SpringBoot 整合 Neo4j 实战:从零搭建经典小说知识图谱完整方案
一、前言
1. 图数据库简介
作为一名后端开发者,我对图数据库在复杂关系处理方面的能力一直很感兴趣。传统关系型数据库在处理多表关联查询时,随着数据量增长性能会急剧下降。比如查询"贾宝玉和刘姥姥之间的最短关系路径",在MySQL中需要多次JOIN操作,复杂度极高。图数据库完美解决了这类问题 。Neo4j采用原生图存储引擎,将数据以节点和边的形式直接存储,复杂关系查询能在毫秒级完成。在我的测试中,三度关系查询在百万节点情况下响应时间仍保持在毫秒级别。
图数据库的核心优势:
- 高效关系遍历:邻接表结构使遍历时间复杂度为O(1)
- 灵活Schema:无需预先定义严格表结构,可动态添加节点和关系类型
- 直观查询语言 :Cypher语法类似SQL但针对图数据设计,配合Neo4j Browser可可视化查看结果
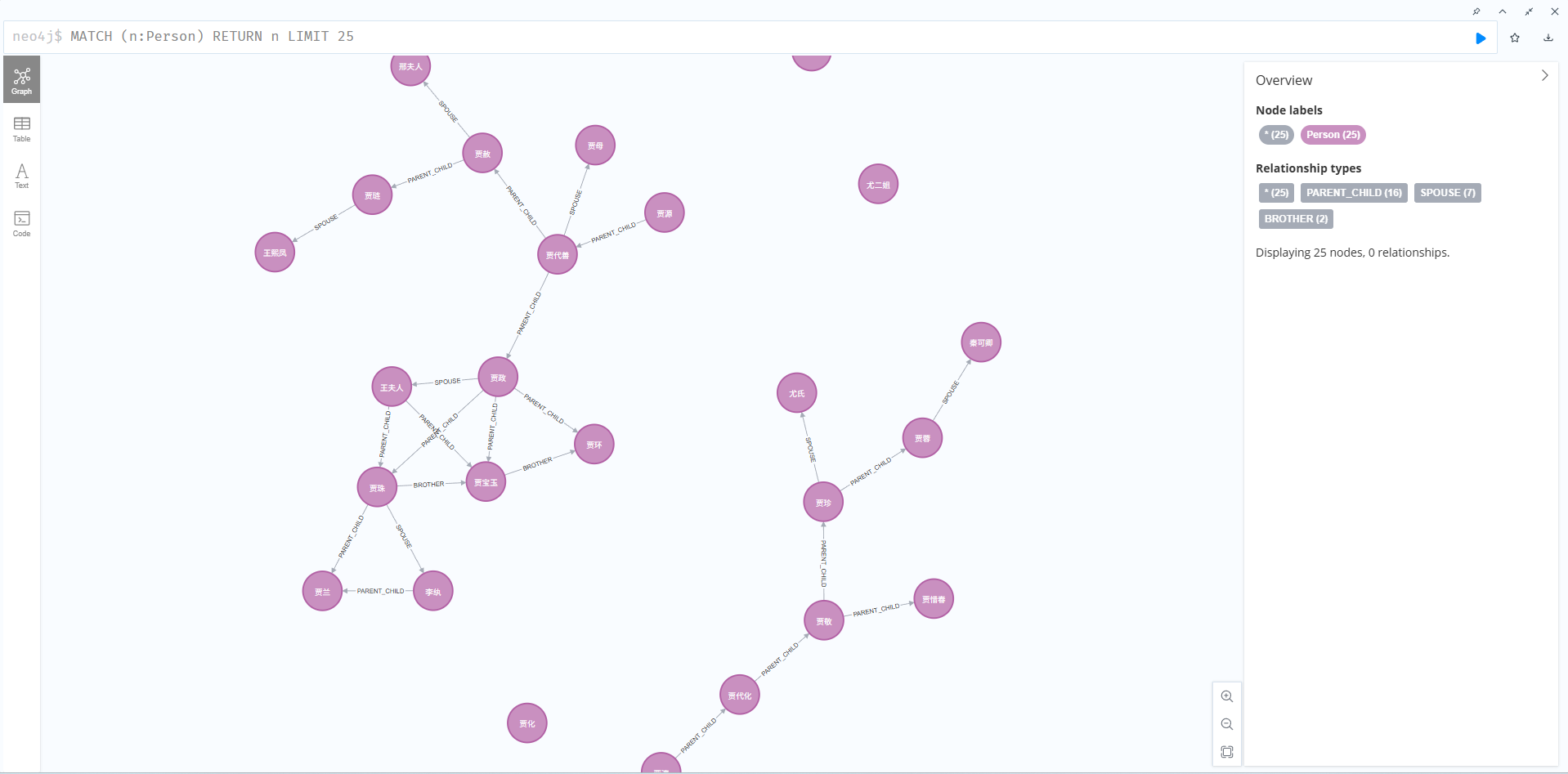
2. 知识图谱应用场景
知识图谱将实体及其关系以图的形式存储,在多个领域有广泛应用:
| 领域 | 应用场景 | 技术要点 |
|---|---|---|
| 文化遗产 | 小说人物关系分析 | 实体抽取、关系建模、路径分析 |
| 社交网络 | 用户关系挖掘 | 社区发现、影响力传播、推荐系统 |
| 金融风控 | 欺诈检测 | 异常模式识别、团伙发现 |
| 医疗健康 | 疾病知识图谱 | 症状-疾病-药物关联 |
| 智能客服 | 问答系统 | 语义理解、知识推理 |
本项目选择经典小说《红楼梦》作为案例,书中四大家族(贾史王薛)的联姻、主仆、血缘关系形成庞大网络,非常适合展示图数据库优势。
二、图数据库结构简介
数据模型设计
设计数据模型时,我平衡了灵活性和查询效率,确定了三种核心节点类型:
| 节点标签 | 属性 | 设计考虑 |
|---|---|---|
Topic |
name, type, description, author, year | 支持多专题管理,便于扩展 |
Person |
name, gender, title, description, family, topic | topic字段实现数据隔离 |
Family |
name, description | 按家族维度查询统计 |
关系类型设计兼顾语义准确性和查询效率:
| 关系名称 | 英文标识 | 方向性 | 说明 |
|---|---|---|---|
| 夫妻 | SPOUSE |
双向 | 婚姻关系 |
| 父母子女 | PARENT_CHILD |
有向 | 从父母指向子女 |
| 兄弟/姐妹 | BROTHER/SISTER |
双向 | 同辈关系 |
| 主仆 | MASTER_SERVANT |
有向 | 从主人指向仆人 |
| 恋人 | LOVER |
双向 | 情感关系 |
| 归属 | BELONGS_TO |
有向 | 从人物指向家族 |
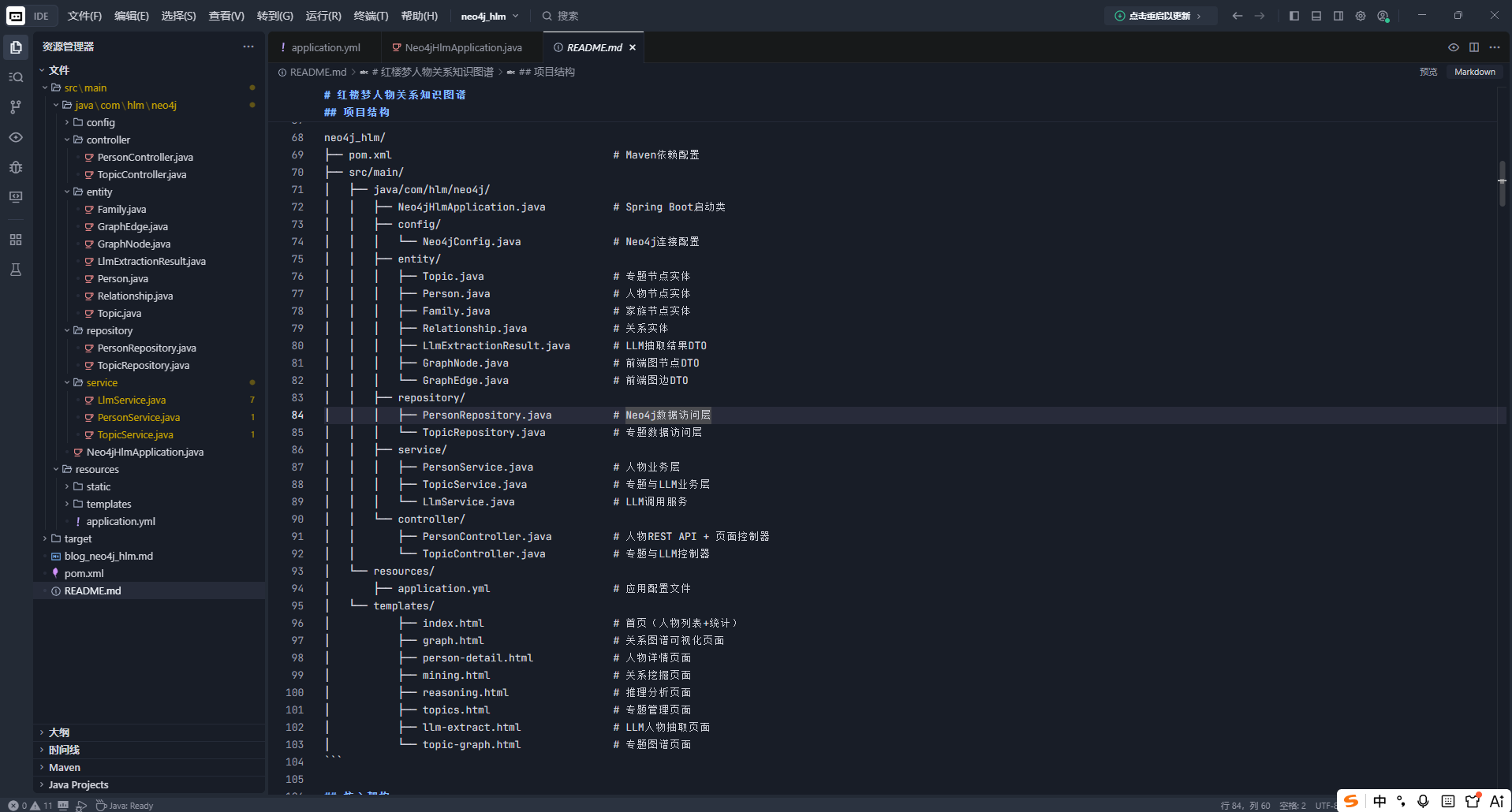
项目架构
neo4j_hlm/
├── pom.xml
├── src/main/java/com/hlm/neo4j/
│ ├── Neo4jHlmApplication.java # 启动类
│ ├── config/Neo4jConfig.java # 连接配置
│ ├── entity/ # 实体类
│ ├── repository/ # 数据访问层
│ ├── service/ # 业务逻辑层
│ └── controller/ # REST API
└── src/main/resources/
├── application.yml
└── templates/架构设计要点:
- 分层架构:Controller-Service-Repository三层
- 专题隔离 :通过
topic属性实现数据隔离 - 双数据源 :同时使用Spring Data Neo4j和原生Session
三、知识图谱构建
1. 环境准备
技术栈: JDK 21(支持文本块)、Maven 3.9+、Neo4j 5.26社区版
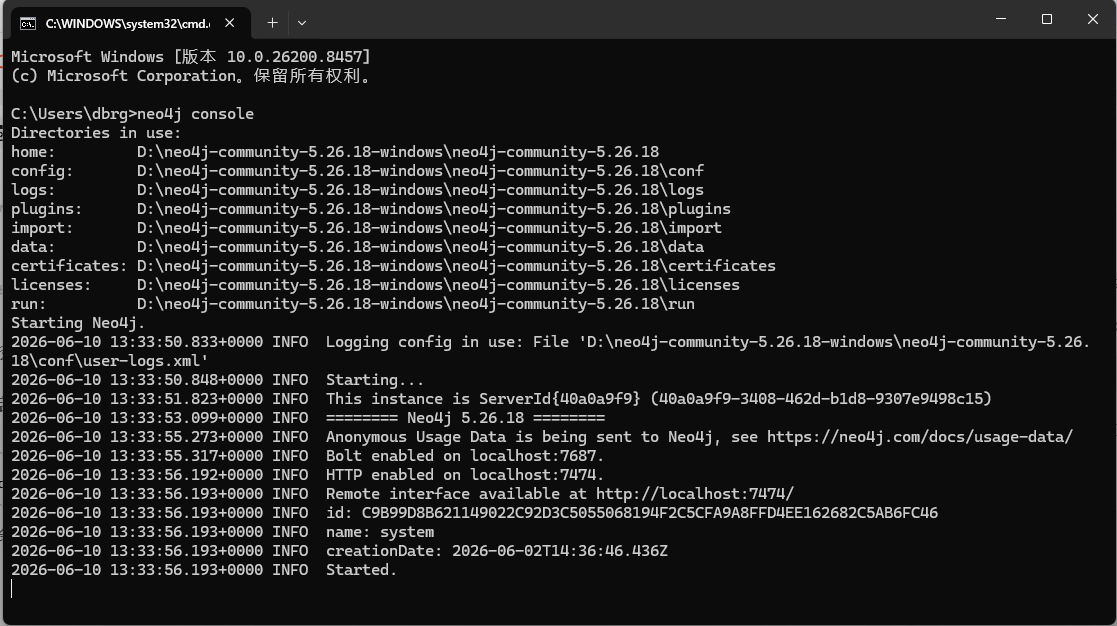
启动Neo4j(本地安装模式):
bash
neo4j console服务启动后,在控制台中看到如下页面说明启动成功:
2. 配置连接
yaml
server:
port: 8080
spring:
neo4j:
uri: bolt://localhost:7687
authentication:
username: neo4j
password: your-password
thymeleaf:
cache: false配置要点:使用Bolt协议性能更好,生产环境密码建议存环境变量。这里方便演示,不做特殊处理。
3. 实体类设计
java
package com.hlm.neo4j.entity;
@Node
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Person {
@Id @GeneratedValue
private Long id;
@Property
private String name;
@Property
private String gender;
@Property
private String title;
@Property
private String family;
@Property
private String topic; // 数据隔离关键字段
@Relationship(type = "PARENT_CHILD", direction = Relationship.Direction.OUTGOING)
private List<Person> children = new ArrayList<>();
@Relationship(type = "SPOUSE", direction = Relationship.Direction.BOTH)
private List<Person> spouses = new ArrayList<>();
}关键点:@Node标识图节点,@Relationship定义关系类型和方向,topic字段实现专题隔离。
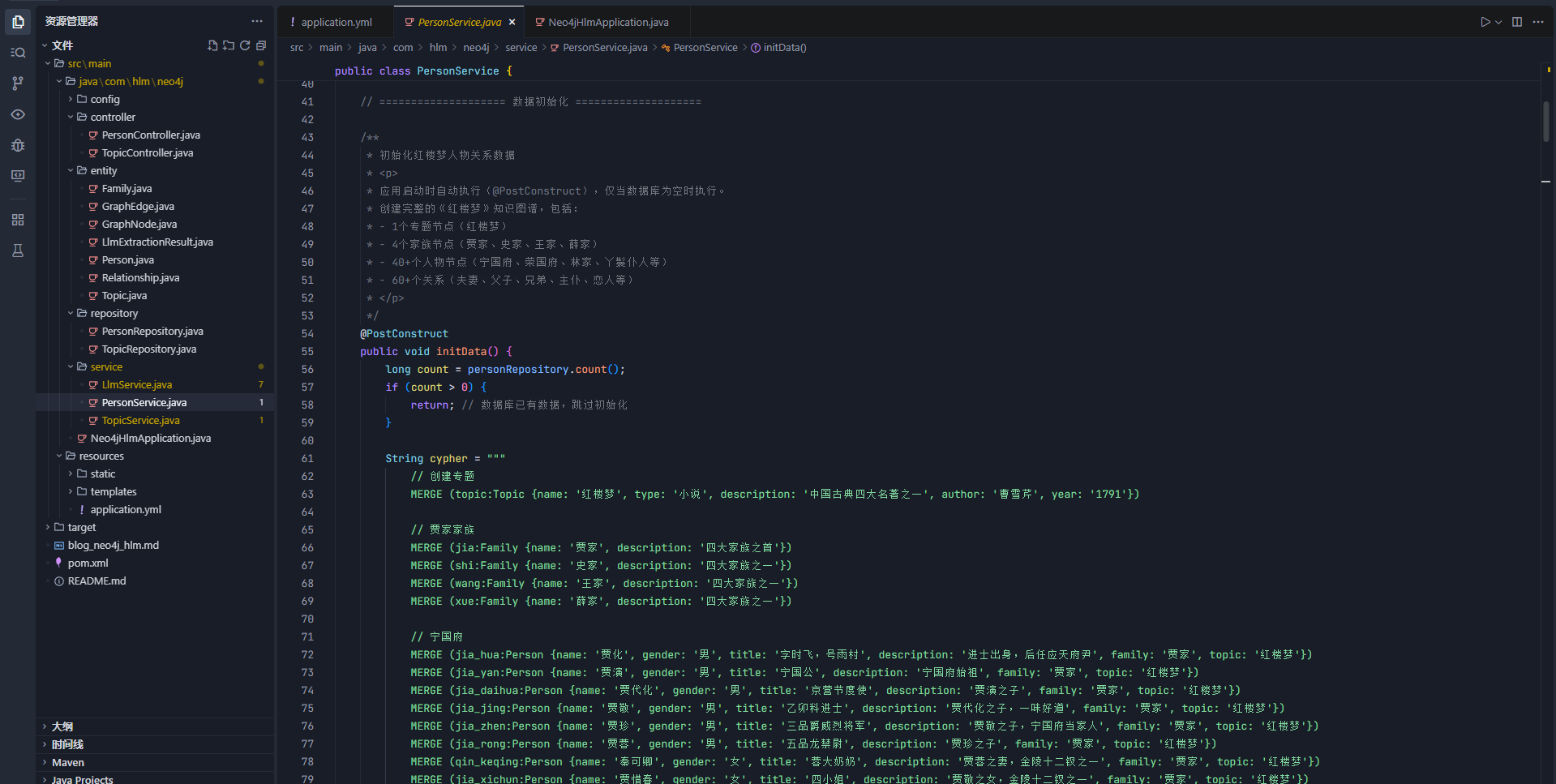
4. 数据初始化
java
@Service
public class PersonService {
private final PersonRepository personRepository;
private final Session neo4jSession;
@PostConstruct
public void initData() {
if (personRepository.count() > 0) return; // 幂等性检查
String cypher = """
MERGE (topic:Topic {name: '红楼梦', type: '小说'})
MERGE (jia:Family {name: '贾家'})
MERGE (wang:Family {name: '王家'})
MERGE (jia_baoyu:Person {name: '贾宝玉', gender: '男', topic: '红楼梦'})
MERGE (lin_daiyu:Person {name: '林黛玉', gender: '女', topic: '红楼梦'})
MERGE (wang_xifeng:Person {name: '王熙凤', gender: '女', topic: '红楼梦'})
MERGE (jia_baoyu)-[:LOVER]->(lin_daiyu)
MERGE (wang_xifeng)-[:FRIEND]->(liu_laolao)
""";
neo4jSession.run(cypher);
}
}技术要点:使用MERGE确保幂等性,@PostConstruct在应用启动时自动执行。
5. Repository层
java
@Repository
public interface PersonRepository extends Neo4jRepository<Person, Long> {
Optional<Person> findByName(String name);
@Query("MATCH (a:Person {name: $name1})--(common:Person)--(b:Person {name: $name2}) RETURN common")
List<Person> findCommonConnections(@Param("name1") String n1, @Param("name2") String n2);
@Query("MATCH path = shortestPath((a:Person {name: $source})-[*1..5]-(b:Person {name: $target})) RETURN path")
List<PathRecord> findShortestPath(@Param("source") String src, @Param("target") String tgt);
@Query("MATCH (p:Person) WITH p, size((p)--()) AS cnt RETURN p.name, cnt ORDER BY cnt DESC")
List<InfluenceRecord> getInfluenceRanking();
}设计技巧:继承Neo4jRepository获得基础CRUD,@Query定义自定义Cypher,@Param绑定参数。
6. 图算法实现
最短路径查询:
cypher
MATCH path = shortestPath(
(a:Person {name: '贾宝玉'})-[*1..5]-(b:Person {name: '刘姥姥'})
)
RETURN path算法说明:shortestPath使用BFS算法,[*1..5]限制路径长度防止超时。
影响力分析:
cypher
MATCH (p:Person)
WITH p, size((p)--()) AS relationCount
RETURN p.name, relationCount
ORDER BY relationCount DESC算法说明:size((p)--())计算度中心性,度数越高影响力越大。
四、成果展示
功能模块
| 模块 | 地址 | 功能 |
|---|---|---|
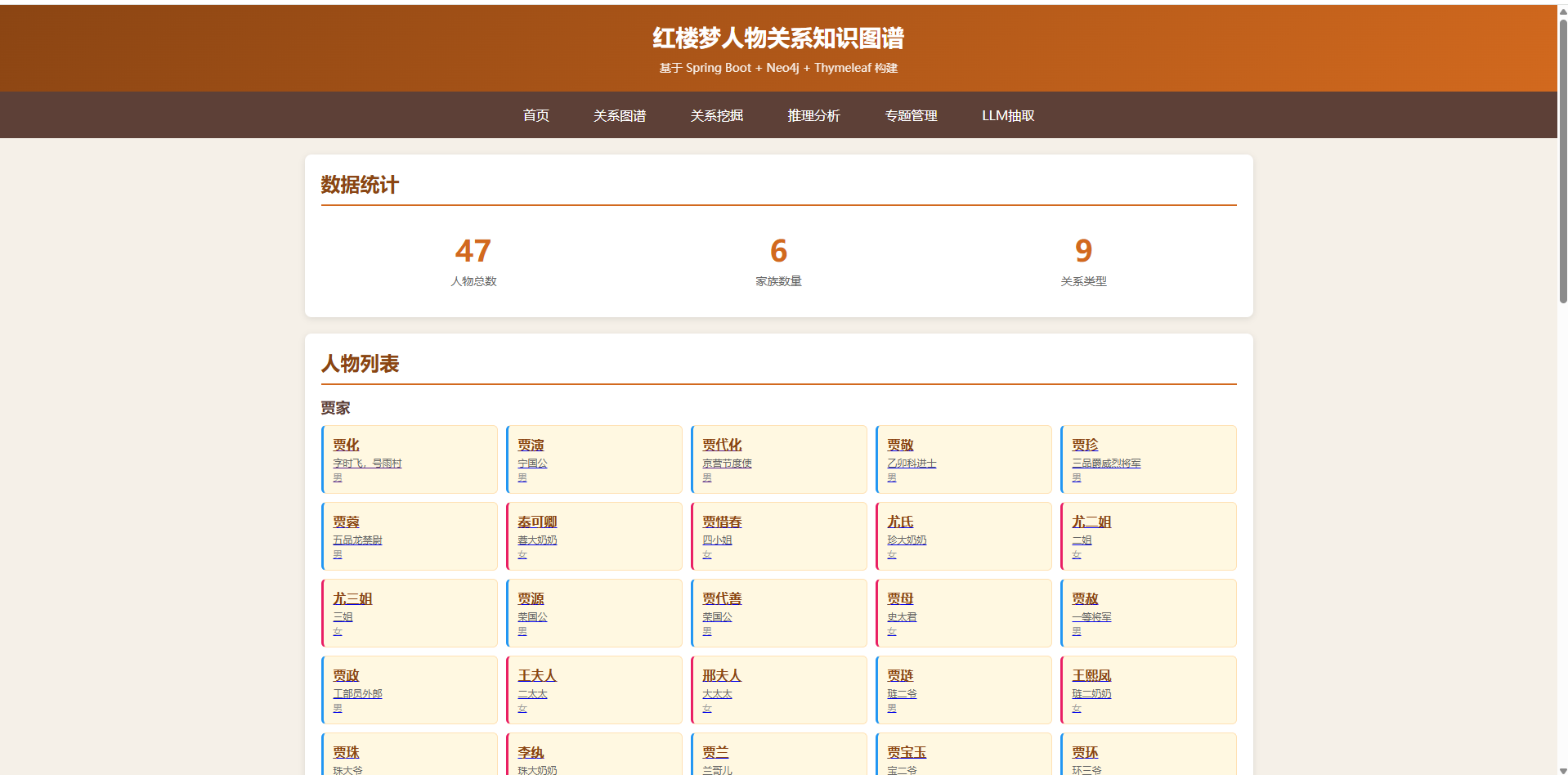
| 首页 | / |
人物列表、家族分类、统计 |
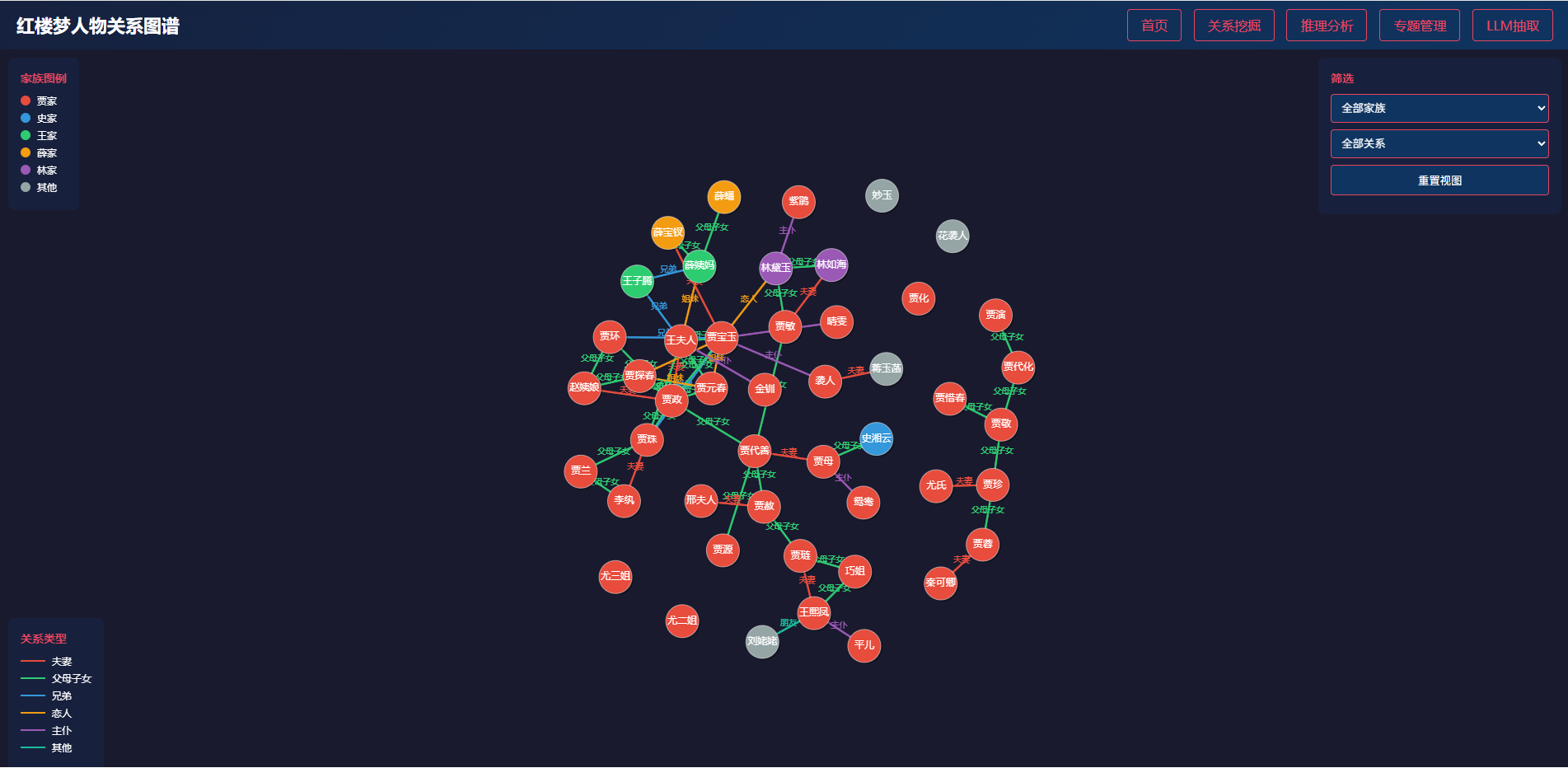
| 图谱可视化 | /graph |
Canvas力导向图,拖拽交互 |
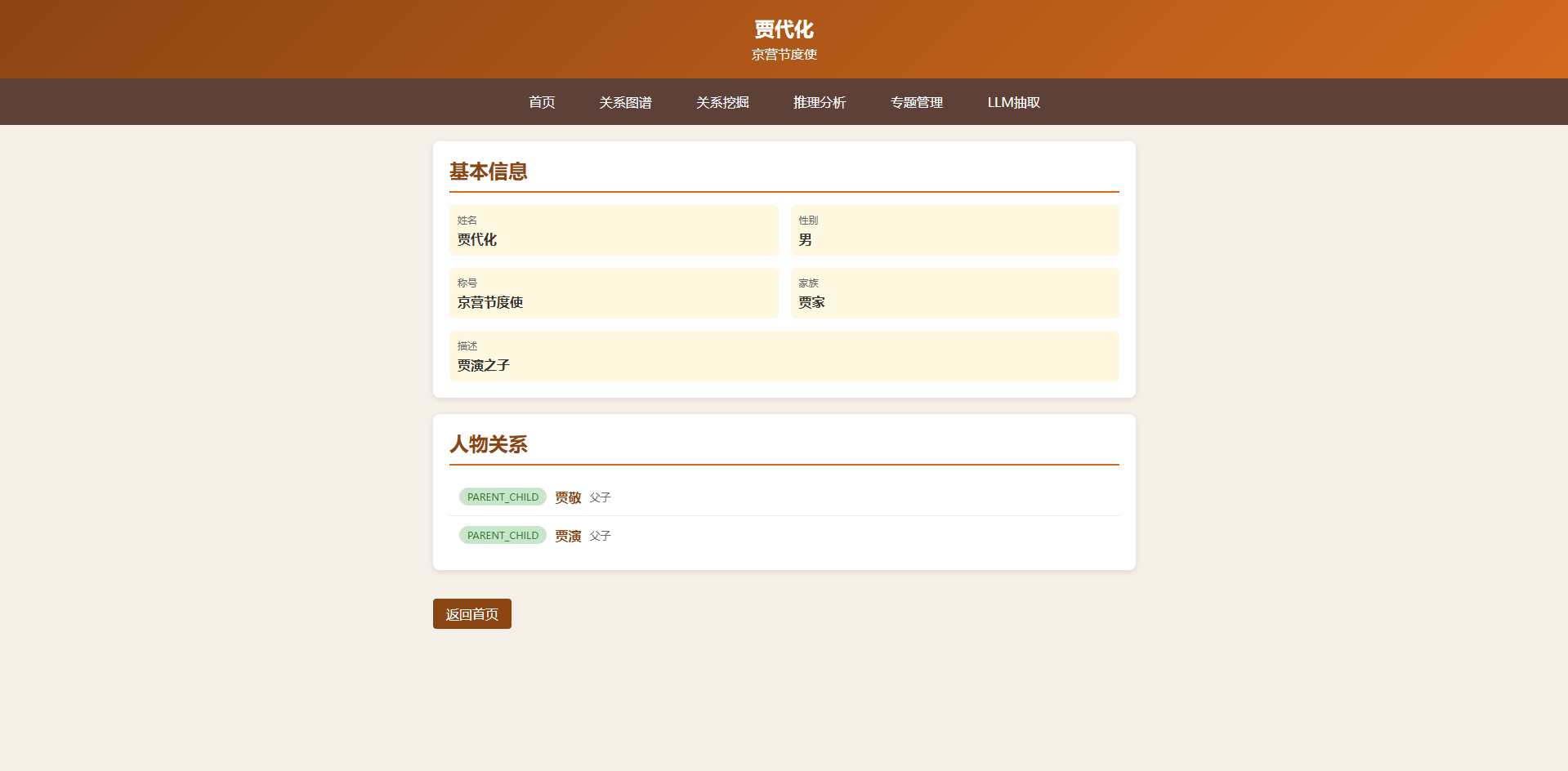
| 人物详情 | /person/{name} |
属性、关系列表 |
| 关系挖掘 | /mining |
最短路径、共同关系人 |
| 推理分析 | /reasoning |
影响力排行、桥梁人物 |
| LLM抽取 | /llm-extract |
文本自动抽取人物关系 |
图谱可视化实现
javascript
function forceLayout() {
// 斥力计算
nodes.forEach((n1, i) => {
nodes.slice(i + 1).forEach(n2 => {
const dx = n2.x - n1.x, dy = n2.y - n1.y;
const dist = Math.sqrt(dx*dx + dy*dy);
const force = repulsion / (dist * dist);
n1.vx -= dx * force; n2.vx += dx * force;
});
});
// 引力计算
edges.forEach(e => {
const dx = e.target.x - e.source.x;
const force = (dist - edgeLength) * attraction;
e.source.vx += dx * force; e.target.vx -= dx * force;
});
// 更新位置(带阻尼)
nodes.forEach(n => {
n.vx *= damping; n.vy *= damping;
n.x += n.vx; n.y += n.vy;
});
}实现要点:Fruchterman-Reingold算法,斥力防重叠,引力保持连接,阻尼系数防震荡。
关系挖掘示例
最短路径: 贾宝玉 → 王熙凤 → 刘姥姥(2度关系)
分析:管家王熙凤是连接核心家族和外部社会的桥梁。
共同关系人: 贾宝玉 & 林黛玉 → 贾母、王夫人、薛宝钗、袭人、紫鹃
分析:两人共享多个关系人,处于贾府核心社交圈。
影响力排行
| 排名 | 人物 | 关系数 | 分析 |
|---|---|---|---|
| 1 | 贾宝玉 | 12 | 全书核心人物 |
| 2 | 王熙凤 | 10 | 管家身份广泛联系 |
| 3 | 贾母 | 9 | 家族最高权威 |
| 4 | 王夫人 | 8 | 连接贾家与王家 |
| 5 | 贾政 | 7 | 荣国府二老爷 |
API接口
| 接口 | 方法 | 说明 |
|---|---|---|
/api/persons |
GET | 人物列表 |
/api/graph |
GET | 图谱数据 |
/api/mining/shortest-path?source=A&target=B |
GET | 最短路径 |
/api/mining/common-connections?name1=A&name2=B |
GET | 共同关系人 |
/api/reasoning/influence |
GET | 影响力排行 |
运行效果
- 人物总数:50+(四大家族及丫鬟仆人)
- 家族数量:5个(贾、史、王、薛、林)
- 关系类型:7种(血缘、婚姻、情感、主仆等)
- 关系总数:60+
五、总结
项目亮点
- 专题隔离机制 :
topic属性实现多小说数据隔离 - LLM集成:自动抽取人物关系,降低录入成本
- 图算法应用:最短路径、度中心性、共同邻居
- 可视化展示:Canvas力导向图,拖拽交互
- RESTful API:完整接口便于集成
技术价值
- 关系表达自然:节点-边模型贴近现实世界
- 查询性能优异:复杂路径毫秒级返回
- 分析能力强大:图算法揭示隐藏关系模式
扩展方向
- 多模态融合:添加人物画像、小说片段
- 智能问答:基于图谱的自然语言问答
- 情感分析:人物情感关系强度分析
- 时序分析:关系随故事发展的变化
结语
这个项目可以让人详细解了图数据库的价值。从数据建模到算法实现,再到可视化展示,每个环节都充满挑战但也收获满满。希望这份实战经验能帮助更多开发者理解图数据库的应用价值。行文仓促,定有不足之处,欢迎各位朋友在评论区批评指正,不胜感激。