zabbix监控-主机-1
主机监控类型:内存、swap使用率、CPU、磁盘剩余空间/IO、系统启动时间、进程数
一、被监控机器
-
接上章: 安装
-
默认端口
说明 端口端口 agent 10050 server 10051
1.1、Zabbix-Agent 两种监控模式
- 被动模式(Server 主动拉取数据)
- 数据流向 :由
zabbix_server内部 poller 进程 主动发起请求,向外访问各客户端zabbix_agentd的 10050 端口,获取监控指标数据。 - 特点:Server 主动上门采集,Agent 被动应答数据。
- 简化:server 连 agent 10050
- 数据流向 :由
- 主动模式(Agent 主动上报数据)
- 数据流向 :各客户端
zabbix_agentd主动发起连接,把采集到的监控数据推送至zabbix_server的 10051 端口,由 Server 的 poller 进程接收入库。 - 特点:Agent 定时主动上报,Server 被动接收数据。
- 简化:agent 连 server 10051
- 数据流向 :各客户端
- 补充
- 服务端组件:
zabbix_server(监控服务器),内置poller进程,分别负责【向外拉取(被动)】、【端口接收(主动)】两类数据; - 客户端组件:
zabbix_agentd,同一 Agent 进程可配置同时兼容主动 / 被动两种工作模式。
- 服务端组件:
1.2、Agent安装
-
依赖与用户
bashyum install gcc make pcre pcre-devel -y groupadd zabbix useradd -g zabbix -s /sbin/nologin zabbix -
源码安装
bash# 与安装zabbix服务端一样 mkdir /opt/software ; cd /opt/software wget https://cdn.zabbix.com/zabbix/sources/stable/7.4/zabbix-7.4.10.tar.gz tar xf zabbix-7.4.10.tar.gz cd zabbix-7.4.10 # 只编译agent,指定安装目录 ./configure --prefix=/opt/mirror/zabbix_agent --enable-agent make -j$(nproc) && make install -
配置修改
bashvim /opt/mirror/zabbix_agent/etc/zabbix_agentd.conf # 被动模式:允许哪个server来拉取监控数据 Server=127.0.0.1,zabbix服务端ip # 主动模式:agent主动上报数据到server ServerActive=zabbix服务端ip # 本机主机名【和Web后台添加的主机名必须一模一样!】 Hostname=eucnode50224 <-- 改成zabbix服务端的主机名 # 监听所有网卡(0.0.0.0全开放,127.0.0.1仅本地) ListenIP=0.0.0.0 # 日志路径 LogFile=/opt/mirror/zabbix_agent/log/zabbix_agentd.log -
自启服务
-
脚本
bashcat > /usr/lib/systemd/system/zabbix-agent.service <<'EOF' [Unit] Description=Zabbix Agent After=network-online.target [Service] Type=simple User=zabbix Group=zabbix Restart=on-failure RestartSec=3 # 你的自定义安装路径 ExecStart=/opt/mirror/zabbix_agent/sbin/zabbix_agentd -f ExecStop=/bin/kill -s TERM $MAINPID # 安全限制(标准配置) NoFile=65536 [Install] WantedBy=multi-user.target EOF -
重载服务并启动
bashsystemctl daemon-reload systemctl enable --now zabbix-agent systemctl status zabbix-agent -
检查服务
bashss -ntlp | grep 10050
-
-
测试 常用项
bash# zabbix_get在服务端zabbix/bin下,获取客户端CPU数据 /opt/mirror/zabbix/bin/zabbix_get -s 被监控机IP -p 10050 -k system.cpu.load[all,avg1] # 像这样 0.310000 返回数字=通信正常;报错=防火墙拦截10050端口
二、后台添加监控主机
2.1、添加默认模式
-
登录 Zabbix 后台:数据采集 → 主机群组 → 创建主机组 (将不同区域的主机或功能进行分组)
-
创建主机: 数据采集 → 主机 → 创建主机 (可见的名称,需要见名知意)
-
模板 → 选择 模板群组 → 搜索
Templates→ 选择 之后 找到Linux by Zabbix agent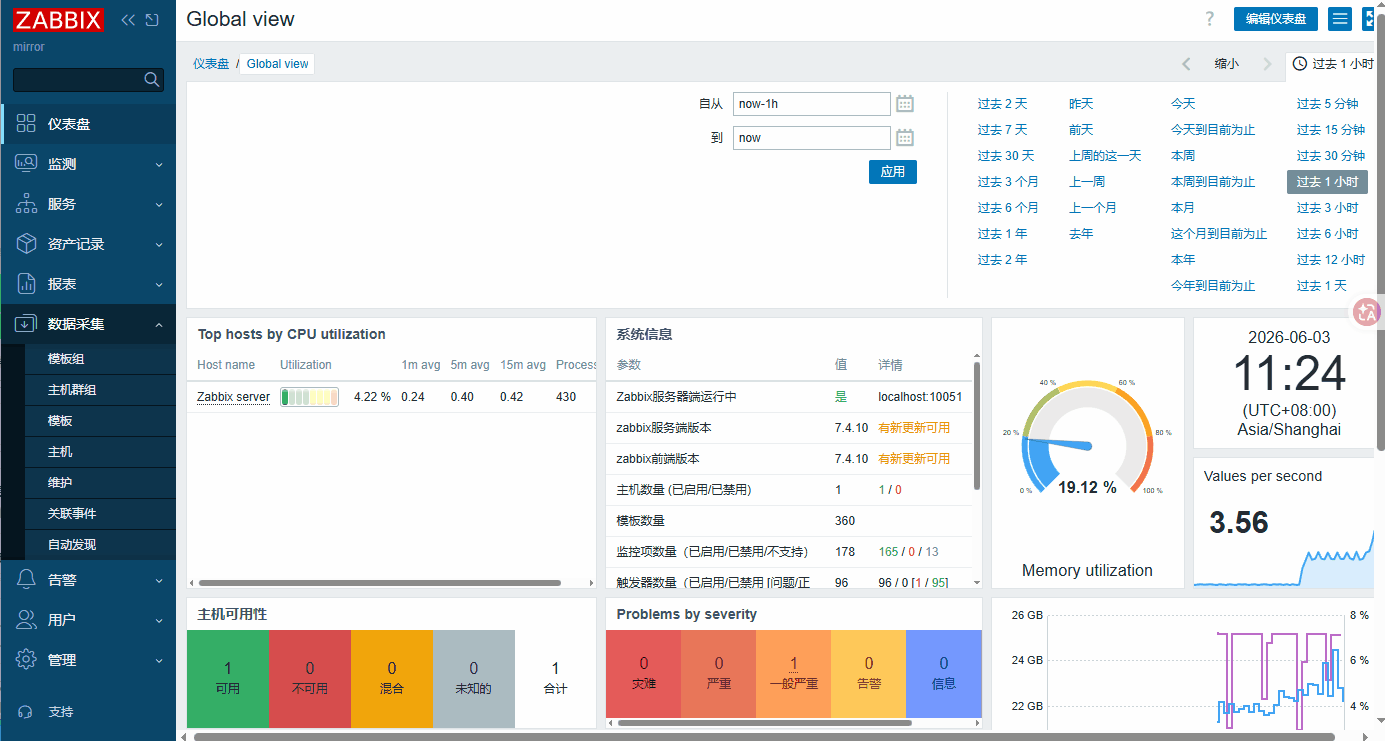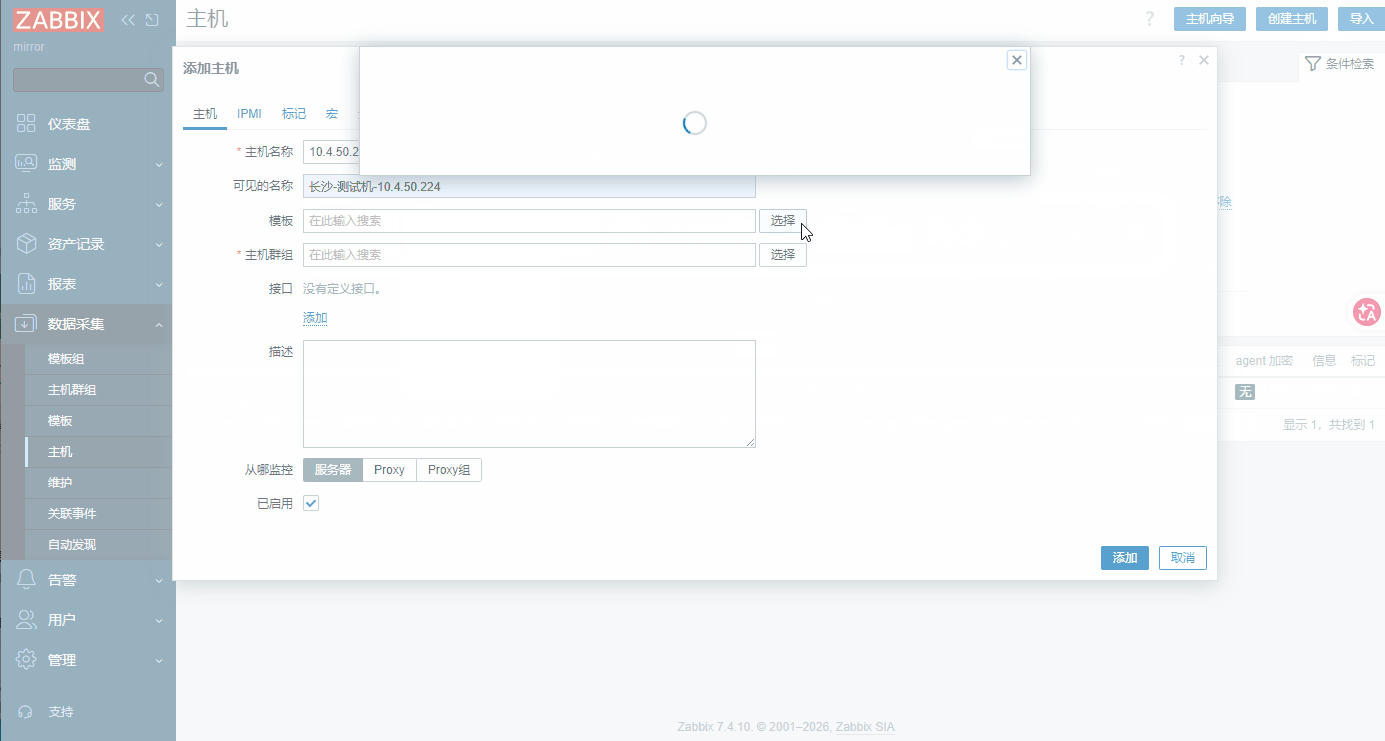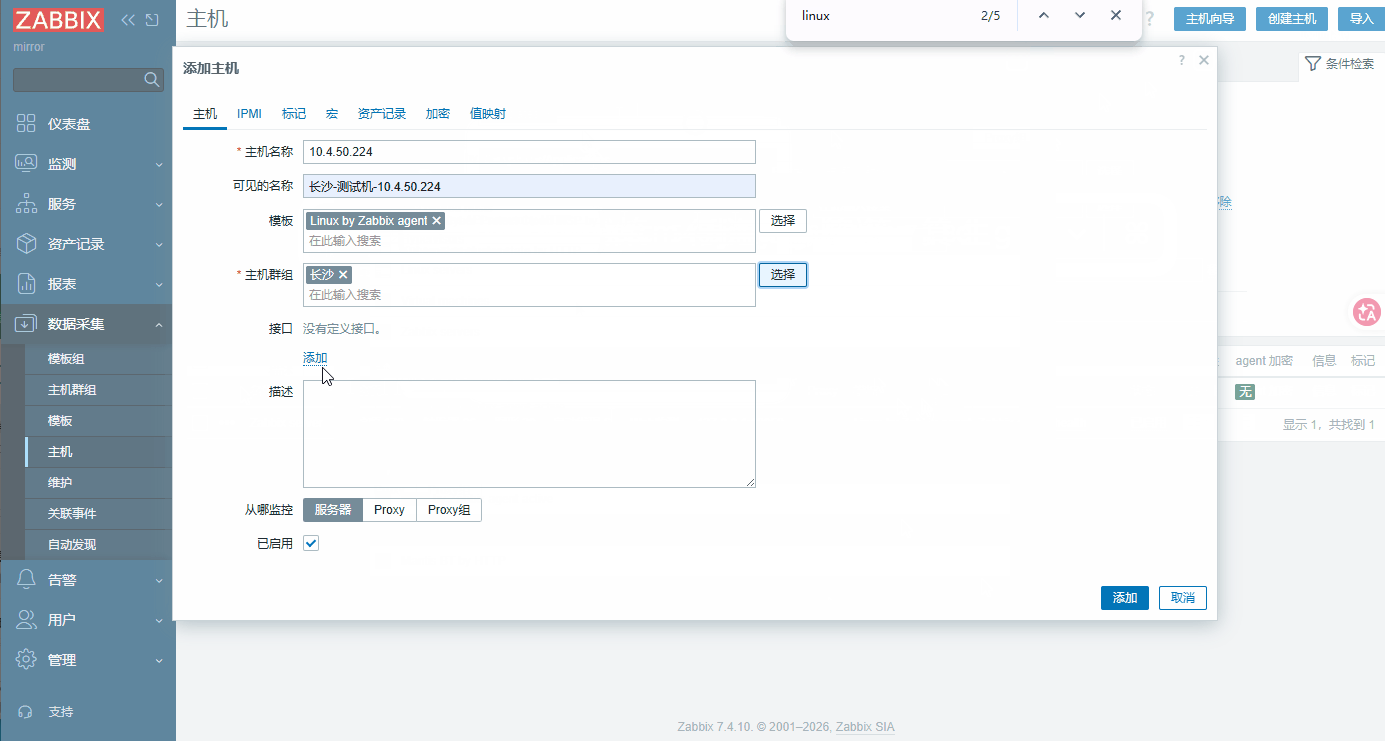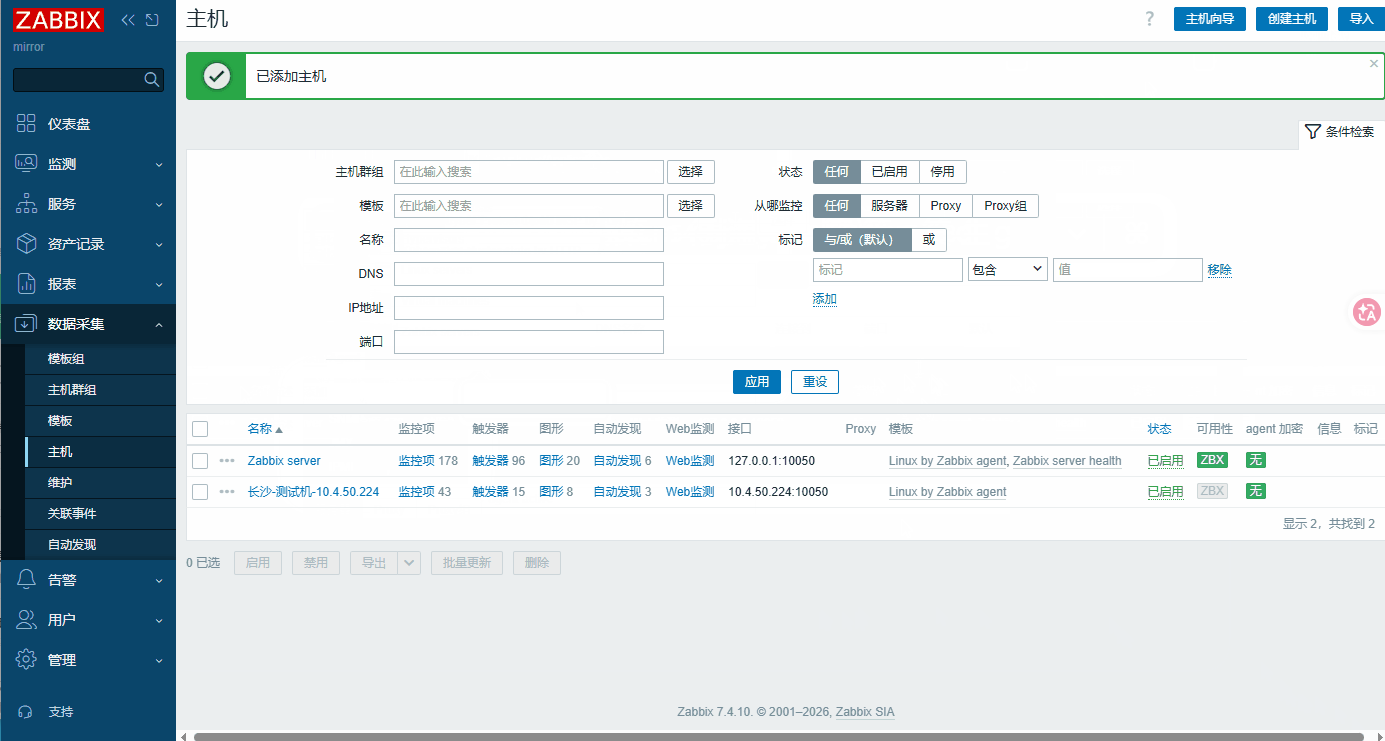
2.2、自定义添加
指标是边学边补充的,如果gif图没录上的话,添加是一样的步骤
2.2.1、磁盘io监控指标
-
核心注意点位
-
单盘读速率 KB/s、单盘写速率 KB/s、单盘读 IOPS、单盘写 IOPS
-
自动发现所有真实磁盘(sda/sdb/vda 等)
-
自动过滤无效磁盘
-
-
核心指标
监控项 key 指标含义 单位 说明 vfs.dev.read{#DEVNAME},sectors 磁盘读扇区 sectors 1 扇区 = 512 字节 vfs.dev.write{#DEVNAME},sectors 磁盘写扇区 sectors 1 扇区 = 512 字节 vfs.dev.read{#DEVNAME},sps 读每秒次数 次 / 秒 vfs.dev.write{#DEVNAME},sps 写每秒次数 次 / 秒 system.cpu.util,iowait IO 等待 CPU % >20% 告警 - 说明:磁盘不止一个分区,直接使用自动发现最靠谱
-
添加步骤: 数据采集 → 主机 → 要添加的主机 → 自动发现 → 创建自动发现规则
bash# 菜单栏上第一列: 自动发现规则 名称: 磁盘设备 IO 自动发现 键值: vfs.dev.discovery 间隔: 1h # 菜单栏上第四列: 过滤器 计算方式: 与/或 {#DEVTYPE} 匹配 disk {#DEVNAME} 匹配 ^[shv]d[a-z]+$|^nvme[0-9]+n[0-9]+$ # 说明 只识别:sda/sdb/vda/nvme0n1,过滤分区 sda1、dm-0、loop 等 # 测试并添加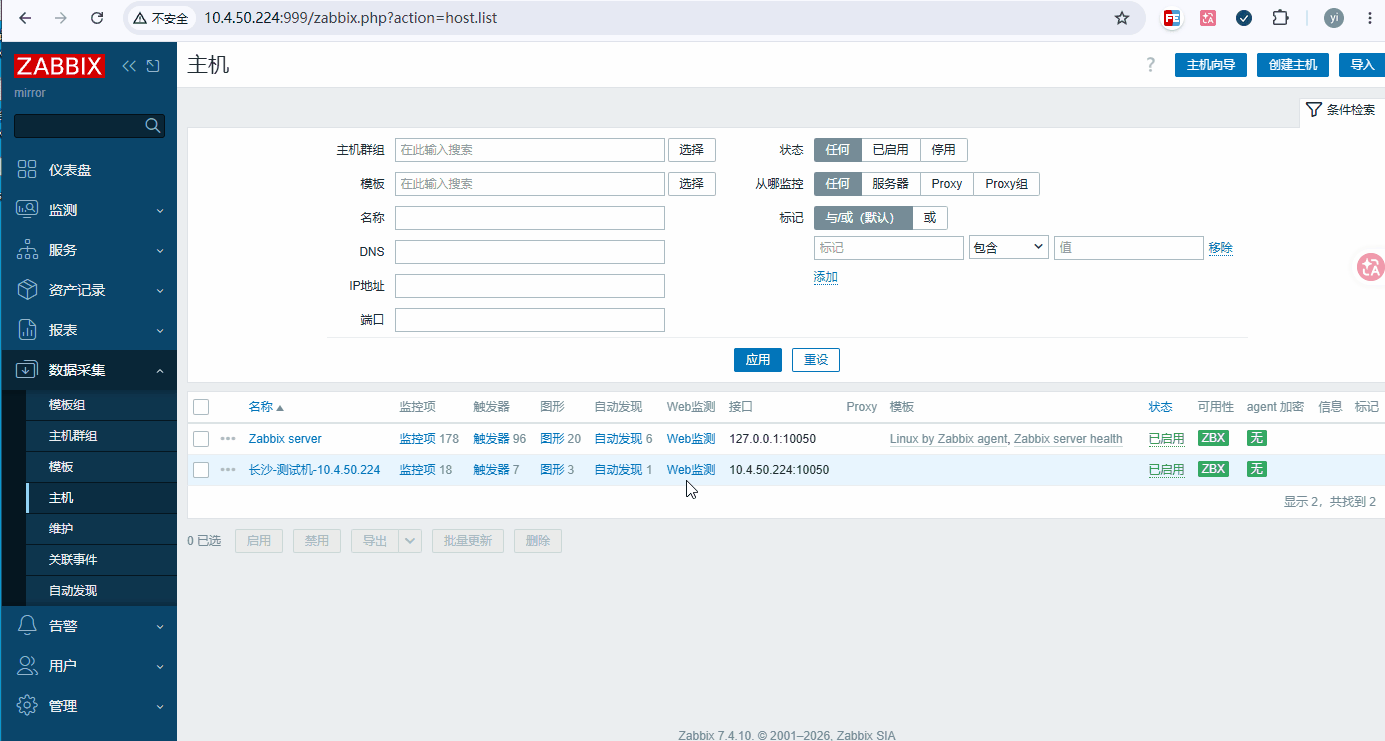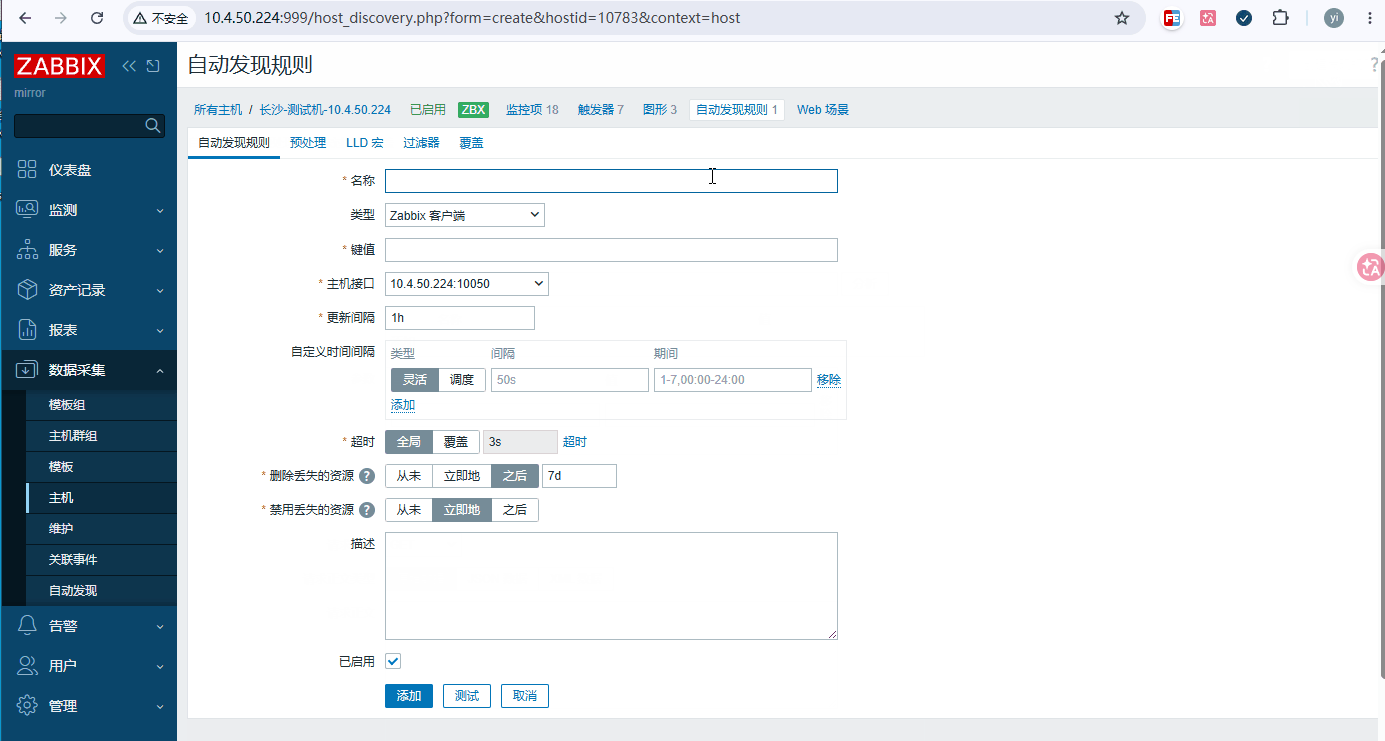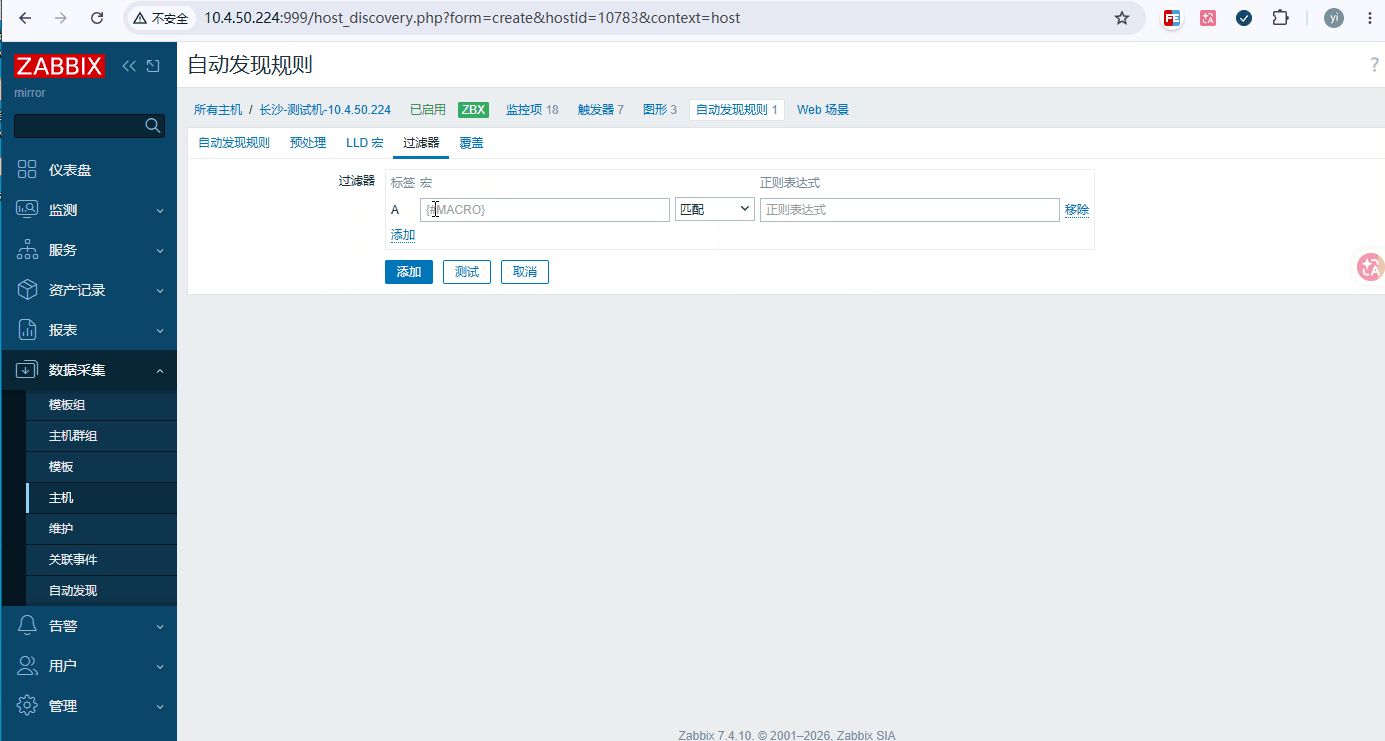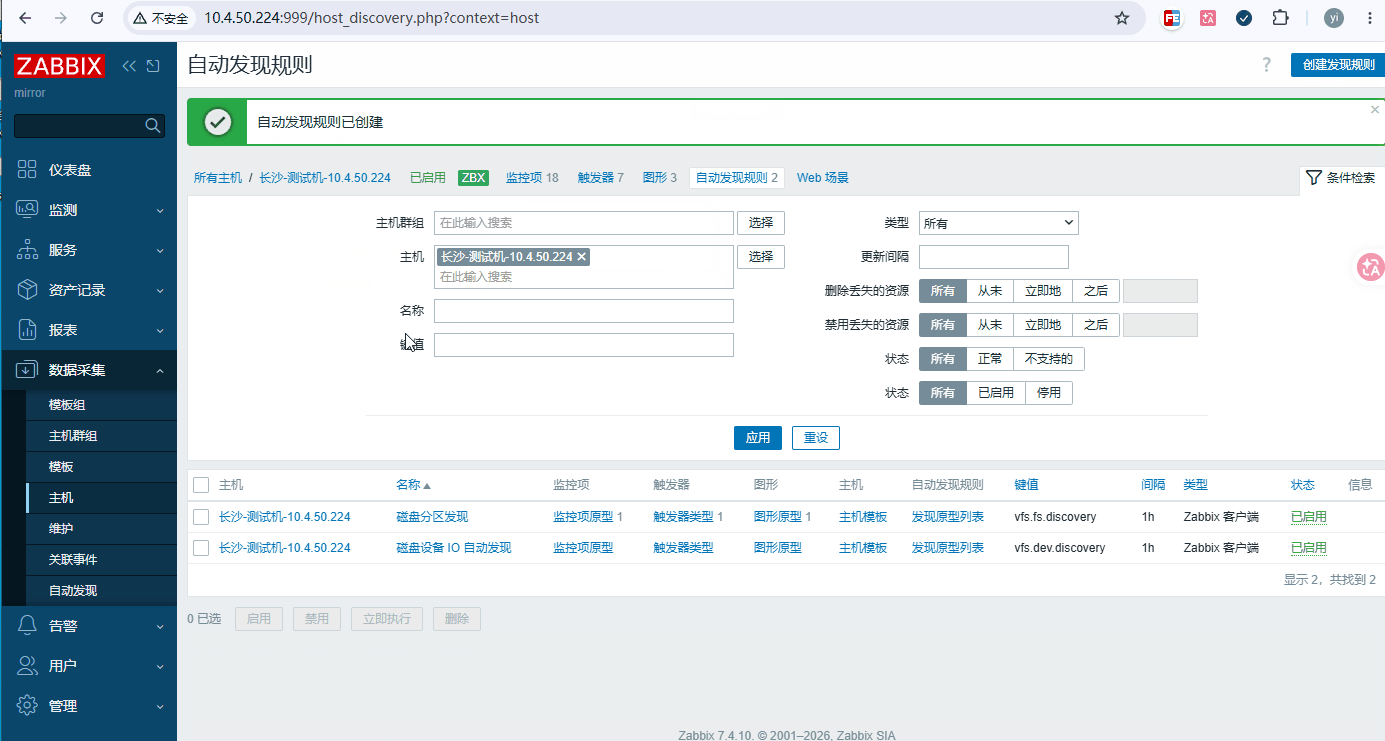
-
添加步骤: 数据采集 → 主机 → 要添加的主机 → 自动发现 → 【磁盘设备 IO 自动发现】 →监控器原形(添加四个)
-
原型 1:{#DEVNAME} 磁盘读速率 KB/s
bash键:vfs.dev.read[{#DEVNAME},sectors] 单位:KB/s 更新间隔:1m 预处理(顺序固定) ① 每秒更改 → 无参数(累计扇区→每秒扇区) ② 自定义倍数 → 512/1024(扇区→KB) 或写成 0.5 -
原型 2:{#DEVNAME} 磁盘写速率 KB/s
bash键:vfs.dev.write[{#DEVNAME},sectors] 单位:KB/s 更新间隔:1m 预处理(顺序固定) ① 每秒更改 → 无参数(累计扇区→每秒扇区) ② 自定义倍数 → 512/1024(扇区→KB)或写成 0.5 -
原型 3:{#DEVNAME} 读 IOPS (次 / 秒)
bash键:vfs.dev.read[{#DEVNAME},ops] 单位:ops/s 不加任何预处理 -
原型 4:{#DEVNAME} 写 IOPS (次 / 秒)
bash键:vfs.dev.write[{#DEVNAME},ops] 单位:ops/s 不加任何预处理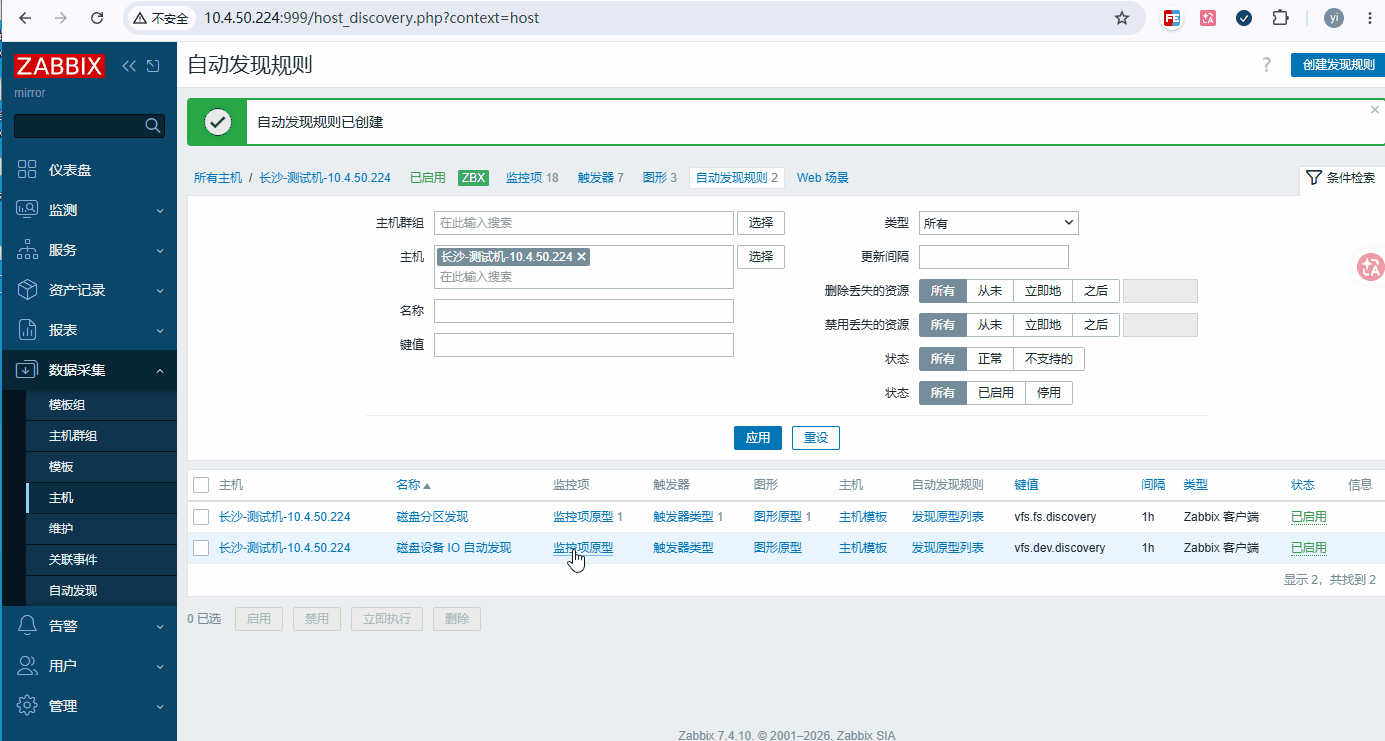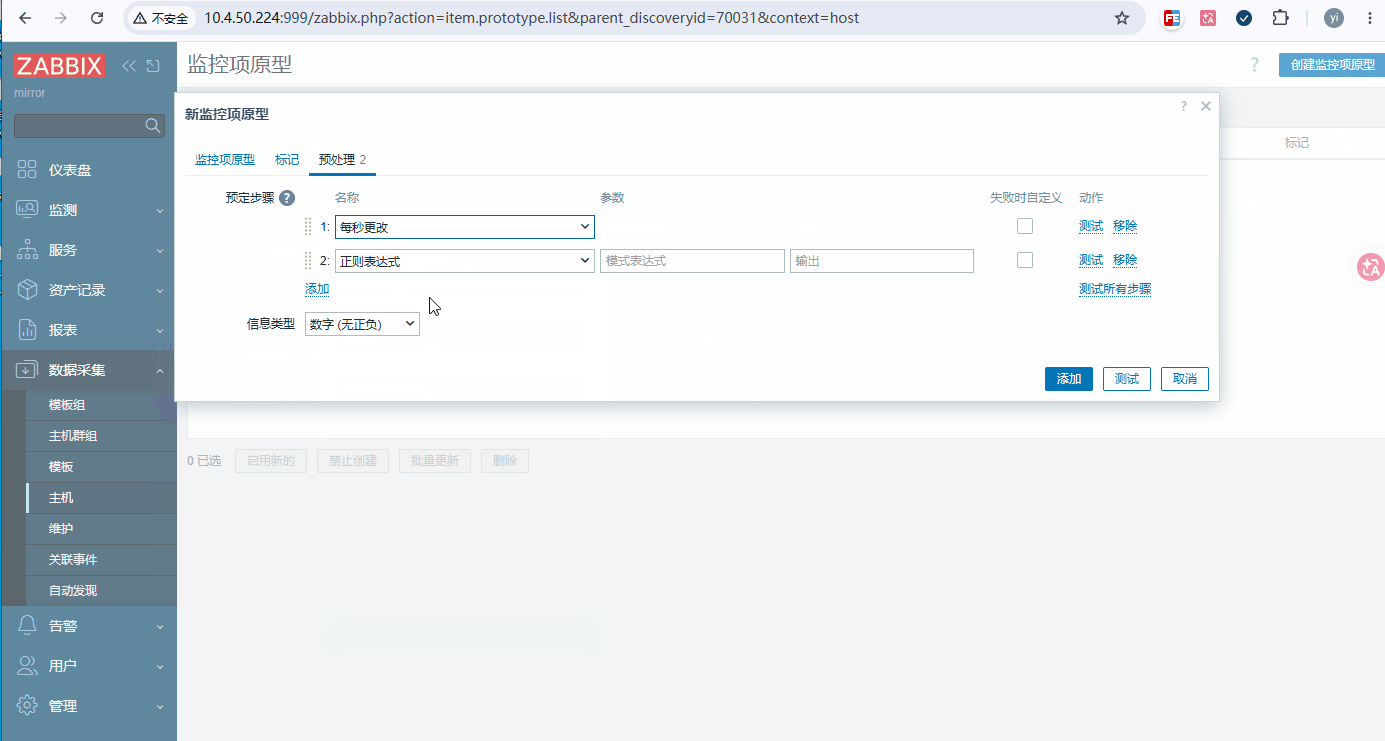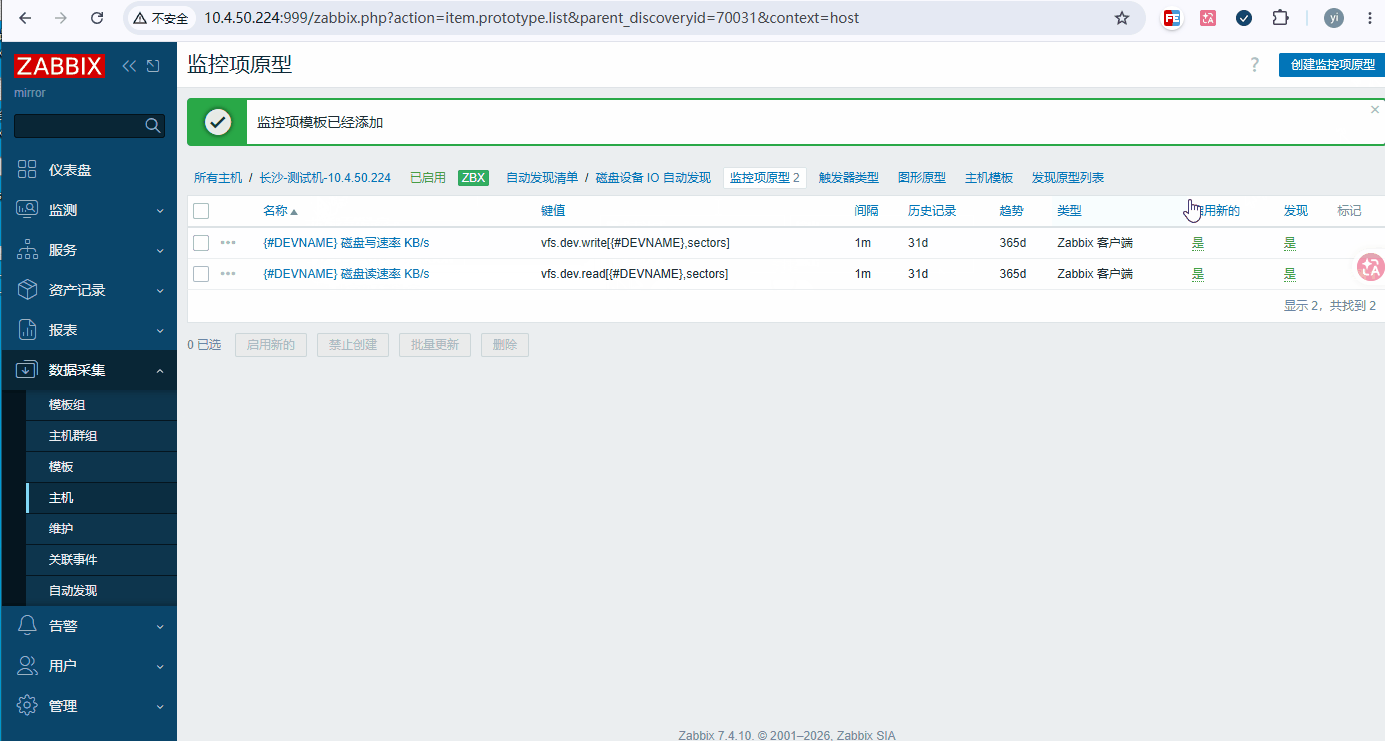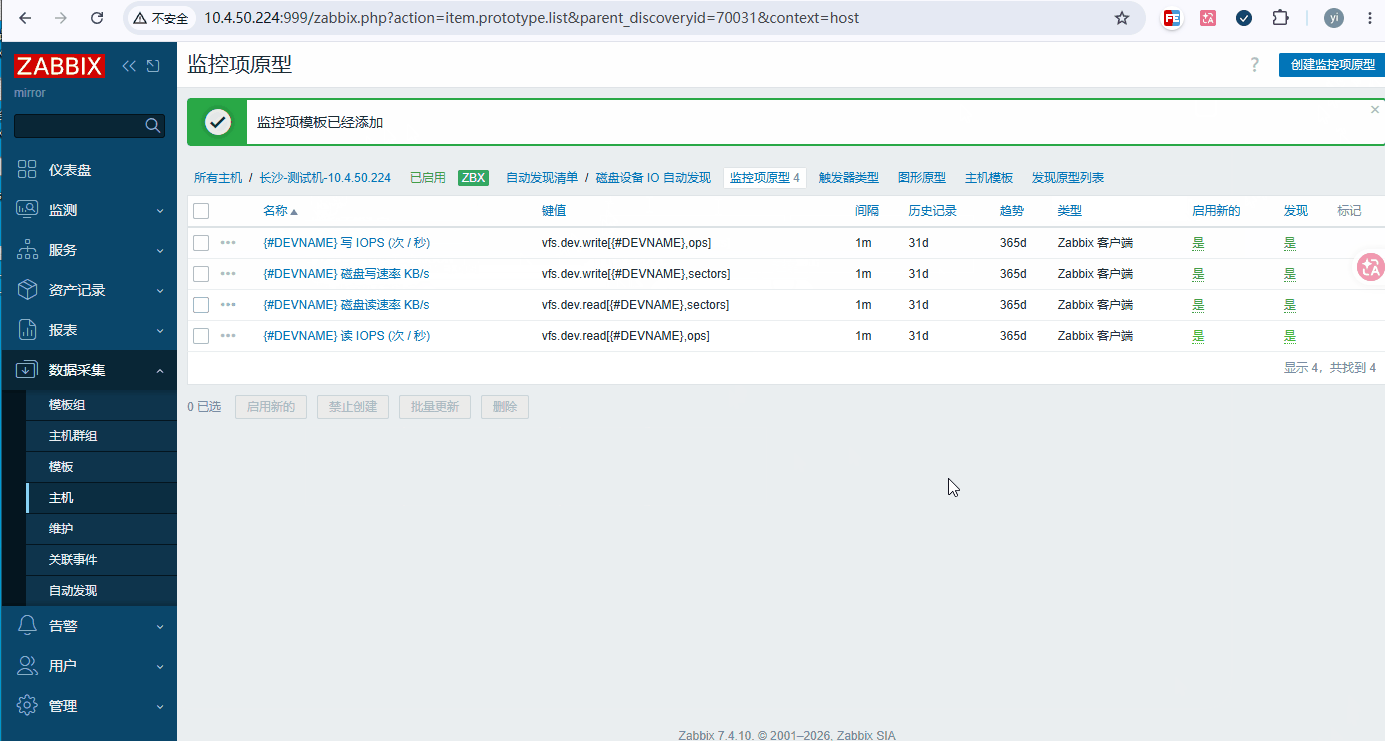
-
-
添加步骤: 数据采集 → 主机 → 要添加的主机 → 自动发现 → 【磁盘设备 IO 自动发现】 → 触发器类型 → 创建(3个)
-
触发器手动点,下面的表达式仅示例, 都是 表达式 --> 添加 --> 选择原型 根据示例公式选
- 普通机械盘:读写阈值 30~50MB/s
- SSD 盘:读写阈值 200~500MB/s,按需修改触发器数字
-
触发器 1:磁盘 {#DEVNAME} 写入流量过高【警告】
bashavg(/./vfs.dev.write[{#DEVNAME},sectors],5m) > 50*1024 [手动计算完填一下实际值51200] # 释义:连续 5 分钟写入>50MB/s 告警 -
触发器 2:磁盘 {#DEVNAME} 读取流量过高【警告】
bashavg(/./vfs.dev.read[{#DEVNAME},sectors],5m) > 50*1024 -
触发器 3:磁盘 {#DEVNAME} IOPS 突增【可选】
bashavg(/./vfs.dev.write[{#DEVNAME},ops],5m)>1000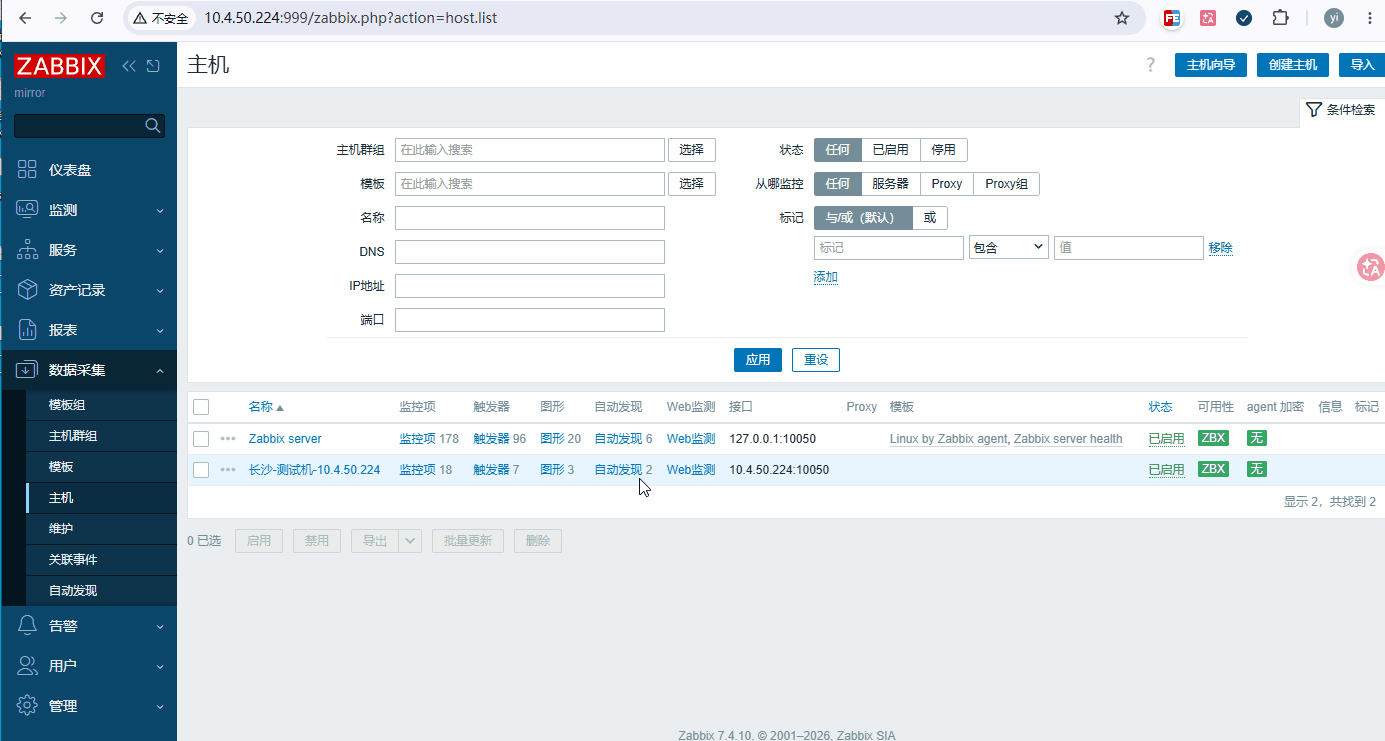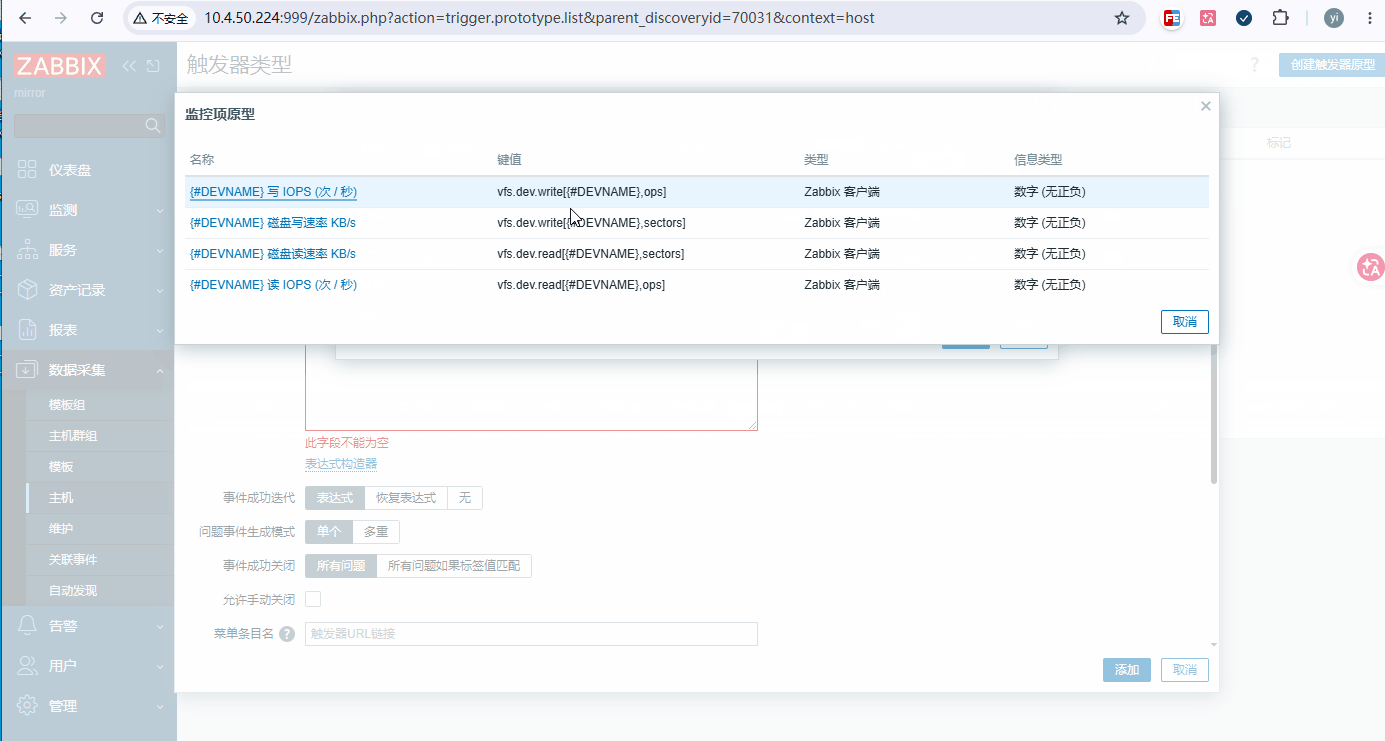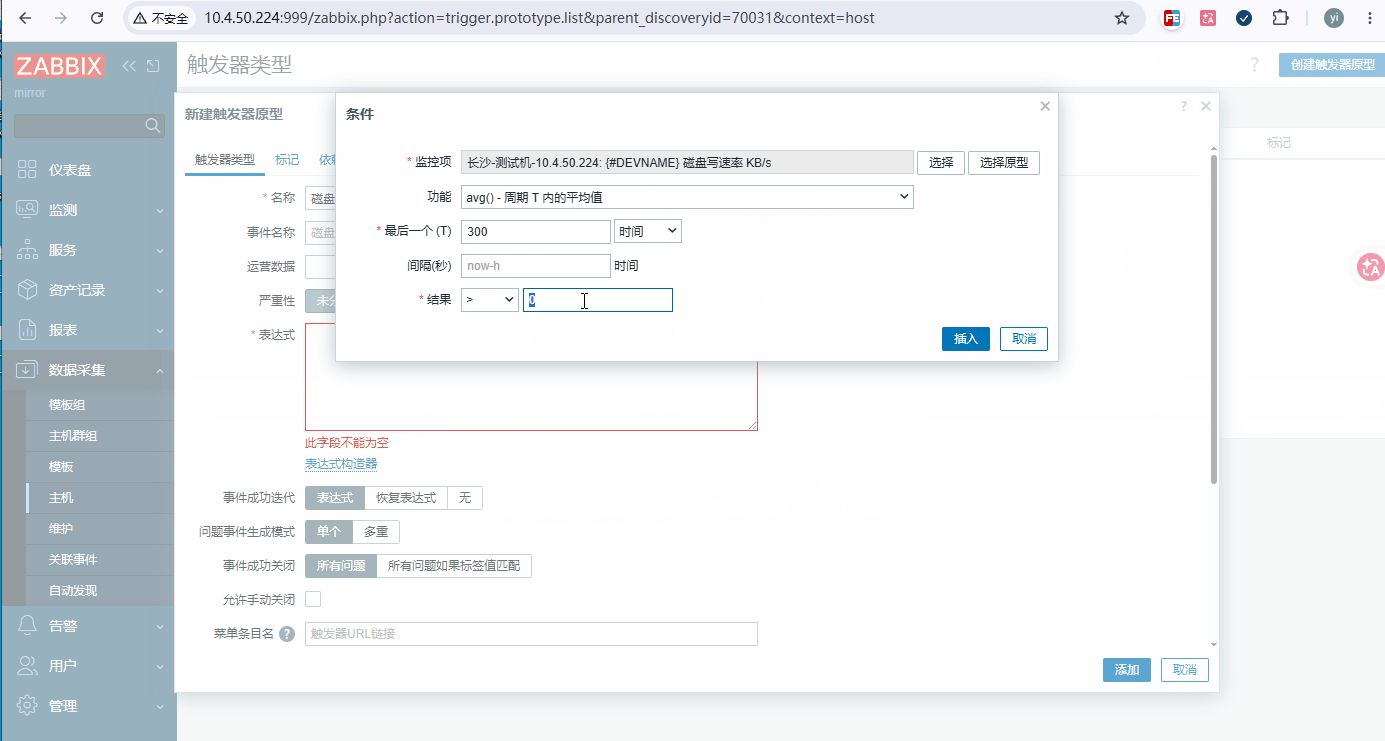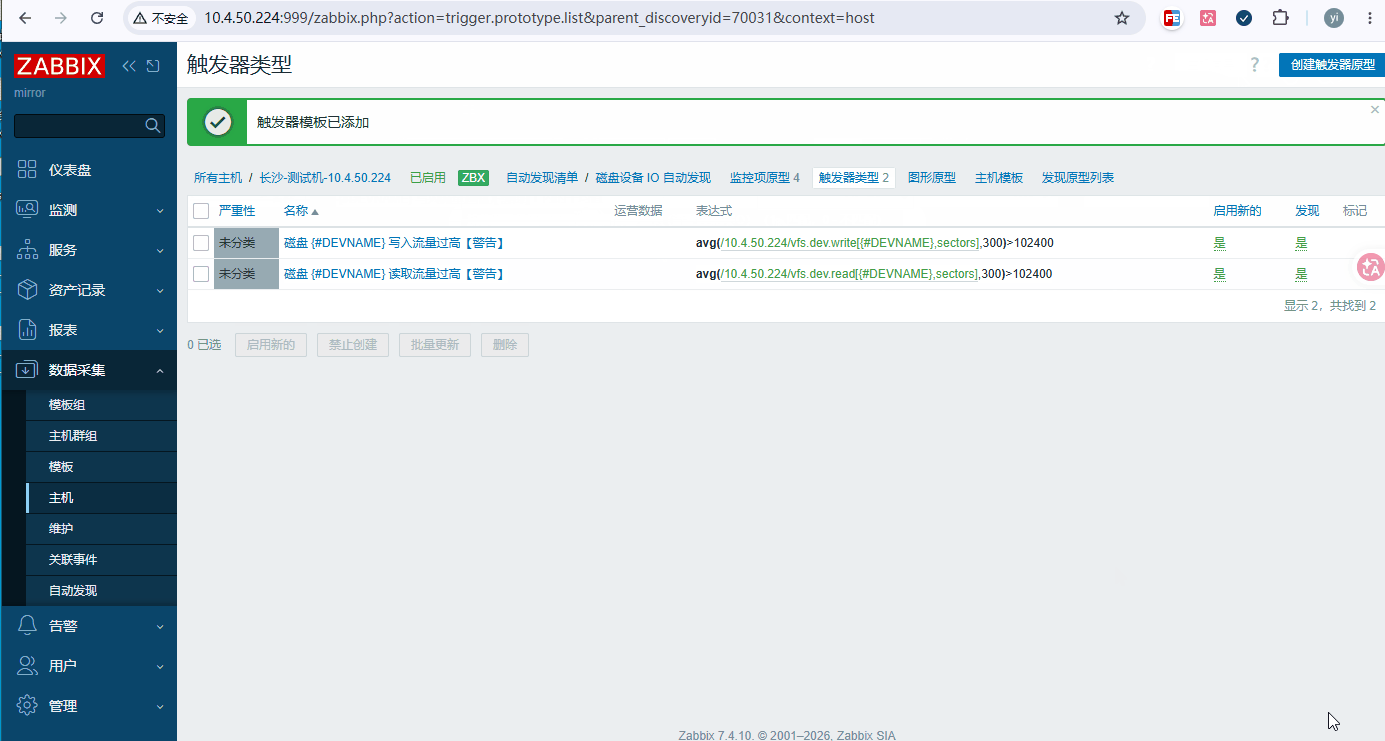
-
-
添加步骤: 数据采集 → 主机 → 要添加的主机 → 自动发现 → 【磁盘设备 IO 自动发现】 → 图形原型 → 创建
bash名称: 磁盘: {#DEVNAME} 速率表 监控项: 添加原形,选择四个原形 -
数据采集 → 主机 → 定义好的主机 → 监控项 → 选择自动发现的四个原形,点立即执行获取数据
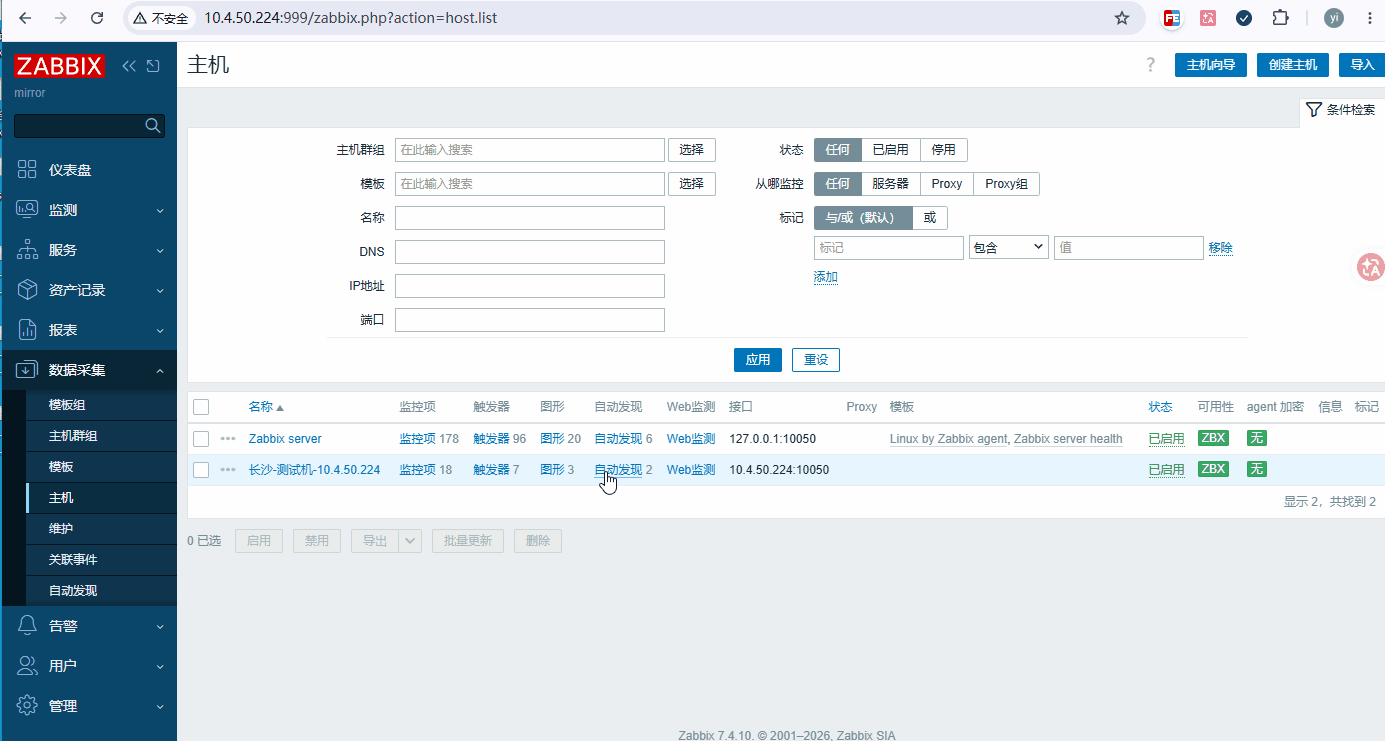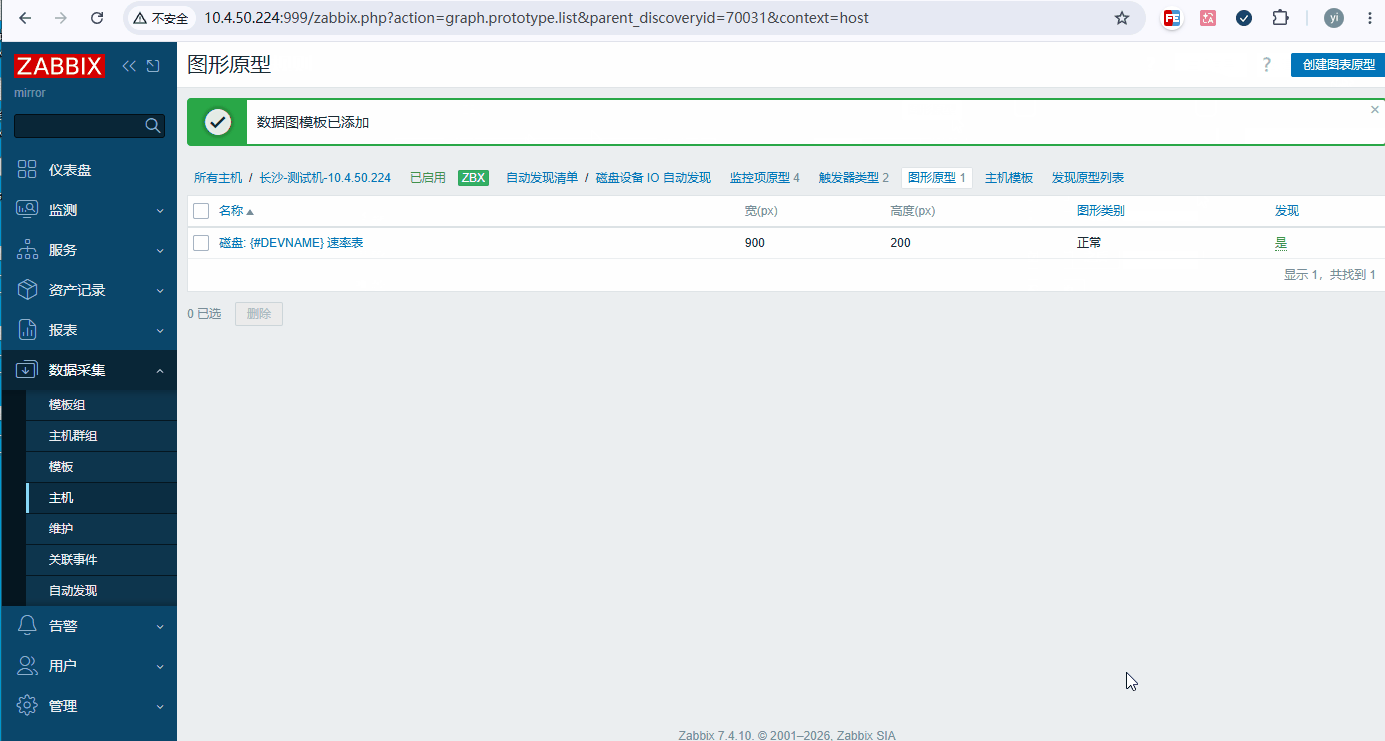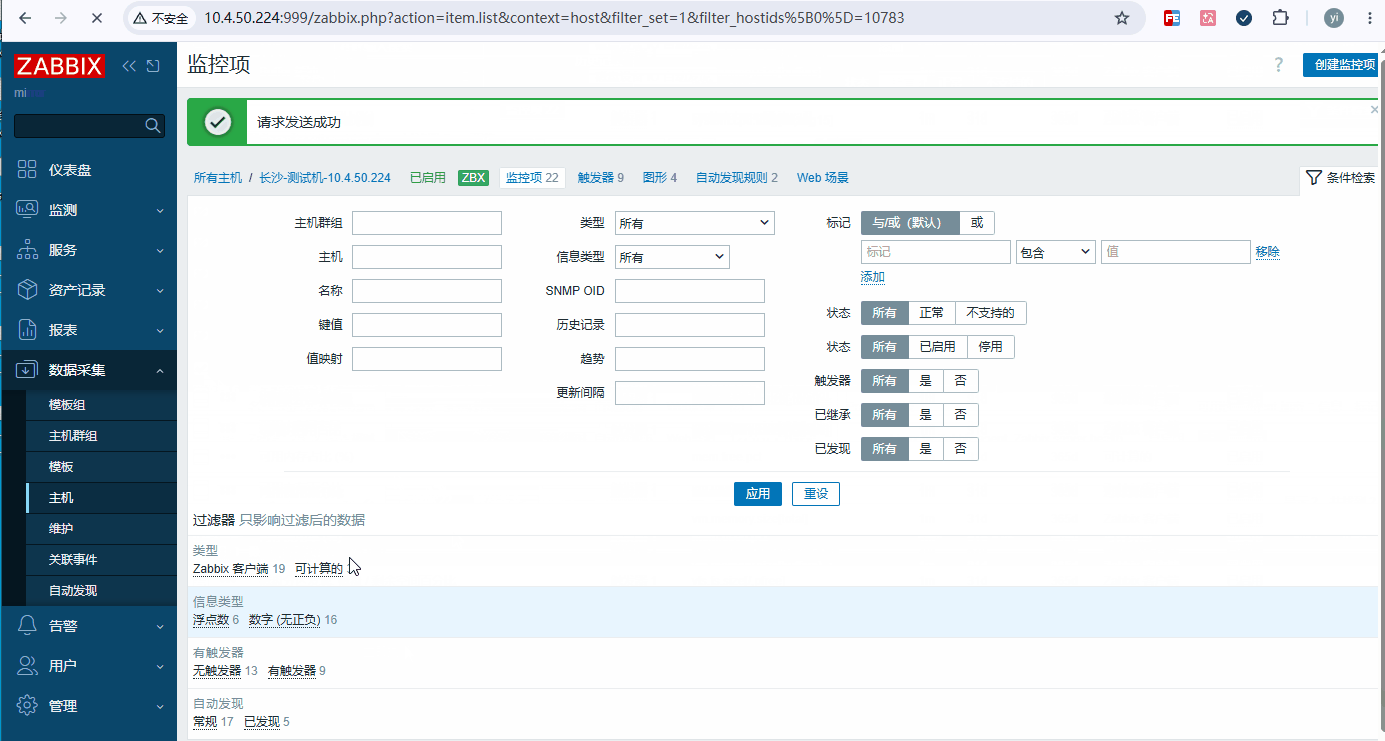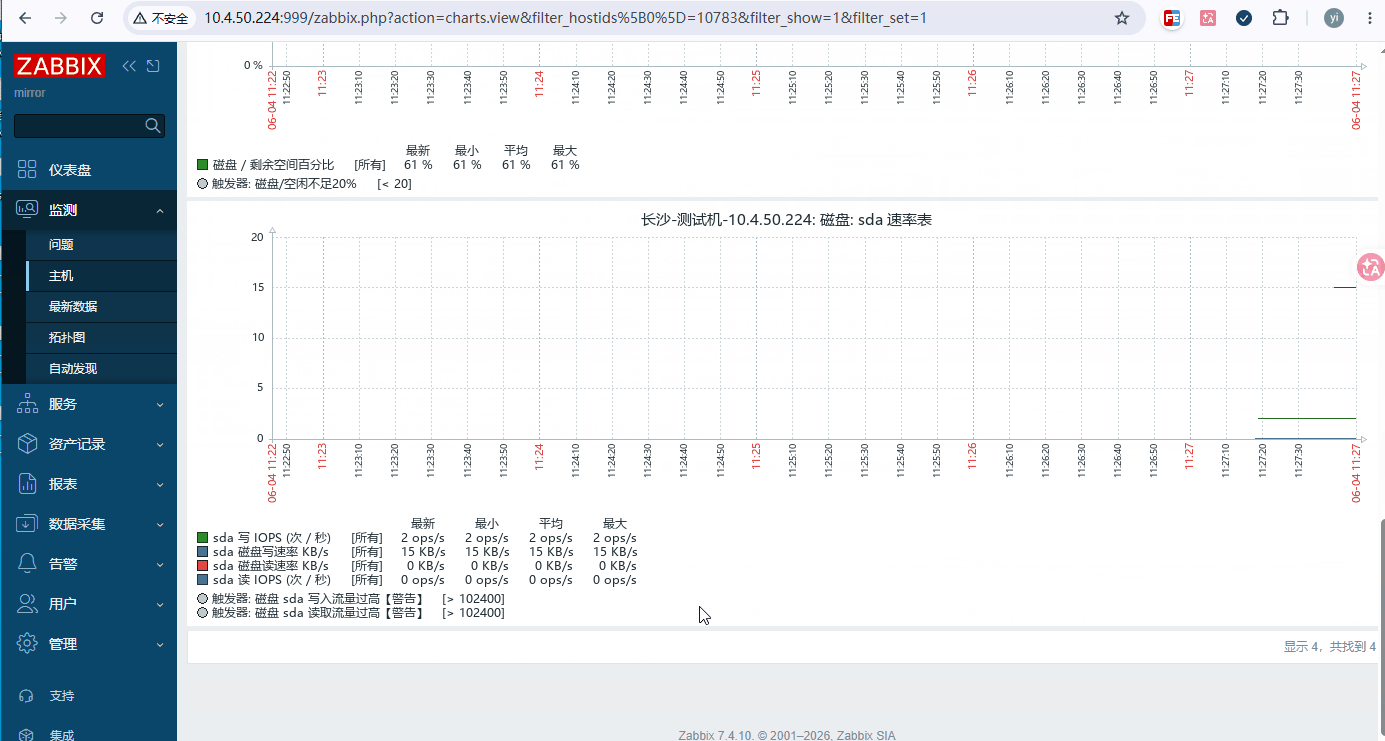
2.2.2、内存监控指标
-
核心指标
-
物理内存
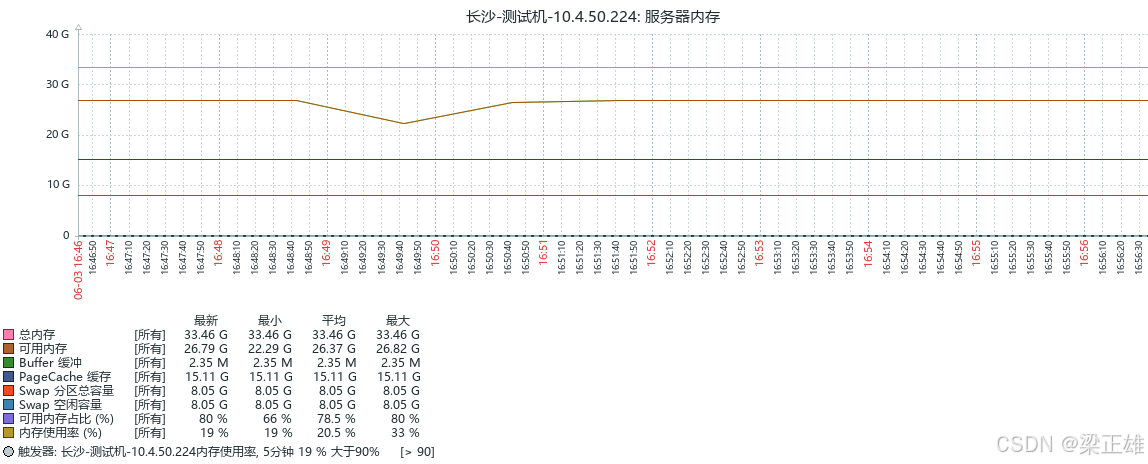
监控项 key 指标含义 告警阈值参考 vm.memory.sizetotal 总内存 基准值 vm.memory.sizeavailable 可用内存(系统真实剩余,最优告警依据) 剩余<10% 总内存告警 vm.memory.sizepavailable 可用内存百分比 - vm.memory.sizebuffers Buffer 缓冲 - vm.memory.sizecached PageCache 缓存 - -
swap内存
监控项 Key 指标说明 单位 告警参考 system.swap.size,total Swap 分区总容量 Byte 基准参考值 system.swap.size,free Swap 空闲容量 Byte - system.swap.size,used Swap 已使用容量 Byte - system.swap.size,pfree Swap 空闲占比 % - system.swap.size,pused Swap 已用占比 % Swap 使用率>30% 持续 10min 预警 -
自定义指标
-
可用内存占比
bash名称: 可用内存占比 (%) <-- 展示的名称 类型:可计算的 键键: mem.free.pct <--键值这里自定义 信息类型: 数字(无正负) 公式: 100 * last(//vm.memory.size[available]) / last(//vm.memory.size[total]) 单位: % -
内存使用率
bash名称: 可用内存占比 (%) <-- 展示的名称 类型:可计算的 键键: mem.used.pct 信息类型: 数字(无正负) 公式: 100 - 100 * last(//vm.memory.size[available]) / last(//vm.memory.size[total]) 单位: %
-
-
-
添加步骤: 数据采集 → 主机 → 要添加的主机 → 监控项 →监控器原形(添加八个)
-
添加列表
bash总内存 \ 可用内存 \ Buffer 缓冲 \ PageCache 缓存 \ Swap 分区总容量 \ Swap 空闲容量 可用内存占比 (%) \ 可用内存占比 (%)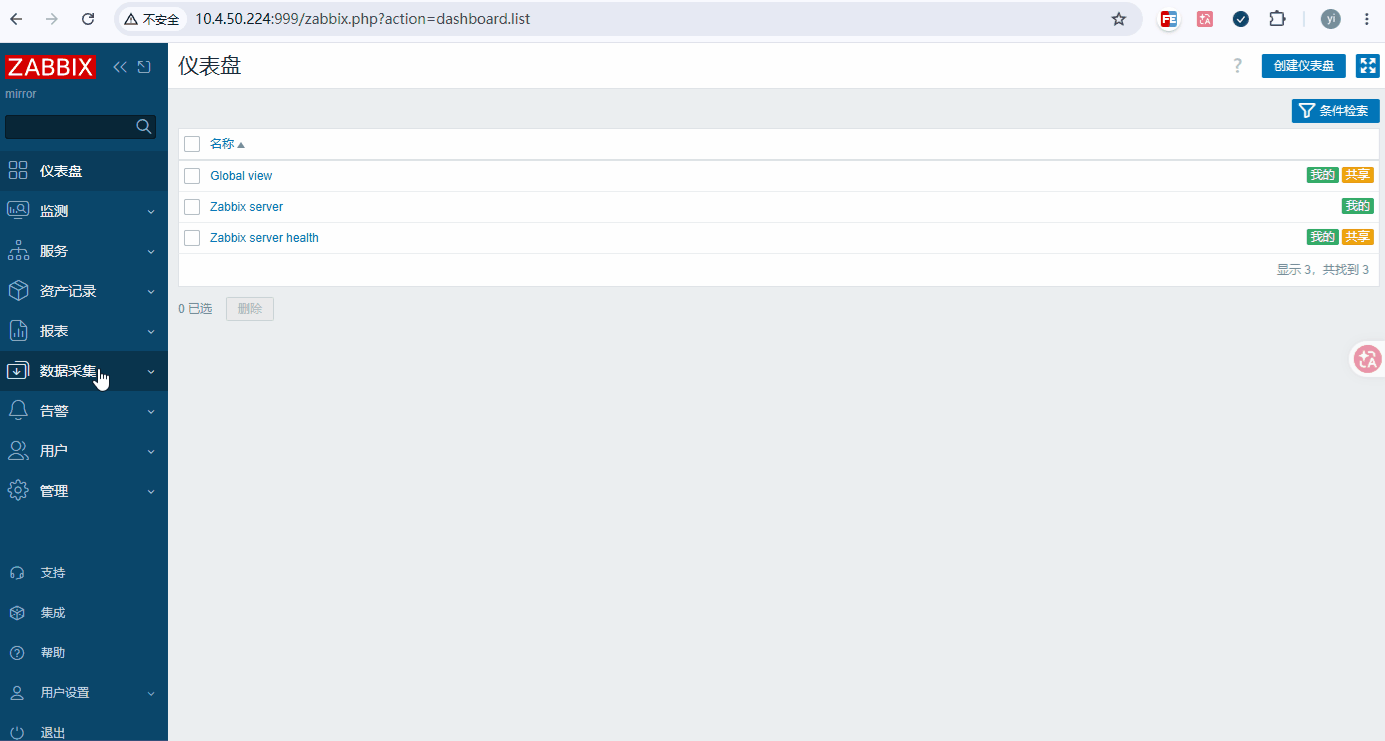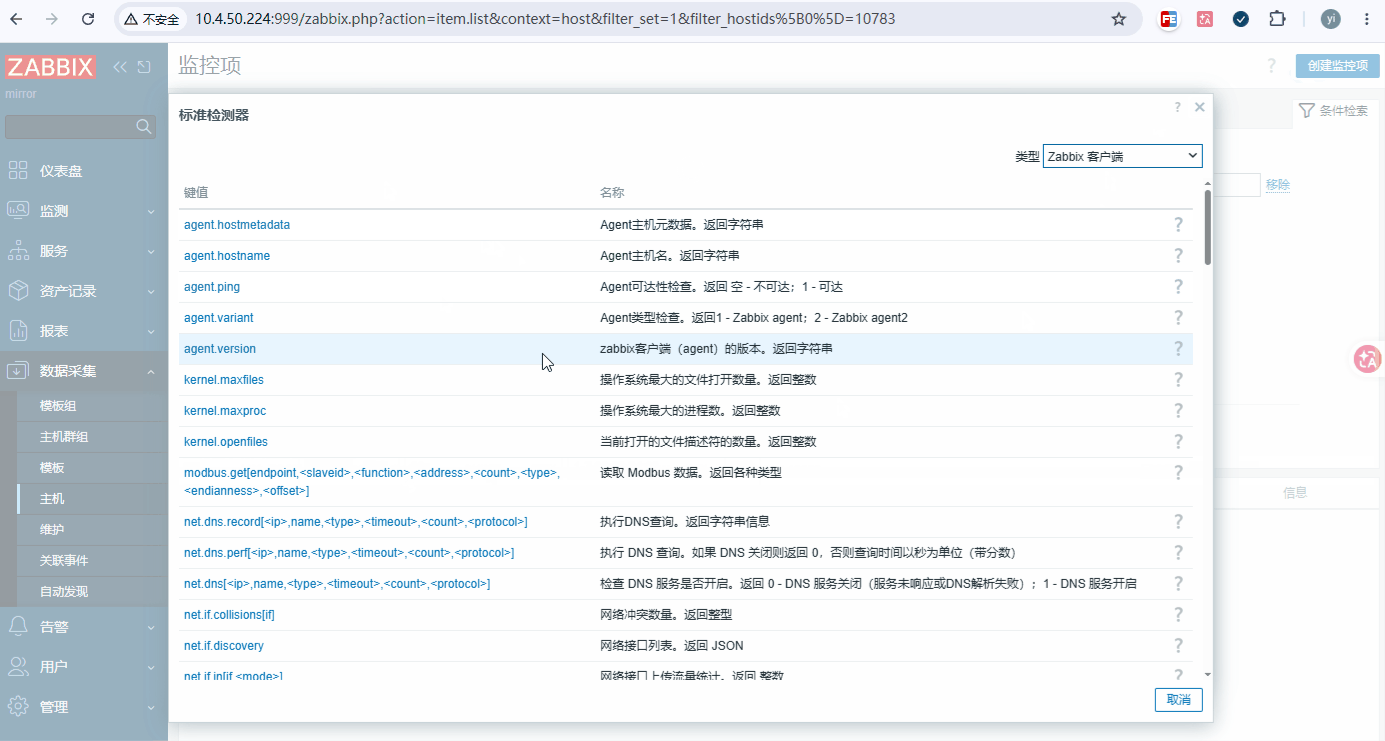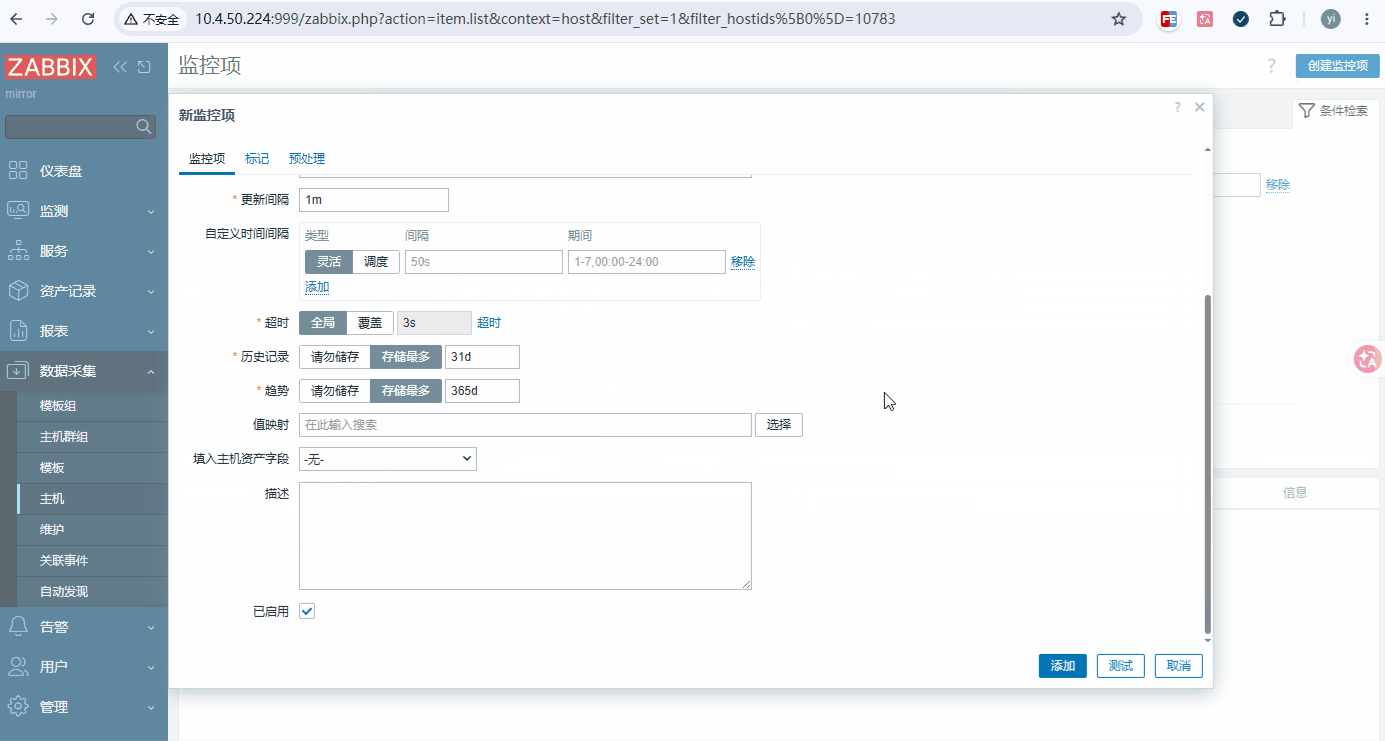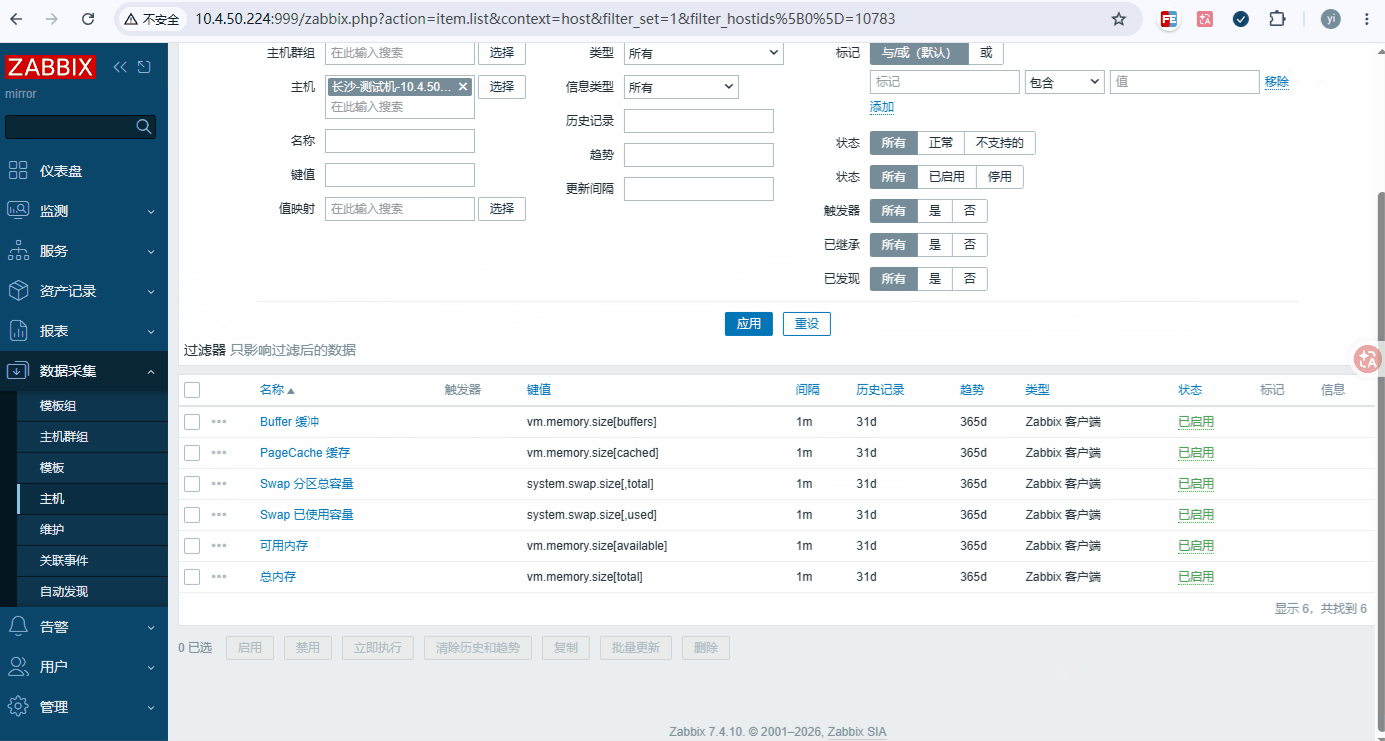
-
-
添加步骤: 数据采集 → 主机 → 要添加的主机 → 图形 → 创建图形
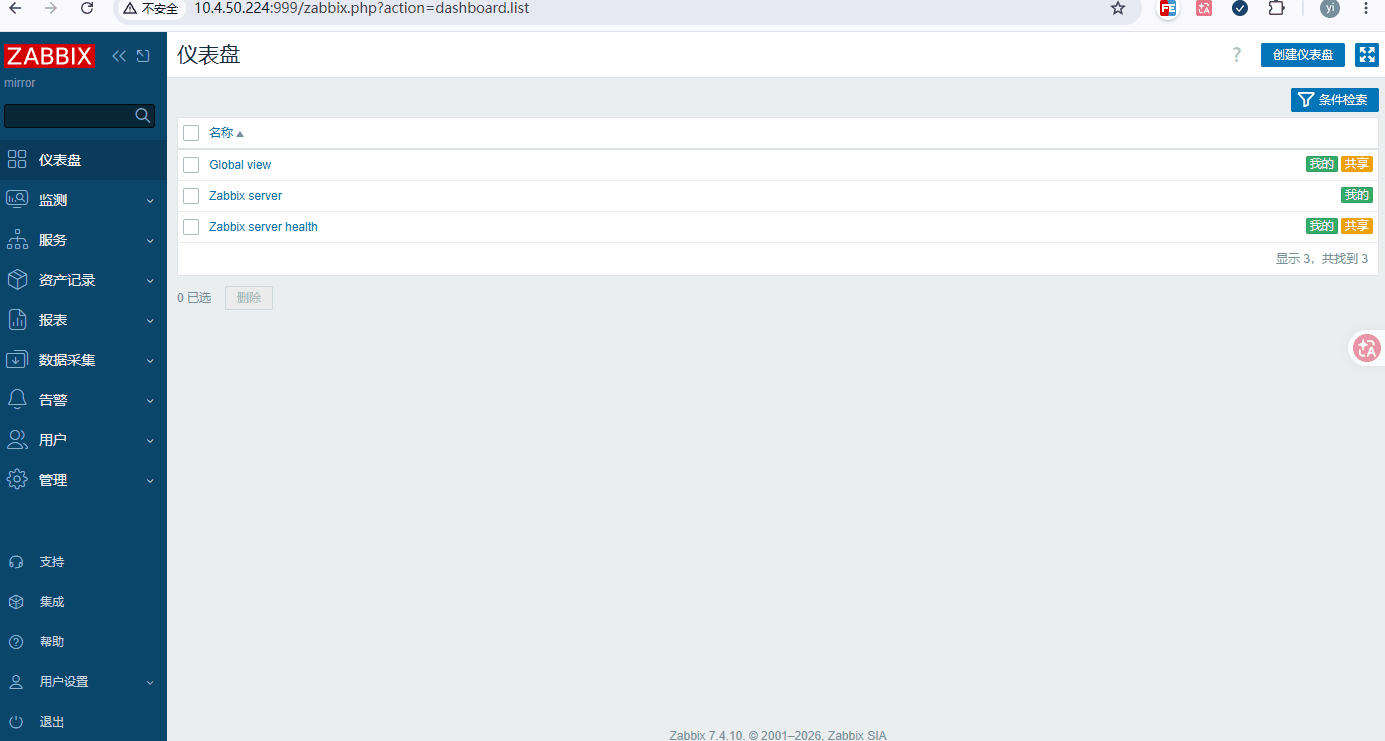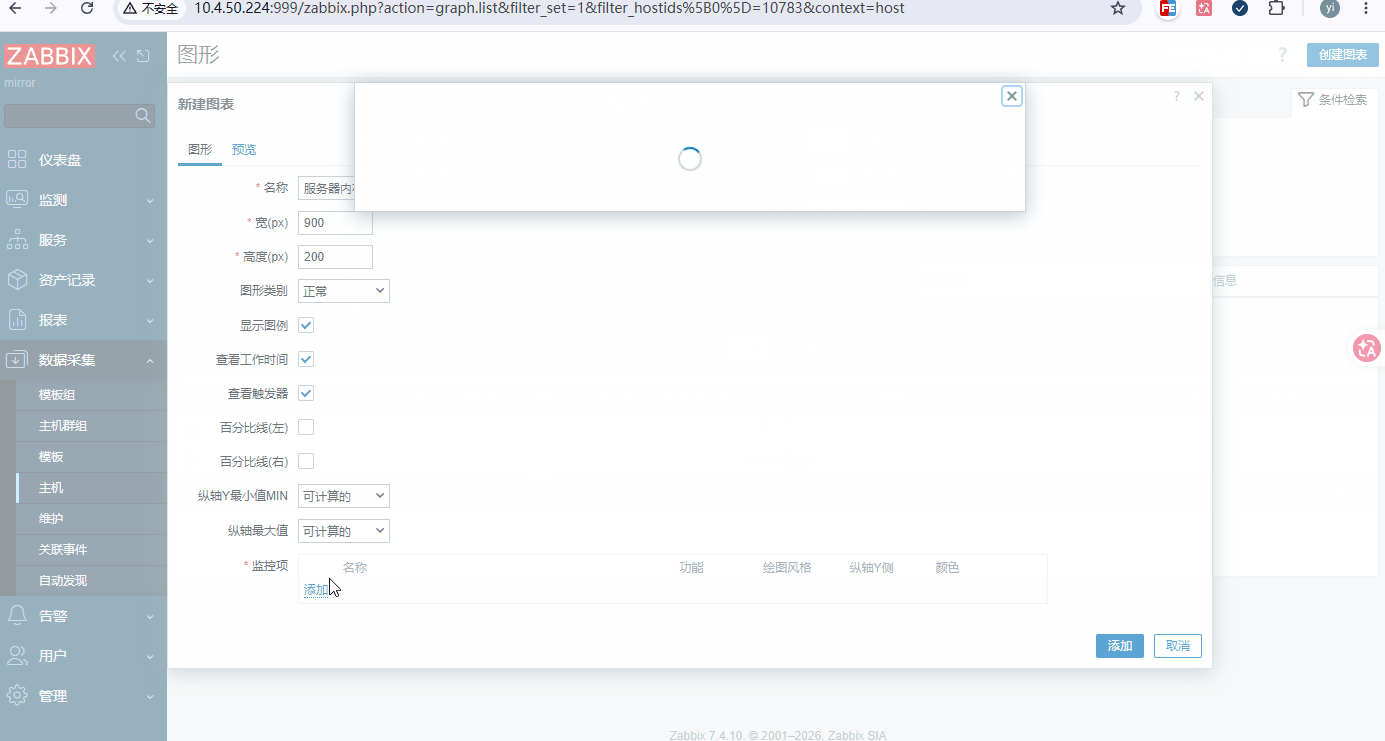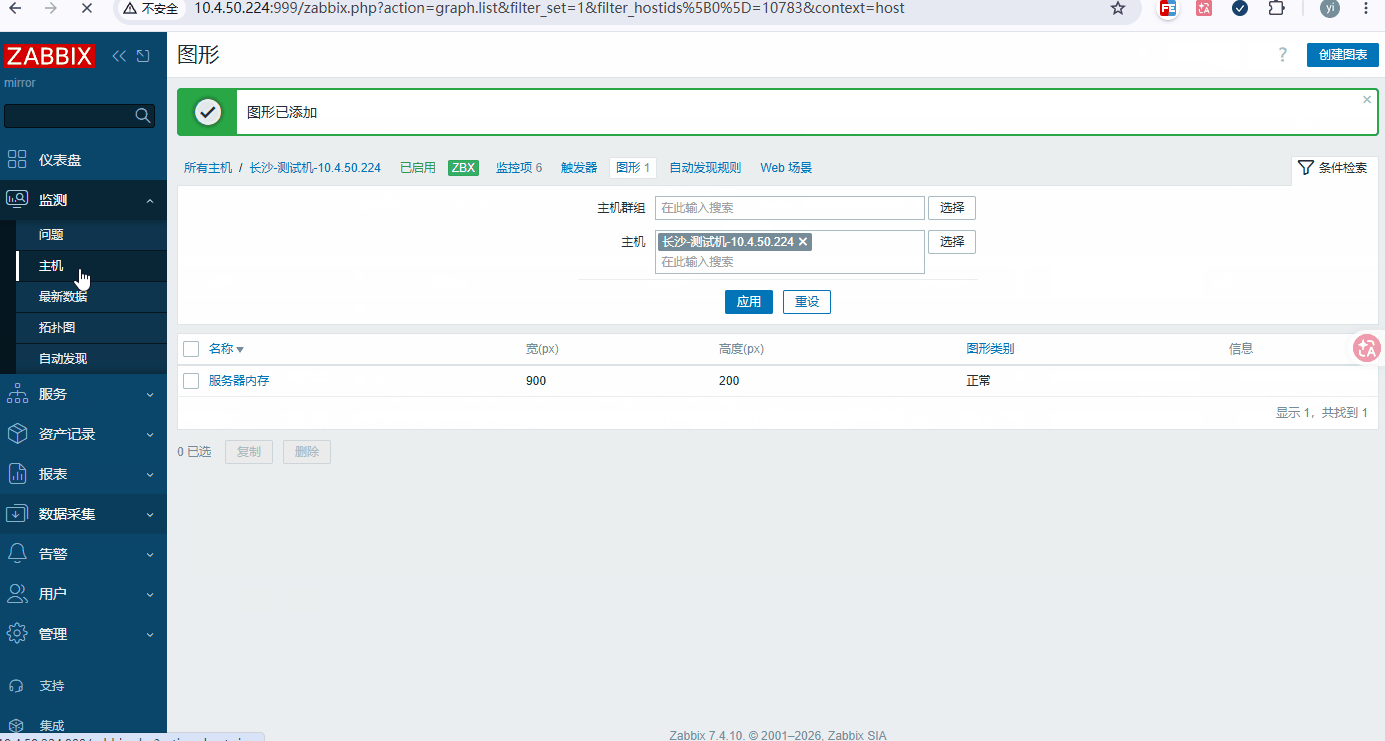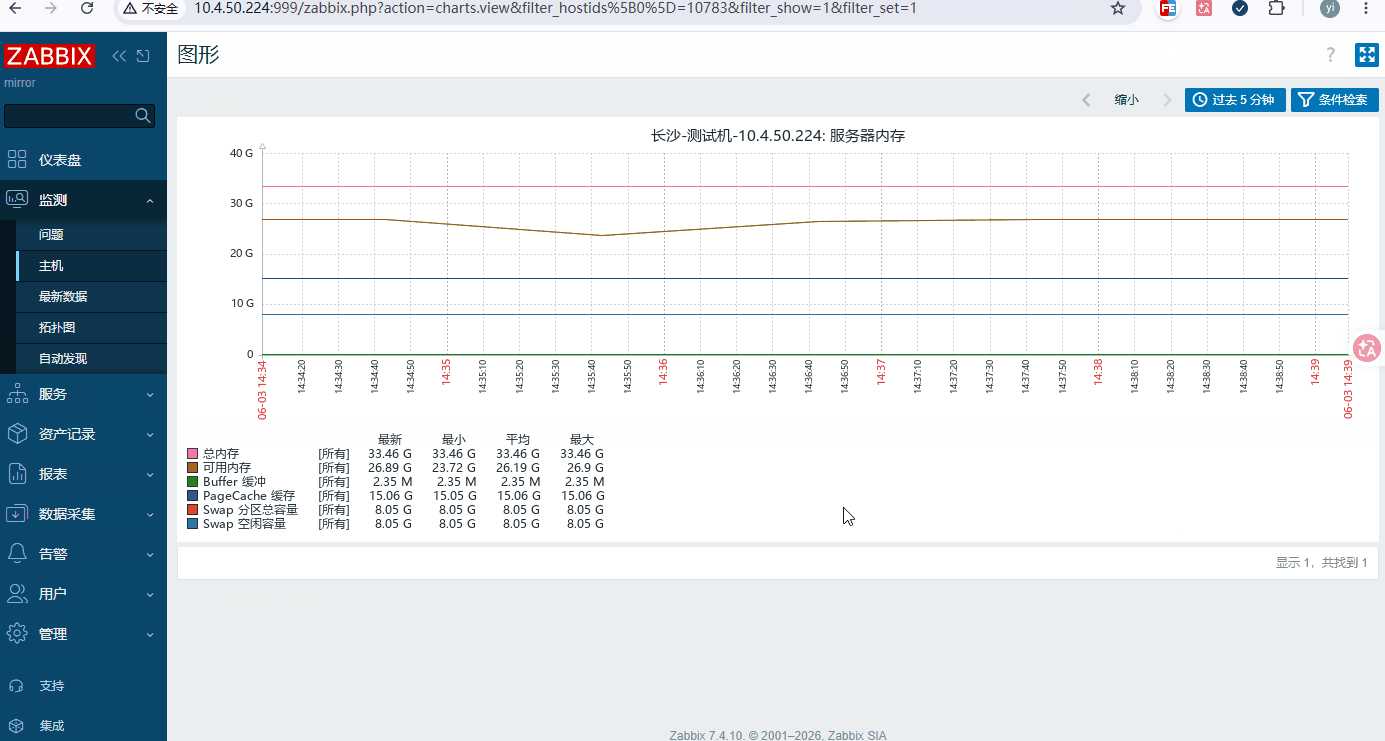
-
添加步骤: 数据采集 → 主机 → 要添加的主机 → 触发器 → 创建触发器
-
注意1:触发器需要手动点,下面的表达式仅示例, 都是 表达式 --> 添加 --> 选择原型 根据示例公式选
-
注意2: 必须要先添加监控项,才能定义触发器
-
注意3:触发器需要配合,钉钉、邮件、微信这种的进行推送
-
触发器 1:内存使用率>90% 持续 5 分钟 警告
bash名称: {HOST.NAME}内存偏高,近5分钟均值{ITEM.LASTVALUE1} 大于90% 表达式: avg(/地址或主机名/mem.used.pct,5m) > 90 -
触发器 2:内存>95% 持续 3 分钟 严重告警
bash名称: {HOST.NAME}内存偏高,近3分钟均值 {ITEM.LASTVALUE1} 大于95% 表达式: avg(/地址或主机名/mem.used.pct,3m) > 95 -
触发器 3:Swap>30% 持续 10 分钟预警
bash名称: {HOST.NAME}swap使用过高,近10分钟均值 {ITEM.LASTVALUE1} 表达式: avg(/地址或主机名/system.swap.size[,pused],10m) >30 -
触发器 4:可用内存百分比原生 key:
vm.memory.size[pavailable]bash名称: {HOST.NAME}内存使用率过高 {ITEM.LASTVALUE1} 剩余不足10% 表达式: avg(/地址或主机名/vm.memory.size[pavailable],5m) < 10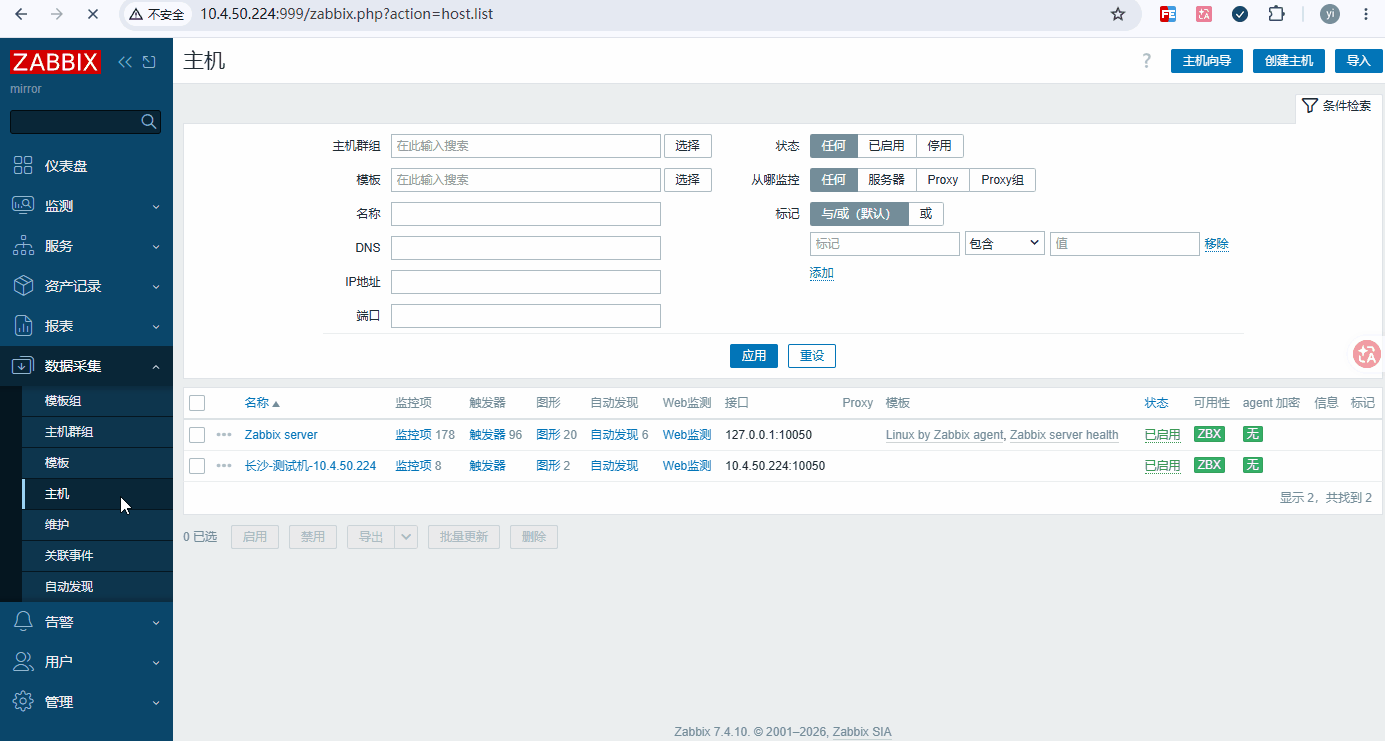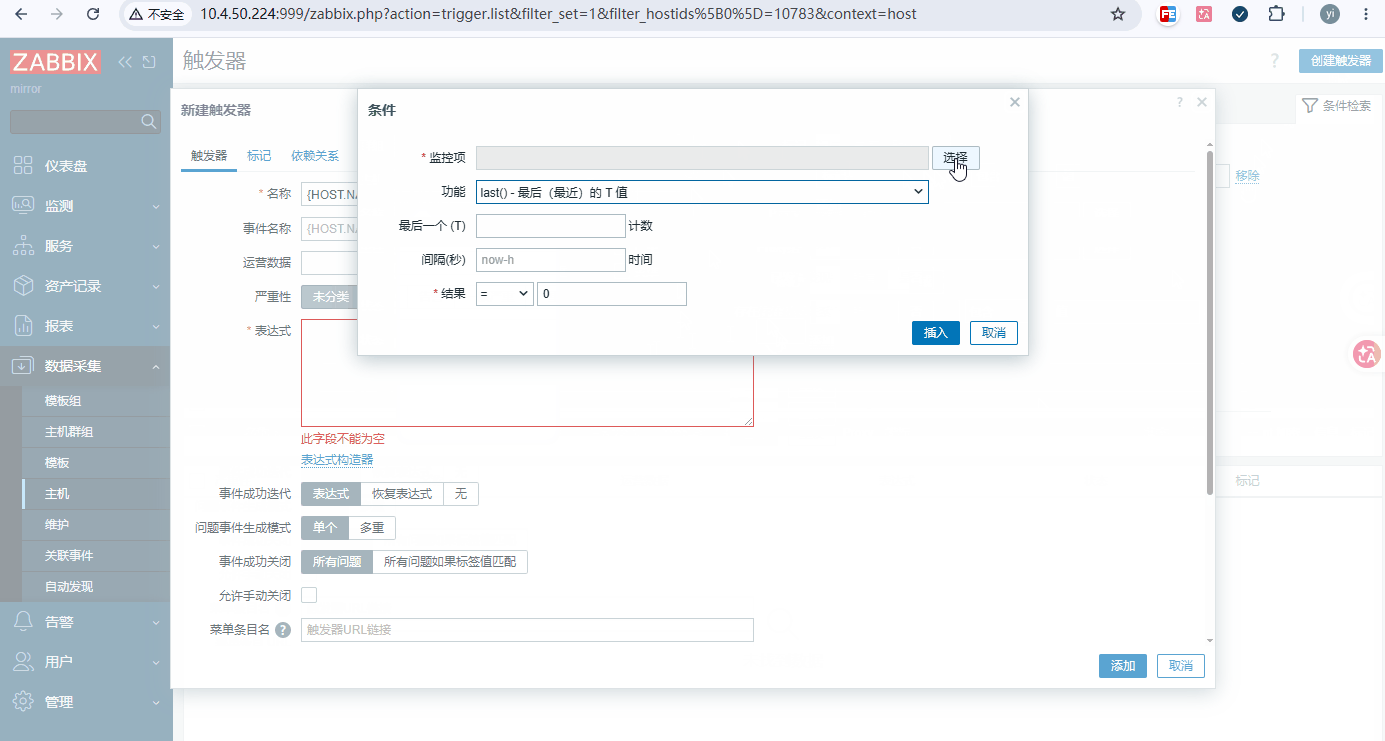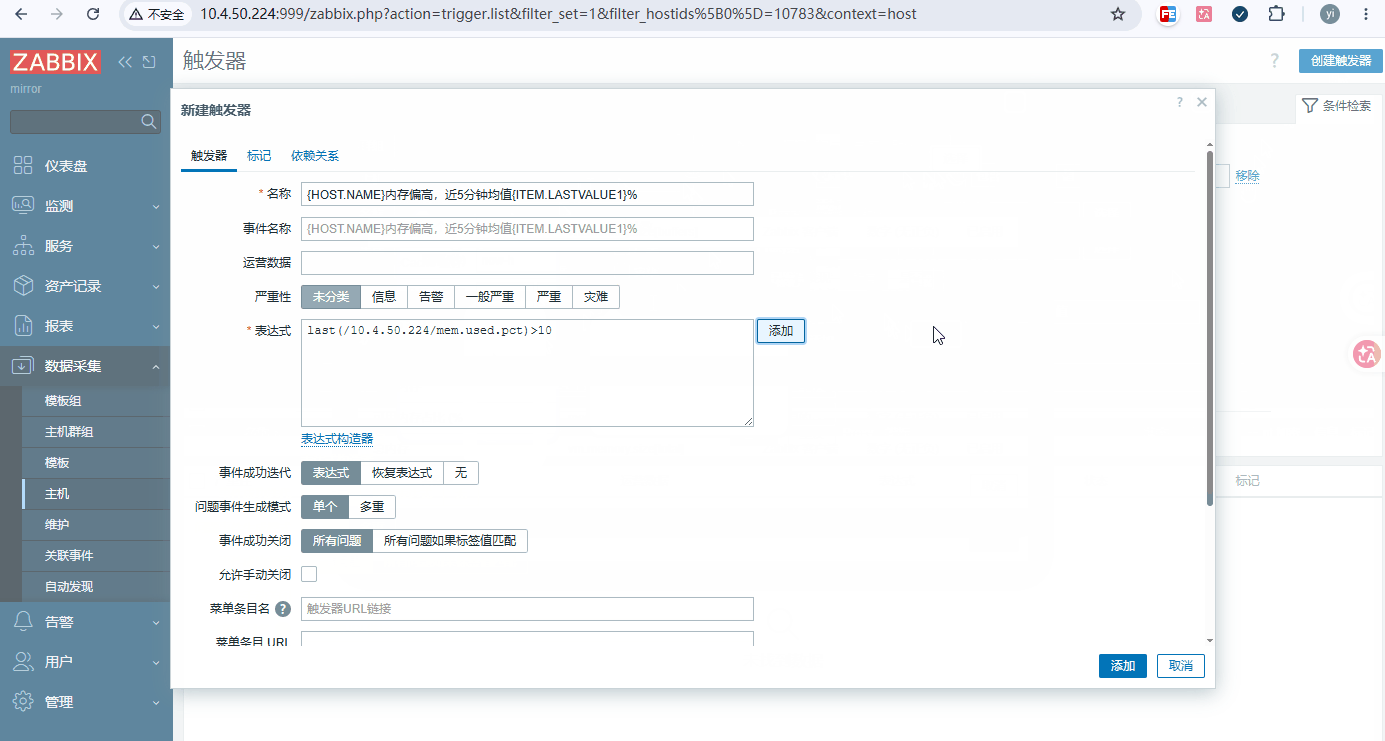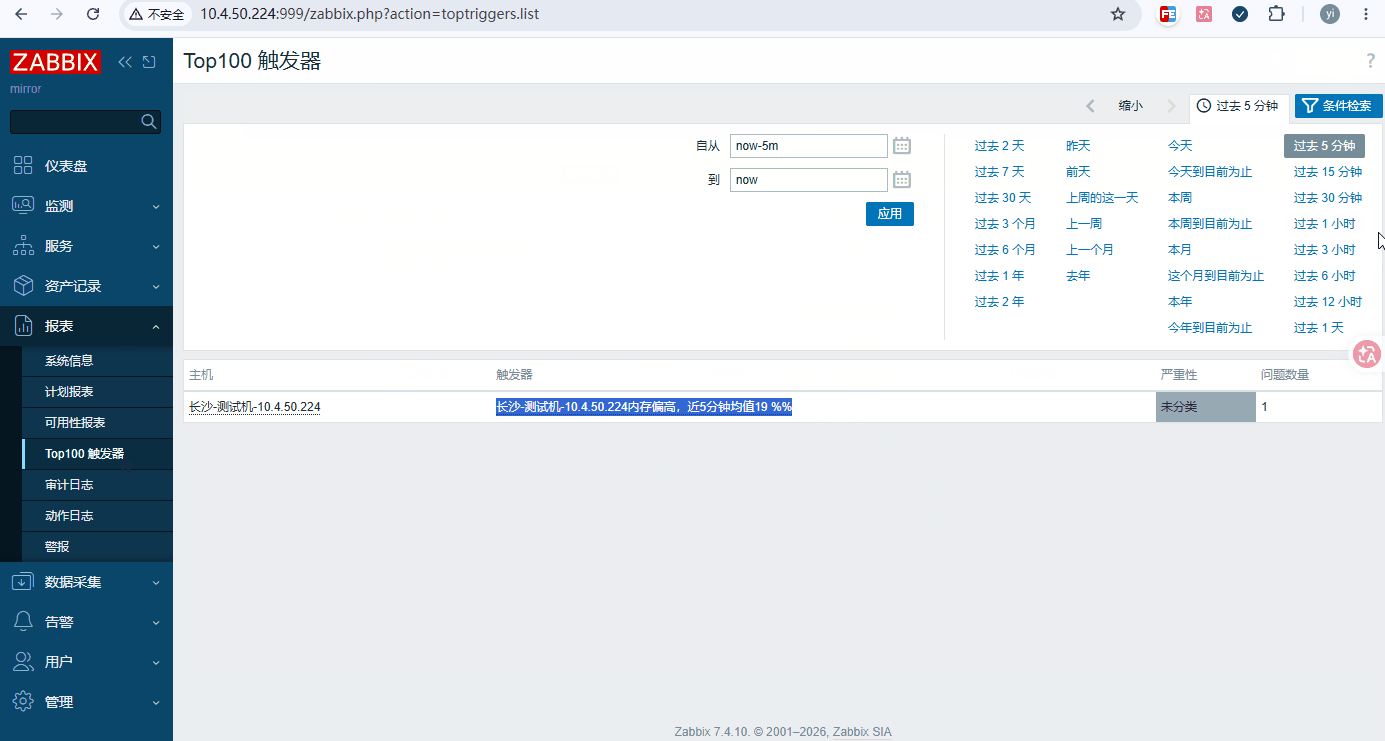
-
-
查看: 监测 → 主机 → 添加好的主机 → 图形
2.2.3、磁盘监控指标
-
核心指标
监控项 key 指标含义 告警阈值参考 vfs.fs.size/,total / 分区总容量 (B) 基准 vfs.fs.size/,free / 分区剩余容量 (B) - vfs.fs.size/,pfree / 剩余空间百分比 % 剩余<20% 警告;<10% 严重 vfs.fs.inode/,pfree inode剩余% 10% 告警 (小文件打满 inode) - 说明:磁盘不止一个分区,直接使用自动发现最靠谱
-
数据采集 → 主机 → 要添加的主机 → 自动发现 → 创建自动发现规则
bash# 菜单栏上第一列: 自动发现规则 名称: 磁盘分区发现 键值: vfs.fs.discovery 间隔: 1h # 菜单栏上第四列: 过滤器 计算方式: 和(同时满足) {#FSNAME} 不匹配 /boot {#FSNAME} 不匹配 /recovery {#FSNAME} 不匹配 ^/(sys|/dev|/run|/proc|.+shm)$ {#FSNAME} 不匹配 tmpfs {#FSTYPE} 匹配 @File systems for discovery {#FSTYPE} 不匹配 devtmpfs # 测试并添加 -
数据采集 → 主机 → 要添加的主机 → 自动发现 → 添加好的规则 →监控器原形
-
原型1 - 磁盘剩余空间百分比
bash名称: 磁盘 {#FSNAME} 剩余空间百分比 键键: vfs.fs.size[{#FSNAME},pfree] 间隔: 1m -
原型2 - 磁盘inode剩余空间百分比
bash名称: 磁盘 {#FSNAME} inode剩余空间百分比 键键: vfs.fs.inode[{#FSNAME},pfree] 间隔: 1m
-
-
数据采集 → 主机 → 要添加的主机 → 自动发现 → 添加好的规则 → 触发器类型 → 创建
-
触发器 1:磁盘剩余百分比
bash名称: 磁盘{#FSNAME}空闲不足20% 表达式: avg(/地址或主机名/vfs.fs.size[{#FSNAME},pfree],300)<20 -
触发器 2:磁盘inode剩余百分比
bash名称: 磁盘{#FSNAME} inode空闲不足10% 表达式: avg(/地址或主机名/vfs.fs.inode[{#FSNAME},pfree],300)<10
-
-
图片是gif录的,没法暂停以文档参考最佳
2.2.4、cpu监控指标
-
核心指标
-
CPU使用率
监控项 key 指标含义 生产告警阈值参考 system.cpu.util,user CPU使用率-用户态 (%) 单值>85% 持续 5min 预警 system.cpu.util,system CPU使用率-内核态 (%) 内核态>30% 持续偏高排查 IO system.cpu.util,idle CPU 空闲率 (%) 连续 5min<10% 资源耗尽告警 system.cpu.util,iowait CPU占比 IO 等待 (%) iowait>20% 持续 5min,磁盘瓶颈预警 -
自定义监控指标1
bash名称: CPU总使用率 类型:可计算的 键键: cpu.total.used.pct 信息类型: 数字(无正负) 公式: 100 - last(//system.cpu.util[,idle]) 单位: %
-
-
CPU负载
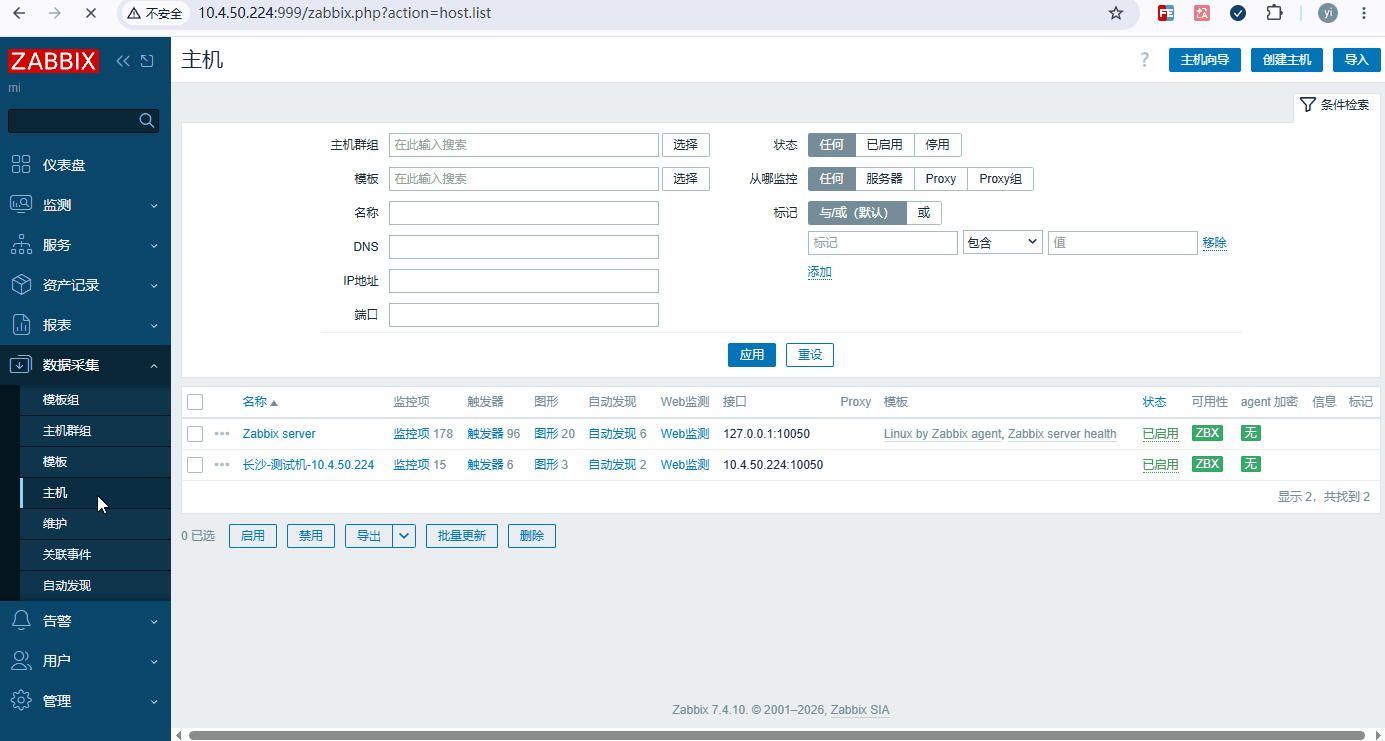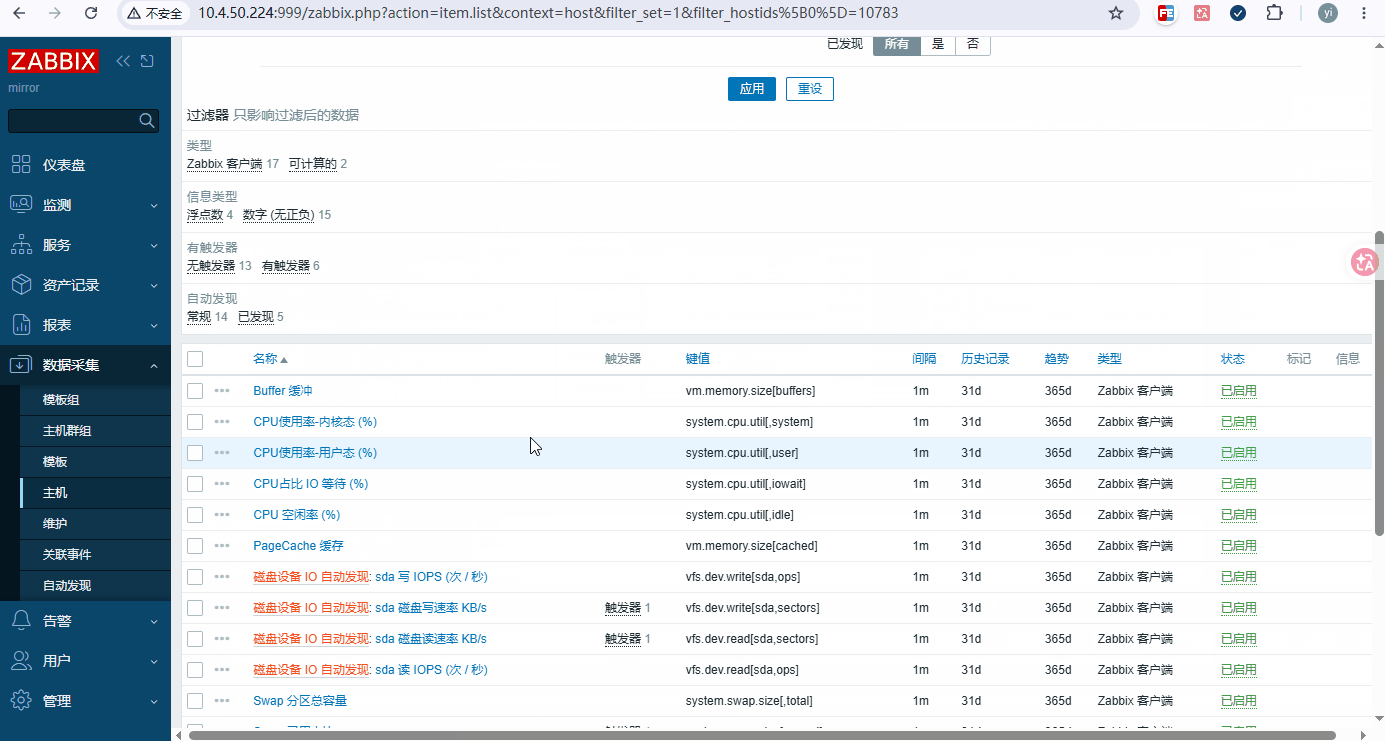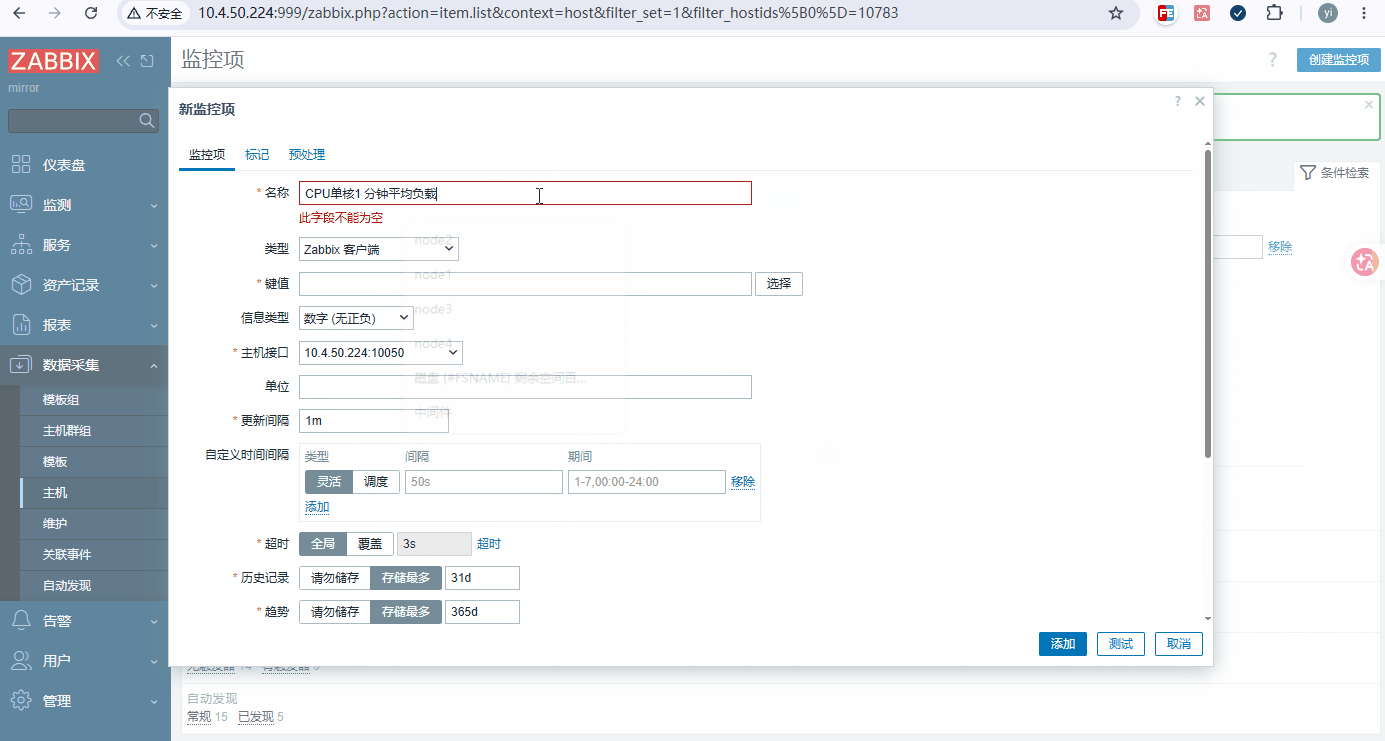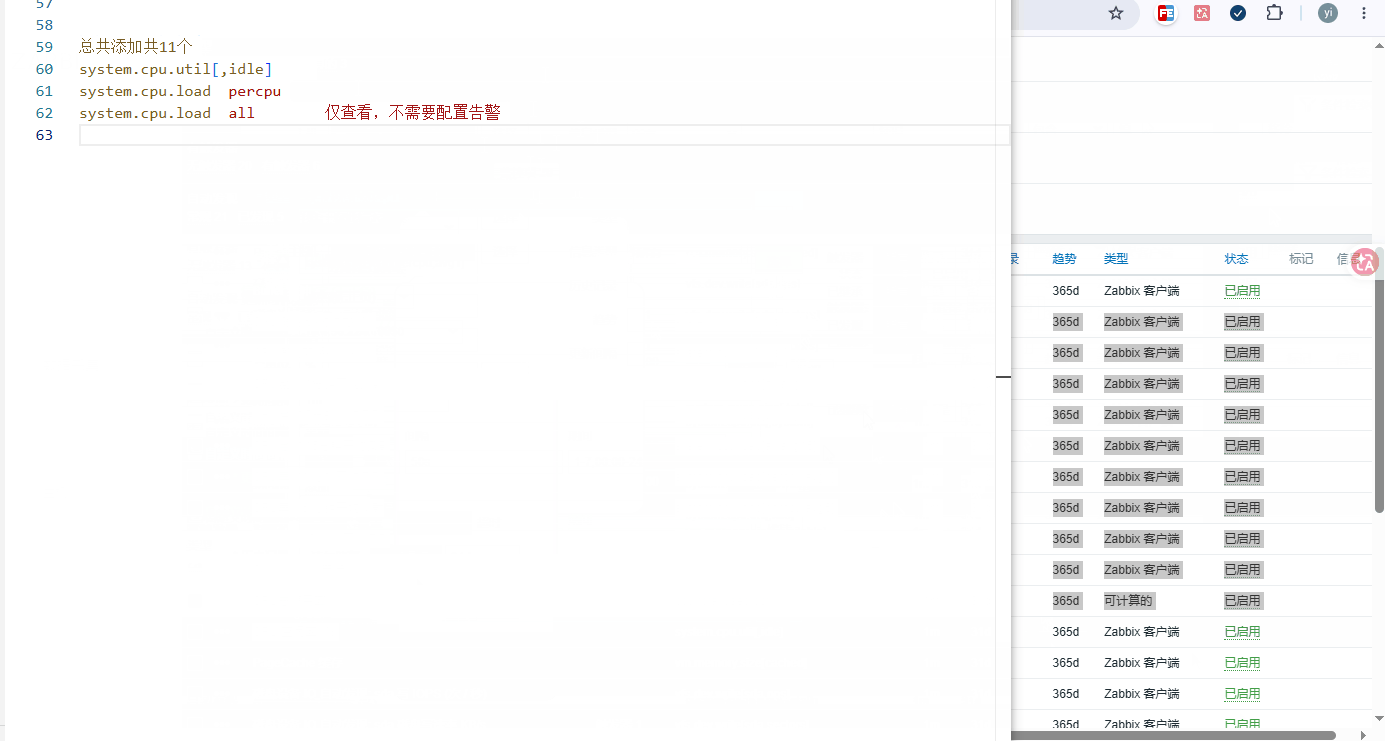
监控项 key 指标含义 生产告警阈值参考 system.cpu.loadpercpu,avg1 CPU单核1 分钟平均负载 连续 5min>0.8 警告 system.cpu.loadpercpu,avg5 CPU单核5 分钟平均负载 连续 5min>1.0 警告 system.cpu.loadpercpu,avg15 CPU单核15 分钟平均负载 连续 5min>1.0 严重 system.cpu.loadall,avg1 CPU全核 1分钟平均负载 仅查看,不配置告警 system.cpu.loadall,avg5 CPU全核 5分钟平均负载 仅查看,不配置告警 system.cpu.loadall,avg15 CPU全核 15分钟平均负载 仅查看,不配置告警 -
注意
指标 含义 适用场景 告警写法 all,avg1 整机总负载 统计查看 不推荐用于告警 percpu,avg1 单核心平均负载 生产监控、告警 >0.8通用所有机器 -
两个指标的精准区别
-
system.cpu.loadall,avg1
- 含义:整个系统所有 CPU 核心的总负载值(不区分核心数)
- 例子:服务器有 4 核 CPU,1 分钟总负载 = 8 → 这个值就是 8
- 问题:无法直接判断服务器压力
- 4 核负载 8 = 压力拉满
- 16 核负载 8 = 服务器很轻松
-
system.cpu.loadpercpu,avg1 推荐使用
-
含义 :平均每个 CPU 核心的负载值(标准化指标)
-
例子:
- 4 核 CPU,总负载 8 →
percpu= 8/4 = 2.0 - 16 核 CPU,总负载 8 →
percpu= 8/16 = 0.5
- 4 核 CPU,总负载 8 →
-
优势: 不管服务器是 1 核、8 核、32 核,数值标准完全统一
- 0~0.7:轻松
- 0.8~1.0:警戒
- 1.0:繁忙 / 过载
-
-
-
-
-
添加步骤: 数据采集 → 主机 → 要添加的主机 → 监控项 →监控器原形(添加11个)
-
添加列表: 需要全部添加
-
-
添加步骤: 数据采集 → 主机 → 要添加的主机 → 触发器 → 创建触发器
-
注意1:触发器需要手动点,下面的表达式仅示例, 都是 表达式 --> 添加 --> 选择原型 根据示例公式选
-
注意2: 必须要先添加监控项,才能定义触发器
-
注意3:触发器需要配合,钉钉、邮件、微信这种的进行推送
-
指标预警定义
-
CPU 使用率区间划分
- user 用户态:业务程序占用 CPU,日常大多在 70 以内;70~85 业务负载偏高关注,超 85 持续 5 分钟告警。
- system 内核态:磁盘读写、系统调用占用,正常<15;15~30 大概率 IO 异常,>30 持续 5min 排查磁盘 / 内核故障。
- iowait:磁盘等待阻塞 CPU,正常 5 以内,5~20 轻微 IO 压力,>20 代表磁盘性能瓶颈。
- idle: 空闲小于30正常, 20~30有点压力,生产跑到90%都正常,95%预警就行
-
负载 percpu 分级
监控项 key 指标含义 正常 偏紧 告警 (5min 持续) system.cpu.loadpercpu,avg1 单核 1min 负载 <0.7 0.7~0.8 >0.8 警告 system.cpu.loadpercpu,avg5 单核 5min 负载 <0.8 0.8~1.0 >1.0 警告 system.cpu.loadpercpu,avg15 单核 15min 负载 <0.8 0.8~1.0 >1.0 严重告警
-
-
触发器 1:CPU 空闲率
bash名称: {HOST.NAME}CPU使用率偏高,近5分钟均值{ITEM.LASTVALUE1} 大于95% 表达式: avg(/地址或主机名/cpu.total.used.pct,300)>95 -
触发器 2:CPU 用户态持续过高
bash名称: {HOST.NAME}CPU用户态使用率偏高,近5分钟均值{ITEM.LASTVALUE1} 大于95% 表达式: avg(/地址或主机名/system.cpu.util[,user],300)>95 -
触发器 3:CPU内核态过高(磁盘/内核异常)
bash名称: {HOST.NAME}CPU内核态 使用率偏高,近5分钟均值{ITEM.LASTVALUE1} 说明,15~30 大概率 IO 异常,>30 持续 5min 排查磁盘/内核故障 表达式: avg(/地址或主机名/system.cpu.util[,system],300)>30 -
触发器 4:CPU IO 等待过高
bash名称: {HOST.NAME}CPU IO 等待过高{ITEM.LASTVALUE1} 说明:5~20 轻微 IO 压力,>20磁盘性能瓶颈 表达式: avg(/地址或主机名/system.cpu.util[,iowait],300)>20 iowait 是 CPU 等待 IO 的百分比: >20% 持续 5~10 分钟:警告告警 >30% 持续 10 分钟:严重告警(磁盘卡死、业务极卡) >80%:几乎不会出现,真出现系统已经挂了 -
触发器 5-7:CPU 分钟负载过高(警告)
bash名称: {HOST.NAME}CPU 1 分钟单核负载,近5分钟均值{ITEM.LASTVALUE1} 表达式: avg(/地址或主机名/system.cpu.load[percpu,avg1],300) > 0.8 名称: {HOST.NAME}CPU 5 分钟单核负载,近5分钟均值{ITEM.LASTVALUE1} 表达式: avg(/地址或主机名/system.cpu.load[percpu,avg5],300) > 0.8 名称: {HOST.NAME}CPU 15 分钟单核负载,近5分钟均值{ITEM.LASTVALUE1} 表达式: avg(/地址或主机名/system.cpu.load[percpu,avg15],300) > 0.8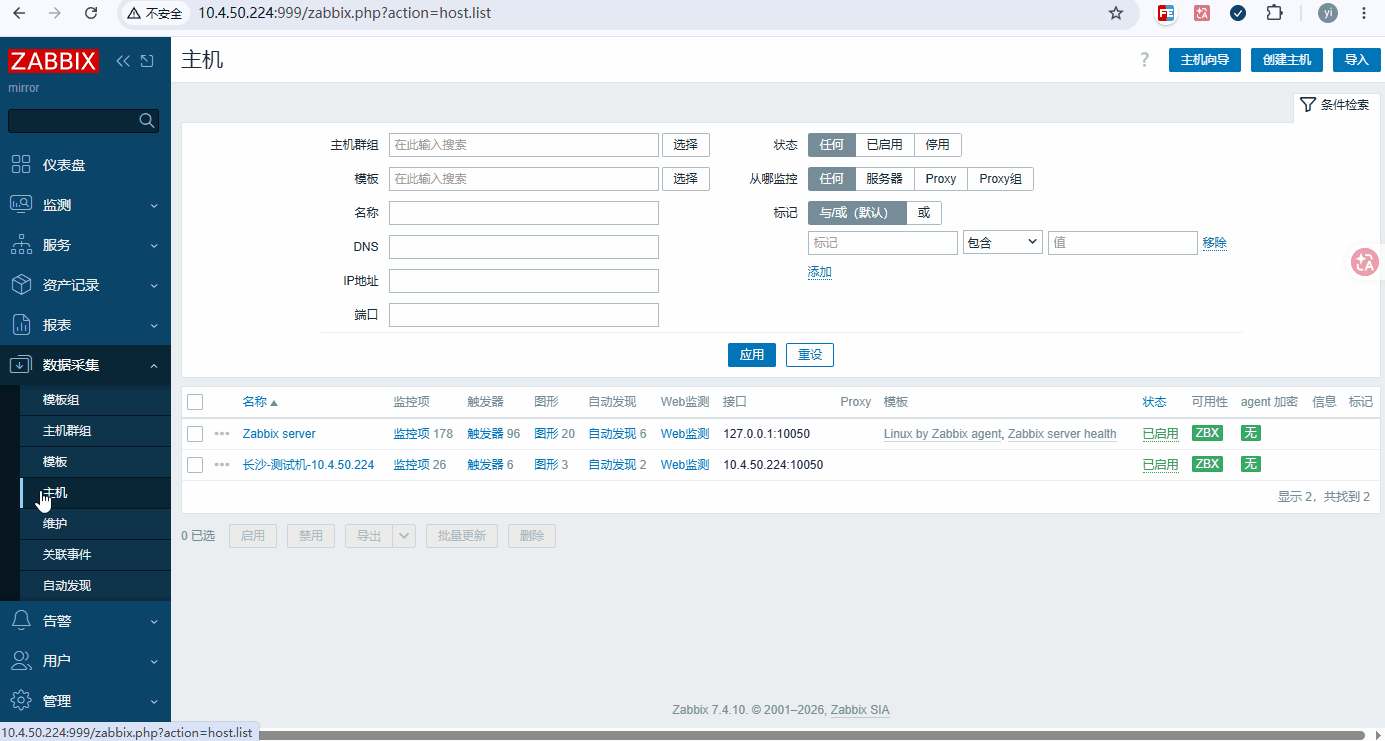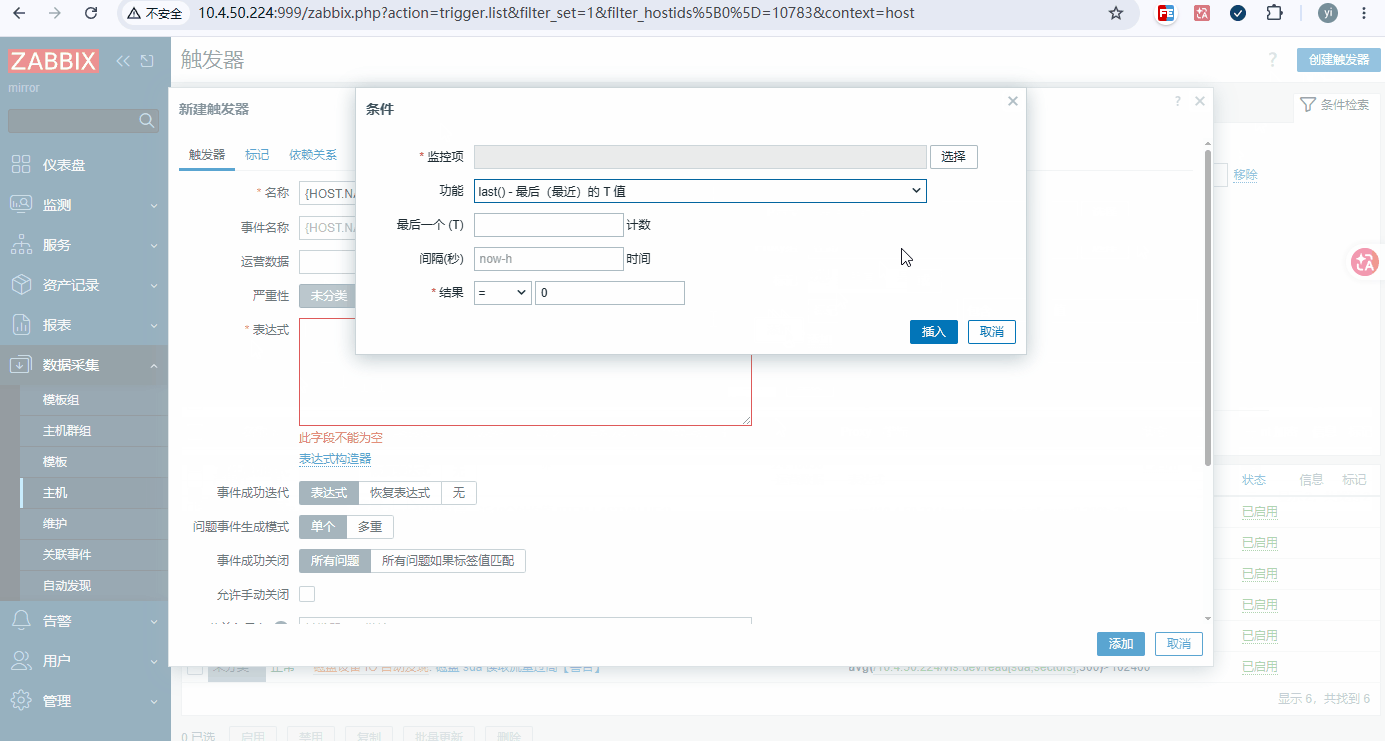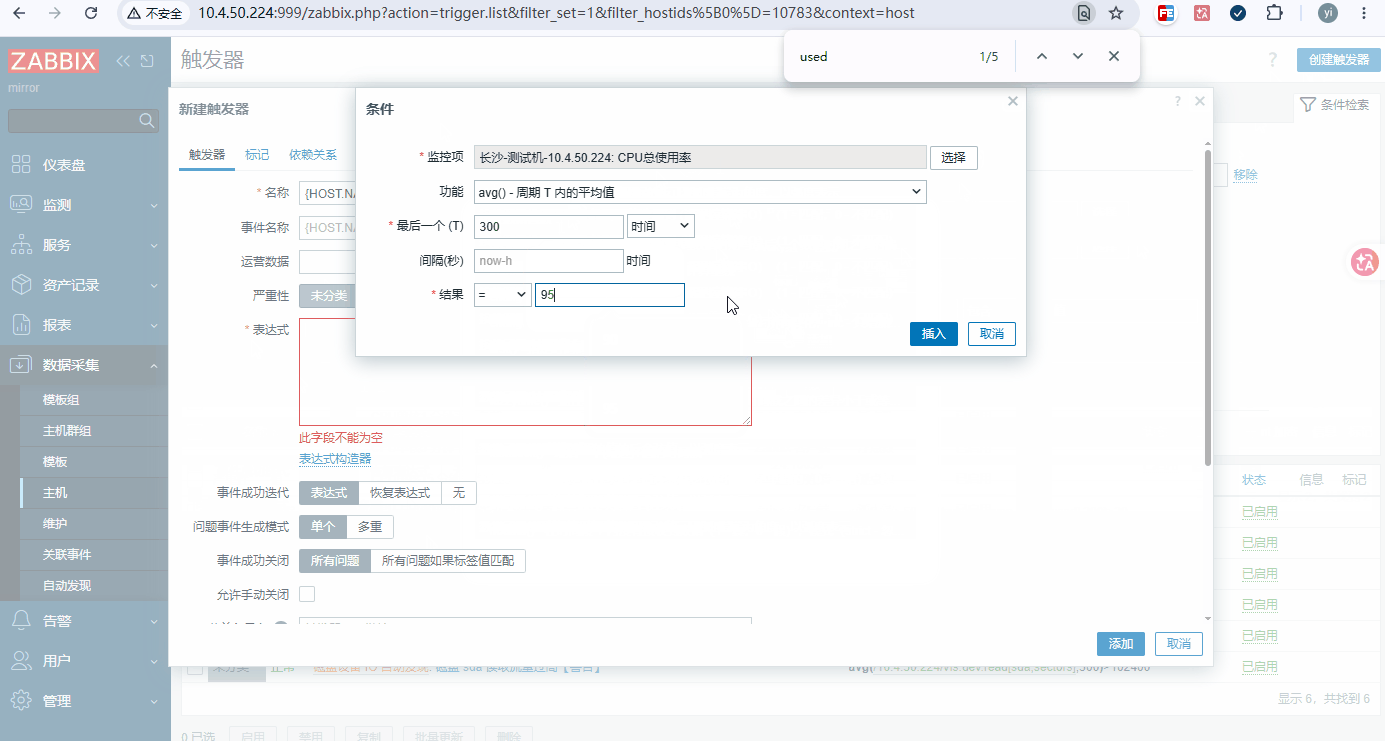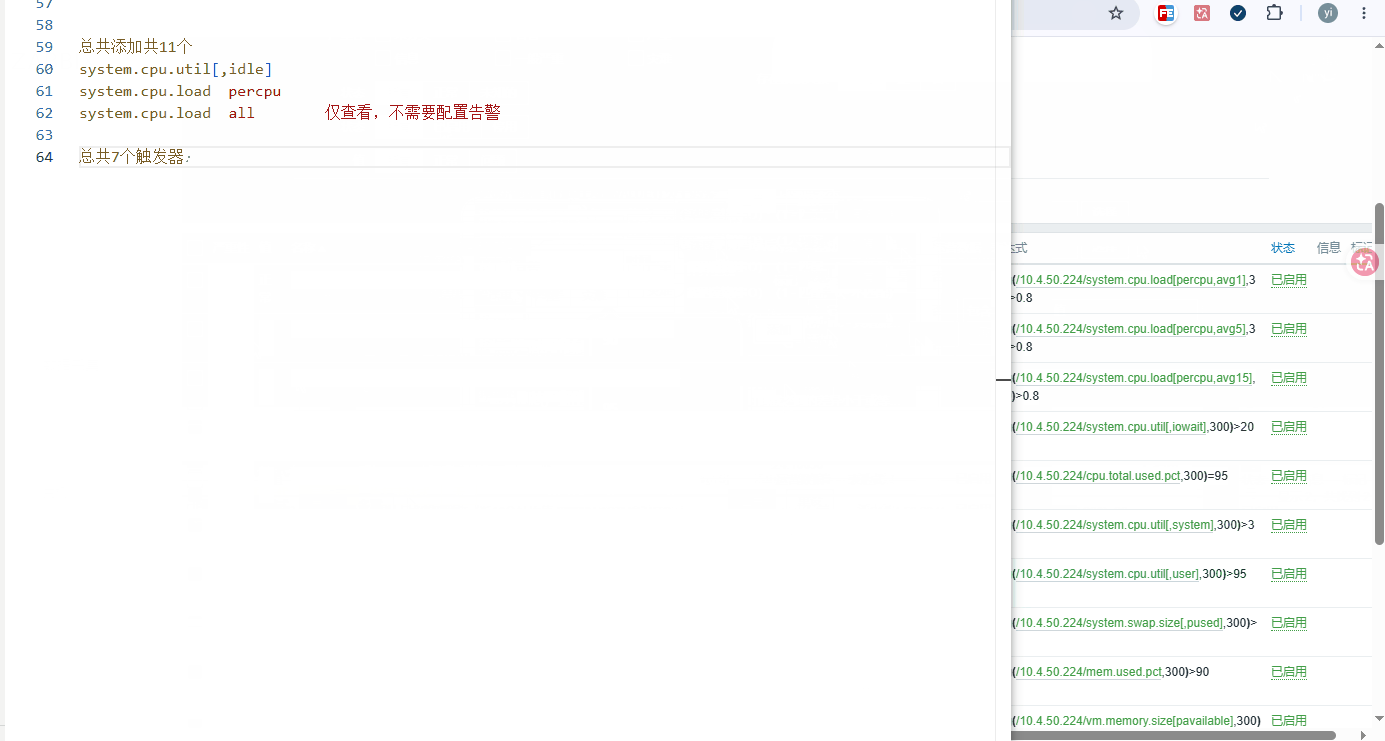
-
-
添加步骤: 数据采集 → 主机 → 要添加的主机 → 图形 → 创建图形
-
添加说明
bash名称: CPU使用率 监控项: 添加所有关于cpu的项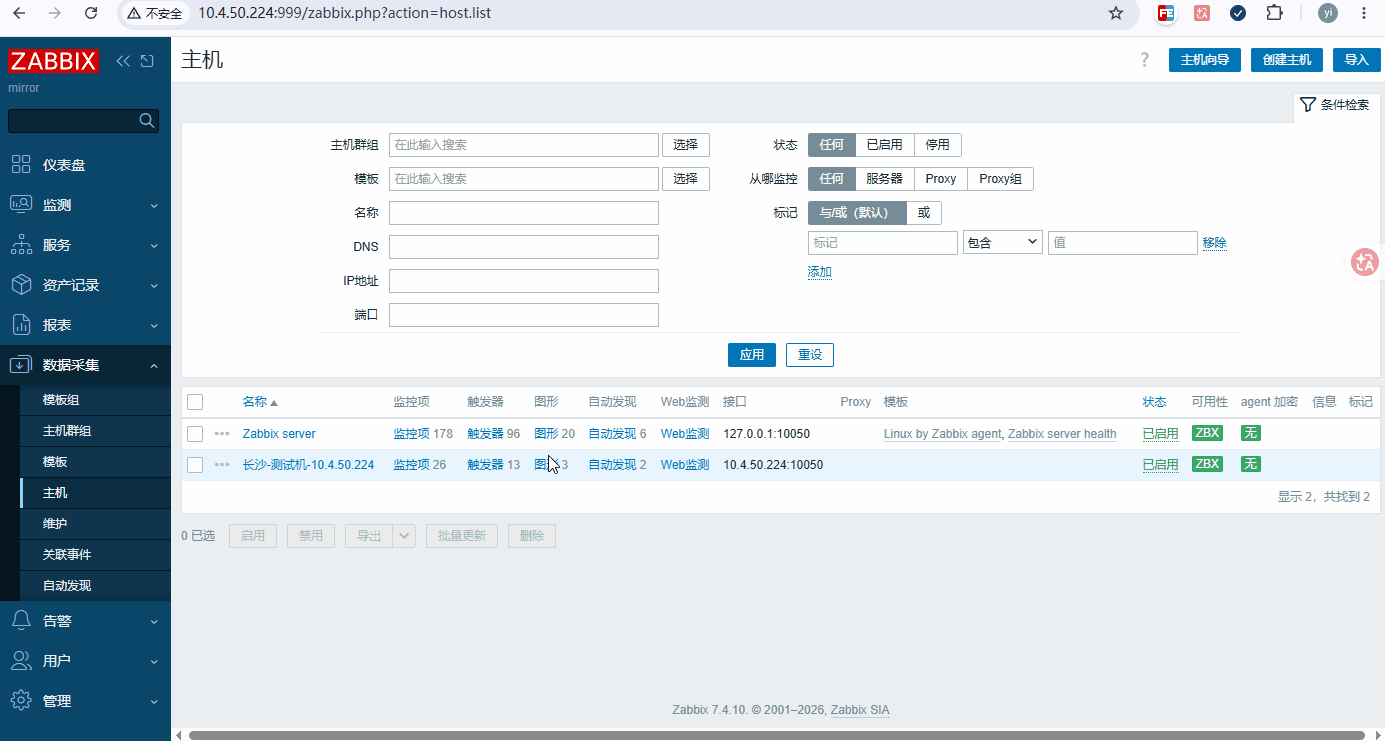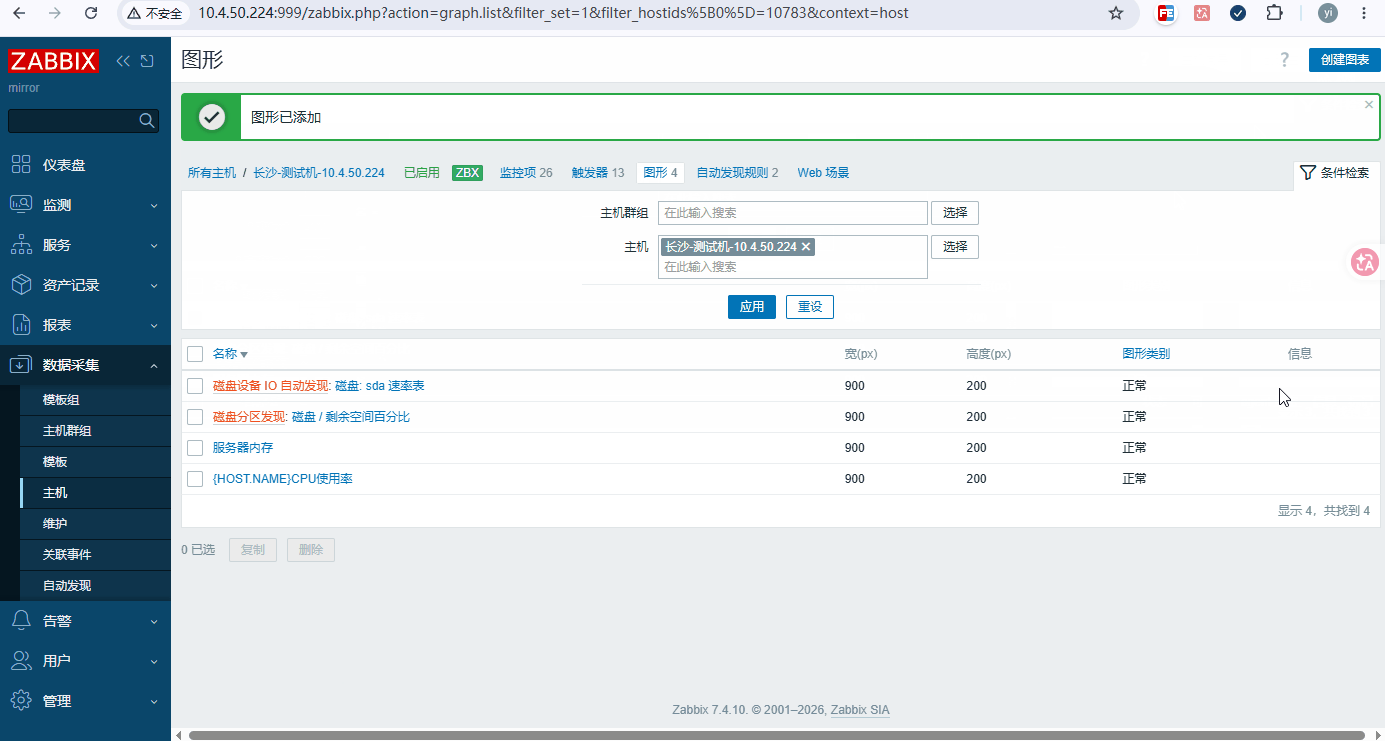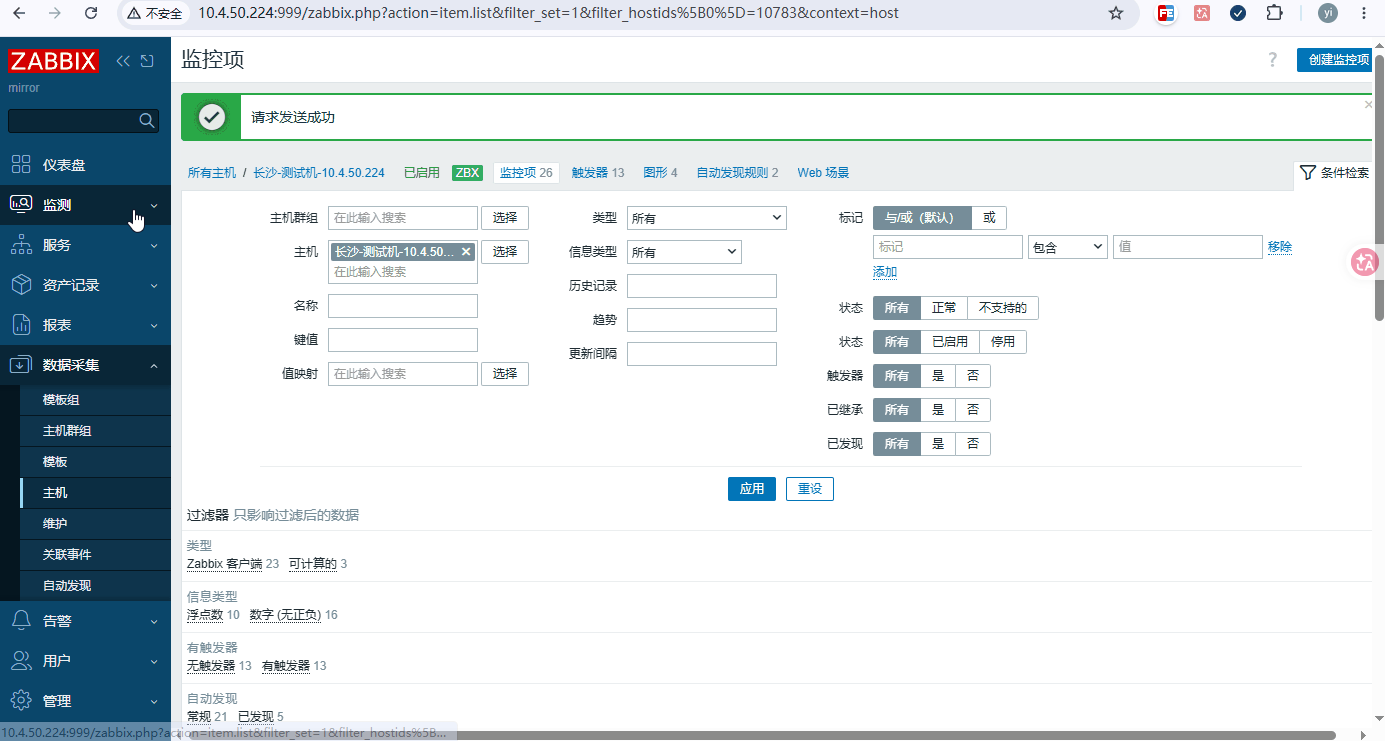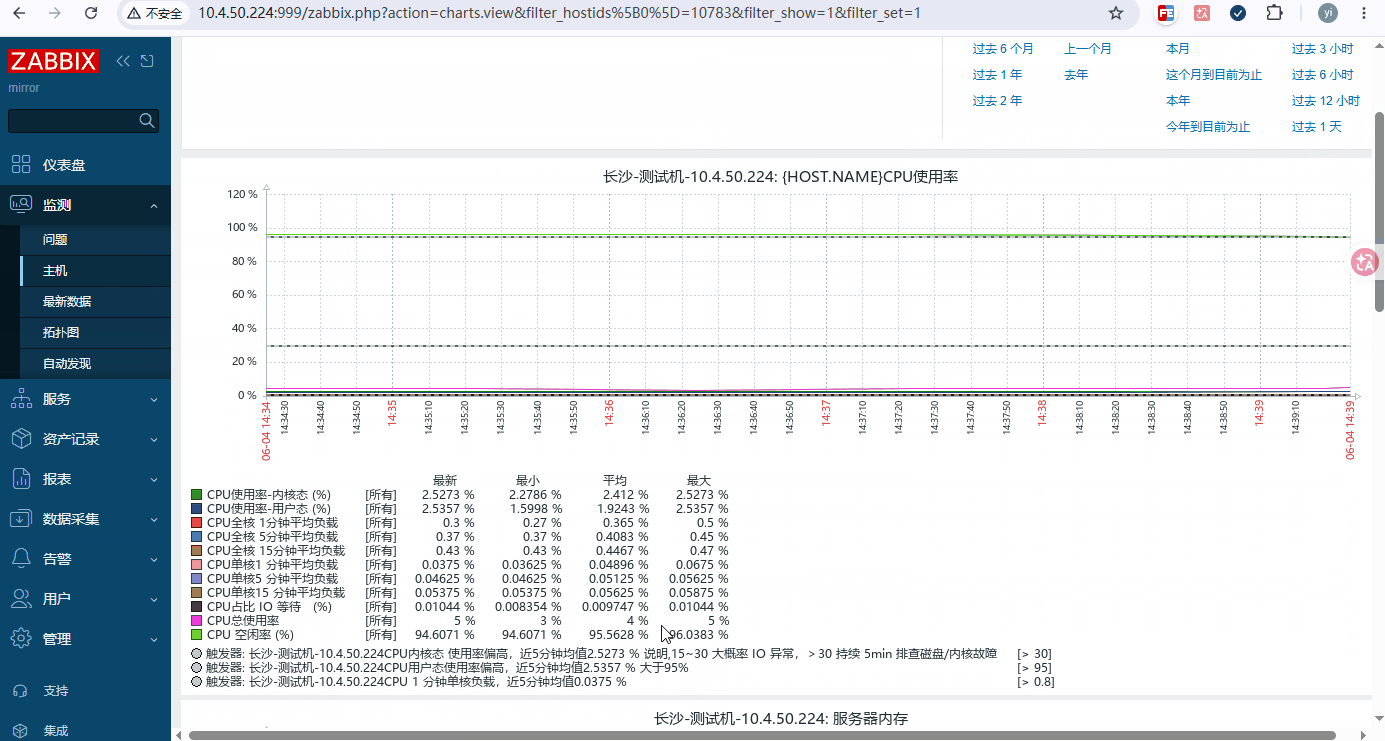
-
三、可计算类型
3.1、公式语法
-
简单公式语法
bashfunction(/host/key,<parameter1>,<parameter2>,...)-
参数说明
function 支持的函数 之一:last、min、max、avg、count 等 host 用于计算的监控项的主机。 可以省略当前主机(即 function(//key,parameter,...))。key 用于计算的监控项的 key。 参数 函数的参数(如果需要)。 -
函数
函数 作用 last() 取最新 1 个值 avg(xxx,5m) 取近 5 分钟平均值(防毛刺首选) max/min 周期最大 / 最小值
-
3.2、示例
-
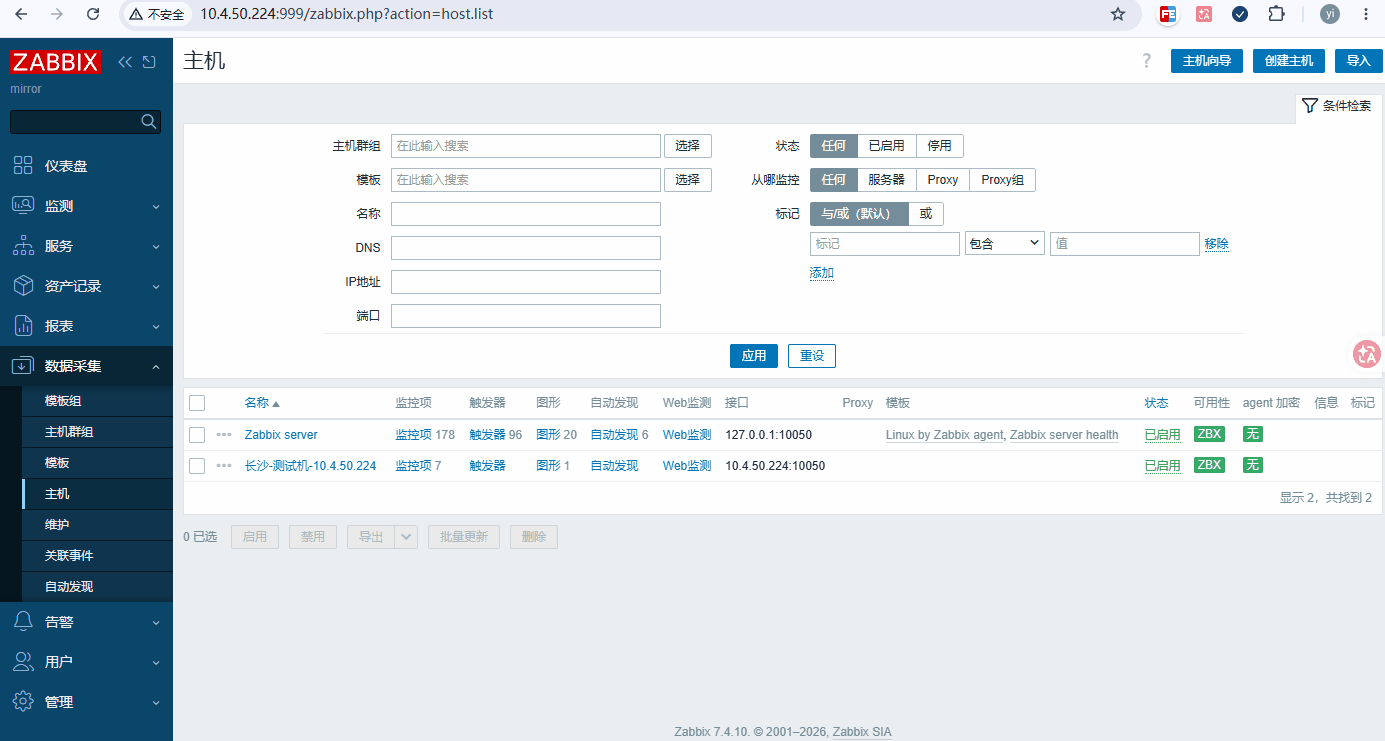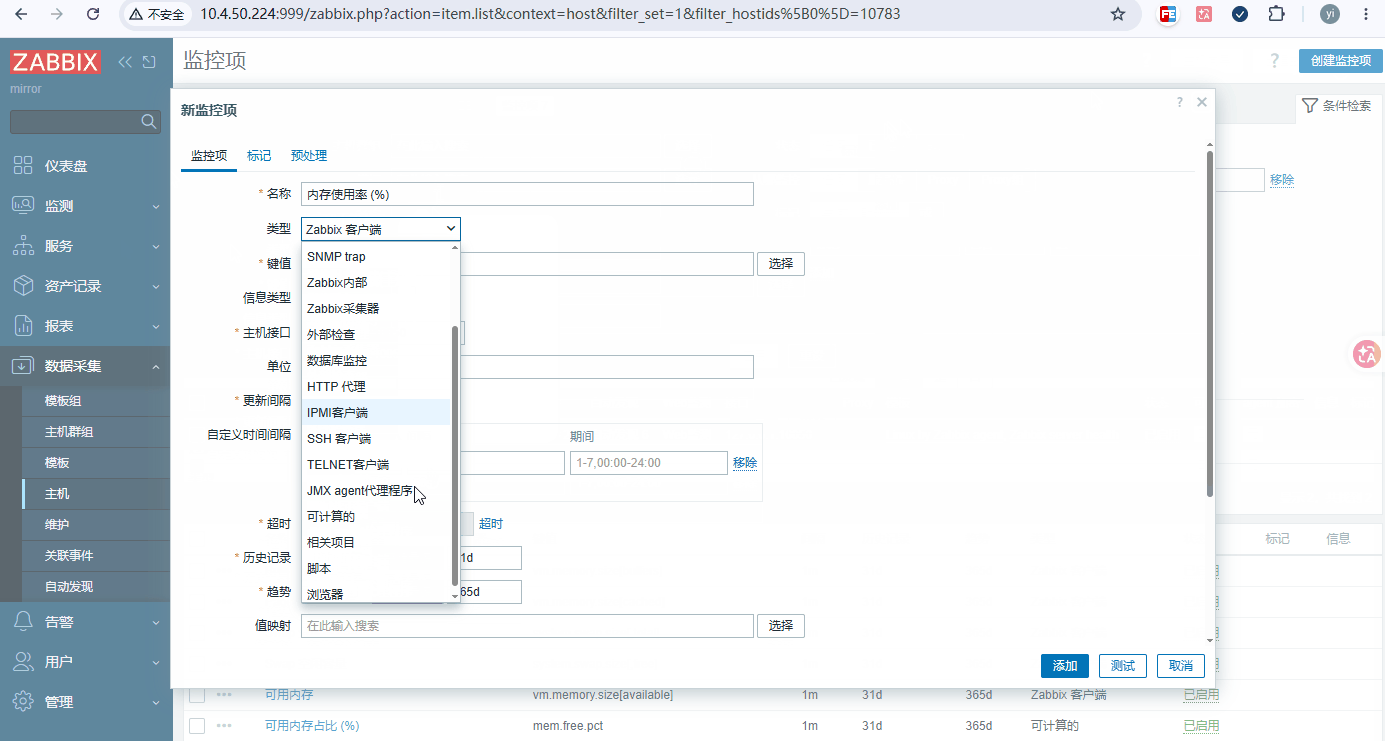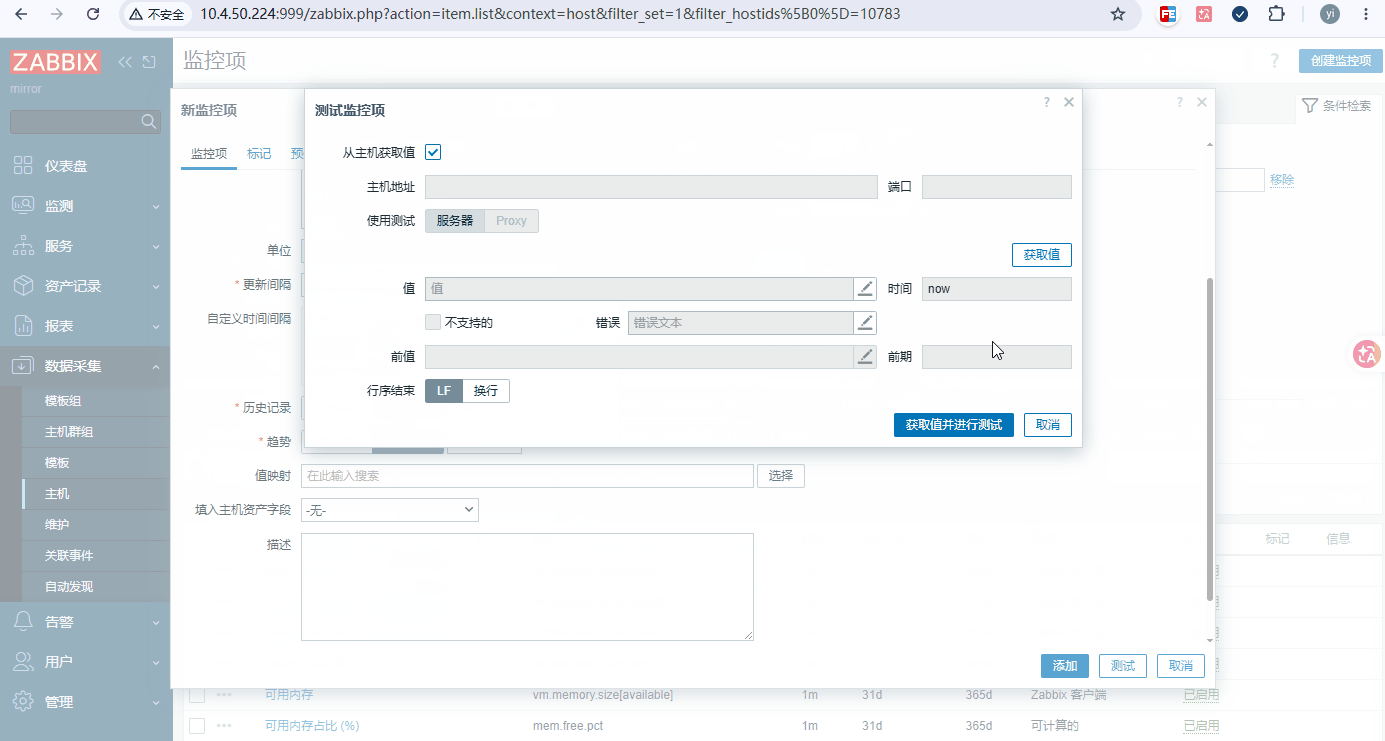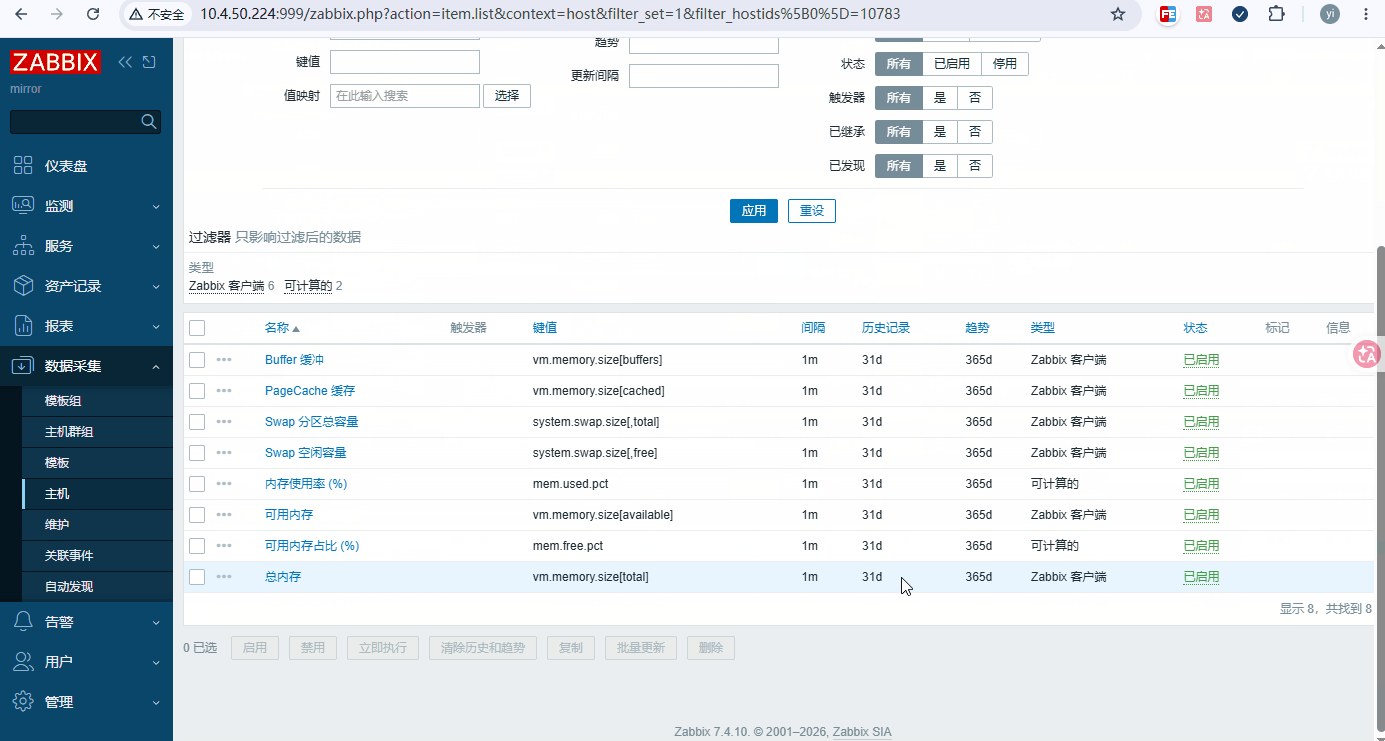
步骤: 数据采集 → 主机 → 要添加的主机 → 监控项 → 创建监控项
-
注意: 必须要先添加监控项,才能定义触发器
-
示例1: 可用内存占比
bash名称: 可用内存占比 (%) <-- 展示的名称 类型:可计算的 键键: mem.free.pct <--键值这里自定义 信息类型: 数字(无正负) 公式: 100 * last(//vm.memory.size[available]) / last(//vm.memory.size[total]) 单位: % -
示例2: 内存使用率
bash名称: 内存使用率 (%) <-- 展示的名称 类型:可计算的 键键: mem.used.pct <--键值这里自定义 信息类型: 数字(无正负) 公式: 100 - 100 * last(//vm.memory.size[available]) / last(//vm.memory.size[total]) 单位: % -
图例
-