前言
很多 RAG 演示项目看起来很简单:上传文档、切成文本块、生成向量、查询向量数据库,再把检索结果交给大模型回答。真正落到生产环境后才会发现,向量数据库只是整个链路中的一环。文档解析是否完整、切分是否破坏语义、用户问题是否被过度改写、候选结果如何融合、重排序接口是否正确,都会直接影响最终回答。
本文记录我在知识库系统中同时接入 Chroma 与 Milvus 的过程。系统既支持轻量的本地 Chroma,也支持 Milvus 的向量与 BM25 混合检索,并在此基础上加入查询扩展、原问题保留、RRF 融合、重排序和 Agent 多轮检索。文章会先介绍 RAG、BM25、向量数据库等基础概念,再说明项目的真实流程、测试结果以及开发中遇到的坑。
一、RAG 到底解决什么问题
大语言模型的知识来自训练数据,存在知识截止时间、私有资料不可见、答案无法溯源以及幻觉等问题。RAG(Retrieval-Augmented Generation,检索增强生成)的核心思想,是在回答前先从外部知识库中找到相关资料,再让模型依据这些资料生成答案。
一条典型链路可以概括为:
text
文档上传
-> 文档解析
-> 文本切分
-> Embedding 向量化
-> 写入向量数据库
-> 用户提问
-> 检索相关文本块
-> 重排序
-> 将上下文交给大模型
-> 生成带依据的答案RAG 并不保证模型自动变得准确,它只是把"模型凭记忆回答"变成"模型依据检索材料回答"。如果检索阶段找错了资料,后面的模型再强,也可能一本正经地总结错误上下文。因此,RAG 工程的重点不是单纯接入一个向量数据库,而是持续提高有效召回率和前几名结果的相关性。
这里需要区分两个概念:
- 召回率:真正有用的内容,有多少被找进了候选集合。
- 排序准确度:找回的内容中,最相关的内容能否排在前面。
我们采用的策略是"宽召回、精排序":先通过向量、BM25 和查询扩展尽量找全,再用重排序模型把最适合回答问题的文本块排到前面。
二、向量检索、BM25 与混合检索
1. 向量检索
Embedding 模型会把问题和文本映射为高维向量。语义接近的文本,其向量在空间中的距离也更接近。本项目使用 BAAI/bge-m3 生成向量。
常见的向量相似度包括:
- 余弦相似度(Cosine Similarity):比较两个向量方向是否一致,值越大通常越相似。
- 点积(Inner Product):同时受向量方向和模长影响,常用于已归一化的向量。
- 欧氏距离(L2):比较空间距离,距离越小越相似。
Milvus 检索使用的是 COSINE。余弦相似度可写为:
text
cos(A, B) = (A · B) / (|A| × |B|)向量检索的优势是能理解同义表达。例如用户问"哪些工厂进行了数字化改造",即使原文写的是"智能制造升级",仍可能被召回。它的弱点也很明显:语义看起来相似、事实却不属于目标范围的段落,也可能获得较高分数。
2. BM25 关键词检索
BM25 是经典的稀疏检索算法。它基于词频、逆文档频率和文档长度,对查询词与文档的匹配程度进行评分。直观理解如下:
- 查询词在某段文本中出现,相关性会上升;
- 越少见、越有区分度的词,权重越高;
- 同一个词重复很多次后,收益会逐渐饱和;
- 对过长文档进行长度归一化,避免长文本天然占优。
BM25 对产品型号、项目名称、专有名词、缩写和精确关键词尤其有效。例如"中国灯塔工厂""胶州空调互联工厂"等词,关键词检索通常比纯向量检索更稳定。但 BM25 不真正理解语义,如果用户换了一种说法,原文又没有对应词汇,就可能漏掉答案。
3. 为什么采用混合检索
向量检索擅长"意思相近",BM25 擅长"字面命中",二者是互补关系。本项目的 Milvus 知识库会对同一查询同时执行:
text
查询文本
├─ BGE-M3 向量 -> Dense Search
└─ 中文分词分析 -> BM25 Sparse Search
↓
WeightedRanker 融合当前向量权重为 0.7,BM25 权重为 0.3。这个比例不是放之四海皆准的标准答案,而是当前资料和测试问题下的折中:以语义召回为主,用关键词命中补强专有名词和项目名称。
三、Chroma、Milvus 与常见向量数据库
Chroma 是一个轻量、易用的向量数据库,非常适合本地开发、单机应用和中小规模知识库。本项目将 Chroma 数据持久化到服务器本地目录,部署简单,不需要额外维护一套分布式服务。
Milvus 更适合数据规模增大、并发提高、需要独立检索服务或混合检索的场景。它支持向量字段、标量过滤和稀疏检索。本项目把 Milvus 当作第三方独立服务使用,只保存文本块、向量、BM25 索引和定位字段。原始文件与解析后的 Markdown 仍保存在应用服务器本地,不依赖 MinIO。
当前系统通过配置开关控制是否启用 Milvus:
ini
[milvus]
enabled = true关闭后,前端只能创建 Chroma 知识库;打开后,创建知识库时可以选择 Milvus 双路检索。一个知识库创建后,其存储后端固定,不在运行中随意切换。
除了 Chroma 和 Milvus,常见方案还有:
| 方案 | 特点 | 适合场景 |
|---|---|---|
| FAISS | 高性能向量检索库,但不是完整数据库 | 单机算法验证、离线检索 |
| pgvector | 在 PostgreSQL 中保存和查询向量 | 已有 PostgreSQL、数据规模适中 |
| Qdrant | 向量检索与过滤能力完善,部署较直接 | 独立向量服务 |
| Weaviate | 支持向量检索和结构化对象管理 | 需要较完整的数据模型 |
| Elasticsearch/OpenSearch | 关键词检索成熟,也可支持向量与混合查询 | 已有搜索基础设施 |
| Pinecone | 托管式向量数据库 | 希望减少基础设施运维 |
技术选型不应只看性能榜单。小型内部知识库使用 Chroma 足够省心;需要 BM25、独立服务和扩展能力时,再选择 Milvus 这样的服务型数据库,通常更合理。
四、文档解析与切分:检索质量的地基
1. 解析后先保存 Markdown
系统上传文档后,不会直接把文件粗暴地按字符截断。PDF 优先通过 PyMuPDF 解析,并根据字号等信息恢复 Markdown 标题层级;解析失败时使用 pypdf 回退。DOCX 会转换为 Markdown,扫描件则可通过 RapidOCR 识别。
解析结果会保存为:
text
src/data/knowledge/uploads/<kb_id>/<file_id>.parsed.md原文件也保存在同一知识库的本地目录。解析结果与向量索引分离有两个好处:一是调整切分参数后可以直接重新索引,不必重新上传;二是可以打开原文或解析全文,为 Agent 补充相邻上下文。
2. 为什么采用 Token 切分
早期常见做法是按字符数切分,例如每 1000 个字符切一块。但中文、英文、数字和标点对应的模型 Token 数量并不相同。最终上下文限制以 Token 计算,因此按字符切分容易出现块大小不稳定的问题。
当前实现基于 tiktoken 的 cl100k_base 编码,默认每块约 512 tokens,重叠 64 tokens。旧配置中的 chunk_size 和 chunk_overlap 仍为兼容字段,但不再驱动新的切分逻辑。
系统提供三种切分预设:
- heading:按 Markdown 标题层级切分,并将标题路径写入文本块;没有标题时自动回退到 general。
- general:以段落为基础进行 Token 贪心组合,超长段落再硬切。
- separator:先按指定分隔符划分,再按 Token 预算组合。
默认使用 heading。它的价值在于保留语义结构。例如"第三章 > 灯塔工厂 > 应用案例"会成为文本块的上下文,即使块内没有重复完整标题,检索模型也能知道这段内容属于什么主题。
3. 切分中的坑
块太大时,一个 Chunk 会混入多个主题,向量表达变得模糊,也会浪费大模型上下文;块太小时,一个事实可能被拆散,检索到其中一半仍无法回答问题。重叠能缓解边界断裂,但重叠过大会产生大量重复结果。
扫描件还有一个特殊问题:OCR 结果通常没有可靠的标题层级,因此 heading 会退化为 general。对表格密集、双栏排版或扫描质量差的 PDF,解析质量往往比向量数据库选型更值得优先检查。
五、两条真实的检索链路
1. Chroma 检索流程
在 Agent 对话中,Chroma 当前的主要流程是:
text
用户原始问题
-> Agent 生成短关键词或扩展查询
-> BGE-M3 生成查询向量
-> Chroma 向量召回 recall_k 条
-> 可选 Rerank
-> 返回 top_k 条
-> Agent 组织答案Chroma 路线轻量、延迟低,但服务端不会自动融合"用户原问题"和"Agent 扩展词"。Agent 可以在结果不足时换一组关键词再次调用工具,因此它仍具有多轮检索能力,只是每次调用本质上是一次向量查询。
2. Milvus 检索流程
Milvus 路线会始终保留用户原始问题,同时允许 Agent 提供更短、更适合搜索的扩展查询:
text
原始问题 ──> 向量 + BM25 ──> 混合结果 A
扩展查询 ──> 向量 + BM25 ──> 混合结果 B
↓
加权 RRF 融合
↓
Rerank
↓
最终 TopK当前原始问题权重为 0.7,扩展查询权重为 0.3。这样既不会因为模型改写丢失用户限定条件,又能利用关键词扩展提高召回。如果原问题与扩展词完全相同,系统只查询一次;某一路失败时,也会回退到另一路结果。
跨查询融合使用加权 RRF(Reciprocal Rank Fusion):
text
RRF_score(d) = Σ weight_i / (k + rank_i(d))其中 query_fusion_rrf_k=60 是排名平滑常数,不是召回数量。它越大,不同名次之间的分差越平缓。当前融合按 kb_id + file_id + chunk_index 去重,避免同一个文本块因命中两路查询而重复进入上下文。
六、Rerank:从"找得到"到"排得准"
首轮向量或混合检索追求召回,因此会先取 recall_k=12 条候选。随后使用 BAAI/bge-reranker-v2-m3 对"问题---候选文本"逐对打分,最后保留 top_k=8 条。
Embedding 是把问题和文档分别编码后进行近似搜索,速度快,适合海量召回;Reranker 会联合阅读问题和候选文本,计算更精细的相关性,成本更高但排序更准。因此不能用 Reranker 替代数据库的第一阶段召回,而应让两者各司其职。
这里踩过一个接口坑:硅基流动的 Embedding 接口是 /v1/embeddings,重排序接口必须使用 /v1/rerank。模型返回值也不一定都是 0 到 1 的概率,有些模型返回 Logit。当前实现采用自动归一化:0 到 1 的分数直接使用,超出范围时经过 Sigmoid 处理,并在接口异常时回退到初始排序。
similarity_threshold=0.0 也是有意设置的。Chroma 距离分、Milvus 混合分、RRF 分和 Rerank 分并不是同一量纲。如果在重排前使用一个未经标定的高阈值,很可能先把真正有用的候选删除。当前策略是先宽松召回,再由 Reranker 完成精排。
七、一次真实的对照测试
为了减少变量,我建立了两个知识库,上传完全相同的 PDF,并确认文件哈希和 142 个 Chunk 的内容一致,唯一差别是检索后端。测试问题是:
中国灯塔工厂在哪里项目上有过应用?
人工标注结果如下:
| 检索方式 | 相关块/Top8 | 噪声块 | NDCG 代理指标 |
|---|---|---|---|
| Chroma,未重排 | 6/8 | 2 | 0.8368 |
| Milvus,未重排 | 7/8 | 1 | 0.8894 |
| Chroma + Rerank | 8/8 | 0 | 0.9599 |
| Milvus + Rerank | 8/8 | 0 | 0.9891 |
未重排时,一些只包含"工业应用案例"但并非灯塔工厂的段落被向量检索误召回。Milvus 通过 BM25 对"灯塔工厂"等关键词进行补强,噪声更少。加入 Rerank 后,两条链路的 Top8 都变成相关内容,而 Milvus 的关键案例排序更靠前。
这组结果说明当前问题上 Milvus 混合检索更好,但不能简单宣布"准确率永久提升了多少"。这是单文档、单问题、人工标注的代理测试,只能证明方案方向有效。严谨评估还需要建立包含事实问答、列表问答、同义改写、长问题、否定条件和无答案问题的测试集,并长期记录 Recall@K、MRR、NDCG、答案正确率与延迟。
测试还暴露出 top_k 过小的问题。部分案例分散在不同 Chunk 中,top_k=4 会漏掉排名稍后的事实,因此列表型问题当前采用 top_k=8。但 TopK 也不是越大越好,过多上下文会增加费用,并可能让模型被噪声干扰。
八、Agentic RAG:让检索成为一个推理过程
传统 RAG 通常只有一次固定查询,而 Agentic RAG 把知识库检索封装成工具,让 Agent 根据问题决定何时检索、查哪个知识库、使用什么关键词,以及结果不足时是否继续。
本项目中,每个已创建知识库都会对应一个独立的 knowledge_query_<kb_id> 工具。Agent 可以先查看知识库,再生成短关键词调用检索;若结果重复、证据不足或问题包含多个子任务,还可以更换关键词继续查询。必要时,Agent 能打开文档全文或相关段落窗口,而不是只依赖孤立 Chunk。
以灯塔工厂问题为例,Agent 可能执行:
text
原问题:中国灯塔工厂在哪里项目上有过应用
扩展词:中国灯塔工厂 项目应用 案例
第一次检索:获取灯塔工厂及项目案例
第二次检索:如证据不足,尝试"灯塔工厂 行业 数字化改造"
打开文档:查看某个命中块的前后文
最终回答:按汽车、家电、钢铁等行业归纳,并引用知识库证据Milvus 的原问题保留机制尤其重要。Agent 可以自由扩展查询,但系统仍会把用户原始问题送入检索并融合两路结果,避免扩展词删掉"中国""在哪里""哪些项目"等限制条件。
Agentic RAG 也需要边界控制:不能无限搜索,连续得到相同结果时应停止;回答必须以工具返回内容为依据;找不到证据时应明确说明,而不是用模型常识补齐。Agent 带来了更灵活的检索策略,也带来了更多延迟和不可预测性,因此日志和离线评测必不可少。
九、开发过程中最值得记录的坑
-
只看最终回答,无法判断问题在哪一层。 回答错误可能来自解析、切分、召回、排序或生成。为此曾增加向量、BM25、混合以及融合后 TopK 日志,评估完成后再通过
diagnostic_logging=false关闭,避免生产日志爆量。 -
模型改写查询可能丢掉关键限定。 只使用扩展查询时,模型可能把长问题压缩得过度。Milvus 改为同时检索原问题和扩展查询,再使用 RRF 融合。
-
关键词越多不一定越准。 "案例""应用"等宽泛词可能把普通工业案例召回。扩展查询应该保留实体和约束,而不是无节制堆词。
-
不同阶段的分数不能直接比较。 向量相似度、BM25、WeightedRanker、RRF 和 Rerank 分数含义不同,不能拿同一个阈值生硬过滤。
-
修改默认配置不会自动改变旧知识库。
top_k、recall_k等参数在创建知识库时会保存到元数据。调整chatbot.ini主要影响新库,旧库需要单独更新或重新索引;配置缓存变更后还应重启相关进程。 -
重排序不是绝对正确。 Reranker 可能把细节块降权,所以要保留足够的召回候选,并通过测试集观察关键证据是否进入最终 TopK。
-
长问题会稀释 BM25 关键词。 当前原问题保留能避免语义丢失,但超长问题直接进入 BM25 仍可能带入大量无效词。后续可增加条件抽取、停用词处理和动态权重,但必须保留原问题作为兜底,不能只依赖模型摘要。
-
解析质量决定上限。 如果表格、标题或扫描文字在解析时已经丢失,再优秀的向量数据库也检索不到不存在的内容。
-
安全配置不能进入文章和仓库。 API Key 应通过环境变量或密钥管理注入,示例配置只能使用占位符,不能复制真实密钥。
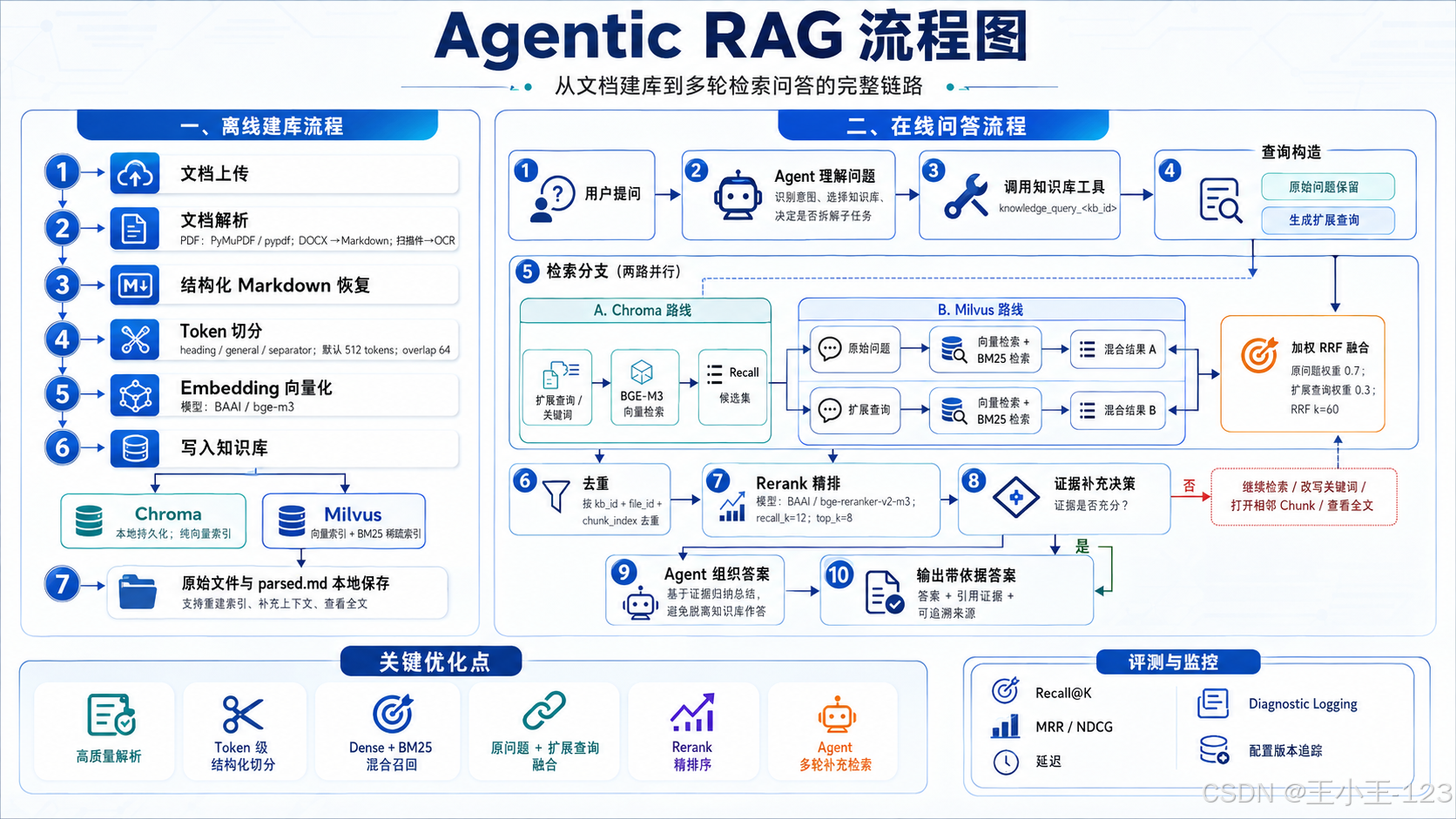
十、当前方案总结与后续方向
这套知识库最终形成了两种层级清晰的方案:
- Chroma:本地持久化、部署简单、纯向量召回,适合默认知识库和中小规模应用。
- Milvus:远程独立服务、向量与 BM25 混合召回,再融合原问题与扩展查询,适合对召回和扩展能力要求更高的场景。
两条链路共同使用 Token 级结构化切分、BGE-M3 Embedding、候选集重排序、本地原文保存和 Agent 工具调用。真正带来效果提升的并不是某一个组件,而是整个链路的组合:
text
高质量解析
+ 合理切分
+ Dense/BM25 多路召回
+ 原问题与扩展查询融合
+ Rerank 精排
+ Agent 多轮补充检索
+ 可复现的评测与日志后续最重要的工作不是继续盲目叠加模型,而是建立稳定的评测集,按问题类型统计效果;对长查询做结构化条件抽取;为标题、文件名、章节等元数据增加可解释的加权;同时记录检索版本、参数、耗时和最终答案。只有能够持续测量,RAG 的"感觉更准"才能逐渐变成可以验证、可以回归的工程指标。
RAG 的本质并不是让模型知道更多,而是让系统在正确的时间找到正确的证据,并让模型忠实地使用这些证据。向量数据库负责"相似",BM25 负责"命中",Reranker 负责"排序",Agent 负责"决定下一步"。把这些环节组合好,知识库才会从一个能演示的功能,变成真正可靠的问答系统。
每文一语
当迷茫之时;需要沉下心;不要盲目的前进;人世间美好的事物多的数不胜数;