铺垫知识
随机森林算法是基于决策树算法而来的。随机森林是有很多棵树构成的,来看一下它和决策树有什么关联。随机森林是⼀种利用多棵树对样本进行训练并预测的分类器,属于 Bagging 的并行式集成学习方法。它通过有放回的采样方式添加样本扰动,同时引入属性扰动,在基决策树的训练过程中,先从候选属性集中随机挑选出⼀个包含 K 个属性的子集,再从这个子集中选择最优划分属性。随机森林中基学习器的多样性不仅来自样本扰动,还来自属性扰动,从而进⼀步提升了基学习器之间的差异度。
解释一下里面的术语词汇:
1、集成学习:不只用一个模型做预测,同时训练一大堆小模型,最后整合所有模型的输出结果,集体决策。逻辑:一个人容易看走眼,一群人一起判断出错概率更低。所有 "组合多个基础模型" 的算法,都属于集成学习。
2、Bagging、并行式集成学习:集成学习分两大流派:Bagging 和 Boosting,随机森林属于 Bagging。
- 并行:所有决策树可以同时分开训练,互不干扰,不用等一棵树训练完再训练下一棵,计算速度更快;
- Bagging 全称:Bootstrap Aggregating,自助聚合 核心思路:拆分数据集,独立训练一堆基础模型,预测时取平均 / 投票。 对比 Boosting(串行):一棵树训练完,根据它的错误调整数据,再训练下一棵,必须顺序训练。
3、样本扰动:先拆解两个词:样本、扰动
- 样本:你的一条条数据,比如 1000 条用户数据,每条就是一个样本;
- 扰动:人为制造 "差别、变化"。
样本扰动:给每棵树分配不一样的训练数据,让每棵树学到的规律不完全一样。实现手段:有放回采样(自助采样 Bootstrap)
4、有放回采样:抓小球抽样,抓完记录,再把小球放回盒子里,下一次还能再次抽到。举例:总共有 1000 条数据,给第一棵树采样 1000 条数据,一条数据可能被重复抽中,也可能完全没抽到;第二棵树再重新独立采样一套数据。每棵树拿到的训练数据集各不相同,这就是样本层面的扰动。
整体一句话概括随机森林:把很多棵决策树放在一起集体投票做判断,树和树之间刻意做出区别,最终综合所有树的结果,比单棵树准确率更高,这套方法就叫随机森林。
Bootstraping/自助法
Bootstraping 的名称来自成语 "pull up by your own bootstraps",意思是依靠你自己的资源,称为自助法,它是⼀种有放回的重抽样方法。
Bootstrap 本义是指高靴子口后面的悬挂物、小环、 带子,是穿靴子时用手向上拉的工具。"pull up by your own bootstraps" 即 "通过拉靴子让自己上升",意思是 "不可能发生的事情"。后来意思发生了转变,隐喻 "不需要外界帮助,仅依靠自身力量让自己变得更好"。
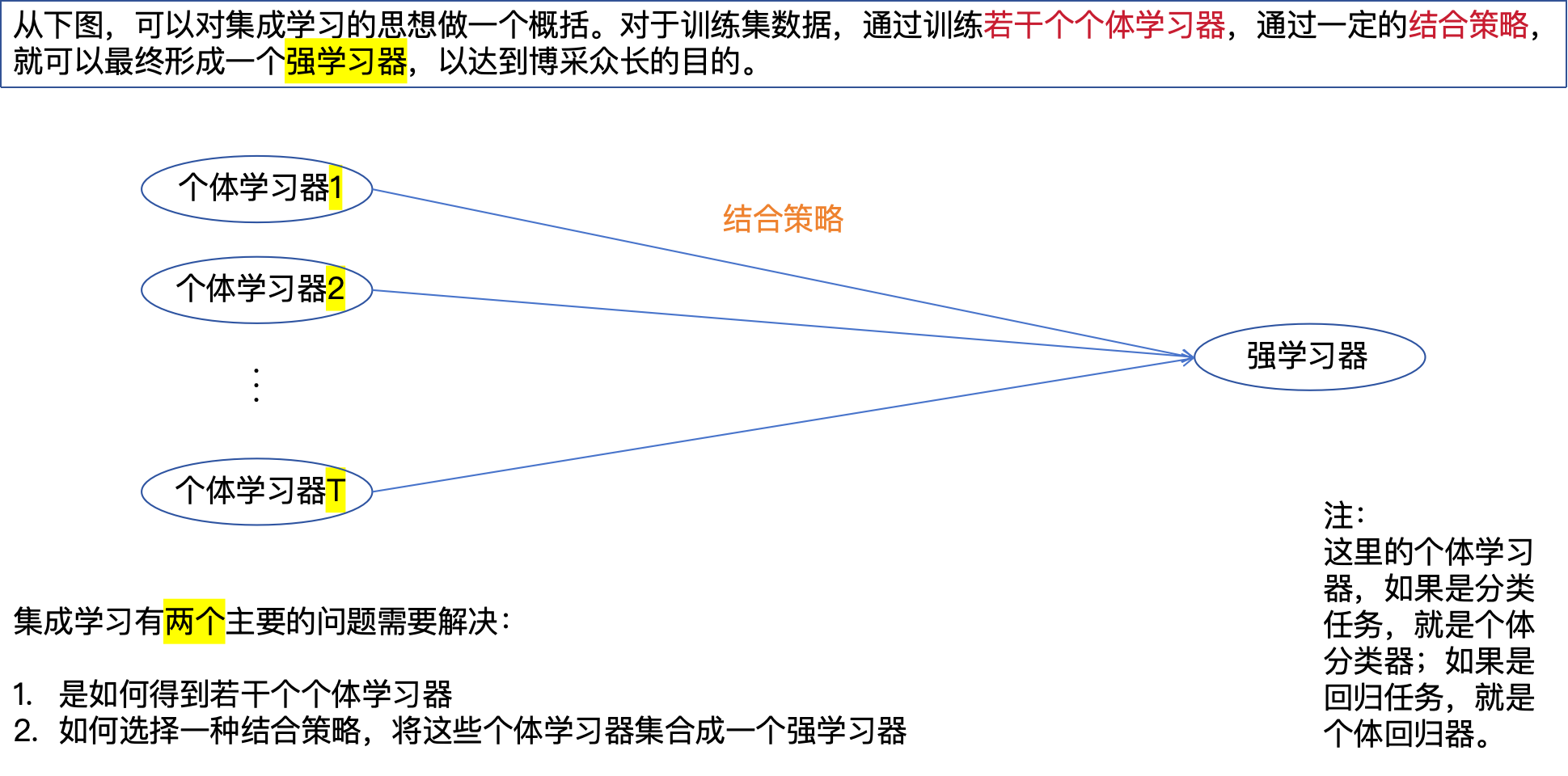
这里注意,不是做了集成之后,它的性能一定能得到提升,主要还是依赖于数据。具体选择什么模型,要根据具体的业务场景决定。接下来看一下套袋法是怎么做的。
Bagging/套袋法
bootstrap aggregation:
- 从样本集中重采样(有重复的)选出 n 个样本。
- 在所有属性上,对这 n 个样本建立学习器 (在分类任务中:ID3、C4.5、SVM、Logistic 回归等)。
- 重复以上两步 m 次,即获得了 m 个学习器。
- 将数据放在这 m 个学习器上,最后根据这m个学习器的投票结果,决定数据属于哪⼀类。
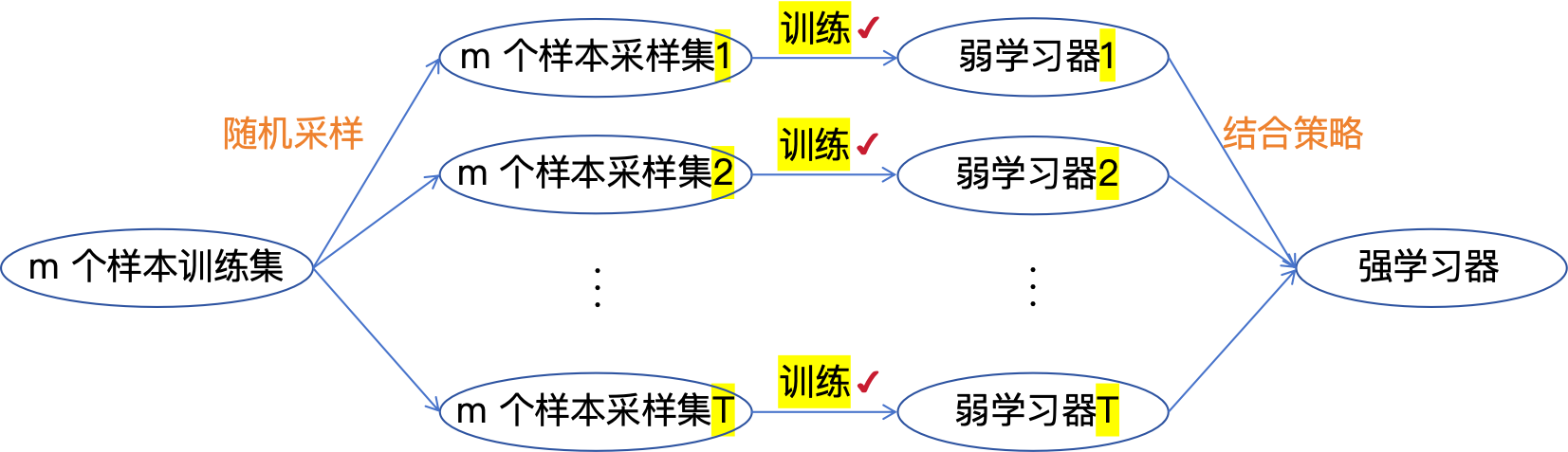
从上图可以看出,Bagging 的弱学习器之间的确没有 boosting 那样的联系。它的特点在 "随机采样"。那么什么是随机采样?随机采样(bootstrap)就是从我们的训练集里面采集固定个数的样本,但是每采集一个样本后,都将样本放回。也就是说,之前采集到的样本在放回后有可能继续被采集到。对于我们的 Bagging 算法,一般会随机采集和训练集样本数 m 一样个数的样本。这样得到的采样集和训练集样本的个数相同,但是样本内容不同。如果我们对有 m 个样本训练集做 T 次的随机采样,则由于随机性,T 个采样集各不相同。
集成学习之结合策略
投票法
平均法
学习法/Stacking
硬投票 & 软投票
这次主要介绍一下投票法。后面会介绍学习法,这次以投票法为准。投票法是比较常见的。投票分为两种方式,一种是硬投票,一种是软投票。
先来看一下硬投票,这里模型 1 2 3 4 5,就是 5 个学习器。可以发现,第一个模型,总共有两个类别。类别 A 和类别 B。首先模型 1 预测出来的,A 类别的概率是 99%,B 类别的概率是 1%。然后模型 2 预测出来的 A 类别是 49% B 类别是 51%,等等。总共有 5 个模型预测 A 和 B。这里的分界点设置的是 50%(实际要根据不同的业务场景手动调整这个阈值)。也就是模型 1 和模型 4 预测出来的是 A 类别,其他模型预测出来的都是 B 类别,所以总共 2 个 A,3 个 B。通过这种硬投票的方法,最终预测结果为 B,因为 B 的票数最多。
还有一个是软投票。软投票是通过概率来进行计算的。首先得到每个模型里面的概率,然后把每个类别的概率全部加起来然后除以模型总数,得到平均值。可以发现,A 的概率平均值更大一点,最终预测结果就是为 A 的。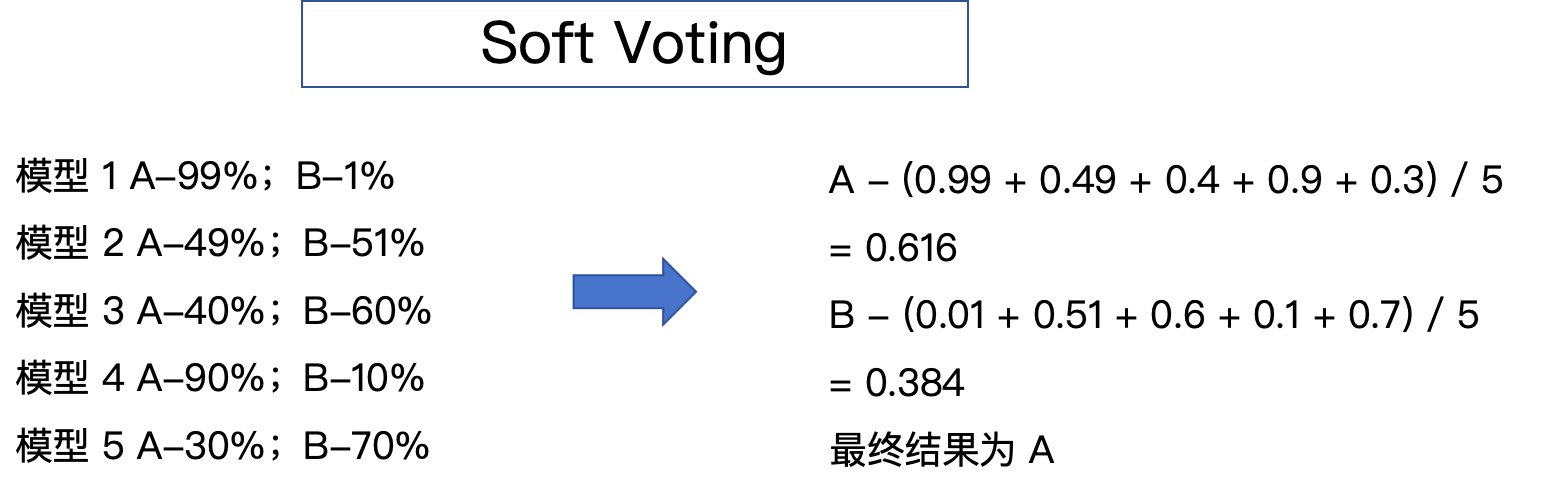
可以发现,不同的结合策略,预测结果是不同的。硬投票,预测出来是 B,软投票,预测出来是 A。接下来用代码的方式来实现一下。
代码实现
打开 jupyter notebook,导入需要的包。numpy,pandas,这几乎是所有情况都要用到的。还有 matplotlib,每次的最后都是要进行图形绘制。还有忽略警告的包。设置文字。如果是 mac 系统,字体设置的那句应改为: "plt.rcParams'font.sans-serif' = 'Songti SC'"。还要设置一下负号,不然会显示成小方块。设置一下字体大小为 15。
python
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings('ignore')
plt.rcParams['font.family']='SimHei'
plt.rcParams['axes.unicode_minus']=False
plt.rcParams['font.size']=15
接下来可以去拿数据了。这里没有使用数据集,我来造一个数据。造数据其实是一个技术活儿,这个模拟数据要看起来和真实数据非常像。随便造数据是很简单的,但是有以假乱真的效果需要花费很多的时间。这里使用一个函数 make_moons 来帮我们生成数据集。
补充一下 make_moons 函数。
make_moons 在 sklearn.datasets,生成两个交错半月(月牙)二维数据集,专门用来测试非线性二分类、聚类算法(决策树、随机森林、SVM、DBSCAN),线性模型很难分割两个月牙。
返回两个变量:
- X:(样本数,2) 二维数组每行 = 1 个数据点,2 列 = 横坐标、纵坐标(特征)例:n_samples=500 -> X.shape=(500,2)
- y:(样本数,) 一维标签只有 0, 1 两类:0 = 第一个月牙,1 = 第二个月牙
使用场景:对比 ** 线性模型 (逻辑回归)和非线性模型 (决策树 / 随机森林)** 的分割效果,测试 DBSCAN、K-Means 聚类(K-Means 很难分开月牙)。
首先对应包进行导入,导入之后就可以使用了。把特征列和目标列进行提取,这里要设置一些参数。第一个参数,n_samples=500,表示生成 500 个数据。第二个,noise=0.30,表示噪声,在产生数据的时候,让它有抖动的效果,看起来更像是真实的数据集。如果不加噪声,数据会看起来非常平滑,很明显是假数据,加了噪声真实性更强一些。然后加上随机种子。下一步就是做训练集和测试集划分。之后就进行图形绘制。然后画一下 X,来看一下 X。
python
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_moons
X,y=make_moons(n_samples=500,noise=0.30,random_state=42)
X_train,X_test,y_train,y_test=train_test_split(X,y,random_state=42)
plt.figure(figsize=(10,6))
plt.plot(X)
会产生这样的数据。可以先单看一下 X 数据。可以明显发现,X 有两个中括号,是一个二维的数据,有两列。其实在使用的时候就相当于划分了两个部分的数据。一个是用蓝色进行表示的,一个是用橙色表示的。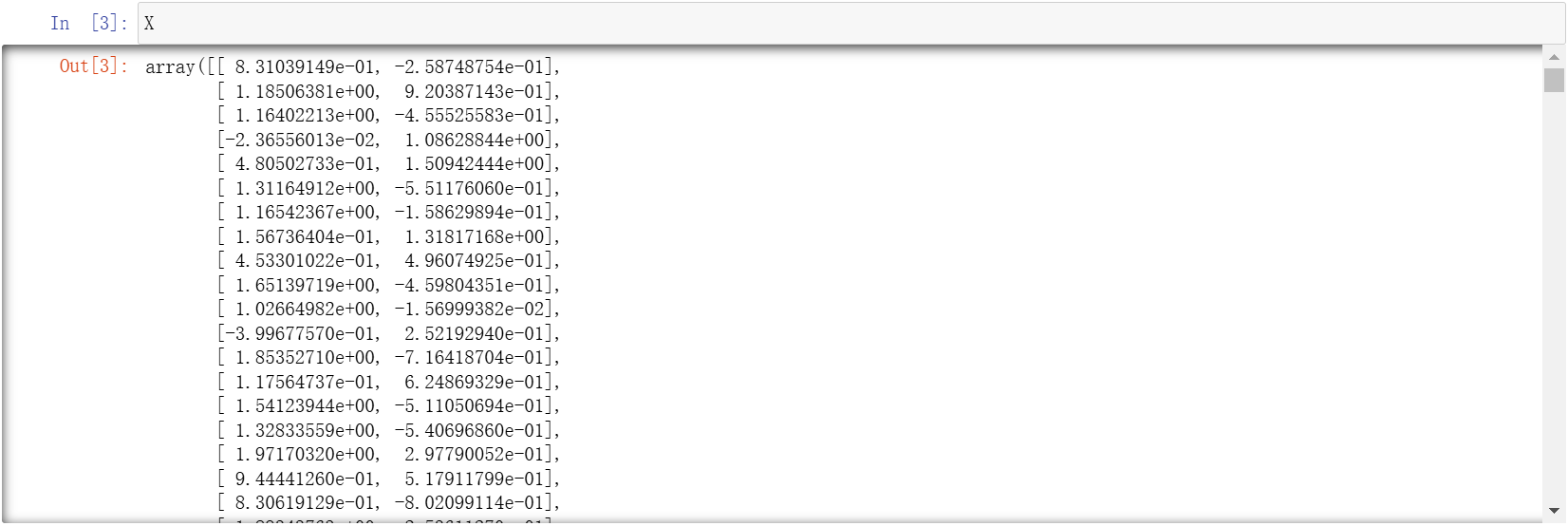
再看一下 y。发现 y 打印出来只有 0 和 1 两个类别的数据。
绘制一下类别 0 和类别 1 图形的效果。只取第 0 列的数据,y = 0 的类别。除了第 0 列,还有第 1 列,也是 y 为 0 类别的时候。类别 1 同理。然后 show 出来看看。
python
plt.plot(X[:,0][y==0],X[:,1][y==0],'yo',alpha=0.6,label='类别0') # 只取第 0 列的数据,然后取筛选过后标签为 0 的数据
plt.plot(X[:,0][y==1],X[:,1][y==1],'bs',alpha=0.6,label='类别1') # 只取第 0 列的数据,然后取筛选过后标签为 1 的数据
plt.legend()
plt.show()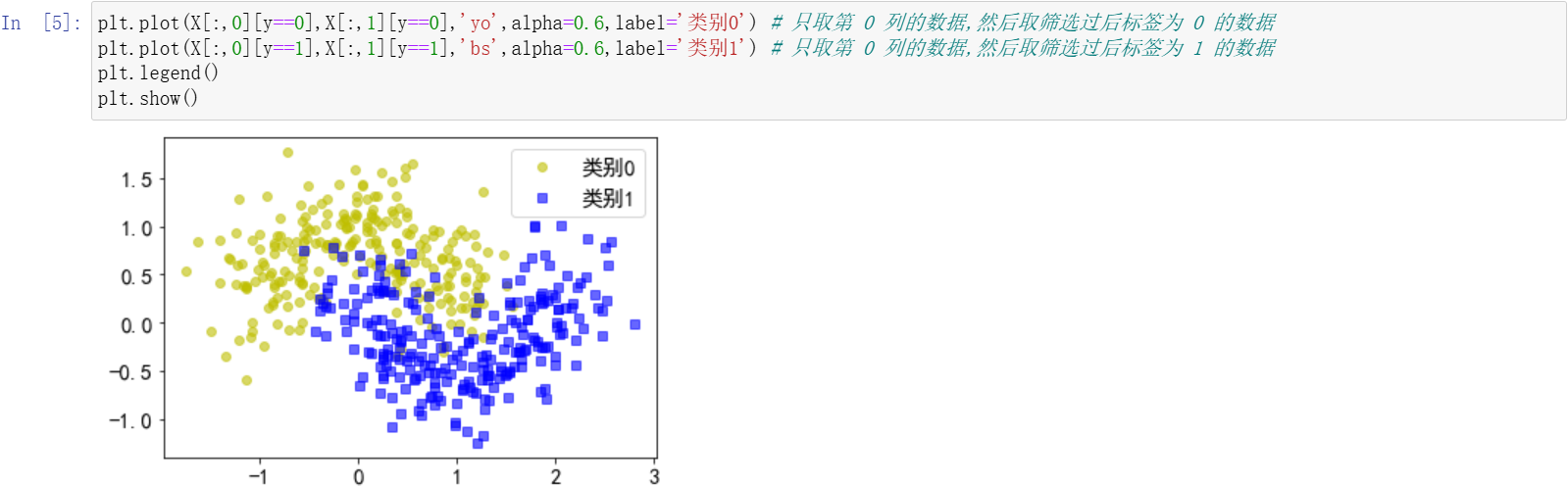
接下来就用前面的,结合策略的方式里面的硬投票。要用到三个基模型,把分类决策树算法的包导入进来,导入投票分类器,导入逻辑回归,最后再导入支持向量机。目前已经把涉及到的算法的包导入进来了。接下来可以去用了。首先导入的几个基模型实例出来,然后设置随机种子。一般树模型的随机种子都设为 42。都拿过来之后下一步,可以去集成算法。这个时候需要用到投票分类器,然后把模型进行引出,小别名可以随便起的,表示的是集成之后的名字。还要设置一下 voting='hard',因为是硬投票。最后进行拟合,把训练集放进去直接进行训练。然后打印出来看一下。
python
# 硬投票
from sklearn.tree import DecisionTreeClassifier # 决策树分类算法
from sklearn.ensemble import VotingClassifier # 表示投票的分类器
from sklearn.linear_model import LogisticRegression # 逻辑回归 分类算法
from sklearn.svm import SVC # 支持向量机算法
log_clf=LogisticRegression(random_state=42)
deci_clf=DecisionTreeClassifier(random_state=42)
svm_clf=SVC(random_state=42)
# 集成
voting_clf=VotingClassifier(estimators=[('lr',log_clf),('deci',deci_clf),('svc',svm_clf)],voting='hard') # voting='hard'表示硬投票
voting_clf.fit(X_train,y_train)
最后出来这样一个效果,三个基模型,最后整合成一个投票分类器。
接下来看一下,基于这三个机模型整合出来的投票分类器的性能怎么样。可以用 for 循环来看一下对应的当中的效果怎么样。先导入一下对应的包。这里主要用准确率来衡量。然后把所有的模型都获取过来,三个基模型加上一个集成之后的模型。在 for 循环里,首先第一步拟合,把 X_train 和 y_train 拿过来。下一步就是开始预测,使用测试集数据预测出来结果。之后使用它的内置函数,一定是两个下划线开头,class,两个下划线结尾,然后再点上两个下划线开头,然后 name,最后两个下划线结尾,得到它的名字,这是内置函数的使用。再把准确率拿过来,拿过来之后把真实值和预测值放进去。之后运行一下,看这 4 个模型的效果怎么样。
python
from sklearn.metrics import accuracy_score
for clf in (log_clf,deci_clf,svm_clf,voting_clf):
clf.fit(X_train,y_train)
y_pred=clf.predict(X_test)
print(clf.__class__.__name__,accuracy_score(y_test,y_pred))
可以发现,三个基模型的性能是差不多的,最好的情况是 svc 的 0.896,但是可以发现,最终集成之后变成 0.904,准确率比这三个基模型都高。这个就是硬投票的使用方式。
再看一下软投票的使用。软投票的使用和硬投票基本上是一样的。代码直接复制粘贴。粘过来后把 voting='hard' 改为 voting='soft'。然后,基模型里面的支持向量机算法没有概率值,软投票是需要计算概率的,直接运行的话会出现报错,所以要在 svc 这个地方显示这个概率。默认是没有的,所以要手动把方法设置一下,把 probability 这个参数设置为 True。现在运行一下。
python
# 软投票
from sklearn.tree import DecisionTreeClassifier # 决策树分类算法
from sklearn.ensemble import VotingClassifier # 表示投票的分类器
from sklearn.linear_model import LogisticRegression # 逻辑回归 分类算法
from sklearn.svm import SVC # 支持向量机算法
log_clf=LogisticRegression(random_state=42)
deci_clf=DecisionTreeClassifier(random_state=42)
svm_clf=SVC(probability=True,random_state=42)
# 集成
voting_clf=VotingClassifier(estimators=[('lr',log_clf),('deci',deci_clf),('svc',svm_clf)],voting='soft') # voting='soft'表示软投票
voting_clf.fit(X_train,y_train)
from sklearn.metrics import accuracy_score
for clf in (log_clf,deci_clf,svm_clf,voting_clf):
clf.fit(X_train,y_train)
y_pred=clf.predict(X_test)
print(clf.__class__.__name__,accuracy_score(y_test,y_pred))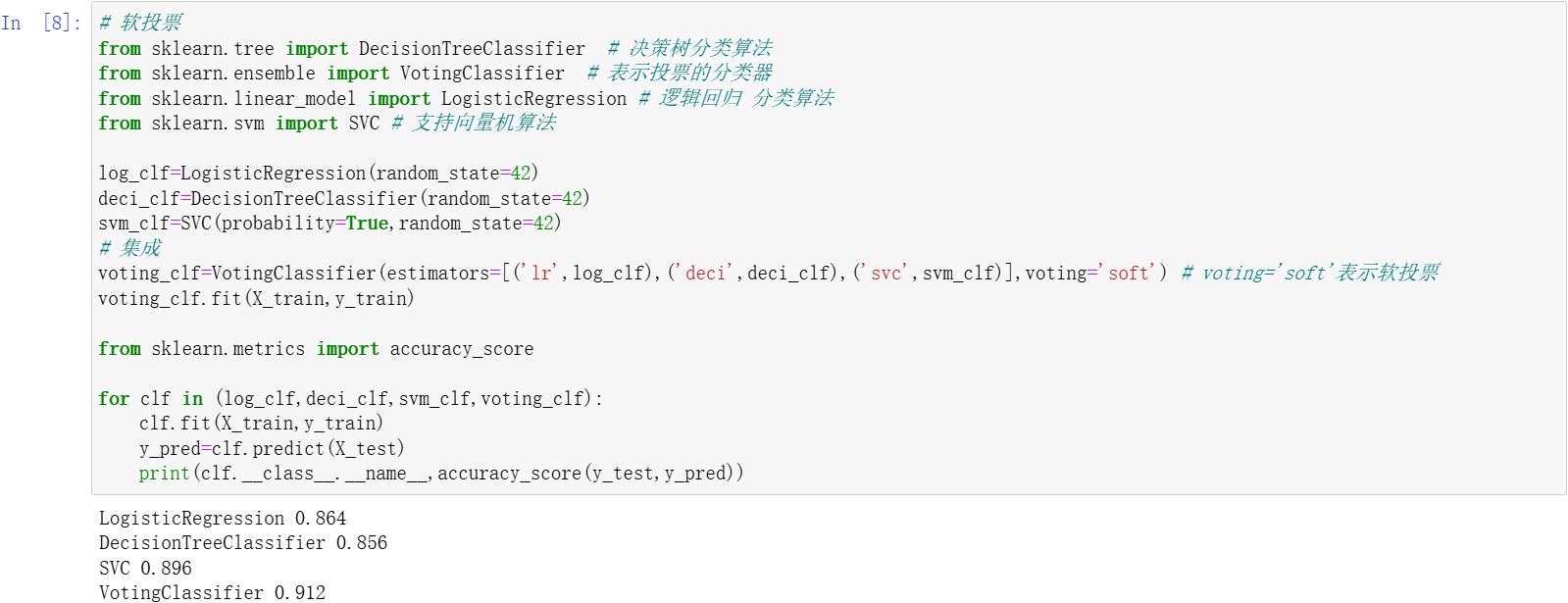
现在出来结果了。可以发现,软投票的性能比刚刚的硬投票稍微高一些。从 0.904 变成 0.912。以上内容就是集成学习里面硬投票和软投票的使用方式。接下来介绍随机森林分类算法。
随机森林分类算法
随机森林算法是集成学习的一种。里面的基模型,全部用的都是决策树。它的随机性体现在:
- 第一个是套袋法,随机有放回地抽样,通过这种方式取得样本的随机性。
- 第二个随机就是决策树的属性选择上是随机的。假如现在数据有 10 个特征,已经选择了三个基模型,决策树 1,决策树 2,决策树 3,在这里每一个模型不会取到所有的字段,而是从 10 个特征当中随机抽取 3 个特征出来,这是它第二个随机,就是抽取随机一部分数据出来。抽取的这样一部分数据,一定是小于数据集里面的全部特征的。这就是随机森林两个随机的体现。
以上部分就是随机森林算法的原理:用 N 表示训练用例的个数(样本),M 特征数目。
- 一次随机选出一个样本,重复 N 次。
- 学习器,建立决策树随机去选出 m 个特征 m<<M。
使用方法:model_name = RandomForestClassifier(参数1,参数2,...)
参数说明:
- n_estimators:决策树的数量,也就是 "森林" 的大小。
- criterion:决定节点分裂的条件。可以是 "gini"(基尼指数)或 "entropy"(信息熵)。基尼指数衡量的是样本的不纯度(purity),信息熵衡量的是信息的量。
- max_depth:决策树的最大深度。
- min_samples_split:一个节点在被考虑分裂前必须具有的最小样本数。
- min_samples_leaf:叶子节点(即最终的预测节点)至少需要包含的最小样本数量。
- max_features:在分裂节点时考虑的最大特征数量。设置为 'auto' 时,通常会根据树的深度动态调整。
- bootstrap:是否使用自举样本(bootstrap samples)训练森林。
- oob_score:是否使用 Out-of-Bag (OOB) 样本进行模型评估。
代码实现
原理清楚了之后,就可以建立随机森林算法了。随机森林的优势是,非常简单,也非常容易实现。开销也比较小,在数据量比较大的时候,进行建模处理,只需要抽取一部分,就可以用集成学习算法。因为在这个集成算法里面,每个在数据集里面只抽取一部分的数据,这样就能大大减少计算的开销,提高计算的效率。回到 jupyter 上,实操一下。
首先导入随机森林分类算法要用到的包。接下来就可以把模型拿过来,一般,树模型,随机种子都设为 42。写 42 的时候性能是最好的,设为别的也没啥太大问题。然后给它拟合一下,把训练集的数据放进去。拟合好了之后,可以使用它去进行预测。把训好的模型拿过来,把测试集数据放进去预测,得到预测值。最后用准确率衡量一下这个模型性能,把真实值和预测值放进去,直接运行看一下。
python
# 随机森林分类算法
from sklearn.ensemble import RandomForestClassifier
tree_clf=RandomForestClassifier(random_state=42)
tree_clf.fit(X_train,y_train)
y_hat=tree_clf.predict(X_test)
accuracy_score(y_test,y_hat)
结果是 0.896。前面单独使用决策树的时候,只有 0.856,使用随机森林,在没有调参,只裸跑默认参数的情况下,准确率达到了 0.896,比单独的决策树更高一些。
随机森林回归算法(直接代码实现)
这个需要使用数据集。先把数据集传上去。上传之后第一步,导入随机森林回归算法的包,接下来读取数据,读取的时候需要指定一下它的编码格式,设置 encoding='gbk' 的格式,不然会编码报错。然后打印出来看一下。
python
# 随机森林回归算法
from sklearn.ensemble import RandomForestRegressor
df=pd.read_csv('insurance.csv',encoding='gbk')
df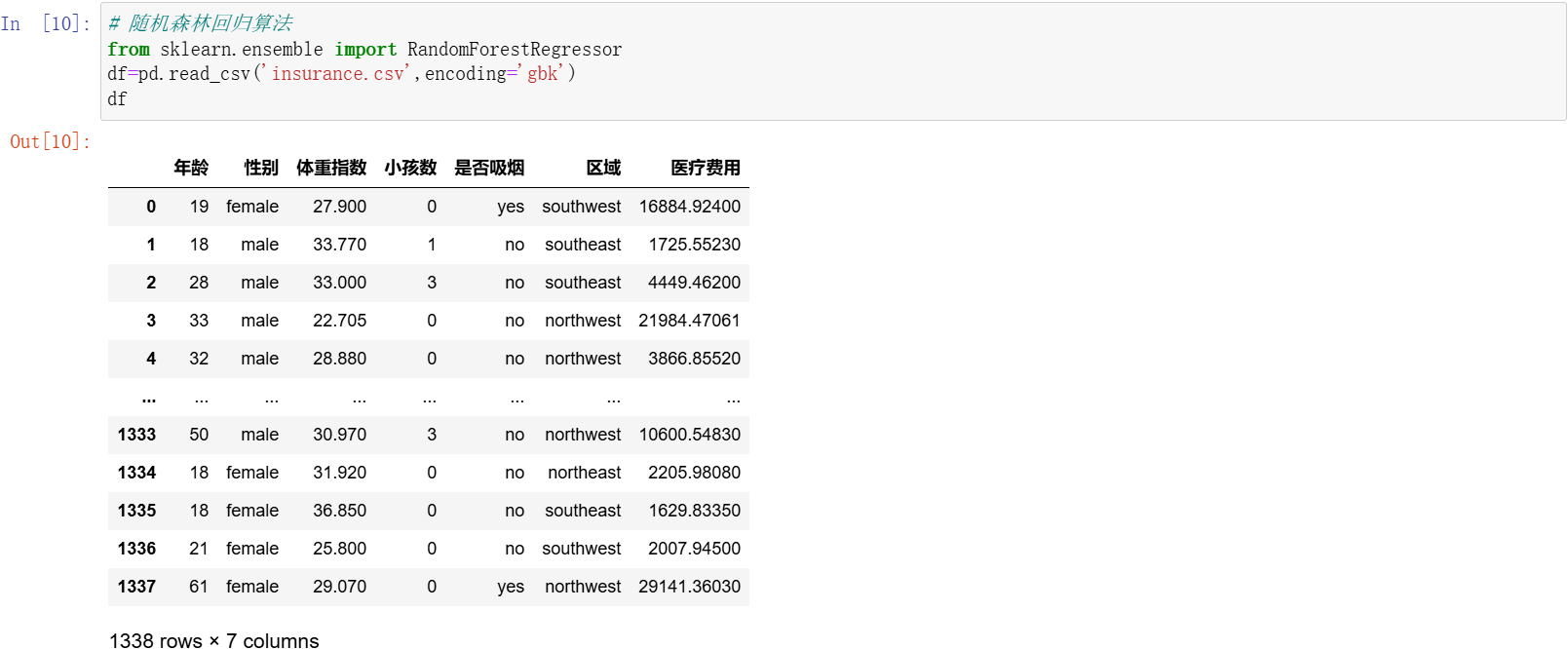
使用 info() 函数来查看一下数据的整体情况。看一下哪些地方有空值,以及数据类型有没有问题。
python
# 查看数据集情况
df.info()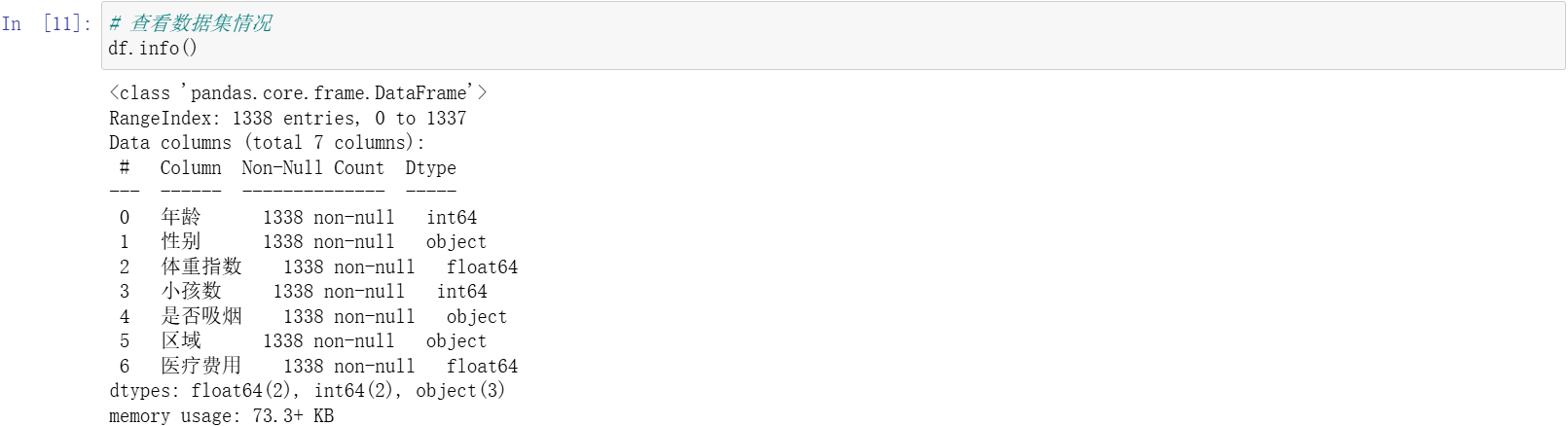
通过运行结果来看,这里数据是没有空值的,所以就不需要进行处理了。再来看一下数据的类型,这里面,现在要保证每一列的数据类型都是一样的。都要先规整之后,然后转成相同的数据类型。可以发现,小孩数全部都为整数类型,没有什么问题。其他列的数据也都没有问题。
接下来看一下数据集当中有没有重复值的情况。直接 df.duplicated().sum() 就可以。
python
# 查看重复值
df.duplicated().sum()
运行之后,发现有一个重复值的情况。可以直接通过删除的方式来进行处理,因为它也没有很多,就 1 条。直接 df.drop_duplicates() 就可以了。运行一下看看。可以看到数据集的数据变成 1337 行了,少了一行,之前是 1338 行。已经把重复值给去除掉了。
python
df.drop_duplicates()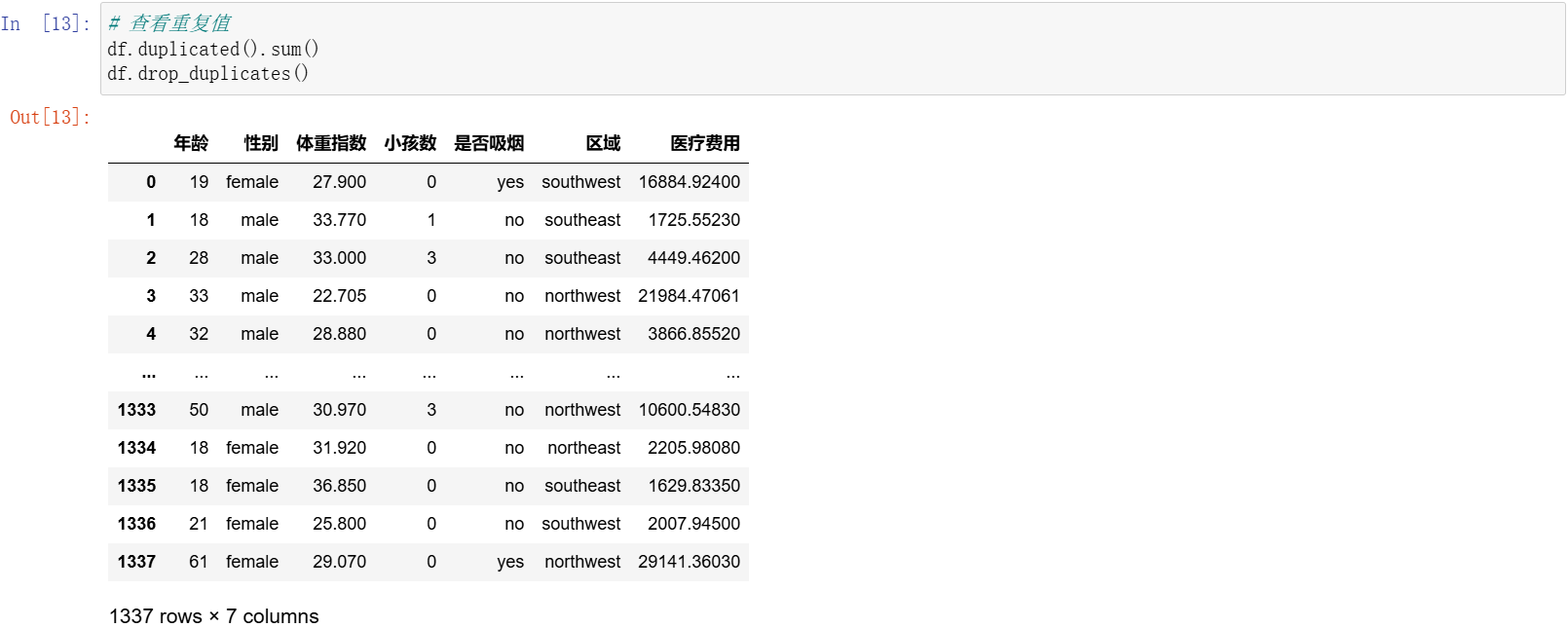
其实在数据集里面也能发现,主要看的是体重指数。判断一下,这个人体重指数达到多少,是偏重还是偏瘦,看这个人有没有小孩,是否吸烟,所在的区域,通过这些属性看医疗费用是多少。这个医疗费用,理论上是连续型数值。所以这个地方使用的是回归算法。
接下来就可以进行相关性分析。这里需要把不是数值类型的字段删除掉。只有数值字段才能进行相关性分析。首先打印一下。
python
# 相关性分析 数值字段
df.columns
相关性分析,它也是二维数组,所以用两个括号给括起来。这些字段刚刚已经打印好了,就可以把这些字段复制粘贴过来。把文本字段去掉。性别肯定不行,还有是否吸烟,区域,这几个都不要了。最后留下年龄、体重指数、小孩数和医疗费用这四个,做相关性分析。然后直接点上 corr,就可以,直接打印一下看看。
python
df[['年龄', '体重指数', '小孩数', '医疗费用']].corr()
在打印出来的数据可以发现,对角线都是为 1 的,因为对角线都是自己对自己。自己和自己肯定是百分百相关的。所以这些地方都是 1。所以对角线不用去看,因为没有很大的意义。主要看医疗费用的相关性,着重看医疗费用这一列就可以了。可以发现小孩数相关性不大,年龄和体重指数有一些相关性。
这个体重指数给它统一一下数据类型。起个名字叫体重指数2,使用 astype('int') 把它统一为 int 类型。然后可以打印看一下。
python
df['体重指数2'] = df['体重指数'].astype('int')
df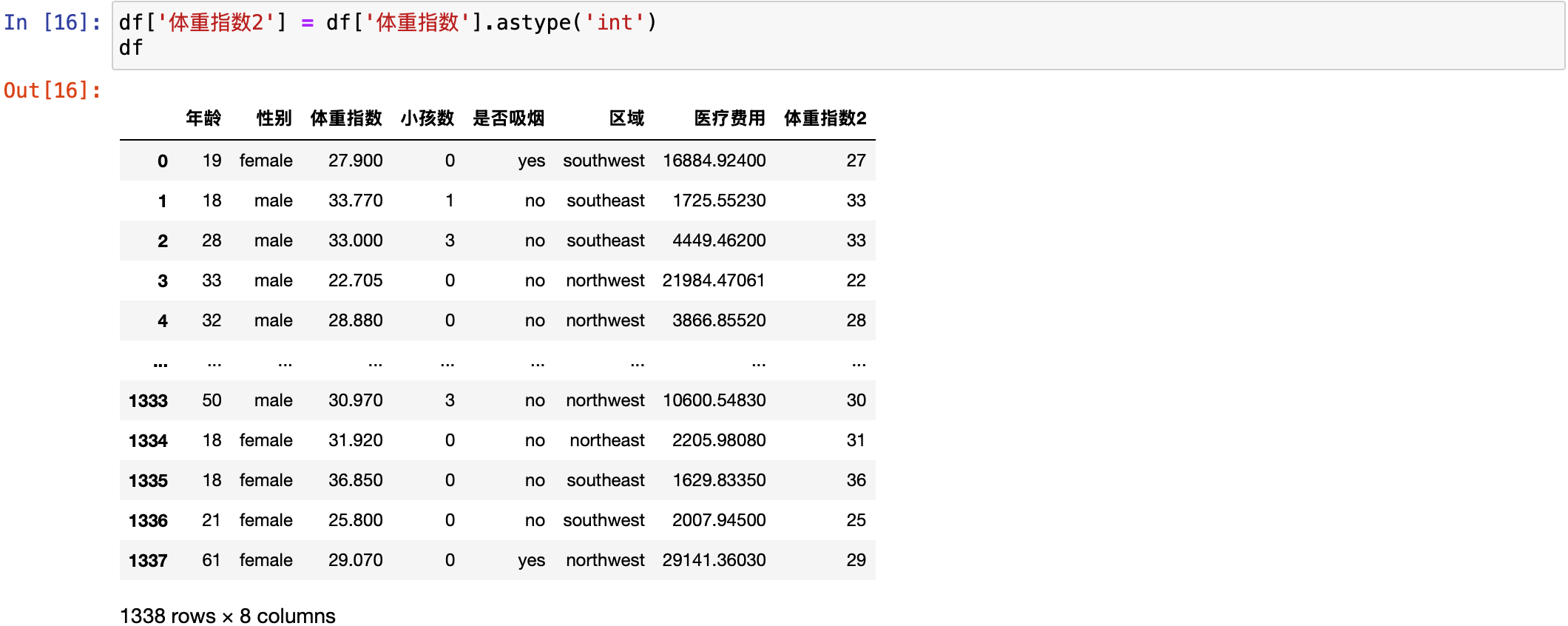
可以看到最后一列,体重指数2,这列数据全部都变成了整数类型的数据。
接下来就可以统一地进行可视化的操作,探索性分析,来观察一下这些字段。把想看的字段都放进去。比如目标列,已经很清晰了不想看,就拿出去,想看体重指数2就放进去。这里放的都是想看一看的字段。放入之后直接 for 循环去画图,首先设置一下画布大小,然后使用 sns.countplot 进行图形绘制,里面放的是数据集和字段,下一步就可以设置一下标题。最后 show 出来。
python
import seaborn as sns
vs=['年龄','性别','小孩数','是否吸烟','区域','体重指数2']
for v in vs:
plt.figure(figsize=(15,3.5))
sns.countplot(data=df,x=v)
plt.title(f'{v}数量分布')
plt.show()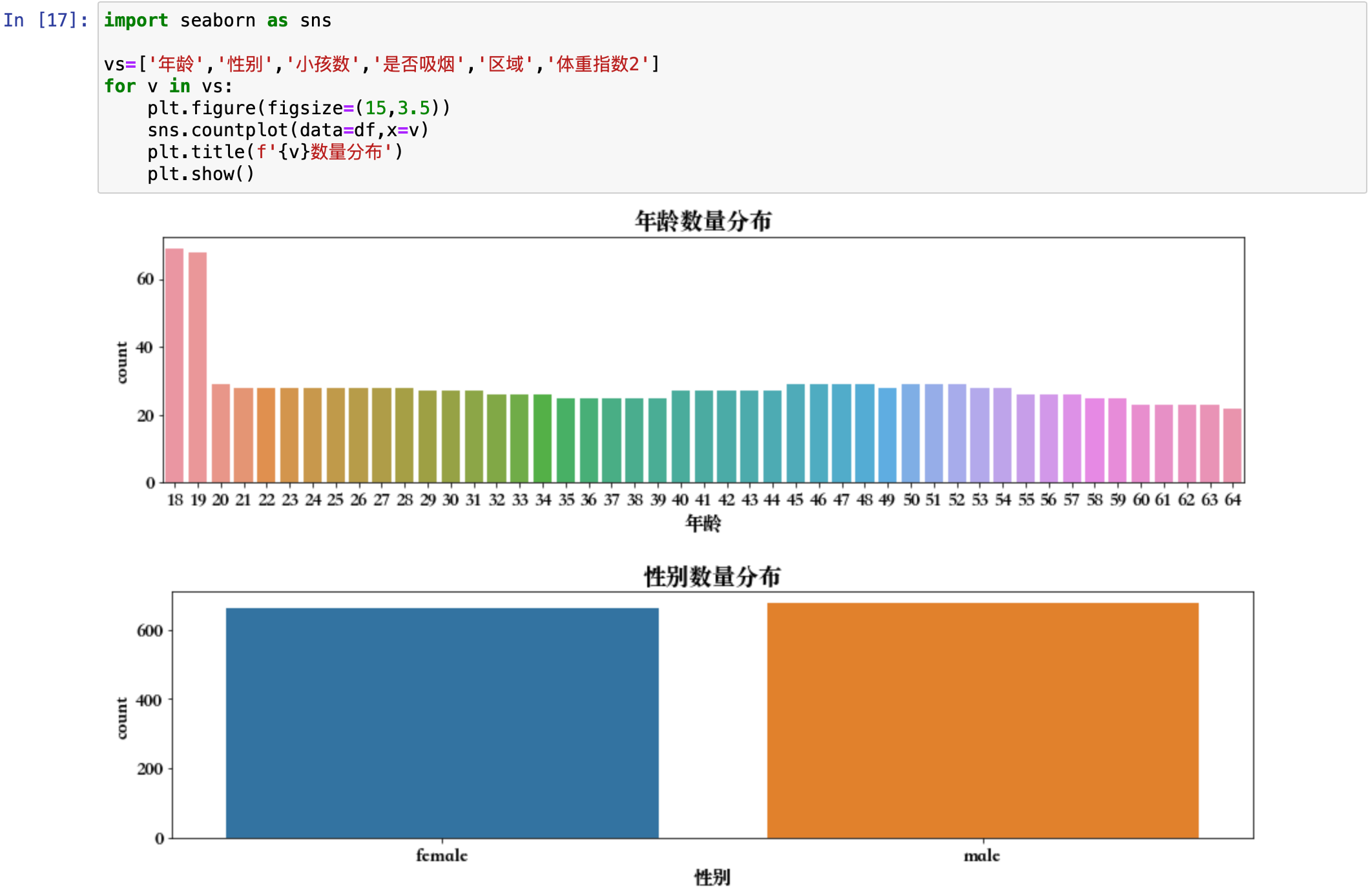
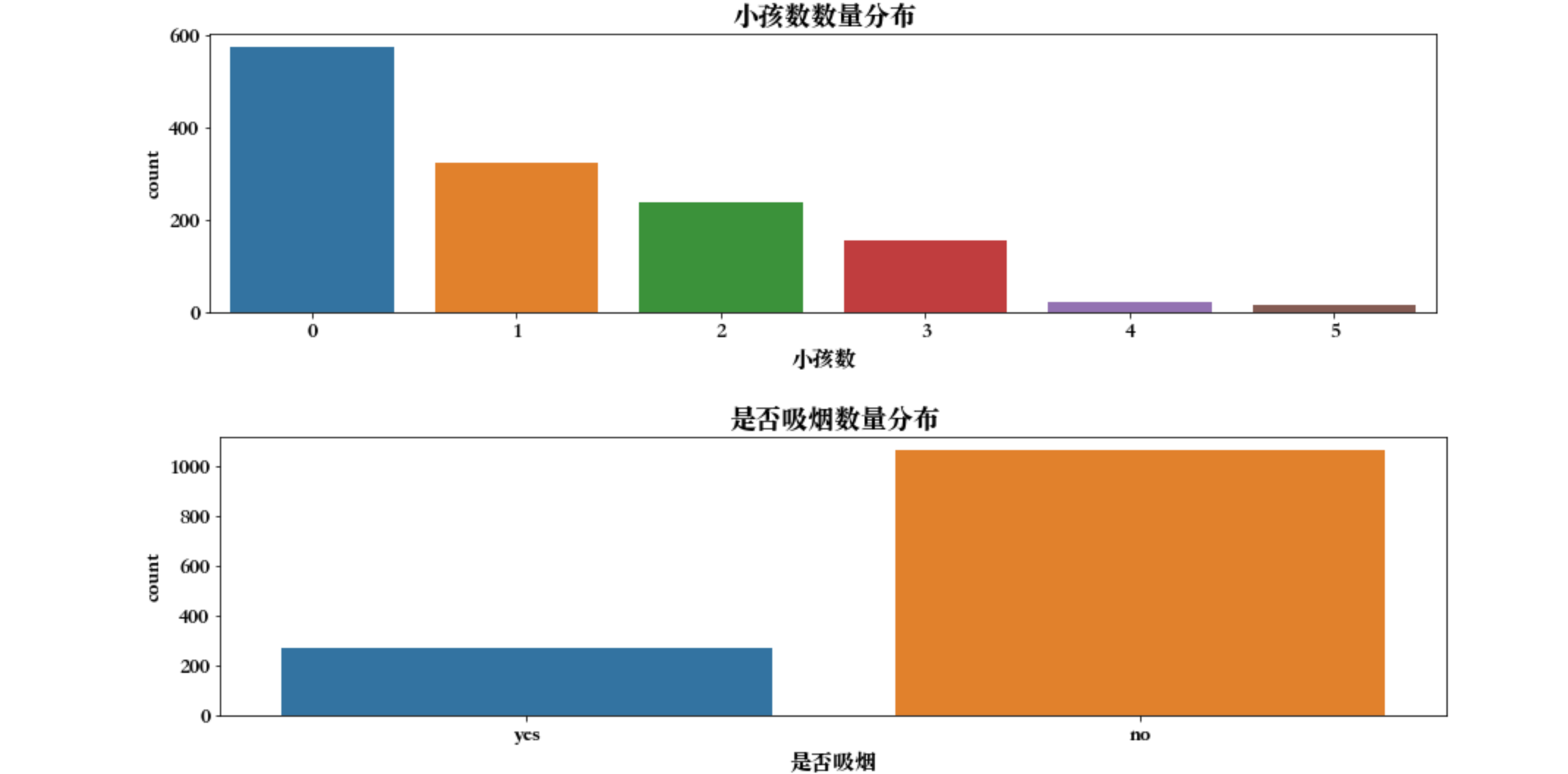
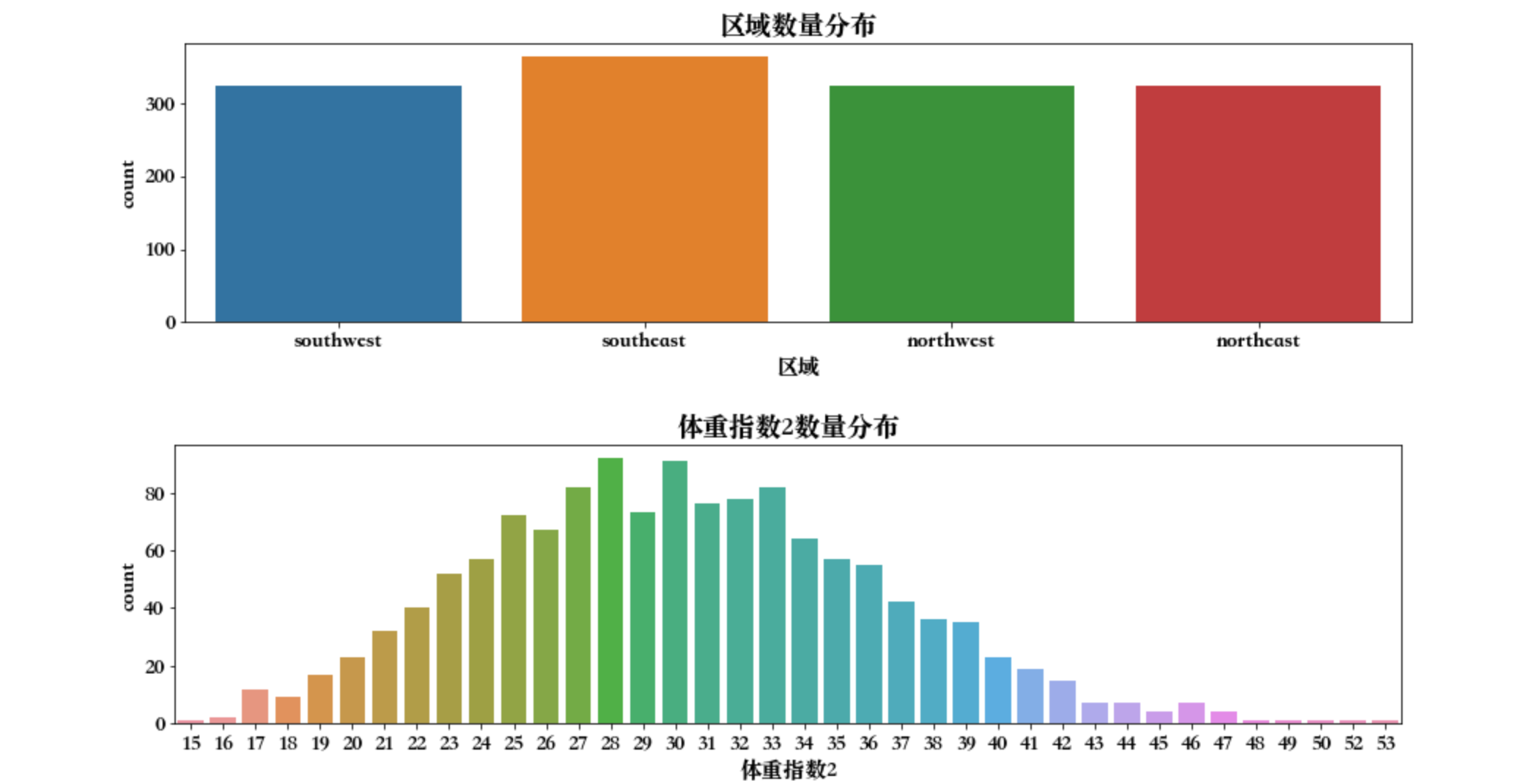
年龄在 18 岁和 19 岁的偏多,小孩数,都是没有小孩的。吸烟数量来看,大部分是不吸烟的。区域可以看出来,主要集中在东南方,其他三个区域没差太多。通过这些图可以看到每一个字段对应的数据呈现的情况。体重指数2这里也可以发现,大部分集中在 22~36 之间。这就是探索性分析的方式,就可以看出来感兴趣的字段的分布。对哪些字段感兴趣就对哪些字段进行图形绘制。
建模之前,发现性别,是否吸烟,还有区域,这些都属于文本类型的字段,在建模的时候需要把它们变成数值字段。在前面特征工程的那篇介绍过三种方式,可以将文本类型转换成数值类型。第一个方法是 pandas 里面的 get_dummies,哑变量处理。第二种方法是机器学习的方式,OneHotEncoder() 独热编码。第三种是标签编码 LabelEncoder()。这三种方式都能将文本类型的数据转换成数值类型的。因为建模只能通过数字代入到公式里面去,文本类型是代入不进去的。所以需要把文本类型的数据转成数值类型的。
现在导入一下对应的包。这次使用标签编码的方式来进行类型转换。把这三个字段直接覆盖做处理。直接去运行一下就可以了。
python
from sklearn.preprocessing import LabelEncoder
le_sex=LabelEncoder()
df['性别']=le_sex.fit_transform(df['性别'])
le_smoker=LabelEncoder()
df['是否吸烟']=le_smoker.fit_transform(df['是否吸烟'])
le_region=LabelEncoder()
df['区域']=le_region.fit_transform(df['区域'])
也可以打印出来看一下。可以看到,性别,是否吸烟,区域这三个的数据类型已经转为了数值类型。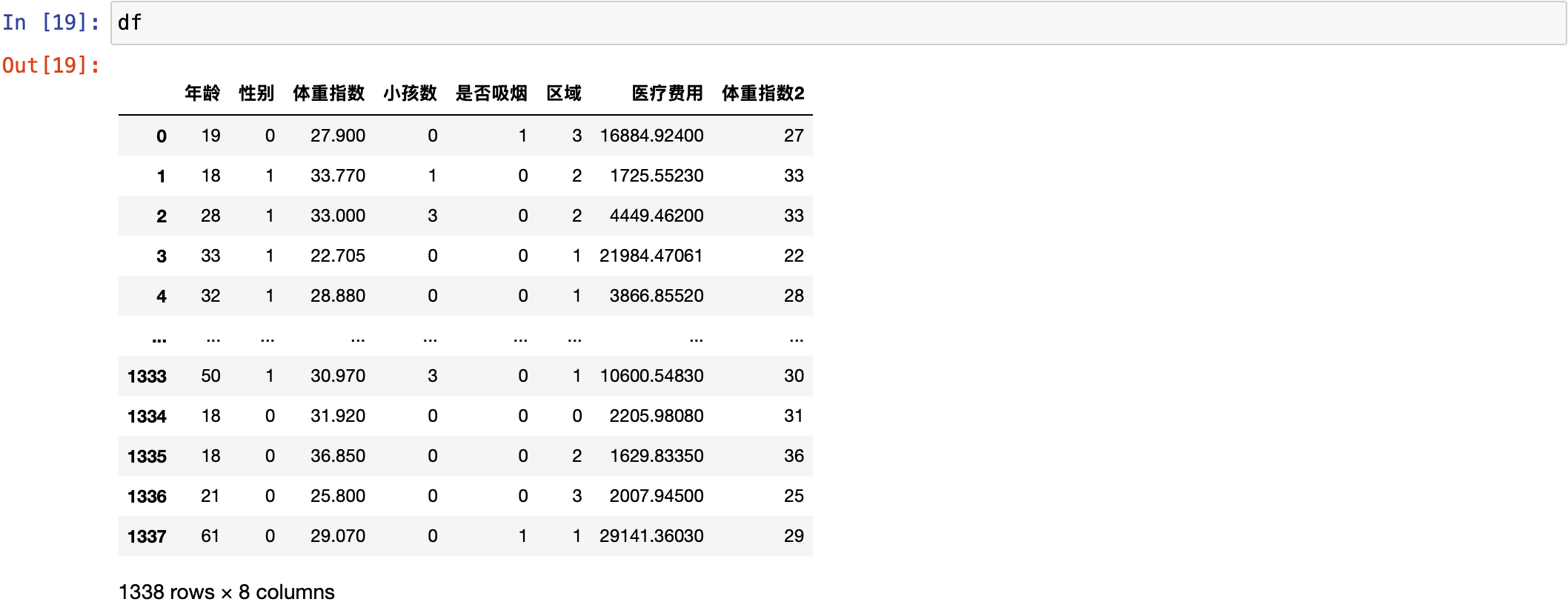
接下来可以看一下跨度大不大,如果跨度太大的话,可以做一个减少量纲的处理。在前面的特征工程介绍过,有两种方式可以减少量纲,分别是标准化和最大最小化。使用 describe 查看跨度。
python
df.describe()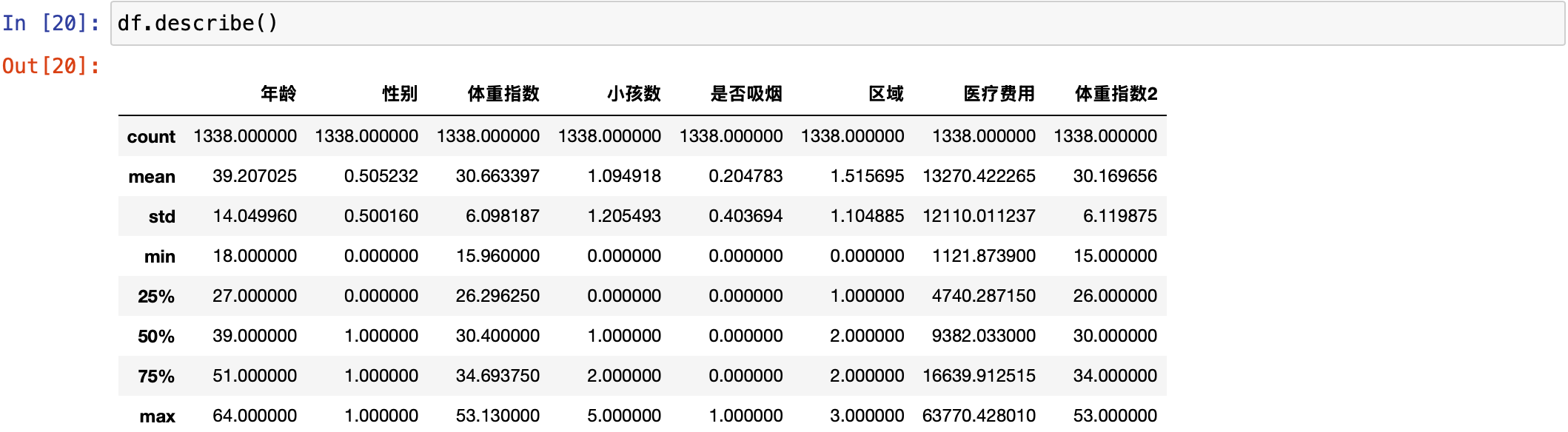
可以发现,这里面的医疗费用,最小的是 1000 多,最大的高达 60000 多。对医疗费用来说,数据跨度太大了,就可以对它进行减小量纲的处理。这里对它采用标准化处理,因为最大最小化处理会受到极值的影响,所以这个地方只能用标准化处理。这是最为保险的,用的比较多的方式也是标准化处理。
现在导入一下标准化处理的包。把特征列和目标列拿过来。这里的医疗费用不需要,新增的体重指数2不需要。设置 axis=1,表示按列删除。drop 的两列用 X 接住。y 就是目标列,是医疗费用,直接医疗费用写进去就可以了。下一步就可以做标准化处理了。把包名复制粘贴过来,对 X 数据做处理,用 X_std 这个变量来存储,然后拟合转化,里面放的是 X,就是特征列。下一步进行训练集和测试集的划分,这个时候拿的就是 X_std 了,因为要拿的是对它进行完处理的数值。最后,把随机森林的包拿过来,注意这里是回归随机森林的包,这里有个参数,估计器设置为 200。它默认的估计器是 100,这个估计器就是学习器,默认是有 100 棵决策树的意思,现在设定为 200。然后拟合一下。最后预测。得到预测值之后可以对它进行一下评估,用 score 来进行评估。
python
from sklearn.preprocessing import StandardScaler # 导入标准化处理的包
X=df.drop(['医疗费用','体重指数2'],axis=1) # 按列删除
y=df['医疗费用']
# 标准化处理
sc=StandardScaler()
X_std=sc.fit_transform(X)
X_train,X_test,y_train,y_test=train_test_split(X_std,y,test_size=0.2,random_state=2)
rnf_regressor=RandomForestRegressor(n_estimators=200) # 表示估计器
rnf_regressor.fit(X_train,y_train)
y_hat=rnf_regressor.predict(X_test)
print(rnf_regressor.score(X_test,y_test))
运行之后可以看到这里评分是 0.834。
这是一种评估方式,还有一种查看特征重要性的方法。把模型拿过来,直接点上feature_importances_,这里注意,下划线不要漏掉。运行一下看看。
python
# 特征重要性
rnf_regressor.feature_importances_
这里的特征重要性,总共是 6 个,可以对它排个序。因为特征重要性的值都不是很大,这里的特征也是一一对应的。当数据特别大的时候可以进行筛选,还有通过交叉验证去获取模型得分的最佳参数。它的计算量是很大的,这种情况,数据量特别大,评估方式又很大的时候,运行速度就会很慢,可能会卡死。但是这次的特征只有 6 个,可以排个序,排完序还可以划分一个分界点,比如大于 0.05,就进行保留,小于这个就可以把它删除,因为这个特征对整体模型的影响比较小,就可以减掉这个特征不要它了。就可以看一下,不要它之后能不能提高模型的整体性能。这是一些延展的部分。