在企业数据平台建设过程中,数据同步是一项非常常见的需求。随着业务规模不断增长,全量同步带来的数据库压力和资源消耗也会越来越大。因此,在实际生产环境中,增量同步往往是更常见的选择。
本次演示将结合 Apache DolphinScheduler 与 Apache SeaTunnel,实现一个典型的离线增量同步场景:通过 DolphinScheduler 获取目标端同步位点,并将该位点作为参数传递给 SeaTunnel,从而实现 MySQL 到 Doris 的增量数据同步。

本文基于实际演示过程整理,完整记录环境准备、SeaTunnel 配置以及 DolphinScheduler 工作流配置过程。
具体操作步骤可参考完整 Demo 演示:
一、实验环境
本案例使用以下组件:
| 组件 | 版本 |
|---|---|
| Apache SeaTunnel | 2.3.9 |
| Apache DolphinScheduler | 3.x |
| MySQL | 8.4 |
| Apache Doris | 2.x |
其中:
- MySQL 作为源数据库;
- Doris 作为目标数据库;
- SeaTunnel 负责数据同步;
- DolphinScheduler 负责任务编排与调度。
二、准备测试数据
在开始配置同步任务之前,首先准备测试环境中的业务数据。
演示中使用 shopping 数据库作为示例库,并创建订单表 orders。
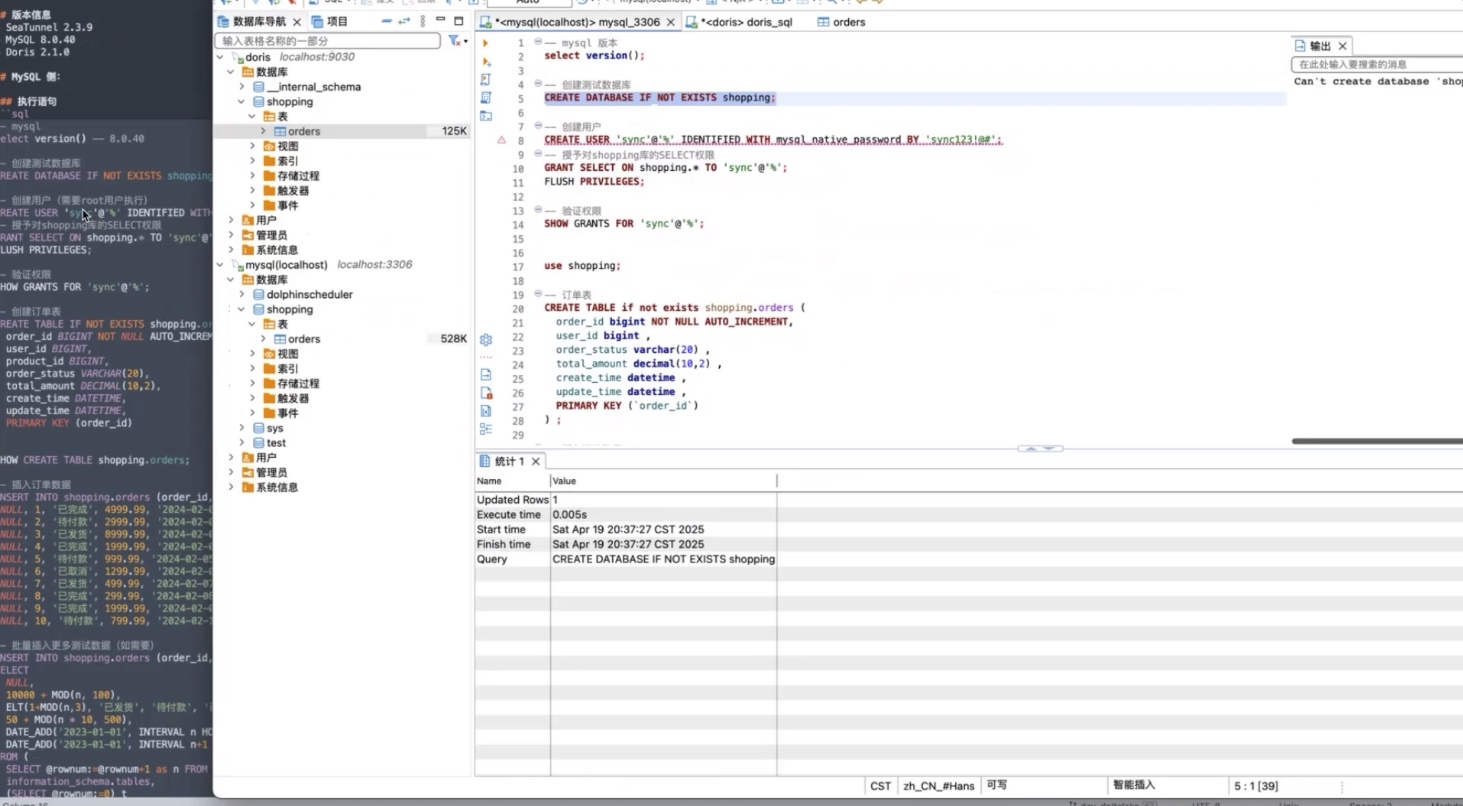
订单表中包含一个自增的订单主键字段:
sql
order_id后续增量同步将以该字段作为同步位点。
为了验证同步效果,演示环境中预先插入了一批测试数据,并通过脚本批量生成约 300 条订单记录。
随后查看表中的数据情况,包括:
- 当前订单总数;
- 当前最大订单 ID。
这些数据将在后续配置增量同步逻辑时作为参考。
需要说明的是,本案例选择 order_id 作为增量字段只是为了便于演示。在实际业务场景中,也可以使用 update_time、create_time 等时间字段作为增量同步条件。
三、增量同步实现思路
在正式配置 SeaTunnel 之前,演示首先介绍了整个增量同步方案的实现逻辑。
核心思路是利用目标端 Doris 中已经同步完成的数据来确定当前同步进度。
具体流程如下:
- 查询 Doris 当前最大的订单 ID;
- 将该值作为同步位点;
- SeaTunnel 从 MySQL 中读取大于该值的数据;
- 将新增数据写入 Doris;
- 下一次同步时继续从新的位点开始读取。
例如:
如果 Doris 当前最大的订单 ID 为:
text
300那么 SeaTunnel 实际执行的查询条件将变成:
sql
WHERE order_id > 300这样可以保证每次任务只处理新增数据,而不会重复同步已经存在的数据。
演示中也特别提到,增量字段并不一定是主键字段,只要能够准确标识新增数据或变更数据即可。
四、编写 SeaTunnel 配置
完成同步思路说明后,开始配置 SeaTunnel 作业。
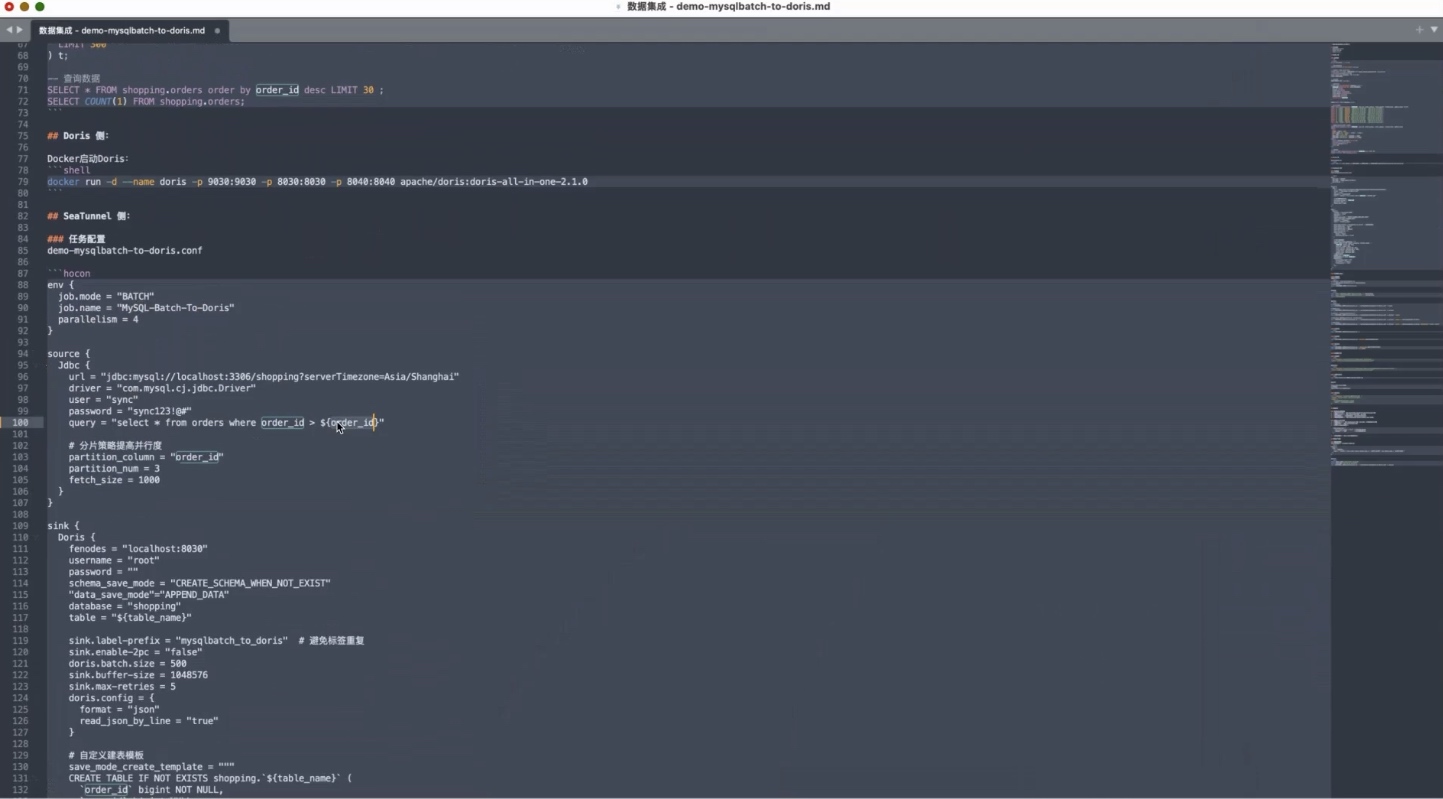
配置 JDBC Source
由于数据来源于 MySQL,因此使用 JDBC Source 读取数据。
核心查询语句如下:
sql
SELECT *
FROM orders
WHERE order_id > ${order_id}这里最关键的部分是:
text
${order_id}该变量并不是固定值,而是后续由 DolphinScheduler 动态传递。
当工作流运行时,SeaTunnel 会根据实际同步位点自动替换该参数,从而实现增量抽取。
配置并行度
演示中同时配置了任务并行度:
hocon
parallelism = 4通过增加并行度,可以提高同步任务的执行效率。
实际生产环境中应根据服务器资源以及数据库负载情况进行合理调整。
配置分区读取
为了提高大表读取效率,演示中还介绍了分区读取配置。
分区字段使用:
text
order_id对应配置:
hocon
partition_column = "order_id"同时配合 partition_num 参数,将数据划分为多个分区并行读取。
这种方式能够有效提升大数据量场景下的同步性能。
配置 Fetch Size
在 JDBC Connector 中,还可以通过 fetch_size 控制单次从数据库获取的数据量。
合理设置该参数能够减少数据库交互次数,从而提高整体读取效率。
五、配置 Doris Sink
完成 Source 配置后,开始配置 Doris Sink。
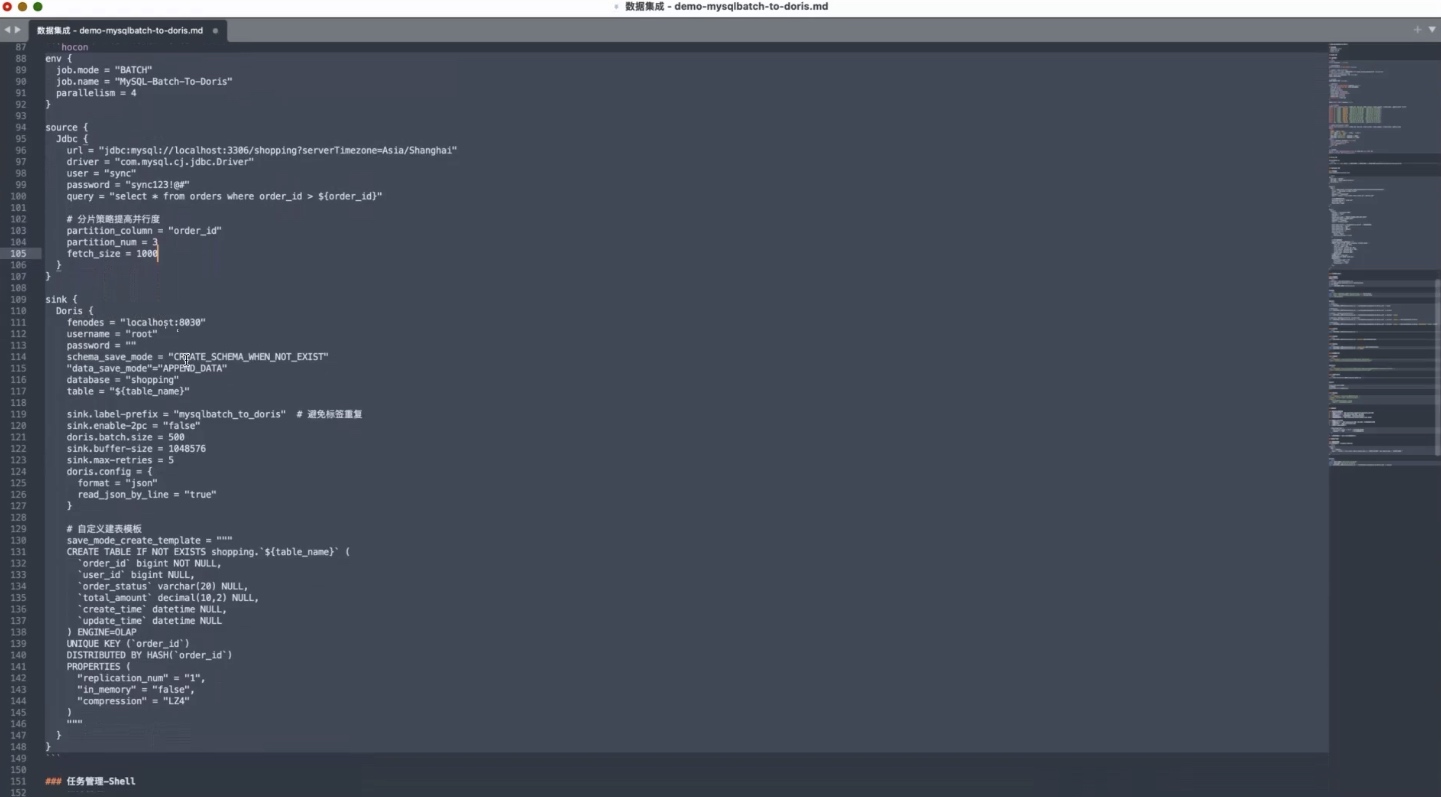
自动建表能力
演示中首先介绍了:
hocon
create_schema该参数用于自动创建目标表。
通过自动建表能力,可以减少人工维护 Doris 表结构的工作量。
配置写入模式
由于本案例采用增量同步,因此选择追加写入模式:
hocon
save_mode = APPEND_DATA之所以使用 APPEND_DATA,是因为每次同步的都是新增数据,不需要覆盖历史记录。
开启两阶段提交
为了保证数据一致性,演示还介绍了:
hocon
enable_2pc = true开启后可以利用两阶段提交机制,实现更可靠的数据写入过程。
同时有助于保障 Exactly Once 语义。
性能相关参数
此外,演示还讲解了多个性能优化参数,包括:
hocon
batch_size以及:
hocon
buffer_size这些参数主要用于控制数据批量写入行为,从而提升 Doris 导入性能。
Create Table Template
对于自动建表场景,演示还展示了 Create Table Template 的配置方式。
其中包括:
sql
UNIQUE KEY(order_id)以及:
sql
DISTRIBUTED BY HASH(order_id)同时还可以配置:
- 副本数;
- 压缩格式;
- 是否启用内存存储;
- 其他 Doris 表属性。
通过模板配置,可以让 SeaTunnel 自动生成符合业务需求的目标表结构。
六、配置 DolphinScheduler 运行环境
完成 SeaTunnel 配置后,开始配置 DolphinScheduler。
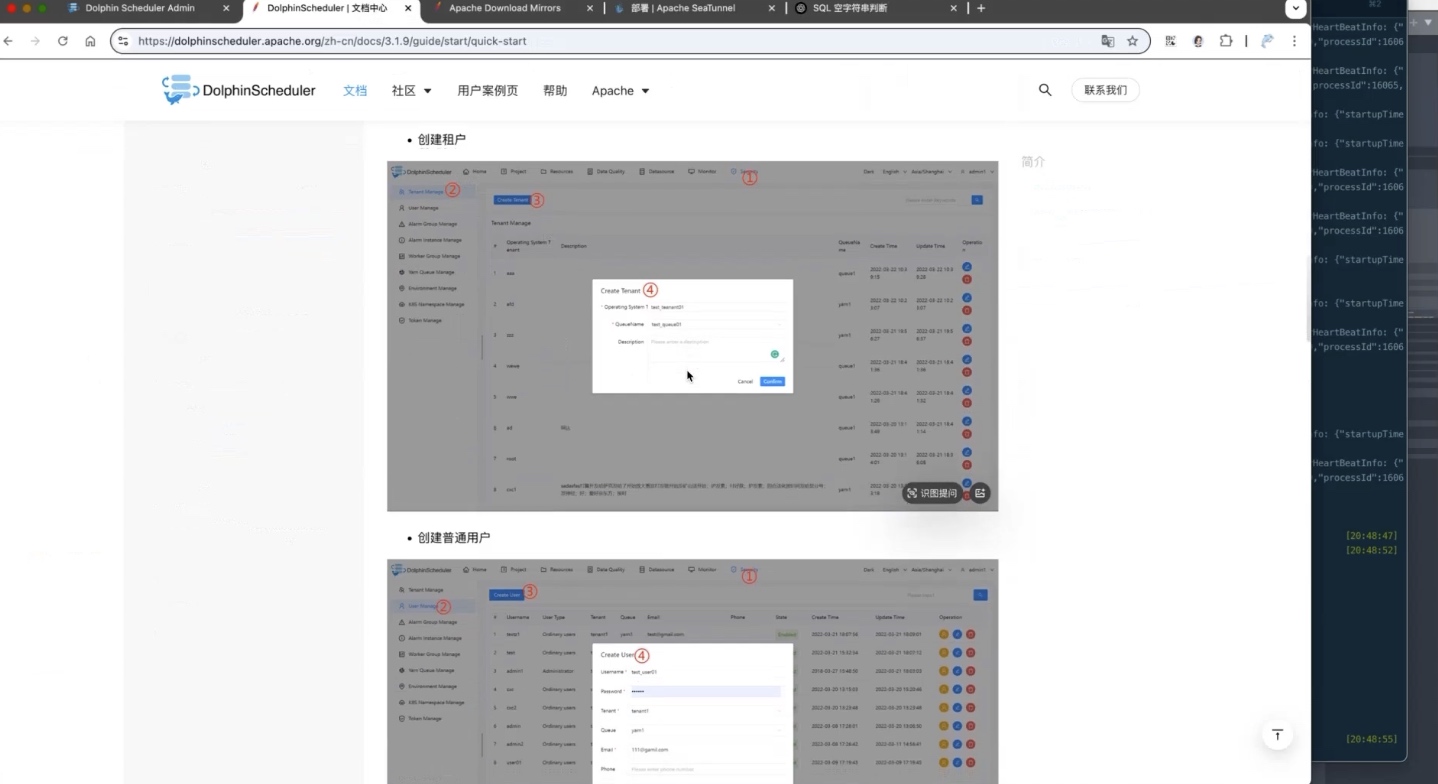
创建租户
首先进入 Security Center。
在租户管理页面创建新的租户。
演示中特别强调:
DolphinScheduler 中的任务最终都是以租户身份运行,因此租户配置是整个环境准备过程中不可缺少的一步。
创建用户并绑定租户
随后进入用户管理页面。
创建对应用户,并将用户关联到前面创建的租户。
完成后,该用户即可拥有对应租户下的任务执行权限。
创建 Environment
接下来进入环境管理页面。
创建 SeaTunnel 运行环境。
在环境变量中配置:
bash
SEATUNNEL_HOME=/soft/seatunnel该配置用于告诉 DolphinScheduler:
SeaTunnel 安装在哪个目录。
当工作流执行 SeaTunnel 节点时,系统会根据该路径找到对应的执行脚本。
演示中特别指出,这一步是必不可少的配置。
七、创建项目与工作流
环境配置完成后,开始创建项目。
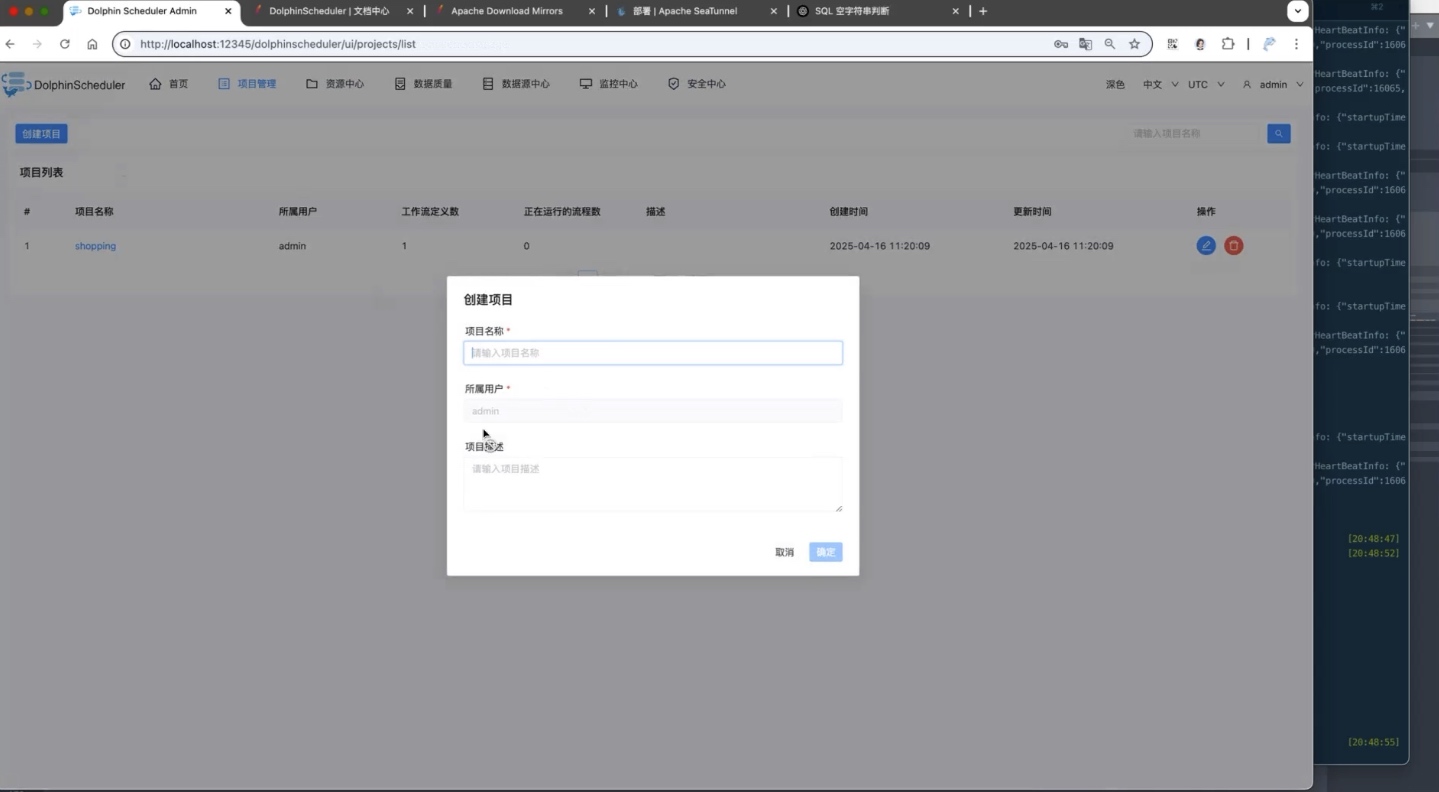
演示中创建项目:
text
shopping进入项目后,新建工作流。
整个案例最终包含两个核心节点:
- SQL 节点;
- SeaTunnel 节点。
其中 SQL 节点负责获取同步位点,SeaTunnel 节点负责执行数据同步。
八、配置 SQL 节点获取同步位点
这是整个案例中最关键的一步。
首先创建 SQL 节点,并选择 Doris 数据源。
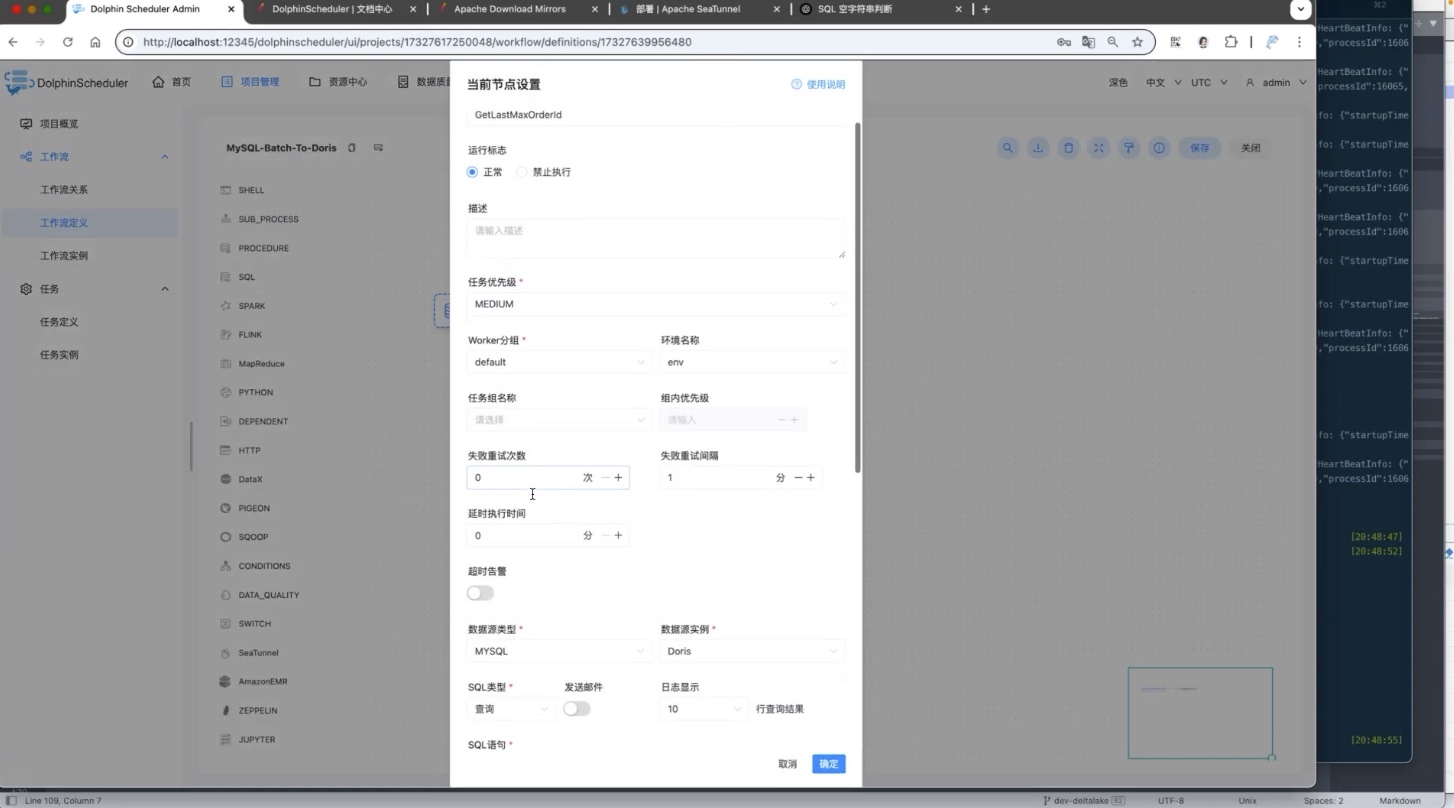
节点作用是查询当前已经同步到哪个订单 ID。
SQL 如下:
sql
SELECT IFNULL(MAX(order_id),0) AS order_id
FROM orders;演示中特别解释了为什么不能直接使用:
sql
SELECT MAX(order_id)
FROM orders;原因是首次同步时 Doris 表可能为空。
此时:
sql
MAX(order_id)返回结果为:
text
NULL如果将 NULL 直接传递给下游 SeaTunnel,最终可能生成非法查询条件。
因此需要使用:
sql
IFNULL(MAX(order_id),0)将空值统一转换为 0。
这样在首次同步时即可从第一条数据开始同步。
配置 OUT 参数
查询结果还需要传递给下游任务。
因此在 SQL 节点中新增自定义参数。
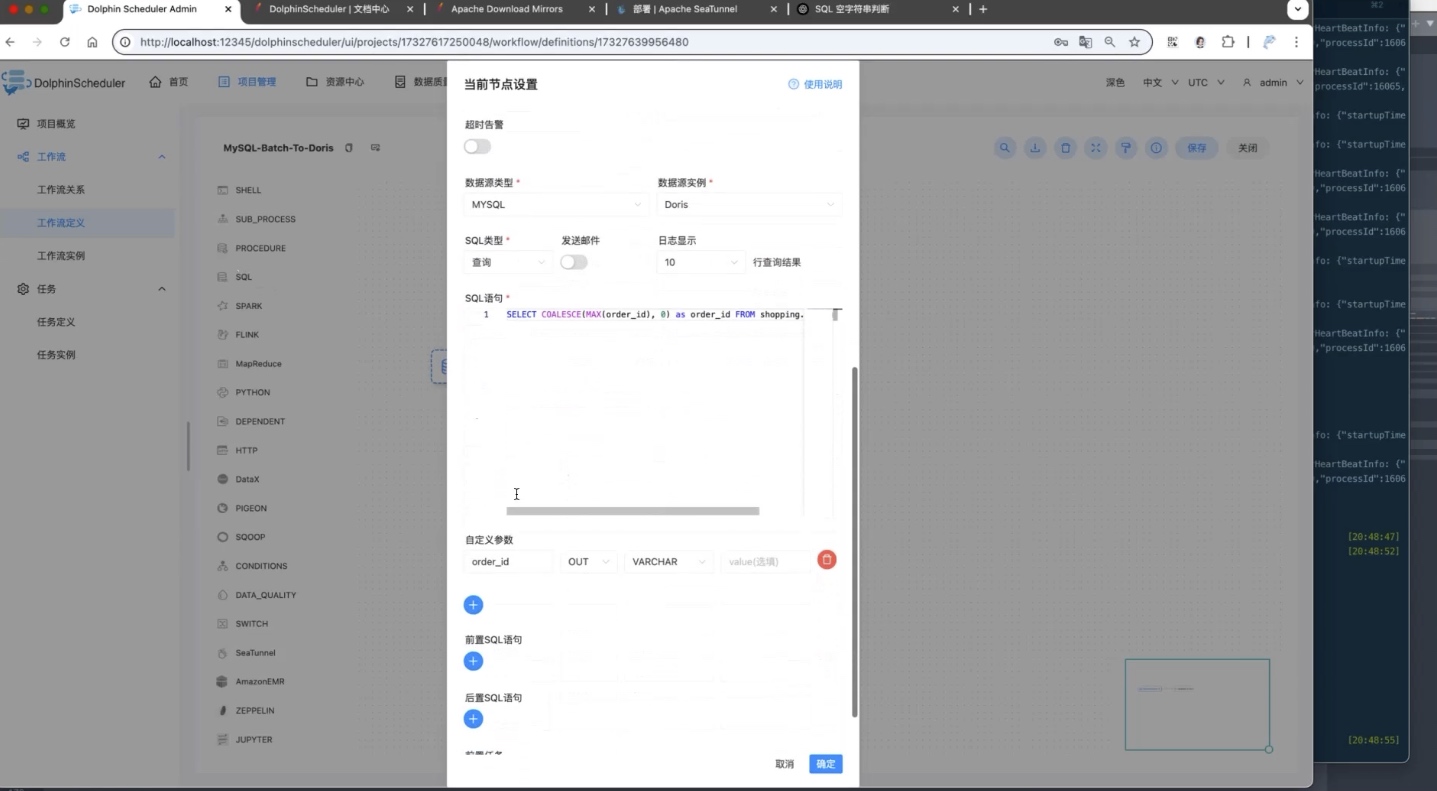
参数类型选择:
text
OUT参数名称设置为:
text
order_id这样 SQL 查询结果就会被保存为工作流变量。
后续 SeaTunnel 节点即可直接引用。
九、后续同步逻辑
完成 SQL 节点配置后,整个增量同步链路已经建立起来。
工作流执行时:
- SQL 节点查询 Doris 当前最大 order_id;
- 将结果保存为变量;
- SeaTunnel 使用
${order_id}作为查询条件; - 从 MySQL 中抽取新增数据。
通过这种方式,即可实现基于业务主键的离线增量同步。
十、总结
本案例展示了如何结合 Apache DolphinScheduler 与 Apache SeaTunnel 实现离线增量同步。
其中,SeaTunnel 负责数据读取与写入,而 DolphinScheduler 负责同步位点获取、参数传递以及任务调度。整个方案的核心在于利用 SQL 节点查询目标端最大 order_id,并通过 OUT 参数将同步位点传递给 SeaTunnel,从而实现增量抽取。
对于数据仓库建设、ODS 数据同步以及周期性离线同步场景而言,这种方案实现简单、易于维护,同时具备较好的扩展能力,具有较高的参考价值。