负载均衡-Nginx 全解析
一、实验概述
本实验旨在通过 Nginx 代理模式实现对 Web 服务器集群的负载均衡访问,清晰展示 Nginx 负载均衡的配置流程、核心原理及不同调度算法的应用效果。
实验环境前提
- 关闭 SELinux 服务,避免权限限制影响实验流程
- 关闭防火墙,防止端口拦截导致请求转发失败
二、网络拓扑
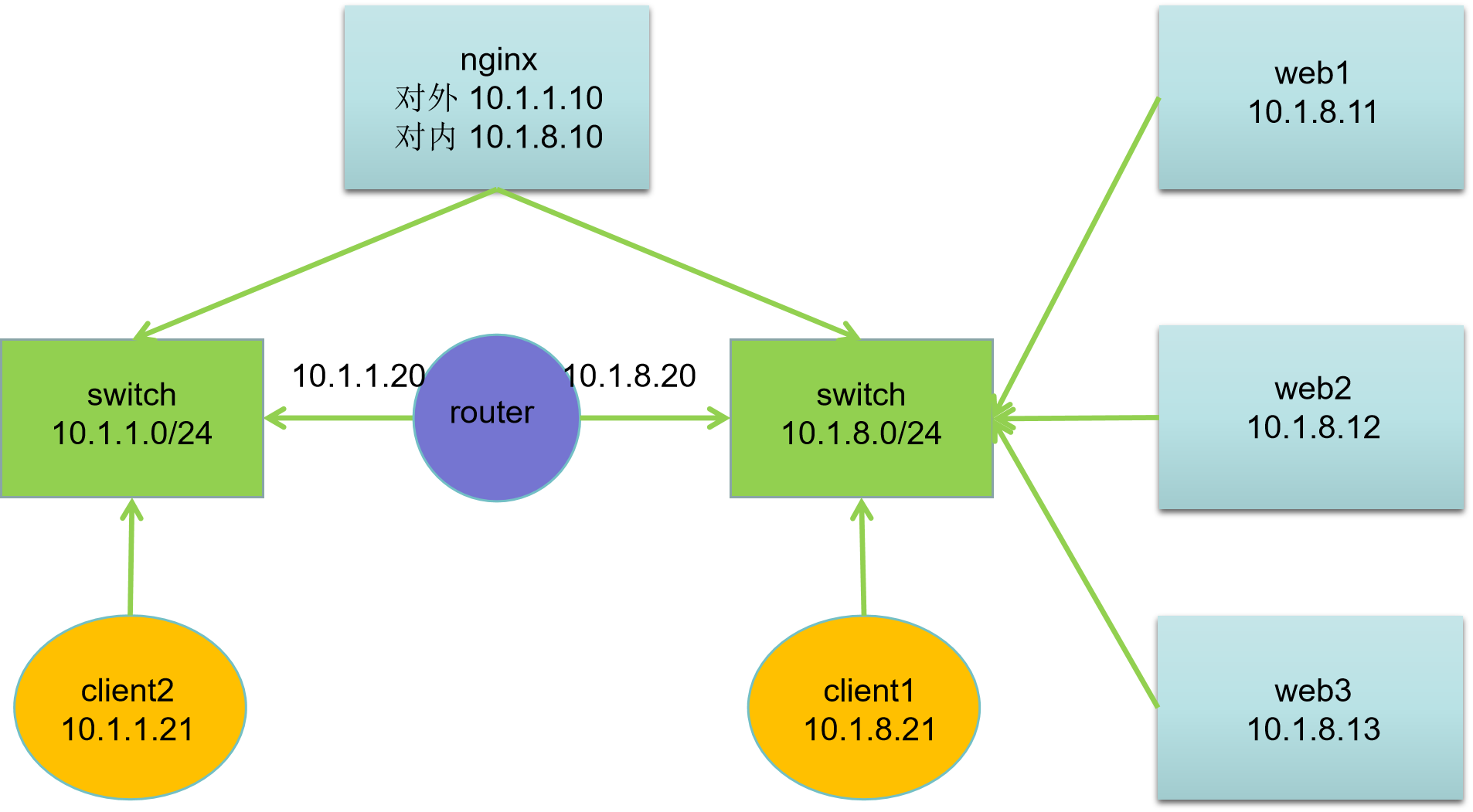
| 主机名 | IP地址 | 服务器角色 |
|---|---|---|
| client2.liu.cloud | 10.1.1.21 | 客户端 |
| client1.liu.cloud | 10.1.8.21 | 客户端 |
| router.liu.cloud | 10.1.1.20, 10.1.8.20 | 路由器 |
| nginx.liu.cloud | 10.1.1.10, 10.1.8.10 | 代理服务器 |
| web1.liu.cloud | 10.1.8.11 | Web 服务器 |
| web2.liu.cloud | 10.1.8.12 | Web 服务器 |
| web3.liu.cloud | 10.1.8.13 | Web 服务器 |
网络说明:
- 所有主机:第一块网卡名为 ens33,第二块网卡名为 ens36
- 默认第一块网卡模式为nat,第二块网卡模式为hostonly
- 网关设置:10.1.1.0/24 网段网关为10.1.1.20,10.1.8.0/24 网段网关为10.1.8.20
三、基础环境配置
需完成各主机的主机名、IP 地址、网关三项核心配置,其中网关配置参考命令如下:
bash
# 配置10.1.1.0/24网段网关(ens33网卡)
nmcli connection modify ens33 ipv4.gateway 10.1.1.20
nmcli connection up ens33
# 配置10.1.8.0/24网段网关(ens33网卡)
nmcli connection modify ens33 ipv4.gateway 10.1.8.20
nmcli connection up ens33四、路由器(router)节点配置
功能说明
开启路由器的 IP 转发功能,配置防火墙地址伪装,实现不同网段主机的通信互通。
bash
# 开启IP转发功能(写入配置文件永久生效)
echo "net.ipv4.ip_forward=1" >> /etc/sysctl.conf
# 备选方式:修改现有配置项开启IP转发
# sed -i "s/ip_forward=0/ip_forward=1/g" /etc/sysctl.conf
# 重新加载sysctl配置,使IP转发生效
sysctl -p
# 启动并开机自启防火墙服务
systemctl enable firewalld.service --now
# 临时开启地址伪装(立即生效)
firewall-cmd --add-masquerade
# 永久开启地址伪装(重启防火墙后生效)
firewall-cmd --add-masquerade --permanent五、Web 服务器节点配置
功能说明
在 web1、web2、web3 节点部署 Nginx 作为 Web 服务,生成差异化首页内容,便于后续验证负载均衡效果。
bash
[root@web1-3 ~]#
# 安装Nginx服务
yum install -y nginx
# 生成包含主机名的首页文件,用于区分不同Web节点
echo Welcome to $(hostname) > /usr/share/nginx/html/index.html
# 启动并开机自启Nginx服务
systemctl enable nginx.service --now
# 验证后端Web服务可访问(在client1节点执行)
[root@client1 ~]# curl 10.1.8.11
Welcome to web1.liu.cloud
[root@client1 ~]# curl 10.1.8.12
Welcome to web2.liu.cloud
[root@client1 ~]# curl 10.1.8.13
Welcome to web3.liu.cloud六、Nginx 代理服务器负载均衡配置
功能说明
在 nginx.liu.cloud 节点安装 Nginx,配置 upstream 后端服务器集群和前端监听规则,实现请求转发与负载均衡。
bash
# 安装Nginx服务
[root@nginx ~ 09:03:40]# yum install -y nginx
# 备份并修改Nginx配置文件,配置负载均衡规则
[root@nginx ~ 09:13:24]# cp /etc/nginx/nginx.conf /etc/nginx/conf.d/proxy.conf
[root@nginx ~ 09:16:19]# vim /etc/nginx/conf.d/proxy.conf
# 定义后端Web服务器集群(upstream模块)
upstream web {
server 10.1.8.11:80; # 后端web1节点
server 10.1.8.12:80; # 后端web2节点
server 10.1.8.13:80; # 后端web3节点
}
# 配置前端监听规则
server {
server_name www.liu.cloud; # 监听的域名
root /usr/share/nginx/html; # 静态资源根目录
location / {
# 将请求转发至定义的web服务器集群
proxy_pass http://web;
}
}
# 启动Nginx服务,加载负载均衡配置
[root@nginx ~ 09:32:02]# systemctl start nginx.service 七、负载均衡效果验证
验证命令及结果
在 client1 节点执行循环请求,验证请求是否均匀分发至后端节点:
bash
[root@client1 ~ 09:36:27]# for i in {1..90};do curl -s www.liu.cloud;done|sort|uniq -c
30 Welcome to web1.liu.cloud
30 Welcome to web2.liu.cloud
30 Welcome to web3.liu.cloud验证结论
后端三台 Web 服务器以轮询方式处理客户端请求,请求分配均匀。
八、Nginx 负载均衡核心原理与算法
Nginx 的 upstream 模块用于声明后端服务器集群,可被 proxy_pass、fastcgi_pass 等指令引用,支持不同端口、Unix Socket 的服务器配置,还可通过参数定义服务器权重、状态等属性。
upstream 核心语法
upstream 集群名称 {
# 服务器及参数配置项
....
}语法示例
json
upstream backend {
server backend1.example.com weight=5 down backup; # 权重5、手动下线、备用节点
server 127.0.0.1:8080 max_fails=3 fail_timeout=30s; # 最大失败次数3、失败超时30秒
server unix:/tmp/backend2; # Unix Socket方式配置
}upstream 常用指令说明
| 指令 | 功能说明 |
|---|---|
| keepalive | 每个 worker 进程缓存的、与 upstream 服务器的连接数 |
| server | 定义后端服务器地址,可附加权重、失败重试等参数 |
| weight | 服务器权重,默认值 1,值越大被分配请求的概率越高 |
| max_fails | 最大失败连接次数,超出后触发 fail_timeout 超时 |
| fail_timeout | 等待目标服务器响应的超时时长,超时则判定为请求失败 |
| backup | 备用节点,仅当所有主节点故障时才接收请求 |
| down | 手动标记服务器下线,不再分配任何请求 |
指令配置示例
json
upstream web {
keepalive 32; # 每个worker缓存32个连接
server 10.1.8.11:80 max_fails=3 fail_timeout=30s weight=2; # 主节点,权重2
server 10.1.8.12:80 max_fails=3 fail_timeout=30s backup; # 备用节点
server 10.1.8.13:80 max_fails=3 fail_timeout=30s down; # 下线节点
}负载均衡调度算法分类
- 静态调度算法:基于预设规则分配请求,不感知后端节点状态(如 rr、ip_hash、generic hash)
- 动态调度算法:根据后端节点实时状态(连接数、响应时间)分配请求(如 least_conn、least_time)
1. 轮询(round-robin)
算法说明
Nginx 默认调度算法,按客户端请求顺序依次分发至后端节点;节点宕机时自动剔除,不影响整体服务。
配置示例
json
upstream web {
server 10.1.8.11:80;
server 10.1.8.12:80;
server 10.1.8.13:80;
}验证结果
bash
[root@client1 ~ 09:36:27]# for i in {1..90};do curl -s www.liu.cloud;done|sort|uniq -c
30 Welcome to web1.liu.cloud
30 Welcome to web2.liu.cloud
30 Welcome to web3.liu.cloud加权轮询(基于 rr 扩展)
算法说明
在轮询基础上为节点设置权重,权重与请求分配量成正比,可适配不同性能的服务器。
配置示例
json
upstream web {
server 10.1.8.11:80 weight=10; # 权重10
server 10.1.8.12:80 weight=20; # 权重20
server 10.1.8.13:80 weight=30; # 权重30
}测试结果
bash
[root@client1 ~ 09:48:45]# for n in {1..90}; do curl http://10.1.8.10 -s; done | sort |uniq -c
15 Welcome to web1.liu.cloud
30 Welcome to web2.liu.cloud
45 Welcome to web3.liu.cloud2. IP 哈希(ip_hash)
算法说明
基于客户端 IP 的哈希结果分配请求,相同 IP 的请求固定分发至同一节点,解决动态网页 Session 共享问题;但 NAT 上网场景下易导致请求分配不均。
配置示例
json
upstream web {
ip_hash; # 启用IP哈希算法
server 10.1.8.11:80;
server 10.1.8.12:80;
server 10.1.8.13:80;
}验证结果
bash
[root@client1 ~ 09:48:49]# while true;do curl -s www.liu.cloud;sleep 1;done
Welcome to web2.liu.cloud
Welcome to web2.liu.cloud
Welcome to web2.liu.cloud
Welcome to web2.liu.cloud
[root@client2 ~ 09:59:10]# while true;do curl -s www.liu.cloud;sleep 1;done
Welcome to web2.liu.cloud
Welcome to web2.liu.cloud3. 通用哈希(generic hash)
算法说明
基于用户自定义键(如 URL、源 IP + 端口)的哈希结果分配请求,可提升后端缓存服务器命中率;需安装 Nginx hash 模块,且 server 节点不能配置 weight 等参数。
配置示例(URL 哈希)
json
upstream web {
hash $request_uri; # 基于请求URI哈希
server 10.1.8.11:80;
server 10.1.8.12:80;
server 10.1.8.13:80;
}前置准备(后端 Web 节点)
bash
[root@web1-3 ~]# mkdir /usr/share/nginx/html/test
[root@web1-3 ~]# echo test from $(hostname -s) > \
/usr/share/nginx/html/test/index.html验证结果
bash
[root@client1 ~]# for n in {1..90}; do curl http://10.1.8.10 -s; done | sort |uniq -c
90 Welcome to web3.liu.cloud4. 最少连接数(least_conn)
算法说明
将请求分发至当前活跃连接数最少的后端节点,适配请求处理耗时差异较大的场景;支持为节点配置权重。
配置示例
json
upstream web {
least_conn; # 启用最少连接数算法
server 10.1.8.11:80;
server 10.1.8.12:80;
server 10.1.8.13:80;
}验证结果
bash
[root@client1 ~]# for n in {1..90}; do curl http://10.1.8.10 -s; done | sort |uniq -c
30 Welcome to web1.liu.cloud
30 Welcome to web2.liu.cloud
30 Welcome to web3.liu.cloud5. 最少时间(least_time)
算法说明
仅 NGINX Plus 版本支持,根据节点平均响应时间 + 活跃连接数分配请求,优先选择响应快、连接少的节点;可指定响应时间计算维度(header/last_byte/last_byte inflight)。
配置示例
json
upstream web {
least_time header; # 基于接收第一个字节的时间排序
server 10.1.8.11:80;
server 10.1.8.12:80;
server 10.1.8.13:80;
}负载均衡 HAProxy 全解析
文档 https://www.haproxy.org/#docs
下载 https://www.haproxy.org/#down
一、HAProxy 核心介绍
HAProxy 是一款开源的高性能负载均衡与代理软件,主打高可用性,同时支持 TCP(四层)和 HTTP(七层)协议代理,兼容虚拟主机部署。它专为高负载 Web 场景设计,尤其适配需要会话保持或七层协议精细化处理的业务场景,可稳定支撑数万级并发连接。其核心优势在于轻量、高效,能安全整合至现有架构,同时隐藏后端 Web 服务器的网络暴露面,提升整体安全性。
1.1 核心运行模型
HAProxy 采用事件驱动的单一进程模型,这是其高并发支撑能力的核心:
- 多进程 / 多线程模型易受内存限制、系统调度锁竞争影响,难以处理数千级并发;
- 事件驱动模型在用户空间完成连接管理、事件处理,资源与时间管理更高效,仅需优化多核适配即可最大化性能。
1.2 极致性能优化点
HAProxy 借助操作系统特性与底层优化实现性能最大化,核心优化维度如下:
- 单进程 + 事件驱动:大幅降低上下文切换开销与内存占用;
- O (1) 事件检查器:高并发下可即时探测任意连接的任意事件;
- 单缓冲机制:读写操作无需复制数据,节省 CPU 周期与内存带宽;
- 零复制转发:基于 Linux 2.6.27.19+ 的 splice () 系统调用实现,Linux 3.5+ 还支持零复制启动;
- 固定内存池分配:会话创建时内存即时分配,缩短建立耗时;
- 弹性二叉树存储:以 O (log (N)) 低开销管理计时器、运行队列、轮询 / 最小连接队列;
- 优化的 HTTP 首部分析:避免重复读取内存区域,提升解析效率;
- 减少系统调用:时间读取、缓冲聚合、文件描述符管理等操作优先在用户空间完成。
上述优化使得 HAProxy 在中等负载下 CPU 占用极低,高负载场景中用户空间占用率仅为系统空间的 1/20(典型占比 5%:95%)。即便七层处理使用户空间占用翻倍,CPU 总占比也仅 10%,因此高端服务器上其七层性能可超越硬件负载均衡设备。
生产场景中,HAProxy 常作为高端硬件负载均衡设备的故障兜底方案:硬件设备基于 "报文级" 处理,难以支持跨报文请求,且无数据缓冲导致响应时间长;而软件负载的 TCP 缓冲特性可处理超长请求,适配更复杂的业务场景。
二、HAProxy 负载均衡调度算法
HAProxy 提供 8 种核心负载均衡算法(balance 指令配置),适配不同业务场景的流量分发需求:
| 算法名称 | 简称 / 说明 |
|---|---|
| roundrobin | rr(动态加权轮询):支持权重调整,动态适配后端服务器性能差异 |
| static-rr | 静态轮询:不支持权重,适用于后端服务器配置完全一致的场景 |
| leastconn | 最小连接优先:优先调度至当前活跃连接数最少的后端服务器,适配长连接场景 |
| source | 源地址哈希:基于客户端 IP 哈希固定调度至某台后端服务器,实现会话保持 |
| uri | URI 哈希:基于请求 URI 哈希分发,适用于静态资源缓存场景 |
| url_param | URL 参数哈希:指定 URL 参数名(如 balance url_param user),按参数值哈希分发 |
| hdr(name) | HTTP 头哈希:基于指定 HTTP 请求头(如 hdr (Host))锁定请求分发目标 |
| rdp-cookie(name) | TCP 层 Cookie 哈希:基于指定 Cookie 名哈希,锁定 TCP 请求的后端服务器 |
三、HAProxy 实战部署
本节通过实操实现四层(TCP)和七层(HTTP)负载均衡,先明确网络拓扑与基础配置,再分场景落地。
3.1 基础环境准备
3.1.1 网络拓扑
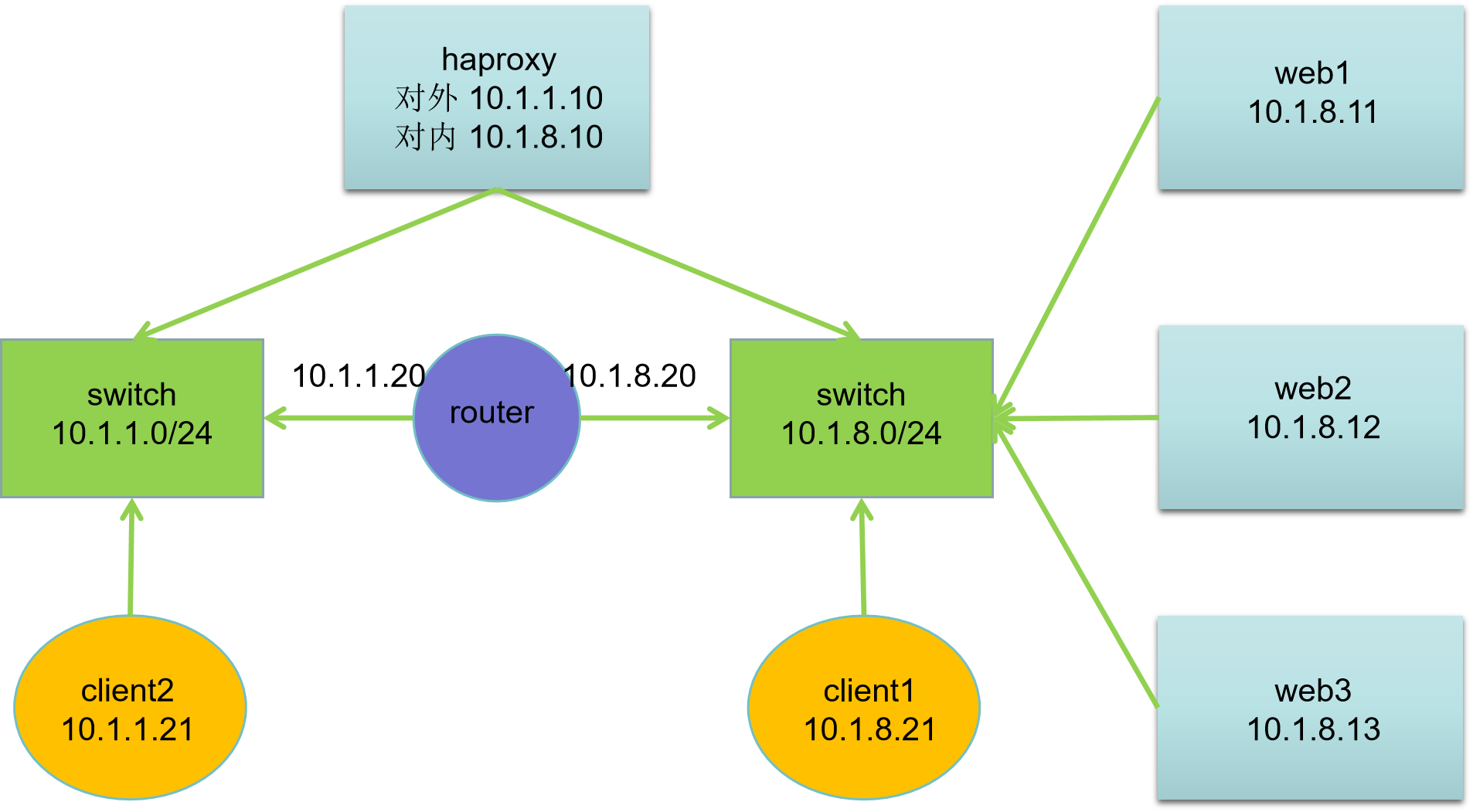
3.1.2 主机规划
| 主机名 | IP地址 | 服务器角色 |
|---|---|---|
| client2.liu.cloud | 10.1.1.21 | 客户端 |
| client1.liu.cloud | 10.1.8.21 | 客户端 |
| router.liu.cloud | 10.1.8.20 10.1.1.20 | 路由器 |
| haproxy.liu.cloud | 10.1.8.10 10.1.1.10 | 代理服务器 |
| web1.liu.cloud | 10.1.8.11 | Web 和 SSH 服务器 |
| web2.liu.cloud | 10.1.8.12 | Web 和 SSH 服务器 |
| web3.liu.cloud | 10.1.8.13 | Web 和 SSH 服务器 |
3.1.3 网络基础配置说明
- 所有主机默认网卡:第一块为 ens33(NAT 模式),第二块为 ens192(HostOnly 模式);
- 网关配置规则:
- 10.1.1.0/24 网段网关为 10.1.1.20;
- 10.1.8.0/24 网段网关为 10.1.8.20。
3.1.4 网关配置命令
bash
# 配置 10.1.1.0/24 网段网关(ens33 网卡)
nmcli connection modify ens33 ipv4.gateway 10.1.1.20
nmcli connection up ens33
# 配置 10.1.8.0/24 网段网关(按需修改)
nmcli connection modify ens33 ipv4.gateway 10.1.8.20
nmcli connection up ens333.1.5 路由器(router.liu.cloud)配置
bash
# 开启内核路由转发
echo "net.ipv4.ip_forward=1" >> /etc/sysctl.conf
sysctl -p
# 防火墙配置(信任所有网段 + 地址伪装)
systemctl enable firewalld.service --now
firewall-cmd --set-default-zone=trusted
firewall-cmd --add-masquerade --permanent # 永久生效
firewall-cmd --add-masquerade # 临时生效(立即生效)3.2 七层(HTTP)负载均衡实战
3.2.1 后端 Web 服务器配置
目标:部署 Nginx 并配置差异化页面,用于验证负载均衡效果。
bash
# 所有 Web 服务器(web1/web2/web3)执行以下操作
# 1. 部署 Nginx 并写入差异化首页
[root@web1 ~ 09:35:29]# echo Welcome to $(hostname) > /usr/share/nginx/html/index.html
[root@web1 ~ 09:37:04]# systemctl enable nginx.service --now
[root@web2 ~ 09:35:35]# echo Welcome to $(hostname) > /usr/share/nginx/html/index.html
[root@web2 ~ 09:37:10]# systemctl enable nginx.service --now
[root@web3 ~ 09:35:40]# echo Welcome to $(hostname) > /usr/share/nginx/html/index.html
[root@web3 ~ 09:37:15]# systemctl enable nginx.service --now
# 2. 验证后端 Nginx 可用性
[root@web1 ~ 10:18:44]# curl 10.1.8.11
Welcome to web1.liu.cloud
[root@web1 ~ 10:35:15]# curl 10.1.8.12
Welcome to web2.liu.cloud
[root@web1 ~ 10:35:20]# curl 10.1.8.13
Welcome to web3.liu.cloud
# 3. 配置虚拟主机(81 端口),用于区分不同规则的转发
[root@web1 ~ 10:35:25]# cat > /etc/nginx/conf.d/vhost-test.conf <<'EOF'
server {
listen 81; # 监听 81 端口
root /test; # 站点根目录
}
EOF
[root@web1 ~ 10:35:47]# systemctl restart nginx
[root@web2 ~ 10:18:54]# cat > /etc/nginx/conf.d/vhost-test.conf <<'EOF'
server {
listen 81;
root /test;
}
EOF
[root@web2 ~ 10:35:58]# systemctl restart nginx
[root@web3 ~ 09:37:16]# cat > /etc/nginx/conf.d/vhost-test.conf <<'EOF'
server {
listen 81;
root /test;
}
EOF
[root@web3 ~ 10:36:04]# systemctl restart nginx
# 4. 准备测试文件(差异化内容,用于验证规则匹配)
[root@web1 ~ 10:36:19]# mkdir /test
[root@web1 ~ 10:36:51]# echo hello txt from $(hostname -s) > /test/index.txt
[root@web1 ~ 10:37:20]# echo hello html from $(hostname -s) > /test/index.html
[root@web2 ~ 10:36:29]# mkdir /test
[root@web2 ~ 10:36:57]# echo hello txt from $(hostname -s) > /test/index.txt
[root@web2 ~ 10:37:27]# echo hello html from $(hostname -s) > /test/index.html
[root@web3 ~ 10:36:39]# mkdir /test
[root@web3 ~ 10:37:06]# echo hello txt from $(hostname -s) > /test/index.txt
[root@web3 ~ 10:37:34]# echo hello html from $(hostname -s) > /test/index.html3.2.2 HAProxy 配置(HTTP 模式)
目标:配置 80 端口转发,实现 "普通请求走 80 端口、.txt 后缀请求走 81 端口" 的规则。
bash
# 1. 安装 HAProxy
[root@haproxy ~ 10:28:01]# yum install -y haproxy
# 2. 备份原始配置文件
[root@haproxy ~ 10:28:52]# cp /etc/haproxy/haproxy.cfg{,.ori}
# 3. 追加 HTTP 负载均衡配置
[root@haproxy ~ 10:33:20]# echo '
######### HTTP 七层代理配置 ###########
frontend front_web
bind *:80 # 监听本机所有网卡的 80 端口
default_backend back_web # 默认转发至 back_web 后端集群
# 定义 ACL 规则:匹配 .txt 后缀的请求(忽略大小写)
acl test url_reg -i \.txt$
# ACL 规则说明:
# acl:固定关键字,用于定义访问控制规则
# test:自定义规则名称
# url_reg:匹配方式(正则匹配 URL)
# -i:忽略大小写
# \.txt$:正则表达式,匹配以 .txt 结尾的 URL
# 规则生效:若匹配 test 规则,转发至 back_test 后端集群
use_backend back_test if test
backend back_web
balance roundrobin # 负载算法:动态加权轮询
# 后端服务器配置格式:server 自定义名称 后端IP:端口 check(开启健康检查)
server web1 10.1.8.11:80 check
server web2 10.1.8.12:80 check
server web3 10.1.8.13:80 check
backend back_test
balance roundrobin # 负载算法:动态加权轮询
server test1 10.1.8.11:81 check
server test2 10.1.8.12:81 check
server test3 10.1.8.13:81 check
' >> /etc/haproxy/haproxy.cfg
# 4. 重启 HAProxy 使配置生效
[root@haproxy ~ 10:34:31]# systemctl restart haproxy3.2.3 HTTP 模式测试
验证普通请求和 .txt 后缀请求的转发效果:
bash
# 测试普通 HTTP 请求(轮询转发至 web1/web2/web3 的 80 端口)
[root@client1 ~ 10:42:21]# while true;do curl -s http://www.liu.cloud;sleep 1;done
# 预期输出(轮询):
# Welcome to web1.liu.cloud
# Welcome to web2.liu.cloud
# Welcome to web3.liu.cloud
# 测试 .txt 后缀请求(轮询转发至 web1/web2/web3 的 81 端口)
[root@client1 ~ 10:42:45]# while true;do curl -s http://www.liu.cloud/index.txt;sleep 1;done
# 预期输出(轮询):
# hello txt from web1
# hello txt from web2
# hello txt from web33.3 HAProxy 监控面板配置
目标:配置 Web 监控面板,可视化查看后端服务器状态,支持在线管理。
bash
# 1. 备份配置文件(重复操作,确保配置可回滚)
[root@haproxy ~ 10:28:52]# cp /etc/haproxy/haproxy.cfg{,.ori}
# 2. 追加监控面板配置
[root@haproxy ~ 11:26:44]# vim /etc/haproxy/haproxy.cfg
# 在配置文件末尾添加以下内容:
'
# HAProxy Web 监控面板配置
listen haproxy_stats
bind *:8404 # 监听本机所有网卡的 8404 端口(建议生产环境改为 127.0.0.1:8404 仅本地访问)
mode http # 工作模式:HTTP
stats enable # 开启统计面板核心开关
stats refresh 10s # 面板自动刷新间隔(10 秒)
stats uri /stats # 访问面板的 URL 路径(http://IP:8404/stats)
stats realm HAProxy\ Monitor # 登录弹窗的提示文字
stats auth admin:123 # 登录账号密码(生产环境务必修改为强密码,支持多行配置多用户)
stats hide-version # 隐藏 HAProxy 版本号,提升安全
stats admin if TRUE # 开启面板管理功能:可在线将后端节点设为维护/排水/上线状态
# 3. 重启 HAProxy 生效
[root@haproxy ~ 11:28:20]# systemctl restart haproxy.service 3.3.1 监控面板访问验证
浏览器访问地址:http://www.liu.cloud:8404/stats
输入账号:admin,密码:123,认证成功后可查看:
- 前端 / 后端服务器的连接状态、流量数据;
- 后端节点的健康状态,支持在线调整节点状态。
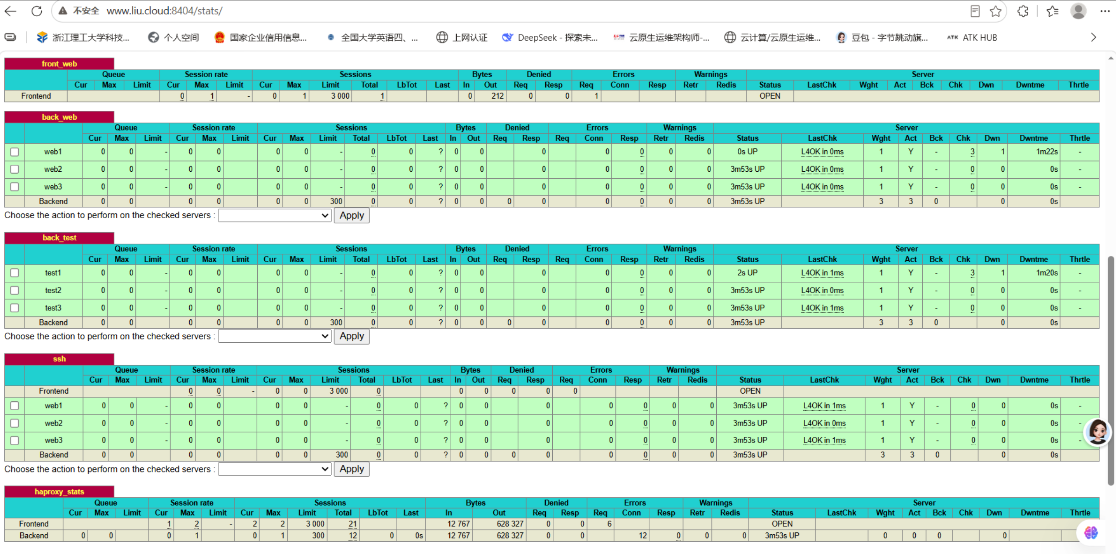
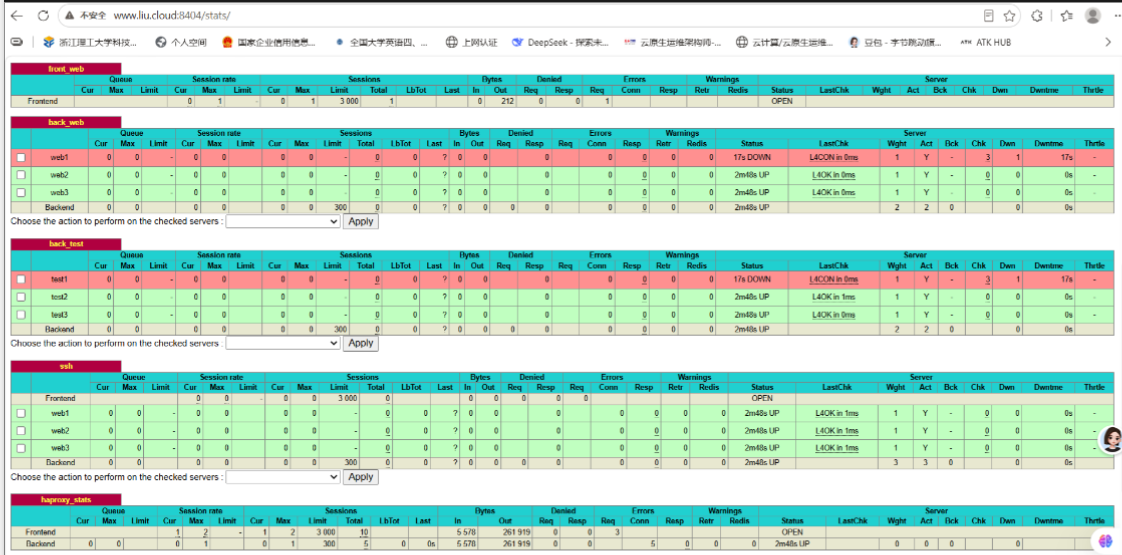
3.4 四层(TCP)负载均衡实战(SSH 代理)
目标:配置 HAProxy 转发 SSH 流量(TCP 层),实现 SSH 连接的负载均衡。
3.4.1 后端 SSH 配置
所有 Web 服务器(web1/web2/web3)安装并启用 SSH 服务:
bash
[root@web1-3 ~]#
yum install -y openssh-server
systemctl enable sshd --now3.4.2 HAProxy 配置(TCP 模式)
bash
# 1. 备份配置文件
cp /etc/haproxy/haproxy.cfg{,.ori}
# 2. 追加 TCP 代理配置(SSH 转发)
[root@haproxy ~ 10:41:10]# echo '
######### TCP 四层代理(SSH)配置 ###########
listen ssh
mode tcp # 工作模式:TCP(四层)
bind *:1022 # 监听本机 1022 端口(转发 SSH 流量)
balance roundrobin # 负载算法:动态加权轮询
# 后端 SSH 服务器配置(开启健康检查)
server web1 10.1.8.11:22 check
server web2 10.1.8.12:22 check
server web3 10.1.8.13:22 check
' >> /etc/haproxy/haproxy.cfg
# 3. 重启 HAProxy 生效
[root@haproxy ~ 11:06:30]# systemctl restart haproxy.service 3.4.3 TCP 模式测试
验证 SSH 流量的轮询转发效果:
bash
[root@client1 ~ 11:09:24]# while true ;do sshpass -p123 ssh -p 1022 root@10.1.8.10 hostname;sleep 1;done
web1.liu.cloud
web2.liu.cloud
web3.liu.cloud
web1.liu.cloud
web2.liu.cloud
web3.liu.cloud四、HAProxy 配置文件全解析
HAProxy 配置文件分为两大核心部分:全局配置(global) 和 代理配置(proxies),其中代理配置又细分为 defaults、frontend、backend、listen 四个模块。
4.1 配置文件结构说明
| 配置段 | 作用说明 |
|---|---|
| global | 定义进程管理、安全、性能相关的全局参数,作用于整个 HAProxy 实例 |
| defaults | 为 frontend/backend/listen 提供默认参数,可被后续 defaults 覆盖 |
| frontend | 定义前端监听套接字,接收客户端请求并匹配转发规则 |
| backend | 定义后端服务器集群,接收 frontend/listen 的转发请求 |
| listen | 整合 frontend + backend 的功能,适用于 TCP 四层代理(简化配置) |
注意:代理名称仅支持大小写字母、数字、-、_、.、:;ACL 名称区分大小写。
4.2 全局配置(global)详解
全局配置分为 "进程管理 / 安全" 和 "性能调优" 两类参数,以下为核心配置示例及说明:
4.2.1 进程管理与安全参数
bash
# 全局日志配置:将日志发送至 127.0.0.1 的 local2 日志设施
log 127.0.0.1 local2
# 日志首部添加主机名(自定义为 haproxy.liu.cloud)
log-send-hostname haproxy.liu.cloud
# 安全加固:切换工作目录并执行 chroot,目录需为空且无写权限
chroot /var/lib/haproxy
# 守护进程模式运行(后台运行)
daemon
# 进程 PID 文件路径
pidfile /var/run/haproxy.pid
# 运行 HAProxy 的 UID/用户名(需提前创建 haproxy 用户)
uid 188
user haproxy
# 运行 HAProxy 的 GID/组名
gid 188
group haproxy
# 启用 Unix Socket,用于读取统计数据
stats socket /var/lib/haproxy/stats
# HA 场景专用:定义当前节点名称(多实例共享 IP 时标识节点)
node ha1.liu.cloud
# 实例描述信息(自定义)
description haproxy server 14.2.2 性能调优参数
bash
# 进程数:指定启动的 HAProxy 进程数(单进程足够,仅高并发场景考虑多进程)
nbproc 2
# 每进程最大文件描述符数(默认自动计算,不建议手动修改)
# ulimit-n <number>
# 每进程最大并发连接数(核心参数,等同于命令行 -n)
maxconn 4000
# 缓冲区大小(默认 16384 字节,小值提升并发,大值适配大 Cookie 场景)
# tune.bufsize <number>
# 检查缓冲区大小(默认适配多数场景,不建议修改)
# tune.chksize <number>
# 单次调度可接受的最大连接数(单进程默认 100,多进程默认 8,-1 禁用限制)
# tune.maxaccept <number>
# 单次系统调用处理的最大事件数(默认随系统,>200 降延迟,<200 省带宽)
# tune.maxpollevents <number>
# 首部重写/追加的缓冲空间(建议 1024 左右,HAProxy 自动扩容)
# tune.maxrewrite <number>
# 内核套接字接收缓冲大小(默认值最优,不建议修改)
# tune.rcvbuf.server <number>4.3 代理配置(proxies)详解
代理配置的默认参数(defaults)是 frontend/backend/listen 的基础,以下为核心参数示例及说明:
bash
# 设置haproxy默认工作模式,支持tcp和http
# tcp,工作在4层,HAProxy分只是简单地转发流量
# http,工作在7层,HAProxy分析协议,并可以随意处理请求和响应内容,例如allowing, blocking, switching, adding,modifying, removing。
mode http
# 日志格式与global配置一致
log global
# 日志发送给本地,facility是local0,level是notice
log 127.0.0.1:514 local0 notice
# 日志类别http日志格式,也可指定为tcplog
option httplog
# 不记录没有数据的心跳检测包
option dontlognull
# 允许server端关闭http连接
option http-server-close
# 在转发的包头前加入except 127.0.0.0/8
option forwardfor except 127.0.0.0/8
# 连接失败后,重新分发连接
option redispatch
# 3次连接失败就认为服务不可用
retries 3
# 客户端建立连接但不请求数据时,关闭客户端连接
timeout http-request 10s
# 队列存在最大时长
timeout queue 1m
# haproxy将客户端请求转发至后端服务器所等待的超时时长
timeout connect 10s
# 客户端非活动状态的超时时长
timeout client 1m
# 客户端与服务端建立连接后,等待服务器端的超时时长
timeout server 1m
# 定义保持连接的超时时长
time http-keep-alive 1m
# 健康状态监测超时时长,过短会误判,过长会消耗更多资源
timeout check 10s五、HAProxy 核心总结
HAProxy 是轻量高性能的开源负载均衡器,核心优势如下:
- 协议支持:覆盖 TCP(四层)、HTTP(七层)代理,适配 Web、数据库、SSH 等多场景;
- 负载策略:提供轮询、加权、IP 哈希、URI 哈希等 8 种算法,满足会话保持、资源缓存等需求;
- 高可用能力:内置后端节点健康检查(主动 / 被动),支持故障自动切换;
- 配置灵活:通过 frontend/backend/listen 模块实现精细化转发规则,支持 SSL 终止、请求过滤、流量控制;
- 可观测性:内置 Web 监控面板,支持节点状态可视化、在线管理;
- 性能优势:事件驱动模型 + 底层优化,高并发下资源占用低,七层性能可超越硬件负载均衡设备。
HAProxy 是高可用架构的核心组件,搭配日志监控、故障转移配置,可显著提升服务稳定性与资源利用率,是中小规模至大型分布式架构的首选负载均衡方案。
LVS (Linux 虚拟服务器) 全解析与实战指南
一、LVS 概述
Linux 虚拟服务器(LVS,Linux Virtual Servers)是由章文嵩博士于 1998 年开发的开源负载均衡软件,其核心价值在于通过负载均衡技术将多台物理服务器整合为一个高可用、高扩展的虚拟服务器集群,为应对快速增长的网络访问需求提供了低成本、易扩展的解决方案。
LVS 工作于 Linux 内核空间,核心机制是根据请求报文的目标 IP 和目标端口,将客户端请求智能调度转发至后端服务器集群中的指定节点,以此实现请求的负载分发。
二、LVS 核心术语
| 术语 | 全称 / 别称 | 说明 |
|---|---|---|
| 调度器 | 负载均衡器 / Director/Virtual Server(VS) | 核心调度节点,负责接收客户端请求并分发至后端真实服务器 |
| 后端服务器 | 真实服务器 / Real Server(RS)/Backend Server | 实际处理客户端请求的业务服务器 |
| VIP | Virtual IP | 调度器对外提供服务的公网 / 业务 IP,客户端请求的目标 IP |
| DIP | Director IP | 调度器与后端 RS 通信的内网 IP |
| RIP | Real Server IP | 后端 RS 的 IP 地址 |
| CIP | Client IP | 发起请求的客户端 IP |
LVS 核心组件
LVS 由用户空间工具和内核空间模块两部分组成:
- ipvsadm:用户空间的命令行管理工具,用于在调度器(Director)上定义集群服务、添加 / 删除后端 Real Server、配置调度算法等核心操作。
- ipvs:运行于内核态 netfilter 框架 INPUT 钩子上的核心程序,负责实际的请求报文转发与调度逻辑处理。
部署注意:将主机配置为 Director 时,需确保内核支持 ipvs 模块并安装 ipvsadm 工具;生产环境中 Director 承担全量请求调度,负载压力大,禁止使用虚拟机部署。
三、LVS 工作原理
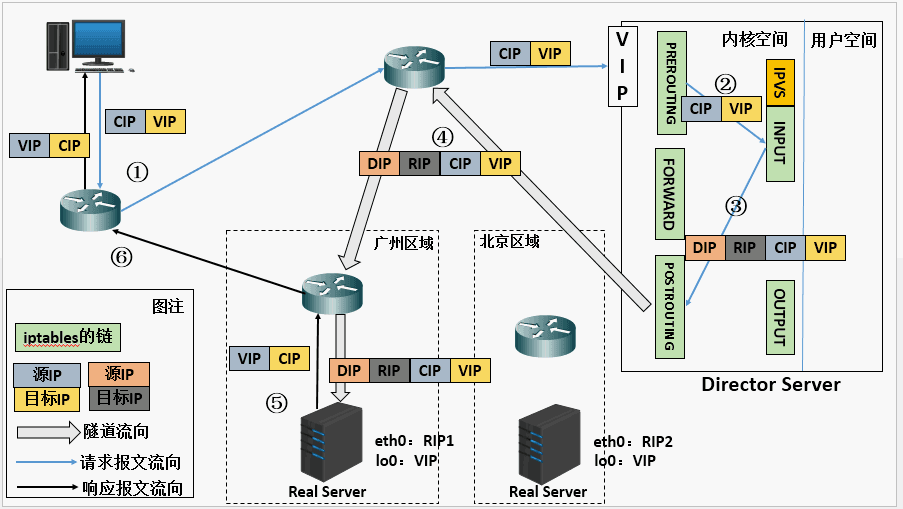
LVS 基于内核 netfilter 子系统完成数据包处理,完整流程如下:
- 客户端向 LVS 调度器(Director Server)发起请求,请求报文进入内核空间;
- PREROUTING 链接收请求报文,检测目标 IP 为调度器本机 VIP,将报文转发至 INPUT 链;
- IPVS 模块(工作在 INPUT 链)比对请求是否匹配已定义的集群服务:
- 匹配:强行修改报文的目标 IP(改为目标 RS 的 RIP)和端口,转发至 POSTROUTING 链;
- 不匹配:按常规内核流程处理;
- POSTROUTING 链接收修改后的报文,通过路由转发至目标后端 Real Server。
四、LVS 核心工作模式
LVS 主流工作模式包含 4 种:NAT、DR、TUN、FullNAT,其中 NAT 和 DR 为生产环境最常用模式,以下为详细解析。
4.1 NAT 模式
4.1.1 报文转发方式
通过修改请求报文的目标 IP(VIP→RIP)和目标端口实现转发,报文 MAC 层信息同步更新为目标 RS 的 MAC 地址。
| 报文阶段 | 源 IP | 源 MAC | 目标 IP | 目标 MAC |
|---|---|---|---|---|
| 原始报文 | Client IP | Client MAC | Director VIP | Director MAC |
| 转发后 | Client IP | Client MAC | RS IP | RS MAC |
4.1.2 工作原理
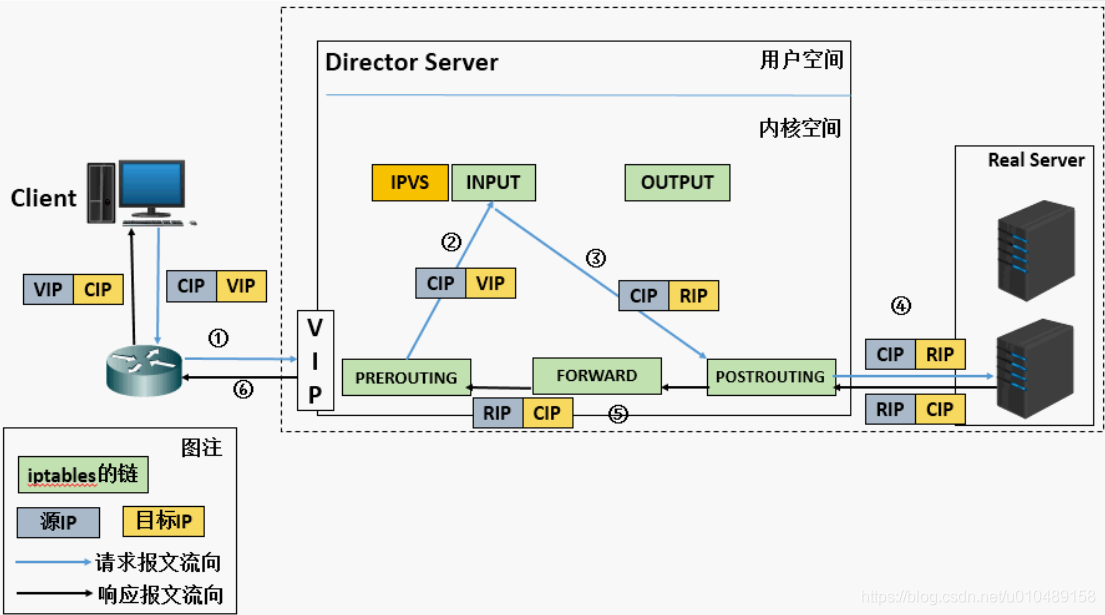
- 客户端请求到达 Director Server,报文进入内核 PREROUTING 链(源 IP=CIP,目标 IP=VIP);
- PREROUTING 检测目标 IP 为本机,将报文送至 INPUT 链;
- IPVS 匹配集群服务后,修改报文目标 IP 为 RIP,转发至 POSTROUTING 链(源 IP=CIP,目标 IP=RIP);
- POSTROUTING 链通过路由将报文发送至 Real Server;
- Real Server 处理请求后,构建响应报文(源 IP=RIP,目标 IP=CIP),因网关指向 DIP,报文回发至 Director;
- Director 修改响应报文源 IP 为 VIP,最终转发至客户端(源 IP=VIP,目标 IP=CIP)。
4.1.3 核心特点
- 网络要求:RS 与 DIP 需使用私网地址,RS 网关必须指向 DIP;
- 转发特性:请求和响应报文均需经过 Director 转发,高负载场景下 Director 易成为性能瓶颈;
- 功能支持:支持端口映射(可将 VIP 的 80 端口映射至 RS 的 8080 端口);
- 系统兼容:RS 可使用任意操作系统;
- 网络约束:RS 的 RIP 与 Director 的 DIP 必须在同一 IP 网段。
核心缺陷:Director 需处理双向报文,在高并发场景下易成为系统瓶颈。
4.2 DR 模式(Direct Routing)
4.2.1 报文转发方式
通过重新封装报文的 MAC 首部实现转发:保留 IP 层信息(源 IP=CIP,目标 IP=VIP),仅修改 MAC 层 ------ 源 MAC 为 DIP 所在网卡 MAC,目标 MAC 为目标 RS 的 MAC 地址。
| 报文阶段 | 源 IP | 源 MAC | 目标 IP | 目标 MAC |
|---|---|---|---|---|
| 原始报文 | Client IP | Client MAC | Director VIP | Director MAC |
| 转发后 | Client IP | Director DIP 对应的 MAC | Director VIP | RS MAC |
4.2.2 工作原理
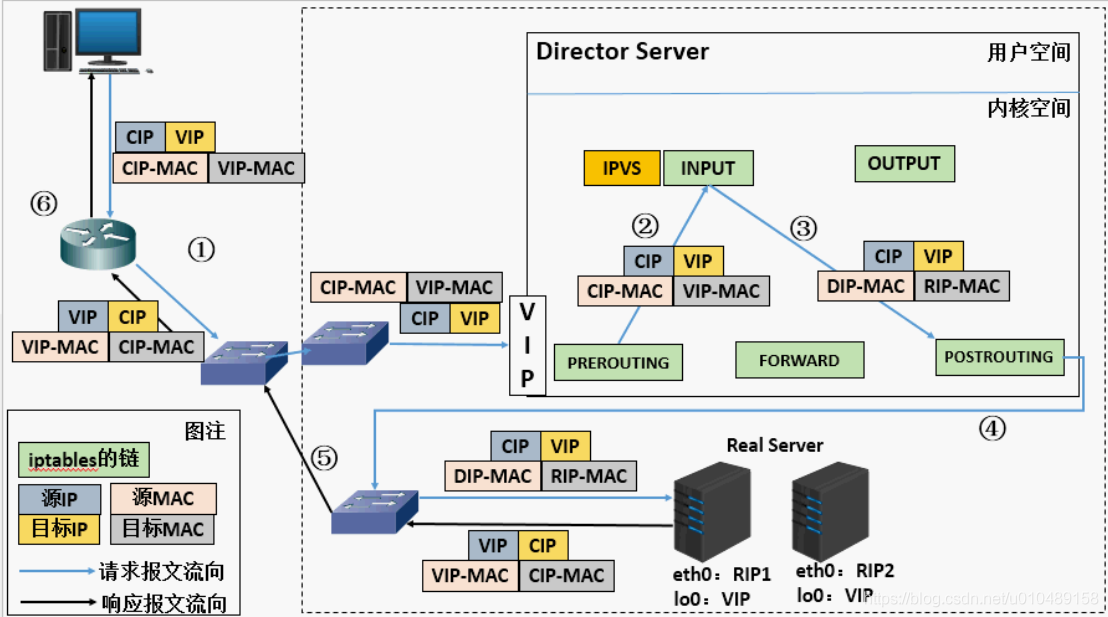
- 客户端请求到达 Director Server,报文进入 PREROUTING 链(源 IP=CIP,目标 IP=VIP);
- PREROUTING 检测目标 IP 为本机,将报文送至 INPUT 链;
- IPVS 匹配集群服务后,仅修改报文 MAC 层(源 MAC=DIP MAC,目标 MAC=RIP MAC),转发至 POSTROUTING 链;
- POSTROUTING 链基于二层 MAC 地址,将报文转发至 Real Server;
- Real Server 接收报文后,发现目标 MAC 为自身 MAC,且 lo 网卡已配置 VIP,处理请求后直接通过 lo 接口 + eth0 网卡发送响应报文(源 IP=VIP,目标 IP=CIP);
- 响应报文无需经过 Director,直接返回至客户端。
4.2.3 核心特点
- VIP 配置:RS 的 lo 网卡必须配置 VIP(32 位子网掩码);
- ARP 隔离:需禁止 RS 响应 VIP 的 ARP 请求(通过 arptables 或内核参数),防止路由器将 VIP 请求转发至 RS;
- 网络约束:RS 的 RIP 与 Director 的 DIP 必须在同一物理网络,RS 网关不能指向 DIP;
- 地址兼容:RS 的 RIP 可使用私网 / 公网地址;
- 转发特性:请求报文经 Director 调度,响应报文由 RS 直接返回客户端;
- 功能限制:不支持端口映射;
核心缺陷:RS 与 Director 必须部署在同一机房(依赖二层 MAC 转发)。
4.3 TUN 模式(IP 隧道模式)
4.3.1 报文转发方式
不修改原始请求报文的 IP 首部,而是在其外层封装新的 IP 首部:新首部源 IP=DIP,目标 IP=RIP,原始 IP 首部(源 IP=CIP,目标 IP=VIP)保留。
| 报文阶段 | 封装源 IP | 封装目标 IP | 源 IP | 源 MAC | 目标 IP | 目标 MAC |
|---|---|---|---|---|---|---|
| 原始报文 | - | - | Client IP | Client MAC | Director VIP | Director MAC |
| 转发后 | DIP | RIP | Client IP | Client MAC | Director VIP | Director MAC |
4.3.2 工作原理
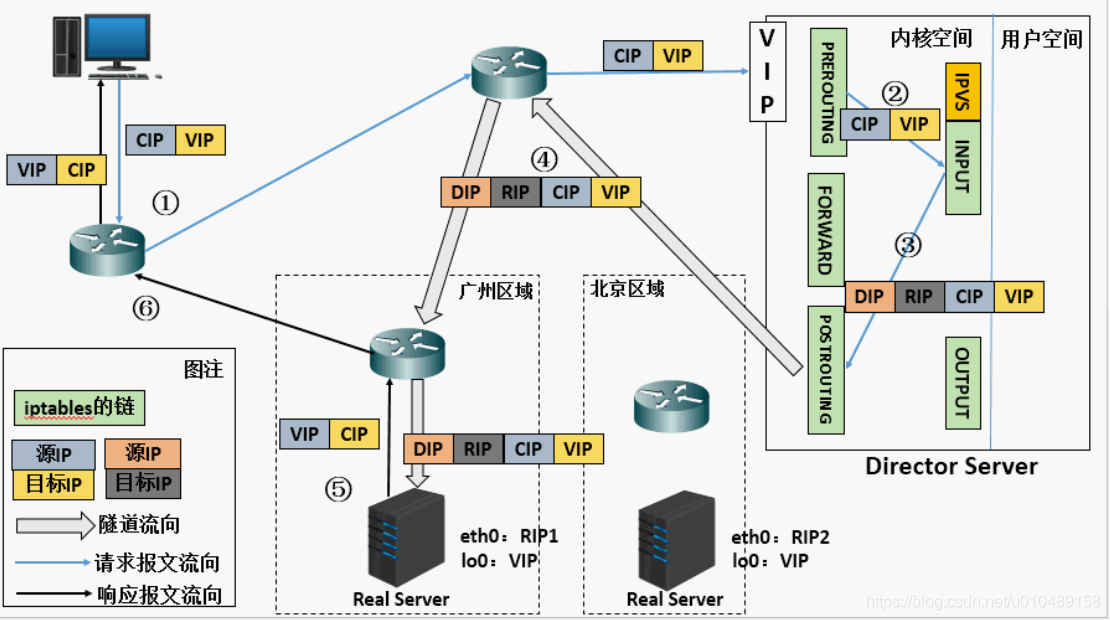
- 客户端请求到达 Director Server,报文进入 PREROUTING 链(源 IP=CIP,目标 IP=VIP);
- PREROUTING 检测目标 IP 为本机,将报文送至 INPUT 链;
- IPVS 匹配集群服务后,封装新 IP 首部(源 = DIP,目标 = RIP),转发至 POSTROUTING 链;
- POSTROUTING 链基于新 IP 首部,通过 IP 隧道将报文发送至 Real Server;
- Real Server 接收报文后,拆除外层 IP 首部,处理内层 VIP 请求,响应报文(源 IP=VIP,目标 IP=CIP)直接返回客户端;
- 响应报文无需经过 Director,直达客户端。
4.3.3 核心特点
- 地址要求:RIP、DIP、VIP 均需为公网地址;
- 网关约束:RS 网关不能指向 DIP;
- 转发特性:请求经 Director 调度,响应由 RS 直接返回;
- 功能限制:不支持端口映射;
- 系统要求:RS 操作系统需支持 IP 隧道功能。
五、LVS 调度算法
LVS 调度算法分为静态算法(不考虑后端负载)和动态算法(基于后端实时负载调度)两大类,适配不同业务场景需求。
5.1 静态调度算法
5.1.1 RR(轮叫调度)
- 逻辑:将客户端请求按顺序轮流分配至集群中的 RS,均等对待每台服务器,不考虑实际连接数和负载;
- 适用场景:所有 RS 性能配置完全一致的场景。
5.1.2 WRR(加权轮叫)
- 逻辑:根据 RS 的处理能力配置权重,权重越高的 RS 分配到的请求越多;调度器可自动探测 RS 负载并动态调整权重;
- 适用场景:RS 性能存在差异的集群(如高配服务器权重高)。
5.1.3 DH(目标地址散列调度)
- 逻辑:以请求的目标 IP 为 HashKey,从静态散列表中匹配对应的 RS;若 RS 可用且未超载则转发,否则返回空;
- 适用场景:Cache 集群(相同目标 IP 请求固定转发至同一 RS,提升缓存命中率)。
5.1.4 SH(源地址散列调度)
- 逻辑:以请求的源 IP 为 HashKey,从静态散列表中匹配对应的 RS;若 RS 可用且未超载则转发,否则返回空;
- 适用场景:需要会话粘滞的业务(同一客户端请求固定转发至同一 RS)。
5.2 动态调度算法
5.2.1 LC(最少连接)
- 逻辑:将请求转发至当前已建立连接数最少的 RS;
- 适用场景:RS 性能相近,请求连接时长差异较大的场景。
5.2.2 WLC(加权最少连接,默认算法)
- 逻辑:在 LC 基础上引入权重,高权重 RS 优先接收新请求,权重与 RS 处理能力正相关;调度器可动态调整权重;
- 适用场景:RS 性能差异大,且请求连接数动态变化的场景。
5.2.3 SED(最短延迟调度)
- 逻辑:基于 WLC 改进,计算公式:Overhead = (ACTIVE+1)*256 / 权重;优先选择 Overhead 最小的 RS;
- 特点:仅考虑活动连接数,+1 避免权重过大导致空闲 RS 无请求;
- 缺陷:权重过高时,空闲 RS 可能长期无请求。
5.2.4 NQ(永不排队 / 最少队列调度)
- 逻辑:SED 的优化版,若存在连接数为 0 的 RS,直接分配请求(无需计算 Overhead);
- 适用场景:避免 RS 长期空闲,如 DNS(UDP)等短连接业务。
5.2.5 LBLC(基于局部性的最少连接)
- 逻辑:针对目标 IP 的负载均衡,优先将请求转发至该目标 IP 最近使用的 RS;若 RS 超载,则按 LC 选择新 RS;
- 适用场景:Cache 集群(提升目标 IP 的缓存命中率)。
5.2.6 LBLCR(带复制的基于局部性最少连接)
- 逻辑:LBLC 的扩展版,维护 "目标 IP→RS 组" 映射;优先从 RS 组中选 LC 的 RS,超载则扩容 RS 组;空闲时删除组内最忙 RS;
- 适用场景:大规模 Cache 集群(平衡缓存命中率与负载)。
六、LVS 实战配置(HTTP 负载均衡)
6.1 基础环境准备
6.1.1 /etc/hosts 配置
bash
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
###### LVS 集群主机映射 ########
# 注意:LVS主机记录需指向VIP,避免ipvs规则VIP异常
10.1.1.10 lvs lvs.liu.cloud
10.1.8.11 web1 web1.liu.cloud
10.1.8.12 web2 web2.liu.cloud
10.1.8.13 web3 web3.liu.cloud
10.1.8.20 router router.liu.cloud
10.1.8.21 client1 client1.liu.cloud
10.1.1.21 client2 client2.liu.cloud6.1.2 通用依赖安装
- Web 服务器(RS):部署 Nginx 提供测试页面
bash
[root@web1-3 ~]#
# 所有Web节点执行
yum install -y nginx
# 生成差异化测试页面,便于验证负载均衡效果
echo Welcome to $(hostname) > /usr/share/nginx/html/index.html
systemctl enable nginx --now- LVS 调度器(Director):安装 ipvsadm 工具
bash
[root@lvs ~]#
yum install -y ipvsadm
# 创建ipvs规则保存文件(ipvsadm服务启动时读取)
touch /etc/sysconfig/ipvsadm6.1.3 ipvsadm 命令
bash
## 定义集群服务
ipvsadm -A|E -t|u|f service-address [-s scheduler]
[-p [timeout]] [-M netmask]
-A: 表示添加一个新的集群服务
-E: 编辑一个集群服务
-t: 表示tcp协议
-u: 表示udp协议
-f: 表示firewall-Mark,防火墙标记
service-address: 集群服务的IP地址,即VIP
-s 指定调度算法
-p 持久连接时长,如#ipvsadm -Lcn ,查看持久连接状态
-M 定义掩码
# 删除一个集群服务
ipvsadm -D -t|u|f service-address
# 清空所有的规则
ipvsadm -C
# 重新载入规则
ipvsadm -R
# 保存规则
ipvsadm -S [-n]
## 管理集群服务中RealServer
ipvsadm -a|e -t|u|f service-address -r server-address
[-g|i|m] [-w weight]
-a 添加一个新的realserver规则
-e 编辑realserver规则
-t tcp协议
-u udp协议
-f firewall-Mark,防火墙标记
service-address realserver的IP地址
-g 表示定八义为LVS-DR模型
-i 表示定义为LVS-TUN模型
-m 表示定义为LVS-NAT模型
-w 定义权重,后面跟具体的权值
# 删除一个realserver
ipvsadm -d -t|u|f service-address -r server-address
# 查看定义的规则
ipvsadm -L|l [options]
ipvsadm -L -n
# 清空计数器
ipvsadm -Z [-t|u|f service-address]6.2 NAT 模式实战
6.2.1 网络拓扑
| 主机名 | IP地址 | 服务器角色 |
|---|---|---|
| client2.liu.cloud | 10.1.1.21 | 客户端 |
| client1.liu.cloud | 10.1.8.21 | 客户端 |
| router.liu.cloud | 10.1.1.20, 10.1.8.20 | 路由器 |
| lvs.liu.cloud | 10.1.1.10, 10.1.8.10 | LVS 服务器 |
| web1.liu.cloud | 10.1.8.11 | Web 服务器 |
| web2.liu.cloud | 10.1.8.12 | Web 服务器 |
| web3.liu.cloud | 10.1.8.13 | Web 服务器 |
网络规则:10.1.1.0/24 网关 = 10.1.1.10,10.1.8.0/24 网关 = 10.1.8.10(均指向 LVS 调度器)。
6.2.2 网关配置(所有节点)
bash
# LVS节点执行:批量设置RS和客户端网关指向DIP
[root@lvs ~ 14:16:41]# for host in 10.1.8.{11..13} 10.1.8.21; do ssh root@$host 'nmcli connection modify ens33 ipv4.gateway 10.1.8.10;nmcli connection up ens33'; done
连接已成功激活(D-Bus 活动路径:/org/freedesktop/NetworkManager/ActiveConnection/2)
连接已成功激活(D-Bus 活动路径:/org/freedesktop/NetworkManager/ActiveConnection/2)
连接已成功激活(D-Bus 活动路径:/org/freedesktop/NetworkManager/ActiveConnection/2)
连接已成功激活(D-Bus 活动路径:/org/freedesktop/NetworkManager/ActiveConnection/2)
# 验证网关配置
[root@lvs ~ 14:16:45]# for host in 10.1.8.{11..13} 10.1.{8,1}.21; do ssh root@$host 'hostname;ip route|grep default;echo'; done
web1.liu.cloud
default via 10.1.8.10 dev ens33 proto static metric 100
web2.liu.cloud
default via 10.1.8.10 dev ens33 proto static metric 100
web3.liu.cloud
default via 10.1.8.10 dev ens33 proto static metric 100
client1.liu.cloud
default via 10.1.8.10 dev ens33 proto static metric 100
client2.liu.cloud
default via 10.1.1.10 dev ens33 proto static metric 100 6.2.3 LVS 调度器核心配置
bash
# 部署 web
yum install -y nginx
echo Welcome to $(hostname) > /usr/share/nginx/html/index.html
systemctl enable nginx.service --now
bash
[root@lvs ~]#
# 开启路由
[root@lvs ~ 14:16:57]# echo "net.ipv4.ip_forward=1">> /etc/sysctl.conf
# 或者
# sed -i "s/ip_forward=0/ip_forward=1/g" /etc/sysctl.conf
[root@lvs ~ 14:33:06]# sysctl -p
net.ipv4.ip_forward = 1
# 设置防火墙
[root@lvs ~ 14:33:19]# systemctl enable firewalld.service --now
Created symlink from /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service to /usr/lib/systemd/system/firewalld.service.
Created symlink from /etc/systemd/system/multi-user.target.wants/firewalld.service to /usr/lib/systemd/system/firewalld.service.
[root@lvs ~ 14:34:11]# firewall-cmd --set-default-zone=trusted
success
[root@lvs ~ 14:34:38]# firewall-cmd --add-masquerade --permanent
success
[root@lvs ~ 14:34:56]# firewall-cmd --add-masquerade
success
[root@lvs ~ 14:35:04]# for host in 10.1.8.{10..13} 10.1.{8,1}.21; do ssh root@$host 'if ping -c2 1.1.1.1 &>/dev/null;then echo ok;else echo no ok;fi'; done
ok
ok
ok
ok
ok
ok
# 安装 ipvsadm
[root@lvs ~ 14:37:05]# yum install -y ipvsadm
# ipvsadm 服务启动的时候,从该文件中读取ipvs规则
[root@lvs ~ 14:38:53]# touch /etc/sysconfig/ipvsadm
[root@lvs ~ 14:39:21]# systemctl enable ipvsadm --now
Created symlink from /etc/systemd/system/multi-user.target.wants/ipvsadm.service to /usr/lib/systemd/system/ipvsadm.service.
# 创建轮询负载
## 增加一个tcp模式虚拟IP,调度模式:轮询
[root@lvs ~ 14:39:43]# ipvsadm -A -t 10.1.1.10:80 -s rr
# 未虚拟IP增加后端真实主机,模式masquerade(NAT)
[root@lvs ~ 14:46:46]# ipvsadm -a -t 10.1.1.10:80 -r 10.1.8.11 -m
[root@lvs ~ 14:50:30]# ipvsadm -a -t 10.1.1.10:80 -r 10.1.8.12 -m
[root@lvs ~ 14:53:16]# ipvsadm -a -t 10.1.1.10:80 -r 10.1.8.13 -m
# 保存转发规则到文件中
[root@lvs ~ 14:53:19]# ipvsadm-save -n > /etc/sysconfig/ipvsadm
# 核实配置是否生效
[root@lvs ~ 14:55:15]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.1.1.10:80 rr
-> 10.1.8.11:80 Masq 1 0 0
-> 10.1.8.12:80 Masq 1 0 0
-> 10.1.8.13:80 Masq 1 0 0
# 多次访问验证
[root@client2 ~ 14:55:33]# for i in {1..90};do curl -s 10.1.1.10;sleep 1;done
Welcome to web3.liu.cloud
Welcome to web2.liu.cloud
Welcome to web1.liu.cloud
Welcome to web3.liu.cloud
Welcome to web2.liu.cloud
Welcome to web1.liu.cloud6.2.4 调整为加权轮询(WRR)
bash
# 修改 调度模式为:带权重的轮询
[root@lvs ~ 14:55:22]# ipvsadm -E -t 10.1.1.10:80 -s wrr
# 设置权重为2
[root@lvs ~ 14:58:17]# ipvsadm -e -t 10.1.1.10:80 -r 10.1.8.12 -m -w 2
# 设置权重为3
[root@lvs ~ 14:59:13]# ipvsadm -e -t 10.1.1.10:80 -r 10.1.8.13 -m -w 3
[root@lvs ~ 14:59:21]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.1.1.10:80 wrr
-> 10.1.8.11:80 Masq 1 0 0
-> 10.1.8.12:80 Masq 2 0 0
-> 10.1.8.13:80 Masq 3 0 0 6.2.5 访问验证
bash
[root@client2 ~ 15:09:19]# for i in {1..90};do curl -s 10.1.1.10;done|sort|uniq -c
15 Welcome to web1.liu.cloud
30 Welcome to web2.liu.cloud
45 Welcome to web3.liu.cloud6.2.6 问题解决:client1 无法访问的修复
问题原因:client1(10.1.8.21)与 RS 同网段,RS 响应报文直接返回 client1,未经过 LVS 转发。
修复方案:为所有 RS 添加静态路由,指向 LVS 的 DIP。
bash
[root@web1 ~ 13:19:13]# nmcli connection modify ens33 ipv4.routes '10.1.8.21 255.255.255.255 10.1.8.10'
[root@web1 ~ 15:14:56]# nmcli connection up ens33
连接已成功激活(D-Bus 活动路径:/org/freedesktop/NetworkManager/ActiveConnection/3)
[root@web2 ~ 10:37:47]# nmcli connection modify ens33 ipv4.routes '10.1.8.21 255.255.255.255 10.1.8.10'
[root@web2 ~ 15:17:24]# nmcli connection up ens33
连接已成功激活(D-Bus 活动路径:/org/freedesktop/NetworkManager/ActiveConnection/3)
[root@web3 ~ 10:37:43]# nmcli connection modify ens33 ipv4.routes '10.1.8.21 255.255.255.255 10.1.8.10'
[root@web3 ~ 15:17:28]# nmcli connection up ens33
连接已成功激活(D-Bus 活动路径:/org/freedesktop/NetworkManager/ActiveConnection/3)
[root@client1 ~ 15:17:51]# for i in {1..90};do curl -s 10.1.1.10;sleep 1;done
Welcome to web3.liu.cloud
Welcome to web2.liu.cloud
Welcome to web3.liu.cloud
Welcome to web2.liu.cloud
Welcome to web1.liu.cloud
Welcome to web3.liu.cloud
Welcome to web3.liu.cloud
Welcome to web2.liu.cloud
Welcome to web3.liu.cloud6.3 DR 模式实战
6.3.1 网络拓扑
| 主机名 | IP地址 | 服务器角色 |
|---|---|---|
| client2.liu.cloud | 10.1.1.21 | 客户端 |
| client1.liu.cloud | 10.1.8.21 | 客户端 |
| router.liu.cloud | 10.1.1.20, 10.1.8.20 | 路由器 |
| lvs.liu.cloud | 10.1.8.10 | LVS 服务器 |
| web1.liu.cloud | 10.1.8.11 | Web 服务器 |
| web2.liu.cloud | 10.1.8.12 | Web 服务器 |
| web3.liu.cloud | 10.1.8.13 | Web 服务器 |
6.3.2 基础网络配置
bash
# 修改client2(10.1.1.21)网关
[root@client2 ~ 16:01:35]# nmcli connection modify ens33 ipv4.gateway 10.1.1.20
[root@client2 ~ 16:02:59]# nmcli connection up ens33
连接已成功激活(D-Bus 活动路径:/org/freedesktop/NetworkManager/ActiveConnection/3)
# 停用仅主机网卡
[root@lvs ~ 16:01:04]# nmcli connection down ens36
成功停用连接 "ens36"(D-Bus 活动路径:/org/freedesktop/NetworkManager/ActiveConnection/2)
# 修改 10.1.8.0/24 网关
[root@lvs ~ 16:02:10]# for host in 10.1.8.{11..13} 10.1.8.21; do ssh root@$host 'nmcli connection modify ens33 ipv4.gateway 10.1.8.20;nmcli connection up ens33'; done
连接已成功激活(D-Bus 活动路径:/org/freedesktop/NetworkManager/ActiveConnection/5)
连接已成功激活(D-Bus 活动路径:/org/freedesktop/NetworkManager/ActiveConnection/5)
连接已成功激活(D-Bus 活动路径:/org/freedesktop/NetworkManager/ActiveConnection/5)
连接已成功激活(D-Bus 活动路径:/org/freedesktop/NetworkManager/ActiveConnection/3)
# 注意路由器的配置:
# 1. 开启转发
# 2. 防火墙开启伪装
[root@router ~ 16:06:26]# echo "net.ipv4.ip_forward=1" >> /etc/sysctl.conf
[root@router ~ 16:10:05]# sysctl -p
net.ipv4.ip_forward = 1
[root@router ~ 16:10:30]# firewall-cmd --add-masquerade
success
[root@router ~ 16:11:05]# firewall-cmd --add-masquerade --permanent
success
[root@router ~ 16:11:21]# firewall-cmd --reload
success
# 验证所有主机网关
[root@lvs ~ 16:07:40]# for host in 10.1.8.{10..13} 10.1.8.{20,21} 10.1.1.21; do ssh root@$host 'echo -n $(hostname):;if ping -c2 1.1.1.1 &>/dev/null;then echo ok;else echo no ok;fi'; done
lvs.liu.cloud:ok
web1.liu.cloud:ok
web2.liu.cloud:ok
web3.liu.cloud:ok
router.liu.cloud:ok
client1.liu.cloud:ok
client2.liu.cloud:ok
bash
[root@web1-3 ~]#
# 部署 web
yum install -y nginx
echo Welcome to $(hostname) > /usr/share/nginx/html/index.html
systemctl enable nginx.service --now6.3.3 后端 RS 配置(所有 Web 节点)
bash
# 增加虚拟网卡,子网掩码一定要设置为 32 位
[root@web1 ~ 16:31:29]# nmcli connection add type dummy ifname dummy con-name dummy ipv4.method manual ipv4.addresses 10.1.8.100/32
连接 "dummy" (00cf5e01-ef96-4e32-a82a-d09a4458f222) 已成功添加。
[root@web1 ~ 16:41:22]# nmcli connection up dummy
连接已成功激活(D-Bus 活动路径:/org/freedesktop/NetworkManager/ActiveConnection/7)
[root@web2 ~ 15:18:40]# nmcli connection add type dummy ifname dummy con-name dummy ipv4.method manual ipv4.addresses 10.1.8.100/32
连接 "dummy" (8ac756b5-b1c4-4415-a8b3-4963dfae1de1) 已成功添加。
[root@web2 ~ 16:41:37]# nmcli connection up dummy
连接已成功激活(D-Bus 活动路径:/org/freedesktop/NetworkManager/ActiveConnection/7)
[root@web3 ~ 15:18:48]# nmcli connection add type dummy ifname dummy con-name dummy ipv4.method manual ipv4.addresses 10.1.8.100/32
连接 "dummy" (4a560e6b-54e9-44d1-8255-605baef92c58) 已成功添加。
[root@web3 ~ 16:41:44]# nmcli connection up dummy
连接已成功激活(D-Bus 活动路径:/org/freedesktop/NetworkManager/ActiveConnection/7)
# 配置 arp 参数,关闭arp对dummy网卡的解析
[root@web1 ~ 16:41:24]# cat >> /etc/sysctl.conf << EOF
net.ipv4.conf.all.arp_ignore = 1
net.ipv4.conf.all.arp_announce = 2
net.ipv4.conf.dummy.arp_ignore = 1
net.ipv4.conf.dummy.arp_announce = 2
EOF
[root@web1 ~ 16:42:01]# sysctl -p
net.ipv4.conf.all.arp_ignore = 1
net.ipv4.conf.all.arp_announce = 2
net.ipv4.conf.dummy.arp_ignore = 1
net.ipv4.conf.dummy.arp_announce = 2
[root@web2 ~ 16:41:38]# cat >> /etc/sysctl.conf << EOF
net.ipv4.conf.all.arp_ignore = 1
net.ipv4.conf.all.arp_announce = 2
net.ipv4.conf.dummy.arp_ignore = 1
net.ipv4.conf.dummy.arp_announce = 2
EOF
[root@web2 ~ 16:42:06]# sysctl -p
net.ipv4.conf.all.arp_ignore = 1
net.ipv4.conf.all.arp_announce = 2
net.ipv4.conf.dummy.arp_ignore = 1
net.ipv4.conf.dummy.arp_announce = 2
[root@web3 ~ 16:41:45]# cat >> /etc/sysctl.conf << EOF
net.ipv4.conf.all.arp_ignore = 1
net.ipv4.conf.all.arp_announce = 2
net.ipv4.conf.dummy.arp_ignore = 1
net.ipv4.conf.dummy.arp_announce = 2
EOF
[root@web3 ~ 16:42:12]# sysctl -p
net.ipv4.conf.all.arp_ignore = 1
net.ipv4.conf.all.arp_announce = 2
net.ipv4.conf.dummy.arp_ignore = 1
net.ipv4.conf.dummy.arp_announce = 2内核参数:net.ipv4.conf.all.arp_ignore
作用:控制主机收到 ARP 请求时,是否回复 ARP 响应(即是否告知对方 "该 IP 对应的 MAC 地址是我")。
参数值及含义:
参数值 行为说明 0(默认) 只要本机有该 IP 地址(无论哪个网卡),就回复 ARP 响应。 问题:多网卡场景下,可能导致 "ARP 漂移"(例如网卡 A 的 IP 被网卡 B 响应)。 1 仅当 ARP 请求的目标 IP 与接收请求的网卡上的主 IP 完全匹配时,才回复响应。 (主 IP 指网卡配置的第一个 IP 地址) 2 仅当 ARP 请求的目标 IP 与接收请求的网卡上的任一 IP(包括 secondary IP)匹配时,才回复响应。 3 不回复 ARP 请求(除非是本地环回地址)。 4-7 更复杂的策略(如忽略来自非本网络的请求),较少使用。 典型场景:
- 服务器有多个网卡(如
eth0、eth1),分别属于不同子网,需避免跨网卡响应 ARP 请求。- 配置虚拟 IP(如 Keepalived 高可用集群的 VIP)时,防止非主节点响应 VIP 的 ARP 请求。
内核参数:net.ipv4.conf.all.arp_announce
作用 :控制主机发送 ARP 通告(主动告知 "我的 IP 对应的 MAC 地址")时,如何选择源 IP 地址。
参数值及含义:
参数值 行为说明 0(默认) 允许使用任意本地 IP 作为 ARP 通告的源 IP(可能选择与目标网络无关的 IP)。 问题:跨子网通信时,可能导致其他主机学习到错误的 IP-MAC 映射。 1 尽量使用与目标 IP 同子网的本地 IP 作为源 IP;若没有,则使用接收接口的 IP。 2(推荐) 严格选择与目标 IP 同子网的本地 IP 作为源 IP;若没有,则不发送 ARP 通告(或使用环回地址)。 典型场景:
- 多网卡服务器访问外部网络时,确保 ARP 通告的源 IP 属于目标网络所在的子网,避免其他主机误将 IP 关联到错误的网卡 MAC。
- 负载均衡或高可用集群中,防止虚拟 IP 被错误的物理网卡 MAC 通告。
6.3.4 LVS 调度器(DS)配置
bash
# 配置虚拟网卡
[root@lvs ~ 16:24:04]# nmcli connection add type dummy ifname dummy con-name dummy ipv4.method manual ipv4.addresses 10.1.8.100/32
连接 "dummy" (c196dfe4-ed25-48ad-acc2-666ebe702bd5) 已成功添加。
[root@lvs ~ 16:43:48]# nmcli connection up dummy
连接已成功激活(D-Bus 活动路径:/org/freedesktop/NetworkManager/ActiveConnection/5)
# 安装 ipvsadm
yum install -y ipvsadm
touch /etc/sysconfig/ipvsadm
systemctl enable ipvsadm --now
#删除之前的轮询负载
[root@lvs ~ 16:47:53]# ipvsadm -D -t 10.1.1.10:80
# 创建轮询负载
[root@lvs ~ 16:43:56]# ipvsadm -A -t 10.1.8.100:80 -s rr
[root@lvs ~ 16:44:32]# ipvsadm -a -t 10.1.8.100:80 -r 10.1.8.11:80
[root@lvs ~ 16:44:58]# ipvsadm -a -t 10.1.8.100:80 -r 10.1.8.12:80
[root@lvs ~ 16:45:02]# ipvsadm -a -t 10.1.8.100:80 -r 10.1.8.13:80
[root@lvs ~ 16:48:46]# ipvsadm-save -n > /etc/sysconfig/ipvsadm
# 核实配置是否生效
[root@lvs ~ 16:48:49]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 10.1.8.100:80 rr
-> 10.1.8.11:80 Route 1 0 0
-> 10.1.8.12:80 Route 1 0 0
-> 10.1.8.13:80 Route 1 0 0
# Forward 值为 Route,代表当前模式为 DR6.3.5 访问验证
bash
[root@client1 ~ 16:49:20]# for i in {1..90};do curl -s 10.1.8.100 ;done|sort|uniq -c
30 Welcome to web1.liu.cloud
30 Welcome to web2.liu.cloud
30 Welcome to web3.liu.cloud
[root@client2 ~ 16:03:04]# for i in {1..90};do curl -s 10.1.8.100 ;done|sort|uniq -c 30 Welcome to web1.liu.cloud
30 Welcome to web2.liu.cloud
30 Welcome to web3.liu.cloud6.4 参考脚本
Real Server 配置
bash
#!/bin/bash
# description : 配置Real Server
. /etc/rc.d/init.d/functions
VIP=10.1.8.100
case "$1" in
start)
echo -n "Start LVS Real Server ... "
# 设置 VIP
if nmcli connection |grep -q dummy;then
nmcli connection modify dummy ipv4.method manual ipv4.addresses $VIP/32
else
nmcli connection add type dummy ifname dummy con-name dummy ipv4.method manual ipv4.addresses $VIP/32
fi
nmcli connection up dummy
# 关闭 ARP
echo "1" >/proc/sys/net/ipv4/conf/all/arp_ignore
echo "2" >/proc/sys/net/ipv4/conf/all/arp_announce
echo "1" >/proc/sys/net/ipv4/conf/dummy/arp_ignore
echo "2" >/proc/sys/net/ipv4/conf/dummy/arp_announce
echo OK
;;
stop)
echo -n "Stop LVS Real Server ... "
# 关闭 VIP
nmcli connection delete dummy
# 启用 ARP
echo "0" >/proc/sys/net/ipv4/conf/dummy/arp_ignore
echo "0" >/proc/sys/net/ipv4/conf/dummy/arp_announce
echo "0" >/proc/sys/net/ipv4/conf/all/arp_ignore
echo "0" >/proc/sys/net/ipv4/conf/all/arp_announce
echo OK
;;
*)
echo "Usage: $0 start|stop"
exit 1
;;
esacDirector Server 配置
bash
#!/bin/bash
# description : 配置 Director Server
. /etc/rc.d/init.d/functions
# 安装 ipvsadm
if rpm -q ipvsadm &>/dev/null;then
true
else
yum install -y ipvsadm &>/dev/null
fi
VIP=10.1.8.100
PORT=80
rs1=10.1.8.11
rs2=10.1.8.12
rs3=10.1.8.13
interface=ens33
con_name=ens33
ipv=/sbin/ipvsadm
case "$1" in
start)
echo -n "Start LVS Director Server ... "
# 设置 VIP
if ip -br addr | grep -q $VIP;then
true
else
nmcli connection modify ${con_name} +ipv4.addresses $VIP/32
nmcli connection up ${con_name}
fi
# 设置 LB
$ipv -C
$ipv -A -t $VIP:${PORT} -s wrr
$ipv -a -t $VIP:${PORT} -r $rs1:${PORT} -g -w 1
$ipv -a -t $VIP:${PORT} -r $rs2:${PORT} -g -w 1
$ipv -a -t $VIP:${PORT} -r $rs3:${PORT} -g -w 1
echo OK
;;
stop)
echo -n "Stop LVS Director Server ... "
# 关闭 VIP
if ip -br addr | grep -q $VIP;then
nmcli connection modify ${con_name} -ipv4.addresses $VIP/32
nmcli connection up ${con_name}
fi
# 关闭 LB
$ipv -C
echo OK
;;
*)
echo "Usage: $0 start|stop"
exit 1
;;
esac