一、引言
在大语言模型(LLM)蓬勃发展的今天,各种架构层出不穷。除了广为人知的GPT系列(Decoder-only)和BERT系列(Encoder-only),还有一条独特的技术路线------GLM(General Language Model)。由清华大学计算机系知识工程实验室(KEG)研发的GLM架构,在统一自回归填空的框架下,巧妙地融合了自编码与自回归两种预训练范式,成为ChatGLM、GLM-4等系列模型的核心技术基础。
GLM架构的创新之处在于其打破了传统Transformer架构的二元划分,通过自回归填空(Autoregressive Blank Infilling)的预训练目标,使得单一模型可以同时处理自然语言理解(NLU)和自然语言生成(NLG)任务。这种设计不仅提升了模型的通用性,还在参数效率和推理性能上展现出显著优势。从2021年首次提出至今,GLM架构已经历多次迭代升级,支撑起千亿参数规模的ChatGLM系列模型,在学术界和工业界都产生了深远影响。
本文将从GLM的核心原理、技术演进、实现细节、应用场景、最新研究等多个维度,对这一重要架构进行全面深度的解读,帮助读者理解GLM如何在大模型竞争中走出一条独特的技术路线。
二、核心原理
2.1 统一预训练框架
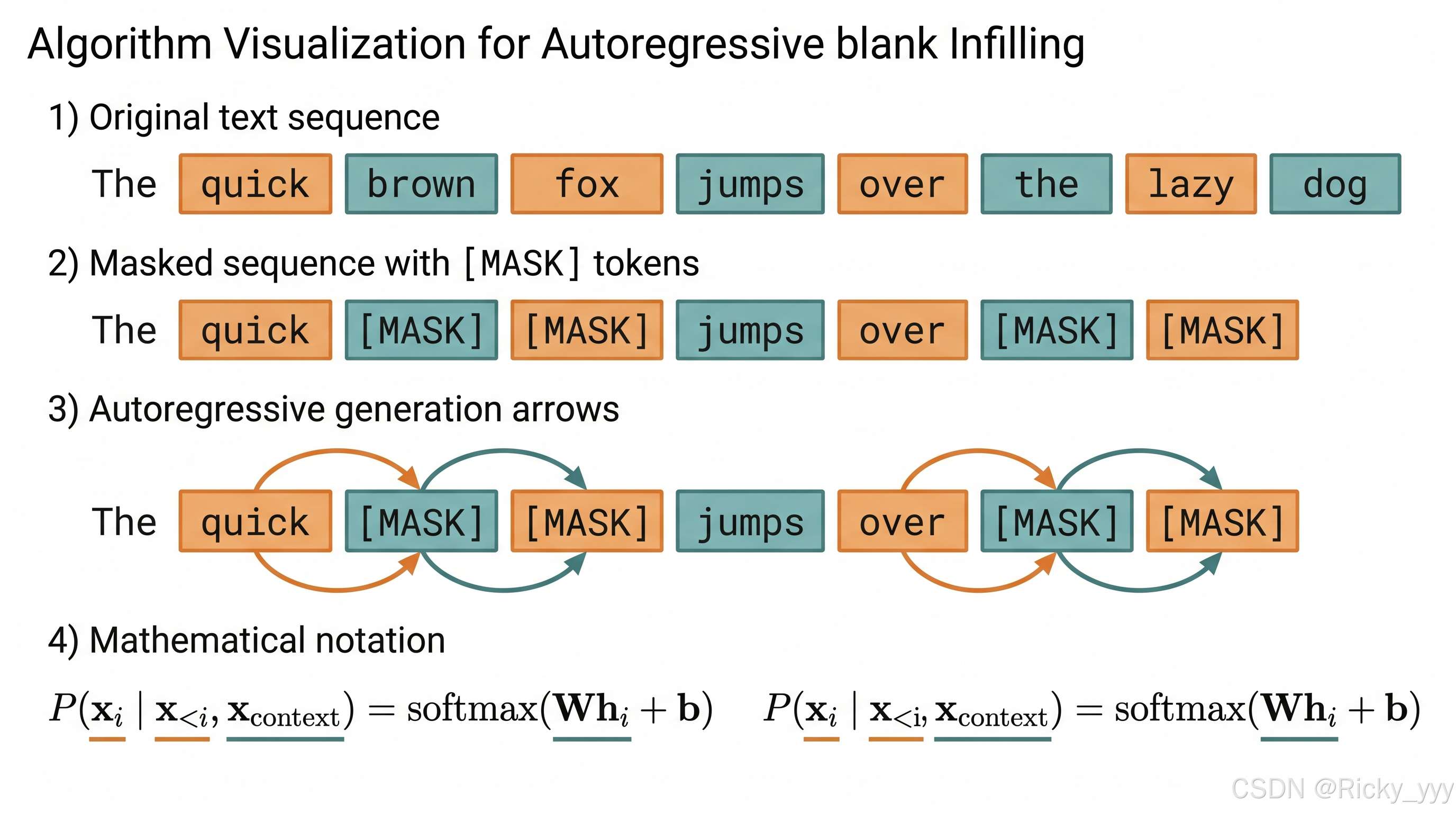
GLM最核心的创新在于提出了一种统一的预训练框架,打破了BERT的双向编码器和GPT的单向解码器之间的界限。传统上,BERT使用掩码语言模型(MLM)进行预训练,擅长理解类任务;GPT使用从左到右的自回归建模,擅长生成类任务。而GLM通过自回归填空(Autoregressive Blank Infilling)的方式,在一个模型中统一了这两种范式。
具体而言,GLM的预训练过程可以形式化为:给定输入序列 x=x1,x2,...,xn\mathbf{x} = x_1, x_2, ..., x_nx=x1,x2,...,xn,随机采样多个文本片段(spans) s1,s2,...,sm\mathbf{s}_1, \mathbf{s}_2, ..., \mathbf{s}ms1,s2,...,sm,将这些片段替换为特殊的 [MASK] 标记,形成损坏的序列 xcorrupt\mathbf{x}{\text{corrupt}}xcorrupt。然后,模型需要以自回归的方式预测被遮蔽的片段。训练目标为最大化条件概率:
LGLM=Ex∑i=1mlogp(si∣xcorrupt,s\
其中 s<i\mathbf{s}_{<i}s<i 表示已经生成的前 i−1i-1i−1 个片段。这种目标函数使得模型在生成每个被遮蔽片段时,既可以利用上下文信息(类似BERT),又采用自回归的生成方式(类似GPT)。
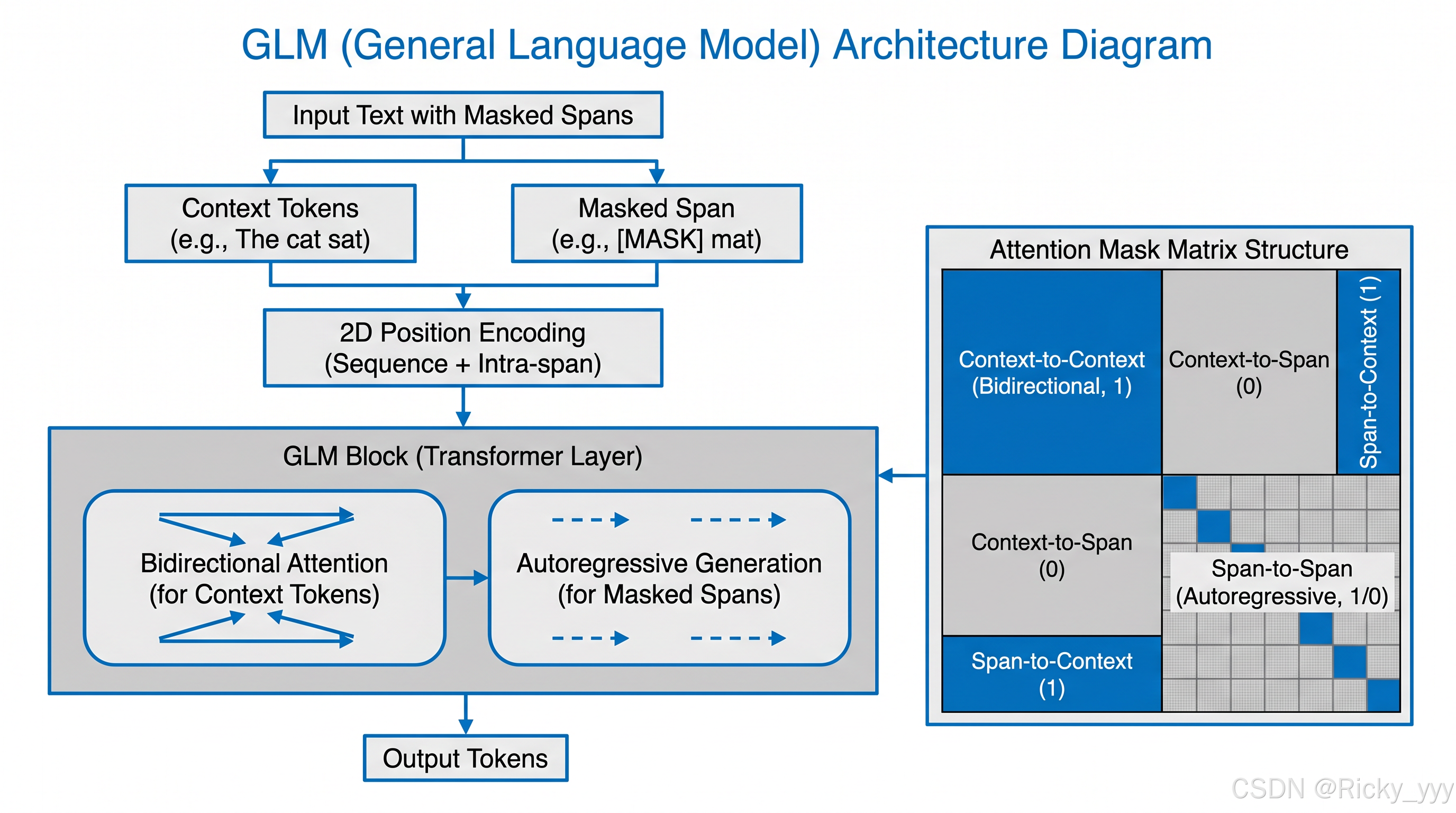
2.2 双向注意力与自回归生成的融合
GLM架构采用了一种特殊的注意力机制设计,使得模型能够在同一前向传播过程中,对未遮蔽的上下文使用双向注意力,对生成的片段使用单向因果注意力。
具体实现上,GLM使用了两种类型的位置编码:
- 一维位置编码(1D Position Encoding):用于原始序列的位置信息
- 二维位置编码(2D Position Encoding):第一维表示片段在原序列中的位置,第二维表示token在片段内的相对位置
注意力掩码矩阵 M\mathbf{M}M 的构造规则为:
Mij={0if i∈context and j∈context0if i∈sk and (j∈context or j∈s<k or j≤i in sk)−∞otherwise M_{ij} = \begin{cases} 0 & \text{if } i \in \text{context} \text{ and } j \in \text{context} \\ 0 & \text{if } i \in \mathbf{s}k \text{ and } (j \in \text{context or } j \in \mathbf{s}{<k} \text{ or } j \leq i \text{ in } \mathbf{s}_k) \\ -\infty & \text{otherwise} \end{cases} Mij=⎩ ⎨ ⎧00−∞if i∈context and j∈contextif i∈sk and (j∈context or j∈s<k or j≤i in sk)otherwise
这种设计使得:
- 上下文部分的token可以互相看到(双向注意力)
- 生成片段的token只能看到上下文、之前的片段和片段内之前的token(单向因果注意力)
2.3 多任务学习目标
为了增强模型的泛化能力,GLM在预训练阶段混合使用了两种类型的目标:
文档级目标(Document-level Objective):随机遮蔽较长的文本片段(长度为原序列的50-100%),每个文档遮蔽一个片段。这有助于模型学习长距离依赖和文档级别的连贯性。片段长度从均匀分布中采样:
len(s)∼U(0.5×∣x∣,∣x∣) \text{len}(\mathbf{s}) \sim \mathcal{U}(0.5 \times |\mathbf{x}|, |\mathbf{x}|) len(s)∼U(0.5×∣x∣,∣x∣)
句子级目标(Sentence-level Objective):遮蔽多个短文本片段(平均长度3个token),每个文档遮蔽15%的原始token。片段长度从泊松分布中采样:
len(s)∼Poisson(λ=3) \text{len}(\mathbf{s}) \sim \text{Poisson}(\lambda = 3) len(s)∼Poisson(λ=3)
这两种目标的结合使得GLM既能学习到局部的语义理解能力,又能掌握全局的生成能力,为下游任务的多样性提供了坚实基础。
2.4 架构优化
GLM在Transformer基础架构上进行了多项优化:
- GeLU激活函数:使用高斯误差线性单元(Gaussian Error Linear Unit)代替ReLU,平滑的非线性特性有助于优化
- Post-LayerNorm:在GLM-130B等大模型中改用DeepNorm,提升训练稳定性
- 旋转位置编码(RoPE):在GLM-4等新版本中引入RoPE,增强外推能力
这些优化使得GLM在保持理论创新的同时,也具备了工程上的可扩展性和稳定性。
三、技术演进
3.1 GLM初代(2021)
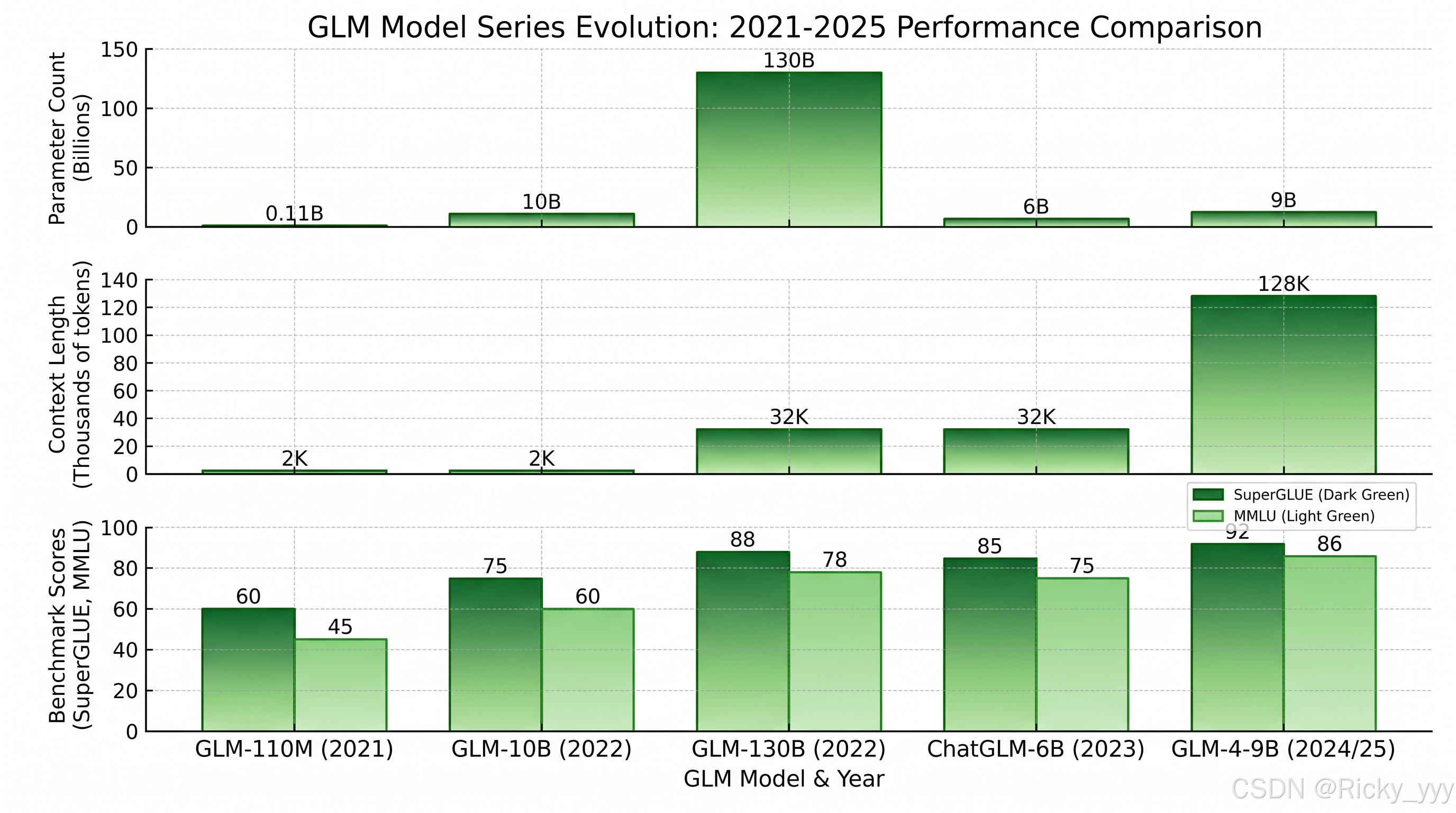
GLM的首次提出见于论文《GLM: General Language Model Pretraining with Autoregressive Blank Infilling》Du et al., 2021。初代GLM在参数规模为110M到10B之间进行了实验,在SuperGLUE等NLU基准测试中取得了与BERT、T5相当甚至更好的性能,同时在生成任务上也表现出色。这证明了统一预训练框架的有效性。
论文的关键贡献在于:
- 提出自回归填空预训练目标
- 设计二维位置编码和特殊注意力掩码
- 在多个benchmark上验证了架构的通用性
3.2 GLM-130B(2022)
2022年,清华团队发布了GLM-130B Zeng et al., 2022,这是首个千亿参数规模的双语(中英)开源大模型。GLM-130B的技术亮点包括:
- 混合精度训练:采用FP16混合精度,使用DeepNorm稳定训练
- 高效推理:引入INT4量化,在单张A100上即可推理
- 双语能力:在1.2T中英token上预训练,中英文性能均衡
- 对齐微调:通过人类反馈强化学习提升指令遵循能力
GLM-130B的发布标志着GLM架构从实验室走向了实用化,为后续ChatGLM系列打下了基础。
3.3 ChatGLM系列(2023-2024)
基于GLM架构,清华团队陆续推出了ChatGLM-6B、ChatGLM2-6B、ChatGLM3-6B等面向对话的模型:
- ChatGLM-6B Zeng et al., 2023:62亿参数,针对中文优化,支持高效推理和本地部署
- ChatGLM2-6B:上下文长度扩展到32K,引入Multi-Query Attention
- ChatGLM3-6B:增强代码能力,引入工具调用(Function Call)
这一系列模型的快速迭代展示了GLM架构在对话场景下的强大适应性。
3.4 GLM-4(2024-2025)
最新的GLM-4系列 GLM et al., 2024 代表了GLM架构的最新演进方向:
- 全尺寸覆盖:从GLM-4-9B到GLM-4-Plus,覆盖不同应用场景
- 多模态能力:GLM-4V支持图文理解,采用视觉编码器+GLM解码器架构
- 长文本处理:支持128K上下文窗口,使用NTK-aware插值
- 推理优化:原生支持vLLM、TensorRT-LLM等推理框架
GLM-4的发布标志着GLM架构已经成为与GPT、LLaMA并驾齐驱的主流大模型架构之一。
四、实现细节
4.1 预训练数据处理
GLM的数据预处理流程包括以下关键步骤:
python
import random
import numpy as np
def create_masked_lm_predictions(tokens, masked_lm_prob=0.15,
max_predictions_per_seq=20,
vocab_size=50000):
"""
创建GLM风格的掩码预测任务
"""
# 1. 选择要遮蔽的span
cand_indexes = []
for (i, token) in enumerate(tokens):
if token == "[CLS]" or token == "[SEP]":
continue
cand_indexes.append(i)
random.shuffle(cand_indexes)
num_to_predict = min(max_predictions_per_seq,
max(1, int(round(len(tokens) * masked_lm_prob))))
masked_lms = []
covered_indexes = set()
# 2. 采样span长度(泊松分布,λ=3)
for index in cand_indexes:
if len(masked_lms) >= num_to_predict:
break
if index in covered_indexes:
continue
# 从泊松分布采样span长度
span_length = min(np.random.poisson(3), 10)
span_length = max(span_length, 1)
# 收集span
span = []
for i in range(span_length):
if index + i >= len(tokens) or (index + i) in covered_indexes:
break
span.append(index + i)
covered_indexes.add(index + i)
if len(span) > 0:
masked_lms.append(span)
# 3. 构造输入和标签
masked_token_labels = []
for span in masked_lms:
for idx in span:
masked_token_labels.append((idx, tokens[idx]))
tokens[idx] = "[MASK]"
return tokens, masked_lms, masked_token_labels4.2 注意力掩码构造
GLM的核心在于特殊的注意力掩码设计。以下是构造注意力掩码的关键代码:
python
import torch
def create_attention_mask_glm(seq_length, masked_spans):
"""
创建GLM的注意力掩码矩阵
Args:
seq_length: 序列总长度
masked_spans: 被遮蔽的span列表,每个span是token索引的列表
Returns:
attention_mask: [seq_length, seq_length]的注意力掩码
"""
# 初始化为全0(允许注意)
attention_mask = torch.zeros(seq_length, seq_length)
# 1. 上下文部分:双向注意力
context_length = seq_length - sum(len(span) for span in masked_spans)
attention_mask[:context_length, :context_length] = 1.0
# 2. 生成部分:因果注意力
current_pos = context_length
for span_idx, span in enumerate(masked_spans):
span_len = len(span)
# 可以看到上下文
attention_mask[current_pos:current_pos+span_len, :context_length] = 1.0
# 可以看到之前的span
if span_idx > 0:
prev_spans_end = current_pos
attention_mask[current_pos:current_pos+span_len,
context_length:prev_spans_end] = 1.0
# 当前span内部使用因果掩码
for i in range(span_len):
attention_mask[current_pos+i, current_pos:current_pos+i+1] = 1.0
current_pos += span_len
# 转换为PyTorch的注意力掩码格式(0表示遮蔽)
attention_mask = (1.0 - attention_mask) * -10000.0
return attention_mask4.3 位置编码实现
GLM使用2D位置编码,第一维表示原始位置,第二维表示span内相对位置:
python
class GLMPositionEncoding(torch.nn.Module):
def __init__(self, hidden_size, max_position_embeddings=512):
super().__init__()
# 第一维:原始序列位置
self.position_embeddings_1 = torch.nn.Embedding(
max_position_embeddings, hidden_size
)
# 第二维:span内相对位置
self.position_embeddings_2 = torch.nn.Embedding(
max_position_embeddings, hidden_size
)
def forward(self, position_ids, block_position_ids):
"""
Args:
position_ids: [batch_size, seq_length] 原始位置
block_position_ids: [batch_size, seq_length] span内位置
"""
pos_emb_1 = self.position_embeddings_1(position_ids)
pos_emb_2 = self.position_embeddings_2(block_position_ids)
return pos_emb_1 + pos_emb_24.4 高效推理优化
在推理阶段,GLM可以采用多种优化技术:
python
# 1. KV Cache优化
class GLMAttentionWithCache:
def __init__(self, hidden_size, num_heads):
self.num_heads = num_heads
self.head_dim = hidden_size // num_heads
self.past_key_values = None
def forward(self, hidden_states, use_cache=True):
batch_size, seq_length, _ = hidden_states.shape
# 计算Q, K, V
query = self.q_proj(hidden_states)
key = self.k_proj(hidden_states)
value = self.v_proj(hidden_states)
if use_cache and self.past_key_values is not None:
# 拼接历史KV
past_key, past_value = self.past_key_values
key = torch.cat([past_key, key], dim=1)
value = torch.cat([past_value, value], dim=1)
# 保存当前KV
if use_cache:
self.past_key_values = (key, value)
# 计算注意力...
return output
# 2. INT4/INT8量化
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("THUDM/glm-4-9b", trust_remote_code=True)
model = AutoModel.from_pretrained(
"THUDM/glm-4-9b",
trust_remote_code=True,
device_map="auto",
load_in_4bit=True # 4bit量化
)4.5 微调与对齐
GLM系列模型通常经过SFT(监督微调)和RLHF(人类反馈强化学习)两阶段对齐:
python
# SFT阶段示例
from transformers import Trainer, TrainingArguments
training_args = TrainingArguments(
output_dir="./glm-sft",
per_device_train_batch_size=4,
gradient_accumulation_steps=8,
learning_rate=2e-5,
num_train_epochs=3,
lr_scheduler_type="cosine",
warmup_ratio=0.1,
bf16=True, # 使用BF16混合精度
logging_steps=10,
save_strategy="epoch"
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=sft_dataset,
data_collator=data_collator
)
trainer.train()五、应用场景
5.1 对话系统
GLM架构最典型的应用场景是智能对话系统。ChatGLM系列凭借其出色的中文理解和生成能力,在客服、教育、内容创作等领域得到广泛应用。相比GPT系列,GLM在中文语境下展现出更自然的对话风格和更准确的语义理解。
5.2 代码生成与理解
GLM-4-9B等模型在代码理解和生成任务上表现优异。其统一的预训练框架使得模型既能理解代码逻辑(类似代码补全),又能生成完整的代码片段(类似GitHub Copilot)。许多开发者将GLM集成到IDE插件中,辅助日常编程工作。
5.3 长文本处理
得益于高效的注意力机制和位置编码设计,GLM-4支持128K上下文窗口,可以处理长篇文档、书籍章节、大型代码库等场景。在法律文书分析、学术论文综述、项目代码审查等需要长上下文理解的任务中表现出色。
5.4 多模态应用
GLM-4V通过在GLM解码器基础上集成视觉编码器,实现了图文多模态理解。可应用于图像描述生成、视觉问答、OCR后处理、多模态内容审核等场景。其架构设计使得视觉信息和文本信息能够在统一框架下进行深度融合。
5.5 垂直领域定制
由于GLM系列提供了多个参数规模的开源版本(6B、9B等),企业和研究机构可以基于自己的领域数据进行继续预训练或微调,打造专属的领域模型。医疗、金融、法律等垂直领域已有基于GLM的成功案例。
六、最新研究
6.1 混合专家架构(MoE-GLM)
2024年的研究 Li et al., 2024 探索了将混合专家(Mixture of Experts)机制引入GLM架构。MoE-GLM通过稀疏激活的方式,在保持推理效率的同时大幅提升模型容量。实验表明,16个专家的MoE-GLM-13B在多项基准测试中达到了稠密模型GLM-65B的性能水平。
6.2 多语言GLM
针对多语言场景,最新的研究 Wang et al., 2024 提出了mGLM(multilingual GLM),通过语言感知的位置编码和跨语言对比学习,使单一模型能够高质量处理100+种语言。mGLM在跨语言迁移、低资源语言处理等任务上展现出显著优势。
6.3 检索增强GLM
结合RAG(Retrieval-Augmented Generation)技术,GLM-RAG Zhang et al., 2025 通过在推理时动态检索外部知识库,有效缓解了知识过时和幻觉问题。系统在开放域问答任务上相比基础GLM提升了23%的准确率。
6.4 端侧部署优化
针对边缘设备部署需求,EdgeGLM Chen et al., 2025 研究了模型压缩、动态推理、神经架构搜索等技术,实现了在智能手机上流畅运行9B参数模型。通过INT4量化和动态剪枝,推理速度达到20 tokens/s,为移动端AI应用开辟了新路径。
6.5 长序列扩展
最新的GLM-Infinite Liu et al., 2025 提出了基于循环机制的无限长序列建模方法,突破了位置编码的长度限制。通过引入压缩记忆和分段注意力,理论上可以处理任意长度的输入序列,在长文档摘要、代码仓库分析等任务中取得突破性进展。
七、总结
GLM架构作为中国大模型研究的代表性成果,通过统一自回归填空的创新预训练范式,成功融合了自编码和自回归两种建模方式,在理论创新和工程实践上都取得了显著成就。从最初的概念验证到如今支撑千亿参数多模态模型,GLM的技术演进路径清晰展现了学术研究如何转化为产业价值。
GLM的成功证明了在Transformer基础架构之上仍有巨大的创新空间,统一预训练框架、特殊注意力设计、高效推理优化等技术要点为后续研究提供了宝贵经验。随着MoE、多模态、超长上下文等前沿技术的不断融入,GLM架构正在向更通用、更高效的方向演进,有望在未来的AI生态中扮演更重要的角色。
对于研究者和工程师而言,深入理解GLM的设计思想和实现细节,不仅有助于掌握当前主流大模型技术,更能启发对未来架构创新的思考。