大模型的剪枝是什么?怎么理解?------从原理到实战,一篇讲透
作者 :Weisian
发布时间:2026年4月

直击痛点:
"面试官:'大模型剪枝是什么?'你:'就是删掉不重要的参数......'面试官:'那结构化剪枝和非结构化剪枝有什么区别?怎么判断哪些参数不重要?'你:'呃......这个......'------这就是剪枝理解不深的'死亡问答':看似简单的概念,却能暴露你对模型压缩底层原理的认知盲区。"
在大模型落地场景里,剪枝是轻量化三剑客(剪枝、量化、蒸馏)里最容易被误解的技术:
- 算法新手:以为剪枝=随便删参数,结果模型直接失效;
- 后端工程师:分不清结构化/非结构化剪枝,部署后GPU利用率不升反降;
- 算法工程师:不懂剪枝后微调策略,精度断崖式下跌;
- 面试者:背了概念却讲不清适用场景,卡在技术深度环节。
解决方案:从原理、分类、效果、代码实战到工程选型,用生活化类比+可运行Ollama代码,一次性讲透大模型剪枝全知识点。
📌 核心一句话 :
模型剪枝是一种"删繁就简"的技术,通过识别并移除神经网络中"不重要"的参数(权重、神经元、甚至整个层),在尽量不损失模型精度的前提下,大幅减小模型体积、加快推理速度。它不是"粗暴裁员",而是"精兵简政"。
📌 面试金句先记牢:
- 剪枝本质:神经网络中存在大量"冗余参数"(60%以上的连接权重接近0),剪掉它们模型照样工作;通过规则删除模型冗余参数,实现轻量化、提速、降显存,是大模型部署必备手段;
- 核心目标:更小体积、更快推理、更低显存,精度尽量无损;
- 结构化 vs 非结构化:结构化剪枝像"砍掉整个部门",硬件友好但压缩率有限;非结构化剪枝像"精确裁员到个人",压缩率高但需要专用硬件支持;
- 三大阶段:训练前剪枝、训练中剪枝、训练后剪枝(主流);
- 关键指标:稀疏率、精度保留率、推理加速比、显存降低率;
- 和量化区别:剪枝是"删参数",量化是"压缩参数精度",可叠加使用;
- 和蒸馏区别:剪枝是"精简自身",蒸馏是"向大模型学知识",常配合使用;
- 适用场景:端侧部署、低显存设备、高并发服务、嵌入式设备;
- 核心流程:训练→评估重要性→剪枝→微调恢复→(可选)迭代重复;
- 压缩效果:可减少30%-90%参数,推理加速2-4倍,精度损失控制在1%-3%;
- 工程原则:优先结构化剪枝,稀疏率控制在30%-50%,剪后必微调;
- 技术本质:大模型参数高度冗余,剪枝是去除冗余,保留核心表达能力。
一、剪枝到底是什么?
1.1 一句话概括
模型剪枝 = 给AI模型做"精准外科手术"
在不影响"智力水平"的前提下,精准删掉模型里没用、重复、冗余的参数,把模型里"不干活光吃饭"的冗余参数切除掉,让模型变得更轻、更快、更省资源。

1.2 通俗类比:图书馆精简藏书
- 完整大模型 = 一座超大图书馆,100万本书,但80%是重复、冷门、没人看的书;
- 模型参数 = 馆里的每一本书;
- 剪枝 = 图书管理员筛选,扔掉重复、无用、极少借阅的书;
- 剪枝后模型 = 保留核心好书,书架变少、占地更小、找书更快;
- 精度损失 = 扔掉了少量有用书,导致偶尔查不到资料。
为什么能剪?
大模型参数天然高度冗余,Transformer里大量神经元、注意力头几乎不参与决策,删掉完全不影响输出。
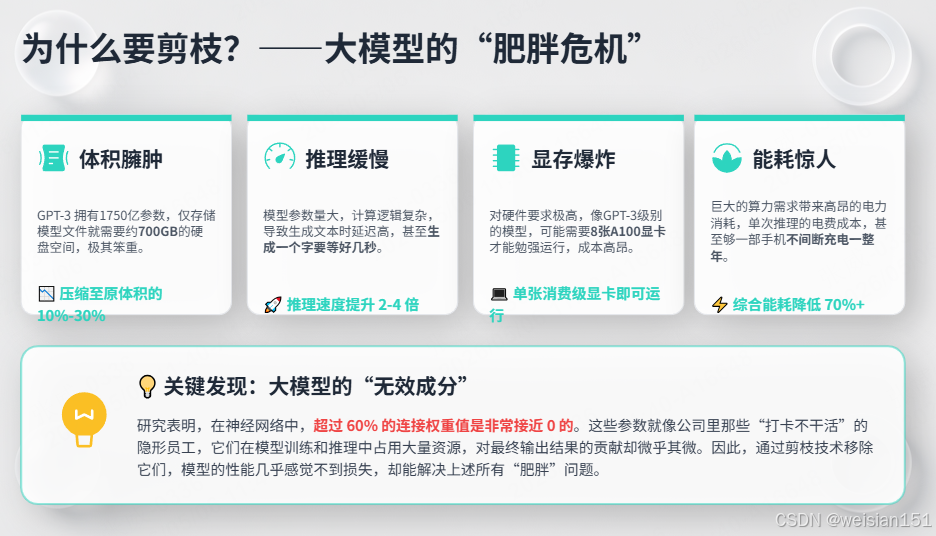
1.3 为什么要剪枝?------大模型的"肥胖危机"
| 痛点 | 大模型的问题 | 剪枝后的解决 |
|---|---|---|
| 体积臃肿 | GPT-3 175B参数,光存储就要700GB | 可压缩到原来的10%-30% |
| 推理缓慢 | 生成一个字要等好几秒 | 速度提升2-4倍 |
| 显存爆炸 | 8张A100才勉强跑起来 | 1张卡就够了 |
| 能耗惊人 | 一次推理的电费够手机充一年 | 能耗降低70%+ |
关键发现 :神经网络中60%以上的连接权重接近0------这些"趋近于0"的参数对模型输出的贡献微乎其微,就像公司里那些"打卡不干活"的员工。剪掉它们,模型几乎感觉不到变化。
1.4 剪枝的完整流程
原始大模型(7B/14B/72B)
↓
分析参数重要性(权重大小、梯度、激活值)
↓
按规则删除冗余参数(结构化/非结构化)
↓
剪枝后稀疏模型
↓
微调恢复精度(关键步骤)
↓
部署推理(更快、更省显存)
1.5 剪枝不是什么?(避坑必看)
- ❌ 不是随便乱删参数,删错会直接导致模型乱输出、不收敛;
- ❌ 不是越剪越好,稀疏率过高精度会雪崩;
- ❌ 不是只减体积,非结构化剪枝可能不提速甚至更慢;
- ❌ 不是替代量化,两者是互补关系,可同时使用。

二、为什么要剪枝?四大真实业务价值
2.1 降显存占用(最核心价值)
- 7B模型原始显存占用≈13GB;
- 剪枝50%后≈7GB;
- 配合4bit量化可压到3-4GB,普通消费级显卡直接跑。
2.2 推理加速
结构化剪枝可真正减少计算量,推理速度提升1.2x~2x,高并发场景延迟大幅降低。
2.3 端侧/嵌入式部署
手机、机器人、边缘设备显存有限,不剪枝根本跑不起来。
2.4 降低服务成本
云服务GPU按显存/算力收费,剪枝后可换更低配GPU,成本降30%-70%。

类比:汽车减重
- 完整模型 = 满载钢材、备用件的重型车,油耗高、跑得慢;
- 剪枝 = 拆掉非必要配重,保留核心结构;
- 结果:车更轻、加速更快、油耗更低。
三、剪枝的核心原理------怎么判断"谁不重要"?
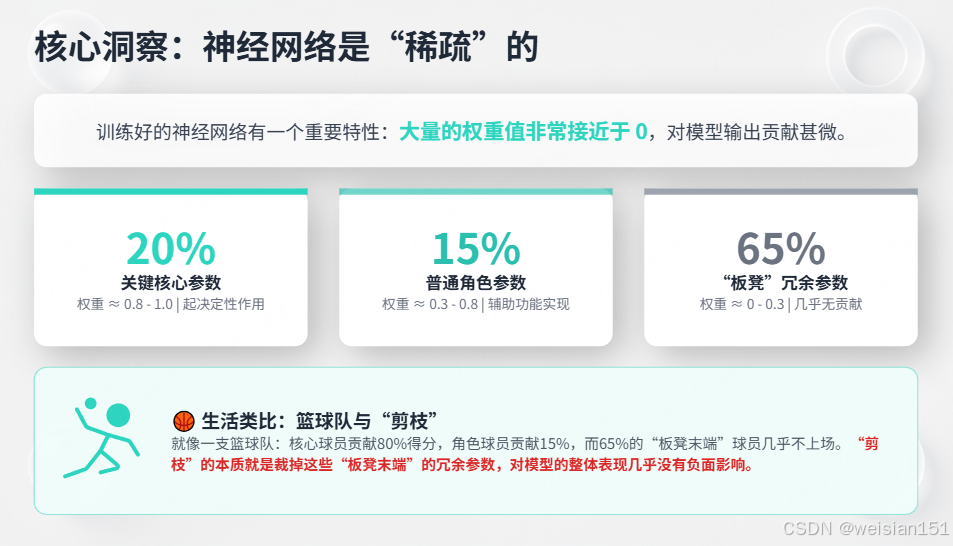
3.1 核心洞察:神经网络是"稀疏"的
训练好的神经网络有一个重要特性:大量的权重值非常接近于0。
训练完成后的权重分布:
┌────────────────────────────────────────┐
│ ████████████ 权重 ≈ 0.8-1.0 (重要) │ ← 20%的参数
│ ████ 权重 ≈ 0.3-0.8 (一般) │ ← 15%的参数
│ ░░░░░░░░░░░░ 权重 ≈ 0-0.3 (不重要) │ ← 65%的参数
└────────────────────────────────────────┘生活类比:
就像一支篮球队。核心球员(重要权重)贡献了80%的得分,角色球员(一般权重)贡献15%,板凳末端的球员(不重要权重)几乎不上场。剪枝就是把板凳末端裁掉,球队实力几乎不受影响。
3.2 重要性评估的三种主流方法
这是面试高频考点:怎么判断一个参数重不重要?
| 方法 | 原理 | 公式/做法 | 特点 |
|---|---|---|---|
| 基于幅度 | 权重绝对值越小越不重要 | 按|w|排序,剪掉最小的 | 简单高效,最常用 |
| 基于梯度 | 梯度小的参数对损失影响小 | 计算梯度×权重 | 更精准,计算量大 |
| 基于泰勒展开 | 移除参数对损失函数的理论影响 | 近似二阶导数 | 理论最优,实现复杂 |
简单理解:
- 幅度法:就像用"工资高低"判断员工价值------工资低的可能不重要(但也可能被低估)。
- 梯度法:就像用"工作变动对公司的影响"判断------换了谁公司最没感觉,谁就可替代。
- 泰勒法:就像用"精确数学模型"计算每个员工的"理论价值"------最精确但也最复杂。

3.3 剪枝的五步法
无论哪种剪枝方法,核心流程都是这五步:
Step 1: 训练原始模型(或使用预训练模型)
↓
Step 2: 评估重要性 → 给每个参数/神经元打分
↓
Step 3: 执行剪枝 → 移除低分参数
↓
Step 4: 微调恢复 → 用少量数据训练恢复精度
↓
Step 5: 迭代优化 → 重复2-4步,直到达到目标
python
# 伪代码:剪枝的核心流程
def prune_model(model, sparsity_ratio=0.3):
"""
sparsity_ratio: 要剪掉多少比例的参数(30%表示剪掉30%)
"""
# Step 1: 评估重要性(基于权重幅度)
importance_scores = {}
for name, param in model.named_parameters():
if 'weight' in name: # 只剪权重矩阵
importance_scores[name] = param.abs().flatten()
# Step 2: 计算全局阈值
all_scores = torch.cat([scores for scores in importance_scores.values()])
threshold = torch.quantile(all_scores, sparsity_ratio) # 第30%分位数
# Step 3: 执行剪枝(低于阈值的置为0)
for name, param in model.named_parameters():
if name in importance_scores:
mask = (param.abs() > threshold).float()
param.data = param.data * mask # 剪枝:置0
# Step 4: 微调恢复(用少量数据训练)
finetune(model, epochs=3, lr=1e-5)
return model四、剪枝的两大流派------结构化 vs 非结构化
这是面试最高频的考点:结构化剪枝和非结构化剪枝有什么区别?
4.1 核心对比
| 维度 | 结构化剪枝 | 非结构化剪枝 |
|---|---|---|
| 生活类比 | 砍掉整个"部门" | 精确"裁员"到个人 |
| 剪枝粒度 | 整个通道/层/注意力头 | 单个权重连接 |
| 硬件友好度 | ✅ 完美适配GPU/TPU | ❌ 需要专用稀疏硬件 |
| 压缩率 | 30%-70% | 70%-90% |
| 精度恢复 | 需要重新训练/微调 | 可通过稀疏存储优化 |
| 实际部署 | 直接可用 | 需要特殊库支持 |

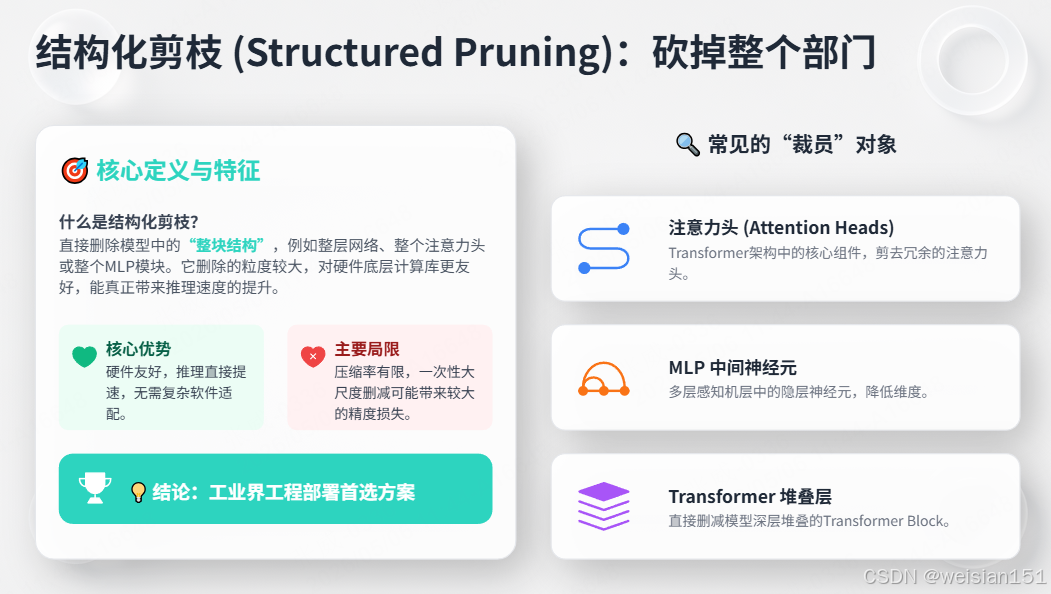
4.2 结构化剪枝(Structured Pruning):砍掉整个部门
定义 :删除整块结构,如整层、整个神经元、整个注意力头、整个MLP模块。
特点:
- 删除单位大,硬件友好,推理真正提速;
- 精度损失相对明显;
- 稀疏规则整齐,框架/显卡天然支持;
- 工程部署首选。
生活类比:
公司有5个部门,你发现"市场部"完全冗余,直接把这个部门整个撤掉。组织结构变清晰了,管理成本降低了。
优点:
- 硬件友好:移除后网络结构规整,GPU能高效并行计算
- 直接加速:不需要特殊库支持,推理速度明显提升
缺点:
- 压缩率有限:通常不超过70%,因为不能"砍太多部门"
- 精度损失可能更大:一次性移除整组参数
常见结构剪枝对象:
- 注意力头(Attention Head)
- MLP中间神经元
- Transformer层
- 词嵌入维度
- 注意力矩阵行/列
代码示例(PyTorch结构化剪枝):
python
import torch.nn.utils.prune as prune
def structured_pruning_example():
"""结构化剪枝:剪掉整个通道"""
import torch
import torch.nn as nn
# 假设有一个卷积层,输入16通道,输出32通道
conv = nn.Conv2d(16, 32, kernel_size=3)
# 结构化剪枝:剪掉30%的输出通道
# dim=0 表示在输出通道维度上剪枝
prune.ln_structured(
conv,
name="weight",
amount=0.3, # 剪掉30%
n=2, # L2范数
dim=0 # 按输出通道剪枝
)
# 移除剪枝掩码,永久生效
prune.remove(conv, 'weight')
print(f"剪枝后权重形状: {conv.weight.shape}")
# 输出: 剪枝后权重形状: torch.Size([22, 16, 3, 3])
# 原来32个输出通道 → 剩下约22个(32*0.7≈22)
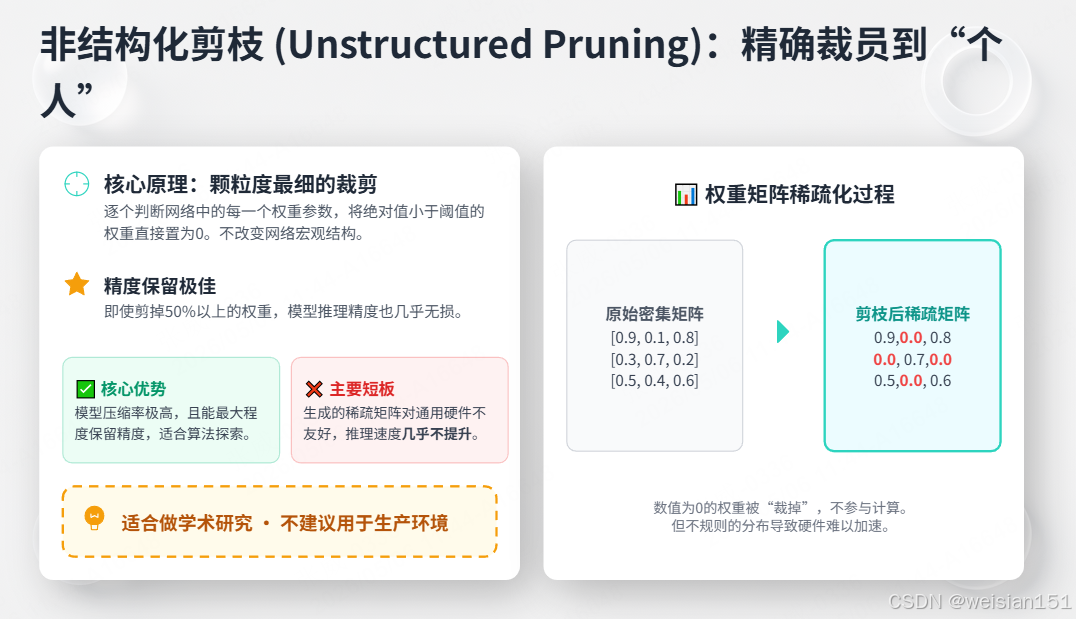
structured_pruning_example()4.3 非结构化剪枝(Unstructured Pruning):精确裁员到个人
原理:逐个权重判断,把绝对值小的权重直接置为0,不改变网络结构。
原始权重矩阵: 剪枝后(稀疏矩阵):
[0.9, 0.1, 0.8] [0.9, 0.0, 0.8]
[0.3, 0.7, 0.2] → [0.0, 0.7, 0.0]
[0.5, 0.4, 0.6] [0.5, 0.0, 0.6]
(约50%的权重变为0)特点:
- 精度保留极好,可剪50%+几乎无损;
- 硬件不友好,推理几乎不提速;
- 形成不规则稀疏矩阵,显卡无法优化;
- 适合研究,不适合生产。
生活类比:
公司有100名员工,你挨个评估每个人的绩效,把绩效最低的50人裁掉。公司组织结构不变,只是人少了。
优点:
- 压缩率极高:可达90%以上
- 精度保持好:可以精准保留重要权重
缺点:
- 硬件不友好:稀疏矩阵导致GPU内存访问不规则,反而可能更慢
- 需要专用硬件:NVIDIA的A100支持细粒度稀疏,但普通GPU不行
代码示例(PyTorch非结构化剪枝):
python
def unstructured_pruning_example():
"""非结构化剪枝:剪掉单个权重"""
import torch
import torch.nn as nn
import torch.nn.utils.prune as prune
# 创建一个简单的线性层
linear = nn.Linear(100, 100)
# 非结构化剪枝:剪掉30%的权重
# 基于L2范数判断重要性
prune.l1_unstructured(
linear,
name="weight",
amount=0.3 # 剪掉30%的权重
)
# 查看剪枝效果
print(f"原始权重非零数量: {linear.weight_orig.nelement()}")
print(f"剪枝后非零数量: {(linear.weight > 0).sum().item()}")
print(f"实际稀疏度: {1 - (linear.weight > 0).sum().item() / linear.weight.nelement():.1%}")
unstructured_pruning_example()4.4 如何选择?一张决策图
你的部署硬件是什么?
│
├── 普通GPU(RTX 3090/4090) → 结构化剪枝
│ (不规则稀疏反而会变慢)
│
├── 专用AI芯片(A100/H100) → 两种都可以
│ (支持细粒度稀疏加速)
│
└── CPU/手机端 → 结构化剪枝
(需要规整的计算图)
4.5 对比表(面试直接背)
| 类型 | 删除单位 | 精度 | 推理提速 | 硬件友好 | 生产可用 |
|---|---|---|---|---|---|
| 结构化剪枝 | 整头/整神经元/整层 | 一般 | 快 | ✅ | ✅ |
| 非结构化剪枝 | 单个参数 | 极好 | 几乎不提速 | ❌ | ❌ |
一句话总结 :
要部署用结构化,要精度用非结构化,生产环境只推荐结构化剪枝。
五、按阶段划分:三大剪枝时机

5.1 训练后剪枝(Post-Training Pruning,主流)
- 先训完整大模型;
- 再分析冗余参数并删除;
- 最后微调恢复精度;
- 简单、稳定、工程常用。
类比:先建好完整图书馆,运营一段时间再精简藏书。
5.2 训练中剪枝(Pruning During Training)
- 训练时逐步删除低贡献参数;
- 节省训练算力;
- 精度控制难度高。
5.3 训练前剪枝(Pre-Training Pruning)
- 初始化时直接删参数;
- 极少用,效果差。
六、怎么判断参数该不该删?四大重要性评估方法
剪枝不是瞎删,必须先算"重要性"。
6.1 权重大小法(最简单)
权重绝对值越小,越不重要,直接删。
重要性 = |权重值|6.2 梯度法
梯度越小,对loss影响越小,可删。
6.3 激活值法
神经元激活值长期接近0,说明几乎不工作,可删。
6.4 注意力熵法
注意力头熵越低,越聚焦,冗余度越高,可删。
类比 :
图书馆里常年没人借的书、借阅次数为0的书,直接清理。

七、剪枝会掉精度吗?怎么救?
7.1 一定会掉,但可控
- 稀疏率<30%:几乎无损
- 稀疏率30%~50%:轻微下降,可接受
- 稀疏率>70%:精度雪崩

7.2 三大恢复手段
- 剪后微调(必做)
- 知识蒸馏
- 结构化剪枝+量化组合
类比 :
减肥后会虚弱,通过"微调"补充营养,快速恢复状态。
八、工业界剪枝实践规范

8.1 稀疏率建议
- 对话模型:30%~40%
- 代码模型:20%~30%
- 垂类领域模型:40%~50%
8.2 必做步骤
- 优先结构化剪枝
- 剪后必须微调
- 配合量化使用
- 保留10%~20%冗余度
8.3 禁止行为
- 非结构化剪枝上生产
- 稀疏率超过60%
- 剪完不微调直接部署
九、剪枝 vs 其他压缩技术
很多人会把剪枝和蒸馏、量化搞混。这里用一个表格说清楚:
| 技术 | 原理 | 生活类比 | 压缩率 | 精度损失 | 适用场景 |
|---|---|---|---|---|---|
| 剪枝 | 删除不重要的参数 | 裁掉摸鱼员工 | 30%-90% | 1%-3% | 已有模型优化 |
| 蒸馏 | 大模型教小模型 | 学霸带学渣 | 60%-90% | 3%-10% | 重新训练新模型 |
| 量化 | 降低数值精度 | 高清→普清照片 | 75% | 0.5%-2% | 推理加速 |
组合使用 :实际生产中最优方案往往是 剪枝 + 量化 或 蒸馏 + 剪枝。
-
先剪枝再量化:剪枝减少参数量,量化减少每个参数的位数,双重瘦身
-
先蒸馏再剪枝:蒸馏得到小模型,剪枝进一步精简,极致压缩
原始大模型
↓
剪枝(瘦身)
↓
量化(压缩)
↓
蒸馏(补精度)
↓
极致轻量化模型
类比:
- 剪枝 = 减肥(减掉肥肉)
- 量化 = 穿紧身衣(压缩体积)
- 蒸馏 = 健身(增强能力)
数据支撑 :三者组合使用,最高可实现50倍压缩比。

十、剪枝的优缺点与适用场景
10.1 三大优势
| 优势 | 说明 | 数据支撑 |
|---|---|---|
| 体积缩小 | 参数量大幅减少,存储成本降低 | 可减少30%-90%参数 |
| 推理加速 | 计算量减少,响应更快 | 速度提升2-4倍 |
| 能耗降低 | 浮点运算减少,电费下降 | 能耗降低70%+ |

10.2 三大挑战(面试必问)
1. 精度损失风险
剪枝就像给模型做手术------切对了恢复很快,切错了可能"致残"。需要精细评估和充分微调来恢复精度。
2. 硬件适配问题
非结构化剪枝产生的不规则稀疏矩阵,在普通GPU上反而会变慢(因为内存访问不连续)。需要专用硬件(如NVIDIA A100的2:4稀疏模式)才能发挥加速效果。
3. 剪枝率与精度的trade-off
剪得越多模型越小,但精度损失也越大。实际应用中需要反复实验找到"甜点区"(通常30%-50%剪枝率是最佳平衡点)。

10.3 什么场景适合剪枝?
| 场景 | 是否适合 | 原因 |
|---|---|---|
| 云端推理 | ✅ 非常适合 | 降低算力成本,提升吞吐量 |
| 移动端App | ✅ 非常适合 | 模型体积小,用户下载意愿高 |
| 实时交互 | ✅ 非常适合 | 低延迟是关键要求 |
| 边缘设备 | ✅ 非常适合 | 资源受限,需要极致压缩 |
| 高精度要求(医疗/金融) | ⚠️ 谨慎使用 | 需充分验证精度恢复效果 |
| 已有稳定模型 | ✅ 非常适合 | 不需要重新训练,直接优化 |

十一、面试高频题详解
Q1:什么是模型剪枝?它的核心思想是什么?
参考答案 :
模型剪枝是一种模型压缩技术,核心思想是移除神经网络中不重要的参数。
核心发现:训练好的神经网络中,60%以上的权重值接近0------这些参数对模型输出贡献微小,剪掉它们模型依然能正常工作。
流程:训练 → 评估重要性 → 剪枝 → 微调恢复 → 迭代优化

Q2:结构化剪枝和非结构化剪枝有什么区别?
参考答案:
| 维度 | 结构化剪枝 | 非结构化剪枝 |
|---|---|---|
| 粒度 | 整个通道/层 | 单个权重 |
| 硬件适配 | 好(规整结构) | 差(需专用硬件) |
| 压缩率 | 30%-70% | 70%-90% |
| 精度恢复 | 需重新训练 | 可微调恢复 |
生活类比:结构化剪枝像"砍掉整个部门",非结构化剪枝像"精确裁员到个人"。

Q3:怎么判断哪些参数不重要?
参考答案 :
三种主流方法:
- 基于幅度:权重绝对值越小越不重要(最常用)
- 基于梯度:梯度小的参数对损失影响小(更精准)
- 基于泰勒展开:计算移除参数对损失的理论影响(最优但复杂)
工程实践:幅度法 + 少量微调,简单有效。

Q4:剪枝后精度下降了怎么办?
参考答案:
- 微调(Fine-tuning):用原始训练数据的1%-5%,训练1-5个epoch恢复精度
- 迭代剪枝:不要一次剪太多,每次剪一小部分,微调后再继续
- 重新训练:从零开始训练一个更小的网络(但成本高)
关键技巧:剪枝率控制在30%-50%,精度损失通常在1%以内,微调后几乎无损。

Q5:剪枝和蒸馏有什么区别?怎么选择?
参考答案:
| 维度 | 剪枝 | 蒸馏 |
|---|---|---|
| 原理 | 删掉不重要的参数 | 大模型教小模型 |
| 模型来源 | 从原模型优化 | 重新训练新模型 |
| 结构变化 | 保留原骨架 | 全新结构 |
| 适用场景 | 已有模型优化 | 重新设计轻量模型 |
选择建议:
- 已有训练好的大模型想加速 → 剪枝
- 想从零设计一个轻量模型 → 蒸馏
- 追求极致压缩 → 两者结合(先蒸馏再剪枝)

Q6:剪枝在实际生产中的应用效果如何?
参考答案:
- DeepSeek结构化剪枝:实现30%-70%压缩率,硬件友好
- 学术SOTA:TRIM方法在80%稀疏度下将Qwen2.5-14B的困惑度降低48%
- 工业实践:证券公司对行情分类模型剪枝,压缩70%参数,推理速度提升60%

Q7:剪枝会影响模型的公平性/偏见吗?
参考答案 :
最新研究(EMNLP 2025)表明:剪枝方法对公平性的影响大于校准数据集的选择。不当剪枝可能放大模型偏见,需要:
- 在剪枝过程中加入公平性约束
- 剪枝后用公平性指标评估
- 对敏感任务谨慎使用高剪枝率

总结
核心知识点速记
剪枝就是做减法,删掉冗余不重要的。
神经网络真奇妙,六成参数贡献小。
幅度梯度泰勒法,评估重要性有高招。
结构化砍整层,硬件友好加速好。
非结构化剪得细,压缩率高硬件挑。
训练评估剪枝微调,迭代优化效果好。
三十五十压缩率,精度损失微乎微。
剪枝蒸馏和量化,三剑合璧威力大。
话术速查表
| 问题类型 | 回答时间 | 核心要点 |
|---|---|---|
| 什么是剪枝 | 10秒 | 移除不重要参数,让模型变轻变快 |
| 为什么能剪枝 | 20秒 | 60%参数接近0,剪掉不影响输出 |
| 结构化 vs 非结构化 | 30秒 | 结构化砍整层(硬件友好),非结构化剪单个(压缩率高) |
| 怎么判断重要性 | 20秒 | 幅度法最常用(|w|小的不重要) |
| 精度下降怎么办 | 20秒 | 微调恢复,1%-5%数据训练几个epoch |
| 剪枝 vs 蒸馏 | 20秒 | 剪枝优化原模型,蒸馏重新训练小模型 |
| 适用场景 | 20秒 | 云端/移动端/边缘设备,追求低延迟低成本 |
写在最后
模型剪枝看似只是"删参数",但它的本质是AI模型的精益化转型------从"大就是好"的粗放模式,走向"够用就好"的精准路线:
- 云端大模型剪枝后,推理成本从"天价"降到"白菜价";
- 手机端剪枝模型,让AI能力从"云端特权"变成"人人可用";
- 边缘设备上的剪枝模型,让智能走进工厂、农田、社区。
面试官问剪枝,不是在考"定义",而是在考察你对模型压缩、工程落地、性能优化的综合理解。能讲清楚剪枝的人,模型部署、成本控制、硬件适配都不会差。
如果觉得有帮助,欢迎点赞、收藏、转发!有问题欢迎在评论区留言交流。