文档会过时。人会忘记。但 lint 规则每次都会执行--每一次,无例外。
一个反直觉的事实
驭缰工程里最有效的约束,不是写在 AGENTS.md 里的那些。
是代码。
OpenAI 的团队发现,他们手写的规范文档经常被智能体忽略或误解。但当同样的规范变成一条 lint 规则后,智能体不仅 100% 遵守--它还会在错误信息中看到修复指令,自己纠正自己。
这个发现改变了一切。
核心洞察:文档是建议,Lint 是法律
| 维度 | 文档 | Lint 规则 |
|---|---|---|
| 执行率 | 智能体可能忽略 | 100% 每次执行 |
| 腐烂速度 | 几周就过时 | 代码不会忘记 |
| 反馈质量 | 模糊的"请遵守" | 精确的"这个文件超 500 行了,拆分方法见 docs/SPLITTING.md" |
| 可验证性 | 靠人肉检查 | CI 自动化验证 |
| 自我纠正 | 不可能 | 错误信息里嵌入修复指令 |
Fowler 的框架把这个思路升维了:
| 确定性(CPU 执行) | 语义性(LLM 判断) | |
|---|---|---|
| 引导(前馈) | bootstrap 脚本、代码生成模板 | AGENTS.md、Skills |
| 感知(反馈) | lint、类型检查、结构测试 | AI code review |
Lint 是左下角--确定性反馈。它便宜、快速、可靠,可以在每次提交时运行。它是 Harness 里最实用的"传感器"。
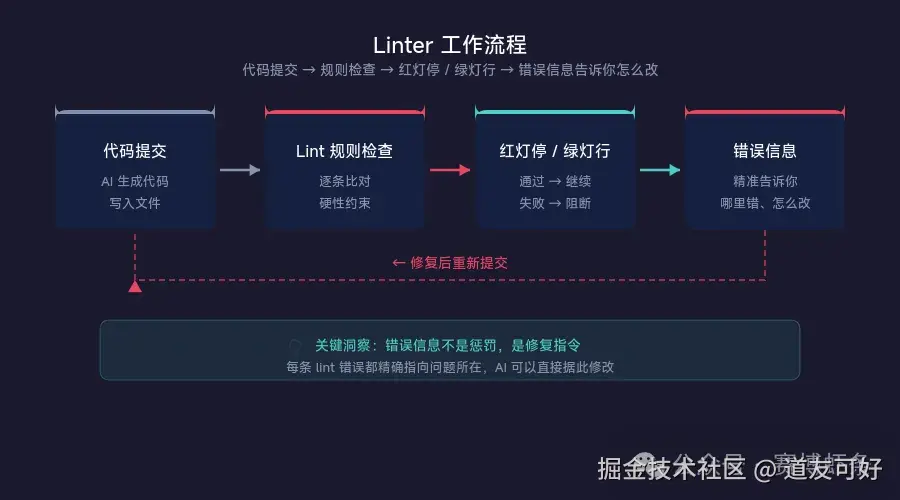
OpenAI 的实际做法
架构约束 = 结构测试
OpenAI 把每个业务域分成固定层:
bash
Types → Config → Repo → Service → Runtime → UI依赖方向只能"向前"。横切关注点(认证、遥测、功能开关)通过单一显式接口进入。
这不是写在文档里的"建议"--是通过自定义结构测试强制执行的。违规的代码根本无法通过 CI。
品味不变式 = 自定义 Linter
除了架构约束,OpenAI 还有一组"品味规则":
- 结构化日志--禁止裸 console.log
- 命名约定--统一的类型和 schema 命名
- 文件大小限制--单个文件不能超过 500 行
- 平台可靠性要求--特定场景的强制检查
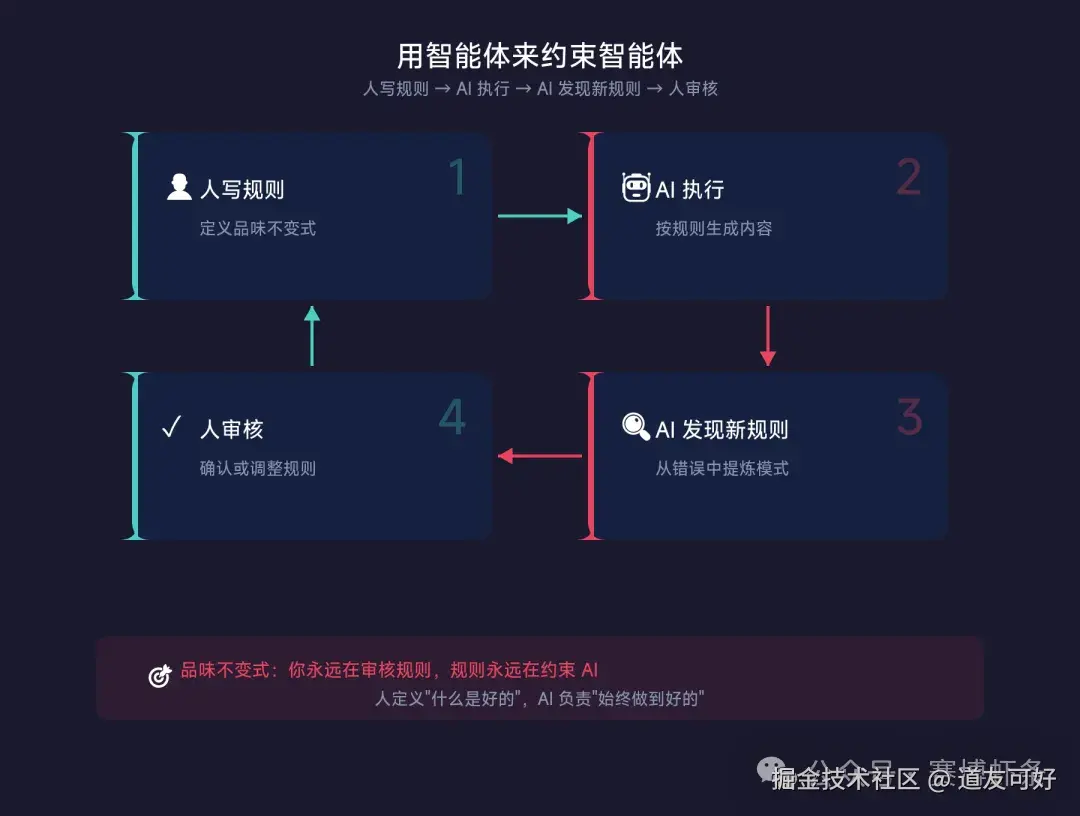
这些 lint 规则都是 Codex 自己写的。 用智能体来约束智能体,效果出奇地好。
最精妙的设计:错误信息 = 修复指令
这是整个机械化执行体系里最精彩的一招:
bash
❌ 普通 lint:
Error: File exceeds 500 lines.
✅ Harness 式 lint:
Error: File exceeds 500 lines.
Fix: Split into domain-specific modules following docs/ARCHITECTURE.md#splitting-guide.智能体看到这个错误信息时,它不仅知道"出错了",还知道"怎么修"。
不需要人类介入,智能体在 lint 报错后可以直接修复并重新提交。
四种机械化执行的策略
从 Claude Code 的工具注册管线(tools.ts)中,我们可以看到四种不同的约束策略:
策略一:无条件注册(核心规则)
bash
类型检查、基础 lint、结构测试
→ 每次 CI 都跑,没有例外策略二:Feature Flag 守卫(实验性规则)
bash
新 lint 规则先对内部团队启用
→ 验证有效后再全面推广策略三:环境变量守卫(特定场景)
bash
某些规则只在特定环境生效
→ 比如 security lint 只在生产环境构建时检查策略四:运行时函数守卫(条件性)
bash
根据代码库状态动态启用/禁用
→ 比如 monorepo 中某些规则只适用于特定子项目实操:从 0 到 1 搭建你的 Harness Lint 体系
第一步:观察智能体的常见错误
让智能体工作一周,记录它最常犯的错。通常集中在这些类:
- 架构违规(跨层调用、循环依赖)
- 命名不一致(同一个概念用不同的名字)
- 日志不规范(裸 print、缺少上下文)
- 文件过大(把所有逻辑塞进一个文件)
- 缺少错误处理
第二步:把前 3 个最高频错误变成 lint 规则
不要贪多。先解决最痛的 3 个。
bash
// 示例:禁止直接使用 console.log
// eslint-rule: custom/structured-logging.js
module.exports = {
create(context) {
return {
CallExpression(node) {
if (node.callee.object?.name === 'console' &&
node.callee.property?.name === 'log') {
context.report({
node,
message: 'Use structured logging via logger.info/warn/error. ' +
'See docs/logging-guide.md for setup.'
});
}
}
};
}
};注意:错误信息里包含修复路径。
第三步:接入 CI,每次提交自动检查
bash
# .github/workflows/harness-lint.yml
name: Harness Lint
on: [push, pull_request]
jobs:
lint:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- run: npm ci
- run: npm run lint:harness # 你的自定义 lint 规则
- run: npm run test:structure # 结构测试第四步:观察 → 迭代 → 扩展
每周看一次 lint 的触发数据:
- 哪些规则触发最多?→ 说明智能体在这里最容易犯错,可能需要更详细的修复指引
- 哪些规则从没触发过?→ 考虑是不是规则太松了,或者智能体已经学会了
- 有没有新的错误模式出现?→ 加新规则
"中央强制边界,本地允许自主"
这是 OpenAI 的核心哲学,也是 Fowler 反复强调的原则。
HumanLayer 的实践也印证了这一点------他们把重型 MCP 服务器替换为一个轻量 CLI + CLAUDE.md 中的 6 条用法示例。节省了数千 token 的工具定义和冗长响应。
原理一样:用更便宜的确定性方案替代昂贵的 AI 方案。 CLI 命令在模型的训练数据中有良好覆盖,agent 用起来比 MCP 更自然、更省 token。
bash
中央层面:强制执行架构边界、依赖方向、质量底线
本地层面:允许智能体在边界内自由选择实现方式你规定"API 边界必须用 Zod 验证数据",但不规定"必须用哪个库的哪个版本"。
你规定"依赖方向只能向前",但不规定"Service 层具体怎么实现"。
约束的是方向,不是脚步。
一个容易犯的错
新手容易走向两个极端:
极端 A:过度约束
- 什么都管,智能体没有自主空间
- 结果:智能体变成执行器,丧失推理能力
- 信号:lint 规则超过 50 条,还在不断增加
极端 B:约束不足
- 只靠文档,不写可执行规则
- 结果:智能体反复犯同样的错
- 信号:你经常在 review 时说"这个我已经说过了"
正确姿势:
bash
先用 AGENTS.md 引导(前馈)
→ 观察智能体哪里犯错
→ 把高频错误变成 lint 规则(反馈)
→ 错误信息里嵌入修复指引(新的前馈)
→ 循环写在最后
机械化执行是驭缰工程从"概念"变成"可操作系统"的关键桥梁。
AGENTS.md 告诉智能体"应该怎么做",但只有 lint 规则能保证"确实这样做了"。
人类的知识是会腐烂的。但代码不会。
把你的工程判断从脑子里、文档里、Slack 讨论里提取出来,变成可执行的代码。这是你能为智能体做的最高杠杆的事。
而且这个过程本身也可以让智能体来做--OpenAI 的自定义 lint 就是 Codex 自己写的。
用智能体来约束智能体。
这是驭缰工程系列的第三篇。上一篇:《写给 AI 的入职手册,AGENTS.md》 下一篇:《AI 写的代码,你怎么知道是对的?》
觉得这篇有用?点赞 + 转发,下一篇更快出炉 👇