前言
做 Agent 系统时,大家最先关注的往往是模型、Tool、工作流和 Prompt,但真正把系统跑到线上之后,最先暴露问题的通常不是模型,而是上下文。
一个用户连续聊了 10 轮,Agent 需要记住最近几轮消息;对话太长了,又要做截断和摘要;服务一旦扩成多实例,用户下一次请求还可能落到另一台机器上。这时候如果你还把会话上下文放在单机内存里,问题会立刻出现:
- 实例之间无法共享会话状态。
- 服务重启后短期记忆直接丢失。
- 对话读写频率高,落数据库太重,延迟也不划算。
- 会话闲置后还要自己清理,维护成本高。
这也是为什么在一套完整的 Agent 架构里,通常会把"记忆"拆成两层:
- 短期记忆:承载最近消息、摘要、临时状态,要求低延迟、可过期、可跨实例共享。
- 长期记忆:承载永久消息、历史会话、知识片段、向量检索结果,要求可归档、可追溯、可分析。
短期记忆这一层,Redis 几乎就是天然解法。
它不是因为"缓存很快"这么简单,而是因为它同时具备了 低延迟读写、TTL 自动过期、多实例共享、灵活数据结构 这四个关键特性。
本期我们就围绕一个具体目标来讲透它:如何用 Redis 为 Agent 构建一套真正可运行的短期记忆层,并和长期记忆存储做好分工。
读完后,大家会得到 3 个结果:
- 知道为什么 Agent 的短期记忆更适合放在 Redis,而不是直接塞进应用内存或数据库。
- 能基于
ioredis + LangChain跑通一个最小可运行示例。 - 明白
List / Hash / String / TTL各自适合承载什么,以及实际工程里该如何分层。
一、短期记忆层:为 Agent 会话上下文争取最低延迟
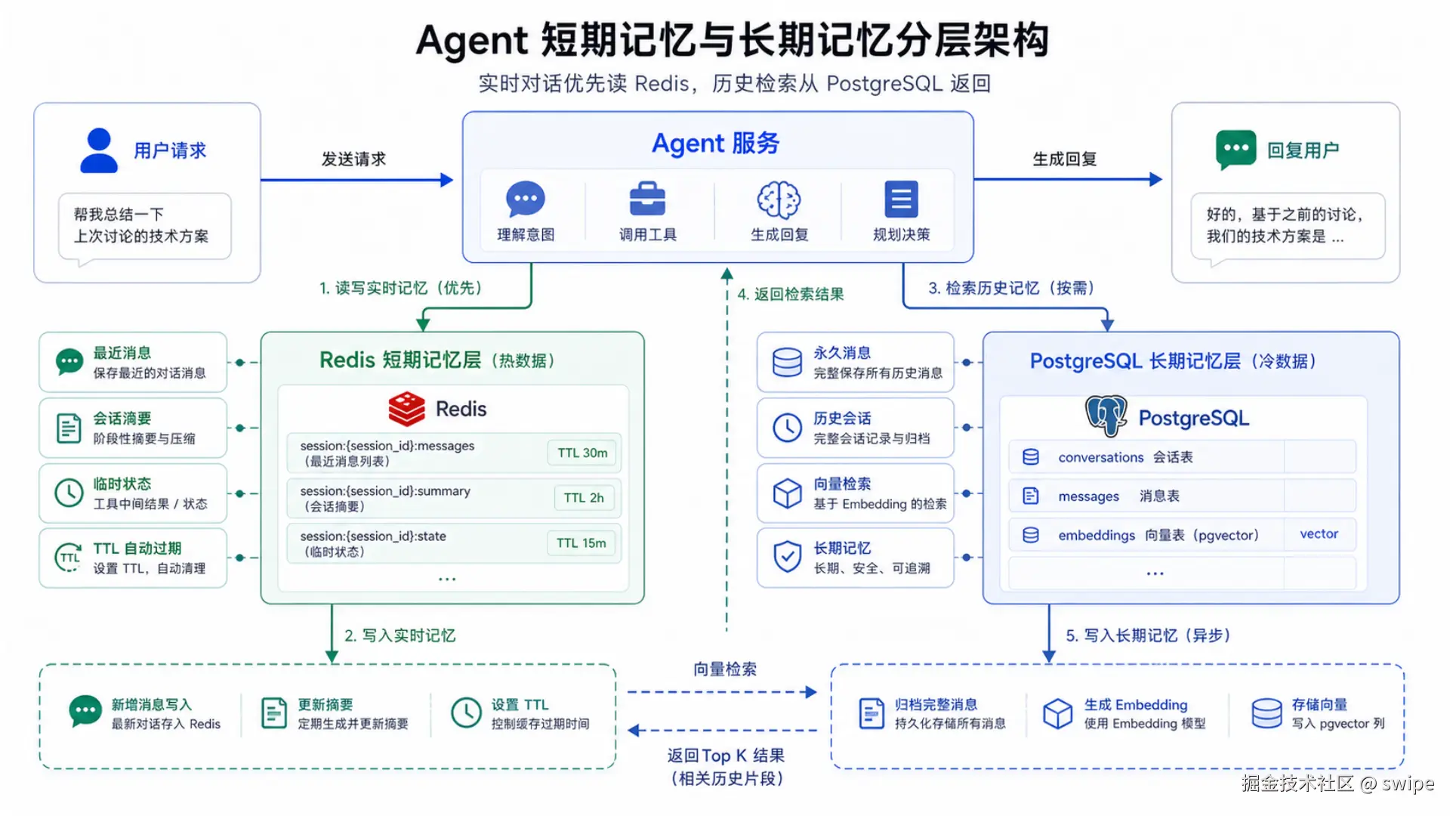
图 1:在线对话优先依赖 Redis 承载短期记忆,而永久消息、历史检索与长期记忆则交给 PostgreSQL。
1.1 为什么需要短期记忆层?
如果把 Agent 看成一个正在持续对话的"运行时程序",那最近几轮消息、当前任务状态、临时摘要,本质上都是它的运行时内存。问题在于,线上服务的运行时内存并不稳定。
在本地 CLI 演示里,我们完全可以把上下文保存在进程变量里。因为:
- 只有一个用户。
- 只有一个进程。
- 进程生命周期和会话生命周期几乎一致。
但一旦到了后端服务,情况就变了:
- 请求会被负载均衡分发到不同实例。
- 单机内存不能天然共享。
- 对话属于高频热数据,读写非常频繁。
- 大量闲置会话会持续占用资源。
- 历史消息还要做截断、摘要和重新拼装。
这时如果还把所有上下文都放进 PostgreSQL,你会遇到两个问题:
- 一是每轮对话都要做多次数据库读写,代价太重。
- 二是很多上下文本质上只是"临时运行态",并不适合永久保存。
所以短期记忆层的价值,不是"再建一个缓存",而是给 Agent 提供一个高频、低延迟、可过期、可共享 的运行时状态空间。
1.2 短期记忆层适用场景
Redis 这一层,特别适合下面几类场景:
-
多轮对话上下文 最近 5 到 20 轮消息需要被持续读取、拼接和截断,典型的高频热数据。
-
对话摘要缓存 当消息数增长到阈值后,把老消息压缩成摘要,后续继续复用。摘要并不一定要永久保存,但在当前会话阶段必须能快速读取。
-
多实例 Agent 服务 用户本轮请求打到 A 实例,下轮请求打到 B 实例,Redis 能让两台机器读到同一份会话上下文。
-
工具执行中的临时状态 比如当前任务步骤、中间结果、最近调用的 Tool 输出,这类状态适合短期保留,不适合直接归档。
-
需要自动失效的会话 用户 30 分钟没说话,会话记忆自动过期,完全符合 Redis 的 TTL 模型。
1.3 短期记忆层核心原理
可以把 Redis 理解成 Agent 身边的一张"工作台",而 PostgreSQL 则是后面的"档案室"。
- 工作台上放的是当前正在处理的材料:最近消息、会话摘要、临时状态。
- 档案室里放的是最终归档材料:永久消息、历史记录、长期记忆。
一次标准的短期记忆流程,大致是这样:
-
输入是什么 输入是一条新的用户消息,以及它所属的
sessionId。 -
触发条件是什么 用户发起一次对话请求,系统需要组装上下文并调用 Agent。
-
中间处理了什么 服务先从 Redis 读取当前会话历史,再把用户消息拼进去;如果消息过长,则用摘要中间件压缩旧消息;最后把新的消息集合写回 Redis,并刷新 TTL。
-
输出结果是什么 输出是一条 Agent 回复,以及一份更新后的短期记忆。
-
对整体系统产生什么影响 会话状态不再依赖单机内存,实例可以横向扩展;历史消息又不会无限膨胀,因为 TTL 和摘要压缩会一起控制规模。
在这个模型里,Redis 解决的是"当前会话如何持续运行 "的问题,而不是"所有聊天记录如何永久保存"的问题。这个边界一定要清楚。
二、快速上手:构建第一个可运行示例
这一节我们直接基于一个真实示例来搭建:
- 用 Docker 启动 Redis 和 RedisInsight。
- 用
ioredis连接 Redis。 - 用
RedisMessageStore管理消息读写。 - 在 Agent 调用前后自动读取和写回会话记忆。
- 用
summarizationMiddleware在消息过多时做压缩。
2.1 环境准备
这个示例使用的技术栈如下:
- Redis 7
ioredislangchain@langchain/openaidotenv
安装依赖:
bash
pnpm add ioredis langchain @langchain/openai dotenv如果你还想直接复用完整示例里的依赖,也可以保留这些包:
json
{
"dependencies": {
"@langchain/langgraph": "^1.3.7",
"@langchain/openai": "^1.4.7",
"deepagents": "^1.10.2",
"dotenv": "^17.4.2",
"ioredis": "^5.11.1",
"langchain": "^1.4.4",
"zod": "^4.4.3"
}
}准备 .env:
env
OPENAI_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
OPENAI_API_KEY=sk-xxxx
MODEL_NAME=qwen-plus
REDIS_HOST=localhost
REDIS_PORT=6379
REDIS_DB=0
MEMORY_TTL_SECONDS=1800
MEMORY_KEY_PREFIX=agent:short_memory
MEMORY_SESSION_ID=demo_user_001这里最关键的几个参数是:
MEMORY_TTL_SECONDS:短期记忆保留多久。MEMORY_KEY_PREFIX:会话记忆的 Redis key 前缀。MEMORY_SESSION_ID:当前会话 ID。
2.2 启动 Redis
先看 docker-compose.yml:
yaml
services:
# Redis 主服务,负责承载 Agent 短期记忆
redis:
image: redis:7-alpine
container_name: agent_redis
restart: always
ports:
- "6379:6379"
volumes:
- ./volumes/redis:/data
# 开启 AOF,降低极端情况下的数据丢失风险
command: redis-server --appendonly yes
healthcheck:
test: ["CMD", "redis-cli", "ping"]
interval: 5s
timeout: 5s
retries: 5
# RedisInsight 图形界面,便于查看 key、TTL 和数据结构
redisinsight:
image: redis/redisinsight:2.50
container_name: redis_insight
restart: always
ports:
- "5540:5540"
volumes:
- ./volumes/redisinsight:/data
environment:
- RI_HOST=0.0.0.0
depends_on:
- redis执行:
bash
docker compose up -d这套配置的整体作用很简单:
redis负责承载会话短期记忆。redisinsight用来可视化查看 key、TTL 和数据结构。appendonly yes表示开启 AOF,降低极端情况下的数据丢失风险。
2.3 先认识 Redis:7 种核心数据类型怎么选?
很多人学 Redis 时,第一反应是"它是一个缓存",第二反应是"我只会 set/get"。但如果你真的要用它承载 Agent 的短期记忆,只会 String 远远不够。
Redis 的真正价值之一,在于它提供了多种针对不同场景优化过的数据结构。它不是单纯把数据"存进去",而是允许你根据访问模式,选择最合适的承载方式。
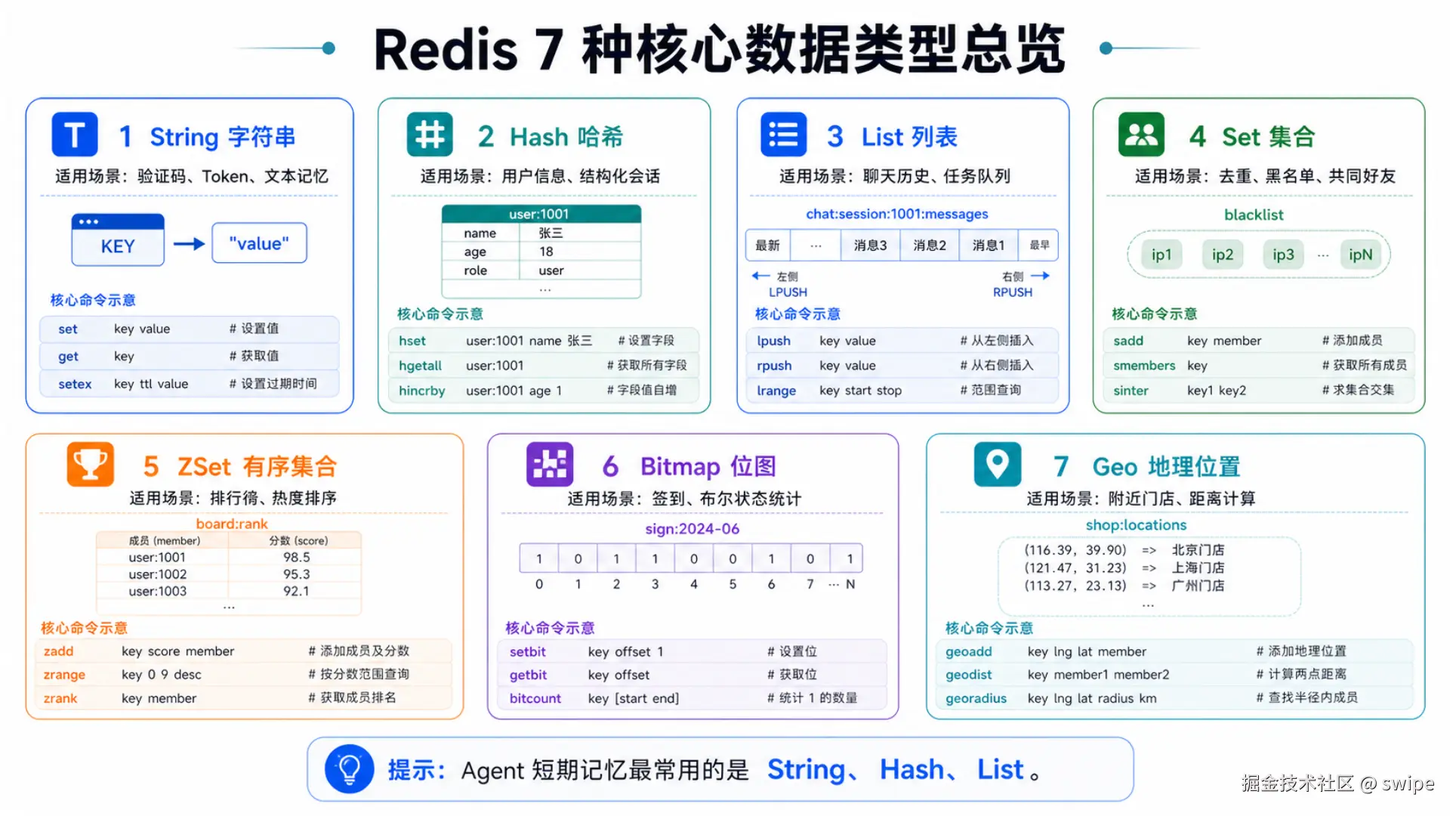
图 2:从通用缓存到会话记忆,Redis 的 7 种核心数据类型各自覆盖了不同的数据组织方式。
这 7 种类型里,和 Agent 短期记忆最相关的是 String、Hash、List,但其余类型在周边能力上也很有价值。下面按实战视角快速过一遍。
String 字符串
- 适用场景:验证码、Token、登录会话、计数器、分布式锁、文本类短期记忆。
- 核心命令:
set、get、setex、incr。 - 真实业务示例:
bash
setex verification:mobile:13800138000 300 "666888"
setex session:token:adf245kjndsa3 86400 "userid:1001"
incr counter:article:1024
set lock:order:2001 "locked" nx ex 10
setex agent:memory:user:1001 3600 "用户想学习 PostgreSQL 向量检索"对 Agent 来说,String 最适合承载对话摘要、临时状态、整段序列化消息 。示例里的 RedisMessageStore,本质上就是把一整段消息数组序列化后放进一个 String。
Hash 哈希
- 适用场景:用户信息、商品资料、电商购物车、结构化对话上下文。
- 核心命令:
hset、hgetall、hkeys、hincrby。 - 真实业务示例:
bash
hset user:info:1001 name "张三" age 28 phone "13800138000"
hset cart:user:1001 product:10086 2 product:10087 1
hset agent:session:user:1001 messages "最近 5 轮对话" summary "对话摘要"Hash 特别适合存结构化会话元信息 ,比如 model、locale、user_id、summary_version、tool_state。它的优势是字段级读写,不需要每次把整个 JSON 反序列化再整体改回去。
List 列表
- 适用场景:消息队列、任务队列、操作日志、聊天历史、有序记录。
- 核心命令:
lpush、rpush、lrange、lpop、llen。 - 真实业务示例:
bash
rpush queue:order "order_1001" "order_1002"
lpush user:history:1001 "查看了 AI 课程" "查看了 Redis 教程"
rpush queue:task "生成对话摘要" "向量入库"如果你希望短期记忆按"最近消息队列"的方式组织,List 就很自然。比如把最近 20 条对话按顺序压进一个 List,再配合 ltrim 保持固定长度,这是一种非常常见的会话窗口设计。
Set 集合
- 适用场景:数据去重、每日签到、IP 黑名单、共同好友、权限标签。
- 核心命令:
sadd、smembers、sismember、sinter。 - 真实业务示例:
bash
sadd sign:20250820:user 1001 1002 1003
sadd blacklist:ip "192.168.1.100" "192.168.1.101"
sinter user:friend:1001 user:friend:1002Set 不一定直接承载聊天消息,但非常适合做 Agent 周边能力,比如已执行 Tool 去重、会话标签、权限集合、已看过的知识片段 ID 集合。
ZSet 有序集合
- 适用场景:排行榜、热度排序、积分排名、权重队列。
- 核心命令:
zadd、zrange、zrevrange、zrank。 - 真实业务示例:
bash
zadd rank:course 98 "PostgreSQL 实战" 95 "AI Agent 开发" 92 "Redis 从入门到精通"
zadd rank:user:points 1000 "张三" 850 "李四"
zadd hot:article 1200 "article:1024" 980 "article:1025"对 Agent 而言,ZSet 特别适合做优先级任务队列、最近活跃会话排序、召回结果打分缓存。如果你希望某些任务"按权重执行",ZSet 会比 List 更灵活。
Bitmap 位图
- 适用场景:海量用户签到、在线状态统计、布尔状态存储。
- 核心命令:
setbit、getbit、bitcount。 - 真实业务示例:
bash
setbit user:sign:1001:202508 5 1
setbit user:sign:1001:202508 10 1
bitcount user:sign:1001:202508Bitmap 不适合直接存会话消息,但在高并发系统里可以承担海量布尔状态统计,比如某个知识片段是否已处理、某个会话是否触发过某类动作。
Geo 地理位置
- 适用场景:附近门店、附近的人、距离计算、位置检索。
- 核心命令:
geoadd、geodist。 - 真实业务示例:
bash
geoadd shop:location 116.481028 39.921983 "北京总店"
geodist shop:location "北京总店" "上海分店" kmGeo 和 Agent 短期记忆关系没那么直接,但一旦你做本地生活、地图服务、到店导购 Agent,它就会立刻变得有用。
为了方便大家快速决策,可以先记住这个简单结论:
| 数据类型 | 典型业务场景 |
|---|---|
String |
验证码、Token、计数器、分布式锁、文本记忆 |
Hash |
用户信息、商品数据、购物车、结构化会话 |
List |
消息队列、任务队列、浏览/聊天历史 |
Set |
签到、数据去重、黑名单、好友关系 |
ZSet |
排行榜、热度排序、积分排名 |
Bitmap |
批量签到、海量布尔状态统计 |
Geo |
位置检索、距离计算、附近门店/人群 |
如果把这张表进一步翻译成 Agent 场景,其实就是一句话:
短期记忆主用 String / Hash / List,状态控制和周边能力按需补 Set / ZSet / Bitmap / Geo。
2.4 完整示例:带短期记忆的 Agent 调用
下面这段代码,就是一个最小可运行的短期记忆实现。它来自实际项目示例,做了适度裁剪,但流程保持一致。
js
import dotenv from "dotenv";
// 读取 .env 配置,并覆盖当前进程环境变量,方便本地调试
dotenv.config({ override: true });
import Redis from "ioredis";
import { ChatOpenAI } from "@langchain/openai";
import {
mapChatMessagesToStoredMessages,
mapStoredMessagesToChatMessages,
} from "@langchain/core/messages";
import { createAgent, HumanMessage, summarizationMiddleware } from "langchain";
// Redis 连接配置
const REDIS_HOST = process.env.REDIS_HOST ?? "localhost";
const REDIS_PORT = Number(process.env.REDIS_PORT ?? 6379);
const REDIS_DB = Number(process.env.REDIS_DB ?? 0);
// 会话短期记忆的 TTL,默认 30 分钟
const MEMORY_TTL = Number(process.env.MEMORY_TTL_SECONDS ?? 1800);
// Redis key 前缀,避免和别的业务 key 冲突
const KEY_PREFIX = process.env.MEMORY_KEY_PREFIX ?? "agent:short_memory";
class RedisMessageStore {
constructor({ redis, keyPrefix, ttlSeconds }) {
this.redis = redis;
this.keyPrefix = keyPrefix;
this.ttlSeconds = ttlSeconds;
}
// 统一生成某个会话的消息 key
messagesKey(sessionId) {
return `${this.keyPrefix}:${sessionId}:messages`;
}
// 从 Redis 读取历史消息,并反序列化成 LangChain 可识别的消息对象
async loadMessages(sessionId) {
const raw = await this.redis.get(this.messagesKey(sessionId));
if (!raw) return [];
return mapStoredMessagesToChatMessages(JSON.parse(raw));
}
// 将消息重新序列化后写回 Redis,同时刷新 TTL
async saveMessages(sessionId, messages) {
const payload = JSON.stringify(mapChatMessagesToStoredMessages(messages));
await this.redis.set(
this.messagesKey(sessionId),
payload,
"EX",
this.ttlSeconds
);
}
// 清空某个会话的短期记忆
async clear(sessionId) {
await this.redis.del(this.messagesKey(sessionId));
}
// 查看当前会话还剩多少秒过期
async ttl(sessionId) {
return this.redis.ttl(this.messagesKey(sessionId));
}
}
async function invokeWithMemory(agent, store, sessionId, userText) {
// 第一步:从 Redis 拿到历史消息
const history = await store.loadMessages(sessionId);
console.log(`↳ 从 Redis 加载 ${history.length} 条历史`);
// 第二步:把本轮用户消息拼接到历史后面,再交给 Agent
const result = await agent.invoke(
{ messages: [...history, new HumanMessage(userText)] },
{ recursionLimit: 30 }
);
// 第三步:把 Agent 返回后的最新消息集合写回 Redis
await store.saveMessages(sessionId, result.messages);
// 第四步:读取 TTL,确认这次写入已经刷新了会话过期时间
const ttl = await store.ttl(sessionId);
console.log(`↳ 写回 Redis ${result.messages.length} 条 (TTL ${ttl}s)`);
return result;
}
// 初始化 Redis 客户端
const redis = new Redis({ host: REDIS_HOST, port: REDIS_PORT, db: REDIS_DB });
// 创建短期记忆存储实例
const store = new RedisMessageStore({
redis,
keyPrefix: KEY_PREFIX,
ttlSeconds: MEMORY_TTL,
});
// 初始化对话模型
const model = new ChatOpenAI({
model: process.env.MODEL_NAME,
apiKey: process.env.OPENAI_API_KEY,
configuration: { baseURL: process.env.OPENAI_BASE_URL },
temperature: 0,
});
// 创建 Agent,并挂上摘要中间件
const agent = createAgent({
model,
tools: [],
systemPrompt: "你是会话助手。记住用户提到的关键事实,中文简短回答。",
middleware: [
summarizationMiddleware({
model,
// 当消息过多时,用中文摘要保留关键上下文
summaryPrompt: `请用中文总结对话,保留关键事实。\n\n{messages}\n\n摘要:`,
// 消息达到 8 条时触发压缩
trigger: { messages: 8 },
// 压缩后保留最近 4 条消息,其余交给摘要承载
keep: { messages: 4 },
}),
],
});
// 发起一次带短期记忆的 Agent 调用
const { messages } = await invokeWithMemory(
agent,
store,
"demo_user_001",
"我上次问过你 Redis 和 PostgreSQL 的分工,你还记得吗?"
);
// 取最后一条消息,通常就是 Agent 的最终回复
console.log(messages.at(-1)?.content);
// 结束前主动关闭 Redis 连接
await redis.quit();这段代码的整体作用,是把一次 Agent 对话变成一个固定流程:
- 先从 Redis 取出会话历史。
- 把当前用户输入拼进消息列表。
- 调用
agent.invoke()。 - 在需要时自动触发摘要压缩。
- 把新的消息集合写回 Redis。
- 刷新 TTL,确保会话在活跃期间持续存在。
2.5 关键依赖与核心 API
这套示例最核心的依赖只有 3 个:
ioredis:负责 Redis 读写。ChatOpenAI:负责模型调用。summarizationMiddleware:负责在消息过长时压缩历史。
其中最关键的 API 有这些:
redis.get():读取当前会话历史。redis.set(key, value, "EX", ttl):写入历史并设置过期时间。redis.ttl():查看当前会话剩余存活时间。agent.invoke():执行一次完整 Agent 调用。summarizationMiddleware():按阈值压缩旧消息。
2.6 运行结果会看到什么?
假设你连续对话几轮,控制台大致会看到类似输出:
text
↳ 从 Redis 加载 6 条历史
↳ 写回 Redis 8 条 (TTL 1800s)
助手:记得。Redis 负责最近消息、短期摘要和会话运行态,PostgreSQL 负责永久消息与长期检索。如果消息数量增长过快,压缩中间件还可能触发类似效果:
text
当前消息数: 6
⚡ 已触发压缩这说明短期记忆并不是无上限堆消息,而是在"保留必要上下文"和"控制上下文体积"之间动态平衡。
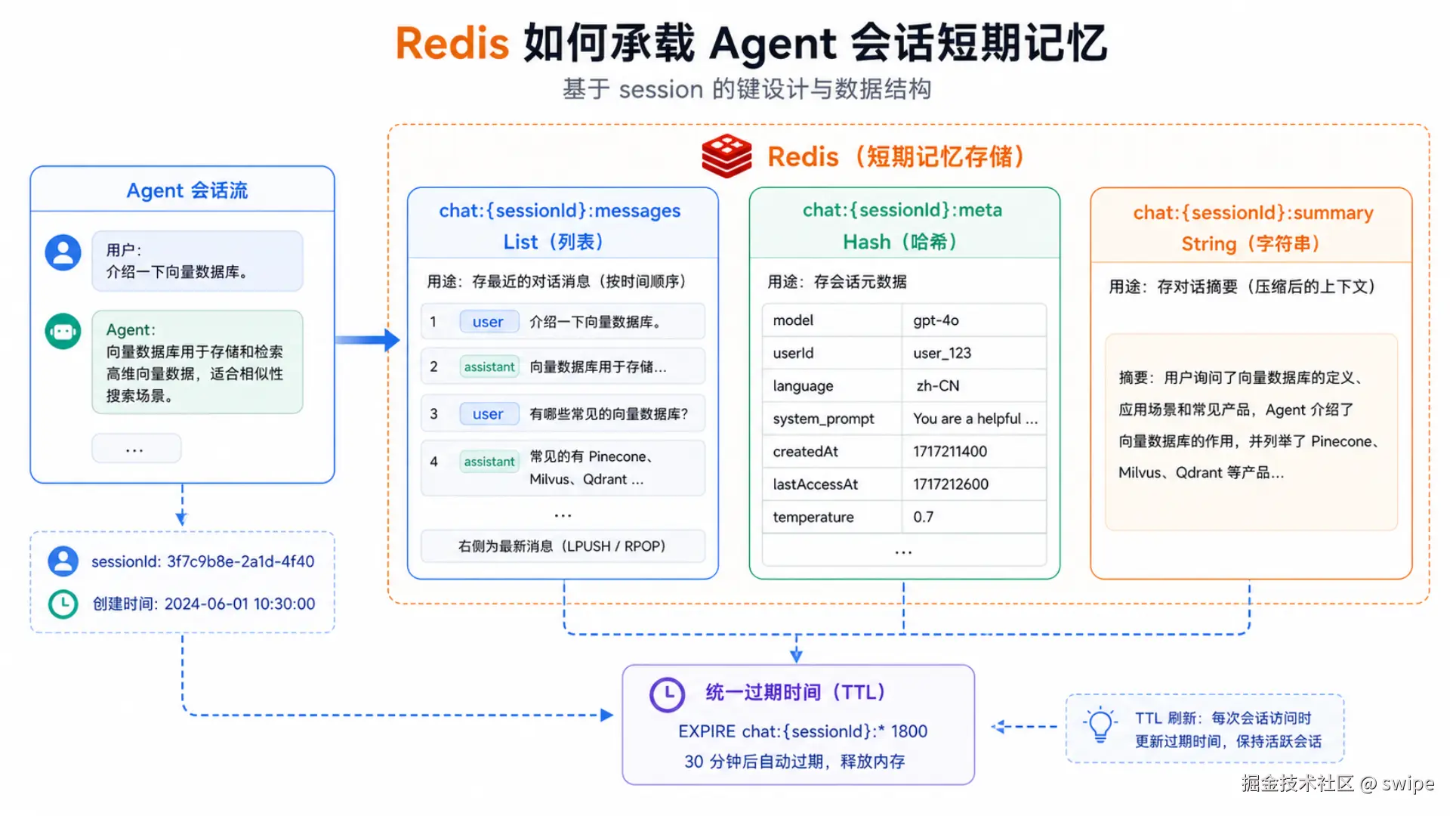
图 3:在生产场景里,短期记忆通常不会只有一种结构,而是会把消息、元数据、摘要拆分到不同 key 中。
三、核心配置 / 关键流程详解
这一节我们不只讲"能跑",而是讲清楚真正影响稳定性的 5 个点。
3.1 MEMORY_TTL_SECONDS:它是什么?
它是什么:
短期记忆的会话过期时间,示例里默认是 1800 秒,也就是 30 分钟。
它控制什么行为:
它决定一段会话在用户停止交互后还能保留多久。
常见配置方式:
900:15 分钟,适合强交互、低成本场景。1800:30 分钟,比较常见。3600:1 小时,适合复杂任务型 Agent。
推荐使用场景:
大多数在线聊天 Agent,都应该给短期记忆设置 TTL,而不是无限保留。
容易踩坑的地方:
TTL 过短,用户切回页面时记忆已经没了;TTL 过长,会堆积大量闲置会话,占用内存。
3.2 RedisMessageStore:它控制什么?
它是什么:
一个基于 Redis 的消息存储层,负责会话消息的加载、保存、清空和 TTL 查看。
它控制什么行为:
它定义了"会话历史在 Redis 里以什么 key 组织、以什么格式读写"。
常见配置方式:
- 简单模式:像示例这样,把整个消息数组序列化成一个 String。
- 拆分模式 :消息用
List,元数据用Hash,摘要用String。
推荐使用场景:
示例里的 String 模式很适合快速验证;正式项目如果会话结构更复杂,建议拆 key。
容易踩坑的地方:
把所有内容都塞进一个超大的 JSON String,后期会造成单 key 过大、局部更新困难。
3.3 summarizationMiddleware:为什么它是关键能力?
它是什么:
LangChain 提供的摘要中间件,用来在消息超阈值后压缩旧历史。
它控制什么行为:
它避免上下文窗口无限膨胀,降低 Token 消耗,同时尽量保留关键信息。
常见配置方式:
js
summarizationMiddleware({
model,
summaryPrompt,
trigger: { messages: 8 },
keep: { messages: 4 },
})推荐使用场景:
一旦你的 Agent 是多轮对话,就应尽早考虑摘要压缩,否则上下文成本会迅速失控。
容易踩坑的地方:
- 触发阈值太低,会导致摘要过于频繁。
- 摘要 Prompt 写得太弱,会丢失关键事实。
- 只做截断不做摘要,用户的重要偏好和任务目标容易被删掉。
3.4 invokeWithMemory:一次完整调用如何串起来?
它是什么:
这个函数把"加载历史 -> 调用 Agent -> 写回记忆"串成一次完整事务流。
它控制什么行为:
它决定每次请求如何和短期记忆交互。
常见配置方式:
js
async function invokeWithMemory(agent, store, sessionId, userText) {
const history = await store.loadMessages(sessionId);
const result = await agent.invoke({
messages: [...history, new HumanMessage(userText)]
});
await store.saveMessages(sessionId, result.messages);
return result;
}推荐使用场景:
所有需要"带记忆调用"的对话接口,都可以抽成这种统一模式。
容易踩坑的地方:
- 调用前忘记加载历史,Agent 每轮都会失忆。
- 调用后忘记写回,下一轮还是拿到旧状态。
- 只写消息不刷新 TTL,会导致活跃会话被提前过期。
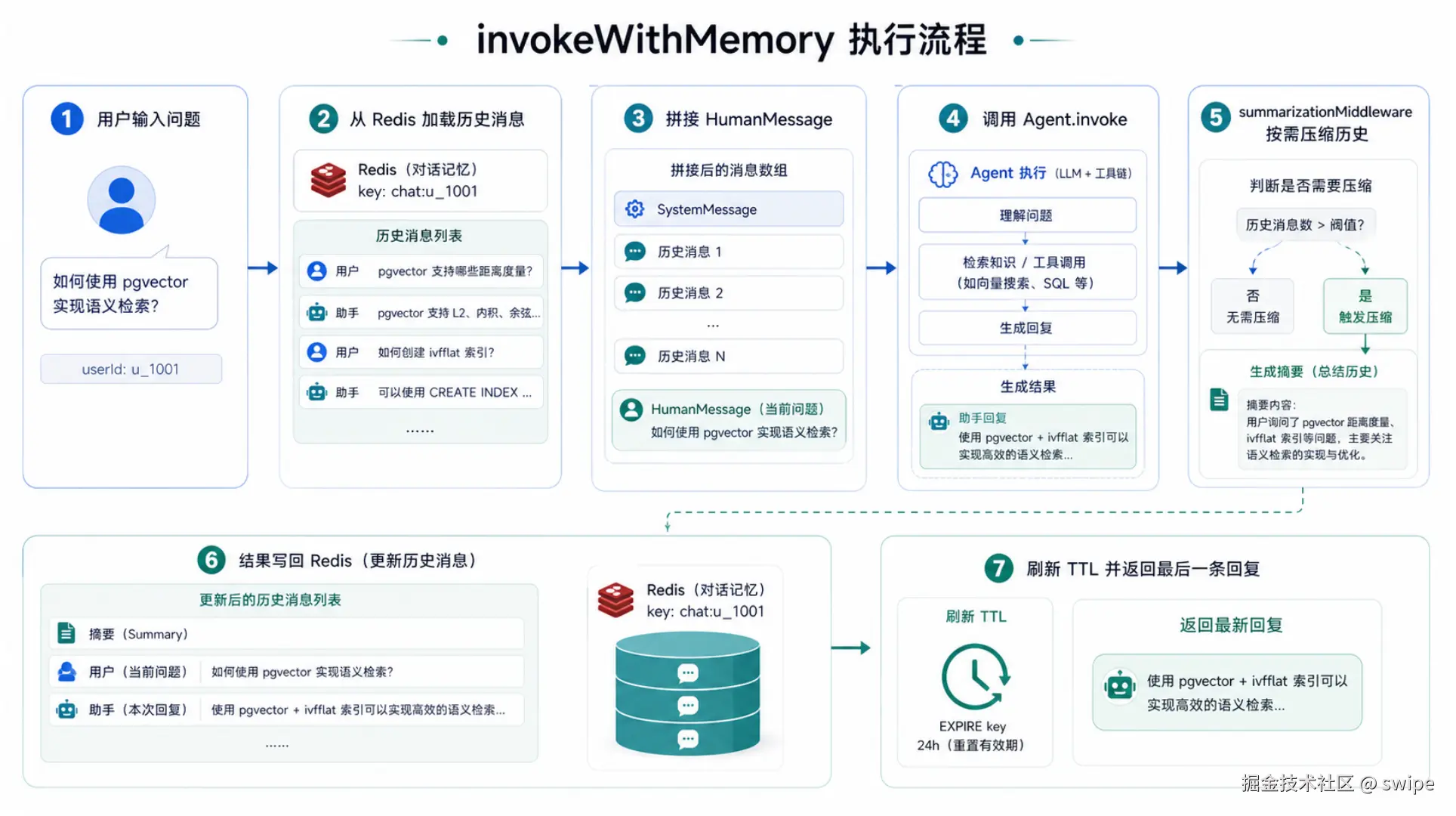
图 4:一次对话请求并不是单纯调用模型,而是一个带状态读写、摘要压缩和 TTL 刷新的完整流程。
3.5 List / Hash / String:生产里怎么选?
它是什么:
这是 Redis 最常用的 3 种短期记忆承载方式。
它控制什么行为:
它决定你如何拆分消息、元数据和摘要。
常见配置方式:
List:存最近消息序列,适合按顺序追加和截断。Hash:存会话元信息,比如模型名、语言、当前状态、用户偏好。String:存摘要、压缩文本、序列化后的整段上下文。
推荐使用场景:
如果只是做 Demo,直接一个 String 就够了;如果已经进入工程阶段,建议拆成多结构。
容易踩坑的地方:
不要因为 Redis 数据结构丰富,就把每个字段都拆成单独 key。过度碎片化会让调试和维护都变得很累。
四、运行效果与扩展思考
把这套示例跑起来之后,你会看到一个很清晰的效果:
- 第一次对话时,Redis 里几乎没有历史。
- 第二次开始,请求会先取回上一轮上下文。
- 对话越来越长时,旧消息会被摘要压缩。
- 每次新对话都会刷新 TTL。
- 用户长时间不活跃后,Redis 中的会话会自动过期。
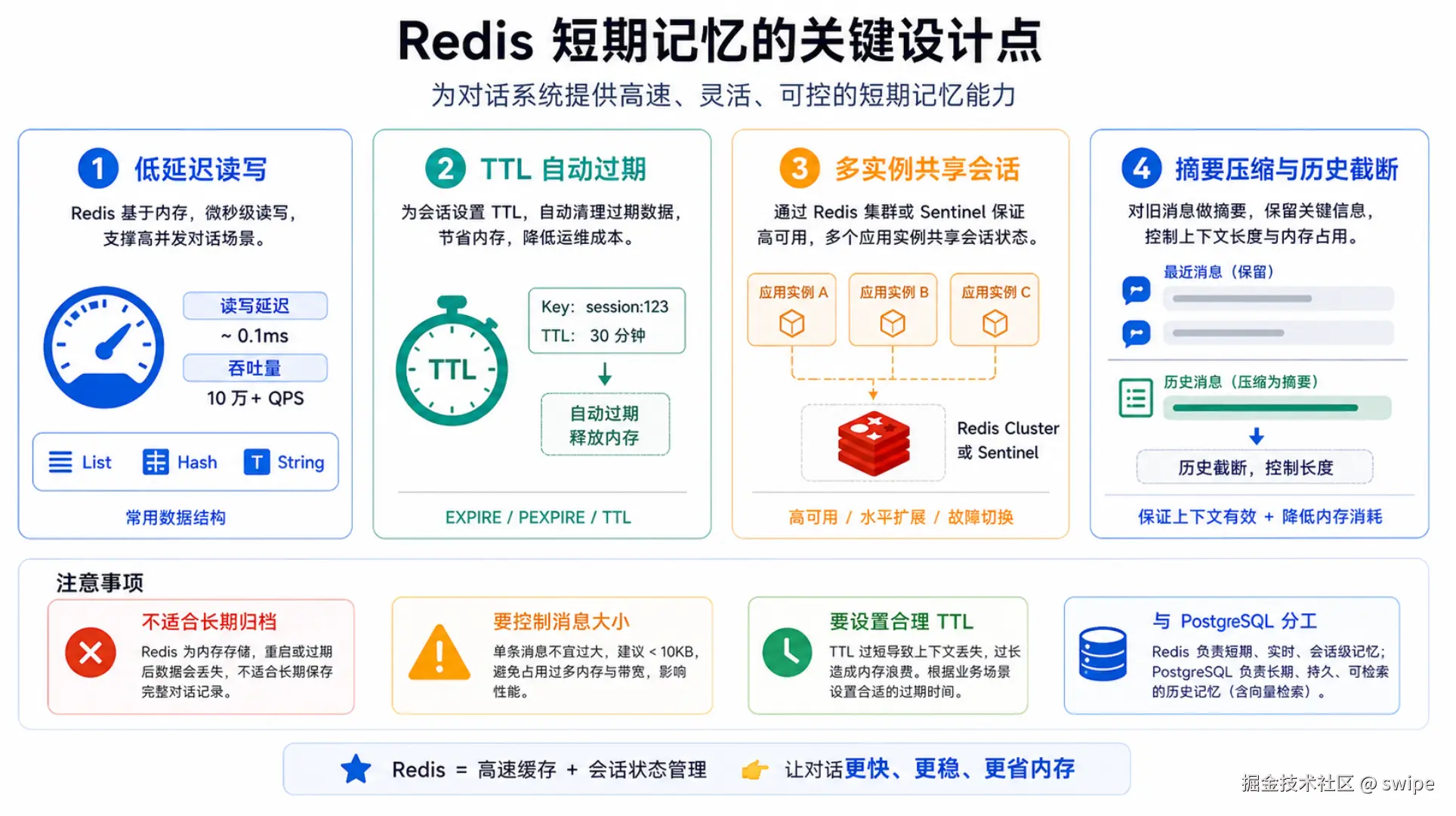
图 5:低延迟、TTL、多实例共享和摘要压缩,是 Redis 能胜任短期记忆层的四个关键原因。
进一步看真实项目,Redis 这层通常不会独立存在,而是和长期存储协同:
- Redis 承载"当前会话运行态"。
- PostgreSQL 承载"永久聊天记录"。
- 向量库或
pgvector承载"长期语义检索"。
这背后的设计原则其实很朴素:短期记忆追求快,长期记忆追求稳。
当然,Redis 也有明确边界:
-
它不适合做永久归档 即便开启 AOF,Redis 也不是给你长期存几十万条历史消息用的。
-
它不适合无限堆大对象 消息越长、会话越多,内存成本越高,所以一定要配合摘要和 TTL。
-
它不能替代业务数据库 用户画像、完整消息表、可审计记录,最终还是应该写回 PostgreSQL。
如果你要继续扩展,这里有几个很自然的方向:
- 把消息和摘要拆成
List + String + Hash多结构组合。 - 给不同租户、不同 Bot 设置不同 TTL 策略。
- 在会话结束后,把 Redis 中的摘要异步同步到长期记忆层。
- 给
invokeWithMemory加分布式锁,避免并发请求写乱同一会话。
五、总结
本期我们围绕一个很具体的问题展开:Agent 的短期记忆为什么适合放在 Redis,以及该怎么把它真正跑起来。
回顾一下核心结论:
- 本文解决的问题,是多实例 Agent 场景下的上下文共享、低延迟读写、会话自动失效和消息膨胀控制。
- Redis 的核心能力,不只是"快",而是它同时提供了 低延迟、TTL、共享状态和灵活数据结构。
- 在工程实现上,最稳妥的路线通常是:Redis 负责短期记忆,PostgreSQL 负责长期记忆,摘要中间件负责控制上下文体积。
- 如果你现在正在做聊天 Agent、任务型 Agent 或 Tool 调度型 Agent,这几乎就是一条非常自然的基础设施路线。
下期如果继续往下讲,就很适合接着深入这几个方向:
- 如何把 Redis 短期记忆和 PostgreSQL 长期记忆串成统一的 Memory Layer。
- 如何设计消息压缩策略,避免摘要把关键事实"压没了"。
- 如何在多实例和高并发下,避免同一会话被重复写乱。
很多人以为 Agent 的记忆问题,核心在"模型能不能记住"。
但到了工程层面你会发现,真正决定系统是否稳定的,往往是记忆存在哪、怎么过期、怎么压缩、怎么跨实例共享。而在短期记忆这件事上,Redis 依然是非常难被替代的那一个。