
🔥个人主页:爱和冰阔乐
🐶学习方向:C++方向学习爱好者
⭐人生格言:得知坦然 ,失之淡然

🏠博主简介

文章目录
- 前言
- [一、Codex 不只是"代码生成器"](#一、Codex 不只是“代码生成器”)
-
- [1.1 我们平时是怎么让 AI 写代码的?](#1.1 我们平时是怎么让 AI 写代码的?)
- [1.2 Codex 接到任务后到底在做什么?](#1.2 Codex 接到任务后到底在做什么?)
- 二、先把一句模糊需求说清楚
-
- [2.1 示例 Bug:登录失败永远只显示一句话](#2.1 示例 Bug:登录失败永远只显示一句话)
- [2.2 一个任务最好包含四部分](#2.2 一个任务最好包含四部分)
- [2.3 改写后的完整提示词](#2.3 改写后的完整提示词)
- [三、别急着改代码,先让 Codex 把仓库读明白](#三、别急着改代码,先让 Codex 把仓库读明白)
-
- [3.1 为什么第一步不是打开 LoginPage?](#3.1 为什么第一步不是打开 LoginPage?)
- [3.2 先调查,不修改](#3.2 先调查,不修改)
- [3.3 Codex 搜索仓库后的结果](#3.3 Codex 搜索仓库后的结果)
- [3.4 让 Codex 先输出调查结论](#3.4 让 Codex 先输出调查结论)
- [四、复杂任务先 Plan,防止改着改着跑偏](#四、复杂任务先 Plan,防止改着改着跑偏)
-
- [4.1 Plan 模式到底有什么用?](#4.1 Plan 模式到底有什么用?)
- [4.2 针对本例的计划](#4.2 针对本例的计划)
- [4.3 什么情况下应该打回计划?](#4.3 什么情况下应该打回计划?)
- 五、开始修改:先保留错误码
-
- [5.1 修改前的 ApiError](#5.1 修改前的 ApiError)
- [5.2 修改 ApiError](#5.2 修改 ApiError)
- [六、增加错误码映射,不直接展示服务端 message](#六、增加错误码映射,不直接展示服务端 message)
-
- [6.1 为什么不能把服务端 message 原样显示?](#6.1 为什么不能把服务端 message 原样显示?)
- [6.2 新增映射文件](#6.2 新增映射文件)
- [6.3 修改 useAuth](#6.3 修改 useAuth)
- 七、补测试:不要只测三个"正确答案"
-
- [7.1 表驱动测试](#7.1 表驱动测试)
- [7.2 登录成功流程也要保护](#7.2 登录成功流程也要保护)
- [7.3 运行测试](#7.3 运行测试)
- [7.4 如果全量测试失败,先别急着认定是自己改坏了](#7.4 如果全量测试失败,先别急着认定是自己改坏了)
- 八、Review:代码写完后的第二次思考
-
- [8.1 先看改了多少文件](#8.1 先看改了多少文件)
- [8.2 Review 时我一般看什么?](#8.2 Review 时我一般看什么?)
-
- [1. 是否改了计划外文件?](#1. 是否改了计划外文件?)
- [2. 是否直接展示服务端内部错误?](#2. 是否直接展示服务端内部错误?)
- [3. 是否存在兜底?](#3. 是否存在兜底?)
- [4. 测试是否真的断言了行为?](#4. 测试是否真的断言了行为?)
- [5. 是否影响成功流程?](#5. 是否影响成功流程?)
- [8.3 用行内评论让 Codex 精确修改](#8.3 用行内评论让 Codex 精确修改)
- [8.4 再用一次 `/review`](#8.4 再用一次
/review)
- [九、Worktree:让 Codex 在后台干活,不碰你正在写的代码](#九、Worktree:让 Codex 在后台干活,不碰你正在写的代码)
-
- [10.1 Worktree 可以理解成什么?](#10.1 Worktree 可以理解成什么?)
- [10.2 哪些任务适合放到 Worktree?](#10.2 哪些任务适合放到 Worktree?)
- [10.3 Worktree 并不是"随便并行"](#10.3 Worktree 并不是“随便并行”)
- [10.4 Handoff](#10.4 Handoff)
- 十、Subagents:把调查、测试和审查拆开
-
- [11.1 为什么要拆子代理?](#11.1 为什么要拆子代理?)
- [11.2 一个可以直接使用的提示词](#11.2 一个可以直接使用的提示词)
- [11.3 并行读取很适合,并行写入要谨慎](#11.3 并行读取很适合,并行写入要谨慎)
- [十一、几种很容易把 Codex 用跑偏的提示词](#十一、几种很容易把 Codex 用跑偏的提示词)
-
- [12.1 "帮我优化一下"](#12.1 “帮我优化一下”)
- [12.2 "只改第 83 行"](#12.2 “只改第 83 行”)
- [12.3 一次塞进去五个任务](#12.3 一次塞进去五个任务)
- [12.4 不让它复现](#12.4 不让它复现)
- [12.5 只说"测试一下"](#12.5 只说“测试一下”)
- [12.6 测试通过就直接提交](#12.6 测试通过就直接提交)
- 十二、几套我认为比较实用的提示词
-
- [13.1 陌生仓库快速理解](#13.1 陌生仓库快速理解)
- [13.2 修复 Bug](#13.2 修复 Bug)
- [13.3 新增小功能](#13.3 新增小功能)
- [13.4 Review 当前修改](#13.4 Review 当前修改)
- [13.5 多代理并行调查](#13.5 多代理并行调查)
- 总结
前言
上一篇文章中,我介绍了 Codex 的 config.toml、权限模式、AGENTS.md、MCP 等配置。配置完成之后,新的问题也就来了:
Codex 配好了,然后呢?
难道只是打开一个项目,对它说一句"帮我写个登录功能",然后等它把代码吐出来吗?
如果只是这样使用,我感觉多少有点浪费了。
因为真正写一个项目,从来不是简单地敲几行代码。就拿一个很普通的 Bug 来说,我们至少要经历下面这些步骤:
- 先把 Bug 复现出来;
- 找到它经过了哪些函数和模块;
- 判断根因到底在前端、后端还是请求封装层;
- 想清楚修改会不会影响其他功能;
- 修改代码;
- 补测试;
- 跑一遍验证命令;
- 最后再看 Git diff,确认没有改出新的问题。
而 Codex 真正有意思的地方,就在于它不只会回答"这段代码应该怎么写",还可以直接读取仓库、搜索调用关系、修改文件、运行命令、查看测试结果,最后再对修改进行 Review。

这篇文章不再讲 Codex 的基础配置,而是换一个方向,完整演示一次:
如何把一句模糊的"帮我修一下登录 Bug",逐步变成一个能够验证、能够 Review、能够真正交付的工程任务。
为了让过程更直观,本文会给出完整提示词、TypeScript 代码、测试代码、终端运行结果、Git diff 和 Worktree 并行开发示例。
本文涉及的 Codex 功能依据 OpenAI 官方文档整理,核对时间为 2026 年 6 月 10 日。
一、Codex 不只是"代码生成器"
1.1 我们平时是怎么让 AI 写代码的?
很多人刚开始使用 Codex,第一句话可能是:
text
帮我修复登录功能。这句话有没有问题?
当然有,而且问题还不小。
Codex 并不知道你说的"登录功能"具体哪里坏了,也不知道正确结果是什么,更不知道哪些文件不能动。
它可能会:
- 修改登录页面;
- 重写请求封装;
- 新增一个错误处理类;
- 顺手换掉 Toast 组件;
- 最后告诉你"已完成"。
代码确实变了,但它到底有没有解决问题,我们并不知道。
这和 Linux 中只看到一条命令执行成功,却不去检查进程状态、返回值和日志,本质上是一样的。
命令能执行,不代表任务完成;代码能编译,也不代表需求正确。
1.2 Codex 接到任务后到底在做什么?
我们可以把 Codex 的工作过程简单理解为一个循环:
text
读取任务
↓
收集上下文
↓
决定下一步动作
↓
读取文件 / 搜索代码 / 运行命令 / 修改文件
↓
观察结果
↓
继续下一步,直到满足完成条件这和传统聊天模型最大的区别是:传统聊天模型通常告诉你"应该怎么做",Codex 可以直接进入仓库"把这件事做完"。
但是问题来了:
Codex 怎么知道什么时候才算"做完"?
答案是:它主要依赖我们给出的任务描述。
如果提示词中只有"修复登录",那么"改了代码"就可能被它当作完成。
如果我们明确要求:
text
完成条件:
1. 密码错误、账号冻结、服务异常显示不同提示;
2. 未知错误有默认兜底;
3. 登录成功流程不受影响;
4. 添加回归测试;
5. 运行测试、类型检查和 lint;
6. 最后检查 Git diff。那么它的终点就不再是"写完代码",而是"验证完成"。
这就是这篇文章最核心的一句话:
不要用生成了多少代码来判断 Codex 是否完成任务,而要看结果有没有被验证。
二、先把一句模糊需求说清楚
这一节我们先不写代码,先看一个真实开发中很常见的问题。
2.1 示例 Bug:登录失败永远只显示一句话
假设项目是一个 React + TypeScript 商城。
当前现象是:
text
密码输入错误 → 登录失败
账号被冻结 → 登录失败
服务器暂时异常 → 登录失败三个完全不同的问题,前端却只显示同一句"登录失败"。
这对开发者来说可能没什么,但对用户来说区别很大:
- 密码错误,可以重新输入;
- 账号冻结,需要联系管理员;
- 服务异常,只能稍后再试。
服务端实际上已经返回了错误码:
json
{
"code": "ACCOUNT_LOCKED",
"message": "account has been locked"
}但是页面没有利用 code,只是统一显示默认文案。
2.2 一个任务最好包含四部分
OpenAI 官方最佳实践中,推荐在提示词里尽量给出下面四部分:
| 部分 | 要解决的问题 |
|---|---|
| Goal | 到底要改变什么行为? |
| Context | Bug 在哪里出现,怎样复现? |
| Constraints | 哪些地方不能改? |
| Done when | 满足什么条件才算完成? |
把它们翻译成更直白的话就是:
text
我要什么?
现在是什么情况?
你不能乱动什么?
最后我要怎么验收?2.3 改写后的完整提示词
text
目标:
修复登录失败提示。前端应该根据服务端错误码显示不同文案:
- INVALID_CREDENTIALS:账号或密码错误
- ACCOUNT_LOCKED:账号已冻结,请联系管理员
- SERVICE_UNAVAILABLE:服务暂时不可用,请稍后重试
上下文:
- 项目使用 React + TypeScript
- 登录页面位于 src/pages/LoginPage.tsx
- 登录逻辑可能位于 src/features/auth
- 请求封装位于 src/api
- 当前所有错误都只显示"登录失败"
复现步骤:
1. npm run dev
2. 进入 /login
3. 使用错误密码登录
4. 页面显示"登录失败"
约束:
- 不修改后端接口结构
- 不新增第三方依赖
- 沿用项目现有 Toast 组件
- 不重构与登录无关的代码
- 修改范围保持最小
完成条件:
- 三种错误显示对应文案
- 未知错误码显示默认兜底文案
- 登录成功流程不受影响
- 添加回归测试
- 运行最小相关测试、typecheck 和 lint
- 最后检查 Git diff 并报告修改文件看起来比一句"帮我修登录"长了不少,但这里的每一句都不是废话。
其中最容易被忽略的是"未知错误码"。
服务端以后很可能增加:
text
TOO_MANY_ATTEMPTS
PASSWORD_EXPIRED
USER_DISABLED如果没有兜底,前端可能直接显示空字符串,甚至把服务端内部错误抛给用户。
所以我们不能只写"正常情况",还要问一句:
如果出现了我现在还不知道的情况,程序会怎么样?
这也是写代码时非常重要的边界意识。
三、别急着改代码,先让 Codex 把仓库读明白
3.1 为什么第一步不是打开 LoginPage?
看到登录提示不对,我们第一反应通常是打开:
text
src/pages/LoginPage.tsx然后搜索"登录失败"。
但是页面只是错误最终显示出来的地方,根因不一定在页面。
一个登录请求大致可能经过:
text
LoginPage.tsx
↓
useAuth.ts
↓
authApi.login()
↓
httpClient.ts
↓
服务端响应假设服务端返回了 ACCOUNT_LOCKED,但 httpClient.ts 在构造异常时只保留了 message:
ts
throw new ApiError(response.message);那么错误码在请求层就已经丢了。
这时我们就算把登录页面翻个底朝天,也拿不到 ACCOUNT_LOCKED。
3.2 先调查,不修改
我比较推荐先给 Codex 一个只读任务:
text
先调查,不修改文件。
请定位登录请求从页面到 API 客户端的完整调用链,重点确认:
1. 服务端错误 code 在哪里被保留或丢失
2. 当前 Toast 文案在哪里生成
3. 项目中是否已有错误码映射模式
4. 是否存在登录相关测试
输出:
- 调用链
- 相关文件
- 根因判断
- 最小修复建议这里特意写了"先调查,不修改文件"。
为什么?
因为在根因没有确认之前,任何修改都可能只是猜。
3.3 Codex 搜索仓库后的结果
它可能会执行类似下面的搜索:
powershell
rg -n "login|INVALID_CREDENTIALS|ACCOUNT_LOCKED" src tests
rg --files src/features/auth tests得到结果:
text
src/pages/LoginPage.tsx:42
src/features/auth/useAuth.ts:28
src/api/httpClient.ts:61
src/features/payment/paymentError.ts:7
tests/auth/login.test.tsx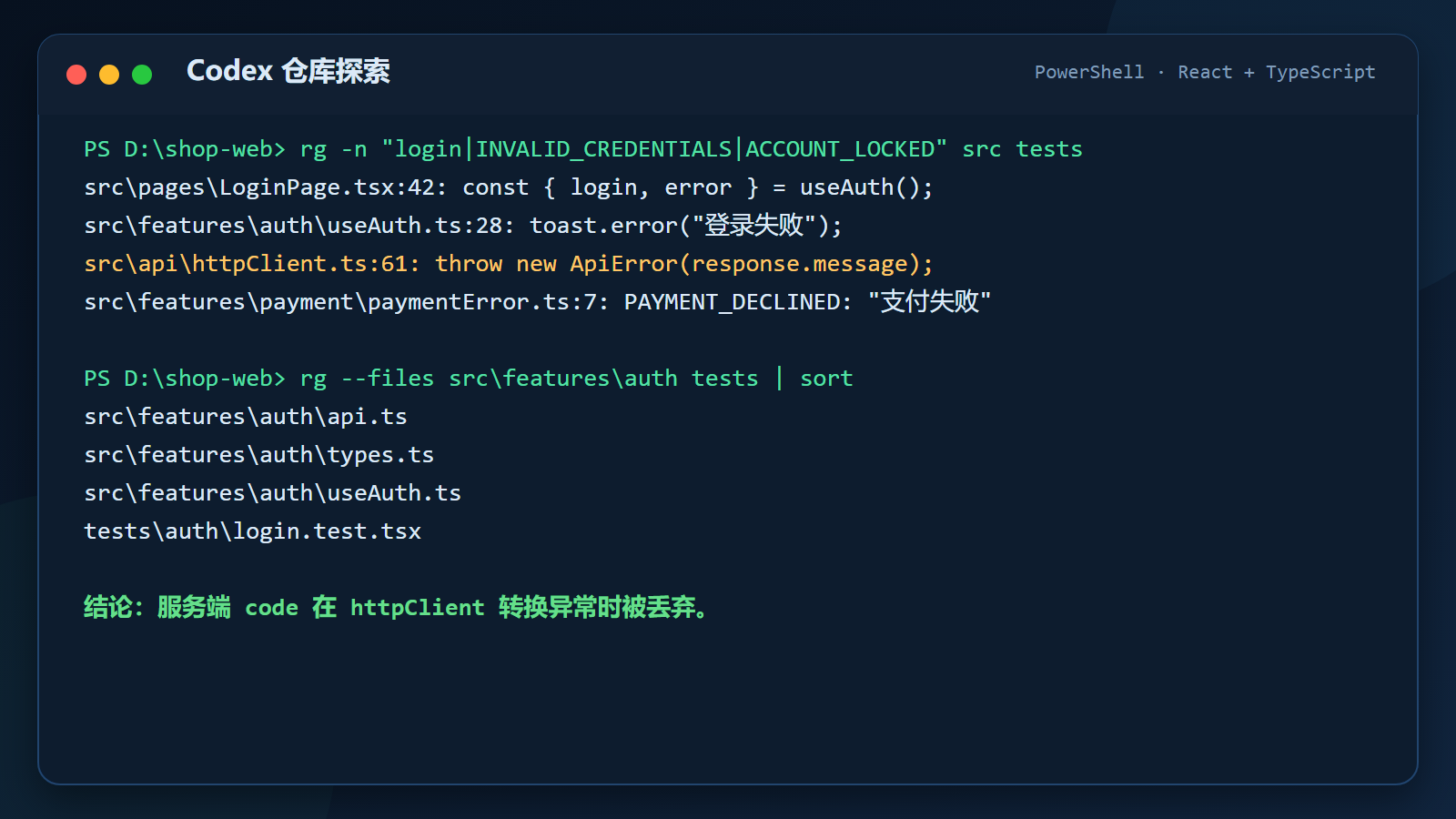
从输出中能看出几个关键点:
ts
// useAuth.ts
toast.error("登录失败");
ts
// httpClient.ts
throw new ApiError(response.message);而支付模块中已经有类似写法:
ts
const paymentErrorMessages: Record<string, string> = {
PAYMENT_DECLINED: "支付失败,请更换支付方式",
};现在根因基本清楚了:
服务端确实返回了
code,但是httpClient在转换异常时只传了message,导致上层无法区分错误类型。
这时候我们再回头看登录页面,就会发现页面并不是根因,它只是最后一个"背锅"的地方。
3.4 让 Codex 先输出调查结论
一个比较好的调查结果应该包含:
text
调用链:
LoginPage.tsx
→ useAuth.ts
→ authApi.login()
→ httpClient response interceptor
根因:
httpClient 在构造 ApiError 时丢失 response.code。
可复用模式:
支付模块已经使用 Record<string, string> 维护错误码文案。
最小方案:
1. ApiError 保留可选 code
2. 登录模块增加局部映射函数
3. useAuth 使用映射后的文案
4. 添加错误码和兜底测试注意,这里说的是"局部映射函数",而不是一上来就重构全站错误系统。
这也是实际开发中很重要的一点:
能用四个文件解决的问题,就不要先设计一个覆盖全公司的异常框架。
四、复杂任务先 Plan,防止改着改着跑偏
4.1 Plan 模式到底有什么用?
很多人理解的 Plan 模式,就是让 Codex 先输出一个目录。
其实不是。
Plan 真正的作用是:
- 在写代码前读取项目;
- 找出还不确定的地方;
- 把实现范围锁定;
- 提前写清楚验证方式。
如果任务只是改一个文案,没必要专门 Plan。
但如果一个 Bug 涉及页面、Hook、请求层、类型和测试,先规划一下还是很有必要的。
4.2 针对本例的计划
text
1. 修改 httpClient,构造 ApiError 时保留 response.code
2. 新增 loginError.ts,维护登录错误码到用户文案的映射
3. useAuth 捕获异常后调用映射函数
4. 为三个已知错误码和未知错误码补测试
5. 运行登录相关测试、typecheck、lint
6. Review Git diff,确认没有修改后端接口和登录成功流程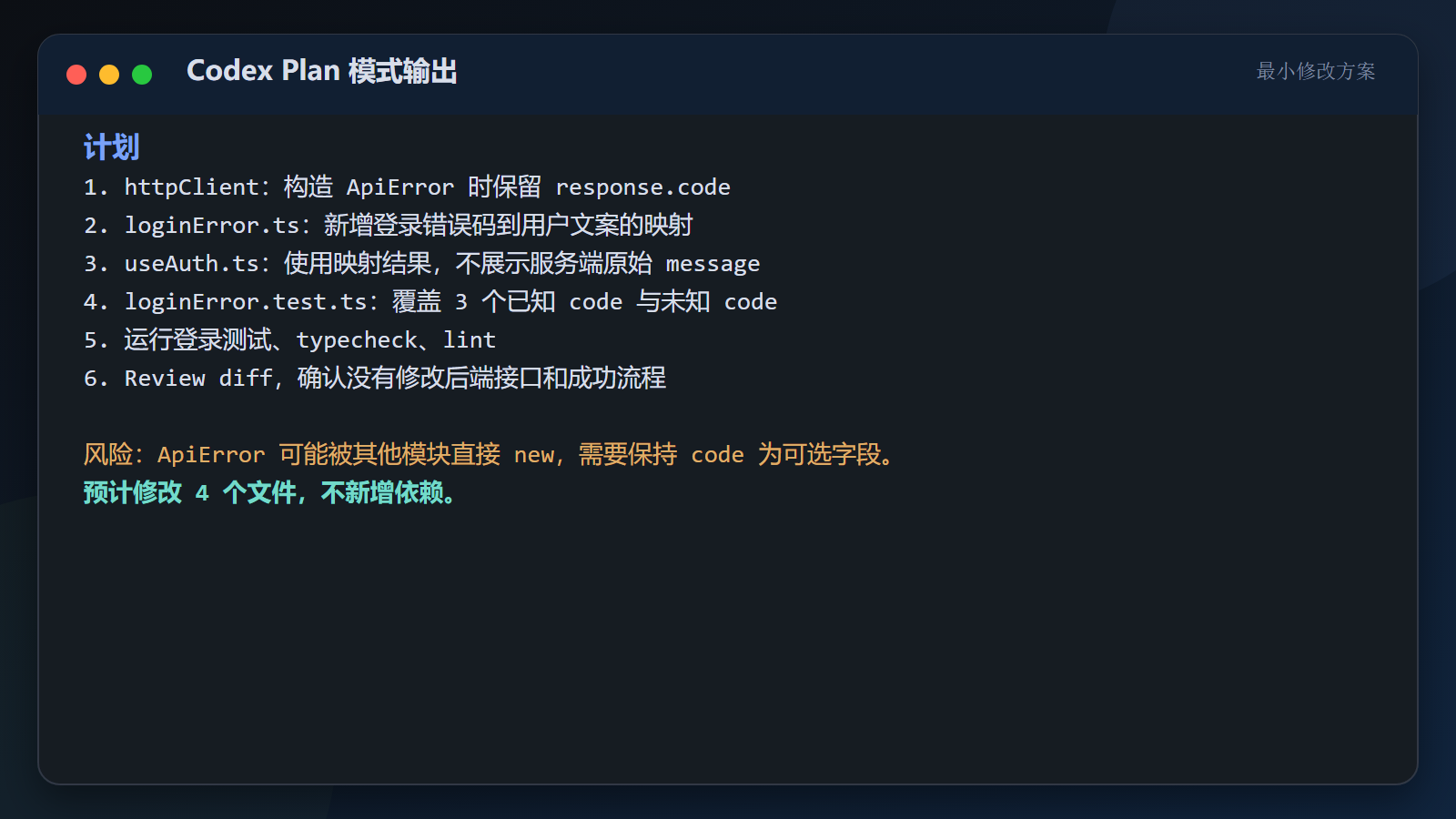
计划中还应该明确风险:
text
风险:
ApiError 可能被其他模块直接创建,因此 code 应该保持可选,
不能强制所有旧代码立刻传入。这个风险很容易被忽略。
如果我们把构造函数改成:
ts
constructor(message: string, code: string)那么项目里所有旧写法:
ts
new ApiError("request failed");都会编译失败。
更稳妥的是:
ts
constructor(message: string, code?: string)这就是 Plan 的价值:代码还没写,兼容性问题已经提前暴露出来了。
4.3 什么情况下应该打回计划?
如果 Codex 给出下面这种方案:
text
1. 重写全局请求库
2. 引入新的错误处理依赖
3. 改造所有业务模块
4. 统一全站文案可以直接回复:
text
范围太大。
本次只修复登录流程,保留现有请求架构。
复用支付模块的映射模式,不新增依赖,
不修改其他业务模块。在计划阶段让它收缩范围,比代码写完以后再全部回滚省事得多。
五、开始修改:先保留错误码
根因已经确定,接下来正式看代码。
5.1 修改前的 ApiError
ts
export class ApiError extends Error {
constructor(message: string) {
super(message);
this.name = "ApiError";
}
}请求失败时:
ts
throw new ApiError(response.message);这里保存了 message,却没有保存 code。
5.2 修改 ApiError
ts
export class ApiError extends Error {
readonly code?: string;
constructor(message: string, code?: string) {
super(message);
this.name = "ApiError";
this.code = code;
}
}然后修改异常转换:
ts
throw new ApiError(response.message, response.code);这个改动看起来非常小,但它打通了服务端到业务层之间缺失的信息。
这里有一个值得思考的问题:
为什么不直接把整个
response都塞进 Error?
例如:
ts
throw new ApiError(response);这样做当然也能拿到 code,但会让 ApiError 与后端具体响应结构绑定得更紧。
今天接口是:
json
{
"code": "ACCOUNT_LOCKED",
"message": "account locked"
}明天后端可能改成:
json
{
"error": {
"code": "ACCOUNT_LOCKED",
"message": "account locked"
}
}请求层应该负责把不同的 HTTP 响应整理成稳定的前端异常类型,上层业务只关心:
ts
error.code
error.message这就是封装的意义。
六、增加错误码映射,不直接展示服务端 message
6.1 为什么不能把服务端 message 原样显示?
有人可能会问:
服务端不是已经返回
message了吗?直接 Toast 出来不就行了?
代码可能是:
ts
toast.error(error.message);看起来省事,但有几个问题:
- 服务端文案可能是英文;
- 文案可能面向开发人员,不适合直接给用户;
- 可能暴露内部实现;
- 后端一改文案,前端显示就跟着变化;
- 同一个错误在不同页面可能需要不同提示。
例如服务端返回:
text
failed to query user table: connection timeout这个信息放日志里很有用,直接展示给用户就不合适了。
6.2 新增映射文件
ts
// src/features/auth/loginError.ts
const loginErrorMessages: Record<string, string> = {
INVALID_CREDENTIALS: "账号或密码错误",
ACCOUNT_LOCKED: "账号已冻结,请联系管理员",
SERVICE_UNAVAILABLE: "服务暂时不可用,请稍后重试",
};
const DEFAULT_LOGIN_ERROR = "登录失败,请稍后重试";
export function mapLoginErrorMessage(code?: string): string {
if (!code) {
return DEFAULT_LOGIN_ERROR;
}
return loginErrorMessages[code] ?? DEFAULT_LOGIN_ERROR;
}这里使用 Record<string, string>,代码并不复杂。
有人可能会想把它写成 switch:
ts
switch (code) {
case "INVALID_CREDENTIALS":
return "账号或密码错误";
case "ACCOUNT_LOCKED":
return "账号已冻结,请联系管理员";
default:
return "登录失败,请稍后重试";
}两种写法都能用。
当前项目的支付模块已经使用对象映射,所以登录模块沿用相同风格更合适。
在已有项目里,和周围代码保持一致,往往比单独追求"最优雅写法"更重要。
6.3 修改 useAuth
修改前:
ts
try {
await authApi.login(values);
navigate("/");
} catch (error) {
toast.error("登录失败");
}修改后:
ts
import { ApiError } from "@/api/ApiError";
import { mapLoginErrorMessage } from "./loginError";
try {
await authApi.login(values);
navigate("/");
} catch (error) {
if (error instanceof ApiError) {
toast.error(mapLoginErrorMessage(error.code));
return;
}
toast.error(mapLoginErrorMessage());
}这里为什么还要判断 instanceof ApiError?
因为 catch 到的东西不一定来自服务端。
它可能是:
- 网络层抛出的错误;
- JSON 解析错误;
- 代码自身的运行时错误;
- 某个第三方库抛出的异常。
如果不判断类型,直接访问:
ts
error.code在 TypeScript 严格模式下本身就不安全。
七、补测试:不要只测三个"正确答案"
代码写完以后,最容易出现的一句话是:
看起来没问题。
"看起来没问题"恰恰是最不可靠的判断。
7.1 表驱动测试
ts
import { describe, expect, it } from "vitest";
import { mapLoginErrorMessage } from "@/features/auth/loginError";
describe("mapLoginErrorMessage", () => {
it.each([
["INVALID_CREDENTIALS", "账号或密码错误"],
["ACCOUNT_LOCKED", "账号已冻结,请联系管理员"],
["SERVICE_UNAVAILABLE", "服务暂时不可用,请稍后重试"],
])("maps %s", (code, expected) => {
expect(mapLoginErrorMessage(code)).toBe(expected);
});
it("falls back for an unknown code", () => {
expect(mapLoginErrorMessage("PASSWORD_EXPIRED"))
.toBe("登录失败,请稍后重试");
});
it("falls back when code is missing", () => {
expect(mapLoginErrorMessage())
.toBe("登录失败,请稍后重试");
});
});这里除了三个已知错误码,还测试了:
text
未知 code
code 不存在为什么要测未知 code?
因为接口一定会变化。
今天只有三个错误,明天后端加一个 PASSWORD_EXPIRED,前端至少应该安全地显示默认文案,而不是崩掉。
7.2 登录成功流程也要保护
我们修的是失败路径,但不能只测失败路径。
还应该确认原来的成功逻辑没有被破坏:
ts
it("keeps the successful login path unchanged", async () => {
authApi.login.mockResolvedValue({
token: "test-token",
});
await login({
username: "demo",
password: "correct-password",
});
expect(navigate).toHaveBeenCalledWith("/");
expect(toast.error).not.toHaveBeenCalled();
});这就是回归测试。
修复一个 Bug 时,不仅要证明"错误路径变正确了",还要证明"原来正确的路径没有被改坏"。
7.3 运行测试
powershell
npm test -- loginError.test.ts
npm run typecheck
npm run lint运行结果如下:
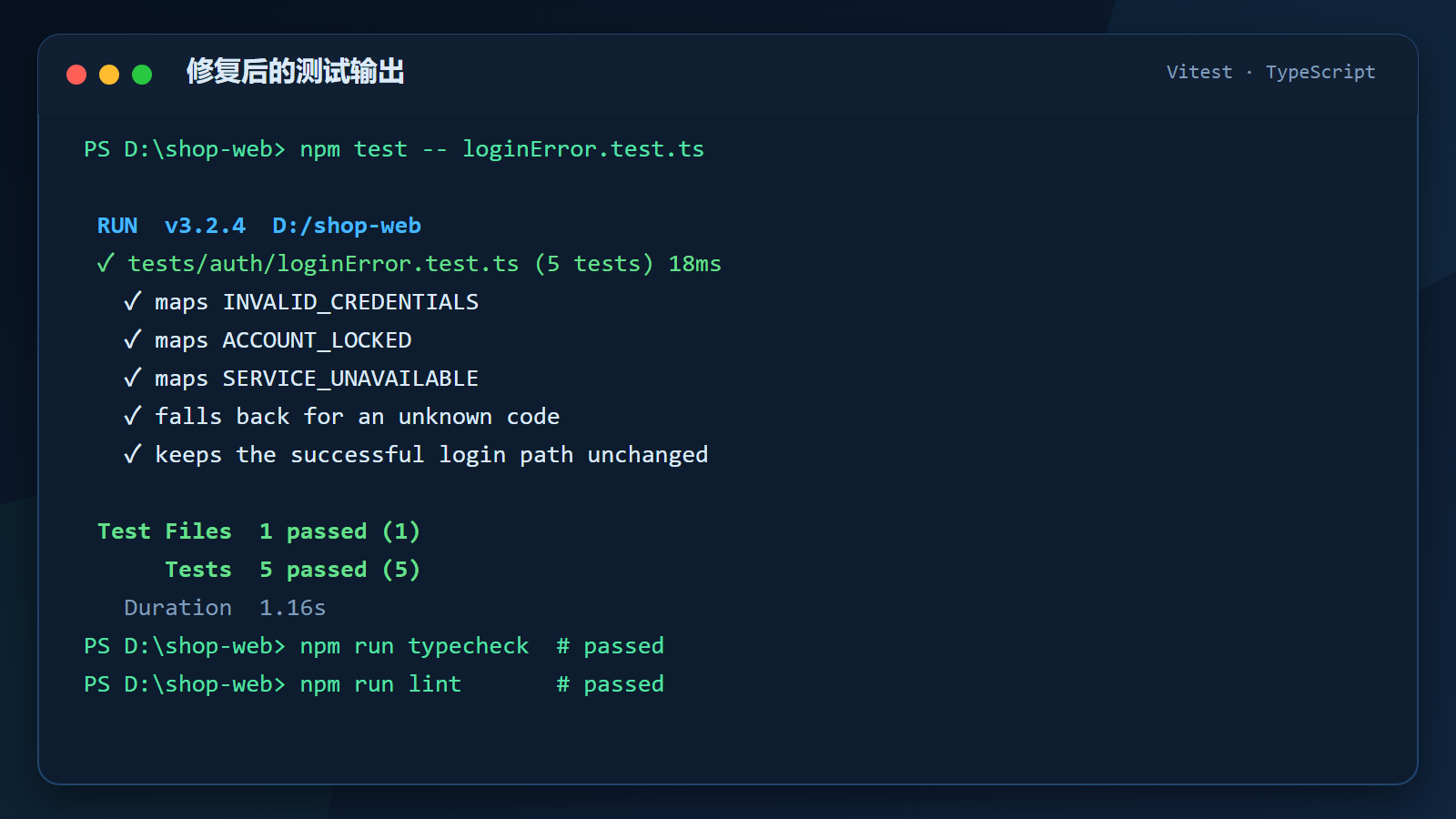
终端输出:
text
Test Files 1 passed (1)
Tests 5 passed (5)
npm run typecheck passed
npm run lint passed到这里能不能说任务完成了?
还不能。
因为测试通过,只能说明被测试覆盖的行为没有问题。它不能告诉我们是否顺手修改了其他文件,也不能发现大面积无关格式化。
所以还要看 diff。
7.4 如果全量测试失败,先别急着认定是自己改坏了
实际项目中经常出现这种情况:
powershell
npm test登录相关测试通过了,但另外两个旧模块失败:
text
loginError.test.ts:通过
UserProfile.test.tsx:失败
NotificationPanel.test.tsx:失败这时不能简单地说"全量测试失败,所以本次修复失败",也不能一句"项目原本就有问题"直接跳过。
需要继续判断:
- 失败文件是否被本次修改;
- 错误调用链是否经过 auth 模块;
- 修改前是否已经失败;
- 单独重跑能否稳定复现;
- 错误堆栈是否与本次代码有关。
比较完整的报告应该是:
text
验证结果:
- 登录错误测试:5 个全部通过
- typecheck:通过
- lint:通过
- 全量测试:存在 2 个失败
现有失败:
- UserProfile.test.tsx
- NotificationPanel.test.tsx
判断:
两个失败文件未被本次修改,调用链不经过 auth 模块。
修改前运行同样失败,因此不属于本次引入的回归。重点不是想办法把失败"说成没问题",而是把证据说清楚。
八、Review:代码写完后的第二次思考
8.1 先看改了多少文件
powershell
git diff --stat输出:
text
src/api/httpClient.ts | 4 +++-
src/features/auth/loginError.ts | 16 ++++++++++++++++
src/features/auth/useAuth.ts | 5 +++--
tests/auth/loginError.test.ts | 28 ++++++++++++++++++++++++++++
4 files changed, 50 insertions(+), 3 deletions(-)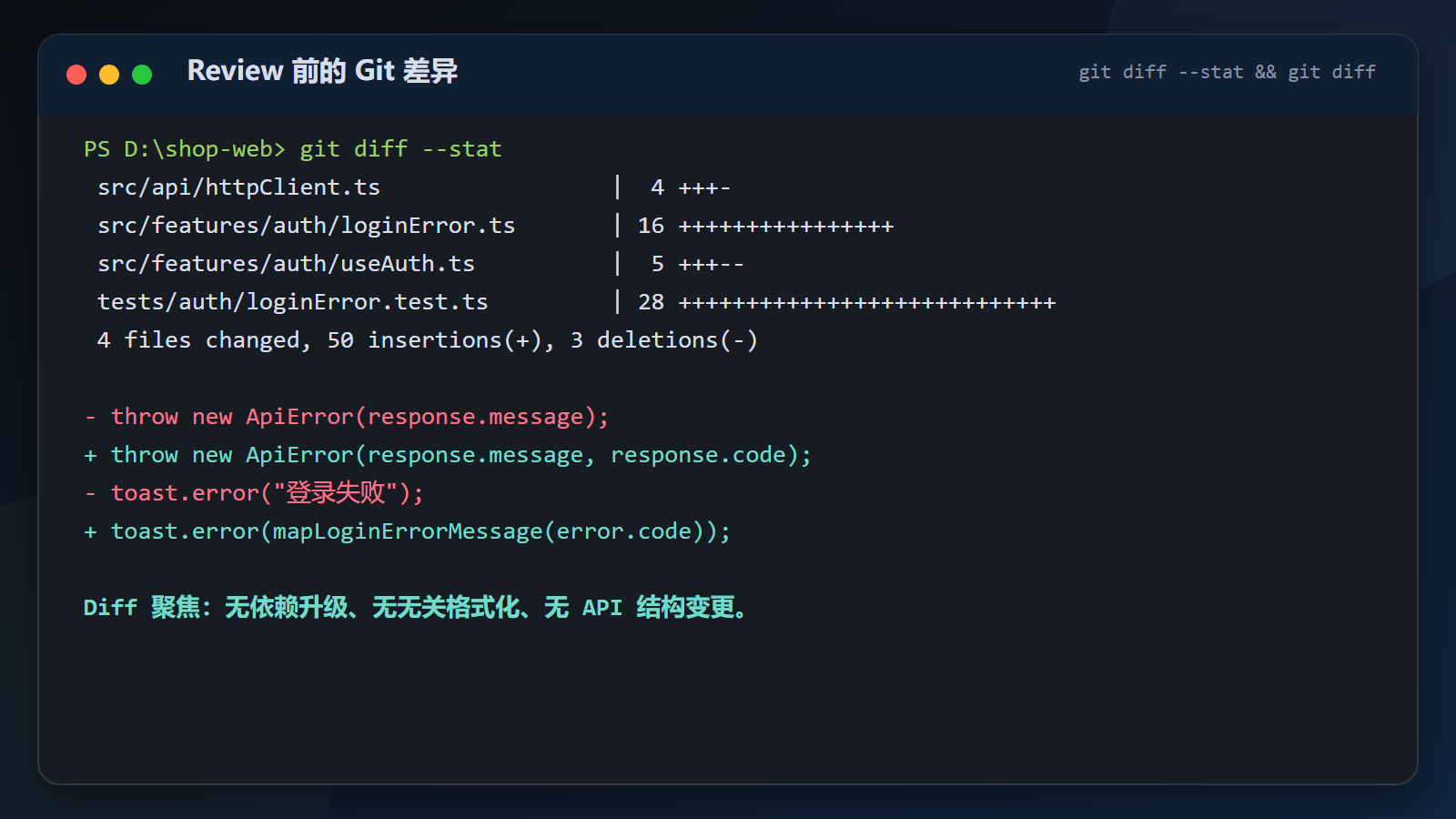
这个 diff 是比较健康的:
- 修改 4 个文件;
- 没有升级依赖;
- 没有全项目格式化;
- 没有修改后端接口;
- 没有重构登录页面;
- 测试代码占了大部分新增行。
8.2 Review 时我一般看什么?
我会重点看下面几个问题:
1. 是否改了计划外文件?
如果只是修登录,却突然出现:
text
package-lock.json
src/pages/HomePage.tsx
src/styles/global.css就需要问一句:为什么?
2. 是否直接展示服务端内部错误?
ts
toast.error(error.message);这种写法要格外注意。
3. 是否存在兜底?
ts
loginErrorMessages[code]如果没有 ?? DEFAULT_LOGIN_ERROR,未知 code 可能返回 undefined。
4. 测试是否真的断言了行为?
下面这种测试价值很低:
ts
expect(mapLoginErrorMessage).toBeDefined();它只证明函数存在,没有证明映射是否正确。
5. 是否影响成功流程?
失败提示改得再好,如果成功登录后不跳转了,也是严重回归。
8.3 用行内评论让 Codex 精确修改
Codex App 的 Review 面板可以在具体代码行上留下评论。
例如看到:
ts
toast.error(error.message);可以评论:
text
这里不要展示服务端原始 message。
保留 message 用于日志,用户文案根据 ApiError.code 映射。然后再发:
text
处理 Review 面板中的行内评论。
保持修改范围最小,完成后重新运行登录测试和 typecheck。这种反馈比一句"你再优化一下"准确得多。
8.4 再用一次 /review
可以让 Codex 对当前未提交修改做独立审查:
text
/review
重点检查:
1. 登录成功流程是否可能回归
2. 是否可能泄露服务端内部信息
3. code 为空时是否安全
4. 是否存在遗漏的错误分支
5. 测试是否真正覆盖修改行为需要注意:
Review 的重点应该是具体 Bug、风险和测试缺口,而不是重新介绍"本次改了四个文件"。
九、Worktree:让 Codex 在后台干活,不碰你正在写的代码
如果你正在本地开发一个功能,同时又想让 Codex 修另一个 Bug,会遇到一个很现实的问题:
两边会不会同时修改同一个项目目录?
如果直接开两个线程,让它们都操作同一份文件,确实可能互相影响。
这时就可以用 Worktree。
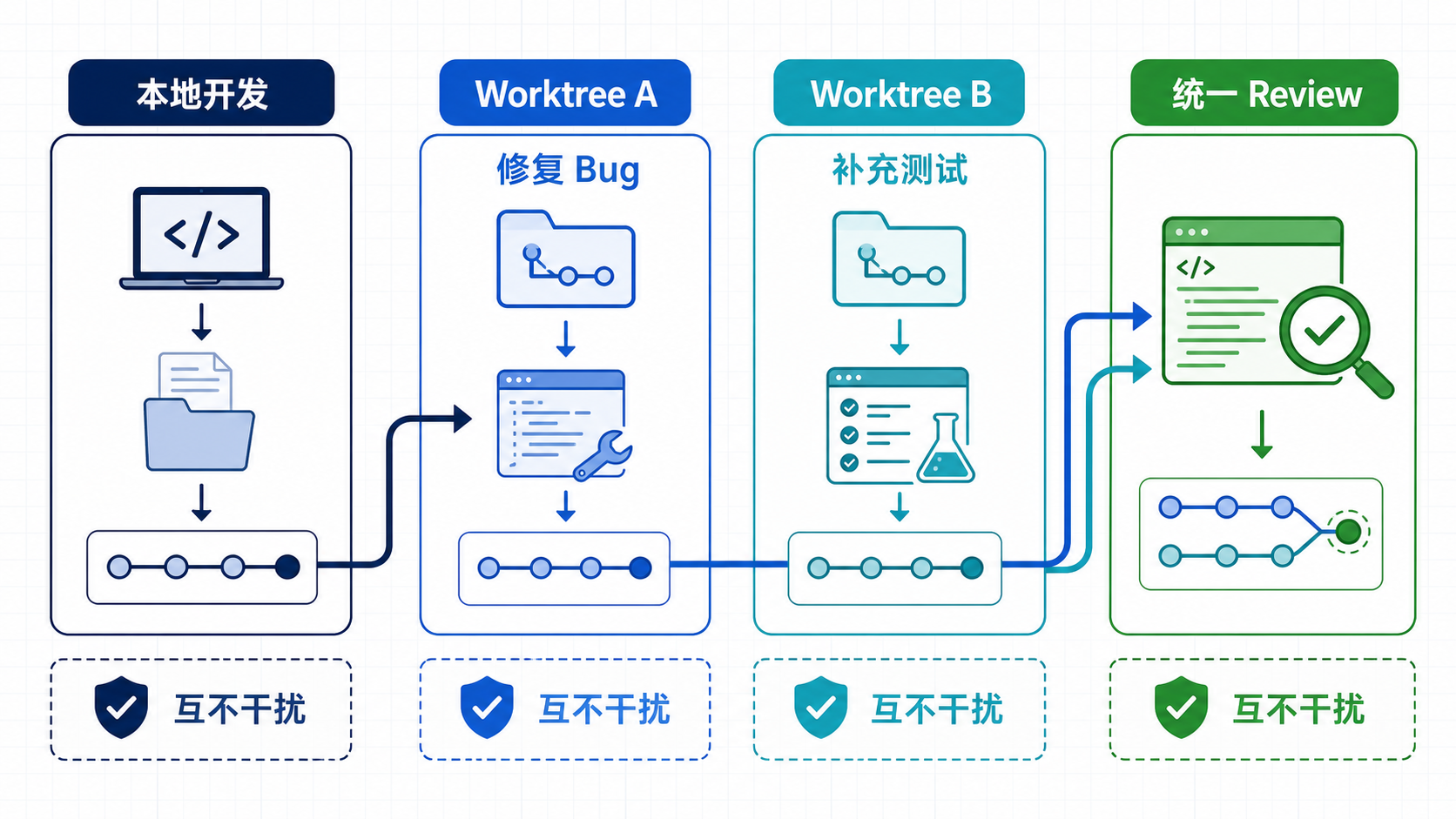
10.1 Worktree 可以理解成什么?
如果借用 Linux 中进程隔离的思路,可以简单理解为:
text
同一份 Git 历史
↓
多个相互独立的工作目录每个 Worktree 都有自己的文件、索引和当前状态,但它们共享仓库的提交对象。
例如:
text
Local:
我继续写用户资料页
Worktree A:
Codex 修复登录错误提示
Worktree B:
Codex 补认证模块测试三个任务互不覆盖。
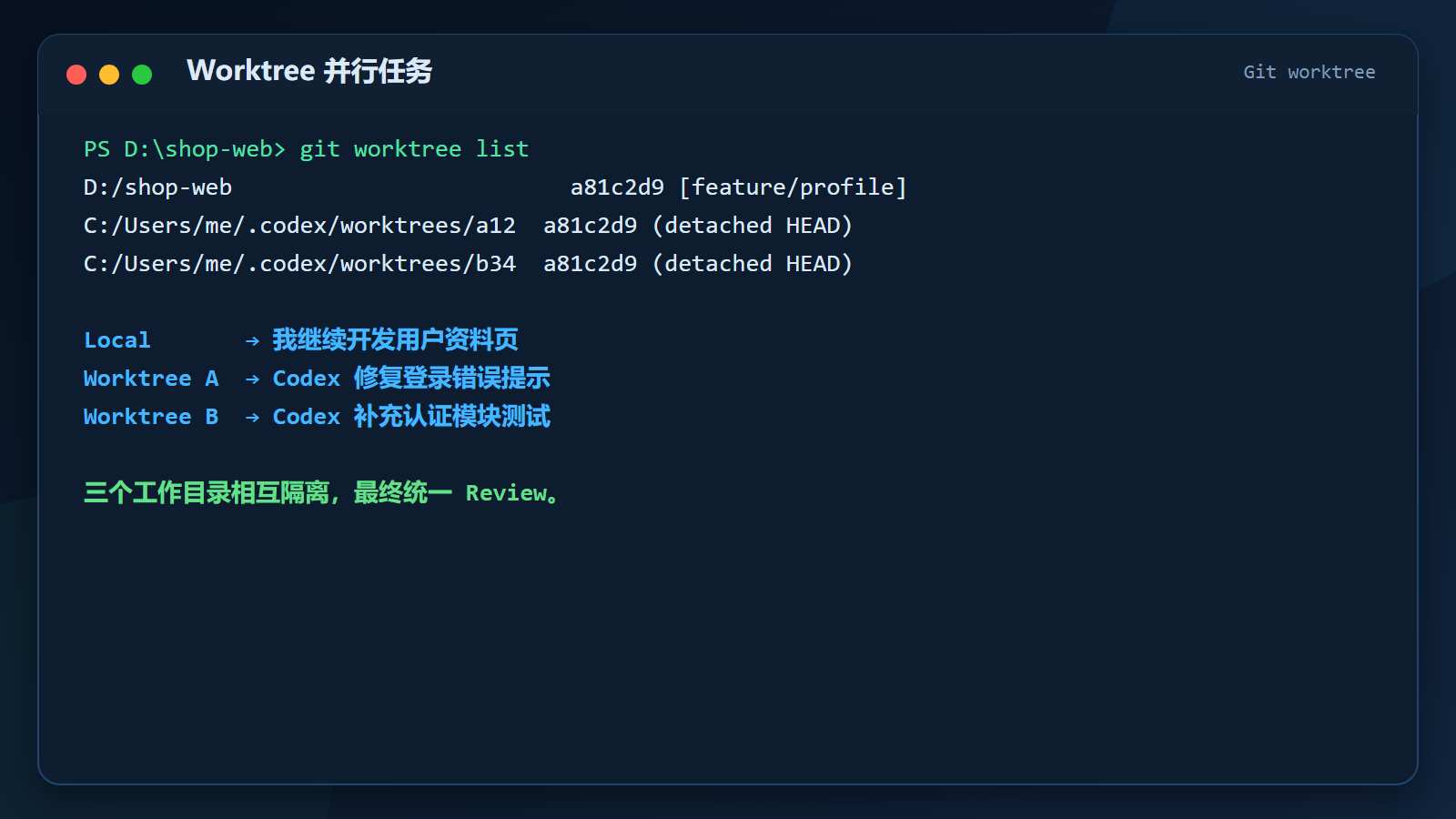
终端中可以看到:
powershell
git worktree list
text
D:/shop-web a81c2d9 [feature/profile]
C:/Users/me/.codex/worktrees/a12 a81c2d9 (detached HEAD)
C:/Users/me/.codex/worktrees/b34 a81c2d9 (detached HEAD)10.2 哪些任务适合放到 Worktree?
适合:
- 独立 Bug 修复;
- 补单元测试;
- 文档更新;
- 依赖升级调查;
- 代码审查;
- 和当前开发文件重叠较少的功能。
不太适合:
- 两个任务都要重写同一个核心文件;
- 必须共用唯一硬件设备;
- 强依赖当前本地开发服务器状态;
- 修改之间存在严格先后关系。
10.3 Worktree 并不是"随便并行"
有人看到 Worktree 以后,可能会同时开五六个任务。
但并行不是越多越好。
如果几个任务最后都要修改:
text
src/api/httpClient.ts那么合并时仍然会产生冲突。
Worktree 解决的是"工作目录相互干扰",它不能消除逻辑冲突。
所以拆任务时依然要考虑模块边界。
10.4 Handoff
Codex App 可以把线程在 Local 和 Worktree 之间 Handoff。
当后台任务完成后,如果需要:
- 在自己常用的 IDE 中检查;
- 运行本地唯一的开发服务;
- 使用本机已有的特殊环境;
就可以把线程带回 Local。
但要注意,Git 不允许同一个分支同时被两个 Worktree 检出。
如果分支已经在 Worktree 中,不要再强行在 Local 中检出同一分支,使用 Handoff 会更合适。
十、Subagents:把调查、测试和审查拆开
11.1 为什么要拆子代理?
一个复杂任务中,可能会产生大量信息:
- 搜索结果;
- 调用链;
- 测试日志;
- 构建输出;
- 安全问题;
- 性能问题;
- Git 差异。
如果所有内容都堆在主线程里,真正重要的需求和决策容易被淹没。
Subagent 的思路是:
text
主代理:
负责需求、决策、计划和最终结论
子代理 A:
只调查调用链
子代理 B:
只搜索可复用模式
子代理 C:
只检查测试缺口最后三个子代理把结论交回主线程。
11.2 一个可以直接使用的提示词
text
使用三个子代理并行调查,暂时不要修改代码:
代理 A:
追踪登录错误从服务端响应到页面 Toast 的完整调用链。
代理 B:
搜索仓库中已有的错误码映射模式,找出最适合复用的实现。
代理 C:
检查登录相关测试、测试工具和可以运行的最小验证命令。
等待三个代理全部完成后,汇总:
- 已确认事实
- 仍然不确定的问题
- 推荐的最小修改方案
- 风险
- 验证计划11.3 并行读取很适合,并行写入要谨慎
子代理特别适合:
- 搜索不同目录;
- 分析不同模块;
- 分类测试失败;
- 从安全、性能、可维护性三个角度 Review。
但是让三个代理同时修改同一个文件,通常不是好主意。
这和多线程程序一样:
只读共享数据比较简单,多个执行单元同时写同一份数据,就要考虑冲突和同步。
所以我更推荐:
text
子代理负责调查
主代理统一制定方案和修改或者:
text
不同 Worktree 修改互不重叠的模块
最后统一 Review十一、几种很容易把 Codex 用跑偏的提示词
12.1 "帮我优化一下"
text
帮我优化登录模块。"优化"到底是什么?
- 更快?
- 更安全?
- 更好看?
- 代码更短?
- 减少重复?
- 提高测试覆盖率?
如果自己都没有定义,Codex 只能猜。
可以改成:
text
减少登录失败处理中的重复 Toast 逻辑,
保持现有 UI 和 API 不变,
把错误码映射集中到 auth 模块,
并补充未知错误码测试。12.2 "只改第 83 行"
text
修改 LoginPage.tsx 第 83 行。这句话把解决方案写死了。
如果根因在 httpClient.ts,强行改第 83 行只是在错误位置打补丁。
更好的说法:
text
我怀疑 LoginPage.tsx 的错误提示有问题,
但请先验证完整调用链,不要假设根因一定在页面。12.3 一次塞进去五个任务
text
修登录 Bug、升级 React、优化数据库、
重写首页,再把测试补全。这种任务很难验证,也很难 Review。
应该拆成多个线程,必要时放进不同 Worktree。
12.4 不让它复现
如果修改前没有复现 Bug,就无法证明修改后 Bug 消失了。
text
先按复现步骤确认当前行为并记录结果,
修改后重复相同步骤进行验证。12.5 只说"测试一下"
"测试一下"太模糊。
应该明确:
text
先运行新增测试文件,
再运行 auth 模块测试,
然后执行 typecheck 和 lint。
如果时间允许再运行全量测试。12.6 测试通过就直接提交
测试不能发现所有问题。
还要检查:
text
git diff --stat
git diff
git status看看有没有:
- 无关文件;
- 调试代码;
- 本地路径;
- 临时日志;
- 大面积格式化;
- 意外生成文件。
十二、几套我认为比较实用的提示词
13.1 陌生仓库快速理解
text
先不要修改代码。
请解释 <功能名称> 的完整调用流程,包括:
- 入口
- 核心业务逻辑
- 数据验证
- 外部依赖
- 错误处理
- 测试位置
最后输出:
1. 编号流程
2. 涉及文件
3. 修改该功能最容易踩的三个坑13.2 修复 Bug
text
Bug:
<描述错误行为>
复现:
1. ...
2. ...
3. ...
期望:
<正确行为>
约束:
- 保持接口兼容
- 修改范围最小
- 不做无关重构
先复现和定位根因,再给出最小方案。
实施后补回归测试,并重新执行复现步骤。
最后报告验证命令和结果。13.3 新增小功能
text
新增功能:<功能名称>
用户行为:
- ...
技术约束:
- 沿用现有组件
- 沿用现有状态管理
- 不新增依赖
- API 结构保持不变
完成条件:
- 正常路径可用
- 空数据有处理
- 异常路径有处理
- 添加测试
- 运行 typecheck、lint 和相关测试13.4 Review 当前修改
text
审查当前未提交修改。
按严重程度检查:
1. 功能错误和回归
2. 安全问题
3. 边界条件
4. 数据兼容性
5. 测试缺口
只报告具体、可以操作的问题。
每个问题给出文件位置、触发条件、影响和修复方向。13.5 多代理并行调查
text
使用三个子代理,只读调查,不修改代码:
- 代理 A:分析业务调用链
- 代理 B:搜索仓库中可以复用的实现
- 代理 C:检查测试覆盖和验证命令
等待全部完成后,统一汇总:
- 事实
- 不确定项
- 推荐方案
- 风险
- 验证步骤总结
这篇文章与上一篇 Codex 配置文章的侧重点完全不同。
【Codex配置实战】从 config.toml 到 AGENTS.md:把 AI 编程助手调成顺手的开发环境
上一篇解决的是:
如何把 Codex 的环境配置好?
这一篇解决的是:
环境已经配置好了,如何让 Codex 真正完成一次能够交付的工程任务?
最后总结几句话:
- 不要只说"帮我写代码"。先说清楚目标、现象、限制和验收条件。
- 不要看到页面报错就只改页面。先追完整调用链,找到信息真正丢失的位置。
- 复杂任务先 Plan。计划的重点不是步骤多,而是修改范围、风险和验证方式是否明确。
- 代码写完不是结束。测试、类型检查、lint、复现步骤和 Git diff 都是任务的一部分。
- 测试通过也要 Review。测试看行为,diff 看修改边界,两者缺一不可。
- 需要后台并行时用 Worktree。不要让多个线程直接在同一个工作目录里互相覆盖。
- 子代理更适合做并行调查。多个代理同时写同一文件,反而可能增加冲突。
Codex 并不是一个"你说一句,它写一段"的代码补全工具。
当我们把需求、调查、计划、实现、测试和 Review 连成一条完整链路之后,它更像是一个能够真正参与项目的工程搭档。
而我们需要做的,也不再是盯着它输出了多少行代码,而是始终追问:
这个结果,真的被证明是正确的吗?
官方参考资料