目录
[1. 数据类型的作用](#1. 数据类型的作用)
[2. MySQL 数据类型概览](#2. MySQL 数据类型概览)
[1. 整数类型](#1. 整数类型)
[2. 小数类型](#2. 小数类型)
[3. 浮点数限制格式语法](#3. 浮点数限制格式语法)
[4. 数值类型选择案例](#4. 数值类型选择案例)
[1. CHAR / VARCHAR](#1. CHAR / VARCHAR)
[2. TEXT 类型](#2. TEXT 类型)
[3. 枚举类与集合类](#3. 枚举类与集合类)
[4. 字符串类型选择案例](#4. 字符串类型选择案例)
[1. DATETIME 与 TIMESTAMP](#1. DATETIME 与 TIMESTAMP)
[2. DATA 与 TIME](#2. DATA 与 TIME)
[3. 日期时间类型选择案例](#3. 日期时间类型选择案例)
[1. BINARY 与 VARBINARY](#1. BINARY 与 VARBINARY)
[2. BLOB 类型](#2. BLOB 类型)
[3. 二进制类型选择案例](#3. 二进制类型选择案例)
[1. 经典设计案例](#1. 经典设计案例)
[2. 数据类型选择原则](#2. 数据类型选择原则)
一、为什么需要数据类型
在上一篇博客中,我们完成了数据库与数据表的物理构建与全周期 DDL 演进。我们已经知道,数据表的本质在底层是一个个托管在 16KB 数据页中的二进制物理文件
然而,空洞的骨架并不能承载复杂的业务。如何定义一个字段、如何挑选最合适的数据容器,将直接影响数据存储的高效性。本文将深入探讨数据库建模中的关键课题:MySQL 数据类型选择与字段设计实践
1. 数据类型的作用
如果在建表时采取 "全面通配" 的粗暴手段:凡是数字全部用 BIGINT,凡是文本全部用 VARCHAR(255)。这种设计虽然在开发初期能够勉强跑通,但一旦步入高并发、大数据量的工业界环境,就会导致严重的性能问题
精准设计数据类型,基于以下三条技术逻辑:
1. 数据类型的三大职能
-
内存与磁盘的物理边界 :数据类型在声明的瞬间,就卡死了该列在物理磁盘以及 MySQL 核心内存中所能占用的最大与最小字节长度
-
数据校验:在 SQL 层的数据输入判定中,数据类型直接对输入值进行强类型约束。例如,当为 INT 列插入一个字符串时,引擎会立刻报错拦截,确保了数据的纯净
-
CPU 的计算特权:不同类型的字段在被执行优化、排序、过滤时,CPU 在底层调用的是完全不同的寄存器算法与指令集。数值计算的速度远超字符串比对
2. 存储空间与性能
MySQL 执行磁盘 I/O 的最小物理单位是 16KB 数据页
-
存储密度与 I/O 吞吐率 :如果字段类型设计得非常合理(例如,原本占 4 字节的 INT 被优化为了占 1 字节的 TINYINT),每一行的体积就会大幅度缩减。这直接意味着,单个 16KB 的数据页中能够平铺、压缩进去更多数量的行记录
-
内存命中率:当数据库进行全表扫描或索引捞取时,一次磁盘 I/O 搬运到内存中的有效记录数会成倍增加,从而极大提高了内存命中率,减少了昂贵的磁盘离散寻道时间
-
索引树高度 :索引字段的体积越小,B+ 树的非叶子节点能够容纳的指针和键值就越多,树的分叉就会越宽,从而直接压低了整棵 B+ 树的物理高度。很多时候,正是由于字段类型选错,导致 B+ 树从 3 层飙升到 5 层,使得每一次查询都平白无故多出了两次磁盘 I/O
合理选择数据类型的能力,是评判架构思维与性能优化水平的重要标准
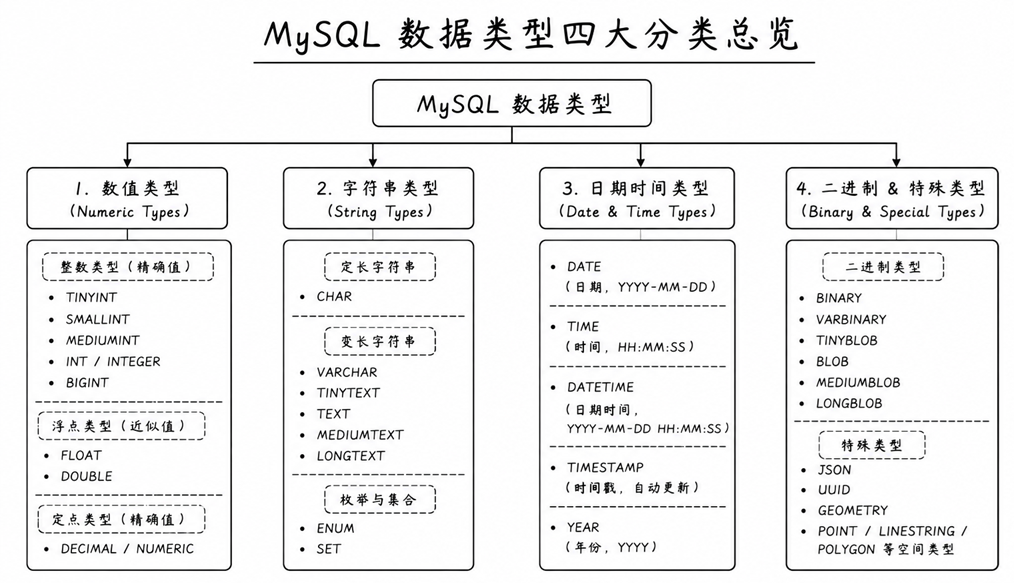
2. MySQL 数据类型概览
我们将 MySQL 支持的数据类型,按照最常用进行归纳
二、数值类型
在数值类型的选择上,后端每增加一个字节都会直接影响底层存储系统。我们将数值类型划分为整数与小数两个类别进行剖析
1. 整数类型
MySQL 提供了五种整数类型,其设计符合计算机组成原理中的字长标准(1 字节 = 8 位):
-
TINYINT (1 字节 / 8 位):能表示 2^8 = 256 个数字
-
有符号范围(默认):-128 ~ 127
-
无符号范围:0 ~ 255
-
-
SMALLINT (2 字节 / 16 位):能表示 2^16 = 65,536 个数字。范围为 -32,768 ~ 32,767
-
INT (4 字节 / 32 位) :高频的标准整数。能表示 2^32 ≈ 42.9 亿个数字。有符号最大约为 21 亿,无符号最大约为 42.9 亿
-
BIGINT (8 字节 / 64位):能表示 2 ^ 64 个数字,范围极其庞大
有符号与无符号
在建表时,默认情况下所有整数类型都是有符号的,底层会拿出最高位作为正负号标记
如果你在字段后显式声明了 UNSIGNED ,则代表该字段不允许存放负数。此时,最高位被解放出来参与数值计算,可以让正数的最大容纳边界直接翻倍
sql
-- 建表案例:
CREATE TABLE order_stock_tbl (
status TINYINT SIGNED COMMENT '订单状态:-1已取消,0待支付,1已发货',
stock_count INT UNSIGNED COMMENT '商品库存:由于库存绝对不可能为负数,用 UNSIGNED 让上限到 42 亿'
);2. 小数类型
MySQL在处理带小数点的业务数据(如价格、坐标、比例等)时,提供了两种完全不同的技术方案。若选择不当,可能引发严重的财务对账问题
1. 近似浮点数:FLOAT / DOUBLE
-
FLOAT (4 字节) / DOUBLE(8 字节)
-
底层逻辑 :它们完全遵循计算机体系结构中的 IEEE 754 标准,在内部使用 "尾数 + 阶码" 的二进制科学计数法来近似模拟十进制小数
-
精度问题 :由于绝大多数十进制有限小数转换成二进制时是无限循环小数,浮点数在存储时只能进行截断。这会导致精度丢失问题:
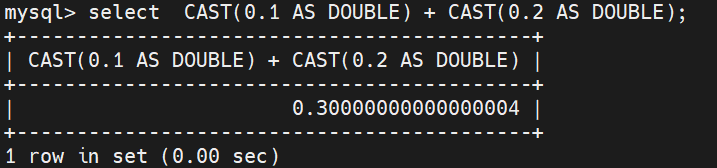
浮点数 FLOAT 和 DOUBLE 绝对禁止用于存储金钱、财务、利息、价格等对数值要求绝对精确的业务中
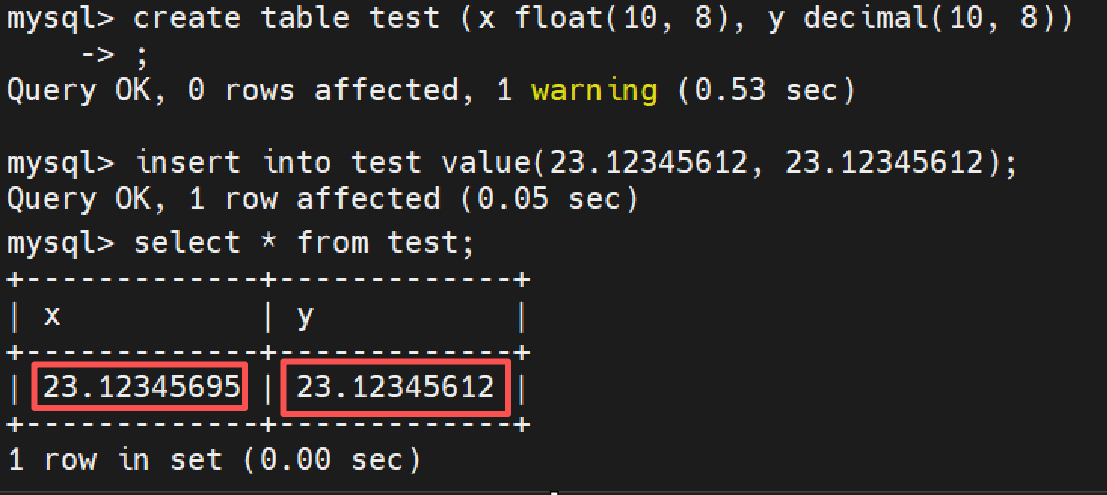
2. 高精定点数:DECIMAL(M, D)
-
底层逻辑 :为了解决浮点数的近似值问题,MySQL 独立实现了一套定点数打包格式。它在底层不再采用科学计数法,而是将数字每 9 位划分为一个独立的小组,将每个小组打包压缩存放在 4 个物理字节中。其小数点是死死固定不动的
-
语法拆解 :DECIMAL(M, D) 中的 M 代表总有效数字位数 (最大 65),D 代表小数点后的精准位数 (最大 30)。例如 DECIMAL(10, 2) 代表数字总共能占 10 位,小数点后强制卡死 2 位,其能表示的最大金额为 99999998.99
3. 浮点数限制格式语法
在 MySQL 的数值类型规范中,FLOAT 和 DOUBLE 有一套与 DECIMAL 高度相似的、用来限定显示宽度的语法格式:
-
M(总位数):指定该浮点数最多可以显示多少位十进制数字(包含整数部分和小数部分,最大限制通常为 255)
-
D(小数位数):指定小数点后精确到多少位(最大限制为 30)
-
UNSIGNED:无符号强约束。加上此关键字后,该列将不允许存入负数
此语法已被废弃:
从 MySQL 8.0.17 开始,官方已经明确宣布:正式废弃 FLOAT(M,D) 和 DOUBLE(M,D) 这种带有精度参数的非标准语法。未来版本中将只保留不带参数的纯 FLOAT 与 DOUBLE。这是因为这种语法属于 MySQL 自身的非标准扩展,极易让开发人员误以为它和 DECIMAL 一样安全,从而在数据中踩坑。因此,在现代设计中,如果需要控精度,请直接使用 DECIMAL
4. 数值类型选择案例
日常设计应做到选型时条件反射般的快速反应
场景一:用户性别、业务状态机、删除标记
-
反面教材:无脑使用 INT(占 4 字节)
-
正选 :TINYINT UNSIGNED(占 1 字节,可表达 0 ~ 255 种状态)。对于 is_deleted(0未删除,1已删除),1 字节的空间利用率是 4 字节的四倍
场景二:分布式高并发下的雪花算法 ID
-
反面教材:错误估算流量,选用了 INT UNSIGNED(上限 42.9 亿)。在千万级日活的互联网电商中,一两年内单表流水就能轻松撑爆 42 亿,引发主键溢出崩溃
-
工业级正选 :分布式全局唯一 ID(如雪花算法产生的 19 位超长数字),必须毫无悬念地锁定 BIGINT
场景三:电商系统中的商品价格(Price)
-
分单位存储法:在架构设计中,统一规定数据库里只存 "分",不存 "元"。因为分是最小货币单位,不存在小数。此时,字段直接选用 BIGINT,在应用层计算时再自发除以 100 转换成元。这种做法计算速度快,空间紧凑
-
高精定点法 :若为了代码的可读性,必须在库里展现 "元" 和 "角分",则必须使用 DECIMAL(10, 2)。绝对不允许使用 FLOAT
三、字符串类型
在关系型数据库中,字符串是承载业务文本的核心载体。如何权衡文本的 "定长" 与 "变长",不仅关乎磁盘空间的利用率,更直接决定了存储引擎在执行数据检索时的效率
1. CHAR / VARCHAR
这一对设计模式堪称关系型数据库领域的经典对照。两者的核心区别在于:采用固定长度的物理存储分配,还是基于动态逻辑计算的处理方式
1. CHAR(M)
-
语法 :M 代表字符数 (注意不是字节数)。一旦声明,无论你在该列中实际写入了多少个字符,存储引擎在底层 16KB 数据页中都会分配 M 个字符的物理空间
-
物理对齐:如果实际写入的字符数小于 M,MySQL 会在底层的二进制数据块右侧用空格进行平铺填充,直到对齐 M 个字符。在反向读取时,SQL 层会自动将右侧的这些填充空格截断抹除后再返回给应用层
-
物理边界:M 的取值范围为 0 ~ 255
**2. VARCHAR(M):**可变长度字符串,M 表示字符长度,最大长度65535个字节
-
物理机制 :VARCHAR(M) 则是按需分配。它在底层分配的物理字节空间等于实际存入的文本字符所占的物理字节 + 额外的长度列表头
-
表头成本:由于是动态伸缩的,存储引擎在取这一列数据时,必须知道这行记录的这一列究竟在哪里结束。因此,VARCHAR 在底层必须有一个二进制位来记录文本的真实字节长度:
-
当实际文本字节数 <= 255 字节时,表头只占 1 个字节 的额外空间
-
当实际文本字节数 > 255 字节时,表头占 2 个字节 的额外空间
-
-
物理边界:M 的理论最大值受限于 MySQL 单行记录最大 65,535 字节的物理限制(排除其他列及表头后,在单列情况下最大约为 65,532 字节)
2. TEXT 类型
当文本字符长度可能超过 VARCHAR 的边界时,必须使用 TEXT 家族(包括 TINYTEXT、TEXT、MEDIUMTEXT 和 LONGTEXT)
- 行溢出存储机制:InnoDB 存储引擎为了保证核心 B+ 树索引的结构紧凑,当单行记录体积过大时,会触发物理上的行溢出机制。它只会把 TEXT 字段的前 768 个字节(或仅 20 字节的指针)保留在叶子节点中,而将庞大的真实文本整体剥离到独立的溢出页中存储
在需要频繁执行排序或分组的核心业务表中,若直接使用 TEXT 字段存储大段备注信息,会导致 MySQL 性能问题。当查询结果集包含 TEXT 列时,系统无法利用内存中的高效临时表进行排序,而是被迫退化为磁盘上的外部临时表。这种操作模式会显著增加 CPU 负载并引发突发的磁盘 I/O 压力
采用主从表垂直拆分方案。将核心表中高频检索的字段(如 ID、状态)保留在主表,将低频读取的 TEXT 大文本字段剥离到一个独立的扩展表中,二者通过主键 ID 关联
sql
CREATE TABLE article_detail_tbl (
article_id BIGINT COMMENT '文章ID',
-- 正文内容长度不可控,采用 TEXT 垂直拆分独立存储
content TEXT COMMENT '文章核心正文内容'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
-- 使用示例:直接存入大段的人类文字信息
INSERT INTO article_detail_tbl VALUES (3001, '这是一篇长达万字的技术分析报告...');3. 枚举类与集合类
对于标准行列式文本之外的情况,MySQL 特别针对超大段落等场景,提供了专用的容器解决方案
1. ENUM 类型(单选枚举)
ENUM 限制该列只能从预设的列表中选择有且仅有一个值 。它在磁盘底层的真实物理存储不是字符串,而是通过 1 或 2 个字节隐式存放的数字索引。例如,ENUM('A', 'B') 存入 'A' 时,底层文件系统实际只写了一个数字 1
虽然 ENUM 物理空间紧凑,但在大型分布式微服务群中应谨慎使用。因为一旦业务变更需要追加枚举项(例如增加一个 "企业账号" 状态),必须在线上执行重型的 DDL 修改表结构(ALTER TABLE),在海量数据表上这极易导致锁表、引发服务中断
对于具有演进可能的业务,工业界普遍使用 TINYINT UNSIGNED,并在应用层(如 Java 的类文件内)通过代码来实现严密的枚举逻辑和解耦。
ENUM 仅推荐用于现实世界中绝对不可能发生变更的永恒单选分类
sql
CREATE TABLE employee_gender_tbl (
emp_id BIGINT COMMENT '员工工号',
-- 性别在生物学上高度收敛,极难发生变更,适合用 ENUM 锁死
gender ENUM('male', 'female', 'unknown') COMMENT '性别枚举:底层存储为 1, 2, 3'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
-- 使用示例:灌入预设内的合法单选值
INSERT INTO employee_gender_tbl VALUES (1001, 'male');2. SET 类型(多选集合)
SET 允许该列选择预设列表中的零个或多个值。其底层是利用位图将各个选项存放在二进制位中。例如定义了 8 个选项,底层只需要 1 个字节(8 位)的二进制数,通过 0 或 1 的状态切换就能表达上百种不同的多选组合
当设计商品标签,或为内容配置文章的多标签功能时,直接采用 SET 类型存储看似节省空间,实则存在明显缺陷。SET 类型不仅难以实现高效的模糊匹配,还无法利用 B+ 树索引进行快速检索。系统将被迫执行全表扫描,导致巨大的 I/O 性能损耗
成熟的数据库建模中,面对高频、可扩展的多对多标签业务,应当彻底抛弃 SET 字段,转而采用关系型解耦设计:文章主体表、标签元数据表、以及文章-标签中间关联表
sql
CREATE TABLE device_support_tbl (
product_id BIGINT COMMENT '产品ID',
-- 针对物理硬件所支持的、且极少变动的通信频段进行多选压缩
network_band SET('2G', '3G', '4G', '5G') COMMENT '支持的网络频段'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
-- 使用示例:一次性灌入多个合法的并存集合值
INSERT INTO device_support_tbl VALUES (2001, '3G,4G,5G');4. 字符串类型选择案例
案例 A:系统硬资产字段
-
业务范例:用户身份证号(18位)、手机号(11位)、MD5 密码哈希加密串(32位)
-
正选 :CHAR(32) 或 CHAR(11)。由于这些字段长度不变,选用 VARCHAR 不仅无法省下任何空间,反而平白无故浪费了 1 字节的长度表头成本,且增加了引擎动态解析的 CPU 损耗
案例 B:用户社会属性字段
-
业务范例:用户昵称(nickname)、收货地址(address)、商品标题(title)
-
正选 :VARCHAR(50) 或 VARCHAR(255)。此类字段由于个体差异极大,必须交由变长机制进行物理紧缩
四、日期与时间类型
在分布式架构中,时间字段的设计若处理不当,可能导致严重的 "时间倒流" 等问题。MySQL 提供了五种标准日期时间类型,其中 DATETIME 和 TIMESTAMP 两种类型的选择成为关注的焦点
1. DATETIME 与 TIMESTAMP
这两个类型虽然都能精确到秒级(甚至微秒级)的人类可读时间,但它们在磁盘底层的二进制编码以及对系统时区的感知力上,走的是完全相反的物理通路
1. DATETIME
-
物理本质 :在 MySQL 5.6.4 之后的版本中,DATETIME 占用了 5 个字节 的物理存储空间。它本质上就是一个将 "年月日时分秒" 进行二进制打包的数字钟表
-
时区 :无论往该字段里插入2026-06-10 11:16:00,存储引擎就在磁盘页里记住这个字面值。无论未来这台服务器被整体迁移到美国的西八区,还是日本的东九区,从该库里取出来的数字永远都是 2026-06-10 11:16:00。它对外界物理环境的时区变更不具备任何感知能力
-
物理边界:支持从 1000-01-01 00:00:00 到 9999-12-31 23:59:59 的超长跨度
2. TIMESTAMP
-
物理本质 :TIMESTAMP(时间戳)在底层对齐了 Unix 时间戳标准,占 4 个字节的物理空间
-
时区自适应内核 :它在底层的存储是一套物理联动机制
-
写入 :当客户端向 TIMESTAMP 字段灌入时间时,MySQL 会首先捕获当前连接的会话时区 ,将该可读时间换算、逆向解构为与时区无关的绝对 Unix 时间戳(从 1970-01-01 00:00:00 UTC 开始计算的整数),然后将这个 4 字节的整数刷入磁盘文件
-
读取 :当客户端读取该数据时,MySQL 服务层会动态读取当前的时区配置,把这个 4 字节的 Unix 秒数正向翻译、转换成该时区下的人类可读文本
-
-
物理边界 :由于 4 字节(32位)有符号整数的最大物理上限是 2,147,483,647。当全球时间来到 2038 年 1 月 19 日 03:14:07 UTC 时,该整数将彻底溢出变为负数。届时,所有采用旧版 TIMESTAMP 容器的系统都将遭遇物理越界
| 维度 | DATETIME | TIMESTAMP | DATE | TIME |
|---|---|---|---|---|
| 字节占用 | 5 字节 | 4 字节 | 3 字节 | 3 字节 |
| 时区关联性 | 无关。直接存储字面值,无转换 | 强相关。进出底层均需经过系统时区物理换算。 | 无关 | 无关 |
| 时间边界 | 1000 年 ~ 9999 年 | 1970 年 ~ 2038-01-19 | 仅保留年月日 | 仅保留时分秒 |
| 场景 | 电商订单时间、财务结算对账大表 | 自动记录行更新的系统行为日志日志 | 员工生日、商品保质期截止日 | 每日定时任务触发点 |
2. DATA 与 TIME
如果用 DATETIME 来承载员工生日或每日定时任务时间。这种设计在底层会强行塞入一堆无用的 00:00:00 零值占位符,白白浪费了部的字节空间
1. DATA
-
物理内核 :DATA 仅占 3 个字节 的物理存储空间。它在底层专门开辟了独立的二进制位,专门用来存放年月日信息,彻底剔除了时分秒的干扰
-
物理边界:1000-01-01 ~ 9999-12-31
-
工业场景:员工生日、合同签署日期、商品保质期截止日、财务按天结算的对账单批次号
2. TIME
-
物理内核 :TIME 同样仅占 3 个字节 的物理空间。它专门用来存放时分秒信息
-
时间跨度:需要注意的是,TIME 在 MySQL 中不仅代表 "几点几分",它在底层更被设计成可以代表 "两个时间点之间的绝对时间间隔"。因此,它的物理边界特殊,支持从 -838:59:59 到 838:59:59。这意味着它最高可以表示过去或未来的近 35 天的时间跨度
-
工业核心场景:每日定时任务的触发点、员工考勤打卡时间等
3. 日期时间类型选择案例
案例 A:跨国跨时区分布式电商系统的订单创建时间
陷阱:若无脑选用 TIMESTAMP。当中国站(东八区)用户在 11:16:00 下单,数据写入磁盘。此时美国西海岸分系统(西八区)通过微服务读取该字段,由于 TIMESTAMP 的自适应机制,系统会自动帮其扣除 16 个小时,显示为前一天的 19:16:00。这在跨国财务对账、物流时效计算中,会带来海量的代码逻辑错乱
正选 :DATETIME 。为了彻底斩断多时区带来的动态转换错乱,现代架构规范中,普遍规定:全站所有时间字段统一锁死 DATETIME,且在应用层代码框架中,入库前一律强行规整、对齐为 UTC(世界标准时间)或 GMT+8(北京时间)的静态字面值。通过应用层的业务代码去接管时区逻辑,实现数据库存储层的纯净与无限生命周期
sql
-- 时间审计字段建表范例:
CREATE TABLE order_timeline_tbl (
order_id BIGINT COMMENT '订单唯一ID',
create_time DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT '订单创建绝对时间(静态锁定)',
update_time DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '行数据每次发生变更时,由引擎自发物理刷新'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;案例 B:智能考勤与员工薪酬基础信息表
陷阱: 在设计员工生日或每日固定的上班打卡时间时,直接使用 DATETIME 可能会导致系统在物理落地时会强行塞入一堆无用的 00:00:00 零值占位符,不仅白白浪费了数据页内部的字节空间,在面对数亿级历史大表执行聚类、索引扫描时,还会引发不必要的内存换页开销
正选: 对于仅关乎周期的日期(如生日、入职日),强制锁定 3 字节的 DATE ;对于仅关乎时间点或时段间隔的场景(如每日排班打卡点、多媒体培训总时长),强制锁定 3 字节的 TIME
sql
-- 创建员工考勤与基础资产表
CREATE TABLE employee_attendance_tbl (
emp_id BIGINT COMMENT '员工全局唯一工号',
-- 针对仅保留日期的正选设计:不需要时分秒,3字节精准存储
birth_date DATE COMMENT '员工出生日期',
entry_date DATE COMMENT '入职日期,便于计算工龄',
-- 针对仅保留时间点的设计
daily_shift_start TIME COMMENT '规定每日上班打卡时间,如 09:00:00',
-- 针对时间间隔的设计
video_training_duration TIME COMMENT '入职培训视频总时长'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='员工考勤与资产基础表';五、文本与二进制类型
在关系型数据库的底层设计中,当数据不再局限于简短的定长或变长文本时,需要引入大文本容器以及直接面向计算机底层的二进制原生态容器。这些类型在处理海量非结构化数据和纯粹的机器码时,有着不同的物理对齐与存储机制
1. BINARY 与 VARBINARY
-
BINARY(M) :定长二进制字符串。它的物理机制与 CHAR 完全对齐,但其右侧填充的不是空格,而是物理上的零字节(\0)
-
VARBINARY(M):变长二进制字符串。它与 VARCHAR 高度对齐,同样需要 1 或 2 个字节的额外表头来记录真实的二进制字节长度
-
核心差异: 这两者在底层比对时,回到计算机最原始的字节码逐位硬匹配。它们不关心外界传入的是中文还是英文,也不受任何大小写敏感规则的影响
当存储纯文本字段(如用户昵称 nickname)时,错误地选用 VARBINARY 类型会导致问题。VARBINARY 类型会忽略大小写敏感校验和标准字符序转换规则,使得应用层在进行拼音排序或不区分大小写的模糊查询时,无法获得预期的业务结果
将 BINARY 与 VARBINARY 精准用于存储加密算法输出的密文、设备生成的机器指纹等
sql
CREATE TABLE secure_token_tbl (
user_id BIGINT COMMENT '用户ID',
-- 密码学的密钥或盐值是不带任何字符集属性的原始机器码,适合用 VARBINARY 承载
crypto_salt_key VARBINARY(64) COMMENT '防篡改加密盐值'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;
-- 使用示例:插入标准的十六进制机器编码密文
INSERT INTO secure_token_tbl VALUES (5001, 0x4E3641427A8901FF);2. BLOB 类型
BLOB 家族(包括 TINYBLOB、BLOB、MEDIUMBLOB 和 LONGBLOB)是专门用于托管海量非结构化二进制数据的大型容器
- 物理内核:BLOB 与 TEXT 在底层的行溢出机制完全一致。但两者的核心区别在于,TEXT 依赖字符集进行文字解码排版,而 BLOB 在存储和读取时,完全不进行任何字符转换,以原生的字节流形式落地
直接选用 LONGBLOB字段,将用户上传的几兆甚至几十兆的原始图片、音视频文件以二进制流的形式强行写入数据库。会导致数据库物理文件体积呈几何级数爆炸。导致数据库服务器的整体吞吐率急速下降
采用**「对象存储+路径指针」**的分离式架构方案,将实体文件存储在外部分布式对象存储系统(如阿里云 OSS 或自建 MinIO 集群),同时在 MySQL 数据库中仅保存文件的相对路径URL(使用标准 VARCHAR 类型字段存储)
3. 二进制类型选择案例
-
应用示例一:存放系统公告的大段图文详情
- 正选:TEXT。公告数据通常超过 VARCHAR 的长度上限,且属于纯文本信息,符合 TEXT 的应用边界
-
应用示例二:存储敏感接口的防刷签名 MD5 二进制截断码
- 正选:BINARY(16)。MD5 可以转化为 16 字节的固定二进制,使用 BINARY 能够实现极致的内存与磁盘物理对齐
-
应用示例三:用户多媒体文件的物理存储
- 正选:外部存储系统挂载 + 数据库内 VARCHAR(255)。避免使用 BLOB
六、数据类型设计案例
在掌握了数值、String、日期时间、文本与二进制等底层容器的物理特性后,我们需要将这些能力聚合成完整的解决方案。以下通过三个高频核心业务场景,来演示如何进行严密的建表字段设计
1. 经典设计案例
场景一:用户表
用户表(user_b_tbl)是所有互联网系统的基石,具有高并发读取、字段多变、数据量庞大的特点。设计核心在于精细化控制非索引字段的体积,提升 Buffer Pool 的缓存密度
sql
CREATE TABLE IF NOT EXISTS user_b_tbl (
user_id BIGINT UNSIGNED NOT NULL COMMENT '全局唯一用户ID,无符号BIGINT完美承载分布式雪花ID',
username CHAR(11) NOT NULL COMMENT '登录手机号,国内11位绝对定长,选用CHAR类型',
password_hash CHAR(32) NOT NULL COMMENT 'MD5或特定算法加密后的密码密文,32位绝对定长',
nickname VARCHAR(50) NOT NULL COMMENT '用户自定义昵称,个体差异大,选用变长VARCHAR',
gender ENUM('male', 'female', 'unknown') NOT NULL DEFAULT 'unknown' COMMENT '生物学性别,不发生变更,选ENUM',
user_status TINYINT UNSIGNED NOT NULL DEFAULT 0 COMMENT '账户状态:0正常,1冻结,2注销。未来有扩展可能,选TINYINT',
birth_date DATE DEFAULT NULL COMMENT '出生日期,不需要时分秒,使用3字节DATE',
create_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '注册时间,使用静态5字节DATETIME,由应用层规范时区',
update_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '最后修改时间',
PRIMARY KEY (user_id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='用户核心主体基础信息表';场景二:商品表
商品表(product_info_tbl)的特征在于必须对价格进行绝对精确的计算
sql
CREATE TABLE IF NOT EXISTS product_info_tbl (
product_id BIGINT UNSIGNED NOT NULL COMMENT '商品全局唯一ID',
product_title VARCHAR(150) NOT NULL COMMENT '商品标题,最大支持50个汉字左右,选VARCHAR',
origin_price DECIMAL(10, 2) NOT NULL COMMENT '商品市场原价,使用高精定点数',
promotion_price DECIMAL(10, 2) NOT NULL COMMENT '商品促销现价,禁止使用FLOAT以防出现对账偏差',
stock_count INT UNSIGNED NOT NULL DEFAULT 0 COMMENT '库存数量,绝对不可能为负数,加UNSIGNED实现翻倍防御,最大42.9亿',
is_on_sale TINYINT UNSIGNED NOT NULL DEFAULT 0 COMMENT '上下架标记:0下架,1上架',
product_desc_url VARCHAR(255) DEFAULT NULL COMMENT '商品图文详情详情页URL路径,避免直接在库内灌入TEXT/BLOB',
PRIMARY KEY (product_id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='商品核心基础资产表';场景三:聊天记录表
聊天记录表(chat_msg_history_tbl)是典型的数据量吞吐极高、且单行内容长度波动巨大的高频写入表。设计的核心在于通过字段切割,防止单行过大撑爆数据页
sql
CREATE TABLE IF NOT EXISTS chat_msg_history_tbl (
msg_id BIGINT UNSIGNED NOT NULL COMMENT '消息全局唯一流水号',
session_id BIGINT UNSIGNED NOT NULL COMMENT '会话房间ID,高频检索字段,创建强索引',
sender_id BIGINT UNSIGNED NOT NULL COMMENT '发送者用户ID',
msg_type TINYINT UNSIGNED NOT NULL DEFAULT 1 COMMENT '消息类型:1文本,2图片,3语音,4视频',
short_content VARCHAR(255) NOT NULL COMMENT '消息文本摘要或OSS多媒体文件相对URL',
raw_payload_key BINARY(16) DEFAULT NULL COMMENT '安全防篡改层:固定16字节的二进制MD5校验码,使用BINARY定长分配',
create_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '消息发送时间,精确到秒',
PRIMARY KEY (msg_id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='聊天消息历史流水表';2. 数据类型选择原则
我们将设计经验总结为四条研发实践中的建模准则:
① 最小化原则
在能够绝对完美承载业务预期的前提下,永远选择占用物理字节空间最小的数据类型
-
能用 TINYINT 就绝不用 INT
-
能用 DATE 表达的业务,绝不平白无故塞入 DATETIME
② 数值优于字符串原则
计算机底层的 CPU 寄存器对数值类型的比对、过滤和排序运算速度,远远超过需要逐位解密字符集编码的字符串
-
存储状态机或分类标签时,应当优选 TINYINT,并在应用层进行代码映射
-
存储固定长度数字(如手机号、纯数字工号)且不需要模糊匹配时,若长度可控,在特定架构下可考虑转化为数值存储
③ 防溢出与强类型
对于任何带有累加性质、绝不为负数的业务字段(如用户积分、商品库存),必须强制声明 UNSIGNED 约束
- 这一步可以在不需要额外付出空间的前提下,直接让正向的存储物理上限扩大一倍,是抵御生产环境数据溢出崩溃的底层防线
④ 将多媒体实体驱移除库
任何时候,严禁在关系型数据库内存储图片、音视频、大文件压缩包的真实二进制实体(BLOB / LONGBLOB)
- 应坚定采用 "分布式对象存储(OSS/S3)+ 数据库 VARCHAR 静态路径指针" 的解耦架构方案。这样能确保关系型数据库核心的 .ibd 物理文件长期保持高效、紧凑的健康状态
总结
综上所述,我们系统学习了 MySQL 中常见的数据类型,包括数值类型、字符串类型、日期时间类型以及二进制类型,并结合实际案例分析了不同场景下的数据类型选择策略
通过本篇内容可以发现,数据类型不仅决定了数据的存储方式,也直接影响着存储空间占用、查询效率以及后续数据库设计的合理性。因此,在设计数据表时,选择合适的数据类型往往比单纯追求功能实现更加重要
不过,仅仅选择合适的数据类型还远远不够。在实际开发中,我们往往还需要进一步保证数据的合法性与完整性。例如:
学号不能重复;年龄不能为负数;用户名不能为空;每条记录都需要唯一标识;
这些规则并不属于数据类型本身,而属于数据库中的约束机制
因此,在下一篇中,我们将继续学习 MySQL 中常见的数据约束,包括主键、外键、唯一约束、非空约束以及默认值等内容,进一步完善数据库表设计体系
