索引可以提高数据库的性能
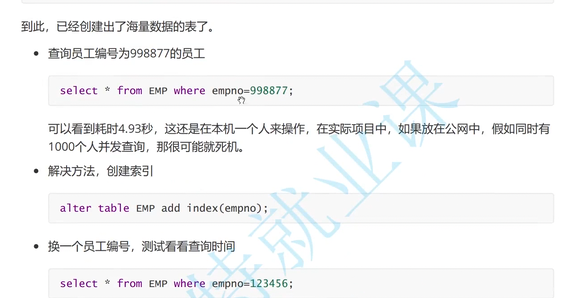
搜索海量数据,如果没有索引,效率会很低
索引主要分为:
主键索引,唯一索引,普通索引,全文索引
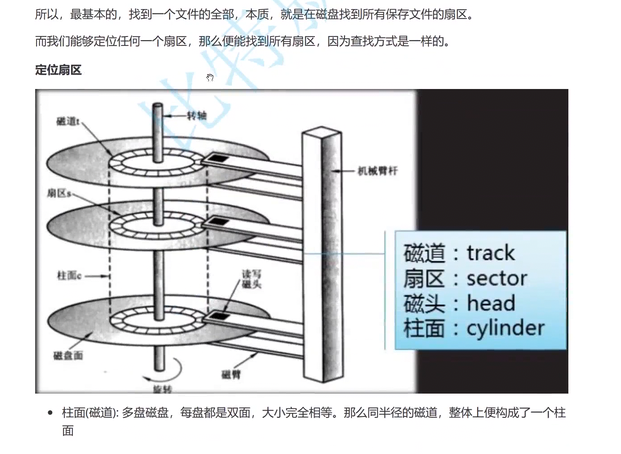
mysql的服务器,本质是在内存中的,所有的数据库的CURD操作,全都是在内存中进行的,索引也是如此

mysql给用户提供存储服务,而存储的都是数据,数据就存储在磁盘中
磁盘本身的效率较低,因此mysql需要提高效率
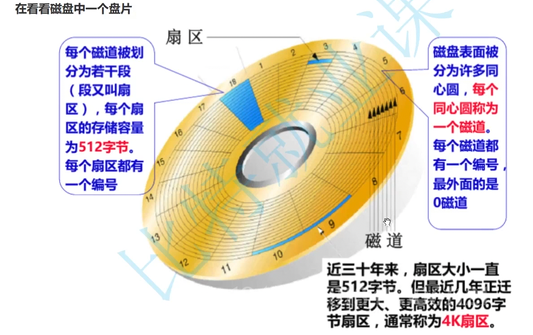
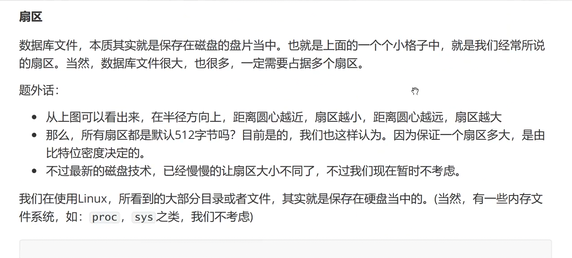
系统读磁盘以块为单位,一个块4kb



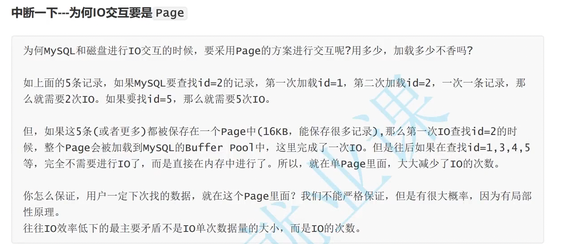
MySQL与磁盘的交互
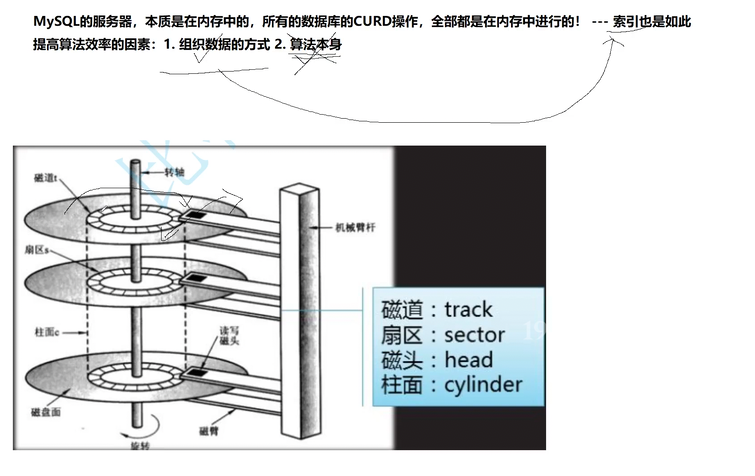
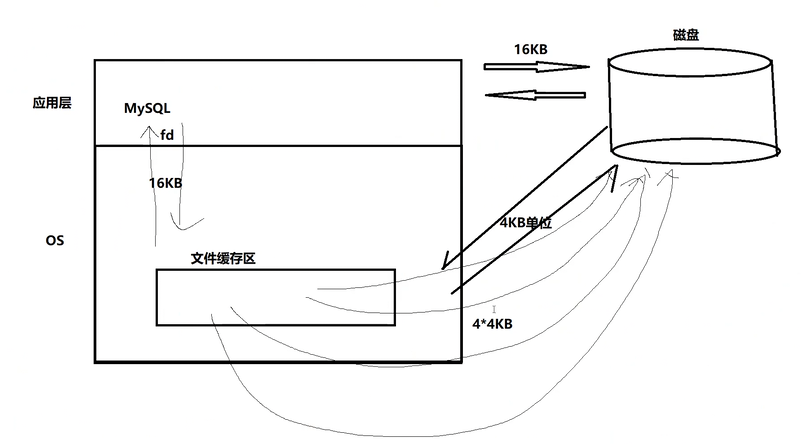
mysql进行io的基本单位是16kb,这个基本数据单元,就是page

MySQL与软件的交互
MySQL是一个应用层软件
MySQL数据文件,是以page为单位保存在磁盘中的
MySQL的CURD操作,都需要通过计算,找到对应的插入位置,或需要修改查询的数据
只要涉及计算,就要CPU参与,因此需要将数据移动到1内存中
所以在特定时间内,数据一定是在磁盘中有,内存中也有
为了更好地进行上面的操作,MySQL服务器在内存中运行时,在服务器内部会申请一块名为BUffer Pool的大内存空间,来进行缓存,方便和磁盘数据进行IO
为了提高效率,一定要尽可能减少系统和磁盘IO的次数

索引

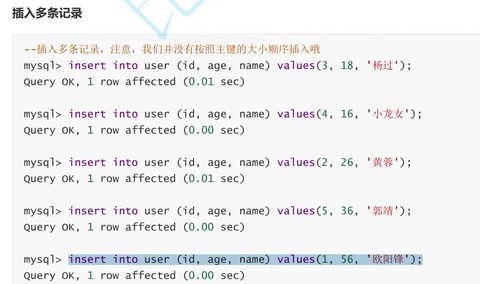

page
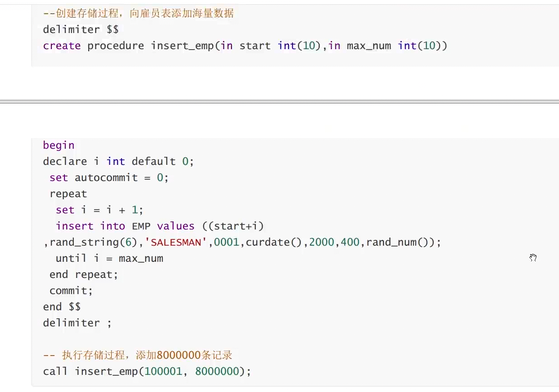
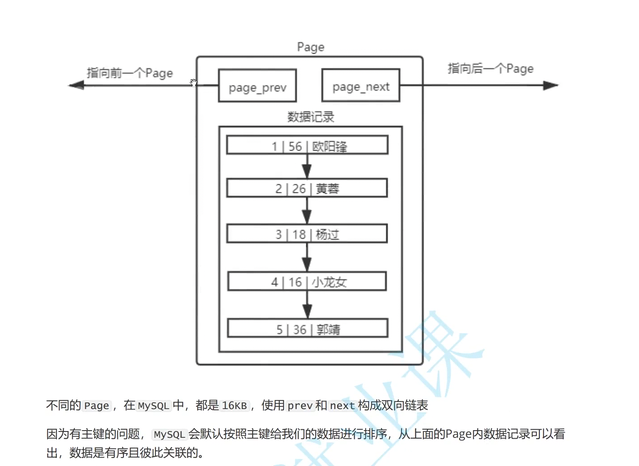
我们向一个具有主键的表中,乱序插入数据,数据会自动排序
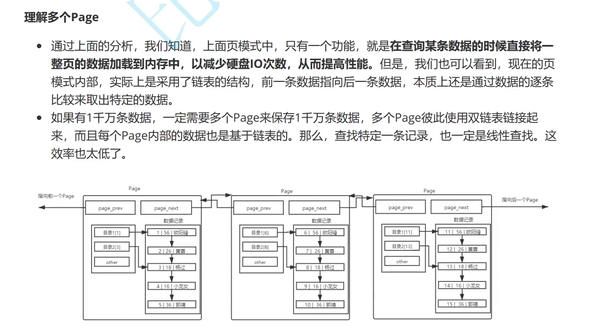
由于MySQL内部一定存在大量的page,这也就决定了,MySQL必须要将多个同时存在的page管理起来
page内部也必须写入对应的管理信息

MySQL使用page和磁盘进行交互,可以有效的减少IO次数
page存在prev和next指针,本质时一个双向链表,方便管理


在查询某条数据时,会直接将一整页的数据加载到内存中,以减少IO次数,从而提高性能
页目录

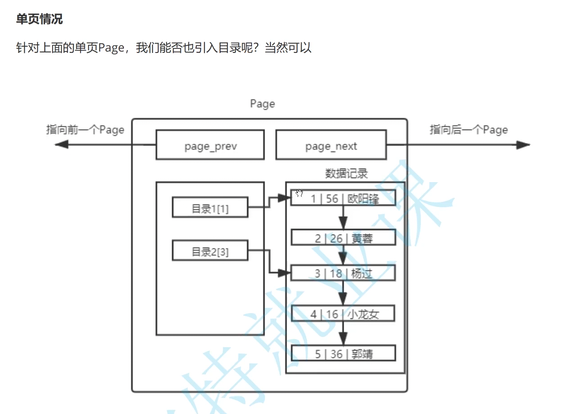
MySQL中每一页都是16k,单个page大小固定,随着数据量的不断变大,16kb不可能存下所有数据,,因此必定存在多个页来存储数据
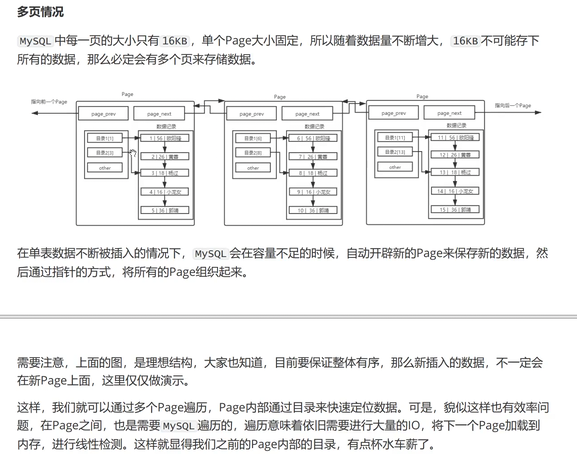
B+树
页表使用B+树存储
叶子节点存储数据,路上节点没有,非叶子节点不保存数据,只要目录项
非叶子节点不存储数据,可以存储更多的目录项,可以管理更多的叶子节点
则这棵树一定是矮胖的,所以途径的路上的节点减少了
所以找到目标数据只需要更少的page,IO次数更少,提高了效率
每一个节点都要目录项,可以大大提高搜索效率
这棵树的叶子节点全部用链表级联起来
这棵树叫做MySQL innode db
一般我们建表时就是在该结构下进行CURD
就算我们建表时没有主键,MySQL会自动生成一个隐藏列充当主键
MySQL会根据这个隐藏列来进行排序(按原顺序直接显示)


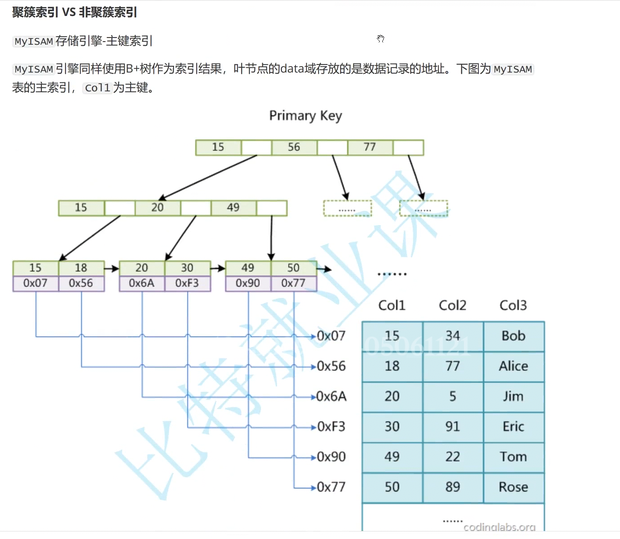
聚簇索引
MyISAM存储引擎同样时使用B+树作为索引结果
但是叶节点的data存放的时数据记录的地址
这种将数据和B+树索引分离的存储方式叫做非聚簇索引
把数据和B+树索引放在一起的存储方式就是聚簇索引

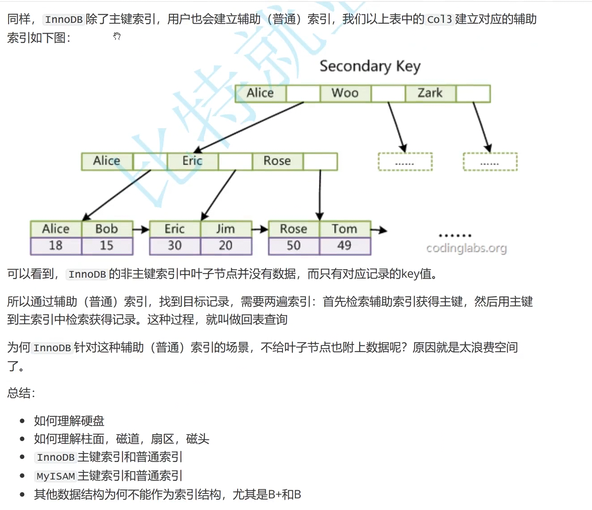
Innode db的非主键索引中的叶子节点没有数据,只有对应记录的key值
所以通过辅助(普通)索引找到目标记录,需要两遍索引
首先检索辅助索引获取主键,然后用主键到主索引中检索获得记录
这种过程叫做回表查询
一张表可能对应多个B+树

索引操作
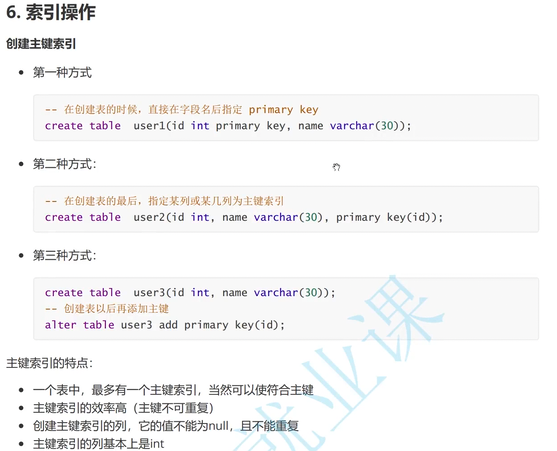
一个表中最多有一个主键索引
主键索引的效率高,但是主键不可重复
创建主键索引的列,值不能为null,且不能重复
主键索引的列基本是int
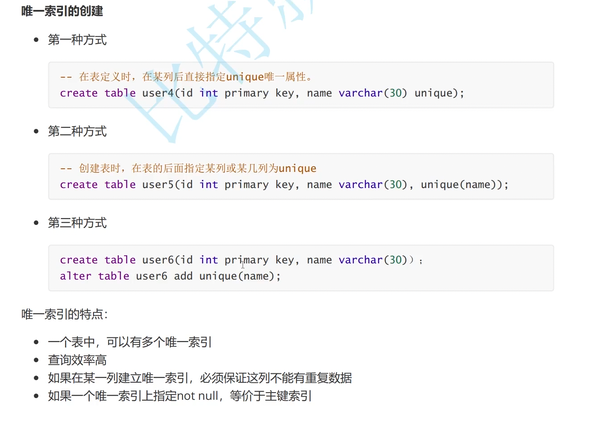
一个表中可以存在多个唯一索引
查询效率高
如果在某一列建立唯一索引,必须保证这列不能有重复数据
如果一个唯一索引上指定not null,则等价于主键索引
普通索引:
在表的最后使用 index(...)可以在表定义的最后,指定某列为索引
创建完表后,可以使用alter table 表名 add index(...)可以在指定某列为普通索引
使用create index idx_name on 表名可以创建名为idx_name 的索引

使用 alter table 表明 drop primary key 可以删除主键索引
使用alter table 表明 drop index 索引名 可以删除其他索引索引

我们还可以将多列创建为索引
这种将多列作为索引的索引,叫做复合索引

比较频繁作为查询条件的字段应该创建索引
唯一性太差的字段不适合单独创建索引,即使频繁作为查询条件
更新非常频繁的字段不适合创建索引
不会出现where字句的字段不该创建索引
