这几天因为私事比较忙,更新断更了几天。抽出零散时间把积压的工作清理了一下,好消息是:目前前台 + 后台已经能完全跑通了!
虽然现在的界面样式还有点"原生态",还没来得及精修,但核心功能已经立住了。咱们这个项目主打两个场景:一是随机推荐"今天吃什么" ,专治选择困难症;二是输入菜品名称获取详细教程。
为了实现这两个功能,这几天我主要在死磕数据处理 。这里有个小插曲分享给大家:最开始为了追求所谓的"标准化",我写脚本把所有的 .md 文档转成了 Word 文档,结果发现后续打标签、清洗数据极其麻烦,Word 的格式简直是自动化的噩梦。最后果断放弃,回归初心------直接将 Markdown (.md) 作为数据源,效率直接起飞
上一篇我们搞定了问答链路的跑通,理论上已经能问出"宫保鸡丁怎么烧"了。但大家都知道,AI有时候很"飘",如果你不给它立好规矩,它可能会给你推荐"可乐炖排骨"这种黑暗料理。
这篇咱们不聊高深的算法,就聊聊最接地气的数据处理 和前后端联调。这也是目前项目中最核心的两个变化:
- 后端:编写全自动脚本把700多份菜谱喂进知识库,并引入标签约束。
- 前端 :使用 Taro 开发 H5 页面,摒弃花哨的打字机特效,采用高效的 JSON 结构化渲染。
🍲 冷启动实录:从MD文档到知识库入库
很多RAG项目死在了第一步:没有数据。我之前尝试过把MD转成Word,结果发现Word格式太重,而且不利于自动化处理。所以现在的策略是:直接以Markdown(.md)为数据源。
我写了一个Node.js脚本,专门负责把本地的菜谱文件"塞"进数据库。
核心逻辑拆解:
- 递归扫描 :脚本会递归遍历你的菜谱文件夹,找到所有
.md后缀的文件。 - 自动归类 :根据文件路径(比如
/dish/、/drink/),自动给文件打上标签(meal,drink,dessert等)。 - 模拟上传 :为了复用之前写好的
privateRagService服务,我构造了一个mockFile对象,模拟了Multer上传的文件格式,直接调用服务层接口。
代码实现(Node.js):
csharp
const fs = require('fs').promises;
const path = require('path');
// 1. 核心:根据路径自动打标签
const getCategory = (filePath) => {
const p = filePath.toLowerCase().replace(/\/g, '/');
if (p.includes('/drink/')) return 'drink';
if (p.includes('/dessert/')) return 'dessert';
if (p.includes('/staple/')) return 'staple';
if (p.includes('/soup/')) return 'soup';
if (p.includes('/condiment/')) return 'condiment';
if (p.includes('/dishes/')) return 'meal'; // 正餐
return 'other';
};
// 2. 批量处理脚本
async function importRecipes(dir, kbId, userId) {
const items = await fs.readdir(dir);
for (const item of items) {
const fullPath = path.join(dir, item);
const stat = await fs.stat(fullPath);
if (stat.isDirectory()) {
await importRecipes(fullPath, kbId, userId); // 递归
} else if (stat.isFile() && item.endsWith('.md')) {
// 构造模拟文件对象
const mockFile = {
path: fullPath,
originalname: item,
mimetype: 'text/markdown',
size: stat.size
};
// 调用服务层入库
console.log(`正在处理: ${item}...`);
const result = await privateRagService.fileVectorization(mockFile, userId, kbId, getCategory(fullPath));
// 防抖,防止CPU炸了或API限流
await new Promise(r => setTimeout(r, 500));
}
}
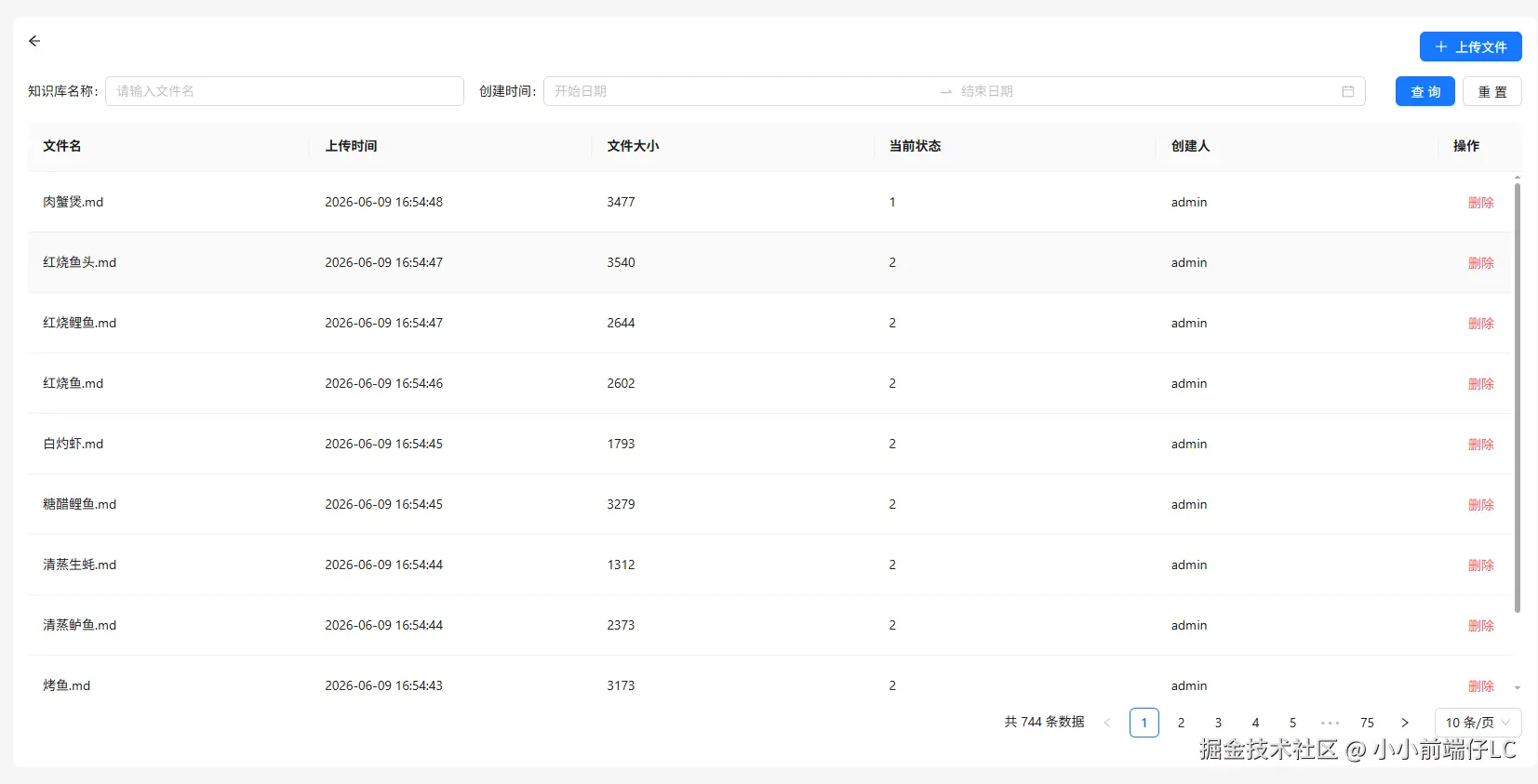
}通过这套脚本,我们成功导入了 744条 高质量菜谱数据(见下图后台管理界面),涵盖了从家常菜到甜品的全品类。
🎯 破解"随便吃点什么"的难题:Prompt工程实战
光有数据还不够,用户的需求是分场景的。用户输入框里打字,和点一下"随机推荐",背后的逻辑完全不同。
场景一:精准查询(输入菜名)
- 逻辑:用户输入了"红烧肉",直接走向量检索,找最相似的菜谱。
- Prompt策略:标准的RAG模板,把检索到的红烧肉做法喂给LLM,让它整理格式。
场景二:随机推荐(点标签)
-
痛点:之前遇到个尴尬事,用户问"今天吃什么",AI给推荐了个"柠檬水"。显然,用户想要的是正餐(meal),而不是饮料(drink)。
-
解决方案:基于标签的过滤。
- 前端点击"随机正餐" -> 后端查询时带上过滤条件
WHERE category = 'meal'。 - 利用数据库的元数据过滤功能,在向量检索前先圈定范围。
- 前端点击"随机正餐" -> 后端查询时带上过滤条件
场景三:模糊意图(大模型判断)
- 逻辑:用户输入"随便"、"不知道"、"来点肉"。
- 策略:这里我纠结了很久,最后决定"先跑起来"。目前的逻辑是:如果检测到"随便"或"随机"这类词,后端直接忽略向量检索,直接从数据库里随机捞一条符合语境(比如包含肉类标签)的菜谱出来。
📱 Taro H5 落地:JSON 结构化输出与无感渲染
有了数据和逻辑,接下来就是如何优雅地展示给用户。
在前面的文章中,我们演示了流式输出(Streaming),但在移动端 H5 场景下,特别是做卡片式推荐 时,结构化 JSON 往往是更好的选择。
为什么要用 JSON 而不是纯文本?
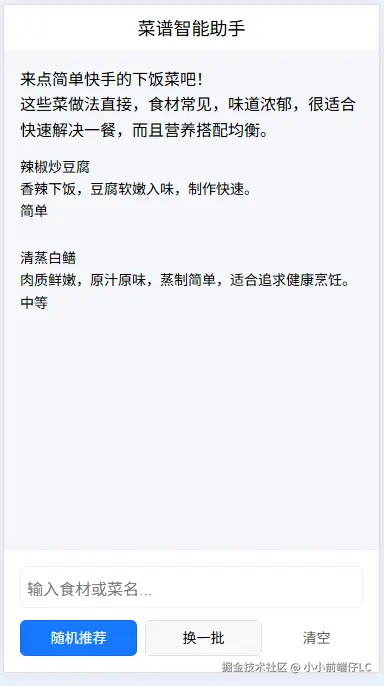
- UI 布局需求:看下面的 H5 截图,我们需要展示"菜名"、"做法描述"和"难度标签"。如果是纯文本,前端很难拆分出这些字段来做样式排版。
- 性能考量:Taro 编译的小程序/H5 对 DOM 操作比较敏感。一次性拿到 JSON 数据直接渲染列表,比看着文字一个字一个字蹦出来(打字机效果)体验更流畅,也更符合"工具类"应用的直觉。
后端改造:强制 LLM 输出 JSON
我们在 System Prompt 中加入严格的指令:
"你是一个菜谱推荐助手。请根据用户的问题,从知识库中检索并推荐 2-3 道菜品。必须且只能 返回一个合法的 JSON 数组,不要包含任何 Markdown 标记或多余的解释性文字。
JSON 格式如下:
[{"title": "菜名", "desc": "简短诱人的描述", "difficulty": "简单/中等/困难"}]"
前端 Taro 实现思路:
在 Taro 项目中,我们不再使用复杂的流式解析器,而是直接调用 API 获取 JSON。(只是demo,能展示而已,其他的还未处理)
typescript
// Taro 组件示例
import { View, Text, Button, Input } from '@tarojs/components'
import { useEffect, useRef, useState } from 'react';
import './index.less'
// 1. 定义消息类型接口
interface Message {
reason: string;
recipes: {
description: string;
difficulty: string;
energy: string;
name: string;
}[];
suggestion: string;
}
export default function Recipe () {
const [content, setContent] = useState("");
const [loading, setLoading] = useState(false); // 加载状态
const [messages, setMessages] = useState<Message>({
reason: '',
recipes: [],
suggestion: ''
});
const onSubmit = () => {
// 如果为空或者在加载中则返回
// if (!content.trim() || loading) return;
fetchStreamAnswer().then(() => {})
}
const fetchStreamAnswer = async () => {
try {
const response = await fetch('/proxy/api/privateRag/invokeChat', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': `Bearer ${localStorage.getItem('token')}`
},
body: JSON.stringify({ question: '随便', category: ['meal', 'staple'] })
});
const resData = await response.json();
console.log('后端完整返回', resData);
setMessages(resData.data);
} catch (error) {
} finally {
}
}
return (
<View className='recipe-page'>
<View className='recipe-title'>菜谱智能助手</View>
<View className="recipe-chat-content">
<View className="suggestion">
{messages.suggestion}
</View>
<View className="reason">
{messages.reason}
</View>
{messages.recipes.map((recipe) => (
<View className='recipe-item'>
{recipe.name}
<div>{recipe.description}</div>
<div>{recipe.difficulty}</div>
</View>
))}
</View>
<View className="recipe-options">
<Input
className='taro-input'
value={content}
onInput={(e) => setContent(e.detail.value)}
placeholder='输入食材或菜名...'
confirmType='send'
onConfirm={onSubmit}
/>
<View className='buttin-container'>
<Button
type='primary'
className='random-btn'
onClick={onSubmit}
>
随机推荐
</Button>
<Button
className='refresh-btn'
>
换一批
</Button>
<Button
className='clear-btn'
>
清空
</Button>
</View>
</View>
</View>
)
}最终效果展示:
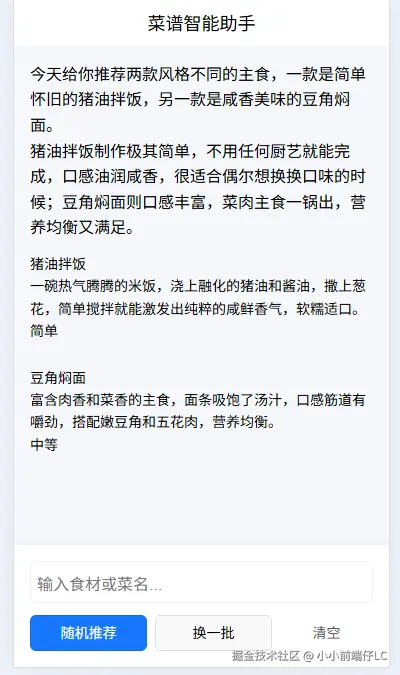
如图所示,当用户点击"随机推荐"时,AI 会根据当前时间或用户偏好,瞬间给出建议。比如图中的"猪油拌饭"和"豆角焖面",既有怀旧风味,又有营养均衡,文案还特别接地气。
📌 总结
这一篇我们完成了项目从"通用问答"到"垂直领域应用"的蜕变。
我们重点解决了三个实战问题:
- 数据冷启动:通过编写自动化脚本,实现了Markdown文档的批量清洗、分类和入库,为AI提供了高质量的"燃料"。
- 意图识别与过滤 :引入了
category标签体系,解决了随机推荐中"牛头不对马嘴"的问题,让"吃什么"推荐更符合人类直觉。 - 前端工程化 :在 Taro 环境下,放弃了不适合卡片展示的流式打字效果,转而采用 JSON 结构化输出,实现了高效、美观的 UI 渲染。
现在,我们的知识库已经不再是冷冰冰的文档集合,而是一个有分类、有逻辑、有界面的菜谱智能助手。
下一步,我们将继续优化这个 H5 应用。敬请期待!