文本,不生成 embedding。
- 记忆消息、知识片段、可召回消息:写文本并生成 embedding。
推荐使用场景:
不是所有文本都值得做向量化。比如纯系统日志、调试输出、瞬时中间状态,未必值得承担 embedding 成本。
容易踩坑的地方:
如果业务上后续需要召回,但创建时没写 embedding,检索时就只能得到空结果。
所以实际项目里,最好提前定义哪些数据是"必须可检索"的。
3.4 消息更新时为什么要同步更新 embedding?
它是什么:
当消息内容发生变化时,除了更新 content,还要重新生成并写入新的 embedding。
它控制什么行为:
它保证文本语义和向量表示始终一致。
常见配置方式:
js
UPDATE messages
SET content = $1, embedding = $2::vector
WHERE id = $3推荐使用场景:
只要消息文本会被编辑,并且这条消息还参与语义检索,就必须同步刷新 embedding。
容易踩坑的地方:
这是最常见的数据一致性问题。很多系统只更新了文本,忘记重算向量,最后检索召回的是"旧语义",看起来像模型不准,实际上是数据层没同步。
3.5 TypeORM 在这里应该扮演什么角色?
它是什么:
TypeORM 是关系模型和应用层之间的 ORM 映射层,用来管理实体关系、常规查询和模块化服务。
它控制什么行为:
它让用户、会话、消息这些标准关系查询更容易维护,但并不意味着所有向量搜索都该完全交给 ORM。
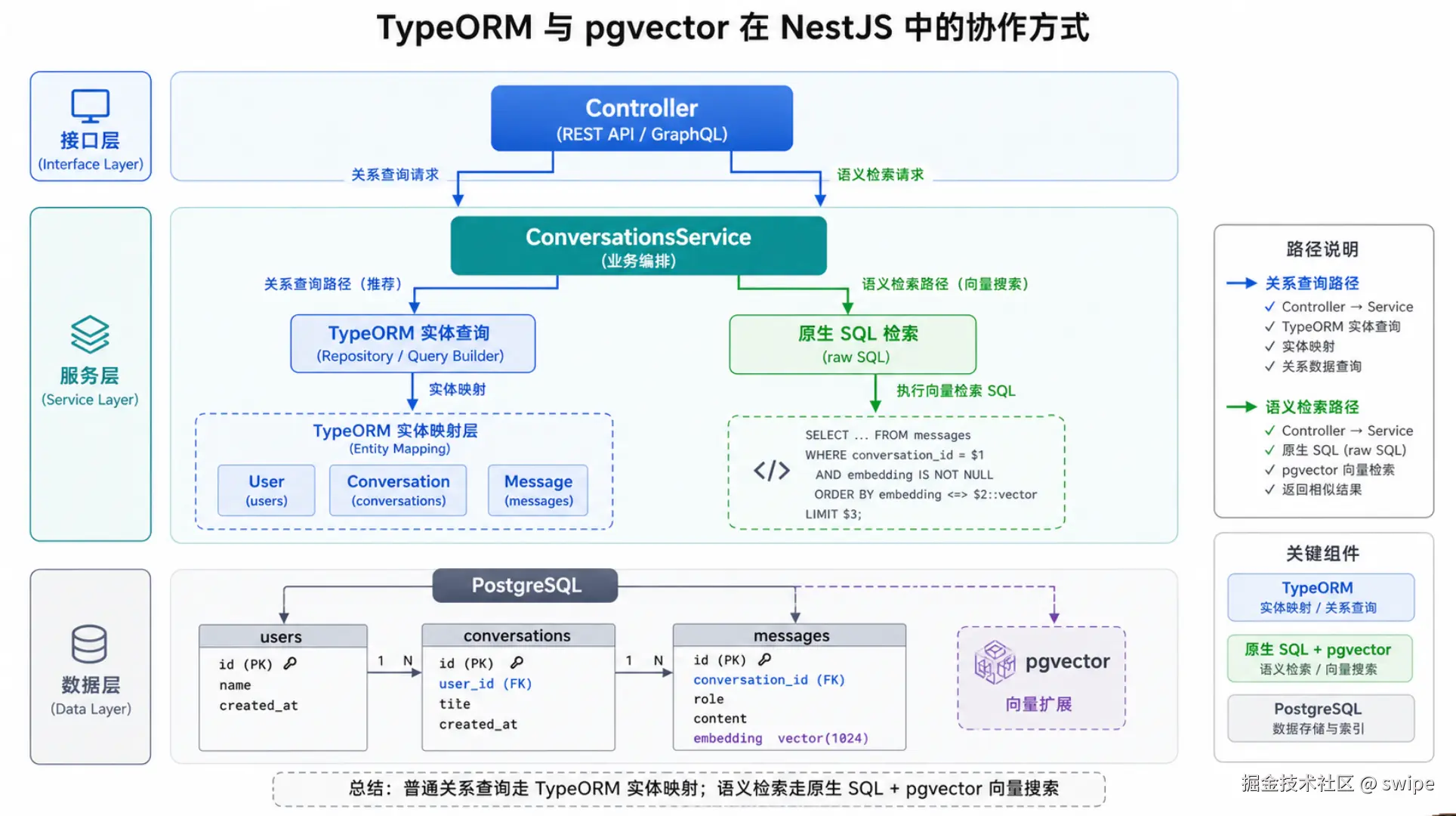
图 5:普通关系查询更适合走 TypeORM 实体映射,语义检索则更适合保留为原生 SQL。
先看实体定义中的关键部分:
ts
@Entity('messages')
export class Message {
@PrimaryGeneratedColumn()
id: number;
@Column({ name: 'conversation_id' })
conversationId: number;
@Column({
type: 'text',
enum: MessageRole,
})
role: MessageRole;
@Column({ type: 'text' })
content: string;
@Column('vector', { length: 1024, nullable: true })
embedding: number[] | null;
}这段定义说明两件事:
- TypeORM 可以把
messages表里的普通字段和向量字段一起映射出来。 - 关系数据适合交给实体管理,但复杂的向量排序 SQL 依然可以通过原生查询完成。
再看一个服务层示例:
ts
const rows = await this.em.query(
`SELECT id, conversation_id, role, content, created_at,
1 - (embedding <=> $1::vector) AS similarity
FROM messages
WHERE conversation_id = $2 AND embedding IS NOT NULL
ORDER BY embedding <=> $1::vector
LIMIT $3`,
[JSON.stringify(vector), conversationId, limit],
);推荐使用场景:
- 普通关系查询:交给 TypeORM,比如按用户查会话、按会话查消息。
- 高表达力 SQL :直接走原生查询,比如带
pgvector距离运算符的语义检索。
容易踩坑的地方:
- 试图把所有查询都抽象成 ORM Builder,最后往往会让向量检索 SQL 变得别扭且难维护。
- 反过来,如果所有地方都只写原生 SQL,也会失去实体关系带来的结构化收益。
更合理的做法是:关系用 ORM,语义搜索保留 SQL。
四、运行效果与扩展思考
当这个示例运行起来后,系统整体会呈现出一个非常清晰的数据闭环:
- 用户被写入
users表。 - 会话被写入
conversations表,并通过外键绑定到用户。 - 消息被写入
messages表。 - 需要参与检索的消息会同步写入 embedding。
- 搜索时会先把查询文本转成向量,再在指定会话内完成相似度排序。
这套方案真正有价值的地方,不是"也能做向量检索",而是它把业务过滤 和语义排序拼到了同一条查询链路里。
举个更接近生产的例子。一个 Agent 在给用户回答问题前,往往会先回看三类上下文:
- 当前会话内近期消息。
- 当前用户的历史偏好。
- 某个业务对象相关的知识片段。
如果这些数据都在 PostgreSQL 里,你完全可以把查询拆成多层条件:
- 先按
user_id过滤。 - 再按
conversation_id缩小范围。 - 再按时间窗口限制候选集。
- 最后按向量相似度排序。
这比"先在向量库搜,再回业务库补字段"的链路明显更顺。
当然,这套方案也有边界:
-
并不是所有规模都该只靠 PostgreSQL 如果你的向量数据规模极大、检索模式极复杂,独立向量数据库仍然可能有价值。
-
Embedding 生成本身有成本 无论你把向量存在哪里,模型调用成本都不会凭空消失。数据层一体化解决的是维护复杂度,不是免费获得 embedding。
-
检索效果不只取决于数据库 向量质量、切片策略、上下文拼装策略,同样会影响最终问答效果。PostgreSQL 只是把数据基础打稳了。
如果要继续扩展,这里有几个很自然的方向:
- 给消息增加
tenant_id、project_id、source_type等业务维度,做多租户隔离。 - 把知识文档切片也放进统一表结构,形成"会话记忆 + 文档知识"的混合检索。
- 在 NestJS 服务层封装统一的 Memory Service,让上层 Agent 不直接感知底层 SQL。
- 对高频搜索结果做缓存,降低重复 embedding 与重复查询成本。
五、总结
本期我们围绕一个很实际的问题展开:AI 应用为什么适合把长期记忆层建在 PostgreSQL 上,以及这件事应该怎么落地。
回顾一下核心结论:
- 本文解决的问题,是把关系数据和语义检索拆成两套系统后带来的双写、一致性和查询拼装成本。
- PostgreSQL 的核心能力,不只是存业务表,而是借助
pgvector把用户、会话、消息和 embedding 放进同一套数据模型。 - 在实际开发中,更推荐的方式是:底层存储统一交给 PostgreSQL,常规关系查询交给 TypeORM,向量检索保留原生 SQL。
- 如果你正处在 AI 应用的第一版架构阶段,这会是一条很稳、很实用的路线。
如果大家后续还想继续深入,下一步可以重点看 3 个方向:
- 如何把文档切片、知识库和会话记忆合并成统一检索层。
- 如何在 NestJS 里封装一个更完整的 Memory Module。
- 如何评估
pgvector在不同数据规模下的索引策略与性能边界。
对于很多 AI 项目来说,真正决定系统是否能长期演进的,不是模型调用本身,而是数据层有没有从第一天就走在一条可维护的路线上。
而 PostgreSQL,恰好就是那条路上非常扎实的一块地基。