
二.tcp数据包报文结构
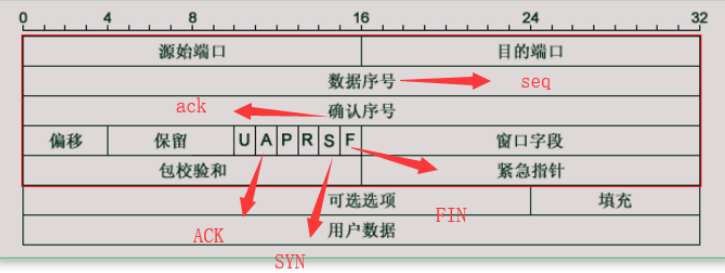



这张图展示的是 TCP报文段(TCP Segment)的首部格式 ,它和你之前看的IP首部设计逻辑完全一致,图里的每一行同样是 32比特(4字节),是设备处理TCP数据的基本单位。
一、和IP首部的核心共性(帮你快速理解)
| 特性 | IP首部 | TCP首部 |
|---|---|---|
| 行结构 | 每一行=32bit(4字节) | 每一行=32bit(4字节) |
| 固定部分 | 最小20字节(5行) | 最小20字节(5行) |
| 最大长度 | 最大60字节(15行) | 最大60字节(15行) |
| 长度标记 | 首部长度字段(单位4字节) | 数据偏移字段(单位4字节) |
TCP是传输层协议,IP是网络层协议,两者都用"按32bit对齐的行结构"来定义报文格式,方便硬件高效解析。
二、逐行拆解TCP首部的字段
我按图里的顺序,把每一行的32比特拆分,结合你标注的关键标志位解释:
第1行(32bit,4字节):端口寻址信息
| 比特位置 | 字段名 | 长度 | 核心作用 |
|---|---|---|---|
| 0-15 | 源端口号 | 16bit | 发送方进程的端口号(如浏览器的临时端口) |
| 16-31 | 目的端口号 | 16bit | 接收方进程的端口号(如服务器的80/443端口) |
- IP负责找到"设备",TCP负责找到设备上的"具体应用进程",端口号就是进程的标识。
第2行(32bit,4字节):数据序号(seq)
- 整个32bit = 序号(Sequence Number,seq)
- 作用:TCP是面向字节流的协议,seq标记了本报文段携带数据的第一个字节的编号。
- 三次握手的SYN包会携带初始seq,用来同步连接状态。
第3行(32bit,4字节):确认序号(ack)
- 整个32bit = 确认号(Acknowledgment Number,ack)
- 作用:表示期望收到对方下一个报文段的序号,同时确认了之前收到的所有数据。
- 规则:
ack = 收到的seq + 收到的数据长度 + 1(SYN/FIN包也要+1,因为它们消耗一个序号)。
第4行(32bit,4字节):控制与流量控制
| 比特位置 | 字段名 | 长度 | 核心作用 |
|---|---|---|---|
| 0-3 | 数据偏移(首部长度) | 4bit | 以4字节为单位,标记TCP首部长度。最小值5(20字节),最大值15(60字节) |
| 4-9 | 保留位 | 6bit | 保留给未来扩展,平时固定为0 |
| 10-15 | 控制标志位(U/ACK/P/R/S/F) | 6bit | TCP连接状态控制的核心 |
| 16-31 | 窗口大小 | 16bit | 接收方缓冲区剩余大小,用于流量控制 |
你图中标注的关键标志位:
- SYN(S) :同步位,发起连接(三次握手前两次会用到),
SYN=1表示请求建立连接。 - ACK(A) :确认位,
ack字段有效时必须为1,三次握手第二次开始ACK=1,后续所有报文都为1。 - FIN(F) :结束位,释放连接(四次挥手时使用),
FIN=1表示发送方无数据可发,请求关闭连接。 - 补充其他标志位:
- URG(U):紧急位,配合紧急指针使用,标记紧急数据
- PSH(P):推送位,接收方收到后立即交给应用层,不缓存
- RST(R):复位位,强制断开异常连接
第5行(32bit,4字节):校验与紧急数据
| 比特位置 | 字段名 | 长度 | 核心作用 |
|---|---|---|---|
| 0-15 | 校验和 | 16bit | 校验整个TCP报文段(首部+数据)的完整性,防止传输错误 |
| 16-31 | 紧急指针 | 16bit | URG=1时有效,指向紧急数据的末尾位置 |
第6-7行(可变部分,最多40字节):可选字段与填充
- 可选字段:扩展功能,比如最大报文段长度(MSS)、窗口扩大因子、时间戳等,三次握手的SYN包会携带MSS选项。
- 填充:若可选字段长度不是4字节的整数倍,用0补齐,确保首部按4字节对齐。
三、嵌入式C语言中的TCP首部结构体(和图1:1对应)
c
struct tcphdr {
// 第1行(32bit)
uint16_t source; // 源端口号
uint16_t dest; // 目的端口号
// 第2行(32bit)
uint32_t seq; // 序号(seq)
// 第3行(32bit)
uint32_t ack_seq; // 确认号(ack)
// 第4行(32bit)
uint16_t res1:4; // 保留位
uint16_t doff:4; // 数据偏移(首部长度)
uint16_t fin:1; // FIN标志
uint16_t syn:1; // SYN标志
uint16_t rst:1; // RST标志
uint16_t psh:1; // PSH标志
uint16_t ack:1; // ACK标志
uint16_t urg:1; // URG标志
uint16_t res2:2; // 保留位
uint16_t window; // 窗口大小
// 第5行(32bit)
uint16_t check; // 校验和
uint16_t urg_ptr; // 紧急指针
};这个结构体的固定部分为20字节,和图中前5行完全对应,编译器会按32bit对齐存储,和TCP协议格式完全匹配。
四、核心字段在三次握手/四次挥手中的作用
- SYN :三次握手第一次(客户端发
SYN=1,请求连接)、第二次(服务器回SYN=1+ACK=1,同意连接) - ACK :三次握手第二次、第三次及后续所有报文,
ACK=1,确认收到对方的包 - FIN :四次挥手时,客户端/服务器发
FIN=1,表示无数据可发,请求关闭连接 - seq/ack:同步初始序列号,保证数据按序、可靠传输,避免乱序和丢包
TCP 是面向字节流的协议,seq 标记了本报文段携带数据的第一个字节的编号---解释
我给你把这句话拆成大白话,用比喻+例子讲透,保证你看完就懂,而且能和你之前看的TCP报文格式对应上。
一、先把这句话"翻译成人话"
这句话可以拆成两个核心部分,我分别用最通俗的方式讲:
- "TCP 是面向字节流的协议" :TCP会把你要发的所有数据,当成一串连续的、编了号的"字节串",不管你实际发的时候,把它们打包成几个"小包裹"(TCP报文段),它只关心每个字节的顺序,不关心包裹怎么分。
- "seq 标记了本报文段携带数据的第一个字节的编号" :你发的每个"小包裹"(TCP报文段),里面装了一串字节,
seq字段就写了这个包裹里,第一个字节的编号是多少,相当于给这个包裹贴了个"起始编号标签"。
二、用"写信撕成几封寄"的比喻,秒懂核心逻辑
你可以把TCP传输想象成这个场景:
你要给朋友写一封1000字的信,怕丢,把每个字按顺序编了号:
1、2、3、4......1000,然后把信撕成了3份,分别装在3个信封里寄出去:
- 信封1:装了第1~300号字
- 信封2:装了第301~700号字
- 信封3:装了第701~1000号字
为了让朋友收到后能按顺序拼起来,你在每个信封上,都写了"我这个信封里,装的第一个字的编号":
- 信封1写:
起始编号:1- 信封2写:
起始编号:301- 信封3写:
起始编号:701
对应到TCP里:
- 信里的每个字 → 一个字节(TCP的最小处理单位)
- 给每个字编的号 → TCP的字节流编号(从初始序列号开始,连续递增)
- 撕成的3个信封 → 3个TCP报文段(你图里的TCP包)
- 信封上写的"起始编号" → 就是TCP的
seq字段!
三、举个带数字的完整例子,彻底搞懂seq
假设你要给对方发8个字节的数据(比如字符串"hello!!",每个字符占1字节,共8个字节),TCP会给这8个字节编上连续的编号。
为了好理解,我们假设TCP的初始序列号是1000(实际是随机的,不影响理解),那么:
| 字节内容 | h |
e |
l |
l |
o |
! |
! |
! |
|---|---|---|---|---|---|---|---|---|
| 字节编号 | 1000 | 1001 | 1002 | 1003 | 1004 | 1005 | 1006 | 1007 |
现在,你有三种打包方式,seq的取值完全不同:
情况1:8个字节一次发完(1个TCP包)
这个包里装了1000~1007号的所有字节,所以:
seq = 1000(这个包携带的第一个字节的编号是1000)- 数据长度 = 8(所以这个包覆盖的字节编号是
1000~1007)
情况2:分成两个包发(前3个+后5个)
- 第1个包:装
1000、1001、1002号字节 →seq = 1000,数据长度=3 - 第2个包:装
1003、1004、1005、1006、1007号字节 →seq = 1003,数据长度=5
情况3:分成三个包发(2个+3个+3个)
- 第1个包:装
1000、1001→seq = 1000,数据长度=2 - 第2个包:装
1002、1003、1004→seq = 1002,数据长度=3 - 第3个包:装
1005、1006、1007→seq = 1005,数据长度=3
你看,不管怎么打包,seq永远等于这个包里第一个字节的编号,和包的顺序、数量无关,只和包里装的第一个字节有关。
四、为什么要这么设计?解决3个核心问题
网络是不可靠的,包可能乱序、丢包、重复,TCP靠这个"字节编号+seq标签"解决所有问题:
-
解决乱序问题:保证数据按顺序拼起来
比如情况2里,第二个包(seq=1003)先到了,接收方看到
seq=1003,就知道"我还没收到1000、1001、1002号的字节",所以先把这个包的数据缓存起来,等seq=1000的包到了,再按1000→1001→1002→1003...的顺序拼好交给应用层。 -
解决丢包问题:精准重传,不浪费带宽
如果seq=1000的包丢了,接收方只收到了seq=1003的包,就会给你回一个
ACK=1000的包,意思是:"我已经收到了所有编号小于1000的字节,下一个我想要1000号的字节"。你收到ACK=1000,就知道seq=1000的包丢了,只需要重传这一个包,不用重传所有数据。 -
解决重复问题:避免数据重复
如果网络里重复发了两次seq=1000的包,接收方收到第二个的时候,看到1000、1001、1002号字节已经收过了,直接丢弃重复的包,不会把数据重复交给应用层。
五、和你之前看的TCP报文图,怎么对应上?
你图里的TCP首部,有几个关键部分,现在可以串起来了:
- 第二行的
seq字段 :就是我们说的"起始编号标签",存的就是这个包的第一个字节的编号(比如1000、1003),占32位,对应图里标红的seq。 - 第三行的
ack字段 :和seq是一对,意思是"我已经收到了所有编号小于ack的字节,下一个我想要ack号的字节"。比如收到seq=1000、长度3的包,就会回ack=1000+3=1003。 - SYN/FIN标志位 :这两个标志位会"消耗一个字节编号",哪怕它们不带数据:
- 三次握手的SYN包:不带数据,但SYN=1,所以会占用一个编号,比如seq=1000,对方回复的ack就是1000+1=1001。
- 四次挥手的FIN包:同理,不带数据但FIN=1,也会占用一个编号,ack也要+1。
六、最后用Wireshark抓包的例子,给你看真实场景
你抓一个TCP包,会看到这些字段:
Sequence number: 1000→ 就是我们说的seq,这个包的第一个字节编号是1000Length: 8→ 这个包带了8个字节的数据Next sequence number: 1008→ 这个包覆盖的字节编号是1000~1007,下一个包的seq应该是1008Acknowledgment number: 2001→ 对方回复的ack,意思是"我已经收到了2000之前的所有字节,下一个想要2001号的"
你看,完全和我们讲的逻辑一致,Wireshark里的这些字段,就是TCP"面向字节流+seq标记起始编号"的直接体现。
简单总结一下:
- TCP把所有数据当成一串编了号的字节流,每个字节都有唯一的编号。
- 每个TCP包的seq,就是这个包里第一个字节的编号,相当于给包贴了个"起始位置标签"。
- 靠这个标签,TCP解决了乱序、丢包、重复的问题,实现了可靠传输。
表示期望收到对方下一个报文段的序号,同时确认了之前收到的所有数据。 ------解释
结合上一轮字节编号、写信打包 的例子,我用角色拆分+数字实例+生活化类比,把这句话拆解得明明白白,全程不用复杂术语。
先定好固定角色,全程不变:
- A = 发送方(发TCP数据)
- B = 接收方(收数据、回复 ACK)
- 规则前置(核心公式,记这一条就够):
A C K = 已经完整收到的最后一个字节编号 + 1 \boldsymbol{ACK = 已经完整收到的最后一个字节编号 + 1} ACK=已经完整收到的最后一个字节编号+1
一、先翻译整句话(人话版)
原句:
(ACK字段)表示期望收到对方下一个报文段的序号,同时确认了之前收到的所有数据。
拆解成两层意思:
- 后半句:确认了之前收到的所有数据
我(接收方B)告诉你:所有编号比这个ACK数字小的字节,我全都安全收到了,不用重发。 - 前半句:期望收到对方下一个报文段的序号
我(接收方B)告诉你:你下一次发数据时,第一个字节请从「这个ACK数字」开始发。
二、沿用之前的字节编号例子,一步步演示
还是这套数据:
A要发8个字节,字节编号依次:1000、1001、1002、1003、1004、1005、1006、1007
场景1:一次性发完全部8字节
-
A 发出一个TCP包:
- 这个包第一个字节编号是 1000 → 所以包内
seq = 1000 - 包里一共 8 个字节(1000 ~ 1007)
- 这个包第一个字节编号是 1000 → 所以包内
-
B 完整收到这8个字节,开始计算ACK:
收到的最后一个字节编号 = 1007
A C K = 1007 + 1 = 1008 \boldsymbol{ACK = 1007 + 1 = 1008} ACK=1007+1=1008
-
B 回复 A 一个报文,里面写着
ACK = 1008对应原句解读:
- ✅ 确认旧数据:
ACK=1008→ 编号 1000~1007 的所有字节,我全部收到了 - ✅ 期待新数据:
ACK=1008→ 你下次再发数据,第一个字节从 1008 开始就行
- ✅ 确认旧数据:
场景2:分两次发包(最贴近真实网络)
网络不会永远一次性传完,大多是分批发送,我们模拟这个过程:
第一步:A 先发第1个包
- 内容:3个字节
1000、1001、1002 - 包内
seq = 1000(第一个字节编号)
第二步:B 收到这3个字节,回复 ACK
最后收到的字节 = 1002
A C K = 1002 + 1 = 1003 \boldsymbol{ACK = 1002 + 1 = 1003} ACK=1002+1=1003
B 发回 ACK=1003,含义:
- 确认:
1000、1001、1002全部收到; - 期待:下一次发数据,第一个字节我要 1003。
第三步:A 收到ACK,继续发第2个包
A 知道对方在等 1003,于是第二个包:
- 内容:剩余5个字节
1003 ~ 1007 - 包内
seq = 1003(和对方期待的编号一致)
第四步:B 再次回复ACK
最后收到的字节 = 1007
A C K = 1007 + 1 = 1008 \boldsymbol{ACK = 1007 + 1 = 1008} ACK=1007+1=1008
含义和场景1一致:前面所有字节收完,等待 1008 号字节。
场景3:模拟「丢包」(理解ACK的核心作用)
网络丢包是常态,看ACK怎么提醒对方重传:
- A 发了
seq=1000的包(1000~1002),这个包在路上丢了; - B 一直没收到任何数据,目前一个字节都没拿到;
- B 此时等待的第一个字节还是
1000,所以持续回复: A C K = 1000 \boldsymbol{ACK=1000} ACK=1000。
解读:
- 确认:没有收到任何数据(小于1000的字节不存在);
- 期待:我现在就要 1000 号字节。
A 反复收到 ACK=1000,就明白:上一个包丢了,立刻重传 seq=1000 的数据包。
三、结合TCP特殊标记:SYN/FIN(无数据但也要算编号)
之前讲过 SYN(建连接)、FIN(断连接),这类包不带业务数据,但TCP规定:
SYN、FIN 标志本身会占用1个字节编号,计算ACK规则不变。
举个三次握手里的SYN包例子:
- A 发起连接,发
SYN=1的包,seq=1000(无数据,仅建连接); - B 收到这个SYN请求;
- 计算ACK:占用了编号1000 → A C K = 1000 + 1 = 1001 \boldsymbol{ACK = 1000 + 1 = 1001} ACK=1000+1=1001。
含义:
- 确认:我收到了你
seq=1000的连接请求; - 期待:接下来我等待编号 1001 的内容。
四、生活化类比(和之前「写信」统一,加深记忆)
把字节 = 信里的每一个字,编号 = 字的页码:
- 你(A)写了一封信,字编号:1000、1001 ... 1007;
- 你把信分成两叠寄出,第一叠是 1000~1002;
- 我(B)收到第一叠,给你回一张纸条:"前面的字我都收到了,下一页请从 1003 开始寄"。
这张纸条上的数字 1003,就是 TCP 的 ACK:
- "前面的字都收到了" = 确认过往所有数据;
- "下一页从1003开始" = 期待下一个起始序号。
五、分清 seq 和 ack,再也不混淆
| 字段 | 是谁发的 | 作用一句话总结 |
|---|---|---|
| seq | 发送方(A) | 我往外发的包,第一个字节的编号 |
| ack | 接收方(B) | 我收到后回复:前面全收完了,下一个我要几号 |
六、极简总结(背诵版)
- 固定公式: A C K = 最后收到的字节编号 + 1 \boldsymbol{ACK = 最后收到的字节编号 + 1} ACK=最后收到的字节编号+1
- ACK 两层含义:
- 小于 ACK 的所有字节 → 全部签收;
- 下一次接收,从 ACK 这个编号 开始。

用**「快递包裹」的比喻**,把这几行拆解得明明白白,
先统一一下「整体类比」
把一个TCP报文当成一个快递包裹:
- 前面的
seq/ack字段:是包裹上的「货物编号+回执单」,用来确认数据顺序、不丢不重 - 截图里的这几行:是包裹上的「控制指令+校验防拆+附加备注」,还有包裹里的「货物本身」
第1行(截图最上方:偏移+保留+UAPRSF标志+窗口字段)
这一行是TCP的**「控制中枢」**,相当于快递单上的「备注+控制指令+收件人剩余容量」,核心是6个标志位和窗口字段:
1. 偏移(数据偏移)
- 人话翻译:告诉设备「TCP首部到哪里结束,数据从哪里开始」
- 作用:TCP首部长度可变(20~60字节),这个字段(单位4字节)标记了首部的结束位置。比如值为
5,就是5×4=20字节,说明到这里首部就结束了,后面是用户数据。 - 例子:就像快递单上标着「单据结束位置,后面是货物」,避免把单据当成货物读。
2. 保留位
- 人话翻译 :留着未来扩展用的空白格子,现在全是
0 - 作用:给以后的TCP版本留扩展空间,平时不用,相当于快递单上的空白栏,暂时不写东西。
3. U/ACK/P/R/S/F 控制标志位(你标注的ACK/SYN/FIN都在这里)
这6个1bit的标志,就是TCP的**「指令按钮」**,每个按钮对应一个动作,大白话解释:
| 标志 | 缩写 | 人话翻译 | 作用&例子 |
|---|---|---|---|
| URG | U | 紧急标记 | 包裹里有「急件」,要跳过缓存,优先处理(比如远程登录的Ctrl+C中断信号) |
| ACK | A | 确认回执 | 「我收到了你的包,回执给你」,三次握手第二次开始,ACK=1,后续所有报文都必须带ACK |
| PSH | P | 直接推送 | 「别缓存了,立刻把数据交给应用层」(比如聊天消息,要对方立刻收到,不要等缓存满) |
| RST | R | 强制重置 | 「连接出问题了,直接断开」(比如你访问对方没开的端口,对方会回RST包拒绝连接) |
| SYN | S | 建连接请求 | 「我要和你建连接,同步初始编号」,三次握手前两次会用到,只有SYN=1的包才是连接请求 |
| FIN | F | 关闭连接请求 | 「我没数据要发了,准备关连接吧」,四次挥手时用,发FIN=1告诉对方要结束通信 |
- 补充:这些标志可以同时设置,比如三次握手第二次的包,就是
SYN=1+ACK=1,代表「我同意你的连接请求,同时确认收到了你的SYN包」。
4. 窗口字段(窗口大小)
- 人话翻译:「我还能收多少数据,你别发太快」
- 作用:TCP的流量控制,告诉发送方「我的接收缓冲区还剩多少空间」,比如窗口大小=1000,就是「你最多再给我发1000字节,我处理完再告诉你新的大小」,避免对方发太快,我接不住丢包。
- 例子:就像快递站告诉你「我现在最多能收10件货,别再发了,我清完库存再说」。
第2行(包校验和 + 紧急指针)
这一行是TCP的**「防拆封+急件定位」**,相当于快递的「防篡改校验码+急件位置标记」:
1. 包校验和(校验和)
- 人话翻译:「整个包裹(单据+货物)有没有被篡改、有没有在运输中损坏」
- 作用:TCP会计算「首部+数据」的校验和,发给对方;对方收到后再算一遍,如果不一样,说明数据坏了,直接丢包,要求重发,避免收到错误的数据。
- 例子:就像快递的防拆封贴纸,撕过了就说明包裹被动过,不能收。
2. 紧急指针
- 人话翻译:「急件在包裹里的位置,到哪里结束」
- 作用:只有
URG=1时才有效,标记紧急数据的结束位置,让应用层先处理这部分急件(比如远程登录的中断信号,要立刻终止程序,不能等普通数据处理完)。 - 例子:就像快递单上标着「包裹里第10个物品是急件,优先拿出来处理」。
第3行(可选选项 + 填充)
这一行是TCP的**「附加备注栏」**,可选的,不是必须的:
1. 可选选项
- 人话翻译:「我还有一些额外的需求/参数要和你协商」
- 作用:扩展TCP功能,比如三次握手时协商:
- MSS(最大分段大小):「我最多一次收1460字节的数据,别发太大」
- 窗口扩大因子:「我缓冲区很大,你别限制我发数据的速度」
- 时间戳:「我发的包带了时间戳,方便你计算延迟」
- 例子:就像快递单上的附加备注「易碎品,轻拿轻放」,不是必须的,但能优化服务。
2. 填充
- 人话翻译:把可选选项的长度补成4字节的整数倍
- 作用:TCP首部必须按4字节对齐,不然设备处理的时候会乱读,所以如果可选选项长度不够,就用
0补满,相当于快递单的格子必须对齐,不然机器读的时候会出错。
第4行(用户数据)
这就是TCP要传输的**「实际货物本身」**,前面所有的首部(seq/ack、标志位、校验和),都是为了把这部分数据可靠地传给对方:
- 比如你发的HTTP请求、聊天消息、文件内容,都存在这里。
- 就像包裹里的东西,前面的单据、校验码、备注,全都是为了把这部分东西安全送到对方手里。
一句话总结这几行的核心作用
| 行号 | 核心作用 |
|---|---|
| 第1行 | 控制连接状态、控制发送速度、标记数据起始位置 |
| 第2行 | 防数据损坏、处理紧急数据 |
| 第3行 | 协商扩展功能、保证格式对齐 |
| 第4行 | 传输真正要发的数据 |