文章目录
-
- 前言
- [1. 首页:一站式 AI 评测与 API 服务智能路由平台](#1. 首页:一站式 AI 评测与 API 服务智能路由平台)
- [2. 模型广场:按模型系列快速筛选](#2. 模型广场:按模型系列快速筛选)
- [3. 模型详情:看价格、上下文、延迟和吞吐](#3. 模型详情:看价格、上下文、延迟和吞吐)
- [4. 服务商广场:比较不同 MaaS / 云服务平台](#4. 服务商广场:比较不同 MaaS / 云服务平台)
- [5. 服务商详情:按服务商查看已评测模型](#5. 服务商详情:按服务商查看已评测模型)
- [6. 产品文档:平台能力总览](#6. 产品文档:平台能力总览)
- [7. 快速入门:从选模型到复制 API 示例](#7. 快速入门:从选模型到复制 API 示例)
- [8. 智能路由:根据性能、价格、可靠性自动调度](#8. 智能路由:根据性能、价格、可靠性自动调度)
- [9. API Key:统一鉴权与额度控制](#9. API Key:统一鉴权与额度控制)
- [10. 文本模型 API:兼容 OpenAI 风格调用](#10. 文本模型 API:兼容 OpenAI 风格调用)
- [11. 工具调用:Agent 接入的关键能力](#11. 工具调用:Agent 接入的关键能力)
- [12. 路由参数:第三方 Agent 工具里也能控制策略](#12. 路由参数:第三方 Agent 工具里也能控制策略)
- [13. JSON 模式:让 Agent 输出稳定结构](#13. JSON 模式:让 Agent 输出稳定结构)
- [14. 缓存命中折扣:降低长上下文 Agent 成本](#14. 缓存命中折扣:降低长上下文 Agent 成本)
- [15. Agent 接入 AI Ping API 推荐配置](#15. Agent 接入 AI Ping API 推荐配置)
- [16. 选定 GLM-5.1 作为 Agent 演示模型](#16. 选定 GLM-5.1 作为 Agent 演示模型)
- [17. 接入任意 LLM API 进行体验](#17. 接入任意 LLM API 进行体验)
- [18. 总结](#18. 总结)

前言
最近在重构 Agent 项目,最让我头大的不是逻辑写不出来,而是模型接口满天飞。有的用 OpenAI 格式,有的用 Anthropic 格式,还有的自己搞一套 SDK。直到我遇到了 AI Ping,这种割裂感才终于消失。
它给我的第一印象就不是个简单的"模型超市"。现在很多平台还在卷谁家的模型多,但 AI Ping 最狠的是"快"。真的是新模型上线速度快得离谱,昨天圈子里刚讨论的 GLM-5.1、DeepSeek-V4-Pro这种顶流,今天它就能直接调了。
对于我们这种追新技术的开发者来说,不用等官方慢慢适配,不用改业务代码,这种"即插即用"的体验简直是救命。统一 API 调用、智能路由、工具调用和结构化输出放到了一条完整链路里。
在用的 AI Ping 确实挺香,关键是现在福利给得足。用这个链接注册,咱俩都能白拿几十块算力金,全场模型通用,写代码、画图随你怎么霍霍。邀请也没上限,纯粹互惠互利,有需要的朋友直接冲👇 体验一下
下面我来向大家介绍下他是个啥东东!
1. 首页:一站式 AI 评测与 API 服务智能路由平台
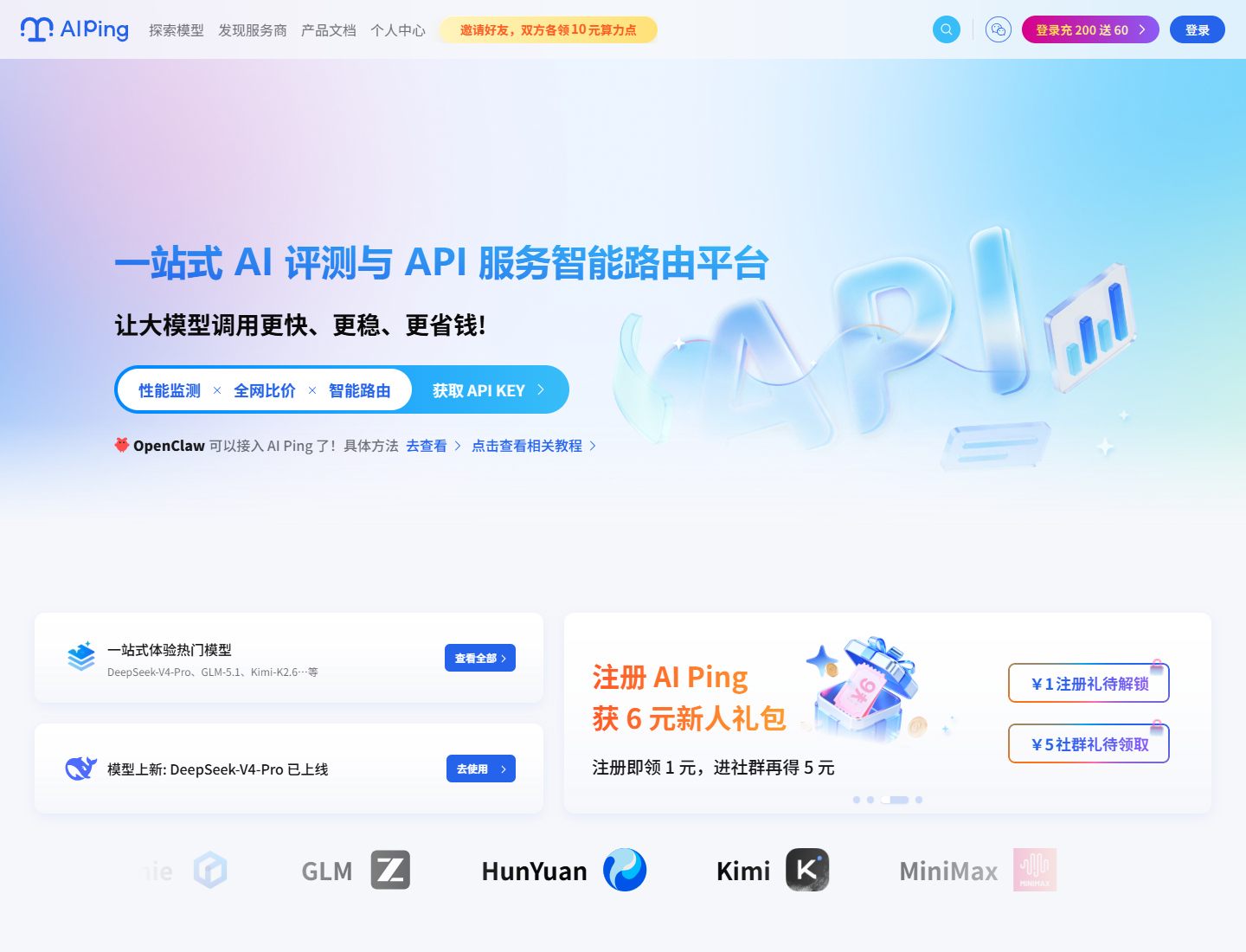
我打开首页后,最先注意到的是它对自己的定位:"一站式 AI 评测与 API
服务智能路由平台"。这个定位和我实际找模型服务时的需求比较吻合,因为
我不只想知道某个模型能不能用,还想知道它在哪个服务商上更稳、更快、
更便宜。
首页把性能监测、全网比价、智能路由这几个入口放得很靠前。对我来说,
这比传统官网式的长篇介绍更直接:我可以马上进入模型、服务商、榜单或
文档,不需要先在营销文案里找半天。
我比较喜欢的一点是,它把可用模型、服务商、性能排行和 API 接入路径放在
同一个主流程里。对于正在做 Agent 接入的人来说,这种信息组织方式更像是
一个工作台,而不是单纯的产品介绍页。
2. 模型广场:按模型系列快速筛选
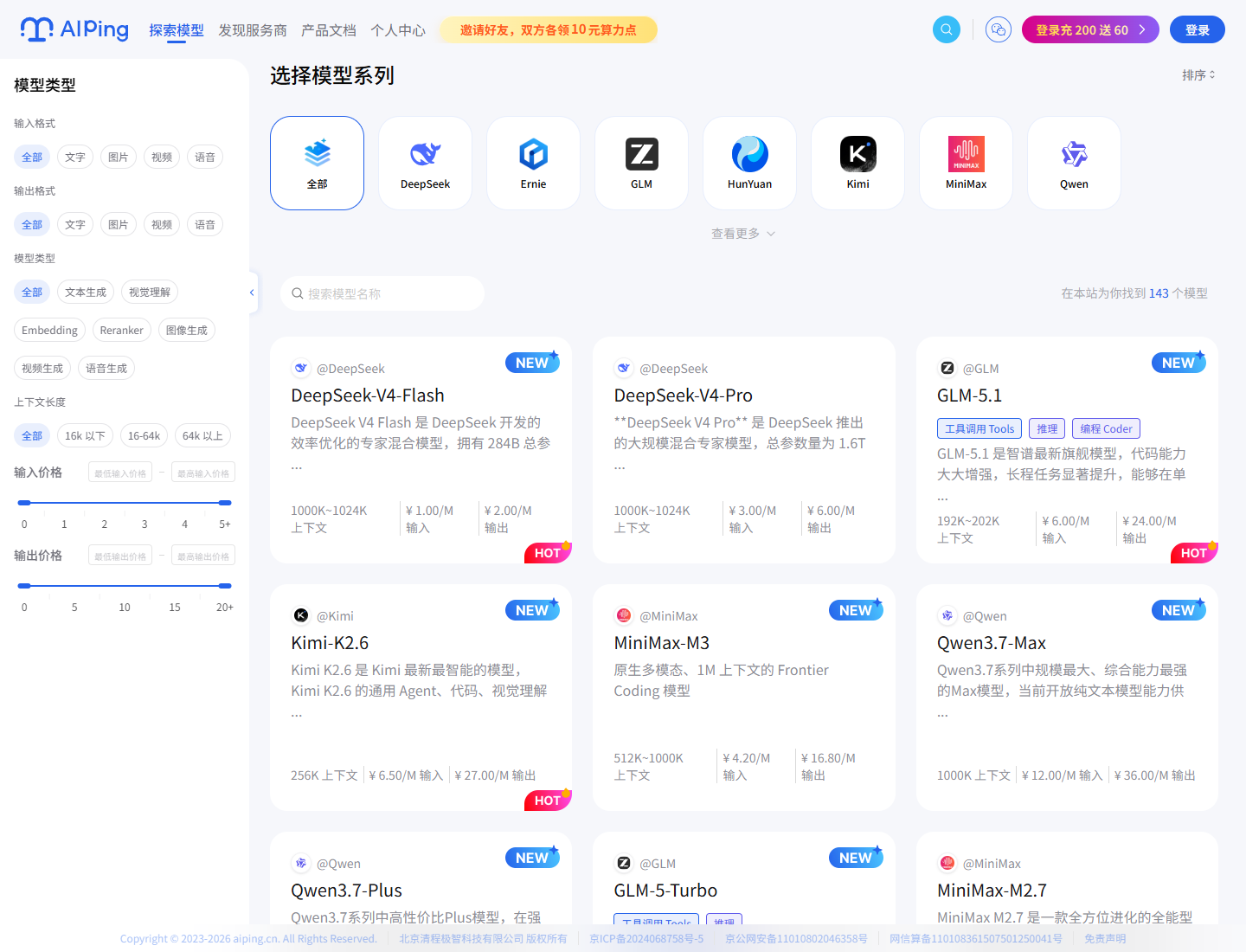
进入模型广场后,我能看到目前有 143 个模型,覆盖 DeepSeek、GLM、Kimi、
MiniMax、Qwen、豆包大模型、Ernie、HunYuan、Kolors、Kling、Vidu 等系列。
如果你平时经常在不同模型之间切换,这种按系列聚合的方式会省不少时间。
我在看模型卡片时,主要会关注这几类信息:
- 模型系列和模型名称。
- 是否支持工具调用、推理、编程、视觉等能力标签。
- 上下文长度。
- 输入 tokens 和输出 tokens 价格。
- 模型能力介绍。
这些信息对 Agent 应用尤其关键。一个 Agent 不只是"会聊天"就够了,它还
可能需要长上下文、工具调用、代码能力、稳定吞吐和可控成本。我在做选型时,
通常会先用这些标签做第一轮筛选,再进入详情页看更具体的服务商表现。
3. 模型详情:看价格、上下文、延迟和吞吐
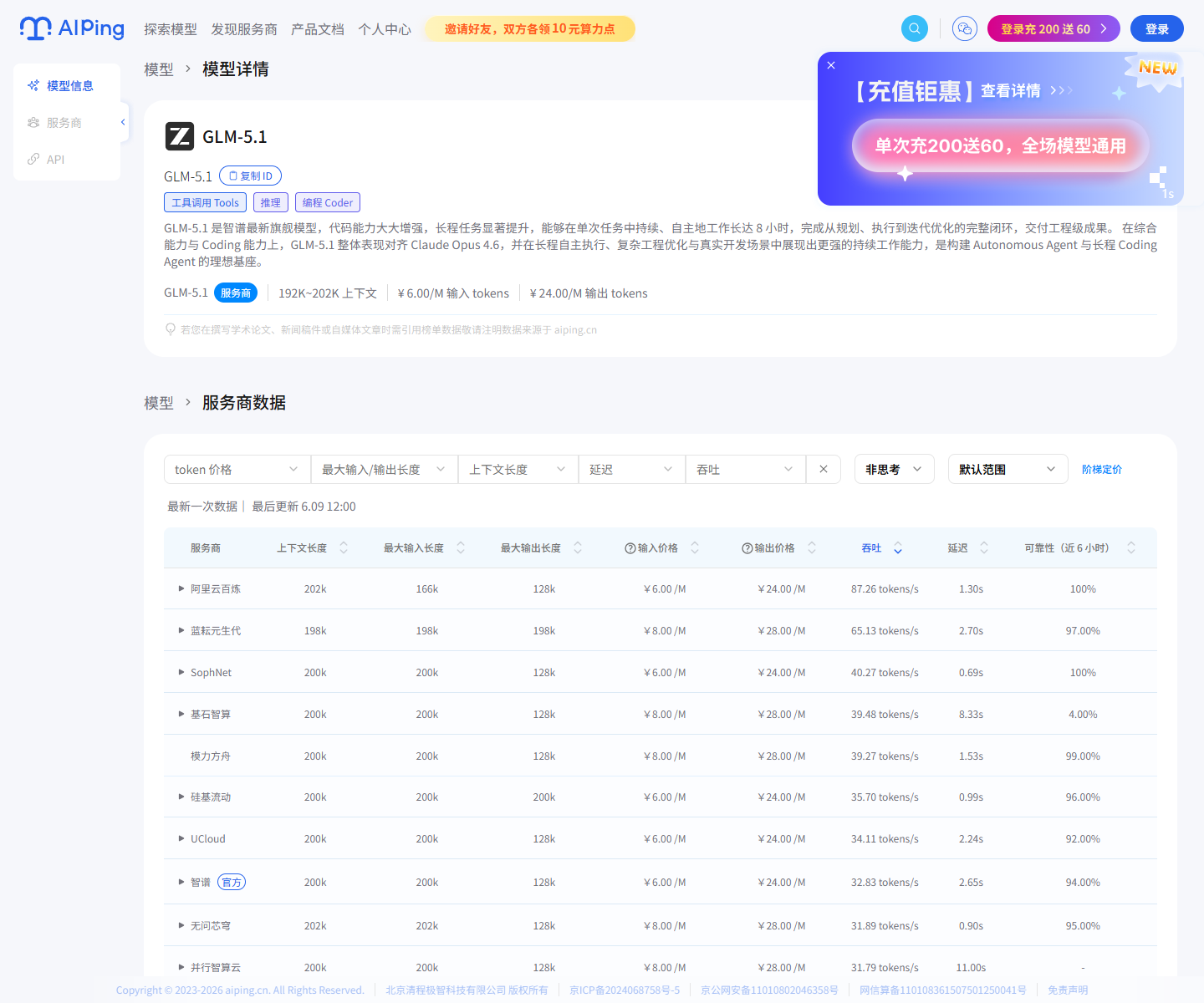
我以 GLM-5.1 的详情页为例看了一下,它的能力标签里包含工具调用、推理和
编程。页面里对这个模型的定位偏向长程任务和 Coding Agent,这一点比较适合
我关注的自动化编程、工程交付和复杂任务拆解场景。
模型详情页真正有用的地方,不只是模型介绍本身,而是能同时看到服务商数据、
token 价格、最大输入/输出长度、上下文长度、延迟和吞吐。也就是说,我可以
从"同一个模型在不同服务商上的表现"这个角度做横向比较,而不是只看模型名。
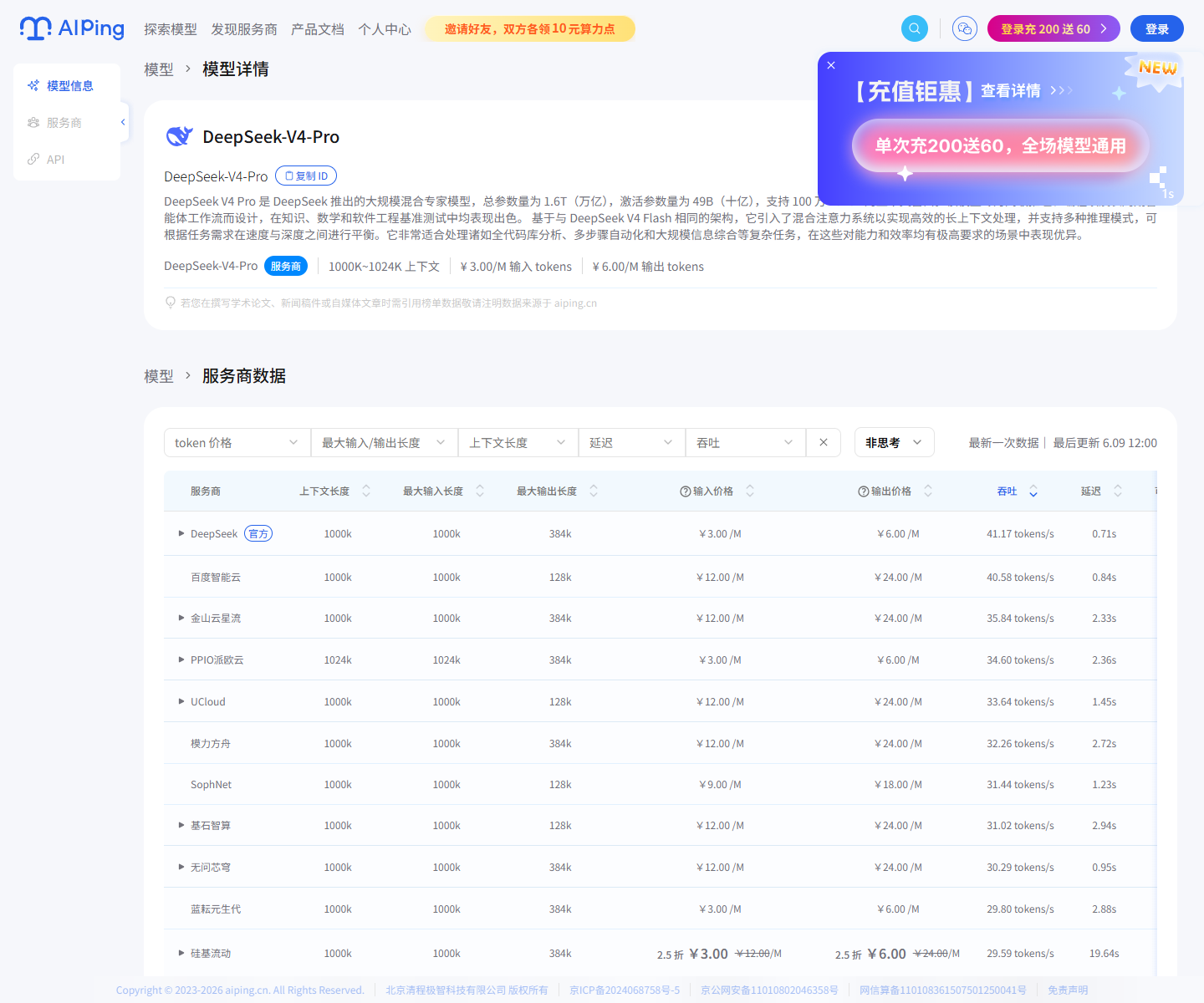
我再看 DeepSeek-V4-Pro 时,比较关注它的 1000K 到 1024K 上下文能力,以及
输入/输出价格。对于全代码库分析、多步骤自动化、大规模信息综合这类 Agent
任务,长上下文不是锦上添花,而是直接影响能不能落地。
不过长上下文也不能只看标称长度。我实际会把服务商稳定性、延迟和吞吐一起看,
因为 Agent 一旦进入多轮调用,慢一次可能只是体验问题,连续慢或连续失败就会
影响整个任务链路。
4. 服务商广场:比较不同 MaaS / 云服务平台
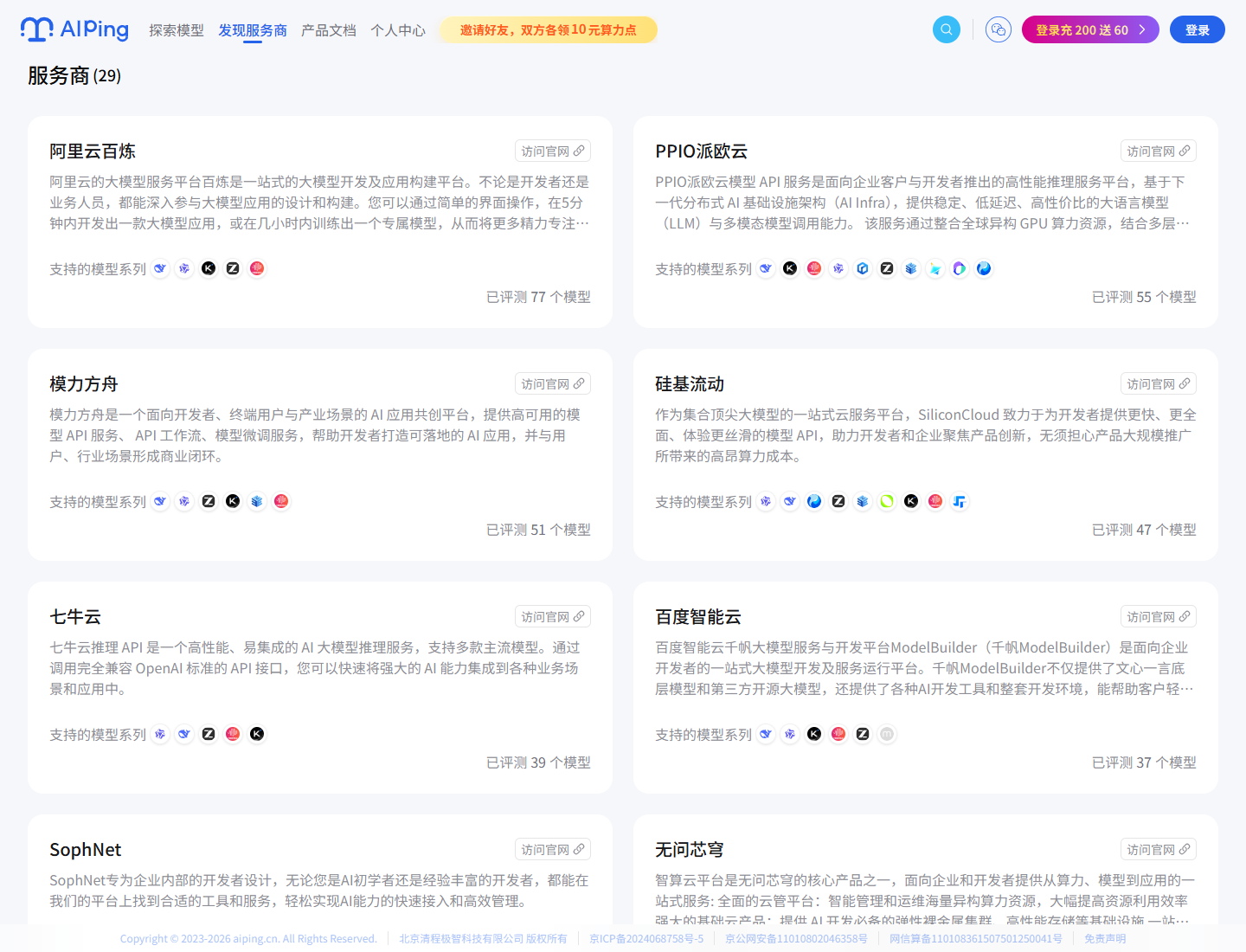
服务商广场目前能看到 29 个服务商,包括阿里云百炼、PPIO 派欧云、模力方舟、
硅基流动、七牛云、百度智能云、UCloud、无问芯穹等。
我看这类页面时,一般不会只看服务商品牌,而会更关心它到底支持哪些模型、
已经评测了多少模型,以及是否方便进一步跳转到官网核对细节。这里每个服务商
卡片基本会给出这些信息:
- 服务商简介。
- 支持的模型系列。
- 已评测模型数量。
- 访问官网入口。
这部分对采购前调研挺实用。我的做法通常是先在 AI Ping 上确认服务商是否
覆盖我需要的模型,再结合性能榜单和价格数据判断是否直接走 AI Ping 统一 API,
或者后续再做服务商自己的独立接入。
5. 服务商详情:按服务商查看已评测模型
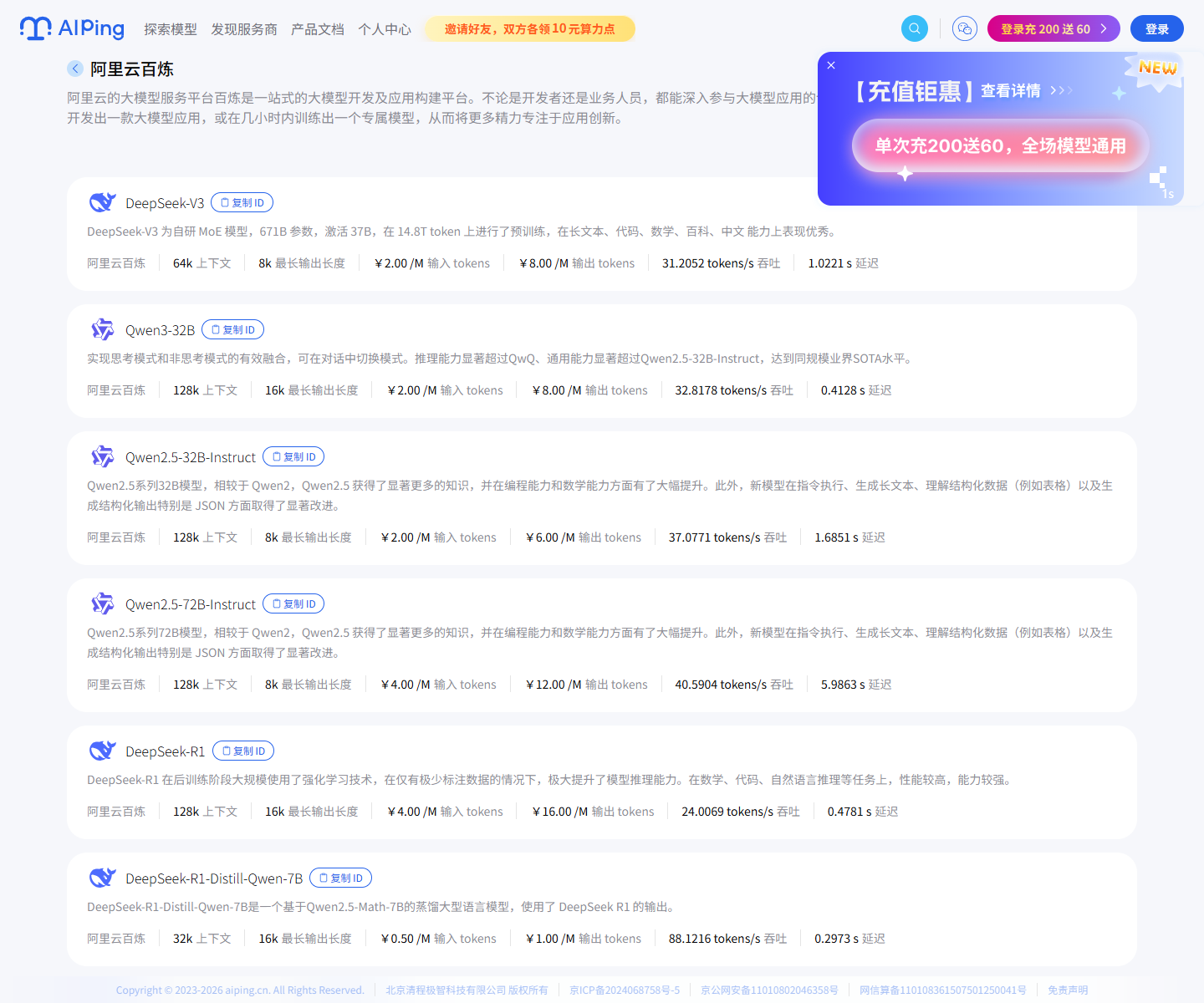
点进阿里云百炼详情页后,我能按服务商维度看到它下面已经测评过的模型。
我觉得这个视角很重要,因为有时我们不是先选模型,而是公司已经有某个云平台
账号或采购体系,这时就需要反过来看"这个服务商能提供哪些模型,表现怎么样"。
在服务商详情里,我会重点看每个模型的上下文、最长输出长度、输入/输出价格、
吞吐和延迟。这些数据比单纯的模型简介更接近真实接入时会遇到的问题。
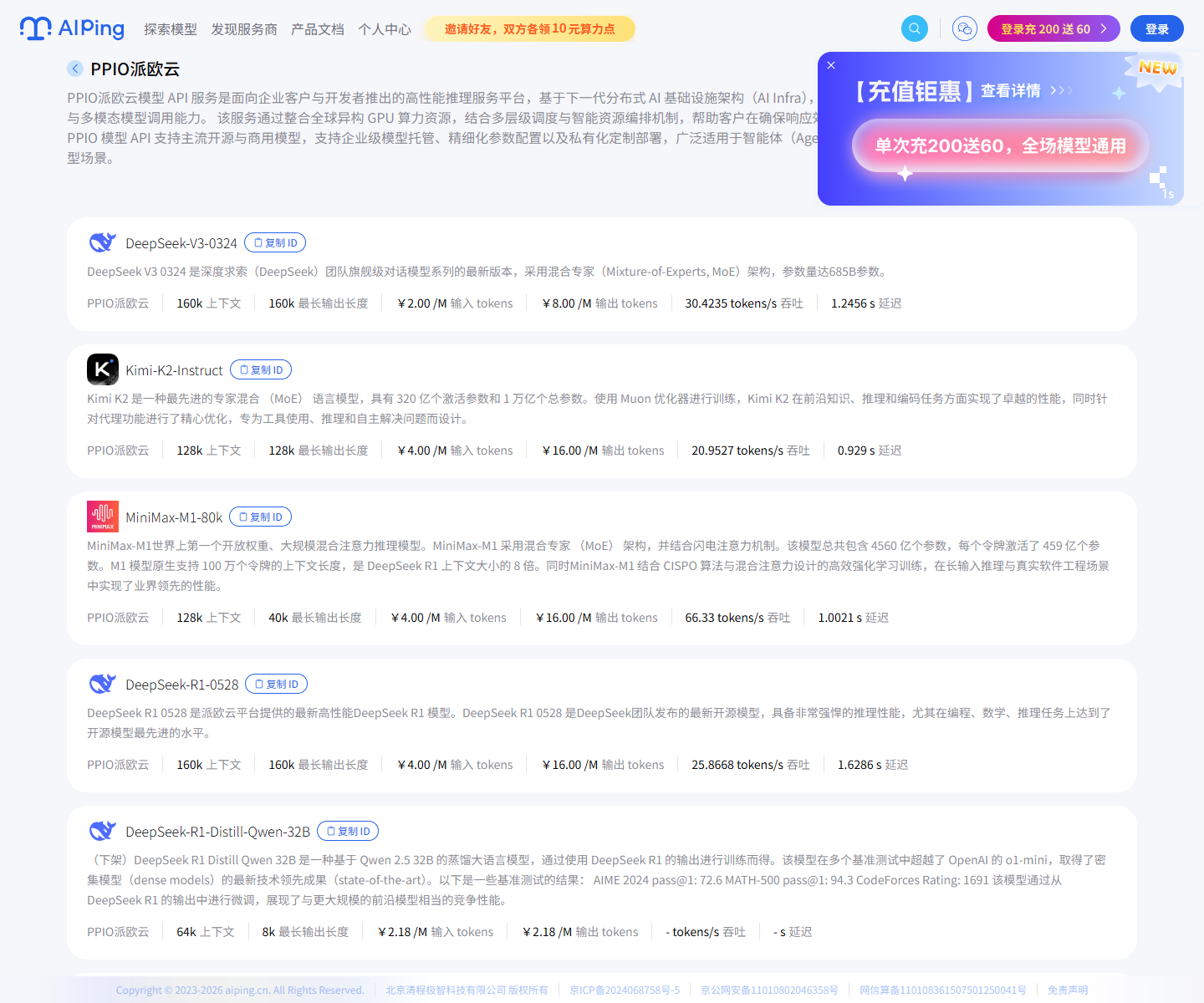
我也看了 PPIO 派欧云的详情页。它的介绍里提到面向企业客户与开发者,提供
低延迟、高性价比的大语言模型和多模态模型调用能力,适用于 Agent、虚拟助手、
内容生成、智能问答、文档摘要等场景。
从我的角度看,服务商详情页适合用来做第二轮筛选:第一轮先确定模型方向,
第二轮再判断哪个服务商更符合当前项目对成本、速度和稳定性的要求。
6. 产品文档:平台能力总览

我看产品文档时,看到 AI Ping 把自己类比成"大模型 API 服务的大众点评"。
这个说法我觉得比较好理解:它不是只列模型名称,而是希望通过持续评测,把
不同服务商之间的性能差异展示出来。
文档里我重点关注了几个能力:
- 模型服务商性能评测榜单:持续监测延迟、吞吐、可靠性等指标。
- 多平台统一调用 API:一个接口访问多家服务商和多个模型。
- 智能路由:按价格、性能、可靠性自动选择服务商。
- 个人数据中心:查看调用模型、服务商、Token 消耗和费用。
如果只是个人体验一个模型,这些能力可能显得有点重。但如果是在做长期运行的
Agent,或者团队里有多个项目共用模型服务,这些监测、路由和费用数据就会变得
很有价值。
7. 快速入门:从选模型到复制 API 示例
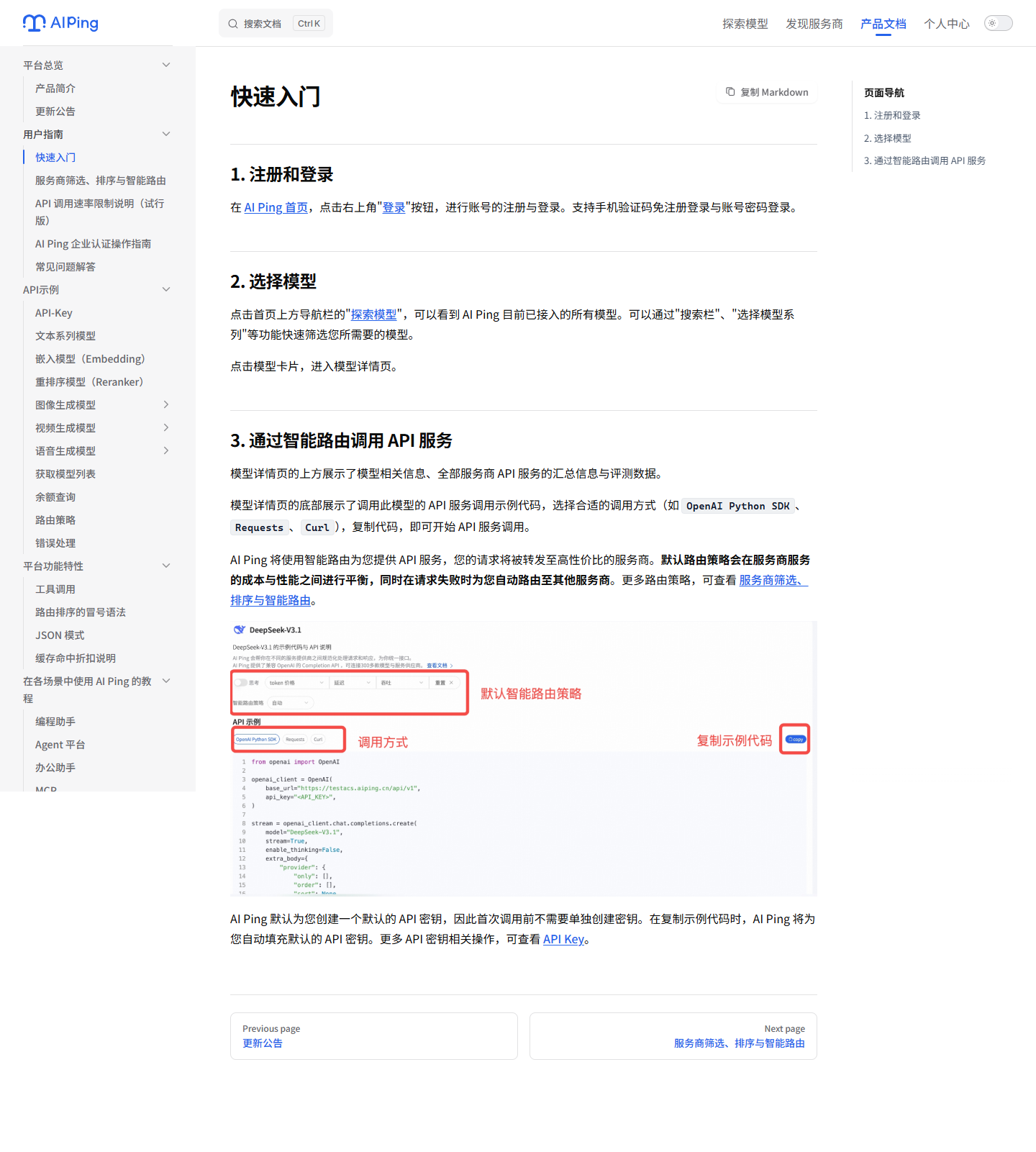
快速入门文档给我的感觉是路径比较直接,不需要先理解一堆平台概念。按它的
流程,大致就是:
- 注册和登录。
- 进入"探索模型"选择模型。
- 打开模型详情页查看服务商数据和评测指标。
- 在底部 API 区域选择 OpenAI Python SDK、Requests 或 Curl 示例。
- 复制示例代码,使用智能路由调用模型。
我比较在意的一点是,AI Ping 会默认为用户创建默认 API Key。首次调用前不一定
需要单独创建密钥,这对快速跑通 demo 很方便。
不过如果要进入生产环境,我还是建议按项目单独创建 Key,并设置额度和轮换策略。
Agent 的调用次数和 Token 消耗经常比普通聊天更难预测,提前做隔离会更稳。
8. 智能路由:根据性能、价格、可靠性自动调度
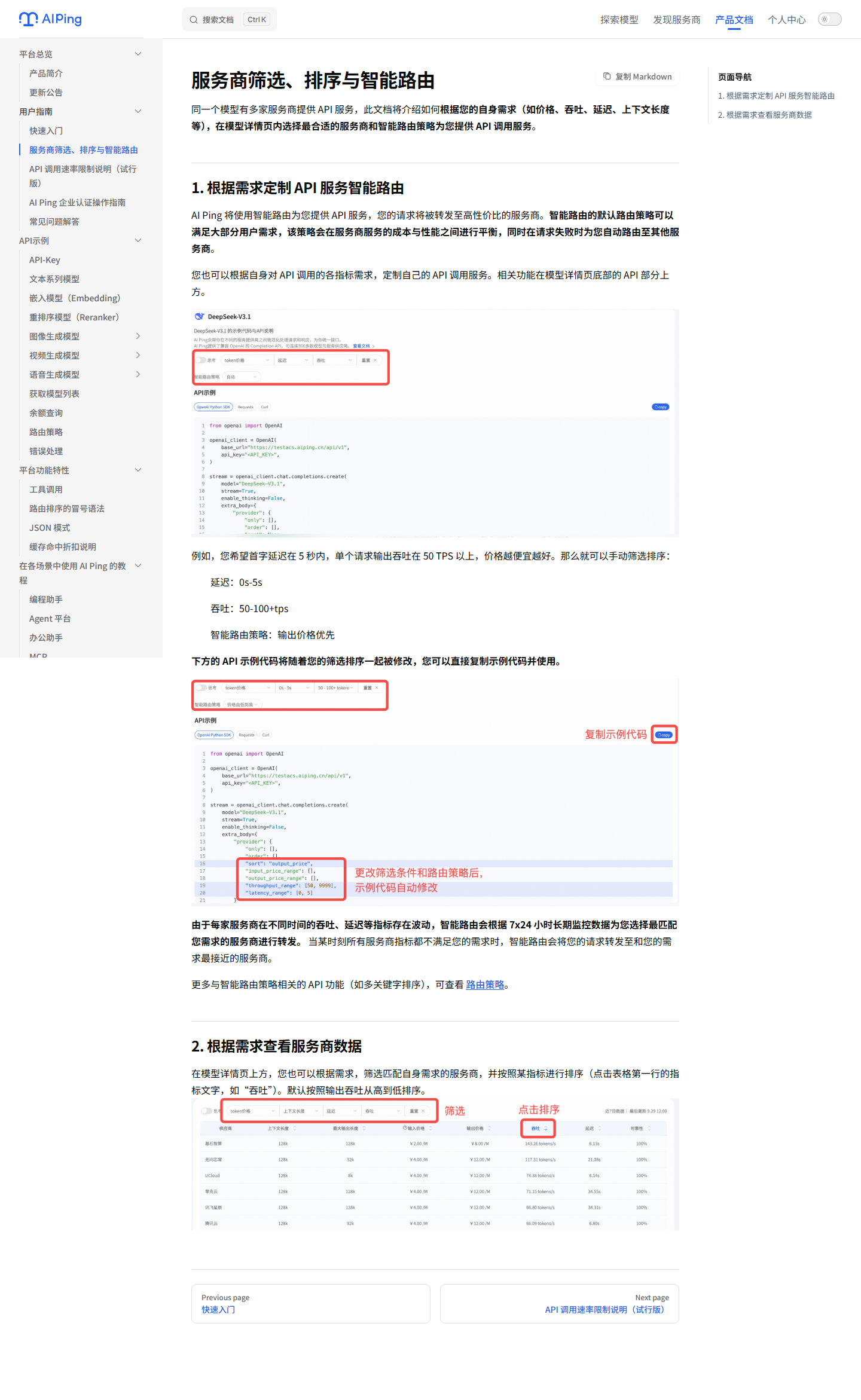
智能路由是我觉得 AI Ping 最适合 Agent 场景的能力之一。原因很简单:同一个
模型可能由多家服务商提供,但不同服务商在某个时间点的价格、延迟、吞吐和
稳定性并不完全一样。
如果我自己硬编码某一家服务商,一旦它延迟升高或调用失败,Agent 的整个任务
体验都会受影响。而 AI Ping 的默认路由策略会在成本和性能之间做平衡,并在
请求失败时自动路由到其他服务商。
如果业务目标更明确,也可以按自己的偏好定制:
- 延迟范围。
- 吞吐范围。
- 输入价格范围。
- 输出价格范围。
- 指定服务商或排除服务商。
- 按价格、延迟、吞吐等策略排序。
我在路由策略文档里看到,可以通过 Chat Completions 请求里的 provider 字段
控制路由。若最优服务商失败,系统会按优先级重试所有可用服务商。这个机制对
长链路 Agent 很实用,因为它降低了单个服务商波动对任务结果的影响。
9. API Key:统一鉴权与额度控制
AI Ping API 使用 Bearer Token 鉴权。调用时在 Header 中加入:
http
Authorization: Bearer <API_KEY>API Key 可以在个人中心管理。文档里提到可以设置固定额度或每月自动刷新额度。
我认为这对团队和 Agent 项目都很重要,因为 Agent 可能会连续调用工具、读取
文件、执行多轮规划,Token 消耗比普通聊天更难预测。
我的建议做法是:
- 每个项目单独创建 API Key。
- 给测试环境设置较低额度。
- 生产环境使用独立 Key。
- 不要把 Key 写入公开仓库、前端代码或日志。
这样做看起来麻烦一点,但后面排查费用、定位调用来源、限制异常消耗都会更方便。
10. 文本模型 API:兼容 OpenAI 风格调用
AI Ping 的文本对话接口为:
text
https://aiping.cn/api/v1/chat/completions如果使用 OpenAI SDK,Base URL 写到 /api/v1:
text
https://aiping.cn/api/v1我更倾向于用 OpenAI SDK 的方式接入,因为很多 Agent 框架本身就支持
OpenAI Compatible Provider,改 Base URL 和 API Key 就能先跑起来。
常规 Python 调用示例:
python
from openai import OpenAI
client = OpenAI(
base_url="https://aiping.cn/api/v1",
api_key="<API_KEY>",
)
stream = client.chat.completions.create(
model="GLM-5.1",
stream=True,
messages=[
{"role": "user", "content": "请帮我规划一个 Agent 文件整理流程"}
],
)
for chunk in stream:
if not getattr(chunk, "choices", None):
continue
content = getattr(chunk.choices[0].delta, "content", None)
if content:
print(content, end="", flush=True)这段代码的重点不是语法本身,而是接入方式比较平滑。对于已经基于 OpenAI SDK
封装过调用层的项目,我基本可以把 AI Ping 当作一个兼容 Provider 来接。
11. 工具调用:Agent 接入的关键能力
我做 Agent 接入时,最关心的能力之一就是工具调用。AI Ping 文档说明它支持
Function / Tool Calling,模型可以根据 JSON Schema 生成结构化参数,客户端
执行工具,再把工具结果返回给模型。
这就是 Agent 系统里很典型的闭环:模型负责规划和参数生成,业务系统负责真实
执行,例如查数据库、调用搜索、读写文件、触发工作流等。
文档还提到 AI Ping 支持 OpenAI 格式与 Anthropic 格式的工具定义与调用,并
支持接入 Claude Code、Codex、Cursor 等外部编程工具。对我来说,这意味着
它不只是给普通聊天接口用,也可以放进更完整的开发工具链里。
一个简化的工具调用结构如下:
python
from openai import OpenAI
client = OpenAI(
base_url="https://aiping.cn/api/v1",
api_key="<API_KEY>",
)
response = client.chat.completions.create(
model="GLM-5.1",
messages=[
{"role": "user", "content": "查询北京今天的天气,然后给我穿衣建议"}
],
tools=[
{
"type": "function",
"function": {
"name": "get_weather",
"description": "查询指定城市天气",
"parameters": {
"type": "object",
"properties": {
"city": {"type": "string", "description": "城市名称"}
},
"required": ["city"]
}
}
}
],
tool_choice="auto",
)客户端拿到工具调用参数后执行 get_weather,再把工具结果作为下一轮消息
返回模型,就能形成完整 Agent 闭环。实际项目里,我会在这个环节加上参数校验、
权限控制和失败重试,避免模型生成的参数直接影响真实业务系统。
12. 路由参数:第三方 Agent 工具里也能控制策略
我觉得路由排序的冒号语法很适合第三方 Agent 客户端。文档说明,可以直接在
模型名字符串中写路由策略,不一定要改 extra_body。
格式如下:
text
模型名:排序方法:参数1,参数2,参数3示例:
text
DeepSeek-V3.2:latency
DeepSeek-R1:throughput:latency<500,input_price<1.0这对 Cline、Cursor、Roo Code、Claude Code、Codex 这类工具很实用。很多第三方
客户端只方便配置 Base URL、API Key 和模型名,如果支持把模型名原样传给服务端,
我就可以通过这种方式表达路由偏好,不用为了一个路由策略去改客户端代码。
13. JSON 模式:让 Agent 输出稳定结构
Agent 经常需要输出结构化结果,例如任务列表、文件修改计划、数据库查询参数、
爬虫字段、表单数据等。我在做这类功能时,会尽量让模型输出稳定 JSON,而不是
依赖自然语言再二次解析。
请求中加入:
json
{
"response_format": {
"type": "json_object"
}
}示例:
bash
curl -X POST https://aiping.cn/api/v1/chat/completions \
-H "Authorization: Bearer <API_KEY>" \
-H "Content-Type: application/json" \
-d '{
"model": "DeepSeek-V3.2",
"messages": [
{
"role": "user",
"content": "把这个需求拆成 JSON 格式的任务列表"
}
],
"response_format": {
"type": "json_object"
}
}'这里我会特别注意一点:JSON 模式不等于生产环境绝对可靠。不同模型和服务商的
表现可能不同,所以真正上线时,我还是会加 JSON Schema 校验、解析失败重试,
必要时还会做结果修复。
14. 缓存命中折扣:降低长上下文 Agent 成本
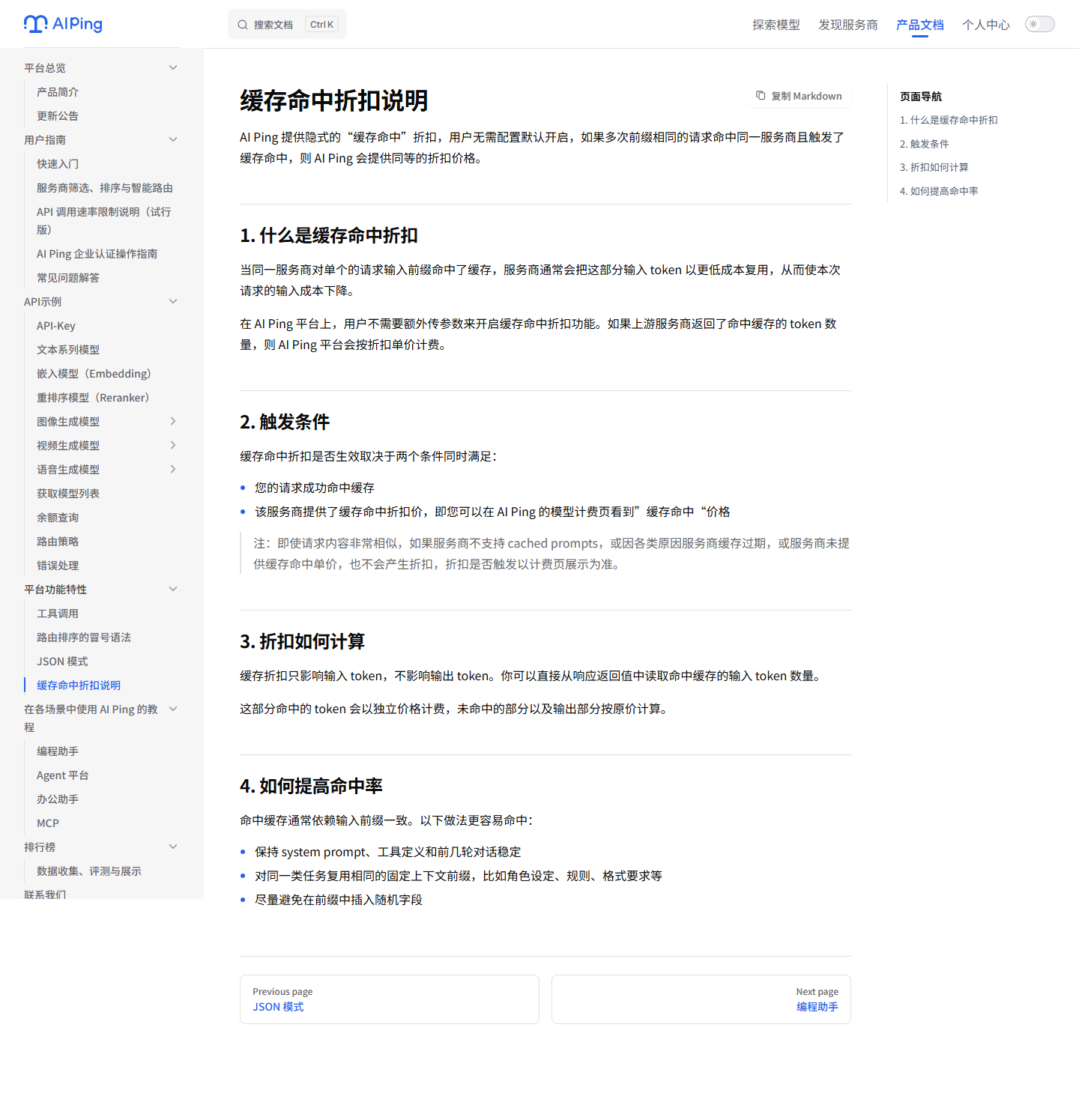
缓存命中折扣是我觉得容易被忽略、但对 Agent 很有价值的点。Agent 往往有固定
系统提示词、工具说明、项目上下文、代码仓库摘要等长前缀。如果多次请求前缀
相同,并且命中同一服务商缓存,上游服务商可能会对命中的输入 tokens 给出折扣。
AI Ping 文档说明,这个能力默认开启,用户无需额外传参数。是否生效主要取决于:
- 请求是否成功命中缓存。
- 服务商是否提供缓存命中折扣价。
- 计费页是否展示对应缓存命中价格。
对长期运行的 Agent,我会尽量保持系统提示词和工具定义稳定,把变化内容放在
用户消息或较靠后的上下文中。这样既能减少重复输入成本,也更容易提高缓存命中率。
15. Agent 接入 AI Ping API 推荐配置
如果你的 Agent 框架支持 OpenAI Compatible Provider,可以按下面配置:
text
Provider 类型:OpenAI Compatible
Base URL:https://aiping.cn/api/v1
API Key:<你的 AI Ping API Key>
Model:GLM-5.1 或 DeepSeek-V4-Pro如果你的 Agent 更关注低延迟,可以尝试:
text
DeepSeek-V3.2:latency如果更关注吞吐和价格过滤,可以尝试:
text
DeepSeek-R1:throughput:latency<500,input_price<1.0如果你的框架支持 extra_body,可以用更明确的 provider 配置:
python
response = client.chat.completions.create(
model="DeepSeek-R1-0528",
stream=True,
messages=[
{"role": "user", "content": "帮我生成一个数据分析 Agent 的执行计划"}
],
extra_body={
"provider": {
"sort": "output_price",
"latency_range": [0, 5],
"throughput_range": [50, 100]
}
}
)实际接入时,我会按场景选策略:
- 编程 Agent:优先工具调用、代码能力、长上下文和稳定性。
- 客服 Agent:优先低延迟、成本和高并发稳定性。
- 数据分析 Agent:优先长上下文、JSON 模式和工具调用。
- RAG Agent:优先缓存命中、结构化输出、吞吐和价格。
- 多模态 Agent:选择支持视觉、图片或视频输入的模型。
我的整体建议是,先用默认智能路由跑通完整链路,再根据实际调用数据去调整
价格优先、延迟优先或吞吐优先。这样比一开始就手动写死策略更稳。
16. 选定 GLM-5.1 作为 Agent 演示模型
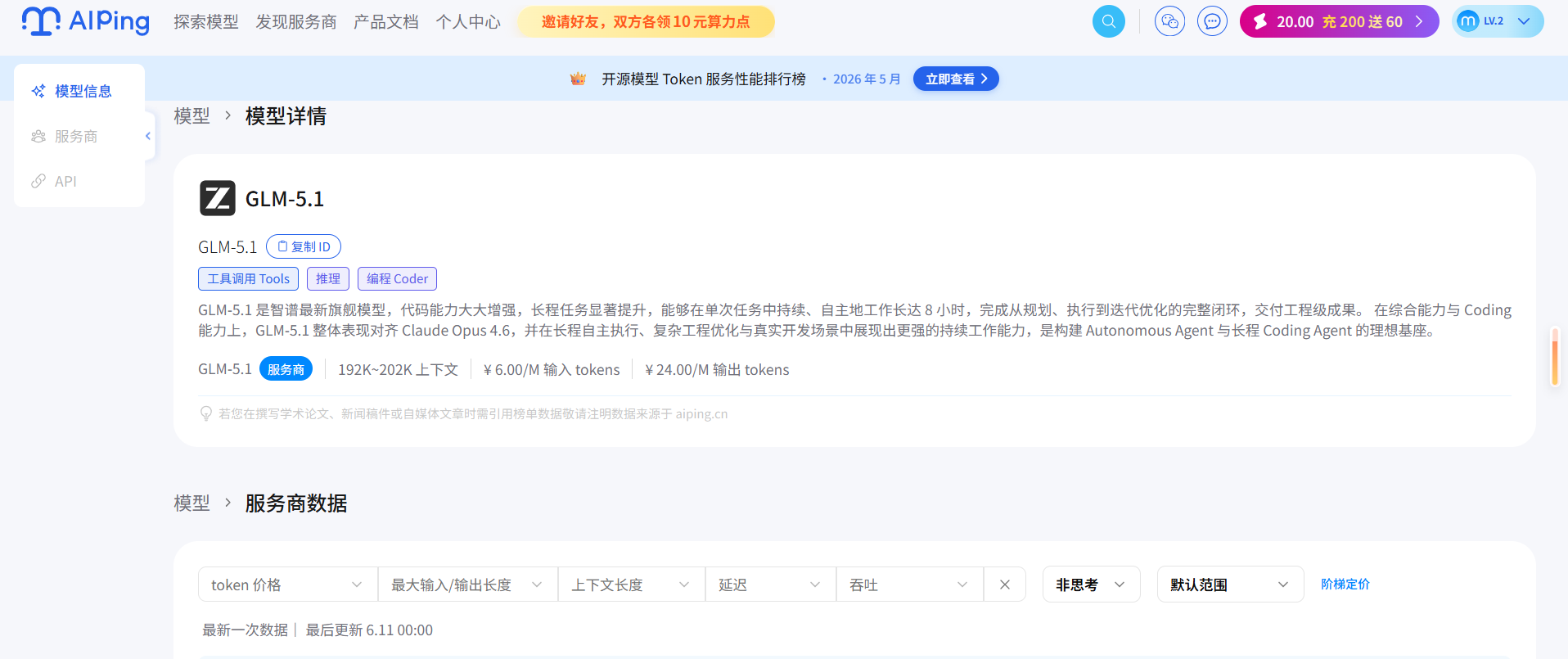
在正式接入 Agent 之前,我需要先确定一个"主力模型"。翻了一圈 AI Ping 的模型广场,GLM-5.1 引起了我的注意。
GLM-5.1 的标签里明确标注了工具调用(Tool Use)、推理(Reasoning)和编程(Coding)。对于一个需要执行多步规划、调用外部 API 的 Agent 来说,这三个能力缺一不可。特别是它支持超长上下文(见下图),这意味着它在处理复杂系统提示词(System Prompt)和长链条对话时,不容易出现"遗忘"的情况。
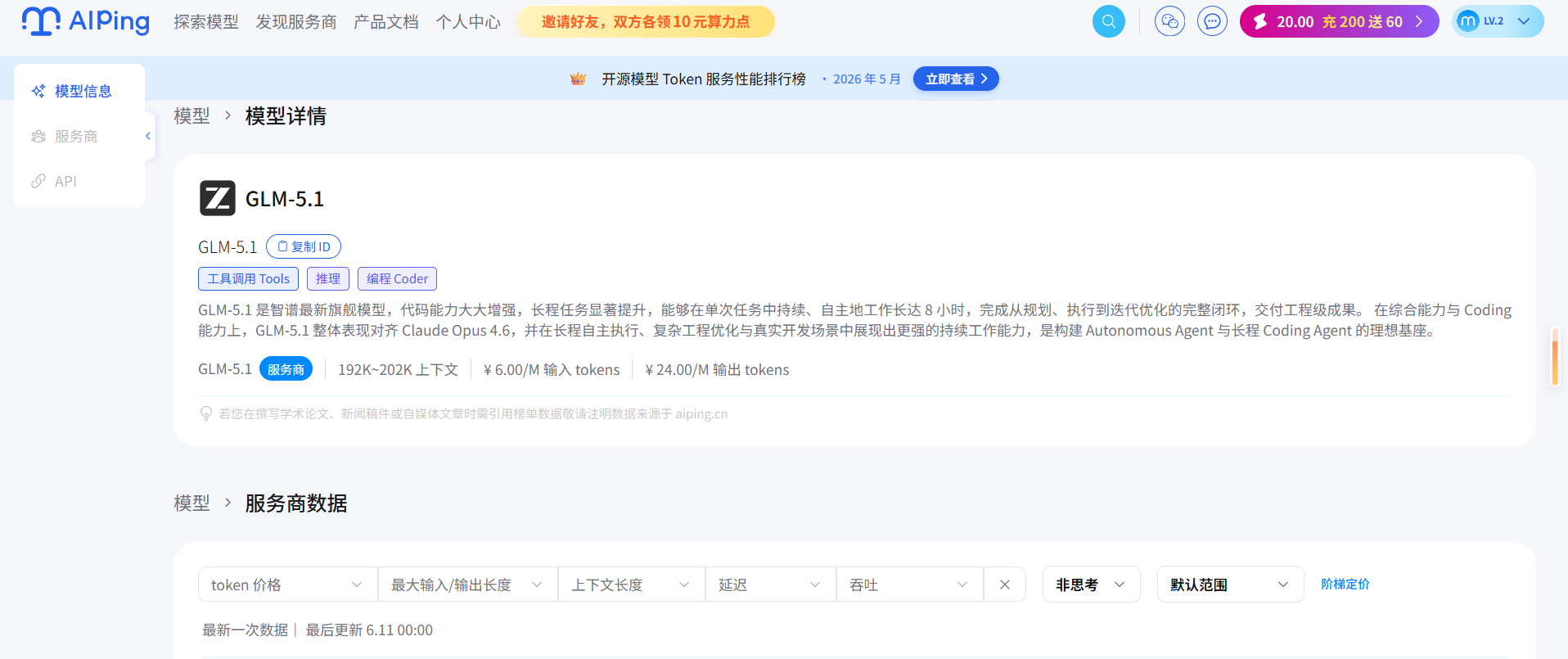
它展示了 GLM-5.1 的核心参数与能力标签。我之所以选它,正是因为它的长上下文(192K~202K)和高推理能力,非常适合作为 Coding Agent 的大脑。它不仅支持复杂的工具调用,还具备强大的代码生成能力,这在后续的 Agent 实操中至关重要。此外,6元/百万输入tokens、24元/百万输出tokens的定价,在同类模型中也具有不错的性价比。
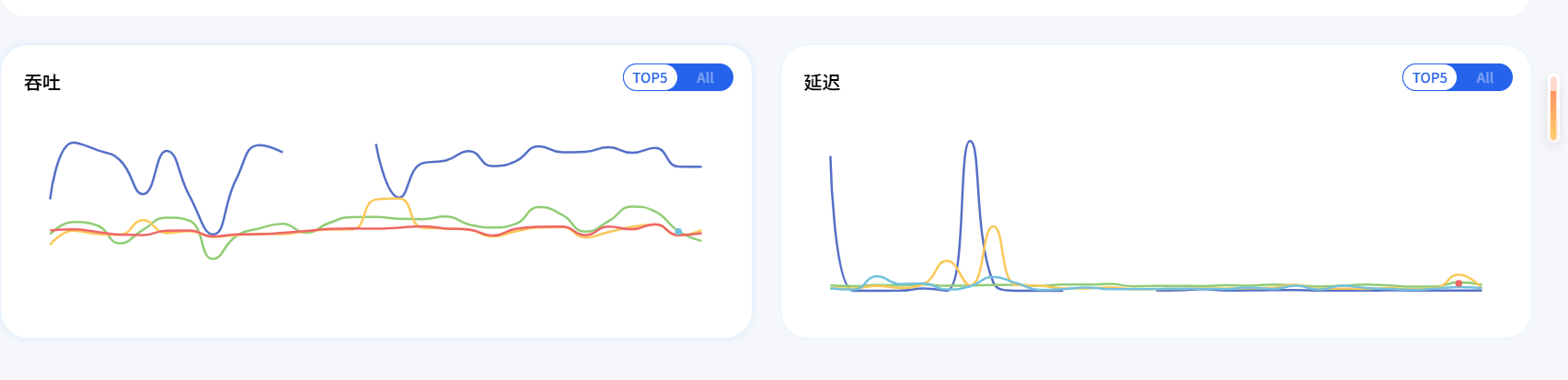
这是我选择 GLM-5.1 的另一个关键原因------性能稳定性。它展示了不同服务商在提供 GLM-5.1 时的吞吐与延迟表现。从曲线可以看出,部分服务商的吞吐表现非常稳定,延迟也控制在较低水平,这意味着我的 Agent 在实际运行中不会因为网络抖动或服务商波动而出现卡顿或超时。这种可视化的性能数据,让我能更放心地将 GLM-5.1 用于生产级 Agent 场景。
确定了模型后,接下来就是把它"塞"进我的应用里。回到项目的 .env 配置文件,把模型名改为 GLM-5.1,并把 Base URL 指向 AI Ping 的统一接口,下来我们慢慢道来。
17. 接入任意 LLM API 进行体验
这一节我想用自己的 Agent 项目做一个更贴近实战的演示。前面介绍 AI Ping 时,
我更多是在看模型、服务商、价格和智能路由;真正落到项目里时,我关心的就变成了
另一个问题:能不能把 AI Ping 当成一个 OpenAI 兼容接口,直接接进现有 Agent 应用,
并且尽量少改业务代码。
我这个项目是一个 LangGraph Agent,配置层使用分层的 Pydantic Settings,所有外部
服务入口都统一放在 .env 里管理。底层 LLM 调用已经通过 langchain-openai 和
langchain-anthropic 做了封装,所以我接入 AI Ping 的思路很简单:不动 Agent 的
任务编排逻辑,只替换模型名、API Key 和 Base URL。
我是怎么判断能不能无缝接入的
项目里的 src/llm.py 有一层 Provider 自动识别逻辑:
- 当
OPENAI_BASE_URL里包含"/messages"或"anthropic"时,走ChatAnthropic。 - 其他 OpenAI 兼容接口统一走
ChatOpenAI。
AI Ping 的接口是 OpenAI Compatible 风格,所以我实际接入时会让它走 ChatOpenAI。
这对我来说很省事,因为流式输出、工具绑定和重试逻辑都可以继续复用原来的
LangChain 封装,不需要为了换一个模型服务商重写 Agent 核心代码。
我实际改的配置
我先打开项目里的 .env.example 对照字段。这里最关键的就是三项:API Key、
模型名和 Base URL。截图里的配置文件结构比较清楚,我只需要把它替换成 AI Ping
后台拿到的参数即可。
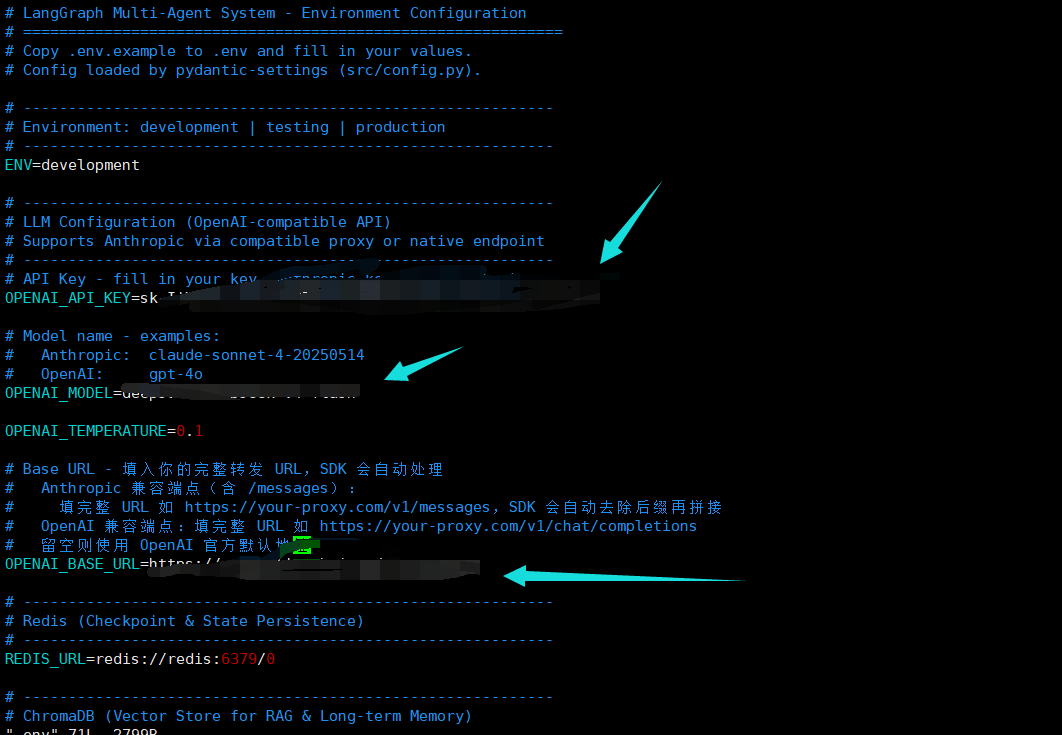
我实际会按下面这种方式配置,API Key 用自己的 AI Ping Key,模型这里我选择
GLM-5.1:
bash
OPENAI_API_KEY=QC-xxxxxxxxxxxxxxxxxxxx
OPENAI_MODEL=GLM-5.1
OPENAI_BASE_URL=https://www.aiping.cn/api/v1改完 .env 之后,我会重新启动应用,让新配置真正进入运行环境:
bash
# 本地开发
python -m uvicorn src.main:app --reload
# Docker 部署
docker compose up -d app --force-recreate --build如果是本地调试,我会先用 uvicorn 看日志,确认请求有没有打到 AI Ping;如果是
Docker 部署,我会直接重建 app 容器,避免旧环境变量还留在运行进程里。
部署后的访问效果
应用启动后,我会先打开页面确认 Agent 服务是否正常加载。这里不是单纯看页面能不能
打开,而是确认前端、后端和 LLM 调用链路都已经串起来。
进入应用后,我会先发一个很短的问题测试连通性。短问题的好处是成本低、响应快,
如果这里都失败,基本可以优先排查 Key、Base URL、模型名或网络配置。
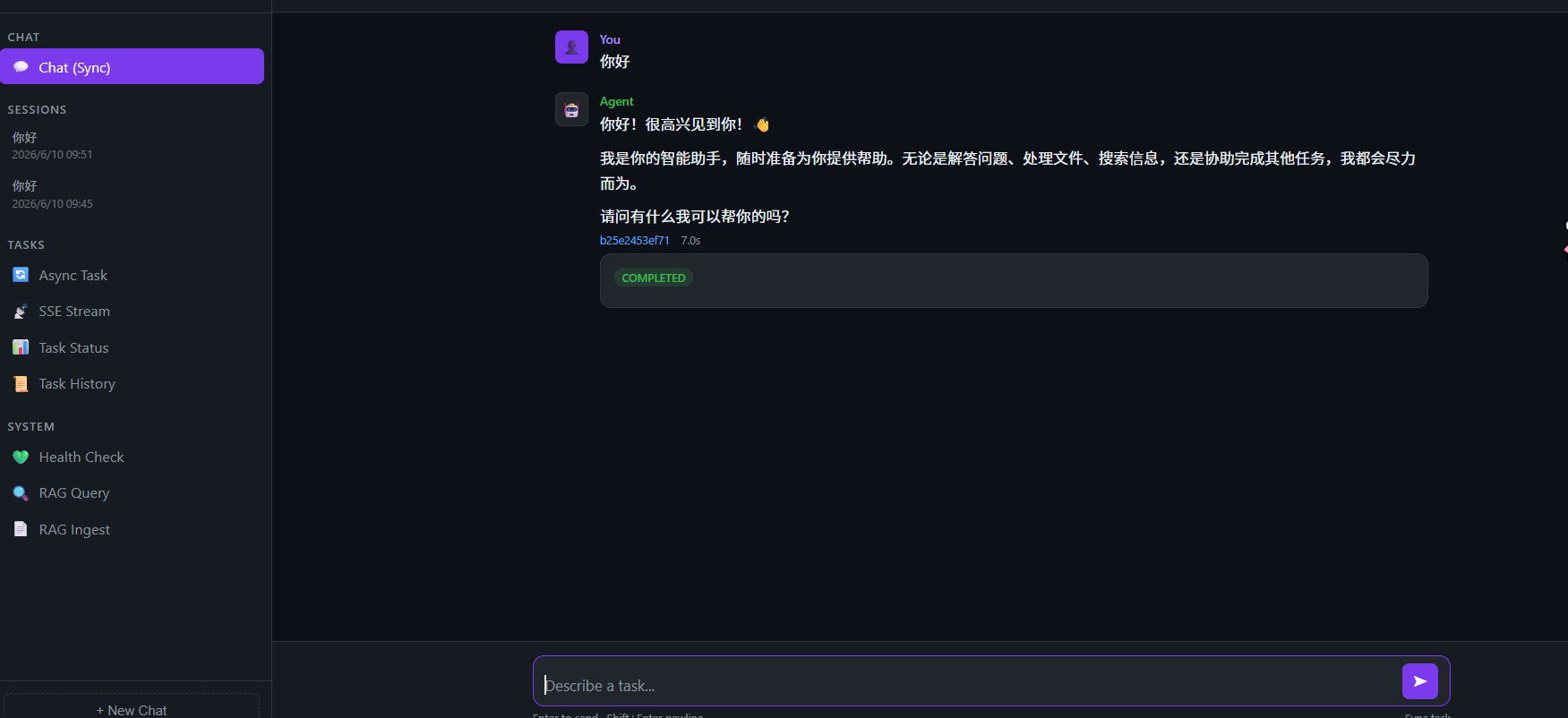
这次我接入的是 GLM-5.1。从调用结果看,模型已经通过 AI Ping 的统一接口进入
我的 Agent 应用,说明原来的 LangGraph 编排、LangChain LLM 封装和 AI Ping API
之间可以正常衔接。
继续测试时,我会观察响应速度、输出稳定性,以及应用里是否能持续完成多轮对话。
如果后续要接工具调用或更复杂的任务,我会再重点检查工具参数、流式输出和异常重试。
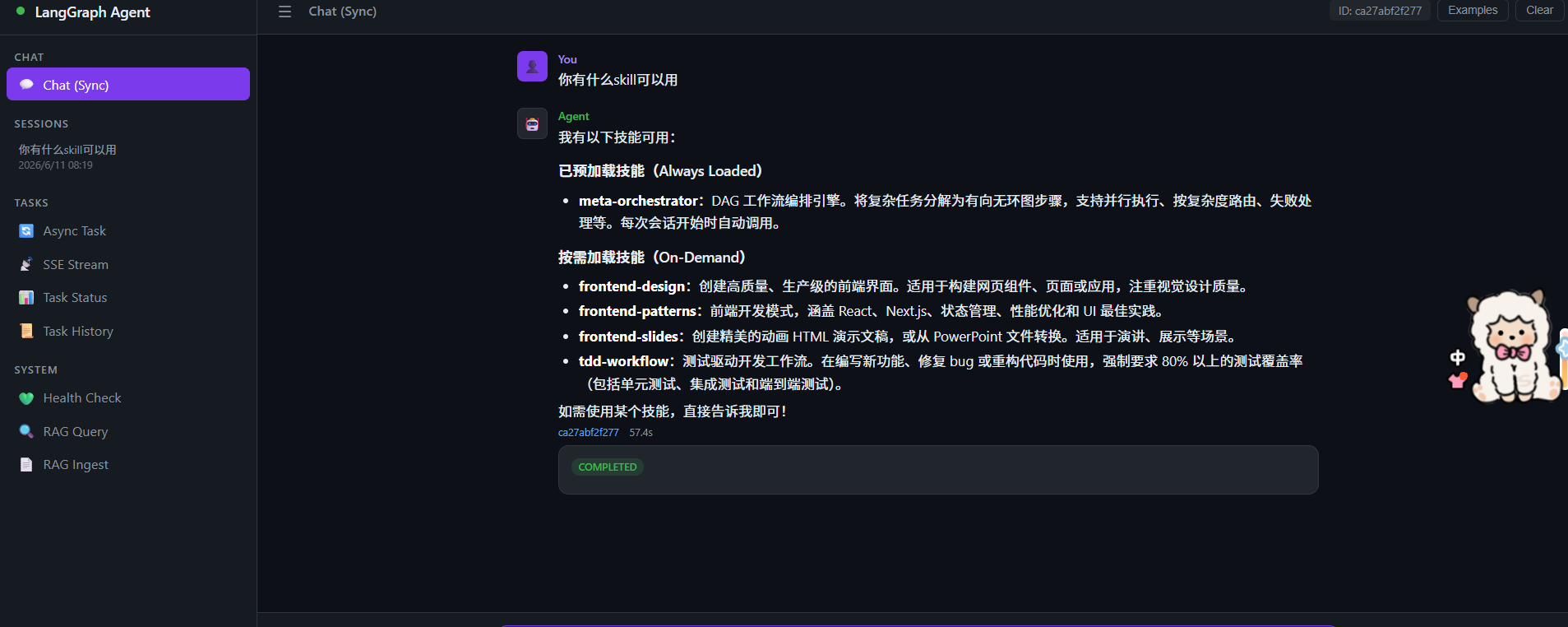
这次接入给我的感觉
整体体验下来,我觉得 AI Ping 比较适合作为 Agent 项目的统一模型入口。它的价值不只
是"能调某个模型",而是我可以用同一套 OpenAI 兼容接入方式,把不同模型和服务商放到
一个路由层后面。
对我这个项目来说,最明显的好处有三点:
- 业务代码基本不用动 :只改
.env,Agent 编排逻辑保持不变。 - 模型切换成本低 :从其他 OpenAI 兼容模型切到
Kimi-K2.6,核心就是替换模型名和接口地址。 - 后续优化空间更大:跑通后还能继续结合 AI Ping 的智能路由、服务商筛选和价格策略做优化。
所以我的建议还是先从最小改动开始:用一个简单问题确认 API 调通,再放进真实 Agent
场景里测试多轮对话、工具调用和长上下文表现。先让应用跑起来,再根据实际调用数据
决定要不要调整路由策略,这样会比一开始就把配置写得很复杂更稳。
18. 总结
从我的体验看,AI Ping 对 Agent 开发者的价值主要集中在四个方面:
- 选模型:通过模型广场和模型详情快速看到能力、上下文和价格。
- 选服务商:通过服务商详情和评测数据比较延迟、吞吐和费用。
- 接 API:使用 OpenAI Compatible API 降低接入成本。
- 做路由:用智能路由在稳定性、速度和成本之间动态平衡。
如果你正在做 Coding Agent、RAG Agent、企业客服 Agent、数据分析 Agent,
或者多模型调用平台,我会把 AI Ping 当作一个模型服务评测入口,也会把它作为
统一 API 和智能路由入口来评估。
它最吸引我的地方,不是单个功能多新,而是把"选模型、看服务商、接 API、
控成本、做路由"这些 Agent 落地时绕不开的事情放在了一起。对需要频繁试模型、
比服务商、做稳定调用的人来说,这个方向是有实际价值的。