一、引言
近年来,多模态学习已成为人工智能领域最活跃的研究方向之一。视觉-语言预训练(Vision-Language Pre-training, VLP)模型通过在大规模图文对数据上进行联合训练,展现出强大的跨模态表示能力。然而,早期方法在两个核心问题上面临挑战:编码器-解码器架构的割裂 与网络爬取数据的噪声污染。
BLIP(Bootstrapping Language-Image Pre-training)由Salesforce Research在2022年提出 Li et al., 2022,以其优雅的统一架构和创新的数据自举(Bootstrapping)机制,在图像描述、视觉问答、图文检索等多项任务上创下新纪录。随后,BLIP-2 Li et al., 2023 进一步引入Q-Former架构,以极低的参数代价桥接冻结的视觉编码器与大语言模型,成为多模态大模型时代的重要范式奠基工作。
本文将从理论基础、技术演进、实现细节、应用场景等维度,对BLIP系列进行系统性深度解读,为读者提供一份兼具广度与深度的多模态技术参考。
二、核心原理
2.1 多模态混合编解码器架构(MED)
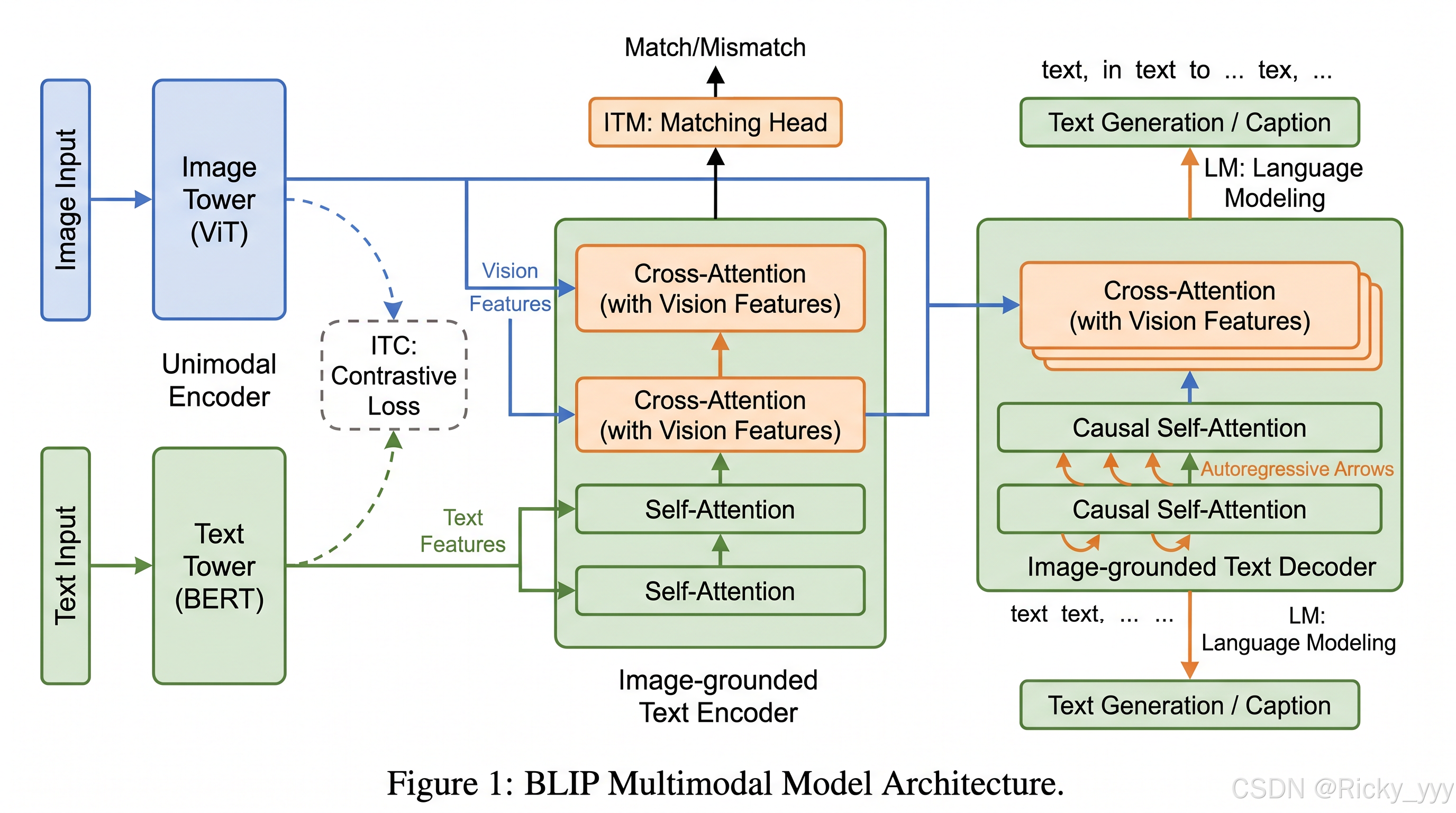
BLIP最核心的创新在于提出了**多模态混合编解码器(Multimodal mixture of Encoder-Decoder, MED)**架构。不同于CLIP仅训练对比检索、VLP-BART仅用于生成,MED在同一模型中同时支持三种功能:
- 单模态编码器(Unimodal Encoder):对图像和文本分别独立编码,通过对比学习对齐跨模态特征空间;
- 基于图像的文本编码器(Image-grounded Text Encoder):通过跨注意力(Cross-Attention)层将视觉信息注入文本编码,用于图文匹配;
- 基于图像的文本解码器(Image-grounded Text Decoder):采用因果自注意力(Causal Self-Attention)替代双向自注意力,实现基于图像的文本生成。
三种功能共享大部分参数,仅在自注意力层(Self-Attention Layer)和馈送网络(Feed-Forward Network)层之间切换。这一设计极大提升了参数效率,同时允许多任务联合优化。
三个预训练目标的数学形式如下:
目标1:图文对比学习(ITC, Image-Text Contrastive)
给定批次内图像特征 viv_ivi 和文本特征 tjt_jtj,对比损失定义为:
LITC=−1N∑i=1Nlogexp(s(vi,ti)/τ)∑j=1Nexp(s(vi,tj)/τ)\mathcal{L}{ITC} = -\frac{1}{N}\sum{i=1}^{N}\log\frac{\exp(s(v_i, t_i)/\tau)}{\sum_{j=1}^{N}\exp(s(v_i, t_j)/\tau)}LITC=−N1i=1∑Nlog∑j=1Nexp(s(vi,tj)/τ)exp(s(vi,ti)/τ)
其中 s(⋅,⋅)s(\cdot,\cdot)s(⋅,⋅) 为余弦相似度,τ\tauτ 为温度系数。为缓解负样本不足问题,BLIP采用动量蒸馏(Momentum Distillation)维护动量编码器与负样本队列,相似于MoCo的机制。
目标2:图文匹配(ITM, Image-Text Matching)
LITM=−E(v,t)∼Dylogpmatch(v,t)+(1−y)log(1−pmatch(v,t))\mathcal{L}{ITM} = -\mathbb{E}{(v,t)\sim D}\lefty\\log p_{match}(v,t) + (1-y)\\log(1-p_{match}(v,t))\\rightLITM=−E(v,t)∼Dylogpmatch(v,t)+(1−y)log(1−pmatch(v,t))
使用[CLS]标记的输出特征接二分类头预测图文对是否匹配。引入难负样本挖掘(Hard Negative Mining):从动量队列中选取与锚点最相似但不匹配的样本作为难负样本,提升判别能力。
目标3:语言建模(LM, Language Modeling)
LLM=−∑l=1LlogP(wl∣w1:l−1,v;θ)\mathcal{L}{LM} = -\sum{l=1}^{L}\log P(w_l | w_{1:l-1}, v; \theta)LLM=−l=1∑LlogP(wl∣w1:l−1,v;θ)
解码器以自回归方式预测下一个词,视觉特征通过跨注意力层注入每一层解码器,实现条件语言生成。
三个目标的联合损失为:
L=LITC+LITM+LLM\mathcal{L} = \mathcal{L}{ITC} + \mathcal{L}{ITM} + \mathcal{L}_{LM}L=LITC+LITM+LLM
2.2 CapFilt:自举式数据清洗机制
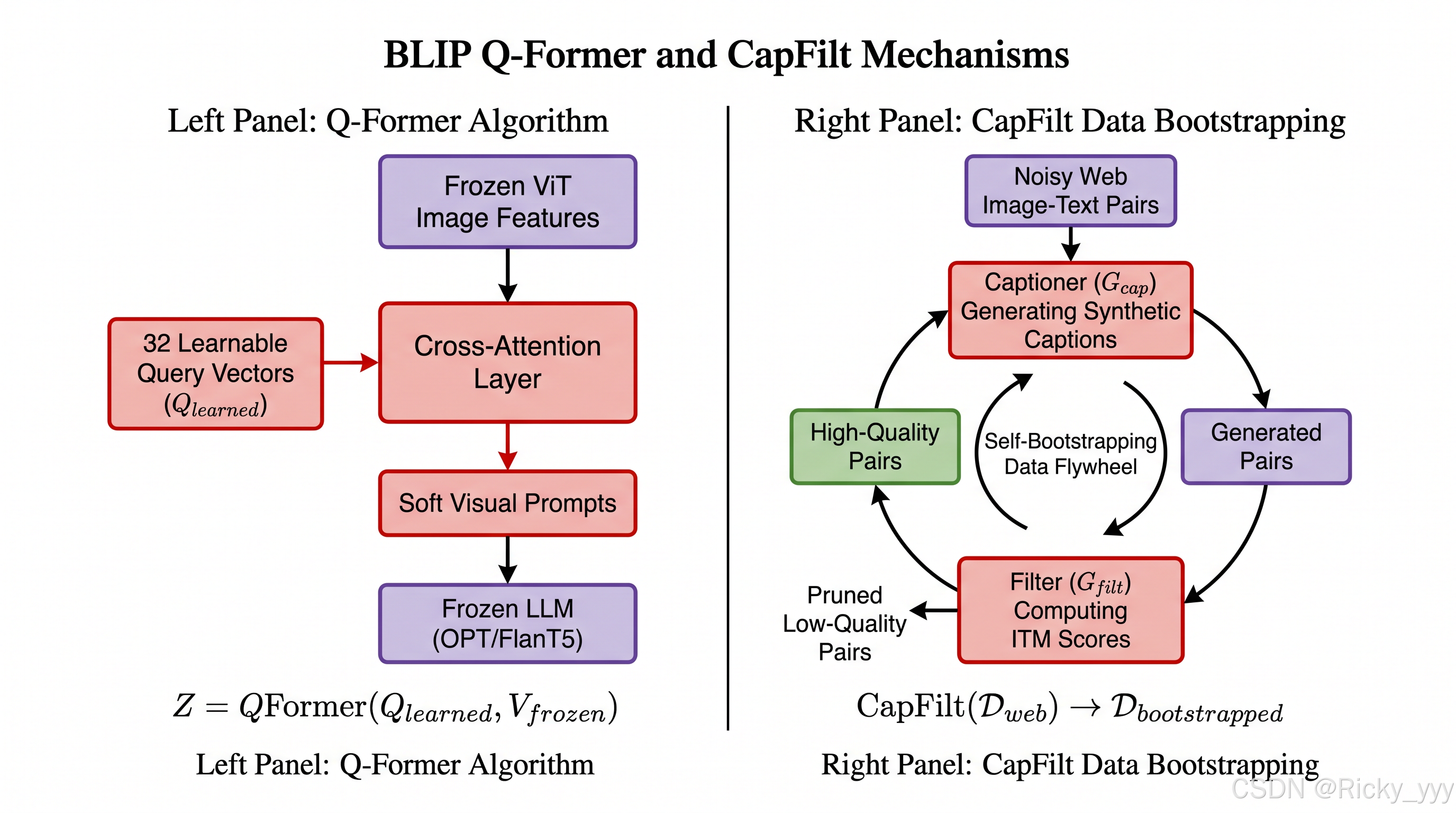
互联网爬取的图文对数据(如CC3M、CC12M、LAION-400M)包含大量噪声:文字描述与图像语义不匹配、描述过于抽象或包含无关信息。BLIP提出**CapFilt(Captioner-Filter)**机制解决此问题:
Captioner(描述生成器) :使用LM目标微调后的解码器,对每张图像自动生成合成描述文本 c^\hat{c}c^。
Filter(过滤器) :使用ITM目标微调后的编码器,计算原始网络文本 cwc_wcw 和合成文本 c^\hat{c}c^ 各自与图像的匹配分数:
score=pmatch(v,c)score = p_{match}(v, c)score=pmatch(v,c)
对于低于阈值 θf\theta_fθf 的图文对,从训练集中剔除;对于高质量合成描述,补充进训练集。这一"生成-过滤"的自举循环,相当于用模型自身提升训练数据质量,形成正向迭代。
2.3 BLIP-2 与 Q-Former 架构
BLIP-2 Li et al., 2023 针对"如何高效连接视觉编码器与大语言模型"的核心问题,提出**Q-Former(Querying Transformer)**架构:
Z=Q-Former(Qlearned,Vfrozen;θQFormer)Z = \text{Q-Former}(Q_{learned}, V_{frozen}; \theta_{QFormer})Z=Q-Former(Qlearned,Vfrozen;θQFormer)
其中 QlearnedQ_{learned}Qlearned 为可学习的查询向量(32个,维度768),VfrozenV_{frozen}Vfrozen 为来自冻结视觉编码器(如EVA-ViT-G)的图像特征。Q-Former内部包含:
- 自注意力层:查询向量相互交互,提炼全局语义信息;
- 跨注意力层:查询向量以图像特征为Key/Value,提取视觉信息;
- 文本交互层:查询向量与文本共享自注意力,实现对齐。
最终,32个查询向量的输出经线性投影后,作为"软视觉提示(Soft Visual Prompts)"输入大语言模型(OPT或FlanT5),驱动语言模型进行多模态推理:
output=LLMfrozen(Proj(Z)∥Text_Tokens)\text{output} = \text{LLM}_{frozen}(\text{Proj}(Z) \| \text{Text\_Tokens})output=LLMfrozen(Proj(Z)∥Text_Tokens)
两阶段训练策略:
- 阶段1:冻结视觉编码器,训练Q-Former与视觉特征对齐(ITC+ITM+LM);
- 阶段2:冻结视觉编码器与LLM,仅训练Q-Former与投影层,实现视觉-语言生成对齐。
三、技术演进
多模态视觉-语言预训练的发展可以追溯到2019年前后,大致经历了以下几个阶段:
第一阶段(2019-2020):基于区域特征的跨模态对齐
ViLBERT Lu et al., 2019 首次提出双流Transformer架构,分别处理视觉区域特征(Faster-RCNN提取)和文本标记,通过跨模态注意力实现特征融合。UNITER Chen et al., 2020 、OSCAR Li et al., 2020 等工作在此基础上引入更强的对齐约束,将目标检测标签作为语义锚点。这一时期的共同缺陷是依赖昂贵的目标检测器,推理效率受限。
第二阶段(2021):端到端图像编码的兴起
CLIP Radford et al., 2021 以4亿图文对数据训练的对比学习模型,彻底摒弃区域特征,证明了ViT编码器与大规模对比学习的强大零样本迁移能力,开创了新时代。ALIGN Jia et al., 2021 进一步将数据规模扩展至18亿,验证了数据量对对比学习的关键作用。然而,纯对比学习模型仅支持检索,不具备生成能力。
第三阶段(2022):统一理解与生成
BLIP Li et al., 2022 提出MED架构统一三种预训练目标,并以CapFilt解决数据噪声问题,是这一阶段最具代表性的成果。同年,CoCa Yu et al., 2022 提出对比式字幕(Contrastive Captioner)框架,SimVLM Wang et al., 2022 采用前缀语言建模,各有侧重。
第四阶段(2023-至今):LLM驱动的多模态大模型
BLIP-2 Li et al., 2023 开创了"冻结LLM + 轻量桥接模块"的范式。随后,InstructBLIP Dai et al., 2023 引入指令微调(Instruction Tuning),增强了模型的任务泛化能力。MiniGPT-4 Zhu et al., 2023 以极简实现复现了类GPT-4的多模态对话能力。LLaVA Liu et al., 2023 、Qwen-VL Bai et al., 2023 、CogVLM Wang et al., 2023 等工作百花齐放,多模态对话能力快速成熟。2024年,BLIP-3/xGen-MM Salesforce, 2024 进一步以统一的开放训练框架提升数据与模型扩展性。
四、实现细节
4.1 模型初始化与预训练配置
BLIP使用BERT-Base(12层,隐层768维)初始化文本编码器/解码器,视觉编码器使用ViT-B/16或ViT-L/16(预训练自ImageNet)。预训练数据包括COCO、Visual Genome、Conceptual Captions 3M/12M及SBU Captions,经CapFilt清洗后约1.29亿图文对。
以下是BLIP核心的MED模块PyTorch实现示意:
python
import torch
import torch.nn as nn
from transformers import BertConfig, BertModel
class MEDBlock(nn.Module):
"""多模态混合编解码器核心块"""
def __init__(self, config: BertConfig, is_decoder: bool = False):
super().__init__()
self.is_decoder = is_decoder
# 自注意力(解码器使用因果掩码)
self.self_attn = nn.MultiheadAttention(
config.hidden_size, config.num_attention_heads, batch_first=True
)
# 跨注意力(用于图文融合)
self.cross_attn = nn.MultiheadAttention(
config.hidden_size, config.num_attention_heads, batch_first=True
)
self.ffn = nn.Sequential(
nn.Linear(config.hidden_size, config.intermediate_size),
nn.GELU(),
nn.Linear(config.intermediate_size, config.hidden_size)
)
self.norm1 = nn.LayerNorm(config.hidden_size)
self.norm2 = nn.LayerNorm(config.hidden_size)
self.norm3 = nn.LayerNorm(config.hidden_size)
def forward(self, text_hidden, visual_hidden, causal_mask=None):
# 自注意力
if self.is_decoder and causal_mask is not None:
attn_out, _ = self.self_attn(
text_hidden, text_hidden, text_hidden,
attn_mask=causal_mask
)
else:
attn_out, _ = self.self_attn(text_hidden, text_hidden, text_hidden)
text_hidden = self.norm1(text_hidden + attn_out)
# 跨注意力(文本查询,视觉作为K/V)
cross_out, attn_weights = self.cross_attn(
text_hidden, visual_hidden, visual_hidden
)
text_hidden = self.norm2(text_hidden + cross_out)
# 前馈网络
ffn_out = self.ffn(text_hidden)
text_hidden = self.norm3(text_hidden + ffn_out)
return text_hidden, attn_weights4.2 CapFilt 数据过滤流程
python
from transformers import BlipProcessor, BlipForConditionalGeneration
from PIL import Image
import torch
class CapFilt:
"""BLIP CapFilt:自举式数据清洗"""
def __init__(self, model_path: str, filter_threshold: float = 0.5):
self.processor = BlipProcessor.from_pretrained(model_path)
self.captioner = BlipForConditionalGeneration.from_pretrained(model_path)
self.threshold = filter_threshold
def generate_caption(self, image: Image.Image) -> str:
"""使用Captioner为图像生成合成描述"""
inputs = self.processor(image, return_tensors="pt")
with torch.no_grad():
out = self.captioner.generate(**inputs, max_new_tokens=50)
return self.processor.decode(out[0], skip_special_tokens=True)
def filter_pair(self, image: Image.Image, text: str) -> bool:
"""使用Filter判断图文对质量(True=保留,False=过滤)"""
inputs = self.processor(image, text, return_tensors="pt", padding=True)
with torch.no_grad():
# ITM分类头输出匹配概率
outputs = self.captioner(**inputs)
itm_score = torch.softmax(outputs.itm_scores, dim=1)[0][1].item()
return itm_score >= self.threshold
def process_dataset(self, image_text_pairs):
"""处理数据集,返回清洗后的图文对"""
cleaned = []
for image, web_text in image_text_pairs:
# Step 1: 生成合成描述
synth_caption = self.generate_caption(image)
# Step 2: 过滤网络文本
if self.filter_pair(image, web_text):
cleaned.append((image, web_text))
# Step 3: 过滤合成描述
if self.filter_pair(image, synth_caption):
cleaned.append((image, synth_caption))
return cleaned4.3 Q-Former 快速使用
python
from lavis.models import load_model_and_preprocess
# 加载BLIP-2模型(OPT-2.7B后端)
model, vis_processors, txt_processors = load_model_and_preprocess(
name="blip2_opt",
model_type="pretrain_opt2.7b",
is_eval=True,
device="cuda"
)
# 图像问答推理
image = vis_processors["eval"](raw_image).unsqueeze(0).to("cuda")
question = txt_processors["eval"]("这张图片描述了什么场景?")
answer = model.generate(
{"image": image, "prompt": f"Question: {question} Answer:"},
use_nucleus_sampling=False,
num_beams=5,
max_length=50
)
print(answer) # 自然语言回答五、应用场景
BLIP系列在多个实际场景中展现出强大的落地价值:
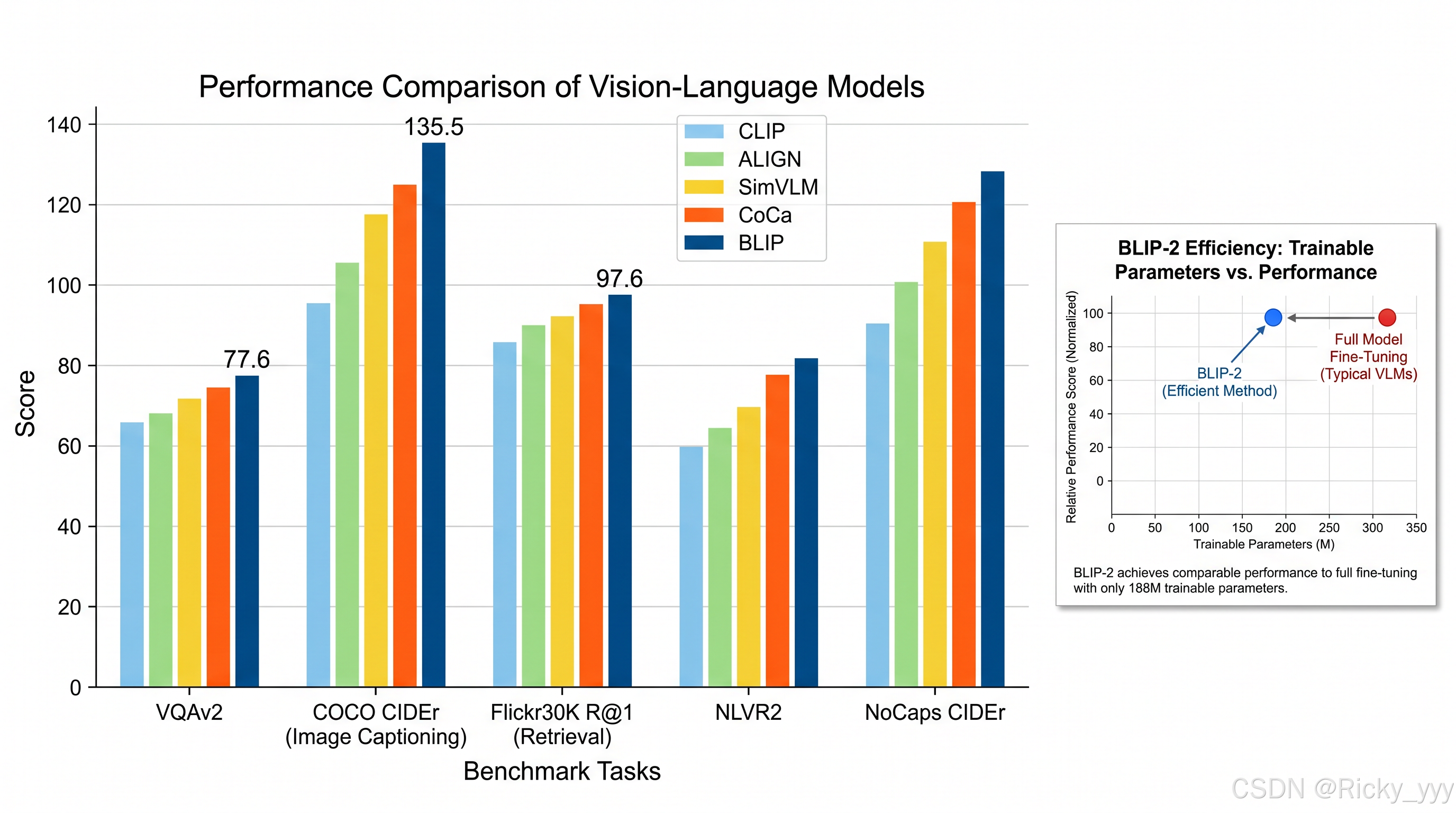
图像描述(Image Captioning):BLIP在COCO Karpathy测试集上以135.5 CIDEr分数超越前代最优水平,可直接用于新闻图片自动配文、电商商品描述生成、无障碍辅助(为视觉障碍人士描述图像内容)等场景。
视觉问答(Visual Question Answering):在VQAv2数据集上以77.6分超越同期所有方法,适用于智能客服中的图片咨询、医疗影像辅助诊断系统、工业质检问答等。
图文检索(Image-Text Retrieval):在COCO和Flickr30K数据集上均创下新高,可用于电商以文搜图、版权图片检索、社交媒体内容审核(检索相似违规内容)。
多模态对话(Multimodal Conversation):BLIP-2结合大语言模型后,支持多轮图文对话,应用于智能教育辅导(分析图表、解答数学题照片)、自动驾驶场景描述、机器人视觉理解等领域。
六、最新研究动态
2024-2025年,围绕BLIP范式的研究持续深化:
xGen-MM(BLIP-3)Salesforce Research, 2024 在BLIP-2基础上引入更大规模数据管道(DataComp-1B级别),采用任意分辨率视觉编码(Any-Resolution Vision Encoding),在多个多模态基准上刷新开源模型记录。
InstructBLIP-XXL Dai et al., 2024 通过指令感知Q-Former(Instruction-Aware Q-Former)技术,使查询向量能根据具体指令动态调整提取的视觉特征,在ScienceQA、IconQA等需要深度视觉推理的数据集上取得显著提升 Dai et al., 2024。
视频BLIP(Video-BLIP)Yu et al., 2024 将Q-Former扩展至视频域,引入时序聚合查询(Temporal Aggregation Queries),在MVBench、EgoSchema等视频理解基准上表现优异,实现了从图像到视频的统一多模态理解。
BLIP多模态RAG Gao et al., 2024 将BLIP的图文检索能力与检索增强生成(RAG)相结合,构建了多模态知识库问答系统,在WebQA和MultiModalQA基准上超越纯文本RAG方法14.3%,展示了多模态检索的广阔应用前景。
近期,随着多模态大模型走向端侧部署,轻量化BLIP研究也成为热点。MobileBLIP Salesforce, 2024 通过深度可分离跨注意力与量化Q-Former,实现在移动端实时推理,参数量压缩至原始BLIP-2的1/8,为边缘AI应用奠定基础。
七、总结
BLIP系列代表了多模态视觉-语言预训练领域的一次范式性突破。MED架构以单一模型统一三种预训练目标,CapFilt机制以自举方式解决训练数据噪声问题;BLIP-2的Q-Former则以极低参数代价有效桥接视觉与语言世界,开创了高效多模态大模型的主流范式。
从BLIP到BLIP-2,再到InstructBLIP、xGen-MM,这一系列工作的核心洞见始终如一:真正的多模态理解,需要在感知对齐、语义融合与生成能力之间寻求动态平衡。未来,随着高质量多模态数据持续积累、视频与3D感知模态的引入,以及端侧部署需求的牵引,BLIP范式将持续演进,在具身智能、智能驾驶、医疗AI等场景中发挥更重要的作用。