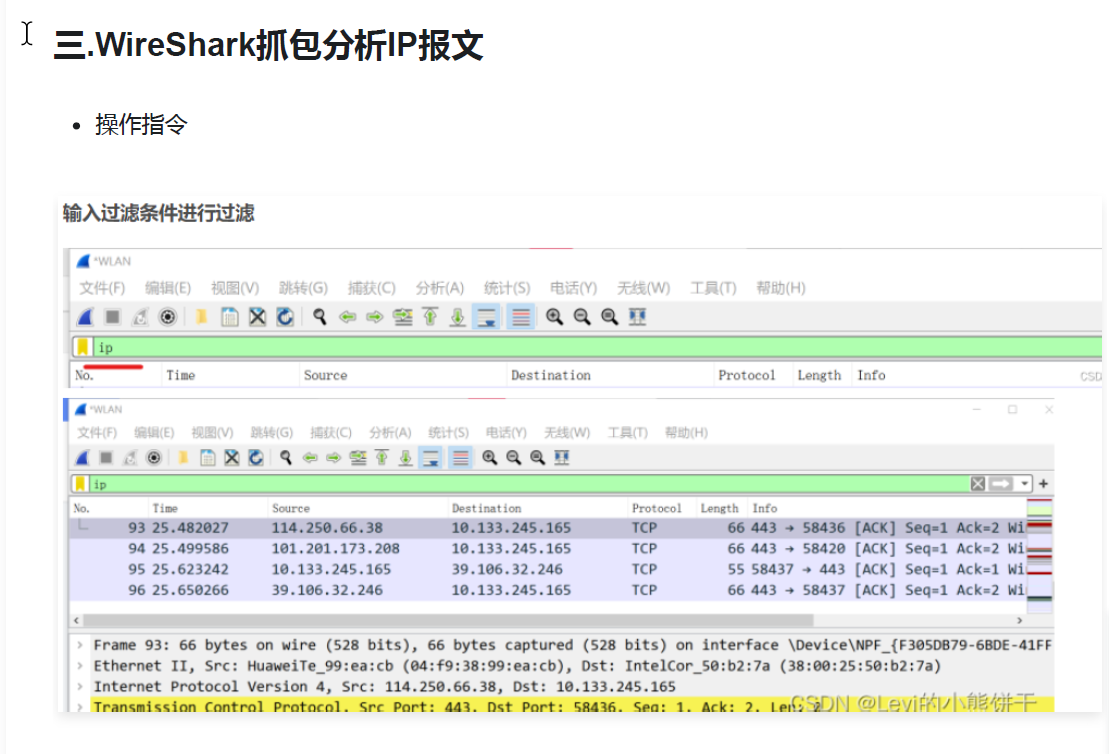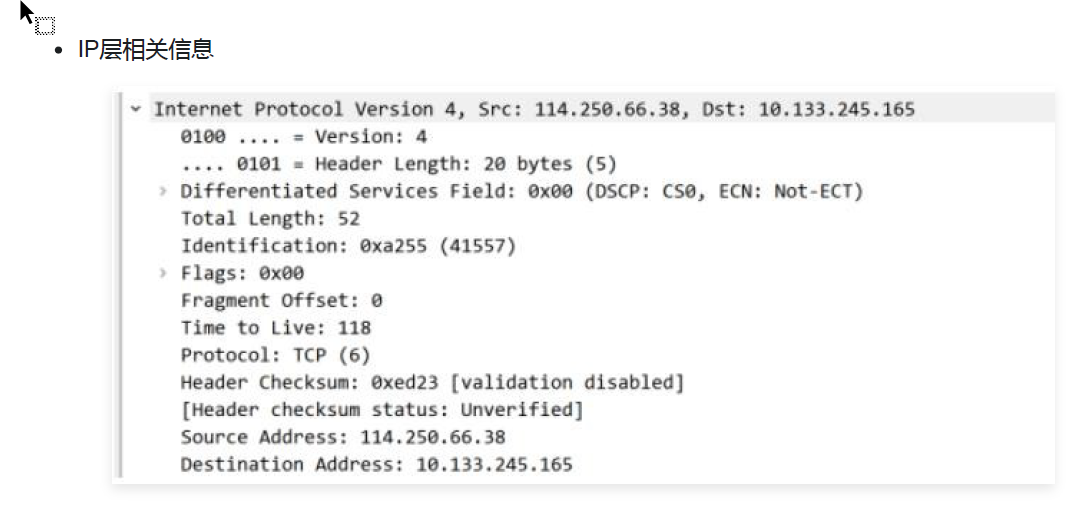


我用最通俗的方式,把这个图"拆碎了讲",帮你彻底搞懂"一行一行到底是什么""为什么要这么画"。
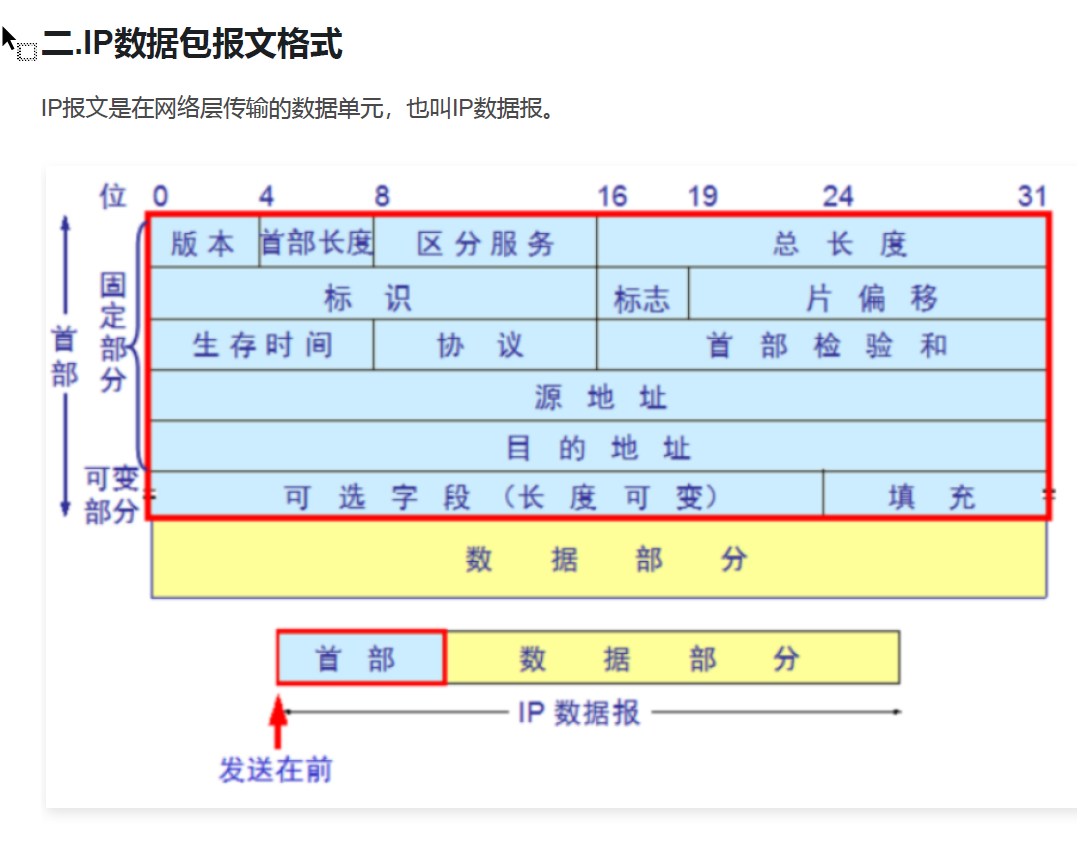
一、先搞懂:图里的"行",到底是什么?
一句话:图里的每一行,代表 32 个比特(也就是 4 个字节)的二进制数据。
你可以把IP报文想象成一串连续的0和1(比如 0100010100000000...),电脑/网络设备处理这串数据的时候,是按32个比特(4字节)为一组来读的,这就是图里的"行"。
最上面标了 0、4、8、16、19、24、31,这些是比特的序号,从0到31,一共32个比特,刚好凑成一行。
举个例子,第一行的32个比特,被分成了4个部分:
- 第0-3位(4个比特):版本号
- 第4-7位(4个比特):首部长度
- 第8-15位(8个比特):区分服务
- 第16-31位(16个比特):总长度
就像一张32格的表格,协议规定了"哪几格用来存什么数据",设备读的时候,直接按这个规则取数据就行。
二、用"快递单"比喻,秒懂这个结构
把IP报文当成一个快递包裹:
- 整个包裹 = IP数据报
- 包裹里的货物 = 数据部分(黄色部分)
- 包裹外面的快递单 = 首部(红色部分)
而这个图,就是快递单的标准模板:
- 快递单的每一行,都印好了"格子",规定了哪些格子写什么信息
- 比如第一行:前4格写"版本号"(相当于"快递单版本"),接下来4格写"快递单长度",再接下来8格写"服务类型"(比如加急/普通件),最后16格写"整个包裹的总重量"
- 快递员/快递系统,看到这张标准模板,就知道该从哪几格取信息,不会乱读
三、逐行拆解:每一行的32比特里,都装了什么?
我把图里的每一行,按"32比特的组成"拆给你看,你就知道为什么要这样分了:
第1行(32比特)
| 比特位置 | 字段名 | 长度 | 作用 |
|---|---|---|---|
| 0-3 | 版本 | 4位 | 标识是IPv4还是IPv6 |
| 4-7 | 首部长度 | 4位 | 说明快递单(首部)占多少 |
| 8-15 | 区分服务 | 8位 | 标记优先级(加急/普通) |
| 16-31 | 总长度 | 16位 | 整个包裹(IP包)的大小 |
→ 这一行凑起来刚好32位,都是"包裹的基础信息",设备读第一行,就知道"这是个什么版本的包、有多大、服务优先级"。
第2行(32比特)
| 比特位置 | 字段名 | 长度 | 作用 |
|---|---|---|---|
| 0-15 | 标识 | 16位 | 给包一个唯一编号 |
| 16-18 | 标志 | 3位 | 控制包能不能分片 |
| 19-31 | 片偏移 | 13位 | 分片后,说明自己是第几片 |
→ 这一行也是32位,都是"分片重组相关的信息",如果包裹太大被拆成好几份,靠这些信息拼回去。
第3行(32比特)
| 比特位置 | 字段名 | 长度 | 作用 |
|---|---|---|---|
| 0-7 | 生存时间(TTL) | 8位 | 包最多能经过多少个路由器 |
| 8-15 | 协议 | 8位 | 里面装的是TCP还是UDP |
| 16-31 | 首部检验和 | 16位 | 校验快递单有没有被改坏 |
→ 这一行32位,是"转发和校验信息",路由器靠这些判断要不要转发、包有没有损坏。
第4行(32比特)
- 全部32位 = 源IP地址(发件人地址)
第5行(32比特)
- 全部32位 = 目的IP地址(收件人地址)
→ 这两行都是纯地址,刚好各占32位,是快递单上最重要的"收发件地址"。
第6行(32比特,可变部分)
- 前半部分:可选字段(长度可变,最多40字节)
- 后半部分:填充(如果前面的可选字段没凑够32位,用0补满)
→ 这一行是可选扩展,平时用得很少,主要是为了兼容未来的新功能。
四、为什么一定要按"32位一行"来设计?
这不是随便画的,是为了硬件和软件都能高效处理,核心原因有3个:
1. 硬件处理效率高
早期的CPU、路由器,处理数据的基本单位就是32位(4字节)。按32位对齐,设备可以直接"按行读取"数据,不用拆分,处理速度更快。
就像快递员拿快递,一次拿一摞(固定数量),比一个一个拿效率高多了。
2. 字段宽度是"按需分配",不浪费空间
每个字段需要的比特数,是根据它的用途定的:
- 版本号:只需要4位(0-15,足够表示IPv4/IPv6)
- 总长度:需要16位(最大能表示65535字节,满足IP包的最大长度)
- IP地址:需要32位(IPv4地址就是32位的)
把这些不同长度的字段,凑成32位一行,刚好不浪费空间,也不用额外的处理。
3. 标准化,所有设备都能看懂
IP协议是全球通用的,这个"按32位划分的格式"是固定的,所有路由器、电脑、手机,都按同一个规则解析IP包。就像所有快递都用统一的快递单模板,不管哪个快递公司都能看懂。
五、结合嵌入式开发,给你看代码里的对应关系
你在C语言里定义IP首部的结构体,和这个图是1:1对应的,用的就是"位域"来划分字段:
c
struct iphdr {
// 第1行(32位)
uint8_t version:4; // 0-3位:版本(4位)
uint8_t ihl:4; // 4-7位:首部长度(4位)
uint8_t tos; // 8-15位:区分服务(8位)
uint16_t tot_len; // 16-31位:总长度(16位)
// 第2行(32位)
uint16_t id; // 0-15位:标识(16位)
uint16_t frag_off; // 16-18位标志 + 19-31位片偏移(共16位)
// 第3行(32位)
uint8_t ttl; // 0-7位:TTL(8位)
uint8_t protocol; // 8-15位:协议(8位)
uint16_t check; // 16-31位:首部校验和(16位)
// 第4-5行(各32位)
uint32_t saddr; // 源IP(32位)
uint32_t daddr; // 目的IP(32位)
};你看,这个结构体的内存布局,和图里的"一行一行"完全对应,编译器会按32位对齐来存储,和IP协议的格式一模一样。
六、总结
- 图里的"行",不是逻辑上的"分层" ,而是物理上的32比特数据块,是设备处理IP包的基本单位。
- 每一行里,被划分成了多个不同长度的字段,每个字段负责一个特定的功能,凑起来刚好32位。
- 这种设计是为了高效、标准化,让所有设备都能快速、统一地解析IP包。
首部是24个字节吗?
❌ 不对哦,IP首部的最小长度是20字节,不是24字节,而且它的长度是可变的,范围在20~60字节之间。我结合你之前的"行"的概念,给你算清楚:
一、先算"行"对应的字节数
图里的每一行,是 32比特(bit) ,而 8比特 = 1字节,所以:
1行 = 32 ÷ 8 = 4字节
二、数清楚"固定部分"的行数
IP首部的固定部分(所有IP包都必须有的部分),对应图里的前5行:
| 行号 | 内容 | 字节数 |
|---|---|---|
| 第1行 | 版本+首部长度+区分服务+总长度 | 4字节 |
| 第2行 | 标识+标志+片偏移 | 4字节 |
| 第3行 | 生存时间+协议+首部检验和 | 4字节 |
| 第4行 | 源IP地址 | 4字节 |
| 第5行 | 目的IP地址 | 4字节 |
所以固定部分的总长度是:5行 × 4字节/行 = 20字节,这是IP首部的最小长度,也是我们平时上网的IP包最常见的情况。
三、"可变部分"不是固定的4字节
你图里的第6行"可选字段+填充",是可选的、长度可变的,不是固定占4字节:
- 可选字段是用来扩展特殊功能的(比如安全、调试选项),实际网络中几乎不用,所以大部分IP包的可变部分长度为0,也就是没有这部分。
- 如果用了可选字段,长度也必须是4字节的整数倍(不够的话用填充位补0),最多可以到40字节(因为整个首部最大60字节,
60-20=40)。
四、为什么会有"24字节"的误解?
你可能是把"固定部分+1行可变部分"算成了 6行 × 4字节 = 24字节,但这只是一种特殊情况(比如IP包带了4字节的可选字段),不是所有IP包的首部都是24字节。
五、补充:首部长度字段的作用
图里的"首部长度(IHL)"字段,就是用来告诉设备"这个IP包的首部到底有多长"的:
- 这个字段占4比特,单位是4字节。
- 最小值是
5(二进制0101) →5×4=20字节(只有固定部分,无可选字段,最常见)。 - 最大值是
15(二进制1111) →15×4=60字节(固定部分+40字节可选字段,极少用)。
举个嵌入式开发里的例子
在C语言里,IP首部的结构体定义是这样的:
c
struct iphdr {
uint8_t version:4; // 版本
uint8_t ihl:4; // 首部长度
uint8_t tos; // 区分服务
uint16_t tot_len; // 总长度
uint16_t id; // 标识
uint16_t frag_off; // 标志+片偏移
uint8_t ttl; // 生存时间
uint8_t protocol; // 协议
uint16_t check; // 首部检验和
uint32_t saddr; // 源IP
uint32_t daddr; // 目的IP
};可以算一下,这个结构体的大小是 20字节,正好对应固定部分的长度。可选字段是在这个结构体后面额外拼接的,不是固定包含的。
简单说:IP首部最小20字节,最大60字节,20字节是所有IP包都有的固定部分,24字节只是带了少量可选字段的特殊情况。