文章目录
- 一.可靠性
- 二、幂等性
- 三、生产环境下的方案
一.可靠性
1.生产者
(1)重试机制
当网络抖动或Leader选举导致发送失败时,Producer会进行自动重试。建议将 retries 重试次数设置为一个较大的值(如 Integer.MAX_VALUE),确保消息在绝大多数故障场景下最终都能成功发送。
设置 retries=0 则对应"最多一次"语义,即只发送一次,不重试
生产者可以采用同步或异步两种方式发送数据:
- 同步发送:调用 send() 后等待 Future.get() 返回结果,能直接感知发送是否成功。
- 异步发送:提供回调函数(Callback),发送完成后回调 onCompletion() 方法,在回调中处理成功或失败逻辑。
(2)生产者确认机制
生产者通过 ACK 机制 控制消息可靠性,共有三个可选配置:
| acks 值 | 含义 | 可靠性 | 性能 |
|---|---|---|---|
| 0 | 生产者只负责发送,不等待任何确认 | 最低(可能丢失) | 最高 |
| 1 | Leader 收到消息后即返回确认 | 中等(Leader 宕机会丢数据) | 中等 |
| all 或 -1 | Leader 等待所有 ISR 副本确认后才返回 | 最高 | 较低 |
(3)事务操作
为了实现跨分区、跨会话的"精确一次"语义,Kafka引入了事务。它将一组消息的发送、消费位移的提交等操作封装在一个原子单元内,要么全部成功,要么全部失败回滚。事务通常用于需要极高数据一致性的场景,如金融交易。
(4)其余兜底策略
- 保存到磁盘再定时扫描:持久化到本地数据库或磁盘文件中,并创建一个独立的补偿任务,定期扫描并尝试重新发送这些消息。
- 死信队列:将最终发送失败的消息,单独写入一个专门用于存放"坏消息"的 Kafka 主题,即死信队列,等待后续人工或自动化程序处理。
- 人工处理:在回调函数中捕获到最终失败异常时,除了记录详细的错误日志外,立刻触发一个实时告警,通知到开发和运维人员进行人工介入。
2.Broker 端
(1)消息持久化
Kafka将消息以追加(append-only)的方式写入磁盘文件,避免了昂贵的随机I/O,在保证持久化的同时提供了高性能。消息会先写入操作系统的页缓存(Page Cache),再异步刷盘(fsync),这使得Kafka兼具了高吞吐和数据持久化的能力。
(2)分区副本机制
每个Partition都可以有多个副本,这些副本分布在不同的Broker上,形成冗余。其中,Leader副本负责处理所有读写请求,而Follower副本则负责从Leader处同步数据。如果Leader所在的Broker宕机,一个Follower可以被选举为新的Leader,继续提供服务,保证系统的高可用。
(3)ISR (In-Sync Replicas) 机制
ISR是一组与Leader保持"同步"的Follower副本集合。
根据replica.lag.time.max.ms参数(默认10秒)来判断副本是否处于同步状态。如果Follower在规定时间内无法追上Leader的进度,就会被踢出ISR;待其追赶上来后,会重新加入。
- min.insync.replicas:定义了"已提交"消息的最低要求。例如,设置为2时,意味着一条消息必须至少被 Leader 和一个 Follower 成功写入,才能被标记为"已提交"并返回ACK给Producer。
- unclean.leader.election.enable:当ISR中所有副本都宕机时,是否允许从落后更多的副本(OSR)中选举新的Leader。建议设置为 false,因为这可能导致数据丢失。宁可服务不可用,也不要提供不一致的数据。
3.消费者
(1)偏移量提交策略
通过offset来记录消费进度。建议关闭自动提交 (enable.auto.commit=false),改为在业务逻辑成功处理完消息后,再手动提交offset。
- 如果采用先提交再处理,一旦处理失败,offset已更新,这条消息就"丢失"了,无法被重新消费。
- 如果采用先处理再提交,即使处理时崩溃,重启后consumer会从旧的offset重新拉取,虽然可能导致重复消费,但至少保证了消息不丢失,这正是"至少一次"语义的实现。
(2)消费语义
- 消费者端的三种语义保障机制如下
| 语义 | 描述 | 实现方式 |
|---|---|---|
| At most once(最多一次) | 消息可能丢失,但不会重复处理 | 先提交 offset,后处理消息。若处理过程失败,消息不会重试。 |
| At least once(最少一次) | 消息不会丢失,但可能重复处理 | 先处理消息,后提交 offset。若提交前崩溃,重启后会重新消费。 |
| Exactly once(精确一次) | 消息既不丢失也不重复 | 需要结合幂等性、事务或外部存储的原子提交。 |
二、幂等性
为了实现生产者的幂等性,Kafka引入了 Producer ID(PID)和 Sequence Number的概念。
- PID:每个Producer在初始化时,都会分配一个唯一的PID,这个PID对用户来说,是透明的。
- Sequence Number:针对每个生产者(对应PID)发送到指定主题分区的消息都对应一个从0开始递增的Sequence Number。
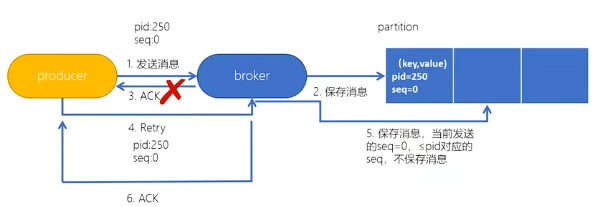
跨会话幂等性的保障
对于上面的幂等性方案来说,仅可以保持单次会话的幂等性,如果重启,会给生产者设置一个新的PID,这个时候就可能重复消费了。
且仅对单分区有效,序号是分区维护的,无法跨分区去重。
事务保障跨会话幂等性:生产者配置 transactional.id,Kafka 会将这个 ID 与 PID 做持久化绑定(存储在内部 Topic __transaction_state 中)。生产者重启后,用同一个 transactional.id 再次初始化,Kafka 会恢复上一次的 PID 和序列号状态,从而可以继续去重。 同时事务还能实现跨分区原子写入(要么都成功,要么都失败)
三、生产环境下的方案
构建高可靠的 Kafka 消息管道,需要端到端的协同配置:
- 生产者端: 使用
acks=all 和 min.insync.replicas(已提交消息的最低要求)配合,确保消息被足够多的副本确认。启用幂等性(enable.idempotence=true) 以防止网络重试导致的重复。对于跨分区的原子写入,使用事务 API。 - Broker 端: 合理设置
replication.factor副本数量(通常 >=3)和 unclean.leader.election.enable=false(防止数据丢失的副本成为领导者)。持续监控 ISR 状态和副本同步滞后,ISR 收缩(某个 Follower 被踢出 ISR)往往预示着 Broker 负载过高、网络延迟或磁盘故障。 - 消费者端: 根据业务容忍度选择消费语义。对于"至少一次"语义(最常用),务必
关闭自动提交,采用手动提交,并将消息处理设计为幂等操作(例如,利用数据库唯一键、Redis SETNX 或消息中的业务唯一标识进行去重)。 - 监控与运维: 监控生产者发送错误率、消费者滞后量 (Lag)、ISR 收缩、控制器活动等关键指标。建立完善的告警机制。