前言
如果你用过元宝的 SKILL 功能,让它帮你写代码、处理文件、跑脚本,你有没有想过:AI 执行完之后,那些文件去哪了?
这个问题背后,藏着一个我们花了不少心思才解决好的工程问题。本文就来讲讲,当 AI Agent 越来越"能干",对底层存储要求越来越高的情况下,我们如何通过升级存储后端与优化客户端配置,将单桶 LIST QPS 提升 100 倍、平均延迟降低 75%,支撑元宝 SKILL 沙箱的高并发访问。
一、沙箱里的 AI,需要一个持久化的空间
要理解这个问题,先得说说什么是沙箱。
AI Agent 在执行任务时,通常运行在一个叫做"沙箱"(Sandbox)的隔离环境里。你可以把它想象成一个临时搭起来的工作台:东西可以放上去,代码可以在上面跑,但工作台本身是临时的------任务结束,工作台收走,上面的东西也就没了。
这种设计的初衷是安全:沙箱里跑的代码出不去,外面的环境也进不来,用户之间互相隔离,不会互相影响。这是必须的,但问题来了:AI Agent 的任务越来越复杂,它不再只是"回答一个问题",比如说:
- 处理用户上传的文件,完成分析后还要把结果交还给用户
- 跨多轮对话持续工作,"记住"上一轮做到哪了、生成了哪些中间文件
- 多个沙箱实例并行跑,需要共享同一份工作目录里的数据
- 任务失败或中断后能够恢复,而不是从头再来
这些需求有一个共同点:数据不能只活在沙箱里,它必须能被持久化保存下来,在沙箱销毁后依然存在,在下次需要时可以被访问到。换句话说,沙箱需要一个路径来持久化的保存数据。
云原生时代,这个持久化空间的最优解就是对象存储。Agent 在执行长时任务、强化学习训练或代码评测时,会产生海量的非结构化数据(如模型权重、日志、数据集、音视频等)。对象存储采用扁平化命名空间,消除了传统文件系统的层级目录限制,能够轻松横向扩展至 PB 甚至 EB 级别。更重要的是,对象存储通常采用多种数据冗余技术,提供高达99.9999999999%(12个9)的数据设计持久性。这意味着即使沙箱所在宿主机发生硬件故障或宕机,Agent的产出物和关键数据依然高可用、不丢失,为沙箱的销毁和重建提供了坚实的数据保险箱。
但是,对象存储原生采用的是 RESTful API( 如S3的PUT/GET/DELETE ),而沙箱内的 Agent 或应用程序通常使用操作系统的标准文件系统调用(如 open()、read()、write())。如果直接使用对象存储,开发者必须修改业务代码,显式地调用 SDK 或 CLI 来上传下载文件,这不仅增加了开发成本,也破坏了代码的通用性。
因此,如果能够既能充分利用对象存储的优势,又能让 Agent 访问更简单,成了一个必须解决的问题。我们的选择是把腾讯云的 COS 对象存储,通过 GooseFS MountPoint 挂载成沙箱内的本地目录,让沙箱像访问本地文件系统一样访问云端数据。
二、GooseFS MountPoint 是什么?它怎么跟沙箱配合?
GooseFS MountPoint (以下简称 MountPoint) 是一款基于 FUSE(Filesystem in Userspace 用户态文件系统)框架开发的高性能客户端,专为腾讯云对象存储 COS 量身打造。产品核心目标是通过本地挂载的便捷方式,实现对 COS 存储的高性能访问,尤其在顺序读写场景中优势显著,可充分释放 COS 高扩展性、低成本、强可靠性与高安全性的核心价值,为用户提供媲美本地文件系统的操作体验。简单来讲,它的核心能力是:把 COS 对象存储"伪装"成一个本地目录,对上层应用完全透明,如下图所示:
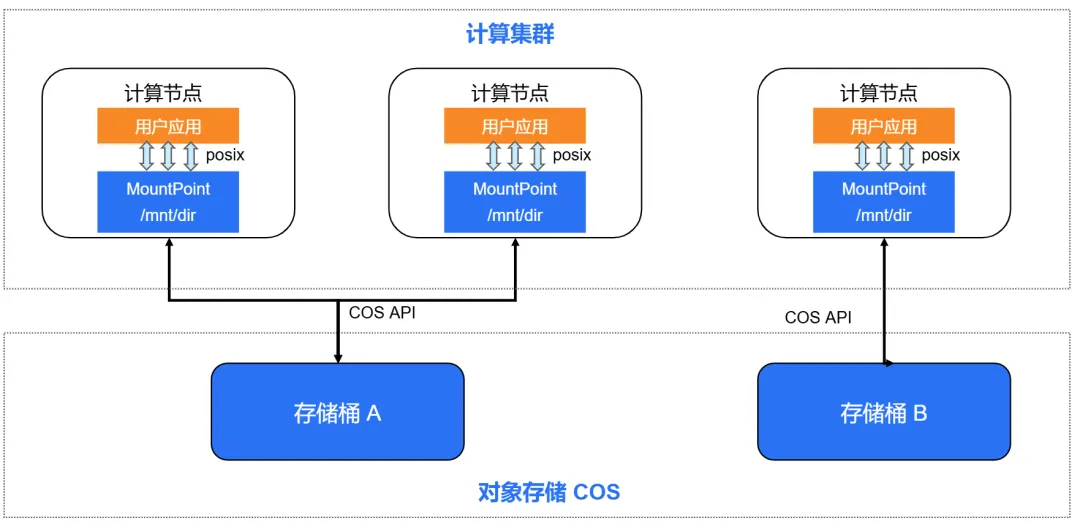
在宿主机收到创建沙箱的请求后,系统会首先生成一个唯一的会话 ID,比如 sess_43ac581ce0b74d94。这个 ID 有业务语义,用于标识这一次会话。之后,系统在 MountPoint 的挂载目录 /mnt/ 下,创建这个沙箱对应的目录:mnt/sess_43ac581ce0b74d94/。由于 /mnt/ 本身是 MountPoint 的挂载点,这个 mkdir 操作会直接穿透到 COS 存储桶,在桶里创建对应的目录前缀。
之后,宿主机启动沙箱运行时,把虚拟文件系统挂载点下那个带哈希的长路径,bind mount 到一个对用户友好的短路径,比如:/data/sess_a/ 。用户不需要知道 路径映射和 MD5 哈希这些底层细节,只需操作一个简洁、有业务语义的固定路径。用户在容器内对这个目录的任何读写操作,都会沿着 bind mount → 软链接穿透 → MountPoint → COS 存储桶这条完整链路透传。整个过程对用户完全透明。完整的数据链路如下图所示:
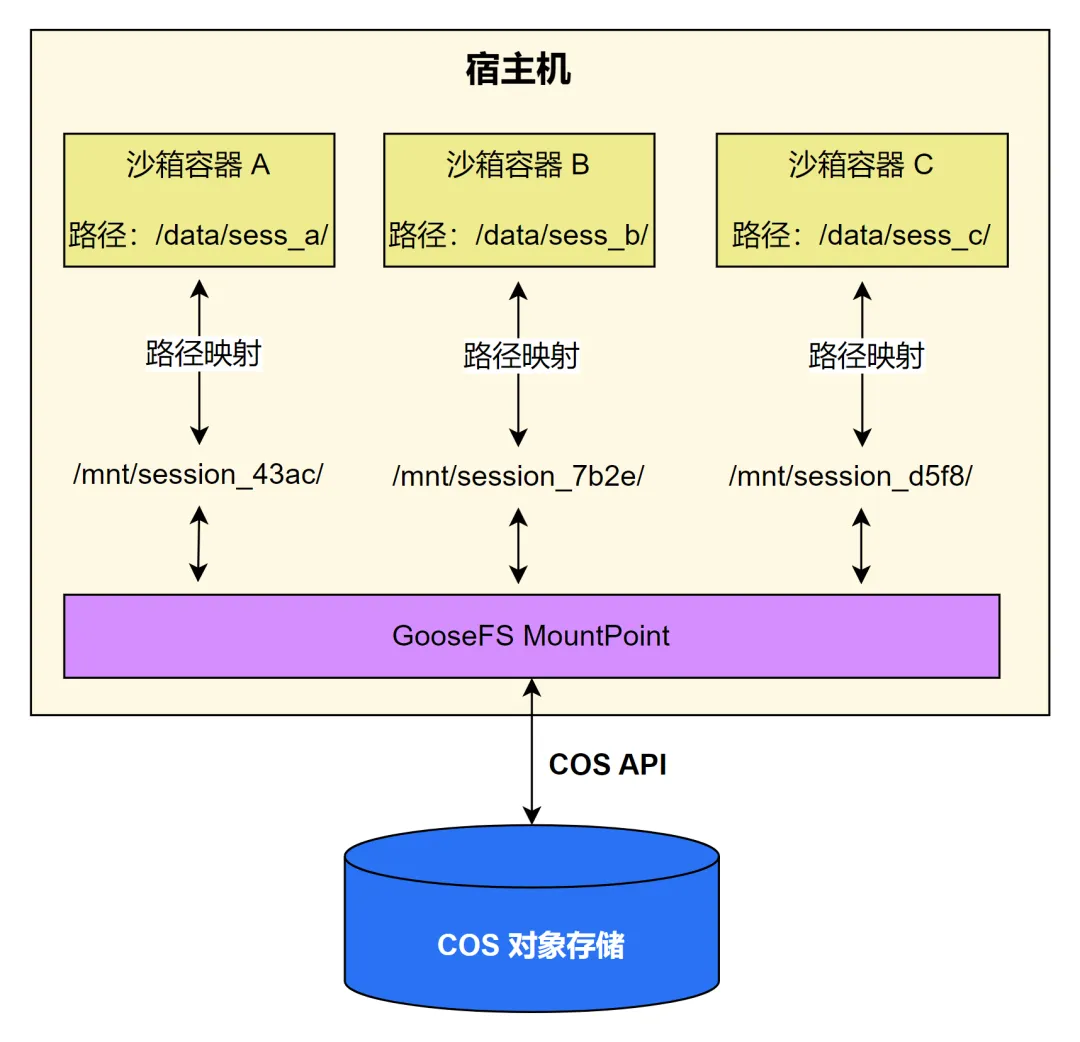
每一层都有自己的职责:路径映射能力把宿主机上的复杂路径映射成用户可见的简洁路径;virtio-fs 是虚拟机内部和宿主机之间的文件系统共享协议,性能比传统 NFS 好很多;virtiofsd 运行在宿主机上,处理来自 MVM 的文件请求,同时承担安全隔离的职责;MountPoint 把 COS 对象语义,翻译成 POSIX 文件系统语义。对 Agent 来说,这一切都是透明的。它只管读文件、写文件,不需要知道背后发生了什么。
三、性能挑战:List 请求把存储打爆了
挂载流程走通了,还有性能上的挑战等着我们。在对接元宝 SKILL 沙箱的过程中,我们碰到了一个让人头疼的问题:在高并发 Agent 场景下,瞬时拉起成百上千个沙箱实例,结果发现沙箱启动变慢了,并且沙箱对挂载路径下的文件访问延迟巨大。经过仔细排查,发现是大量发给 COS 的 LIST 请求被频控了。当前版本的 COS,单个存储桶的 List 类请求,默认频控阈值是 1000 QPS。听起来 1000 QPS 不少,在对象访问场景完全够用,但在文件系统场景里,这个数字远远不够。原因在于,对象存储和文件系统在设计哲学上有根本的差异:
对象存储天然是扁平的 KV 结构。你把文件扔进去,靠 key 来取,LIST 是低频的管理操作,一般只有在"列一下桶里有什么"这类场景才会用到。文件系统则完全不同。每一次 stat、ls、open、路径遍历,背后都可能触发多次 LIST 或 HEAD 请求。
具体来说,当你访问一个路径 /a/b/c/d/file,操作系统内核需要从根目录开始,逐级确认 /a、/a/b、/a/b/c、/a/b/c/d 是否存在,每一级是文件还是目录。MountPoint 为了实现 POSIX 语义,对每一级路径节点都需要发出查询------未知类型的路径,默认会同时发出 HEAD 请求和 LIST 请求,等两者都返回才能得出结论。
还有一种更糟糕的情况:访问不存在的路径。对象存储没有"目录"的概念,目录是隐式的(通过对象 key 的前缀来模拟)。因此,判断一个路径是否存在,必须兜底走一次 ListObjects(prefix=xxx/, max-keys=1) 才能确认,无法像本地文件系统那样简单地用 dentry 缓存拦截掉。这种"不存在路径的探测"在沙箱场景中特别常见:训练任务在查找 checkpoint 文件、业务代码在做存在性检查......这些访问大量命中"不存在"的情况,每次都必须打穿到 COS 后端。
再叠加沙箱的规模:元宝 SKILL 沙箱在 k8s 上部署,生产环境下成百上千个沙箱实例同时运行,共用同一个存储桶。单个沙箱的请求量不大,但汇总到桶级别, QPS 轻轻松松就超过 1000。一旦被频控,后果是一连串的雪崩:COS 返回 503 SlowDown → MountPoint 客户端触发指数退避 → 文件操作开始卡顿 → ls 变慢、stat 超时 → 任务卡住不动 → 最终报 I/O error,用户直接感受到 AI 工具"卡死了"或者"报错了"。
这种问题的根因不是某个具体的 bug,而是两种存储范式之间的天然错配------当对象存储被用于文件系统场景时,原本低频的 LIST 操作变成了高频操作,而现有的 COS 架构在设计上没有预见这种用法。
四、解法:换新引擎,串行改并行,减少无效请求
解决这个问题,我们从两个方向入手:一是提升后端能力,二是减少不必要的前端请求。
4.1 接入 newCOS:从根本上提升 List 性能
newCOS 是腾讯云对象存储的全新升级架构,在可靠性、可用性、性能、产品能力、成本、可维护性等方面均带来不同维度的提升。
YottaIndex 是 newCOS 的索引存储子系统------它不存放对象的二进制内容,只负责对象的逻辑标识、元数据和路由信息。它是为 newCOS 量身定制的索引存储------不追求做一个"通用的什么都能存"的系统,而是专注于把对象存储索引这件事做到极致。针对 List 场景,YottaIndex 从以下五个维度进行了端到端优化:
1. 索引列瘦身
拆分索引字段,列表查询仅读取少量轻量数据,大幅减少数据读取量与磁盘开销,查询更快。
2. 原生支持目录能力
底层适配目录逻辑,查询子目录无需遍历全部文件,大幅减少数据扫描量,效率显著提升。
3. 数据有序存储
不打散数据分片,列表查询可顺序读取,无需跨分片拼接结果,读取流程更顺畅。
4. 热点快速弹性扩容
采用小分片设计,检测到流量热点后秒级完成扩容,从容应对突发高并发。
5. 智能优化各类复杂场景
自动跳过空分片、预估分片大小并自适应并发,同时支持超时断点续查,规避各类查询卡顿问题。
为了验证 newCOS 在沙箱场景下的真实表现,我们分别对老 COS 和 newCOS 做了压测,压测全部使用完全不存在的路径来构造请求,这是刻意的------不存在的路径无法命中本地缓存,每次都必须打到 COS 后端,模拟的是最恶劣的真实场景(大量"负缓存穿透")。
压测结果:
|-----------|-----------|---------------------|
| 指标 | 老 COS | 接入 newCOS 后 |
| LIST QPS | 1,000 | 100,000(提升100倍) |
| LIST 平均延迟 | 基准 | 降低约 75% |
4.2 MountPoint 配置调优:让每次查询少一点浪费
光靠后端提速还不够。我们还分析了 MountPoint 客户端在沙箱场景下的请求行为,找到了两个可以在配置层面优化的地方。
问题一:串行查询导致的相互阻塞。
MountPoint 对未知类型路径的默认 lookup 流程是:先发 HEAD 请求,再发 LIST 请求,串行执行。当 HEAD 请求遇到流控触发指数退避时,LIST 请求也跟着被阻塞,整体 QPS 上不去,这是一个"最长者阻塞"的问题。解法是开启并行 lookup:
disable-parallel-lookup-unknown-type: false # false = 开启并行
开启后,HEAD 和 LIST 同时发出,不再互相等待。即使 HEAD 遇到流控,LIST 也能继续推进,两者不再互相拖累。
问题二:沙箱场景下不存在"显式目录"。
在普通的 COS 对象存储场景中,目录有时候是用户显式创建的(创建了一个以 / 结尾的空对象),有时候是隐式的(只靠 key 前缀模拟)。MountPoint 默认会先检查"显式目录"是否存在,也就是多发一次 HEAD 请求。但在沙箱场景中,目录全部是隐式的,不存在任何显式创建的目录对象,所以这次 HEAD 是多余的。解法是关掉这个选项:
lookup-explicit-dirs-first: false # 沙箱桶内无显式目录,省掉这次多余的 HEAD
两个参数的叠加效果:
每次路径查询的 COS 请求从"3 次串行"变成"2 次并行"。
原来:HEAD → HEAD(查显式目录)→ LIST,三步串行,任何一步的流控都会阻塞后续
现在:HEAD + LIST 同时发出,完全并行,只需等较快的那个返回
HEAD 请求数量减半,流控压力直接降低 50%;LIST 也不再被 HEAD 的延迟拖累,两者并行推进,整体吸吐量显著提升。
五、现在,这套方案在哪里跑着?
目前,基于 MountPoint + newCOS 的沙箱存储方案已经在以下业务的生产环境中稳定运行:
元宝 SKILL 沙箱: 本次压测和优化的直接受益方。元宝 SKILL 是面向用户的 AI Agent 功能,支持代码执行、文件处理、工具调用等复杂任务,对沙箱存储的并发能力和稳定性要求最高,也是推动我们做这次优化的直接动力。
ima 沙箱: ima(AI 助手)的沙箱环境,同样需要在对话过程中持久化用户文件,跨轮次共享工作状态。
某用户: 企业 Agent 沙箱接入场景,对数据隔离和存储可靠性有严格要求。
这三个业务覆盖了从内部 AI 产品到外部客户服务的不同场景,验证了这套方案在不同负载特征和安全要求下的通用性。
后记
回顾整个过程,有几点值得总结:对象存储 ≠ 文件系统,但它们可以融合。 这两种存储范式有根本的差异,强行把对象存储当文件系统用会暴露很多问题。但通过客户端 (MountPoint) 和后端存储服务 (newCOS) 的精心配合,针对性的参数调优,可以让两者协同工作,发挥各自的优势。