1.作者介绍
郭政,男,西安工程大学电子信息学院,2025级研究生,张宏伟人工智能课题组
研究方向:机器视觉与人工智能
电子邮件:1225301905@qq.com
作者:李逸超,西安工程大学电子信息学院,2025级研究生张宏伟人工智能课题组
研究方向:机器视觉与人工智能
联系邮箱:2317314922@qq.com
2.背景介绍
2.1 行业痛点
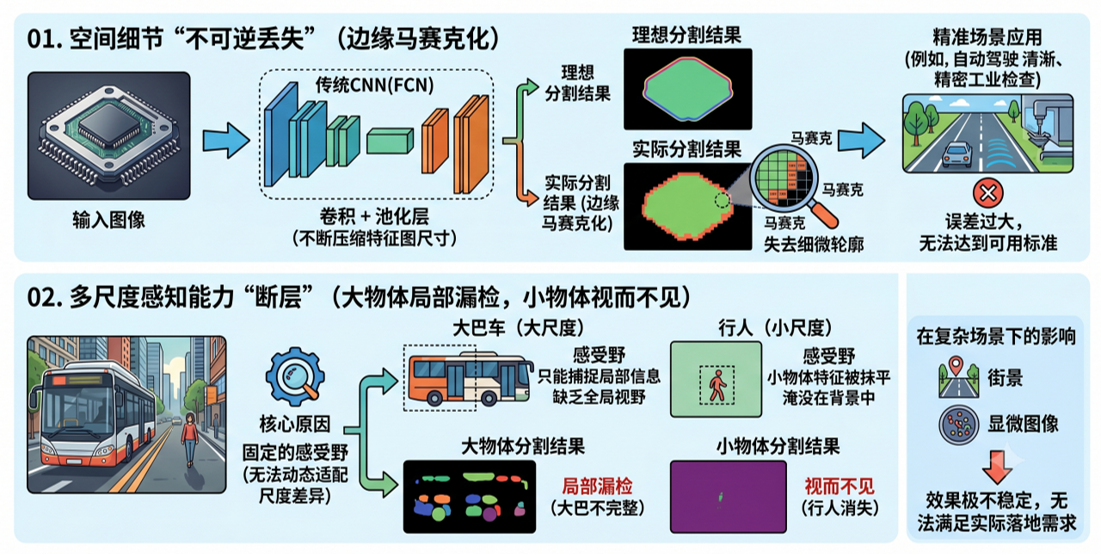
2014年左右,图像分割技术面临着两大困境。第一,为提取特征而进行的池化操作,会严重丢失图像细节,导致分割边缘模糊。第二,模型很难同时处理画面中大小差异巨大的物体
2.2 deeplab相关人物介绍
在这一技术痛点背景下,Google 团队推出的 DeepLab 系列模型针对性拆解化解上述难题,依靠独特的空洞卷积(扩张卷积)、空间金字塔池化等核心模块重构特征提取逻辑,从底层卷积运算、多尺度特征融合两个维度革新像素级分割范式 面对传统 CNN 分割架构受池化带来的细节永久丢失、轮廓马赛克失真、多尺度目标感知失衡这两大核心瓶颈,学界急需一套能够不粗暴压缩分辨率、灵活适配多尺度目标、精细还原物体边缘轮廓的全新分割架构思路。



3.算法原理介绍
3.1 deeplab框架
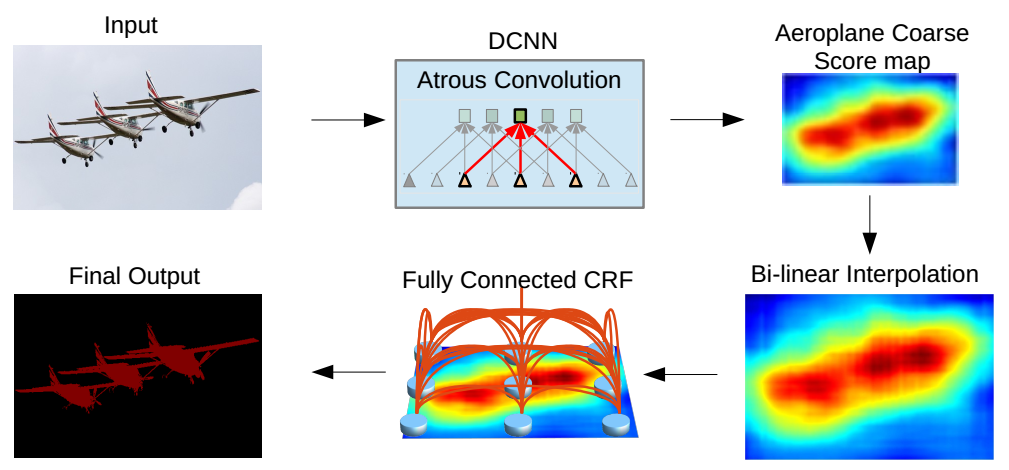
DeepLab 模型框架:输入图像经由引入空洞卷积的全卷积网络提取特征并生成分割得分图,再通过双线性插值还原分辨率,最后借助全连接条件随机场优化物体边缘,得到最终语义分割结果。
3.2 空洞卷积
普通标准卷积是网孔紧密的小渔网,抓取范围小;空洞卷积在卷积核权重元素之间插入零值空洞,相当于把渔网网孔拉大,卷积核本身参数数量不变,但单次扫描能覆盖更大的图像区域,不用池化下采样就能放大感受野。
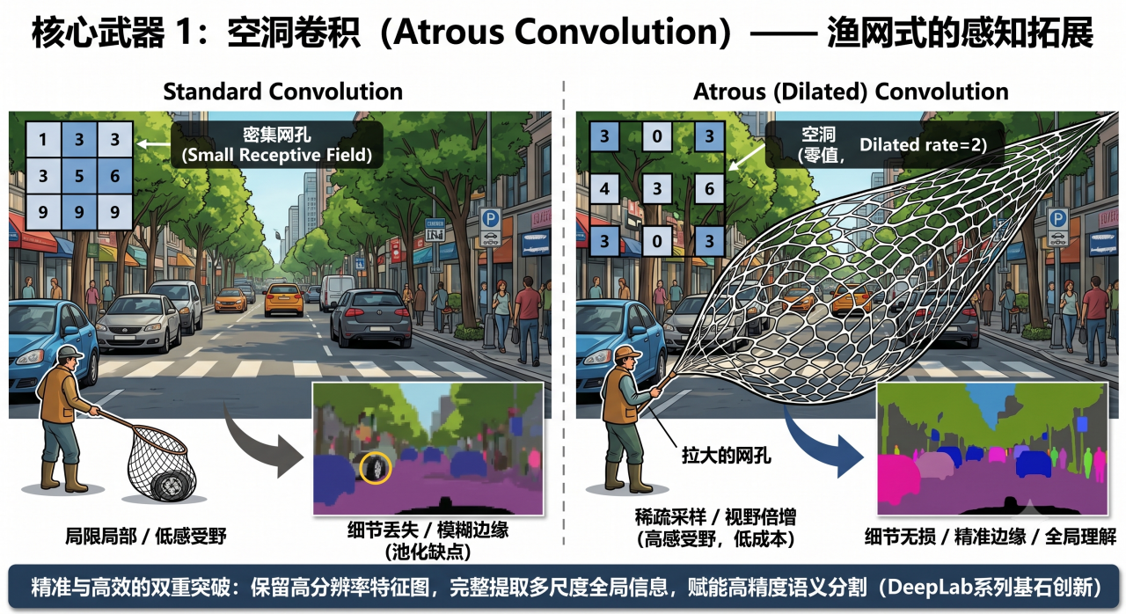
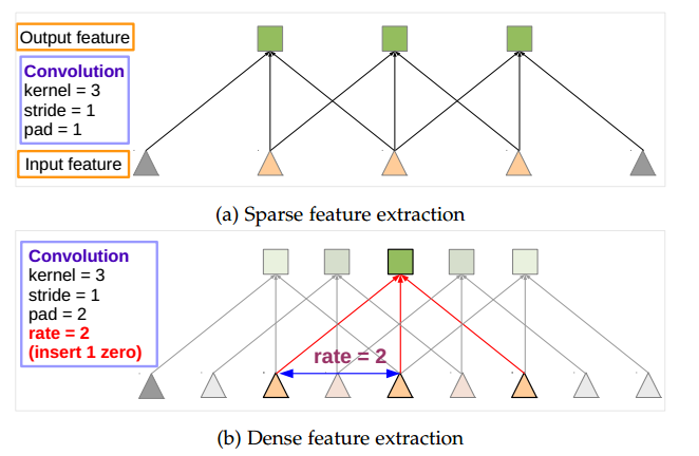
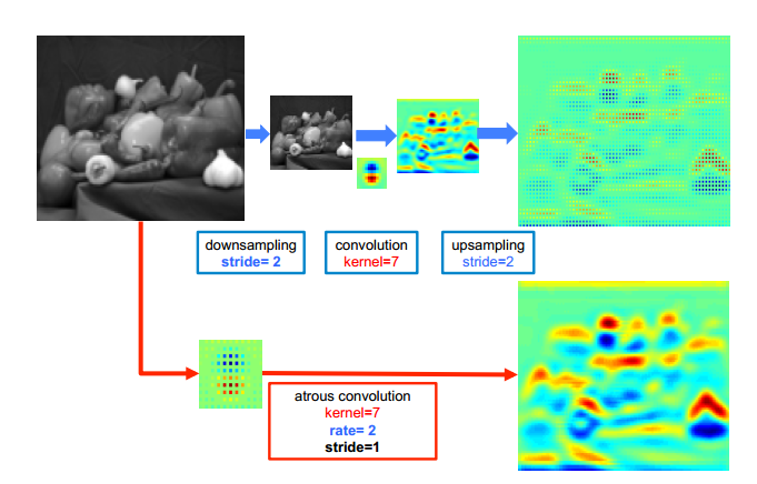
分别为一维空洞卷积与二维空洞卷积示意图
3.3 ASPP:多尺度并行感知
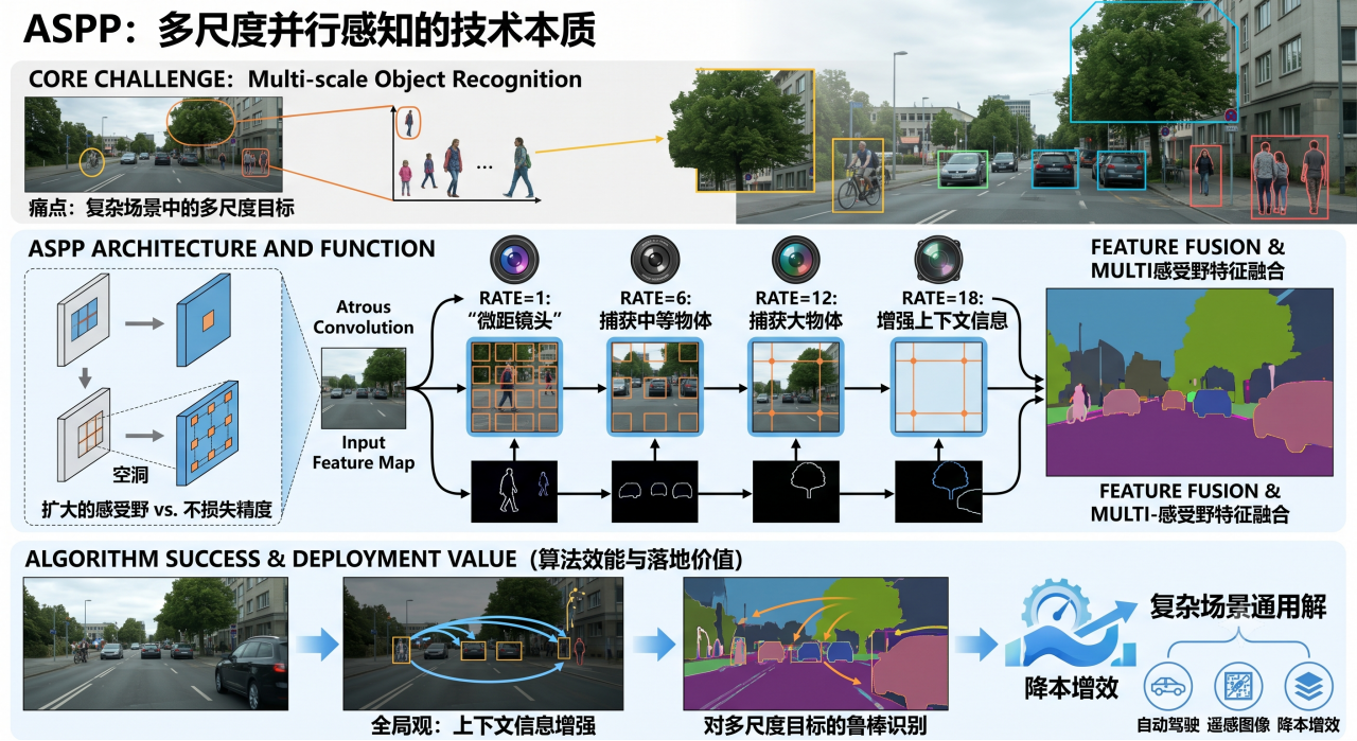
这张街道实拍图,画面里东西大小差得特别多: 有自行车、路边行人这
种 超小目标 ;小轿车属于 中等大小物体 ;路边大树、楼房又是 巨型目标 。 如果
咱们只用单一倍率的空洞卷积,就会顾此失彼: 用小视野只能看清行人,大树
整体轮廓抓不住;开大视野看大树,行人、单车的细小细节又直接糊掉。 复杂
场景里大小物体混在一起识别不准,这就是分割任务最大的拦路虎,而 ASPP 就
是专门治这个 "大小失衡" 问题的。
二、中间核心:ASPP 的工作逻辑 ------ 四路镜头同时拍照
我们把 ASPP 想象成一台装了四个不同焦距镜头的相机,同一张画面同时拍四张
不同视野的照片:
- 输入统一分发 :一张提取好的图像特征图,直接分给四条完全并行的空洞卷积支
路,互不干扰; - 四条支路各司其职(对应四个 rate 空洞率)
- Rate=1 :相当于微距镜头,视野最小,死死盯住行人、自行车这类小物件,抠精
细轮廓; - Rate=6 :标准中焦镜头,完美适配小轿车这类中等尺寸车辆;
- Rate=12 :长焦镜头,专门捕捉大树、整栋楼房这种大尺寸物体的整体形态;
- Rate=18 :超广远景镜头,放眼整条街道,抓取道路、建筑之间的全局上下文关
系,防止模型认错场景; 左边小插图也能印证:空洞卷积天生能拉大观察视野,
还不会压缩图片损失像素精度,这是 ASPP 能多尺度提取的根基。 - 多特征融合汇总 四条镜头各自提取完专属特征后,全部拼接融合到一起。最后
输出的特征图里,小行人、中汽车、大树、整片街道环境的信息全部齐全,没有
任何尺寸被忽略。
3.4应用场景

3.5 技术落地公司

3.6 语义模型汇总
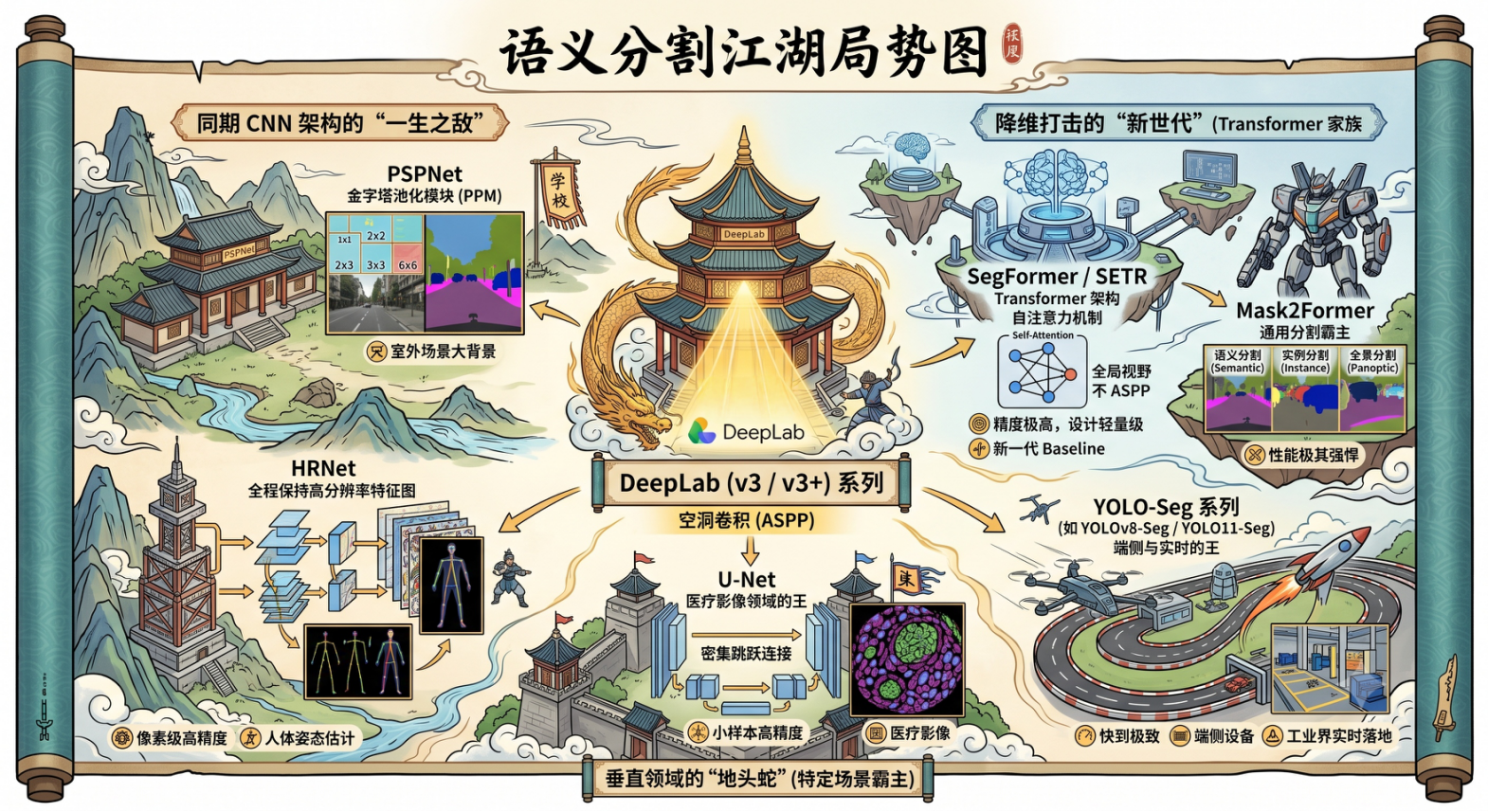
画面正中间这座盘龙古楼就是咱们前几页重点拆解的 DeepLab 系列,算是语义
分割界深耕多年的标杆大门派,江湖地位稳如泰山。 它的独门内功就是咱们讲
透的 空洞卷积 + ASPP 空洞空间金字塔 ,既能拉大观察视野不丢细节,又能同时
搞定大小不一的多尺度物体。综合实力均衡,通用场景表现稳定,长久以来都是
很多项目的基准对照模型,相当于武林里武当少林级别的老牌强者,也是咱们本
次研究的核心主体。
二、左侧阵营:同期 CNN 架构,DeepLab 的一生劲敌
左边两大宗门,都是和 DeepLab 同一时代的 CNN 顶尖高手,各有独门招式分庭
抗礼:
- PSPNet (山间古院落) 它的看家本领是 PPM 金字塔池化模块,最擅长室外开
阔大场景,比如整座城市街道、大范围航拍画面。它靠多层池化抓取全局背景信
息,当年和 DeepLab 同台竞技,是室外场景里最强竞争对手。 - HRNet (高塔造型宗门) 这门派走极致精细路线,武功精髓是全程保持高分辨
率特征图。别的网络提取特征时图片越卷越小,它从头到尾牢牢守住高清尺寸,
像素级精度拉满。做人姿态、人体轮廓分割天下一绝,精细像素任务没人能轻易
比得过它。
三、画卷下方:垂直领域地头蛇 ------U-Net
城墙造型的 U-Net 不跟大家抢通用大场景,牢牢霸占 医疗影像 这块专属地盘,
是细分领域的无冕之王。 它靠密集跳跃连接的独门招式取胜,哪怕医疗病理切
片、CT 影像的样本数量很少(小样本数据),也能精准分割病灶、细胞组织。
现在医院 AI 阅片、病理筛查几乎全都标配 U-Net,属于垂直赛道里稳稳扎根的
地头蛇。
四、右侧阵营:新世代 Transformer 家族,降维打击的后起强者
右边浮空岛屿、机甲、火箭赛道代表新生代选手,靠着 Transformer 自注意力
新内功,很多场景实现性能反超,属于后生可畏的新锐门派: - SegFormer / SETR (浮空中枢) 抛弃卷积老路子,用自注意力机制抓取全局视野,
视野范围比 ASPP 还要广阔。精度拉满同时模型更轻量化,现在已经成为很多新
实验的新一代基准模型。 - Mask2Former (机甲战神) 全能型霸主,一身功夫通吃三大分割任务:普通语
义分割、逐个物体实例分割、全景分割,三样性能全都顶尖,综合实力目前站在
性能天花板位置。 - YOLO-Seg 系列(火箭竞速赛道) 它不拼极致精度,主打一个 " 快 " 字!像
YOLOv8-Seg 、 YOLO11-Seg 速度拉满,能在手机、无人机、工业摄像头这种小型
端侧设备上实时跑起来,工业流水线、自动驾驶实时识别落地首选,讲究极速实
用。
最后整体总结门派选择逻辑
给大家捋一个落地选型口诀: 做通用基础实验、稳妥 baseline → 选老牌
DeepLab;医疗影像小样本分割 → 认准 U-Net;室外超大场景 → PSPNet;人 体姿态、超精细像素分割 → HRNet;追求顶尖高精度、前沿创新 → Transformer
家族(SegFormer/Mask2Former);需要设备实时快速跑、工业落地 → YOLO-Seg。
整个语义分割江湖百花齐放,没有绝对无敌的门派,只有适配场景的最优选择。
4 代码实现
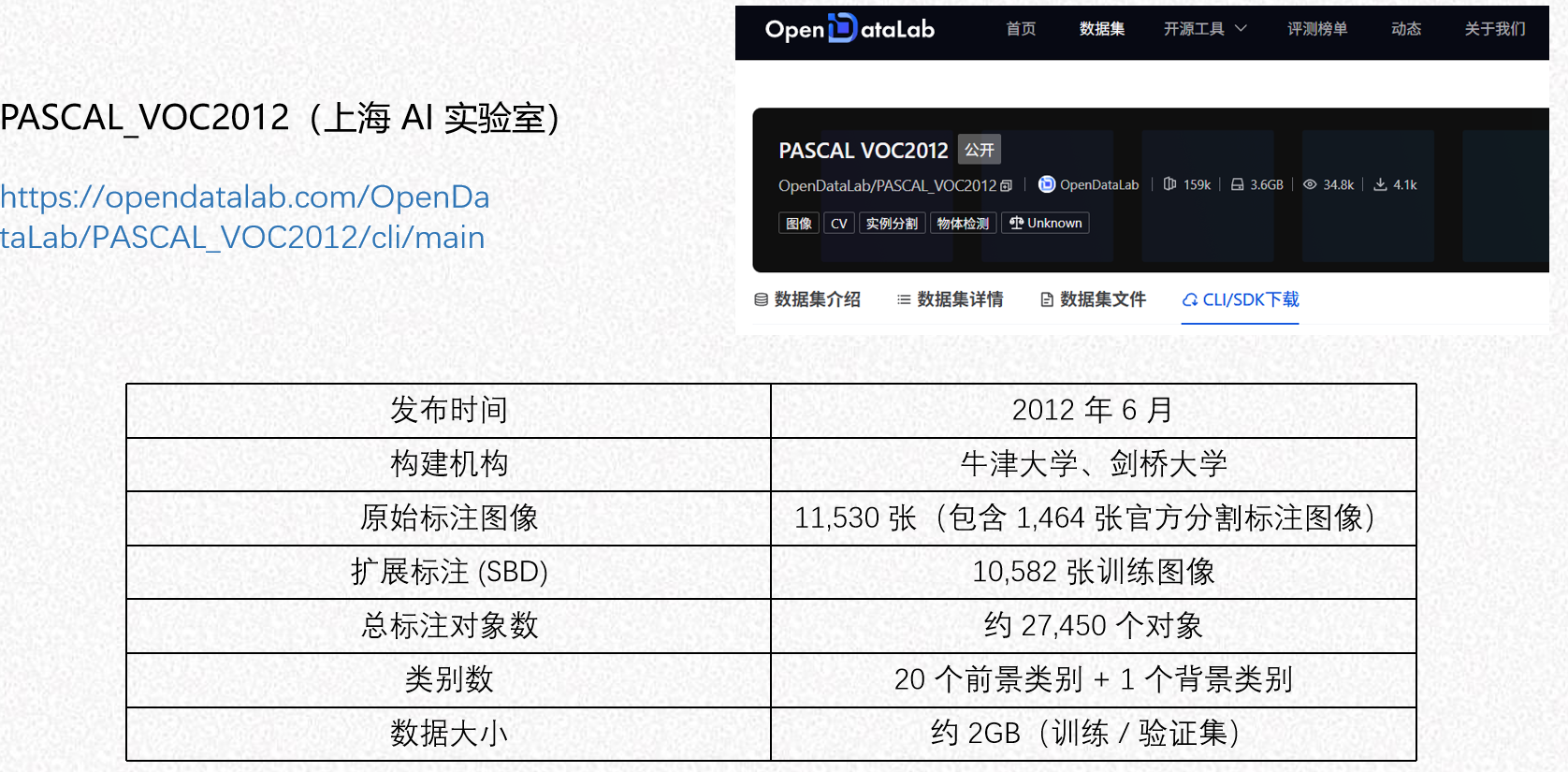
4.1 数据集下载
4.2实验核心代码
基于 PyTorch 的 DeepLabv3+ 语义分割全流程实战
项目概述
本项目利用 PyTorch 框架,在 PASCAL VOC 2012 数据集上微调(Fine-tune)官方预训练的 DeepLabv3+ 模型,实现对 20 种常见物体的像素级语义分割。
第一步:环境配置
在一个干净的虚拟环境中安装 PyTorch 及相关依赖,避免与其他项目冲突。
- 创建并激活 Conda 虚拟环境:
Bash
conda create -n deeplab_voc python=3.10 -y
conda activate deeplab_voc- 安装 PyTorch(推荐 CUDA 11.8 版本以保证最大兼容性)及辅助工具:
Bash
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
pip install matplotlib pillow tqdm numpy第二步:项目结构与数据准备
合理的项目结构能极大提升开发效率,避免路径混乱。
1. 创建目录结构 在你的工作空间中创建如下结构:
Plaintext
deeplab/
├── data/ # 存放解压后的 VOCdevkit
├── weights/ # 存放训练生成的 .pth 权重文件
├── test_images/ # 存放测试图片和输出结果
├── train.py # 训练脚本
└── predict.py # 推理脚本2. 数据集处理 为了避免跨国下载限速和网络中断导致的坏包问题,采用手动下载与解压的方式:
-
通过国内镜像源(如 OpenDataLab)下载
VOCtrainval_11-May-2012.tar压缩包。 -
将压缩包放入
data/目录下,并手动解压提取出VOCdevkit文件夹。 -
重要提示: 解压完成后,务必删除残留的
.tar压缩包,防止 PyTorch 数据加载器误判。
第三步:编写与运行训练脚本
创建 train.py。该脚本负责加载本地数据集、替换模型分类头、定义交叉熵损失(忽略背景边界像素 255)并执行训练循环。
完整 train.py 代码:
Python
import os
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision.datasets import VOCSegmentation
from torchvision.transforms import v2
from torchvision.models.segmentation import deeplabv3_resnet50, DeepLabV3_ResNet50_Weights
from tqdm import tqdm
def main():
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"Using device: {device}")
# 动态获取当前脚本所在目录,确保路径绝对正确
base_dir = os.path.dirname(os.path.abspath(__file__))
os.makedirs(os.path.join(base_dir, 'weights'), exist_ok=True)
transforms = v2.Compose([
v2.Resize((512, 512)),
v2.ToImage(),
v2.ToDtype(torch.float32, scale=True),
v2.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
target_transforms = v2.Compose([
v2.Resize((512, 512), interpolation=v2.InterpolationMode.NEAREST),
v2.ToImage(),
v2.ToDtype(torch.long, scale=False)
])
print("Loading VOC2012 Dataset from local directory...")
data_dir = os.path.join(base_dir, 'data')
train_dataset = VOCSegmentation(
root=data_dir,
year='2012',
image_set='train',
download=False, # 禁止联网下载,直接读本地数据
transform=transforms,
target_transform=target_transforms
)
train_loader = DataLoader(train_dataset, batch_size=4, shuffle=True, num_workers=4)
print("Initializing DeepLabv3+ Model...")
weights = DeepLabV3_ResNet50_Weights.DEFAULT
model = deeplabv3_resnet50(weights=weights)
# 修改输出通道数为 21 (20类物体 + 1类背景)
model.classifier[4] = nn.Conv2d(256, 21, kernel_size=(1, 1), stride=(1, 1))
model.aux_classifier[4] = nn.Conv2d(256, 21, kernel_size=(1, 1), stride=(1, 1))
model = model.to(device)
criterion = nn.CrossEntropyLoss(ignore_index=255)
optimizer = optim.SGD([
{'params': model.backbone.parameters(), 'lr': 0.001},
{'params': model.classifier.parameters(), 'lr': 0.01},
{'params': model.aux_classifier.parameters(), 'lr': 0.01}
], momentum=0.9, weight_decay=1e-4)
num_epochs = 10
print("Starting Training Loop...")
for epoch in range(num_epochs):
model.train()
running_loss = 0.0
pbar = tqdm(train_loader, desc=f"Epoch {epoch+1}/{num_epochs}")
for images, masks in pbar:
images = images.to(device)
masks = masks.squeeze(1).to(device)
optimizer.zero_grad()
outputs = model(images)
loss_main = criterion(outputs['out'], masks)
loss_aux = criterion(outputs['aux'], masks)
loss = loss_main + 0.5 * loss_aux
loss.backward()
optimizer.step()
running_loss += loss.item()
pbar.set_postfix({'loss': f"{loss.item():.4f}"})
epoch_loss = running_loss / len(train_loader)
print(f"Epoch {epoch+1} Completed | Average Loss: {epoch_loss:.4f}")
save_path = os.path.join(base_dir, f"weights/deeplabv3_epoch_{epoch+1}.pth")
torch.save(model.state_dict(), save_path)
if __name__ == '__main__':
main()运行命令: python train.py
第四步:编写与运行推理脚本
创建 predict.py。该脚本负责加载训练好的权重,对新图片进行推理,在终端打印识别出的物体类别,并生成彩色分割掩码图像。
完整 predict.py 代码:
Python
import os
import torch
import torch.nn as nn
from torchvision.models.segmentation import deeplabv3_resnet50
from torchvision.transforms import v2
from PIL import Image
import numpy as np
import matplotlib.pyplot as plt
VOC_COLORMAP = [
[0, 0, 0], [128, 0, 0], [0, 128, 0], [128, 128, 0],
[0, 0, 128], [128, 0, 128], [0, 128, 128], [128, 128, 128],
[64, 0, 0], [192, 0, 0], [64, 128, 0], [192, 128, 0],
[64, 0, 128], [192, 0, 128], [64, 128, 128], [192, 128, 128],
[0, 64, 0], [128, 64, 0], [0, 192, 0], [128, 192, 0],
[0, 64, 128]
]
VOC_CLASSES = [
'background (背景)', 'aeroplane (飞机)', 'bicycle (自行车)', 'bird (鸟)', 'boat (船)',
'bottle (瓶子)', 'bus (巴士)', 'car (小汽车)', 'cat (猫)', 'chair (椅子)', 'cow (牛)',
'diningtable (餐桌)', 'dog (狗)', 'horse (马)', 'motorbike (摩托车)', 'person (人)',
'pottedplant (盆栽)', 'sheep (羊)', 'sofa (沙发)', 'train (火车)', 'tvmonitor (显示器)'
]
def decode_segmap(image_idx):
r = np.zeros_like(image_idx).astype(np.uint8)
g = np.zeros_like(image_idx).astype(np.uint8)
b = np.zeros_like(image_idx).astype(np.uint8)
for l in range(0, 21):
idx = image_idx == l
r[idx] = VOC_COLORMAP[l][0]
g[idx] = VOC_COLORMAP[l][1]
b[idx] = VOC_COLORMAP[l][2]
return np.stack([r, g, b], axis=2)
def main():
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
base_dir = os.path.dirname(os.path.abspath(__file__))
# 开启 aux_loss=True 确保模型结构与训练时完全一致
model = deeplabv3_resnet50(weights=None, aux_loss=True)
model.classifier[4] = nn.Conv2d(256, 21, kernel_size=(1, 1), stride=(1, 1))
model.aux_classifier[4] = nn.Conv2d(256, 21, kernel_size=(1, 1), stride=(1, 1))
weight_path = os.path.join(base_dir, "weights/deeplabv3_epoch_10.pth")
print(f"Loading weights from: {weight_path}")
model.load_state_dict(torch.load(weight_path, map_location=device))
model = model.to(device)
model.eval()
transform = v2.Compose([
v2.Resize((512, 512)),
v2.ToImage(),
v2.ToDtype(torch.float32, scale=True),
v2.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
image_path = os.path.join(base_dir, "test_images/test.jpg")
if not os.path.exists(image_path):
print(f"找不到测试图片!请确保上传了照片到: {image_path}")
return
img_pil = Image.open(image_path).convert("RGB")
input_tensor = transform(img_pil).unsqueeze(0).to(device)
print("Running inference...")
with torch.no_grad():
output = model(input_tensor)['out'][0]
prediction = torch.argmax(output, dim=0).cpu().numpy()
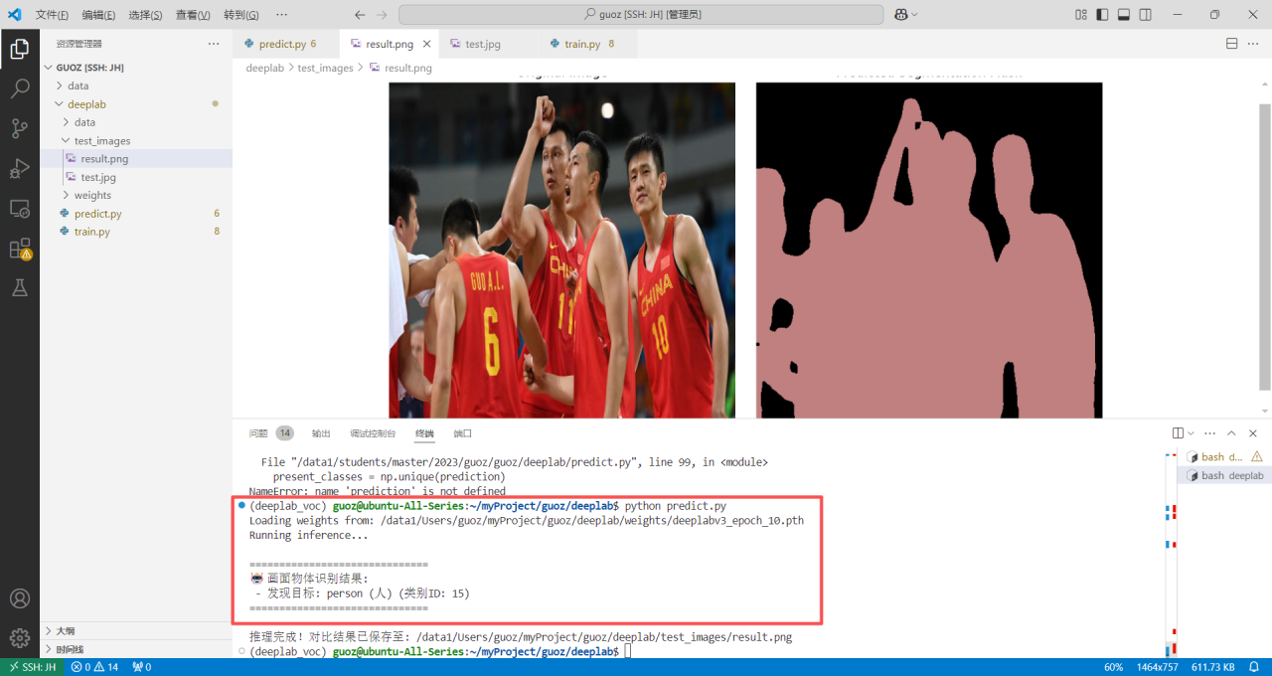
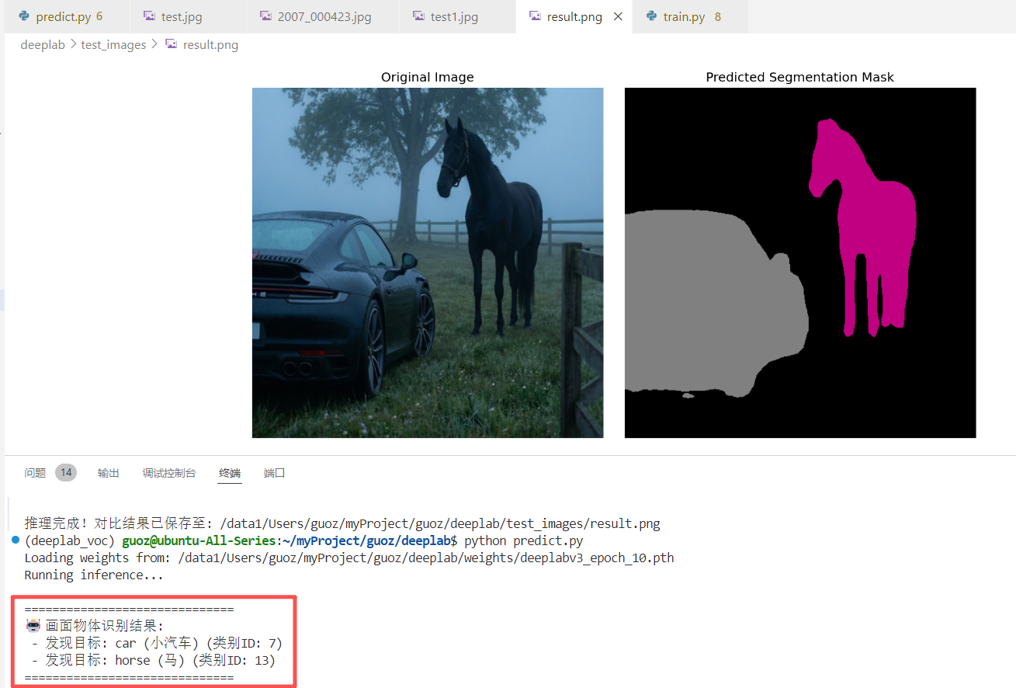
present_classes = np.unique(prediction)
print("\n" + "="*30)
print("画面物体识别结果:")
for class_id in present_classes:
if class_id == 0:
continue
print(f" - 发现目标: {VOC_CLASSES[class_id]} (类别ID: {class_id})")
print("="*30 + "\n")
colorized_mask = decode_segmap(prediction)
result_path = os.path.join(base_dir, "test_images/result.png")
os.makedirs(os.path.join(base_dir, 'test_images'), exist_ok=True)
fig, ax = plt.subplots(1, 2, figsize=(10, 5))
ax[0].imshow(img_pil.resize((512, 512)))
ax[0].set_title('Original Image')
ax[0].axis('off')
ax[1].imshow(colorized_mask)
ax[1].set_title('Predicted Segmentation Mask')
ax[1].axis('off')
plt.tight_layout()
plt.savefig(result_path, bbox_inches='tight', dpi=150)
print(f"推理完成!对比结果已保存至: {result_path}")
if __name__ == '__main__':
main()运行说明: 将任意 .jpg 照片重命名为 test.jpg,放进 test_images/ 目录,然后执行 python predict.py 即可在同目录下查看生成的 result.png。
4.3实验结果