文章目录
- [RISC-V 基础知识扫盲](#RISC-V 基础知识扫盲)
-
- [1. RISC-V 基础概念](#1. RISC-V 基础概念)
-
- [1.1 寄存器](#1.1 寄存器)
- [1.2 指令格式](#1.2 指令格式)
- [2. 算术指令](#2. 算术指令)
-
- [2.1 ADD - 寄存器加法](#2.1 ADD - 寄存器加法)
- [2.2 ADDI - 立即数加法](#2.2 ADDI - 立即数加法)
- [2.3 ADD2 - 处理负数的加法](#2.3 ADD2 - 处理负数的加法)
- [2.4 SUB - 寄存器减法](#2.4 SUB - 寄存器减法)
- [2.5 SUBI - 立即数减法(伪指令)](#2.5 SUBI - 立即数减法(伪指令))
- [2.6 NEG - 取负(伪指令)](#2.6 NEG - 取负(伪指令))
- [2.7 LUI - 加载高位立即数](#2.7 LUI - 加载高位立即数)
- [2.8 AUIPC - PC相对加立即数](#2.8 AUIPC - PC相对加立即数)
- [3. 逻辑指令](#3. 逻辑指令)
-
- [3.1 AND - 逻辑与](#3.1 AND - 逻辑与)
- [3.2 ANDI - 立即数与](#3.2 ANDI - 立即数与)
- [3.3 NOT - 位反(伪指令)](#3.3 NOT - 位反(伪指令))
- [4. 移位指令](#4. 移位指令)
-
- [4.1 SLLI - 逻辑左移](#4.1 SLLI - 逻辑左移)
- [4.2 SRLI - 逻辑右移](#4.2 SRLI - 逻辑右移)
- [4.3 SRAI - 算术右移](#4.3 SRAI - 算术右移)
- [5. 跳转指令](#5. 跳转指令)
-
- [5.1 BNE - 不相等分支](#5.1 BNE - 不相等分支)
- [5.2 JALR - 跳转并链接寄存器](#5.2 JALR - 跳转并链接寄存器)
- [6. 内存访问指令](#6. 内存访问指令)
-
- [6.1 LA - 加载地址(伪指令)](#6.1 LA - 加载地址(伪指令))
- [6.2 LB - 加载字节(符号扩展)](#6.2 LB - 加载字节(符号扩展))
- [6.3 LBU - 加载字节(零扩展)](#6.3 LBU - 加载字节(零扩展))
- [6.4 SB - 存储字节](#6.4 SB - 存储字节)
- [7. 常用伪指令](#7. 常用伪指令)
-
- [7.1 LI - 加载立即数](#7.1 LI - 加载立即数)
- [7.2 MV - 移动寄存器](#7.2 MV - 移动寄存器)
- [7.3 NOP - 空操作](#7.3 NOP - 空操作)
- [8. 函数调用约定](#8. 函数调用约定)
-
- [8.1 叶子函数调用](#8.1 叶子函数调用)
-
- [8.1.1 完整栈流程示意图](#8.1.1 完整栈流程示意图)
- [8.1.2 调试](#8.1.2 调试)
- [8.2 嵌套函数调用](#8.2 嵌套函数调用)
-
- [8.2.1 逐段解析](#8.2.1 逐段解析)
- [8.2.2 完整调用流程](#8.2.2 完整调用流程)
- [8.2.3 叶子函数 vs 嵌套函数](#8.2.3 叶子函数 vs 嵌套函数)
- [8.3 调用约定总结](#8.3 调用约定总结)
- [9. 汇编与C混合编程](#9. 汇编与C混合编程)
-
- [9.1 汇编调用C函数](#9.1 汇编调用C函数)
- [9.2 C调用汇编函数(内联汇编)](#9.2 C调用汇编函数(内联汇编))
- [10. 构建和调试](#10. 构建和调试)
-
- [10.1 构建系统文件](#10.1 构建系统文件)
- [10.2 常用命令](#10.2 常用命令)
- [10.3 GDB调试配置](#10.3 GDB调试配置)
- 附录:指令速查表
RISC-V 基础知识扫盲
1. RISC-V 基础概念
1.1 寄存器
RISC-V有32个通用寄存器,每个32位(RV32架构):
| 寄存器 | 别名 | 用途 |
|---|---|---|
| x0 | zero | 恒为0,写入被忽略 |
| x1 | ra | 返回地址 |
| x2 | sp | 栈指针 |
| x3 | gp | 全局指针 |
| x4 | tp | 线程指针 |
| x5-x7 | t0-t2 | 临时寄存器 |
| x8 | s0/fp | 保存寄存器/帧指针 |
| x9 | s1 | 保存寄存器 |
| x10-x17 | a0-a7 | 函数参数/返回值 |
| x18-x27 | s2-s11 | 保存寄存器 |
| x28-x31 | t3-t6 | 临时寄存器 |
1.2 指令格式
RISC-V指令有多种格式:
- R型 :寄存器-寄存器操作(如
add x5, x6, x7) - I型 :寄存器-立即数操作(如
addi x5, x6, 1) - S型 :存储操作(如
sb x6, 0(x5)) - B型 :分支操作(如
bne x5, x6, loop) - U型 :长立即数操作(如
lui x5, 0x12345) - J型 :跳转操作(如
jal x5, target)
2. 算术指令
2.1 ADD - 寄存器加法
文件 :add/test.s
asm
li x6, 1 # x6 = 1
li x7, 2 # x7 = 2
add x5, x6, x7 # x5 = x6 + x7 = 3说明:
- 格式:
ADD RD, RS1, RS2 - 功能:RS1 和 RS2 相加,结果存入 RD
- 这是R型指令
2.2 ADDI - 立即数加法
文件 :addi/test.s
asm
li x6, 2 # x6 = 2
addi x5, x6, 1 # x5 = x6 + 1 = 3说明:
- 格式:
ADDI RD, RS1, IMM - 功能:将符号扩展的12位立即数(-2048~+2047)加到RS1
- 这是I型指令
2.3 ADD2 - 处理负数的加法
文件 :add2/test.s
asm
li x6, 1 # x6 = 1
li x7, -2 # x7 = -2 (补码表示)
add x5, x6, x7 # x5 = 1 + (-2) = -1说明:
- RISC-V使用补码表示负数
add指令可以处理正数加负数
2.4 SUB - 寄存器减法
文件 :sub/test.s
asm
li x6, -1 # x6 = -1
li x7, -2 # x7 = -2
sub x5, x6, x7 # x5 = -1 - (-2) = 1说明:
- 格式:
SUB RD, RS1, RS2 - 功能:用RS1减去RS2
2.5 SUBI - 立即数减法(伪指令)
文件 :subi/test.s
asm
li x6, 30 # x6 = 30
addi x5, x6, -20 # x5 = 30 + (-20) = 10说明:
- RISC-V没有 SUBI 指令!
- 减法通过加负数实现:
addi支持负立即数 x5 = x6 - 20等价于addi x5, x6, -20
2.6 NEG - 取负(伪指令)
文件 :neg/test.s
asm
li x6, 1 # x6 = 1
neg x5, x6 # x5 = -x6
# 实际汇编为: sub x5, x0, x6说明:
- NEG 是伪指令
- 实际汇编为
SUB RD, x0, RS - 因为 x0=0,所以
0 - x6 = -x6
2.7 LUI - 加载高位立即数
文件 :lui/test.s
asm
lui x5, 0x12345 # x5 = 0x12345 << 12 = 0x12345000
addi x5, x5, 0x678 # x5 = x5 + 0x678 = 0x12345678说明:
- 这条指令的作用是:把立即数放到寄存器的高20位,低12位全部填0
- 格式:
LUI RD, IMM - 将20位立即数放到寄存器的高20位,低12位清零
- 配合
ADDI可构造任意32位值

为什么这样设计?
因为 addi 只能表示 -2048 ~ +2047 的立即数范围(12位有符号)
| 指令 | 立即数位数 | 能表示的范围 |
|---|---|---|
| ADDI | 12位 | -2048 ~ +2047 |
| LUI | 20位 | 0 ~ 0xFFFFF_000 |
两者配合就能构造任意32位整数:
- LUI 负责高20位
- ADDI 负责低12位(分多次加也行)
2.8 AUIPC - PC相对加立即数
文件 :auipc/test.s
asm
auipc x5, 0x12345 # x5 = PC + (0x12345 << 12)
auipc x6, 0 # x6 = PC (获取当前PC值)说明:
- 格式:
AUIPC RD, IMM - 用于构建PC相对地址
- 设置立即数为0可获取当前PC值
假设你有一段数据在距离当前PC 0x1000 字节的地方:
auipc x5, 0 # x5 = PC(当前地址)
addi x5, x5, 0x1000 # x5 = PC + 0x1000(数据地址)为什么要用PC相对地址?
因为程序可以被加载到内存的任意位置!
| 加载方式 | 问题 |
|---|---|
| 绝对地址 | 如果程序被加载到不同位置,地址就错了 |
| PC相对 | 不管加载到哪里,PC + offset 都能正确找到 |
这就是所谓的 位置无关代码 (PIC - Position Independent Code)。

3. 逻辑指令
3.1 AND - 逻辑与
文件 :and/test.s
asm
li x6, 0x10 # x6 = 0b00010000
li x7, 0x11 # x7 = 0b00010001
and x5, x6, x7 # x5 = 0b00010000 = 0x10说明:
- 格式:
AND RD, RS1, RS2 - 功能:RS1 与 RS2 按位与
- 常用于位掩码操作
3.2 ANDI - 立即数与
文件 :andi/test.s
asm
li x6, 0x10 # x6 = 0b10000000
andi x5, x6, 0x01 # x5 = 0b00000000 = 0说明:
- 格式:
ANDI RD, RS1, IMM - 立即数同样符号扩展
3.3 NOT - 位反(伪指令)
文件 :not/test.s
asm
li x6, 0xffff0000
not x5, x6 # x5 = ~x6 = 0x0000ffff
# 实际汇编为: xori x5, x6, -1说明:
- NOT 是伪指令
- 实际为
XORI RD, RS, -1
4. 移位指令
4.1 SLLI - 逻辑左移
文件 :slli/test.s
asm
li x6, 1 # x6 = 1
slli x5, x6, 3 # x5 = x6 << 3 = 8说明:
- 格式:
SLLI RD, RS1, IMM - 低位补零
- 等价于乘以 2^n
4.2 SRLI - 逻辑右移
文件 :srli/test.s
asm
li x6, 0x80000000 # x6 = 0b10000000... (无符号最大)
srli x5, x6, 3 # x5 = x6 >> 3 = 0x10000000说明:
- 格式:
SRLI RD, RS1, IMM - 高位补零(无符号数右移)
- 等价于无符号除以 2^n
对应C代码(srli/test.c):
c
unsigned int i = 0x80000000;
i = i >> 4; // 编译生成 srli4.3 SRAI - 算术右移
文件 :srai/test.s
asm
li x6, 0x80000000 # x6 = 负数 (符号位为1)
srai x5, x6, 4 # x5 = 算术右移4位,符号位扩展说明:
- 格式:
SRAI RD, RS1, IMM - 高位用符号位填充(处理有符号数)
- 等价于有符号除以 2^n(向下取整)
对应C代码(srai/test.c):
c
int i = 0x80000000;
i = i >> 4; // 编译生成 srai5. 跳转指令

5.1 BNE - 不相等分支
文件 :bne/test.s
asm
li x5, 0 # i = 0
li x6, 5 # 循环上限
loop:
addi x5, x5, 1 # i++
bne x5, x6, loop # if (i != 5) goto loop说明:
- 格式:
BNE RS1, RS2, IMM - 不相等时跳转到PC相对地址
- 用于实现循环和条件分支
5.2 JALR - 跳转并链接寄存器
文件 :jalr/test.s
asm
_start:
li x6, 1
li x7, 2
jal x5, sum # 调用 sum,返回地址存入 x5
sum:
add x6, x6, x7 # x6 = x6 + x7
jalr x0, 0(x5) # 返回 (x0=0 表示丢弃返回值)说明:
- 格式:
JALR RD, RS1, IMM - 基址寄存器 + 偏移寻址
- ±1 KiB 寻址范围
- 常用于函数调用和返回
一句话总结
jal x5, sum:跳去 sum,把返回地址存 x5jalr x0, 0(x5):跳回 x5 存的地址,返回地址不要了(存到 x0 等于丢弃)
6. 内存访问指令
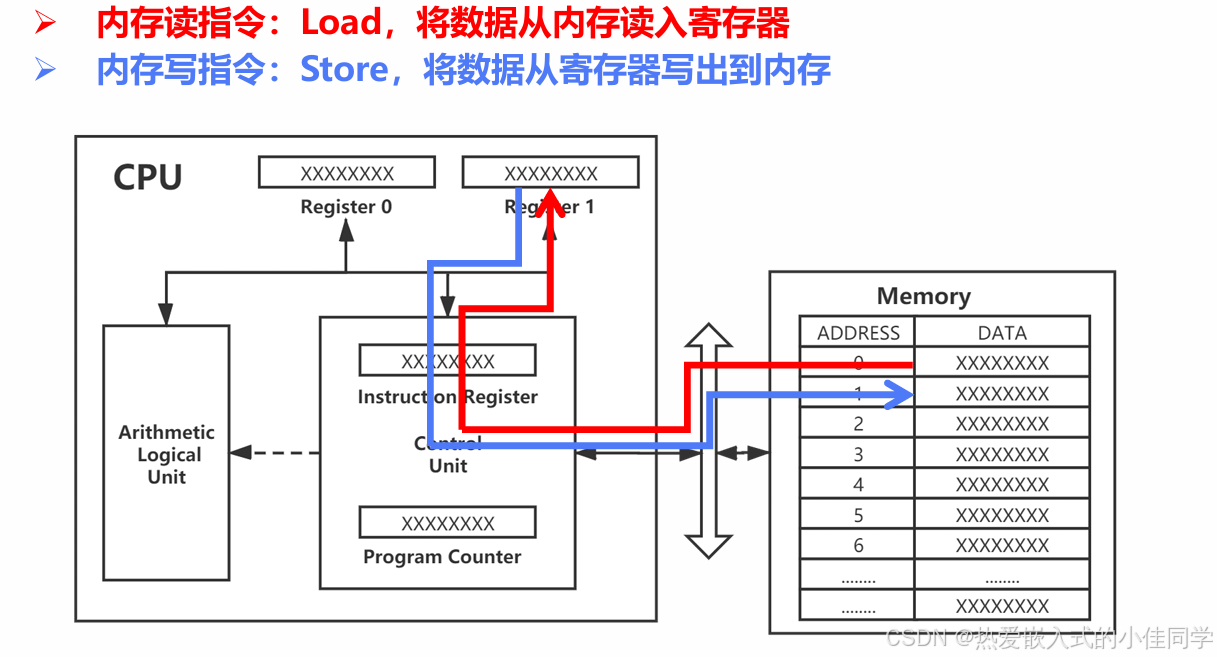


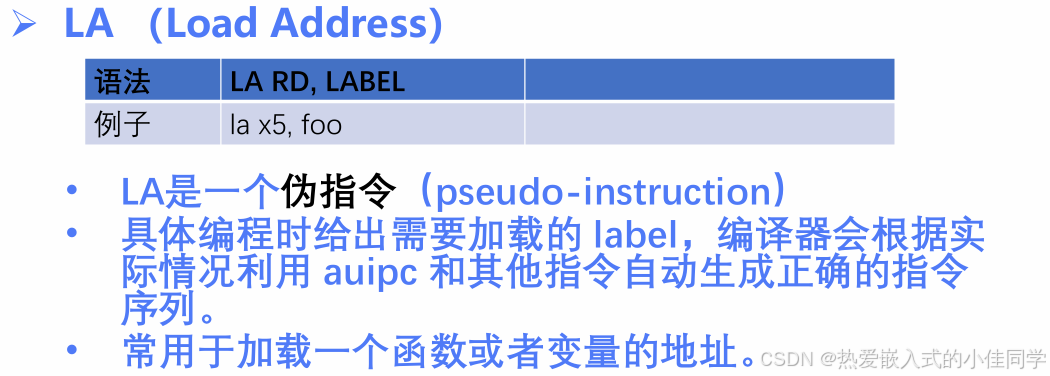
6.1 LA - 加载地址(伪指令)
文件 :la/test.s
asm
la x5, _start # x5 = &_start
jr x5 # 跳转到 x5 中的地址说明:
- LA 是伪指令
- 实际汇编为
AUIPC+ADDI两条指令 - 用于访问任意32位地址
6.2 LB - 加载字节(符号扩展)
文件 :lb/test.s
asm
la x5, _array # x5 = array 的地址
lb x6, 0(x5) # x6 = *(char*)x5 (符号扩展)
lb x7, 1(x5) # x7 = *(char*)(x5+1) (符号扩展)说明:
- 格式:
LB RD, IMM(RS1) - 加载8位,符号扩展到32位
- 偏移范围:-2048 ~ 2047
la 是伪指令,实际会变成两条指令:
- 把
_array标签的地址 装进x5(不是数据本身!)
asm
auipc x5, 0 # x5 = PC
addi x5, x5, offset # x5 = PC + offset什么是符号扩展?
假设内存中存的是 0xff(-1的补码表示):
| 指令 | 扩展方式 | 结果 |
|---|---|---|
lb |
符号扩展 | 0xff → 0xffffffff(-1) |
lbu |
零扩展 | 0xff → 0x000000ff(+255) |
8位只能表示256个值,但需要表示正负数怎么办?
计算机用 补码 来同时表示正数和负数:
| 值 | 8位二进制 | 作为无符号 | 作为有符号 |
|---|---|---|---|
| 0xFF | 11111111 | 255 | -1 |
| 0xFE | 11111110 | 254 | -2 |
| ... | ... | ... | ... |
| 0x02 | 00000010 | 2 | 2 |
| 0x01 | 00000001 | 1 | 1 |
| 0x00 | 00000000 | 0 | 0 |
最高位是符号位:
- 0 → 正数(0 ~ 127)
- 1 → 负数(补码计算:-256 ~ -1)
怎么算负数的补码?
负数 = 256 - 正数
例如 -1: 256 - 1 = 255 = 0xFF
例如 -5: 256 - 5 = 251 = 0xFB符号扩展 vs 零扩展
-
零扩展(LBU)- 你是正数
0xFF (8位) → 000000FF (32位) = 255
↑
前面全补0 -
符号扩展(LB)- 你是负数
0xFF (8位) → FFFFFFFF (32位) = -1
↑
前面全补1(因为最高位是1,表示负数)
例如:
c
char c1 = 255; // 在C里 char 是有符号的,255 = -1
unsigned char c2 = 255; // 无符号,就是255
// 汇编:假设之前的代码让x5和x6指向了某个存了0xFF的地址
lb x5, 0(x5) // 取出来是 -1
lbu x6, 0(x6) // 取出来是 2556.3 LBU - 加载字节(零扩展)
文件 :lbu/test.s
asm
la x5, _array # x5 = array 的地址
lbu x6, 0(x5) # x6 = *(unsigned char*)x5 (零扩展)
lbu x7, 1(x5) # x7 = *(unsigned char*)(x5+1) (零扩展)说明:
- 格式:
LBU RD, IMM(RS1) - 加载8位,零扩展到32位
- 用于无符号字节数据
6.4 SB - 存储字节
文件 :sb/test.s
asm
li x6, 0xffffffab # x6 = 0xffffffab
la x5, _array # x5 = array 的地址
sb x6, 0(x5) # *x5 = (char)x6 = 0xab说明:
- 格式:
SB RS2, IMM(RS1) - 存储RS2的低8位到内存
7. 常用伪指令
7.1 LI - 加载立即数
文件 :li/test.s
asm
# 小范围立即数 [-2048, +2047]
li x5, 0x80
# 汇编为:
# addi x5, x0, 0x80
# 大范围立即数
li x6, 0x12345001
# 汇编为:
# lui x6, 0x12345
# addi x6, x6, 0x001
# lower-12最高位为1(需要补偿)
li x7, 0x12345FFF
# 汇编为:
# lui x7, 0x12346 # 0x12346 = 0x12345 + 1
# addi x7, x7, -1说明:
- LI 是伪指令
- 根据立即数范围汇编为不同序列
可以通过 make debug 看具体的汇编指令:
shell
zgl@zgl-virtual-machine:~/code/risc_v/riscv-operating-system-mooc/code/asm/li$ make debug
Press Ctrl-C and then input 'quit' to exit GDB and QEMU
-------------------------------------------------------
Reading symbols from test.elf...
Breakpoint 1 at 0x80000000: file test.s, line 32.
0x00001000 in ?? ()
=> 0x00001000: 97 02 00 00 auipc t0,0x0
1: /z $x5 = 0x00000000
2: /z $x6 = 0x00000000
3: /z $x7 = 0x00000000
Breakpoint 1, _start () at test.s:32
32 li x5, 0x80
=> 0x80000000 <_start+0>: 93 02 00 08 li t0,128
1: /z $x5 = 0x80000000
2: /z $x6 = 0x00000000
3: /z $x7 = 0x00000000
(gdb) s
34 addi x5, x0, 0x80
=> 0x80000004 <_start+4>: 93 02 00 08 li t0,128
1: /z $x5 = 0x00000080
2: /z $x6 = 0x00000000
3: /z $x7 = 0x00000000
(gdb)
38 li x6, 0x12345001
=> 0x80000008 <_start+8>: 37 53 34 12 lui t1,0x12345
0x8000000c <_start+12>: 13 03 13 00 addi t1,t1,1 # 0x12345001
1: /z $x5 = 0x00000080
2: /z $x6 = 0x00000000
3: /z $x7 = 0x00000000
(gdb)
40 lui x6, 0x12345
=> 0x80000010 <_start+16>: 37 53 34 12 lui t1,0x12345
1: /z $x5 = 0x00000080
2: /z $x6 = 0x12345001
3: /z $x7 = 0x00000000
(gdb)
41 addi x6, x6, 0x001
=> 0x80000014 <_start+20>: 13 03 13 00 addi t1,t1,1
1: /z $x5 = 0x00000080
2: /z $x6 = 0x12345000
3: /z $x7 = 0x00000000
(gdb)
45 li x7, 0x12345FFF
=> 0x80000018 <_start+24>: b7 63 34 12 lui t2,0x12346
0x8000001c <_start+28>: 93 83 f3 ff addi t2,t2,-1 # 0x12345fff
1: /z $x5 = 0x00000080
2: /z $x6 = 0x12345001
3: /z $x7 = 0x00000000
(gdb)
47 lui x7, 0x12346
=> 0x80000020 <_start+32>: b7 63 34 12 lui t2,0x12346
1: /z $x5 = 0x00000080
2: /z $x6 = 0x12345001
3: /z $x7 = 0x12345fff
(gdb)
48 addi x7, x7, -1
=> 0x80000024 <_start+36>: 93 83 f3 ff addi t2,t2,-1
1: /z $x5 = 0x00000080
2: /z $x6 = 0x12345001
3: /z $x7 = 0x12346000
(gdb)
stop () at test.s:51
51 j stop # Infinite loop to stop execution
=> 0x80000028 <stop+0>: 6f 00 00 00 j 0x80000028 <stop>
1: /z $x5 = 0x00000080
2: /z $x6 = 0x12345001
3: /z $x7 = 0x12345fff7.2 MV - 移动寄存器
文件 :mv/test.s
asm
li x6, 30
mv x5, x6 # x5 = x6
# 等价于: addi x5, x6, 07.3 NOP - 空操作
文件 :nop/test.s
asm
nop # do nothing
# 等价于: addi x0, x0, 08. 函数调用约定
8.1 叶子函数调用
文件 :cc_leaf/test.s
asm
# 调用 square(3)
li a0, 3
call square
square:
addi sp, sp, -8 # prologue: 分配栈空间
sw s0, 0(sp) # 保存 s0
sw s1, 4(sp) # 保存 s1
mv s0, a0 # s0 = 参数
mul s1, s0, s0 # s1 = s0 * s0
mv a0, s1 # 返回值放入 a0
lw s0, 0(sp) # epilogue: 恢复 s0
lw s1, 4(sp) # 恢复 s1
addi sp, sp, 8 # 恢复栈指针
ret说明:
- 叶子函数:不调用其他函数的函数
- 不需要保存
ra - 需要保存
s0-s11(被调用者保存寄存器)
叶子函数 square(n) 完整解析,这是一个计算 n² 的函数。
8.1.1 完整栈流程示意图
注意:
- 寄存器在 CPU 内部,不在内存中
- 栈在 内存 中
- 两者是完全独立的存储位置
所以:
- 寄存器变化确实从栈的示意图中看到
- 需要用调试器(如GDB)才能观察
假设:
- 初始
sp = 0x1000(栈底,高地址) - 栈向下增长(向低地址)
- 每个格子 = 4字节(1 word)
第0步:调用前 (caller 准备)
高地址
0x1008 ┌────────────┐
│ ? │ (未使用)
0x1004 ├────────────┤
│ ? │
0x1000 ├────────────┤ ← sp (初始指向0x1000)
│ ? │
0xFFC ├────────────┤
│ ? │
0xFF8 └────────────┘
低地址
状态:
- a0 = 3
- ra = 返回地址 (假设 0x1234)
- sp = 0x1000
第1步:进入 square,执行 addi sp, sp, -8
高地址
0x1008 ┌────────────┐
│ ? │
0x1004 ├────────────┤
│ ? │
0x1000 ├────────────┤ ← 旧的栈顶 (即将变)
│ ? │
0xFFC ├────────────┤
│ 空闲1 │
0xFF8 ├────────────┤ ← sp (新位置: 0xFF8)
│ 空闲2 │
0xFF4 └────────────┘
低地址
变化: sp = 0x1000 - 8 = 0xFF8
栈已分配8字节 (0xFF8 ~ 0xFFF)第2步:执行 sw s0, 0(sp)
保存 s0 的旧值(假设调用前 s0 = 0xABCD)
高地址
0x1008 ┌────────────┐
│ ? │
0x1004 ├────────────┤
│ ? │
0x1000 ├────────────┤
│ ? │
0xFFC ├────────────┤
│ 空闲1 │
0xFF8 ├────────────┤ ← sp (0xFF8)
│ s0=0xABCD │ ← 已保存
0xFF4 └────────────┘
低地址
现在栈内容:
- 0xFF8: 0xABCD (原 s0 值)
- 0xFFC: 未使用
- 寄存器: s0 暂未改变,仍是 0xABCD第3步:执行 sw s1, 4(sp)
保存 s1 的旧值(假设调用前 s1 = 0x1234)
高地址
0x1008 ┌────────────┐
│ ? │
0x1004 ├────────────┤
│ ? │
0x1000 ├────────────┤
│ ? │
0xFFC ├────────────┤
│ s1=0x1234 │ ← 已保存
0xFF8 ├────────────┤ ← sp (0xFF8)
│ s0=0xABCD │
0xFF4 └────────────┘
低地址
现在栈内容:
- 0xFF8: 0xABCD (原 s0)
- 0xFFC: 0x1234 (原 s1)
- 寄存器: s0, s1 仍是原值第4步:执行 mv s0, a0 和 mul s1, s0, s0
计算过程中,栈不变
高地址
0x1008 ┌────────────┐
│ ? │
0x1004 ├────────────┤
│ ? │
0x1000 ├────────────┤
│ ? │
0xFFC ├────────────┤
│ s1=0x1234 │ (栈中未变)
0xFF8 ├────────────┤ ← sp
│ s0=0xABCD │
0xFF4 └────────────┘
低地址
寄存器变化:
- s0 = 3 (从 a0 来)
- s1 = 9 (3×3)
- a0 = 9 (准备返回值)
注意: 栈中保存的还是旧值,没有被修改第5步:执行 mv a0, s1
返回值设置,栈仍然不变
高地址
0x1008 ┌────────────┐
│ ? │
0x1004 ├────────────┤
│ ? │
0x1000 ├────────────┤
│ ? │
0xFFC ├────────────┤
│ s1=0x1234 │
0xFF8 ├────────────┤ ← sp
│ s0=0xABCD │
0xFF4 └────────────┘
低地址
寄存器:
- a0 = 9 (返回值)
- s0 = 3, s1 = 9 (被修改了,但栈中还有旧值)第6步:执行 lw s0, 0(sp)
从栈恢复 s0 的旧值
高地址
0x1008 ┌────────────┐
│ ? │
0x1004 ├────────────┤
│ ? │
0x1000 ├────────────┤
│ ? │
0xFFC ├────────────┤
│ s1=0x1234 │
0xFF8 ├────────────┤ ← sp
│ s0=0xABCD │ → 读回 s0 寄存器
0xFF4 └────────────┘
低地址
效果:
- s0 从 3 恢复为 0xABCD
- 栈内容不变(只是读取)第7步:执行 lw s1, 4(sp)
从栈恢复 s1 的旧值
高地址
0x1008 ┌────────────┐
│ ? │
0x1004 ├────────────┤
│ ? │
0x1000 ├────────────┤
│ ? │
0xFFC ├────────────┤
│ s1=0x1234 │ → 读回 s1 寄存器
0xFF8 ├────────────┤ ← sp
│ s0=0xABCD │
0xFF4 └────────────┘
低地址
效果:
- s1 从 9 恢复为 0x1234
- 所有寄存器恢复到调用前的状态第8步:执行 addi sp, sp, 8
释放栈空间
高地址
0x1008 ┌────────────┐
│ ? │
0x1004 ├────────────┤
│ ? │
0x1000 ├────────────┤ ← sp (恢复为 0x1000)
│ ? │
0xFFC ├────────────┤
│ 废弃数据 │ (逻辑上已释放)
0xFF8 ├────────────┤
│ 废弃数据 │
0xFF4 └────────────┘
低地址
变化: sp = 0xFF8 + 8 = 0x1000
栈内容还在,但下次函数调用会覆盖第9步:执行 ret
返回 caller
高地址
0x1008 ┌────────────┐
│ ? │
0x1004 ├────────────┤
│ ? │
0x1000 ├────────────┤ ← sp (回到初始位置)
│ ? │
0xFFC ├────────────┤
│ (空闲) │
0xFF8 ├────────────┤
│ (空闲) │
0xFF4 └────────────┘
低地址
最终状态:
- sp = 0x1000 (恢复)
- a0 = 9 (返回值)
- s0, s1 恢复原值
- 栈干净,返回 caller 继续执行栈变化总结表
| 步骤 | sp 值 | 栈中 | 说明 |
|---|---|---|---|
| 初始 | 0x1000 | 空 | - |
| addi sp,sp,-8 | 0xFF8 | 8字节空闲 | 分配空间 |
| sw s0,0(sp) | 0xFF8 | 0xFF8: s0旧值 | 保存s0 |
| sw s1,4(sp) | 0xFF8 | 0xFF8: s0旧值 0xFFC: s1旧值 | 保存s1 |
| 计算 | 0xFF8 | 不变 | 修改寄存器 |
| lw s0,0(sp) | 0xFF8 | 不变 | 恢复s0 |
| lw s1,4(sp) | 0xFF8 | 不变 | 恢复s1 |
| addi sp,sp,8 | 0x1000 | 废弃 | 释放空间 |
| ret | 0x1000 | 空闲 | 返回 |
8.1.2 调试
实际debug查看:我们会发现s0和s1为0,这是因为旧值就是0,以实际为主
shell
zgl@zgl-virtual-machine:~/code/risc_v/riscv-operating-system-mooc/code/asm/cc_leaf$ make debug
Press Ctrl-C and then input 'quit' to exit GDB and QEMU
-------------------------------------------------------
Reading symbols from test.elf...
Breakpoint 1 at 0x80000000: file test.s, line 19.
0x00001000 in ?? ()
=> 0x00001000: 97 02 00 00 auipc t0,0x0
1: /z $sp = 0x00000000
2: /z $ra = 0x00000000
3: /z $a0 = 0x00000000
4: /z $s0 = 0x00000000
5: /z $s1 = 0x00000000
6: /z $s2 = 0x00000000
Breakpoint 1, _start () at test.s:19
19 la sp, stack_end # prepare stack for calling functions
=> 0x80000000 <_start+0>: 17 01 00 00 auipc sp,0x0
0x80000004 <_start+4>: 13 01 01 07 addi sp,sp,112 # 0x80000070
1: /z $sp = 0x00000000
2: /z $ra = 0x00000000
3: /z $a0 = 0x00000000
4: /z $s0 = 0x00000000
5: /z $s1 = 0x00000000
6: /z $s2 = 0x00000000
(gdb) s
_start () at test.s:21
21 li a0, 3
=> 0x80000008 <_start+8>: 13 05 30 00 li a0,3
1: /z $sp = 0x80000070
2: /z $ra = 0x00000000
3: /z $a0 = 0x00000000
4: /z $s0 = 0x00000000
5: /z $s1 = 0x00000000
6: /z $s2 = 0x00000000
(gdb)
22 call square
=> 0x8000000c <_start+12>: ef 00 80 00 jal ra,0x80000014 <square>
1: /z $sp = 0x80000070
2: /z $ra = 0x00000000
3: /z $a0 = 0x00000003
4: /z $s0 = 0x00000000
5: /z $s1 = 0x00000000
6: /z $s2 = 0x00000000
(gdb)
square () at test.s:31
31 addi sp, sp, -8
=> 0x80000014 <square+0>: 13 01 81 ff addi sp,sp,-8
1: /z $sp = 0x80000070
2: /z $ra = 0x80000010
3: /z $a0 = 0x00000003
4: /z $s0 = 0x00000000
5: /z $s1 = 0x00000000
6: /z $s2 = 0x00000000
(gdb)
32 sw s0, 0(sp)
=> 0x80000018 <square+4>: 23 20 81 00 sw s0,0(sp)
1: /z $sp = 0x80000068
2: /z $ra = 0x80000010
3: /z $a0 = 0x00000003
4: /z $s0 = 0x00000000
5: /z $s1 = 0x00000000
6: /z $s2 = 0x00000000
(gdb)
33 sw s1, 4(sp)
=> 0x8000001c <square+8>: 23 22 91 00 sw s1,4(sp)
1: /z $sp = 0x80000068
2: /z $ra = 0x80000010
3: /z $a0 = 0x00000003
4: /z $s0 = 0x00000000
5: /z $s1 = 0x00000000
6: /z $s2 = 0x00000000
(gdb)
37 mv s0, a0
=> 0x80000020 <square+12>: 13 04 05 00 mv s0,a0
1: /z $sp = 0x80000068
2: /z $ra = 0x80000010
3: /z $a0 = 0x00000003
4: /z $s0 = 0x00000000
5: /z $s1 = 0x00000000
6: /z $s2 = 0x00000000
(gdb)
38 mul s1, s0, s0
=> 0x80000024 <square+16>: b3 04 84 02 mul s1,s0,s0
1: /z $sp = 0x80000068
2: /z $ra = 0x80000010
3: /z $a0 = 0x00000003
4: /z $s0 = 0x00000003
5: /z $s1 = 0x00000000
6: /z $s2 = 0x00000000
(gdb)
39 mv a0, s1
=> 0x80000028 <square+20>: 13 85 04 00 mv a0,s1
1: /z $sp = 0x80000068
2: /z $ra = 0x80000010
3: /z $a0 = 0x00000003
4: /z $s0 = 0x00000003
5: /z $s1 = 0x00000009
6: /z $s2 = 0x00000000
(gdb)
42 lw s0, 0(sp)
=> 0x8000002c <square+24>: 03 24 01 00 lw s0,0(sp)
1: /z $sp = 0x80000068
2: /z $ra = 0x80000010
3: /z $a0 = 0x00000009
4: /z $s0 = 0x00000003
5: /z $s1 = 0x00000009
6: /z $s2 = 0x00000000
(gdb)
43 lw s1, 4(sp)
=> 0x80000030 <square+28>: 83 24 41 00 lw s1,4(sp)
1: /z $sp = 0x80000068
2: /z $ra = 0x80000010
3: /z $a0 = 0x00000009
4: /z $s0 = 0x00000000
5: /z $s1 = 0x00000009
6: /z $s2 = 0x00000000
(gdb)
44 addi sp, sp, 8
=> 0x80000034 <square+32>: 13 01 81 00 addi sp,sp,8
1: /z $sp = 0x80000068
2: /z $ra = 0x80000010
3: /z $a0 = 0x00000009
4: /z $s0 = 0x00000000
5: /z $s1 = 0x00000000
6: /z $s2 = 0x00000000
(gdb)
square () at test.s:46
46 ret
=> 0x80000038 <square+36>: 67 80 00 00 ret
1: /z $sp = 0x80000070
2: /z $ra = 0x80000010
3: /z $a0 = 0x00000009
4: /z $s0 = 0x00000000
5: /z $s1 = 0x00000000
6: /z $s2 = 0x00000000
(gdb)
stop () at test.s:26
26 j stop # Infinite loop to stop execution
=> 0x80000010 <stop+0>: 6f 00 00 00 j 0x80000010 <stop>
1: /z $sp = 0x80000070
2: /z $ra = 0x80000010
3: /z $a0 = 0x00000009
4: /z $s0 = 0x00000000
5: /z $s1 = 0x00000000
6: /z $s2 = 0x000000008.2 嵌套函数调用
文件 :cc_nested/test.s
asm
_start:
la sp, stack_end # prepare stack for calling functions
# aa_bb(3, 4);
li a0, 3
li a1, 4
call aa_bb
stop:
j stop # Infinite loop to stop execution
# int aa_bb(int a, int b)
# return a^2 + b^2
aa_bb:
# prologue
addi sp, sp, -16
sw s0, 0(sp)
sw s1, 4(sp)
sw s2, 8(sp)
sw ra, 12(sp)
# cp and store the input params
mv s0, a0
mv s1, a1
# sum will be stored in s2 and is initialized as zero
li s2, 0
mv a0, s0
jal square
add s2, s2, a0
mv a0, s1
jal square
add s2, s2, a0
mv a0, s2
# epilogue
lw s0, 0(sp)
lw s1, 4(sp)
lw s2, 8(sp)
lw ra, 12(sp)
addi sp, sp, 16
ret
# int square(int num)
square:
# prologue
addi sp, sp, -8
sw s0, 0(sp)
sw s1, 4(sp)
# `mul a0, a0, a0` should be fine,
# programing as below just to demo we can contine use the stack
mv s0, a0
mul s1, s0, s0
mv a0, s1
# epilogue
lw s0, 0(sp)
lw s1, 4(sp)
addi sp, sp, 8
ret
# add nop here just for demo in gdb
nop
# allocate stack space
stack_start:
.rept 12
.word 0
.endr
stack_end:
.end # End of file说明:
- 嵌套函数:调用其他函数的函数
- 必须保存
ra,因为jal会覆盖它 - 调用子函数前保存所有被调用者保存寄存器
这是一个嵌套函数调用 的例子:aa_bb 函数内部调用了 square 函数。
C语言对应的逻辑
c
int square(int num) { return num * num; }
int aa_bb(int a, int b) {
return square(a) + square(b); // 嵌套调用!
}
aa_bb(3, 4) = square(3) + square(4) = 9 + 16 = 258.2.1 逐段解析
第1段:调用者准备
asm
_start:
la sp, stack_end # 设置栈指针
li a0, 3 # 参数 a = 3
li a1, 4 # 参数 b = 4
call aa_bb # 调用 aa_bb(a, b)| 指令 | 作用 |
|---|---|
la sp, stack_end |
初始化栈(为函数调用准备) |
li a0, 3 |
参数1 = 3 |
li a1, 4 |
参数2 = 4 |
call aa_bb |
跳转到 aa_bb,并把返回地址存入 ra |
第2段:aa_bb 的 prologue
asm
aa_bb:
addi sp, sp, -16 # 分配16字节栈空间
sw s0, 0(sp) # 保存 s0(被调用者保存寄存器)
sw s1, 4(sp) # 保存 s1
sw s2, 8(sp) # 保存 s2
sw ra, 12(sp) # 保存返回地址!← 关键!为什么要保存 ra?
call aa_bb时,返回地址已经存到了ra- 但接下来
aa_bb要调用square,会用jal指令 jal会覆盖 ra!- 所以必须先把原来的 ra 保存到栈上
栈布局(分配16字节后):
sp + 0 → s0(保存)
sp + 4 → s1(保存)
sp + 8 → s2(保存)
sp + 12 → ra(保存返回地址)← 关键!
sp + 16 → ← 新的 sp(往上走)第3段:保存参数
asm
mv s0, a0 # s0 = a = 3
mv s1, a1 # s1 = b = 4| 指令 | 作用 |
|---|---|
mv s0, a0 |
参数 a 暂存到 s0(因为后面 a0 要用来传参给 square) |
mv s1, a1 |
参数 b 暂存到 s1 |
第4段:第一次调用 square(a)
asm
li s2, 0 # s2 = 0(累加和初始化)
mv a0, s0 # a0 = 3(准备传参)
jal square # 调用 square(3),返回地址存入 ra
add s2, s2, a0 # s2 = s2 + 返回值 = 0 + 9 = 9jal square 做了什么?
- 跳转到
square函数 - 把返回地址(
call下一条指令的地址)存入ra
此时栈状态:
aa_bb 的栈 square 的栈(在上面)
sp+16 ──────────────────
sp+12 │ 旧 ra(aa_bb的返回值) │ ← 被覆盖前保存过
sp+8 │ s2 = 0 │
sp+4 │ s1 = 4 │ ← s1 被覆盖前保存过
sp+0 │ s0 = 3 │ ← s0 被覆盖前保存过
├───────────────────
│ square 的栈帧 │
└───────────────────第5段:第二次调用 square(b)
asm
mv a0, s1 # a0 = 4(准备传参)
jal square # 调用 square(4),返回地址存入 ra
add s2, s2, a0 # s2 = 9 + 16 = 25jal square 再次覆盖 ra,但没关系,aa_bb 已经不需要它了(因为已经保存了)。
第6段:设置返回值
asm
mv a0, s2 # a0 = 25(返回值)第7段:aa_bb 的 epilogue
asm
lw s0, 0(sp) # 恢复 s0
lw s1, 4(sp) # 恢复 s1
lw s2, 8(sp) # 恢复 s2
lw ra, 12(sp) # 恢复返回地址!← 关键!
addi sp, sp, 16 # 释放栈空间
ret # 返回到 _start(跳转到 ra 存的地址)为什么恢复 ra?
_start调用aa_bb时,返回地址存在ra里call aa_bb覆盖了ra,但之前保存过了- 现在从栈里读回来,
ret才能正确返回到stop标签
第8段:square 函数(叶子函数)
asm
square:
addi sp, sp, -8 # 分配8字节
sw s0, 0(sp) # 保存 s0
sw s1, 4(sp) # 保存 s1
mv s0, a0 # s0 = 参数(3或4)
mul s1, s0, s0 # s1 = s0 * s0
mv a0, s1 # 返回值 a0 = s1
lw s0, 0(sp) # 恢复 s0
lw s1, 4(sp) # 恢复 s1
addi sp, sp, 8 # 释放栈
ret # 返回到 aa_bb(跳转到 ra)square 不需要保存 ra?
- 对!因为
square是叶子函数(不再调用其他函数) ret用的是ra,而ra不会被再次覆盖(因为 square 内部没有 call)
8.2.2 完整调用流程
_start:
li a0, 3
li a1, 4
call aa_bb ──────────┐
│
aa_bb: │
addi sp, sp, -16 │
sw ra, 12(sp) 保存 ra │
... │
jal square ─────────────┼────┐
│ │
square: │ │
... │ │
mul s1, s0, s0 计算 3² │ │
mv a0, s1 返回值=9 │ │
ret ──────────────────┘ │
│
aa_bb: │
add s2, s2, a0 第一次结果 │
jal square ─────────────┼────┐
│ │ │
square: │ │ │
... │ │ │
mul s1, s0, s0 计算 4² │ │ │
mv a0, s1 返回值=16 │ │ │
ret ──────────────────┘ │
│
aa_bb: │
add s2, s2, a0 第二次结果 │
mv a0, s2 │ │
lw s0, 0(sp) │ │
lw s1, 4(sp) │ │
lw s2, 8(sp) │ │
lw ra, 12(sp) 恢复 ra │ │
addi sp, sp, 16 │ │
ret ──────────────────┘
stop:
j stop8.2.3 叶子函数 vs 嵌套函数
| 叶子函数 (square) | 嵌套函数 (aa_bb) | |
|---|---|---|
| 调用其他函数? | 否 | 是(调用了 square) |
| 需要保存 ra? | 不需要 | 需要 |
| 保存哪些寄存器? | s0, s1 | s0, s1, s2, ra |
关键区别:
- 嵌套函数 :调用者可能覆盖
ra,必须保存 - 叶子函数 :不再调用别人,
ra不会被覆盖,不用保存
8.3 调用约定总结
| 寄存器 | 别名 | 说明 |
|---|---|---|
| a0-a7 | 参数/返回值 | 函数参数(前8个)和返回值 |
| ra | 返回地址 | 保存返回调用者的地址 |
| sp | 栈指针 | 指向栈顶 |
| s0-s11 | 保存寄存器 | 被调用者负责保存 |
| t0-t6 | 临时寄存器 | 调用者负责保存 |
9. 汇编与C混合编程
9.1 汇编调用C函数
文件 :asm2c/
汇编代码 (asm2c/test.s):
asm
la sp, stack_end # 设置栈指针
li a0, 1 # 参数1 = 1
li a1, 2 # 参数2 = 2
call foo # 调用 C 函数 foo(int a, int b)C代码 (asm2c/test.c):
c
int foo(int a, int b)
{
int c = a + b; // 纯C函数,实现加法
return c;
}说明:
- 汇编通过
a0-a7传递参数 - C函数是普通的C函数
- 返回值通过
a0传出
9.2 C调用汇编函数(内联汇编)

文件 :c2asm/
汇编代码 (c2asm/test.s):
asm
_start:
la sp, stack_end
li a0, 1
li a1, 2
call foo # 调用 fooC代码 (c2asm/test.c):
c
int foo(int a, int b)
{
int c;
asm volatile (
"add %[sum], %[add1], %[add2]"
:[sum]"=r"(c)
:[add1]"r"(a), [add2]"r"(b)
);
return c;
}说明:
- C函数内部使用
asm volatile内联汇编 : [sum]"=r"(c)表示输出操作数,结果存到 c: [add1]"r"(a), [add2]"r"(b)表示输入操作数,从 a、b 取值- 返回值通过
a0传出
10. 构建和调试
10.1 构建系统文件
build.mk - 章节配置:
makefile
SECTIONS_Arithmetic = add add2 sub addi subi neg nop mv lui li
SECTIONS_Logical = and andi not
SECTIONS_Shifting = slli srli srai
SECTIONS_Load_Store = lb lbu sb auipc la
SECTIONS_Branch = bne
SECTIONS_Jump = jalr
SECTIONS_CallingConventions = cc_leaf cc_nested
SECTIONS_others = asm2c c2asmrule.mk - 构建规则:
makefile
CROSS_COMPILE = riscv64-unknown-elf-
CFLAGS = -nostdlib -fno-builtin -march=rv32g -mabi=ilp32 -g -Wall10.2 常用命令
bash
# 编译
make
# 运行(QEMU)
make run
# 调试(QEMU + GDB)
make debug10.3 GDB调试配置
gdbinit:
gdb
display/z $x5 # 有符号十进制显示 x5
display/z $x6
display/z $x7
set disassemble-next-line on
b _start
target remote : 1234
c附录:指令速查表
算术指令
| 指令 | 格式 | 功能 |
|---|---|---|
| add | ADD RD, RS1, RS2 | RD = RS1 + RS2 |
| addi | ADDI RD, RS1, IMM | RD = RS1 + IMM |
| sub | SUB RD, RS1, RS2 | RD = RS1 - RS2 |
| neg | NEG RD, RS | RD = -RS (伪指令) |
| lui | LUI RD, IMM | RD = IMM << 12 |
| auipc | AUIPC RD, IMM | RD = PC + (IMM << 12) |
逻辑指令
| 指令 | 格式 | 功能 |
|---|---|---|
| and | AND RD, RS1, RS2 | RD = RS1 & RS2 |
| andi | ANDI RD, RS1, IMM | RD = RS1 & IMM |
| not | NOT RD, RS | RD = ~RS (伪指令) |
移位指令
| 指令 | 格式 | 功能 |
|---|---|---|
| slli | SLLI RD, RS1, IMM | RD = RS1 << IMM (逻辑左移) |
| srli | SRLI RD, RS1, IMM | RD = RS1 >> IMM (逻辑右移) |
| srai | SRAI RD, RS1, IMM | RD = RS1 >> IMM (算术右移) |
跳转指令
| 指令 | 格式 | 功能 |
|---|---|---|
| bne | BNE RS1, RS2, IMM | if (RS1 != RS2) PC += IMM |
| jal | JAL RD, IMM | RD = PC+4; PC += IMM |
| jalr | JALR RD, RS1, IMM | RD = PC+4; PC = RS1 + IMM |
内存指令
| 指令 | 格式 | 功能 |
|---|---|---|
| lb | LB RD, IMM(RS1) | RD = (int8_t)(RS1+IMM) |
| lbu | LBU RD, IMM(RS1) | RD = (uint8_t)(RS1+IMM) |
| sb | SB RS2, IMM(RS1) | (uint8_t)(RS1+IMM) = RS27:0 |
| la | LA RD, label | RD = &label (伪指令) |
伪指令
| 伪指令 | 等价指令 | 功能 |
|---|---|---|
| li | lui/addi | 加载立即数 |
| mv | addi | 移动寄存器 |
| nop | addi x0, x0, 0 | 空操作 |
| not | xori rd, rs, -1 | 位反 |
| neg | sub rd, x0, rs | 取负 |