**摘要:**本研究提出了一种创新的作物条件语义分割架构,能够无缝整合上下文元数据(作物信息)。该方法通过在模型后期阶段融合上下文信息实现,从而可与包括新型架构在内的任何语义分割方案兼容。为评估该方法的有效性,我们精心构建了一个包含超过10万张手机拍摄真实场景图像的挑战性数据集。该数据集涵盖21种疾病的多个病程阶段及七种作物(小麦、大麦、玉米、水稻、油菜籽、葡萄和黄瓜),且单张图像中常存在多种疾病共存的复杂情况。实验表明,引入多作物上下文信息能显著提升植物病害检测语义分割模型的性能:相较于传统方法(F1=0.24,r=0.68),我们的方法在不同作物上均展现出更高的准确率和更好的泛化能力(F1=0.68,r=0.75);此外,采用基于单株病害植株伪标注的半监督学习方法,为植物病害分割与定量分析带来显著优势(F1=0.73,r=0.95)。该方法通过同时利用标注数据与未标注数据,有效降低了对耗时且成本高昂的手动标注工作的依赖,从而全面提升模型性能。该算法的部署有望彻底革新作物保护产品测试的数字化流程,在确保实验结果可重复性的同时最大限度减少人为主观因素的影响。通过解决语义分割与病害定量分析中的难题,我们助力实现更高效、精准的表型分析,从而为优化作物管理和保护策略提供有力支持。
 数据集中包含小麦、葡萄和黄瓜物种的图像示例,可直观反映实际田间采集条件。
数据集中包含小麦、葡萄和黄瓜物种的图像示例,可直观反映实际田间采集条件。
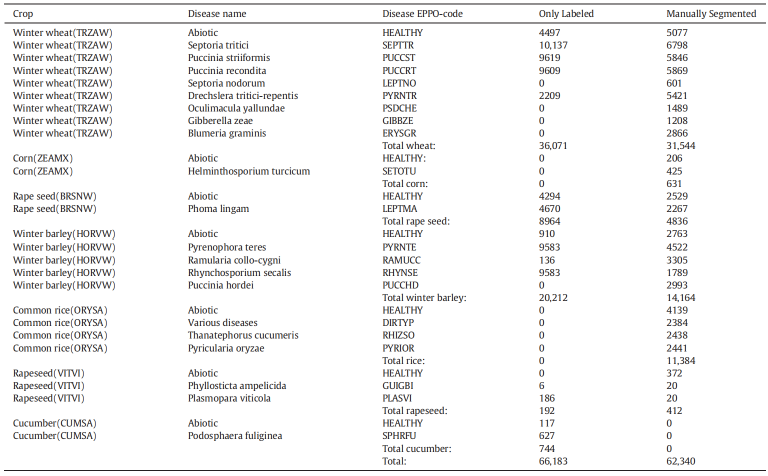 已获取并标注完成的图像数据集
已获取并标注完成的图像数据集
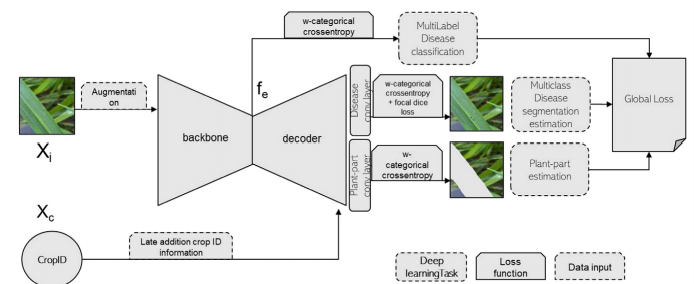 作物病害条件分割架构:首先对图像进行增强处理后输入网络编码器(主干网络),主干网络提取的特征向量用于生成分类任务;随后加入语义分割解码器,该解码器同时处理两个分割任务------植物部位分割与病害分割。作物标识信息通过后期拼接方式整合至解码器各层。
作物病害条件分割架构:首先对图像进行增强处理后输入网络编码器(主干网络),主干网络提取的特征向量用于生成分类任务;随后加入语义分割解码器,该解码器同时处理两个分割任务------植物部位分割与病害分割。作物标识信息通过后期拼接方式整合至解码器各层。
 疾病分割算法的结果。图中展示了clf任务类型及多作物元数据的影响。
疾病分割算法的结果。图中展示了clf任务类型及多作物元数据的影响。
**结论:**本研究提出了一种创新的作物条件语义分割架构,该架构能够无缝整合上下文元数据(即作物信息)。这一目标是通过在模型的后期层阶段融合上下文信息实现的。半监督方法不仅提高了训练过程的效率,还能确保模型在不同数据集上具有更好的泛化能力。我们的研究通过融合神经网络架构、上下文信息及半监督学习技术,显著提升了农业病害评估的效率与实用性。该算法的应用有望彻底革新作物保护产品检测的数字化流程,在确保检测结果可重复性的同时最大限度降低人为主观因素的影响。通过攻克语义分割与病害定量分析等关键技术难题,我们为实现更高效精准的表型分析提供了支持,最终助力制定更优的作物管理与防护策略。